IMPLEMENTASI FUZZY OLAPPADA DATA POTENSI DESA DI PROVINSI JAWA BARAT TAHUN 2003 DAN 2006
SOFIYANTI INDRIASARI G64103046
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
ABSTRAK
SOFIYANTI INDRIASARI. Implementasi Fuzzy OLAPpada Data Potensi Desa di Provinsi Jawa Barat Tahun 2003 dan 2006. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan SRI NURDIATI.
Kurangnya pemanfaatan atau pengolahan terhadap gunung data yang sebenarnya dapat menghasilkan suatu informasi atau pengetahuan yang penting untuk mendukung pengambilan keputusan. Data Potensi Desa yang bersumber dari Badan Pusat Statistik (BPS) memiliki peranan yang cukup strategis di masa yang akan datang dan merupakan produk unggulan BPS. Untuk itu sangat penting melakukan analisis data Podes secara efisien dan cepat. Data warehouse adalah tempat penyimpanan data terintegrasi yang dapat digunakan untuk query dan analisis. Operasi query ini dilakukan dengan On-line Analytical Processing (OLAP). Data real dijumpai sering kali mengandung informasi yang tidak tepat dan ketidakpastian (uncertain). Teori himpunan fuzzy digunakan untuk menangani masalah tersebut. Penelitian ini bertujuan membangun data warehouse untuk data Potensi Desa di Provinsi Jawa Barat tahun 2003 dan 2006 yang direpresentasikan dalam model data multidimensi dengan menggunakan teori himpunan fuzzy dan mengimplementasikan operasi OLAP.
Ruang lingkup penelitian adalah dibatasi pada implementasi fuzzy OLAP untuk data Potensi Desa di Provinsi Jawa Barat tahun 2003 dan 2006. Sistem yang akan dibangun mengikuti arsitektur data warehouse tiga tingkat. Struktur data pada data warehouse digambarkan dengan skema galaksi. Operasi-operasi yang diimplementasikan adalah operasi roll-up, drill-down, slice, dice, dan pivot. Operasi untuk fuzzy OLAP dilakukan sesuai dengan konsep pengoperasian data multidimensi fuzzy.
Hasil penelitian ini adalah terbentukya data warehouse yang diimplementasikan dengan konsep fuzzy serta data warehouse untuk data crisp sebagai pelengkap penyajian informasi. Data warehouse yang dibangun menggunakan konsep fuzzy terlebih dahulu melalui tahapan praproses data dan proses clustering menggunakan algoritma FCM untuk mendapatkan himpunan fuzzy dan nilai derajat keanggotaan tiap atribut. Data warehouse tersebut memiliki 4 kubus data yaitu penduduk, rumah tangga, lahan, dan sekolah. Data dapat ditampilkan dalam bentuk crosstab atau grafik. Penelitian ini memberikan informasi berupa data fuzzy dan data crisp. Data fuzzy yang disajikan memberikan informasi natural dengan mendefinisikan variabel linguistic. Data crisp disajikan sebagai penunjang untuk mendapatkan informasi.
IMPLEMENTASI FUZZY OLAPPADA DATA POTENSI DESA DI PROVINSI JAWA BARAT TAHUN 2003 DAN 2006
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
SOFIYANTI INDRIASARI G64103046
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Implementasi Fuzzy OLAPpada Data Potensi Desa di Provinsi Jawa Barat Tahun 2003 dan 2006
Nama : Sofiyanti Indriasari
NIM : G64103046
Menyetujui:
Pembimbing I, Pembimbing II,
Imas S. Sitanggang, S.Si, M.Kom Dr. Ir. Sri Nurdiati, M.Sc
NIP 132 206 235 NIP 131 578 805
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131 473 999
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala
curahan rahmat dan karunia-Nya sehingga penelitian ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2007 ini ialah data warehouse, dengan judul Implementasi Fuzzy OLAPpada Data Potensi Desa di Provinsi Jawa Barat Tahun 2003 dan 2006
Penyelesaian penelitian ini tidak terlepas dari bantuan berbagai pihak, karena itu penulis mengucapkan terima kasih sebesar-besarnya kepada:
1. Ayahanda Achmad Azhari dan Ibunda Syafa’atur Rofiah , Kakakku Sofyan Rizalanda, serta adik-adikku Asrofi Hanafiah dan Asrofi Hanifah atas doa, kasih sayang, dan kehangatannya yang tidak pernah berhenti tercurah selama ini,
2. Ibu Imas S. Sitanggang, S.Si., M.Kom. selaku pembimbing I, Ibu Dr. Ir. Sri Nurdiati, M.Sc. selaku pembimbing II dan Bapak Hari Agung Adrianto, S.Kom. selaku dosen penguji,
3. Keluarga besar Ibu Sri Nurdiati di Bogor yang telah menjadi keluarga kedua bagi penulis,
4. Kak Hendra dan Kak Ifnu atas kesabarannya menjawab pertanyaan penulis, serta Diku atas tumpangannya mengangkut komputer untuk keperluan penelitian ini,
5. Sahabat penulis: Gibtha, Meynar, Firat, Pandi, Qwill, Ratih, Ghofar, Jemi, Hida, Dina, Vita, dan Nanik atas saran, dukungan, kerjasama, bantuan, dan hiburannya,
6. Teman-teman seperjuangan Ilkomers 40 lainnya untuk pengalaman dan kenangan yang tak ternilai, 7. Mas Irvan atas bantuannya mencari referensi untuk penelitian ini dan Pak Soleh atas bantuan dan
nasehatnya,
8. Departemen Ilmu Komputer, staf dan dosen yang telah begitu banyak membantu baik selama penelitian maupun pada masa perkuliahan.
Segala kesempurnaan hanya milik Allah SWT, semoga hasil penelitian ini dapat bermanfaat, Amin.
Bogor, Mei 2007
RIWAYAT HIDUP
Penulis dilahirkan di Blitar pada tanggal 5 Oktober 1984 dari ayah Achmad Azhari dan ibu Syafa’atur Rofiah. Penulis merupakan putri kedua dari empat bersaudara. Tahun 2003 penulis lulus dari SMU Negeri I Sidoarjo. Pada tahun yang sama penulis diterima di Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur USMI.
DAFTAR ISI
Halaman
DAFTAR TABEL... viii
DAFTAR GAMBAR... viii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 1
Data Warehouse... 1
Model Data Multidimensi... 2
On-line Analytical Processing (OLAP) ... 2
Himpunan Fuzzy... 4
Fuzzy C-Means (FCM) ... 5
Ukuran Kevalidan Cluster... 5
Kubus Data Fuzzy... 6
Dimensi Fuzzy... 6
METODE PENELITIAN ... 7
Tahapan Penelitian... 7
Praproses Data... 7
Arsitektur Sistem ... 8
Lingkungan Pengembangan Sistem ... 8
HASIL DAN PEMBAHASAN ... 8
Praproses Data... 8
Tingkat Bawah (Bottom Tier)... 10
Tingkat Tengah (Middle Tier) ... 13
Tingkat Atas (Top Tier) ... 13
KESIMPULAN DAN SARAN ... 18
Kesimpulan ... 18
Saran... 19
DAFTAR PUSTAKA ... 19
DAFTAR TABEL
Halaman
1 Validasi atribut lahan bukan sawah untuk non pertanian 2006 ... 10
2 Validasi atribut lahan bukan sawah untuk non pertanian 2003 ... 10
3 Tabel dimensi yang terbentuk dalam pengembangan data warehouse untuk data crisp... 10
4 Tabel fakta yang terbentuk dalam pengembangan data warehouse untuk data crisp... 10
5 Tabel dimensi yang terbentuk dalam pengembangan data warehouse untuk data fuzzy... 11
6 Tabel fakta yang terbentuk dalam pengembangan data warehouse untuk data fuzzy... 11
DAFTAR GAMBAR
Halaman 1 Skema bintang (Han & Kamber 2001)... 22 Skema snowflake (Han & Kamber 2001)... 2
3 Skema galaksi (Han & Kamber 2001) ... 2
4 Contoh operasi roll-up (Han & Kamber 2001)... 3
5 Contoh operasi drill-down (Han & Kamber 2001) ... 3
6 Contoh operasi slice (Han & Kamber 2001)... 4
7 Contoh operasi dice (Han & Kamber 2001) ... 4
8 Contoh operasi pivot (Han & Kamber 2001) ... 4
9 Contoh kubus data fuzzy 3 dimensi (Alhajj & Mehmet 2003) ... 6
10 Contoh path pada dimensi fuzzy... 7
11 Tahap praproses data ... 7
12 Arsitektur tiga tingkat data warehouse (Han & Kamber 2001) ... 8
13 Skema galaksi untuk data crisp... 12
14 Skema galaksi untuk data fuzzy... 12
15 Contoh tampilan fuzzy OLAP untuk subjek penduduk tahun 2003 pada level desa... 14
16 Contoh operasi roll-up pada dimensi lokasi... 14
17 Contoh tampilan data crisp untuk contoh kasus tampilan subjek penduduk tahun 2003. ... 15
18 Contoh tampilan modul_desa ... 16
19 Contoh tampilan modul_kecamatan... 17
20 Contoh tampilan modul_kabupaten ... 18
DAFTAR LAMPIRAN
Halaman 1 Atribut-atribut yang terpilih dari hasil ekstraksi ... 212 Hasil validasi cluster... 23
3 Contoh hasil clustering berupa linguistic dan derajat keanggotaan ... 29
4 Skema galaksi yang disesuaikan dengan kebutuhan software Oracle... 31
5 Skema relasi modul pendukung ... 32
6 Contoh tampilan fuzzy OLAP dan hasil operasinya... 35
7 Tampilan data yang dikombinasikan dengan bentuk visualisasi model graph... 38
8 Tampilan query builder... 38
PENDAHULUAN
Latar Belakang
Dewasa ini, ketersediaan data semakin melimpah, apalagi ditunjang dengan banyaknya kegiatan yang sudah dilakukan secara terkomputerisasi. Namun seringkali data tersebut hanya disimpan tanpa diolah lebih lanjut untuk keperluan di masa mendatang. Padahal jika dianalisis lebih dalam, data tersebut dapat menghasilkan informasi atau pengetahuan yang penting dan berharga. Data Potensi Desa (Podes) yang bersumber dari Badan Pusat Statistik (BPS) memiliki peranan yang cukup strategis di masa yang akan datang dan merupakan produk unggulan BPS. Untuk itu sangat penting dilakukan analisis data Podes secara efisien dan cepat.
Data warehouse adalah tempat penyimpanan
data terintegrasi yang dapat digunakan untuk query dan analisis. Operasi query ini dilakukan dengan On-line Analytical Processing (OLAP). OLAP akan menghasilkan data dalam bentuk ringkasan. Dengan operasi ini query dapat dijalankan lebih mudah dan lebih efisien. OLAP muncul dengan sebuah cara pandang data multidimensi. Cara pandang multimensi ini didukung oleh teknologi basis data multidimensi.
Data warehouse dan On-Line Analytical
Processing (OLAP) merupakan elemen penting
dalam mendukung proses pengambilan keputusan.
Data real yang dijumpai sering kali mengandung informasi yang tidak tepat dan ketidakpastian (uncertain). Teori himpunan
fuzzy digunakan untuk menangani masalah
tersebut.
Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Membangun data warehouse untuk data Potensi Desa tahun 2003 dan 2006. Aplikasi yang dibangun mengolah data yang direpresentasikan dalam model data multidimensi dengan menggunakan teori himpunan fuzzy.
2. Mengimplementasikan operasi-operasi OLAP, yaitu roll-up, drill-down, slice, dice,
dan pivot dengan menggunakan pendekatan
fuzzy.
Ruang Lingkup Penelitian
Penelitian ini dibatasi pada implementasi fuzzy OLAP pada data Potensi Desa di Provinsi Jawa Barat tahun 2003 dan 2006 yang bersumber dari Badan Pusat Statistik (BPS). Penelitian ini akan menghasilkan aplikasi fuzzy OLAP yang dapat menampilkan informasi untuk mendukung proses pengambilan keputusan.
Manfaat Penelitian
Aplikasi yang dihasilkan pada penelitian ini diharapkan dapat digunakan oleh pihak yang berkepentingan untuk mendapatkan informasi yang menarik dan akurat sebagai pendukung proses pengambilan keputusan terkait dengan data Potensi Desa. Sistem diharapkan dapat menyediakan informasi ringkas dan jelas secara cepat melalui operasi-operasi OLAP seperti roll-up, drill-down, slice,dice, dan pivot.
TINJAUAN PUSTAKA
Data Warehouse
Data Warehouse adalah sekumpulan data
berorientasi subjek, terintegrasi, time-variant,
dan non-volatile yang mendukung proses
manajemen pembuatan keputusan (Inmon 1996). Kata kunci dari pengertian data warehouse di atas adalah (Han & Kamber 2001):
• Berorientasi subjek: data warehouse diorganisasikan berdasarkan subjek-subjek utama, seperti pelanggan, produk atau penjualan. Data warehouse menyediakan tampilan yang sederhana dan ringkas untuk subjek tertentu dengan menghilangkan data yang tidak berguna dalam proses pembuatan keputusan.
• Terintegrasi: data warehouse dibangun dengan mengintegrasikan berbagai sumber data yang heterogen, seperti basis data relasional, flat file, dan transaksi on-line. Teknik pembersihan dan integrasi data digunakan untuk memastikan data tetap konsisten.
• Time-variant: data disimpan untuk
menyediakan informasi berdasarkan kejadian yang sudah lewat.
Model Data Multidimensi
Model data multidimensi menampilkan data dalam bentuk kubus data. Kubus data memungkinkan data dimodelkan dan ditampilkan dalam dimensi banyak. Kubus data disebut juga cuboid. Pola-pola cuboid dapat dibuat apabila diberikan satu kumpulan dimensi. Masing-masing pola menampilkan data pada tingkat kesimpulan yang berbeda-beda (Han & Kamber 2001).
Untuk menggambarkan hubungan antardata pada data multidimensi digunakan skema multidimensi. Pada data warehouse, skema merupakan sekumpulan tabel yang berhubungan. Skema digunakan untuk menunjukkan hubungan antara tabel dimensi dengan tabel fakta. Skema ditentukan berdasarkan kebutuhan data
warehouse dan keinginan pembuat data
warehouse. Data warehouse membutuhkan
skema yang ringkas dan berorientasi subjek. Tipe-tipe skema multidimensi antara lain (Han & Kamber 2001):
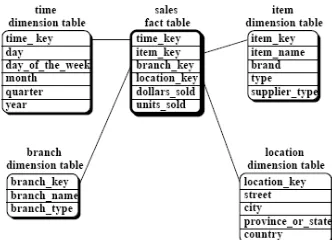
• Skema bintang (star schema)
Skema bintang adalah skema data
warehouse yang paling sederhana. Skema ini
disebut skema bintang karena hubungan antara tabel dimensi dan tabel fakta menyerupai bintang di mana satu tabel fakta dihubungkan dengan beberapa tabel dimensi. Titik tengah skema bintang adalah satu tabel fakta besar dan sudut-sudutnya adalah tabel-tabel dimensi. Bentuk skema bintang dapat dilihat pada Gambar 1. Keuntungan yang didapat jika menggunakan skema ini adalah peningkatan kinerja data warehouse, pemrosesan query yang lebih efisien, dan waktu respon yang cepat.
Gambar 1 Skema bintang (Han & Kamber 2001)
• Skema snowflake (snowflake schema)
Skema snowflake adalah variasi dari skema bintang di mana beberapa tabel dimensi dinormalisasi, jadi dihasilkan beberapa tabel tambahan. Bentuk skema snowflake dapat dilihat pada Gambar 2. Keuntungan yang didapat dengan menggunakan skema ini adalah penghematan memory, tapi waktu yang dibutuhkan untuk pemrosesan query menjadi lebih lama.
Gambar 2 Skema snowflake (Han & Kamber 2001)
• Skema galaksi (fact constellation)
Pada skema galaksi, beberapa tabel fakta berbagi tabel dimensi. Bentuk skema galaksi dapat dilihat pada Gambar 3. Keuntungan menggunakan skema ini adalah menghemat
memory dan mengurangi kesalahan yang
mungkin terjadi.
Gambar 3 Skema galaksi (Han & Kamber 2001)
On-line Analytical Processing (OLAP)
OLAP adalah operasi basis data untuk mendapatkan data dalam bentuk ringkasan dengan menggunakan agregasi sebagai mekanisme utama. OLAP menyediakan tampilan data yang fleksibel dari sudut pandang yang berbeda dan menyediakan lingkungan yang user-friendly untuk membantu analisis data.
IMPLEMENTASI FUZZY OLAPPADA DATA POTENSI DESA DI PROVINSI JAWA BARAT TAHUN 2003 DAN 2006
SOFIYANTI INDRIASARI G64103046
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
ABSTRAK
SOFIYANTI INDRIASARI. Implementasi Fuzzy OLAPpada Data Potensi Desa di Provinsi Jawa Barat Tahun 2003 dan 2006. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan SRI NURDIATI.
Kurangnya pemanfaatan atau pengolahan terhadap gunung data yang sebenarnya dapat menghasilkan suatu informasi atau pengetahuan yang penting untuk mendukung pengambilan keputusan. Data Potensi Desa yang bersumber dari Badan Pusat Statistik (BPS) memiliki peranan yang cukup strategis di masa yang akan datang dan merupakan produk unggulan BPS. Untuk itu sangat penting melakukan analisis data Podes secara efisien dan cepat. Data warehouse adalah tempat penyimpanan data terintegrasi yang dapat digunakan untuk query dan analisis. Operasi query ini dilakukan dengan On-line Analytical Processing (OLAP). Data real dijumpai sering kali mengandung informasi yang tidak tepat dan ketidakpastian (uncertain). Teori himpunan fuzzy digunakan untuk menangani masalah tersebut. Penelitian ini bertujuan membangun data warehouse untuk data Potensi Desa di Provinsi Jawa Barat tahun 2003 dan 2006 yang direpresentasikan dalam model data multidimensi dengan menggunakan teori himpunan fuzzy dan mengimplementasikan operasi OLAP.
Ruang lingkup penelitian adalah dibatasi pada implementasi fuzzy OLAP untuk data Potensi Desa di Provinsi Jawa Barat tahun 2003 dan 2006. Sistem yang akan dibangun mengikuti arsitektur data warehouse tiga tingkat. Struktur data pada data warehouse digambarkan dengan skema galaksi. Operasi-operasi yang diimplementasikan adalah operasi roll-up, drill-down, slice, dice, dan pivot. Operasi untuk fuzzy OLAP dilakukan sesuai dengan konsep pengoperasian data multidimensi fuzzy.
Hasil penelitian ini adalah terbentukya data warehouse yang diimplementasikan dengan konsep fuzzy serta data warehouse untuk data crisp sebagai pelengkap penyajian informasi. Data warehouse yang dibangun menggunakan konsep fuzzy terlebih dahulu melalui tahapan praproses data dan proses clustering menggunakan algoritma FCM untuk mendapatkan himpunan fuzzy dan nilai derajat keanggotaan tiap atribut. Data warehouse tersebut memiliki 4 kubus data yaitu penduduk, rumah tangga, lahan, dan sekolah. Data dapat ditampilkan dalam bentuk crosstab atau grafik. Penelitian ini memberikan informasi berupa data fuzzy dan data crisp. Data fuzzy yang disajikan memberikan informasi natural dengan mendefinisikan variabel linguistic. Data crisp disajikan sebagai penunjang untuk mendapatkan informasi.
IMPLEMENTASI FUZZY OLAPPADA DATA POTENSI DESA DI PROVINSI JAWA BARAT TAHUN 2003 DAN 2006
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
SOFIYANTI INDRIASARI G64103046
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Implementasi Fuzzy OLAPpada Data Potensi Desa di Provinsi Jawa Barat Tahun 2003 dan 2006
Nama : Sofiyanti Indriasari
NIM : G64103046
Menyetujui:
Pembimbing I, Pembimbing II,
Imas S. Sitanggang, S.Si, M.Kom Dr. Ir. Sri Nurdiati, M.Sc
NIP 132 206 235 NIP 131 578 805
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP 131 473 999
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puji dan syukur penulis panjatkan kepada Allah SWT atas segala
curahan rahmat dan karunia-Nya sehingga penelitian ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2007 ini ialah data warehouse, dengan judul Implementasi Fuzzy OLAPpada Data Potensi Desa di Provinsi Jawa Barat Tahun 2003 dan 2006
Penyelesaian penelitian ini tidak terlepas dari bantuan berbagai pihak, karena itu penulis mengucapkan terima kasih sebesar-besarnya kepada:
1. Ayahanda Achmad Azhari dan Ibunda Syafa’atur Rofiah , Kakakku Sofyan Rizalanda, serta adik-adikku Asrofi Hanafiah dan Asrofi Hanifah atas doa, kasih sayang, dan kehangatannya yang tidak pernah berhenti tercurah selama ini,
2. Ibu Imas S. Sitanggang, S.Si., M.Kom. selaku pembimbing I, Ibu Dr. Ir. Sri Nurdiati, M.Sc. selaku pembimbing II dan Bapak Hari Agung Adrianto, S.Kom. selaku dosen penguji,
3. Keluarga besar Ibu Sri Nurdiati di Bogor yang telah menjadi keluarga kedua bagi penulis,
4. Kak Hendra dan Kak Ifnu atas kesabarannya menjawab pertanyaan penulis, serta Diku atas tumpangannya mengangkut komputer untuk keperluan penelitian ini,
5. Sahabat penulis: Gibtha, Meynar, Firat, Pandi, Qwill, Ratih, Ghofar, Jemi, Hida, Dina, Vita, dan Nanik atas saran, dukungan, kerjasama, bantuan, dan hiburannya,
6. Teman-teman seperjuangan Ilkomers 40 lainnya untuk pengalaman dan kenangan yang tak ternilai, 7. Mas Irvan atas bantuannya mencari referensi untuk penelitian ini dan Pak Soleh atas bantuan dan
nasehatnya,
8. Departemen Ilmu Komputer, staf dan dosen yang telah begitu banyak membantu baik selama penelitian maupun pada masa perkuliahan.
Segala kesempurnaan hanya milik Allah SWT, semoga hasil penelitian ini dapat bermanfaat, Amin.
Bogor, Mei 2007
RIWAYAT HIDUP
Penulis dilahirkan di Blitar pada tanggal 5 Oktober 1984 dari ayah Achmad Azhari dan ibu Syafa’atur Rofiah. Penulis merupakan putri kedua dari empat bersaudara. Tahun 2003 penulis lulus dari SMU Negeri I Sidoarjo. Pada tahun yang sama penulis diterima di Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur USMI.
DAFTAR ISI
Halaman
DAFTAR TABEL... viii
DAFTAR GAMBAR... viii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA ... 1
Data Warehouse... 1
Model Data Multidimensi... 2
On-line Analytical Processing (OLAP) ... 2
Himpunan Fuzzy... 4
Fuzzy C-Means (FCM) ... 5
Ukuran Kevalidan Cluster... 5
Kubus Data Fuzzy... 6
Dimensi Fuzzy... 6
METODE PENELITIAN ... 7
Tahapan Penelitian... 7
Praproses Data... 7
Arsitektur Sistem ... 8
Lingkungan Pengembangan Sistem ... 8
HASIL DAN PEMBAHASAN ... 8
Praproses Data... 8
Tingkat Bawah (Bottom Tier)... 10
Tingkat Tengah (Middle Tier) ... 13
Tingkat Atas (Top Tier) ... 13
KESIMPULAN DAN SARAN ... 18
Kesimpulan ... 18
Saran... 19
DAFTAR PUSTAKA ... 19
DAFTAR TABEL
Halaman
1 Validasi atribut lahan bukan sawah untuk non pertanian 2006 ... 10
2 Validasi atribut lahan bukan sawah untuk non pertanian 2003 ... 10
3 Tabel dimensi yang terbentuk dalam pengembangan data warehouse untuk data crisp... 10
4 Tabel fakta yang terbentuk dalam pengembangan data warehouse untuk data crisp... 10
5 Tabel dimensi yang terbentuk dalam pengembangan data warehouse untuk data fuzzy... 11
6 Tabel fakta yang terbentuk dalam pengembangan data warehouse untuk data fuzzy... 11
DAFTAR GAMBAR
Halaman 1 Skema bintang (Han & Kamber 2001)... 22 Skema snowflake (Han & Kamber 2001)... 2
3 Skema galaksi (Han & Kamber 2001) ... 2
4 Contoh operasi roll-up (Han & Kamber 2001)... 3
5 Contoh operasi drill-down (Han & Kamber 2001) ... 3
6 Contoh operasi slice (Han & Kamber 2001)... 4
7 Contoh operasi dice (Han & Kamber 2001) ... 4
8 Contoh operasi pivot (Han & Kamber 2001) ... 4
9 Contoh kubus data fuzzy 3 dimensi (Alhajj & Mehmet 2003) ... 6
10 Contoh path pada dimensi fuzzy... 7
11 Tahap praproses data ... 7
12 Arsitektur tiga tingkat data warehouse (Han & Kamber 2001) ... 8
13 Skema galaksi untuk data crisp... 12
14 Skema galaksi untuk data fuzzy... 12
15 Contoh tampilan fuzzy OLAP untuk subjek penduduk tahun 2003 pada level desa... 14
16 Contoh operasi roll-up pada dimensi lokasi... 14
17 Contoh tampilan data crisp untuk contoh kasus tampilan subjek penduduk tahun 2003. ... 15
18 Contoh tampilan modul_desa ... 16
19 Contoh tampilan modul_kecamatan... 17
20 Contoh tampilan modul_kabupaten ... 18
DAFTAR LAMPIRAN
Halaman 1 Atribut-atribut yang terpilih dari hasil ekstraksi ... 212 Hasil validasi cluster... 23
3 Contoh hasil clustering berupa linguistic dan derajat keanggotaan ... 29
4 Skema galaksi yang disesuaikan dengan kebutuhan software Oracle... 31
5 Skema relasi modul pendukung ... 32
6 Contoh tampilan fuzzy OLAP dan hasil operasinya... 35
7 Tampilan data yang dikombinasikan dengan bentuk visualisasi model graph... 38
8 Tampilan query builder... 38
PENDAHULUAN
Latar Belakang
Dewasa ini, ketersediaan data semakin melimpah, apalagi ditunjang dengan banyaknya kegiatan yang sudah dilakukan secara terkomputerisasi. Namun seringkali data tersebut hanya disimpan tanpa diolah lebih lanjut untuk keperluan di masa mendatang. Padahal jika dianalisis lebih dalam, data tersebut dapat menghasilkan informasi atau pengetahuan yang penting dan berharga. Data Potensi Desa (Podes) yang bersumber dari Badan Pusat Statistik (BPS) memiliki peranan yang cukup strategis di masa yang akan datang dan merupakan produk unggulan BPS. Untuk itu sangat penting dilakukan analisis data Podes secara efisien dan cepat.
Data warehouse adalah tempat penyimpanan
data terintegrasi yang dapat digunakan untuk query dan analisis. Operasi query ini dilakukan dengan On-line Analytical Processing (OLAP). OLAP akan menghasilkan data dalam bentuk ringkasan. Dengan operasi ini query dapat dijalankan lebih mudah dan lebih efisien. OLAP muncul dengan sebuah cara pandang data multidimensi. Cara pandang multimensi ini didukung oleh teknologi basis data multidimensi.
Data warehouse dan On-Line Analytical
Processing (OLAP) merupakan elemen penting
dalam mendukung proses pengambilan keputusan.
Data real yang dijumpai sering kali mengandung informasi yang tidak tepat dan ketidakpastian (uncertain). Teori himpunan
fuzzy digunakan untuk menangani masalah
tersebut.
Tujuan Penelitian
Tujuan dari penelitian ini adalah :
1. Membangun data warehouse untuk data Potensi Desa tahun 2003 dan 2006. Aplikasi yang dibangun mengolah data yang direpresentasikan dalam model data multidimensi dengan menggunakan teori himpunan fuzzy.
2. Mengimplementasikan operasi-operasi OLAP, yaitu roll-up, drill-down, slice, dice,
dan pivot dengan menggunakan pendekatan
fuzzy.
Ruang Lingkup Penelitian
Penelitian ini dibatasi pada implementasi fuzzy OLAP pada data Potensi Desa di Provinsi Jawa Barat tahun 2003 dan 2006 yang bersumber dari Badan Pusat Statistik (BPS). Penelitian ini akan menghasilkan aplikasi fuzzy OLAP yang dapat menampilkan informasi untuk mendukung proses pengambilan keputusan.
Manfaat Penelitian
Aplikasi yang dihasilkan pada penelitian ini diharapkan dapat digunakan oleh pihak yang berkepentingan untuk mendapatkan informasi yang menarik dan akurat sebagai pendukung proses pengambilan keputusan terkait dengan data Potensi Desa. Sistem diharapkan dapat menyediakan informasi ringkas dan jelas secara cepat melalui operasi-operasi OLAP seperti roll-up, drill-down, slice,dice, dan pivot.
TINJAUAN PUSTAKA
Data Warehouse
Data Warehouse adalah sekumpulan data
berorientasi subjek, terintegrasi, time-variant,
dan non-volatile yang mendukung proses
manajemen pembuatan keputusan (Inmon 1996). Kata kunci dari pengertian data warehouse di atas adalah (Han & Kamber 2001):
• Berorientasi subjek: data warehouse diorganisasikan berdasarkan subjek-subjek utama, seperti pelanggan, produk atau penjualan. Data warehouse menyediakan tampilan yang sederhana dan ringkas untuk subjek tertentu dengan menghilangkan data yang tidak berguna dalam proses pembuatan keputusan.
• Terintegrasi: data warehouse dibangun dengan mengintegrasikan berbagai sumber data yang heterogen, seperti basis data relasional, flat file, dan transaksi on-line. Teknik pembersihan dan integrasi data digunakan untuk memastikan data tetap konsisten.
• Time-variant: data disimpan untuk
menyediakan informasi berdasarkan kejadian yang sudah lewat.
Model Data Multidimensi
Model data multidimensi menampilkan data dalam bentuk kubus data. Kubus data memungkinkan data dimodelkan dan ditampilkan dalam dimensi banyak. Kubus data disebut juga cuboid. Pola-pola cuboid dapat dibuat apabila diberikan satu kumpulan dimensi. Masing-masing pola menampilkan data pada tingkat kesimpulan yang berbeda-beda (Han & Kamber 2001).
Untuk menggambarkan hubungan antardata pada data multidimensi digunakan skema multidimensi. Pada data warehouse, skema merupakan sekumpulan tabel yang berhubungan. Skema digunakan untuk menunjukkan hubungan antara tabel dimensi dengan tabel fakta. Skema ditentukan berdasarkan kebutuhan data
warehouse dan keinginan pembuat data
warehouse. Data warehouse membutuhkan
skema yang ringkas dan berorientasi subjek. Tipe-tipe skema multidimensi antara lain (Han & Kamber 2001):
• Skema bintang (star schema)
Skema bintang adalah skema data
warehouse yang paling sederhana. Skema ini
disebut skema bintang karena hubungan antara tabel dimensi dan tabel fakta menyerupai bintang di mana satu tabel fakta dihubungkan dengan beberapa tabel dimensi. Titik tengah skema bintang adalah satu tabel fakta besar dan sudut-sudutnya adalah tabel-tabel dimensi. Bentuk skema bintang dapat dilihat pada Gambar 1. Keuntungan yang didapat jika menggunakan skema ini adalah peningkatan kinerja data warehouse, pemrosesan query yang lebih efisien, dan waktu respon yang cepat.
Gambar 1 Skema bintang (Han & Kamber 2001)
• Skema snowflake (snowflake schema)
Skema snowflake adalah variasi dari skema bintang di mana beberapa tabel dimensi dinormalisasi, jadi dihasilkan beberapa tabel tambahan. Bentuk skema snowflake dapat dilihat pada Gambar 2. Keuntungan yang didapat dengan menggunakan skema ini adalah penghematan memory, tapi waktu yang dibutuhkan untuk pemrosesan query menjadi lebih lama.
Gambar 2 Skema snowflake (Han & Kamber 2001)
• Skema galaksi (fact constellation)
Pada skema galaksi, beberapa tabel fakta berbagi tabel dimensi. Bentuk skema galaksi dapat dilihat pada Gambar 3. Keuntungan menggunakan skema ini adalah menghemat
memory dan mengurangi kesalahan yang
mungkin terjadi.
Gambar 3 Skema galaksi (Han & Kamber 2001)
On-line Analytical Processing (OLAP)
OLAP adalah operasi basis data untuk mendapatkan data dalam bentuk ringkasan dengan menggunakan agregasi sebagai mekanisme utama. OLAP menyediakan tampilan data yang fleksibel dari sudut pandang yang berbeda dan menyediakan lingkungan yang user-friendly untuk membantu analisis data.
• Roll-up
Operasi ini melakukan pengelompokan pada kubus data dengan cara mengurutkan suatu hirarki konsep secara menaik (ascending) atau mereduksi dimensi. Contoh operasi roll-up untuk kubus data penjualan dapat dilihat pada Gambar 4.
Contoh :
Suatu hirarki lokasi: kota < provinsi < negara
Operasi roll-up melakukan pengelompokan dengan mengurutkan hirarki lokasi dari tingkat kota sampai pada tingkat negara.
• Drill-down
Drill-down adalah kebalikan dari roll-up.
Drill-down dapat dilakukan dengan cara
mengurutkan suatu hirarki konsep secara menurun (descending) atau dengan menambahkan nilai dimensi. Contoh operasi drill-down untuk kubus data penjualan dapat dilihat pada Gambar 5.
Contoh :
Suatu hirarki waktu: bulan < kuartal < tahun
Drill-down melakukan pengelompokan
dengan mengurutkan hirarki waktu dari tingkat tahun ke tingkat yang lebih detil yaitu tingkat bulan.
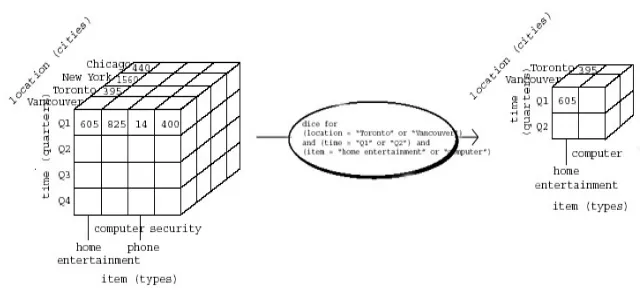
• Slice dan dice
Operasi slice melakukan pemilihan satu dimensi dari kubus data sehingga menghasilkan bagian kubus (subcube). Contoh operasi slice untuk kubus data penjualan dapat dilihat pada Gambar 6. Operasi dice menghasilkan bagian kubus (subcube) dengan melakukan pemilihan dua atau lebih dimensi. Contoh operasi dice untuk kubus data penjualan dapat dilihat pada Gambar 7.
• Pivot (rotate)
Pivot adalah operasi yang memutar
koordinat data pada tampilan dengan tujuan untuk menyediakan alternatif tampilan data. Contoh operasi pivot untuk kubus data penjualan dapat dilihat pada Gambar 8.
Gambar 4 Contoh operasi roll-up (Han & Kamber 2001)
Gambar 6 Contoh operasi slice (Han & Kamber 2001)
Gambar 7 Contoh operasi dice (Han & Kamber 2001)
Gambar 8 Contoh operasi pivot (Han & Kamber 2001)
Himpunan Fuzzy
Konsep logika fuzzy pertama kali diperkenalkan oleh Prof. Lutfi A Zadeh dari Universitas California pada bulan Juni 1965. Logika fuzzy merupakan generalisasi dari logika klasik yang hanya memiliki dua nilai keanggotaan 0 dan 1. Dalam logika fuzzy nilai
berbeda dalam masing-masing himpunan. Derajat keanggotaan menujukkan nilai keanggotaan suatu objek pada suatu himpunan. Nilai keanggotaan ini berkisar antara 0 sampai 1 (Cox 2005). Teori himpunan fuzzy telah banyak digunakan dalam pembangunan sistem data
mining. Alhajj dan Mehmet (2003) telah
menggunakan himpunan fuzzy untuk membangun kubus data fuzzy.
Fuzzy C-Means (FCM)
Menurut Jang et al. (1997), Fuzzy C-Means merupakan algoritma clustering data di mana setiap titik data masuk dalam sebuah cluster dengan ditandai oleh derajat keanggotaan. FCM membagi sebuah koleksi dari n data vektor xj (j=1, 2, …, n) menjadi c cluster, dan menemukan sebuah pusat cluster (center) untuk tiap kelompok dengan meminimalisasi ukuran dari fungsi objektif. Pada FCM hasil dari
clustering adalah sebuah titik data dapat
menjadi anggota untuk beberapa cluster yang ditandai oleh derajat keanggotaannya antara 0 dan 1.
Berikut tahapan clustering menggunakan algoritma FCM:
1. Inisialisasi keanggotaan matriks U yang berisi derajat keanggotan terhadap cluster dengan nilai antara 0 dan 1, sehingga
n bernilai antara 0 dan 1,
• dij = ||ci - xj|| adalah jarak antara pusat cluster ke-i dan titik data ke-j,
• ci adalah pusat cluster ke-i,
• m
∈
[1,∞
] adalah parameterfuzzifikasi. Nilai m yang umum
digunakan untuk clustering data fuzzy adalah sama dengan 2. Kemudian melihat kondisi berhenti : • Jika (|Jt –Jt-1| < nilai toleransi
terkecil yang diharapkan) atau (t > maksimal iterasi) maka proses berhenti.
• Jika tidak : t = t + 1, mengulangi langkah 3.
4. Penghitungan matriks U baru menggunakan formula berikut:
Ukuran Kevalidan Cluster
Menurut Xie dan Beni (1991), ukuran kevalidan cluster merupakan proses evaluasi hasil clustering untuk menentukan cluster mana yang terbaik. Kevalidan sebuah cluster (S) ditentukan oleh dua hal yaitu: ukuran kedekatan antaranggota pada tiap cluster (compactness), dan ukuran keterpisahan antarcluster satu dengan cluster yang lainnya (separation). Semakin kecil nilai S, maka cluster tersebut semakin valid.
• n adalah banyaknya titik data, • V adalah pusat cluster,
2 adalah variation dari cluster
ke-i,
• dij adalah jarak antara Xj dan Vi yang diboboti oleh derajat keanggotaan fuzzy titik ke-j pada cluster ke-i,
merupakan jarak minimum antarpusat cluster.
Kubus Data Fuzzy
Himpunan fuzzy dapat didefinisikan untuk atribut kuantitatif, misalkan x, dengan fungsi keanggotaan setiap himpunan fuzzy sedemikian sehingga nilai dari x memenuhi persyaratan berada dalam satu atau lebih himpunan-himpunan fuzzy tersebut. Misalkan Fx =
f adalah himpunan dari n himpunan fuzzy untuk atribut x. Fungsi keanggotaan dari himpunan fuzzy ke-j dalam Fx, dinotasikan dengan j
x
f
µ , menyatakan pemetaan dari domain untuk x ke dalam interval [0, 1]. Jika
)
merupakan anggota untuk himpunan fuzzy fxj. Jika j(v)
x
f
µ = 0 berarti bahwa v bukanlah
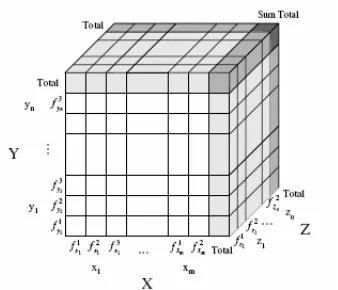
anggota dari fxj. Semua nilai yang lain di antara 0 dan 1, menentukan keanggotaan parsial (Alhajj & Mehmet 2003). Konsep tersebut selanjutnya digunakan untuk membangun kubus data fuzzy.
Gambar 9 menunjukkan kubus data fuzzy 3 dimensi, di mana setiap dimensi memiliki dua atribut dan banyaknya fungsi keanggotaan dari setiap atribut berkisar 2 dan 3. Dalam Gambar 9, setiap dimensi dari kubus data mengandung
∑
fungsi keanggotaan dari atribut xi, k adalah banyaknya atribut, keduanya dalam dimensi X, dan “+1” menunjukkan nilai total di mana setiap sel menyimpan nilai agregasi dari baris-baris sebelumnya. Seperti halnya dalam kubus data crisp, terhadap kubus data fuzzy dapat diaplikasikan operasi-operasi seperti dice, slice, roll-up dan drill-down.
Gambar 9 Contoh kubus data fuzzy 3 dimensi (Alhajj & Mehmet 2003)
Dimensi Fuzzy
Elemen (sel) pada dimensi data crisp dapat digabungkan menjadi satu elemen pada level di atasnya. Untuk kasus fuzzy, suatu elemen dapat direlasikan dengan lebih dari satu elemen pada level di atasnya dan derajat dari relasi tersebut berada pada interval [0,1]. Kinship relation mendefinisikan derajat dari relasi tersebut sebagai berikut (Molina et al. 2006 ):
Untuk tiap pasangan level li dan lj di mana lj
∈
Hi, didefinisikanµ
ij : li × l j → [0,1]Setiap derajat dari elemen-elemen dimasukkan di dalam satu elemen pada level
parent dapat dilakukan dengan menggunakan
relasi tersebut. Dengan menggunakan relasi antarelemen dalam dua level berurutan, dapat didefinisikan relasi antara tiap-tiap pasangan nilai dalam level yang berbeda di suatu dimensi yang disebut extended kinship relation. Untuk menghasilkan suatu nilai agregasi, dilakukan pertimbangan terhadap semua kemungkinan path antarelemen dalam hirarki. Masing-masing nilai dikalkulasikan dengan mengagregasikan
kinship relation pada dua level menggunakan
Gambar 10 Contoh path pada dimensi fuzzy
Gambar 10 menunjukkan path yang akan menjadi alur untuk mengkalkulasikan nilai agregasi. Proses kalkulasi nilai-nilai dari contoh tersebut adalah sebagai berikut:
(1
⊗
0.7)⊕
(1⊗
0.3)⊕
(1⊗
0) = 0.7METODE PENELITIAN
Tahapan Penelitian
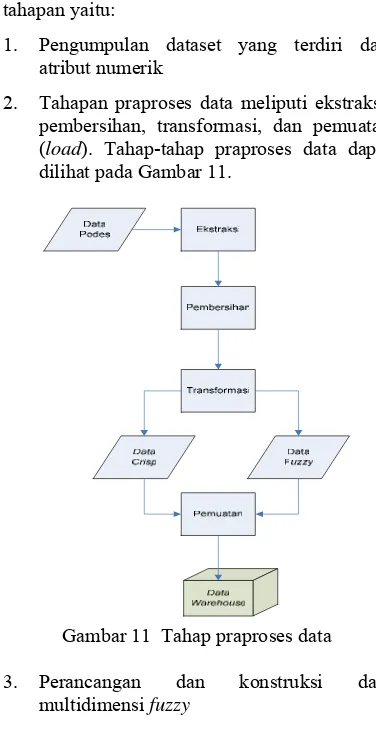
Tahapan penelitian terdiri dari empat tahapan yaitu:
1. Pengumpulan dataset yang terdiri dari atribut numerik
2. Tahapan praproses data meliputi ekstraksi, pembersihan, transformasi, dan pemuatan (load). Tahap-tahap praproses data dapat dilihat pada Gambar 11.
Gambar 11 Tahap praproses data
3. Perancangan dan konstruksi data multidimensi fuzzy
4. Perancangan antarmuka kueri Fuzzy OLAP.
Praproses Data
Praproses data adalah proses yang harus dilakukan sebelum membuat data warehouse. Proses-proses tersebut adalah:
1 Ekstraksi (extraction)
Ekstraksi adalah pengambilan data yang relevan untuk analisis dari basis data operasional sebelum masuk ke data warehouse. Pada ekstraksi, atribut-atribut dan record-record yang diinginkan dipilih dan diambil dari basis data operasional. Hal ini perlu dilakukan karena tidak semua elemen data berguna dalam analisis dan pembuatan keputusan. Elemen data yang diperlukan adalah atribut pada data Podes Jawa Barat tahun 2003 dan 2006 yang bersifat numerik agar dapat diimplementasikan konsep fuzzy dan merupakan atribut data yang mengandung konsep hirarki agar dapat terlihat pola agregasi pada saat pengimplementasian operasi OLAP, serta atribut yang terdapat pada data Potensi Desa Jawa Barat tahun 2003 dan 2006 antartahun.
2 Pembersihan (cleaning)
Pada pembersihan semua kesalahan dihilangkan dan diperbaiki. Pembersihan dilakukan untuk menghilangkan kesalahan
(error). Kesalahan yang umum terjadi
adalah nilai yang hilang (missing values),
noise, dan data yang tidak konsisten.
Pembersihan dilakukan dengan mengisi nilai yang kosong dan menghilangkan noise.
3 Transformasi (transformation)
Pada transformasi, data Podes Jawa Barat tahun 2003 dan 2006 yang terpilih diberikan format dan nama yang umum. Proses transformasi dilakukan agar data tetap konsisten. Transformasi yang paling penting adalah transformasi nama agar tidak ada nama atribut yang sama atau atribut yang sama memiliki nama yang berbeda pada basis data yang berbeda. Setelah transformasi nama, semua elemen data harus dikonversikan ke format yang sama.
himpunan fuzzy dan derajat keanggotaannya. Langkah selanjutnya adalah menentukan validitas cluster. Tujuan dilakukannya validasi terhadap fuzzy clustering yaitu untuk mencari skema clustering di mana sebagian besar vektor dari suatu himpunan datamenunjukkan derajat keanggotaan yang tinggi dalam suatu cluster. Pengukuran kevalidan cluster dilakukan menurut metode Xie dan Beni (1991) yang menjelaskan bahwa kevalidan sebuah cluster (S) ditentukan oleh dua hal yaitu: ukuran kedekatan antaranggota pada tiap cluster
(compactness), dan ukuran keterpisahan
antarcluster satu dengan cluster yang lainnya (separation). Semakin kecil nilai S, maka cluster tersebut semakin valid.
4 Pemuatan (loading)
Setelah tahap ekstraksi, pembersihan, dan transformasi dilakukan, maka data dapat dimasukkan ke data warehouse.Data yang dimasukkan ke dalam data warehouse adalah data crisp dan data fuzzy.
Arsitektur Sistem
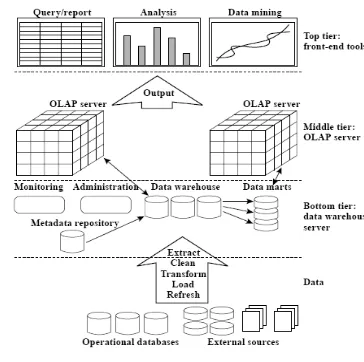
Sistem yang akan dibangun mengikuti arsitektur data warehouse tiga tingkat seperti terlihat pada Gambar 12:
Gambar 12 Arsitektur tiga tingkat data warehouse (Han & Kamber 2001)
1 Tingkat bawah (bottom tier)
Tingkat bawah arsitektur data warehouse adalah server basis data
warehouse yang biasanya sebuah sistem
basis data relasional. Tahap ini data
diambil dari basis data operasional dan sumber eksternal lainnya. Data disimpan sebagai data warehouse.
2 Tingkat tengah (middle tier)
Pada tingkat tengah, operasi OLAP dilakukan pada data warehouse yang sudah terbentuk. Implementasi operasi OLAP disesuaikan dengan struktur data Podes Jawa Barat 2003 dan 2006, yang mencakup struktur hirarki data. Pada penelitian ini, operasi OLAP diimplementasikan sesuai dengan aturan-aturan pada konsep fuzzy, termasuk fungsi agregasi fuzzy yang digunakan.
3 Tingkat atas (top tier)
Pada tingkat atas, data warehouse telah terbentuk dan digunakan oleh pengguna. Perangkat analisis berupa perangkat query dan grafik dibuat untuk memudahkan analisis data.
Lingkungan Pengembangan Sistem
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam pengembangan sistem adalah sebagai berikut:
a. Perangkat keras berupa komputer personal dengan spesifikasi: b. Perangkat lunak:
- Sistem operasi: Microsoft Windows XP Professional
- DBMS: Oracle 10g Release 2
- Data Warehouse dan OLAP: Analytic
Workspace Manager dan Measure Data Viewer
- MATLAB 7 untuk clustering data - Microsoft SQL Server 2000 dan
Microsoft Excel untuk praproses data.
HASIL DAN PEMBAHASAN
Praproses Data
1. Ekstraksi
Tahapan ekstraksi adalah melakukan pemilihan atribut yang relevan untuk analisis yaitu atribut numerik, atribut berhirarki, dan atribut yang ada pada data Potensi Desa Jawa Barat tahun 2003 dan 2006 antartahun. Atribut pada data Potensi Desa Jawa Barat tahun 2003 dan 2006 yang terpilih adalah atribut lokasi meliputi desa, kecamatan, dan kabupaten di Jawa Barat, serta atribut yang berhubungan dengan kependudukan yang meliputi jumlah penduduk dan jumlah rumah tangga prasejahtera 1 serta jumlah keluarga keseluruhan di masing-masing desa, luasan lahan, dan pendidikan yang meliputi jumlah sekolah dari TK sampai SMA. Atribut-atribut yang terpilih dan deskripsinya dapat dilihat pada Lampiran 1.
2. Pembersihan
Tahap pembersihan data tidak perlu dilakukan, karena data yang digunakan sudah bersih.
3. Transformasi
Tahap transformasi adalah memberikan format yang umum pada data, meliputi menyamakan nama atribut yang sama pada data tahun 2003 dan 2006 atau memberikan nama atribut dengan nama yang umum sehingga atribut antartahun menjadi seragam dan lebih informatif. Selain itu, juga dilakukan penggabungan atribut pada data tahun 2003 karena pada data tahun 2006 beberapa atribut yang sesuai dengan atribut data tahun 2003 dijadikan satu. Pembentukan atribut baru juga dilakukan yang bertujuan untuk mendefinisikan secara lengkap hirarki data. Atribut baru yang dibuat adalah atribut ”Keluarga bukan Prasejahtera I ”. Nilai-nilai atribut tersebut didapatkan dari mengurangi nilai atribut jumlah keluarga keseluruhan dengan nilai atribut jumlah keluarga Prasejahtera I, sehingga nantinya akan dapat didefinisikan hirarki data untuk dimensi rumah tangga.
Pada penelitian kali ini, data yang akan dimasukkan ke dalam data warehouse bukan hanya data fuzzy tetapi juga data dalam bentuk crisp. Praproses data yang telah dilakukan sebelumnya adalah
menghasilkan data crisp, untuk itu perlu adanya proses lanjutan untuk menghasilkan data dalam bentuk fuzzy. Pembentukan data fuzzy dilakukan dengan proses clustering terhadap seluruh atribut yang telah terpilih dengan menggunakan algoritma FCM untuk menentukan himpunan fuzzy dan fungsi keanggotaannya.
Proses clustering menggunakan algoritma FCM dapat menentukan jumlah cluster yang diinginkan. Akan tetapi, untuk memilih cluster yang terbaik dilakukan pengukuran kevalidan cluster, sehingga proses clustering dicobakan berulang-ulang dengan jumlah cluster yang berbeda-beda kemudian dilihat nilai kevalidan
cluster. Cluster yang valid adalah yang
memiliki nilai kevalidan cluster (S) terkecil.
Pada penelitian kali ini, penentuan himpunan fuzzy tidak hanya berdasarkan pada ukuran kevalidan cluster tetapi juga memperhatikan kesamaan jumlah cluster pada dimensi yang sama. Hal ini dilakukan dengan pertimbangan bahwa dalam struktur data
warehouse atribut dalam satu dimensi yang
sama harus sama jumlahnya termasuk measure yang digunakan juga harus sama.
Clustering dilakukan terpisah antara atribut-atribut dalam data tahun 2003 dan 2006, sehingga memungkinkan terjadinya ketidaksamaan jumlah cluster yang valid antartahun pada dimensi yang sama. Jika terjadi ketidaksesuaian maka dilakukan penyesuaian dengan memilih selisih nilai S terkecil. Atribut yang memiliki selisih S terkecil akan dipilih cluster yang jumlahnya sama dengan atribut yang berada pada dimensi yang sama dan memiliki selisih nilai S lebih besar. Jadi pemilihan cluster pada atribut tersebut bukan berdasarkan pada nilai S terkecilnya, tapi disesuaikan dengan nilai S terkecil atribut lain dalam satu dimensi. Selain itu, percobaan untuk menentukan jumlah cluster hanya dibatasi sampai lima cluster saja. Hal ini disebabkan jika lebih dari lima cluster yang terbentuk maka variabel linguistic yang dihasilkan menjadi kurang informatif.
nilai S antara jumlah cluster dua dan tiga pada Tabel 1 sama dengan 0.10084. Selisih selisih nilai S antara jumlah cluster dua dan tiga pada Tabel 2 sama dengan 0.00001. Oleh karena selisih nilai S antara jumlah cluster dua dan tiga pada Tabel 2 lebih sedikit daripada selisih nilai S antara jumlah cluster dua dan tiga pada Tabel 1, maka pemilihan jumlah cluster untuk Tabel 2 disesuaikan dengan jumlah cluster valid yang terbentuk pada Tabel 1, jadi jumlah cluster yang terpilih untuk dua atribut tersebut adalah sama dengan dua cluster.
Tabel 1 Validasi atribut lahan bukan sawah untuk non pertanian 2006
Tabel 2 Validasi atribut lahan bukan sawah untuk non pertanian 2003
Jumlah
Cluster Compactness Separation S
2 4,69E+05 1,19E+10 0,00004
3 7,70E+04 2,68E+09 0,00003
4 4,54E+04 6,15E+04 0,73807 5 2,78E+03 4,48E+04 0,06198
Hasil keseluruhan pengukuran kevalidan
cluster dapat dilihat pada Lampiran 2 dan
beberapa contoh hasil dari proses clustering yaitu derajat keanggotaan dan linguistic yang sesuai dengan jumlah cluster validyang terpilih dapat dilihat pada Lampiran 3.
4. Pemuatan (loading)
Tahap pemuatan atau loading adalah tahap pemasukan data yang sudah siap ke data warehouse.
Tingkat Bawah (Bottom Tier)
Pada tingkat ini data diambil dari basis data operasional. Selain itu, dilakukan penyesuaian struktur data terhadap skema data warehouse. Data yang dimasukkan ke dalam data
warehouse disesuaikan dengan rancangan
skema data multidimensi yang dinginkan, untuk menggambarkan hubungan antardata. Sebelum skema didefinisikan, terlebih dahulu dilakukan
pembuatan tabel-tabel yang nantinya akan digunakan untuk mendefinisikan hubungan antardata yang digambarkan pada skema. Tabel-tabel yang perlu dibuat adalah Tabel-tabel dimensi yang terlihat pada Tabel 3 dan 5, serta dan tabel fakta yang terlihat pada Tabel 4 dan 6.
Tabel 3 Tabel dimensi yang terbentuk dalam pengembangan data warehouse untuk data crisp Nama Tabel Deskripsi
Dim_Lokasi_Crisp Berisikan kode dan lokasi atau daerah dari tingkat desa sampai tingkat provinsi di Jawa Barat
Dim_Tahun_Crisp Berisikan kode dan tahun data yang digunakan
Dim_Penduduk_Crisp Berisikan kode dan penjelasan tentang struktur penduduk
Dim_Rt_Crisp Berisikan kode dan penjelasan struktur rumah tangga
Dim_Lahan_Crisp Berisikan kode dan penjelasan struktur atau macam-macam pengelompokan lahan
Dim_Sekolah_Crisp Berisikan kode dan penjelasan struktur atau macam-macam sekolah
Tabel 4 Tabel fakta yang terbentuk dalam pengembangan data warehouse untuk data crisp Nama Tabel Deskripsi
Fakta_Penduduk_Crisp Berisikan kode dan nilai numerik atau measure data crisp penduduk yang berupa jumlah penduduk dalam satuan orang Jumlah
Cluster Compactness Separation S
2 4,E+04 3,E+07 0,00117
3 2,E+04 2,E+05 0,10201
4 9,E+03 1,E+05 0,06102
Tabel 4 lanjutan
Nama Tabel Deskripsi
Fakta_Lahan_Crisp Berisikan kode dan nilai numerik atau measure data crisp lahan yang berupa luas lahan dalam satuan Ha
Fakta_Sekolah_Crisp Berisikan kode dan nilai numerik atau measure data crisp sekolah yang berupa jumlah sekolah dalam satuan unit
Fakta_Rt_Crisp Berisikan kode dan nilai numerik atau measure data crisp rumah tangga yang berupa jumlah rumah tangga dalam satuan keluarga
Tabel 5 Tabel dimensi yang terbentuk dalam pengembangan data warehouse untuk data fuzzy Nama Tabel Deskripsi
Dim_Lokasi Berisikan kode dan lokasi atau daerah dari tingkat desa sampai tingkat provinsi di Jawa Barat
Dim_Tahun Berisikan kode dan tahun data yang digunakan
Dim_Penduduk Berisikan kode dan penjelasan tentang struktur penduduk termasuk linguistic penduduk
Dim_Rt Berisikan kode dan penjelasan tentang struktur rumah tangga termasuk linguistic rumah tangga
Tabel 5 lanjutan
Nama Tabel Deskripsi
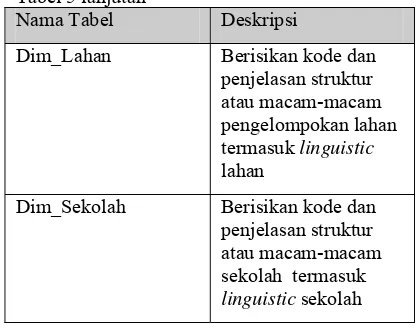
Dim_Lahan Berisikan kode dan penjelasan struktur atau macam-macam pengelompokan lahan termasuk linguistic lahan
Dim_Sekolah Berisikan kode dan penjelasan struktur atau macam-macam sekolah termasuk linguistic sekolah
Tabel 6 Tabel fakta yang terbentuk dalam pengembangan data warehouse untuk data fuzzy Nama Tabel Deskripsi
Fakta_Penduduk Berisikan kode dan nilai numerik atau measure yang berupa nilai-nilai derajat keanggotaan sesuai dengan linguistic-nya
Fakta_Rt Berisikan kode dan nilai numerik atau measure yang berupa nilai-nilai derajat keanggotaan sesuai dengan linguistic-nya
Fakta_Lahan Berisikan kode dan nilai numerik atau measure yang berupa nilai-nilai derajat keanggotaan sesuai dengan linguistic-nya
Fakta_Sekolah Berisikan kode dan nilai numerik atau measure yang berupa nilai-nilai derajat keanggotaan sesuai dengan linguistic-nya
Setelah itu, dilakukan perancangan skema yang digunakan untuk menunjukkan hubungan antara tabel dimensi dengan tabel fakta. Skema ditentukan berdasarkan kebutuhan data
warehouse dan keinginan pembuat data
galaksi untuk menggambarkan hubungan antardata. Skema galaksi untuk data crisp yang terbentuk dapat dilihat pada Gambar 13 dan skema galaksi untuk data fuzzy terlihat pada Gambar 14.
Skema yang terlihat pada Gambar 13 dan 14 akan digunakan sebagai kerangka untuk pembangunan data warehouse utama. Masing-masing skema memiliki enam tabel dimensi yang mendefinisikan atribut-atribut kategorik serta hirarki data dan memiliki 4 tabel fakta yang berisikan nilai-nilai numerik berupa
primary key dari setiap dimensi yang
dihubungkan serta nilai measure yang akan dioperasikan. Dimensi lokasi dan dimensi tahun digunakan secara bersama-sama (shared). Pada tiap-tiap skema terbentuk masing-masing empat kubus data sesuai dengan subjeknya. Kubus data dibentuk berdasarkan kombinasi dari beberapa tabel dimensi dan tabel fakta yang saling berhubungan seperti yang telah tergambarkan pada skema yang ditunjukkan pada Gambar 13 dan 14.
Untuk keperluan implementasi, dibuat skema galaksi yang menyesuaikan keperluan
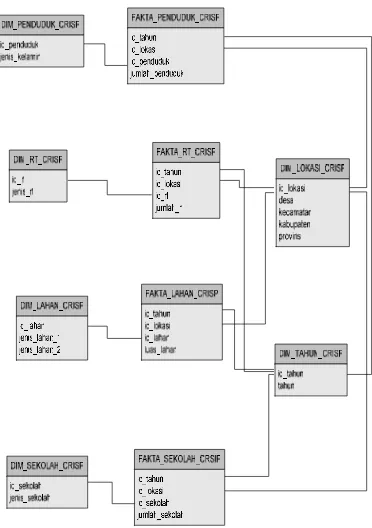
software Oracle. Skema tersebut merupakan
pengembangan dari skema yang terlihat pada Gambar 13 dan 14. Skema yang dihasilkan dapat dilihat di Lampiran 4.
Data warehouse dalam bentuk crisp terdiri dari empat kubus data dengan masing-masing subjeknya yaitu penduduk, rumah tangga, lahan, dan sekolah. Pada tiap-tiap kubus data memiliki
measure secara berurutan sesuai subjeknya
adalah jumlah penduduk (orang), jumlah rumah tangga (keluarga), luas (Ha), dan jumlah sekolah (unit)
Data warehouse dalam bentuk fuzzy juga
terdiri dari empat kubus data dengan subjek yang sama dengan data warehouse crisp. Hal yang membedakan adalah pada data warehouse fuzzy memiliki measure yang merupakan nilai derajat keanggotaan pada tiap-tiap fungsi keanggotaan hinpunan fuzzy yang telah didefinisikan pada masing-masing dimensinya. Misalnya nilai fuzzy penduduk pada kubus data penduduk merupakan nilai derajat keanggotaan terhadap variabel linguistic banyak dan sedikit yang telah terdefinisi pada dimensi penduduk.
Gambar 13 Skema galaksi untuk data crisp
Selain melakukan loading data crisp dan data fuzzy ke dalam dua warehouse yang terpisah, dibuat juga modul tambahan berisi table-tabel pendukung yang bertujuan untuk menjelaskan tentang pemaknaan nilai-nilai agregasi yang terdapat pada kubus data fuzzy, serta penggabungan antara nilai crisp dan fuzzy. Modul yang dibangun ada tiga yaitu modul_desa, modul_kecamatan, dan modul_kabupaten. Rancangan skema relasi untuk masing-masing modul dapat dilihat pada Lampiran 5.
Tingkat Tengah (Middle Tier)
Pada tingkat tengah adalah implementasi operasi OLAP pada data warehouse yang sudah terbentuk. Operasi OLAP yang diimplementasikan meliputi operasi roll-up,
drill-down, slice, dice, dan pivot. Pada
penelitian ini, operasi OLAP pada data crisp menggunakan fungsi agregasi biasa yaitu menggunakan operator agregasi berupa sum, seperti yang terlihat pada Gambar 17 bahwa untuk nilai di level kecamatan, kabupaten, dan provinsi adalah hasil penjumlah nilai sel-sel di level bawahnya. Untuk data fuzzy operasi OLAPdiimplementasikan sesuai dengan aturan-aturan pada konsep fuzzy. Untuk menghasilkan suatu nilai agregasi, dilakukan pertimbangan terhadap semua kemungkinan path antarelemen dalam hirarki. Masing-masing nilai dikalkulasikan dengan mengagregasikan kinship
relation menggunakan operator
⊗
dan⊕
dimana operator tersebut secara berurutan adalah
t-norm dan t-conorm. Nilai pada level yang
saling berurutan di suatu path dikalkulasikan dengan menggunakan operator t-norm kemudian hasil dari kalkulasi tiap-tiap path diagregasikan menggunakan operator t-conorm untuk mendapatkan nilai agregasi pada level yang lebih tinggi. Fungsi t-norm adalah mengambil nilai minimum dari path yang levelnya berurutan, sedangkan fungsi t-conorm adalah mengambil nilai maksimum dari hasil kalkulasi pada tiap-tiap path yang telah dikalkulasikan dengan fungsi t-norm sebelumnya. Misalnya seperti yang terlihat pada Gambar 15 desa Malasari untuk kasus penduduk laki-laki nilai pada linguistic banyak nilainya sama dengan 0.02 dan nilai pada linguistic sedikit 0.98, maka nilai untuk derajat keanggotaan laki-laki secara keseluruhan adalah
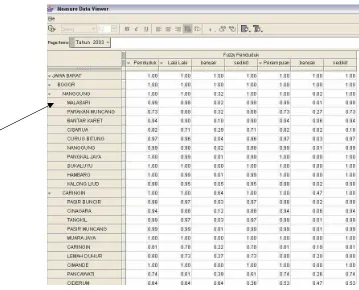
0.98. Nilai tersebut adalah nilai maksimum antara linguistic banyak dan linguistic sedikit. Maksud dari ringkasan nilai laki-laki sama dengan 0.98 adalah menjelaskan bahwa jumlah penduduk laki-laki di desa Malasari masuk ke dalam kategori linguistic banyak.
Tingkat Atas (Top Tier)
Pada tingkat top tier adalah menampilkan data warehouse yang telah terbentuk, sehingga dapat digunakan oleh pengguna.Penyajian data dapat dilakukan dari berbagai sudut pandang, misalnya ringkasan data yang menampilkan elemen-elemen yang merupakan potensi daerah di Provinsi Jawa Barat atau penyajian data secara detil di elemen terkecil yaitu tingkat desa. Gambar 15 adalah contoh tampilan kubus data fuzzy untuk subjek penduduk tahun 2003 di level paling bawah yaitu level desa. Operasi OLAP yang diimplementasikan salah satunya adalah operasi roll-up seperti yang terlihat pada Gambar 16 yang merupakan hasil dari operasi roll-up pada dimensi lokasi untuk contoh kasus yang terlihat pada Gambar 15, di mana nilai pada setiap sel di kecamatan adalah hasil agregasi yang merupakan nilai maksimum dari derajat keanggotaan di masing-masing desa. Contoh tampilan hasil operasi OLAP lainnya dapat dilihat pada Lampiran 6.
Tampilan yang terbentuk juga dilengkapi dengan grafik sebagai bentuk visualisasi data seperti yang terlihat pada Lampiran 7. Selain itu, juga dilengkapi dengan query builder dalam bentuk query wizard yang dapat mempermudah pengguna untuk menjalankan operasi OLAP. Bentuk query builder dapat dilihat di Lampiran 8.
Gambar 15 Contoh tampilan fuzzy OLAP untuk subjek penduduk tahun 2003 pada level desa
Gambar 17 Contoh tampilan data crisp untuk contoh kasus tampilan subjek penduduk tahun 2003.
Nilai-nilai yang ditampilkan pada kubus data fuzzy adalah nilai derajat keanggotaan terhadap himpunan fuzzy yang telah dibentuk dan diproses terlebih dahulu. Nilai derajat keanggotaan pada level lebih tinggi merupakan nilai maksimum dari level di bawahnya. Untuk memahami makna nilai agregasi tersebut adalah dengan mempertimbangkan perbandingan nilai derajat keanggotaan antarlinguisticnya, misalnya jika derajat keanggotaan pada linguistic A lebih besar daripada nilai derajat keanggotaan pada linguistic B maka nilai tersebut masuk ke dalam kategori A. Contohnya pada Gambar 15 derajat keanggotaan penduduk laki-laki di kecamatan Nanggung sama dengan 1 dan dikatakan panduduk laki-laki di kecamatan Nanggung termasuk sedikit. Hal ini diperoleh dari nilai maksimum antara linguistic banyak dan sedikit pada kecamatan tersebut. Oleh karena nilai linguistic banyak sama 0.32 dan nilai linguistic sedikit sama dengan 1 maka kecamatan Nanggung masuk ke kategori sedikit. Akan tetapi, jika nilai hasil agregasi menunjukkan
penduduk di kecamatan Nanggung masuk kategori sedikit.
Modul-modul tambahan yang telah dibuat untuk membantu dalam memahami makna nilai agregasi fuzzy terdiri dari:
• Modul_desa
Modul_desa menampilkan nilai crisp dan nilai derajat keanggotaan. Contoh tampilan modul desa dapat dilihat pada Gambar 18.
Derajat keanggotaan yang ditampilkan adalah derajat keanggotaan dasar pada level terbawah untuk dimensi subjeknya yaitu dimensi penduduk dan dimensi lokasi. Selain itu, juga menampilkan nilai crisp yang dapat diagregasikan berdasarkan dimensi lokasi. Pada Gambar 18 terlihat di level desa dijelaskan secara rinci baik itu nilai cirsp maupun nilai di setiap linguistic-nya.
Gambar 18 Contoh tampilan modul_desa
• Modul_kecamatan
Modul_kecamatan menampilkan nilai
crisp dan kategori umum untuk tingkat
kecamatan. Beberapa keterangan mengenai kategori umum dapat dilihat pada Lampiran 9. Contoh tampilan modul_kecamatan dapat dilihat pada Gambar 19. Nilai crisp dan kategori umum yang ditampilkan tidak dapat langsung disimpulkan dengan menghubungkan keduanya. Pada Gambar 19 terlihat bahwa untuk kecamatan Majalaya jumlah penduduk laki-laki 61983 orang dan
yang lebih dari 0,5 pada linguistic sedikit, sehingga jumlah penduduk laki-laki di kecamatan Majalaya masuk kategori umum 1 yaitu banyak atau dapat dikatakan bahwa jumlah penduduk laki-laki di kecamatan Majalaya secara umum di masing-masing daerahnya masuk kategori banyak. Untuk kecamatan Rancaekek meskipun secara real jumlah penduduk laki-laki lebih besar daripada jumlah penduduk laki-laki di
kecamatan Majalaya, kecamatan Rancaekek masuk ke dalam ketegori umum 2 yaitu sedikit. Hal ini dikarenakan jumlah derajat keanggotaan yang lebih dari 0,5 pada linguistic sedikit lebih besar daripada jumlah derajat keanggotaan yang lebih dari 0,5 pada linguistic banyak atau secara umum jumlah penduduk laki-laki pada masing-masing daerah di kecamatan Rancaekek termasuk dalam kategori sedikit.
Gambar 19 Contoh tampilan modul_kecamatan
• Modul_kabupaten
Modul_kabupaten menampilkan nilai
crisp dan kategori umum untuk tingkat
kabupaten. Beberapa keterangan mengenai kategori umum dapat dilihat pada Lampiran 9. Contoh tampilan modul_ kabupaten dapat dilihat pada Gambar 20. Sama halnya seperti pada modul_kecamatan, nilai crisp dan kategori umum yang ditampilkan tidak dapat langsung disimpulkan dengan menghubungkan keduanya. Pada Gambar 20 terlihat bahwa untuk kabupaten Cimahi jumlah penduduk laki-laki 201781 orang dan
kabupaten Cimahi masuk kategori umum 1 yaitu banyak atau dapat dikatakan bahwa jumlah penduduk laki-laki di kabupaten Cimahi secara umum di masing-masing daerahnya masuk kategori banyak. Untuk kabupaten Cianjur meskipun secara real jumlah penduduk laki-laki lebih besar daripada jumlah penduduk laki-laki di kabupaten Cimahi, kabupaten Cianjur masuk
ke dalam ketegori umum 2 yaitu sedikit. Hal ini dikarenakan jumlah derajat keanggotaan yang lebih dari 0,5 pada linguistic sedikit lebih besar daripada jumlah derajat keanggotaan yang lebih dari 0,5 pada linguistic banyak atau secara umum jumlah penduduk laki-laki pada masing-masing daerah di kabupaten Cianjur termasuk dalam kategori sedikit.
Gambar 20 Contoh tampilan modul_kabupaten
KESIMPULAN DAN SARAN
Kesimpulan
Penelitian ini menghasilkan data warehouse yang dibangun berdasarkan konsep fuzzy serta
data warehouse untuk data crisp sebagai
pelengkap penyajian informasi. Data warehouse yang dibangun menggunakan konsep fuzzy selain melalui tahapan praproses data juga melalui proses clustering menggunakan algoritma FCM untuk mendapatkan himpunan fuzzy dan nilai derajat keanggotaan tiap atribut. Nilai derajat keanggotaan yang didapatkan merupakan
measure, sedangkan linguistic yang
didefinisikan dari jumlah cluster merupakan salah satu dari atribut pada level terbawah dalam dimensi yang terkait. Data warehouse fuzzy memiliki 4 kubus data yaitu penduduk, rumah tangga, lahan, dan sekolah.
Penelitian ini memberikan informasi berupa data fuzzy dan data crisp. Data fuzzy yang disajikan memberikan informasi natural dengan mendefinisikan variabel linguistic. Data crisp disajikan sebagai penunjang untuk mendapatkan informasi.
Saran
Saran untuk pengembangan fuzzy OLAP adalah mengembangkan sistem yang mengintegrasikan fuzzy OLAP dengan beberapa algoritma dalam data mining seperti algoritma
association rules. Sistem tersebut diharapkan
akan menyajikan report yang lebih lengkap dan lebih bermakna untuk melihat pola atau model data dengan lebih jelas, sehingga lebih informatif untuk mendukung pengambilan keputusan.
DAFTAR PUSTAKA
Alhajj R, Mehmet K. 2003. Integrating
Fuzziness into OLAP for Multidimensional
Fuzzy Association Rules Mining. Proceedings of the Third IEEE International Conference on Data mining.
Cox, E. 2005. Fuzzy Modeling and Algorithms
for Data mining and Exploration. USA:
Academic Press.
Han J, Kamber M. 2001. Data Mining: Concepts
and Techniques. San Diego, USA: Morgan
Kaufmann.
Inmon WH. 1996. Building the Data warehouse. New York, USA: John Wiley & Sons.
Jang JSR, Sun CT, Mizutani Eiji. 1997. Neuro-Fuzzy and Soft Computing. London: Prentice-Hall International, Inc.
Molina Carlos, Ariza LR, S Daniel, Vila
M.Amparo. 2006. A New Fuzzy
Multidimensional Model. IEEE Transaction
On Fuzzy System.
Lampiran 1 Atribut-atribut yang terpilih dari hasil ekstraksi
a. Atribut tentang lokasi untuk data tahun 2003 dan 2006 Atribut Deskripsi
Provinsi Berisikan nama provinsi
Kabupaten Berisikan nama kabupaten
Kecamatan Berisikan nama kecamatan
Desa Berisikan nama desa
b. Atribut tentang kependudukan yang terpilih untuk data tahun 2003 Atribut Deskripsi
V402A Berisikan jumlah penduduk laki-laki di tingkat desa
V402B Berisikan jumlah penduduk perempuan di tingkat desa
V402C Berisikan jumlah keluarga atau rumah tangga di tingkat desa
V403A1 Berisikan jumlah rumah tangga atau keluarga yang termasuk di dalam kategori keluarga prasejahtera I di tingkat desa
c. Atribut tentang kependudukan yang terpilih untuk data tahun 2006 Atribut Deskripsi
R401A Berisikan jumlah penduduk laki-laki di tingkat desa
R401B Berisikan jumlah penduduk perempuan di tingkat desa
R401C Berisikan jumlah rumah tangga atau keluarga di tingkat desa
R401E Berisikan jumlah rumah tangga atau keluarga yang termasuk di dalam kategori keluarga prasejahtera I di tingkat desa
d. Atribut tentang luas lahan yang terpilih untuk data tahun 2003 Atribut Deskripsi
V1201 Berisikan luas desa
V1202 Berisikan luas lahan sawah di masing-masing desa
V1202A Berisikan luas lahan sawah berpengairan yang diusahakan di masing-masing desa
V1202B Berisikan luas lahan sawah tidak berpengairan yang diusahakan di masing-masing desa
V1202C Berisikan luas lahan sawah sementara yang tidak diusahakan di masing-masing desa
V1203 Berisikan luas lahan bukan sawah di masing-masing desa
V1203A Berisikan luas tambak/kolam/padang/rumput di masing-masing desa
V1203B Berisikan luas perkebunan di masing-masing desa
V1203C Berisikan luas hutan rakyat di masing-masing desa
V1203D Berisikan luas lahan perumahan dan pemukiman di masing-masing desa
V1203E Berisikan luas lahan untuk bangunan industri di masing-masing desa