1
I.1.
Latar Belakang Masalah
Layanan internet sebagai media informasi yang semakin meningkat sudah
mulai merambah ke setiap kalangan, tidak hanya remaja atau orang dewasa akan
tetapi kalangan anak-anak pun sudah menggunakan layanan internet sebagai media
pencarian informasi baik untuk kepentingan pribadi maupun untuk pendidikan. Hal
ini memiliki dampak positif maupun negatif, sehingga terdapat beberapa
vendor
yang menyediakan aplikasi atau layanan untuk memonitoring serta dapat
membatasi kegiatan internet anak. Dodo Kids Browser merupakan salah satu
perangkat lunak yang berfungsi sebagai
parental controlling
untuk kegiatan
internet anak. Aplikasi ini dapat memberikan pemberitahuan kepada orang tua
ketika anak melakukan pencarian.
Berdasarkan hasil observasi yang dilakukan dengan cara mencoba layanan
yang disediakan pada aplikasi Dodo Kids Browser di antaranya yaitu penyaringan
konten pada kata kunci yang dimasukan anak ketika melakukan pencarian, aplikasi
ini akan melakukan pemblokiran pada setiap kata kunci yang bermakna negatif
sehingga setiap kata yang memiliki makna negatif akan selalu dilakukan
pemblokiran walaupun kata kunci yang dimasukan memiliki makna yang positif
ketika menjadi sebuah frase atau kalimat. Hal ini menyebabkan masalah pada
ketersediaan informasi yang seharusnya dapat diakses oleh anak akan tetapi
menjadi tidak bisa dilakukan karena pada kata kunci yang dimasukan tersebut
terdapat kata yang bermakna negatif. Sebagai contoh ketika anak melakukan
pencarian dalam bahasa inggris dengan kata kunci “
how to avoid violence
”,
dalam
kata kunci yang dimasukan tersebut terdapat kata “
violence
” yang memiliki makna
Berdasarkan permasalahan yang telah dipaparkan tersebut dibutuhkan suatu
solusi yang dapat mengklasifikasikan kata kunci yang dimasukan oleh anak ketika
melakukan pencarian untuk menghasilkan kesimpulan positif atau negatif dari kata
kunci yang dimasukan tersebut. Hal ini dimungkinkan dengan penggunaan
text
mining
yaitu proses yang semi otomatis melakukan klasifikasi dari pola yang
berasal dari database tidak terstruktur. Hasil dari klasifikasi dapat dijadikan sebagai
media untuk memberikan saran untuk orang tua dalam menentukan aksi terhadap
anak ketika melakukan suatu pencarian di internet.
Dalam melakukan pengklasifikasian terdapat banyak algoritma yang dapat
digunakan dalam mengklasifikasikan kata kunci pencarian ke dalam kelas negatif
atau positif salah satunya yaitu
naïve bayes. Berdasarkan beberapa penelitian
mengenai perbandingan kinerja algoritma
naïve bayes
dengan algoritma lain
disimpulkan
naïve bayes
memiliki tingkat akurasi 87.88% untuk data kategori yang
lebih baik dari tingkat akurasi algoritma
decision tree
yang memiliki 84.85% [1].
Selain itu pula terdapat penelitian mengenai penerapan naïve bayes pada
pengklasifikasian
spam
dari data latih 80 sms memiliki tingkat akurasi 85,11% [2].
Berdasarkan hal tersebut memungkinkan algoritma
naïve bayes
untuk diterapkan
dalam mengklasifikasikan kata kunci pencarian. Selain itu naïve bayes merupakan
salah satu algoritma yang konvensional dan sederhana oleh karena itu
naïve bayes
cocok untuk diimplementasikan dalam pada aplikasi pengawasan penggunaan
inter
net anak “Dodo Kids Browser”.
I.2.
Perumusan Masalah
Berdasarkan latar belakang yang telah dipaparkan sebelumnya maka dapat
dirumuskan permasalahan yang terjadi yaitu bagaimana mengimplementasikan
text
mining
pada aplikasi pengawasan penggunaan internet anak “Dodo Kids Browser”.
I.3.
Maksud dan Tujuan
Maksud dari penelitian ini yaitu mengimplementasikan
text mining
pada
Adapun tujuan dalam penelitian ini yaitu memberikan informasi berupa
saran yang diberikan untuk membantu orang tua dalam menentukan aksi terhadap
anak yang sedang melakukan
surfing
yang terindikasi terdapat kata dengan konteks
negatif pada web browser.
I.4.
Batasan Masalah
Dalam penelitian ini dilakukan pembatasan sebagai upaya agar tujuan yang
ingin dicapai tidak menyimpang. Berikut ini merupakan batasan masalah dalam
penelitian ini.
1.
Data yang digunakan berasal dari setiap pencarian yang dilakukan
pengguna.
2.
Hasil klasifikasi disajikan berupa saran untuk orang tua.
3.
Metode yang digunakan untuk pengklasifikasian dalam penelitian ini adalah
Naïve Bayes Classifier.
4.
Pendekatan analisis dan desain pada penelitian ini menggunakan
pendekatan
Object-Oriented Analysis and Design
(OOAD).
I.5.
Metodologi Penelitian
Metodologi yang digunakan dalam penelitian ini menggunakan metode
penelitian deskriptif. Metode deskriptif adalah suatu metode dalam meneliti suatu
objek, set kondisi, suatu kelas peristiwa yang terjadi pada masa sekarang. Metode
ini bertujuan untuk membuat gambaran secara sistematis dan faktual mengenai
fakta dan perilaku dari objek yang diteliti. [3]
I.5.1. Metode Pengumpulan Data
Metode pengumpulan data yang digunakan dalam penelitian ini adalah
sebagai berikut.
1. Studi Literatur
tesis maupun bacaan ilmiah lainnya yang dapat dijadikan referensi dalam
penelitian.
2. Observasi
Observasi merupakan metode pengumpulan data dengan cara mengamati
objek yang berkaitan dengan penelitian secara langsung.
I.5.2. Metode Pembangunan Perangkat Lunak
Metode pembangunan perangkat lunak dalam penelitian ini menggunakan
metode
waterfall
Ian Sommerville. Metode ini memiliki tahapan yang sistematis.
Model
waterfall
menurut Ian Sommerville dapat dilihat pada Gambar I.1.
Gambar I.1 Model
Waterfall
Ian Sommerville [4]
Berikut penjelasan dari masing-masing tahapan model
waterfall
Ian Sommerville.
[4]
Pada tahap ini dilakukan analisis kebutuhan, batasan, dan tujuan perangkat
lunak dengan berkonsultasi dengan pengguna sistem kemudian didefinisikan
secara rinci.
2.
System and Software Design
Pada tahap dilakukan pengalokasian kebutuhan perangkat lunak maupun
perangkat keras dengan merancang arsitektur sistem secara keseluruhan.
Dalam tahap ini digambarkan pula abstraksi sistem perangkat lunak yang
mendasar.
3.
Implementation and Unit Testing
Desain perangkat lunak yang telah dirancang kemudian diimplementasikan
menjadi unit program kemudian dilakukan pengujian yang melibatkan
verifikasi bahwa setiap unit yang telah didefinisikan sebelumnya telah
memenuhi spesifikasi.
4.
Integration and System Testing
Pada tahap ini unit program yang telah terintegrasi dilakukan pengujian sebagai
sistem yang lengkap untuk memastikan kebutuhan perangkat lunak sudah
terpenuhi. Setelah hal tersebut dilakukan perangkat lunak siap diberikan
kepada pengguna.
5.
Operation and Maintenance
Pada tahap ini dilakukan pengoperasian dan pemeliharan sistem. Dalam tahap
ini memungkinkan terjadinya fase siklus hidup. Pemeliharaan sistem
melibatkan pengkoreksian kesalahan yang pada tahap sebelumnya tidak
ditemukan atau peningkatan layanan sistem sebagai kebutuhan perangkat lunak
baru.
I.5.3. Metode Text Mining
Metode yang digunakan dalam implementasi text mining pada aplikasi
pengawasan penggunaan internet anak "Dodo Kids Browser" memiliki beberapa
langkah sebagai berikut.
Pada tahap ini dilakukan penentuan sumber data yang akan digunakan. Sumber
data yang digunakan berhubungan pada proses pencarian pada web browser.
2.
Preprocessing
Dalam tahap ini setelah menentukan sumber data dilakukan preprocessing
terhadap sumber data untuk pengoptimalan klasifikasi yang akan dilakukan.
3.
Proses Klasifikasi
Proses klasifikasi ini menentukan apakah pencarian sebagai sumber data
termasuk pada kelas negatif atau positif.
4.
Implementasi Sistem
Pada tahap ini dilakukan implementasi hasil analisis yang telah dilakukan ke
dalam sebuah sistem.
5.
Pengujian Sistem
Pengujian dilakukan untuk menentukan tingkat akurasi dari hasil klasifikasi
yang telah diimplementasikan ke dalam sistem.
I.6.
Sistematika Penulisan
Sistematika penulisan laporan penelitian ini disusun untuk memberikan
gambaran umum mengenai penelitian yang dilakukan. Sistematika penulisan dalam
penelitian ini adalah:
BAB 1 PENDAHULUAN
Bab ini menerangkan tentang latar belakang masalah, rumusan masalah,
maksud dan tujuan penelitian, batasan masalah, metodologi penelitian serta
sistematika penulisan.
BAB 2 TINJAUAN PUSTAKA
Bab ini membahas sekilas tentang Dodo Kids Browser dan teori-teori yang
berhubungan dengan topik penelitian yang dilakukan.
Bab ini berisi tentang analisis sistem yang terdiri dari analisis masalah,
analisis sistem yang sedang berjalan, analisis arsitektur sistem, analisis sumber data,
analisis
preprocessing, analisis penerapan algoritma
naïve bayes classifier,
menentukan spesifikasi kebutuhan perangkat lunak, analisis kebutuhan fungsional,
analisis kebutuhan non fungsional, analisis data, analisis
user. Selain itu terdapat
pula perancangan antarmuka untuk aplikasi yang akan dibangun.
BAB 4 IMPLEMENTASI DAN PENGUJIAN SISTEM
Bab ini berisi tahap implementasi dari hasil analisis dan perancangan sistem
ke dalam aplikasi yang diteliti kemudian dibahas juga pengujian terhadap perangkat
lunak yang telah diimplementasikan
text mining
tersebut.
BAB 5 KESIMPULAN DAN SARAN
9
II.1.
Dodo Kids Browser
Dodo Kids Browser merupakan aplikasi parental
controlling
terhadap
kegiatan internet anak. Aplikasi ini terdiri dari dua jenis platform yaitu berupa
extension
pada
web browser desktop
dan
mobile
Windows Phone. Dodo Kids
Browser Extension pada
web browser desktop
digunakan sebagai fungsi tambahan
pada aplikasi web browser untuk melakukan
filtering
terhadap aktifitas pencarian
anak di mana jika anak melakukan pencarian dengan menggunakan
keyword
yang
mengandung kata negative maka aplikasi ini akan mengirimkan notifikasi kepada
orang tua yang menggunakan aplikasi Dodo Kids Browser versi
mobile
Windows
Phone yang berguna untuk memberikan aksi kepada anak yang sedang melakukan
browsing
tersebut seperti memberikan suatu pesan atau nasihat. Selain untuk
memberikan aksi aplikasi Dodo Kids Browser Windows Phone yang digunakan
oleh orang tua dapat melakukan monitoring terhadap aktifitas browsing anak. Pada
aplikasi
mobile
version-nya tersebut pun dapat memiliki
kids
mode yang dapat
digunakan oleh anak untuk melakukan
browsing
aman dengan menggunakan
perintah suara (speech recognition) atau teks seperti biasa.
II.2.
Text Mining
Text Mining
merupakan suatu langkah dari analisis teks yang dilakukan
secara otomatis oleh sistem komputer untuk menghasilkan informasi baru yang
belum diketahui sebelumnya yang diambil dari suatu rangkaian teks yang
terangkum dalam sebuah dokumen [5]. Text Mining adalah bidang multi disiplin
yang melibatkan information retrieval, text analysis, information extraction,
clustering, categorization, visualization, machine learning dan teknik lainnya [6].
Text mining menggunakan penerapan data mining untuk mengubah data tidak
terstruktur menjadi data terstruktur melalui tahap-tahap yaitu [6]:
2.
Feature Generation
/
Text Transformation
yaitu mengubah kata-kata ke dalam
bentuk dasar sekaligus mengurangi jumlah kata-kata tersebut.
3.
Feature Selection
yaitu seleksi feature untuk mengurangi dimensi dari suatu
kumpulan teks.
4.
Text Mining
/
Pattern Discovery
yaitu dapat berupa
unsupervised learning
(clustering) atau
supervised learning
(classification).
5.
Interpretation / Evaluation
yaitu pengukuran efektifitas untuk mengevaluasi
metode yang diterapkan menggunakan parameter
precision.
II.3.
Analisis Sentimen
Analisis sentimen atau dapat disebut juga
opinion mining
merupakan proses
memahami, mengekstrak dan mengolah data teks tekstual secara otamatis untuk
mendapatkan informasi sentiment yang terkandung dalam suatu kalimat opini [7].
Analisi sentimen bertujuan menentukan suatu isi dari dataset yang berbentuk
tesktual atau kalimat apakah bernilai sentimen positif atau negatif [8].
Opinion
mining
dapat dianggap pula sebagai kombinasi antara
text mining
dan natural
language processing. Metode klasifikasi merupakan metode yang dapat digunakan
untuk menyelesaikan masalah pada
text mining. Salah satunya yaitu dengan
menggunakan algoritma
Naïve Bayes Classifier
(NBC). Sedangkan Natural
language processing
befungsi untuk memberikan kelas kata (tag) ke setiap kata
dalam suatu kalimat.
II.4.
Preprocessing
Preprocessing
merupakan tahapan sebelum proses pengklasifikasian yang
diperlukan untuk membersihkan, menghilangkan, mengubah sumber data, baik itu
berupa karakter non alfabet maupun kata-kata yang tidak diperlukan. Hal ini
bertujuan agar data yang digunakan lebih optimal ketika digunakan pada proses
pengklasifikasiannya.Tahapan preprocessing setiap kasus dapat berbeda-beda.
Berikut ini merupakan tahapan preprocessing dan penjelasannya yang digunakan
dalam penelitian ini.
Cleansing
merupakan proses membersihkan data yang akan digunakan dari
karakter-karakter bahkan kata-kata yang tidak diperlukan. Hal ini bertujuan untuk
mengurangi noise yang dapat menimbulkan proses perhitungan dalam
pengklasifikasian tidak optimal.
2.
Case Folding
Case Folding
merupakan proses pengubahan data menjadi format yang
sesuai. Hal ini bertujuan mengurangi redudansi data yang akan digunakan dalam
proses pengklasifikasian sehingga proses perhitungan pun menjadi optimal.
Contohnya mengubah format data menjadi lowercase atau uppercase sesuai dengan
kebutuhan yang dibutuhkan dalam proses pengklasifikasiannya.
3.
Tokenizing
Tokenizing
merupakan proses pemisahan atau memotong data baik berupa
frasa, klausa, atau kalimat menjadi kata perkata berdasarkan delimeter yang
digunakan yaitu space.
II.5.
Naïve Bayes Classifier
(NBC)
Naïve Bayes Classifier
merupakan suatu metode
classifier
yang mengacu
pada teorema
bayes
yaitu teorema yang mengacu pada konsep probabilitas
bersyarat. Pada metode ini diperlukan kombinasi pengetahuan sebelumnya dengan
pengetahuan yang baru [9]. Dalam melakukan pengklasifikasiannya diperlukan
training
set sebagai data latih. Pada setiap
sample
dari data latih tersebut memiliki
kelas label tersendiri. Berikut merupakan model matematis
naïve bayes classifier
yaitu:
( | ) =
( ) ( | )( )
[2]
Di mana:
X
= Data dengan kelas yang belum diketahui
H
= Hipotesa data X merupakan suatu kelas spesifik
p(H|X)
= Probabilitas hipotesis H berdasarkan kondisi X (posterior
probability)
II.6.
Object-Oriented Analysis and Design
(OOAD)
Object-Oriented Analysis and Design
(OOAD) merupakan suatu metode
analisis dalam pembangunan perangkat lunak yang berorientasi pada objek. Proses
analisis yang dilakukan yaitu dengan memeriksa kebutuhan berdasarkan sudut
pandang kelas dan objek yang terdapat pada ruang lingkup permasalahan. Proses
analisis dilakukan menggunakan model menurut konsep sekitar dunia nyata yang
dalam konsep tersebut ialah objek yang merupakan gabungan dari struktur data
serta perilaku dalam suatu entitas. Dalam metode OOAD terdapat konsep umum
salah satunya yaitu kelas. Kelas merupakan kumpulan dari objek-objek yang
memiliki karakter serupa. Sebuah kelas memiliki atribut, operasi/metode, relasi,
dan arti. Atribut dalam kelas merupakan suatu variable global berupa nilai atau
elemen data suatu objek. Metode dalam kelas berguna untuk mengoperasikan suatu
objek tertentu. Suatu kelas dapat mewarisi sebagian objek atau seluruhnya ke kelas
yang baru di mana hal ini disebut dengan
inheritance
(pewarisan). Dalam suatu
kelas terdapat objek yaitu suatu entitas yang dapat menyimpan informasi serta
mampu melakukan operasi tertentu.
Dalam memodelkan OOAD terdapat
tools
yang biasa digunakan yaitu UML
(Unified Modeling Languages). UML merupakan sebuah bahasa standar dalam
industri untuk proses visualsasi, perancangan, dan pendokumentasian perangkat
lunak. Berikut adalah diagram yang umum digunakan dalam analisis dan desain.
1.
Use Case Diagram
Use Case Diagram menggambarkan fungsional berdasarkan sistem yang akan
dibangun. Dalam sebuah usecase terdapat aktor yang menunjukan interaksi
pengguna dengan fungsional dalam suatu sistem. [10]
2.
Use Case Scenario
Use case scenario digunakan untuk mendeskripsikan informasi dari interaksi
aktor dan sistem secara detail.
Activity diagram
menggambarkan alur dari aktifitas satu secara sekuensial use
case mulai dari awal fungsional dijalankan hingga sampai tercapainya tujuan
dari use case itu sendiri.
4.
Class Diagram
Class diagram
menggambarkan hubungan antara class, interface, beserta objek
pada suatu sistem.
5.
Sequence Diagram
Sequence diagram
menggambarkan interaksi di antara
object
secara berurutan
mulai dari objek diciptakan sampai berakhir aktifitas pada objek tersebut.
II.7.
JSON
JSON (JavaScript Object Notation) merupakan format pertukaran data yang
ringan, mudah dibaca dan ditulis oleh manusia serta mudah dibuat dan
diterjemahkan oleh komputer [11]. JSON terdiri dari objek dan
array. Objek
merupakan sepasang nama dan nilainya yang tidak memiliki urutan. Objek
menggunakan simbol { (kurung kurawal terbuka) dan } (kurung kurawal tertutup)
sebagai pembuka dan penutup. Array merupakan kumpulan nilai yang memiliki
urutan dengan [ (kurung siku buka) sebagai pembuka dan ](kurung siku tutup)
sebagai penutup array. Setiap objek dan array dapat di definisikan oleh item dan
nilainya dimana nama item dan nilainya dipisahkan dengan : (titik dua) dan diakhir
dengan , (koma) bila memiliki item terurut lebih dari satu.
II.8.
XML
II.9.
Pengujian Black box
Pengujian
black box
merupakan pengujian yang berfokus pada persyaratan
fungsional perangkat lunak. Pengujian black box memungkinkan pengembang
perangkat lunak untuk mengetahui berbagai kondisi masukan terhadap
syarat-syarat fungsional suatu sistem. Pengujian black box ini merupakan upaya untuk
menemukan kesalahan-kesalahan antara lain yaitu kesalahan fungsi atau fungsi
yang hilang, kesalahan antarmuka, kesalahan struktur data, kesalahan performa, dan
kesalahan dalam inisialisasi dan terminasi. Pada pengujian black box terdapat
teknik pengujian yang membagi domain input dari suatu program menjadi beberapa
kelas data dari kasus ujicoba yang dihasilkan. Metode pengujian black box tersebut
dinamakan equivalence partioning. Equivalence Partioning berfokus pada kasus uji
untuk menemukan sejumlah jenis kesalahan dan mengurangi jumlah kasus ujicoba
yang harus dibuat. Kondisi input yang diuji pada metode Equivalence Partioning
ini merepresentasikan apa yang dihasilkan oleh inputan tersebut valid atau tidak.
Misalkan kondisi input yang diharapkan sebuah program yang diinginkan yaitu
sebuah teks dengan format yang telah ditetapkan, sehingga jika kondisi tidak sesuai
maka hasilnya menjadi tidak valid.
II.10. Pengujian White Box
Pengujian
White Box
merupakan metode
test case
dengan menggunakan
struktur control desain prosedural untuk memperoleh kasus-kasus uji. Tujuan dari
pengujian white box ini, pengembang perangkat lunak dapat menghasilkan
kasus-kasus uji sebagai berikut:
1.
Menjamin bahwa seluruh
independent paths
dalam modul telah dilakukan
sedikitnya satu kali.
2.
Melakukan seluruh keputusan logika baik dari segi yang benar maupun yang
salah.
3.
Melakukan seluruh perulangan sesuai dengan batasan yang telah ditentukan.
4.
Menguji struktur data internal untuk memastikan validitasnya.
1.
Kesalahan logika dan asumsi.
61
V.1.
Kesimpulan
Berdasarkan dari hasil penelitian yang telah dilakukan bahwa penerapan text
mining dalam aplikasi pengawasan penggunaan internet anak “dodo kids browser”
dengan memberikan solusi berupa suatu pemberian informasi berupa saran hasil
klasifikasi dari kata kunci yang digunakan oleh anak dalam suatu pencarian di web
browser untuk membantu orang tua dalam memberikan aksi terhadap anak ketika
anak tersebut terindikasi menggunakan kata kunci dengan konteks negatif telah
diimplementasikan sesuai dengan analisis dan perancangan sebelumnya. Sehingga
dapat disimpulkan bahwa hasil klasifikasi ini mampu membantu orang tua dalam
mendapatkan informasi berupa saran dalam menentukan aksi yang tepat untuk anak
yang terindikasi melakukan pencarian ketika
surfing
dengan kata yang mengandung
makna buruk.
V.2.
Saran
Kab.Bandung Jawa Barat 40977.
Phone
:
+628987089452
:
Personal Information
Place & D.O.B
:
Bandung, June 6
th1993
Marital Status
:
Single
Religion
:
Moslem
Languages Known
:
Sunda, Indonesian, English
Formal Education
Indonesia Computer
University
Majoring Informatics
Engineering
2011
–
present
SMK Pasundan 2 Banjaran
Majoring Computer and
Network Engineering
2008
–
2011
SMPN 1 Katapang
2005
–
2008
SDN Cingcin I
1999
–
2005
Professional Experiences
Present
-
Freelancer Windows Phone Developer
-
C# Developer
July 2014 – Present, member of Unikom Codelabs
-
Windows Phone Developer
September 2010 – October 2010, BAPAPSI Kab.Bandung
-
Network Implementation
Projects Experience
NETWORKING
•
Laundry Application using C (console).
•
Musicalius Application (Sistem Informasi Penjualan CD Musik) using WPF C#.
•
Fruitophia Application (Sistem Informasi Penjualan Buah-buahan) using WPF
C#.
•
Sistem Informasi Rekam Medis Klinik Serba Bakti using WPF C#.
WEB APPLICATION
•
Karaoke Online
•
Game edukasi gerbang logika using constract 2
•
parttty.com (aplikasi pencarian pekerjaan bagi freelancer)
•
firdausakhmad.com (aplikasi penjualan unit airsoft)
ANDROID APPLICATION
•
Aplikasi Workshop Internal Divisi CodeLabs UNIKOM.
WINDOWS PHONE APPLICATION
•
UNIKOM Apps University Profile.
•
Dapurmasak.com versi mobile
•
Bantu Anak Asuh
•
Dodo Kids Browser
•
Chatting Application with JSON-RPC
WINDOWS RT APPLICATION
•
Calcio Store Application
•
Chloropaint
•
Game Ya Bisa Jadi Tidak
Skills
Operating System
:
Microsoft Windows XP
Microsoft Windows 7
Microsoft Windows 8
Microsoft Windows 8.1
Integrated Development Environment
:
Eclipse
Adobe DreamWeaver CS5
WeBuilder
Microsoft Visual Studio 2013
Dev C++
PHP
Java
C / C++ / C#
Swift
Network Simulation
:
Cisco Packet Tracer
Achievement
2014
INAICTA 2014
Finalis category E-Inclusion
(Indonesia ICT Award)
Project name : Bantu Anak Asuh
2015
Imagine Cup Indonesia
2015
Winner 1
stCategory Innovation
Project Name: Dodo Kids Browser
2015
Imagine Cup World Wide
2015
SKRIPSI
Diajukan untuk menempuh Ujian Akhir Sarjana
FIRDAUS AKHMAD MUTTAQIN
10111371
PROGRAM STUDI TEKNIK INFORMATIKA
FAKULTAS TEKNIK DAN ILMU KOMPUTER
vi
vii
63
dan Naive Bayes dalam Prediksi Kebangkrutan," UG Repository, Jakarta,
2014.
[2] E. A.W, M. and T. , "Penerapan Naive Bayes Untuk Sistem Klasifikasi SMS
Pada Smartphone Android," EPrints 3 , Palembang, 2013.
[3] M. Nazir, Metode Penelitian, Bogor: Ghalia Indonesia, 2005.
[4] S. Ian, Software Engineering, Addison Wesley, 2007.
[5] S. Andini, "Klasifikasi Dokument Teks Menggunakan Algoritma Naïve
Bayes Dengan Bahasa Pemograman Java,"
Jurnal Teknologi Informasi &
Pendidikan,
vol. 6, pp. 140-147, 2013.
[6] A. Nurani, B. Susanto and U. Proboyekti, "Implementasi Naive Bayes
Classifier Pada Program Bantu Penentuan Buku Referensi Matakuliah,"
Jurnal Informatika,
vol. 3, pp. 32-36, 2007.
[7] I. F. Rozi, S. H. Pramono and E. A. Dahlan, "Implementasi Opinion Mining
(Analisis Sentimen) Untuk Ekstraksi Data Opini Publik pada Perguruan
Tinggi,"
Jurnal EECCIS,
vol. 6, pp. 37-43, 2012.
[8] J. Ling, I. P. E. N. Kencana and T. B. Oka, "Analisis Sentimen Menggunakan
Metode Naive Bayes Classifier Dengan Seleksi Fitur Chi Square,"
E-Jurnal
Matematika,
vol. 3, pp. 92-99, 2014.
[9] S. F. Rodiyansyah and E. Winarko, "Klasifikasi Posting Twitter Kemacetan
Lalu Lintas Kota Bandung Menggunakan Naive Bayesian Classification,"
IJCCS,
vol. 6, pp. 91-100, 2012.
[10] R. Miles and K. Hamilton, Learning UML 2.0, Sebastopol: O'Reilly Media,
Inc, 2006.
64
Available: http://rifiana.staff.gunadarma.ac.id. [Accessed 2015 Agustus 19].
[14] A. R. Sentiaji, "Analisis Sentimen Terhadap Acara Televisi Indonesia
Firdaus Akhmad Muttaqin1, Adam Mukaharil Bachtiar2
1,2Teknik Informatika - Universitas Komputer Indonesia
Jl. Dipati Ukur No. 112-116, Bandung 40132
E-mail: [email protected], [email protected]2
ABSTRAK
Dodo Kids Browser merupakan perangkat lunak parental kontrol untuk kegiatan pencarian atau surfing di internet oleh anak. Pengawasan dilakukan dengan cara memblokir setiap kata yang memiliki konteks negatif yang kemudian muncul pesan pada aplikasi mobile milik orang tua untuk memberikan aksi, namun kurangnya informasi mengenai sentimen darikeywordyang dimasukan menyulitkan orang tua untuk mengetahui apakahkeywordtersebut termasuk pada sentimen negatif atau tidak. Hal tersebut berdampak pada pemilihan aksi yang akan diberikan oleh orang tua. Penerapan text mining dapat dijadikan sebagai solusi.
Implementasi teks mining digunakan untuk melakukan proses klasifikasi terhadap pencarian anak dalam mendapatkan informasi mengenai sentimennya. Tahapan yang dilakukan untuk proses klasifikasi yang pertama yaitu preprocessing data. Selanjutnya hasil data hasil preprocessing tersebut diterapkan pada algoritma Naïve Bayes Classifier
untuk proses klasifikasi. Hasil klasifikasi yang ditampilkan yaitu berupa informasi mengenai saran dalam menentukan aksi oleh orang tua.
Hasil implementasi text mining terhadap sistem yang telah dilakukan pengujian fungsionalitas sistem, menguji algoritma naïve bayes classifier, dan pengujian terhadap beberapa sampel data uji. Hasil dari pengujian tersebut menyimpulkan bahwa sistem yang dibangun mampu memberikan informasi berupa saran yang mampu membantu orang tua dalam memutuskan pemberia aksi terhadap aktifitas internet anaknya.
Kata Kunci:Text Mining, Analisis Sentimen, Naïve Bayes Classifier, Klasifikasi.
1. PENDAHULUAN
Layanan internet sebagai media informasi yang semakin meningkat sudah mulai merambah ke setiap kalangan, tidak hanya remaja atau orang dewasa akan tetapi kalangan anak-anak pun sudah menggunakan layanan internet sebagai media pencarian informasi baik untuk kepentingan pribadi maupun untuk pendidikan. Hal ini memiliki dampak positif maupun
negatif, sehingga terdapat beberapa vendor yang menyediakan aplikasi atau layanan untuk memonitoring serta dapat membatasi kegiatan internet anak. Dodo Kids Browser merupakan salah satu perangkat lunak yang berfungsi sebagaiparental controllinguntuk kegiatan internet anak. Aplikasi ini dapat memberikan pemberitahuan kepada orang tua ketika anak melakukan pencarian.
Berdasarkan hasil observasi yang dilakukan dengan cara mencoba layanan yang disediakan pada aplikasi Dodo Kids Browser di antaranya yaitu penyaringan konten pada kata kunci yang dimasukan anak ketika melakukan pencarian, aplikasi ini akan melakukan pemblokiran pada setiap kata kunci yang bermakna negatif sehingga setiap kata yang memiliki makna negatif akan selalu dilakukan pemblokiran walaupun kata kunci yang dimasukan memiliki makna yang positif ketika menjadi sebuah frase atau kalimat. Hal ini menyebabkan masalah pada ketersediaan informasi yang seharusnya dapat diakses oleh anak akan tetapi menjadi tidak bisa dilakukan karena pada kata kunci yang dimasukan tersebut terdapat kata yang bermakna negatif. Sebagai contoh ketika anak melakukan pencarian dalam
bahasa inggris dengan kata kunci “how to avoid violence”, dalam kata kunci yang dimasukan tersebut terdapat kata “violence” yang memiliki makna negatif
bagi anak akan tetapi jika dalam sebuah kalimat, kata kunci yang dimasukan tersebut memiliki makna yang positif. Hal tersebut disebabkan karena keterbatasan kemampuan untuk menghasilkan kesimpulan dari kata kunci pencarian yang dimasukan oleh anak. Hal ini dapat menyulitkan orang tua dalam mendapatkan referensi untuk menentukan aksi yang tepat kepada anak.
banyak algoritma yang dapat digunakan dalam mengklasifikasikan kata kunci pencarian ke dalam kelas negatif atau positif salah satunya yaitu naïve bayes. Berdasarkan beberapa penelitian mengenai perbandingan kinerja algoritma naïve bayes dengan algoritma lain disimpulkan naïve bayes memiliki tingkat akurasi 87.88% untuk data kategori yang lebih baik dari tingkat akurasi algoritma decision tree yang memiliki 84.85% [1]. Selain itu pula terdapat penelitian mengenai penerapan naïve bayes pada pengklasifikasian spam dari data latih 80 sms memiliki tingkat akurasi 85,11% [2]. Berdasarkan hal tersebut memungkinkan algoritmanaïve bayesuntuk diterapkan dalam mengklasifikasikan kata kunci pencarian. Selain itu naïve bayes merupakan salah satu algoritma yang konvensional dan sederhana oleh karena itu naïve bayes cocok untuk diimplementasikan dalam pada aplikasi pengawasan
penggunaan internet anak “Dodo Kids Browser”.
1.1 Text Mining
Text Mining merupakan suatu langkah dari analisis teks yang dilakukan secara otomatis oleh sistem komputer untuk menghasilkan informasi baru yang belum diketahui sebelumnya yang diambil dari suatu rangkaian teks yang terangkum dalam sebuah dokumen [3]. Text Mining adalah bidang multi disiplin yang melibatkan information retrieval, text analysis, information extraction, clustering, categorization, visualization, machine learning dan teknik lainnya [4]. Text mining menggunakan penerapan data mining untuk mengubah data tidak terstruktur menjadi data terstruktur melalui tahap-tahap yaitu [4]:
1. Text Preprocess yaitu pemecahan sekumpulan karakter ke dalam kata-kata.
2. Feature Generation / Text Transformation yaitu mengubah kata-kata ke dalam bentuk dasar sekaligus mengurangi jumlah kata-kata tersebut. 3. Feature Selection yaitu seleksi feature untuk
mengurangi dimensi dari suatu kumpulan teks. 4. Text Mining / Pattern Discovery yaitu dapat
berupa unsupervised learning (clustering) atau supervised learning (classification).
5. Interpretation / Evaluation yaitu pengukuran efektifitas untuk mengevaluasi metode yang diterapkan menggunakan parameter precision.
1.2 Analisis Sentimen
Analisis sentimen atau dapat disebut jugaopinion mining merupakan proses memahami, mengekstrak dan mengolah data teks tekstual secara otamatis untuk mendapatkan informasi sentiment yang terkandung dalam suatu kalimat opini [5]. Analisi sentimen bertujuan menentukan suatu isi dari dataset yang
mining dan natural language processing. Metode klasifikasi merupakan metode yang dapat digunakan untuk menyelesaikan masalah pada text mining. Salah satunya yaitu dengan menggunakan algoritma
Naïve Bayes Classifier (NBC). Sedangkan Natural language processing befungsi untuk memberikan kelas kata (tag) ke setiap kata dalam suatu kalimat.
1.3Preprocessing
Preprocessing merupakan tahapan sebelum proses pengklasifikasian yang diperlukan untuk membersihkan, menghilangkan, mengubah sumber data, baik itu berupa karakter non alfabet maupun kata-kata yang tidak diperlukan. Hal ini bertujuan agar data yang digunakan lebih optimal ketika digunakan pada proses pengklasifikasiannya. Tahapanpreprocessing setiap kasus dapat berbeda-beda. Berikut ini merupakan tahapan preprocessing dan penjelasannya yang digunakan dalam penelitian ini.
1. Cleansing
Cleansingmerupakan proses membersihkan data yang akan digunakan dari karakter-karakter bahkan kata-kata yang tidak diperlukan. Hal ini bertujuan untuk mengurangi noise yang dapat menimbulkan proses perhitungan dalam pengklasifikasian tidak optimal.
2. Case Folding
Case Foldingmerupakan proses pengubahan data menjadi format yang sesuai. Hal ini bertujuan mengurangi redudansi data yang akan digunakan dalam proses pengklasifikasian sehingga proses perhitungan pun menjadi optimal. Contohnya mengubah format data menjadi lowercase atau uppercase sesuai dengan kebutuhan yang dibutuhkan dalam proses pengklasifikasiannya.
3. Tokenizing
Tokenizing merupakan proses pemisahan atau memotong data baik berupa frasa, klausa, atau kalimat menjadi kata perkata berdasarkan delimeter yang digunakan yaitu space.
1.4 Algoritma Naïve Bayes
Naïve Naïve Bayes Classifier merupakan suatu metodeclassifieryang mengacu pada teoremabayes
yaitu teorema yang mengacu pada konsep probabilitas bersyarat. Pada metode ini diperlukan kombinasi pengetahuan sebelumnya dengan pengetahuan yang baru [7]. Dalam melakukan pengklasifikasiannya diperlukantrainingset sebagai data latih. Pada setiapsampledari data latih tersebut memiliki kelas label tersendiri. Berikut merupakan model matematisnaïve bayes classifieryaitu:
( | ) =
( ) ( | )spesifik
p(H|X)= Probabilitas hipotesis H berdasarkan kondisi X (posterior probability)
p(H) = Probabilitas hipotesis H (prior probabilty)
2. ISI PENELITIAN
Isi penelitian ini bertujuan untuk memaparkan penelitian yang dilakukan dari proses analisis hinga implementasi ke dalam sistem. Berikut bahasan dari penelitian ini.
2.1 Analisis Masalah
Permasalahan yang terjadi pada penelitian ini yaitu orang tua sebagai pengguna perlu menentukan aksi yang tepat terhadap pencarian yang dilakukan oleh anak apakah bersifat positif atau negative, sehingga diperlukan informasi hasil klasifikasi pencarian tersebut berupa saran untuk menentukan aksi yang akan diberikan.
2.2 Sumber Data
Sumber data yang digunakan berupa kata kunci pencarian berupa URL suatu search engine. Dalam melakukan request pencarian, suatu search engine akan melakukan request data dengan menggunakan metode GET dengan contoh yaitu dengan mengirimkan suatu parameter yang berisi kata kunci yang dimasukan. Berikut merupakan contoh dari sumber data tersebut yang disajikan pada Tabel 1.
Tabel 1 Sumber Data Kata
kunci Pencarian
Format URL Nama Parameter Good people example http://www.bing.com/ search?q=good+peop le+example&go=Sub mit&qs=n&form=QB LH&pq=good+peopl e+example&sc=0- 0&sp=-1&sk=&cvid=f83230 14b9c64795b681234 61eb2a982 q
Kind of cas https://www.google.c om/search?q=Search +something&gws_rd =ssl
q
How to avoid violence https://www.google.c om/search?q=Search +something&gws_rd =ssl#q=what+do+i+s earch q
How to bully people https://www.google.c om/search?q=How+t q o+bully+people&gws _rd=ssl Example of violence https://www.google.c om/search?q=How+t o+bully+a+people&g ws_rd=ssl q Good violence http://www.bing.com/ search?q=Good+viol ence&go=Submit&qs =n&form=QBRE&pq =Good+violence&sc =8-10&sp=-1&sk=&cvid=166e13 1d89424cefa4e2aec4 be4891fd q
2.3 Implementasi Preprocessing
Proses preprocessing dilakukan guna mengubah sumber data menjadi format yang sesuai dan mudah untuk dilakukan proses pengklasifikasian sehingga proses klasifikasi tersebut dapat lebih optimal. Tahapan preprocessing yang dilakukan pada penelitian ini yaitu mulai dari prosescleansing,case folding, dan yang terakhir adalah proses tokenizing. Tahapan-tahapan tersebut dilihat pada Gambar 1.
Gambar 1 Tahapan Preprocessing
Berikut ini merupakan implementasi penjelasan dari tahapan-tahapan tersebut.
1. Cleansing
Pada tahap ini dilakukan pembersihan simbol dan huruf yang tidak diperlukan. Selain itu dilakukan pula perubahan simbol tertentu yang berhubungan dengan kata kunci pencarian yaitu formatspace, yang dalam hal ini space akan berubah menjadi simbol + (plus), sehingga dilakukan pengubahan kembali menjadispace. Langkah-langkah proses
Gambar 2 Flowchart Proses Cleansing
[image:30.595.71.287.387.766.2]Data masukan pada proses cleansing ini berupa URL yang dihasilkan ketika melakukan pencarian pada web browser. Berikut merupakan contoh dari penerapan proses cleansing yang disajikan pada Tabel 2
Tabel 2 Proses Cleansing Data Masukan Hasil Cleansing http://www.bing.com /search?q=good+peo ple+example&go=Su bmit&qs=n&form=Q BLH&pq=good+peo ple+example&sc=0- 0&sp=-1&sk=&cvid=f83230 14b9c64795b681234 61eb2a982
Good people example
https://www.google.c om/search?q=Search +something&gws_rd =ssl
Kind of cas
https://www.google.c om/search?q=Search +something&gws_rd =ssl#q=what+do+i+s earch
How to avoid violence
https://www.google.c om/search?q=How+t o+bully+people&gws _rd=ssl
How to bully people
https://www.google.c om/search?q=How+t o+bully+a+people&g ws_rd=ssl
Example of violence
http://www.bing.com /search?q=Good+viol ence&go=Submit&qs Good violence =8-10&sp=-1&sk=&cvid=166e13 1d89424cefa4e2aec4 be4891fd
2. Case Folding
Pada tahap case folding dilakukan pengubahan data hasil proses cleansing menjadi ke dalam bentuk yang sama. Dalam kasus ini pengubahan dilakukan menjadi ke dalam format lower case. Berikut merupakan tahapan proses case folding
yang disajikan dalam bentuk flowchart pada gambar.
Gambar 3 Flowchart Proses Cleansing
Berdasarkan Gambar 3, berikut merupakan contoh dari penerapan proses case folding yang disajikan pada Tabel 3.
Tabel 3 Penerapan Proses Case Folding Data Masukan HasilCase Folding
Good people example good people example Kind of cats kind of cats
How to avoid violence how to avoid violence How to bully people how to bully people Example of violence example of violence Good violence good violence
3. Tokenizing
Tokenizing merupakan tahapan melakukan pemecahan suatu gabungan dua kata atau lebih atau dapat disebut juga seperti suatu frasa atau kalimat sehingga menjadi persatu satu. Dalam kasus ini pemisahan yang dilakukan berdasarkan
Gambar 4 Flowchart Proses Tokenizing
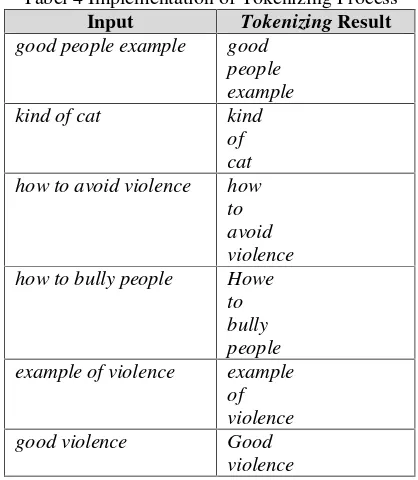
[image:31.595.323.514.360.627.2]Berdasarkan Gambar 4, berikut merupakan contoh dari penerapan proses tokenizing yang disajikan pada Tabel 4.
Tabel 4 Penerapan Proses Tokenizing Data Masukan HasilTokenizing
good people example good people example
kind of cat kind
of cat how to avoid violence how
to avoid violence how to bully people Howe
to bully people example of violence example
of violence
good violence Good
violence
Berdasarkan tabel, data masukan tersebut merupakan data hasil dari proses case folding
yang kemudian dilakukan proses tokenizing
sehingga dihasilkan pemisahan setiap kata.
2.4 Implementasi Algoritma Naïve Bayes
Tahap Pada tahap ini dilakukan proses analisis algoritma Naïve Bayesyang merupakan hal penting dalam melakukan pengklasifikasian terhadap sumber
yaitu proses pembelajaran dan proses pengklasifikasian. Berikut merupakan penjelasan masing-masing proses.
1. Proses Pembelajaran
Dalam proses ini naïve bayes classifier perlu diberi pengetahuan awal untuk dijadikan acuan agar dapat melakukan pengklasifikasian terhadap data tekstual berdasarkan sentimennya. Dalam proses pembelajaran atau learning ini terdapat tiga langkah utama. Berikut merupakan ketiga langkah utama tersebut beserta penjelasannya. a. Penentuan Kelas Data Latih
Pada tahap ini dilakukan penentuan kelas suatu data. Penentuan kelas tersebut ditentukan dengan bantuan pengguna dengan cara memberikan opini terhadap suatu keyword pencarian apakah termasuk pada kelas positif atau kelas negatif. Berikut merupakan contoh dari penentuan kelas data latih yang disajikan pada Tabel 5.
Tabel 5 Penentuan Kelas Data
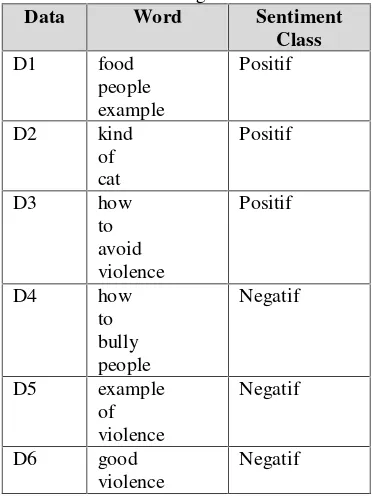
Data Kata Kelas
Sentimen D1 food people example Positif D2 kind of cat Positif D3 how to avoid violence Positif D4 how to bully people Negatif D5 example of violence Negatif D6 good violence Negatif
b. Perhitungan Probabilitas
[image:31.595.74.281.407.653.2]Pada tahap ini dilakukan perhitungan probabilitas terhadap data yang telah ditentukan kelasnya. Tabel 6 merupakan perhitungan probabilitas dari setiap kelas.
Tabel 6 Perhitungan Probabilitas
[image:31.595.320.519.707.760.2]Negatif 0 0 0 4 3 2 9/19 Total 3 3 4 4 3 2 1
c. Menentukan Probabilitas Item
Setelah probabilitas setiap kelas dihitung, selanjutnya dilakukan perhitungan probabilitas setiap itemnya. Berikut merupakan rumus untuk menghitung probabilitas per-item tersebut.
( ) = ( ) ( ) Dimana,
( )= Probabilitas item ( )= Frekuensi item
( )= Frekuensi total item berdasarkan kelas sentimennya.
[image:32.595.395.471.87.373.2]Berikut merupakan perhitungan probabilitas setiap item yang disajikan pada Tabel 7.
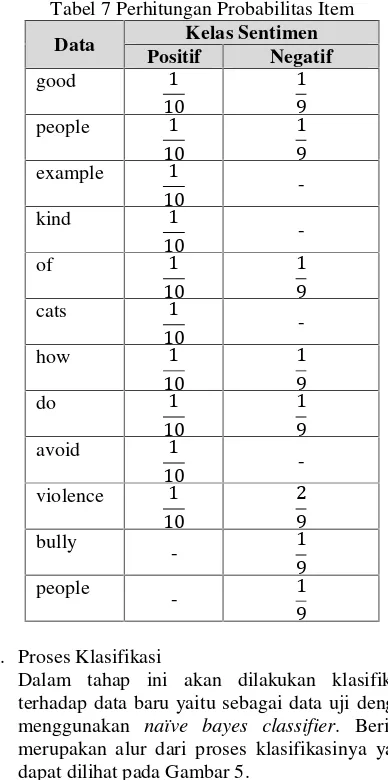
Tabel 7 Perhitungan Probabilitas Item
Data Kelas Sentimen Positif Negatif good 1 10 1 9 people 1 10 1 9 example 1 10 -kind 1 10 -of 1 10 1 9 cats 1 10 -how 1 10 1 9 do 1 10 1 9 avoid 1 10 -violence 1 10 2 9 bully - 1 9 people - 1 9
2. Proses Klasifikasi
Dalam tahap ini akan dilakukan klasifikasi terhadap data baru yaitu sebagai data uji dengan menggunakan naïve bayes classifier. Berikut merupakan alur dari proses klasifikasinya yang dapat dilihat pada Gambar 5.
Gambar 5 Flowchart Proses Klasifikasi
[image:32.595.76.270.346.736.2] [image:32.595.316.524.470.545.2]Berdasarkan pada Gambar 5 tersebut tahap awal yang dilakukan yaitu melakukan input data uji. Data uji yang digunakan berasal dari sumber data yang telah dilakukan preprocessing. Berikut merupakan contoh data uji yang disajikan pada Tabel 8.
Tabel 8 Contoh Data Uji Data Latih
Sebelumpreprocessing Setelah
preprocessing https://www.google.com/sea rch?q=Violence+in+classroo m &gws_rd=sal violence in classroom
Tahap selanjutnya merupakan proses yang sangat penting yaitu menghitung probabilitas tiap kelas, baik negatif maupun positif. Proses tersebut akan dijelaskan sebagai berikut.
a. Menghitung Probabilitas
Pada tahap ini dilakukan proses perhitungan probabilitas dengan menggunakan naïve bayes classifier. Data uji tiap kelas akan ditentukan nilai probabilitasnya berdasarkan dari proses learning. Berikut merupakan proses perhitungannya.
1). Perhitungan untuk probabilitas positif
= P P(violence|positif)
= 0,000005263
2). Perhitungan untuk probabilitas negative
= P P(violence|negatif)
P(in|negatif)*P(classroom|negatif)
= 0.4737 2 9 1 9 1 9 = 0,001299588
b. Menentukan Probabilitas Sentimen Maksimum.
Dari hasil perhitungan sebelumnya dibandingkan anatara nilai Ppositif dan Pnegatif, didapatkan nilai tertinggi yaitu Pnegatif sehingga dapat disimpulkan bahwa pencarian yang dilakukan diklasifikasikan ke dalam sentiment negatif.
2.5 Implementasi Sistem
Tahap implementasi merupakan tahap penerapan elemen-elemen yang telah dilakukan pada tahap analisis dan perancangan sistem untuk diimplementasikan ke dalam sebuah sistem. Tahapan ini meliputi lingkungan implementasi, implementasi data, dan implementasi antarmuka.
1. Lingkungan Implementasi
Lingkungan implementasi merupakan penjelasan dari penerapan sistem yang terdiri atas dua lingkungan yaitu pada lingkungan perangkat lunak dan lingkungan perangkat keras. Spesifikasi perangkat lunak dalam implementasi sistem yaitu sebagai berikut.
a. Sistem Operasi Windows 8.1 Pro b. WeBuilder 2014
c. MySQL DBMS d. Visual Studio 2013 e. MySQL Workbench 6.3 f. StarUML 5.0.2.1570
Spesifikasi perangkat keras pada sistem yang dibangun adalah sebagai berikut.
a. Processor Core i3 M380 @2.53GHz b. RAM 6 GB
c. HDD 256 GB d. Monitor LED e. Keyboard dan Mouse
2. Implementasi Data
[image:33.595.314.525.123.263.2]Data yang terlibat pada sistem yang dibangun yaitu berasal dari rangkaian teks pencarian pada suatu web browser dengan menggunakan extension. Berikut merupakan struktur dari implementasi data
Tabel 9 Penggunaan Data
No Koleksi Data yang Dikirim 1 Data Testing a. uid: integer
b. post_id : string c. kontent: string d. sugest: string e. id_notif: integer f. uri
2 Data Training
a. id_post: integer b. word: string c. status: string
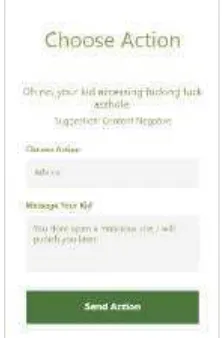
3. Implementasi Antarmuka
[image:33.595.362.473.413.582.2]Implementasi antarmuka berisi tampilan antarmuka dari sistem yang dibangun hasil implementasi dari perancangan sebelumnya. Antarmuka yang dibangun ini diimplementasikan kepada antarmuka pada aplikasi Dodo: Kids Browser versi mobile Windows Phone yang di dalamnya merupakan visualisasi dari hasil klasifikasi yang telah dilakukan berupa informasi saran untuk orang tua. Berikut merupakan tampilan yang implementasi antarmuka dari sistem yang dibangun dapat dilihat pada Gambar 6.
Gambar 6 Antarmuka Visualisasi Hasil Klasifikasi
3. PENUTUP
Berdasarkan dari hasil penelitian yang telah dilakukan bahwa penerapan text mining dalam
aplikasi pengawasan penggunaan internet anak “dodo kids browser” dengan memberikan solusi berupa
anak yang terindikasi melakukan pencarian ketika
surfingdengan kata yang mengandung makna buruk.
DAFTAR PUSTAKA
[1] D. Oktafia and D. C. Pardede, "Perbadingan Kinerja Algoritma Decision Tree dan Naive Bayes dalam Prediksi Kebangkrutan," UG Repository, Jakarta, 2014.
[2] E. A.W, M. and T. , "Penerapan Naive Bayes Untuk Sistem Klasifikasi SMS Pada Smartphone Android," EPrints 3 , Palembang, 2013.
[3] I. F. Rozi, S. H. Pramono and E. A. Dahlan, "Implementasi Opinion Mining (Analisis Sentimen) Untuk Ekstraksi Data Opini Publik pada Perguruan Tinggi,"Jurnal EECCIS,vol. 6, pp. 37-43, 2012.
[4] J. Ling, I. P. E. N. Kencana and T. B. Oka, "Analisis Sentimen Menggunakan Metode Naive Bayes Classifier Dengan Seleksi Fitur Chi Square,"E-Jurnal Matematika,vol. 3, pp. 92-99, 2014.
[5] S. Andini, "Klasifikasi Dokument Teks Menggunakan Algoritma Naïve Bayes Dengan Bahasa Pemograman Java," Jurnal Teknologi Informasi & Pendidikan, vol. 6, pp. 140-147, 2013.
[6] A. Nurani, B. Susanto and U. Proboyekti, "Implementasi Naive Bayes Classifier Pada Program Bantu Penentuan Buku Referensi Matakuliah,"Jurnal Informatika,vol. 3, pp. 32-36, 2007.
Firdaus Akhmad Muttaqin1, Adam Mukaharil Bachtiar2
1,2Teknik Informatika - Universitas Komputer Indonesia
Jl. Dipati Ukur No. 112-116, Bandung 40132
E-mail: [email protected], [email protected]2
ABSTRACT
Dodo Kids Browser is a parental control software for search activities or surf the Internet by children. Supervision carried by blocking every word that has a negative context then a message appears on the mobile application belongs to the parents for give the action, however lack of information about the sentiment of the keywords being entered difficult for parents to know whether the keyword included on negative sentiment or not. It has an impact on the selection of action will be provided by parents. The application of text mining can be used as a solution.
Implementation of text mining is used for perform the classification process to search the child in obtaining information about the sentiment. Steps being taken for process the first classification is preprocessing of data. Furthermore, the results of the result data preprocessing algorithm applied to the Naïve Bayes classifier for the classification process. Classification results are displayed in the form of information about the advice in determining action by parents.
The results of text mining implementation of the system has been testing the functionality of the system, test the naïve Bayes classifier algorithm, and testing of some samples of test data. Results of these tests concluded that the system is able to provide information in the form of advice that can help parents in deciding pemberia action against her internet activity.
Key World:Text Mining, Sentiment Analysis, Naïve Bayes Classifier, Classification.
1. INTRODUCTION
Internet service as a medium of information is increasing has started to spread to all people, not just teenagers or adults but the kids were already using the internet as a media service information retrieval either for personal benefit or for education. It has a positive and negative impact, so there are several vendors that provide applications or services for monitoring and can restrict children's internet activities. Dodo Kids Browser is a software that serves as parental controlling for child's internet activity. This
application can provide notification to parents when children do a search.
Based on observations made by trying the service provided on the application Dodo Kids Browser among them are content filtering on keywords entered the child when performing a search, the app will do the blocking on any keyword significantly negative so that each word has a negative meaning will always be subject to blocking even though the keyword entered has a positive meaning when it becomes a phrase or sentence. This causes problems in the availability of information that should be accessible to children but become can not be done because the entered keywords are words that are negative. For example, when a child doing a search in the English language with the keywords "how to avoid violence", the keyword being entered that contained the word "violence" which has a negative meaning for the child but if in a sentence, the keywords being entered has a meaning positive. This was due to the limited ability to generate conclusions of search keywords entered by a child. It can be difficult for parents to get a reference for determining the appropriate action to children.
Based on the outlined problem that needed a solution that can classify the keywords entered by the child when doing a search to produce a positive or negative conclusion of the keywords entered. This is possible with the use of text mining is a process that is semi-automatic classification of patterns derived from unstructured database. Results from the classification can be used as a medium to provide advice to parents in determining action against child when doing a search on the internet.
usage monitoring application "Dodo Kids Browser".
1.1 Text Mining
Text Mining is a measure of text analysis is done automatically by the computer system to generate new information that has not been known previously taken from a series of texts which are summarized in a document [3]. Text Mining is a multi-disciplinary field involving information retrieval, text analysis, information extraction, clustering, Categorization, visualization, machine learning and other techniques [4]. Text mining using data mining application to convert unstructured data into structured data through the stages, namely [4]:
1. Text preprocess is solving a set of characters into words.
2. Feature Generation / Text Transformation is changing the words into a basic shape while reducing the number of words.
3. Feature Selection is the selection of features to reduce the dimensions of a collection of texts. 4. Text Mining / Pattern Discovery that can be
unsupervised learning (clustering) or supervised learning (classification).
5. Interpretation / Evaluation that measurement to evaluate the effectiveness of methods applied using precision parameter.
1.2 Sentiment Analysis
Sentiment analysis or can be called opinion mining is the process of understanding, extracting and processing the textual otamatis text data to obtain information sentiment contained in an opinion sentence [5]. Sentiment analysis aims to determine the contents of a dataset shaped tesktual or sentence whether positive or negative sentiment worth [6]. Opinion mining can be considered also as a combination of text mining and natural language processing. Classification method is a method that can be used to solve problems on text mining. One of them is by using an algorithm Naïve Bayes Classifier (NBC). Natural language processing whereas befungsi to provide word class (tag) to each word in a sentence.
1.3Preprocessing
A preprocessing stage before the classification process is necessary for cleaning, removing, changing the data source, whether it be a non-alphabetic characters and words are not needed. It is intended that the data used is optimal when used in the classification process. Preprocessing stages each case can vary. Here's a preprocessing stage and the explanation used in this study.
needed. It aims to reduce the noise that can lead to the calculation process in the classification is not optimal. 2. Case Folding
Case Folding is the process of converting data into the appropriate format. It aims to reduce redundancy of data that will be used in the classification process so that the calculation process becomes optimal. For example change the format of the data into lowercase or uppercase according to the needs required in the process of classification.
3. Tokenizing
Tokenizing is a separation process or cut the data in the form of phrases, clauses, or sentences being said perkata based delimiters were used that space.
1.4 Naïve Bayes Algorithm
Naïve Naïve Bayes classifier is a classifier method which refers to the Bayes theorem is a theorem which refers to the concept of conditional probability. In this method required a combination of previous knowledge to new knowledge [7]. In carrying out the necessary classification training set as training data. At each sample from the training data has a class of its own label. The following is a mathematical model that is naïve Bayes classifier:
(
)
✁( ) ( ✂ ) ( ) ✥
[2]
Where:X = Data with unknown class
H = hypothesis of data X is a specific class
p (H | X) = probability of the hypothesis H is based on the condition X (posterior probability)
p (H) = The probability of the hypothesis H (prior probabilty)
2. RESEARCH CONTENTS
Fill this study aims to describe a study conducted of the analysis process hinga implementation into the system. The following discussion of this study.
2.1 Analysis of The Problem
The problems that occurred in this study is the parents as users need to determine the appropriate action to searches conducted by children whether positive or negative, so that the necessary information classification search results in the form of suggestions for determining the action to be awarded.
2.2 Data Source
words name Good people example http://www.bing.com/ search?q=good+peop le+example&go=Sub mit&qs=n&form=QB LH&pq=good+peopl e+example&sc=0- 0&sp=-1&sk=&cvid=f83230 14b9c64795b681234 61eb2a982 q
Kind of cas https://www.google.c om/search?q=Search +something&gws_rd =ssl
q
How to avoid violence https://www.google.c om/search?q=Search +something&gws_rd =ssl#q=what+do+i+s earch q
How to bully people https://www.google.c om/search?q=How+t o+bully+people&gws _rd=ssl q Example of violence https://www.google.c om/search?q=How+t o+bully+a+people&g ws_rd=ssl q Good violence http://www.bing.com/ search?q=Good+viol ence&go=Submit&qs =n&form=QBRE&pq =Good+violence&sc =8-10&sp=-1&sk=&cvid=166e13 1d89424cefa4e2aec4 be4891fd q
2.3 Preprocessing Implementation
[image:37.595.70.284.97.549.2]Preprocessing process is done in order to transform the source data into the appropriate format and easy to do the classification process so that the classification process can be optimized. Preprocessing stages conducted in this study is from the cleansing process, case folding, and the last is tokenizing process. These stages seen on Gambar 1.
Gambar 1 Preprocessing Steps
[image:37.595.394.474.201.429.2]At this stage cleaning of symbols and letters are not necessary. Additionally done also change certain symbols associated with search keywords that space format, which in this case space will be transformed into the + (plus), so do the conversion back into space. Step-by-step cleansing process is presented in the form of a flowchart which can be seen in Gambar 2.
Gambar 2 Cleansing Flowchart
Data input in this cleansing process in the form of a URL is generated when performing a search on a web browser. Here is an example of the application of the cleansing process is presented in Tabel 2
Tabel 2 Cleansing Proses
Input Cleansing Result http://www.bing.com /search?q=good+peo ple+example&go=Su bmit&qs=n&form=Q BLH&pq=good+peo ple+example&sc=0- 0&sp=-1&sk=&cvid=f83230 14b9c64795b681234 61eb2a982
Good people example
https://www.google.c om/search?q=Search +something&gws_rd =ssl
Kind of cas
https://www.google.c om/search?q=Search +something&gws_rd =ssl#q=what+do+i+s earch
[image:37.595.311.526.475.752.2] [image:37.595.92.276.671.737.2]o+bully+people&gws _rd=ssl https://www.google.c om/search?q=How+t o+bully+a+people&g ws_rd=ssl
Example of violence
http://www.bing.com /search?q=Good+viol ence&go=Submit&qs =n&form=QBRE&pq =Good+violence&sc =8-10&sp=-1&sk=&cvid=166e13 1d89424cefa4e2aec4 be4891fd Good violence
2. Case Folding
[image:38.595.71.284.76.297.2]At this stage of folding case made of converting data into a cleansing process results into the same shape. In this case the conversion is done be in lower case format. Here is a case folding process steps shown in flowchart form in FIG.
Gambar 3 Flowchart Cleansing Process
[image:38.595.395.474.182.399.2]BBased on Gambar 3, The following is an example of the application process are presented in folding case Tabel 3.
Tabel 3 Implementation of Case Folding Process Input Case FoldingResult
Good people example good people example Kind of cats kind of cats
How to avoid violence how to avoid violence How to bully people how to bully people Example of violence example of violence Good violence good violence
two words or more, or may be called as a phrase or sentence so that it becomes one by one. In this case the separation is done based on space as a delimiter. The following is a tokenizing process steps presented in the form of a flowchart in Gambar 4.
Gambar 4 Flowchart Tokenizing Process
Based on Gambar 4, The following is an example of the application of the tokenizing process served on Tabel 4.
Tabel 4 Implementation of Tokenizing Process Input TokenizingResult
good people example good people example
kind of cat kind
of cat how to avoid violence how
to avoid violence how to bully people Howe
to bully people example of violence example
of violence
good violence Good
violence
[image:38.595.154.233.380.598.2] [image:38.595.313.522.481.721.2]2.4 Implementation of Naïve Bayes Algorithm Stage In this stage, Naïve Bayes algorithm analysis process which is important in the classification of the sources of data on its sentiment is positive or negative. In this phase there are two main processes to do the classification is the process of learning and classification process. The following is an explanation of each process.
1. Learing Process
In this process naïve Bayes classifier needs to be given prior knowledge to be used as a reference in order to perform the classification of the textual data based on sentiments. In the process of teaching or learning, there are three main steps. Here are the three main steps including its explanation.
[image:39.595.320.509.341.675.2]a. Determination of Data Class Practice At this stage, the determination of the class of data. Determination of the class is determined with the help of users by providing an opinion on whether the search keywords included in the positive class or negative class. Here is an example of the determination of class training data are presented on Tabel 5.
Tabel 5 Determining The Data Class Data Word Sentiment
Class D1 food people example Positif D2 kind of cat Positif D3 how to avoid violence Positif D4 how to bully people Negatif D5 example of violence Negatif D6 good violence Negatif b. Probability
At this stage, probability calculations on the data that has been determined class. Tabel 6 the calculation of the probability of each class.
nt class
1 2 3 4 5 6 Positif 3 3 4 0 0 0 10/19 Negatif 0 0 0 4 3 2 9/19 Total 3 3 4 4 3 2 1
c. Determining The Probability of a Item Once the probability of each class is calculated, then calculated the probability of each item. Here is the formula to calculate the probability per-item.
( )✄ ( ) ( ) p (i) = Probability item f (i) = Frequency item
f (c) = The total number of items based on class sentiments.
The following is a calculation of the probability of each item presented on Tabel 7.
Tabel 7 Count Item robability
Data Sentiment Class Positive Negative good ☎ ☎ ✆ ☎ ✝ people ☎ ☎ ✆ ☎ ✝ example ☎ ☎ ✆ -kind ☎ ☎ ✆ -of ☎ ☎ ✆ ☎ ✝ cats ☎ ☎ ✆ -how ☎ ☎ ✆ ☎ ✝ do ☎ ☎ ✆ ☎ ✝ avoid ☎ ☎ ✆ -violence ☎ ☎ ✆ ✞ ✝ bully - ☎ ✝ people - ☎ ✝
2. Classification Process
[image:39.595.83.272.415.672.2] [image:39.595.84.270.418.670.2]Gambar 5 clasikfikactnu Flowchart
[image:40.595.76.282.453.534.2]Bsaed on Gambar 5 The initial stage is to input test data. Test data used comes from a data source that has been done preprocessing. Here is an example of test data presented in Tabel 8.
Tabel 8 Testing Data Data Testing
Beforepreprocessing After
preprocessing https://www.google.com/sea rch?q=Violence+in+classroo m &gws_rd=sal violence in classroom
The next stage is a very important process that calculates the probability of each class, both negative and positive. The process will be explained as follows.
a. Count Probability
At this stage the probability calculation process by using naïve Bayes classifier. The test data of each class will be determined based on the probability value of the learning process. The following is the calculation process.
1). Probability calculations for positive
Ppositif = P_ (c +) * P ("violence"│positif) * P ("in"│positif) * P (classroom | positive) Ppositif = 0.5263 * 1/10 * 1/10 * 1/10 Ppositif = 0.000005263
Pnegatif = 0.4737 * 2/9 * 1/9 * 1/9 Pnegatif = 0.001299588
b. Determing maximum sentimen.
From the results of previous calculations compared anatara Ppositif and Pnegatif value, obtained the highest score is Pnegatif so that it can be concluded that the search conducted classified into negative sentiment.
2.5 System Implementation
Implementation stage is the stage of implementation of the elements that have been performed on the stage of the analysis and design of systems to be implemented into a system. This phase includes the implementation environment, the implementation of the data, and interface implementation.Lingkungan Implementasi
a. Sistem Operasi Windows 8.1 Pro b. WeBuilder 2014
c. MySQL DBMS d. Visual Studio 2013 e. MySQL Workbench 6.3 f. StarUML 5.0.2.1570
Hardware spesification .
a. Processor Core i3 M380 @2.53GHz b. RAM 6 GB
c. HDD 256 GB d. Monitor LED e. Keyboard dan Mouse
1. Data Implementations
The data involved in a system built that is derived from a series of text searches on a web browser by using extension. Here is the structure of the implementation of the data used in a system built served on Tabel 9.
Tabel 9 Data Usage No Collection Data sent 1 Data Testing a. uid: integer
b. post_id : string c. kontent: string d. sugest: string e. id_notif: integer f. uri
2 Data Training
a. id_post: integer b. word: string c. status: string
2. Interface Implementation
[image:40.595.314.522.573.711.2]classification of the information that has been done in the form of advice for parents. Here is a view that implementation of the system built interfaces can be seen in Gambar 6.
Gambar 6 Interface of Application
3. CLOSING
Based on the results of research that has been done that the application of text mining in surveillance applications internet use child "dodo kids browser" by providing solutions in the form of a provision of information in the form of suggestions classification results from keywords used by children in a search on the web browser to help parents in giving action against the child when the child is indicated using keywords with a negative context has been implemented in accordance with the previous design and analysis. It
![Gambar I.1 Model Waterfall Ian Sommerville [4]](https://thumb-ap.123doks.com/thumbv2/123dok/619429.74549/4.595.105.462.311.598/gambar-i-model-waterfall-ian-sommerville.webp)