DETEKSI KANKER SERVIKS BERDASARKAN CITRA SEL
PAP SMEAR
DENGAN KLASIFIKASI
NAÏVE BAYES
DIAN LESTARI AULIANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Deteksi Kanker Serviks Berdasarkan Citra Sel Pap Smear dengan Klasifikasi Naïve Bayes adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
DIAN LESTARI AULIANI. Deteksi Kanker Serviks Berdasarkan Citra Sel Pap Smear dengan Klasifikasi Naïve Bayes. Dibimbing oleh HARI AGUNG ADRIANTO.
Tingginya angka kematian pada pengidap kanker serviks salah satunya disebabkan oleh keterlambatan penanganan secara medis. Hal ini juga dapat diakibatkan oleh pendeteksian kanker serviks secara manual yang sarat potensi kesalahan prosedur atau human error. Salah satu solusi yang dapat dilakukan adalah dengan mengotomatisasi pendeteksian kanker serviks berdasarkan citra sel pap smear. Penelitian ini menggunakan metode Naïve Bayes untuk mengidentifikasi sel normal dan abnormal serta mengelompokkannya ke dalam tujuh kelas yang lebih spesifik. Data yang digunakan adalah data citra sel tunggal pap smear. Penelitian ini menitikberatkan kepada metode klasifikasi dan tidak melakukan proses segmentasi serta ekstraksi ciri. Hasil yang diperoleh menunjukkan akurasi 97% untuk dua kelas klasifikasi dan 9% untuk tujuh kelas klasifikasi. Rendahnya akurasi pada tujuh kelas klasifikasi disebabkan oleh terjadinya overlapping pada fitur-fitur yang digunakan. Metode klasifikasi Naïve Bayes memberikan hasil yang memuaskan pada klasifikasi dua kelas target, tetapi metode ini belum memberikan hasil yang baik untuk klasifikasi tujuh kelas target. Kata kunci: citra sel pap smear, kanker serviks, klasifikasi Naïve Bayes
ABSTRACT
DIAN LESTARI AULIANI. Detection of Cervical Cancer Based on Pap Smear Cell Images and Naïve Bayes Classification. Supervised by HARI AGUNG ADRIANTO.
One cause of the high mortality rate in patients with cervical cancer is late medical treatment. It can also be caused by the manual detection of cervical cancer that is ridden by potential procedural or human errors. One of the solutions that can be done is automating the detection of cervical cancer using pap smear cell image. This study uses the Naïve Bayes method to identify normal and abnormal cells and group them into seven more specific classes. The data used is single cell images from pap smear. This research focuses on a classification method and does not perform segmentation and feature extraction process. The results showed 97% accuracy for two-class classification and 9% for the seven-class seven-classification. The low accuracy in seven-classification of seven seven-classes is caused by overlapping on the features used. Naïve Bayes gives satisfactory results on the two-class classification but for the seven-class classification this method has not given good results.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DETEKSI KANKER SERVIKS BERDASARKAN CITRA SEL
PAP SMEAR
DENGAN KLASIFIKASI
NAIVE BAYES
DIAN LESTARI AULIANI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Penguji:
Judul Skripsi : Deteksi Kanker Serviks Berdasarkan Citra Sel Pap Smear dengan Klasifikasi Naïve Bayes
Nama : Dian Lestari Auliani
NIM : G64090102
Disetujui oleh
Hari Agung Adrianto, SKom MSi Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Juni 2013 ini adalah pendeteksian kanker, dengan judul Deteksi Kanker Serviks Berdasarkan Citra Sel Pap Smear dengan Klasifikasi Naïve Bayes.
Terima kasih penulis ucapkan kepada pihak- pihak yang telah membantu dalam penyelesaian tugas akhir ini, yaitu:
1 Ayahanda Harmen Kasudi, Ibunda Hernayetti, kakak Yetha Rezika Harmen, dan kakak Yetha Mega Hayati, serta seluruh keluarga atas segala doa, dukungan, dan kasih sayangnya.
2 Bapak Hari Agung Adrianto, SKom MSi selaku dosen pembimbing yang telah memberikan arahan dan bimbingan kepada penulis dalam menyelesaikan tugas akhir ini.
3 Ibu Dr Ir Sri Nurdiati MSc atas bantuan dan arahan kepada penulis. 4 Bapak Endang Purnama Giri, SKom MKom dan Ibu Dr Yeni Herdiyeni,
SSi MKom selaku dosen penguji.
5 Rekan – rekan di Departemen Ilmu Komputer angkatan 45 dan 46 atas segala kebersamaan, motivasi, semangat, dukungan, masukan, dan saran selama proses pengerjaan skripsi ini.
6 Teman-teman yang tidak dapat disebutkan satu per satu atas bantuan, kebersamaan, dan dukungannya.
7 Seluruh staf Departemen Ilmu Komputer IPB atas layanan terbaik yang telah diberikan.
Semoga karya ilmiah ini bermanfaat.
DAFTAR ISI
DAFTAR ISI vii
DAFTAR TABEL viii
DAFTAR GAMBAR viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 2
Data Citra Sel Pap Smear 3
Ekstraksi Ciri 4
K-Fold Cross Validation 5
Klasifikasi 5
Evaluasi 6
HASIL DAN PEMBAHASAN 6
SIMPULAN DAN SARAN 15
Simpulan 15
Saran 16
DAFTAR PUSTAKA 16
LAMPIRAN 17
DAFTAR TABEL
1 Rincian jumlah data 4
2 Subset data latih dan data uji 5
3 Akurasi setiap subset pada dua dan tujuh kelas target 7 4 Confusion matrix dengan akurasi maksimum pada dua kelas target 7 5 Confusion matrix dengan akurasi maksimum pada tujuh kelas target 7
6 Matriks korelasi antar fitur 13
7 Evaluasi terhadap model yang dibentuk oleh regresi logistik 14 8 Hasil uji klasifikasi oleh model regresi logistik 14
9 Hasil uji terhadap fitur - fitur yang digunakan 15
DAFTAR GAMBAR
1 Alur penelitian 3
2 Citra asli (kiri) dan citra hasil segmentasi modul CHAMP (kanan) 3 3 Sebaran nilai fitur intensitas cahaya inti pada tujuh kelas klasifikasi 8 4 Sebaran nilai fitur diameter inti pada tujuh kelas klasifikasi 9 5 Sebaran nilai fitur keliling inti pada tujuh kelas klasifikasi 9 6 Sebaran nilai fitur posisi inti pada tujuh kelas klasifikasi 10 7 Sebaran nilai fitur maksimum sitoplasma pada tujuh kelas klasifikasi 10 8 Sebaran nilai fitur intensitas inti pada dua kelas klasifikasi 11 9 Sebaran nilai fitur diameter inti pada dua kelas klasifikasi 11 10 Sebaran nilai fitur keliling inti pada dua kelas klasifikasi 12 11 Sebaran nilai fitur posisi inti pada dua kelas klasifikasi 12 12 Sebaran nilai fitur maksimum sitoplasma pada dua kelas klasifikasi 13
LAMPIRAN
PENDAHULUAN
Latar Belakang
Data WHO pada tahun 2010 menunjukkan bahwa 13762 kasus baru terjadi setiap tahunnya dan 7493 orang wanita meninggal dunia akibat kanker serviks di Indonesia. Menurut data dari 13 pusat patologi di Indonesia kanker serviks berada pada peringkat pertama di antara semua kanker (23,43% dari 10 jenis kanker paling umum di kalangan laki-laki dan perempuan serta 31% dari 10 jenis kanker paling umum di kalangan wanita)(Nuranna et al. 2012).
Tingginya jumlah kasus dan angka kematian disebabkan oleh tidak adanya gejala yang dirasakan oleh pengidap kanker serviks pada stadium awal. Gejala mulai dirasakan ketika kanker telah berada pada stadium lanjut sehingga penanganan medis sulit dilakukan. Menurut Nuranna et al.(2012) sekitar 70% pengidap yang datang ke rumah sakit telah berada pada stadium lanjut.
Oleh karena itu banyak penelitian yang dilakukan untuk menghasilkan metode pendeteksian dini terhadap kanker serviks. Salah satu metode yang populer dan banyak digunakan oleh negara-negara di dunia, termasuk Indonesia, adalah metode pap smear. Pap smear merupakan suatu metode pemeriksaan sel-sel yang diambil dari leher rahim dan kemudian diperiksa di bawah mikroskop (Kurniawan et al. 2013).
Di negara-negara maju, proses skrining secara rutin dengan pap smear dapat menekan angka kejadian dan angka kematian hingga 70-80% dan 90% (Nuranna et al. 2012). Kendala utama yang dihadapi oleh negara berkembang seperti Indonesia untuk menerapkan metode pap smear adalah keterbatasan jumlah ahli patologi anatomi di Indonesia. Ahli patologi anatomi memiliki peran penting untuk memberikan diagnosa atau menginterpretasikan sel pap smear. Data dari IAPI (Ikatan Ahli Patologi Indonesia) pada tahun 2010, terdapat 292 patolog yang harus melayani penduduk Indonesia yang berjumlah 237 juta orang (data dari BPS 2010) (Nuranna et al. 2012). Selain itu interpretasi visual citra pap smear secara manual memiliki banyak keterbatasan, membutuhkan waktu yang lama, dan rawan kesalahan prosedur (Kurniawan et al. 2013). Hal ini menyebabkan perlunya sistem pendeteksian kanker serviks secara otomatis.
Banyak penelitian yang telah dilakukan dengan berbagai metode untuk otomatisasi deteksi kanker serviks. Giri (2008) menerapkan pendekatan kualitatif untuk tahap ekstraksi fitur yang selanjutnya dianalisis menggunakan Association Rules. Penelitian Giri (2008) menghasilkan nilai akurasi sebesar 38.48% untuk tujuh kelas klasifikasi sel dan 89.14% untuk dua kelas klasifikasi sel. Martinez et al.(2006) mendeteksi kanker serviks dengan cara menggabungkan beberapa model serta mengambil atribut yang relevan dari model-model tersebut dengan menggunakan pendekatan Bayesian. Penelitian tersebut mengeliminasi atribut yang tidak relevan dan dependen. Akurasi penelitian tersebut mencapai 89% dengan menggunakan metode Naïve Bayes.
2
yang bersifat independen berdasarkan penilaian secara subjektif sehingga Naïve Bayes dianggap mampu mengklasifikasikan data dengan baik.
Tujuan Penelitian
Tujuan penelitian ini adalah menerapkan metode Naïve Bayes pada sistem pendeteksian kanker serviks berbasis citra pap smear.
ManfaatPenelitian
Manfaat yang diperoleh dari penelitian ini yaitu dihasilkan suatu sistem berbasis citra yang mampu mendeteksi kanker serviks berdasarkan ciri morfologi dan intensitas cahaya pada objek. Diharapkan sistem tersebut dapat membantu tenaga medis dan ahli patologi anatomi untuk mendeteksi kanker serviks secara otomatis. Dengan demikian dapat mengurangi angka kematian pengidap yang disebabkan oleh keterlambatan penanganan medis.
Ruang Lingkup Penelitian
Lingkup dari penelitian ini, yaitu:
1 Penelitian ini dibatasi pada citra pap smear sel tunggal.
2 Penelitian ini tidak melakukan proses segmentasi dan ekstraksi ciri.
3 Penelitian ini mengadopsi hasil ekstraksi ciri pada penelitian Giri (2008) dengan fitur intensitas cahaya, diameter terpanjang, keliling, dan posisi nukleus, serta jumlah piksel maksimal dalam jendela ketetanggaan 3x3 pada sitoplasma.
4 Proses klasifikasi dilakukan untuk dua kelas (normal dan abnormal) dan tujuh kelas, yaitu: kelas normal superficial, normal intermediate, normal columnar, light dysplasia, moderate dysplasia, severe dysplasia, dan carcinoma in situ.
5 Menggunakan metode klasifikasi Naïve Bayes.
METODE
3
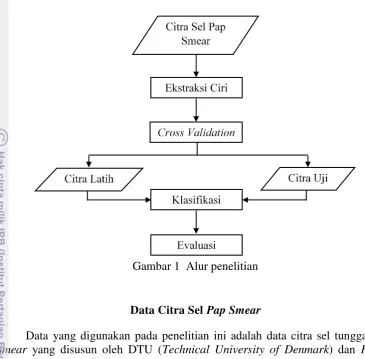
Data Citra Sel Pap Smear
Data yang digunakan pada penelitian ini adalah data citra sel tunggal pap smear yang disusun oleh DTU (Technical University of Denmark) dan Herlev University Hospital di Denmark. Data ini dapat diakses dan digunakan secara bebas untuk keperluan akademik pada situs University of the Aegean (http://labs.fme.aegean.gr/decision/downloads).
Data tersebut berjumlah 917 pasang citra sel tunggal pap smear yang secara umum terbagi menjadi 242 pasang kelas normal dan 675 pasang kelas abnormal (Tabel 1). Satu pasang citra terdiri atas citra asli dan citra hasil segmentasi modul CHAMP, aplikasi berbayar yang dikeluarkan oleh DIMAC (perusahaan yang membangun software di Denmark). Contoh satu pasang citra dapat dilihat pada Gambar 2. Pada gambar tersebut nukleus ditandai dengan warna biru muda, sitoplasma ditandai warna biru tua, dan latar belakang ditandai warna merah.
Gambar 1 Alur penelitian
4
Secara lebih rinci data citra sel dapat dibagi menjadi 7 kelas, yaitu: normal superficial, normal intermediate, normal columnar, light dysplasia, moderate dysplasia, severe dysplasia, dan carcinoma in situ. Contoh citra masing-masing kelas disajikan pada Lampiran 1.
Ekstraksi Ciri
Penelitian ini tidak melakukan proses ekstraksi ciri sehingga fitur dan nilai fitur yang digunakan pada penelitian ini disadur dari penelitian Giri (2008). Giri (2008) melakukan seleksi fitur dari 20 fitur yang digunakan pada penelitian Martin (2003) dengan menggunakan metode SFFS (Sequential Floating Forward Selection). Kelima fitur tersebut adalah:
1 Derajat intensitas cahaya nukleus
Derajat intensitas cahaya nukleus dihitung dari nilai rata-rata intensitas cahaya yang dimiliki oleh area nukleus dengan menggunakan rumus:
Y = 0.299 x Red + 0.587 x Green + 0.114 x Blue
Y melambangkan luminance, salah satu koordinat ruang warna untuk sistem transmisi atau model warna NTSC (National Television System Committee). NTSC merupakan komite nasional yang menciptakan standar warna (RN, GN, BN) untuk pesawat penerima televisi (Putra, 2010). Komponen luminance merepresentasikan informasi grayscale (Prasetyo, 2011) sedangkan nilai Red, Green, dan Blue merupakan nilai rataan intensitas untuk setiap warna. Setiap bobotnya merupakan ukuran yang merepresentasikan intensitas cahaya yang diterima secara persepsi oleh mata manusia bagi setiap warna (Giri, 2008).
2 Diameter terpanjang nukleus
Merupakan diameter terkecil dari sebuah lingkaran yang dapat dibentuk untuk mengelilingi sebuah nukleus. Dapat diukur sebagai jarak terpanjang di antara dua piksel pada area lingkar luar nukleus (Giri, 2008).
3 Perimeter nukleus atau keliling nukleus
Keliling nukleus didapatkan dengan menghitung jumlah piksel yang terdapat pada tepi citra nukleus (Giri, 2008).
4 Posisi nukleus
Tabel 1 Rincian jumlah data
No Tipe Sel Kategori Jumlah Total
1. Normal Superficial Normal 74
242
2. Normal Intermediate Normal 70
3. Normal Columnar Normal 98
4. Light Dysplasia Abnormal 182
675
5. Moderate Dysplasia Abnormal 146
6. Severe Dysplasia Abnormal 197
5 Dihitung dengan mencari jarak antara pusat nukleus dengan pusat sitoplasma (Giri, 2008).
5 Maksimum sitoplasma
Merupakan jumlah piksel berlabel sitoplasma yang berada pada jendela ketetanggaan ukuran 3x3 yang berisi piksel sitoplasma terbanyak. Nilai ini dapat dihitung dengan menentukan jumlah piksel terbanyak yang ada pada sebuah jendela ketetanggaan 3x3 terlebih dahulu, misal sebanyak 6 piksel. Selanjutnya ditentukan berapa banyak jendela ketetanggaan 3x3 yang berisi piksel sitoplasma terbanyak tersebut, misal ada 10 jendela. Maka nilai maksimum sitoplasma adalah 6x10 yaitu 60 piksel (Giri, 2008).
Nilai masing-masing fitur yang diwakili oleh 15 data untuk kelas normal superficial (mewakili kelas normal) dan carcinoma in situ (mewakili kelas abnormal) tersedia pada Lampiran 2 dan Lampiran 3.
K-Fold Cross Validation
Seluruh data hasil ekstraksi ciri dibagi menjadi data latih dan data uji dengan menggunakan metode k-fold cross validation dengan menggunakan kombinasi k = 10. Data akan dibagi menjadi 10 subset (S1, S2, S3, S4, S5, S6, S7, S8, S9, S10). Data latih menggunakan k-1 subset dan 1 subset sebagai data uji. Kemudian diulangi pada tahap kedua dengan menggunakan data pengujian yang berbeda (Giri 2008). Subset yang digunakan untuk data latih dan data uji secara lengkap disajikan pada Tabel 2.
Klasifikasi
Klasifikasi dapat dilakukan setelah data hasil ekstraksi ciri terbagi menjadi data latih dan data uji. Ada dua macam kelas target pada penelitian ini yaitu dua kelas dan tujuh kelas. Pada target dua kelas, data dipetakan pada kategori normal dan abnormal. Sementara itu pada target tujuh kelas data terbagi pada kategori yang lebih rinci, yaitu kelas normal superficial, normal intermediate, normal columnar, light dysplasia, moderate dysplasia, severe dysplasia, dan carcinoma in situ.
Tabel 2 Subset data latih dan data uji
6
Penelitian ini menggunakan metode klasifikasi Naïve Bayes. Metode Naïve Bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes dengan asumsi independensi yang kuat (Prasetyo, 2012). Oleh karena itu suatu fitur tidak terikat atau terpengaruh oleh keberadaan fitur lain pada data yang sama. Teorema Bayes dirumuskan sebagai :
P H|E1,E2,E3 = P(E1|H) x P(EP(E 2|H) x P(E3|H) x P(H) 1) x P(E2) x P(E3)
Keterangan:
P (H|Ei) = Probabilitas akhir bersyarat suatu hipotesis H terjadi jika E ke-i terjadi P (Ei|H) = Probabilitas sebuah bukti E ke-i akan memengaruhi hipotesis H P (H) = Probabilitas H terjadi tanpa memandang bukti apapun
P (Ei) = Probabilitas E ke-i terjadi tanpa memandang hipotesis atau bukti yang lain.
Dalam hal klasifikasi, H merupakan atribut kelas yang menjadi target klasifikasi dan E merupakan fiturnya. Jadi teorema Bayes tersebut dapat diartikan sebagai peluang atau probabilitas perolehan kelas H setelah fitur-fitur E diamati. Proses pengamatan ini disebut juga sebagai proses pembelajaran untuk membangun model dari setiap kombinasi H dengan semua fitur E berdasarkan informasi yang didapatkan dari data latih (Prasetyo, 2012).
Proses pelatihan dilakukan dengan menggunakan data latih untuk membentuk suatu model yang digunakan untuk menentukan kelas data uji. Peluang setiap data uji terhadap masing-masing kelas target dihitung. Nilai peluang terbesar yang dihasilkan data uji merepresentasikan kelas data uji tersebut.
Evaluasi
Evaluasi dilakukan berdasarkan nilai akurasi klasifikasi yang dihitung dengan persamaan:
akurasi = ∑data uji benar∑data uji × 100%
HASIL DAN PEMBAHASAN
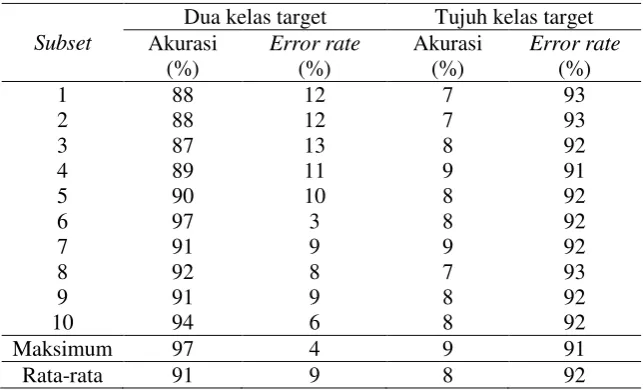
7 Klasifikasi dua kelas target memiliki akurasi maksimum 97% dengan error rate 3% saat menggunakan S6 sebagai data uji dan subset lainnya sebagai data latih. Klasifikasi tujuh kelas target memiliki akurasi maksimum yang sangat rendah yaitu 9% dengan error rate yang sangat tinggi yaitu 91%. Confusion matrix dengan akurasi maksimum pada dua dan tujuh kelas target disajikan pada Tabel 4 dan Tabel 5.
Tabel 3 Akurasi setiap subset pada dua dan tujuh kelas target
Subset
Dua kelas target Tujuh kelas target Akurasi
Tabel 4 Confusion matrix dengan akurasi maksimum pada dua kelas target
Kelas sel Normal Abnormal Akurasi
Normal 22 2 92%
Abnormal 1 66 99%
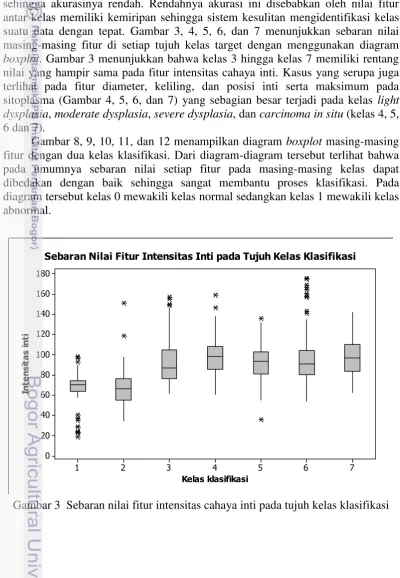
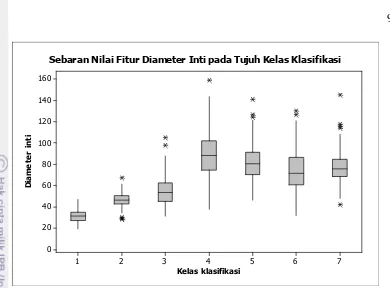
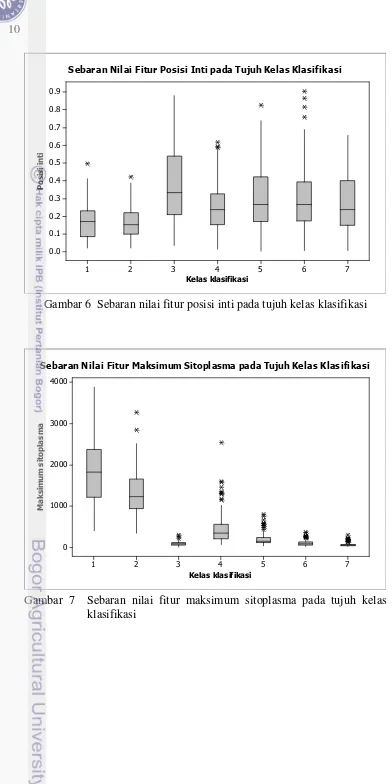
8 sehingga akurasinya rendah. Rendahnya akurasi ini disebabkan oleh nilai fitur antar kelas memiliki kemiripan sehingga sistem kesulitan mengidentifikasi kelas suatu data dengan tepat. Gambar 3, 4, 5, 6, dan 7 menunjukkan sebaran nilai masing-masing fitur di setiap tujuh kelas target dengan menggunakan diagram boxplot. Gambar 3 menunjukkan bahwa kelas 3 hingga kelas 7 memiliki rentang nilai yang hampir sama pada fitur intensitas cahaya inti. Kasus yang serupa juga terlihat pada fitur diameter, keliling, dan posisi inti serta maksimum pada sitoplasma (Gambar 4, 5, 6, dan 7) yang sebagian besar terjadi pada kelas light dysplasia, moderate dysplasia, severe dysplasia, dan carcinoma in situ (kelas 4, 5, 6 dan 7).
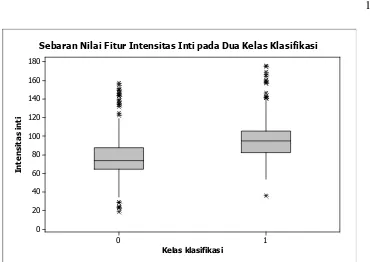
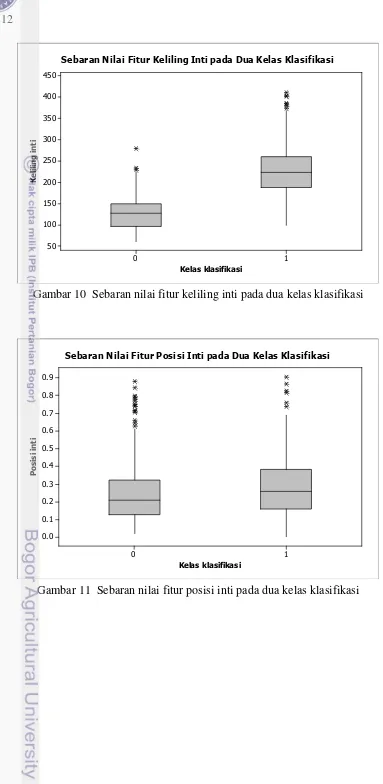
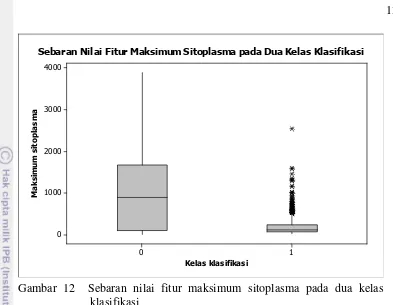
Gambar 8, 9, 10, 11, dan 12 menampilkan diagram boxplot masing-masing fitur dengan dua kelas klasifikasi. Dari diagram-diagram tersebut terlihat bahwa pada umumnya sebaran nilai setiap fitur pada masing-masing kelas dapat dibedakan dengan baik sehingga sangat membantu proses klasifikasi. Pada diagram tersebut kelas 0 mewakili kelas normal sedangkan kelas 1 mewakili kelas abnormal.
Gambar 3 Sebaran nilai fitur intensitas cahaya inti pada tujuh kelas klasifikasi
Kelas klasifikasi
9
Gambar 4 Sebaran nilai fitur diameter inti pada tujuh kelas klasifikasi
Gambar 5 Sebaran nilai fitur keliling inti pada tujuh kelas klasifikasi Kelas klasifikasi
Sebaran Nilai Fitur Diameter Inti pada Tujuh Kelas Klasifikasi
Kelas klasifikasi
10
Gambar 6 Sebaran nilai fitur posisi inti pada tujuh kelas klasifikasi
Gambar 7 Sebaran nilai fitur maksimum sitoplasma pada tujuh kelas
Sebaran Nilai Fitur Posisi Inti pada Tujuh Kelas Klasifikasi
Kelas klasifikasi
11
Gambar 8 Sebaran nilai fitur intensitas inti pada dua kelas klasifikasi
Gambar 9 Sebaran nilai fitur diameter inti pada dua kelas klasifikasi Kelas klasifikasi
Sebaran Nilai Fitur Intensitas Inti pada Dua Kelas Klasifikasi
Kelas klasifikasi
12
Gambar 10 Sebaran nilai fitur keliling inti pada dua kelas klasifikasi
Gambar 11 Sebaran nilai fitur posisi inti pada dua kelas klasifikasi Kelas klasifikasi
Sebaran Nilai Fitur Keliling Inti pada Dua Kelas Klasifikasi
Kelas klasifikasi
13
Untuk melihat hubungan atau asosiasi antar fitur, dilakukan perhitungan nilai korelasi terhadap nilai-nilai fitur tersebut. Matriks korelasi antar fitur ditampilkan pada Tabel 6. Sebagian besar fitur bersifat independen, terlihat dari nilai korelasi antar fitur yang mendekati 0. Akan tetapi terdapat dua fitur yang saling berhubungan (nilai korelasi mendekati 1) yaitu fitur diameter maksimum dengan keliling inti sel. Meskipun demikian keberadaan fitur yang dependen ini tidak memberikan pengaruh yang cukup besar terhadap proses klasifikasi. Hal ini dibuktikan dari akurasi proses klasifikasi dua kelas dan tujuh kelas target yang hanya menggunakan empat fitur (salah satu fitur yang dependen tidak digunakan) sama dengan akurasi klasifikasi yang menggunakan lima fitur. Jadi Naïve Bayes telah mengasumsikan bahwa kedua fitur yang dependen tersebut bersifat independen.
Dalam proses klasifikasi terdapat fitur yang memberikan pengaruh paling besar yang dapat dilihat dari hasil pemodelan regresi logistik. Metode regresi logistik digunakan untuk membentuk model hubungan antara variabel terikat dengan satu atau lebih variabel bebas secara non-linier. Variabel terikat yang digunakan bersifat dikotomi (terdiri atas dua nilai) yang mewakili kemunculan atau tidak adanya suatu kejadian yang biasanya diberi angka 0 atau 1. Dalam
Sebaran Nilai Fitur Maksimum Sitoplasma pada Dua Kelas Klasifikasi
Tabel 6 Matriks korelasi antar fitur
14
penelitian ini yang berlaku sebagai variabel terikat adalah dua kelas target sedangkan yang menjadi variabel bebas adalah lima fitur yang digunakan.
Model yang dihasilkan oleh regresi logistik memiliki p-value (sig) sebesar 0 hal ini menyatakan bahwa terdapat minimal satu fitur yang signifikan mempengaruhi kelas (Tabel 7) sehingga model dapat digunakan untuk analisis lebih lanjut. Secara keseluruhan model yang dihasilkan oleh regresi logistik sangat baik karena mampu memodelkan data hingga 93.2% (Tabel 8).
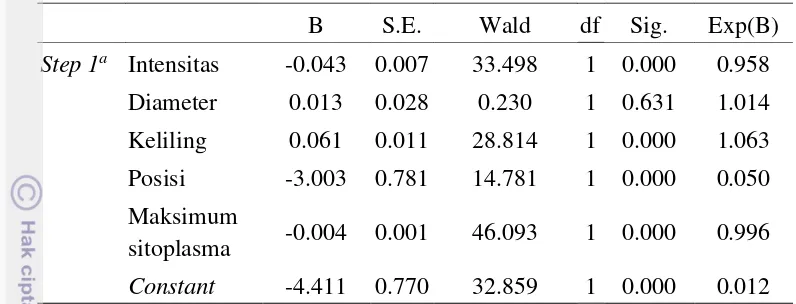
Pada regresi dikenal istilah H0 dan H1 untuk menyatakan hipotesis terhadap suatu kejadian. Tabel 9 menampilkan fitur-fitur yang digunakan serta p-value masing-masing fitur. Oleh karena itu, pada kasus ini hipotesis yang digunakan adalah variabel fitur X tidak signifikan mempengaruhi kelas klasifikasi (H0) dan variabel fitur X signifikan mempengaruhi kelas klasifikasi (H1). Keputusan tolak H0 digunakan saat nilai signifikansi < 0.05 (Tabel 9). Dari kelima fitur yang digunakan, hanya fitur diameter maksimum inti yang dinilai tidak signifikan mempengaruhi kelas karena memiliki p-value (signifikansi) lebih dari 0.05.
Pada regresi logistik koefisiennya akan sulit untuk diinterpretasikan secara langsung. Oleh karena itu interpretasi akan dilakukan dengan menggunakan nilai odds ratio. Odds adalah peluang terjadinya suatu kejadian dibandingkan peluang tidak terjadinya kejadian tersebut. Jika peluang terjadinya suatu kejadian tersebut sama dengan phi, maka odds dapat dinyatakan sebagai
odds = 1 - ππ
sehingga odds ratio adalah nilai perbandingan dari dua odds.
Tabel 9 (kolom Exp (B)) menampilkan odds ratio antara odds masing-Tabel 8 Hasil uji klasifikasi oleh model regresi logistik
15
dihasilkan memiliki hubungan yang positif dengan kelas target. Interpretasi dari odds ratio tersebut adalah:
1 Jika intensitas cahaya pada inti sel meningkat 1 Cd (Candela, satuan intensitas cahaya) maka kecenderungan citra tersebut tergolong kepada kelas abnormal menjadi 0.958 kali lipat lebih rendah. Jadi semakin tinggi intensitas cahaya inti sel tersebut, semakin cenderung tergolong kepada kelas normal.
2 Semakin besar diameter dan keliling inti sel suatu data, data tersebut semakin cenderung termasuk kepada kelas abnormal. Fitur diameter dan keliling inti sel memiliki hubungan yang positif dengan kelas klasifikasi.
3 Inti sel yang berada tepat atau mendekati pusat sitoplasma cenderung digolongkan sebagai sel yang abnormal. Posisi inti sel yang jauh dari pusat sitoplasma memiliki peluang yang lebih besar dikenali sebagai sel normal. 4 Sel yang memiliki sitoplasma yang lebih besar dibandingkan dengan inti
selnya memiliki kecenderungan untuk tidak digolongkan sebagai sel abnormal.
SIMPULAN DAN SARAN
Simpulan
Program dapat mengklasifikasikan citra pap smear sel tunggal dengan akurasi maksimum sebesar 97% untuk dua kelas target dan 9% untuk tujuh kelas target. Rendahnya akurasi pada tujuh kelas target disebabkan oleh rentang atau sebaran nilai fitur pada setiap kelas yang tidak jauh berbeda sehingga sistem sulit menempatkan suatu data pada kelas yang tepat. Sebaliknya, pada dua kelas target klasifikasi masing-masing kelas memiliki rentang atau sebaran nilai fitur yang berbeda sehingga membantu proses klasifikasi. Dari lima fitur yang digunakan, fitur yang tidak signifikan memberikan pengaruh terhadap kelas klasifikasi adalah fitur diameter maksimum inti. Secara keseluruhan fitur yang digunakan telah baik (informatif dan representatif) karena memiliki p-value kecil dari 0.05.
Pada penelitian ini terdapat fitur yang dependen yaitu fitur diameter maksimum inti dengan keliling inti namun keberadaan fitur yang dependen tersebut tidak berpengaruh terhadap akurasi. Hal ini dibuktikan dari akurasi
Tabel 9 Hasil uji terhadap fitur - fitur yang digunakan
16
klasifikasi menggunakan empat fitur (salah satu fitur yang dependen tidak digunakan) sama dengan akurasi klasifikasi yang menggunakan lima fitur.
Jadi metode Naïve Bayes memiliki kinerja yang sangat baik untuk klasifikasi dua kelas target tapi untuk tujuh kelas target metode ini belum menghasilkan akurasi yang tinggi karena sebaran nilai fitur pada setiap kelas memiliki kemiripan.
Saran
Penelitian selanjutnya disarankan untuk menganalisis data secara kuantitatif terlebih dahulu sehingga dapat menentukan dengan tepat metode yang akan digunakan.
DAFTAR PUSTAKA
Giri EP. 2008. Model klasifikasi berbasiskan Association Rules untuk Biomedical Image Retrieval System (studi kasus: citra pap smear) [tesis]. Depok (ID): Universitas Indonesia.
Kurniawan R, Sasmito DEK, Suryani F. 2013. Klasifikasi sel serviks menggunakan analisis fitur nuclei pada citra pap smear. Di dalam Seminar Nasional Informatika Medis 2013 [Internet]. Yogyakarta (2013 Nov 9).
Yogyakarta (ID); [diunduh 2014 Apr 21]. Tersedia pada:
http://fit.uii.ac.id/files/snimed/2013/006.pdf.
Martinez M, Sucar LE, Acosta HG, Cruz N. 2006. Bayesian model combination and its application to cervical cancer detection. Di dalam: Sichman JS, Coelho H, Rezende SO, editor. Advances in Artificial Intelligence – IBERAMIA – SBIA 2006; 2006 Okt 23–27; Ribeirao Preto, Brazil. Berlin (DE): Springer Berlin
Prasetyo E. 2011. Pengolahan Citra Digital dan Aplikasinya Menggunakan Matlab. Yogyakarta (ID): ANDI.
Prasetyo E. 2012. Data Mining Konsep dan Aplikasi Menggunakan Matlab. Yogyakarta (ID): ANDI.
17
LAMPIRAN
Lampiran 1 Tujuh citra sel pap smear asli dan hasil segmentasi modul CHAMP
Normal
Citra hasil segmentasi modul CHAMP
Lampiran 2 Sampel nilai lima fitur pada data citra kelas normal superficial
Data Intensitas cahaya inti
Diameter maksimum
inti Keliling inti Posisi inti
18
Lampiran 3 Sampel nilai lima fitur pada data citra kelas carcinoma in situ
Data Intensitas cahaya inti
Diameter
maksimum inti Keliling inti Posisi inti
Maksimum sitoplasma
1 115.9272 75.50497 229.625 0.582529 49
2 134.0267 81.78631 208.5 0.343481 67
3 95.45186 66.85058 181.125 0.177919 42
4 106.2089 66.0303 198.25 0.302238 48
5 83.98065 62.96825 151.875 0.065234 53
6 122.6021 81.9329 259.75 0.123775 51
7 85.45121 59.5063 164.75 0.494562 52
8 142.0622 82.9759 285.375 0.389702 178
9 122.3841 145.279 411.375 0.552429 50
10 132.0261 107.8378 365.25 0.182104 108
11 127.7329 82.21922 293 0.12582 69
12 79.86122 83.24062 223.625 0.180499 69
13 76.57464 76.00658 269.125 0.196989 72
14 84.32426 71.02112 179.25 0.147333 67
19
RIWAYAT HIDUP
Penulis dilahirkan di Batusangkar, Sumatera Barat pada tanggal 19 November 1991. Penulis merupakan anak ketiga dari 3 bersaudara dari ayah Harmen Kasudi dan ibu Hernayetti. Penulis menamatkan pendidikan di SMA Negeri 1 Batusangkar pada tahun 2009. Pada tahun yang sama, penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) di Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam melalui jalur Seleksi Nasional Masuk Perguruan Tinggi Negeri (SNMPTN).