PENERAPAN SMOTE PADA METODE CRUISE UNTUK
PENENTUAN FAKTOR KEBERHASILAN STUDI
MAHASISWA BUD
HABIBAH RAHMAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Penerapan SMOTE pada Metode CRUISE untuk Penentuan Faktor Keberhasilan Studi Mahasiswa BUD adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2013
Habibah Rahmah
ABSTRAK
HABIBAH RAHMAH. Penerapan SMOTE pada Metode CRUISE untuk Penentuan Faktor Keberhasilan Studi Mahasiswa BUD. Dibimbing oleh INDAHWATI dan AAM ALAMUDI.
Pohon klasifikasi merupakan salah satu metode sederhana untuk mengetahui faktor yang berpengaruh terhadap suatu peubah respon bertipe kategorik. Namun, metode ini memiliki beberapa permasalahan. Pertama, bias di dalam pemilihan peubah penjelas (disebut seleksi bias) dan bias akibat data hilang (missing value). Masalah ini dapat ditangani oleh metode pohon klasifikasi CRUISE
(Classification Rule with Unbiased Interaction Selection and Estimation) 2D.
Permasalahan lainnya yaitu ketidakseimbangan data, yakni terdapat kategori peubah respon yang jumlah amatannya jauh lebih banyak (disebut kelas mayor) daripada kategori lainnya (disebut kelas minor), sehingga amatan pada kelas minor akan diklasifikasikan ke dalam kelas mayor. SMOTE (Synthetic
Minority-Over Sampling Technique) with majority under sampling merupakan salah satu
metode yang dapat digunakan untuk mengatasinya. Penelitian ini bertujuan untuk mengetahui faktor yang berpengaruh terhadap keberhasilan studi mahasiswa BUD (Beasiswa Unit Daerah) pada Tingkat Persiapan Bersama (TPB), yang memiliki jumlah mahasiswa DO (Drop Out) yang jauh lebih banyak dari mahasiswa tidak DO. Pohon CRUISE 2D tanpa SMOTE memiliki kemampuan klasifikasi sangat buruk, sehingga pohon yang digunakan adalah pohon dari SMOTE with majority
under sampling dengan persen kenaikan 400 dan persen penurunan sebesar 125.
ABSTRACT
Habibah Rahmah. Application of SMOTE on CRUISE Method to Determine Factors of BUD Student’s Academic Success. Advised by INDAHWATI and AAM Alamudi.
Classification tree is a simple method to determine the factors that influence a response variable whose type is categorical. However, this method has some problems. First, selection bias on explanatory variables (called selection bias ) and bias due to missing value . This problem can be solved by CRUISE (Classification Rule with Unbiased Interaction Selection and Estimation) 2D. Another problem is the imbalance of data, so that observations in the minority class (a class that have less observation’s number) can’t be classified correctly. SMOTE (Synthetic Minority-Over Sampling Technique) with majority under-sampling is a method that can be used to handle those problems. The aim of this study is determining academic success factors of BUD (Beasiswa Unit Daerah) students, which has majority class (‘non-drop out’ category) and minority class (‘drop out’ category). The classification capability of CRUISE 2D tree without SMOTE is very bad, so it’s better to choose the tree from SMOTE with majority under-sampling which use 300 percent of increasing and 133.34 percent of decreasing. This tree has 12 terminals and 5 of them have high risk to be dropped out. Variables that influence the academic result of BUD students are the origin island, the average value of the national exam, the father and mother's education, sponsorship type, parent’s income, and mother’s education. About 73.7% observations with DO class in testing data can be classified correctly by this tree.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
PENERAPAN SMOTE PADA METODE CRUISE UNTUK
PENENTUAN FAKTOR KEBERHASILAN STUDI
MAHASISWA BUD
HABIBAH RAHMAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Penerapan SMOTE pada Metode CRUISE untuk Penentuan Faktor Keberhasilan Studi Mahasiswa BUD
Nama : Habibah Rahmah NIM : G14090031
Disetujui oleh
Dr Indahwati, MSi Pembimbing I
Ir Aam Alamudi, MSi Pembimbing II
Diketahui oleh
Dr Ir Hari Wijayanto, MSi Ketua Departemen
PRAKATA
Alhamdulillah, terima kasih kepada Allah SWT yang telah memberikan segala izin, rahmat, dan karunia-Nya sehingga penulis dapat menyelesaikan karya ilmiah yang ditujukan sebagai syarat untuk mendapatkan gelar SStat ini.
Penulis menyampaikan rasa terima kasih kepada semua pihak yang telah membantu selama masa perkuliahan dan penyusunan karya ilmiah ini, di antaranya adalah:
1. Ibu Indahwati dan Bapak Aam Alamudi selaku pembimbing. Terima kasih karena telah bersedia meluangkan waktunya, memberikan arahan serta masukan yang sangat berarti dalam proses penyusunan.
2. Bapak Bagus Sartono yang telah berbaik hati berbagi ilmunya yang sangat membantu dalam proses pembuatan karya tulis ini.
3. Seluruh dosen Departemen Statistika atas ilmu yang telah diberikan.
4. Tata Usaha Departemen Statistika atas bantuannya dalam kelancaran administrasi, terutama Ibu Mar yang tidak bosannya bersedia membuatkan beberapa surat pengantar untuk mendapatkan data.
5. Pihak Sekretariat TPB, PPMB, dan Sekretariat BUD yang telah mengizinkan penulis menggunakan datanya.
6. Casia, Rosi, Toro, Aci, Miko, Lusi, Astuti, Aep, dan Ayip yang telah membantu memberikan ilmunya selama masa penyusunan. Mas Akrom, temen SF3SI, serta teman-teman lainnya atas dukungan dan do’anya.
7. Keluarga tercinta.
8. Sahabat-sahabat di Cirebon dan penghuni Kos Wahdah Indah atas kebaikan, kerjasama, dan kenangan indahnya.
9. Teman-teman satu bimbingan dan teman-teman Statistika 46 atas dukungan dan kisah indahnya selama ini.
Penulis sadar bahwa karya ilmiah ini masih memiliki banyak kekurangan. Oleh karena itu, penulis mengharapkan saran yang membangun agar penulis bisa memperbaikinya di masa mendatang. Semoga karya ilmiah ini bermanfaat bagi siapapun yang membacanya.
Bogor, November 2013
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR GAMBAR viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Tujuan Penelitian 2
METODOLOGI 3
Data 3
Metode 3
HASIL DAN PEMBAHASAN 5
Deskripsi Data 5
Pohon Klasifikasi Cruise 2D tanpa SMOTE 6
Pohon Klasifikasi Cruise 2D dengan Data Bangkitan. 6
SIMPULAN DAN SARAN 9
Simpulan 9
Saran 9
DAFTAR PUSTAKA 9
LAMPIRAN 10
DAFTAR TABEL
1 Persen penaikan dan penurunan data SMOTE
with majority under sampling 4
2 Kesalahan klasifikasi pohon asli 6
3 Nilai ROC dan TP-rate pada berbagai persen penaikan dan
penurunan 6
4 Karakteristik mahasiswa berpeluang DO tinggi 8
DAFTAR GAMBAR
1 Persentase amatan kelompok DO dan tidak DO 5
2 Frekuensi mahasiswa berdasarkan peubah penjelas non-keluarga 6 3 Frekuensi mahasiswa berdasarkan profil orang tua 6
4 Pohon CRUISE 2D akhir 7
DAFTAR LAMPIRAN
1 Persentase mahasiswa drop out dari masing-masing jalur 10
2 Daftar peubah penjelas 10
3 Algoritme SMOTE- NC 11
4 Algoritme CRUISE 2D 12
1
PENDAHULUAN
Latar Belakang
Beasiswa Utusan Daerah (BUD) merupakan sebuah cara penerimaan mahasiswa program sarjana dan pascasarjana Institut Pertanian Bogor (IPB) yang direkomendasikan dan dibiayai oleh pemerintah pusat, pemerintah daerah, perusahaan atau lembaga swasta. Mereka diharapkan dapat kembali ke daerah asal masing-masing setelah lulus untuk membangun daerah tersebut.
Beberapa tahun belakangan ini, hampir pada setiap tahun ajaran, persentase mahasiswa BUD yang mengalami drop out (DO) di Tingkat Persiapan Bersama (TPB) lebih besar daripada mahasiswa yang masuk melalui jalur lain (Lampiran 1). Jumlah tersebut terdiri atas dua kelompok, yakni mereka yang mengundurkan diri sebelum menempuh satu tahun TPB dan mahasiswa yang tidak mencukupi syarat IPK TPB (IPK ≤ 1.50) untuk melangkah ke semester berikutnya. Kelompok mahasiswa seperti ini perlu ditelusuri karakteristiknya, sehingga dapat diambil langkah penanganan awal terhadap mahasiswa angkatan baru untuk meminimalkan kejadian DO.
Pohon klasifikasi merupakan salah satu metode yang dapat digunakan untuk mengalokasikan amatan-amatan ke dalam suatu kelas prediksi, sekaligus dapat mengetahui faktor-faktor yang berpengaruh terhadap suatu peubah respon bertipe kategorik, dengan demikian metode ini bisa digunakan untuk menelusuri faktor-faktor yang berpengaruh terhadap keberhasilan studi mahasiswa BUD yang memiliki peubah respon berupa DO dan tidak DO.
Pohon klasifikasi memiliki beberapa keunggulan yakni menghasilkan tampilan grafis yang mudah diinterpretasikan, bersifat non-parametrik sehingga tidak membutuhkan asumsi-asumsi. Pohon ini akan menghasilkan simpul akhir (disebut terminal) yang akan menggambarkan segmentasi dari peubah respon. Struktur pohon harus mudah dipahami dan tidak berbias dalam pemilihan peubah pemisah agar informasinya bermanfaat. Beberapa algoritme pohon klasifikasi yang ada masih menghasilkan seleksi bias, yakni apabila peubah-peubah penjelas saling bebas dengan kelas/kategori pada peubah respon, peubah penjelas tersebut tidak memiliki peluang yang sama untuk terpilih menjadi patokan dalam tahap pemisahan (splitting), sehingga sulit untuk memastikan apakah peubah yang terpilih tersebut memang peubah yang paling penting, atau terpilih hanya karena seleksi bias (Kim dan Loh 2001). Salah satu metode yang mampu mengatasi masalah ini adalah CRUISE (Classification Rule with Unbiased Interaction Selection and Estimation).
CRUISE dikembangkan oleh Hyunjoong Kim dan Wei-in Loh pada tahun 2001. CRUISE memperbaiki konsep QUEST (Quick, Unbiased, Efficient
Statistical Tree) dalam pemilihan peubah pemisah, yaitu dengan menggunakan
2
Tree). Sementara pada FACT masih terdapat bias dalam pemilihan peubah pemisah (Loh dan Shih 1997). CRUISE juga memiliki koreksi untuk menangani data hilang (missing value) yang sering menjadi masalah dalam CART
(Classification and Regression Tree). CRUISE memanfaatkan konsep
pemangkasan pada CART (konsep pemangkasan CART terdapat pada Breiman et al. 1993).
CRUISE menawarkan pemisahan kombinasi linier dan pemisahan tunggal (terdiri atas metode 1D dan 2D) dalam melakukan pemisahan. Pemisahan kombinasi linier akan menghasilkan pohon yang sulit diinterpretasikan, sedangkan pada pemisahan tunggal, metode 2D unggul karena dapat mendeteksi interaksi berpasangan antar peubah dan menghasilkan tingkat kesalahan klasifikasi yang lebih rendah atau sama dengan metode 1D. Berdasarkan pertimbangan tersebut, penelitian ini menggunakan metode 2D sebagai metode pemisahan.
Metode CRUISE digunakan di dalam beberapa penelitian, di antaranya penelitian yang dilakukan oleh Faridhan (2003) dan Sadik (2008). Faridhan membandingkan hasil dari beberapa pohon klasifikasi (CHAID, QUEST, CRUISE 1D dan CRUISE 2D), dalam hal ini ia bermaksud mengklasikasikan jamur bergenus Agaricus dan Lepiota ke dalam kategori ‘dapat dimakan’ dan ‘beracun atau tidak dapat dimakan’. Hasil penelitiannya menunjukkan bahwa metode CRUISE memiliki tingkat ketepatan klasifikasi yang paling baik. Sementara Sadik menggunakan CRUISE untuk mengklasifikasikan status mahasiswa TPB (berdasarkan Indeks Massa Tubuh menurut umur) ke dalam kategori ‘kurus’, ‘normal’, dan ‘gemuk’.
Permasalahan lain yang sering timbul dalam metode klasifikasi adalah ketidakseimbangan jumlah amatan pada masing-masing kelas peubah respon, yakni terdapat kelas yang lebih mendominasi (mayor) dan kelas yang jumlah amatannya jauh lebih sedikit (minor). Kondisi ini akan menyebabkan amatan pada kelas minor tidak dapat diklasifikasikan dengan benar. Oleh karena itu, dibutuhkan suatu metode pendahuluan untuk menangani kelas minor. Salah satu alternatifnya adalah SMOTE (Synthetic Minority Over-Sampling Technique) with
majority under sampling yang dikembangkan oleh Chawla et al. (2002). Metode
tersebut merupakan kombinasi SMOTE dan penurunan jumlah amatan kelas mayor melalui pengambilan contoh acak. SMOTE merupakan sebuah metode yang akan menambahkan jumlah amatan pada kelas minor sebesar N persen (disebut persen kenaikan) dengan membentuk data sintetik berdasarkan k tetangga terdekatnya.
Tujuan Penelitian
1. Menelusuri faktor-faktor yang mempengaruhi IPK mahasiswa BUD dengan menggunakan pendekatan CRUISE sehingga diperoleh pengklasifikasian mahasiswa BUD yang mengalami drop out beserta karakteristiknya.
3
METODOLOGI
Data
Data penelitian ini merupakan data mahasiswa BUD angkatan 45-48 yang terdiri peubah respon (Y) berupa drop out (1) dan tidak drop out (2), dan 11 peubah penjelas yang dirinci pada Lampiran 2. Data berasal dari Sekretariat TPB, Sekretariat BUD, dan PPMB (Panitia Penerimaan Mahasiswa Baru). Data tersebut diperoleh dari formulir BUD yang diisi oleh calon mahasiswa saat mendaftarkan diri melalui jalur tersebut.
Metode
Tahapan dalam penelitian ini adalah sebagai berikut: 1. Melakukan penanganan data awal.
• Membuang amatan-amatan yang tidak memiliki keterangan IPK TPB. • Peubah pekerjaan ibu memiliki banyak sekali data hilang, sehingga
diasumsikan bahwa data hilang itu adalah ibu rumah tangga. Data hilang pada peubah lainnya dibiarkan kosong.
• Mengkategorikan peubah provinsi asal dengan merujuk pada daftar provinsi di seluruh Indonesia tahun 2010 pada http://indonesiadata.co.id. Setelah itu provinsi dikelompokkan lagi sesuai pulau.
• Mengkategorikan akreditasi sekolah asal dengan merujuk pada halaman Badan Akreditasi Negara (BAN) Sekolah Menengah (http://www.ban-sm.or.id), yakni dengan melihat akreditasi sekolah yang bersangkutan pada saat mahasiswa tersebut akan mendaftar ke IPB. Sekolah yang namanya tidak ditemukan di dalam halaman tersebut dianggap belum mendaftarkan diri untuk mengikuti proses akreditasi oleh BAN, dimasukkan dalam kategori BT (Belum Terakreditasi). Sedangkan kategori TT (Tidak Terakreditasi) ditujukan bagi sekolah yang telah mendaftar tetapi dinyatakan tidak lulus akreditasi oleh BAN.
• Mengkategorikan tipe sponsor dengan merujuk pada halaman BUD IPB (http://bud.ipb.ac.id/index.php/mitra).
• Peubah penghasilan dikategorikan agar tidak bermasalah dengan nilai pencilan.
• Mengubah nilai UN ke dalam rataan karena pada data ini terdapat mahasiswa yang berasal dari SMK, sehingga jumlah mata pelajaran UN-nya berbeda.
• Menghapus nilai penghasilan yang tidak rasional, misalnya ada anak yang ayahnya buruh dan ibunya hanya ibu rumah tangga tetapi memiliki penghasilan Rp 10 000 000.
4
• Estimated Prior, besarnya peluang prior mengikuti peluang
masing-masing kategori peubah respon.
• Equal misclassification cost, maksudnya, diasumsikan bahwa cost atau
harga C(Tidak DO|DO) = C(DO|Tidak DO).
• Jumlah minimum amatan pada pada simpul adalah 3% dari total data. Jika suatu simpul memiliki amatan kurang dari batas tersebut, maka proses pemisahan berhenti dan simpul itu menjadi terminal.
• Pemangkasan dengan 10-Cross Validation.
• Penanganandata hilang: to fit (available cases) and impute
(Lampiran 5).
• Penanganan data hilang selama proses pemangkasan: alternate split
(Lampiran 6).
Algoritme CRUISE 2D terdapat pada Lampiran 4, bagan tersebut disusun berdasarkan alur yang dikemukakan oleh Kim dan Loh (2001).
3. Membagi data menjadi dua, yakni data untuk membentuk pohon (learning data) dan data untuk tes (testing data). Learning data adalah data angkatan 45-47, sedangkan testing data adalah data angkatan 48.
4. Menangani ketidakseimbangan data menggunakan SMOTE with majority
under sampling dengan bantuan R Package DMwR. Data yang digunakan
untuk tahap ini adalah learning data. Penurunan dan penaikan jumlah amatan dilakukan dengan ketentuan berikut:
• Persen penurunan dihitung dari besarnya kenaikan jumlah amatan kelas minor. Sebagai contoh, jika jumlah data kelas minor adalah 50 dan akan dinaikkan 300%, besarnya penambahan adalah 150. Jika persen penurunannya=50%, jumlah amatan yang akan diambil secara acak adalah 75.
• Persen kenaikan kelas DO dilakukan dari 300 sampai 600. Sementara jumlah amatan tidak DO diturunkan hingga mencapai perbandingan jumlah kelas DO dan kelas tidak DO sebesar 50:50 dan 40:60. Rinciannya terdapat pada Tabel 1.
Tabel 1 Persen penaikan dan penurunan data SMOTE withmajority under Sampling
Algoritme SMOTE (disusun sesuai alur yang dikemukakan oleh Chawla et al.
2002) untuk data dengan peubah penjelas bertipe numerik dan kategorik (SMOTE- NC) terdapat pada Lampiran 3.
5 6. Membuat kurva Receiver Operating Characteristic (ROC) dengan menggunakan data SMOTE dari tahap 4. Peubah yang digunakan adalah Y aktual dan Y prediksi (Y berdasarkan hasil pohon). Sumbu Y pada kurva tersebut merupakan TP-rate, yang rumusnya:
%TP (TP ����) = TP
(TP+FN) , sedangkan sumbu X pada kurva tersebut
didapatkan dengan rumus %FP = FP
(TN+FP).
7. Menghitung TP-rate menggunakan learning data (hasilnya diinisialkan sebagai TP1) dan menggunakan testing data (hasilnya diinisialkan sebagai TP2). TP-rate menggambarkan kemampuan pohon untuk mengklasifikasikan amatan DO dengan benar.
8. Mengevaluasi pohon yang akan digunakan, yakni dengan melihat nilai Area
Under Curve (AUC) dari ROC pada tahap 6 dan TP2 dengan tetap
mempertimbangkan TP1 serta ukuran pohon. Akan dicari pohon yang nilai AUC dan TP yang besar tetapi memiliki TP1 yang tidak rendah dan ukuran pohon yang tidak terlalu besar.
9. Menginterpretasi pohon yang didapatkan dari tahap 8, tahap ini difokuskan pada terminal dengan peluang DO tinggi.
HASIL DAN PEMBAHASAN
Deskripsi Data
Bagian ini ditujukan untuk mendapatkan gambaran umum data berdasarkan peubah penjelasnya. Data yang digunakan hanya mahasiswa yang mengikuti perkuliahan TPB hingga usai.
Gambar 1 menunjukkan bahwa jumlah mahasiswa DO jauh lebih sedikit (hanya 51), sedangkan mahasiswa tidak DO jumlahnya 828. Kondisi ini menunjukkan ketidakseimbangan jumlah amatan pada setiap kategori peubah respon.
Gambar 1 Persentase amatan kelompok DO dan tidak DO
6
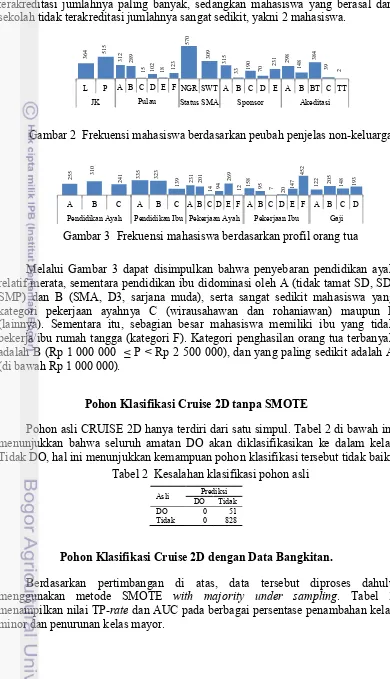
(C), dan E (pemerintah pusat). Mahasiswa yang berasal dari sekolah belum terakreditasi jumlahnya paling banyak, sedangkan mahasiswa yang berasal dari sekolah tidak terakreditasi jumlahnya sangat sedikit, yakni 2 mahasiswa.
Gambar 2 Frekuensi mahasiswa berdasarkan peubah penjelas non-keluarga
Gambar 3 Frekuensi mahasiswa berdasarkan profil orang tua
Melalui Gambar 3 dapat disimpulkan bahwa penyebaran pendidikan ayah relatif merata, sementara pendidikan ibu didominasi oleh A (tidak tamat SD, SD, SMP) dan B (SMA, D3, sarjana muda), serta sangat sedikit mahasiswa yang kategori pekerjaan ayahnya C (wirausahawan dan rohaniawan) maupun F (lainnya). Sementara itu, sebagian besar mahasiswa memiliki ibu yang tidak bekerja/ibu rumah tangga (kategori F). Kategori penghasilan orang tua terbanyak adalah B (Rp 1 000 000 ≤ P < Rp 2 500 000), dan yang paling sedikit adalah A (di bawah Rp 1 000 000).
Pohon Klasifikasi Cruise 2D tanpa SMOTE
Pohon asli CRUISE 2D hanya terdiri dari satu simpul. Tabel 2 di bawah ini menunjukkan bahwa seluruh amatan DO akan diklasifikasikan ke dalam kelas Tidak DO, hal ini menunjukkan kemampuan pohon klasifikasi tersebut tidak baik.
Tabel 2 Kesalahan klasifikasi pohon asli
Asli Prediksi
DO Tidak
DO 0 51
Tidak 0 828
Pohon Klasifikasi Cruise 2D dengan Data Bangkitan.
Berdasarkan pertimbangan di atas, data tersebut diproses dahulu menggunakan metode SMOTE with majority under sampling. Tabel 3 menampilkan nilai TP-rate dan AUC pada berbagai persentase penambahan kelas minor dan penurunan kelas mayor.
A B C
255 310 335 323
7 Tabel 3 Nilai ROC dan TP-rate pada berbagai persen penaikan dan Penurunan
Terlihat bahwa nilai TP-rate dari data bangkitan SMOTE with majority
under sampling lebih baik daripada pohon tanpa SMOTE. Pemilihan pohon akhir
dilakukan dengan mempertimbangkan TP-rate, AUC, dan juga ukuran pohon. Pohon N3 dan N7 memiliki nilai AUC serta TP2 yang lebih tinggi daripada lainnya. Nilai TP1 untuk N3 dan N7 juga relatif baik. Pohon N3 dipilih sebagai pohon akhir karena nilai AUC dan TP2 yang paling tinggi, ukuran pohonnya yang tidak terlalu besar, dan pohon ini pun terbentuk dari data sintetik SMOTE dengan persen kenaikan yang tidak terlalu besar.
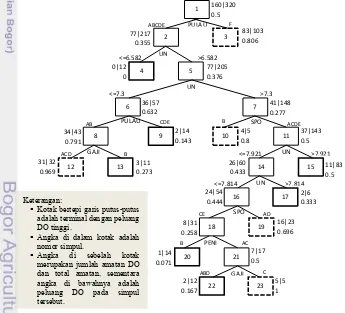
Pohon klasifikasi ini (Gambar 4) memperlihatkan peubah-peubah yang berhubungan dengan keberhasilan studi mahasiswa BUD. Semakin ke bawah menunjukkan bahwa pengaruh peubah penjelas yang bersangkutan terhadap peubah respon semakin lemah.
Gambar 4 Pohon CRUISE 2D akhir
160|320
<=6.582 >6.582
<=7.3 >7.3
<=7.921 >7.921
>7.814
Kotak bertepi garis putus-putus
adalah terminal dengan peluang DO tinggi.
Angka di dalam kotak adalah
nomor simpul.
Angka di sebelah kotak
8
Peubah pemisah pertama adalah pulau. Terlihat bahwa mahasiswa dari pulau F (Maluku dan Papua) memiliki potensi DO yang besar, yakni 0.806. Golongan ini harus diprioritaskan oleh pihak IPB untuk diberikan perlakuan khusus. Peluang DO dari pulau lain relatif kecil, hanya 0.355.
Simpul 5 tersekat oleh peubah UN dan terbagi menjadi simpul 6 dan 7. Simpul 6 memiliki nilai UN yang lebih rendah sekaligus peluang DO yang lebih tinggi. Kemudian, simpul 6 tersekat oleh peubah pulau. Mahasiswa yang berasal dari pulau C (Bali dan Nusa Tenggara), D (Kalimantan), dan E (Sulawesi) pada simpul 9 memiliki peluang DO yang rendah daripada mahasiswa yang berasal dari pulau A (Sumatera) dan B (Jawa) (simpul 8). Meskipun simpul 8 memiliki peluang DO yang tinggi, namun peluang DO-nya akan menjadi rendah jika mahasiswa tersebut memiliki orang tua dengan kategori penghasilan B (Rp 1 000 000 ≤ P < 2 500 000), dan akan meningkat jika kategori penghasilan orang tuanya paling rendah (A) serta paling tinggi (C dan D).
Sementara itu, simpul 7 tersekat oleh peubah sponsor. Simpul 10 dengan tipe sponsor B (yayasan/lembaga lain) memiliki peluang DO relatif tinggi, hal ini dapat menjadi indikasi bahwa pihak pemberi sponsor tersebut harus lebih selektif lagi dalam menyeleksi mahasiswa yang akan diberi beasiswa. Berbicara tentang pihak sponsor, pada simpul 19 pun terlihat bahwa pemerintah kota/kabupaten (A) dan pemerintah provinsi (D) harus sedikit berhati-hati dalam menyeleksi calon mahasiswa sekalipun mahasiswa yang masuk pada simpul ini adalah mereka yang nilai UN-nya relatif tinggi (7.814≤UN≤7.921).
Simpul 18 memiliki peluang DO yang rendah, namun pengaruh peubah pendidikan ibu akan mengubah peluang tersebut. Jika kategori pendidikan ibunya A (tidak tamat SD, SD, SMP) dan C (S1, S2, S3) maka peluangnya meningkat menjadi 0.5, sementara jika pendidikan ibunya B (SMA, D3, sarjana muda) peluang DO-nya menurun menjadi 0.071. Adapun rincian mengenai karakteristik mahasiswa yang berpotensi DO tinggi terdapat pada Tabel 4.
Tabel 4 Karakteristik mahasiswa berpeluang DO tinggi
Simpul No
Peluang DO
Karakteristik Mahasiswa
3 0.806 Berasal dari pulau F (Maluku dan Papua)
10 0.8 Bukan berasal dari pulau F, memiliki nilai UN>7.3, disponsori oleh yayasan atau lembaga lain (B)
12 0.969 Berasal dari pulau A (Sumatera) dan B (Jawa), memiliki 6.582 < UN ≤ 7.3, kategori penghasilan orang tuanya adalah A (P < Rp 1 000 000),
C (Rp 2 500 000 ≤ P < Rp 5 000 000), dan D (≥ Rp 5 000 000).
19 0.696 Bukan berasal dari pulau F, memiliki 7.3 < UN ≤ 7.814, memiliki sponsor berupa pemerintah kota/kabupaten (A) dan pemerintah provinsi (D)
23 1 Bukan berasal dari pulau F, memiliki 7.3 < UN ≤ 7.814, disponsori oleh pemerintah pusat (E ) dan perusahaan (C ), memiliki ibu yang berpendidikan tidak tamat SD, SD, dan SMP (kategori A) dan C (S1, S2, S3), kategori penghasilan orang tuanya C (Rp 2 500 000 ≤ P < Rp 5 000 000)
9 (angkatan 48) dimasukkan, pohon ini akan memiliki TP-rate sebesar 73.7%. Pohon yang terbentuk melalui data sintetik SMOTE with majority under sampling
ini jelas memiliki kemampuan mengklasifikasikan amatan DO yang lebih baik daripada pohon tanpa SMOTE.
Penelitian ini memiliki satu kekurangan yang mungkin terbilang penting, yakni tidak adanya peubah nilai rapor karena peubah ini sulit didapatkan. Padahal, nilai rapor SMA/SMK cukup mampu mencerminkan tingkat prestasi mahasiswa selama sekolah.
SIMPULAN DAN SARAN
Simpulan
Penelitian ini memiliki masalah ketidakseimbangan data yang menyebabkan pohon CRUISE 2D tidak mampu mengklasifikasikan amatan DO dengan benar, sehingga pohon akhir yang digunakan adalah pohon yang terbentuk melalui SMOTE with majority under sampling dengan kenaikan kelas minor sebanyak 400% dan persen penurunan kelas mayor sebesar 125. Pohon ini mampu mengkasifikasikan secara tepat amatan DO pada data tes sebesar 73.7%. Terminal-terminal berpeluang DO tinggi menggambarkan karakteristik mahasiswa yang harus diperhatikan ekstra sehingga dapat meminimalkan kejadian DO pada mahasiswa BUD selanjutnya, terlebih mahasiswa yang berasal dari Pulau Maluku dan Papua.
Saran
Pendeteksian lebih dini terhadap karakteristik mahasiswa BUD yang berpotensi DO tinggi setidaknya dapat dijadikan rujukan awal bagi pihak IPB untuk memberikan tutorial ekstra maupun perlakuan khusus lainnya bagi mahasiswa yang memiliki karakteristik bersesuaian dengan terminal-terminal yang memiliki peluang DO tinggi. Selama ini, pihak IPB memang telah memberikan tutorial bagi mahasiswa BUD yang memiliki nilai buruk, tetapi ini baru dilakukan setelah hasil evaluasi Indeks Prestasi (IP) semester satu keluar. Alangkah baiknya jika tutorial tersebut diberikan sejak awal perkuliahan.
DAFTAR PUSTAKA
Breiman L, Friedman J, Olshen R, Stone C. 1993. Classification and Regression
Trees. New York (US): Chapman & Hall.
Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. 2002. SMOTE: Synthetic Minority Over-Sampling Technique. Journal of Artificial Intelligence
Research [Internet]. [diunduh 2013 Juni 15]; 16:321-357. Tersedia pada:
10
Faridhan YE. 2003. Metode klasifikasi berstruktur pohon dengan algoritme CRUISE, QUEST, dan CHAID [Tesis]. Bogor(ID): Institut Pertanian Bogor.
Faridhan YE, Susetyo B, Alamudi A. 2006. Metode klasifikasi berstruktur pohon dengan algoritme CRUISE, QUEST, dan CHAID. Forum Statistika dan
Komputasi [Internet]. [diunduh 2013 Mei 05]; 11(1): 20-28. Tersedia pada:
http://journal.ipb.ac.id/index.php/statistika /article/view File/5461/4025. Kim H, Loh WY. 2001.Classification trees with unbiased multiway splits. J. Am.
Statist. Assoc [Internet]. [diunduh 2013 April 08]; 96: 598-604. Tersedia
pada: http://www.stat.wisc.edu/~loh/treeprogs/cruise/cruise.pdf
Loh WY, Shih YS. 1997. Split Selection Methods for Classification Trees.
Statistica Sinica [Internet]. [diunduh 2013 Mei 05]; 7: 815-840. Tersedia
pada: http://www3.stat.sinica.edu.tw/statistica/oldpdf/A7n41.pdf. Pham H. 2006. Handbook of Engineering Statistics. London: Springer.
Sadik K. 2008. CRUISE sebagai metode berstruktur pohon (tree-structured) pada data non-biner. Di dalam: Ansori M, Djakaria I, Wutsqa DU, Abadi AM, Rudhito MA, Sa’adah U, Karyati, Pratiwi H, editor. Seminar Nasional Mahasiswa S3 Matematika [Internet]. [Waktu dan tempat pertemuan tidak diketahui]. Yogyakarta (ID): [Penerbit tidak diketahui]. hlm. 433-446; [diunduh pada 2013 April 8]. Tersedia pada: http:// repository.ipb.ac.id /bitstream/handle/123456789/59475/_(433-446)CRUISE%20sebagai%20 Metode%20Berstruktur%20Pohon%20(Tree-Structured)%20pada%20Da ta %20Non-Biner.pdf?sequence=1.
LAMPIRAN
Lampiran 1 Persentase mahasiswa drop out dari masing-masing jalur Tahun Jalur Masuk
USMI SPMB BUD
11 Lampiran 2 Daftar peubah penjelas
Peubah Kode Kategori
Jenis Kelamin JK 1 (laki-laki), 2 (perempuan) Pulau Pulau • A (Sumatera)
Status SMA Stat NGR (negeri), SWT (swasta) Pendidikan Ayah/
C: Sarjana, S2/Master, S3/Doktor
Pekerjaan Ayah PekA A: PNS, TNI/POLRI
B: pensiunan Pegawai Negeri, veteran, purnawirawan C: wirausahawan, rohaniawan
D: pegawai swasta, pegawai BUMN, Eksekutif muda/profesional E: nelayan, petani, buruh
F: Lainnya *
*F pada Pekerjaan Ibu adalah Ibu Rumah Tangga Pekerjaan Ibu PenI
Penghasilan
Tipe Sponsor Spo A: Pemerintah Kabupaten/Kota B: Yayasan dan Lembaga Lain C: Perusahaan
D: Pemerintah Provinsi E: Pemerintah Pusat
Akreditasi SMA Asal
Akre A B C TT BT
Ket: TT berarti telah mengikuti proses akreditasi namun dinyatakan tidak terakteditasi oleh BAN. BT berarti seoklah tersebut belum mendaftarkan diri untuk diakreditasi
Lampiran 3 Algoritme SMOTE-NC
Didapat pasangan amatan asli dan tetangga terpilih AWAL
Tentukan nilai k, misal 5
Hitung jarak Euclidian antar amatan*
Cari k tetangga terdekat
Tentukan nilai persen over
(N) Pilih secara acak dari k tetangga itu sesuai
banyaknya data sintetik tambahan yang dibutuhkan.
Kalau N< 100
Kalau N ≥100
Untuk peubah numerik, hitung selisih dari vektor amatan tetangga terpilih dan amatan asli, nyatakan dalam dif.
Untuk peubah kategorik, gunakan kategori mayoritas
yang terdapat pada k tetangganya untuk peubah
yang bersangkutan Bangkitkan gap, yaitu bilangan
acak yang nilainya 0 sampai 1
Amatan baru= amatan asli+(gap*dif)
Vektor amatan baru Misal, nilai X1, X2, X3, X4, X5, X6
adalah sebagai berikut: Amatan asli F1 = 1 2 3 A B C Tetangga F2 = 4 5 6 A D E
Euclidian = sqrt [ (4−1)2+ (5−2)2+ (6−3)2+ (med)2+ (med)2]
Med adalah nilai median dari standar deviasi peubah-peubah numerik pada kelas minor, pada contoh ini median hanya dihitung dua kali karena peubah X4 sama-sama memiliki kategori A, sehingga tidak perlu dimasukkan ke dalam perhitungan.
12
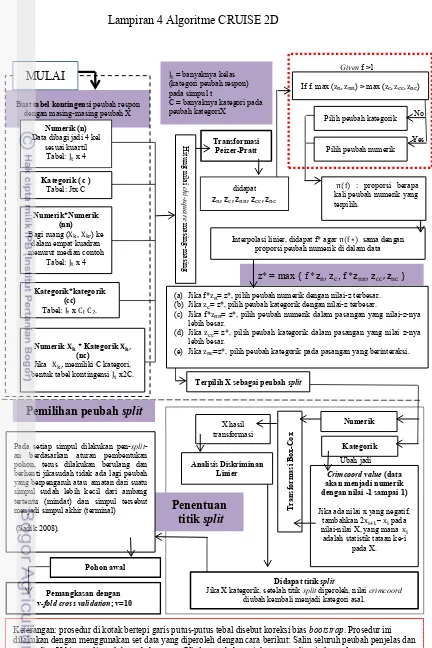
Lampiran 4 Algoritme CRUISE 2D
Penentuan titik split
Pada setiap simpul dilakukan pen-split-
an berdasarkan aturan pembentukan pohon, terus dilakukan berulang dan berhenti jikasudah tidak ada lagi peubah yang berpengaruh atau amatan dari suatu simpul sudah lebih kecil dari ambang tertentu (mindat) dan simpul tersebut menjadi simpul akhir (terminal)
(Sadik 2008).
Ubah jadi
Pemangkasan dengan v-fold cross validation; v=10
Pohon awal
Pemilihan peubah split
Numerik
Crimcoord value (data akan menjadi numerik dengan nilai -1 sampai 1)
Jika ada nilai x yang negatif,
tambahkan 2xi+1– xi pada
nilai-nilai X, yang mana xi
adalah statistik tataan ke-i pada X. X hasil
transformasi
Analisis Diskriminan Linier
Didapat titik split
Jika X kategorik, setelah titik split diperoleh, nilai crimcoord
diubah kembali menjadi kategori asal. Given f >1
If f. max (zn, znn) > max (zc, zcc, znc)
Pilih peubah kategorik
Pilih peubah numerik
π(f) : proporsi berapa
kali peubah numerik yang terpilih.
Interpolasi linier, didapat f* agar π(f∗) sama dengan
proporsi peubah numerik di dalam data
z* = max { f *zn, zc, f *znn, zcc, znc }
(a) Jika f*zn= z*, pilih peubah numerik dengan nilai-z terbesar.
(b) Jika zc= z*, pilih peubah kategorik dengan nilai-z terbesar.
(c) Jika f*znn= z*, pilih peubah numerik dalam pasangan yang nilai-z-nya
lebih besar.
(d) Jika zcc= z*, pilih peubah kategorik dalam pasangan yang nilai z-nya
lebih besar.
(e) Jika znc=z*, pilih peubah kategorik pada pasangan yang berinteraksi.
Terpilih X sebagai peubah split
H
(kategori peubah respon) pada simpul t
C = banyaknya kategori pada peubah kategoriX
zn, zc, znn, zcc, znc didapat Buat tabel kontingensi peubah respon
dengan masing-masing peubah X
Numerik (n) Data dibagi jadi 4 kel
sesuai kuartil
bentuk tabel kontingensi Jt x2C.
Kategorik*kategorik
dalam empat kuadran menurut median contoh
Tabel: Jt x 4
Yes No
MULAI
Keterangan: prosedur di kotak bertepi garis putus-putus tebal disebut koreksi bias bootstrap. Prosedur ini dilakukan dengan menggunakan set data yang diperoleh dengan cara berikut: Salin seluruh peubah penjelas dan
13 Lampiran 5 Penanganan data hilang dalam tahap pemisahan
1. Hitung p-value untuk setiap pasang peubah pada algoritme CRUISE 2D dengan menggunakan amatan yang ada pada X.
2. Jika X* adalah peubah pemisah terpilih, gunakan amatan yang ada pada x* untuk mendapatkan titik pisah.
3. Jika X* adalah peubah numerik, gunakan rataan sesuai kategori Y (rataan kelas) pada simpul tersebut untuk menutupi amatan data hilang pada X. Jika X* peubah kategorik, gunakan modus pada simpul tersebut sesuai kategori Y masing-masing
4. Data yang telah dilengkapi kemudian dimasukkan ke dalam simpul-simpul anak hasil pemisahan.
5. Hapus kembali data masukan pada tahap 3 untuk mengembalikan data ke dalam kondisi aslinya.
(Kim dan Loh 2001)
Lampiran 6 Penanganan data hilang pada tahap pemangkasan
Metode penanganan data hilang pada tahapan pruning ini disebut alternate split. Algoritmenya sebagai berikut:
Misal X adalah peubah paling signifikan dan s adalah pemisahan yang berhubungan dengannya. Misal X’ dan s’ adalah peubah kedua yang paling signifikan dan pemisahan yang bersangkutannya, maka:
1. Jika X’ adalah peubah tanpa data hilang, gunakan s’ untuk memprediksi kelas X. Kemudian input data hilang pada X dengan menggunakan rataan (jika X peubah numerik) dari nilai non-missing
pada X sesuai dengan kelas prediksi Y pada simpul tersebut. Jika X peubah kategorik, gunakan modus.
2. Jika X’ adalah peubah dengan data hilang, input data hilang X dengan rataan umum (bukan rataan yang bersesuaian dengan kelas Y-nya) atau modus umum pada simpul tersebut.
14
RIWAYAT HIDUP
Penulis lahir di Cirebon pada tanggal 13 Februari 1992 dan merupakan anak pertama dari 4 bersaudara dari pasangan Bapak Abdurachman dan Ibu Aflaha. Tahun 2006 penulis lulus dari Sekolah Menengah Pertama SMP Muhammadiyah 1 Kota Cirebon, tahun 2009 lulus dari Sekolah Menengah Atas Negeri 2 Kota Cirebon, kemudian melanjutkan ke jurusan Statistika Institut Pertanian Bogor pada tahun yang sama melalui jalur masuk USMI.
Selama mengikuti perkuliahan, penulis aktif sebagai staf Database Centre di Himpunan Keprofesian Gamma Sigma Beta Tahun 2011 dan Staf departemen
Science Tahun 2012. Penulis juga aktif pada beberapa kepanitiaan event dan dunia
blogger. Bulan Februari-April 2013 penulis mengikuti kegiatan praktik lapang di