KLASIFIKASI DATA TITIK API DI BENGKALIS RIAU
MENGGUNAKAN ALGORITME POHON KEPUTUSAN
BERBASIS
SPATIAL ENTROPY
INDRY DESSY NURPRATAMI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Klasifikasi Data Titik Api di Bengkalis Riau Menggunakan Algoritme Pohon Keputusan Berbasis Spatial Entropy adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Juli 2014
ABSTRAK
INDRY DESSY NURPRATAMI. Klasifikasi Data Titik Api di Bengkalis Riau Menggunakan Algoritme Pohon Keputusan Berbasis Spatial Entropy. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Kebakaran hutan dapat dipantau dengan menggunakan satelit yang mendeteksi titik api sebagai indikator kebakaran pada waktu dan lokasi tertentu. Tujuan penelitian ini adalah mengembangkan sebuah pohon keputusan untuk memprediksi munculnya titik api di kabupaten Bengkalis provinsi Riau, Indonesia menggunakan algoritme pohon keputusan berbasis spatial entropy. Data yang digunakan pada penelitian adalah data kebakaran hutan di daerah Bengkalis, Riau. Data tersebut meliputi pusat kota, sungai, jalan, sumber pendapatan, tutupan lahan, populasi, curah hujan, sekolah, temperatur, dan kecepatan angin. Hasil penelitian dengan menggunakan metode uji 5-fold cross validation adalah 5 pohon keputusan dengan akurasi rata-rata 52.05% dan 89.04% masing-masing pada data uji dan data latih. Pohon keputusan terbaik memiliki akurasi data uji sebesar 56% pada data uji yang mempunyai 560 node dengan node akar adalah layer tutupan lahan. Dari pohon keputusan tersebut diperoleh 255 aturan untuk mengklasifikasikan titik api. Terdapat juga sebanyak 20 objek pada data uji dengan pohon keputusan terbaik yang tidak dapat diklasifikasikan oleh pohon. Kata kunci: bengkalis, kebakaran hutan, spatial decision tree, spatial entropy, titik api
ABSTRACT
INDRY DESSY NURPRATAMI. Classification of Hotspot Dataset in Bengkalis Using Spatial Entropy-Based Decision Tree Algorithm. Supervised by IMAS SUKAESIH SITANGGANG.
Forest fire can be monitored using satellite by detecting hotspots as fire indicators at certain times and locations. The purpose of this research is to develop a decision tree for predicting hotspot occurences in Bengkalis district, Riau province Indonesia using the spatial entropy-based decision tree algorithm. The data used in this research are forest fire data of Bengkalis area. The data include city centre, river, road, income source, land cover, population, precipitation, school, temperature, and wind speed. This research, using the 5-fold cross validation, yields five decision trees with the average accuracy of 52.05% and 89.04% on the testing set and the training set respectively.The best accuracy of decision tree is 56% on the testing set that has 560 nodes with the land cover layer as the root node. From the decision tree, as 255 rules for classifying hotspot occurences are obtained. There are 20 objects in the testing set that cannot be classified by the decision tree with the highest accuracy on the testing set.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
KLASIFIKASI DATA TITIK API DI BENGKALIS RIAU
MENGGUNAKAN ALGORITME POHON KEPUTUSAN
BERBASIS
SPATIAL ENTROPY
INDRY DESSY NURPRATAMI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Klasifikasi Data Titik Api di Bengkalis Riau Menggunakan Algoritme Pohon Keputusan Berbasis Spatial Entropy Nama : Indry Dessy Nurpratami
NIM : G64100032
Disetujui oleh
Dr Imas S. Sitanggang, SSi, MKom Pembimbing I
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen Ilmu Komputer
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wata’ala atas segala karunia-Nya sehingga tugas akhir dengan judul Klasifikasi Data Titik Api di Bengkalis Riau Menggunakan Algoritme Pohon Keputusan Berbasis Spatial Entropy dapat diselesaikan. Penyelesaian tugas akhir ini tidak terlepas dari bantuan beberapa pihak. Oleh karena itu, penulis ingin menyampaikan terima kasih kepada semua pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain:
1 Mama, Papa, dan Adik-adik serta seluruh keluarga atas segala doa, kasih sayangnya dan semangat yang telah diberikan kepada penulis.
2 Ibu Dr Imas Sukaesih Sitanggang, SSi, MKom selaku dosen pembimbing yang selalu memberikan saran dan arahan selama penelitian dan penulisan tugas akhir ini.
3 Bapak Hari Agung Adrianto, SKom, MSi dan Bapak Endang Purnama Giri, SKom, MKom yang telah bersedia menjadi dosen penguji
4 Rekan-rekan mahasiswa bimbingan Ibu Dr Imas Sukaesih Sitanggang, SSi, MKom terutama Umil dan Ana atas informasi dan kerjasamanya selama penyelesaian tugas akhir ini.
5 Rekan-rekan Sunda Karya yang memberi motivasi dalam penyelesaian tugas akhir ini, yaitu Poet, Eka, Pupu, kak Ade, Ria, Beti, Jesi, dan putri. 6 Teman-teman S1 Ilmu Komputer angkatan 47 (Pixels 47) yang telah memberikan motivasi dan bantuan dalam penyelesaian tugas akhir ini khususnya Bayu Sasrabau yang telah membantu dan mengajari dalam pembuatan fungsi jarak dengan bahasa Python dan Ayu Riza Bestary serta rekan-rekan lainnya yang tentu tidak bisa disebutkan satu persatu atas bantuan dan motivasinya.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama pengerjaan penyelesaian tugas akhir ini yang tidak dapat disebutkan satu-persatu. Penulis menyadari bahwa masih terdapat kekurangan dalam penulisan skripsi ini. Semoga skripsi ini dapat memberikan manfaat.
Bogor, Juli 2014
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Data dan Area Studi 3
Tahapan Penelitian 4
Peralatan Penelitian 7
HASIL DAN PEMBAHASAN 7
Praproses Data 7
Pembuatan Model Klasifikasi Spasial Menggunakan Algoritme Pohon
Keputusan Berbasis Spatial Entropy 11
Evaluasi Model 15
SIMPULAN DAN SARAN 16
Simpulan 16
Saran 16
DAFTAR PUSTAKA 16
LAMPIRAN 18
DAFTAR TABEL
1 Layer target 9
2 Hasil perhitungan jarak hotspot ke jalan terdekat 9 3 Hasil perhitungan jarak hotspot ke sungai terdekat 10 4 Hasil perhitungan jarak hotspot ke pusat kota terdekat 10 5 Hasil penggabungan objek target dan objek-objek penjelas 11
6 Hasil normalisasi atribut ordinal 12
7 Hasil perhitungan intra distance dan extra distance 12
8 Akurasi data uji dan data latih 15
DAFTAR GAMBAR
1 Layer titik api 3
2 Layer temperatur 3
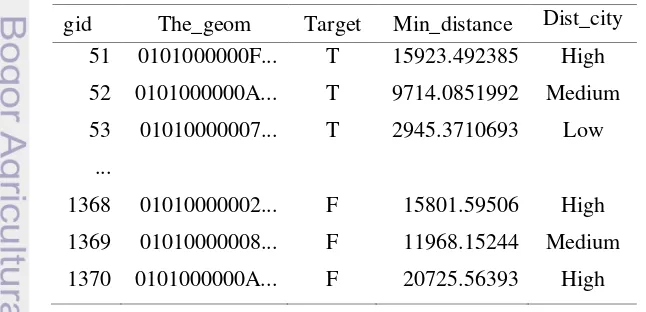
3 Tahapan Penelitian 4
4 Titik hotspot dan nonhotspot 8
5 Query pembuatan layer target 8 6 Query jarak minimum dari target ke jalan terdekat 9
7 Kode program perhitungan spatial entropy 13
8 Kode program perhitungan information gain 14
9 Kode program Python untuk membuat pohon keputusan 14
DAFTAR LAMPIRAN
1 Aturan dari model pohon keputusan data latih 1 18
2 Aturan dari model pohon keputusan data latih 2 19
3 Aturan dari model pohon keputusan data latih 3 20
4 Aturan dari model pohon keputusan data latih 4 21
PENDAHULUAN
Latar Belakang
Menurut UU RI No. 41 tahun 1999 tentang kehutanan, hutan merupakan suatu kesatuan ekosistem berupa hamparan lahan yang berisi sumber daya alam hayati yang didominasi oleh pepohonan dalam lingkungan alam yang tidak dapat dipisahkan antara yang satu dengan yang lainnya. Food and Agricultural Organization (FAO) dalam buku State of the World’s Forests menempatkan Indonesia di urutan ke-8 dari sepuluh negara dengan luas hutan alam terbesar di dunia (FWI 2011). Akan tetapi, luas hutan di Indonesia berkurang setiap tahun dengan laju kerusakan hutan mencapai 1.87 juta hektar pertahun dalam kurun waktu 2000 sampai 2005 (FWI 2011). Salah satu penyebab utama kerusakan hutan di Indonesia adalah kebakaran hutan.
Kebakaran hutan merupakan keadaan saat hutan dilanda api yang mengakibatkan terjadinya kerusakan hutan dan dapat menimbulkan kerugian bagi kehidupan manusia. Kerugian yang dialami berupa tercemarnya lingkungan, terganggunya kesehatan manusia, dan melemahnya roda perekonomian bangsa (Deliknews 2013). Secara umum, penyebab kebakaran hutan adalah kondisi suhu udara yang tinggi dan curah hujan yang rendah sehingga sisa-sisa bahan olahan kayu, daun, dan rumput kering yang bergesekan mudah terbakar. Apabila di permukaan tanah terdapat mineral berwarna terang, mineral tersebut dapat berfungsi sebagai lensa yang menghasilkan titik api sehingga kobaran api mulai terbentuk dan akan menyebar luas dengan adanya tiupan angin (Badungkab 2013). Kebakaran hutan dapat dipantau dengan menggunakan satelit yang mendeteksi titik api (hotspot) pada waktu dan lokasi tertentu. Berdasarkan data satelit NOAA-18 (National Oceanic and Atmospheric Administration), jumlah titik api yang terpantau di Indonesia dari Januari hingga September 2012 sudah mencapai 24663 titik. Provinsi dengan konsentrasi titik api terbanyak adalah Kalimantan Barat 5027 titik api, Riau 4318 titik, Sumatera Selatan 4297 titik, Jambi 1895 titik, Kalimantan Tengah 1736 titik, dan Kalimantan Timur 1058 titik api (Sigit 2012). Banyaknya jumlah kemunculan titik api tersebut menyebabkan besarnya ukuran data titik api.
2
kemunculan titik api. Data tersebut meliputi pusat kota, sungai, jalan, sumber pendapatan, tutupan lahan, populasi, curah hujan, sekolah, temperatur, dan kecepatan angin.
Perumusan Masalah
Dengan mengklasifikasikan kemunculan titik api dapat diketahui pada keadaan seperti apa kebakaran itu terjadi sehingga mengklasifikasikan titik api penting dilakukan karena dapat mencegah terjadinya kebakaran hutan. Perumusan masalah dalam penelitian ini adalah bagaimana cara menerapkan algoritme pohon keputusan berbasis spatial entropy (Li dan Claramunt 2006) pada data kebakaran hutan di Kabupaten Bengkalis, Riau untuk mengklasifikasikan kemunculan titik api.
Tujuan Penelitian Tujuan dari penelitian ini ialah:
1 Menerapkan algoritme pohon keputusan berbasis spatial entropy (Li dan Claramunt 2006) pada data titik api di kabupaten Bengkalis, Riau.
2 Mengevaluasi pohon keputusan berbasis spatial entropy untuk prediksi kemunculan titik api di kabupaten Bengkalis, Riau.
Manfaat Penelitian
Penelitian ini diharapkan dapat memberikan karakterisitik wilayah yang berpotensi munculnya titik api. Hal ini berguna dalam pencegahan terjadinya kebakaran hutan.
Ruang Lingkup Penelitian Ruang lingkup penelitian yang dilakukan meliputi:
1 Data yang digunakan terdiri dari data titik api tahun 2008 di wilayah Kabupaten Bengkalis, Riau.
2 Karakteristik wilayah mencakup sungai, jalan, pusat kota, tutupan lahan dan batas administratif.
3
METODE
Data dan Area Studi
Data spasial adalah data yang merepresentasikan aspek-aspek keruangan dari fenomena yang terdapat di dunia nyata. Data spasial memiliki 2 tipe, yaitu vektor dan raster. Model data raster menampilkan, menempatkan, dan menyimpan data spasial dengan menggunakan struktur matriks atau piksel-piksel yang membentuk grid, sedangkan model data vektor menggunakan titik, garis atau kurva, atau poligon beserta atributnya. Contoh umum dari data vektor adalah peta, desain grafik, dan representasi 3D dari susunan rantai molekul protein (Han dan Kamber 2006).
Penelitian ini menggunakan data titik api di Kabupaten Bengkalis Provinsi Riau pada tahun 2008. Kabupaten Bengkalis memiliki luas wilayah 7793.93 km2 yang terbagi dalam 8 kecamatan dan 102 desa/kelurahan. Wilayah Kabupaten Bengkalis merupakan dataran rendah dengan rata-rata ketinggian antara 2 sampai 6.1 meter di atas permukaan laut dan sebagian besar merupakan tanah organosol, yaitu jenis tanah yang banyak mengandung bahan organik (Riau 2014). Karakteristik wilayah yang digunakan mencakup sungai, jalan, dan pusat kota, tutupan lahan dan batas administratif. Data persebaran dan koordinat titik api pada tahun 2008 diperoleh dari NOAA AVHR dan FIRMS MODIS Fire/Hotspot, NASA/University of Maryland (Gambar 1). Data cuaca terdiri atas temperatur harian (Gambar 2), maksimum hujan harian, dan kecepatan angin diperoleh dari BMKG. Data lahan gambut yang terdiri atas tipe dan kedalaman diperoleh dari Wetland International. Data sosial-ekonomi yang mencakup sumber pendapatan diperoleh dari Badan Pusat Statistika (BPS) pada tahun 2008. Peta digital terdiri atas peta jalan, sungai, pusat kota, tutupan lahan, dan batas administratif diperoleh dari Bakosurtanal (saat ini menjadi Badan Informasi Geospasial (BIG)). Data cuaca didapatkan dari penerapan metode Cokriging untuk melakukan interpolasi spasial. Hasil interpolasi spasial untuk data cuaca dikonversi ke dalam format SHP sehingga data tersebut dapat diintegrasikan dengan data spasial lainnya untuk pemodelan yang akan dilakukan (Sitanggang 2013).
4
Tahapan Penelitian
Penelitian ini dilaksanakan dalam beberapa tahap seperti yang disajikan pada Gambar 3.
Gambar 3 Tahapan penelitian. Praproses Data
Pada tahap ini, seleksi data dilakukan untuk mendapatkan data yang relevan. Eksplorasi data juga dilakukan untuk mengetahui karakteristik data serta permasalahan keberadaan missing value dan duplikasi data.
Pembagian Dataset
Pada tahap ini, pemisahan data uji dan data latih dilakukan dengan menggunakan 5-fold cross validation. Pada 5-fold cross validation, suatu dataset akan dibagi sebanyak 5 buah subset. Empat subset digunakan sebagai data latih dan 1 subset digunakan sebagai data uji seperti ditunjukkan dalam Tabel 1.
Tabel 1 Pembagian dataset
Percobaan Data latih Data uji
5 Pembuatan Model Klasifikasi Spasial Menggunakan Spatial Entropy
Klasifikasi adalah proses menemukan model (fungsi) yang menjelaskan dan membedakan kelas-kelas atau konsep dengan tujuan agar model yang diperoleh dapat digunakan untuk mengetahui kelas atau objek yang memiliki label kelas yang tidak diketahui. Klasifikasi termasuk ke dalam kategori predictive data mining. Model yang diperoleh berdasarkan pada analisis dari data training. Proses klasifikasi data dibagi menjadi dua yaitu tahap pembelajaran dan klasifikasi. Pada tahap pembelajaran, sebagian data yang telah diketahui kelas datanya digunakan untuk membentuk model. Selanjutnya pada klasifikasi, model yang sudah terbentuk diuji dengan sebagian data lainnya untuk mengetahui akurasi dari model tersebut. Jika akurasinya mencukupi, model tersebut dapat dipakai untuk prediksi kelas data yang belum diketahui (Han dan Kamber 2006).
Klasifikasi spasial merupakan metode yang menganalisis objek pada data spasial. Dalam membangun model klasifikasi spasial dapat digunakan algoritme pohon keputusan berbasis spatial entropy. Langkah-langkah pada metode spatial entropy adalah:
1 Menghitung jarak nominal dan jarak ordinal.
2 Menghitung jarak intra dan jarak extra pada masing-masing kategori. 3 Menghitung entropi spasial.
4 Menghitung information gain.
5 Jika layer D memiliki nilai information gain tertinggi, maka perhitungan akan dilanjutkan dengan mencari node.
6 Kembali ke perhitungan entropi spasial dengan mengurangi atribut yang telah menjadi akar.
1 Menghitung jarak antarobjek
Perhitungan jarak antarobjek dapat dilakukan berdasarkan tipe atribut pada data. Pada penelitian ini terdapat dua tipe atribut, yaitu atribut nominal dan atribut ordinal. Untuk atribut ordinal, nilai pada setiap kategori disusun berdasarkan peringkatnya kemudian diubah menjadi bilangan sebanyak kategori yang ada. Lalu pada tahap selanjutnya dilakukan normalisasi yang dirumuskan sebagai berikut (Han dan Kamber 2006):
f ff-- f (1)
Dimana f adalah nilai pada setiap kategori ke-i yang telah dirubah menjadi bilangan. Mf adalah banyaknya kategori yang ada pada data. Kemudian dist(j,k) pada atribut ordinal dapat dihitung dengan menggunakan jarak euclidean yang dirumuskan sebagai berikut (Han dan Kamber 2006):
Nilai xjp adalah nilai hasil normalisasi pada baris ke-j dan atribut ke-p. xkp adalah nilai hasil normalisasi pada baris ke-k dan atribut ke-p. Untuk menghitung dist(j,k) pada atribut nominal dapat dirumuskan sebagai berikut (Han dan Kamber 2006):
6
Nilai p adalah jumlah atribut keseluruhan yang memiliki tipe nominal. m adalah jumlah atribut yang bernilai sama. Setelah nilai dist(j,k) pada atribut ordinal dan atribut nominal didapatkan, nilai dist(j,k) untuk keseluruhan atribut pendukung dapat diolah dengan menggunakan rumus jarak pada atribut tipe campuran seperti yang dirumuskan sebagai berikut (Han dan Kamber 2006): Jika hasil dist(j,k) pada atribut ordinal atau atribut nominal bernilai nol
akan bernilai nol.Selainnya, jika hasil dist(j,k) tersebut tidak sama dengan
nol, akan bernilai satu (Han dan Kamber 2006).
2 Menghitung intra-distance (diint) dan extra-distance (diext) seperti yang dirumuskan sebagai berikut:
d nt - (5)
de t - - (6)
Nilai C adalah himpunan entitas spasial dari dataset yang diberikan, Ci menunjukkan subset dari entitas C yang termasuk dalam kategori ke-i dari klasifikasi, diint adalah jarak rata-rata antara Ci, diext adalah jarak rata-rata antara entitas Ci dan entitas dari kategori lain, dist(j,k) memberikan jarak
l h o y g mb l l c l
adalah konstanta yang diambil relatif tinggi, konstanta ini menghindari efek
‘noise’ l null dalam perhitungan jarak rata-rata (Li dan Claramunt 2006).
3 Menghitung spatial entropy yang dirumuskan sebagai berikut:
o y - log (7) Dengan adalah proporsi jumlah kategori elemen i dari record, n
adalah jumlah kategori dalam domain yang disebutkan dari atribut target GA. Berdasarkan hasil pehitungan Li dan Claramunt (2006) pada data sampel landslide didapatkan bahwa ketika jumlah kategori dan proporsi identik, entropi spasial akan bervariasi dengan perubahan distribusi spasial dari entitas spasial (Li dan Claramunt 2006).
4 Menghitung nilai information gain dengan menggunakan rumus berikut:
o y -
o y
l (8)
merupakan nilai information gain antar atribut target GA dengan atribut pendukung SA. Values(SA) memberikan domain yang disebutkan dari atribut atribut pendukung SA, GAv menunjukkan subset dari GA dimana nilai yang sesuai dengan SAv untuk setiap record, |GAv| dan |GA| berturut-turut melambangkan kardinalitas GAv dan GA. Perhitungan pada pohon keputusan merupakan proses yang berulang-ulang (Li dan Claramunt 2006).
7 pohon keputusan spasial berhenti ketika kategori yang berbeda di kelas dapat dibedakan secara jelas dalam ruang. Entitas spasial cenderung memiliki autokorelasi spasial positif yaitu diint< diext. Ambang entropi spasial dapat juga digunakan untuk mengontrol dan menghentikan pertumbuhan pohon keputusan spasial. Jika entropi spasial data pada cabang tertentu lebih rendah dari ambang batas maka cabang telah mencapai daun pohon. Ambang batas dapat mengurangi kedalaman pohon dan nomor daun tanpa mengorbankan kinerja klasifikasi. Hal ini memberikan sejumlah kecil kelas dan memfasilitasi penemuan aturan klasifikasi yang paling dominan (Li dan Claramunt 2006).
Evaluasi Model
Pada tahap ini, hasil klasifikasi dievaluasi dengan menghitung tingkat akurasi dari model yang dicari. Akurasi dapat dihitung dengan menggunakan confusion matrix, yaitu menghitung banyaknya label kelas yang diprediksi benar dibagi total banyaknya prediksi.
Presentasi Model
Data hasil klasifikasi dengan metode spatial entropy direpresentasikan ke dalam kumpulan aturan yang dibangkitkan dari pohon keputusan.
Peralatan Penelitian
Perangkat lunak dan perangkat keras yang digunakan dalam mengembangkan penelitian ini adalah sebagai berikut:
Perangkat Lunak:
1 Python 2.7.5 sebagai bahasa pemrosesan.
2 PostgreSQL 9.2.1 sebagai sistem manajemen basis data.
3 PostGIS sebagai ekstensi PostgreSQL untuk pengelolaan data spasial. 4 Quantum GIS 2.0.1 untuk pemrosesan dan visualisasi data spasial. 5 Microsoft Office Excel 2007 dan Notepad++
6 Sistem operasi Microsoft Windows 7 Home Premium 64-bit
Perangkat Keras:
1 Processor: Intel(R) Core(TM) i3-2310M CPU @ 2.10GHz 2 Memory: 4.00 GB RAM
HASIL DAN PEMBAHASAN
Praproses Data
Tahapan yang dilakukan dalam praproses data adalah sebagai berikut: 1 Membuat tabel target.
8
layer hotspot dengan jarak buffer sebesar 0.907374 km (Sitanggang 2013). Hasil pemrosesan dari buffer tersebut dicari difference dalam geoprocessing tools untuk menentukan area yang berada di luar buffer. Setelah itu dilakukan pembangkitan 685 titik secara acak sebagai titik non-hotspot. Hasil dari proses buffer dapat dilihat pada Gambar 4.
Kemudian tahapan selanjutnya dilakukan dengan menggunakan pernyataan query pada DBMS PostgreSQL yaitu membuat layer target yang merupakan gabungan dari layer true alarm dengan layer false alarm seperti ditunjukkan pada Gambar 5.
Gambar 5 Query pembuatan layer target.
Langkah ini menghasilkan layer baru yang terdiri dari 1370 fitur titik yang menunjukkan titik non-hotspot dan hotspot dapat dilihat pada Tabel 2. Gid merupakan identitas data, the_geom merupakan lokasi dari objek spasial.
9 Tabel 2 Layer target.
gid The_geom Target 1 01010000006... T
2 0101000000D... T
...
1369 01010000008... F
1370 0101000000A... F
2 Membuat tabel distance city, distance river dan distance road.
Tahap ini dilakukan dengan menggunakan query pada DBMS PostgreSQL untuk mencari jarak antara objek-objek di layer target dengan objek-objek di layer-layer penjelas seperti ditunjukkan pada Gambar 6.
Gambar 6 Query jarak minimum dari target ke jalan terdekat.
Untuk layer road dilakukan perhitungan jarak minimum dari objek target ke objek jalan terdekat (min_distance) seperti ditunjukkan pada Gambar 7. Kemudian jarak dalam numerik diubah dalam data kategorik (dist_road) sesuai ketentuan berikut (Sitanggang 2013):
Low : min_distance ≤ 2500 m
Medium: 2500 m < min_distance ≤ 5000 m
High : min_distance > 5000 m
Hasil perhitungan jarak ke titik api untuk beberapa objek di layer road dapat dilihat pada Tabel 3.
Tabel 3 Hasil perhitungan jarak hotspot ke jalan terdekat. gid The_geom Target Min_distance Dist_road
1 01010000006... T 17158.54171 High
9 0101000000A... T 4854.698642 Medium
10 0101000000F... T 456.8011663 Low
...
1368 01010000002... F 23.25410674 Low
1369 01010000008... F 4427.468245 Medium
10
Untuk layer river dilakukan juga perhitungan jarak minimum dari objek target ke objek sungai terdekat (min_distance). Kemudian jarak dalam numerik diubah ke dalam data kategorik (dist_river) sesuai ketentuan berikut (Sitanggang 2013):
Low : min_distance ≤ 1500 m
Medium: 1500 m < min_distance ≤ 3000 m
High : min_distance > 3000 m
Hasil perhitungan jarak ke titik api untuk beberapa objek di layer river dapat dilihat pada Tabel 4.
Tabel 4 Hasil perhitungan jarak hotspot ke sungai terdekat. gid The_geom Target Min_distance Dist_river
8 01010000006... T 918.3817908 Low
9 0101000000A... T 1968.958422 Medium
10 0101000000F... T 4006.426486 High
...
1368 01010000002... F 2343.056961 Medium
1369 01010000008... F 4418.838336 High
1370 0101000000A... F 44.61247693 Low
Demikian halnya untuk layer city, dilakukan juga perhitungan jarak minimum dari objek target ke objek pusat kota terdekat (min_distance). Kemudian jarak dalam numerik diubah ke dalam data kategorik (dist_city) sesuai ketentuan berikut (Sitanggang 2013):
Low : min_distance ≤ 7000 m
Medium: 7000 m < min_distance ≤ 14000 m
High : min_distance > 14000 m
Hasil perhitungan jarak ke titik api untuk beberapa objek di layer city dapat dilihat pada Tabel 5.
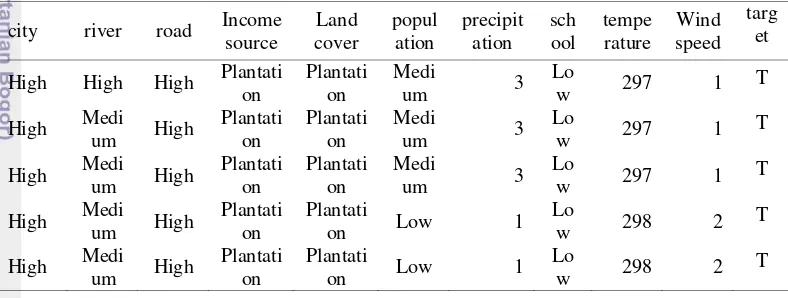
Tabel 5 Hasil perhitungan jarak hotspot ke pusat kota terdekat. gid The_geom Target Min_distance Dist_city
51 0101000000F... T 15923.492385 High
52 0101000000A... T 9714.0851992 Medium
53 01010000007... T 2945.3710693 Low
...
1368 01010000002... F 15801.59506 High
1369 01010000008... F 11968.15244 Medium
11 3 Menghapus kolom-kolom yang tidak digunakan.
Tahap ini dilakukan penghapusan kolom-kolom yang tidak diperlukan pada layer land cover, layer income source, layer school, dan layer population sehingga setiap layer akan memiliki 3 field data, yaitu gid, the_geom, dan exp_attr. exp_attr merupakan nilai dari masing-masing objek penjelas.
4 Menggabungkan data menjadi satu layer data.
Pada tahap ini, setiap layer data penjelas dan layer target digabung menjadi satu layer. Sehingga didapatkan data sebesar 1512 record. Objek-objek dalam layer gabungan inilah yang digunakan untuk membuat model klasifikasi spasial menggunakan algoritme pohon keputusan berbasis entropi spasial. Akan tetapi pada proses pembuatan model klasifikasi spasial, field the_geom dan gid tidak dipergunakan sehingga field tersebut dihapus. Setelah field the_geom dan gid dihapus, dilakukan penghapusan duplikasi data sehingga didapatkan data sebesar 600 record. Tabel 6 menunjukkan hasil penggabungan objek target dan objek-objek penjelas setelah field the_geom dan gid dihapus. Data dalam Tabel 6 merupakan data akhir dan digunakan pada proses pembuatan model klasifikasi spasial menggunakan algoritme pohon keputusan berbasis spatial entropy.
Tabel 6 Hasil penggabungan objek target dan objek-objek penjelas.
city river road Income
Pembuatan Model Klasifikasi Spasial Menggunakan Algoritme Pohon Keputusan Berbasis Spatial Entropy
Pada tahap ini dilakukan pembuatan pohon keputusan spasial menggunakan algoritme pohon keputusan berbasis spatial entropy (Li dan Claramunt 2006). Algoritme pohon keputusan berbasis spatial entropy di implementasikan menggunakan bahasa pemrograman Python dengan memodifikasi kode program untuk algoritme ID3 (Roach 2006). Langkah-langkah utama dalam membentuk pohon keputusan menggunakan algoritme pohon keputusan berbasis spatial entropy adalah:
1 Menghitung jarak antar objek
2 Menghitung intra-distance (diint) dan extra-distance (diext) 3 Menghitung spatial entropy
12
Menghitung jarak antar objek
Berdasarkan Tabel 6, dapat dilihat bahwa atribut city, river, road, population, precipitation, school, temperature dan wind speed merupakan atribut ordinal. Sedangkan atribut income source dan land cover merupakan atribut nominal. Setelah dilakukan pengolahan data, didapatkan hasil normalisasi untuk atribut ordinal seperti pada Tabel 7.
Tabel 7 Hasil normalisasi atribut ordinal.
Atribut Nilai rif Normalisasi
city, river, road,
Dari Tabel 7 dapat dilihat bahwa atribut city, river, road, population, school, dan temperature memiliki nilai Mf = 3 sedangkan wind speed dan precipitation memiliki nilai Mf = 5 sehingga hasil normalisasi untuk atribut Mf = 3 akan memiliki nilai yang sama, demikian halnya dengan atribut Mf = 5. Nilai hasil normalisasi inilah yang digunakan pada perhitungan jarak.
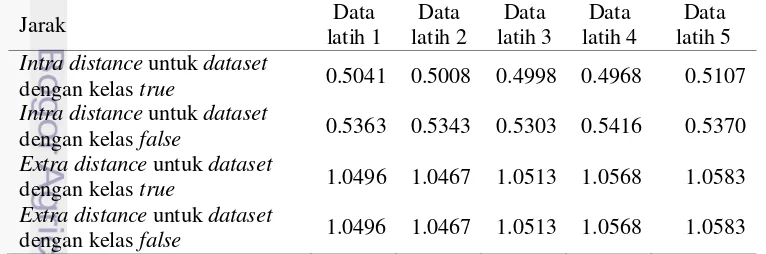
Menghitung intra-distance (di dataset dengan kelas true dihitung untuk mengetahui jarak rata-rata antara entitas pada kategori true dengan kategori lainnya. Demikian halnya dengan intra distance untuk dataset dengan kelas false dan extra distance untuk dataset dengan kelas false. Tabel 8 menunjukkan hasil perhitungan intra distance dan extra distance.
Tabel 8 Hasil perhitungan intra distance dan extra distance.
Jarak Data
13 jarak antar objek k dan j, sehingga hasilnya akan bernilai sama. Hasil jarak inilah yang akan digunakan pada perhitungan entropi spasial.
Menghitung spatial entropy
Spatial entropy dihitung menggunakan persamaan 7. Contoh perhitungan entropi spasial untuk data latih 1:
o y log log
Pada perhitungan diatas terdapat nilai 131 dan 349 yang berturut-turut merupakan banyaknya frekuensi target yang bernilai true dan false. Sedangkan nilai 480 merupakan total keseluruhan data latih 1. Sehingga hasil yang didapatkan dari perhitungan entropi dapat dipergunakan pada perhitungan information gain.
Kode program perhitungan spatial entropy dengan menggunakan bahasa pemrograman Python dapat dilihat pada Gambar 7 (Roach 2006).
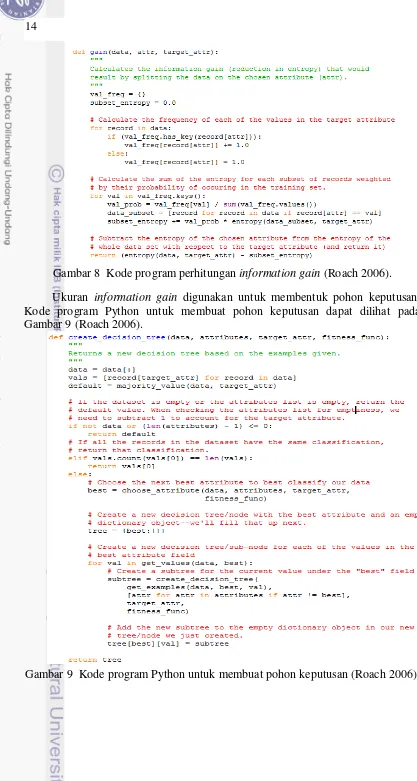
Gambar 7 Kode program perhitungan spatial entropy (Roach 2006). Menghitung information gain
14
Gambar 8 Kode program perhitungan information gain (Roach 2006). Ukuran information gain digunakan untuk membentuk pohon keputusan. Kode program Python untuk membuat pohon keputusan dapat dilihat pada Gambar 9 (Roach 2006).
15 Evaluasi Model
Hasil evaluasi model pohon keputusan berbasis spatial entropy dapat dilihat pada Tabel 9.
Tabel 9 Akurasi data uji dan data latih Percobaan Pohon terbesar berada pada percobaan ke 2 dengan tingkat akurasi 56% dan akurasi yang terbesar pada data latih berada pada percobaan ke 5 dengan tingkat akurasi 90.21%. Didapatkan juga tingkat akurasi rata-rata dari 5 percobaan sebesar 52.05% untuk data uji dan 89.04% untuk data latih.
Hasil dari akurasi ini menunjukkan bahwa tingkat akurasi pada data latih lebih besar daripada data uji. Hal ini dikarenakan pengujian data latih dilakukan pada pohon keputusan yang berasal dari data latih tersebut. Pada hasil prediksi terdapat juga data yang tidak terklasifikasi atau tidak termasuk ke dalam kelas true maupun kelas false. Hal ini dikarenakan pada data uji tersebut tidak ada data yang termasuk ke dalam aturan manapun, sehingga data tersebut tidak terklasifikasi.
Dari pohon keputusan tersebut didapatkan aturan sebanyak 241 aturan untuk percobaan 1 (Lampiran 1), 255 aturan untuk percobaan 2 (Lampiran 2), 256 aturan untuk percobaan 3 (Lampiran 3), 235 aturan untuk percobaan 4 (Lampiran 4), dan 255 aturan untuk percobaan 5 (Lampiran 5). Pohon keputusan dengan akurasi terbaik terdapat pada percobaan 2. Contoh aturan yang didapatkan dari hasil model pohon keputusan untuk percobaan2 yaitu:
1 JIKA tutupan lahan = unirrigated agricultural field DAN sumber keberadaan titik api adalah true.
3 JIKA tutupan lahan = paddy field DAN sumber pendapatan = plantation DAN jarak minimum ke pusat kota terdekat > 14 km MAKA keberadaan titik api adalah true.
4 JIKA tutupan lahan = mix garden DAN jarak minimum ke jalan terdekat > 5
m D N m/ ≤ c g < m/ D N m m m g
16
5 JIKA tutupan lahan = plantation DAN sumber pendapatan = forestry DAN jarak minimum ke pusat o m D N m/ ≤ c
g < m/ D N m < m m m g ≤ m
MAKA keberadaan titik api adalah true.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menghasilkan pohon keputusan berbasis spatial entropy dari data kebakaran hutan yang terdiri dari 11 atribut, yaitu 10 atribut penjelas dan 1 atribut target. Hasil penelitian dengan dengan menggunakan metode uji 5-fold cross validation adalah 5 pohon keputusan akurasi rata-rata 52.05% dan 89.04% masing-masing pada data uji dan data latih. Pohon keputusan terbaik memiliki akurasi data uji sebesar 56% yang mempunyai 560 node dengan node akar adalah layer tutupan lahan. Dari pohon keputusan tersebut diperoleh 255 aturan untuk mengklasifikasikan titik api. Hasil percobaan menunjukkan bahwa pohon keputusan terbaik juga tidak dapat mengklasifikasikan sebanyak 20 objek pada data uji Bengkalis.
Saran
Penelitian ini masih memiliki kekurangan, antara lain masih kecilnya tingkat akurasi yang didapatkan pada data uji untuk wilayah Bengkalis. Saran yang dapat disampaikan untuk penelitian selanjutnya adalah menguji pohon keputusan yang dihasilkan pada data uji real untuk wilayah lain dan menerapkan algoritme pohon keputusan spasial lainnya untuk mendapat akurasi yang lebih baik serta membuat pohon keputusan yang dapat melihat aturan yang penting dengan menggunakan bahasa pemrograman Python.
DAFTAR PUSTAKA
Badungkab. 2013. Kebakaran Hutan [internet]. [diacu 2013 Nov 1]. Tersedia dari: http://www.badungkab.go.id/index2.php?option=com_content&do_pdf=1&id= 2894.
Deliknews. 2013. Kebakaran Hutan di Riau, Sebabkan Kerugian Besar [internet].
[diacu 2013 Des 3]. Tersedia dari:
http://www.deliknews.com/2013/06/21/kebakaran-hutan-di-riau-sebabkan-kerugian-besar/#.Up26NsQW15Y.
17 Han J, Kamber M. 2006. Data Mining Concepts and Techniques. San Francisco
(US): Morgan-Kaufmann.
Li X, Claramunt C. 2006. A Spatial Entropy-Based Decision Tree for Classification of Geographical Information.Transaction in GIS. 10(3): 451-467. Riau. 2013. Kabupaten Bengkalis [internet]. [diacu 2014 Mar 15]. Tersedia dari:
http://www.riau.go.id/index.php?/detail/6.
Roach C. 2006. Building Decision Trees in Python [internet].[diacu 2014 Mei 13].
Tersedia dari:
http://www.onlamp.com/pub/a/python/2006/02/09/ai_decision_trees.html?CM P=OTC-UD6648202101&ATT=Building+Decision+Trees+in+Python
Sigit R. 2012. Kaleidoskop Tata kelola Hutan di Indonesia: Hutan Masih Terbakar (Bagian-2) [internet]. [diacu 2013 Nov 1]. Tersedia dari: http://www.mongabay.co.id/2012/12/31/kaleidoskop-tata-kelola-hutan-di-indonesia-hutan-masih-ter-dibakar-bagian-2/.
18
19
20
21
Unirrigated agricultural field
wind_speed
22
23