Informasi Dokumen
- Penulis:
- Desfa Maulani
- Pengajar:
- Prof. Dr. Muhammad Zarlis, MSc.
- Ibu Maya Silvi Lydia, BSc, MSc.
- Dr. Poltak Sihombing, M.Kom.
- Sekolah: Universitas Sumatera Utara
- Mata Pelajaran: Ilmu Komputer
- Topik: Implementasi Algoritma K-Means Clustering Dalam Menentukan Berat Badan Ideal
- Tipe: skripsi
- Tahun: 2013
- Kota: Medan
Ringkasan Dokumen
I. Pendahuluan
Bagian ini menjelaskan latar belakang pentingnya penentuan berat badan ideal dan bagaimana algoritma K-Means Clustering dapat digunakan dalam konteks ini. Penelitian ini bertujuan untuk mengembangkan perangkat lunak yang dapat membantu dokter dalam menentukan berat badan ideal pasien berdasarkan berbagai parameter seperti tinggi badan, berat badan, usia, dan ukuran kerangka. Dengan memanfaatkan teknologi komputer, sistem ini diharapkan dapat meningkatkan efisiensi dan akurasi dalam pengelolaan kesehatan pasien.
1.1 Latar Belakang
Perkembangan teknologi komputer dalam bidang kedokteran sangat pesat, terutama dalam penentuan berat badan ideal. Penggunaan algoritma K-Means Clustering memungkinkan pengelompokan data yang relevan untuk menentukan status kesehatan pasien. Dengan sistem ini, dokter dapat memberikan rekomendasi diet yang lebih tepat berdasarkan analisis data yang akurat.
1.2 Rumusan Masalah
Rumusan masalah dalam penelitian ini adalah merancang perangkat lunak yang dapat menentukan berat badan ideal dengan menggunakan algoritma K-Means Clustering, serta bagaimana algoritma ini dapat diterapkan dalam praktik klinis.
1.3 Batasan Masalah
Batasan dalam penelitian ini meliputi fokus pada penghitungan berat badan ideal berdasarkan tinggi badan, berat badan, ukuran kerangka, dan kebutuhan kalori pasien. Selain itu, perangkat lunak yang digunakan adalah Microsoft Visual Basic 6.0 dan DBMS Microsoft Access 2007.
1.4 Tujuan Penelitian
Tujuan penelitian ini adalah untuk mengetahui cara menentukan berat badan ideal pasien serta cara kerja algoritma K-Means Clustering dalam pengelompokan data. Penelitian ini juga bertujuan untuk menganalisis dan merancang sistem penentuan berat badan ideal.
1.5 Manfaat Penelitian
Manfaat dari penelitian ini adalah perangkat lunak yang dihasilkan dapat digunakan dalam bidang kedokteran untuk membantu menentukan berat badan ideal pasien, sehingga dapat mendukung program diet dan kesehatan yang lebih efektif.
1.6 Metodologi Penelitian
Metodologi penelitian ini mencakup studi literatur, analisis data, dan perancangan perangkat lunak. Setiap tahap dilakukan untuk memastikan bahwa sistem yang dibangun dapat berfungsi dengan baik dan memenuhi kebutuhan pengguna.
1.7 Sistematika Penulisan
Sistematika penulisan dibagi menjadi beberapa bab, dimulai dari pendahuluan yang membahas latar belakang, rumusan masalah, hingga metodologi penelitian. Bab selanjutnya akan membahas landasan teori, analisis, perancangan, implementasi, dan pengujian sistem.
II. Landasan Teori
Bab ini membahas teori-teori yang mendasari penelitian, termasuk konsep clustering dan algoritma K-Means. Penjelasan mengenai data clustering dan aplikasinya dalam konteks kesehatan juga disertakan, memberikan pemahaman yang lebih dalam tentang bagaimana sistem ini bekerja.
2.1 Clustering
Clustering adalah proses pengelompokan data berdasarkan kesamaan karakteristik tanpa adanya label kelas yang ditentukan sebelumnya. Proses ini membantu dalam memahami struktur data dan mendukung pengambilan keputusan yang lebih baik.
2.2 Data Clustering
Data clustering merupakan metode data mining yang tidak terarah, di mana K-Means adalah salah satu metode yang umum digunakan. Metode ini membagi data ke dalam cluster berdasarkan karakteristik yang sama, memudahkan analisis lebih lanjut.
2.2.1 Perkembangan Penerapan K-Means
Pengembangan K-Means mencakup pemilihan ruang jarak, metode pengalokasian data, dan fungsi objektif yang digunakan. Hal ini penting untuk meningkatkan akurasi dan efisiensi algoritma dalam pengelompokan data.
2.3 Beberapa Permasalahan yang Terkait dengan K-Means
Beberapa tantangan dalam penerapan K-Means termasuk pemilihan jumlah cluster yang tepat, kegagalan untuk konvergen, dan deteksi outliers. Memahami masalah ini penting untuk meningkatkan kinerja algoritma.
2.4 K-Means untuk Data yang Mempunyai Bentuk Khusus
K-Means dapat disesuaikan untuk dataset dengan bentuk khusus, di mana metode kernel trick dapat digunakan untuk meningkatkan hasil pengelompokan. Pendekatan ini membantu dalam menangani kompleksitas data yang lebih tinggi.
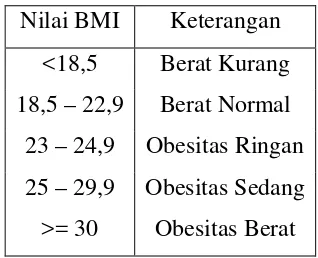
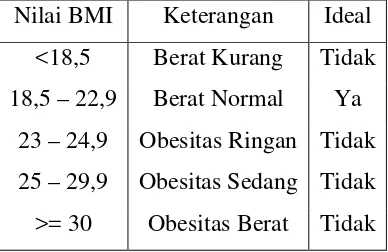
2.5 Berat Badan Ideal
Berat badan ideal sangat penting untuk kesehatan. Penelitian ini menggunakan BMI dan ukuran kerangka sebagai parameter untuk menentukan berat badan ideal, yang dapat diukur dengan rumus-rumus tertentu.
2.6 Penelitian Terkait
Penelitian terkait menunjukkan bagaimana K-Means telah diterapkan dalam konteks yang berbeda, termasuk pengelompokan mahasiswa berdasarkan BMI. Ini memberikan gambaran tentang keberhasilan metode dalam aplikasi nyata.
III. Analisis dan Perancangan
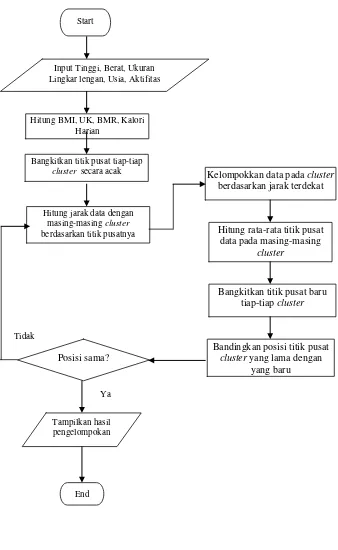
Bagian ini menjelaskan analisis sistem yang akan dibangun, termasuk langkah-langkah dalam pengelompokan pasien menggunakan algoritma K-Means. Perancangan antarmuka pengguna dan alur sistem juga dibahas untuk memastikan kemudahan penggunaan.
3.1 Analisis
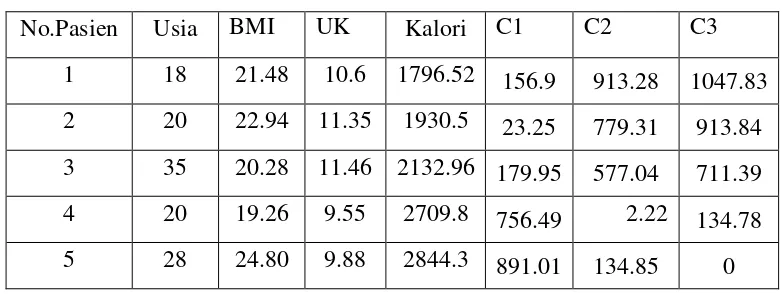
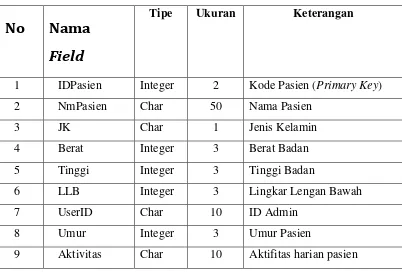
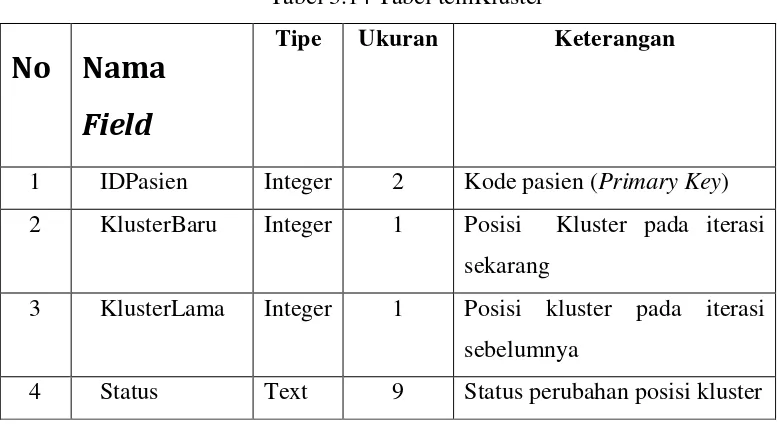
Analisis sistem dilakukan dengan mengumpulkan data fisik pasien, termasuk tinggi badan, berat badan, usia, dan ukuran lingkar lengan. Proses pengelompokan menggunakan K-Means akan mempermudah pengelolaan data dan memberikan hasil yang akurat.
3.2 Perancangan
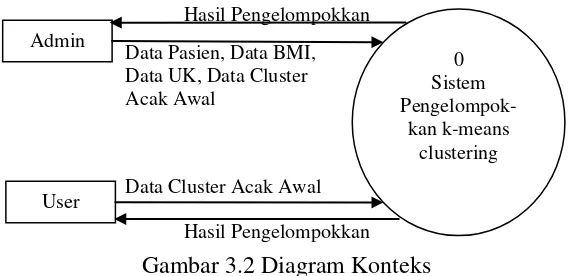
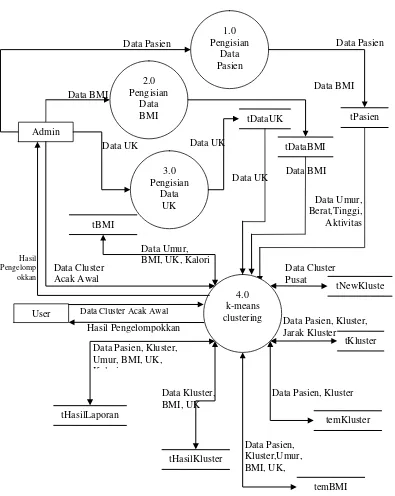
Perancangan sistem mencakup pembuatan diagram konteks, data flow diagram, dan desain antarmuka pengguna. Semua elemen ini dirancang untuk memastikan sistem dapat berfungsi dengan baik dan mudah digunakan oleh dokter dan pasien.
IV. Implementasi dan Pengujian Sistem
Bab ini membahas langkah-langkah implementasi sistem yang telah dirancang, serta pengujian untuk memastikan bahwa sistem berfungsi sesuai dengan yang diharapkan. Pengujian dilakukan untuk mengevaluasi performa algoritma K-Means dalam pengelompokan data.
4.1 Implementasi
Implementasi sistem dilakukan dengan membangun antarmuka pengguna dan mengintegrasikan algoritma K-Means. Setiap fitur diuji untuk memastikan bahwa sistem dapat berjalan dengan baik dalam kondisi nyata.
4.2 Pengujian Sistem
Pengujian dilakukan untuk mengevaluasi hasil pengelompokan yang dihasilkan oleh K-Means. Hasil pengujian dibandingkan dengan nilai yang diharapkan untuk memastikan akurasi dan efisiensi sistem.
V. Kesimpulan dan Saran
Bagian ini menyimpulkan hasil penelitian dan memberikan saran untuk pengembangan lebih lanjut. Penelitian ini menunjukkan bahwa algoritma K-Means Clustering dapat digunakan secara efektif dalam menentukan berat badan ideal.
5.1 Kesimpulan
Kesimpulan dari penelitian ini adalah bahwa K-Means Clustering dapat membantu dalam menentukan berat badan ideal pasien dengan akurasi yang baik. Sistem yang dibangun dapat digunakan dalam praktik klinis untuk mendukung keputusan kesehatan.
5.2 Saran
Saran untuk penelitian selanjutnya adalah melakukan pengembangan lebih lanjut pada algoritma dan memperluas cakupan penelitian untuk mencakup lebih banyak parameter yang mempengaruhi kesehatan.
Referensi Dokumen
- BMR Formula ( BMR Calculator )
- Harris Benedict Equation ( BMR Calculator )
- Statistical Physics of Clustering Algorithms ( Graepel, T. )
- Terapi Gizi & Diet Rumah Sakit ( Hartono, Andry )
- Data Clustering: 50 Years Beyond K-Means ( Jain, Anil )