KAJIAN METODE PENGGEROMBOLAN DUA TAHAP
UNTUK DATA YANG MENGANDUNG PENCILAN
ARNI NURWIDA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN SUMBER
INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Kajian Metode Penggerombolan Dua Tahap untuk Data yang Mengandung Pencilan adalah benar karya saya dengan arahan dari komisi pembimbing dan belum pernah diajukan dalam bentuk apa pun kepada perguruan tinggi atau lembaga mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Maret 2014
Arni Nurwida
ABSTRAK
ARNI NURWIDA. Kajian Metode Penggerombolan Dua Tahap untuk Data yang Mengandung Pencilan. Dibimbing oleh KUSMAN SADIK dan INDAHWATI.
Analisis gerombol seringkali ditemui dalam berbagai penelitian. Analisis gerombol klasik, seperti metode penggerombolan berhierarki dan k-rataan tidak dapat menangani peubah penggerombolan yang bertipe kategorik maupun campuran dari numerik dan kategorik. Selain itu, penentuan banyaknya gerombol optimal masih tergantung dari subjektivitas peneliti serta tidak dapat menangani data yang berukuran sangat besar, yaitu lebih besar dari 500. Salah satu pendekatan untuk menangani masalah ini adalah dengan menggunakan metode penggerombolan dua tahap. Keakuratan metode penggerombolan dua tahap dalam menduga banyaknya gerombol yang dihasilkan serta dalam pengklasifikasian keanggotaan gerombol khususnya pada data yang mengandung pencilan merupakan hal yang penting untuk dikaji. Pada data yang mengandung pencilan kecil (1%), metode ini memberikan hasil yang lebih akurat dibandingkan dengan data yang mengandung pencilan besar (5% atau 15%). Penggunaan besaran penanganan pencilan pada data yang mengandung pencilan harus lebih besar daripada besaran pencilannya itu sendiri. Metode penggerombolan dua tahap sangat akurat dalam menghasilkan banyaknya gerombol yang sesuai dengan banyaknya gerombol populasi sebenarnya pada data yang tidak mengandung pencilan, khususnya pada peubah yang sebagian besar bertipe numerik dan sisanya kategorik. Penggerombolan Desa/Kelurahan di Indonesia berdasarkan faktor kemajuan dan ketertinggalan desa dengan menggunakan metode penggerombolan dua tahap menghasilkan 7 gerombol optimal.
ABSTRACT
ARNI NURWIDA. Assessment Method for Two-Step Clustering Data Containing Outliers. Supervised by KUSMAN SADIK and INDAHWATI.
Cluster analysis is often encountered in various studies. Analysis of classical clusters, such as hierarchical clustering method and k-means clustering cannot handle categorical variables or a mixture of numerical and categorical. In addition, the determination of the optimal number of clusters are still dependent on the subjectivity of the researcher and cannot handle very large datasets, which is larger than 500. One approach to addressing this problem is to use a two-step clustering method. The accuracy of the two-step clustering method of predicting the number of clusters generated as well as the classification of cluster membership, especially in the data containing outliers is important to be studied. Outliers in the data containing a small (1%), this method provides more accurate compared with the results of data containing a large outliers (5% or 15%). Scale use of outliers handling in the data containing outliers must be greater than the amount of outliers itself. Two-step clustering method is very accurate in producing a number of clusters associated with the actual number of population clusters that do not contain data outliers, especially in the most variable of type numeric and categorical rest. Clustering villages in Indonesia by a factor of progress and backwardness villages using a two-step clustering method generates optimal cluster 7.
KAJIAN METODE PENGGEROMBOLAN DUA TAHAP
UNTUK DATA YANG MENGANDUNG PENCILAN
ARNI NURWIDA
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi: Kajian Metode Penggerombolan Dua Tahap untuk Data yang Mengandung Pencilan
Nama : Arni Nurwida
NIM : G14080022
Disetujui oleh
Dr. Ir. Kusman Sadik, M.Si Dr. Ir. Indahwati, M.Si
Pembimbing I Pembimbing II
Diketahui oleh
Dr. Anang Kurnia, M.Si. Ketua Departemen
PRAKATA
Alhamdulillah, segala puji penulis panjatkan kehadirat Allah SWT atas rahmat dan karunia-Nya sehingga karya ilmiah ini dapat diselesaikan. Shalawat serta salam penulis haturkan kepada nabi besar Muhammad SAW serta kepada para keluarga, sahabat dan umatnya yang senantiasa istiqomah hingga akhir zaman. Karya ilmiah yang disusun sejak bulan Desember 2012 sampai dengan Maret 2013 ini berjudul Metode Penggerombolan Dua Tahap untuk Peubah Bertipe Campuran.
Penulis menyampaikan terima kasih kepada semua pihak yang telah membantu, antara lain kepada Bapak Dr. Ir. Kusman Sadik, M.Si dan Ibu Dr. Ir. Indahwati, M.Si selaku komisi pembimbing yang telah memberikan bimbingan, arahan, serta masukan selama proses penulisan karya ilmiah ini. Bapak, Ibu, Mbak Ayis, Rathi dan Mas Hasnan atas doa, semangat, bantuan, dan kasih sayang yang diberikan kepada penulis. Bapak Dr. Ir. Hari Wijayanto, M.Si. beserta seluruh staf pengajar Departemen Statistika Institut Pertanian Bogor yang telah memberikan berbagai bekal ilmu selama penulis melaksanakan studi di Departemen Statistika. Seluruh staf administrasi dan karyawan Departemen Statistika yang selalu siap membantu penulis dalam menyelesaikan berbagai keperluan terkait penyelesaian karya ilmiah ini. Aci, Ami, Dania, Ai, Nurul dan Didin atas segala masukan, diskusi dan motivasinya. Mba Dwi, Ika, Pujul, Sumi, Muti, Risa, Kak Ery, Kak Kindy, Kak Arjun, Kak Miftah, Mbak Endang, Abas, Titi, Iril, Adit, Yekti, Hepi, Tika, Nopi, Eka, Fathia, Ida, Yuyun, Arbi, Endah, Herlin, Ririn, Dina, Rida, Eka, Chanifah, Neng, Rey, Riza, Nyama, Fika, Gita, Yusti, Suci, Zaiful, Ita, Sonia, Nahdhi, Aini, Nurul, Dian, Banu, Fatul, Andi, Aziz, Hendi, Ridho, Agit, Winda, Anggun, Ririn, Euis, Salsa, Indah, Yasin, Okta, Hamdan, Faiz, Aldi, Wulan, Nada, Carissa, Sarah, Sunny, Sarah, Andri, Nova, Gita, Hesti, Indri, dan Nita atas segala motivasi dan dukungannya. Kakak-kakak STK 44 serta adik-adik STK 46 dan STK 47. Serta seluruh pihak yang telah memberikan dukungan, do’a dan motivasi dalam penyelesaian karya ilmiah ini.
Semoga segala kebaikannya dibalas oleh Allah SWT dan semoga karya ilmiah ini bermanfaat bagi semua orang yang membacanya.
Bogor, Maret 2014
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan 2
TINJAUAN PUSTAKA 2
Desa/Kelurahan Tertinggal 2
Analisis Gerombol 2
Metode Berhirarki 2
Metode Tak Berhirarki 2
Metode Penggerombolan Dua Tahap 3
Tahap Pertama: Pembentukan Gerombol Awal 3
Penanganan Pencilan 4
Tahap Kedua: Pembentukan Gerombol Optimal 5
METODOLOGI 6
Data 6
Metode Penelitian 7
Metode Pembangkitan Data 7
Penerapan pada Data Riil 9
HASIL DAN PEMBAHASAN 9
Kajian pada Kasus Data Khusus 9
Penerapan pada Data Riil 11
Deskripsi Data 11
Pereduksian Data 11
Penggerombolan dengan Metode Penggerombolan Dua
Tahap 12
Karakteristik Gerombol Desa/Kelurahan 13
KESIMPULAN DAN SARAN 16
Kesimpulan 16
Saran 16
DAFTAR PUSTAKA 17
DAFTAR TABEL
1 Kriteria 2 model peubah campuran 6
2 Kombinasi data simulasi 7
3 Pembangkitan ukuran data gerombol dan proporsi pencilan 7 4 Kriteria nilai transformasi untuk peubah kategorik 8
5 Ilustrasi salah klasifikasi 9
6 Persentase salah banyaknya gerombol yang dihasilkan dengan banyaknya gerombol populasi sebenarnya
10
7 Persentase salah klasifikasi gerombol yang dihasilkan dengan banyaknya gerombol populasi sebenarnya
10
8 Penggerombolan Dua Tahap dengan kriteria penggerombolan BIC 12
9 Distribusi hasil penggerombolan 12
10 Frekuensi dan persentase peubah kategorik pada setiap gerombol 13
11 Rentang nilai pada setiap peubah numerik 15
DAFTAR GAMBAR
1 Grafik tingkat kepentingan peubah kategorik �2 pada setiap gerombol 14 2 Grafik tingkat kepentingan peubah kategorik �5 pada setiap gerombol 14
DAFTAR LAMPIRAN
1 Daftar peubah penggerombolan sebelum dilakukan pereduksian 18
2 Diagram alir metode pembangkitan data 19
3 Diagram alir metode penggerombolan dua tahap pada data riil 21 4 Grafik tingkat kepentingan peubah numerik pada setiap gerombol 22 5 Tingkat rataan nilai peubah numerik pada setiap gerombol 23
PENDAHULUAN
Latar Belakang
Analisis gerombol adalah salah satu analisis peubah ganda yang bertujuan untuk menggerombolkan objek (individu atau amatan) menjadi beberapa gerombol berdasarkan pengukuran kemiripan atau ketakmiripan. Permasalahan utama dalam penerapan analisis gerombol adalah peubah penggerombolan bertipe kategorik maupun campuran dari numerik dan kategorik. Algoritma analisis gerombol klasik seperti metode penggerombolan berhierarki dikembangkan untuk peubah numerik berskala interval atau rasio saja, walaupun telah tersedia pilihan berbagai konsep jarak untuk peubah biner. Sementara itu, metode k-rataan ( k-means) mensyaratkan peubah penggerombolan berskala rasio, interval, atau biner. Permasalahan lainnya adalah banyaknya objek yang ingin digerombolkan relatif sangat besar, yaitu lebih besar dari 500 dan penentuan banyaknya gerombol optimal membutuhkan uji statistik. Penggerombolan berhierarki dikembangkan untuk banyaknya objek yang relatif kecil, yaitu umumnya kurang dari 250 dan penggerombolan k-rataan dikembangkan untuk banyaknya objek yang relatif besar yaitu lebih besar dari 200 (Garson 2012). Di samping itu, pada penggerombolan berhierarki maupun k-rataan, penentuan banyaknya gerombol optimal sangat ditentukan oleh subjektivitas peneliti dan tidak terdapat uji statistik untuk mengetahui ketepatan banyaknya gerombol optimal sehingga hasil penggerombolan sangat bergantung pada pengetahuan, pengalaman, serta subjektivitas peneliti (Hair et al. 2010).
Metode Penggerombolan Dua Tahap (Two Step Clustering) dapat mengatasi peubah bertipe kategorik maupun campuran dari numerik dan kategorik (Chiu et al. 2001). Selain itu, dapat mengatasi data yang berukuran sangat besar, yaitu lebih besar dari 500 dan penentuan banyaknya gerombol optimal dilakukan melalui uji statistik (Bacher et al. 2004).
Selanjutnya keakuratan metode penggerombolan dua tahap dalam menduga banyaknya gerombol yang dihasilkan maupun dalam pengklasifikasian keanggotaan gerombol khususnya pada data yang mengandung pencilan merupakan hal yang penting untuk dikaji. Hal ini disebabkan karena banyak data yang ditemui di lapang merupakan data yang mengandung pencilan dan pencilan tersebut merupakan data atau amatan berpengaruh yang tidak mungkin dihilangkan sehingga perlu diikutkan dalam proses analisisnya.
2
Tujuan
Tujuan penelitian ini adalah mengkaji metode penggerombolan dua tahap untuk data yang mengandung pencilan dalam hal (1) menduga banyaknya gerombol yang dihasilkan dibandingkan banyaknya gerombol populasi sebenarnya, dan (2) pengklasifikasian keanggotaan gerombol.
TINJAUAN PUSTAKA
Desa/Kelurahan Tertinggal
RUU PDT (Rancangan Undang-Undang Pembangunan Daerah Tertinggal) dalam Bab I Pasal 1 Nomor 2 menjelaskan bahwa desa tertinggal adalah desa yang berdasarkan kriteria ditetapkan sebagai desa tertinggal. Beberapa faktor diduga menjadi penyebab kemajuan atau ketertinggalan suatu desa, yaitu (1) faktor alam/lingkungan, (2) faktor kelembagaan, (3) faktor sarana, prasarana dan akses, serta (4) faktor sosial ekonomi penduduk.
Analisis Gerombol
Analisis gerombol adalah analisis statistik peubah ganda yang digunakan untuk mencari pola dari suatu gugus data dengan mengelompokkan n objek yang mempunyai p peubah ke dalam k gerombol. Tujuannya adalah untuk menemukan penggerombolan optimal dimana objek-objek yang berada dalam satu gerombol adalah mirip sedangkan yang berada dalam gerombol-gerombol yang berbeda adalah tidak mirip (Rencher 2002), dan penggerombolannya dilakukan berdasarkan basis kemiripan atau ketakmiripan (Johnsons dan Wichern 2007).
Menurut Hair et al. (2010) terdapat tiga metode dalam analisis gerombol, yaitu (1) metode berhierarki, (2) metode tak berhierarki dan (3) penggabungan kedua metode penggerombolan tersebut. Dengan rumitnya masalah yang dihadapi dalam menggerombolkan gugus data berukuran sangat besar, mendorong berkembangnya teknik-teknik penggerombolan baru yang prosesnya dilakukan secara bertahap, salah satunya adalah metode penggerombolan dua tahap.
Metode Berhierarki
Metode penggerombolan berhierarki digunakan jika banyaknya gerombol yang akan dibentuk belum diketahui sebelumnya. Menurut Garson (2012), metode ini cocok untuk ukuran data yang relatif kecil, yaitu kurang dari 250.
Metode berhierarki dibedakan menjadi dua, yaitu metode penggabungan dan metode pemisahan (Hair et al. 2010). Jenis peubah yang dapat digerombolkan dengan metode berhierarki adalah peubah numerik (rasio dan interval) serta fungsi jarak yang umum digunakan adalah jarak Euclidean atau jarak Mahalanobis.
Metode Tak Berhierarki
3
berhierarki adalah k-rataan. Garson (2012) mengemukakan bahwa metode
k-rataan cocok digunakan pada data yang berukuran besar, yaitu lebih besar dari 200 serta menggunakan konsep jarak Euclidean sehingga peubah kriteria penggerombolannya haruslah semuanya berskala rasio atau interval.
Metode Penggerombolan Dua Tahap
Algoritma metode penggerombolan dua tahap dikembangkan oleh Chiu et al. (2001). Metode penggerombolan dua tahap relatif baru, dan seperti yang dikemukakan oleh Hair et al. (2010), metode ini dikembangkan untuk menangani peubah bertipe campuran dari numerik dan kategorik serta untuk data yang berukuran sangat besar, yaitu lebih besar dari 500.
Fungsi jarak yang digunakan adalah jarak Euclidean atau jarak log-likelihood (Bacher et al. 2004). Jarak Euclidean hanya dapat digunakan apabila semua peubah yang digunakan bertipe numerik. Dimisalkan ada dua gerombol, yaitu gerombol j dan s, dan dari p peubah maka jarak Euclidean antara kedua gerombol dapat didefinisikan sebagai berikut:
d(j,s) = { � − � =1 2}1 2
Dimana d(j,s) menunjukkan jarak antara gerombol j dengan s, � adalah nilai tengah gerombol ke-j, � adalah nilai tengah gerombol ke-s, dan p adalah banyaknya peubah penggerombolan.
Sedangkan jarak log-likelihood digunakan untuk peubah bertipe campuran dari numerik dan kategorik. Jarak antara gerombol j dan s didefinisikan sebagai kategorik, �2 adalah ragam dari peubah numerik ke-k di dalam keseluruhan gugus data, �2 adalah ragam dari peubah numerik ke-k di dalam gerombol j, adalah jumlah kategori untuk peubah kategorik ke-k, dan � adalah jumlah objek di dalam gerombol j untuk peubah kategorik ke-k dengan kategori ke-l.
Ukuran jarak log-likelihood didasarkan pada tiga asumsi, yaitu peubah penggerombolannya saling bebas, peubah kategorik diasumsikan berdistribusi multinomial, dan peubah numerik diasumsikan berdistribusi normal. Metode penggerombolan dua tahap cukup kekar (robust) terhadap asumsi kebebasan dan asumsi distribusi tersebut (Norusis 2010).
Tahap Pertama: Pembentukan Gerombol Awal
Tahap pertama dari penggerombolan dua tahap adalah pembentukan gerombol awal (pre-clustering) yang menggunakan pendekatan penggerombolan secara sekuensial (Li dan Sun 2011). Pendekatan ini diimplementasikan dengan membentuk Pohon Ciri Gerombol (Cluster Feature Tree/ CF Tree) (Zhang et al.
4
Pohon ciri gerombol terdiri dari beberapa tingkatan cabang (nodes) dan masing-masing cabang berisikan objek yang dientrikan (entries). Apabila dimisalkan sebuah pohon maka tingkatan cabang tersebut terdiri dari batang pohon, dahan dan daun. Pada pohon ciri gerombol, tingkatan daun yang terdapat pada cabang dinamakan daun entri (Leaf Entry) atau entrain pada cabang daun yang merepresentasikan hasil akhir anak gerombol atau sub gerombol (subcluster).
Algoritma pertama pada pohon ciri gerombol adalah memasukkan objek satu per satu secara acak (SPSS Technical Report 2001). Objek yang masuk dihitung jaraknya pada daun entri yang telah ada dengan menggunakan ukuran jarak yang telah ditentukan. Apabila jarak tersebut kurang dari kriteria ukuran penerimaan (threshold distance) maka objek tersebut masuk ke dalam daun entri yang telah ada, tetapi jika sebaliknya maka objek membentuk daun entri baru.
Jika suatu cabang daun tidak lagi memiliki ruang untuk menambah daun entri baru maka cabang daun tersebut akan dipecah menjadi dua. Apabila dimisalkan pada sebuah pohon, dari satu dahan kemudian membelah menjadi dua dahan. Berlaku pula untuk cabang dahan membelah menjadi dua grup (pohon). Proses ini berlanjut sampai semua objek selesai dimasukkan.
Jika pohon ciri gerombol berkembang melewati batas ukuran maksimum ruang maka pohon ciri gerombol yang telah ada akan dibangun ulang dengan cara meningkatkan kriteria ukuran penerimaan. Pohon ciri gerombol yang melewati batas ukuran maksimum biasanya dikarenakan pada saat proses algoritma pohon ciri gerombol dijalankan, terbentuk daun entri yang beranggotakan pencilan. Pencilan pada metode penggerombolan dua tahap adalah data yang tidak dapat dimasukkan ke dalam gerombol manapun sehingga dimasukkan ke dalam satu gerombol yang baru. Pada saat pohon ciri gerombol akan dibangun ulang maka akan diperiksa daun entri yang berpotensi sebagai pencilan.
Pencilan diasumsikan menyebar mengikuti sebaran seragam. Ketika mendeteksi, suatu objek dinyatakan sebagai pencilan atau tidak, dilakukan perhitungan jarak log-likelihood dari objek yang bersangkutan ke daun entri terdekat yang bukan merupakan pencilan (closest non noise cluster). Objek yang diduga sebagai pencilan dimasukkan ke dalam daun entri terdekat yang bukan merupakan pencilan bilamana jarak log-likelihood lebih kecil dari titik kritis:
C = log (V), dimana
V= ∏� ∏
Selanjutnya, � menunjukkan range dari peubah kontinu ke-k dan adalah banyaknya kategori untuk peubah kategori ke-m.
Selain itu, Bacher (2000) dalam Kudsiati (2006) menjelaskan bahwa bila terjadi tumpang tindih antara dua gerombol yang saling berdekatan akan memungkinkan terjadinya penduga yang bias bagi profil gerombol. Kelompok data yang dapat mengakibatkan terjadinya bias dalam penetapan keanggotaan gerombol disebut sebagai pencilan atau gangguan (noise). Mengatasi hal ini, Bacher (2004) menyarankan agar pengguna SPSS menentukan nilai opsi penanganan pencilan, misalnya sebesar 5 (=5%).
5
banyaknya objek per cabang maksimum adalah 8. Dengan demikian, banyaknya dahan daunmaksimum sebanyak 83 = 512 anak gerombol (Bacher et al. 2004).
Tahap Kedua: Pembentukan Gerombol Optimal
Tahap kedua adalah pembentukan gerombol akhir yang ditandai dengan terbentuknya gerombol optimal. Daun entri dari pohon ciri gerombol hasil tahap pertama dan tanpa mengikutsertakan pencilan digerombolkan menggunakan metode penggerombolan berhierarki penggabungan (Norusis 2010), yaitu dimulai dengan mengasumsikan bahwa setiap objek merupakan satu gerombol, dan selanjutnya secara bertahap dilakukan penggabungan pada objek-objek yang paling dekat (Hair et al. 2010).
Pada tahap kedua ini, penentuan jumlah gerombol optimal ditentukan secara otomatis dengan melalui dua langkah (Li dan Sun 2011). Langkah pertama adalah menghitung nilai Kriteria Informasi Bayes/Akaike (Bayesian/Akaike Information Criterion/ BIC/AIC) untuk setiap gerombol. Kriteria informasi BIC dan AIC untuk
j buah gerombol dirumuskan sebagai berikut:
= −2 =1� + log �
= −2 =1� + 2 , dimana:
= J 2 + =1 −1 dan N adalah jumlah total data.
Kontribusi dari masing-masing peubah dalam pembentukan setiap gerombol dilakukan melalui uji t-Student untuk peubah numerik dan uji khi-kuadrat untuk peubah kategorik (Schiopu 2010). keseluruhan gugus data, dan � adalah estimasi rataan dari peubah numerik ke-k
di dalam gerombol j. Hipotesis nol ( 0) menyatakan bahwa peubah tidak berpengaruh pada pembentukan gerombol. � adalah jumlah objek di dalam keseluruhan gugus data untuk peubah kategorik ke-k dengan kategori ke-l. Derajat bebas uji t-Student adalah � dan uji khi-kuadrat adalah dengan kasus dua arah. Di dalam Bacher et al. (2004), Chiu et al. (2001) mengemukakan atau menghasilkan penduga awal yang baik bagi banyaknya gerombol maksimum. Banyaknya gerombol maksimum ditentukan sama dengan banyaknya gerombol yang memiliki rasio perubahan BIC (Ratio of BIC Change) /
yang pertama kali lebih kecil dari 1 (SPSS menetapkan 1 = 0.04 yang didasarkan atas studi simulasi) (SPSS Technical Report 2001).
Selanjutnya dalam langkah kedua, digunakan nilai rasio ukuran jarak (Ratio of Distance Measure) untuk j buah gerombol, yaitu R(j) = −1/ . Dimana −1 adalah jarak jika j buah gerombol digabungkan menjadi j-1 gerombol. Jarak dapat diperoleh dari hasil perhitungan = −1− , dimana:
6
Banyaknya gerombol diperoleh berdasarkan ketentuan ditemukannya perbedaan yang nyata pada rasio perubahan gerombol. Rasio ukuran jarak untuk dua nilai terbesar dari R(j) (j = 1,2,…, �; � didapatkan dari langkah pertama) dihitung dengan �( 1)/�( 2).
Jika rasio perubahan lebih besar daripada nilai batas 2 (SPSS menetapkan nilai 2 = 1.15 berdasarkan studi simulasi), banyaknya gerombol ditetapkan sama dengan 1, selainnya banyak gerombol sama dengan maksimum 1, 2.
METODOLOGI
Data
Data yang digunakan dalam penelitian ini adalah data simulasi dan data riil. Data simulasi didapatkan melalui pembangkitan data dengan menggunakan perangkat lunak statistika, sedangkan data riil didapatkan dari data Podes tahun 2011 khususnya pada peubah-peubah yang menjadi kriteria kemajuan atau ketertinggalan suatu desa. Peubah-peubah tersebut dapat dilihat pada Lampiran 1. Data Podes 2011 terdiri atas 77961 objek desa/kelurahan di Indonesia.
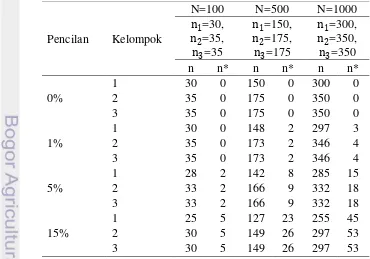
Data simulasi yang dibangkitkan merupakan data dengan kasus khusus. Data bangkitan berasal dari data yang menyebar Normal (i,�2 = 1) yang kemudian disebut sebagai data populasi dengan i = gerombol 1, 2, dan 3. Data populasi ini beranggotakan 3 gerombol yang saling tumpang tindih satu sama lain (overlap) atau tidak terpisah secara tegas. Peubah yang dibangkitkan merupakan peubah campuran numerik dan kategorik dengan asumsi saling bebas, model komposisi peubahnya disajikan pada Tabel 1.
Tabel 1 Kriteria 2 model peubah campuran
Peubah Kriteria
V1 Peubah campuran dengan sebagian besar bertipe numerik (10) dan sisanya kategorik (3)
V2 Peubah campuran dengan sebagian besar bertipe kategorik (10) dan sisanya numerik (3)
Setiap peubah numerik pada gerombol 1 dibangkitkan dari sebaran yang sama, yaitu menyebar Normal (1,1), begitu pula untuk setiap peubah numerik pada gerombol 2 dibangkitkan dari sebaran yang sama, yaitu menyebar Normal (2,1) dan setiap peubah numerik pada gerombol 3 dibangkitkan dari sebaran yang sama pula, yaitu menyebar Normal (3,1).
Data populasi ini diberikan pencilan dengan pencilan ditempatkan secara sistematik dengan pembagian yang sama pada setiap peubah numerik serta pada objek yang sama. Banyaknya pencilan data yang dibangkitkan terdiri atas 0%, 1%, 5%, dan 15% dari keseluruhan data bangkitan. Ukuran data (N) yang dibangkitkan terdiri atas 100, 500, dan 1000 data bangkitan. Kombinasi data simulasi pada penelitian ini dapat dilihat pada Tabel 2.
7
kombinasi data. Setiap kombinasi akan diulang sebanyak 30 kali sehingga diperlukan data bangkitan untuk dianalisis sebanyak 720 gugus data.
Tabel 2 Kombinasi data simulasi
Model peubah campuran Ukuran data Pencilan data (%) 100 0, 1, 5, 15
Metode pembangitan data yang ditampilkan adalah untuk model peubah campuran V1, ukuran data sebesar 500 dan banyaknya pencilan sebesar 5%. 1. Menetapkan parameter 1,2,3, 1,2 dan3 dimana 1= −6, 2= 0, 3=
Tabel 3 Pembangkitan ukuran data gerombol dan proporsi pencilan
8
memiliki sebaran yang sama, yaitu N(μ2,1) dan setiap peubah (�1,…,�10) dari
gerombol 3 memiliki sebaran yang sama pula, yaitu N(μ3,1). Lalu
menggabungkan data peubah yang sama dari setiap gerombol menjadi satu gugus data peubah tersebut. Lebih jelasnya dapat dilihat pada Tabel 3.
3. Membangkitkan × kategorik seperti ditunjukkan pada Tabel 4. Cara ini hanyalah salah satu cara metode membuat data peubah kategorik.
Tabel 4 Kriteria nilai transformasi untuk peubah kategorik Peubah
Kriteria nilai transformasi peubah Y ke-
1 2 3 data pencilan 5% untuk gerombol 1, gerombol 2 dan gerombol 3 dengan n1 =
30% × N, n2 = 35% × N, n3 = 35% × N, N = 25, dan p = 10 seperti
ditunjukkan pada Tabel 3.
6. Menggabungkan data gerombol 1 beserta pencilannya, gerombol 2 beserta pencilannya dan data gerombol 3 beserta pencilannya ke dalam 1 gugus data dengan pencilan ditempatkan secara sistematik dengan pembagian yang sama pada setiap peubah numerik serta pada objek yang sama.
7. Melakukan uji pencilan univariat terhadap data bangkitan peubah numerik beserta pencilannya dengan melihat nilai baku Z data {Z = (x - µ) / σ}. Suatu data dikatakan data pencilan jika memiliki nilai baku Z lebih besar dari 3 atau kurang dari -3 (Hair et al. 2010).
8. Melakukan penggerombolan dengan metode penggerombolan dua tahap dengan membandingkan nilai penanganan pencilan sebesar 1%, 5% dan 15%, serta tanpa melakukan penanganan pencilan atau 0%.
9. Mengulangi langkah 1-8 sebanyak 30 kali ulangan.
10. Mengukur tingkat keakuratan algoritma penggerombolan dua tahap dalam mendeteksi banyaknya gerombol sebenarnya. Tingkat keakuratan (A) didefinisikan sebagai persentase jumlah percobaan yang menghasilkan banyaknya gerombol yang sama dengan gerombol sebenarnya, yaitu A =
9
sama dengan banyaknya gerombol sebenarnya dan bernilai 0 jika selainnya dan N adalah banyaknya ulangan percobaan, yaitu sebanyak 30 ulangan. 11. Melakukan perhitungan tingkat salah klasifikasi dari anggota gerombol, yaitu
total persentase semua objek yang berasal dari suatu gerombol namun teridentifikasi sebagai anggota gerombol lain pada proses penggerombolan. Hal ini diilustrasikan pada Tabel 5.
Tabel 5 Ilustrasi salah klasifikasi
Hasil penggerombolan
Keanggotaan pada populasi yang sebenarnya
Populasi 1 Populasi 2
Gerombol-1 1 2
Gerombol-2 3 4
Salah klasifikasi pada 2 gerombol adalah ( 2 + 3) / ( 1 + 2+ 3 + 4)
12. Mengulangi langkah 1-12 untuk setiap kombinasi data simulasi (Tabel 2) dengan jumlah data dan jumlah pencilan disajikan pada Tabel 2.
Diagram alir (flowchart) metode pembangkitan data dapat dilihat pada Lampiran 2.
Penerapan pada Data Riil
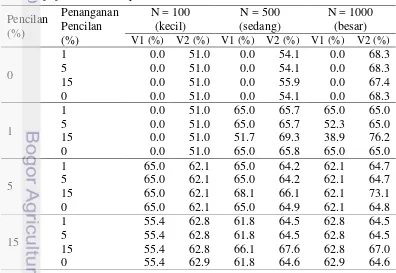
Berikut adalah langkah-langkah untuk penerapan pada data riil. 1. Melakukan standarisasi peubah numerik ke bentuk baku Z.
2. Melakukan pemeriksaan hubungan antar peubah. Peubah numerik menggunakan nilai korelasi Pearson, sedangkan untuk peubah kategorik menggunakan uji khi-kuadrat.
3. Melakukan pereduksian peubah, yaitu memilih peubah yang saling bebas dari setiap peubah numerik dan kategorik.
4. Melakukan penggerombolan dua tahap terhadap peubah yang sudah direduksi dengan menggunakan ukuran jarak Log-likelihood, kriteria penggerombolan
BIC dan menggunakan penanganan pencilan sebesar 15%.
5. Menjelaskan karakteristik dari setiap gerombol optimal yang terbentuk. Taraf
nyata (α) yang digunakan adalah sebesar 5%.
Diagram alir metode penggerombolan dua tahap penerapan pada data riil dapat dilihat pada Lampiran 3.
HASIL DAN PEMBAHASAN
Kajian pada Kasus Data Khusus
10
Tabel 6 Persentase salah banyaknya gerombol yang dihasilkan dengan banyaknya gerombol populasi sebenarnya
V1: peubah campuran sebagian besar bertipe numerik (10) dan sisanya kategorik (3), V2: peubah campuran sebagian besar bertipe kategorik (10) dan sisanya numerik (3).
Tabel 7 Persentase salah klasifikasi gerombol yang dihasilkan dengan gerombol populasi sebenarnya
11
Tabel 6 memperlihatkan persentase salah banyaknya gerombol yang dihasilkan dari metode penggerombolan dua tahap dengan banyaknya gerombol populasi sebenarnya. Selanjutnya Tabel 7 memperlihatkan persentase salah klasifikasi gerombol yang dihasilkan dari metode penggerombolan dua tahap dengan gerombol populasi sebenarnya.
Tabel 6 dan Tabel 7 membuktikan beberapa kesimpulan dari penggunaan metode penggerombolan dua tahap pada kasus data khusus tersebut. Pertama, pada data yang mengandung pencilan kecil, penggunaan metode penggerombolan dua tahap memberikan hasil yang lebih akurat dibandingkan dengan data yang mengandung pencilan besar.
Kedua, pada data yang tidak mengandung pencilan khususnya pada peubah kriteria penggerombolan yang sebagian besar bertipe numerik dan sisanya kategorik, metode ini memberikan hasil yang sangat akurat, sedangkan pada peubah yang sebagian besar bertipe kategorik dan sisanya numerik memberikan hasil yang tidak akurat. Ketiga, disebabkan karena pencilan ditempatkan secara sistematik pada setiap peubah dengan pembagian yang sama serta pada objek yang sama maka metode ini dalam melakukan penggerombolannya akan mendeteksi objek pencilan sebagai suatu gerombol yang terpisah atau sebagai suatu gerombol pencilan atau bahkan keduanya.
Keempat, secara umum metode ini kurang akurat ketika menangani peubah penggerombolan yang sebagian besar bertipe kategorik dan sisanya numerik. Kelima, apabila salah banyaknya gerombol yang dihasilkan tinggi maka salah klasifikasi keanggotaan gerombol cenderung tinggi pula. Terakhir, apabila data mengandung pencilan maka besaran penanganan pencilan yang digunakan harus lebih besar daripada pencilannya itu sendiri.
Penerapan pada Data Riil
Deskripsi Data
Desa/kelurahan di Indonesia terdiri atas 77961 desa. Dari data Podes tahun 2011 yang merupakan faktor kemajuan dan ketertinggalan suatu desa, terdapat data pencilan sebesar 1%. Di samping itu, sebagian besar peubah kriteria penggerombolannya bertipe numerik dan sisanya bertipe kategorik.
Pereduksian Peubah
Pereduksian peubah dilakukan untuk memilih peubah-peubah yang saling bebas. Langkah ini dilakukan dengan cara memeriksa hubungan antar peubah. Peubah numerik menggunakan nilai korelasi Pearson, sedangkan untuk peubah kategorik menggunakan uji khi-kuadrat. Khusus untuk peubah numerik dilakukan standarisasi ke bentuk baku (Z) terlebih dahulu.
Dari 52 peubah terpilihlah 23 peubah yang saling bebas yang terdiri dari 21 peubah numerik dan 2 peubah kategorik. Faktor alam dan lingkungan diwakili oleh peubah 2, faktor kelembagaan diwakili oleh peubah 5, faktor sarana, prasarana dan akses diwakili oleh peubah 8, 10, 12, 15, 24, 25, 26, 27,
28, 31, 32, dan 33, serta faktor sosial ekonomi penduduk diwakili oleh
12
Penggerombolan dengan Metode Penggerombolan Dua Tahap
Metode penggerombolan dua tahap dilakukan terhadap 23 peubah terpilih yang saling bebas. Ukuran jarak yang digunakan adalah jarak Log-likelihood
karena data yang digunakan bertipe campuran dari numerik dan kategorik. Penentuan banyaknya gerombol menggunakan kriteria penggerombolan BIC
karena memiliki sifat koreksi terhadap ukuran data (N). Serta menggunakan penanganan pencilan sebesar 15%.
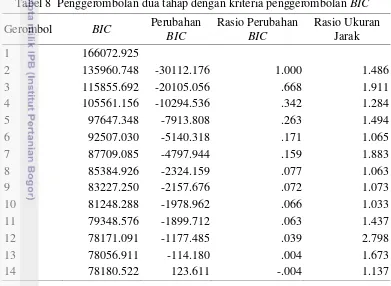
Tabel 8 menunjukkan bahwa nilai rasio perubahan BIC yang pertama kali lebih kecil dari batas nilai konstanta 1 = 0.040 ada pada solusi 12 gerombol, yaitu
0.039. Hal ini dapat disimpulkan bahwa jumlah gerombol maksimum yang dihasilkan pada tahap pertama sebanyak 12 gerombol.
Tabel 8 Penggerombolan dua tahap dengan kriteria penggerombolan BIC
Gerombol BIC Perubahan
BIC
Pada jumlah gerombol yang kurang dari jumlah gerombol maksimum (12), nilai rasio perubahan gerombol untuk dua nilai rasio ukuran jarak (R(j)) yang terbesar, terdapat pada solusi 3 gerombol (R(j) = 1.911) dan 7 gerombol (R(j) = 1.883). Rasio kedua nilai ini sebesar 1.015 dan lebih kecil dari batas nilai konstanta 2 = 1.15. Dengan demikian, 7 gerombol merupakan solusi optimal. Pendistribusian desa/kelurahan di setiap gerombol dapat dilihat pada Tabel 9.
Tabel 9 Distribusi hasil penggerombolan
Ket Gerombol
1 2 3 4 5 6 7 Pencilan Total
Jumlah 16024 5349 4729 5981 19959 21395 3434 1090 77961 Prs (%) 20.6 6.9 6.1 7.7 25.6 27.4 4.4 1.4 100.0
13
Karakteristik Gerombol Desa/Kelurahan
Karakteristik setiap gerombol dapat dijelaskan melalui data frekuensi peubah kategorik (Tabel 10), grafik tingkat kepentingan uji khi-kuadrat untuk peubah kategorik (Gambar 1 dan 2), grafik tingkat kepentingan uji-t untuk peubah numerik (Lampiran 4) dan tingkat rataan nilai peubah numerik (Lampiran 5).
Gerombol pencilan atau gerombol desa/kelurahan terpencil tidak dapat dikatakan sebagai gerombol optimal. Hal ini disebabkan karena anggota didalamnya merupakan desa/kelurahan yang memencil dan tidak dapat dimasukkan ke dalam gerombol optimal yang terbentuk, yaitu gerombol akhir yang memiliki kemiripan karakteristik antar anggotanya.
Tabel 10 menunjukkan bahwa gerombol yang maju dalam faktor alam dan lingkungan adalah gerombol 6, sedangkan yang tertinggal adalah gerombol 7. Kemudian gerombol yang maju dalam faktor kelembagaan adalah gerombol 6, sedangkan yang tertinggal adalah gerombol 4.
Tabel 10 Frekuensi dan persentase peubah kategorik pada setiap gerombol
Gerombol
Peubah mana saja yang berpengaruh terhadap pembentukan setiap gerombol, dapat dilihat melalui grafik tingkat kepentingan masing-masing peubah pada setiap gerombol. Apabila terdapat peubah yang memiliki statistik uji lebih besar dari nilai kritis (garis lurus vertikal) maka peubah tersebut berpengaruh terhadap pembentukan gerombol yang dimaksud.
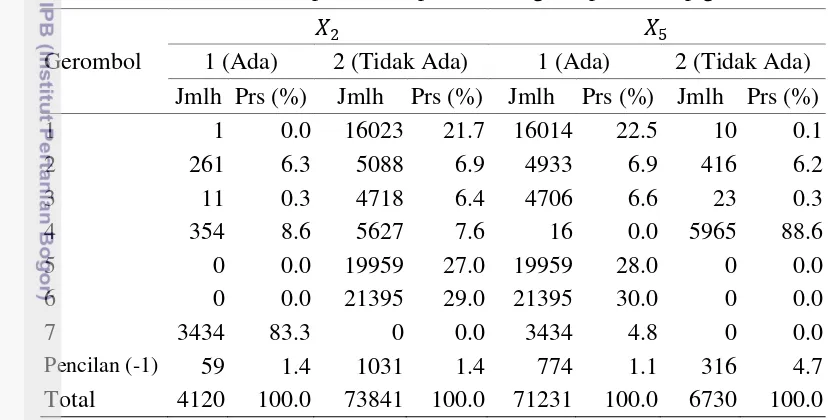
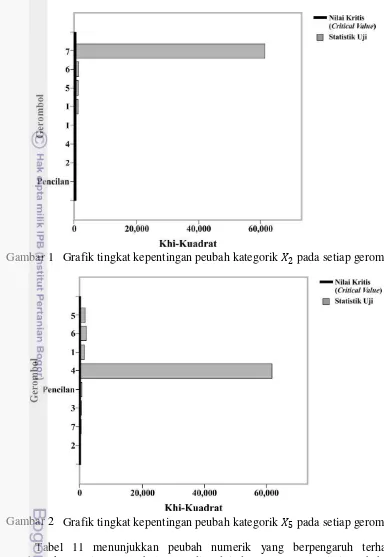
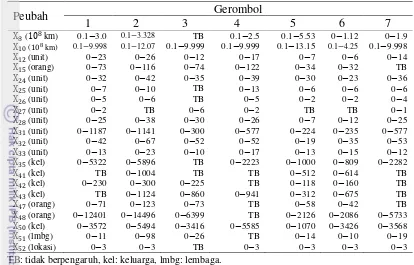
Gambar 1 memperlihatkan bahwa gerombol yang pembentukannya dipengaruhi oleh peubah 2 adalah gerombol 1, 5, 6 dan 7. Kemudian Gambar 2 memperlihatkan bahwa gerombol yang pembentukannya dipengaruhi oleh peubah
14
Gambar 1 Grafik tingkat kepentingan peubah kategorik 2 pada setiap gerombol
Gambar 2 Grafik tingkat kepentingan peubah kategorik 5 pada setiap gerombol
Tabel 11 menunjukkan peubah numerik yang berpengaruh terhadap pembentukan setiap gerombol yang ditandai dengan rentang nilai peubahnya, sedangkan yang tidak berpengaruh ditandai dengan keterangan “TB”.
Lampiran 5 memperlihatkan bahwa gerombol pencilan memiliki tingkat rataan peubah numerik yang cenderung tinggi dibandingkan dengan gerombol lainnya. Peubah atau ciri kuat pada gerombol 1 hanya terdapat pada 2 peubah, yaitu peubah 35 dan 48 dan ciri lemahnya terdapat pada peubah 8 dan 10.
15
Tabel 11 Rentang nilai pada setiap peubah numerik
Peubah Gerombol
TB: tidak berpengaruh, kel: keluarga, lmbg: lembaga.
7, yaitu bukan merupakan ciri kuat maupun ciri lemah atau berada dipertengahan. Kecuali pada peubah 27 yang masuk ke dalam ciri kuat dan peubah 47 yang masuk ke dalam ciri lemah untuk gerombol 3, dan peubah 25 dan 50 yang masuk ke dalam ciri kuat dan peubah 35 yang masuk ke dalam ciri lemah untuk gerombol 4.
Peubah atau ciri kuat gerombol 5 hanya terdapat pada 2 peubah, yaitu peubah 8 dan 10, sedangkan peubah lainnya masuk ke dalam ciri lemah. Gerombol 6 tidak memiliki peubah atau ciri kuat karena sebagian besar peubah cenderung masuk ke dalam ciri lemah.
Lampiran 6 memperlihatkan hasil akhir dari karakteristik setiap gerombol yang terbentuk. Gerombol satu merupakan gerombol desa/kelurahan yang maju dalam faktor alam dan lingkungan; faktor kelembagaan; serta memiliki jarak kantor desa dengan kantor camat dan dengan kantor bupati/walikota lain terdekat yang tidak jauh. Akan tetapi merupakan gerombol desa/kelurahan yang memiliki jumlah keluarga pertanian dan jumlah warga penerima kartu JAMKESMAS/ JAMKESDA selama tahun 2010 yang tinggi.
Gerombol dua merupakan gerombol desa/kelurahan yang maju dalam faktor sarana, prasarana dan akses. Akan tetapi merupakan gerombol desa/kelurahan yang tertinggal dalam faktor sosial ekonomi penduduk. Gerombol tiga merupakan gerombol desa/kelurahan yang tidak maju maupun tidak tertinggal pada semua faktor kemajuan maupun ketertinggalan suatu desa yang mempengaruhinya. Akan tetapi merupakan gerombol desa/kelurahan yang memiliki jumlah Koperasi Unit Desa (KUD) yang masih aktif yang tinggi dan memiliki jumlah penderita gizi buruk selama 3 tahun terakhir yang rendah.
16
memiliki jumlah bank umum yang tinggi dan memiliki jumlah keluarga pertanian yang rendah. Gerombol lima merupakan gerombol desa/kelurahan yang maju dalam faktor alam dan lingkungan; faktor kelembagaan; dan faktor sosial ekonomi penduduk. Akan tetapi merupakan gerombol desa/kelurahan yang tertinggal dalam faktor sarana, prasarana dan akses.
Gerombol enam merupakan gerombol desa/kelurahan yang maju dalam faktor alam dan lingkungan; faktor kelembagaan; dan faktor sosial ekonomi penduduk. Akan tetapi merupakan gerombol desa/kelurahan yang tertinggal dalam faktor sarana, prasarana dan akses. Di samping itu, kondisi faktor sarana, prasarana dan akses gerombol enam lebih maju dibandingkan gerombol lima dan kondisi faktor sosial ekonomi penduduk gerombol enam lebih rendah dibandingkan gerombol lima. Gerombol tujuh merupakan gerombol desa/kelurahan yang tertinggal dalam faktor alam dan lingkungan.
KESIMPULAN DAN SARAN
Kesimpulan
Penggunaan metode penggerombolan dua tahap pada kasus data khusus yaitu pada data yang mengandung pencilan dengan pencilan ditempatkan secara sistematik pada setiap peubah numerik, dan setiap peubah numerik dibangkitkan dari sebaran yang sama untuk masing-masing gerombol memberikan beberapa kesimpulan, diantaranya pada data yang mengandung pencilan kecil (1%) metode ini memberikan hasil yang lebih akurat dibandingkan dengan data yang mengandung pencilan besar (5% atau 15%).
Penggunaan besaran penanganan pencilan pada data yang mengandung pencilan harus lebih besar daripada besaran pencilannya itu sendiri. Algoritma metode penggerombolan dua tahap menyediakan perhitungan untuk peubah bertipe kategorik sehingga mempermudah melakukan penggerombolan pada peubah bertipe kategorik maupun campuran dari numerik dan kategorik. Akan tetapi, metode ini kurang akurat apabila menangani peubah campuran yang sebagian besar bertipe kategorik dan sisanya numerik.
Metode penggerombolan dua tahap sangat akurat dalam menghasilkan banyaknya gerombol yang sesuai dengan banyaknya gerombol sebenarnya pada data yang tidak mengandung pencilan khususnya pada peubah penggerombolan yang sebagian besar bertipe numerik dan sisanya kategorik. Secara umum apabila salah banyaknya gerombol yang dihasilkan tinggi, maka salah klasifikasi keanggotaan gerombol cenderung tinggi pula. Penggerombolan Desa/Kelurahan di Indonesia berdasarkan faktor kemajuan dan ketertinggalan suatu desa dengan metode penggerombolan dua tahap menghasilkan 7 gerombol akhir/optimal.
Saran
17
pencilan ditempatkan secara random pada keseluruhan data dan tidak secara sistematik pada setiap peubah dan objek, serta setiap peubah numerik pada setiap gerombol dibangkitkan dari sebaran yang berbeda, yaitu dengan sebaran Normal Ganda dengan nilai tengah dan ragam yang berbeda.
DAFTAR PUSTAKA
Bacher J, Wenzig K, Vogler M. 2004. SPSS two step cluster – a first evaluation. RC33 Sixth International Conference on Social Science Methodology: Recent Developments and Applications on Social Science Research Methodology [Internet]. [diunduh 18 Mei 2012]; Amsterdam, Netherlands. Tersedia pada http://www.statisticalinnovations.com/products/Two Step. pdf.
Chiu T, Fang D, Chen J, Wang Y., and Jeris C. 2001. A robust and scalable clustering algorithm for mixed type attributes in large database environment. Di dalam: Doheon Lee, Mario Schkolnick, Foster J Provost, Ramakrishnan Srikant. Proceedings of the 7th ACM SIGKDD International Confererence on Knowledge Discovery and Data Mining (KDD-2001); 2001 Agus 26-29; San Francisco, United States. New York (US): ACM Press. hlm 263-264.
Garson DG. 2012. Cluster Analysis. Blue Book Series. North Carolina (US): North Carolina State University.
Hair J.F.Jr, R.E. Anderson, B.J. Babin, & W.C. Black. 2010. Multivariate Data Analysis. Volume ke-7. New Jersey (US): Prentice-Hall.
Johnson RA, Wichern DW. 2002. Applied Multivariate Statistical Analysis.
Volume ke-6. New Jersey (US): Prentice-Hall.
Kudsiati. 2006. Pengkajian keakuratan TwoStep Cluster dalam menentukan banyaknya gerombol populasi [tesis]. Bogor (ID): Institut Pertanian Bogor. Li H, Sun J. 2011. Mining business failure predictive knowledge using two-step
clustering. AJBM. 5(11):4107-4120.
Norusis MJ. 2004. SPSS 19.0 Statistical Procedures Companion. Upper Saddle River, NJ (US): Prentice-Hall. hlm 375-404.
Rencher CA. 2002. Methods of Multivariate Analysis. Volume ke-2. New York (US): John Wiley & Sons Inc.
Schiopu, D. 2010. Applying two step cluster analysis for identifying bank
customers’ profile. EI-TC. 62(3):66-75.
SPSS Inc. 2001. The SPSS twostep cluster component. A scalable component to segment your customers more effectively. White paper – technical report [Internet]. [diunduh 18 Mei 2012]; Chicago. Tersedia pada http://www.spss. ch/upload/1122644952_The%20SPSS%20TwoStep%20Cluster%20Compo nent.pdf
18
Lampiran 1 Daftar peubah penggerombolan sebelum dilakukan pereduksian
Kategori Kode Peubah Keterangan
Faktor alam dan lingkungan
X1 Jumlah penduduk pada Januari 2011 Numerik
X2 Keberadaan bencana gempa bumi selama 3 tahun terakhir 2 Kategori
X3 Lokasi desa/kelurahan terhadap kawasan hutan 3 Kategori
Faktor kelembagaan
X4 Status pemerintahan 2 Kategori
X5 Keberadaan Badan Perwakilan Desa/Dewan Kelurahan 2 Kategori
X6 Keberadaan Satuan Lingkungan Setempat (SLS) terkecil di
bawah desa/kelurahan
X7 Keberadaan dan lokasi kantor kepala desa (lurah) 3 Kategori
X8 Jarak kantor desa dengan kantor camat Numerik
X9 Jarak kantor desa dengan kantor bupati/walikota Numerik
X10 Jarak kantor desa dengan kantor bupati/walikota lain terdekat Numerik
X11 Ketersediaan penerangan di jalan utama desa/kelurahan 2 Kategori
X12 Jumlah sarana pendidikan negeri Numerik
X13 Jumlah sarana pendidikan swasta Numerik
X14 Jumlah sarana kesehatan Numerik
X15 Jumlah tenaga kesehatan yang menetap di desa/kelurahan Numerik
X16 Ketersediaan telepon umum koin/ kartu yang masih aktif 2 Kategori
X17 Ketersediaan Base Transcelver Station (BTS)/ menara telepon 2 Kategori
X18 Kondisi sinyal telepon seluler/hand phone 3 Kategori
X19 Ketersediaan Wartel/ kiospon/ warpostel/ warparpostel 2 Kategori
X20 Ketersediaan Warung internet (Warnet) 2 Kategori
X21 Ketersediaan Kantor Pos/ Pos Pembantu/ rumah pos 2 Kategori
X22 Ketersediaan Kelompok Pertokoan 2 Kategori
X23 Ketersediaan Pasar dengan bangunan permanen/ semi permanen 2 Kategori
X24 Jumlah Minimarket Numerik
X25 Jumlah Bank Umum Numerik
X26 Jumlah Bank Perkreditan Rakyat (BPR) Numerik
X27 Jumlah Koperasi Unit Desa (KUD) yang masih aktif Numerik
X28 Jumlah Koperasi Non KUD yang masih aktif Numerik
X29 Ketersediaan perlengkapan keselamatan bencana alam 2 Kategori
X30 Jumlah tempat beribadah Numerik
X31 Jumlah industri kecil dan mikro Numerik
X32 Jumlah restoran/rumah makan Numerik
X33 Jumlah hotel Numerik
X34 Keberadaan pos polisi 2 Kategori
Faktor sosial ekonomi penduduk
X35 Jumlah keluarga pertanian Numerik
X36 Sumber penghasilan utama sebagian besar penduduk 7 Kategori
X37 Jumlah keluarga pengguna listrik PLN Numerik
X38 Bahan bakar memasak yang digunakan sebagian besar keluarga 5 Kategori
X39 Tempat buang sampah sebagian besar keluarga 5 Kategori
X40 Tempat buang air besar sebagian besar keluarga 5 Kategori
X41 Jumlah keluarga yang tinggal di bantaran sungai Numerik
X42 Jumlah keluarga yang tinggal di bawah Saluran Udara Tegangan
Ekstra Tinggi (SUTET) Numerik
X43 Jumlah keluarga yang tinggal di pemukiman kumuh Numerik
X44 Adanya pencemaran air selama setahun terakhir 2 Kategori
X45 Adanya pencemaran tanah selama setahun terakhir 2 Kategori
X46 Adanya pencemaran udara selama setahun terakhir 2 Kategori
X47 Jumlah penderita gizi buruk selama 3 tahun terakhir Numerik
X48 Jumlah warga penerima kartu JAMKESMAS/JAMKESDA
selama tahun 2010 Numerik
X49 Sumber air untuk minum/memasak sebagian besar keluarga 8 Kategori
X50 Jumlah keluarga yang berlangganan telepon kabel Numerik
X51 Jumlah lembaga non-profit Numerik
19
Lampiran 2 Diagram alir metode pembangkitan data
NB: Bersambung ke halaman selanjutnya
Diulang 30 kali
Mengukur tingkat keakuratan algoritma Penggerombolan Dua Tahap dalam mendeteksi banyaknya gerombol sebenarnya
Banyaknya gerombol
Menggabungkan data peubah yang sama dari setiap gerombol menjadi gugus data peubah tsb
Membangkitkan ��1~N(1,1), ��2~N(2,1) dan ��3~N(3,1)
Mentrasformasi data Y menjadi data bertipe kategorik
Membangkitkan ��1~N(1,1), ��2~N(2,1) dan ��3~N(3,1)
Menggabungkan data gerombol 1 beserta pencilannya, data gerombol 2 beserta pencilannya dan data gerombol 3 beserta pencilannya kedalam satu gugus data
Melakukan uji pencilan univariat terhadap data peubah numerik beserta pencilannya
Data memiliki
Melakukan Penggerombolan Dua Tahap dengan membandingkan nilai penanganan pencilan sebesar 1%, 5% dan 15%, serta tanpa melakukan penanganan pencilan atau 0%
20
Bersambung ke halaman ini
Melakukan perhitungan tingkat salah klasifikasi dari anggota gerombol
Objek berasal dan teridentifikasi pada gerombol
yang sama
Tidak salah klasifikasi
Salah Klasifikasi Tidak
Ya
21
Lampiran 3 Diagram alir metode penggerombolan dua tahap pada data riil
Selesai
Melakukan standarisasi peubah numerik ke bentuk baku Z
Melakukan pemeriksaan hubungan antar peubah.
Melakukan Penggerombolan Dua Tahap
Menjelaskan karakteristik dari setiap gerombol optimal yang terbentuk
Mulai
Peubah
saling bebas Direduksi Tidak
22
Lampiran 4 Grafik tingkat kepentingan peubah numerik pada setiap gerombol
25
Lampiran 6 Karakteristik pada setiap gerombol
Gerombol
4 Tertinggal Jumlah keluarga
26
RIWAYAT HIDUP
Penulis bernama Arni Nurwida dan dilahirkan di Jakarta pada tanggal 31 Januari 1990, anak dari pasangan Ir. Herwin Nur dan Ir. Dwi Budi Utami, M.Si. Penulis merupakan putri ketiga dari tiga bersaudara.
Tahun 2002 penulis menamatkan pendidikan sekolah dasar di MI Darunnajah Ulujami Jakarta Selatan. Kemudian penulis melanjutkan studinya di Pondok Pesantren MTs Darunnajah Ulujami Jakarta Selatan dan lulus pada tahun 2005. Tahun 2008 penulis lulus dari SMAN 47 Jakarta dan pada tahun yang sama lulus seleksi masuk IPB melalui jalur Undangan Seleksi Masuk IPB (USMI). Penulis mengambil mayor Statistika Fakultas Matematika dan Ilmu Pengetahuan Alam dengan minor Ekonomi dan Studi Pembangunan dari Fakultas Ekonomi Manajemen.