Lampiran 1
Tabel 3.1 Data Sekunder Survival Time
No. ¼½ ¼¾ ¼¿ ¼À »
1. 6.7 62 81 2.59 200 2. 5.1 59 66 1.70 101 3. 7.4 57 83 2.16 204 4. 6.5 73 41 2.01 101 5. 7.8 65 115 4.30 509 6. 6.0 85 28 2.98 87 7. 5.8 38 72 1.42 80 8. 5.7 46 63 1.91 80 9. 3.7 68 81 2.57 127 10. 6.0 67 92 2.50 202 11. 3.7 76 94 2.40 203 12. 6.3 84 83 4.13 329 13. 6.7 51 43 1.89 65 14. 5.8 83 88 3.95 330 15. 11.2 76 90 5.59 574 16. 7.7 62 67 3.40 168 17. 7.4 74 68 2.40 217 18. 3.7 51 41 1.55 34 19. 7.3 68 74 3.56 215 20. 5.6 57 87 3.02 172 21. 5.2 52 76 2.86 109 22. 5.8 96 114 3.95 830 23. 3.4 83 53 1.12 136 24. 8.7 45 23 2.52 58 25. 5.8 72 93 3.30 295 26. 6.3 59 100 2.95 276 27. 5.8 72 93 3.30 104 28. 3.2 64 65 0.74 71 29. 5.3 57 99 2.60 184 30. 2.6 74 86 2.05 118 Sumber : Soemartini. Deteksi Outlier
Keterangan:
= blood clotting = prognostic index = enzyme function test ¹ = liver function test
Lampiran 2
Perhitungan Menentukan Parameter Regresi Linear Berganda
No. ¼½¾ ¼¾¾ ¼¿¾ ¼À¾ »¾ ¼½» ¼¾» ¼¿» ¼À»
No. ¼½¼¾ ¼½¼¿ ¼½¼À ¼¾¼¿ ¼¾¼À ¼¿¼À 1. 415,4 542,7 17,353 5.022 160,58 209,79
2. 300,9 336,6 8,67 3.894 100,3 112,2
3. 421,8 614,2 15,984 4.731 123,12 179,28 4. 474,5 266,5 13,065 2.993 146,73 82,41
5. 507,0 897,0 33,54 7.475 279,5 494,5
6. 510,0 168,0 17,88 2.380 253,3 83,44
7. 220,4 417,6 8,236 2.736 53,96 102,24
8. 262,2 359,1 10,887 2.898 87,86 120,33 9. 251,6 299,7 9,509 5.508 174,76 208,17
10. 402,0 552,0 15,00 6.164 167,5 230
11. 281,2 347,8 8,88 7.144 182,4 225,6
12. 529,2 522,9 26,019 6.972 346,92 342,79 13. 341,7 288,1 12,663 2.193 96,39 81,27 14. 481,4 510,4 22,91 7.304 327,85 347,6 15. 851,2 1008 62,608 6.840 424,84 503,1
16. 477,4 515,9 26,18 4.154 210,8 227,8
17. 547,6 503,2 17,76 5.032 177,6 163,2
18. 188,7 151,7 5,735 2.091 79,05 63,55
19. 496,4 540,2 25,988 5.032 242,08 263,44 20. 319,2 487,2 16,912 4.959 172,14 262,74 21. 270,4 395,2 14,872 3.952 148,72 217,36 22. 556,8 661,2 22,91 10.944 379,2 450,3
23. 282,2 180,2 3,808 4.399 92,96 59,36
24. 391,5 200,1 21,924 1.035 113,4 57,96
25. 417,6 539,4 19,14 6.696 237,6 306,9
26. 371,7 630,0 18,585 5.900 174,05 295
27. 417,6 539,4 19,14 6.696 237,6 306,9
28. 204,8 208,0 2,368 4.160 47,36 48,1
29. 302,1 524,7 13,78 5.643 148,2 257,4
30. 192,4 223,6 5,33 6.364 151,7 176,3
Lampiran 3
Menentukan nilai residual
No. »Ô »XÔ »Ô− »XÔ 8»Ô− »XÔ:¾
1. 200 233,800 -33,800 1.142,465
2. 101 93,320 7,680 58,984
3. 204 236,528 -32,528 1.058,098
4. 101 129,058 -28,058 787,269
5. 509 435,025 73,975 5.472,339
6. 87 134,692 -47,692 2.274,547
7. 80 25,819 54,181 2.935,563
8. 80 35,606 44,394 1.970,855
9. 127 154,657 -27,657 764,888
10. 202 275,855 -73,855 5.454,626
11. 203 245,878 -42,878 1.838,531
12. 329 359,303 -30,303 918,296
13. 65 23,776 41,224 1.699,456
14. 330 352,701 -22,701 515,320
15. 574 537,434 36,566 1.337,042
16. 168 224,932 -56,932 3.241,207
17. 217 273,845 -56,845 3.231,395
18. 34 -98,294 132,294 17.501,724
19. 215 270,567 -55,567 3.087,731
20. 172 192,369 -20,369 414,898
21. 109 107,238 1,762 3,103
22. 830 521,867 308,133 94.945,833
23. 136 105,794 30,206 912,376
24. 58 -4,810 62,810 3.945,112
25. 295 306,347 -11,347 128,744
26. 276 277,960 -1,960 3,840
27. 104 306,347 -202,347 40.944,126
28. 71 37,586 33,414 1.116,506
29. 184 223,085 -39,085 1.527,633
30. 118 160,714 -42,714 1.824,525
Lampiran 4
Deteksi pencilan dengan Leverage(ℎ )
Lampiran 5
Deteksi pencilan dengan Discrepancy
Lampiran 6
Deteksi pencilan dengan menggunakan metode DfFITS (Difference in fit Standardized)
No. 2u,
! DfFITS |DfFITS|
Lampiran 7
Mengestimasi menggunakan metode LTS: Iterasi 1
No. ¼½ ¼¾ ¼¿ ¼À » »XÔ 8»Ô− »XÔ:¾ 1. 6,7 62 81 2,59 200 233,800 1.142,465 2. 5,1 59 66 1,70 101 93,320 58,984 3. 7,4 57 83 2,16 204 236,528 1.058,098 4. 6,5 73 41 2,01 101 129,058 787,269 5. 7,8 65 115 4,30 509 435,025 5.472,339 6. 6,0 85 28 2,98 87 134,692 2.274,547 7. 5,8 38 72 1,42 80 25,819 2.935,563 8. 5,7 46 63 1,91 80 35,606 1.970,855 9. 3,7 68 81 2,57 127 154,657 764,888 10. 6,0 67 92 2,50 202 275,855 5.454,626 11. 3,7 76 94 2,40 203 245,878 1.838,531 12. 6,3 84 83 4,13 329 359,303 918,296 13. 6,7 51 43 1,89 65 23,776 1.699,456 14. 5,8 83 88 3,95 330 352,701 515,320 15. 11,2 76 90 5,59 574 537,434 1.337,042 16. 7,7 62 67 3,40 168 224,932 3.241,207 17. 7,4 74 68 2,40 217 273,845 3.231,395 18. 3,7 51 41 1,55 34 -98,294 17.501,724 19. 7,3 68 74 3,56 215 270,567 3.087,731 20. 5,6 57 87 3,02 172 192,369 414,898 21. 5,2 52 76 2,86 109 107,238 3,103 22. 5,8 96 114 3,95 830 521,867 94.945,833 23. 3,4 83 53 1,12 136 105,794 912,376 24. 8,7 45 23 2,52 58 -4,810 3.945,112 25. 5,8 72 93 3,30 295 306,347 128,744 26. 6,3 59 100 2,95 276 277,960 3,840 27. 5,8 72 93 3,30 104 306,347 40.944,126 28. 3,2 64 65 0,74 71 37,586 1.116,506 29. 5,3 57 99 2,60 184 223,085 1.527,633 30. 2,6 74 86 2,05 118 160,714 1.824,525 S 178.2 1.976 2.259 81,42 6.179 6.179 201.057,033
Dimana untuk memperoleh jumlah data pada iterasi kedua dengan:
ℎ = ‡ ˆ ‡(¹I )ˆ =17,5 ≈ 18 data. Sedangkan nilai ∑dN =201.057,033. Dan model regresi linear berganda pada iterasi 1 adalah:
Lampiran 8
Iterasi 2
No. ¹ h 8 − h :
1. 5,2 52 76 2,86 109 102,489 42,394 2. 6,3 59 100 2,95 276 254,389 467,034 3. 5,1 59 66 1,70 101 92,83551 66,659 4. 5,8 72 93 3,30 295 283,9873 121,279 5. 5,6 57 87 3,02 172 178,3381 40,172 6. 5,8 83 88 3,95 330 332,5531 6,518 7. 3,7 68 81 2,57 127 135,6398 74,647 8. 6,5 73 41 2,01 101 151,0395 2.503,954 9. 3,4 83 53 1,12 136 103,0099 1.088,344 10. 6,3 84 83 4,13 329 345,0836 258,682 11. 7,4 57 83 2,16 204 230,3445 694,034 12. 3,2 64 65 0,74 71 28,70136 1.789,175 13. 6,7 62 81 2,59 200 226,3314 693,341 14. 11,2 76 90 5,59 574 537,434 1.337,042 15. 5,3 57 99 2,60 184 197,0933 171,435 16. 6,7 51 43 1,89 65 50,82487 200,934 17. 2,6 74 86 2,05 118 131,2249 174,899 18. 3,7 76 94 2,40 203 213,1429 102,878 S 100,5 1.207 1.409 47,63 3.595 3.595,000 9.794,411
Dimana untuk memperoleh jumlah data pada iterasi ketiga dengan:
ℎ = ‡ Lj ‡(¹I )ˆ = 11,5 ≈ 12 data. Sedangkan nilai ∑dN =9.794,411. Dan model regresi linear bergandanya adalah:
Lampiran 9
Iterasi 3
No. ¼½ ¼¾ ¼¿ ¼À » »XÔ 8»Ô− »XÔ:¾ 1. 5,8 83 88 3,95 330 325,491 20,331 2. 5,6 57 87 3,02 172 179,986 63,783 3. 5,2 52 76 2,86 109 101,532 55,771
4. 5,1 59 66 1,70 101 99,877 1,260
5. 3,7 68 81 2,57 127 124,910 4,366
6. 3,7 76 94 2,40 203 204,874 3,512
7. 5,8 72 93 3,30 295 284,235 115,895 8. 5,3 57 99 2,60 184 201,603 309,869
9. 2,6 74 86 2,05 118 116,704 1,680
10. 6,7 51 43 1,89 65 66,597 2,549
11. 6,3 84 83 4,13 329 339,649 113,406 12. 6,3 59 100 2,95 276 263,541 155,219
S 62,1 792 996 33,42 2.309 2.309,000 847,642
Model regresi linear bergandanya adalah:
h = -649 + 48,3 5,06 3,06 1,42 ¹
DAFTAR PUSTAKA
Draper, N. dan Smith, H. 1992. Analisis Regresi Terapan. Edisi Kedua. Bambang Sumantri. Jakarta: Gramedia Pustaka Utama.
Huber, Peter, J., and Ronchetti, Elvezio, M. 2009. Robust Statistics. A John Wiley and Sons, Inc., Publication. Hoboken. New Jersey.
Musafirah, Raupong, Nasrah. 2010. Perbandingan Metode Robust Least Trimmed Square (LTS) Dengan Metode Scale Dalam Mengestimasi Parameter Regresi Linear Berganda Untuk Data Pencilan. Universitas Hasanuddin Oktarinanda, Arista . Jurnal Ilmiah. Perbandingan LTS dan Scale Dalam
Mengestimasi Parameter Regresi Linear Berganda. Universitas Hasanuddin.
Rousseeuw, P.J., & A. M. Leroy. 1987. Robust Regression and Outlier Detection. John Wiley & Sons Inc: New York.
Ronald, E. Walpole. 1982. Pengantar Statistika. PT. Gramedia Pustaka Utama Jakarta.
Santoso, S. 2000. Buku Latihan SPSS Statistik Parametrik. Elex Media Komputindo. Jakarta
Sembiring. R.K . Analisis Regresi. ITB. Bandung
Siregar, Sofyan. 2015. Statistika Terapan Untuk Perguruan Tinggi. PT.Kharisma Putra Utama. Jakarta
Siregar, Sofyan. Ir. 2014. Statistik Parametrik untuk Penelitian Kuantitatif. PT. Bumi Aksara. Jakarta
Suyanti, Sukestiryano, YL. Jurnal Ilmiah.2014. Deteksi Outlier Menggunakan Diagnosa Regresi Berbasis Estimator Parameter Robust. Universitas Negeri Semarang.
BAB 3
HASIL DAN PEMBAHASAN
3.1. Least Trimmed Square (LTS)
Sebelum membahas mengenai least trimmed square (LTS), akan dibahas terlebih dahulu sifat-sifat ke-equivariant-an yang harus dimiliki oleh suatu estimator (equivariant dalam statistik merujuk pada transformasi sebagaimana mestinya. Kebalikan dari equivariant yaitu invariant yang merujuk pada kuantitas yang tetap tidak berubah), yaitu: regresi equivariant, skala equivariant, dan affine equivariant. Sifat-sifat tersebut diperlukan agar hasil transformasi tetap dapat diartikan sama dengan data sebelum ditransformasi. Suatu estimator T disebut sebagai regresi equivariant jika memenuhi:
(–(+ , L + + 7); = 1,2, ⋯ , !—) = (–(+ , L ); = 1,2, ⋯ , !—) + 7 (3.1)
Dengan 7 merupakan sebarang vektor kolom. Regresi equivariant
digunakan dalam mendeskripsikan bagaimana studi Monte Carlo dilakukan dimulai ˜ = 00, yang berarti hasil transformasi valid pada sebarang vektor
parameter. Suatu estimator T disebut sebagai skala equivariant jika memenuhi:
(–(+ , ™L ); = 1,2, ⋯ , !— = ™ – + , L ; = 1,2, ⋯, !— (3.2)
untuk sebarang konstanta ™, skala equivariant menyebabkan bahwa kecocokan secara esensial independen dari pemilihan satuan pengukuran pada variabel terikat L . Sedangkan, suatu estimator adalah affine equivariant jika memenuhi:
untuk sebarang matrik persegi A yang nonsingular. Dimana affine equivariant menjelaskan transformasi linear dari + akan berpengaruh langsung pada
estimator , karena LM = + ˜ = (+ š)(šD ˜). Sehingga dengan demikian
peubah bebas dapat menggunakan sistem kordinat lainnya tanpa berpengaruh pada hasil estimasi LM.
Sifat Umum Estimator Regresi LTS
Estimator LTS mempunyai sifat regresi equivariant, skala equivariant, dan affine equivariant.
Regrsi Equivariant : ∑ ((L + 7 − + –7 + ˜—) )dN :/= ∑d9N L − + ˜ :/ Skala Equivariant : ∑dN ™L − + –™˜— :/ = ™ ∑d9N L − + ˜ :/ Affine Equivariant : ∑dN L –+ š—–šD ˜— :/ = ∑d9N L − + ˜ :/ dengan
7 = vektor kolom sebarang ™ = konstanta sebarang
š = matriks bujur sangkar non-singular
˜ = Transformasi (T)
Teorema 3.1. Sebarang regresi equivariant dari estimator memenuhi:
/∗ , ‹ ≤•‡
›œ• C ˆI €
/ (3.5
pada seluruh sampel ‹.
Menurut Rousseeuw least trimmed square (LTS) didefinisikan sebagai:
min¡X∑/N ] :/ (3.6)
Sebelumnya dengan menyusun residual kuadrat dari yang terkecil sampai dengan yang terbesar, yaitu:
:/ ≤ :/ ≤ ⋯ ≤ :/
Dengan ℎ = ‡/ˆ + 1, sehingga LTS akan memiliki breakdown point
yang sama dengan Y•‡
› CˆD[I €
[] menyatakan bagian bilangan bulat terbesar yang kurang dari atau sama
dengan bilangan bulat tersebut. Selain itu, untuk ℎ = ‡/ˆ + ‡([I )ˆ LTS yang
mungkin mencapai nilai maksimum dari teorema 3.1.
Sifat ke-robust-an dari LTS didasarkan pada breakdown point-nya yang didefinisikan oleh Rousseeuw. Nilai breakdown point dari metode LTS yang didefinisikan pada persamaan 3.5 dengan ℎ = ‡/ˆ + ‡([I )ˆ sama
dengan: /∗( , ‹) =•‡
(›œ•) C ˆI €
/`
Bukti: Asumsikan bahwa semua pengamatan dengan variabel 8+ , + , ⋯ , +[: = 0 dihapuskan dan pengamatan-pengamatannya merupakan dalam keadaan umum. Yang dimaksud dalam keadaan umum adalah jika sebarang , dari variabel bebas menentukan ˜ secara unik.
Langkah pertama adalah dengan menunjukkan bahwa /∗ , ‹ ≥ •‡›œ•C ˆI €
/` karena sampel ‹ = – + , L ; = 1,2, ⋯ , !— terdiri dari n titik dalam kondisi yang umum, hal ini akan memenuhi:
¤ = inf –¦ > 0;terdapat suatu , − 1 dimensi subruang dari § L = 0 ,
sedemikian hingga §′ meliputi sekurang-kurangnya , dari + — yang selalu bernilai positif, dengan §′ adalah himpunan dari semua variabel bebas dengan
jarak terhadap § tidak lebih dari ¦. Andaikan ˜ meminimumkan persamaan
3.5 untuk ‹, dan dinotasikan dengan e yang berkorespondensi dengan hyperplane yang diberikan dengan persamaan L = +˜ . Diberikan c =
Œ^+ |] | dengan ] = L − + ˜. Sekarang akan dikontruksikan sebarang
sampel terkontaminasi ‹0 = – +0, L0 ; = 1,2, ⋯, !— dengan menyimpan
! − ‡/D[ ˆ = ‡/I[I ˆ pengamatan-pengamatan dari ‹ dan dengan
yang berkorespondensi merupakan hal yang berbeda dari e . Tanpa
kehilangan keumumannya dapat diasumsikan bahwa ˜′ ≠ ˜ , karena itu e′ ≠ e.
Dengan teorema dimensi dari aljabar linear, irisan dari e ∩ e′
mempunyai dimensi , − 1. Jika ,](e ∩ e′ merupakan proyeksi vertical dari
e ∩ e′ terhadap L = 0 , sehingga diasumsikan paling banyak , − 1 dari +
yang baik (bukan pencilan) dapat terletak pada 8,] e ∩ e′ :¬. Sekarang
didefinisikan š sebagai himpunan pengamatan-pengamatan baik yang tersisa. Kemudian misalkan sebarang +m, Lm termasuk di š dan ]m= Lm− +m˜ dan
]m0= Lm− +m˜0. Kontruksikan vertical plane 2-dimensi -m melalui +m, Lm dan tegak lurus terhadap ,] e ∩ e0 . Sebelumnya akan dikontruksikan nilai
residual pada -m yaitu sebagai berikut menurut Rousseeuw:
|] | = |+ ˜ − L | ≥ ®|+ ˜| − |L |® dengan |+ ˜| > ¤|tan ~ | , dengan ~
merupakan sudut dalam •−±,±€ yang dibentuk antara e dengan garis
horizontal pada -m. Oleh karena itu, |~| merupakan sudut antara garis tegak
lurus terhadap e dan 0,1 , karena itu:
|~| = ^]™™6•²| −˜, 1 0,1‖−˜, 1‖‖0,1‖ ³ = ^]™™6•²−0| 1
´1 + ‖˜‖ ³
Dan akhirnya diperoleh |tan ~ | = ‖˜‖.
Berdasarkan pernyataan diatas, maka:
| m0 − m| = |+m˜0− +m˜| > ¤|tan ~0 − tan ~ |
≥ ¤®|tan ~0 | − |tan ~ |®
= ¤|‖˜0‖ − ‖˜‖|
Karena
‖˜0− ˜‖ ≤ ‖˜‖ + ‖˜0‖ = 2‖˜‖ + ‖˜0‖ − ‖˜‖ ≤ |‖˜0‖ − ‖˜‖| + 2‖˜‖
Berdasarkan pertidaksamaan diatas diperoleh:
dengan m dan m0 adalah residual yang berhubungan dengan e dan e0
berkorespondensi dengan titik +m, Lm . Sekarang diperoleh jumlah ℎ residual kuadrat pertama dari sampel baru ‹0 yang berhubungan dengan ˜ yang
sebelumnya, dimana sekurang-kurangnya nilai ‡ /I[I ˆ ≥ ℎ dari
residual-residual ini menjadi sama seperti sebelumnya, yaitu kurang dari atau sama
dengan ℎc . Karena ˜0 berkorespondensi dengan ‹0 berdasarkan pernyataan ini diperoleh:
∑d L0− +0˜0 :/≤ ℎc
N (3.7)
Jika diasumsikan bahwa:
‖˜0− ˜‖ ≥ 2‖˜‖ + c 1 + √ℎ
¤
Maka untuk semua ^ di š memenuhi
| m0 − m| > ¤ ‖˜0− ˜‖ − 2‖˜‖ ≥ c 1 + √ℎ
Jadi,
| m0| ≥ | m0 − m| − | m| > c81 + √ℎ: − c = c√ℎ
Sekarang perhatikan bahwa ! − |š| ≤ ℎ − 1. Oleh karena itu, himpunan ℎ
dari +0, L0 harus terdiri sekurangnya satu dari +m, Lm , maka:
∑d L0− +0˜0 :/ ≥ m0 > ℎc
N (3.8)
Suatu kontradiksi. Ini menyebabkan bahwa
‖˜0− ˜‖ < 2‖˜‖ + c 1 + √ℎ
¤ < ∞
Untuk semua sampel ‹0.
Langkah kedua adalah mendapatkan pertidaksamaan sebaliknya yaitu
/∗ , ‹ ≤•‡
›œ• C ˆI €
Cara lain menginterpretasikan persamaan 3.5 adalah dengan mengasumsikan
bernilai terbatas jika nilainya lebih dari (! + , − 1) pengamatan dan tidak
terkontaminasi nilai dari h. Dimana ℎ menghasilkan nilai yang maksimum dari breakdown point. Di sisi lain, jumlah pengamatan yang tidak baik ! −|š| harus tetap kurang dari ℎ dan |š| − 1 ≥ ! − ℎ dan |š| − 1 ≥ ℎ − ,, yang
menghasilkan ℎ = ‡/ˆ + ‡[I ˆ. Pada umumnya, ℎ mungkin bergantung pada
beberapa proporsi trimming ~ , dengan menggunakan ℎ = 2! 1 − ~ 3 +
2~ , + 1 3~ atau ℎ = 2! 1 − ~ 3 + 1. Maka dengan breakdown point /∗
sama dengan proporsi ~. Untuk ~ mendekati 50%, maka akan didapatkan LTS estimator, sedangkan untuk ~ mendekati 0% maka diperoleh OLS estimator.
Suatu estimator LTS juga akan memenuhi sifat kecocokan yang tepat yang dinyatakan sebagai berikut:
Jika terdapat beberapa ˜ sedemikian hingga cendrung lebih dari ! + , − 1
dari suatu observasi yang memenuhiL = + ˜ secara tepat dan dalam posisi
umum, maka penyelesaian LTS sama dengan ˜ apapun bentuk observasinya.
LTS mempunyai kekonvergenan !DFC dengan efisiensi keasimptotikan terhadap distribusi normal.
Langkah-langkah penentuan estimasi dengan menggunakan LTS adalah sebagai berikut:
1. Bentuk ! − ℎ + 1 subsampel dengan tiap subsampel terdiri dari ℎ
observasi.
2. Setiap subsampel dihitung:
LM =1ℎ S L:/
d
N
⋮
LM /DdI = 1
ℎ S L:/
/
3. Hitung jumlah kuadrat dari tiap subsampel:
„( )= S·L:/− LM( )¸ d
N
⋮
„(/DdI )= S ·L:/− LM(/DdI )¸
/
( N/DdI )
4. Solusi yang dipilih adalah LM(9) yang memberikan nilai „(9) paling kecil.
3.2.Contoh Ilustrasi Kasus
Data yang digunakan dalam penelitian ini merupakan data sekunder dengan empat variabel bebas yaitu: blood clotting(+ ), prognostic index(+ ), enzyme function test (+ ), liver function test (+¹) dan survival time ( ), dengan jumlah data ! = 30 seperti pada tabel 3.1.
Tabel 3.1. Data Regresi Linear Berganda
No. » ¼½ ¼¾ ¼¿ ¼À No. » ¼½ ¼¾ ¼¿ ¼À
3.2.1. Estimasi Parameter Regresi Dengan Ordinary Least Square
Berdasarkan data pada tabel 3.1 maka akan ditentukan persamaan regresi linear berganda sebagai berikut:
= + + + + … + +
Dapat ditulis dengan notasi matrix yaitu:
= P +
Dengan P adalah suatu vektor kolom "-unsur dari penduga kuadrat
terkecil biasa parameter regresi dan adalah suatu vektor kolom ! + 1 dari
! residual.
Menduga parameter model regresi linear berganda menggunakan metode ordinary least square. Prosedur OLS biasa dilakukan dengan memilih nilai parameter yang tidak diketahui sehingga jumlah kuadrat kesalahan diperoleh ∑ sekecil mungkin, sehingga dapat dinyatakan
dengan:
S = S8 − P − P − P − ⋯ − P :
Berdasarkan perhitungan pada lampiran 2 dan 3 diperoleh
nilai-nilai yang akan disubsitusikan untuk memperoleh nilai-nilai P , P , P , P dan
P¹ ke dalam persamaan berikut:
∑ = ! P + P ∑ +P ∑ + P ∑ + P¹∑ ¹
∑ = P ∑ + P ∑ + P ∑ + P ∑ + P¹∑ ¹
∑ = P ∑ + P ∑ + P ∑ + P ∑ + P¹∑ ¹
∑ = P ∑ + P ∑ + P ∑ + P ∑ + P¹∑ ¹
∑ ¹ = P ∑ ¹ + P ∑ ¹ + P ∑ ¹ + P ∑ ¹ + P¹∑ ¹
Sehingga diperoleh persamaan sebagai berikut:
6.179 = 30 P + 178,2 P + 1.976 P + 2.259 P + 81,42 P¹
541.877 = 2.259 P + 13.430,6P + 151.311 P + 185.761P + 6.479,03P¹ 20.582,08 = 81,42 P + 517,636 P + 5.538,47P + 6.479,03 P + 252,292 P¹
Berdasarkan persamaan yang telah dijabarkan maka diperoleh persamaan regresi linear berganda yaitu:
h = −682 + 37,2 − 5,42 + 3,80 − 8,8 ¹
3.2.2. Menghitung Nilai Residual
Nilai residual dapat dihitung dengan mengurangkan variabel terikat
terhadap variabel penduga. Perhitungan dapat dilihat pada lampiran 4.
Nilai residual yang distudenkan yaitu:
p =
•´1 − ℎ ≈ p/D[D
Dengan:
• =/D[∑
= D¹ 201.057,033
• = 7.740,696
= √7.740,696
• = 87,981
dimana : ℎ = [
/ =
.¹= 0,26
Maka diperoleh nilai p:
p = tB
j´ DdBB
= tB
= tB
ÈË,ÊÇ
Dengan memasukkan nilai residualnya maka diperoleh p sampai
dengan p¹ sebagai berikut:
0.447; 0,101; 0,430; 0,371; 0,977; 0,630; 0,716; 0,587; 0,365; 0,976; -0,567; -0,400; 0,545; -0,300; 0,483; -0,752; -0,751; 1,748; -0,734; -0,269; 0,023; 4,071; 0,399; 0,830; -0,150; -0,026; -2,674; 0,442; -0,516; -0,564
Berdasarkan nilai = 0,766 yang artinya hanya 76,6% variabel bebas , , dan ¹ yang mempengaruhi variabel terikat .
Kesimpulan
Jika p > pd |l/Ì dianggap sebagai data pencilan. Dimana pd |l/Ì=
pÍ,/D[D = p , Ë. D¹D = p , Ë. Ë= 1,699. Maka data yang mengandung pencilan yaitu:
• Pengamatan ke-18 dengan 1,748 > 1,699
• Pengamatan ke-22 dengan 4,071 > 1,699
• Pengamatan ke-27 dengan ±2,674 > 1,699
3.2.3. Uji Normalitas Dari Residual
Hipotesis:
e = Sampel berasal dari populasi yang berdistribusi normal
e = Sampel tidak berasal dari populasi yang berdistribusi normal
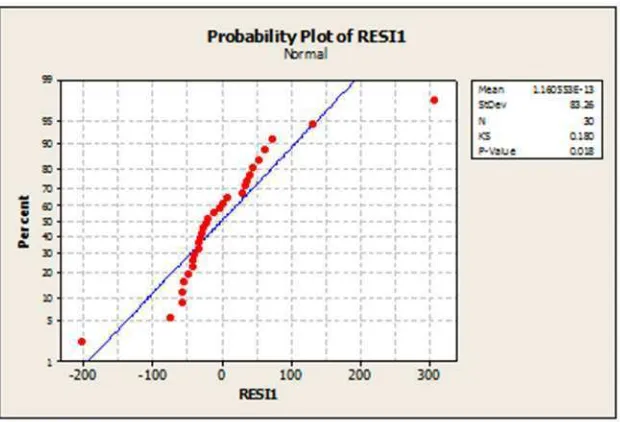
Gambar 3.1 Normal Plot dari Residual Persamaan
Residual yang dihasilkan oleh persamaan h = −682 37,2 5,42 3,80 - 8,8 ¹ tidak berdistribusi normal dimana terdapat titik yang menjauh dari garis regresinya pada Gambar 3.1 dimana titik
tersebut merupakan pencilan pada himpunan data. Berdasarkan uji normalitas tidak terpenuhi karena nilai --value-nya 0,018 lebih kecil dari
nilai ~ yaitu 0,05. Oleh karena itu persamaan yang diperoleh tidak dapat
digunakan karena tidak memenuhi asumsi metode OLS yaitu asumsi uji normalitas.
3.2.4. Uji Asumsi Multikolinearitas
Pengujian selanjutnya adalah uji multikoliniearitas sebagai uji asumsi yang perlu dipenuhi dalam regresi berganda.
Hipotesis
e = model regresi memiliki masalah multikolinearitas e = model regresi tidak memiliki masalah multikolinearitas
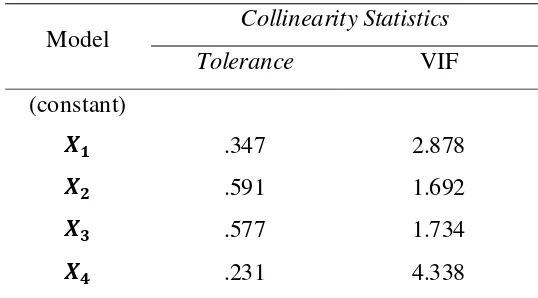
Tabel 3.3 Nilai Tolerance dan VIF
Model Collinearity Statistics Tolerance VIF (constant)
¼½ .347 2.878
¼¾ .591 1.692
¼¿ .577 1.734
¼À .231 4.338
Intepretasi Data
Dari tabel 3.3 terlihat bahwa variabel nilai tolerance nya adalah .347 dan VIF nya adalah 2.878, nilai tolerance nya adalah .591 dan VIFnya adalah 1.692, nilai tolerance nya adalah .577dan nilai VIFnya 1.734 dan
¹ nilai tolerance nya .231 dan VIFnya 4.338.
Kesimpulan
Dari tabel 3.3 terlihat bahwa semua variabel bebas mempunyai nilai tolerance lebih dari 0,1 dan memiliki nilai VIF kurang dari 10 sehingga bisa diduga bahwa antar variabel bebas tidak terjadi persoalan multikolinearitas. Untuk itu pada penelitian ini digunakan semua variabel prediktor untuk pemodelan. Karena antar variabel tidak mengandung multikolinearitas maka langkah selanjutnya yaitu pendeteksian pencilan.
3.2.5. Deteksi Pencilan
Pada penelitian ini, untuk mendeteksinya digunakan scatter plot, metode
leverage values, discrepancy (externally studientized residual) dan metode
DfFITS (difference in fit residual).
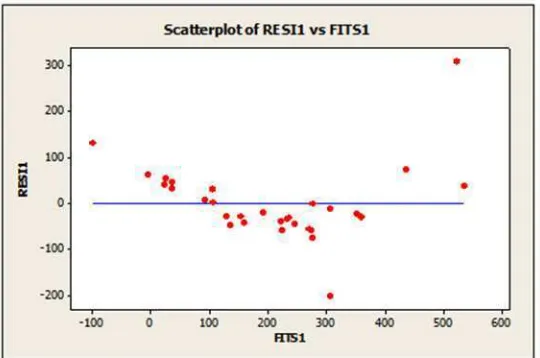
1. Scatter Plot
Gambar 3.1.1Scatter Plot antara Residual ( ) dan nilai prediksi
2. Leverage
Leverage value disebabkan adanya data pencilan pada variabel bebas (independent). Deteksi yang digunakan adalah dengan melihat nilai ℎ dan dengan membandingkan nilai cutoffnya. Data ℎ yang lebih besar dari cutoff nya merupakan pencilan. Nilai centroid (mean) variabel bebas dan nilai ℎ yang melebihi nilai cutoff ([I )
/ dengan ,
merupakan banyaknya variabel bebas dan ! adalah banyaknya data.
0,40 0,35 0,30 0,25 0,20 0,15 0,10 0,05 300 200 100 0 -100 -200 HI1 R E S I1
Scatterplot of RES I1 vs HI1
Gambar 3.1.2Scatter Plot antara Leverage(ℎ ) dan nilai prediksi ( )
3. Discrepancy
Penentuan nilai pencilan berdasarkan nilai Externally studientized residuals berdasarkan penentuan nilai cutoffnya yang mengikuti distribusi pdengan o = ! - , - 1. Jika nilai p lebih besar dari nilai pTm}Vn dengan derajat kepercayaan ~, maka data tersebut memiliki nilai discrepancy yang besar dan dikategorikan sebagai pencilan. Untuk data pada tabel 3.1 nilai pTm}Vn dengan derajat kepercayaan ~ =0.05 adalah ±1.7081. Nilai discrepancynya adalah data ke-18, 22 dan 27 dengan nilai Externally studientized residuals masing-masing adalah 1.7836, 6.4455 dan -2.5748 yang lebih besar dari nilai pTm}Vn.
600 500 400 300 200 100 0 -100 6 4 2 0 -2 tITS1 T R E S 2
Scatterplot of TRES2 vs tITS1
Dari plot pda gambar 3.1.2 dapat dilihat bahwa terdapat data pencilan yang berpengaruh pada variabel Y. Hasil pendeteksian data diperoleh menggunakan software MINITAB dan pendeteksian terlampir pada lampiran 5.
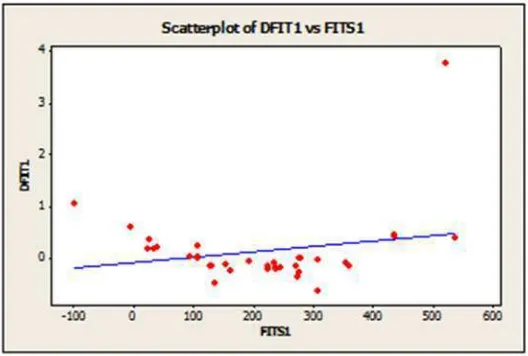
4. Metode DfFITS (Difference in fit Standardized)
Deteksi pencilanselanjutnya adalah melihat nilai DfFIT (Difference in fit Standardized). Sebelumnya akan disajikan gambar scatter plot yang menyajikan DfFITS dan variabel Unstandartized Predicted Value.
Gambar 3.1.4Scatter Plot antara Difference in fit standartized( ) dan nilai Residual ( )
Dari plot pada gambar 3.1.4 menunjukan bahwa ada titik yang menjauh dari titik lainnya, artinya terdapat data yang teridentifikasi sebagai pencilan. Maka perlu pengecekan data. Selanjutnya pada hasil pengolahan data menggunakan metode DfFITS untuk masing-masing data seperti pada lampiran. Dengan ketentuan jika nilai DfFITS masing-masing
data yang lebih dari 2u[
/ maka dikategorikan sebagai pencilan. Batas nilai
penentuan berdasarkan DfFITS f 0,7303 merupakan data pencilan. Dari
dilakukan analisis regresi menggunakan metode yang robust untuk data yang menggandung pencilan, agar hasil regresi yang dihasilkan lebih tepat dan efisien.
Langkah selanjutnya adalah melakukan analisis regresi untuk mendapatkan nilai estimasi parameter dari data tersebut menggunakan metode robust Least Trimmed Square (LTS).
3.2.6. Estimasi Least Trimmed Square (LTS)
Mengestimasi mengguanakan metode robust least trimmed square (LTS) memerlukan beberapa iterasi untuk mendapatkan model terbaik. Pada iterasi pertama diperoleh persamaan model regresi linear berganda dengan
menggunakan metode OLS adalah h = −682 + 37,2 - 5,42 3,80 -8,8 ¹ dan nilai residualnya adalah ∑dN =201.057,033.
Karena ℎ = ‡ ˆ + ‡(¹I )ˆ = 17,5 ≈ 18 data, maka pada iterasi
selanjutnya data yang digunakan sebanyak 18 data dengan mengurutkan nilai residual dari terkecil. Estimasi menggunakan bantuan software MINITAB 15,SPSS 21 dan Microsoft Excel dapat dilihat pada lampiran 7.
Selanjutnya dilakukan iterasi ke-2 karena pada iterasi pertama masih terdapat pencilan pada himpunan data. Iterasi ke-2 terdiri dari 18 data diperoleh model regresi linear bergandanya adalah h = −628 + 40,4 5,13 2,94 10,5 ¹ dan ∑dN =9.794,411 . Berdasarkan data pada lampiran 8 terlihat bahwa nilai residual pada iterasi ke-2 lebih baik dari nilai residual pada iterasi pertama. Iterasi ke-2 merupakan iterasi terakhir. Hal ini dikarenakan tidak terdapat pencilan pada iterasi selanjutnya.
Tabel 3.4. Hasil iterasi least trimmed square (LTS)
Iterasi ? ℎ P(/) P(/) P(/) P(/) P¹(/) S
d
N
1 30 18 -682 37,2 5,42 3,80 8,8 201.057,033 2 18 12 -628 40,4 5,13 2,94 10,5 9.794,411
Dari tabel 3.4. terlihat bahwa ∑dN terkecil adalah pada iterasi
ke-2. Artinya bahwa model regresi linear berganda yang paling baik yang diperoleh dengan metode Least Trimmed Square (LTS) adalah model
h = −682 + 40,4 + 5,13 + 2,94 + 10,5 ¹
3.2.7. Uji Parameter LTS Serentak
Uji parameter serentak digunakan untuk mengetahui ada tidaknya
pengaruh variabel terikat terhadap variabel bebasnya. Hipotesis
[image:30.595.131.495.502.608.2]e ∶ = = = = ¹= 0 e : ∃ ≠ 0; dimana = 1,2,3,4
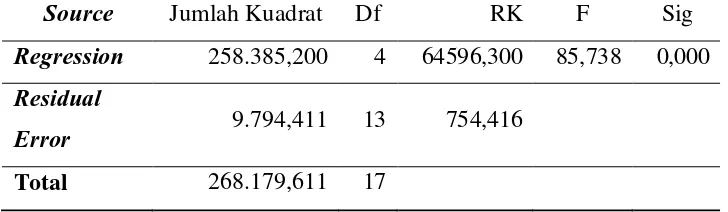
Tabel 3.5. Analisis Variansi LTS
Source Jumlah Kuadrat Df RK F Sig
Regression 258.385,200 4 64596,300 85,738 0,000
Residual
Error 9.794,411 13 754,416
Total 268.179,611 17
Taraf signifikansi: ~ = 0,05
Uji statistik
Kriteria Uji
• Tolak e jika d |l/Ì> (0.05: ,: ! − , − 1)
• Tolak e jika nilai signifikasi < ~
Keputusan
Diperoleh nilai d |l/Ì= 85,738 dan (0.05:,: ! − , − 1) = 3,26. Karena d |l/Ì> (0.05:,: ! − , − 1), dengan demikian e ditolak.
Kesimpulan
Karena e ditolak maka dapat disimpulkan bahwa e diterima dengan e : ∃ ≠ 0; dimana = 1,2,3,4 yang berpengaruh terhadap
model. Berdasarkan tabel 3.5 terlihat bahwa nilai signifikan adalah 0,00 < 0,05 yang artinya bahwa variable bebas memberikan pengaruh secara serentak pada model.
3.2.8. Uji Parsial Parameter LTS
Uji parsial parameter dilakukan untuk mengetahui pengaruh masing-masing variabel bebas terhadap variabel terikatnya.
Hipotesis
[image:31.595.143.518.578.748.2]e : = 0; untuk suatu = 1,2,3,4 e : ∃ ≠ 0; untuk suatu = 1,2,3,4
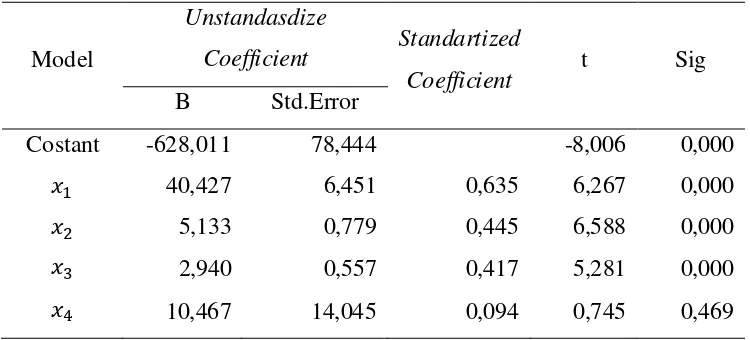
Tabel 3.6. Coefficient LTS
Model
Unstandasdize
Coefficient Standartized
Coefficient t Sig B Std.Error
Costant -628,011 78,444 -8,006 0,000
+ 40,427 6,451 0,635 6,267 0,000
+ 5,133 0,779 0,445 6,588 0,000
+ 2,940 0,557 0,417 5,281 0,000
Taraf signifikansi: ~ = 0,05
Uji statistik
pd |l/Ì=
P
u•po 78 P :
dengan
P adalah estimasi parameter
•po 78 P : adalah estimasi standar deviasi dari
Kriteria Uji
e ditolak jika ®pd |l/Ì® > pÍ/ ,Ó atau tolak e jika nilai signifikansi kurang dari ~.
Keputusan
Berdasarkan tabel 3.6 diperoleh nilai signifikan , , dan
adalah 0,000 dan nilai signifikan ¹ adalah 0,469.
Kesimpulan
Berdasarkan nilai signifikan pada keputusan yang diperoleh parameter memiliki nilai signifikannya 0,00 < 0,05 maka e ditolak. Parameter , dan memiliki nilai signifikan 0,00 < 0,05 maka e
ditolak atau e diterima dimana , , ≠ 0 artinya parameter , dan
mempunyai pengaruh terhadap variabel terikat . Sedangkan untuk
parameter ¹ memiliki nilai signifikan 0,469 > 0,05 maka e diterima
dimana ¹= 0, artinya ¹ tidak memiliki pengaruh terhadap variabel terikat. Jadi variabel bebas + , + , + berpengaruh secara parsial terhadap
model regresi linear berganda. Sedangkan variabel bebas +¹ tidak
BAB 4
KESIMPULAN DAN SARAN
4.1. Kesimpulan
Mengestimasi parameter regresi linear berganda dapat menggunakan metode Ordinary Least Square (OLS) dimana metode OLS harus memenuhi setiap asumsi dari Best Linear Unbiased Estimator (BLUE). Proses pengestimasian yang tidak memenuhi asumsi BLUE karena adanya pencilan dilihat dari data tidak berdistribusi normal maka metode OLS tidaklah efisien untuk digunakan. Cara mengatasinya dengan menggunakan metode robust least trimmed square dimana nilai-nilai konstanta dan koefisien dari least trimmed square tidak terpengaruh akan adanya data pencilan karena least trimmed square memiliki breakdown point sampai 50%. Dengan breakdown point /∗ sama dengan proporsi ~ untuk ~ mendekati 50%, maka akan didapatkan LTS
estimator, sedangkan untuk ~ mendekati 0% maka diperoleh OLS estimator.
Sifat metode LTS, jika terdapat beberapa ˜ sedemikian hingga cendrung lebih
dari (! + , − 1) dari suatu pengamatan yang memenuhi L = + ˜ secara
tepat dan dalam posisi umum, maka penyelesaian LTS sama dengan ˜ apapun
bentuk pengamatannya. LTS mempunyai kekonvergenan !DFC dengan efisiensi
keasimptotikan terhadap distribusi normal. Estimasi menggunakan least trimmed square menghasilkan persamaan yang lebih baik dilihat berdasakan jumlah kuadrat total yang memiliki nilai semakin kecil. Semakin kecil nilai jumlah kuadrat totalnya maka akan semakin baik garis regresi yang diperoleh.
4.2.Saran
BAB 2
TINJAUAN PUSTAKA
2.1. Regresi Linear Berganda
Regresi linear berganda adalah regresi dimana variabel terikatnya
dihubungkan atau dijelaskan dengan lebih dari satu variabel bebas
, , …, dengan syarat variabel bebas masih menunjukkan hubungan
yang linear dengan variabel terikat. Hubungan fungsional antara variabel terikat dengan variabel bebas , , … , secara umum dapat
dituliskan sebagai berikut:
• Untuk populasi
= + + + + … + + (2.1)
• Untuk sampel
= + + + + … + + (2.2)
di mana:
= 1,2, ⋯ , !
= variabel terikat pada pengamatan ke-
, , … , = variabel bebas pada pengamatan ke-"variabel ke- , , , … , = parameter regresi
= nilai kesalahan (error)
Apabila terdapat sejumlah ! pengamatan dan " variabel bebas maka
untuk setiap pengamatan atau responden mempunyai persamaannya seperti berikut:
= + + + + … + +
= + + + + … + +
= + + + + … + +
⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮ ⋮
Apabila persamaan regresi linear berganda untuk setiap pengamatan dinyatakan dengan notasi matriks maka menjadi:
$ % % % & ⋮ ' ( ( ( ) = $ % % % &11 1 ⋮
1 ⋮ ⋮ ⋮
⋯ ⋯ ⋯ ⋱ ⋯ ⋮ '( ( ( ) $ % % % & ⋮ ' ( ( ( ) + $ % % % & ⋮ ' ( ( ( ) atau
= + (2.3)
dengan:
adalah vektor variabel terikat berukuran ! + 1.
adalah matriks variabel bebas berukuran ! + , − 1 . adalah vektor parameter berukuran , + 1.
adalah vektor error berukuran ! + 1.
Menurut Gujarati penggunaan analisis regresi linear berganda tidak terlepas dari asumsi-asumsi error berikut:
1. Asumsi = 0 menyatakan bahwa rata-rata atau nilai harapan vektor
setiap komponennya bernilai nol. Dengan adalah vektor kolom ! + 1 dan
0 adalah vektor nol. Maka = 0, berarti:
$ % % % & ⋮ /'( ( ( ) = $ % % % & ⋮ / ' ( ( ( )
= 0 (2.4)
2. Asumsi 0 1 merupakan suatu notasi yang mencakup 2 hal, yaitu
varian dan kovarian kesalahan pengganggu.
0 = $ % % % & ⋮ /'( ( ( )
2 , , , ⋯ , /3 (2.5)
Dimana 0 adalah transpose dari vektor kolom , dengan melakukan
= 0 = 4 ⋮ / ⋮ / ⋯ ⋯ ⋮ ⋯ / / ⋮ /
5 (2.6)
Dengan menggunakan nilai harapan untuk setiap unsur dalam
matriks (2.6) sehingga diperoleh:
0 = 4 ⋮ / ⋮ / ⋯ ⋯ ⋮ ⋯ / / ⋮ /
5 (2.7)
Karena adanya asumsi tentang homoskedastisitas, yaitu bahwa setiap kesalahan pengganggu mempunyai varian yang sama = 1 , untuk semua dan tidak ada korelasi serial artinya antar kesalahan pengganggu
yang satu dengan yang lainnya bebas, "678 9: = 0.
0 = 410 10 ⋯⋯ ⋮
0 0⋮ ⋯⋱
0 0 ⋮ 1 5
= 1 <
1 0 ⋯ 0 1 ⋯
⋮
0 0⋮ ⋯⋱
0 0 ⋮ 1
= = 1 (2.8)
Dengan adalah matriks identitas berukuran ! + !. Matriks (2.7)
dan (2.8) disebut matriks varians-kovarians dari kesalahan penggangu .
Unsur pada diagonal utama dari matrik (2.7) memberikan varians dan unsur diluar diagonal utama memberikan kovarian, berdistribusi normal
dengan mean nol dan varians konstan 1 . ~? 0, 1
Pada rumus parameter regresi dan dalam regresi linear
sederhana dan parameter regresi , , ,⋯, pada regresi linear
berganda, diduga secara berturut-turut dengan , dan , , ,⋯,
2.2.Koefisien Determinasi Berganda
Menyatakan keeratan hubungan antara variabel terkat dan variabel
bebas , , ⋯ , / pada regresi linear berganda akan dinyatakan dengan
koefisien determinasi berganda. Besarnya koefisien determinasi berganda
dari persamaan regresi linear berganda yaitu:
= 1 −∑∑
= ∑ ∑− ∑
dimana:
∑ = ∑ − − − ⋯ −
= ∑ − − − ⋯ − karena = − −
− ⋯ −
= ∑ − ∑ − ∑ −⋯ − ∑
= ∑ ; (dimana ∑ = ∑ = ⋯ = ∑ = 0
= ∑ − − − ⋯ −
= ∑ − ∑ − ∑ − ⋯ − ∑
= ∑ ABCD ∑ABCDEF∑GFBABDEC∑GCBABD⋯DEB∑ GHBAB
∑ABC
= EF∑GFBABIEC∑ GCBABI⋯∓∑ GHBAB ∑ ABC
dimana nilai berada dalam interval 0 ≤ ≤ 1.
Adapun semakin besar nilai artinya semakin baik suatu garis
regresi linear digunakan sebagai suatu pendekatan. Dan apabila nilai sama
dengan 1 (satu) berarti pendekatan tersebut semakin baik.
2.3. Residual
Residual atau sisaan dalam regresi linear sederhana merupakan selisih dari nilai prediksi dengan nilai yang sebenarnya atau = L − LM . Namun
penggunaan jarak = L − LM tidaklah memuskan. Dengan meminimumkan
diperoleh hasil yang umum seperti berikut :
∑ = ∑/ L − LM
N /
Jika nilai pengamatan terletak dalam garis regresi maka nilai residualnya sama dengan nol. Jadi, jika total jarak atau nilai mutlak dari residual sama dengan nol ∑ | | = 0/N artinya semua nilai pengamatan
berada pada garis regresi. Semakin besar nilai residualnya maka garis regresi semakin kurang tepat digunakan untuk memprediksi. Yang diharapkan adalah total residualnya kecil sehingga garis regresi cukup baik untuk digunakan.
2.4. Metode Ordinary Least Square (OLS)
Metode Ordinary Least Square (OLS) merupakan suatu metode untuk mendapatkan garis regresi yang baik yaitu sedekat mungkin dengan datanya sehingga menghasilkan prediksi yang baik (Widarjono, 2005).
Metode OLS harus memenuhi asumsi-asumsi yang ada dalam proses pengestimasian parameter sehingga hasil estimasinya memenuhi sifat Best Linear Unbiased Estimator (BLUE). Pada dasarnya metode OLS meminimumkan jumlah kuadrat error.
P = $ % % % % &PP
P ⋮ P '(
( ( ( )
⇒ = P + ⇒ = − P (2.10)
Dengan P adalah suatu vektor kolom "-unsur dari estimasi OLS parameter regresi dan adalah suatu vektor kolom ! + 1 dari ! residual.
Untuk mengestimasi parameter model regresi linear berganda digunakan metode OLS. Prosedur metode OLS dilakukan dengan memilih nilai parameter yang tidak diketahui sehingga jumlah error diperoleh ∑ sekecil mungkin, sehingga dapat dinyatakan dengan:
$ % % % & ⋮ /'( ( ( ) = $ % % % & ⋮ /' ( ( ( ) − $ % % % &11 1 ⋮
1 /⋮ ⋮/ ⋮/
= − − − − ⋯− ∑/
N = ∑/N − − − − ⋯ − (2.11)
Kemudian, untuk menentukan , , , ⋯ , dengan meminimumkan
jumlah kuadrat residualnya ∑/N secara parsial terhadap P , P , P , ⋯, P
dan samakan dengan 0 maka dapat dituliskan: R ∑
R P = 2 S8 − P − P − P − ⋯ − P : −1 = 0
/
N R ∑
R P = 2 S8 − P − P − P − ⋯− P : − = 0
/
N R ∑
R P = 2 S8 − P − P − P − ⋯− P : − = 0
/
N ⋮
R ∑
R P = 2 S8 − P − P − P − ⋯ − P : − = 0
/
N
Jika persamaannya disederhanakan dan disusun maka akan menjadi:
! P + P ∑ +P ∑ + ⋯ + P ∑ = ∑
P ∑ + P ∑ + P ∑ + ⋯ + P ∑ = ∑
P ∑ + P ∑ + P ∑ + ⋯ + P ∑ = ∑ (2.12)
⋮
P ∑ + P ∑ + P ∑ + ⋯ + P ∑ = ∑
dimana persamaan 2.12 disebut sebagai persamaan normal
Dengan menjumlahkan persamaan = P + P + P + ⋯ + P untuk seluruh pengamatan ! memberikan persamaan pertama dalam persamaan (2.12) kemudian mengalikannya dengan pada kedua sisinya dan
menjumlahkan untuk seluruh ! maka dihasilkan persamaan kedua. Begitu
Dinyatakan dalam bentuk matriks, persamaan normal akan menjadi:
$ % % % & !∑
∑ ⋮ ∑ ∑ ∑ ∑ ⋮ ∑ ∑ ∑ ∑ ⋮ ∑ ⋯ ⋯ ⋯ ⋮ ⋯ ∑ ∑ ∑ ⋮ ∑ '( ( ( ) $ % % % % & PP
P ⋮ P '(
( ( ( ) = $ % % %
& 1 1 ⋯⋯
⋮ ⋮ ⋯⋮ ⋯ 1 ⋮ /' ( ( ( ) $ % % % & ⋮ /' ( ( ( )
T P = T (2.13)
Persamaan (2.13) diperoleh dari menurunkan persamaan mariks terhadap P,
sehingga diperoleh: U VWV
UEX = −2 T + 2 T P , kemudian samakan hasil dengan 0, sehingga
diperoleh:
−2 T + 2 T P = 0
2 T P = 2 T
T P = T ; kali dengan T D sehingga diperoleh
T D T P = T D T
P = T D T
P = T D T (2.14)
Dengan T D = 4
! ∑ / ⋯ ∑ / ∑ / ⋯ ⋮ ∑ / ⋮ ∑ / / ⋯ ⋯ ∑ ∑ / / ⋮ ∑ / 5
Untuk menunjukkan bahwa ∑/N minimum, maka hasil turunan
pertama dari jumlah kuadrat residualnya harus diturunkan sekali lagi sehingga menghasilkan turunan kedua, dan nilainya harus lebih besar dari nol. Maka dapat dituliskan:
R ∑
R P =
R R PY
R8 T − 2 PT T + PT T P:
R P Z
= R PR 8−2 T + 2 T P:
Dipastikan bahwa turunan kedua dari ∑/N terhadap P haruslah bernilai positif.
Sehingga nilai ∑/N akan minimum apabila nilai 2 T lebih besar dari nol.
Karena matriks T adalah turunan positif dengan semua unsur diagonalnya
berbentuk kuadrat, maka turunan kedua dari ∑/N terhadap P bernilai positif
yang artinya P = T D T minimum.
2.5.Pencilan (Outliers)
Pencilan adalah suatu data yang menyimpang dari sekumpulan data yang lain. Pencilan diartikan pula sebagai pengamatan yang tidak mengikuti sebagian besar pola dan terletak jauh dari pusat data. (Ferguson, 1961)
Pengamatan yang dikategorikan sebagai pencilan mempunyai nilai residual yang relatif besar untuk ukuran residual pada ketepatan pengamatan. Diasumsikan bahwa hubungan antara dua variabel + dan L diperkirakan
dengan garis lurus. Berdasarkan model regresi linear berganda pada persamaan (2.1) dengan dan , , ⋯ , adalah parameter regresi untuk diestimasi.
Nilai kesalahan ( ) yang tidak diperhatikan dan diasumsikan berdistribusi
normal.
2.5.1. Jenis Pencilan
Model regresi menggambarkan hubungan dari beberapa variabel bebas
( , , ⋯ , / dengan variabel terikat ( , , ⋯ , / . Model regresi
diperoleh dengan menggunakan metode estimasi ordinary least square (OLS). Metode OLS didasarkan pada asumsi bahwa terjadinya kesalahan pada model yang dihasilkan yang seharusnya berdistribusi normal. Karena dengan residual berdistribusi normal metode OLS memberikan estimasi parameter yang optimal bagi model regresi.
diperoleh menjadi tidak efisien. Keberadaan pencilan pada data mungkin terdapat pada variabel bebasnya ( ) ataupun variabel terikatnya ( ).
Pencilan pada arah-L akan memberikan nilai residual yang sangat
besar (positif atau negatif). Hal ini disebabkan karena data pencilan mempunyai jarak yang sangat besar terhadap garis OLS. Sedangkan data pencilan pada arah-+ memberikan pengaruh yang sangat besar pada estimator metode OLS karena pencilan pada arah-+ disebut sebagai titik
leverage.
Secara umum, suatu pengamatan + ,L dikatakan suatu titik
leverage ketika + terletak jauh dari sebagian besar data pengamatan dalam sampel. Sebagai catatan, suatu titik leverage tidak memasukkan nilai L ke dalam perhitungan, jadi titik + , L tidak harus menjadi
pencilan pada regresi. Ketika + , L dekat terhadap garis regresi yang
ditentukan dengan sebagian besar data, maka hal tersebut dapat diasumsikan sebagai titik leverage yang baik. Oleh karena itu, untuk menyimpulkan bahwa + , L adalah suatu titik leverage hanya merujuk pada kepotensialnya besar mempengaruhi koefisien-koefisien regresi (karena pencilannya hanya + ). Titik + ,L tidak selalu dilihat sebagai
penyebab pengaruh yang besar terhadap koefisien-koefisien regresi, karena bisa saja titik + , L tepat pada garis yang ditentukan
kecendrungannya dengan sejumlah besar himpunan data lainnya.
Regresi linear berganda + , + , ⋯ , + terletak pada suatu ruang berdimensi ,. Suatu titik leverage tetap didefinisikan sebagai suatu titik 8+ , ⋯ , + [, L : dimana 8+ ,⋯ , + [: merupakan titik-titik yang terpisah dari himpunan data. Suatu titik leverage yang berpotensial berpengaruh besar pada koefisien regresi OLS, bergantung pada nilai aktual dari L ,
2.5.2. Deteksi Pencilan
Langkah awal yang harus dilakukan dalam mendeteksi pencilan yaitu dengan melihat kemungkinan bahwa pencilan merupakan data yang
berpengaruh (terkontaminasi). Data pencilan dapat dikenali dengan memeriksa data mentahnya (raw) secara visual atau dari diagram pencar pada variabel bebas (Jacob, 2003: 394). Jika terdapat lebih dari dua variabel bebas, beberapa pencilan akan sangat sulit untuk dideteksi dengan pemeriksaan visual. Oleh karena itu, dibutuhkan bantuan lain pada pemeriksaan visual yang dapat membantu dalam pendeteksian pencilan.
Dalam statistik, data pencilan harus dilihat terhadap posisi dan
sebaran data yang lainnya sehingga akan dievaluasi apakah data pencilan tersebut perlu dihapus atau tidak. Ada berbagai macam metode yang dapat digunakan untuk mendeteksi adanya data pencilan yang berpengaruh dalam koefisien regresi diantaranya adalah metode grafis, boxplot, scatter plot, leverage values, discrepancy, cook’s distance, DfBETA(s), Goodness of FIT,dan metode DfFITS. Namun pada skripsi ini pendeteksian pencilan yang akan dibahas menggunakan scatter plot, metode leverage values, discrepancy, dan metode DfFITS .
2.5.2.1. Leverage Values
Pendeteksian dengan menggunakan leverage values hanya menggambarkan pengamatan yang terjadi pada variabel bebas. Leverage values menginformasikan seberapa jauh pengamatan tersebut dari nilai mean himpunan data variabel bebas. Jika hanya terdapat satu variabel bebas, leverage dapat dituliskan seperti:
\ 7 ]^_ = ℎ =/+ GBD`aC
∑bC (2.15)
meannya. Jika pengamatan ke- bernilai cb, maka bentuk kedua dari persamaan (2.15) akan 0 dan ℎ akan memiliki nilai kemungkinan yang
minimum
/. Misalkan pengamatan ke- nilai pada jauh dari cb, maka nilai leverage akan naik. Nilai maksimum dari ℎ adalah 1 nilai mean dari leverage untuk !-pengamatan dalam suatu sampel adalah cdBB= I
/ , dengan " merupakan jumlah variabel bebas.
Penjabaran perhitungan leverage yang dijelaskan merupakan hitungan untuk pengamatan satu variabel bebas, dapat digeneralisasi untuk pengamatan dengan variabel bebas lebih dari satu. Untuk pengamatan dengan banyak variabel bebas, hal yang menarik adalah seberapa jauh nilai-nilai untuk setiap " variabel untuk pengamatan ke- , , , ⋯, ,
dari centroid variabel bebas. Centroid merupakan mean dari data, c , c , ⋯, c . Perhitungan nilai ℎ untuk pengamatan ini dengan mengguanakan persamaan:
e = 0 D 0 (2.16)
dengan e merupakan matriks ! + ! dan merupakan matriks ! + " + 1 . Dimana ! merupakan banyaknya data, dan " merupakan jumlah koefisien ( variabel bebas ditambah 1 sebagai konstanta . Diagonal
dari e berisi nilai leverage. Jadi, leverage untuk pengamatan ke- , ℎ merupakan nilai dari baris ke- dan kolom ke- dari e.
Penentuan nilai yang memiliki leverage yang besar didasarkan pada nilai cutoff. Nilai ℎ yang melebihi nilai cutoff dideteksi sebagai pencilan. Adapun nilai cutoff yang telah ditentukan menurut Jacob Cohen adalah I
/ untuk data yang jumlahnya ! > 15, sedangkan untuk data
yang jumlahnya ! ≤ 15 digunakan cutoff I
2.5.2.2. Discrepancy
Mengidentifikasi pencilan menggunakan discrepancy yang banyak digunakan adalah dengan Externally Studientized Residuals. Externally studientized residuals dengan memisalkan jika data pencilan sebuah pengamatan dihapuskan dari himpunan data. Misalkan h nilai yang
merupakan prediksi pengamatan ke- , tetapi pengamatan ke- dihapuskan
dari himpunan data. Pencilan berkontribusi secara substansial terhadap estimasi variansi residual sekitar garis regresi dan disimbolkan dengan c iVj klmn . Sedangkan c iVj klmn untuk variansi residual dengan pengamatan ke- yang merupakan pencilan dihapuskan dari himpunan data. Misalkan o sebagai perbedaan antara data asli, , dengan nilai
prediksi untuk pengamatan ke- yang berasal dari himpunan data dengan
pengamatan ke- yang dihapuskan yaitu o = − h . Externally studientized residuals untuk pengamatan ke- , p dihitung dengan:
p = kB
qrsB (2.17)
dimana o merupakan nilai residual yang dihapuskan:
o = tB
DdBB (2.18)
dan nilai standar residual juga dapat dihitung dengan:
kB= u
`qvwxBsyz{ B
DdBB (2.19)
Jika persamaan (2.18) dan (2.19) dimasukkan kedalam persamaan (2.17) maka akan menjadi:
p = tB
u`qvwxBsyz{ B DdBB
(2.20)
nilai p > p|m}Vn dengan derajat kepercayaan ~ , maka data tersebut
memiliki nilai discrepancy yang besar dan dikategorikan sebagai pencilan.
2.5.2.3. Metode DfFITS
Difference fitted value FITS merupakan metode yang menampilkan nilai perubahan dalam harga yang diprediksi bilamana kasus tertentu dikeluarkan, yang sudah distandarkan. Perhitungan DfFITS di rumuskan sebagai berikut :
= p • dBB DdBB€
F
C (2.21)
dimana p adalah studentized deleted residual untuk pengamatan ke- dan ℎ adalah nilai pengaruh untuk kasus ke- dengan:
p = u•‚ƒ Dd/D D BB DtBCW
(2.22)
adalah residual ke- dan JKG adalah jumlah kuadrat galat.
Suatu data yang mempunyai nilai absolute DfFITS lebih besar dari 2u I/ maka didefinisikan sebagai pencilan, dengan " banyaknya variabel
bebas dan ! banyaknya observasi (Soemartini: 2007).
2.6. Regresi Robust
Regresi robust merupakan metode yang penting untuk menganalisis suatu himpunan data yang mengandung pencilan. Regresi robust digunakan untuk mendeteksi pencilan dan memberikan hasil yang resisten terhadap adanya data pencilan. Menurut Aunuddin 1999, regresi robust tujuannya untuk mengatasi adanya data ekstrim serta meniadakan pengaruhnya terhadap hasil pengamatan tanpa terlebih dahulu melakukan identifikasi.
a. Sama baiknya dengan metode ordinary least square ketika semua asumsi terpenuhi dan tidak terdapat titik data yang berpengaruh.
b. Dapat menghasilkan model regresi yang lebih baik daripada ordinary least square ketika asumsi tidak terpenuhi dan terdapat titik data yang berpengaruh.
c. Perhitungan cukup sederhana dengan melakukan iterasi sampai memperoleh estimasi terbaik yang mempunyai standar error parameter yang paling kecil ataupun konvergen ke nol.
2.7. Least Trimmed Square (LTS)
Estimasi least trimmed square adalah dengan high breakdown point yang dikenalkan oleh Roesseuw (1984). LTS merupakan suatu metode estimator parameter regresi robust untuk meminimumkan jumlah kuadrat h residual (fungsi objektif) dan sebagai metode alternatif robust untuk mengatasi kelemahan metode OLS, yaitu dengan menggunakan sebanyak ℎ ℎ ≤ ! .
„…Tq = S :/
d
N
di mana:
„…Tq : Estimasi least trimmed square
h : ‡/ˆ + ‡ [Inˆ
: kuadrat error yang diurutkan dari yang terkecil ke terbesar < < < … < < … < d < … < /
Jumlah h menunjukkan sejumlah subset data dengan kuadrat fungsi objektif terkecil. Nilai h pada persamaan diatas akan membangun breakdown point yang besar sebanding dengan 50%. Untuk mendapatkan nilai residual pada LTS, digunakan algoritma LTS menurut Rousseeuw dan Van Driessen
= 8 − P − P − P − ⋯ − P :
Setelah itu menghitung ∑dNŠ dengan ℎ = ‡/ˆ + ‡([In)ˆ pengamatan
dengan nilai terkecil. Tahapan-tahapan dilakukan sampai diperoleh nilai
residual terkecil dan konvergen.
2.8. Breakdown Point
Breakdown point dari suatu regresi estimator adalah salah satu cara yang dapat digunakan untuk mengukur ke-robust-an suatu estimator. Breakdown point merupakan proporsi minimal dari banyaknya pencilan dibandingkan seluruh data pengamatan. Salah satu regresi robust yang mempunyai breakdown point adalah regresi robust dengan metode Least Trimmed Square (LTS). Metode estimasi LTS mempunyai breakdown point 50%. Breakdown point 50% adalah breakdown point yang tinggi.
Definisi T adalah sebuah estimator, Z adalah sebuah sampel dari ! pengamatan dimana (‹) = P. Misalkan ‹0 bagian ‹ dimana Œ dari ! pengamatan yang mengandung pencilan. Bias maksimal yang menyebabkan data menjadi rusak yaitu
^•(Œ; , ‹) = sup ’W || (‹
0) − (‹)||
Maka breakdown point( /∗) dapat didefinisikan dengan
/∗( , ‹) = Œ ! ”Œ! ; ^• (Œ; , ‹) ^o^\^ℎ ! ! p •
Untuk OLS , dapat dilihat jika adanya pencilan cukup diperhatikan pada T untuk semua batas. Oleh karena itu, breakdown point sama dengan:
BAB 1
PENDAHULUAN
1.1. Latar Belakang
Regresi linear berganda merupakan salah satu metode statistik yang digunakan untuk memodelkan dan menyelidiki hubungan antara satu variabel terikat (dependent ) dengan dua atau lebih variabel bebas (independent ). Mendapatkan model regresi linear berganda dapat diperoleh dengan melakukan estimasi terhadap parameter-parameternya dengan menggunakan metode tertentu. Salah satu metode yang dapat digunakan untuk mengestimasi parameter-parameter adalah metode kuadrat terkecil (Ordinary Least Square/OLS). Metode OLS harus memenuhi asumsi-asumsi yang ada dalam proses pengestimasian parameter sehingga hasil estimasinya memenuhi sifat Best Linear Unbiased Estimator (BLUE). Beberapa asumsinya antara lain adalah residual harus berdistribusi normal, variansnya homogen dan tidak terjadi multikolonieritas. Apabila data tidak memenuhi salah satu asumsi misalnya disebabkan adanya pencilan, maka penduga OLS yang diperoleh menjadi tidak efisien.
Pencilan (outlier) adalah data yang tidak mengikuti pola umum. Pencilan disebabkan karena adanya sumber data yang berbeda dan error pada saat pengukuran dan pengumpulan data. Adanya pencilan dapat menggangu proses analisis data, sehingga dapat mengakibatkan varians menjadi besar dan interval kepercayaan memiliki rentang yang lebar. Jika terdapat pencilan maka OLS tidak akurat untuk mengestimasi parameter. Untuk mengatasi masalah data yang mengandung pencilan salah satu metode yang dapat digunakan adalah metode regresi robust.
besar data. Suatu estimator robust mempunyai kemampuan mendeteksi pencilan sekaligus menyesuaikan estimasi parameter regresi. Metode robust memiliki delapan macam metode yaitu M-Estimator, Least Trimmed Square (LTS), Scale Estimator, MM-Estimator, Least Mean Square Estimator, Weigth Estimator, L-Estimator dan Ridge Estimator.
Metode robust estimasi LTS memiliki kemampuan yang lebih baik dibandingkan dengan metode-metode lainnya karena mampu mengatasi pencilan yang disebabkan oleh variabel bebas maupun variabel terikatnya dengan menggunakan algoritma LTS yang lebih mudah. Metode LTS merupakan penaksir dengan high breakdown point. Dimana konsep dari high breakdown point yaitu untuk mengetahui kemampuan suatu penaksir dalam menghasilkan nilai taksiran yang resisten terhadap adanya pencilan dalam jumlah tertentu. Dalam proses estimasinya, LTS hanya akan memangkas sebaran data berdasarkan jumlah pencilan yang teramati sehingga menghasilkan fungsi objektif yang mengecil dan konvergen ke nol (0). Adapun tujuan yang ingin dicapai yakni mendapatkan nilai parameter model regresi linear berganda yang robust terhadap kehadiran pencilan. Metode LTS tidak membuang bagian data pencilan tetapi menemukan model fit dari himpunan data (Rousseeuw, 1984).
Menentukan metode yang lebih efisien ada berbagai kriteria yang bisa ditetapkan sebagai acuannya, namun pada penelitian ini akan dilihat dari kriteria nilai (koefisien determinasi) dan nilai residualnya. Jika nilai
besar atau mendekati 1 berarti variabel-variabel bebas memberikan hampir semua informasi yang dibutuhkan untuk memprediksi variansi variabel terikat sebaliknya jika nilai mendekati 0 maka semakin kecil (tidak baik) nilai
Peneliti akan mengkaji metode least trimmed square dalam proses mengestimasi parameter regresi linear berganda untuk mengetahui tingkat efisiensinya dengan judul tugas akhir yaitu “Kajian Metode Robust Least Trimmed Square (LTS) dalam Mengestimasi Parameter Regresi Linear Berganda Untuk Data Yang Mengandung Pencilan”.
1.2. Perumusan Masalah
Berdasarkan latar belakang yang telah diuraikan, permasalahan dalam penelitian ini adalah mengkaji metode robust Least Trimmed Square (LTS) dalam mengestimasi parameter pada model regresi linear berganda yang
datanya mengandung pencilan. Dengan menentukan efisiensi metode Least Trimmed Square (LTS) terhadap data yang mengandung pencilan. Metode LTS sebagai salah satu metode penduga parameter regresi robust terhadap data yang mengandung pencilan.
1.3.Batasan Masalah
Pada skripsi ini, untuk menghindari pemecahan masalah yang akan melebar maka batasan masalahnya adalah:
1. Hanya mengkaji metode robust least trimmed square dalam mengestimasi parameter regresi linear berganda untuk data yang mengandung pencilan. 2. Pengidentifikasian adanya pencilan hanya menggunakan metode leverage
values, discrepancy dan metode DfFITS.
1.4. Tujuan Penelitian
Berdasarkan permasalahan yang telah dirumuskan, tujuan dilakukannya penelitian adalah:
2. Mengetahui cara mengidentifikasi data pencilan dengan menggunakan leverage values, discrepancy dan metode DfFITS.
1.5. Manfaat Penelitian
Manfaat dari penelitian ini adalah:
1. Mengetahui efisiensi penggunan metode robust least trimmed square (LTS) dalam mengestimasi parameter regresi linear berganda untuk data yang mengandung pencilan.
2. Dapat mengetahui cara pengidentifikasian pencilan dengan menggunakan
metode leverage values, discrepancy dan metode DfFITS
1.6.Metodologi Penelitian
Dalam penelitian ini penulis melakukan studi literatur dan mencari bahan dari buku dan internet yang membahas mengenai metode robust least trimmed square, mengestimasi parameter regresi linear berganda untuk data yang mengandung pencilan dalam sebuah pengamatan. Adapun langkah-langkahnya adalah:
a. Mengkaji metode robust least trimmed square (LTS) dalam mengestimasi parameter regresi linear berganda.
b. Melakukan pengamatan terhadap data yang mengandung pencilan.
c. Melakukan estimasi parameter regresi linear berganda untuk data yang
mengandung pencilan dari hasil pengamatan.
KAJIAN METODE ROBUST LEAST TRIMMED SQUARE (LTS) DALAM MENGESTIMASI PARAMETER REGRESI LINEAR BERGANDA
UNTUK DATA YANG MENGANDUNG PENCILAN
ABSTRAK
Menentukan parameter regresi linear berganda dapat menggunakan metode Ordinary Least Square (OLS). Metode OLS harus memenuhi asumsi dari Best Linear Unbiased Estimator (BLUE) untuk menghasilkan model persamaan regresi linear berganda yang baik dimana dapat dilihat berdasarkan nilai residualnya (kuadrat sisanya). Saat mengestimasi menggunakan metode OLS jika terdapat pencilan pada himpunan data maka metode OLS tidak efektif untuk menghasilkan model persamaan regresi linear berganda yang baik. Metode robust least trimmed square (LTS) merupakan metode alternative yang dapat digunakan apabila terdapat pencilan pada himpunan data. Metode robust least trimmed square bertujuan untuk menghasilkan model persamaan regresi linear berganda yang efisien tanpa menghilangkan pencilan tersebut. Model persamaan regresi linear berganda yang baik setelah melakukan estimasi menggunakan metode robust least trimmed square (LTS) yaitu dengan melihat nilai residualnya (kuadrat sisanya) yang semakin kecil atau konvergen ke nol.
ASSESSMENT METHOD ROBUST LEAST TRIMMED SQUARE (LTS) TO ESTIMATION MULTIPLE LINEAR REGRESSION PARAMETERS
FOR DATA THAT CONTAIN OUTLIERS
ABSTRACT
Determining parameters of multiple linear regression can use the method of ordinary least squares (OLS). OLS must meet the assumption of Best Linear Unbiased Estimator (BLUE) to produce a multiple linear regression model was good which can be seen based on the residual value (the square of the rest). When using the OLS estimate if there are outliers in the data set then OLS is not effective to produce multiple linear regression model was good. Robust method of least trimmed square (LTS) is an alternative method that can be used if there are outliers in the data set. Robust method of least trimmed square method aims to generate a multiple linear regression model that efficiently without removing the outliers. Multiple linear regression model was good after a robust estimation method least trimmed square (LTS) by looking at the residual value (the remaining squares) are getting smaller or converging to zero.
KAJIAN METODE ROBUST LEAST TRIMMED SQUARE (LTS) DALAM MENGESTIMASI PARAMETER REGRESI LINEAR BERGANDA
UNTUK DATA YANG MENGANDUNG PENCILAN
SKRIPSI
ADE AFFANY 120803016
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
KAJIAN METODE ROBUST LEAST TRIMMED SQUARE (LTS) DALAM MENGESTIMASI PARAMETER REGRESI LINEAR BERGANDA
UNTUK DATA YANG MENGANDUNG PENCILAN
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
ADE AFFANY 120803016
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : Kajian Metode Robust Least Trimmed Square
(LTS) Dalam Mengestimasi Parameter Regresi Linear Berganda Untuk Data Yang Mengandung Pencilan
Kategori : Skripsi
Nama : Ade Affany
Nomor Induk Mahasiswa : 120803016
Program Studi : Sarjana (S1) Matematika
Departemen : Matematika
Fakultas : Matematika Dan Ilmu Pengetahuan Alam Universitas Sumatera Utara
Disetujui di Medan, Juli 2016
Komisi Pembimbing :
Pembimbing 2, Pembimbing 1,
Drs. Pengarapen Bangun, M.Si Dr. Pasukat Sembiring, M.Si NIP. 19560815 198503 1 005 NIP. 19531113 198503 1 002
Disetujui Oleh
Departemen Matematika FMIPA USU Ketua,
Gambar

Dokumen terkait
Ada beberapa metode dalam regresi robust yang dapat digunakan untuk menangani data pencilan, salah satunya adalah metode Least Trimmed Squares (LTS).Olehnya itu, penulis
Berdasarkan hasil yang diperoleh pada penelitian ini, regresi robustpenaksir LTSmemberikan hasil yang lebih baik daripada penaksir LMS dan metode OLS dengan kriteria
Ada beberapa metode dalam regresi robust yang dapat digunakan untuk mengatasi data outlier , diantaranya Least Median of Square (LMS), Least Trimmed Squares
Hasil penelitian ini menunjukkan bahwa metode LTS ( Least Trimmed Square ) hanya tegar terhadap pencilan sebesar 20% dari jumlah data keseluruhan dan tidak tegar terhadap
Analisis Regresi Robust pada Data Mengandung Pencilan dengan Menggunakan Metode Least Median Square ; Hufron Haditama; 051810101096; 2011; 33 Halaman; Jurusan Matematika
Analisis Regresi Robust pada Data Mengandung Pencilan dengan Menggunakan Metode Least Median Square ; Hufron Haditama; 051810101096; 2011; 33 Halaman; Jurusan Matematika
Regresi Robust disarankan dapat mengatasi masalah pencilan dalam data untuk mengestimasi parameter, salah satunya adalah Metode Momen (MM) yang digunakan untuk
Persamaan regresi linier berganda yang mengandung pencilan dengan menggunakan estimasi regresi robust MM-estimator yang diperoleh dalam tugas akhir ini adalah:. Robust Regression
