PENGKLASIFIKASIAN GENRE MUSIK BERDASARKAN
SINYAL AUDIO MENGGUNAKAN SUPPORT
VECTOR MACHINE
ARIEF DARMAWAN
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pengklasifikasian Genre Musik Berdasarkan Sinyal Audio Menggunakan Support Vector Machine adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbirkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
ABSTRAK
ARIEF DARMAWAN. Pengklasifikasian Genre Musik Berdasarkan Sinyal Audio Menggunakan Support Vector Machine. Dibimbing oleh MUSHTHOFA dan AZIZ KUSTIYO.
Genre musik adalah label bagi seni musik untuk mencirikan dan mengkategorikan musik. Penentuan genre musik dilakukan berdasarkan kemiripan antar musik. Penentuan genre musik kebanyakan masih dilakukan secara manual. Cara tersebut membutuhkan tenaga dan waktu yang cukup besar bila terdapat database musik yang berukuran besar. Tujuan penelitian ini adalah membangun model support vector machine untuk pengklasifikasian genre musik dan menerapkan metode pengekstraksian fitur permukaan musik dan ritme. Model yang telah dibangun kemudian digunakan untuk menentukan genre dari musik yang belum diketahui genrenya. Support vector machine adalah sistem pembelajaran yang pengklasifikasiannya menggunakan ruang hipotesis berupa fungsi-fungsi linear dalam sebuah ruang fitur berdimensi tinggi. Sedangkan fitur permukaan musik dan ritme yang dimaksud adalah centroid, roll off, flux, zero crossings, low energy, dan empat titik tertinggi dari hasil perhitungan autokorelasi sinyal. Hasil dari penelitian ini adalah model pengklasifikasian dengan tingkat akurasi rata-rata sebesar 65%.
Kata kunci: genre musik, sinyal audio, support vector machine
ABSTRACT
ARIEF DARMAWAN. Musical Genre Classification Based On Audio Signal Using Support Vector Machine. Supervised by MUSHTHOFA and AZIZ KUSTIYO.
Musical genre is a label for musical art to characterize and categorize music. The determination of musical genre is done based on the similarity between the music. Most of the classification of musical genre is done manually, which requires a lot of effort and time especially when there is a big database of music. The purpose of this research is to build a support vector machine model to automatically classify the musical genre and implement the method to extract the musical surface and rhythm features. The developed model is then utilized to determine the genre from the unknown music. Support vector machine is a learning system whose classification uses a hypothesis space in the form of linear functions in a high dimension of feature space. The extracted musical surface and rhythm features are the centroid, roll off, flux, zero crossings, low energy, and four peaks of the signal‟s autocorrelation calculation. The result of this research is a classification model with an average accuracy of 65%.
PENGKLASIFIKASIAN GENRE MUSIK BERDASARKAN
SINYAL AUDIO MENGGUNAKAN SUPPORT
VECTOR MACHINE
ARIEF DARMAWAN
Skripsi
sebagai salah satu syarat memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Pengklasifikasian Genre Musik Berdasarkan Sinyal Audio Menggunakan Support Vector Machine
Nama : Arief Darmawan NIM : G64090108
Disetujui oleh
Mushthofa, SKom, MSc Pembimbing I
Aziz Kustiyo, SSi, MKom Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi, MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia, rahmat dan ridho-Nya sehingga karya ilmiah ini berhasil diselesaikan. Penelitian ini berfokus pada bidang kecerdasan komputasi dengan menitikberatkan pada support vector machine sebagai salah satu proses untuk mengklasifikasikan genre dari suatu data musik. Hal yang menjadi motivasi penulis dala memilih topik ini yaitu kecerdasan komputasi sebagai salah satu bidang ilmu yang selalu menawarkan metode-metode baru untuk menyelesaikan masalah kecerdasan buatan.
Terima kasih penulis ucapkan kepada Bapak Mushtofa, SKom MSc selaku pembimbing pertama yang senantiasa selalu membimbing, mengawasi dan mengingatkan penulis pada penelitian ini, serta penulis juga ucapkan terima kasih kepada Bapak Aziz Kustiyo, SSi MKom selaku pembimbing kedua yang telah memberikan masukan dan analisis untuk memperbaiki perhitungan dalam penelitian ini. Tak lupa pula penulis menyampaikan terima kasih kepada ayah, ibu dan kakak yang selalu mendukung dan mendoakan selama penelitian ini berlangsung. Ungkapan terima kasih juga disampaikan kepada teman-teman satu bimbingan yaitu Putra, Resti, serta rekan-rekan satu angkatan Ilmu Komputer angkatan 46 yang secara langsung dan tidak langsung membantu penulis pada penelitian ini.
Semoga karya ilmiah ini bermanfaat bagi perkembangan ilmu pengetahuan secara umum dan ilmu komputer pada khususnya.
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
METODE 3
Studi Pustaka 3
Perumusan Masalah 3
Data Musik 3
Ekstraksi Fitur 4
Pembagian Data Latih dan Data Uji 8
Pelatihan 8
Pengujian 11
Lingkungan Pengembangan 11
HASIL DAN PEMBAHASAN 11
Data Musik 11
Ekstraksi Fitur Permukaan Musik 12
Ekstraksi Fitur Ritme 13
Pelatihan dan Pengujian 14
Pembahasan 14
SIMPULAN DAN SARAN 17
Simpulan 17
Saran 17
DAFTAR PUSTAKA 18
LAMPIRAN 19
DAFTAR TABEL
1 Hasil 4-fold cross validation 14
2 Hasil pengklasifikasian fold-1 15
3 Hasil perbandingan data X 16
DAFTAR GAMBAR
1 Metodologi penelitian 3
2 Tahapan ekstraksi fitur permukaan musik 4
3 Tahapan ekstraksi fitur ritme 4
4 Proses texture windowing 5
5 Proses analysis windowing 5
6 Contoh centroid 6
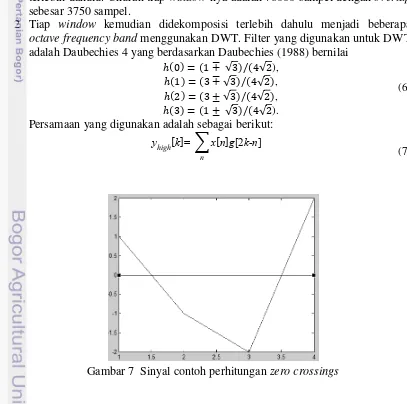
7 Sinyal contoh perhitungan zero crossings 7
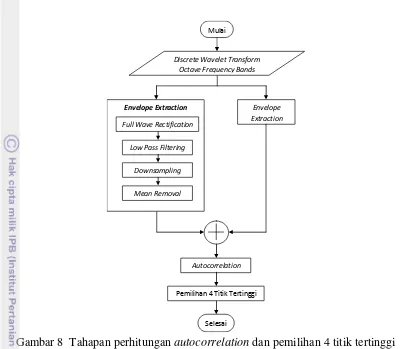
8 Tahapan perhitungan autocorrelation dan pemilihan 4 titik tertinggi 9
9 SVM pada data terpisah secara linier 10
10 SVM pada data yang terpisah secara nonlinier 10
11 Data yang akan digunakan 12
12 Hasil proses texture windowing 12
13 Hasil proses analysis windowing 12
14 Data dalam 1 window 13
15 Hasil dekomposisi filter highpass 13
16 Hasil dekomposisi filter lowpass 13
17 Hasil autocorrelation 13
18 Hasil akurasi tiap genre 15
DAFTAR LAMPIRAN
1 Data musik 19
2 Hasil pengklasifikasian 22
PENDAHULUAN
Latar Belakang
Genre musik adalah kategori dari karya seni, dalam hal ini khususnya musik, untuk mencirikan dan mengkategorikan musik yang kini tersedia dalam berbagai bentuk dan sumber (Tzanetakis dan Cook 2002). Genre musik di dunia ada banyak dan beragam, http://musicgenreslist.com/ menunjukkan terdapat 38 kategori musik utama dari seluruh dunia. Beberapa kategori yang dinyatakan di halaman situs tersebut bukan merupakan genrenya, melainkan label generalisasi dari kumpulan genre. Hal ini tergolong penting bagi masyarakat yang menyukai musik, karena dapat membantu dalam memilih dan mencari musik berdasarkan genrenya.
Penentuan genre musik dilakukan berdasarkan kemiripan antar musik. Penentuan tersebut kebanyakan masih harus dilakukan secara manual oleh manusia. Penentuan secara manual ini dapat menghasilkan penentuan dengan tingkat keakuratan yang tinggi, namun membutuhkan biaya, dalam hal ini adalah tenaga dan waktu, yang cukup besar untuk jumlah fail musik yang besar. Harga alat penyimpanan data yang semakin menurun juga mempermudah masyarakat mengoleksi musik dalam jumlah besar. Misal dimiliki sebuah flash drive berkapasitas 8 GB, dengan tiap fail musik berukuran 5 MB, flash drive tersebut dapat menyimpan lebih dari 1600 fail musik. Dapat dibayangkan berapa banyak tenaga dan waktu yang diperlukan untuk menentukan genre dari masing-masing fail musik tersebut. Karena sebagian besar fail musik sudah tersedia dalam bentuk digital, penentuan genre dengan mesin pun menjadi suatu hal yang memungkinkan untuk mengurangi biaya tersebut. Oleh sebab itu, pengklasifikasian genre musik secara otomatis dapat menjadi hal yang sangat membantu dalam pengembangan sistem temu-kembali untuk data audio, maupun untuk pengunaan pengklasifikasian musik bagi individu.
Musik yang dimainkan dan didengarkan secara langsung merupakan sinyal audio analog atau gelombang suara yang berasal dari getaran pita suara manusia, senar gitar yang dipetik, gendang yang dipukul, dll. Gelombang suara tersebut memiliki lembah dan bukit, satu buah lembah dan bukit menghasilkan satu periode. Periode tersebut berlangsung berulang-ulang yang menghasilkan konsep frekuensi. Frekuensi adalah jumlah periode yang dapat dihasilkan dalam 1 detik. Satuan bagi frekuensi adalah hertz (Hz). Batasan frekuensi yang dapat diterima telinga manusia adalah 20 – 20 000 Hz. Sedangkan kekuatan sinyal disebut amplitudo dapat dihitung sebagai jarak dari titik tertinggi bukit hingga titik terendah lembah dari gelombang suara. Panjang gelombang suara dapat dihitung sebagai jarak antara titik gelombang dengan titik ekuivalen pada fasa berikutnya.
2
Beberapa penelitian mengenai pengklasifikasian genre musik sudah pernah dilakukan sebelumnya. Berbagai metode yang sudah pernah dikembangkan antara lain k-nearest neighbour, linear discriminant analysis, learning vector quantization, dan support vector machine (SVM). Sebelumnya, metode SVM dengan kernel polinomial berderajat 6 dan fitur audio spectral dasar serta spectral contrast digunakan dalam penelitian oleh Augustianto (2010) dengan tingkat akurasi sebesar 86%. Sedangkan penelitian Tzanetakis dan Cook (2002) menggunakan fitur permukaan musik dan ritme dari lagu dan pengklasifikasi yang dipakai adalah Gaussian mixture model, menghasilkan tingkat akurasi 61%. Akan tetapi, penelitian yang dilakukan Tzanetakis dan Cook menggunakan data selama 30 detik yang diambil dari cd audio, fail mp3, dan siaran radio. Oleh sebab itu, penelitian kali ini akan mencoba untuk mengklasifikasikan 8 jenis genre musik dari data lagu wav dan menggunakan metode pengklasifikasi SVM. Sedangkan, ciri yang akan diekstraksi adalah ciri permukaan musik dan ritme.
Perumusan Masalah
Rumusan masalah dalam penelitian ini adalah bagaimana membangun model klasifikasi dengan data audio digital. Sebelum dapat menghasilkan model klasifikasi yang baik, terdapat masalah bagaimana mengakuisisi data yang dapat meningkatkan keakuratan model. Masalah lain dalam penelitian ini adalah bagaimana menerapkan metode pengekstrakan fitur dari data audio digital.
Tujuan Penelitian
Tujuan dari penelitian ini adalah membangun model support vector machine untuk pengklasifikasian genre musik dengan data musik yang ada di Indonesia. Serta menerapkan metode pengekstraksian fitur permukaan musik dan ritme seperti yang telah digunakan oleh Tzanetakis dan Cook (2002).
Manfaat Penelitian
Manfaat dari penelitian ini dalam jangka pendek diharapkan dapat membantu masyarakat dalam mengklasifikasikan genre musik dengan lebih mudah dan cepat. Dalam jangka panjang, model klasifikasi dapat dikembangkan sehingga menjadi sistem pengklasifikasi yang berjalan secara kontinu dan mengklasifikasikan sinyal audio dari radio atau sumber lain. Selain sistem pengklasifikasi yang kontinu, model klasifikasi dengan genre musik yang mendukung lebih banyak genre dan spesifik dapat menjadi pengenalan suasana hati seorang pendengar musik.
Ruang Lingkup Penelitian
Ruang lingkup yang digunakan pada penelitian ini antara lain:
1 Genre musik yang akan diklasifikasikan dibatasi, yaitu hanya anak-anak, klasik, dangdut, dubstep, jazz, keroncong, reggae, dan rock.
3
METODE
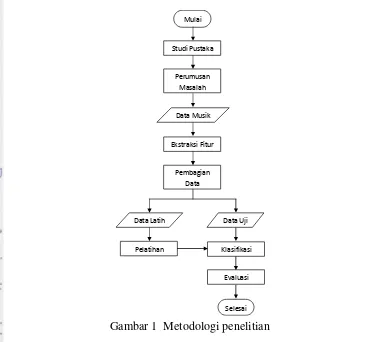
Tahapan proses yang dilakukan dalam penelitian ini dapat dilihat pada Gambar 1.
Studi Pustaka
Pada tahap ini, semua informasi dan literatur yang terkait dengan penelitian ini dikumpulkan. Informasi dan literatur yang dimaksud berupa skripsi penelitian, artikel dari jurnal dan internet, laporan proyek, dan tulisan pelatihan.
Perumusan Masalah
Pada tahap ini, analisis terhadap pemilihan data musik yang akan digunakan, penentuan bagian yang akan dipotong dari tiap data musik, dan pembagian data menjadi data latih dan data uji.
Data Musik
Untuk penelitian ini, akan digunakan 160 buah data dengan pembagian 20 data untuk setiap genre. Data tersebut terdiri atas 8 genre, yaitu lagu hanya anak-anak, klasik, dangdut, dubstep, jazz, keroncong, reggae, dan rock. Judul-judul lagu yang akan dipakai dapat dilihat pada Lampiran 1. Data musik dipilih dengan
Gambar 1 Metodologi penelitian Klasifikasi Pelatihan
Evaluasi
Selesai Data Latih Data Uji
Data Musik
Ekstraksi Fitur
Pembagian Data Studi Pustaka
Perumusan Masalah
4
pertama-tama mencari band atau musisi yang sudah dikenali genre musiknya. Kemudian, dipilih salah satu lagu dari musisi tersebut yang dikenali cocok dengan genre musiknya. Sebagai contoh, dicari band atau musisi jazz. Kemudian dipilih band RAN sebagai salah satu band yang beraliran jazz. Lalu dipilih salah satu lagu dari RAN, misal lagu RAN yang berjudul “Piano”. Maka lagu “Piano” tersebut dimasukkan ke dalam data musik sebagai data dari genre jazz. Demikian untuk seluruh data musik yang digunakan dalam penelitian ini.
Ekstraksi Fitur
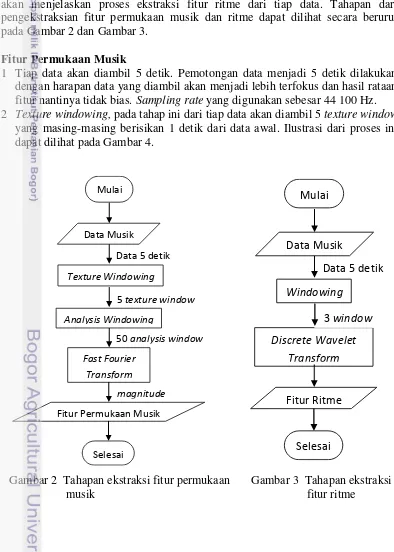
Ekstraksi fitur dibagi menjadi dua bagian. Bagian pertama akan menjelaskan proses ekstraksi fitur permukaan musik dari tiap data. Sedangkan bagian kedua akan menjelaskan proses ekstraksi fitur ritme dari tiap data. Tahapan dari pengekstraksian fitur permukaan musik dan ritme dapat dilihat secara berurut pada Gambar 2 dan Gambar 3.
Fitur Permukaan Musik
1 Tiap data akan diambil 5 detik. Pemotongan data menjadi 5 detik dilakukan dengan harapan data yang diambil akan menjadi lebih terfokus dan hasil rataan fitur nantinya tidak bias. Sampling rate yang digunakan sebesar 44 100 Hz. 2 Texture windowing, pada tahap ini dari tiap data akan diambil 5 texture window
yang masing-masing berisikan 1 detik dari data awal. Ilustrasi dari proses ini dapat dilihat pada Gambar 4.
Gambar 2 Tahapan ekstraksi fitur permukaan musik
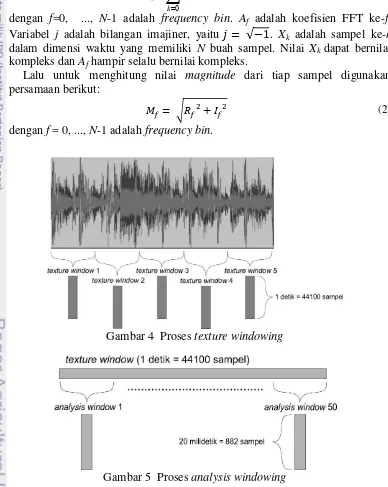
5 3 Pada tahap analysis windowing ini, hasil dari tiap texture window, akan dibagi menjadi 50 analysis window yang berisikan 20 milidetik dari texture window. Gambar 5 memperlihatkan ilustrasi dari proses ini.
4 Hasil dari proses analysis windowing akan digunakan untuk perhitungan fast Fourier transform (FFT).
FFT adalah suatu algoritma untuk menghitung discrete Fourier transform (DFT) secara lebih cepat dan efisien (Cochran et al. 1967).
5 Pada proses ini, diperlukan nilai magnitude dari data audio digital. Nilai tersebut dapat diperoleh dengan terlebih dahulu menghitung nilai riil dan nilai imajiner dari data audio digital menggunakan FFT. Persamaan yang digunakan adalah sebagai berikut:
∑ e- ⁄
-
(1)
dengan f=0, ..., N-1 adalah frequency bin. Af adalah koefisien FFT ke-f.
Variabel j adalah bilangan imajiner, yaitu √ . Xk adalah sampel ke-k
dalam dimensi waktu yang memiliki N buah sampel. Nilai Xkdapat bernilai
kompleks dan Af hampir selalu bernilai kompleks.
Lalu untuk menghitung nilai magnitude dari tiap sampel digunakan persamaan berikut:
√ (2)
dengan f = 0, ..., N-1 adalah frequency bin.
Gambar 4 Proses texture windowing
6
Setelah mendapat nilai magnitude dari tiap sampel dalam analysis window, maka dapat dihitung nilai mean-centroid, mean-rolloff, mean-flux, mean-zerocrossings, std-centroid, std-rolloff, std-flux, std-zerocrossings, dan lowenergy. Tahapan perhitungan seluruh fitur permukaan musik tersebut diadopsi dari penelitian Tzanetakis dan Cook (2002).
Fitur awal, yaitu centroid, rolloff, flux, dan zerocrossings, dihitung pada tiap analysis window. Kemudian nilai rata-rata (mean) dan standar deviasi (std) dihitung dari setiap 50 analysis window untuk disimpan sebagai hasil bagi texture window-nya. Sehingga, fitur yang akan dipakai untuk pelatihan dan pengujian dari tiap data adalah rata-rata dari lima texture window yang ada.
Centroid adalah nilai dari spectral brightness. Persamaan dari centroid:
∑
∑
⁄ (3)
Dalam persamaan 3, f = 0, ..., N-1 adalah frequency bin dan M[f] adalah nilai magnitude dari frequency bin f tersebut. Centroid mencari nilai titik berat dari sinyal audio. Ilustrasi area magnitude dan centroid dapat dilihat pada Gambar 6. Dari ilustrasi tersebut dapat dilihat bahwa titik centroid terdapat pada titik (5.6 , 0). Nilai tersebut didapat dari hasil pembagian jumlah nilai magnitude dikali frequency bin-nya yang bernilai 158 dengan jumlah nilai magnitudenya yang bernilai 28.
M[f] pada rolloff adalah nilai magnitude dari frequency bin f. Rolloff mencari perbandingan jumlah frequency bin (R) yang diperlukan untuk mencapai hasil yang sama atau lebih dari jumlah frequency bin (N) yang diboboti.
Flux adalah nilai spectral change. Persamaan yang digunakan:
(5)
Dengan i = 1, 2, 3, ..., 50. Variabel i sendiri adalah indeks dari analysis window data. Dalam Flux, dicari perubahan energi dari satu window dengan window
7 sebelumnya. Namun pada kasus i = 0, energi pada window tersebut dikurangi dengan nilai 0. Sehingga hasilnya adalah window itu sendiri. Selanjutnya pada i = 1, ..., N-1, energi window ke-f akan dikurangi energi dari window sebelumnya pada tiap titik yang sama posisinya dalam window. Kemudian, tiap hasil pengurangan akan dikuadratkan. Lalu, hasil kuadrat dari tiap titik tersebut akan dijumlahkan. Terakhir, dihitung akar dari total penjumlahan tersebut.
Zerocrossings adalah jumlah dari penyebrangan sinyal dalam 1 window yang melalui nilai 0. Misalnya terdapat sinyal bernilai [1, -1, -2, 2], yang dapat dilihat pada Gambar 7. Dari sinyal tersebut terdapat 2 ZeroCrossings, yaitu dari nilai 1 ke -1 dan dari -2 ke 2.
LowEnergy adalah persentase dari jumlah “analysis” windows yang memiliki energi kurang dari rataan seluruh “analysis” windows dalam satu data musik. Misalkan terdapat 5 “analysis” windows dalam satu data musik, rataan seluruh “analysis” windows adalah 5 , dan terdapat 8 “analysis” windows yang jumlah energinya kurang dari 500. Maka LowEnergy adalah persentase dari 80/250.
Fitur Ritme
1 Pada proses ekstraksi fitur ritme, data audio perlu dipotong menjadi 3 window terlebih dahulu. Ukuran tiap window-nya adalah 76000 sampel dengan overlap sebesar 3750 sampel.
2 Tiap window kemudian didekomposisi terlebih dahulu menjadi beberapa octave frequency band menggunakan DWT. Filter yang digunakan untuk DWT adalah Daubechies 4 yang berdasarkan Daubechies (1988) bernilai
√ √ ), √ √ , √ √ , √ √ ).
(6)
Persamaan yang digunakan adalah sebagai berikut:
h h ∑ n n
n (7)
8
3 Lalu dapat dihitung beberapa variabel per octave frequency band-nya, yaitu full wave rectification (FWR), low pass filtering (LPF), downsampling (↓), normalization (NR). Setelah nilai variabel-variabel dari setiap octave frequency band tersebut didapat, akan dihitung nilai autocorrelation-nya (AR) dan dipilih empat nilai tertinggi dari hasil autocorrelation. Keempat titik tertinggi tersebut adalah fitur ritme yang akan digunakan untuk pengklasifikasian dan pengujian. Tahapan perhitungan untuk fitur ritme diadopsi dari penelitian Tzanetakis dan Cook (2002).
Full wave rectification (FWR) dihitung dengan persamaan:
(9)
Low pass filtering (LPF) dihitung menggunakan persamaan:
(10)
Downsampling (↓) dihitung dengan persamaan :
(11)
Normalization (NR) dihitung menggunakan persamaan:
(12)
Tahapan perhitungan autocorrelation dan pemilihan titik-titik tertinggi dapat dilihat pada Gambar 8. Autocorrelation (AR) dihitung menggunakan FFT agar proses komputasi lebih efisien dengan persamaan:
∑ (13)
Pembagian Data Latih dan Data Uji
Data latih dan data uji dibagi dengan 75% sebagai data latih dan sisanya sebagai data uji. Sehingga untuk setiap genre akan ada 15 data latih dan 5 data uji. Pemilihan data sebagai data latih akan dilakukan secara acak.
Pelatihan
9
dari program tersebut adalah sebuah model pemisah. Model tersebutlah yang akan menjadi fungsi pemisah saat mengklasifikasikan data uji maupun data baru. Parameter yang dibutuhkan oleh program tersebut adalah label kelas dan fitur-fitur dari data. Sedangkan parameter yang perlu ditentukan sebelumnya untuk program tersebut antara lain nilai cost dan gamma.
SVM adalah salah satu pembelajaran komputasional yang mencari suatu garis pembatas antara dua kelas, dan garis pembatas tersebut memiliki jarak yang terbesar di antara dua anggota terdekat dari kedua kelas. Menurut Cristianini dan Taylor (2000), support vector machine (SVM) adalah sistem pembelajaran yang pengklasifikasiannya menggunakan ruang hipotesis berupa fungsi-fungsi linear dalam sebuah ruang fitur (feature space) berdimensi tinggi, dilatih dengan algoritma pembelajaran yang didasarkan pada teori optimasi dengan mengimplementasikan learning bias yang berasal dari teori pembelajaran statistik. Keluaran yang dihasilkan dari SVM adalah suatu fungsi yang dapat digunakan untuk memprediksi suatu fitur dari data yang akan datang, dalam hal ini pemrediksi genre dari suatu data audio.
SVM dapat diterapkan pada dua kasus data, data yang dapat dipisahkan secara linier dan non-linier. Pada kasus data yang dapat dipisahkan secara linier, misalkan {X , …, Xn} adalah dataset dan {+ ,-1} adalah label kelas dari data Xi. Pada Gambar 9 dapat dilihat berbagai alternatif bidang pemisah yang dapat memisahkan semua data set sesuai dengan kelasnya. Namun, bidang pemisah terbaik tidak hanya dapat memisahkan data tetapi juga memiliki margin paling besar.
10
Salah satu metode untuk mengklasifikasikan data yang tidak dapat dipisahkan secara linier adalah dengan mentransformasikan data ke dalam dimensi ruang fitur (feature space) sehingga dapat dipisahkan secara linier pada feature space. Caranya, data dipetakan dengan menggunakan fungsi pemetaan (transformasi) ) ( ) k k x →ϕ x ke dalam feature space sehingga terdapat bidang pemisah yang dapat memisahkan data sesuai dengan kelasnya (seperti pada Gambar 10).
Kelebihan metode SVM dari metode klasifikasi lainnya, antara lain: generalisasi, curse of dimensionality, dan feasibility. Generalisasi adalah kemampuan suatu metode untuk mengklasifikasikan data yang tidak termasuk dalam fase pembelajaran. Pada umumnya, strategi pembelajaran dalam metode machine learning difokuskan pada usaha meminimalkan error pada training set. Strategi ini disebut empirical risk minimization (ERM). Adapun SVM selain meminimalkan error pada training set, juga meminimalkan error dimensi VC. Strategi pada SVM ini disebut structural risk minimization (SRM).
Curse of dimensionality didefinisikan sebagai masalah yang dihadapi suatu metode pattern recognition dalam menentukan parameter dikarenakan jumlah sampel data yang relatif sedikit dibandingkan dimensional ruang vektor data tersebut. Semakin tinggi dimensional ruang vektor informasi yang diolah, semakin banyak jumlah data yang diperlukan dalam proses pembelajaran. Cortes dan Vapnik (1995) membuktikan bahwa tingkat generalisasi yang diperoleh oleh SVM tidak dipengaruhi oleh dimensi dari input vektor. Hal ini merupakan alasan mengapa SVM merupakan salah satu metode yang tepat dipakai untuk memecahkan masalah berdimensi tinggi, dalam keterbatasan sampel data yang ada.
Gambar 9 SVM pada data terpisah secara linier
11 Kelebihan metode SVM yang ketiga adalah implementasinya yang relatif mudah pada problem yang berskala kecil, karena proses penentuan support vector dapat dirumuskan dalam QP problem. Oleh sebab itu, jika kita memiliki library untuk menyelesaikan QP problem, dengan sendirinya SVM dapat diimplementasikan dengan mudah.
Kelemahan metode SVM adalah cukup sulit untuk diimplementasikan dalam problem berskala besar. Selain itu, secara teoritik SVM dikembangkan untuk problem klasifikasi dengan dua kelas. Namun seiring dengan perkembangan teknologi dan ilmu pengetahuan, SVM telah dimodifikasi agar dapat menyelesaikan masalah dengan kelas lebih dari dua, antara lain strategi one versus rest dan strategi tree structures.
Pengujian
Pengujian model akan dilakukan menggunakan program „svmpredict‟ yang juga terdapat dalam LIBSVM (Chang dan Lin 2011). Hasil dari program tersebut adalah label kelas dari data yang diprediksi menggunakan model yang telah dibentuk.
Lingkungan Pengembangan
Perangkat lunak yang digunakan dalam penelitian ini adalah: Sistem operasi Windows 7 Professional
Audacity 2.0.2
Matlab 7.7.0471 (R2008b)
12
Ekstraksi Fitur Permukaan Musik
Data musik yang telah dipotong menjadi 5 detik tersebut kemudian dibagi menjadi 5 texture window yang masing-masing berisikan 44 100 titik sinyal atau setara dengan 1 detik data. Gambar 12 mengilustrasikan salah satu texture window hasil proses texture windowing.
Hasil proses texture windowing kemudian akan dimasukkan ke dalam proses analysis windowing. Dalam proses ini, satu texture window akan dibagi menjadi 50 analysis window yang masing-masing berisikan 882 titik sinyal atau setara dengan 20 milidetik data. Hasil dari proses analysis windowing dapat dilihat pada Gambar 13.
Setelah didapatkan 250 analysis window dari tiap data, dapat dihitung nilai FFT dan magnitude dari FFT nya. Selanjutnya dapat dihitung fitur-fitur permukaan musik yaitu mean-centroid, mean-rolloff, mean-flux, mean-zerocrossings, std-centroid, std-rolloff, std-flux, std-mean-zerocrossings, dan lowenergy untuk setiap texture window-nya.
Sebagai contoh, pada centroid akan dihitung nilai centroid dari 50 analysis window pertama lalu dihitung mean-centroid dan std-centroid yang berarti dimiliki oleh texture window pertama. Demikian pula untuk rolloff, flux, dan zerocrossings. Sedangkan untuk lowenergy tidak menggunakan mean dan std, karena yang dihitung adalah persentase analysis window yang nilai energi nya kurang dari rata-rata energi yang diperlukan dalam satu texture window-nya. Hasil
Gambar 11 Data yang akan digunakan
Gambar 12 Hasil proses texture windowing
13 akhir dari proses ekstraksi fitur permukaan musik ini adalah suatu matriks berukuran 9 N, dengan N adalah jumlah data yang dimasukkan ke dalam proses.
Ekstraksi Fitur Ritme
Data musik yang telah dipotong menjadi 3 window kemudian didekomposisi terlebih dahulu menjadi beberapa octave frequency band setiap window-nya dengan DWT. Gambar 14 menunjukkan data yang digunakan dalam 1 window. Gambar 15 menunjukkan hasil dekomposisi filter highpass dari 1 window dan Gambar 16 menunjukkan hasil dekomposisi filter lowpass dari 1 window.
Setelah didapat hasil dekomposisi filter rendah dan tinggi, nilai variabel full wave rectification (FWR), low pass filtering (LPF), downsampling (↓), normalization (NR) dari tiap filter dapat dihitung. Hasil normalization (NR) dari kedua filter kemudian dijumlahkan dan dimasukkan ke dalam proses autocorrelation. Hasil dari proses autocorrelation dapat dilihat pada Gambar 17. Kemudian dilakukan pemilihan 4 titik tertinggi dari hasil autocorrelation tersebut. Hasil akhir dari proses ekstraksi fitur ritme ini adalah suatu matriks berukuran 4×N, dengan N adalah jumlah data yang dimasukkan ke dalam proses.
Hasil dari ekstraksi fitur pemukaan musik dan ritme akan digabung menjadi satu matriks berukuran 13×N. Matriks tersebutlah yang akan dijadikan masukan untuk pembentukan model dan pelatihan dalam SVM. Seluruh hasil ekstraksi fitur dapat dilihat pada Lampiran 2.
Gambar 14 Data dalam 1 window Gambar 15 Hasil dekomposisi filter highpass
Gambar 16 Hasil dekomposisi filter lowpass
14
Pelatihan dan Pengujian
Setelah ekstraksi fitur selesai, dilanjutkan dengan pelatihan dan pengujian model. Data akan dibagi menggunakan metode 4-fold cross validation. Data yang digunakan adalah 20 data musik digital tiap genrenya dari 8 genre. Jadi pada tiap fold akan terdiri dari 15 data musik digital tiap genrenya untuk pelatihan dan 5 data musik digital tiap genrenya untuk pengujian. Hasil dari 4-fold cross validation dapat dilihat pada Tabel 1.
Pembentukan model dan pencocokkan klasifikasi dilakukan menggunakan SVM. Parameter yang digunakan dalam SVM antara lain adalah tipe dari SVM, tipe kernel, cost, dan gamma.
Tipe SVM yang digunakan adalah C-SVC. C-SVC merupakan salah satu tipe pengklasifikasi untuk data yang terdiri atas lebih dari 2 kelas. SVM juga menggunakan fungsi kernel. Terdapat 4 macam kernel dalam SVM, yaitu kernel linier, polinomial, radial basis function (rbf), dan sigmoid. Tipe kernel yang digunakan dalam penelitian ini adalah kernel radial basis function. Kernel tersebut dipilih berdasarkan performanya yang sama dengan kernel linier pada parameter tertentu, perilakunya yang sama dengan kernel sigmoid pada parameter tertentu, dan rentang nilainya yang kecil [0,1]. Nilai cost dan gamma dicari melalui proses grid search dan uji manual, yang menghasilkan nilai cost dan gamma berturut-turut adalah 1096 dan 1.7×10-8. Cost berfungsi untuk menentukan besar penalti akibat kesalahan dalam pengklasifikasian data latih.
Pembahasan
Pengujian dilakukan dengan data yang dibagi menjadi 4 fold. Pada fold 1, didapat hasil dengan akurasi 55%. Hasil pengklasifikasian fold tersebut dapat dilihat pada Tabel 2 dan hasil pengklasifikasian fold sisanya dapat dilihat pada Lampiran 3. Kelas Ak dalam Tabel 2 dan dalam Lampiran 3 mewakili genre anak-anak. Kelas Kl mewakili genre klasik. Kelas Dg mewakili genre dangdut. Kelas Ds mewakili genre dubstep. Kelas Jz mewakili genre jazz. Kelas Kr mewakili genre keroncong. Kelas Re mewakili genre reggae. Kelas Ro mewakili genre rock. Genre yang menghasilkan akurasi terbaik adalah klasik dengan 100%. Sedangkan dalam fold tersebut genre reggae memiliki tingkat akurasi terburuk, yaitu 0%. Genre reggae tersebut lebih dikenali sebagai genre rock.
Tabel 1 Hasil 4-fold cross validation
15
Pada fold 2, didapat hasil dengan akurasi 72.5%. Kali ini, genre klasik, dubstep, dan keroncong menghasilkan akurasi terbaik dengan 100%. Genre reggae dan dangdut kini menghasilkan akurasi terburuk, yaitu 40%.
Fold 3 menghasilkan akurasi 57.5%. Pada fold kali ini genre anak-anak menghasilkan akurasi terbaik sebesar 100%. Pada fold ini, akurasi terburuk dimiliki oleh genre jazz dengan 0%. Genre jazz tersebut lebih dikenali sebagai genre reggae.
Sedangkan fold 4 menghasilkan akurasi tertinggi dengan 75%. Dalam fold ini, genre anak-anak, klasik, dubstep, dan keroncong kembali menghasilkan akurasi terbaik dengan akurasi 100%. Genre dangdut menghasilkan akurasi sebesar 20%. Genre dangdut tersebut lebih dikenali sebagai genre anak-anak.
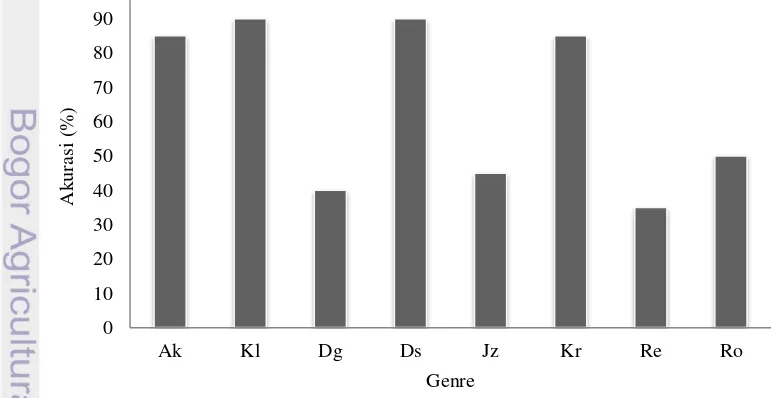
Setelah dilakukan pengujian tersebut, secara umum dapat dilihat bahwa reggae merupakan salah satu genre yang paling sulit diklasifikasikan dan lebih dikenali sebagai genre jazz. Grafik akurasi pengklasifikasian tiap genre dapat dilihat pada Gambar 18. Hasil pengklasifikasian gabungan dari 4 fold dapat dilihat
Tabel 2 Hasil pengklasifikasian fold-1
Kelas Jumlah data tiap kelas Akurasi (%)
Ak Kl Dg Ds Jz Kr Re Ro
Gambar 18 Hasil akurasi tiap genre
16
pada Lampiran 3. Hasil pengklasifikasian tiap data musik dapat dilihat pada Lampiran 4.
Untuk mencari penyebab terjadinya kesalahan yang cukup banyak dalam mengklasifikasikan genre reggae ke genre jazz, perbandingan antara rataan fitur dari seluruh data bergenre reggae dan data bergenre jazz dicoba dibandingkan dengan data X (salah satu data yang salah diklasifikasikan dari genre reggae ke jazz). Hasil perbandingan dapat dilihat pada tabel 3. Hasil perbandingan menunjukkan bahwa fitur dari data X tidak lebih banyak yang lebih dekat atau lebih kecil selisihnya dengan rataan fitur dari genre jazz. Sehingga belum dapat diketahui penyebab banyaknya kesalahan dalam pengklasifikasian genre reggae ke genre jazz tersebut.
Dari hasil percobaan, dapat dilihat secara rata-rata model yang dibuat dengan parameter yang telah disebutkan sebelumnya menghasilkan akurasi sebesar 65%. Dibandingkan dengan hasil percobaan oleh Tzanetakis dan Cook (2002) yang menghasilkan akurasi 61%, tingkat akurasi percobaan ini sedikit lebih tinggi. Dengan data yang digunakan setengahnya adalah musik dari Indonesia berbeda dengan percobaan Tzanetakis dan Cook (2002). Karena percobaan sebelumnya mengklasifikasikan dengan menggunakan fitur yang sama hanya untuk data musik luar Indonesia.
17
SIMPULAN DAN SARAN
Simpulan
Dari hasil percobaan, didapatkan bahwa penelitian ini telah berhasil mengimplementasikan pengekstrakan fitur permukaan musik dan membangun model untuk melakukan pengklasifikasian dengan SVM.
Tingkat akurasi rata-rata yang didapat dalam penelitian ini adalah 65%. Sedikit lebih tinggi bila dibandingkan dengan hasil penelitian oleh Tzanetakis dan Cook (2002) yang menghasilkan akurasi 61%.
Hasil dari 4-fold cross validation menunjukkan bahwa secara rata-rata genre reggae memiliki tingkat akurasi paling rendah dari 8 genre. Genre reggae lebih dikenali sebagai genre jazz.
Perbandingan antara fitur dari data X (data yang salah diklasifikasikan dari genre reggae menjadi genre jazz) dengan rataan fitur dari seluruh data bergenre jazz menunjukkan fitur data X tersebut tidak lebih dekat daripada data X dengan rataan fitur dari seluruh data bergenre reggae. Namun selisih dari data X dengan kedua genre tersebut tidak berbeda jauh.
Saran
Saran untuk penelitian selanjutnya:
1 Menambah jumlah data tiap genre dengan harapan memperjelas perbedaan ciri tiap genre.
18
DAFTAR PUSTAKA
Augustianto R. 2009. Klasifikasi genre musik berdasarkan fitur audio menggunakan support vector machines [skripsi]. Surabaya (ID): Institut Teknologi Sepuluh Nopember.
Chang CC, Lin CJ. 2011. LIBSVM: A library for support vector machines. ACM Transactions on Intelligent Systems and Technology. 2(3):1-27.
Cristianini N, Taylor JS. 2000. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods. Cambridge (UK): Cambridge University Pr.
Cochran WT, Cooley JW, Favin DL, Helms HD, Kaenel RA, Lang WW, Maling GC Jr, Nelson DE, Rader MC, Welch PD. 1967. What is the fast Fourier transform?. Proceedings of the IEEE. 55(10):1664-1674.
Cortes C, Vapnik V. 1995. Support-vector networks. Machine Learning. 20(3):273-297.
Daubechies I. 1988. Orthonormal bases of compactly supported wavelets. Communications on Pure and Applied Mathematics. 41(7): 909-996.
Fansuri MR. 2011. Klasifikasi genre musik menggunakan learning vector quantization [skripsi]. Bogor (ID): Institut Pertanian Bogor.
19
LAMPIRAN
Lampiran 1 Data musik
1 Daftar lagu anak-anak yang digunakan pada penelitian
No. Judul lagu No. Judul lagu
1 Aku anak gembala 11 Disini senang disana senang 2 Aku seorang kapiten 12 Dua mata saya
2 Daftar lagu klasik yang digunakan pada penelitian
No. Judul lagu No. Judul lagu
17 Symphony No. 24 [B-flat Major] III. Allegro
20
Lampiran 1 Lanjutan
3 Daftar lagu dangdut yang digunakan pada penelitian
No. Judul lagu No. Judul lagu
1 A Rafiq – Pandangan pertama 11 johana satar - tinggal kenangan 2 Camelia Malik - colak colek 12 Kristina - Jatuh Bangun 3 cici paramida - wulan merindu 13 Meggy Z - Cinta Hitam 4 elvy sukaesih - malam asmara 14 melinda - cinta satu malam 5 Evie Tamala - Rembulan Malam 15 mukhsin alatas - Bersemilah 6 Ida Laila - Cinta Dan Air Mata 16 noer halimah - patah hati cipt
rhoma irama
7 Ikke Nurjanah - Yang Terbaik 17 rhoma irama - bujangan 8 inul daratista - goyang inul 18 rita sugiarto - kejam
9 Inul Daratista-goyang dombret 19 saipul jamil - air mata dan doa 10 iyet bustami - laksamana raja dilaut 20 zaskia - sudah cukup sudah
4 Daftar lagu dubstep yang digunakan pada penelitian
No. Judul lagu No. Judul lagu
1 Nicky Romoro - Symphonica Bare Remix
5 Daftar lagu jazz yang digunakan pada penelitian
No. Judul lagu No. Judul lagu
1 Abdul & The Coffee Theory - Tanda Tanda Cinta
11 John Mayer - Gravity
2 Andien - Bernyanyi Untukmu 12 Louis Armstrong - Blueberry Hill
3 Barry Likumahuwa - Mati Saja 13 Louis Armstrong - What A Wonderful World
4 Billie Holiday - Gloomy Sunday 14 maliq & d'essentials-Terdiam 5 Diana Krall - Dancing In The Dark 15 Marcell -I Knew I Loved You 6 Ella Fitzgerald - Crying My Heart Out
To You
16 Raisa - Could It Be
7 Ello - Hadapi Dengan Senyuman 17 RAN - Piano 8 Frank Sinatra - Someone To Watch Over
Me
18 Soulvibe - Gravitasi
9 Glenn Fredly - Malaikat Juga Tahu 19 Tony Bennett - Being Alive 10 Jamie Cullum - Mind Trick 20 Tony Bennett - Close Enough
21
Lampiran 1 Lanjutan
6 Daftar lagu keroncong yang digunakan pada penelitian
No. Judul lagu No. Judul lagu 10 Layu Sebelum Berkembang 20 Kalung Mutiara
7 Daftar lagu reggae yang digunakan pada penelitian
No. Judul lagu No. Judul lagu
1 Alton Ellis You Make Me So Very Happy
11 Ras Muhammad - Musik Reggae Ini
2 Bob Marley - Stir It Up 12 Scientist - Your Teeth In My Neck
3 Coconut Head - Hello Brother 13 Sean Kingston - Beautiful Girls 4 Coffee Reggae Stone – Demon 14 Souljah – Bagaimana Caranya
19 Twinkle Brothers - Faith Can Move Mountains
10 Mbah Surip - Tak Gendong 20 Wayne Smith - Under Me Sleng Teng
8 Daftar lagu rock yang digunakan pada penelitian
22
Lampiran 2 Hasil pengklasifikasian 1 Hasil fold-2
Kelas Jumlah data tiap kelas Akurasi
(%)
Kelas Jumlah data tiap kelas Akurasi
23 Lampiran 2 Lanjutan
4 Hasil seluruh fold
Kelas Jumlah data tiap kelas Akurasi
(%)
Ak Kl Dg Ds Jz Kr Re Ro
Ak 17 0 2 0 0 0 1 0 85.0
Kl 0 18 0 0 0 2 0 0 90.0
Dg 3 0 8 1 1 2 3 2 40.0
Ds 0 0 0 18 0 0 0 2 90.0
Jz 0 0 3 0 9 1 7 0 45.0
Kr 0 2 0 0 0 17 1 0 85.0
Re 1 0 3 1 4 2 7 2 35.0
Ro 3 0 3 3 1 0 0 10 50.0
Rata-Rata 65.0
5 Akurasi rata-rata tiap genre
Kelas Tingkat akurasi pada fold (%) Rata-Rata
Akurasi (%)
1 2 3 4
Ak 60 80 100 100 85
Kl 100 100 60 100 90
Dg 60 40 40 20 40
Ds 80 100 80 100 90
Jz 40 60 0 80 45
Kr 60 100 80 100 85
Re 0 40 60 40 35
24
Lampiran 3 Hasil pengklasifikasian data musik
1 Hasil pengklasifikasian data musik bergenre anak-anak
No. Genre hasil prediksi No. Genre hasil prediksi
1 Dangdut 11 Anak-Anak
2 Hasil pengklasifikasian data musik bergenre klasik
No. Genre hasil prediksi No. Genre hasil prediksi
1 Klasik 11 Klasik
3 Hasil pengklasifikasian data musik bergenre dangdut
No. Genre hasil prediksi No. Genre hasil prediksi
25 Lampiran 3 Lanjutan
4 Hasil pengklasifikasian data musik bergenre dubstep
No. Genre hasil prediksi No. Genre hasil prediksi
1 Dusbtep 11 Dusbtep
5 Hasil pengklasifikasian data musik bergenre jazz
No. Genre hasil prediksi No. Genre hasil prediksi
1 Reggae 11 Reggae
6 Hasil pengklasifikasian data musik bergenre keroncong
No. Genre hasil prediksi No. Genre hasil prediksi
26
Lampiran 3 Lanjutan
7 Hasil pengklasifikasian data musik bergenre reggae
No. Genre hasil prediksi No. Genre hasil prediksi
1 Jazz 11 Jazz
2 Keroncong 12 Reggae
3 Dangdut 13 Jazz
4 Rock 14 Reggae
5 Rock 15 Reggae
6 Anak-Anak 16 Reggae
7 Reggae 17 Reggae
8 Dangdut 18 Dangdut
9 Reggae 19 Jazz
10 Dusbtep 20 Keroncong
8 Hasil pengklasifikasian data musik bergenre rock
No. Genre hasil prediksi No. Genre hasil prediksi
1 Rock 11 Dangdut
2 Rock 12 Rock
3 Dusbtep 13 Rock
4 Anak-Anak 14 Anak-Anak
5 Dusbtep 15 Anak-Anak
6 Dangdut 16 Rock
7 Rock 17 Rock
8 Jazz 18 Dangdut
9 Rock 19 Rock
27
RIWAYAT HIDUP
Penulis lahir di Bekasi pada tanggal 17 Nopember 1991. Penulis merupakan anak bungsu dari dua bersaudara dari pasangan Bapak Atos Ausri dan Ibu Noormawati. Pada tahun 2009, penulis lulus dari SMA Negeri 48 Jakarta Timur dan pada tahun itu pula penulis lulus masuk Institut Pertanian Bogor melalui jalur SNMPTN (Seleksi Nasional Masuk Perguruan Tinggi Negeri) dan diterima di jurusan Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam.