ANA RISQA JL
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2016
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa tesis berjudul “Pemodelan Regresi Komponen Utama Fungsional pada Data Spektroskopi” adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Januari 2016
Ana Risqa JL
RINGKASAN
ANA RISQA JL. Pemodelan Regresi Komponen Utama Fungsional pada Data Spektroskopi. Dibimbing oleh AJI HAMIM WIGENA dan ERFIANI.
Data Spektroskopi adalah data fungsional berupa pengamatan spektrum yang merupakan fungsi dari panjang gelombang. Data spektrum dapat digunakan dalam banyak bidang. Dalam industri farmasi analisis spektrum digunakan dalam mengendalikan mutu untuk menentukan kandungan peubah tertentu seperti jumlah senyawa aktif pada tanaman obat. Pada penelitian ini, data spektroskopi yang digunakan ialah data pengukuran senyawa aktif Kurkumin pada Temulawak. Data Kurkumin diperoleh dari tanaman Temulawak hasil pengamatan dua daerah sentral produksi tanaman obat yaitu Kulonprogo, D.I Yogyakarta dan Karanganyar, Jawa Tengah. Pada data variabel Y merupakan hasil pengukuran senyawa aktif Kurkumin dengan menggunakan HPLC (High Performance Liquid
Chromatography) sedangkan variabel X merupakan hasil pengukuran senyawa
aktif Kurkumin dengan menggunakan FTIR (Fourier Transform Infrared). Pada penelitian ini data di random kemudian dibagi menjadi dua bagian yaitu 70% data menjadi data untuk pemodelan dan 30 % untuk data validasi dan dilakukan pengulangan sebanyak 150 kali.
Data spektroskopi umumnya berdimensi besar dan mengandung multikolinieritas karena biasanya data spektroskopi memiliki jumlah peubah bebas (p) lebih besar dari jumlah pengamatan (p>>n). Kedua masalah tersebut dapat diatasi dengan metode analisis komponen utama fungsional (AKUF). Metode ini merupakan perluasan dari metode analisis komponen Utama (AKU) dengan menggunakan pendekatan fungsional. Data sebelum direduksi dengan metode AKUF terlebih dahulu dilakukan transformasi menggunakan transformasi basis polinomial dan basis B-spline. Pola pada data spektroskopi sebelum dan sesudah ditransformasi akan memiliki pola yang sama namun pada data yang telah ditransformasi pola datanya lebih halus jika dibandingkan dengan sebelumnya.
Hasil penelitian ini menunjukkan bahwa model RKUF B-spline sangat baik digunakan dalam memprediksi jumlah senyawa aktif kurkumin yang terkandung dalam tanaman obat temulawak dibandingkan dengan model RKUF polinomial ataupun RKU. Namun jika diperbandingkan antara model RKU dan RKUF polinomial maka model RKUF polinomal lebih baik dalam memprediksi jumlah senyawa aktif kurkumin yang terkandung dalam tanaman obat temulawak.
SUMMARY
ANA RISQA JL. The Modeling of Functional Principal Component Regression on Spectroscopy Data. Superviced by AJI HAMIM WIGENA and ERFIANI.
Spectroscopy data is a functional data which have spectrum observation which is the function of the wave length. Spectrum can be used in many areas. In Industrial Farmacy, spectrum analysis is used to control the quality to determine specific variables such as the amount of active compound in herbs. In this research, the spectroscopy data used is the data of curcumin active compound in curcuma. The curcumin data was obtained from the observation of curcuma herbs from two herbs central production area such as Kulonprogo D.I. Yogyakarta and Karanganyar, Central Java. The Y variable is the concentration of the curcumin active compound measured by HPLC (High Performance Liquid Chromatography), while X variable is the result of the curcumin active compound measured by FTIR (Fourier Transform Infrared). In this research, the data was randomly divided into two parts that are 70 % data for the model and 30 % data for validation and was treated by 150 times repetitions.
Spectroscopy data generally have large dimension and contain multicolinearities because usually in spectroscopy data the number of independent variables (p) is greater than the number of observations (p>>n). Both problems can be overcome using Functional Principal Component Analysis (FPCA) method. This method is based on Principal Component Analysis (PCA). In FPCA, the data is transformed using polynomial and B-Spline basis before data reduction. The original scpectroscopy data pattern has similar to the pattern of the transformed data, but the transformed data are the smoother pattern.
The number of the principal components used in this research was determinded based on the proportion of cumulative variance. This research used two components with the proportion of cumulative variance 95.33% in PCA, 98.84% in polynomial FPCA, and 94.93% in B-spline FPCA. The model of Principal Component Regression (PCR), Polynomial FPCR (Functional Principal Component Regression) , and B-spline FPCR (Functional Principal Component Regression) showed that the pattern of predicted and actual curcumin concentration were similar. B-spline FPCR model gave more accurate prediction and also more consistent compared to polynomial FPCR or PCR. These facts were based on the standard deviation of RMSEP for B-Spline FPCR (0.09) which was less than that for polynomial FPCR (0.13) and PCR (0.15). Likewise, the standard deviation of correlation for B-Spline FPCR (0.10) which was less than that for polynomial FPCR (0.22) and PCR (0.26)
© Hak Cipta Milik IPB, Tahun 2016
Hak Cipta Dilindungi Undang-Undang
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Statistika Terapan
ANA RISQA JL
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2016
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala karunia-Nya sehingga karya ilmiah yang berjudul “Pemodelan Regresi Komponen Utama Fungsinal pada data Spektroskopi” ini berhasil diselesaikan dengan baik.
Keberhasilan penulisan karya ilmiah ini tidak lepas dari bimbingan dan petunjuk dari berbagai pihak. Oleh karena itu penulis menyampaikan penghargaan dan uacapan terima ksih yang sebesar-besarnya khususnya kepada :
1. Bapak Dr Ir Aji Hamim Wigena, M.Sc selaku pembimbing pertama dan Ibu Dr Ir Erfiani, M.Si selaku pembimbing kedua yang dengan penuh kesabaran telah banyak memberikan bimbingan, arahan, saran dan motivasi kepada penulis selama penyusunan karya ilmiah ini.
2. Bapak Dr Ir I Made Sumertajaya, M.Si selaku penguji luar komisi pada ujian tesis yang telah banyak memberikan kritikan, masukan dan arahan yang sangat membangun dalam penyusunan karya ilmiah ini.
3. Seluruh staf pengajar pascasarjana Departemen Statistika IPB yang telah banyak memberikan ilmu dan arahan selama perkuliahan sampai dengan penyusunan karya ilmiah ini.
4. Kedua orangtua penulis, Bapak Jaswar Arsan, S.Kep dan Ibu Hamatun Bahri, M.PdI yang telah banyak memberikan dukungan moril, materi, doa, dan kasih sayang yang tulus kepada penulis.
5. Adik-adik penulis (Ana Rahmatika H JL, S.KG dan Khollaqul Arief JL) yang selalu memberikan semangat, dukungan dan doa yang tak henti-hentinya kepada penulis.
6. Riyan Arizona, S.T; teman-teman 2013 baik STT, STT BPS dan STK; dan seluruh staf Program Studi Statistika (Bapak Heriawan dan Bapak Suherman) yang telah banyak membantu penulis selama penyusunan karya ilmiah ini.
Penulis menyadari bahwa banyak terdapat kekurangan dalam penulisan karya ilmiah ini. Oleh karena itu, penulis mengharapkan saran dan kritik yang membangun penulisan karya ilmiah selanjutnya. Semoga karya ilmiah ini bermanfaat.
Bogor, Januari 2016
DAFTAR ISI
DAFTAR TABEL xi
DAFTAR GAMBAR xi
DAFTAR LAMPIRAN xi
1 PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
2 TINJAUAN PUSTAKA 3
Teknik Kemometrik 3
Analisis Komponen Utama(AKU) 3
Analisis Data Fungsional(ADF) 7
Analisis Komponen Utama Fungsional(AKUF) 8
3 METODE PENELITIAN 10
Data 10
Metode Analisis 10
4 HASIL DAN PEMBAHASAN 19
Eksplorasi Data 13
Regresi Komponen Utama (RKU) 14
Regresi Komponen Utama Fungsional (RKUF) basis Polinomial 15
Regresi Komponen Utama Fungsional (RKUF) basis B-Spline 16
Validasi dan Kestabilan 17
Kestabilan Prediksi 19
5 SIMPULAN 20
DAFTAR PUSTAKA 21
LAMPIRAN 22
DAFTAR TABEL
1. Keragaman setiap Komponen model RKU 14
2. Penduga Parameter dan Statistik uji pada model RKU 14
3. Keragaman setiap Komponen model RKU F Polinomial 15
4. Penduga Parameter dan Statistik uji pada model RKUF Polinomial 15
5. Keragaman setiap Komponen model RKUF B-Spline 17
6. Penduga Parameter dan Statistik uji pada model RKU 17
7. Kestabilan Prediksi 19
DAFTAR GAMBAR 1. Plot Spektrum Keluaran FTIR 13
2. Penentuan n-basis 16
3. Nilai RMEP pada RKU, RKUF polinomial, dan RKUF B-Spline 18
4. Nilai Korelasi pada RKU, RKUF polinomial, dan RKUF B-Spline 18
DAFTAR LAMPIRAN 1. Proporsi Keragaman pada Analisis Komponen Utama 23
2. Proporsi Keragaman pada AKUF Polinomial 31
3. Proporsi Keragaman pada AKUF B-Spline 39
4. Plot data transpormasi polynomial 47
1. PENDAHULUAN Latar Belakang
Kemometrik merupakan aplikasi matematika untuk memproses, mengevaluasi, dan menginterpretasi sejumlah besar data yang dihasilkan oleh suatu percobaan kimia. Teknik Kemometrik biasa digunakan untuk menemukan korelasi statistik antara spektrum dan informasi kimia yang telah diketahui sebelumnya dari suatu contoh antara lain kadar senyawa aktif. Dalam menganalisis data spektroskopi masih terbatas karena spektrum cukup kompleks. Saat ini, teknik kemometrik dapat digunakan untuk mengekstrak informasi yang relevan dari data spektroskopi sehingga kesulitan menginterpretasikan data spektroskopi dapat diatasi. Data Spektroskopi berupa data fungsional yang merupakan fungsi dari panjang gelombang. Dalam industri farmasi analisis spektrum digunakan untuk mengendalikan mutu tanaman obat berdasarkan kandungan senyawa aktifnya (Alfeeli 2005).
Secara kualitatif dan kuantitatif suatu senyawa aktif dapat diperoleh melalui metode HPLC. Pengukuran menggunakan HPLC dapat menghasilkan keluaran konsentrasi senyawa aktif namun proses ini memerlukan biaya dan waktu yang cukup besar dan mahal. Metode kualitatif lain yang sering dipakai adalah spektroskopi FTIR . Pengukuran dengan FTIR akan menghasilkan pola spektrum tertentu sesuai dengan senyawa aktif yang diamati. Proses ini memerlukan biaya dan waktu yang tidak terlalu besar. Namun permasalahannya dalam penentuan kandungan senyawa aktif pada tanaman obat harus dilakukan secara cepat dan akurat. Salah satu solusi yang dapat dilakukan ialah pemodelan statistik yang menggambarkan hubungan antara data spektrum dari FTIR dan data konsentrasi senyawa aktif yang diperoleh dari HPLC. Model yang dihasilkan akan mempercepat waktu proses dan mengurangi biaya dan juga dapat digunakan untuk memprediksi konsentrasi senyawa aktif dalam tanaman obat (Erfiani 2005).
Pada tahapan analisis dalam penyusunan model statistik sering kali ada permasalahan pada dimensi data yang cukup besar, sehingga diperlukan pereduksian dimensi terlebih dahulu. Permasalahan yang sering terjadi akibat dimensi data yang cukup besar yakni kekolinearan ganda (multikolinieritas) antara peubah bebas (X) dan jumlah peubah bebas (p) yang jauh lebih besar dibandingkan dengan jumlah pengamatan (n). Analisis Komponen Utama (AKU) dapat digunakan untuk menyederhanakan dimensi suatu data dengan mentransformasi data secara linear sehingga terbentuk sistem koordinat baru dengan keragaman yang maksimum, sehingga AKU dapat mengatasi masalah dimensi yang besar, multikolinear dan p>>n. Namun AKU masih memiliki banyak kekurangan yaitu dengan adanya jumlah p yang besar proses perhitungan AKU biasanya akan mengalami kendala dalam matriks ragam peragamnya yang berukuran sangat besar, dan akan kehilangan informasi dari data karena AKU digunakan untuk data bersifat diskrit sedangkan data yang digunakan merupakan data fungsi kecuali dilakukan statistik yang lebih banyak.
Fungsional (AKUF) adalah solusinya. AKUF memiliki cara kerja yang sama dengan AKU sehingga dapat mengatasi masalah dimensi data yang besar, multikolinear serta p>>n namun tidak menghilangkan informasi yang ada dalam data. Dalam hal ini datanya berupa fungsi atau kontinu, sehingga pada proses pereduksian dimensi dilakukan dengan tidak menghilangkan pola data dan data spektrum menjadi lebih mulus.
Metode AKUF mengkonversi matriks data non fungsional menjadi matriks data fungsional yang merupakan kombinasi linier dari basis fungsi antara lain basis polinomial, basis B-spline dan basis Fourier. Dwi Nabila Lestari (2014) menerapkan AKUF dan Regresi Komponen Utama Fungsional (RKUF) untuk memprediksi curah hujan dengan menggunakan data GCM dan Shang (2011) melakukan kajian penggunaan metode RKUF. Aguilera et al (2013) melakukan penelitian menggunakan metode RKUF pada data spektroskopi. Saeys et al (2007) telah melakukan kajian tentang data spektroskopi menggunakan analisis data fungsional dengan basis fungsi B-spline. Penelitian ini menerapkan metode AKU, AKUF dengan basis fungsi polinomial dan AKUF dengan basis fungsi B-spline pada data spektroskopi.
Tujuan Penelitian
Penelitian ini bertujuan menerapkan dan membandingkan metode AKU,
2. TINJAUAN PUSTAKA Teknik Kemometrik
Kemometrik adalah disiplin ilmu kimia yang menggunakan matematika, statistik, dan logika formal yang digunakan untuk merancang atau memilih prosedur eksperimental yang optimal, untuk memberikan informasi kimia maksimum yang relevan dengan menganalisis data kimia, dan untuk memperoleh pengetahuan tentang suatu sistem kimia. Teknik ini merupakan penerapan metode statistik dan matematik untuk merancang prosedur optimum untuk memberikan informasi kimia yang maksimal melalui analisis data kimia. Kemometrik menyediakan teknik untuk mengurangi dimensi data yang berukuran besar diperoleh dari instrumen seperti spektrofotometer. Selanjutnya model ini dapat digunakan untuk menduga sampel yang tidak data ketahui. Metode ini menghasilkan persamaan regresi berdasarkan spektrofotometri dan informasi analitik yang diketahui. Selanjutnya, model yang telah dibuat dapat digunakan untuk memprediksi sampel yang memiliki pola data tidak kasar (Heryanto 2005).
Secara umum ada dua teknik yang digunakan untuk menganalisa sifat dari suatu campuran senyawa kimia, yaitu kromatografi dan spektroskopi. Teknik spektroskopi berhubungan dengan interaksi antara material yang diuji dengan radiasi elektromagnetik dalam bentuk absorpsi, emisi dan sebaran energi radiasi (Alfeeli 2005). Teknik spektroskopi menggunakan radiasi elektromagnetik atau spektrum cahaya untuk membedakan kadar serapan (absorpsi) antar komponen yang terkandung. Teknik spektroskopi cukup banyak variasinya, mulai dari spektroskopi Raman, spektroskopi NIR (Near-infrared) dan spektroskopi UV-Vis
(Ultraviolet Visible) yang secara umum menggunakan radiasi elektromagnetik
untuk berinteraksi dengan senyawa kimia yang diuji. Radiasi elektromagnetik adalah suatu bentuk dari energi yang diteruskan melalui ruang dengan kecepatan yang luar biasa, seperti contohnya radiasi cahaya tampak, sinar gamma, sinar x, sinar ultra-violet, dan infra merah (Nur & Adijuwana 1989). Data Spektroskopi adalah data panjang gelombang dari radiasi elektromagnetik.
Analisis Komponen Utama (AKU)
Jika didefinisikan peubah acak X1, X2,…..,Xp memiliki matriks ragam komponen utama dan menjamin keunikan nilai vektor ciri tersebut. Komponen utama (KU) dihasilkan dari himpunan pasangan nilai akar ciri dan vektor ciri dari maktriks korelasi atau matriks ragam peragam. Matriks ragam peragam dari peubah X digunakan apabila tidak terdapat perbedaan satuan antar peubah prediktor. Sebaliknya, matriks korelasi peubah X digunakan jika ada perbedaan satuan antar peubah prediktor dan juga saat terdapat keragaman yang besar dalam matriks peubah prediktor. Jika menggunakan matriks korelasi maka terlebih dahulu data harus distandarisasi. Perlu dilakukan Standarisasi data agar menghindari dominansi satu atau lebih peubah prediktor dalam KU. Menurut Jhonson dan Wichern 2007 akan diperoleh w yang merupakan kombinasi linear dari peubah asal jika terdapat
′= [ , , … … . . , tidak berkorelasi dan memiliki ragam maksimum. Syarat KU yang dibentuk agar memiliki ragam maksimum ialah dengan memilih vektor ciri �′yang terdiri dari
� , � , … … , �� sedemikian rupa sehingga V�r ( ) = �′∑ � maksimum dengan
� ialah kombinasi linier �′ dengan memaksimumkan V�r �′ peragamnya jadi untuk persamaan � ,
= �′ = + + + (3)
dengan v�r ( ) = �′∑ �� = � j = , , … . . , p (4)
cov ( , ) = �′∑ �
� = j ≠ j′ = , , … . . , p (5)
Sehingga matriks ragam peragam untuk adalah
� = [� ⋱
� ] (6)
Total keragaman yang bisa dijelaskan oleh KU akan sama dengan total keragaman pada peubah asal sehingga dapat dituliskan
σ + σ + + σ = + + +
∑ v�r = = tr � = ∑ v�r = (7)
Karena total keragaman populasi ialah σ + σ + + σ = + + + , maka kontribusi keragaman relatif yang mampu dijelaskan oleh � ialah :
tr ѵ = + + … … . . +
Seandainya KU yang digunakan sebanyak r komponen dengan r < p, maka besarnya keragaman komulatif untuk r buah KU ialah :
∑=
∑= × %
Seperti telah di jelaskan sebelumnya selain dengan matriks ragam peragam, KU dapat dibentuk dengan matriks korelasi. KU dengan menggunakan matriks korelasi terlebih dahulu dilakukan transformasi peubah asal X menjadi bentuk baku Z dengan cara sebagai berikut :
Z = x − √σ
Dengan notasi matriksnya :
Dengan
= di�g (√σ , √σ , … … . , √σ ) (9)
E � = (10)
Dan Z ialah matriks peubah asal X yang telah dibakukan dan keragaman matriks Z :
cov � = − � − = � (11)
Dan � ialah matriks korelasi dari peubah asal X. KU ke-j yang terbentuk dari peubah-peubah yang telah dibakukan Z dapat dihasilkan dari vektor ciri yang telah di peroleh dari matriks korelasi X dengan persamaan KU sebagai berikut :
= �′� = + + + (12)
Dengan proporsi total keragaman yang dapat dijelaskan oleh KU ke-j dari Z = � dengan ialah nilai akar ciri dari matriks korelasi. Teras matriks korelasi sama dengan nilai p.
Untuk menetukan jumlah KU yang akan digunakan dalam RKU ada beberapa metode yang digunakan. Beberapa peneliti menggunakan aturan untuk memilih KU yang mempunyai nilai akar ciri lebih dari satu dan ada pula yang membuang komponen yang memiliki nilai akar ciri kecil karena akar ciri yang kecil memiliki sedikit informasi atau melihat persentase keragaman dari total keragaman (lebih dari 85% ataupun lebih).
Jika telah terpilih komponen utamanya, maka selanjutnya regresikan KU yang terpilih dengan peubah respon dengan menggunakan RKU. Misalkan terdapat matriks A ialah matriks orthogonal yang isinya merupakan vektor ciri dari matriks ragam peragam peubah asal X memenuhi persamaan �′� = ��′= �. Dalam Dengan menggantikan peubah prediktor dengan KU dalam model regresi. Model RKU yang dihasilkan oleh matriks korelasi hampir sama dengan matriks ragam peragam yaitu dengan mengganti peubah-peubah X menjadi peubah yang telah dibakukan Z. Model RKU yang dibentuk oleh matriks korelasi sama dengan
Analisis Data Fungsional (ADF)
Ramsay pada tahun 1982 pertama kali memperkenalkan Analisis Data Fungsional (ADF). Menurut Ingrassia & Costanzo (2005) ADF biasanya dipakai pada data deret waktu, lokasi (spasial) dan panjang gelombang. Pada data spektroskopi biasanya merupakan data panjang gelombang. Benko (2004) menyatakan implementasi pada data fungsional menggunakan ekspansi basis fungsional. Langkah pertama pada data fungsional adalah mengkonversi matriks data non fungsional menjadi data fungsional yang merupakan kombinasi linier dari basis fungsi. Dalam ADF basis fungsi yang digunakan ialah basis polinomial, basis B-spline dan basis Fourier. Basis Fourier digunakan pada data deret waktu yang cukup panjang dan bersifat periodik. Sementara basis polinomial dan basis B-spline digunakan untuk data non periodik.
Transformasi Polinomial
Misalkan terdapat peubah acak X1, X2,…..,Xp , dengan panjang data
sebanyak n. Peubah-pubah tersebut ditransformasi menggunakan basis polinomial. Salah satu persamaan transformasi polinomial ialah sebagai berikut :
� ≈ ∑�= �, ∅ � (15)
∅ � = � − (16)
dengan :
� : output Transformasi Polinomial
� : data awal
Transformasi B-Spline
Misalkan = { } ialah himpunan + knot pada selang [ , ]. Fungsi basis B-Spline berderajat q ke-i �, didefinisikan secara rekursif dengan persamaan berikut :
B, � = output transformasi basis B-Spline = jumlah knot
Analisis Komponen Utama Fungsional (AKUF)
Data fungsional mirip dengan data peubah ganda begitu pula model dan metode untuk menganalisis data nya. Analisis yang sering digunakan dalam fungsional data analisis adalah AKUF. AKUF banyak digunakan untuk menganalisis data fungsional dengan cara kerja yang sama dengan AKU. Salah satu perbedaan metode AKU dengan metode AKUF ialah metode AKU digunakan untuk analisis peubah ganda (x) sedangkan AKUF untuk menganalisis data fungsional (x(s)) (Ramsay & Silverman 2005 ). AKUF mampu menjelaskan struktur keragaman data dengan lebih baik walaupun jumlah peubah lebih besar dari jumlah pengamatan (p >n) (tran 2008). Jika dalam AKU komponen utama yang dperoleh merupakan kombinasi linear dari semua pengamatan yang diamati dan bersifat orthogonal, namun dalam AKUF komponen utama yang diperoleh merupakan kombinasi linear dari fungsi dalam himpunan data nya. Ide utama AKUF ialah mengganti vektor menjadi fungsi dan matriks ragam peragam dengan matriks ragam peragam fungsional.
Jika terdapat peubah acak X1, X2,…..,Xp yang akan direduksi. Unit sampel
yang digunakan sebanyak n , sehingga kombinasi linier peubah fungsional yang diperoleh ialah = [ , , … . . , ] . Metode AKUF juga merupakan kombinasi linier dari , ∈ [ , ]. Elemen matriks ragam peragam untuk data fungsional , dapat dituliskan sebagai berikut :
( , ) = ∑= � ( )� (19)
Untuk = , … , �; = , . . � � ≠ .
Pada data fungsional rumus umum mencari nilai akar ciri dan vektor ciri dapat dituliskan sebagai berikut :
∫ ( , )� = �� (20)
Dengan � ialah vektor ciri fungsional, ρ ialah akar ciri fungsional dan ialah matriks ragam peragam. Nilai vektor ciri fungsional memenuhi ∫xxp � s ds =
untuk memaksimalkan ragam komponen utama dan menjamin keunikan nilai vektor ciri fungsional. Nilai skor komponen utama fungsionl (kf) dapat dinotasikan sebagai berikut :
= ∫�� � �
� . untuk i n (21)
Tujuan utama AKUF yang dinyatakan oleh Ramsay dan Silverman (2002) ialah penentuan bobot fungsi �� � yang memaksimumkan nilai keragaman dari skor untuk fungsi kendala ‖� ‖ = ∫�� � = dan
∫��� � �′ = ∀i, i′deng�n i < i′
3. METODE PENELITIAN Data
Data yang digunakan dalam penelitian ini adalah data hasil pengukuran
HPLC dan FTIR pada ekstrak rimpang temulawak. Hasil pengukuran HPLC berupa konsentrasi kurkumin dari serbuk rimpang temulawak. Hasil pengukuran FTIR berupa transmitan kurkumin dari serbuk rimpang temulawak pada interval gelombang tertentu. Data ini merupakan hasil penelitian Erfiani (2005).
Pada data peubah Y sebanyak 21 konsentrasi merupakan hasil pengukuran senyawa aktif kurkumin dengan menggunakan HPLC sedangkan peubah X sebanyak 1866 bilangan gelombang merupakan hasil pengukuran senyawa aktif kurkumin dengan menggunakan FTIR. Pada penelitian ini data di random kemudian dibagi menjadi dua bagian yaitu 70% data menjadi data untuk pemodelan dan 30 % untuk data validasi dan dilakukan pengulangan sebanyak 150 kali.
Metode Analisis
Tahapan analisis data yang akan dilakukakan dalam penelitian ini dengan menggunakan metode AKU, AKUF, dan AKUF dengan basis fungsi B-spline menggunakan software R versi 3.02. Langkah awal tahapan yang akan dilakukan dalam penelitian ini ialah melakukan eksplorasi data spektroskopi untuk melihat pola data, multikolinieritas dan pencilan. Tahap selanjutnya pada kedua metode adalah sebagai berikut :
Regresi Komponen Utama (RKU)
1. Membuat matriks ragam peragam dari data spektroskopi.
2. Menentukan jumlah komponen utama yang akan digunakan berdasarkan proporsi keragaman kumulatif >90%.
3. Menghitung nilai skor komponen utama.
4. Memprediksi data spektroskopi menggunakan peubah prediktor nilai skor komponen utama.
Regresi Komponen Utama Fungsional (RKUF) dengan basis polinomial
1. Mentransformasi data spektroskopi dengan menggunakan basis fungsi polinomial.
2. Menentukan jumlah komponen utama yang akan digunakan berdasarkan proporsi keragaman kumulatif > 90%.
3. Menghitung nilai skor komponen utama fungsional.
Regresi Komponen Utama Fungsional (RKUF) dengan basis B-Spline
1. Mentransformasi data spektroskopi dengan menggunakan basis B-Spline. 2. Menentukan jumlah komponen utama yang akan digunakan berdasarkan
proporsi keragaman kumulatif > 90%.
3. Menghitung nilai skor komponen utama fungsional.
4. Memprediksi data spektroskopi menggunakan peubah prediktor sebagai nilai skor komponen utama fungsional.
Selanjutnya Uji kelayakan model digunakan untuk mengetahui apakah model layak atau tidak digunakan. Statistik yang digunakan adalah nilai Root Mean Square
Error (RMSEP). RMSEP dihitung pada data pemodelan menggunakan rumus:
̂�merupakan data hasil pendugaan dan �menyatakan data asliya.
Validasi model menggunakan korelasi dan root mean square error of
prediction (RMSEP). Nilai RMSEP dihitung menggunakan rumus (i), namun data
yang digunakan adalah data pengujian. Semakin kecil nilai RMSEP, maka semakin kecil perbedaan antara nilai dugaan dengan nilai aktual, yang berarti model yang dibentuk semakin akurat dalam menghasilkan nilai dugaan.
Korelasi antara data aktual dengan nilai dugaan dihitung menggunakan rumus:
Diagram Alir dari penelitian ini adalah :
Input data Spektroskopi mulai
Mereduksi data spektroskopi dengan metode AKUF Mereduksi data spektroskopi
dengan metode AKU
Menggunakan data transformasi polinomial Menggunakan data awal
Eksplorasi data
validasi Memprediksi data spektroskopi dengan menggunakan RKUF
Skor komponen (KU) Skor komponen fungsional
(kf)
Melakukan perbandingan nilai RMSEP dan korelasi
Validasi Memprediksi data spektroskopi dengan menggunakan metode RKU
Selesai.
4 HASIL DAN PEMBAHASAN
Eksplorasi data Kurkumin
Hasil pengukuran HPLC berupa konsentrasi kurkumin dari serbuk rimpang temulawak, sebanyak 21 konsentrasi kurkumin. HPLC adalah salah satu metode kromatografi yang termasuk kromatografi cair modern. Sistem kerja HPLC
menggunakan cairan sebagai fase gerak dan sebagai fase diam dapat berupa suatu padatan atau senyawa tertentu yang terikat secara kimia dengan padatan pendukungnya. HPLC biasanya digunakan untuk memisahkan senyawa yang tidak dapat dipisahkan dengan kromatografi gas, karena sifatnya yang tidak mudah menguap, sehingga tidak mampu melewati kolom dan sampel tidak tahan pada suhu tinggi sehingga akan mengalami dekomposisi pada kondisi pemisahan. HPLC dapat mengatasi masalah tersebut, karena HPLC mampu memisahkan senyawa yang tidak mudah menguap dan stabil pada suhu tinggi.
Pada hasil pengukuran serbuk kurkumin dengan menggunakan FTIR, jumlah pasangan titik bilangan gelombang dan persentase transmittan yang dihasilkan untuk setiap spektrum sebanyak 1866 titik. FTIR merupakan salah satu teknik spektroskopi infra merah, spektrum infra merah terletak pada daerah dengan bilangan gelombang dari 12800 sampai 1 cm-1. Dilihat dari segi instrumentasi dan aplikasi spektrum infra merah dibagi menjadi tiga jenis yaitu infra merah dekat (bilangan gelombang 12800-4000 cm-1), infra merah pertengahan (bilangan gelombang 4000-200 cm-1), dan infra merah jauh (bilangan gelombang 200-10 cm
-1). Sedangkan FTIR termasuk dalam jenis infra merah pertengahan yakni bilangan
Gambar 1. Plot spektrum keluaran FTIR untuk 21 contoh
Berdasarkan gambar 1 terlihat bahwa 21 spektrum memiliki pola yang sama, karena setiap senyawa aktif memiliki pola spektrum tertentu. Setelah dilihat pola spektrum lalu data dianalisis dengan dua tahap. Tahap pertama data dianalisis menggunakan RKU dan tahap kedua data ditransformasi menjadi data fungsional. Transformasi yang digunakan ialah transformasi polinomial dan B-Spline. Data yang telah ditransformasi kemudian dilakukan analisis menggunakan RKUF.
Regresi Komponen Utama (RKU)
Pada metode RKU digunakan data hasil pengukuran serbuk kurkumin dengan menggunakan FTIR sebagai peubah prediktor dan data hasil pengukuran serbuk kurkumin dengan menggunakan HPLC sebagai peubah respon. Hasil analisis dengan menggunakan RKU pada Tabel 1, menunjukkan bahwa rata-rata komponen utama pertama (Z1) mampu menjelaskan sebanyak 89.09% dari keragaman yang
ada dan rata-rata komponen kedua (Z2) mampu menjelaskan 4.67% dari keragaman
yang ada dan rata-rata komponen ketiga (Z3) mampu menjelaskan 3,39% dari
keragaman.
Tabel 1 Keragaman setiap Komponen model RKU
Rata-rata Komponen
Z1 Z2 Z3
Proporsi Keragaman 0.8909 0.0467 0.0339 Proporsi Komulatif 0.8909 0.9376 0.9715
Rata-rata Komponen Z1 dan Z2 mampu menjelaskan keragaman pada data
hasil pengukuran serbuk kurkumin sebesar 93.76% sehingga peubah yang digunakan untuk analisis pada metode RKU adalah Z1 dan Z2. Penduga Parameter
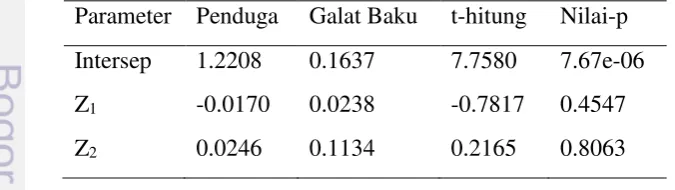
dan statistik uji pada satu kali pengulangan terdapat pada Tabel 2. Tabel 2 Penduga parameter dan Statistik ujinya. Parameter Penduga Galat Baku t-hitung Nilai-p Intersep 1.2208 0.1637 7.7580 7.67e-06 Z1 -0.0170 0.0238 -0.7817 0.4547
Tabel 2 menunjukkan tidak ada satupun komponen yang berpengaruh terhadap hasil pengukuran serbuk kurkumin. Hal ini juga dijelaskan dengan hasil nilai kebaikan model yang hanya 8.3% yang berarti bahwa peubah Z1 dan Z2 hanya
mampu menerangkan total keragaman hasil pengukuran serbuk kurkumin sebesar 8.3%. Model akhir meode RKU dapat ditulis sebagai berikut :
y = 1.2208 – 0.017 Z1 + 0.0246 Z2 (i)
Regresi Komponen Utama Fungsional (RKUF) basis Polinomial
Peubah prediktor yang digunakan pada metode RKUF ialah data spektrum keluaran FTIR yang telah di transformasi menjadi data fungsional dengan menggunakan basis polinomial. Sedangkan data konsentrasi senyawa aktif keluaran HPLC digunakan sebagai peubah respon. Hasil analisis menggunakan metode RKUF dengan transformasi polinomial pada Tabel 3, menunjukkan bahwa rata-rata komponen utama fungsional pertama basis polinomial (kfp1) mampu menjelaskan sebanyak 92.31% dari keragaman yang ada dan rata-rata komponen utama fungsional kedua basis polinomial (kfp2) mampu menjelaskan 4.12% dari keragaman yang ada dan rata-rata komponen utama fungsional ketiga basis polinomial (kfp3) mampu menjelaskan 1.49% dari keragaman.
Tabel 3 proporsi rata-rata keragaman setiap komponen
Rata-rata Komponen
kfp1 kfp2 kfp3
Proporsi Keragaman 0.9231 0.0412 0.0149 Proporsi Komulatif 0.9231 0.9643 0.9792
Tabel 4 Penduga Parameter dan Statistik ujinya
Parameter Penduga Galat Baku t-hitung Nilai-p Intersep 1.1942 0.0828 13.5243 1.07e-04
kf1 0.0209 0.0165 1.2665 0.0218
kf2 0.0413 0.0679 0.6843 0.0039
Tabel 4 merupakan tabel penduga parameter untuk metode RKUF basis polinomial dengan menggunakan dua skor komponen utama fungsional polinomial dengan proporsi rata-rata keragaman sebesar 97.89% dan model RKUF basis polinomial menghasilkan nilai kebaikan model sebesar 73.3% yang berarti bahwa peubah kfp1 dan kfp2 mampu menjelaskan total keragaman hasil pengukuran serbuk kurkumin sebesar 73.3%. Ini lebih baik dibandingkan dengan menggunakan metode RKU. Model akhir metode RKUF sebagai berikut :
y = 1.1942 + 0.0209 kf1 + 0.0413 kf2 (ii)
Regresi Komponen Utama Fungsional (RKUF) basis B-Spline
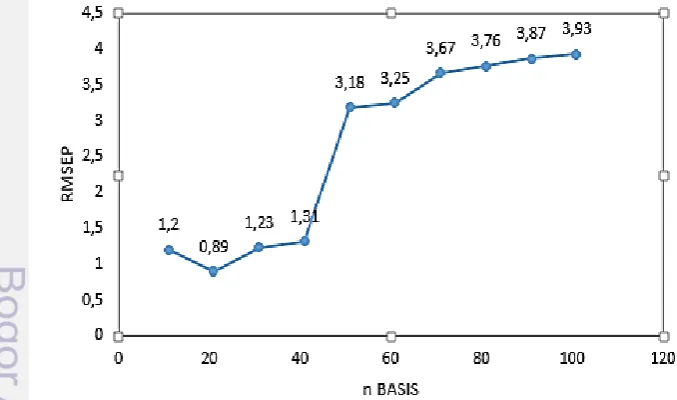
Metode RKUF menggunakan peubah prediktor data hasil pengukuran serbuk kurkumin dengan menggunakan FTIR yang telah di transformasi menjadi data fungsional dengan basis B-Spline dan data hasil pengukuran serbuk kurkumin dengan menggunakan HPLC sebagi peubah respon. Penentuan basis dalam transformasi B-Spline dapat dengan menggunakan nilai RMSEP. Pada penelitian ini pemilihan basis terbaik dilihat dari nilai RMSEP terkecil. Gambar 2 menunjukkan bahwa basis yang baik digunakan dalam metode AKUF dengan transformasi
B-Spline adalah basis 21 dengan nilai RMSEP terkecil yakni 0,89.
Hasil analisis menggunakan metode RKUF dengan transformasi B-Spline pada Tabel 5, menunjukkan bahwa rata-rata komponen utama fungsional basis B-Spline
pertama (kfb1) mampu menjelaskan sebanyak 92.05% dari total keragaman dan rata-rata komponen utama fungsional basis B-Spline kedua (kfb2) mampu menjelaskan 3.33% dari total keragaman dan rata-rata komponen utama fungsional basis B-Spline ketiga (kfb3) mampu menjelaskan 2.99% dari total keragaman.
Tabel 5 proporsi rata-rata keragaman setiap komponen
Rata-rata Komponen
kfb1 kfb2 kfb3
Proporsi Keragaman 0.9205 0.0333 0.0299 Proporsi Komulatif 0.9205 0.9538 0.9837
Tabel 5 menunjukkan rata-rata keragaman setiap komponen utama fungsional basis B-Spline (kfb). Tabel 5 memberikan informasi bahwa metode AKUF dengan transformasi B-Spline dapat memepertahankan keragaman data lebih baik dibandingkan dengan AKU. Hal ini dilihat dari proporsi rata-rata keragaman kfb1 yakni 92.05 %. Namun untuk menjaga kesamaan dalam membandingkan kedua metode tersebut, maka skor komponen utama fungsional yang di gunakan pada RKUF dengan transformasi B-Spline sebanyak dua yaitu kfb1 dan kfb2 sesuai dengan jumlah komponen utama yang digunakan pada metode RKU dalam membentuk model regresi.
Tabel 6 Penduga Parameter dan Statistik ujinya
Parameter Penduga Galat Baku t-hitung Nilai-p Intersep 1.1182 0.0780 11.129 5.09e-06
kf1 0.0676 0.0183 1.2767 0.0349
Kf2 0.0782 0.0847 0.6481 0.0058
Tabel 6 merupakan tabel penduga parameter untuk metode RKUF transformasi
B-Spline dengan menggunakan dua skor komponen utama fungsional basis
B-Spline dengan proporsi rata-rata keragaman sebesar 94.76% dan model RKUF
menggunakan metode RKU dan metode RKUF polinomial. Model akhir metode RKUF B-Spline sebagai berikut :
y = 1.1182 + 0.0676 kf1 + 0.0782 kf2 (iii)
Validasi dan Kestabilan
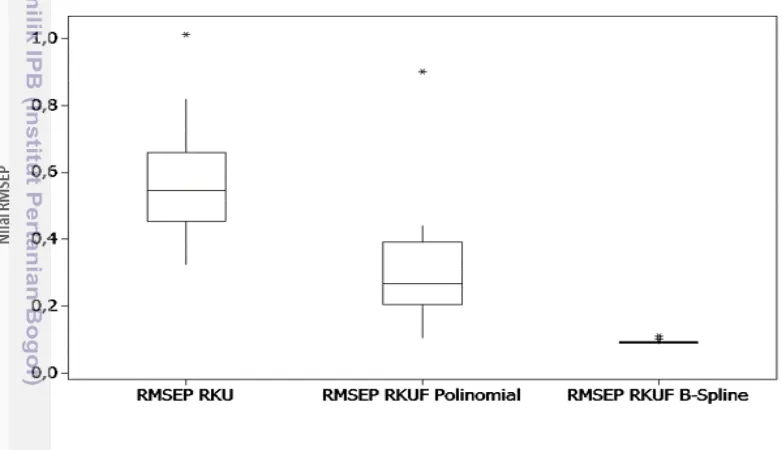
Validasi merupakan salah satu tahap penting untuk dilakukan. Hasil prosedur validasi mencerminkan keakuratan hasil prediksi model yang terbentuk. Pada gambar 6 terlihat bahwa nilai RMSEP pada RKU lebih menyebar dan lebih cenderung besar nilainya, sedangkan pada RKUF polinomial nilai RMSEP
cenderung lebih mengumpul dan nilai nya cenderung lebih kecil dibandingkan pada RKU. Pada RKUF B-Spline nilai RMSEP nya lebih mengumpul dan cenderung lebih kecil nilainya dibandingkan pada RKU dan RKUF polinomial .
Gambar 6. Diagram kotak garis untuk nilai RMSEP pada RKU, RKUF polinomial dan RKUF B-Spline.
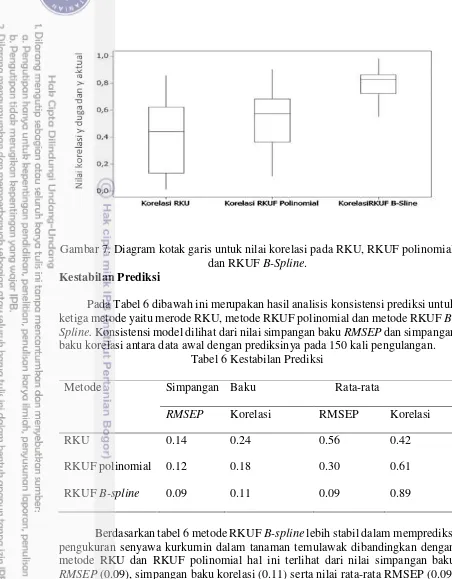
Gambar 7 menyajikan nilai korelasi antara nilai y aktual dan y duga. Pada gambar 7 terlihat nilai median untuk korelasi dengan menggunakan metode RKU lebih kecil dibandingkan nilai median untuk korelasi pada metode RKUF polinomial dan metode RKUF B-Spline. Hal ini mengartikan bahwa selisih nilai dugaan y dan nilai y aktualnya pada RKU lebih besar dibandingkan dengan metode RKUF polinomial dan metode RKUF B-Spline. Sedangkan selisih nilai dugaan y dan nilai aktualnya pada metode RKUF polinomial lebih besar dibandingkan pada metode RKUF B-Spline. Selisih nilai dugaan y dan aktualnya pada metode RKUF
B-Spline terkecil dari ketiga metode, hal ini terlihat dari nilai korelasi yang tinggi
Gambar 7. Diagram kotak garis untuk nilai korelasi pada RKU, RKUF polinomial dan RKUF B-Spline.
Kestabilan Prediksi
Pada Tabel 6 dibawah ini merupakan hasil analisis konsistensi prediksi untuk ketiga metode yaitu merode RKU, metode RKUF polinomial dan metode RKUF
B-Spline. Konsistensi model dilihat dari nilai simpangan baku RMSEP dan simpangan
baku korelasi antara data awal dengan prediksinya pada 150 kali pengulangan. Tabel 6 Kestabilan Prediksi
Metode Simpangan Baku Rata-rata
RMSEP Korelasi RMSEP Korelasi
RKU 0.14 0.24 0.56 0.42
RKUF polinomial 0.12 0.18 0.30 0.61
RKUF B-spline 0.09 0.11 0.09 0.89
Berdasarkan tabel 6 metode RKUF B-spline lebih stabil dalam memprediksi pengukuran senyawa kurkumin dalam tanaman temulawak dibandingkan dengan metode RKU dan RKUF polinomial hal ini terlihat dari nilai simpangan baku
RMSEP (0.09), simpangan baku korelasi (0.11) serta nilai rata-rata RMSEP (0.09)
5 SIMPULAN
Secara umum metode RKUF B-Spline lebih baik dan stabil dibandingkan dengan metode RKU dan RKUF polinomial biasa dalam memprediksi kadar senyawa aktif kurkumin pada tanaman Temulawak. Jika diperbandingkan antara model RKU dan RKUF polinomial maka model RKUF polinomal lebih baik dalam memprediksi jumlah senyawa aktif kurkumin yang terkandung dalam tanaman obat temulawak.
DAFTAR PUSTAKA
Aguilera AM, Escabias M, Valderrama MJ, Morillo MCA. 2013. Functional Analysis of Chemometric Data. Journal of Statistics (3): 334-343
Alfeeli B. 2005. Miniature Gas Sensing Device Based On Near-Infrared
Spectroscopy. Blacksburg: Virginia Polytechnic Institute and State
University
Bellman RE. 1961. Adaptive Control Process : a Guided Tour, Princeton University Press, New Jersey : Princeton.
Croux C, Ruiz – Gazen A. 2005. High breakdown estimators for principal component : The projection – pursuit approach revisited. Journal of
Multivariate Analysis 95: 206 – 226.
Erfiani. 2005. Pengembangan Model Kalibrasi dengan Pendekatan Bayes (Studi kasus Tanaman obat) [Disertasi]. Bogor (ID): Sekolah Pascasarjana, Institut Pertanian Bogor.
Ferraty F. & Vieu, P. 2006. Nonparametric Functional Data Analysis : Theory and Practise. New York : Springer.
Ingrassia S, Costanzo GD. 2005. Functional Principal Component Analysis of
Financial Timeseries, Springer – Verlag, Inc., Berlin.
Johnson RA, Wichern DW. 1998. Applied Multivariate Statistical Analysis . United States of America : Prentice Hall International. Inc.
Jolliffe IT. 2002 . Principal Component Analysis Second Edition. Ed ke-2. New York (US) : Springer-Verlag.
Lestari DN. 2014. Pemodelan statistical downscaling dengan analisis komponen utama fungsional untuk prediksi curah hujan [tesis]. Bogor (ID): Sekolah Pascasarjana, Institut Pertanian Bogor.
Nur MA, Adijuwana H. 1989. Teknik Spektroskopi Dalam Analisis Biologi. Bogor: Pusat antar Universitas Ilmu Hayat, Institut Pertanian Bogor.
Ramsay OJ, Silverman WB . 2005. Functional Data Analysis. Ed ke-2. New York (US) : Springer.
Saeys W, Ketelaere BD, Darius P. 2007. Potential Application of Functional Data Analysis in Chemometrics. Journal of Chemometrics 2008 (22): 335-344. Shang HL. 2011. A Survey of functional principal component analysis.
Departement of econometrics and business Statistics Monash University, (working papers, 06/11).
Lampiran 1 Proporsi Keragaman pada Analisis Komponen utama
Komulatif 0.8992 0.96157 100.00 100.00
Lampiran 1 Proporsi Keragaman pada Analisis Komponen utama (lanjutan)
Komulatif 90.02 0.95121 100.00
Ulangan ke Proporsi KU 1 KU 2 ... KU 18 TOTAL 141 Keragaman 0.9001 0.0398 0.00
Komulatif 0.9001 0.9399 100.00 100.00
142 Keragaman 93.72 0.12 0.00
Komulatif 93.72 93.84 100.00 100.00
143 Keragaman 90.39 0.99 0.00
Komulatif 90.39 91.38 100.00 100.00 144 Keragaman 0.7995 0.1801 0.00
Komulatif 0.7995 0.9796 100.00 100.00
145 Keragaman 92.31 0.92 0.00
Komulatif 92.31 93.23 100.00 100.00
146 Keragaman 90.06 2.04 0.00
Komulatif 90.06 92.10 100.00 100.00
147 Keragaman 90.07 0.99 0.00
Komulatif 90.07 91.06 100.00 100.00
148 Keragaman 90.56 2.18 0.00
Komulatif 90.56 92.74 100.00 100.00
148 Keragaman 90.22 2.08 0.00
Komulatif 90.22 92.30 100.00 100.00
150 Keragaman 92.02 0.23 0.00
Lampiran 2 Proporsi Keragaman pada AKUF Polinomial (lanjutan)
Ulangan ke Proporsi Kf 1 Kf 2 ... Kf 6 TOTAL
141 Keragaman 92.34 0.12 0.00
Komulatif 92.34 92.46 100.00 100.00
142 Keragaman 93.21 0.18 0.00
Komulatif 93.21 93.39 100.00 100.00
143 Keragaman 90.02 2.39 0.00
Komulatif 90.02 92.41 100.00 100.00
144 Keragaman 91.27 0.23 0.00
Komulatif 91.27 91.50 100.00 100.00
145 Keragaman 90.04 3.56 0.00
Komulatif 90.04 93.60 100.00 100.00
146 Keragaman 90.89 2.11 0.00
Komulatif 90.89 93.00 100.00 100.00
147 Keragaman 90.78 0.77 0.00
Komulatif 90.78 91.55 100.00 100.00
148 Keragaman 90.67 0.99 0.00
Komulatif 90.67 91.66 100.00 100.00
148 Keragaman 90.56 1.87 0.00
Komulatif 90.56 92.43 100.00 100.00
150 Keragaman 93.77 0.88 0.00
Lampiran 3 Proporsi Keragaman pada AKUF B-Spline (lanjutan)
Ulangan
ke Proporsi Kfb 1 Kfb 2 ... Kfb 6 TOTAL
141 Keragaman 94.17 0.92 0.00
Komulatif 94.17 95.09 100.00 100.00
142 Keragaman 91.00 0.99 0.00
Komulatif 91.00 91.99 100.00 100.00
143 Keragaman 90.04 1.78 0.00
Komulatif 90.04 91.82 100.00 100.00
144 Keragaman 90.29 3.87 0.00
Komulatif 90.29 94.17 100.00 100.00
145 Keragaman 90.08 2.33 0.00
Komulatif 90.08 92.41 100.00 100.00
146 Keragaman 92.09 0.88 0.00
Komulatif 92.09 92.97 100.00 100.00
147 Keragaman 90.78 3.29 0.00
Komulatif 90.78 94.07 100.00 100.00
148 Keragaman 92.34 0.42 0.00
Komulatif 92.34 92.76 100.00 100.00
148 Keragaman 91.88 1.01 0.00
Komulatif 91.88 92.89 100.00 100.00
150 Keragaman 90.77 0.91 0.00
Lampiran 4 Plot data transformasi menggunakan polinomial.
RIWAYAT HIDUP