POST PRUNING POHON KEPUTUSAN SPASIAL
UNTUK KLASIFIKASI KEMUNCULAN
TITIK PANAS
ANDI DYNAWAVY NURZAKYAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN SUMBER
INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Post Pruning Pohon Keputusan Spasial untuk Klasifikasi Kemunculan Titik Panas adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
ANDI DYNAWAVY NURZAKYAH. Post Pruning Pohon Keputusan Spasial untuk Klasifikasi Kemunculan Titik Panas. Dibimbing oleh IMAS SUKAESIH SITANGGANG.
Data pembangun pohon keputusan yang mengandung noise dan outlier dapat menyebabkan ukuran pohon keputusan menjadi besar dengan nilai akurasi yang rendah. Keadaan ini disebut overfitting. Salah satu cara untuk mengurangi ukuran pohon keputusan sehingga akurasinya meningkat adalah dengan metode pruning. Penelitian ini bertujuan untuk melakukan pruning pada pohon keputusan yang telah dibangun pada penelitian sebelumnya menggunakan metode post pruning. Metode post pruning untuk pohon keputusan tersebut menghasilkan pohon keputusan yang lebih sederhana dengan ukuran yang lebih kecil dibandingkan pohon keputusan awal. Pohon keputusan hasil post pruning mengalami rata - rata peningkatan akurasi paling kecil adalah sebesar 0.53% dan paling besar adalah sebesar 28.17%.
Kata kunci: pohon keputusan, pruning, post pruning
ABSTRACT
ANDI DYNAWAVY NURZAKYAH. Post Pruning Spatial Decision Tree for Hotspot Occurences Classification. Supervised by IMAS SUKAESIH SITANGGANG.
The data with noises and outliers to build a decision tree tend to make the size of the decision tree large with low accuracy. This situation is called overfitting. Pruning method is one way to reduce size of the decision tree for increasing its accuracy. This study aims to prune decision trees from previous studies using the post pruning method. The post pruning method gives simple trees with higher accuracies compared to the original trees. The lowest average accuracy of decision tree after post pruning is 0.53% and 28.17% is the highest average accuracy of decision tree after post pruning.
POST PRUNING POHON KEPUTUSAN SPASIAL UNTUK
KLASIFIKASI KEMUNCULAN TITIK PANAS
ANDI DYNAWAVY NURZAKYAH
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Ilmu Komputer
pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Penguji 1: Hari Agung Adrianto, SKom MSi
PRAKATA
Alhamdulillahi rabbil' alamin, puji syukur penulis panjatkan ke hadirat Allah subhanahu wa Ta'ala atas berkat, rahmat, taufik, dan hidayah-Nya sehingga penyusunan skripsi yang berjudul Post Pruning Pohon Keputusan Spasial untuk Klasifikasi Kemunculan Titik Panas dapat diselesaikan dengan baik. Penyelesaian tugas akhir ini tidak lepas dari dukungan dan bantuan beberapa pihak, antara lain:
1 Ayahanda Andi Hendra Samudra, ibunda Rolliyatul Farida, serta seluruh keluarga besar atas segala doa dan dukungannya yang telah diberikan kepada penulis.
2 Ibu Dr Imas Sukaesih Sitanggang, SSi MKom selaku pembimbing yang selalu memberikan saran dan arahan untuk membantu penulis dalam menyusun tugas akhir ini.
3 Bapak Hari Agung Adrianto, SKom MSi dan Bapak Muhammad Asyhar Agmalaro, SSi MKom selaku penguji dalam tugas akhir ini.
4 Terima kasih kepada seluruh staf dan dosen Departemen Ilmu Komputer IPB atas segala bimbingan dan kemudahan layanan.
5 Teman-teman Ilmu Komputer Alih Jenis angkatan 7 khususnya teman-teman satu bimbingan atas kebersamaan dan semangatnya, serta semua pihak lain yang telah membantu penulis yang tidak dapat disebutkan satu persatu.
Penulis menyadari bahwa masih terdapat banyak kekurangan dalam penulisan skripsi ini. Semoga skripsi ini dapat memberikan manfaat.
DAFTAR ISI
DAFTAR TABEL vii
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN vii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE PENELITIAN 2
Data Penelitian 2
Pohon Keputusan Spasial 3
Pruning Pohon Keputusan 3
Spesifikasi Kebutuhan Perangkat Sistem 4
Tahapan Penelitian 4
Pruning Pohon Keputusan 4
Evaluasi Pohon Keputusan 4
HASIL DAN PEMBAHASAN 5
Pohon Keputusan 5
Data Uji 5
Modul dan Fungsi 6
Modul Pruning 7
Modul Pengujian 8
Modul Ukuran Pohon Keputusan 10
Evaluasi Hasil 10
SIMPULAN DAN SARAN 14
Simpulan 14
Saran 14
DAFTAR PUSTAKA 15
LAMPIRAN 16
DAFTAR TABEL
1 Data yang digunakan untuk membuat pohon keputusan 2
2 Contoh keterangan layer 6
3 Dataset pohon keputusan 6
4 Daftar modul dan fungsi Python untuk post pruning pohon keputusan 6 5 Hasil post pruning pohon keputusan Sitanggang et al. (2014) 11 6 Hasil post pruning pohon keputusan Nurpratami (2014) menggunakan
data uji 11
7 Hasil post pruning pohon keputusan Nurpratami (2014) menggunakan
data latih 11
DAFTAR GAMBAR
1 Tahapan penelitian 4
2 Contoh data uji (Nurpratami 2014) 6
3 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 4 12 4 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 4 12 5 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 5 13 6 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 5 13
DAFTAR LAMPIRAN
1
PENDAHULUAN
Latar Belakang
Decision tree (pohon keputusan) memiliki keunggulan selain mudah dibaca juga dapat membagi proses pengambilan keputusan yang kompleks menjadi sederhana (Han et al. 2011). Dalam penelitian Sitanggang et al. (2013) model pohon keputusan dapat digunakan untuk menggambarkan karakteristik area atau wilayah munculnya titik panas berdasarkan data kebakaran hutan di wilayah Rokan Hilir di Provinsi Riau. Model ini berguna sebagai sistem peringatan awal untuk mencegah terjadinya kebakaran hutan (Sitanggang et al. 2013).
Keberhasilan suatu pohon keputusan dalam mengklasifikasikan data dapat dilihat dari nilai akurasi yang dihasilkan. Data yang digunakan untuk membangun pohon keputusan tersebut dapat mempengaruhi nilai akurasi. Data yang mengandung noise dan outlier dapat menyebabkan ukuran pohon menjadi besar dengan nilai akurasi yang rendah. Keadaan ini disebut overfitting (Han et al. 2011). Overfitting dapat dihindari dengan cara pre pruning yaitu menghentikan pembangunan pohon keputusan sebelum data latih terklasifikasi sempurna atau dengan post pruning yang mengembangkan pohon keputusan terlebih dahulu hingga selesai dan lengkap lalu dilakukan penyederhanaan dengan cara pruning (pemangkasan) (Tan et al. 2006).
Sitanggang et al. (2014) telah membangun sebuah pohon keputusan untuk mendeteksi kemunculan titik panas berdasarkan dataset di wilayah Rokan Hilir, Provinsi Riau, Indonesia tahun 2008. Algoritme yang digunakan adalah pohon keputusan spasial dengan nilai akurasi yang diperoleh sebesar 71.12 %. Nurpratami (2014) dengan menggunakan dataset di wilayah Bengkalis, Provinsi Riau, Indonesia tahun 2008 telah membangun pohon keputusan dengan menggunakan algoritme Entropy Based Spatial Decision Tree.
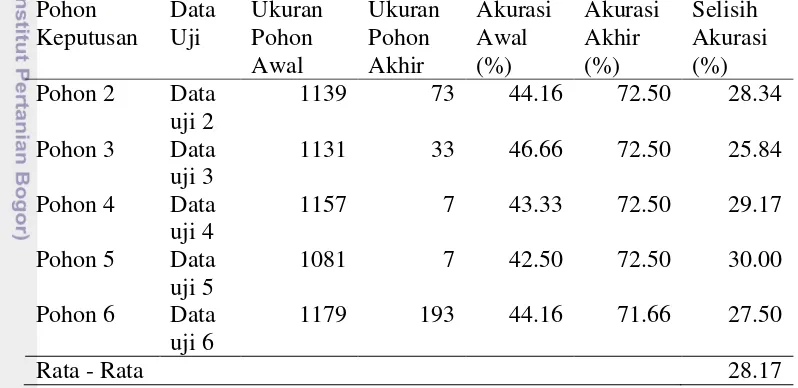
Dataset yang digunakan dalam penelitian Nurpratami (2014) dibagi menjadi 5 bagian menggunakan 5-fold cross validation. Pohon keputusan yang dihasilkan masing masing memiliki akurasi 44.16%, 46.66%, 43.33%, 42.5%, dan 44.16%. Pohon keputusan hasil penelitian tersebut akan digunakan dalam penelitian ini untuk disederhanakan menggunakan metode post pruning. Post pruning pohon keputusan diharapkan dapat membuat pohon keputusan menjadi lebih sederhana dengan akurasi lebih tinggi atau nilai akurasi sama dengan pohon keputusan sebelum dipangkas tetapi memiliki jumlah node yang lebihsedikit.
Perumusan Masalah
2
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan algoritme post pruning pada pohon keputusan untuk mendapatkan pohon keputusan dengan nilai akurasi yang lebih tinggi atau minimal sama tetapi memiliki jumlah node yang lebih sedikit dari pohon keputusan sebelum dipangkas.
Manfaat Penelitian
Pohon keputusan dari hasil pruning yang memiliki nilai akurasi lebih tinggi diharapkan dapat digunakan untuk memprediksi kemunculan titik panas di suatu wilayah berdasarkan karakteristik wilayah tersebut.
Ruang Lingkup Penelitian
Lingkup dari penelitian ini, yaitu:
1 Penelitian ini mengimplementasikan metode post pruning pohon keputusan untuk klasifikasi kemunculan titik panas.
2 Pohon keputusan yang digunakan merupakan hasil dari penelitian Sitanggang et al. (2014) dan Nurpratami (2014).
METODE PENELITIAN
Data Penelitian
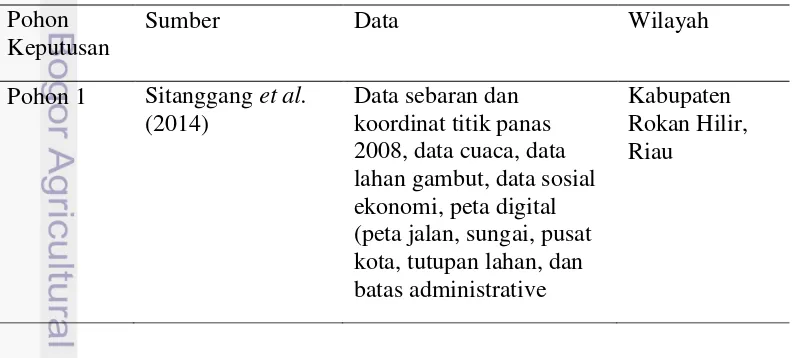
Penelitian ini menggunakan pohon keputusan sebelumnya untuk disederhanakan menggunakan metode post pruning. Data yang digunakan untuk membuat pohon keputusan dapat dilihat pada Tabel 1.
Tabel 1 Data yang digunakan untuk membuat pohon keputusan Pohon
Keputusan
Sumber Data Wilayah
Pohon 1 Sitanggang et al. (2014)
Data sebaran dan koordinat titik panas 2008, data cuaca, data lahan gambut, data sosial ekonomi, peta digital (peta jalan, sungai, pusat kota, tutupan lahan, dan batas administrative
3
Pohon Keputusan
Sumber Data Wilayah
Pohon 2 Nurpratami (2014) Data sebaran dan koordinat titik panas tahun 2008, data cuaca, data lahan gambut, data sosial ekonomi, peta digital (peta jalan, sungai, pusat kota, tutupan lahan, dan batas administratif
Pohon keputusan merupakan suatu metode klasifikasi dan model prediksi menggunakan struktur pohon atau struktur hirarki (Han et al. 2011). Pohon keputusan spasial merupakan suatu pohon keputusan yang mengklasifikasikan data spasial. Setiap internal node-nya adalah sebuah node keputusan dari suatu lapisan yang mengandung data spasial, masing-masing cabang menunjukkan hasil pengujian dan setiap daun merepresentasikan nilai suatu kelas (Rinzivillo dan Turini 2004). Pada algoritme pohon keputusan spasial, spatial information gain didefinisikan untuk mengambil layer penjelas yang memberikan pemisahan terbaik dari dataset spasial (Sitanggang et al. 2013).
Pruning Pohon Keputusan
Pruning merupakan suatu teknik untuk mengurangi ukuran pohon keputusan dengan cara menghilangkan bagian pada pohon keputusan yang memiliki kemungkinan kecil untuk mengklasifikasikan kelas. Tujuan utama pruning yaitu untuk menghilangkan kompleksitas pohon keputusan namun memiliki akurasi yang tinggi dalam memprediksi kelas. Terdapat dua teknik pruning yaitu pre pruning dan post pruning (Han et al. 2011).
Pre pruning merupakan teknik yang efisien karena dilakukan saat proses pohon keputusan dibangun (Tan et al. 2006). Pre pruning dilakukan dengan cara berhenti memecah subset data latih pada node tertentu. Berbeda dengan pre pruning,post pruning dilakukan setelah pohon keputusan selesai dibentuk. Teknik ini dilakukan dengan cara menghapus beberapa aturan atau node yang telah terbentuk dengan tujuan pohon keputusan setelah pruning berukuran lebih kecil dengan nilai akurasi yang lebih baik atau minimal akurasi sebelum dan sesudah pruning sama (Han et al. 2011).
Penyederhanaan pohon keputusan dengan menggunakan metode post pruning dilakukan dengan cara mengganti subtree dengan ketentuan sebagai berikut (Tan et al. 2006):
1 Daun yang digunakan untuk menggantikan subtree merupakan daun dengan label kelas yang mendominasi subtree yang akan diganti tersebut, atau
4
Spesifikasi Kebutuhan Perangkat Sistem
Penelitian ini menggunakan spesifikasi perangkat keras dan lunak sebagai berikut:
1 Perangkat keras
Intel® Celeron® Processor @ 1.10 GHz Memori 4GB
2 Perangkat lunak
Windows 8 Enterprise 32-bit sebagai sistem operasi Python 2.7.3 sebagai bahasa pemrograman
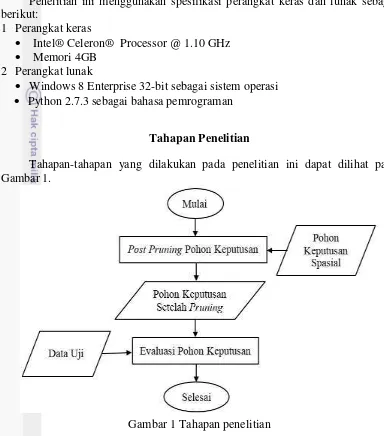
Tahapan Penelitian
Tahapan-tahapan yang dilakukan pada penelitian ini dapat dilihat pada Gambar 1.
Gambar 1 Tahapan penelitian
Pruning Pohon Keputusan
Suatu pohon keputusan terdiri dari beberapa subtree. Pruning dilakukan dengan menggunakan metode Post Pruning. Metode ini dilakukan dengan cara menghilangkan beberapa subtree yang terkandung dalam pohon untuk digantikan oleh daun yang merupakan atribut kelas. Nilai akurasi pohon keputusan dengan leaf (daun) ketika dihilangkan akan dibandingkan dengan akurasi pohon keputusan sebelum daun tersebut dihilangkan. Apabila nilai akurasi pohon keputusan setelah menghilangkan subtree lebih besar dibandingkan sebelum subtree dihilangkan maka subtree tersebut boleh dihilangkan dan diganti menjadi daun.
Evaluasi Pohon Keputusan
5
baru yang sudah dipangkas akan dievaluasi menggunakan data uji. Perhitungan akurasi menggunakan rumus sebagai berikut:
��� � � = ∑ data yang benarBanyak data uji x %
HASIL DAN PEMBAHASAN
Algoritme post pruning diimplementasikan dalam bahasa pemrograman Python dengan memodifikasi kode program untuk algoritme ID3(Roach2013) dan pruning (Sitanggang et al. 2014). Pohon keputusan dipangkas dengan cara menghapus bagian subtree. Sebuah subtree pada node tertentu dipangkas dengan cara menghilangkan cabang untuk diganti menjadi daun. Daun tersebut diberi label sesuai dengan kelas yang mendominasi subtree yang akan diganti tersebut. Proses pemangkasan pohon keputusan dilakukan dari level paling bawah ke yang paling atas (Han et al. 2011).
Pohon Keputusan
Input dari algoritme pohon keputusan dalam penelitian ini merupakan format dictionary (dict.). Format dictionary dalam bahasa pemrograman Python versi 2.7.3 merupakan salah satu format yang dapat menyimpan sejumlah object tidak tetap. Dictionaries terdiri dari sepasang keys dan values yang terkait dalam setiap item-nya. Sintaks umum dari format dictionary sebagai berikut (Python Developer, 2014).
dict = {'Key1': 'Value1', 'key2': 'Value2', 'Key3': 'Value3'}.
Contoh penyajian pohon keputusan sebagai berikut.
{'l3': {'l3v5': {'l4': {'l4v6': {'l9': {'l9v2': {'l8': {'l8v2': {'l7': {'l7v1': 'F', 'l7v4': 'T'}}}}, 'l9v0': 'T'}}, 'l4v7': {'l9': {'l9v0': {'l8': {'l8v2': 'F', 'l8v0': 'T'}}}}.
Setiap key dipisahkan oleh titik dua (:) dengan nilai value, sementara itu masing-masing item dipisahkan oleh koma (,), dan keseluruhannya diapit oleh kurung kurawal ({}). Key bersifat unik akan tetapi value boleh sama. Atribut value dalam dictionary boleh bertipe apa saja sedangkan atribut key harus bertipe data tetap seperti string, numbers, atau tuples (Python 2014).
Data Uji
6
beserta kelasnya seperti pada Gambar 2 yang akan diklasifikasikan pada saat proses perhitungan akurasi pohon keputusan.
Gambar 2 Contoh data uji (Nurpratami 2014)
Setiap atribut merupakan representasi dari suatu layer. Misal layer 0 atau l0 merupakan representasi dari dist_city atau jarak kota seperti pada contoh Tabel 2. Keterangan layer lebih lengkap dapat dilihat pada Lampiran 1 dan Lampiran 2. Setiap data uji terdiri dari kelas True dan False seperti yang terdapat pada Tabel 3.
Tabel 2 Contoh keterangan layer
Kode Layer Nama Layer Kode Atribut Nilai Atribut
l0 dist_city l0v1 Low : <= 7 km
l0v0 Medium: (7 km, 14 km]
l0v2 High: > 14 km
l1 dist_river l1v0 Low: <= 1.5 km
l1v1 Medium: (1.5 km, 3]
l1v2 High: > 3 km
l2 dist_road l2v0 Low: <= 2.5 km
l2v1 Medium: (2.5 km, 5 km]
l2v2 High: > 5 km
Tabel 3 Dataset pohon keputusan
Dataset Wilayah Jumlah True Jumlah False
Data uji 1 Kabupaten Rokan Hilir 235 326
Data uji 2 Kabupaten Bengkalis 33 87
Data uji 3 33 87
Data uji 4 33 87
Data uji 5 33 87
Data uji 6 32 88
Modul dan Fungsi
Algoritme post pruning diimplementasikan kedalam beberapa modul menggunakan bahasa pemrograman Python, Tabel 4 merupakan modul – modul Python yang digunakan.
Tabel 4 Daftar modul dan fungsi Python untuk post pruning pohon keputusan
Nama Modul Daftar Fungsi Kegunaan
tree_pruning.py ls_tree_pruning, ls_simple_subtree, isDict, isAtomorFlat, leafPaths, simple_subtree, isSubtree, maj_value, update_tree
7
Nama Modul Daftar Fungsi Kegunaan
test_dtree.py get_file, run_test, akurasi _awal, get_classification, classify, accuracy, number _rules
Mengklasifikasikan pohon keputusan terhadap data uji serta menghitung akurasi pohon keputusan
size_tree.py ls_size, size Menghitung ukuran
pohon keputusan
run.py get_treeinput Meminta input pohon
keputusan dan memanggil semua modul
Modul Pruning
Modul pruning dibuat untuk menghasilkan list (daftar) subtree yang telah disederhanakan. Input dari modul ini yaitu berupa suatu pohon keputusan dalam format dictionary (dict.). Modul ini disimpan dengan nama fail tree_pruning.py. Langkah – langkah utama dalam membuat daftar pohon yang lebih sederhana adalah:
1 Menentukan subtree dari pohon keputusan 2 Menyederhanakan subtree
3 Update pohon keputusan dengan pohon yang lebih sederhana
1 Menentukan subtree dari pohon keputusan
Subtree dari pohon keputusan terletak diantara root (akar) dan leaf (daun) dari pohon keputusan tersebut. Suatu node disebut subtree apabila node tersebut memiliki parent dan daun. Apabila suatu node merupakan key dari suatu value atau masih berbentuk dictionary maka node tersebut merupakan subtree. Daun pada pohon keputusan terdeteksi ketika nilai dari suatu node adalah value yang bernilai string.
2 Menyederhanakan subtree
Sebuah pohon keputusan memiliki banyak subtree. Post pruning bertujuan untuk menyederhanakan setiap subtree yang terdapat dalam pohon keputusan yang telah selesai terbentuk. Hal ini dilakukan dengan cara melihat key dan value dalam setiap subtree. Apabila suatu node merupakan key yang memiliki nilai value masih dalam bentuk dictionary maka pencarian diteruskan sampai menemukan node yang memiliki nilai value string. Node yang memiliki nilai value berupa string akan dihitung masing-masing jumlah kelasnya untuk mengetahui kelas yang mendominasi subtree tersebut. Kelas dengan jumlah terbanyak akan menggantikan subtree. Setiap penyederhanaan subtree akan dimasukkan kedalam list dengan fungsi ls_simple_subtree. Fungsi mendapatkan subtree yang lebih sederhana dapat dilihat sebagai berikut (Sitanggang et al. 2014):
def simple_subtree(subtree):
for key,value in subtree.items(): if type(value) == dict:
8
3 Update pohon keputusan dengan pohon yang lebih sederhana
Pohon keputusan akan di-update dengan pohon yang telah disederhanakan. Ketika subtree dihilangkan atau diganti dengan mayoritas kelasnya maka pohon keputusan akan di-update. Setiap subtree yang telah disederhanakan dalam list akan di-update pada pohon keputusan. Pohon keputusan dengan subtree yang telah di-update akan dimasukkan kedalam list dengan variable ls_up_tree. Fungsi untuk mengganti nilai pohon keputusan dengan yang lebih sederhana adalah sebagai berikut (Sitanggang et al. 2014):
def update_tree(d, u):
Modul ini digunakan untuk mengklasifikasikan data uji pada setiap pohon keputusan dalam ls_up_tree yang bertujuan untuk mengetahui masing – masing nilai akurasinya. Modul ini disimpan dalam fail test_dtree.py. Input dari modul ini berupa data uji untuk masing- masing pohon keputusan. Pohon keputusan sederhana dengan nilai akurasi tertinggi akan diambil untuk disederhanakan kembali menggunakan modul tree_pruning.py. Langkah– langkah dalam membuat modul perhitungan akurasi adalah:
1 Membaca data uji pohon keputusan
2 Melakukan klasifikasi pohon keputusan menggunakan data uji 3 Menghitung akurasi pohon keputusan
4 Memilih pohon keputusan yang telah disederhanakan dengan akurasi yang tinggi untuk disederhanakan kembali
1 Membaca data uji pohon keputusan
Untuk menghitung nilai akurasi dari suatu pohon keputusan dibutuhkan data uji. Data uji yang digunakan disimpan dalam format .csv. Fungsi untuk membaca data uji dapat dilihat sebagai berikut (Roach 2013):
def get_file():
filename= 'data_uji1' try:
9
print "Error: The file '%s' was not found on this system." % filename
sys.exit(0) return fin
2 Melakukan klasifikasi pohon keputusan menggunakan data uji
Klasifikasi pohon keputusan menggunakan data uji dilakukan untuk mengetahui berapa banyak kelas yang terklasifikasi dengan benar dan tidak. Hal ini dilakukan untuk keperluan menghitung akurasi pohon keputusan tersebut. Fungsi klasifikasi ini secara rekursif menelusuri pohon keputusan dan mengembalikan nilai klasifikasi dari data uji yang telah diberikan. Apabila node yang diperiksa merupakan string maka itu merupakan node daun dan nilai daun tersebut dikembalikan sebagai kelas. Fungsi klasifikasi pohon keputusan dapat dilihat sebagai berikut (Roach 2013):
def get_classification(record, tree):
3 Menghitung akurasi pohon keputusan
Setiap penyederhanaan subtree akan dilihat pengaruhnya terhadap pohon keputusan yang tersebut. Hal ini dilakukan dengan menghitung nilai akurasi pada setiap pohon keputusan yang telah di-update dalam ls_up_tree. Fungsi perhitungan akurasi ini akan menghitung banyak kelas yang terklasifikasi dengan baik untuk dibagi dengan banyak data ujinya. Hasil dari pembagian tersebut akan dikalikan 100 untuk mendapatkan nilai akurasi dalam bentuk persen (%). Fungsi untuk menghitung akurasi dapat dilihat sebagai berikut (Roach 2013):
def accuracy(actual, predicted):
match=[i for i,j in zip(actual, predicted)if i == j] return (len(match)/(len(actual)))*100
4 Memilih pohon keputusan yang telah disederhanakan dengan akurasi yang tinggi untuk disederhanakan kembali
10
adanya perubahan hasil. Ketentuan post pruning berlangsung dapat dilihat sebagai berikut:
if maxAk - akurasi < 0.00001 and maxAk >= akurasi: stop = stop + 1;
Ukuran suatu pohon keputusan dapat dihitung dengan cara menghitung jumlah node. Node yang dihitung adalah akar, internal node, dan daun. Modul ini disimpan dalam fail size_tree.py. Pohon keputusan dalam bentuk dictionary memiliki key dan value. Dalam hal ini akar pohon keputusan merupakan keys dan daun dari setiap cabang adalah values. Daun dari pohon keputusan dapat diketahui ketika ditemukan values yang bernilai string. Panjang keys dan values dijumlah untuk mendapatkan ukuran dari pohon keputusan. Setiap update pohon keputusan yang terdapat dalam ls_up_tree dihitung ukurannya dengan menggunakan fungsi sebagai berikut (Sitanggang et al. 2014):
def size(d):
11
penyederhaan pohon keputusan diklasifikasikan menggunakan data uji dapat dilihat pada Tabel 6. Hasil pada Tabel 7 diperoleh dengan menggunakan data penyusun pohon keputusan atau data latih dari penelitian Nurpratami (2014). Perhitungan akurasi tidak memperhatikan objek – objek yang tidak dapat diklasifikasikan oleh pohon keputusan.
Tabel 5 Hasil post pruning pohon keputusan Sitanggang et al. (2014) Pohon
Peningkatan akurasi 0.53
Tabel 6 Hasil post pruning pohon keputusan Nurpratami (2014) menggunakan data uji
12
Dari Tabel 4 dapat dilihat bahwa karakteristik pohon keputusan hasil penelitian Sitanggal et al. (2014) yaitu Pohon 1 memiliki ukuran pohon awal yang lebih kecil dibandingkan kelima pohon keputusan awal Nurpratami (2014). Setelah diterapkan post pruning menggunakan data uji, karakteristik Pohon 1 tidak jauh berbeda dengan pohon awalnya dibandingkan pohon keputusan lainnya. Nilai akurasi sebelum diterapkan post pruning yaitu sebesar 71.12% dengan ukuran 613 node meningkat sedikit menjadi 71.65% dengan ukuran 545 node. Peningkatan akurasi yang terjadi pada Pohon 1 hanya sebesar 0.53%.
Pohon keputusan hasil penelitian Nurpratami (2014) yang terbagi menjadi 5 pohon keputusan pada penelitian ini dicobakan menggunakan data uji dan data latih. Setiap pohon keputusan memiliki nilai akurasi awal dibawah 70% terhadap data uji dan nilai akurasi awal diatas 75% apabila menggunakan data latih. Ukuran awal kelima pohon keputusan yang besar mengalami penurunan yang besar setelah diterapkan post pruning dibandingkan Pohon 1.
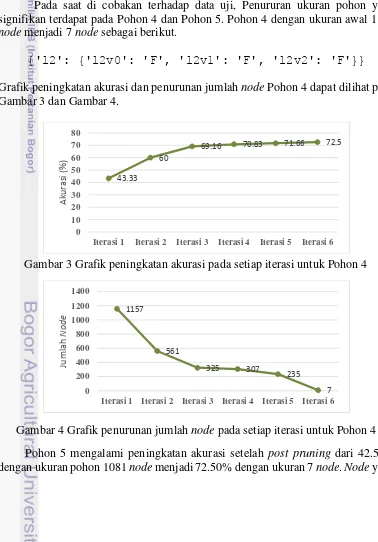
Pada saat di cobakan terhadap data uji, Penururan ukuran pohon yang signifikan terdapat pada Pohon 4 dan Pohon 5. Pohon 4 dengan ukuran awal 1157 node menjadi 7 node sebagai berikut.
{'l2': {'l2v0': 'F', 'l2v1': 'F', 'l2v2': 'F'}}
Grafik peningkatan akurasi dan penurunan jumlah node Pohon 4 dapat dilihat pada Gambar 3 dan Gambar 4.
Gambar 3 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 4
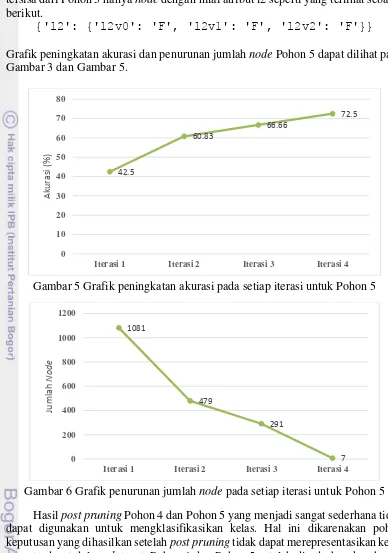
Gambar 4 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 4 Pohon 5 mengalami peningkatan akurasi setelah post pruning dari 42.50% dengan ukuran pohon 1081 node menjadi 72.50% dengan ukuran 7 node. Node yang
43.33
Iterasi 1 Iterasi 2 Iterasi 3 Iterasi 4 Iterasi 5 Iterasi 6
Aku
Iterasi 1 Iterasi 2 Iterasi 3 Iterasi 4 Iterasi 5 Iterasi 6
13
tersisa dari Pohon 5 hanya node dengan nilai atribut l2 seperti yang terlihat sebagai berikut.
{'l2': {'l2v0': 'F', 'l2v1': 'F', 'l2v2': 'F'}}
Grafik peningkatan akurasi dan penurunan jumlah node Pohon 5 dapat dilihat pada Gambar 3 dan Gambar 5.
Gambar 5 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 5
Gambar 6 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 5 Hasil post pruning Pohon 4 dan Pohon 5 yang menjadi sangat sederhana tidak dapat digunakan untuk mengklasifikasikan kelas. Hal ini dikarenakan pohon keputusan yang dihasilkan setelah post pruning tidak dapat merepresentasikan kelas yang terdapat dalam dataset. Pohon 4 dan Pohon 5 setelah disederhanakan hanya merepresentasikan kelas dengan nilai False.
Apabila dilihat dari Gambar 5 dan Gambar 6, Pohon 5 mengalami peningkatan akurasi dan penurunan jumlah node yang signifikan diantara pohon keputusan hasil post pruning lainnya. Hal ini membuat Pohon 5 memiliki selisih nilai akurasi yang lebih besar dibandingkan pohon lainnya yaitu sebesar 30%. Rata – rata peningkatan pohon keputusan Nurpratami (2014) menggunakan data uji yaitu sebesar 28.17%. Hasil post pruning Pohon 2, Pohon 3, dan Pohon 6 dalam bentuk
42.5
Iterasi 1 Iterasi 2 Iterasi 3 Iterasi 4
Aku
Iterasi 1 Iterasi 2 Iterasi 3 Iterasi 4
14
dictionary dapat dilihat pada Lampiran 3 sampai Lampiran 5. Grafik peningkatan nilai akurasi dan penurunan jumlah node Pohon 1, Pohon 2, Pohon 3, dan Pohon 6 dapat dilihat pada Lampiran 6 sampai Lampiran 13.
Pohon keputusan yang dicobakan menggunakan data latih memiliki nilai akurasi awal yang tinggi dibandingkan pohon lainnya. Pada saat pohon keputusan disederhanakan, peningkatan akurasi lebih kecil dibandingkan pohon keputusan menggunakan data uji. Rata – rata peningkatan akurasi yang terjadi sebelum dan sesudah post pruning pada pohon keputusan Nurpratami (2014) dengan menggunakan data latih adalah sebesar 7.1%.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini menerapkan metode post pruning yang bertujuan untuk menghasilkan pohon keputusan yang berukuran lebih kecil dengan akurasi lebih tinggi dibandingkan pohon keputusan sebelum disederhanakan. Dari hasil penelitian ini dapat disimpulkan bahwa pohon keputusan yang dibangun dari dataset Rokan Hilir memiliki nilai akurasi dan ukuran awal lebih kecil. Pohon keputusan tersebut mengalami peningkatan akurasi paling kecil diantara pohon lainnya yaitu sebesar 0.53%.
Pohon keputusan yang dibangun dari dataset Bengkalis mengalami peningkatan akurasi rata – rata sebesar 28.17% menggunakan data uji dan 7.1% menggunakan data latih. Salah satu pohon keputusan dengan menggunakan data uji Bengkalis mengalami peningkatan akurasi dan penurunan ukuran pohon yang signifikan. Akurasi awal sebesar 42.50% dengan ukuran 1081 node setelah disederhanakan menjadi 72.50% dengan ukuran 7 node yang hanya terdapat kelas False saja pada pohon keputusan tersebut. Ukuran pohon keputusan hasil post pruning yang sangat kecil tersebut tidak dapat digunakan karena tidak merepresentasikan kelas dalam dataset.
Saran
15
DAFTAR PUSTAKA
Han J, Kamber M, Pei J. 2011. Data Mining: Concepts and Techniques, 3rd ed. Massachusetts (US): Morgan Kaufmann.
Nurpratami ID. 2014. Klasifikasi data titik api di Bengkalis Riau menggunakan algoritme pohon keputusan berbasis Spatial Entropy. [skripsi]. Bogor (ID): IPB.
[Python Developer]. 2014. Data Structures-Python 2.7 Documentation [internet]. [diacu 2014 November 20]. Tersedia pada: https://docs.python.org/2/ tutorial/datastructures.html#dictionaries
Rinzivillo S, Turini F. 2004. Classification in geographical information systems. Proceedings of the 8th European Conference on Principles and Practice of Knowledge Discovery in Databases. [diunduh 2014 Juni 7]. Springer-Verlag (NY): New York Inc. hlm 374-385.doi:10.1007/978-3-540-30116-5_35. Tersedia pada: http://www.informatik.unitrier.de/~ley/pers/hy/r /Rinzivillo: Salvatore.html.
Roach C. 2013. Building Decision Trees in Python [internet]. [diacu 2014 Agustus 21]. Tersedia dari: https://github.com/croach/dtree/blob/master/test.py. Sitanggang IS, Yaakob R, Mustapha N, Ainuddin AN. 2013. Classification model
for hotspot occurences using spatial decision tree algorithm. Science Publication. [Internet]. [diunduh 2014 Feb 10]. 9(2):244-251. doi:10.3844/jcssp.2013.244.251. Tersedia pada: http://www.thescipub. com/jcs.toc.
Sitanggang IS, Yaakob R, Mustapha N, Ainuddin AN. 2014. A dcision tree based on spatial relationships for predicting hotspots in peatlands. Telkomnika. [Internet]. [diunduh 2014 Jun 28]. 12(2):511-518. doi:10.12928/ TELKOMNIKA.v12i2.2036. Tersedia pada:http:// www.jogjapress.com / index.php/TELKOMNIKA/article/view/ 2036.
16
LAMPIRAN
Lampiran 1 Keterangan layer pohon keputusan wilayah Rokan Hilir Kode
l3 income_source l3v0 Plantation l3v1 Others
l4 land_cover l4v0 Plantation
l4v1 Dryland_forest
17 l7 peatland_depth l7v0 D1: (Shallow/Thin 50-100 cm)
l7v1 D4: (very deep/very thick > 400 cm)
l7v2 D3: (Deep/Thick 200-400 cm), l7v3 non_peatland
l7v4 D2: (Moderate 100-200 cm) l8 screen_temp l8v0 298: [298 K, 299 K)
Lampiran 2 Keterangan layer pohon keputusan wilayah Bengkalis Kode
l6 screen_temperature l6v0 low
l6v1 Medium
18
l8 income_source l8v0 Plantation
l8v1 Other_agriculture
l9 land_cover l9v0 Plantation
l9v1 Shrubs
l9v2 Dryland forest l9v3 Bare land
l9v4 Unirrigated agriculture field
l9v5 Swamp
l9v6 Paddy field l9v7 Mangrove l9v8 Mix garden l9v9 Settlement
Lampiran 3 Hasil post pruning Pohon 2 menggunakan data uji 2
{'l3': {'l3v1': 'F', 'l3v0': 'F', 'l3v2': {'l1':
Lampiran 4 Hasil post pruning Pohon 3 menggunakan data uji 3
19
Lampiran 5 Hasil post pruning Pohon 6 menggunakan data uji 6
{'l9': {'l9v7': 'F', 'l9v6': 'F', 'l9v5': 'F', 'l9v4': {'l1': {'l1v2': {'l5': {'l5v2': 'F', 'l5v1': 'T', 'l5v0': 'T'}}, 'l1v1': {'l3': {'l3v1': {'l5': {'l5v1': 'F', 'l5v0': {'l0': {'l0v2': {'l8': {'l8v3': {'l7': {'l7v3': {'l6': {'l6v1': {'l4': {'l4v0': {'l2': {'l2v0': 'T'}}}}}}}}}}, 'l0v1': 'F'}}}}, 'l3v0': 'F', 'l3v2': 'F'}}, 'l1v0': {'l7': {'l7v1': {'l3': {'l3v1': {'l0': {'l0v2': 'T', 'l0v1': 'F'}}, 'l3v0': 'T', 'l3v2': 'F'}}, 'l7v0': 'F', 'l7v3': {'l5': {'l5v2': {'l8': {'l8v3': 'F', 'l8v6': 'F', 'l8v4': 'T'}}, 'l5v1': 'F', 'l5v0': 'T'}}, 'l7v2': 'F'}}}}, 'l9v3': 'F', 'l9v2': {'l8': {'l8v2': 'F','l8v3': {'l0': {'l0v2': {'l2': {'l2v1': 'T', 'l2v2': 'F'}}, 'l0v0': 'F', 'l0v1': 'T'}}, 'l8v0': {'l2': {'l2v0': 'F', 'l2v1': {'l0': {'l0v2': 'F', 'l0v0': {'l7': {'l7v1': {'l6': {'l6v0': {'l5': {'l5v0':{'l4': {'l4v2': {'l3': {'l3v0': {'l1': {'l1v2': 'T'}}}}}}}}}}}}, 'l0v1': 'T'}}, 'l2v2': {'l4': {'l4v2': {'l1': {'l1v2': {'l0': {'l0v2': {'l7': {'l7v1': 'F', 'l7v2': {'l6': {'l6v1': {'l5': {'l5v0': {'l3': {'l3v0': 'T'}}}}}}}}, 'l0v0': {'l7': {'l7v1': {'l6': {'l6v0': {'l5': {'l5v0': {'l3': {'l3v0': 'T'}}}}}}}}, 'l0v1': 'F'}}, 'l1v1': {'l3': {'l3v1': 'F', 'l3v0': {'l7': {'l7v1': 'F', 'l7v2': {'l0': {'l0v2': 'F', 'l0v1': 'T'}}}}, 'l3v2': 'T'}}, 'l1v0': 'F'}}, 'l4v3': {'l3': {'l3v1': 'T', 'l3v0': 'F'}}, 'l4v1': 'T'}}}}, 'l8v1': 'F', 'l8v6': 'F'}}, 'l9v1': 'F', 'l9v0': 'F', 'l9v9': 'F', 'l9v8': {'l2': {'l2v0': {'l7': {'l7v1': 'F', 'l7v0': 'F', 'l7v3': {'l5': {'l5v2': 'F', 'l5v1': 'F', 'l5v0': {'l1': {'l1v1': 'F', 'l1v0': {'l8': {'l8v3': {'l6': {'l6v1':
{'l4': {'l4v1': {'l3': {'l3v0': {'l0': {'l0v1':
'T'}}}}}}}}}}}}}}, 'l7v2': 'F'}}, 'l2v1': {'l5':
20
Lampiran 6 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 1
Lampiran 7 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 1
Lampiran 8 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 2
71.12
Iterasi 1 Iterasi 2 Iterasi 3 Iterasi 4 Iterasi 5 Iterasi 6 Iterasi 7 Iterasi 8
Aku
ra
si
(%
21
Lampiran 9 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 2
Lampiran 10 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 3
Lampiran 11 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 3
1139
Iterasi 1 Iterasi 2 Iterasi 3 Iterasi 4 Iterasi 5 Iterasi 6 Iterasi 7 Iterasi 8
22
Lampiran 12 Grafik peningkatan akurasi pada setiap iterasi untuk Pohon 6
Lampiran 13 Grafik penurunan jumlah node pada setiap iterasi untuk Pohon 6
44.16
Iterasi 1Iterasi 2Iterasi 3Iterasi 4Iterasi 5Iterasi 6Iterasi 7Iterasi 8Iterasi 9
23