DETEKSI PENCILAN DATA TITIK API DI PROVINSI RIAU
MENGGUNAKAN ALGORITME CLUSTERING K-MEANS
DHIYA AULIA MUHAMAD BAEHAKI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Deteksi Pencilan Data Titik Api di Provinsi Riau Menggunakan Algoritme Clustering K-Means adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
Dhiya Aulia Muhamad Baehaki
ABSTRAK
DHIYA AULIA MUHAMAD BAEHAKI. Deteksi Pencilan Data Titik Api di Provinsi Riau Menggunakan Algoritme Clustering K-Means. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Kebakaranhutan merupakan masalah yang selalu berulang di Provinsi Riau. Salah satu solusi dari masalah ini adalah memanfaatkan data titik api hasil penginderaan jarak jauh. Tujuan penelitian ini adalah mendeteksi pencilan yang terdapat pada data titik api di Provinsi Riau dari tahun 2001 hingga 2012. Deteksi pencilan dilakukan dengan menggunakan metode clustering k-means serta digunakan pendekatan pencilan global dan kolektif. Pada fungsi kmeans
digunakan nilai k sebesar 10 sehingga dihasilkan nilai sum of squared error
sebesar 18 526.14. Hasil menunjukkan bahwa berdasarkan pendekatan pencilan kolektif dideteksi pencilan titik api terdapat pada cluster 5, 7, dan 10. Di samping itu diperoleh 30 pencilan titik api berdasarkan pendekatan pencilan global. Kemunculan pencilan pada data titik api banyak terjadi pada bulan Februari, Maret, Juni, dan Agustus. Frekuensi pencilan titik api tertinggi terjadi pada tahun 2005 yaitu sebanyak 1118 titik api pada 21 Juni 2005. Adapun frekuensi pencilan titik api terkecil yaitu sebanyak 295 titik api pada tahun 2005 dan rata-rata frekuensi pencilan titik api sebesar 482.22.
Kata kunci: clustering, k-means, pencilan, Riau, titik api
ABSTRACT
DHIYA AULIA MUHAMAD BAEHAKI. Outlier Detection on Hotspot Data in Province Riau using K-Means Clustering Algorithm. Supervised by IMAS objective of this research is to detect outliers on hotspot data in Riau Province for the period 2001 to 2012. Outlier detection was done using the clustering k-means algorithm, and use a approach global outliers and collective outlier. The best clustering result was selected on the number of cluster 10 and the sum of squared error value is 18526.14. The results showed that based on a collective outlier approach, the outliers were obtained on cluster 5, 7 and 10. In addition, 30 outliers on hotspot data were detected based on the global outlier approach. The outliers on the hotspot data were mostly occurred in February, March, June, and August. The highest frequency of outliers occurred in 2005 reach 1118 hotspots on 21 June 2005. While the lowest frequency of outliers is 295 in 2005 and the average frequency of outliers is 482.22.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
DETEKSI PENCILAN DATA TITIK API DI PROVINSI RIAU
MENGGUNAKAN ALGORITME CLUSTERING K-MEANS
DHIYA AULIA MUHAMAD BAEHAKI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Deteksi Pencilan Data Titik Api di Provinsi Riau Menggunakan Algoritme Clustering K-Means
Nama : Dhiya Aulia Muhamad Baehaki NIM : G64100073
Disetujui oleh
Dr Imas Sukaesih Sitanggang, SSi MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Januari 2014 ini ialah pencilan, dengan judul Deteksi Pencilan Data Titik Api di Provinsi Riau Menggunakan Algoritme Clustering K-Means.
Penulis menyadari bahwa dalam proses penulisan skripsi ini banyak mengalami kendala, namun berkat bantuan, bimbingan, kerjasama dari berbagai pihak dan berkah dari Allah subhanahu wa ta'ala sehingga kendala-kendala yang dihadapi tersebut dapat diatasi. Untuk itu penulis menyampaikan ungkapan Terima kasih juga disampaikan kepada ayah, ibu serta seluruh keluarga atas segala doa dan kasih sayangnya. Serta ucapan Terima kasih dan penghargaan kepada Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku pembimbing yang telah dengan sabar, tekun, tulus dan ikhlas meluangkan waktu, tenaga, dan pikiran memberikan bimbingan, motivasi, arahan, dan saran-saran yang sangat berharga kepada penulis selama menyusun skripsi. Ucapan Terima kasih juga saya saya tujukan kepada Bapak Toto Haryanto, SKom MSi dan Bapak Asyhar Agmalaro, SSi MKom selaku penguji atas segala masukan dan saran yang telah diberikan.
Semoga karya ilmiah ini bermanfaat.
Bogor, Juli 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Data Penelitian 2
Tahapan Penelitian 2
Pengumpulan Data 3
Praproses Data 3
Analisis Data 4
Clustering Data Titik Api Menggunakan Algoritme K-Means 4 Deteksi Pencilan Titik Api Berdasarkan Hasil Clustering K-Means 5
Analisis Pencilan 6
Lingkungan Pengembangan 6
HASIL DAN PEMBAHASAN 6
Praproses 6
Analisis Data Time Series Titik Api 6
Clustering Data Titik Api Menggunakan Algoritme K-Means 8 Deteksi Pencilan Titik Api Berdasarkan Hasil Clustering K-Means 10 Deteksi Pencilan Berdasarkan Pendekatan Pencilan Kolektif 10 Deteksi Pencilan Berdasarkan Pendekatan Pencilan Global 10
Analisis Pencilan 13
SIMPULAN DAN SARAN 16
Simpulan 16
DAFTAR PUSTAKA 17
DAFTAR TABEL
1 Nilai SSE untuk hasil clustering nilai k = 2 hingga 10 8
2 Selisih nilai SSE pada k sebesar 2 hingga 10 9
3 Hasil clustering menggunakan fungsi kmeans dengan nilai k = 10 10 4 Deteksi pencilan berdasarkan ukuran outlier score terbesar 11
5 Pencilan pendekatan global dan kolektif 14
DAFTAR GAMBAR
1 Tahapan penelitian 3
2 Titik api tahun 2000 hingga 2013 terhadap peta Provinsi Riau 7 3 Dekomposisi data time series titik api di Provinsi Riau tahun 2001
hingga 2012 7
4 Visualisasi hasil clustering menggunakan fungsi kmeans dengan nilai k
= 10 9
5 Visualisasi pencilan dengan pendekatan kolektif 12
6 Visualisasi pencilan dengan pendekatan global 12
7 Jumlah objek deteksi pencilan di setiap bulan pada tahun 2001 hingga
2012 15
8 Jumlah objek deteksi pencilan pertahun 15
9 Visualisasi pencilan tahun 2005 15
10 Visualisasi pencilan tahun 2006 16
DAFTAR LAMPIRAN
1 Data penelitian 18
PENDAHULUAN
Latar Belakang
Hutan di Indonesia memiliki luas yang sangat besar. Luas kawasan hutan Indonesia pada tahun 2009/2010 berdasarkan hasil penafsiran citra satelit Landsat 7 ETM+ mencapai 98.56 juta ha (Kemenhut 2012). Data tersebut merupakan 52.3% dari total luas daratan Indonesia. Adapun luas hutan yang berada pada Provinsi Riau sebesar 8.6 juta ha. Akan tetapi, hutan di Indonesia mengalami masalah yang selalu berulang, salah satunya kebakaran hutan.
Penelitian dalam remote sensing menghasilkan cara untuk memantau perkembangan titik api dipermukaan bumi. Salah satu satelit yang memantau titik api yaitu satelit Terra yang diluncurkan pada 18 Desember 1999 dan satelit Aqua yang diluncurkan pada 4 Mei 2002 (Giglio 2010). Satelit-satelit ini bekerja dengan mengamati titik api, yaitu area yang memiliki temperatur yang tinggi dibandingkan dengan lingkungan sekitarnya. Pengamatan yang dilakukan satelit ini dilakukan secara berulang-ulang sehingga memiliki urutan waktu. Satelit tersebut disebut Moderate Resolution Imaging Spectro Radio Meter(MODIS).
Dalam analisis terbaru, World Resources Institute (WRI) meneliti tren historis peringatan titik api di Sumatera. Satelit NASA mencatat total 734 peringatan titik api dengan tingkat keyakinan deteksi tinggi di provinsi-provinsi pulau Sumatera pada periode 22 hingga 27 Agustus 2013 (Sizer et al. 2013). Bahkan pada awal Maret 2014 Global Forest Watch mendeteksi 3101 peringatan titik api dengan tingkat keyakinan tinggi sejak tanggal 20 Februari hingga 11 Maret 2014. Angka tersebut melebihi puncak krisis kebakaran dan kabut asap sebelumnya pada 13 hingga 30 Juni 2013 yaitu berjumlah 2643 peringatan titik api (Sizer et al. 2014).
Dengan mengamati hasil dari amatan sensor MODIS, dapat dibuat sebuah model untuk menganalisis kejadian titik api sebagai indikator kebakaran hutan pada waktu mendatang. Salah satu analisis yang dilakukan adalah analisis pencilan untuk melihat anomali kemunculan titik api. Sehingga didapatkan informasi yang menyimpang jauh dari bentuk data secara umum. Penelitian ini melakukan pendeteksian pencilan dalam data titik api di Provinsi Riau tahun 2001 hingga 2012 menggunakan metode clustering k-means.
Perumusan Masalah
2
Tujuan Penelitian Tujuan penelitian ini adalah
1 Menerapkan algoritme clustering k-means pada data titik api di Provinsi Riau, 2 Menentukan pencilan pada data titik api di Provinsi Riau berdasarkan hasil
clustering data titik api di Provinsi Riau, dan 3 Analisis pencilan data titik api yang dihasilkan.
Manfaat Penelitian
Manfaat dari penelitian ini adalah mendapatkan informasi yang tersembunyi berupa pencilan data titik api sebagai indikator kebakaran hutan. Hasil yang diperoleh diharapkan dapat bermanfaat dalam pencegahan kebakaran hutan.
Ruang Lingkup Penelitian
Penelitian ini menggunakan data yang didapatkan dari sensor MODIS selama 12 tahun, mulai dari tahun 2001 hingga 2012. Data yang didapat dari sensor MODIS dilakukan transformasi menjadi data frekuensi titik api harian dan bulanan. Dalam mendeteksi pencilan digunakan pendekatan pencilan global dan kolektif. Fungsi yang digunakan dalam penelitian seperti kmeans, ts, decompose,
set.seed, plot, points, text, lines, summary, dan library DBI dan RPosrgreSQL yang telah tersedia dalam perangkat lunak statistika R.
METODE
Data Penelitian
Data yang digunakan dalam penelitian ini adalah data frekuensi titik api yang ada di Provinsi Riau dari tahun 2001 hingga 2012. Data didapat dari penelitian sebelumnya yang dilakukan oleh Dinov (2014) yang dapat diunduh pada halaman web1. Data lain yang digunakan yaitu data peta Provinsi Riau yang berisi batas wilayah kabupaten dan kota se-Indonesia yang dapat diunduh dari halaman web2.
Tahapan Penelitian
Tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 1.
1
3
Gambar 1 Tahapan penelitian Pengumpulan Data
Data penelitian yang digunakan adalah data titik api yang diperoleh dari penelitian sebelumnya yang dilakukan oleh Dinov (2014). Data titik api terdiri dari data titik api tahun 2000 hingga tahun 2013 di wilayah pulau Sumatera. Data tersebut terdiri dari atribut latitude, longitude, brightness, scan, track, acq_date, acq_time, satellite, confidence, version, bright_t31, dan frp. Setiap barisnya menjelaskan satu kemunculan titik api yang diperoleh dari penginderaan jarak jauh menggunakan sensor MODIS. Contoh data dapat dilihat pada Lampiran 1. Namun data yang didapatkan pada tahun 2000 dan 2013 tidak lengkap. Karena, walaupun satelit Terra pertama kali memperoleh data pada bulan Februari tahun 2000, satelit Terra mengalami masalah crosstalk dan kalibrasi hingga awal bulan November tahun 2000 (Giglio 2010). Adapun pada tahun 2013 data hanya tersedia hingga bulan September.
Data lainnya yaitu data peta Indonesia. Data ini berisikan batas kabupaten dan kota yang ada di Indonesia. Peta ini digunakan untuk memperoleh data titik api yang terdapat di Provinsi Riau.
Praproses Data
Menurut Han et al. (2012), dalam tahap praproses data terdapat beberapa tahap utama, yaitu pembersihan data, pengintegrasian data, seleksi data, dan transformasi data. Dalam penelitian ini dilakukan pembersihan dan transformasi data. Pembersihan data dilakukan untuk memilih data titik api yang berada di Provinsi Riau juga memilih peta Provinsi Riau dari peta kabupaten dan kota se-Indonesia. Langkah ini dilakukan untuk menghilangkan data titik api yang berada di luar Provinsi Riau. Tahap ini dilakukan menggunakan perangkat lunak
Deteksi pencilan titik api
Clustering data titik api menggunakan algoritme
4
PostgreSQL, PostGIS 2.0 Shapefile and DBF Loader Exporter, dan Quantum GIS 2.0 Dufour.
Setelah data bersih, dilakukan pemilihan data titik api pada tahun 2001 hingga 2012 menggunakan kueri pada DBMS PostgreSQL dan transformasi data berupa agregasi data. Agregasi data adalah operasi penjumlahan jumlah kejadian titik api menjadi data harian, bulanan, ataupun tahunan.
Analisis Data
Data titik api merupakan data yang yang diambil oleh sensor MODIS berdasarkan urutan waktu. Maka data titik api merupakan data time series (Hasan 1999). Analisis data time series dilakukan menggunakan dekomposisi data time series. Dekomposisi data time series berfungsi untuk melihat komponen data time series yaitu tren sekuler, variasi musim, dan variasi residu atau irregular.
Tren sekuler merupakan gerakan teratur atau gerakan rata-rata dalam jangka waktu yang panjang, lebih dari 10 jangka waktu. Tren dapat digambarkan berupa garis tertentu yang memiliki bentuk garis meningkat, menurun, horizontal atau naik atau turun seperti huruf S. Adapun variasi musim (seasonal variation) merupakan variasi yang berulang-ulang dan regular dengan periode waktu yang pendek, yaitu satu tahun atau kurang. Variasi musim biasanya dipengaruhi oleh pengaruh-pengaruh seperti musim, adat istiadat, kebiasaan. Dan variasi residu merupakan gerakan yang berbeda-beda dalam waktu singkat, tidak diikuti pola yang teratur, serta tidak dapat diperkirakan. Variasi residu timbul dari kejadian-kejadian yang terjadi secara mendadak atau tidak diprediksikan sebelumnya, seperti perang, bencana alam, dan kebiasaan baru (Hasan 1999).
Clustering Data Titik Api Menggunakan Algoritme K-Means
Clustering disebut juga segmentasi data, pembagian data yang besar ke dalam beberapa kelompok berdasarkan kesamaan yang dimiliki. Clustering dapat digunakan untuk deteksi pencilan (Han et al. 2012).
Dalam tahapan ini diterapkan fungsi kmeans pada perangkat lunak R. Fungsi tersebut diberikan masukkan atau argumen berupa data frekuensi titik api harian dari tahun 2001 hingga 2012 juga nilai k sebesar 2 hingga 10. Algoritme kmeans dapat dilihat di bawah ini:
1 Pilih sebanyak k objek dari set data sebagai pusat cluster (centroid) secara acak. 2 Ulangi hingga tidak ada perubahan cluster atau hingga masa/epoch yang
ditentukan:
a Masukkan setiap objek ke dalam cluster yang memiliki kemiripan tertinggi terhadap nilai rataan cluster (centroid).
b Perbaharui nilai rataan cluster (centroid) pada setiap cluster.
Untuk menentukan nilai k terbaik digunakan fungsi sum of squared error
(SSE). SSE didefinisikan sebagai berikut (Tan et al. 2006):
5 : objek dalam kelas i,
: centroid atau titik pusat kelas i, dan
: fungsi jarak, yaitu jarak Euclidian.
Dengan mengetahui nilai SSE dari tiap nilai k maka dapat diketahui
clustering yang menghasilkan nilai kesamaan atau kemiripan terbaik. Clustering
yang memiliki nilai SSE terkecil adalah clustering dengan hasil terbaik. Deteksi Pencilan Titik Api Berdasarkan Hasil Clustering K-Means
Setelah diketahui nilai k terbaik kemudian dilakukan pendeteksian pencilan pada hasil clustering k-means. Secara umum pada deteksi pencilan terdapat tiga pendekatan, yaitu pencilan global, kontekstual, dan kolektif.
Pendekatan pertama, pencilan global adalah pendeteksian objek yang menyimpang secara signifikan dari set data. Pencilan global disebut juga point outlier. Pendekatan kedua, pencilan kontekstual yaitu pendeteksian pencilan jika objek menyimpang secara signifikan dari kondisi atau kebiasaan tertentu. Pendekatan ini disebut juga conditional outlier, karena melihat objek berdasarkan kondisi tertentu. Bila objek keluar dari kondisi yang biasa maka objek diidentifikasi sebagai pencilan. Namun pada penelitian ini pendekatan pencilan kolektif tidak digunakan karena membutuhkan data pendukung lainnya seperti cuaca dan tutupan lahan. Pendekatan ketiga, pencilan kolektif yaitu bilamana ada sekelompok objek atau cluster yang menyimpang secara signifikan dari set data (Han et al. 2012).
Dalam metode pendeteksian pencilan menggunakan clustering k-means,
pendekatan pencilan global dapat diartikan apabila sebuah objek memiliki jarak yang jauh antara objek dan centroid, maka objek tersebut dapat diidentifikasi sebagai pencilan. Pendekatan ini dapat diukur menggunakan nilai outlier score, semakin besar nilai outlier score sebuah objek maka kemungkinan bahwa objek tersebut merupakan pencilan semakin besar (Aggarwal 2013). Rasio untuk mengukur jarak sebuah objek yang didefinisikan sebagai berikut (Han et al.
co : centroid atau titik pusat terdekat dari objek data,
: fungsi jarak antara objek data dan centroid terdekat dari objek data, dan
: rata-rata .
Semakin besar nilai outlier score, objek tersebut semakin jauh dari centroid
maka lebih mirip dengan pencilan. Pendapat ini sama seperti yang diutarakan (Zhao 2012) bahwa pencilan adalah objek yang memiliki jarak terbesar antara objek dengan centroid.
6
Analisis Pencilan
Pada tahap ini diperlihatkan objek-objek pencilan dari data penelitian. Data hasil deteksi pencilan dianalisis untuk mengetahui informasi yang terdapat pada data seperti ukuran pemusatan dan tanggal-tanggal yang terdeteksi sebagai pencilan serta plotting pencilan titik api pada peta Provinsi Riau.
Lingkungan Pengembangan
Spesifikasi perangkat keras dan perangkat lunak yang digunakan dalam penelitian ini adalah sebagai berikut:
1 Perangkat keras berupa komputer personal dengan spesifikasi Prosesor AMD A6-3400M dan
Memori RAM 4 GB. 2 Perangkat lunak
Komputasi statistika R versi 3.0.1, RStudio versi 0.98.501,
Database management system (DBMS) PostgreSQL dengan ekstensi PostGIS,
PostGIS 2.0 shapefile and DBF loader exporter,
Pengolah data spatial Quantum GIS 2.0 Dufour, dan Microsoft Excel 2010.
HASIL DAN PEMBAHASAN
Praproses
Data awal pada penelitian ini adalah sebanyak 156 703 data. Kemudian data tersebut dilakukan tahap pembersihan data dari data titik api yang terdapat diluar dari Provinsi Riau sehingga didapatkan data titik api di Provinsi Riau sebanyak 111 091. Selanjutnya dilakukan pemilihan data titik api dari tahun 2001 hingga 2012 sehinggga didapatkan sebanyak 96 456 data. Data tersebut diolah dalam sebuah basis data spatial DBMS PostgreSQL. Kemudian dilakukan evaluasi data pada perangkat lunak Quantum GIS dengan menambahkan layer data titik api yang telah dilakukan pembersihan data juga peta Provinsi Riau.
Hasil dari evaluasi data titik api dapat dilihat pada Gambar 2. Gambar tersebut merupakan peta Provinsi Riau dan titik api yang terjadi pada Provinsi Riau tahun 2001 hingga 2012. Pada Gambar 2 seluruh titik api berada hanya di dalam Provinsi Riau.
Tahap selanjutnya dilakukan transformasi data, yaitu agregasi data. Dari tahap tersebut diperoleh frekuensi data titik api harian sebanyak 4383 data dan frekuensi data titik api bulanan sebanyak 144 data.
Analisis Data Time Series Titik Api
Setelah frekuensi data titik api harian didapatkan, dilakukan dekomposisi dengan menjalankan kode R berikut:
library(DBI)
library(RPostgreSQL)
drv <- dbDriver("PostgreSQL")
7
query <-"SELECT gen_month,count(acq_date)
FROM generate_series(DATE '2001-01-01', DATE '2012-12-31', '1 DAY') m(gen_month)
LEFT OUTER JOIN hotspot0013
ON (acq_date BETWEEN gen_month AND gen_month + INTERVAL '1 DAY' - INTERVAL '1' DAY)
GROUP BY gen_month ORDER BY gen_month" rs <- dbSendQuery(con, query)
data.kmeans <- fetch(rs,n=-1) dbDisconnect(con)
dbUnloadDriver(drv)
write.csv(data.kmeans, 'data/data.kmeansall.csv') data <- data.frame(index(2001, 2012), data.kmeans) names(data) <- c("y_dd", "tgl", "frek")
time <- ts(data$frek, frequency=365, start=c(2001,1)) dec <- decompose(time)
plot(dec)
Fungsi library digunakan untuk memanggil packages yang tersedia di dalam perangkat lunak R. Dalam hal ini fungsi library digunakan untuk memanggil
packages DBI dan RPostgreSQL yaitu untuk mengakses data dari basis data. Fungsi dbDriver dan dbConnect digunakan untuk konfigurasi basis data. Fungsi ts untuk membuat data deret waktu sedangkan fungsi decompose berfungsi untuk mendekomposisi data deret waktu.
Gambar 2 Titik api tahun 2000 hingga 2013 terhadap peta Provinsi Riau Setelah kode program dijalankan, didapatkan visualisasi yang dapat dilihat pada Gambar 3.
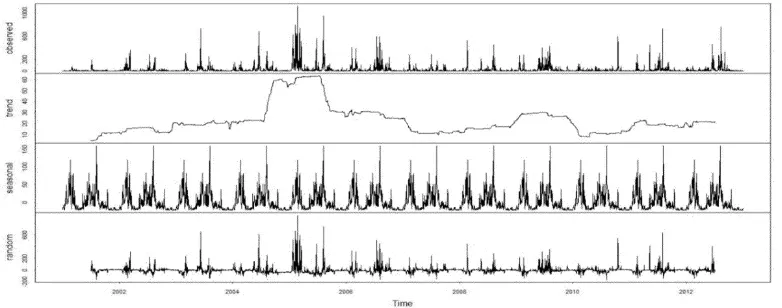
Gambar 3 Dekomposisi data time series titik api di Provinsi Riau tahun 2001 hingga 2012
8
Pada Gambar 3 menunjukkan hasil dekomposisi harian data titik api dengan asumsi jumlah hari pada satu tahun sebanyak 365 hari. Label observed merupakan frekuensi data titik api harian dari tahun 2001 hingga 2012. Label trend
menunjukkan kenaikkan frekuensi titik api hingga di awal tahun 2005 kemudian menurun kembali hingga awal tahun 2007 dan mengalami kenaikkan pada awal tahun 2009 dan kembali turun pada akhir tahun 2009 dan menaik kembali hingga akhir tahun 2012. Pada label seasonal ditunjukkan frekuensi titik api mengalami kenaikkan pada awal dan di pertengahan tahun.
Clustering Data Titik Api Menggunakan Algoritme K-Means
Hasil dari penggunaaan fungsi kmeans pada data titik api Provinsi Riau tahun 2001 hingga 2012 untuk menentukan nilai k terbaik dapat dilihat pada Tabel 1, hasil tersebut didapatkan dengan menjalankan kode berikut:
data <- read.csv('data/data.kmeansall.csv') start <- 2
finish <- 10
for(start in start : finish){ set.seed(1000)
hasil <- kmeans(data$frek, start)
centers <- hasil$centers[hasil$cluster] jarak <- sqrt((data$frek - centers)^2) total <- sum(jarak)
persen <- 100*(hasil$betweenss/hasil$totss)
gab<- data.frame(start, total, hasil$tot.withinss, persen) if(start == 2) {
names(sse) <- c("kelas", "sse", "tot.within", "persen")
Fungsi-fungsi yang digunakan dalam mencari nilai SSE sudah tersedia pada aplikasi statistik R yaitu pada package stats dan base. Fungsi kmeans berguna untuk melakukan algoritme kmeans pada data frekuensi titik api harian.
Tabel 1 Nilai SSE untuk hasil clustering nilai
9
Dari Tabel 1 dapat dilihat bahwa nilai k yang menghasilkan nilai SSE terkecil adalah nilai k sebesar 10 juga perubahan selisih nilai SSE sudah tidak signifikan dapat dilihat pada Tabel 2. Maka fungsi kmeans yang akan dilakukan deteksi pencilan diberi masukkan argumen k sebesar 10.
Tabel 2 Selisih nilai SSE pada k sebesar 2 hingga 10 Selisih k Nilai selisih
2 dan 3 23 465.22 3 dan 4 16 873.31 4 dan 5 6 826.54 5 dan 6 8 736.77 6 dan 7 4 742.01 7 dan 8 3 819.64 8 dan 9 1 335.63 9 dan 10 1 082.75
Hasil clustering menggunakan fungsi kmeans dengan masukan argumen k
bernilai 10 dapat dilihat pada Tabel 3. Dan visualisasi hasil clustering
digambarkan pada Gambar 4.
Gambar 4 Visualisasi hasil clustering menggunakan fungsi kmeans dengan nilai
k = 10
Visualisasi yang terdapat pada Gambar 4 dibuat dengan menggunakan kode R yang dapat dilihat pada Lampiran 2. Pada Lampiran 2 perintah untuk membuat visualisasi clustering digunakan fungsi plot dan didukung fungsi lines dan text yang berguna untuk membuat garis centroid dan teks penjelas pada tahun dan nomor cluster.
10
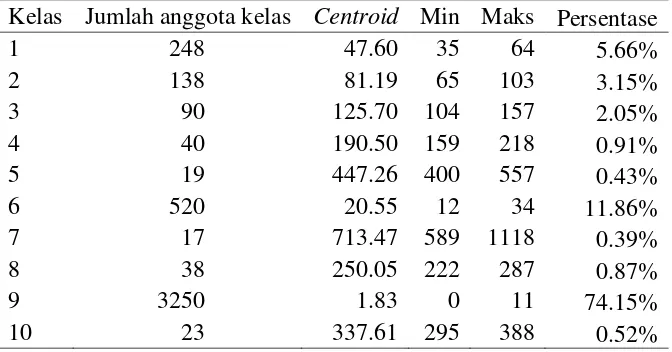
Tabel 3 Hasil clustering menggunakan fungsi kmeans dengan nilai k = 10
Kelas Jumlah anggota kelas Centroid Min Maks Persentase
1 248 47.60 35 64 5.66%
Deteksi Pencilan Titik Api Berdasarkan Hasil Clustering K-Means
Deteksi Pencilan Berdasarkan Pendekatan Pencilan Kolektif
Penentuan pencilan kolektif didasarkan pada jumlah keanggotaan setiap
cluster. Cluster yang memiliki anggota yang sedikit ditetapkan sebagai pencilan. Dari Tabel 3 dapat dilihat bahwa kelas yang memiliki anggota terkecil adalah
cluster 7 dengan 17 anggota, cluster 5 dengan 19 anggota, dan cluster 10 dengan 23 anggota. Seluruh cluster 7, 5, dan 10 memiliki jumlah anggota jauh di bawah 1%. Maka berdasarkan pendekatan pencilan kolektif ditetapkan bahwa cluster 7, 5, dan 10 merupakan pencilan.
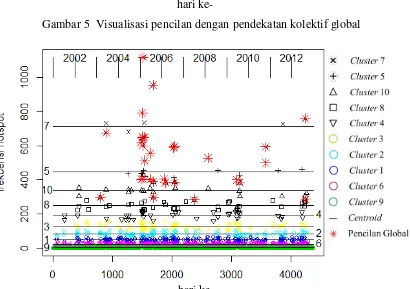
Visualisasi pencilan kolektif dapat dilihat pada Gambar 5. Visualisasi dilakukan dengan menambahkan tanda pada cluster yang telah ditetapkan sebagai pencilan. Penandaan tersebut dilakukan dengan nambahkan perintah di bawah ini pada kode R untuk membuat visualisasi clustering:
points(data[(hasil$cluster==5),c("no","frek")], pch=13, col=2, cex=1.5)
points(data[(hasil$cluster==7),c("no","frek")], pch=13, col=2, cex=1.5)
points(data[(hasil$cluster==10),c("no","frek")], pch=13, col=2, cex=1.5)
Arti dari argumen pch dalam fungsi points adalah untuk memilih jenis karakter yang mewakili pencilan. Adapun argumen col digunakan untuk mengatur warna karakter dan cex digunakan untuk mengatur ukuran karakter.
Deteksi Pencilan Berdasarkan Pendekatan Pencilan Global
Penentuan pencilan berdasarkan pendekatan pencilan global, dilakukan dengan diambil 30 data frekuensi titik api yang memiliki nilai outlier score
terbesar. Tiga puluh data yang memiliki outlier score terbesar diartikan sebagai objek yang memiliki nilai kesamaan yang rendah dalam cluster. Tiga puluh objek tersebut diidentifikasi sebagai pencilan. Data tersebut dapat dilihat pada Tabel 4.
Pada Tabel 4 outlier score dihasilkan dari rasio jarak setiap objek kepada
11 Tabel 4 Deteksi pencilan berdasarkan ukuran outlier
score terbesar
Outlier score Frekuensi harian Tanggal Kelas
95.71 1118 21/2/2005 7 jarak <- sqrt((data$frek - centers)^2) lco <- mean(jarak)
os <- jarak/lco
outlier_index <- (data$no[order(os, decreasing=T)[1:30]]) outlier_frek <- (data$frek[outlier_index])
outlier_os <- (os[order(os, decreasing=T)[1:30]])
12
outlier <- data.frame(outlier_index, outlier_frek, outlier_os, outlier_kelas, outlier_date)
write.csv(outlier, "30 pencilan outlier score.csv")
Perintah read.csv berfungsi untuk membaca data frekuensi titik api harian yang berada pada file data.kmeansall.csv. Kemudian dijalankan fungsi kmeans lalu dicari jarak setiap objek terhadap centroid-nya dengan menjalankan kode program centers <- hasil$centers[hasil$cluster] dan jarak <- sqrt((data$frek - centers)^2). Selanjutnya rata-rata dari jarak dicari
dengan menjalankan kode lco <- mean(jarak).
hari ke-
Gambar 6 Visualisasi pencilan dengan pendekatan global hari ke-
13 Analisis Pencilan
Pencilan yang dihasilkan adalah objek-objek pada kelas 7, 5, dan 10 serta 30 objek yang memiliki nilai outlier score terbesar. Pencilan yang dihasilkan dapat dilihat pada Tabel 5. Dari objek-objek yang terdeteksi sebagai pencilan dapat dilihat objek merupakan titik api dengan frekuensi harian sangat tinggi.
Pada pencilan global, anggota pencilan memiliki frekuensi titik api harian mulai dari 295 hingga 1118 titik api yang terdiri dari anggota kelas 5, 7, dan 10. Adapun anggota pencilan kolektif terdiri dari kelas 5, 7, 8, dan 10 dengan frekuensi titik api terkecil sebesar 284 dan tertinggi sebesar 1118.
Kedua pendekatan pencilan tersebut menghasilkan pencilan yang berbeda. Pada pendekatan kolektif kelas yang dideteksi sebagai pencilan adalah 5, 7, dan 10 sedangkan dengan pendekatan global pencilan dideteksi terdapat pada anggota kelas 5, 7, 8, dan 10. Perbedaan ini disebabkan pada pendekatan global, pencilan dideteksi berdasarkan derajat kesamaan objek dengan anggota cluster-nya masing-masing yang diukur dengan outlier score. Objek-objek yang memiliki derajat kesamaan yang rendah terhadap anggota cluster-nya atau menyimpang dari objek-objek didalam cluster-nya maka diidentifikasi sebagai pencilan.
Adapun pendekatan pencilan kolektif didasarkan pada pendeteksian cluster
minoritas atau cluster yang berbeda dari cluster-cluster lainnya. Dalam penelitian ini perbedaan tersebut didasarkan pada jumlah keanggotaan cluster.
Dalam pencilan global tidak seluruh objek pada cluster 5, 7, 8, dan 10 dideteksi sebagai pencilan. Hanya objek-objek yang memiliki outlier score
terbesar saja yang dideteksi sebagai pencilan.
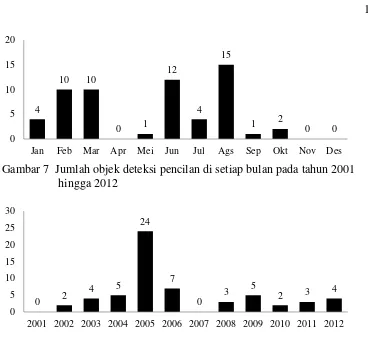
Dari Tabel 5 dapat dilihat bahwa jumlah pencilan yang terdeteksi sebanyak 61 objek. Pencilan banyak terjadi pada bulan Februari, Maret, Juni dan Agustus. Kemudian terlihat ada pergeseran deteksi pencilan dari tahun ke tahun, mulanya pencilan muncul setiap awal tahun berubah menuju pertengahan tahun, yaitu bulan Juni dan Agustus mulai dari tahun 2006. Kemunculan pencilan paling banyak terdeteksi pada tahun 2005 yaitu sebanyak 24 objek. Rata-rata dari pencilan yang terdeteksi adalah 481.22 titik api. Jumlah deteksi pencilan dapat dilihat pada Gambar 5 dan 6.
Dari Gambar 6 dapat dilihat bahwa, grafik jumlah pencilan pertahun yang ditampilkan menyerupai tren yang dihasilkan pada dekomposisi data time series
frekuensi titik api harian. Jumlah deteksi pencilan terus menaik hingga tahun 2005 lalu menurun hingga tahun 2007 kemudian menaik kembali hingga tahun 2012.
Adapun Gambar 5 menunjukkan seperti label seasonal (variasi musiman) hasil dekomposisi data time series frekuensi titik api harian. Pencilan muncul secara signifikan pada bulan Februari, Maret, Juni dan Agustus. Berarti frekuensi titik api harian dideteksi banyak muncul pada awal dan pertengahan tahun.
14
Tabel 5 Pencilan pendekatan global dan kolektif
15
Gambar 7 Jumlah objek deteksi pencilan di setiap bulan pada tahun 2001 hingga 2012
Gambar 8 Jumlah objek deteksi pencilan per tahun
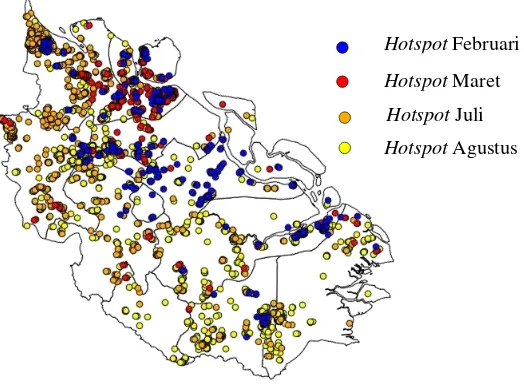
Dari Gambar 6 dapat dilihat bahwa pencilan banyak terjadi pada tahun 2005 sebanyak 24 objek dan 2006 sebanyak 7 objek. Dari tiap tahun dibuat visualisasi pencilan yang terjadi pada tahun 2005 dan 2006. Visualisasi tersebut dapat dilihat pada Gambar 7 untuk visualisasi pencilan tahun 2005 dan Gambar 8 untuk visualisasi pencilan tahun 2006.
Gambar 9 Visualisasi pencilan tahun 2005
Dari Gambar 7 dapat dilihat bahwa objek yang terdeteksi sebagai pencilan pada tahun 2005 menyebar diseluruh Provinsi Riau. Pada bulan Januari pencilan
4
Jan Feb Mar Apr Mei Jun Jul Ags Sep Okt Nov Des
0 2
2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012
Hotspot Januari
Hotspot Februari
Hotspot Maret
Hotspot Juni
16
terdeteksi berkumpul pada tenggara Kota Dumai, bagian timur laut Kabupaten Indragiri Hilir, serta menyebar pada kabupaten Siak dan Bengkalis. Pada bulan Februari dan Maret pencilan mayoritas muncul di bagian timur dari Provinsi Riau. Pada bulan Januari hingga Maret pencilan tidak terdeteksi di kabupaten Kuantan Singing. Adapun pada bulan Juni pencilan mayoritas muncul di utara Provinsi Riau. Dan pada bulan Agustus pencilan muncul secara merata di seluruh Provinsi Riau.
Gambar 10 Visualisasi pencilan tahun 2006
Pada tahun 2006 dideteksi terdapat 7 objek pencilan. Dari visualisasi Gambar 8 dapat dilihat bahwa pada bulan Februari pencilan muncul pada kabupaten Rokan Hilir, Kota Dumai, Bengkalis, Siak, Kampar, Pelalawan, Indragiri Hulur. Pada bulan Maret pencilan dideteksi muncul pada kabupaten Rokan Hilir, Kota Dumai, dan Bengkalis. Pada bulan Juli pencilan muncul di wilayah utara dan timur Provinsi Riau. Adapun pada bulan Agustus pencilan menyebar di seluruh Provinsi Riau.
SIMPULAN DAN SARAN
Simpulan
Kesimpulan dari penelitian ini adalah objek yang menjadi pencilan adalah objek dengan frekuensi titik api terbesar, yaitu berada pada kelas 7, 5, dan 10 berdasarkan pendekatan kolektif sebanyak 59 titik api serta 30 objek berdasarkan pendekatan global. Pencilan terjadi pada bulan Januari, Februari, Maret, Mei, Juni, Juli, Agustus, September, dan Oktober tanpa bulan April, November, dan Desember. Rata-rata pencilan yang terdeteksi adalah sebesar 481.22 titik api. Frekuensi titik api minimum yang terdeteksi sebagai pencilan sebesar 284 titik api dan terbesar adalah 1118 titik api.
Hotspot Februari
Hotspot Maret
Hotspot Juli
17 Saran
Penelitian ini masih memiliki kekurangan, antara lain penentuan nilai k
untuk fungsi kmeans, saran yang dapat disampaikan untuk penelitian selanjutnya adalah menggunakan algoritme lain selain kmeans salah satunya adalah k-medoids serta melakukan deteksi pencilan berdasarkan spasial dan temporal. Juga dapat dilakukan deteksi pencilan menggunakan pendekatan kontekstual berdasarkan kondisi cuaca dan tutupan lahan serta menambahkan data titik api hingga data terbarukan.
DAFTAR PUSTAKA
Aggarwal C C. 2013. Outlier analysis[internet]. [diunduh 16 Des 2013]. Tersedia pada: http://www.charuaggarwal.net/outlierbook.pdf.
Dinov I A. 2014. Hierarchical clustering pada data time series hotspot Provinsi Riau[skripsi]. Bogor (ID): Institut Pertanian Bogor.
Giglio L. 2010. MODIS collection 5 active fire product user’s guide version 2.4[internet]. [diunduh 2014 Jan 16]. Tersedia pada : http://earthdata.nasa.gov/sites/default/files/field/document/MODIS_Fire_users_G uide_2.4.pdf.
Hasan M I. 1999. Pokok-Pokok Materi Statistik 1: Statistik Deskriptif. Jakarta (ID): Bumi aksara.
Han J, Kamber M, Pei J. 2012. Data Mining: Concepts and Techniques. Massachusetts (US): Morgan Kaufmann.
[Kemenhut] Kementerian Kehutanan. 2012. Statistik kehutanan Indonesia 2011 [internet]. [diunduh 17 Des 2013 ]. Tersedia pada: http://agungwi.files.wordpress.com/2012/11/buku-statistik-juli-2012_terbaru.pdf. Sizer N, Anderson J, Stolle F, Alisjahbana A, Putraditama A. 2013. Indonesia
burning: forest fires flare to alarming levels[internet]. [diakses 19 Mei 2014]. Tersedia pada: http://www.wri.org/blog/2013/08/indonesia-burning-forest-fires-flare-alarming-levels.
Tan P, Kumar V, Steinbach M. 2006. Introduction to Data Mining. Pearson Education.
18
Lampiran 1 Data penelitian
gid latitude Longitude acq_date
19 Lampiran 2 Perintah dalam R untuk visualisasi clustering
opar <- par(bg = "white")
w <- c(4,5,7,1,1,6,1,1,3,1) #pilihan warna untuk setiap cluster
warna <- w[hasil$cluster]
p <- c(1,1,1,6,3,1,4,0,1,2) #jenis karakter setiap cluster
point <- p[hasil$cluster]
lines(x=c(0,4383), y=c(hasil$centers[i], hasil$centers[i])) }
lines(x=c(i*365+j,i*365+j), y=c(1000,1118)) }
else{
20
RIWAYAT HIDUP
Penulis dilahirkan di Bogor kelurahan Tanah Sareal kecamatan Tanah Sareal Provinsi Jawa Barat pada tanggal 25 Juli 1992. Penulis adalah anak pertama dari lima bersaudara, anak dari pasangan Dadang Baehaki dan Evalia Nurkurnia.