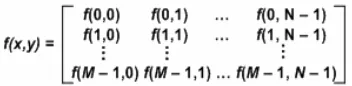THESSI CAHYANINGTIAS
G64103040
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PENGENALAN WAJAH DENGAN PEMROSESAN AWAL
TRANSFORMASI WAVELET
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
THESSI CAHYANINGTIAS
G64103040
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Wavelet. Dibimbing oleh AZIZ KUSTIYO dan ARIEF RAMADHAN.
Biometrik adalah suatu sistem pengenalan pola yang melakukan proses identifikasi personal menggunakan karakteristik fisiologis manusia seperti mata, sidik jari, wajah, tangan, suara, dan lain lain. Karena wajah merupakan salah satu karakteristik fisiologis manusia yang tidak mudah dipalsukan, maka penelitian pengenalan pola ini menggunakan biometri wajah.
Data yang digunakan pada penelitian ini sebanyak 100 wajah yang didapat dari University Cambridge terdiri atas 10 wajah dengan 10 ekspresi dan variasi berbeda. Wajah yang menjadi
input proses pengenalan wajah terbagi menjadi dua perlakukan, yaitu wajah tanpa pemrosesan awal transformasi wavelet dan wajah yang mengalami pemrosesan awal transformasi wavelet. Induk wavelet yang digunakan adalah Haar. Proses transformasi digunakan untuk mengekstraksi fitur sekaligus mereduksi dimensi citra yang berukuran besar menjadi lebih kecil, sehingga mempercepat waktu komputasi proses pengenalan wajah. Proses transformasi menerapkan bank filter untuk mendekomposisi citra hingga level 3. Proses dekomposisi menghasilkan citra pendekatan dan citra detil. Citra yang digunakan pada proses pengenalan wajah adalah citra pendekatan level 1, level 2, dan level 3.
Proses pengenalan wajah pada penelitian ini menggunakan Jaringan Syaraf Tiruan Propagasi Balik karena dinilai dapat menangani pengenalan pola-pola kompleks dengan sangat baik. Parameter yang diamati adalah nilai generalisasi optimum untuk mendapatkan kombinasi hidden neuron, toleransi kesalahan, dan level dekomposisi.
Hasil dari percobaan ini menyatakan bahwa nilai generalisasi yang berasal dari citra pendekatan hasil dekomposisi lebih baik daripada citra tanpa praproses dekomposisi. Nilai generalisasi rata-rata mencapai 98% yang berasal dari citra pendekatan level 3 dengan toleransi kesalahan 10-3. Jumlah hidden neuron saat mencapai nilai generalisasi terbaik adalah 40, 70, dan 90.
Persembahan Ananda untuk Mama, Papa, dan Adikku
“Maaf Ma, Pa...., Ci kurang bisa dijadikan teladan”
“Za...., kau harapan kedua dan terakhir Mama, Papa”
“Kan Ku raih citaku dengan segenap kekuatanku”
“Dan Ku mohon ridha Mu ya Allah dalam meraih citaku”
“Ilmu itu pemimpin, dan amal adalah pengikutnya”
Hr.Ibn Abdul al-Barr.
“Begitu luas Ilmu Mu ya Allah,
NIM :
G64103040
Menyetujui,
Pembimbing I
Aziz Kustiyo, S.Si., M.Kom.
NIP 132206241
Pembimbing II
Arief Ramadhan, S.Kom.
Mengetahui,
Dekan Fakultas Matematika Dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, M.S.
NIP 131473999
RIWAYAT HIDUP
Penulis dilahirkan di Subang tanggal 18 Mei 1985. Penulis adalah anak pertama dari dua bersaudara pasangan Ir. Agustias Amin dan Nining Choeriah, BSc.
rahmat-Nya penulis dapat menyelesaikan tugas akhir mengenai pengenalan wajah dengan pemrosesan awal transformasi wavelet. Kegiatan ini telah dilakukan selama kurang lebih enam bulan. Pelaksanaan kegiatan ini dimulai dari pertengahan Januari 2007 sampai dengan awal Juni 2007.
Selama proses penyelesaian tugas akhir ini penulis dibimbing oleh Bapak Aziz Kustiyo, S.Si, M.Kom selaku dosen pembimbing 1 dan Bapak Arief Ramadhan, S.Kom selaku dosen pembimbing 2. Selama menyelesaikan tugas akhir ini, penulis mendapatkan pengetahuan baru mengenai proses transformasi suatu citra digital, dimana dalam penelitan ini metode transformasi yang digunakan adalah wavelet.
Melalui skripsi ini penulis ucapkan terima kasih kepada berbagai pihak yang telah membantu dalam pelaksanaan tugas akhir ini, di antaranya yaitu:
1 Kepada kedua orang tua dan adik tercinta atas dukungan, doa, dan perhatian selama proses penyelesaian tugas akhir.
2 Bapak Aziz Kustiyo, S.Si, M.Kom selaku dosen pembimbing 1 dan Bapak Arief Ramadhan, S.Kom selaku dosen pembimbing 2 yang telah banyak memberikan masukan berupa saran dan nasihat dalam menghadapi permasalahan yang terjadi saat mengerjakan tugas akhir. 3 Teman-teman Malea Ilkom (Enno, Atik, Hida, Yustin) yang bersedia mendengarkan keluh
kesah atas kesulitan yang penulis hadapi, terima kasih juga atas saran-saran yang diberikan kepada penulis.
4 Kakak Icut yang tinggal di Malea juga, terima kasih atas kelakarnya sehingga membuat penulis tertawa, walaupun terkadang kesal. Terima kasih juga sudah bersedia menemani begadang ketika dibutuhkan.
5 Egi teman satu bimbingan atas masukan dan sarannya.
6 Teman-teman RZ yang sudah memberikan tempat berteduh sementara di kala lelah. 7 Teman-teman Ilkom 40 atas dukungan dan kehadirannya ketika seminar hasil tugas akhir. 8 Pihak-pihak lain yang tidak dapat dituliskan namanya yang telah membantu dalam
pelaksanaan tugas akhir.
Penulisan skripsi ini masih jauh dari sempurna, sehingga kritik dan saran akan selalu diterima dengan terbuka. Semoga tulisan ini bermanfaat.
Bogor, Juli 2007
viii
DAFTAR ISI
Halaman
DAFTAR TABEL... ix
DAFTAR GAMBAR ... ix
DAFTAR LAMPIRAN... x
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan... 1
Ruang Lingkup ... 1
Manfaat... 1
TINJAUAN PUSTAKA ... 1
Representasi Citra Digital ... 1
Transformasi Wavelet ... 2
Dekomposisi Haar ... 2
Jaringan Syaraf Tiruan ... 4
Propagasi Balik ... 4
METODE PENELITIAN... 5
Data... 5
Proses Pengenalan Wajah ... 5
Pengenalan Wajah Menggunakan JST Propagasi Balik ... 5
Parameter Percobaan... 6
Lingkungan Pengembangan... 6
HASIL DAN PEMBAHASAN ... 6
Percobaan 1: Pengenalan Wajah tanpa Proses Dekomposisi... 6
Percobaan 2: Pengenalan Wajah dengan Praproses Dekomposisi Wavelet ... 7
Proses Pengenalan Wajah ... 8
Perbandingan Kedua Jenis Percobaan ... 10
KESIMPULAN DAN SARAN ... 10
Kesimpulan... 10
Saran ... 11
DAFTAR TABEL
Halaman
1 Struktur JST propagasi balik ... 6
2 Definisi kelas target ... 6
3 Generalisasi terbaik tiap toleransi kesalahan... 7
4 Generalisasi terbaik level 1... 8
5 Generalisasi terbaik level 2... 9
6 Generalisasi terbaik level 3... 10
7 Generalisasi terbaik percobaan 1 dan percobaan 2 ... 10
8 Perbandingan waktu komputasi pengenalan wajah (detik)... 10
DAFTAR GAMBAR
Halaman 1 Fungsi koordinat sebagai representasi citra digital. ... 22 Blok diagram analisis filter... 2
3 Proses dekomposisi wavelet Haar level 3. ... 2
4 Tampilan citra hasil dekomposisi. ... 2
5 Bank filter Haar. ... 2
6 Bank filter Haar menggunakan algoritma piramida Mallat. ... 3
7 Algoritma piramida Mallat. ... 3
8 Matriks yang akan didekomposisi. ... 3
9 Nilai a dan c kolom pertama. ... 3
10 Matriks nilai a dan c perkolom. ... 3
11 Nilai a dan c baris pertama. ... 3
12 Hasil akhir dekomposisi... 3
13 Model JST sederhana... 4
14 Arsitektur JST propagasi balik. ... 4
15 Tahapan proses pengenalan wajah . ... 5
16 Generalisasi dengan toleransi kesalahan 0.1. ... 6
17 Generalisasi dengan toleransi kesalahan 0.01. ... 6
18 Generalisasi dengan toleransi kesalahan 0.001. ... 7
19 Citra dekomposisi level 1. ... 7
20 Citra dekomposisi level 2. ... 7
21 Citra dekomposisi level 3. ... 7
22 Deskripsi citra dekomposisi... 7
23 Generalisasi Haar level 1 dengan toleransi kesalahan 0.1. ... 8
24 Generalisasi Haar level 1 dengan toleransi kesalahan 0.01. ... 8
25 Generalisasi Haar level 1 dengan toleransi kesalahan 0.001. ... 8
26 Generalisasi Haar level 2 dengan toleransi kesalahan 0.1. ... 8
27 Generalisasi Haar level 2 dengan toleransi kesalahan 0.01. ... 9
28 Generalisasi Haar level 2 dengan toleransi kesalahan 0.001. ... 9
29 Generalisasi Haar level 3 dengan toleransi kesalahan 0.1. ... 9
30 Generalisasi Haar level 3 dengan toleransi kesalahan 0.01. ... 9
31 Generalisasi Haar level 3 dengan toleransi kesalahan 0.001. ... 10
x
DAFTAR LAMPIRAN
Halaman
1 Algoritma jaringan syaraf tiruan propagasi balik... 13
2 Citra wajah untuk data pelatihan ... 15
3 Citra wajah untuk data pengujian ... 16
4 Tabel generalisasi toleransi kesalahan 0.1... 17
5 Tabel generalisasi toleransi kesalahan 0.01 ... 22
PENDAHULUAN
Latar Belakang
Sistem biometrik adalah suatu sistem pengenalan pola yang melakukan identifikasi personal dengan menentukan keotentikan dari karakteristik fisiologis dari perilaku tertentu yang dimiliki seseorang. Karakteristik fisiologis manusia yang digunakan pada sistem biometrik harus memenuhi beberapa kriteria, yaitu universal, unik, permanen, dan dapat diukur secara kuantitatif, di antaranya mata (retina dan iris), sidik jari, tangan, suara, dan wajah. Salah satu karakteristik fisiologis yang tidak mudah dipalsukan yaitu wajah, oleh karena itu penelitian ini menggunakan biometrik wajah.
Secara umum sistem pengenalan citra wajah terbagi menjadi dua jenis, yaitu system feature based (fitur yang diekstraksi berasal dari komponen citra wajah seperti mata, hidung, mulut) yang memodelkan secara geometris hubungan antara fitur-fitur tersebut dan metode kedua menggunakan informasi mentah dari piksel citra yang kemudian direpresentasikan dalam metode tertentu (transformasi wavelet, principal component analysis (PCA), dan lain lain) untuk digunakan pada pelatihan dan pengujian identitas citra.
Penelitian ini menggunakan pendekatan kedua, yaitu piksel citra wajah diproses terlebih dahulu menggunakan transformasi wavelet. Transformasi wavelet pada penelitian ini digunakan sebagai metode ekstraksi fitur sekaligus mereduksi dimensi citra wajah yang berukuran besar menjadi lebih kecil untuk mempercepat waktu komputasi pada saat melakukan proses pengenalan citra wajah.
Pemilihan transformasi wavelet ini didasarkan pada dua penelitian sebelumnya yang pertama berjudul Pengenalan Citra Wajah dengan Pemrosesan Awal Transformasi Wavelet oleh Resmana Lim, dan kawan kawan. Pada penelitian ini induk wavelet yang digunakan adalah Daubechies dan metode untuk klasifikasi adalah k-nearest neighbour. Penelitian ini mencapai nilai keberhasilan sebesar 94%. Pada penelitian yang kedua berjudul Klasifikasi Sidik Jari dengan Pemrosesan Awal Transformasi Wavelet oleh Minarni, penelitian ini menggunakan induk wavelet Haar dan Daubechies dengan metode klasifikasi LVQ (Learning Vector Quantizations). Penelitian ini membandingkan unjukkerja kedua induk
wavelet, dengan hasil Daubechies dapat meningkatkan unjukkerja pengenalan sebesar 1%.
Metode yang digunakan dalam proses pengenalan wajah pada penelitian ini adalah jaringan syaraf tiruan propagasi balik karena metode ini dinilai sangat baik dalam menangani pengenalan pola-pola kompleks (Puspaningrum 2006).
Tujuan
Penelitian ini bertujuan untuk menganalisis kinerja jaringan syaraf tiruan dalam pengenalan wajah yang mengalami praproses transformasi wavelet dengan jaringan syaraf tiruan tanpa praproses transformasi wavelet.
Ruang Lingkup
Penelitian ini melakukan proses pengenalan citra wajah menggunakan citra berskala keabuan, dengan ukuran citra sebenarnya 48x48 piksel dan menerapkan proses ekstraksi fitur menggunakan transformasi wavelet. Induk wavelet yang digunakan pada penelitian ini adalah wavelet Haar.
Metode yang digunakan pada proses pengenalan wajah adalah jaringan syaraf tiruan propagasi balik dengan inisialisasi bobot Nguyen Widrow. Fungsi aktivasi yang digunakan sigmoid biner dan laju pembelajaran 0.1.
Manfaat
Penelitian ini diharapkan dapat menambah pustaka dalam sistem biometrik terutama identifikasi manusia dengan wajah untuk kemudian dapat diimplementasikan pada bidang-bidang lain, misalnya bidang hukum dan sistem keamanan.
TINJAUAN PUSTAKA
Representasi Citra Digital
Citra didefinisikan sebagai suatu fungsi dua dimensi f(x,y), dengan x, y merupakan koordinat spasial, dan f disebut sebagai kuantitas bilangan skalar positif yang memiliki maksud secara fisik ditentukan oleh sumber citra. Suatu citra digital yang diasumsikan dengan fungsi f(x,y)
2
Gambar 1 Fungsi koordinat sebagai representasi citra digital.
Setiap elemen dari array matriks disebut
image element, picture element, pixel, atau pel
(Gonzales & Woods 2002).
Citra dengan skala keabuan berformat 8-bit memiliki 256 intensitas warna yang berkisar pada nilai 0 sampai 255. Nilai 0 menunjukkan tingkat paling gelap (hitam) dan 255 menunjukkan tingkat paling cerah (putih).
Transformasi Wavelet
Wavelet berasal dari sebuah fungsi penyekala (scaling function) (Stollnitz et al. 1995a). Fungsi ini dapat membuat sebuah induk wavelet (mother Wavelet). Wavelet - wavelet lainnya akan muncul dari hasil penyekalaan, dilasi dan pergeseran induk wavelet.
Secara umum transformasi wavelet kontinu dituliskan
∫
=
f
t
t
dt
s
,
)
(
)
s(
)
(
τ
ψ
,τγ
(1)Persamaan (1) menunjukkan bagaimana suatu fungsi f(t) didekomposisi ke dalam suatu himpunan dengan fungsi dasar
ψ
s,τ(
t
)
yangdisebut sebagai wavelet. Variabel s, dan
τ
menunjukkan skala dan pergeseran (Burrus & Guo 1998).Valens (2004) mengatakan wavelet yang diturunkan dari wavelet dasar tunggal
)
(
t
ψ
yang disebut induk wavelet dengan skala (scaling) dan pergeseran (translation) dituliskan dalam persamaan (2).⎟
⎠
⎞
⎜
⎝
⎛ −
=
s
t
s
t
sτ
ψ
ψ
,τ(
)
1
(2)Pengembangan sinyal berdimensi dua (2D) biasanya diterapkan bank filter untuk melakukan proses dekomposisi citra. Citra yang mengalami dekomposisi akan menghasilkan citra pendekatan berupa koefisien pendekatan (approximation coefficients) dan citra detil berupa koefisien detil (detail coefficients) sebagaimana ditunjukkan pada Gambar 2.
Gambar 2 Blok diagram analisis filter. Koefisien pendekatan dihasilkan oleh low-pass (g[n]) dan koefisien detil dihasilkan oleh
high-pass (h[n]).
Pada penelitian ini proses dekomposisi dilakukan sampai dengan level tiga. Adapun prosesnya ditunjukkan pada Gambar 3.
Gambar 3 Proses dekomposisi wavelet Haar level 3.
Variabel cD[n] pada Gambar 3 sebagai citra detil yang terdiri atas horizontal, vertikal, dan diagonal, variabel cA[n] sebagai citra pendekatan. Adapun tampilan dalam bentuk citra diperlihatkan pada Gambar 4.
Gambar 4 Tampilan citra hasil dekomposisi. Proses dekomposisi akan mengekstraksi fitur sekaligus mereduksi ukuran citra menjadi lebih kecil, sehingga mempercepat proses pengenalan wajah.
Dekomposisi Haar
Proses dekomposisi Haar menerapkan
bank filter dengan h0 = h1= 1 2 sebagai
koefisien low-pass yang menghasilkan citra pendekatan, dan g0=1 2, g1=−1 2 sebagai
koefisien high-pass yang menghasilkan citra detil. Adapun bank filter Haar dapat dilihat pada Gambar 5.
Gambar 5 Bank filter Haar.
Mallat (Stollnitz et al. 1995b). Mallat memberi nilai koefisien low-pass, h0 = h1 =
2
1 dan koefisien high-pass, g0=12, g1=−12,
sehingga bank filter Haar menjadi seperti yang ditunjukkan Gambar 6.
Gambar 6 Bank filter Haar menggunakan algoritma piramida Mallat.
Variabel ai pada Gambar 6 merupakan citra
pendekatan, ci merupakan citra detil, dan si
adalah himpunan bilangan yang akan didekomposisi. Adapun piramida Mallat ditunjukkan pada Gambar 7.
Gambar 7 Algoritma piramida Mallat. Inti dari piramida Mallat untuk dekomposisi level 1 adalah nilai ai diperoleh
dengan rumus
2
1
+
+ = i i i
s s
a , dan nilai ci
diperoleh dengan rumus ci=si−ai. Si adalah
piksel citra yang diambil perkolom. Kemudian hasil dari dekomposisi kolom didekomposisi kembali perbaris.
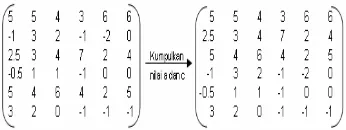
Contoh proses dekomposisi level 1 suatu matriks berukuran 6x6 yang dapat dilihat pada Gambar 8.
Gambar 8 Matriks yang akan didekomposisi. Langkah pertama ambil piksel matriks perkolom, sebagai contoh piksel kolom pertama yang bernilai 4 6 2 3 8 2. Kemudian hitung nilai a dan c (Gambar 9).
Gambar 9 Nilai a dan c kolom pertama. Proses penghitungan nilai a dan c dilanjutkan sampai dengan kolom terakhir, sehingga didapat hasil yang ditunjukkan Gambar 10.
Gambar 10 Matriks nilai a dan c perkolom. Langkah kedua, ambil piksel matriks perbaris dari Gambar 10, sebagai contoh piksel baris pertama bernilai 5 5 4 3 6 6. Kemudian hitung nilai a dan c (Gambar 11).
Gambar 11 Nilai a dan c baris pertama. Nilai a dan c dihitung sampai baris terakhir, kemudian kumpulkan nilai a dan c. Matriks hasil pengumpulan nilai a dan c merupakan hasil akhir proses dekomposisi level satu. Gambar matriks hasil dekomposisi level satu diperlihatkan pada Gambar 12.
Gambar 12 Hasil akhir dekomposisi. Bilangan matriks yang diberi warna merah adalah citra pendekatan dan sisanya citra detil. Jika ingin melanjutkan proses dekomposisi ke level dua, maka bilangan matriks yang digunakan adalah bilangan yang termasuk citra pendekatan, berikut seterusnya jika menambah level dekomposisi.
4
Jaringan Syaraf Tiruan
Jaringan syaraf tiruan (JST) adalah suatu pemrosesan informasi yang memiliki karakteristik-karakteristik menyerupai jaringan syaraf biologis.
JST ditentukan oleh tiga hal (Siang 2005):
a Pola hubungan antar neuron (arsitektur jaringan).
b Metode untuk menentukan bobot penghubung (metode training/learning/ algoritma).
c Fungsi aktivasi.
Arsitektur dari jaringan syaraf tiruan terdiri dari 3 macam, yaitu lapisan tunggal (single layer), lapisan jamak (multilayer), dan lapisan kompetitif (competitive layer). Lapisan tunggal adalah arsitektur yang memiliki satu lapisan hubungan bobot. Lapisan jamak adalah arsitektur jaringan dengan satu lapisan atau lebih dari neuron yang tersembunyi antara input dan output
neuron. Lapisan kompetitif adalah arsitektur yang membentuk satu bagian dari sejumlah besar jaringan-jaringan syaraf.
Metode penentuan bobot terdiri atas tiga jenis, yaitu melalui pelatihan terbimbing (supervised learning), pelatihan tidak terbimbing (unsupervised learning), dan jaringan bobot tetap (fixed weight). Pelatihan terbimbing adalah pelatihan tanpa vektor
output target yang didefinisikan. Jaringan bobot tetap adalah pelatihan untuk masalah optimasi.
Fungsi aktivasi yang umum digunakan jaringan syaraf tiruan adalah:
• Fungsi Sigmoid biner
α − + = e x f 1 1 ) (
• Fungsi Sigmoid bipolar
α α − − + − = e e x f 1 1 ) (
Contoh model JST sederhana ditunjukkan pada Gambar 13.
Gambar 13 Model JST sederhana.
Y menerima input dari neuron x1,x2, dan x3
dengan hubungan masing-masing bobot w1,
w2, dan w3. Ketiga impuls neuron dijumlahkan
net = x1w1 + x2w2 + x3w3
Besarnya impuls yang diterima oleh Y mengikuti fungsi aktivasi y = f(net). Jika nilai fungsi aktivasi cukup kuat, maka sinyal akan diteruskan.
Propagasi Balik
Jaringan syaraf tiruan propagasi balik adalah jaringan multilayer feedforward yang menggunakan metode pembelajaran propagasi balik dan supervised learning. Jaringan syaraf tiruan propagasi balik tidak memiliki hubungan arus balik (feedback) artinya suatu lapisan tidak memiliki hubungan dengan lapisan sebelumnya, namun galat yang didapat diumpankan kembali ke lapisan sebelumnya selama pelatihan, kemudian dilakukan penyesuaian bobot. Model propagasi balik dengan satu hidden neuron dapat dilihat pada Gambar 14.
Gambar 14 Arsitektur JST propagasi balik. Pelatihan sebuah jaringan yang menggunakan propagasi balik terdiri atas tiga langkah, yaitu pelatihan pola input secara
feedforward, propagasi balik kesalahan, dan penyesuaian bobot (Fausett 1994).
Sebelum melakukan ketiga langkah pelatihan JST, bobot awal diinisialisasi yang dapat diisi dengan bilangan acak (random) kecil dalam interval [-0.5,0.5] atau Nguyen Widrow yang didefinisikan
Vij 2
(baru)= βvij (lama)= βvij (lama)
Vj (lama)
∑
=
p
i v
1
ij2(lama)
Variabel vij(lama) adalah nilai acak antara -0.5
dan 0.5, sedangkan bobot pada bias bernilai antara –β dan β.
n = jumlah unit input
p = jumlah unit tersembunyi
β = faktor pengali
Berikut ini penjelasan tiap langkah pelatihan jaringan syaraf tiruan :
- Feedforward
Selama kondisi feedforward setiap unit
input (xm) menerima sinyal input dan
menyebarkannya ke setiap unit tersembunyi (zp). Setiap unit tersembunyi
menghitung fungsi aktivasi dan mengirim sinyal ke setiap unit output. Unit output
kemudian menghitung fungsi aktivasi (yi)
untuk membentuk respon dalam jaringan yang diberikan pola input. Fungsi aktivasi yang digunakan pada aplikasi ini adalah fungsi sigmoid biner.
- Pelatihan
Selama pelatihan, setiap unit output
membandingkan penghitungan aktivasi (yj)
dengan nilai target (tk) untuk menentukan
kesalahan pola pada unit. Berdasarkan nilai kesalahan ini, nilai
δ
kdihitung,δ
k digunakan untuk mendistribusikan kesalahan pada unit output ke semua unit pada lapisan sebelumnya. Kondisi ini juga digunakan untuk memperbaiki bobot di antara output dan lapisan tersembunyi,k
δ
digunakan untuk memperbaiki bobot di antara layer tersembunyi dan lapisan input. Setelah semua faktorδ
ditentukan, bobot semua lapisan disesuaikan secara simultan. - Penyesuaian bobotBobot (wkj) disesuaikan (dari unit
tersembunyi zk ke unit output yj)
berdasarkan
δ
k dan aktivasi zk pada unittersembinyi yj. Penyesuaian bobot vik (dari
unit input xi ke unit tersembunyi zk)
didasarkan pada faktor
δ
j dan aktivasi xipada unit input.
Algoritma jaringan syaraf tiruan propagasi balik secara lengkap dapat dilihat pada Lampiran 1.
METODE PENELITIAN
Data
Data yang digunakan berjumlah 100 buah berasal dari 10 wajah dengan 10 ekspresi dan posisi berbeda. Setiap file citra
berukuran 48 x 48 piksel dengan format bmp skala keabuan 8 bit. Data ini diperoleh dari laboratorium komputer Universitas Cambrigde melalui internet dengan alamat http://homepages.Cae.wisc.edu/~ece533/im ages/facedatabase/.
Citra wajah yang berjumlah 100 dibagi dua menjadi 50 untuk data pelatihan dan 50 untuk data pengujian dengan memperhatikan variasi posisi dan ekspresi. Citra wajah yang digunakan pada penelitian ini dapat dilihat pada Lampiran 2 dan Lampiran 3.
Proses Pengenalan Wajah
Data yang diperoleh pada penelitian ini akan mengalami dua perlakuan, yaitu melalui tahapan praproses menggunakan transformasi wavelet dan tanpa transformasi. Hasil dari kedua perlakuan tersebut kemudian diproses menggunakan JST propagasi balik. Tahapan proses pengenalan wajah ditunjukkan pada Gambar 15.
Gambar 15 Tahapan proses pengenalan wajah.
Pengenalan Wajah Menggunakan JST Propagasi Balik
6
Tabel 1 Struktur JST propagasi balik
Karakteristik Spesifikasi
• Arsitektur 1 layerhidden
Neuron input Sesuai dimensi citra
Neuron hidden 10, 20, 30, 40, 50, 60, 70, 80, 90, 100
Neuron output Banyaknya kelas target, yaitu 10
• Inisialisasi bobot Nguyen-Widrow
• Fungsi aktivasi Sigmoid biner
• Toleransi kesalahan
0.1, 0.01 dan 0.001
• Laju pembelajaran 0.1
Banyaknya kelas target pada penelitian ini adalah 10 (10 wajah individu berbeda). Setiap target mewakili satu model wajah yang direpresentasikan dengan nilai 0 dan 1. Definisi target secara lengkap dapat dilihat pada Tabel 2.
Tabel 2 Definisi kelas target
Kelas Target
Wajah 1 1000000000 Wajah 2 0100000000 Wajah 3 0010000000 Wajah 4 0001000000 Wajah 5 0000100000 Wajah 6 0000010000 Wajah 7 0000001000 Wajah 8 0000000100 Wajah 9 0000000010 Wajah 10 0000000001
Parameter Percobaan
Hasil penelitian diukur dengan parameter konvergensi dan generalisasi (Setiawan 1999, diacu dalam Achelia 2005). Konvergensi adalah tingkat kecepatan jaringan mempelajari pola input, yang dinyatakan dengan satuan waktu atau satuan epoch. Dilain pihak, generalisasi dihitung sebagai berikut:
100%
jumlah pola yang dikenal
Generalisasi x
jumlah seluruh pola
=
Lingkungan Pengembangan
Perangkat keras dan perangkat lunak yang digunakan pada penelitian ini adalah sebagai berikut:
Perangkat keras
• Prosesor AMD Sempron(tm) 2200+
• RAM 512 MB
• Harddisk 110 GB Perangkat Lunak
• Windows XP sebagai sistem operasi
• Matlab R2006b (7.3) untuk program aplikasi
HASIL DAN PEMBAHASAN
Percobaan yang dilakukan pada penelitian ini menerapkan dua perlakuan berbeda, yaitu citra yang akan mengalami proses pengenalan wajah tanpa dekomposisi sebagai percobaan 1 dan citra wajah yang akan mengalami praproses dekomposisi sebagai percobaan 2. Setiap percobaan mengamati nilai generalisasi terbaik untuk menemukan kombinasi hidden neuron, toleransi kesalahan, dan level dekomposisi (untuk percobaan 2). Adapun tabel generalisasi hasil kedua jenis percobaan ini dapat dilihat pada Lampiran 4, 5, dan 6.
Percobaan 1: Pengenalan Wajah tanpa Proses Dekomposisi
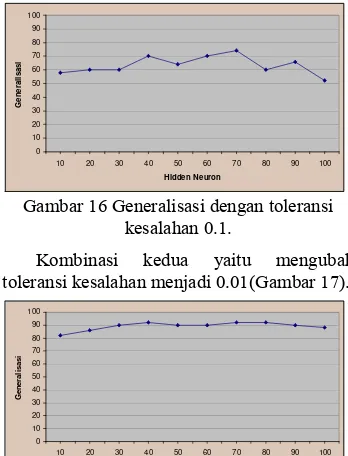
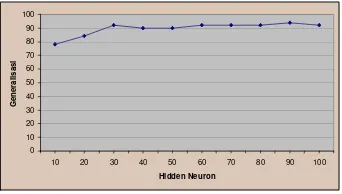
Kombinasi pertama yang dilakukan pada percobaan 1 adalah menggunakan toleransi kesalahan 0.1 dengan 10 buah hidden neuron. Kombinasi ini menghasilkan generalisasi maksimum 74% saat hidden neuron 70. Namun mengalami penurunan hingga mencapai nilai 52% saat hidden neuron 100. Grafiknya dapat dilihat pada Gambar 16.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G en er al isasi
Gambar 16 Generalisasi dengan toleransi kesalahan 0.1.
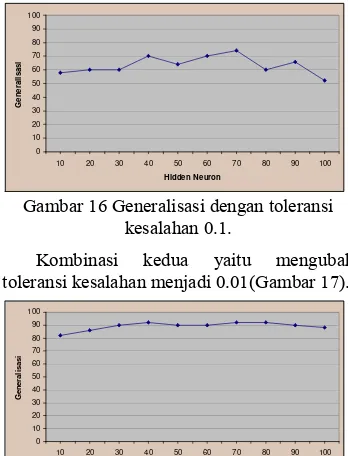
Kombinasi kedua yaitu mengubah toleransi kesalahan menjadi 0.01(Gambar 17).
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G en er al isasi
Pada Gambar 17 dapat dilihat bahwa peningkatan generalisasi mencapai 92% saat
hidden neuron 40, 70, dan 80. Ketiga hidden neuron ini memiliki nilai epoch yang berbeda, nilai epoch terkecil terdapat pada hidden neuron 80. Kombinasi percobaan ini mengalami penurunan generalisasi mulai dari
hidden neuron 90.
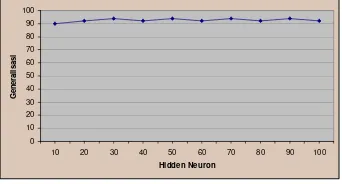
Kombinasi ketiga, nilai toleransi kesalahan diturunkan menjadi 0.001. Penurunan ini tidak memperlihatkan peningkatan nilai generalisasi yang signifikan. Bahkan hidden neuron 10 mengalami sedikit penurunan, sekaligus menunjukkan bahwa generalisasi optimum berkisar pada nilai 92%. Grafik kombinasi ini dapat dilihat pada Gambar 18.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron
G
en
er
al
isasi
Gambar 18 Generalisasi dengan toleransi kesalahan 0.001.
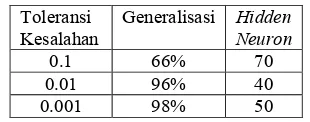
Ketiga kombinasi pada percobaan pertama dapat disimpulkan bahwa nilai generalisasi paling baik diperoleh saat nilai toleransi kesalahan 0.001. Titik keseimbangan diperoleh dengan hidden neuron 90. Data selengkapnya dapat dilihat pada Tabel 3. Tabel 3 Generalisasi terbaik tiap toleransi
kesalahan Toleransi Kesalahan
Generalisasi Hidden Neuron
0.1 74% 70 0.01 92% 80 0.001 94% 90
Percobaan 2: Pengenalan Wajah dengan Praproses Dekomposisi Wavelet
Pada percobaan ini diterapkan praproses menggunakan dekomposisi wavelet Haar. Data yang digunakan mengalami proses dekomposisi hingga level tiga. Citra hasil dekomposisi yang digunakan pada proses pengenalan wajah adalah citra pendekatan tiap level. Oleh karena itu, jumlah citra hasil dekomposisi yang akan mengalami proses pengenalan wajah sebanyak 3 buah untuk satu model wajah.
Pada penelitian ini reduksi citra hasil dekomposisi level 3 dengan ukuran citra sebenarnya 48x48 piksel adalah 24x24 piksel untuk dekomposisi level 1, 12x12 piksel untuk dekomposisi level 2, dan 6x6 piksel untuk dekomposisi level 3. Contoh citra untuk tiap level dekomposisi dapat dilihat pada Gambar 19, 20, 21, dan Gambar 22 untuk deskripsi citra pendekatan dan citra detil.
Gambar 19 Citra dekomposisi level 1.
Gambar 20 Citra dekomposisi level 2.
Gambar 21 Citra dekomposisi level 3.
8
Proses Pengenalan Wajah
Proses pengenalan wajah dengan menggunakan citra pendekatan level 1 yang dihasilkan oleh proses dekomposisi Haar dikombinasikan dengan nilai toleransi kesalahan 0.1 menghasilkan grafik generalisasi terhadap hidden neuron yang ditunjukkan pada Gambar 23.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G en er al isasi
Gambar 23 Generalisasi Haar level 1 dengan toleransi kesalahan 0.1.
Nilai generalisasi pada Gambar 23 secara umum mengalami peningkatan, walaupun diiringi dengan penurunan setiap terjadi peningkatan. Hal tersebut terjadi pada hidden neuron 20 yang mengalami peningkatan dari 52% menjadi 60%. Pada hidden neuron 40 generalisasi meningkat kembali menjadi 62%, namun sebelumnya generalisasi turun menjadi 52% pada hidden neuron 30. Hal serupa terjadi pada hidden neuron 50 yang meningkat menjadi 64% diiringi penurunan pada hidden neuron 60 menjadi 54%. Generalisasi kembali meningkat menjadi 66% diikuti penurunan menjadi 60% pada hidden neuron berikutnya. Pola tersebut dialami pula pada hidden neuron
90, walaupun generalisasi yang dicapai sama dengan hidden neuron 70, yaitu 66% diiringi dengan penurunan di hidden neuron 10.
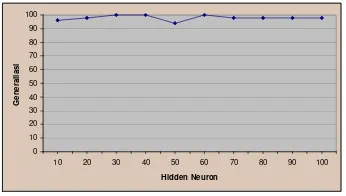
Percobaan selanjutnya diperlihatkan pada Gambar 24 dengan toleransi kesalahan 0.01. Percobaan ini mengalami peningkatan hingga mencapai nilai 96% sekaligus sebagai generalisasi tertinggi pada hidden neuron 40. Namun, nilai generalisasi mengalami penurunan dari hidden neuron 50 sampai 70 dengan nilai 88%.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G e n er al isasi
Gambar 24 Generalisasi Haar level 1 dengan toleransi kesalahan 0.01.
Toleransi kesalahan kemudian diturunkan kembali menjadi 0.001 menghasilkan grafik yang dapat dilihat pada Gambar 25. Nilai generalisasi yang dihasilkan hampir stabil pada nilai 92% dan mencapai generalisasi tertinggi 98% pada
hidden neuron 50.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G en er al isasi
Gambar 25 Generalisasi Haar level 1 dengan toleransi kesalahan 0.001.
Perbandingan nilai generalisasi tertinggi yang menggunakan citra pendekatan level 1 untuk ketiga toleransi kesalahan dapat dilihat pada Tabel 4.
Tabel 4 Generalisasi terbaik level 1 Toleransi
Kesalahan
Generalisasi Hidden Neuron
0.1 66% 70 0.01 96% 40 0.001 98% 50 Pengenalan wajah kemudian dilanjutkan menggunakan citra pendekatan level 2. Grafik hasil generalisasi yang diperoleh untuk toleransi kesalahan 0.1 ditunjukkan pada Gambar 26. 0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G e n e r a lis a s i
Gambar 26 Generalisasi Haar level 2 dengan toleransi kesalahan 0.1.
Pada Gambar 26 tersebut dapat dilihat bahwa generalisasi mencapai nilai tertinggi 78% pada hidden neuron 60. Pencapaian nilai tersebut diiringi dengan penurunan nilai generalisasi baik sebelum maupun sesudah mencapai nilai tertinggi.
dengan nilai 84% meningkat hingga mencapai 94% pada hidden neuron 30. Seperti percobaan sebelumnya yang menggunakan toleransi kesalahan 0.1, setelah mencapai nilai tertinggi generalisasi kembali turun. Pada percobaan ini generalisasi turun menjadi 90%.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
HIdden Neuron G e n er al isasi Gambar 27 Generalisasi Haar level 2 dengan
toleransi kesalahan 0.01.
Kombinasi terakhir untuk citra pendekatan level 2 adalah menurunkan kembali nilai toleransi kesalahan menjadi 0.001 yang dapat dilihat pada Gambar 28. Nilai generalisasi yang diperoleh pada percobaan ini mencapai nilai 96% sekaligus sebagai generalisasi terbaik, kemudian turun menjadi 92% dan kembali naik menjadi 96%. Hal tersebut terus berulang sampai hidden neuron 100 yang diakhiri dengan penurunan nilai generalisasi. 0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G en e r al isa si
Gambar 28 Generalisasi Haar level 2 dengan toleransi kesalahan 0.001.
Hasil generalisasi terbaik pengenalan wajah yang menggunakan input citra pendekatan level 2 dapat dilihat pada Tabel 5. Tabel 5 Generalisasi terbaik level 2
Toleransi Kesalahan
Generalisasi Hidden Neuron
0.1 78% 60
0.01 94% 30, 70 0.001 94% 30, 70, 90 Kombinasi tiga terakhir percobaan 2 dimulai seperti yang dilakukan sebelumnya, yaitu toleransi kesalahan 0.1 dengan menggunakan citra pendekatan hasil dekomposisi level 3 yang dapat dilihat pada grafik Gambar 29. Pada kombinasi ini nilai generalisasi hampir stabil, karena peningkatan
dan penurunan nilai generalisasi yang dicapai tidak jauh berbeda dengan nilai sebelum maupun setelahnya. Nilai generalisasi terbaik pada kombinasi ini adalah 60% pada hidden neuron 40.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G en e r al is asi
Gambar 29 Generalisasi Haar level 3 dengan toleransi kesalahan 0.1.
Grafik generalisasi selanjutnya diperoleh dengan toleransi kesalahan 0.01 yang ditunjukkan pada Gambar 30.
0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G e n er al isasi
Gambar 30 Generalisasi Haar level 3 dengan toleransi kesalahan 0.01.
Pada percobaan ini nilai generalisasi mencapai nilai terbaik 98% pada hidden neuron 50 dan 60. Seperti kombinasi percobaan sebelumnya pencapaian nilai generalisasi tertinggi selalu diiringi dengan penurunan generalisasi, kali ini generalisasi turun empat poin dari 98% menjadi 94%.
Percobaan dua diakhiri dengan menurunkan nilai toleransi kesalahan menjadi 0.001. Nilai generalisasi mulai stabil dengan nilai 98% yang terjadi pada hidden neuron 70 sampai dengan hidden neuron 100. Nilai generalisasi terbaik yang dicapai adalah sebesar 100% terjadi pada hidden neuron 30, 40, dan 60. Grafiknya ditunjukkan pada Gambar 31.
10 0 10 20 30 40 50 60 70 80 90 100
10 20 30 40 50 60 70 80 90 100
Hidden Neuron G e n er al iasi
Gambar 31 Generalisasi Haar level 3 dengan toleransi kesalahan 0.001.
Data generalisasi terbaik hasil pengenalan wajah dengan menggunakan
input citra pendekatan hasil dekomposisi level 3 dapat dilihat pada Tabel 6.
Tabel 6 Generalisasi terbaik level 3. Toleransi
Kesalahan
Generalisasi Hidden Neuron
0.1 60% 40
0.01 98% 50, 60 0.001 100% 30, 40, 60
Perbandingan Kedua Jenis Percobaan
Dari dua jenis percobaan pengenalan wajah ini secara garis besar menyatakan bahwa generalisasi hasil pengenalan wajah dengan praposes dekomposisi Wavelet lebih baik dibandingkan dengan pengenalan wajah tanpa dekomposisi. Semakin kecil toleransi kesalahan, dan semakin tinggi level dekomposisi maka nilai generalisasi yang dicapai akan semakin tinggi. Walaupun ada pengecualian pada toleransi kesalahan 10-1 nilai generalisasi terbaik berasal dari dekomposisi level 2. Perbandingan generalisasi terbaik percobaan 1 dan 2 dapat dilihat pada Tabel 7.
Tabel 7 Generalisasi terbaik percobaan 1 dan percobaan 2
Percobaan 2 (tiap level) Toleransi
Kesalahan
Percobaan 1
1 2 3
0.1 74% 66% 78% 60%
0.01 92% 96% 94% 98%
0.001 94% 98% 94% 100%
Pada Gambar 32 dapat dilihat bahwa perbandingan generalisasi terbaik dua jenis percobaan yang terdiri atas pengenalan wajah tanpa dekomposisi (T), dan pengenalan wajah dengan pemrosesan awal dekomposisi Haar level 1 (HL1), dekomposisi Haar level 2 (HL2), dan dekomposisi Haar level 3 (HL3) dalam bentuk diagram batang.
0% 20% 40% 60% 80% 100%
T HL1 HL2 HL3
Hidden Neuron G en er al iasi
Toleransi Kesalahan 0.1 Toleransi Kesalahan 0.01 Toleransi Kesalahan 0.001
Gambar 32 Perbandingan generalisasi terbaik dari dua jenis percobaan.
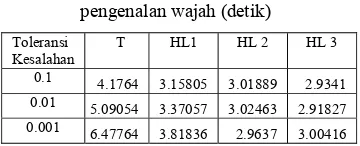
Waktu komputasi yang diperlukan saat proses pengenalan wajah yang melalui praproses dekomposisi pun terbukti lebih cepat dibandingkan dengan pengenalan wajah tanpa dekomposisi citra. Data selengkapnya dapat dilihat pada Tabel 8.
Tabel 8 Perbandingan waktu komputasi pengenalan wajah (detik)
Toleransi Kesalahan
T HL1 HL 2 HL 3
0.1 4.1764 3.15805 3.01889 2.9341
0.01 5.09054 3.37057 3.02463 2.91827
0.001 6.47764 3.81836 2.9637 3.00416
Berdasarkan data pada Tabel 8 dapat disimpulkan bahwa semakin tinggi level dekomposisi, maka waktu yang diperlukan untuk proses pengenalan wajah semakin cepat. Namun, jika dilihat dari penurunan toleransi kesalahan, waktu yang diperlukan semakin lama. Hal ini berbanding lurus dengan peningkatan nilai generalisasi.
KESIMPULAN DAN SARAN
Kesimpulan
Berdasarkan penelitian yang telah dilakukan, maka dapat disimpulkan bahwa: 1 Pengenalan wajah dengan pemrosesan
awal transformasi wavelet dapat meningkatkan nilai generalisasi, bahkan dapat mencapai nilai 100% pada dekomposisi level 3 dengan toleransi kesalahan 10-3 pada hidden neuron 30, 40, dan 60. Secara umum rata-rata generalisasi yang dicapai saat toleransi kesalahan 10-3 berkisar pada nilai 98%. 2 Setiap nilai generalisasi mencapai nilai
terbaik selalu diiringi dengan penurunan nilai generalisasi pada hidden neuron
selanjutnya. Walaupun penurunan tersebut tidak selalu berselangan satu
3 Waktu komputasi saat proses pengenalan wajah yang mengalami proses dekomposisi Wavelet pun lebih cepat dibandingkan dengan proses pengenalan wajah tanpa proses dekomposisi. Waktu komputasi akan semakin kecil seiring dengan penambahan level dekomposisi. 4 Dilihat dari diagram batang pada Gambar
31, nilai generalisasi akan semakin tinggi seiring dengan penambahan level dekomposisi dan penurunan nilai toleransi kesalahan.
5 Dilihat dari jumlah hidden neuron saat nilai generalisasi terbaik pada percobaan 1 dan percobaan 2, seringnya dicapai saat berada pada jumlah 40, 70 ,dan 90.
6 Proses dekomposisi wavelet Haar penghitungannya sederhana, sehingga mudah dimengerti, karena kesederhanaannya itu juga waktu komputasi menjadi lebih cepat. Kesederhanaan dan kemudahan dalam proses penghitungan itulah yang menjadi keunggulan dari induk wavelet Haar.
Saran
Penelitian ini dapat dikembangkan menjadi penelitian baru dengan saran sebagai berikut:
• Menggunakan gabungan citra pendekatan dan citra detil sebagai input dalam proses pengenalan wajah, sehingga masukan pada JST propagasi balik lebih banyak informasi dibandingkan dengan hanya menggunakan citra pendekatan sebagai input. Kemudian dibandingkan akurasi yang diperoleh antara input citra pendekatan dengan input gabungan citra pendekatan dan citra detil.
• Membandingkan nilai generalisasi yang didapat dengan induk wavelet lainnya, misalnya Haar dengan Daubechies, karena Daubechies merupakan induk wavelet yang diperoleh dari hasil pengembangan Haar.
• Menggunakan citra wajah yang ukuran baris dan kolomnya berbeda, misalnya citra wajah berukuran 112x92 piksel.
DAFTAR PUSTAKA
Achelia, E. 2005. Pengenalan Wajah dalam Berbagai Sudut Pandang Terkelompok Menggunakan Jaringan Syaraf Tiruan Propagasi balik [skripsi]. Bogor: Depertemen Ilmu Komputer, FMIPA, IPB.
Burrus, C. S. & Guo H. 1998. Introduction to Wavelets and Wavelet Transforms, A Primer. Upper Saddle River, NJ(USA): Prentice-Hall.
Fausett, Laurene. 1994. Fundamentals of Neural Networks. New Jersey : Prentice-Hall.
Gonzales, R. C. & R.E. Woods. 2002. Digital Image Processing. 2nd Edition. New Jersey: Prentice-Hall.
Lim, Resmana et al. 2000. Pengenalan Citra Wajah dengan Pemrosesan Awal Transformasi Wavelet. Proceeding Digital Signal Prosessing, Teknologi dan Aplikasinya (DSPTA). Surabaya: Gedung Pasca Sarjana ITS.
Minarni. 2004. Klasifikasi Sidik Jari dengan Pemrosesan Awal Transformasi Wavelet. Transmisi 8(2):37-41.
Puspaningrum. 2006. Pengantar Jaringan Saraf Tiruan. Yogyakarta: ANDI.
Setiawan, W. 1999. Pengenalan Wajah Menggunakan Jaringan Neural Buatan Berbasis Eigenfaces [tesis]. Depok: Program Studi Ilmu Komputer, Fakultas Pascasarjana Universitas Indonesia. Siang, J. J. 2005. Jaringan Syaraf Tiruan dan
Pemrogramannya Menggunakan Matlab.
Yogyakarta: ANDI.
Stollnitz, Eric J et al. 1995a. Wavelets for Computer Graphics: A Primer Part 1. University of Washington. http://grail.cs.washington.edu/projects/
wavelets/article/wavelet1.pdf [ 1 Februari 2007]
Stollnitz, Eric J et al. 1995b. Wavelets for Computer Graphics: A Primer Part 2. University of Washington. http://grail.cs.washington.edu/projects/
wavelets/article/wavelet1.pdf [ 1 Februari 2007]
Lampiran 1 Algoritma jaringan syaraf tiruan propagasi balik Langkah 0 Inisialisasi bobot
Langkah 1 Selama kondisi berhenti bernilai salah, lakukan langkah 2-9. Langkah 2 Untuk setiap pasangan pelatihan, lakukan langkah 3-8.
Feedforward:
Langkah 3 Setiap unit input (Xi, i =1,..., m) menerima sinyal input xi
dan menyebarkan sinyal tersebut ke semua unit lapisan atas (unit tersembunyi).
Langkah 4 Setiap unit tersembunyi (Zk, k = 1,...,p) menjumlahkan
bobot sinyal input
∑
+= vok xivik k
z_in
dan mengaplikasikan fungsi aktivasi untuk menghitung sinyal output
(
k)
k f z in
z = _
kemudian mengirim sinyal tersebut ke semua unit pada lapisan atas (unit output).
Langkah 5 Setiap unit output (Yj, j = 1,..., n) menjumlahkan bobot
sinyal input
∑
+
=
oj k kjj
w
z
w
in
y
_
dan mengaplikasikan fungsi aktivasi untuk menghitung sinyal output
(
j)
j f y in
y = _
Propagasi balik:
Langkah 6 Setiap unit output (Yj, j = 1,..., n) menerima sebuah pola
yang bersesuaian dengan pola input pelatihan, kemudian menghitung informasi kesalahan
(
j j) (
j)
j = t − y f y_in δ
kemudian menghitung koreksi bobot (digunakan untuk memperbaiki bobot wkj)
k j
kj z
w =αδ
∆
Dan akhirnya menghitung koreksi bias (digunakan untuk memperbaiki w0j)
j j
w =αδ
∆ 0
Kemudian mengirimkan δjke unit lapisan bawah
Langkah 7 Setiap lapisan tersembunyi (Zk, k = 1,...,p) menjumlahkan
input delta (dari unit lapisan atas)
∑
=
j kjk
w
in
δ
δ
_
kalikan nilai di atas dengan turunan fungsi aktivasi untuk menghitung informasi kesalahan
(
k)
k
k _in f z_in
'
δ
δ
=kemudian hitung koreksi bobot (digunakan untuk memperbaiki vik)
i k
ik x
v =αδ ∆
dan hitung koreksi bias (digunakan untuk memperbaiki vok)
14
Lanjutan
Perbaiki bobot dan bias:
Langkah 8 Setiap unit output (Yj, j = 1,..., n) memperbaiki bias dan
bobot (k = 0,..., p)
kj old kj new
kj w w
w ( ) = ( )+∆
Setiap unit tersembunyi (Zk, k = 1,...,p) memperbaiki bias
dan bobot (i = 0,..., m)
ik old ik new
ik v v
v ( ) = ( )+∆
Langkah 9 Tes kondisi berhenti
Keterangan simbol-simbol yang digunakan pada algoritma JST propagasi balik adalah sebagai berikut:
x Input vektor pelatihan x = (x1, ... xi, ... xm)
t Output vektor target t = (tn, ... tj, ... xn)
j
δ Informasi kesalahan unit Yj yang disebarkan kembali ke unit tersembunyi.
k
δ Informasi kesalahan dari lapisan output ke unit tersembunyi Zk.
α
Laju pembelajaran (learning rate).Xi Unit input i, untuk sebuah unit input, sinyal input dan sinyal output adalah sama, yaitu Xi.
V0k Bias pada unit tersembunyi k.
Zk Unit tersembunyi k, input jaringan ke Zk disimbolkan dengan z_ink
∑
+
=
v
okx
iv
ikk
z_in
Sinyal output (aktivasi) pada Zk disimbolkan dengan zk
(
k)
k f z in
z = _
Woj Bias pada unit tersembunyi j.
Yj Unit tersembunyi j, input jaringan ke Yj disimbolkan dengan y_inj
∑
+
=
oj k kjj
w
z
w
in
y
_
Sinyal output (aktivasi) pada Yj disimbolkan dengan yj
(
j)
j f y in
Lampiran 2 Citra wajah untuk data pelatihan 1 Orang pertama
2 Orang kedua
3 Orang ketiga
4 Orang keempat
5 Orang kelima
6 Orang keenam
7 Orang ketujuh
8 Orang kedelapan
9 Orang kesembilan
10 Orang kesepuluh
16
Lampiran 3 Citra wajah untuk data pengujian 1 Orang pertama
2 Orang kedua
3 Orang ketiga
4 Orang keempat
5 Orang kelima
6 Orang keenam
7 Orang ketujuh
8 Orang kedelapan
9 Orang kesembilan
10 Orang kesepuluh
Lampiran 4 Tabel generalisasi toleransi kesalahan 0.1 Hidden
Neuron Spesifikasi Ulangan ke- Dikenal TakDikenal Epoch Waktu Generalisasi
10 Tanpa Wavelet 1 21 29 7 3.66867 42%
2 25 25 9 3.92472 50%
3 29 21 7 3.63343 58%
4 17 33 9 3.90764 34%
5 17 33 8 3.8213 34%
Haar Level 1 1 17 33 6 3.34103 34%
2 17 33 7 3.31579 34%
3 24 26 6 3.46015 48%
4 26 24 6 3.35603 52%
5 25 25 9 3.34462 50%
Level 2 1 21 29 6 3.21024 42%
2 29 21 6 3.25553 58%
3 21 29 6 3.28952 42%
4 15 35 7 3.22985 30%
5 21 29 5 4.27092 42%
Level 3 1 19 31 6 3.11993 38%
2 13 37 4 3.14792 26%
3 25 25 7 3.23243 50%
4 28 22 6 3.09662 56%
5 25 25 6 3.57169 50%
20 Tanpa Wavelet 1 20 30 5 4.05464 40%
2 23 27 6 3.85607 46%
3 22 28 6 3.45951 44%
4 30 20 5 4.04487 60%
5 19 31 6 3.8204 38%
Haar Level 1 1 25 25 5 3.375 50%
2 17 33 5 3.30404 34%
3 30 20 4 3.39023 60%
4 19 31 4 3.31782 38%
5 21 29 4 3.31782 42%
Level 2 1 30 20 4 3.26795 60%
2 16 34 4 3.23746 32%
3 18 32 4 3.34291 36%
4 21 29 3 3.19694 42%
5 33 17 4 3.22962 66%
Level 3 1 28 22 3 3.07635 56%
2 12 28 3 3.17799 24%
3 32 18 3 3.21019 64%
4 17 33 3 3.16804 34%
5 24 26 4 3.27171 48%
30 Tanpa Wavelet 1 30 20 4 5.79091 60%
2 26 24 4 4.23904 52%
3 25 25 4 3.60717 50%
4 22 28 4 3.58328 44%
18
Lanjutan Hidden Neuron
Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
Haar Level 1 1 23 27 4 3.03688 46%
2 18 32 3 2.95961 36%
3 26 24 4 3.03066 52%
4 20 30 3 2.98818 40%
5 19 31 3 2.97459 38%
Level 2 1 33 17 3 2.80115 66%
2 28 22 3 3.00637 56%
3 31 19 4 2.97068 62%
4 25 25 4 2.93058 50%
5 18 32 3 2.85238 36%
Level 3 1 28 22 4 2.95881 56%
2 21 29 3 2.86948 42%
3 22 28 4 2.8613 44%
4 24 26 2 2.92043 48%
5 18 32 3 2.84785 36%
40 Tanpa Wavelet 1 29 21 3 3.42182 58%
2 35 15 3 3.45878 70%
3 25 25 4 3.69904 50%
4 28 22 4 3.66504 56%
5 34 16 3 3.43075 68%
Haar Level 1 1 24 26 3 3.06279 48%
2 27 23 3 3.01307 54%
3 31 19 4 3.11941 62%
4 28 22 3 3.00999 56%
5 23 27 3 3.06864 46%
Level 2 1 30 20 3 2.99912 60%
2 22 28 2 2.91099 44%
3 28 22 3 2.88104 56%
4 32 18 3 2.93269 64%
5 27 23 3 2.95062 54%
Level 3 1 22 28 4 2.94008 44%
2 13 37 1 2.84569 26%
3 18 32 2 2.9147 36%
4 30 20 3 2.9341 60%
5 28 22 3 2.85802 58%
50 Tanpa Wavelet 1 22 28 4 4.12208 44%
2 23 27 4 4.44407 46%
3 24 26 4 3.64053 48%
4 32 18 2 3.45733 64%
5 26 24 3 3.6503 52%
Haar Level 1 1 28 22 3 3.22922 56%
2 32 18 3 3.26356 64%
3 25 25 3 3.20185 50%
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
5 32 18 3 3.17742 64%
Level 2 1 31 19 2 2.92322 62%
2 20 30 2 2.92763 40%
3 2 30 2 2.93699 40%
4 28 22 3 2.97585 56%
5 12 38 2 3.72386 24%
Level 3 1 17 33 2 3.00976 34%
2 21 29 2 3.00373 42%
3 25 25 2 2.96197 50%
4 28 22 2 2.90796 56%
5 23 27 3 2.99614 46%
60 Tanpa Wavelet 1 33 17 2 3.59066 66%
2 31 19 3 3.98323 62%
3 28 22 3 3.86374 56%
4 35 15 3 3.877 70%
5 33 17 2 3.70978 66%
Haar Level 1 1 28 22 3 3.29841 56%
2 28 22 3 3.28548 56%
3 26 24 3 3.16982 52%
4 27 23 3 3.19412 54%
5 25 25 2 3.06622 50%
Level 2 1 33 17 3 3.01889 66%
2 25 25 2 3.07177 50%
3 29 21 2 2.97046 58%
4 39 11 3 3.00708 78%
5 27 23 3 2.94466 54%
Level 3 1 27 23 2 2.86935 54%
2 15 35 2 3.50734 30%
3 18 32 2 2.87957 36%
4 26 24 2 2.91847 52%
5 19 31 2 2.87546 38%
70 Tanpa Wavelet 1 28 22 3 3.91067 56%
2 33 17 4 3.88299 66%
3 29 21 3 3.94607 58%
4 24 26 3 3.9071 48%
5 37 13 4 4.1764 74%
Haar Level 1 1 33 17 3 3.15805 66%
2 25 25 3 3.18807 50%
3 22 28 2 3.10935 44%
4 29 21 3 3.22763 58%
5 28 22 2 3.07925 56%
Level 2 1 20 30 2 2.95407 40%
2 21 29 2 2.95221 42%
3 36 14 3 2.96024 72%
20
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
5 28 22 3 2.94201 56%
Level 3 1 20 30 2 2.88546 40%
2 18 32 1 2.87355 36%
3 22 28 2 2.87627 44%
4 26 24 2 3.00199 52%
5 14 36 1 2.80507 28%
80 Tanpa Wavelet 1 20 30 3 4.11081 40%
2 26 24 3 4.15893 52%
3 30 20 4 4.47281 60%
4 28 22 3 4.16253 56%
5 26 24 3 4.05596 52%
Haar Level 1 1 30 20 2 3.1202 60%
2 20 30 2 3.17981 40%
3 27 23 3 3.23209 54%
4 30 20 3 3.35739 60%
5 26 24 3 3.22616 52%
Level 2 1 30 20 2 2.84257 60%
2 17 33 2 2.82819 34%
3 24 26 2 2.76932 48%
4 25 25 2 2.82929 50%
5 26 24 2 2.94113 52%
Level 3 1 23 27 2 2.8384 46%
2 18 32 2 2.78566 36%
3 13 37 2 2.81085 26%
4 26 24 2 2.78858 52%
5 19 31 2 2.75243 38%
90 Tanpa Wavelet 1 29 21 3 4.00791 58%
2 33 17 4 4.32437 66%
3 23 27 3 3.99694 46%
4 27 23 3 3.99841 54%
5 24 26 3 3.99687 48%
Haar Level 1 1 25 25 3 3.16392 50%
2 30 20 3 3.17013 60%
3 33 17 3 3.27328 66%
4 25 25 2 3.15942 50%
5 31 19 3 3.1582 62%
Level 2 1 26 24 2 2.90684 52%
2 28 22 2 2.84917 56%
3 18 32 2 2.86209 36%
4 29 21 2 2.84993 58%
5 20 30 2 2.84791 40%
Level 3 1 22 28 2 2.81421 44%
2 26 24 2 2.77413 52%
3 16 34 2 2.82109 32%
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
5 29 21 2 2.80766 58%
100 Tanpa Wavelet 1 26 24 4 4.54596 52%
2 23 27 3 4.2035 46%
3 22 28 2 3.82633 44%
4 25 25 2 4.52491 50%
5 24 26 2 3.8859 48%
Haar Level 1 1 16 34 3 3.16067 32%
2 20 30 2 3.09696 40%
3 29 21 2 3.07039 58%
4 23 27 2 3.09341 46%
5 27 23 2 3.04071 54%
Level 2 1 22 28 2 2.85943 44%
2 15 35 2 2.84908 30%
3 29 21 2 2.85629 58%
4 23 27 2 2.8838 46%
5 35 15 2 2.84403 70%
Level 3 1 19 31 2 2.8049 38%
2 19 31 2 2.79791 38%
3 23 27 2 2.86199 46%
4 24 26 2 2.85242 48%
22
Lampiran 5 Tabel generalisasi toleransi kesalahan 0.01 Hidden
Neuron Spesifikasi Ulangan ke- Dikenal TakDikenal Epoch Waktu Generalisasi
10 Tanpa Wavelet 1 35 15 42 9.52921 70%
2 35 15 53 6.25389 70%
3 41 9 20 4.05155 82%
4 26 24 169 13.2132 52%
5 38 12 23 4.25284 76%
Haar Level 1 1 34 16 32 3.60345 68%
2 41 9 28 3.48288 82%
3 38 12 46 3.91949 76%
4 31 19 36 3.71386 62%
5 43 7 23 3.43493 86%
Level 2 1 40 10 15 3.05256 80%
2 41 9 44 3.43399 82%
3 42 8 21 3.092 84%
4 42 8 29 3.25973 84%
5 41 9 20 3.07955 82%
Level 3 1 48 2 19 2.99384 96%
2 45 5 17 3.66407 90%
3 47 3 12 2.90833 94%
4 47 3 30 3.25383 94%
5 43 7 21 3.01714 86%
20 Tanpa Wavelet 1 43 7 14 4.14338 86%
2 41 9 17 4.39326 82%
3 42 8 14 4.26613 84%
4 38 12 14 4.22103 76%
5 40 10 15 4.27707 80%
Haar Level 1 1 38 12 17 3.33427 76%
2 46 4 13 3.24058 92%
3 44 6 12 3.15942 88%
4 40 10 16 3.2783 80%
5 42 8 13 3.19076 84%
Level 2 1 42 8 8 2.84808 84%
2 41 9 7 2.83739 82%
3 42 8 9 2.86107 84%
4 44 6 17 3.52594 88%
5 41 9 11 2.87273 82%
Level 3 1 47 3 11 2.79685 94%
2 47 3 9 2.74901 94%
3 43 7 11 2.8448 86%
4 44 6 11 2.73432 88%
5 47 3 12 2.77632 94%
30 Tanpa Wavelet 1 44 6 13 4.55447 88%
2 45 5 10 4.26302 90%
3 44 6 16 5.03602 88%
4 41 9 10 4.28493 82%
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
Haar Level 1 1 40 10 10 3.27077 80%
2 44 6 11 3.24649 88%
3 40 10 9 3.132 80%
4 42 8 9 3.11671 84%
5 42 8 10 3.1769 84%
Level 2 1 45 5 6 2.91462 90%
2 42 8 6 2.94061 84%
3 47 3 9 3.02463 94%
4 43 7 7 2.95173 86%
5 42 8 6 2.9494 84%
Level 3 1 45 5 10 2.92347 90%
2 46 4 11 2.96562 92%
3 46 4 14 3.00998 92%
4 45 5 10 2.88776 90%
5 47 3 9 2.9613 94%
40 Tanpa Wavelet 1 41 9 10 8.63329 82%
2 46 4 9 5.23931 92%
3 43 7 8 4.48346 86%
4 46 4 9 4.68313 92%
5 42 8 9 4.60128 84%
Haar Level 1 1 46 4 8 3.29066 92%
2 41 9 9 3.39865 82%
3 46 4 9 3.49816 92%
4 48 2 7 3.37057 96%
5 45 5 12 3.63646 90%
Level 2 1 41 9 6 3.09374 82%
2 43 7 8 3.09374 86%
3 44 6 10 4.50323 88%
4 42 8 6 2.99826 84%
5 45 5 6 2.95225 90%
Level 3 1 44 6 8 3.04717 88%
2 48 2 13 3.05898 96%
3 46 4 8 2.99326 92%
4 44 6 9 2.96554 88%
5 46 4 7 2.8837 92%
50 Tanpa Wavelet 1 42 8 10 4.89233 84%
2 43 7 9 4.81285 86%
3 42 8 12 5.37986 84%
4 45 5 8 4.57214 90%
5 41 9 11 5.14072 82%
Haar Level 1 1 40 10 7 3.34218 80%
2 44 6 7 3.26476 88%
3 43 7 8 3.44123 86%
4 44 6 7 3.26682 88%
5 46 4 7 3.25235 92%
Level 2 1 46 4 10 2.88321 92%
24
Lanjutan Hidden
Neuron Spesifikasi UIangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
3 46 4 7 2.95524 92%
4 43 7 7 2.93324 86%
5 44 6 6 2.94317 88%
Level 3 1 44 6 7 2.86675 88%
2 47 3 8 2.89775 94%
3 46 4 7 2.88122 92%
4 46 4 9 2.89505 92%
5 49 1 10 2.91827 98%
60 Tanpa Wavelet 1 44 6 8 4.76902 88%
2 44 6 9 5.05544 88%
3 43 7 8 4.79424 86%
4 43 7 9 5.09142 86%
5 45 5 8 4.73778 90%
Haar Level 1 1 42 8 7 3.27042 84%
2 46 4 8 3.41948 92%
3 43 7 7 3.29829 86%
4 44 6 6 3.20173 88%
5 45 5 8 3.35194 90%
Level 2 1 41 9 5 2.93551 82%
2 45 5 7 2.96088 90%
3 43 7 8 2.93206 86%
4 42 8 6 2.93028 84%
5 45 5 5 2.89768 90%
Level 3 1 46 4 10 2.99888 92%
2 48 2 9 2.93951 98%
3 46 4 9 2.90539 92%
4 46 4 8 2.88886 92%
5 47 3 9 2.88872 94%
70 Tanpa Wavelet 1 46 4 7 4.90758 92%
2 42 8 8 5.25788 84%
3 42 8 7 5.00787 84%
4 44 6 7 5.04215 88%
5 45 5 8 5.37144 90%
Haar Level 1 1 44 6 7 3.50014 88%
2 44 6 7 3.47547 88%
3 44 6 9 3.69967 88%
4 41 9 7 3.55728 82%
5 44 6 8 3.51952 88%
Level 2 1 47 3 6 3.13583 94%
2 44 6 5 3.01505 88%
3 44 6 9 3.19409 88%
4 44 6 8 3.25239 88%
5 44 6 6 3.1891 88%
Level 3 1 46 4 8 2.91442 92%
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
3 46 4 8 3.00316 92%
4 47 3 9 2.91978 94%
5 46 4 8 3.00432 92%
80 Tanpa Wavelet 1 41 9 7 5.32489 82%
2 46 6 6 5.09054 92%
3 44 6 6 5.11483 88%
4 43 7 8 5.7276 86%
5 45 5 9 5.81347 90%
Haar Level 1 1 44 6 6 3.44412 88%
2 45 5 7 3.66227 90%
3 45 5 7 3.51661 90%
4 42 8 8 3.81029 84%
5 46 4 8 3.70653 92%
Level 2 1 44 6 5 3.00591 88%
2 45 5 7 3.07211 90%
3 46 4 9 2.92417 92%
4 47 3 9 2.96427 94%
5 49 1 6 3.0448 98%
Level 3 1 44 6 7 2.98711 88%
2 49 1 8 3.01084 98%
3 48 2 8 2.98098 96%
4 46 4 7 2.90497 92%
5 47 3 6 2.94859 94%
90 Tanpa Wavelet 1 42 8 6 5.28202 84%
2 45 5 5 4.8775 90%
3 43 7 6 5.20583 86%
4 44 6 9 6.27082 88%
5 43 7 8 5.86533 86%
Haar Level 1 1 44 6 6 3.54331 88%
2 42 8 6 3.47366 84%
3 45 5 8 3.64716 90%
4 44 6 7 3.54324 88%
5 45 5 6 3.43316 90%
Level 2 1 45 1 5 2.9637 90%
2 42 8 5 3.08343 84%
3 43 7 8 3.13472 86%
4 45 5 8 3.1571 90%
5 41 9 6 3.17313 82%
Level 3 1 48 2 7 3.09314 98%
2 44 6 8 3.05461 88%
3 47 3 9 3.09179 94%
4 47 3 7 2.92314 94%
5 45 5 7 2.91244 90%
100 Tanpa Wavelet 1 43 7 7 5.8899 86%
2 43 7 6 5.50052 86%
3 42 8 8 6.13163 84%
26
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
5 44 6 7 5.78095 88%
Haar Level 1 1 42 8 6 3.58979 84%
2 44 6 6 3.68623 88%
3 43 7 6 3.6274 86%
4 45 5 6 3.58965 90%
5 43 7 7 3.60833 86%
Level 2 1 43 7 6 2.79349 86%
2 42 8 8 2.79383 84%
3 43 7 6 2.72639 86%
4 44 5 6 2.72225 88%
5 45 5 6 2.82878 90%
Level 3 1 47 3 8 2.70053 94%
2 47 3 6 2.62088 94%
3 44 6 7 2.57511 88%
4 47 3 9 2.73701 94%
Lampiran 6 Tabel generalisasi toleransi kesalahan 0.001 Hidden
Neuron Spesifikasi Ulangan ke- Dikenal TakDikenal Epoch Waktu Generalisasi
10 Tanpa Wavelet 1 30 20 139 15.2035 60%
2 39 11 305 21.7434 78%
3 25 25 123 10.648 50%
4 26 24 169 13.5012 52%
5 27 23 154 12.7228 54%
Haar Level 1 1 40 10 100 5.49568 80%
2 35 15 86 5.01748 70%
3 38 12 77 5.17253 76%
4 38 12 118 5.17253 76%
5 37 13 103 5.44331 74%
Level 2 1 45 5 23 3.11743 90%
2 37 13 64 3.76408 74%
3 44 6 47 3.50905 88%
4 40 10 53 4.51446 80%
5 42 8 56 3.67476 84%
Level 3 1 48 2 36 3.23994 96%
2 48 2 38 3.43694 96%
3 46 4 21 3.03272 92%
4 47 3 36 3.31074 94%
5 46 4 43 3.34449 92%
20 Tanpa Wavelet 1 37 13 37 6.33186 74%
2 42 8 26 5.47177 84%
3 42 8 22 5.57458 84%
4 40 10 46 7.16451 80%
5 41 9 23 5.15997 82%
Haar Level 1 1 37 13 31 3.84656 74%
2 45 5 30 3.85416 90%
3 43 7 20 3.52831 86%
4 43 7 24 3.67159 86%
5 40 10 21 3.58655 80%
Level 2 1 44 6 19 3.26383 88%
2 45 5 11 3.13257 90%
3 45 5 13 3.2339 90%
4 41 9 31 3.54305 82%
5 46 4 31 3.4789 92%
Level 3 1 49 1 18 3.14925 98%
2 49 1 20 3.08562 98%
3 44 6 31 3.25502 88%
4 49 1 19 3.03405 98%
5 48 2 17 3.0183 96%
30 Tanpa Wavelet 1 46 4 14 4.65481 92%
2 44 6 17 5.10172 88%
3 46 4 18 5.26994 92%
4 41 9 16 4.94389 82%
28
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
Haar Level 1 1 44 6 18 3.53773 88%
2 43 7 19 4.07395 86%
3 46 4 14 3.71935 92%
4 42 12 3.3472 84%
5 45 5 29 4.33479 90%
Level 2 1 46 4 18 3.22587 92%
2 47 3 11 3.87073 94%
3 46 4 17 3.20744 92%
4 46 4 13 2.93842 92%
5 45 5 12 2.96733 90%
Level 3 1 48 2 13 3.18683 96%
2 48 2 17 2.98542 96%
3 48 2 16 3.01476 96%
4 48 2 12 2.99273 96%
5 50 0 22 3.08827 100%
40 Tanpa Wavelet 1 42 8 13 5.06192 84%
2 44 6 11 4.86924 88%
3 45 5 19 6.06457 90%
4 45 5 13 5.27029 90%
5 45 5 19 6.21504 90%
Haar Level 1 1 46 4 11 3.46967 92%
2 46 4 11 3.48405 92%
3 45 5 11 3.55848 90%
4 42 8 22 4.08364 84%
5 46 4 13 3.56601 92%
Level 2 1 44 6 9 3.0113 88%
2 45 5 8 3.00007 90%
3 45 5 17 3.20974 90%
4 46 4 9 3.0149 92%
5 45 5 14 3.13056 90%
Level 3 1 48 2 16 3.0496 96%
2 49 1 14 3.04562 98%
3 49 1 14 3.06826 98%
4 50 0 17 3.03949 100%
5 48 2 14 3.02003 96%
50 Tanpa Wavelet 1 45 5 20 6.97832 90%
2 45 5 14 5.81931 90%
3 42 8 16 6.12359 84%
4 43 7 21 7.19986 86%
5 45 5 15 5.97352 90%
Haar Level 1 1 48 2 14 3.81836 98%
2 45 5 12 3.59629 90%
3 42 8 11 3.49521 84%
4 45 5 10 3.48174 90%
5 47 3 13 3.80302 94%
Level 2 1 46 4 14 3.31448 92%
2 46 4 9 3.13647 92%
Lanjutan Hidden
Neuron Spesifikasi Ulangan ke- Dikenal Tak Dikenal Epoch Waktu Generalisasi
4 47 3 10 3.16762 94%
5 43 7 7 3.07244 86%
Level 3 1 46 4 14 3.07249 92%
2 48 2 11 3.03689 96%
3 48 2 13 3.0419 96%
4 49 1 13 3.03322 98%
5 48 2 22 3.19093 96%
60 Tanpa Wavelet 1 44 6 11 5.57719 88%
2 46 4 11 5.53839 92%
3 45 5 11 5.36374 90%
4 43 7 11 5.50413 86%
5 44 6 17 6.80093 88%
Haar Level 1 1 48 2 12 3.63012 96%
2 45 5 20 4.28765 90%
3 43 7 22 4.4847 86%
4 45 5 10 3.65034 90%
5 44 6 10 3.57959 88%
Level 2 1 46 4 10 3.2556 92%
2 44 6 12 3.27579 88%
3 46 4 7 3.15911 92%
4 46 4 10 3.1372 92%
5 46 4 7 3.12255 92%
Level 3 1 50 0 13 3.00416 100%
2 49 1 12 2.99916 98%
3 47 3 12 3.01578 94%
4 47 3 16 3.60453 94%
5 48 2 17 3.17744 96%
70 Tanpa Wavelet 1 43 7 11 6.11691 86%
2 46 4 9 5.55623 92%
3 45 5 16 7.33698 90%
4 45 5 17 7.68728 90%
5 45 5 19 8.15541 90%
Haar Level 1 1 46 4 9 3.75058 92%
2 45 5 17 4.4487 90%
3 45 5 9 3.67154 90%
4 47 3 14 4.18288 94%
5 45 5 10 4.01053 90%
Level 2 1 45 5 17 3.54952 90%
2 46 4 10 3.29174 92%
3 47 3 10 3.21936 94%
4 47 3 8 3.29211 94%
5 47 3 7 3.1737 94%
Level 3 1 47 3 18 3.24886 94%