KOMPUTASI PARALEL UNTUK SISTEM IDENTIFIKASI
TUMBUHAN OBAT MENGGUNAKAN FUZZY LOCAL
BINARY PATTERN
NGAKAN NYOMAN KUTHA KRISNAWIJAYA
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI TESIS DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
∗∗∗∗Dengan ini saya menyatakan bahwa tesis berjudul Komputasi Paralel Untuk Sistem Identifikasi Tumbuhan Obat Menggunakan Fuzzy Local Binary Pattern benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, September 2013
Ngakan Nyoman Kutha Krisnawijaya NRP G651110071
∗Pelimpahan hak cipta atas karya tulis dari penelitian kerjasama dengan pihak luar
RINGKASAN
NGAKAN NYOMAN KUTHA KRISNAWIJAYA. Komputasi Paralel untuk Sistem Identifikasi Tumbuhan Obat Menggunakan Fuzzy Local Binary Pattern. Dibimbing oleh YENI HERDIYENI dan BIB PARUHUM SILALAHI.
Seiring dengan bertambahnya jumlah database citra tumbuhan obat, maka penelitian mengenai sistem identifikasi otomatis suatu spesies tumbuhan obat semakin dikembangkan untuk penelitian maupun pemantauan spesies tumbuhan obat. Penelitian ini menerapkan High Performance Computing (HPC) pada sistem identifikasi tumbuhan obat. Penelitian ini mengusulkan komputasi paralel pada pengolahan citra tanaman obat menggunakan Fuzzy Local Binary Pattern (FLBP). Tujuan utama penelitian ini adalah mengukur efisiensi komputasi paralel dalam pengolahan citra tumbuhan obat dan mengevaluasi model paralel yang dibangun.
Penelitian ini membangun dua model perancangan paralel untuk identifikasi tumbuhan obat menggunakan FLBP. Model 1 menggunakan teknik data paralel dan model 2 menggunakan teknik task paralel pada proses FLBP. Kedua model perancangan ini diterapkan pada komputer cluster terdiri dari delapan komputer dengan spesifikasi yang sama. Pengembangan model perancangan paralel menggunakan model message-passing dengan library MPI dan bahasa pemrograman C/C++.
Evaluasi model perancangan paralel menggunakan percepatan, efisiensi dan isoefisiensi. Hasil evaluasi menunjukkan bahwa kedua model perancangan mampu mengurangi waktu komputasi ekstraksi fitur citra pada sistem identifikasi tumbuhan obat. Nilai percepatan model 1 pada saat proses ekstraksi 1 440 data citra menggunakan 8 prosesor sebesar 7.64 dengan nilai efisiensi sebesar 0.95. Model 2 menggunakan 8 prosesor menghasilkan nilai percepatan sebesar 6.9 dengan nilai efisiensi sebesar 0.87. Hasil perbandingan nilai percepatan dan efisiensi kedua model perancangan menunjukkan bahwa model 1 lebih baik pada saat proses ekstraksi 1 440 data citra daun. Hal ini dipengaruhi oleh proses pembagian area citra pada model 2 memerlukan biaya komunikasi yang kompleks. Hasil analisis pada model 2, jika penambahan sejumlah prosesor mempengaruhi biaya komunikasi yang dikeluarkan. Kondisi ini tidak terjadi pada model 1 sehingga percepatan dan efisiensi yang dihasilkan lebih baik dibandingkan model 2. Evaluasi model perancangan paralel pada proses ekstraksi citra kueri menunjukkan nilai percepatan model 1 sebesar 6.73 dengan nilai efisiensi 0.84. Model 2 menghasilkan nilai percepatan sebesar 7.96 dengan nilai efisiensi sebesar 0.99. Perbedaan nilai percepatan dan efisiensi yang dihasilkan dipengaruhi oleh pembagian data dari kedua model paralel. Model 1 membagi 20 kombinasi operator dan threshold FLBP. Proses pembagian data pada model 1 memungkinkan terjadinya pembagian data yang tidak ideal. Pembagian data yang ideal adalah pada saat setiap prosesor mengolah data dengan jumlah yang sama. Pembagian data yang tidak ideal dapat menyebabkan terjadinya kondisi idle. Kondisi idle dapat mempengaruhi kinerja dan waktu paralel yang dihasilkan oleh model 1. Pembagian data pada model 2 sangat ideal sehingga nilai percepatan dan efisiensi yang dihasilkan lebih baik dibandingakan model 1.
SUMMARY
NGAKAN NYOMAN KUTHA KRISNAWIJAYA. Parallel Computing for Medicinal Plant Identification System Using Fuzzy Local Binary Pattern. Supervised byYENI HERDIYENI and BIB PARUHUM SILALAHI.
As biological image databases are increasing rapidly, automated species identification based on digital data is of great interest for accelerating biodiversity assessment, research and monitoring. This research applied high performance computing (HPC) on medicinal plant identification system. We propose parallel computing on medicinal plant image processing using Fuzzy Local Binary Pattern (FLBP). The main goal of the research was to measure the efficiency of parallel computing on medicinal plant image processing and evaluation whether this approach is reasonable for handling large data sets.
This research proposes two models of parallel design to identify medicinal plant. The first model used data parallel design and the second model used task parallel design on FLBP process. Both of model are applied on the computer cluster, which consists of eight computers with the same spesicification. The development of the parallel design used the message-passing model with MPI library and the C/C++ language programming.
The parallel computation performance was evaluated by speed up, efficiency and iso-efficiency. The experimental result shows that both of the parallel design models can reduce the computing time of the image feature extraction on a medicinal plant identification system. The values of the speedup on the first model by the time of the extraction was 1 440 image data by using 8 processors, is 7.64 with efficiency value of 0.95. The second model uses 8 processors generated the value of the speedup is 6.9 with efficiency value 0.87. The result of the comparation values between the speedup and the efficiency of both design model shows that first model has better performance by the time of the extraction 1 440 leaf images. This is affected by the process of image area dividing on the second model that requires more complex of communication cost. We analyzed that in the second model if we add processor would effect on communication cost. This condition did not occurred on the first model, so that the speedup and efficiency are better than the second model. The experimental result of query image extraction shows that the speedup on the first model is 6.73, with efficiency value of 0.84. The second model produces speedup value is 7.96, with efficiency value of 0.99. The different between speedup value and efficiency produced is affected by the dividing of data from those two parallel models. The first model divides 20 combination of the operator and FLBP threshold. The process of data dividing on first model enables unideal data partitioning. The ideal data dividing is at the time of each processors compute the data with the same volume. The unideal data dividing may cause an idle condition. The idle condition can affect the performance and the parallel time generated by the first model. The dividing of the data on second model by dividing the image area equal to the processors used. The data dividing on the second model is ideal condition, so that the speedup and efficiency are better than first model.
© Hak Cipta Milik IPB, Tahun 2013
Hak Cipta Dilindungi Undang-Undang
Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik, atau tinjauan suatu masalah; dan pengutipan tersebut tidak merugikan kepentingan IPB
KOMPUTASI PARALEL UNTUK SISTEM IDENTIFIKASI
TUMBUHAN OBAT MENGGUNAKAN FUZZY LOCAL
BINARY PATTERN
NGAKAN NYOMAN KUTHA KRISNAWIJAYA
Tesis
sebagai salah satu syarat untuk memperoleh gelar Magister Komputer
pada
Program Studi Ilmu Komputer
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
Judul Tesis : Komputasi Paralel untuk Sistem Identifikasi Tumbuhan Obat menggunakan Fuzzy Local Binary Pattern
Nama : Ngakan Nyoman Kutha Krisnawijaya NIM : G651110071
Disetujui oleh Komisi Pembimbing
Dr Yeni Herdiyeni, SSi MKom Dr Ir Bib Paruhum Silalahi, MKom
Ketua Anggota
Diketahui oleh
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr Yani Nurhadryani, SSi MT Dr Ir Dahrul Syah, MScAgr
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan September 2012 sampai Agustus 2013 adalah Komputasi Paralel Untuk Sistem Identifikasi Tumbuhan Obat Menggunakan Fuzzy Local Binary Pattern.
Dalam menyelesaikan karya ilmiah ini penulis mendapatkan banyak sekali bantuan, bimbingan dan dorongan dari berbagai pihak. Oleh karena itu, penulis ingin mengucapkan terima kasih kepada Ibu Dr Yeni Herdiyeni, SSi MKom dan Bapak Dr Ir Bib Paruhum Silalahi, MKom selaku pembimbing, serta Bapak Dr Eng Heru Sukoco, SSi MT selaku penguji dalam sidang tesis. Ungkapan terima kasih juga disampaikan kepada kedua orangtua, Bapak Ngakan Kutha Parthawijaya dan Ibu Ni Wayan Sariani atas doa, dukungan moral dan materi, kedua saudaraku tersayang, Ngakan Made Kutha Indrawijaya, SP dan Desak Rai Kutha Asriwijaya. Desak Nyoman Widyanthini atas perhatian, semangat dan dukungannya. Bapak Ir Ngakan Komang Kutha Ardhana, MSc dan keluarga atas nasihat, bantuan dan motivasinya. Penulis juga tidak lupa untuk mengucapkan terima kasih kepada semua teman seperjuangan Pasca Ilkom 13, atas kebersamaannya dalam perkuliahan, teman lima sekawan atas motivasi, diskusi, kritik selama kuliah dan penyelesaian penelitian ini, Yunda, Kak Ismi, Bang Ardiansyah, Rizky, Mega, Desta, Rahmat, Wahyuni, Mbak Gibtha dan semua teman LAB CI, atas diskusi, bantuan dan motivasinya serta pengelola pasca sarjana, seluruh dosen dan staf akademik Ilmu Komputer IPB atas bantuan dan bimbingannya selama penulis mengikuti perkuliahan di Ilmu Komputer IPB.
Penulis juga mengucapkan terima kasih kepada semua pihak yang telah membantu selama penyelesaian karya ilmiah ini yang tidak dapat disebutkan satu-persatu. Semoga karya ini dapat memberi manfaat.
Bogor, September 2013
DAFTAR ISI
Local Binary Pattern (LBP) 3
Fuzzy Local Binary Pattern (FLBP) 4
Probabilistic Neural Network (PNN) 6
High Performance Computing (HPC) 8
Perancangan Desain Komputasi Paralel 10
Evaluasi Kinerja Paralel 12
Komputasi Paralel pada Aplikasi Pengolahan Citra Digital 13
Message Passing Interface (MPI) 14
3 METODE 15
Data Penelitian 16
Preprocessing 16
Ekstraksi Fitur dengan Fuzzy Local Binary Pattern 16
Komputasi Paralel 16
Pembagian Data Latih dan Uji 21
Klasifikasi dengan Probabilistic Neural Network 22
Evaluasi 22
Perangkat Keras dan Perangkat Lunak 22
4 HASIL DAN PEMBAHASAN 23
Preprocessing Citra Daun Tumbuhan Obat 23
Ekstraksi Fitur dengan Fuzzy Local Binary Pattern 23
Komputasi Paralel 24
Evaluasi kinerja paralel model 1 29
Model 1 untuk citra kueri 31
Evaluasi kinerja paralel untuk citra kueri 32
Klasifikasi dan Evaluasi 33
Evaluasi kinerja paralel model 2 38
Model 2 untuk citra kueri 40
Evaluasi kinerja paralel untuk citra kueri 41
Perbandingan kinerja model 1 dan model 2 43
Perbandingan akurasi model 1 dan model 2 45
5 SIMPULAN DAN SARAN 47
2 Pembagian data citra setiap spesies untuk setiap prosesor 28 3 Hasil evaluasi percepatan dan efisiensi model 1 29
4 Hasil evaluasi isoefisiensi model 1 31
5 Hasil evaluasi percepatan dan efisiensi model 1 untuk citra kueri 32 6 Hasil evaluasi percepatan dan efisiensi model 2 38
7 Hasil evaluasi isoefisiensi model 2 40
8 Hasil evaluasi percepatan dan efisiensi model 1 untuk citra kueri 41
DAFTAR GAMBAR
9 Model perancangan paralel Flynn 10
10 Metode Foster 11
11 Message passing antar prosesor 14
12 Metode penelitian 15
13 Model 1 paralel pembagian data 18
14 Model 1 untuk citra kueri 19
15 Model 2 paralel pembagian data dan proses FLBP 20
16 Model 2 untuk citra kueri 21
17 Hasil preprocessing citra tumbuhan obat 23
18 Histogram FLBP pada tumbuhan obat 24
21 Percepatan model 1 29
22 Efisiensi model 1 30
23 Percepatan model 1 untuk citra kueri 32
24 Efisiensi model 1 untuk citra kueri 33
25 Perbandingan akurasi per kelas model 1 34
26 Contoh citra data latih dan data uji kelas 7 (Pegagan) 34 27 Contoh citra data latih dan data uji kelas 5 (Akar Kuning) 34
28 Proses pembagian area citra daun 35
29 Proses ekstraksi fitur FLBP pada area citra daun 35
30 Proses point-to-point communication 36
31 Topologi virtual GRID_COMM 37
32 Topologi virtual communicator coll_comm 37
33 Proses komunikasi pada communicator coll_comm 38
34 Percepatan model 2 39
35 Efisiensi model 2 40
36 Percepatan model 2 untuk citra kueri 41
37 Efisiensi model 2 untuk citra kueri 42
38 Perbandingan akurasi per kelas model 2 43
39 Contoh citra data latih dan data uji kelas 29 (Jambu Biji) 43
40 Perbandingan percepatan 44
41 Perbandingan efisiensi 44
42 Perbandingan akurasi model 1 dan model 2 45 43 Perbandingan akurasi model 1 dan model 2 (Lanjutan) 45
44 Citra teridentifkasi salah pada model 2 46
1
PENDAHULUAN
Latar Belakang
Indonesia memiliki keanekaragaman hayati lebih dari 38 000 spesies tumbuhan (Bappenas 2003). Groombridge dan Jenkins (2002) mencatat bahwa terdapat 22 500 spesies tumbuhan obat di Indonesia. Spesies tumbuhan yang sudah digunakan sebagai tumbuhan obat sejumlah 1 000 spesies. Ini berarti persentase tumbuhan obat yang sudah dimanfaatkan hanya sebesar 4.4% dari sumber daya yang tersedia. Salah satu penyebab kurangnya pemanfaatan tumbuhan obat adalah pengetahuan masyarakat tentang potensi tumbuhan obat masih minim. Peningkatan pengetahuan masyarakat tentang tumbuhan obat dapat dibantu dengan dikembangkannya sistem identifikasi tumbuhan obat.
Penelitian tentang sistem identifikasi tumbuhan obat berdasarkan hasil ekstraksi fitur citra tumbuhan obat telah banyak dilakukan. Proses identifikasi dilakukan menggunakan organ vegetatif yang paling mudah ditemukan seperti daun. Valerina (2012) menggunakan metode ekstraksi fitur Fuzzy Local Binary Pattern (FLBP) dan metode klasifikasi Probabilistic Neural Network (PNN) untuk mengidentifikasi tumbuhan obat. Akurasi yang diperoleh dari sistem sebesar 66.3%. Herdiyeni dan Wahyuni (2012) juga menggunakan metode ekstraksi fitur dan klasifikasi yang sama untuk identifikasi tumbuhan obat. Sistem identifikasi telah dikembangkan di dalam aplikasi mobile berbasis Android. Pengembangan sistem identifikasi berbasis mobile bertujuan untuk memudahkan user dalam mengidentifikasi tumbuhan obat. Laxmi (2012) menerapkan Multiobjective Genetic Algorithm (MOGA) dalam sistem identifikasi tumbuhan obat. MOGA diterapkan untuk optimasi metode FLBP pada saat proses ekstraksi citra daun tumbuhan obat yang memiliki keragaman tekstur yang cukup tinggi. Laxmi (2012) mencatat bahwa penerapan metode FLBP untuk ekstraksi fitur memiliki waktu komputasi yang paling lama di dalam sistem yang dibangun. Hal ini terjadi karena FLBP merupakan metode ekstraksi fitur yang menggunakan fuzzification untuk mendapatkan pola tekstur dari citra. Semakin besar rentang fuzzy yang digunakan akan semakin banyak piksel citra yang diolah di dalamnya dan semakin besar waktu komputasi yang dibutuhkan. Rentang fuzzy pada FLBP ditentukan melalui threshold yang digunakan pada saat ekstraksi fitur. Selain algoritme yang digunakan dalam ekstraksi menggunakan FLBP, jumlah data yang diolah juga mempengaruhi waktu komputasi untuk esktraksi fitur.
menganalisis waktu komputasi, Petryniak (2008) juga menganalisis waktu komunikasi paralel dari setiap model perancangan yang digunakan. Hasil dari penelitian ini adalah komputasi paralel dapat meningkatkan efisiensi pengolahan citra.
Permasalahan waktu komputasi yang terjadi saat proses ekstraksi fitur FLBP pada sistem identifikasi tumbuhan obat memberikan motivasi untuk menerapkan metode HPC pada sistem identifikasi tumbuhan obat. Penerapan metode HPC diharapkan mampu mengurangi waktu komputasi pada saat ekstraksi fitur sistem identifikasi tumbuhan obat. Metode klasifikasi yang digunakan adalah Probabilistic Neural Network (PNN). Percepatan, efisiensi dan isoefisiensi digunakan untuk mengukur seberapa baik model perancangan paralel yang diterapkan.
Tujuan Penelitian
Penelitian ini bertujuan menerapkan komputasi paralel pada proses ekstraksi fitur untuk identifikasi tumbuhan obat. Metode klasifikasi ekstraksi fitur yang digunakan adalah FLBP.
Ruang Lingkup Penelitian
Ruang Lingkup penelitian ini adalah:
1. Data yang digunakan adalah citra daun 30 spesies tumbuhan obat di Indonesia. 2. Operator LBP yang digunakan adalah operator LBP (8,1) dan (8,2). Threshold
FLBP menggunakan rentang dari 1 sampai dengan 10.
3. Desain perancangan paralel berdasarkan pembagian data dan pembagian area citra.
Manfaat Penelitian
2
TINJAUAN PUSTAKA
Fitur Tekstur
Fitur tekstur merupakan gambaran visualisasi dari sebuah objek. Tekstur dapat dicirikan sebagai variasi intensitas pencahayaan pada sebuah citra. Analisis tekstur memiliki peranan yang cukup penting dalam aplikasi pengolahan citra digital. Meskipun warna merupakan hal yang penting dalam mendeskripsikan citra akan tetapi informasi warna tidak cukup untuk mendeskripsikan suatu citra. Informasi yang terkandung pada tekstur adalah area, kekasaran, regularity, linearitas, dan frekuensi (Maenpaa 2003).
Local Binary Pattern (LBP)
Analisis tekstur digunakan di sebagian besar aplikasi seperti remote sensing, pengolahan citra pada biomedical, visual inspection dan identifikasi citra. Sejak awal 1970-an penelitian dan pengembangan metode ekstraksi fitur telah banyak diusulkan. Metode Local Binary Pattern (LBP) merupakan salah satu metode untuk merepresentasikan tekstur berdasarkan binary pattern (pola biner). Metode LBP cukup efektif di dalam menggambarkan pola tekstur lokal dari citra (Keramidas et al. 2011).
Menurut Iakovidis et al. (2008) proses Local Binary Pattern (LBP) merepresentasikan tekstur lokal disekitar tekstur pusat berdasarkan operator ketetanggaan LBP. Setiap pola tekstur LBP direpresentasikan oleh sembilan elemen = { , , , … , }, merupakan nilai piksel pusat dan
(0 ≤ ≤ 7) merupakan nilai piksel sekelilingnya (circular sampling). Nilai
circular sampling dapat dicirikan oleh nilai biner (0 ≤ ≤ 7) seperti pada Gambar 1(b) dengan Persamaan 1:
= 0 , ∆ < 0
1 , ∆ ≥ 0 (1)
(a) Gamb
Nilai biner yang dihasi untuk mendapatkan nilai LBP
!"#
Nilai-nilai LBP yang dihasi Histogram akan menunjukkan Menurut Ahonen dan Pie dengan menggunakan berbaga Pengamatan piksel ketetang merupakan sampling points da dengan operator LBP yang di sampling points yang digunak mendapatkan nilai LBP.
(8,1) Ga (A
Fuzzy L
Fuzzification pada prose variabel fuzzy berdasarkan pa Berdasarkan penelitian Iakovi fuzzy rule untuk menentukan Penentuan nilai fuzzy berdasar pi dan piksel pusat pcenter ( pi)
(b) (c)
bar 1 Skema komputasi LBP (Iakovidis et al. 2008)
asilkan kemudian akan dikonversi ke nilai des P menggunakan Persamaan 2 berikut:
!"#= $i= di . i , LBP% & '
asilkan akan direpresentasikan melalui histog an frekuensi kemunculan dari setiap nilai LBP.
Pietikainen (2008) operator LBP dapat dikembang agai ukuran sampling points dan radius (Gamba nggaan, akan digunakan notasi ( , () diman dan R merupakan radius. Nilai LBP dihasilkan se digunakan. Semakin kecil radius dan semakin b akan maka semakin banyak piksel yang diolah u
,1) (16,2) (8,2)
Gambar 2 Ukuran operator LBP (Ahonen dan Pietikainen 2008)
y Local Binary Pattern (FLBP)
oses LBP adalah transformasi variabel input men pada sekumpulan fuzzy rule (Iakovidis et al. 20 ovidis et al. (2008), penelitian ini menggunakan
an representasi nilai biner dan mencari nilai fu sarkan deskripsi selisih antara nilai circular samp
5
1 Rule R0: Semakin negatif nilai ∆ , maka nilai kepastian terbesar dari
adalah 0.
2 Rule R1: Semakin positif nilai ∆ , maka nilai kepastian terbesar dari
adalah 1.
Berdasarkan rules R0 dan R1 dua fungsi keanggotaan) ( ) dan ) ( )
dapat ditentukan (Gambar 3). Fungsi keanggotaan) ( ) mendefinisikan derajat adalah 0. Fungsi keanggotaan ) ( ) adalah fungsi menurun yang didefinisikan pada Persamaan 3:
) ( ) =
0 , ∆ ≥ *
+,∆-.
/.+ , – * < ∆ < *
1 , ∆ ≤ −*
(3)
fungsi keanggotaan ) ( ) mendefinisikan derajat adalah 1. Fungsi
) ( ) didefinisikan pada Persamaan 4:
) ( ) =
1 , ∆ ≥ *
+2∆-.
/.+ , – * < ∆ < *
0 , ∆ ≤ −*
(4)
Fungsi keanggotaan ) ( ) dan ) ( ), * % (0,255) merepresentasikan threshold FLBP (F) yang mengontrol derajat ketidakpastian. Semakin besar nilai threshold yang digunakan maka semakin banyak nilai piksel yang diolah di dalam rentang fuzzy. Penentuan nilai threshold berdasarkan dari tekstur citra yang diekstraksi. Citra yang memiliki tekstur homogen cukup menggunakan nilai threshold yang kecil, sedangkan citra yang memiliki tekstur heterogen menggunakan nilai threshold yang lebih besar. Penggunaan threshold yang besar mempengaruhi waktu komputasi pada saat proses ekstraksi fitur.
Gambar 3 Fungsi keanggotaan m0() dan m1() sebagai fungsi dari pi
Metode Fuzzy Local Binary Pattern menghasilkan satu atau lebih kode LBP, sedangkan metode LBP original hanya menghasilkan satu kode LBP saja. Nilai-nilai LBP yang dihasilkan FLBP memiliki tingkat kontribusi (56 , 57) yang berbeda, bergantung pada nilai-nilai fungsi keanggotaan ) () dan ) () yang dihasilkan. Untuk ketetanggaan 3x3, kontribusi CLBP dari setiap kode LBP pada
histogram FLBP didefinisikan pada Persamaan 5 (Iakovidis et al. 2008):
5:7;= < )> =( ) (5)
Total kontribusi ketetanggaan 3x3 ke dalam bin histogram FLBP dihitung dengan menggunakan Persamaan 6:
$/??:7;> 5:7;= 1 (6)
Kode LBP tersebut akan direpresentasikan dengan histogram yang dihitung dengan menjumlahkan kontribusi CLBPdari setiap nilai LBP seperti pada Gambar
4.
Gambar 4 Skema komputasi FLBP dengan F=10 (Iakovidis 2008)
Probabilistic Neural Network (PNN)
7
Gambar 5 Struktur PNN
Keunggulan yang dimiliki PNN adalah tingkat keakuratan yang cukup tinggi dan waktu pelatihan yang cukup singkat. Akurasi PNN dipengaruhi oleh nilai dari parameter penghalusan (@) dan pola pelatihan yang diberikan. Jika nilai
(@) tepat maka akurasi akan mendekati 100%. Struktur PNN terdiri atas empat lapisan yaitu lapisan masukan, pola, penjumlahan, dan keputusan.
1. Lapisan masukan(input layer)
Lapisan masukan merupakan input x yang terdiri atas k nilai ciri yang akan diklasifikasikan pada salah satu kelas dari n kelas.
2. Lapisan pola (pattern layer)
Pada lapisan pola dilakukan perkalian titik (dot product) antara input x dan vektor bobot xA, yaitu ZA = x xAi, ZA kemudian dibagi dengan penghalusan
(@) tertentu dan dimasukkan ke dalam fungsi Parzen, yaitu A(B) = exp(−B). Persamaan yang digunakan pada lapisan pola didefinisikan Persamaan 7:
A(B) = exp E−(F,FG.)H(F,FG.)
/IJ K (7) dengan xAisebagai vektor bobot atau vektor latih kelas ke-A urutan ke-i.
3. Lapisan penjumlahan (summation layer)
Pada lapisan penjumlahan, setiap pola pada masing-masing kelas dijumlahkan sehingga menghasilkan population density function untuk setiap kelas. Persamaan 8 digunakan pada lapisan ini.
(L6) (BML6) =
(/N)OJIOPG$ QB E−
(F,FG.)H(F,FG.) /IJ K PG
> (8)
dengan
(L6) = peluang kelas A
(BML6) = peluang bersyarat x jika masuk ke dalam kelas A
R6 = jumlah pola pelatihan kelas A
@ = bias atau penghalusan 4. Lapisan keputusan (output layer)
Pada lapisan keputusan, input x akan diklasifikasikan ke kelas A jika nilai pA(x) paling besar dibandingkan kelas lainnya.
High Performance Computing (HPC)
HPC merupakan metode yang digunakan untuk memecahkan permasalahan yang memiliki kompleksitas yang tinggi seperti algoritme yang rumit dan terkait beban pekerjaan dengan jumlah data yang besar. HPC mampu mengurangi waktu komputasi akibat kompleksitas yang tinggi sehingga pekerjaan sistem menjadi efisien dan informasi yang dihasilkan lebih cepat didapatkan. Komputasi paralel dan distributed computing merupakan teknik yang digunakan dalam metode HPC. HPC telah dikembangkan dan digunakan dalam bidang bioinformatika, pengolahan citra dan bidang ilmu lainnya (Nasir et al. 2012).
Model Perancangan HPC
Menurut Quinn (2004) model perancangan paralel terbagi menjadi tiga yaitu: 1. Shared memory merupakan model perancangan dengan satu komputer
memiliki banyak prosesor (multiprocessor). Dalam model perancangan ini dua atau lebih prosesor melakukan komputasi secara bersamaan dan mengakses memori yang sama. Gambar 6 menunjukkan skema shared memory.
Gambar 6 Shared memory (Quinn 2004)
9
Gambar 7 Distributed memory (Quinn 2004)
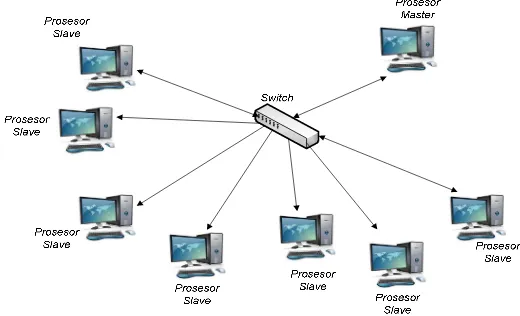
Menurut Prajapati dan Vij (2011) terdapat dua skema utama di dalam distributed memory yaitu:
a. Master-slave. Dalam skema ini, terdapat satu komputer sebagai unit pengontrol yaitu komputer master. Tugas dari komputer master adalah mendistribusikan data atau pekerjaan ke komputer slave. Komputer slave bekerja secara paralel untuk menyelesaikan pekerjaan yang diberikan kemudian hasilnya akan dikumpulkan kembali ke komputer master.
b. Peer-to-peer. Dalam skema ini tidak ada komputer master sebagai unit pengontrol seperti pada skema master-slave. Seluruh prosesor memiliki kapabilitas yang sama dan saling terkoneksi untuk bekerja secara paralel. 3. Hybrid system merupakan penggabungan dari distributed memory dan shared
memory. Dewasa ini model perancangan ini lebih dikembangkan untuk menghasilkan sistem yang lebih besar dan lebih cepat. Gambar 8 menunjukkan model perancangan hybrid system.
Gambar 8 Hybrid system (Quinn 2004)
Gambar 9 Model perancangan paralel Flynn (Quinn 2004)
Perancangan Desain Komputasi Paralel
Komputasi paralel adalah penggunaan sejumlah prosesor yang saling bekerjasama untuk mencari suatu solusi tunggal dari suatu permasalahan. Tujuan pemrosesan paralel adalah untuk mempercepat waktu eksekusi dan mendistribusikan pencarian solusi dari permasalahan yang sangat kompleks (Quinn 2004).
Metode Foster
Menurut Quinn (2004), Ian Foster pada tahun 1995 menemukan suatu metode desain sistem paralel. Metode perancangan desain dimulai dari pembagian data/komputasi ke dalam beberapa bagian, menentukan komunikasi antar bagian tersebut. Jika komunikasi antar bagian terlalu besar maka dikelompokkan bagian yang memiliki komunikasi intensif dengan bagian lain. Langkah terakhir adalah memetakan kelompok tersebut pada sejumlah prosesor yang ada.Menurut Foster, langkah-langkah untuk mendesain algoritme paralel (Gambar 10) adalah sebagai berikut:
a. Partisi (partitioning)
Langkah pertama dalam merancang suatu proses paralelisme adalah memilah dan mencari bagian-bagian yang mungkin dikerjakan secara paralel (primitive task). Bagian yang mungkin dikerjakan pada proses paralel adalah bagian yang independent atau tidak saling terkait satu dengan lainnya. Partitioning adalah pembagian instruksi kerja (komputasi) dan data ke dalam beberapa bagian. Partitioning yang baik mampu membagi data dan komputasi ke dalam bagian yang sangat kecil.
11
proses partitioning adalah mengidentifikasi sebanyak mungkin primitive task, karena primitive task adalah modal dasar dalam melakukan proses paralelisme.
b. Komunikasi (communication)
Setelah mendapatkan primitive task dari masalah yang diselesaikan dengan komputasi paralel, selanjutnya menentukan komunikasi antar task. Ada dua jenis komunikasi yang digunakan yaitu global dan local. Local communication adalah jika suatu task membutuhkan suatu nilai dari task lainnya, maka akan dibuat channel dari task penghasil data ke task yang memerlukan data. Global communication digunakan ketika sejumlah besar primitive task harus menghasilkan data untuk menunjang suatu proses komputasi. Contoh dari komunikasi global adalah kalkulasi penjumlahan nilai yang dilakukan oleh suatu proses primitive.
c. Aglomerasi (agglomeration)
Aglomerasi adalah proses pengelompokan task ke dalam task yang lebih besar guna meningkatkan kinerja maupun menyederhanakan pemrograman. Jumlah task yang berhubungan kadang-kadang lebih besar daripada jumlah prosesor yang digunakan. Tujuan utama dari aglomerasi adalah mengurangi overhead pada komunikasi.
d. Pemetaan (mapping)
Pemetaan adalah proses penandaan task ke prosesor. Tujuan dari pemetaan adalah memaksimalkan kemampuan prosesor dan meminimalkan komunikasi antar prosesor. Kemampuan prosesor adalah persentase rata-rata waktu prosesor dalam mengeksekusi suatu task untuk menyelesaikan suatu masalah dan memberi suatu solusi penyelesaian. Kemampuan prosesor maksimal jika komputasi berjalan seimbang sehingga memungkinkan semua prosesor memulai dan mengakhiri proses eksekusi pada waktu yang sama. Di sisi lain, kemampuan prosesor minimal jika satu atau lebih prosesor mengalami idle.
Evaluasi Kinerja Paralel
Hukum Amdahl
Menurut Amdahl (1967) dalam Quinn (2004), peningkatan pemrosesan paralel tidak hanya bergantung pada banyaknya prosesor yang digunakan, tetapi lebih dipengaruhi oleh fraksi rasio antara instruksi sekuensial dengan keseluruhan instruksi pada suatu program seperti pada Persamaan 9:
S = TU
Percepatan juga dapat dihitung apabila hanya diketahui waktu pemrosesan instruksi paralel dan waktu pemrosesan instruksi sekuensial saja. Percepatan didefinisikan seperti pada Persamaan 10:
S = TY2TZ
TY2 HZV (10)
dengan
S : nilai percepatan
W; : waktu yang dibutuhkan sebuah prosesor untuk mengeksekusi perintah paralel
W[ : waktu yang dibutuhkan sebuah prosesor untuk mengeksekusi perintah sekuensial
: banyaknya prosesor Efisiensi (Efficiency)
Efisiensi adalah rasio antara waktu sekuensial dengan waktu paralel, yang didefinisikan seperti pada Persamaan 11:
\ = TY
- × TV (11) dengan
\ : nilai efisiensi
W; : waktu yang dibutuhkan sebuah prosesor untuk mengeksekusi perintah paralel
W[ : waktu yang dibutuhkan sebuah prosesor untuk mengeksekusi perintah sekuensial
: banyaknya prosesor
13
Hukum Gustafson-Barsis
Menurut Quinn (2004) selain Hukum Amdhal, kinerja paralel diukur juga dengan menghitung skalabilitas (isoefficiency) menggunakan Hukum Gustafson-Barsis (1988). Pengukuran skalabilitas ini dengan menambahkan sejumlah data (N) dan prosesor (p) untuk menjaga nilai effisiensi dari program paralel. Isoeffisiency didefinisikan pada Persamaan 12:
^_`Q a Qbac (d) = (\ 1 − \e ) Wf
Ti : waktu yang dibutuhkan sebuah prosesor untuk mengeksekusi perintah paralel
Tj : waktu yang dibutuhkan sebuah prosesor untuk mengeksekusi perintah sekuensial
Tk : selisih proses paralel dengan sekuensial
Komputasi Paralel pada Aplikasi Pengolahan Citra Digital
Model perancangan paralel yang ada yaitu shared memory, distributed memory dan hybrid system. Ketiga model perancangan tersebut memiliki kekurangan dan kelebihan tersendiri sehingga pemilihan model perancangan tergantung pada kebutuhan aplikasi yang dibangun. Penerapan paralel pada aplikasi pengolahan citra digital dapat dilakukan dengan tiga cara (Prajapati dan Vij 2011) yaitu:
1. Data paralel
Data paralel adalah beberapa prosesor melakukan pekerjaan yang sama dengan data yang berbeda-beda (Quinn 2004). Proses paralel pada pengolahan citra digital dapat dilakukan dengan membagi proses pengolahan citra ke setiap prosesor. Pembagian yang ideal adalah setiap prosesor mendapatkan jumlah data yang sama. Pembagian data dapat dilakukan dengan salah satu dari tiga cara yaitu (1) paralel piksel, (2) baris atau kolom paralel dan (3) blok paralel yaitu citra dibagi per blok untuk diolah secara paralel (Prajapati dan Vij 2011).
2. Task paralel
3. Pipeline
Pipeline adalah skema paralel yang dilakukan pada setiap tahapan dari algoritme pengolahan citra digital. Beberapa algoritme pengolahan citra digital memiliki tahapan-tahapan yang dapat diparalelkan. Tahapan tersebut adalah praproses, ekstraksi fitur, klasifikasi dan lain sebagainya. Tahapan inilah yang di proses secara paralel. Satu prosesor menangani satu tahapan dan prosesor lain menerima hasil tahapan dari prosesor sebelumnya sesuai dengan tahapan pada algoritme pengolahan citra digital.
Message Passing Interface (MPI)
MPI merupakan protokol untuk program paralel yang dikembangkan dalam skema distributed memory (Prajapati dan Vij 2011). MPI mengijinkan pertukaran data (message) antara prosesor yang terlibat (Gambar 11). Library MPI dapat berjalan di dalam bahasa pemrograman C, C++ dan Fortran.
Prosesor dapat berkomunikasi satu dengan lainnya melalui fungsi komunikasi yang ada di MPI. MPI menyediakan sebuah grup proses (communicator) untuk tempat berkomunikasi prosesor yang tergabung di dalam model perancangan paralel. Informasi mengenai communicator ini disimpan di dalam variabel dengan tipe MPI_Comm. Communicator standar dari MPI yaitu MPI_Comm_World. Tipe komunikasi pada MPI yaitu point-to-point communication dan collective communication. Point-to-point communication adalah komunikasi yang melibatkan sepasang prosesor untuk saling bertukar data. Library MPI menyediakan MPI_Send dan MPI_Recv untuk melakukan point-to-point communication. Collective communication pada MPI melibatkan komunikasi antara semua prosesor yang terlibat di dalam communicator. Collective communication memiliki keuntungan dibandingkan point-to-point communication yaitu kompleksitas komunikasi yang lebih sederhana (Grama et al. 2003).
3
METODE
Penelitian ini membangun sistem identifikasi spesies tumbuhan obat menggunakan metode ekstraksi fitur FLBP dan HPC. Terdapat dua perancangan paralel yang dilakukan yaitu paralel pembagian data (model 1) dan paralel proses FLBP (model 2). Citra yang akan diidentifikasi dikirimkan ke server untuk diolah. Pengolahan di server yaitu preprocessing dan juga ekstraksi fitur citra menggunakan metode FLBP. Proses ekstraksi FLBP ini dilakukan dengan paralel untuk mendapatkan hasil ekstraksi lebih cepat. Output dari server adalah informasi spesies tumbuhan obat citra input. Penerapan komputasi paralel dengan metode HPC diharapkan mampu mempercepat informasi output dari sistem yang dibangun. Tahapan seluruh proses identifikasi tumbuhan obat diilustrasikan pada Gambar 12.
•
• •
• •
•
•
•
• •
•
•
• • •
• •
•
Data Penelitian
Pengambilan data 30 spesies tumbuhan obat dilakukan di rumah kaca Pusat Konservasi Ex-Situ Tumbuhan Obat Hutan Tropika Indonesia, Fakultas Kehutanan, IPB dan kebun Biofarmaka IPB. Pemotretan dilakukan dengan menggunakan lima kamera digital yang berbeda (7210 Supernova, DSC-W55, Samsung PL100, EX-Z35 dan Canon Digital Axus 95 IS). Total citra adalah sebanyak 1 440 citra yang terdiri atas 30 spesies dengan masing-masing spesies terdiri atas 48 citra yang disajikan pada Lampiran 1.
Preprocessing
Preprocessing merupakan tahap awal dari proses identifikasi tumbuhan obat. Proses yang dilakukan pada tahap ini adalah mengganti latar belakang citra daun dengan warna putih. Ukuran citra diperkecil menjadi 270 B 240 piksel. Mode warna citra diubah menjadi grayscale sebagai input untuk proses ekstraksi fitur.
Ekstraksi Fitur dengan Fuzzy Local Binary Pattern
Ekstraksi fitur menggunakan metode FLBPP,R. FLBP merupakan metode untuk merepresentasikan pola tekstur dari suatu citra. Langkah pertama untuk mendapatkan informasi tekstur dari suatu citra adalah dengan menentukan operator LBP dan juga threshold FLBP. Setelah penentuan operator dan threshold, citra akan dibagi ke dalam beberapa blok (local region) sesuai dengan operator circular neighborhood (P, R), yaitu sampling point (P) dan radius (R) yang digunakan. Selanjutnya adalah proses scanning citra (convolution) menggunakan local region untuk mendapatkan nilai LBP dari setiap local region. Nilai LBP akan direpresentasikan melalui histogram FLBP. Histogram tersebut menggambarkan frekuensi dari kontribusi nilai LBP yang muncul pada sebuah citra. Penelitian ini menggunakan operator (8,1) dan (8,2) yang disajikan pada Tabel 1 dan rentang threshold dari 1 sampai dengan 10 sehingga proses ekstraksi menggunakan 20 kombinasi operator dan threshold.
Tabel 1 Operator LBP (Valerina 2012)
( , () Ukuran Blok (piksel) Kuantisasi sudut
(8,1) (3B3) 45o
(8,2) (5B5) 45o
Komputasi Paralel
17
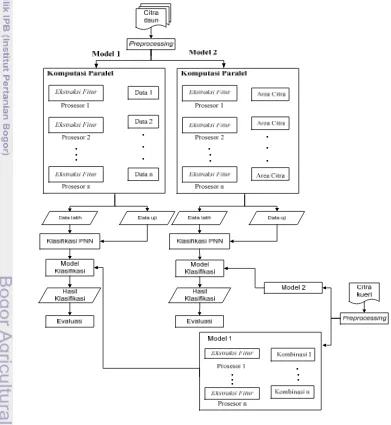
waktu) akan dilakukan secara bersamaan dengan beberapa prosesor. Desain komputasi paralel dilakukan dengan mengikuti langkah-langkah dari metode Foster (1995) dalam Quinn (2004). Langkah-langkah tersebut adalah partisi, komunikasi, aglomerasi dan mapping. Penelitian ini menggunakan desain model perancangan seperti pada Gambar 13, 14, 15 dan 16. Desain model perancangan dirancang dengan menggunakan model perancangan distributed memory.
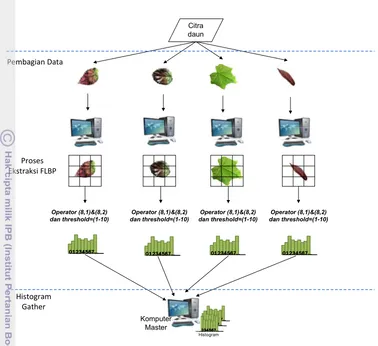
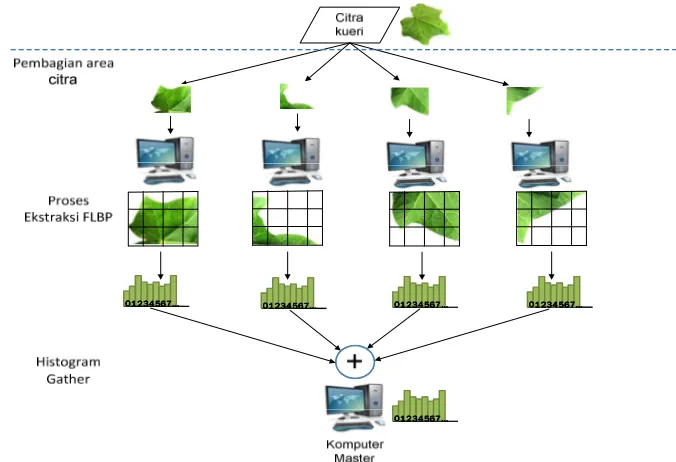
Model 1 yaitu paralel pembagian data (Gambar 13). Arsitekur ini menggunakan teknik data paralelisasi. Data citra daun tumbuhan obat dibagi dan didistribusikan oleh prosesor master ke setiap prosesor slave. Proses ekstraksi fitur daun citra tumbuhan obat dilakukan pada setiap prosesor slave. Hasil ekstraksi yaitu histogram ciri dari setiap citra dikumpulkan dari prosesor slave ke prosesor master. Model 1 didesain juga untuk ekstraksi citra kueri (Gambar 14). Data yang dibagi adalah kombinasi operator LBP dan threshold FLBP. Masing-masing prosesor slave mendapatkan kombinasi yang berbeda. Citra kueri diekstraksi pada setiap prosesor slave menggunakan kombinasi operator LBP dan threshold FLBP yang berbeda.
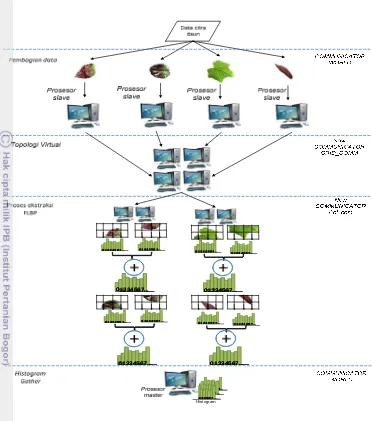
Model 2 yaitu paralel dengan membagi data citra daun tumbuhan obat dan paralel proses FLBP (Gambar 15). Model 2 menggunakan teknik data paralelisasi dan task paralelisasi. Model perancangan ini didesain selain memparalelkan data citra daun, juga memparalelkan proses FLBP pada saat ekstraksi dengan cara membagi area citra daun. Area citra daun dibagi oleh prosesor master dan didistribusikan ke setiap prosesor slave. Prosesor slave mengekstraksi area citra daun dan hasil ekstraksi dikumpulkan ke prosesor master. Prosesor master menjumlahkan hasil ekstraksi setiap area citra untuk menjadi histogram ciri dari daun tumbuhan tersebut. Desain model 2 untuk citra kueri (Gambar 16) dengan membagi area citra sebanyak jumlah prosesor yang digunakan.
a. Model 1
Histogram
Gambar 13 Model 1 paralel pembagian data
Langkah kedua adalah menentukan komunikasi dalam desain paralel. Komunikasi terjadi pada saat proses pembagian data citra daun dari prosesor master ke sejumlah prosesor slave. Komunikasi juga terjadi pada saat pengumpulan histogram hasil ekstraksi fitur menggunakan FLBP dari prosesor slave ke prosesor master. Komunikasi yang terjadi adalah collective communication. Collective communication merupakan komunikasi yang terjadi antara prosesor master dengan semua prosesor slave yang ada. Desain model 1 tidak membutuhkan proses aglomerasi dan mapping karena hanya sedikit proses komunikasi yang terjadi.
19
Histogram
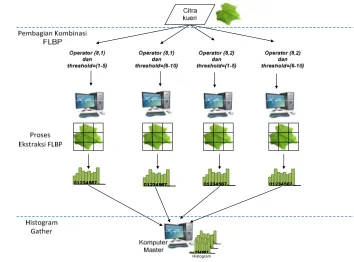
Gambar 14 Model 1 untuk citra kueri
Desain paralel untuk ekstraksi fitur citra kueri pada model 1 berbeda dengan ekstraksi fitur seluruh data citra daun. Proses partisi pada paralel ekstraksi fitur citra kueri dibuat dengan cara membagi kombinasi operator LBP dan threshold FLBP. Penelitian ini menggunakan 20 kombinasi operator LBP dan threshold FLBP untuk ekstraksi seluruh citra daun dan citra kueri. Proses ekstaksi satu kombinasi dengan kombinasi lainnya merupakan proses yang independent. Kombinasi-kombinasi operator LBP dan threshold FLBP ini yang akan dibagi dan didistribusikan ke prosesor slave. Masing-masing prosesor slave akan mengekstraksi citra kueri menggunakan kombinasi yang berbeda. Proses komunikasi sama seperti desain model perancangan paralel untuk ekstraksi seluruh citra daun.
b. Model 2
Histogram
Gambar 15 Model 2 paralel pembagian data dan proses FLBP
21
Selain ekstraksi fitur seluruh data citra daun, desain paralel model 2 juga dibuat untuk ekstraksi fitur citra kueri. Perancangan desain paralel citra kueri pada model 2 (Gambar 16) dengan cara membagi area citra kueri ke sejumlah p prosesor. Setiap prosesor akan mengekstraksi area citra kueri dengan 20 kombinasi operator dan threshold.
Gambar 16 Model 2 untuk citra kueri
Desain paralel untuk ekstraksi fitur citra kueri pada model 2 dirancang dengan membagi area citra dan mendistribusikannya ke sejumlah prosesor. Area citra diekstraksi secara paralel dengan sejumlah p prosesor. Hasil histogram masing-masing area akan dikumpulkan di prosesor master. Prosesor master akan menjumlahkan tiap-tiap histogram untuk mendapatkan histogram FLBP dari citra kueri. Proses komunikasi menggunakan point-to-point communication. Proses point-to-point communication adalah proses komunikasi antara prosesor master dengan satu prosesor slave (point-to-point). Perancangan komunikasi ini bertujuan untuk membagi area citra. Setiap prosesor slave mendapatkan area citra kueri yang berbeda sehingga pembagiannya menggunakan komunikasi point-to-point communication.
Pembagian Data Latih dan Uji
data latih dan uji dengan komposisi masing-masing 80% dan 20%. Data latih untuk setiap kelas berjumlah 38 citra, sedangkan data uji setiap kelas berjumlah 10 citra.
Klasifikasi dengan Probabilistic Neural Network
Klasifikasi dilakukan menggunakan vektor histogram hasil ekstraksi menggunakan operator LBP dan threshold FLBP. Klasifikasi spesies tumbuhan obat dilakukan dengan PNN. Model perancangan PNN terdiri atas lapisan masukan, pola, penjumlahan dan keputusan. Lapisan masukan berupa vektor-vektor histogram hasil ekstraksi tumbuhan obat. Lapisan pola memiliki satu model PNN dengan menggunakan nilai bias (@) tetap. Nilai bias ditentukan dengan cara melakukan percobaan untuk menghaluskan fungsi kernel PNN. Lapisan pola juga menghitung jarak vektor data latih ke vektor data uji dan menghasilkan nilai kedekatan vektor data uji ke vektor data latih. Nilai kedekatan ini akan dijumlahkan dengan nilai kedekatan hasil perhitungan dari lapisan pola lainnya yang masih berada dalam satu kelas. Hasil penjumlahan berupa nilai probabilitas. Lapisan keputusan mengambil nilai probabilitas maksimum dari seluruh kelas. Nilai maksimum merupakan hasil klasifikasi dari data input.
Evaluasi
Pengujian data dilakukan untuk menilai tingkat keberhasilan klasifikasi citra kueri oleh sistem. Evaluasi dari kinerja model klasifikasi didasarkan pada banyaknya data uji yang diprediksi secara benar oleh model. Hasil perhitungan klasifikasi data uji ditampilkan dalam tabel confussion matrix. Tabel confussion matrix diproses untuk mendapatkan nilai akurasi. Nilai akurasi merupakan nilai perbandingan antara jumlah data yang berhasil dikenali oleh classifier dengan jumlah total data pengujian. Hal ini dapat dihitung menggunakan akurasi yang didefinisikan pada Persamaan 13.
opqrs_ =7t utv ut - = vX ut w x t
Tf ty xt utv ut =t t × 100% (13) Selain evaluasi akurasi, evaluasi juga dilakukan dengan menguji sistem paralel yang diterapkan. Pengujian menggunakan Persamaan 9, 10, 11 dan 12.
Perangkat Keras dan Perangkat Lunak
4
histogram FLBPP,R berga yaitu 2P. Pada penelitian bin pada histogram FLBP FLBP seperti pada GambHASIL DAN PEMBAHASAN
gan paralel didesain dengan dua pendekatan yan gi dan mendistribusikan data citra sedangkan pada kan dengan membagi data citra dan juga para
processing Citra Daun Tumbuhan Obat
dilakukan dengan tujuan mempercepat waktu p ssing data citra tumbuhan obat dilakukan den
citra menjadi 270B240 dan mengubah mode w sil dari preprocessing seperti pada Gambar 17.
17 Hasil preprocessing citra tumbuhan obat (Laxmi 2012)
ksi Fitur dengan Fuzzy Local Binary Pattern
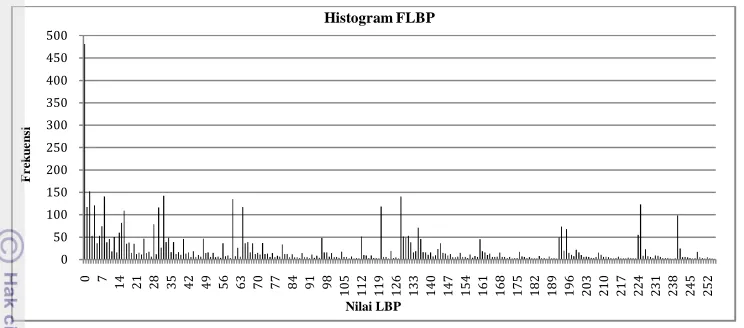
hasil preprocessing digunakan sebagai input pa raksi dilakukan menggunakan operator pada Tab an mengekstraksi citra menggunakan nilai yang berbeda. Nilai threshold FLBP yang diguna 0. Nilai threshold FLBP menentukan nilai biner pat sejumlah ) nilai ∆ yang berada dalam ren kan nilai biner sebanyak 2{. Semakin besar nilai akin besar rentang nilai fuzzy pada saat pemba ng fuzzy ini berbanding lurus dengan nilai biner komputasi pada saat ekstraksi fitur menggunakan F
menghasilkan histogram frekuensi nilai LBP. an CLBP dari nilai LBP. Panjang bin yang dihasi
Gambar 18 Histogram FLBP pada tumbuhan obat
Komputasi Paralel
Analisis performance metrics
Analisis performance metric meliputi analisis algoritme sekuensial dan algoritme paralel proses ekstraksi fitur menggunakan metode FLBP. Analisis ini untuk mendapatkan persamaan-persamaan matematis dalam mengukur kinerja dari proses ekstraksi fitur menggunakan metode FLBP.
Analisis sekuensial
Analisis kinerja algoritme ekstraksi fitur metode FLBP pada sistem identifikasi tumbuhan obat secara sekuensial diukur pada persamaan kompleksitas. Waktu eksekusi dipengaruhi oleh ukuran data yaitu jumlah spesies dan jumlah citra, teknik ekstraksi metode FLBP yaitu jumlah operator LBP dan jumlah threshold FLBP serta ukuran citra. Sehingga apabila jumlah spesies sebanyak spesies, jumlah citra setiap spesies adalah | citra, jumlah operator sebanyak k, rentang threshold } dan ukuran citra adalah ) B b maka kompleksitasnya adalah sebagai berikut.
WX = ~ ( × | × p × }) + () × b) % ~ ( × | × p × })
dengan WX adalah waktu sekuensial pemrosesan ekstraksi fitur menggunakan metode FLBP.
Analisis paralel
25
Model 1
Model 1 membagi data input ke setiap prosesor. Proses ekstraksi fitur dilakukan di setiap prosesor dengan data input yang berbeda. Satu proses (prosesor master) bertugas membagi data, melakukan komputasi lokal dan mengumpulkan hasil komputasi dari proses lainnya, sedangkan proses lainnya bertugas melakukan komputasi lokal sesuai dengan data citra dan metode ekstraksi yang harus dikerjakan. Hasil komputasi lokal setiap proses dikumpulkan ke proses master. Waktu yang diperlukan sebanyak p prosesor untuk menyelesaikan masalah yang sama, maka kompleksitas untuk waktu eksekusi paralel dirumuskan sebagai berikut:
W- = ~ × €(| × p × })• + 2(}`A/ )
dengan W- merupakan waktu paralel dan 2(}`A/ ) adalah waktu komunikasi yang dibutuhkan untuk membagi data input dan mengumpulkan hasil ekstraksi. Nilai percepatan model 1 dihitung dengan menggunakan Persamaan 9 seperti berikut:
S = WWX
-=
( × | × p × }) × E(‚×v×y)- K + 2(}`A/ )
Selain nilai percepatan, dapat juga menghitung efisiensi dari model 1 dengan menggunakan Persamaan 11 seperti berikut:
5 = W- = ( × | × p × }) + 2 (}`A/ )
\ = W5 = X ( × | × p × }) + 2 (}`A( × | × p × })
/ )
dengan 5 merupakan biaya paralel yang dikeluarkan oleh model 1. Untuk mempertahankan efisiensi yang konstan, W ukuran masalah harus proporsional terhadap W`(d, ), atau Persamaan 12 harus terpenuhi.
d = ƒWf(d, )
Total overhead Wf adalah sebagai berikut:
W-− WX= 2 (}`A/ )
Model 2
Parelisasi pada model 2 diterapkan pada saat proses pembagian data input ke setiap prosesor dan juga pada saat ekstraksi citra daun (proses FLBP). Citra daun akan dibagi areanya sebanyak jumlah prosesor dan area tersebut diekstraksi. Hasil ekstraksi setiap area dikumpulkan ke prosesor master. Waktu yang diperlukan sebanyak p prosesor untuk menyelesaikan masalah yang sama, maka kompleksitas untuk waktu eksekusi paralel dirumuskan sebagai berikut:
W- = ~ × €(| × p × })• + 2(}`A/ ) +
dengan W- merupakan waktu paralel, 2(}`A/ ) proses komunikasi pada saat pembagian data citra dan merupakan proses komunikasi pembagian area citra. Nilai percepatan model 2 dapat dirumuskan dengan Persamaan 9 sebagai berikut:
S = WWX
- =
( × | × p × }) × E(‚×v×y)- K + 2(}`A/ ) +
Nilai efisiensi dapat dirumuskan menggunakan Persamaan 11 dengan biaya paralel (5) dihitung terlebih dahulu. Persamaan nilai efisiensi dari model 2 adalah sebagai berikut:
5 = W- = ( × | × p × }) + 2 (}`A/ ) + /
\ = W5 = X ( × | × p × }) + 2 (}`A( × | × p × })
/ ) + /
Untuk mempertahankan efisiensi yang konstan, W ukuran masalah harus proporsional terhadap W`(d, ), atau Persamaan 12 harus terpenuhi. Total overhead Wf adalah sebagai berikut:
W-− WX = 2 (}`A/ ) + /
Artinya jika jumlah proses bertambah dari p menjadi p′, ukuran input citra daun tumbuhan obat harus bertambah sebesar 2 ′(}`A/ ′) + ′/ kali lipat, misal jumlah proses bertambah dari empat menjadi enam, maka ukuran input harus bertambah sebesar 72/32 = 2.25 kali lipat.
Analisis hasil percobaan
27
sebanyak 1 440 citra sehingga menghasilkan sebanyak 28 800 vektor histogram FLBP.
Proses ekstraksi 1 440 data citra latih yang dilakukan secara sekuensial (menggunakan satu komputer) memerlukan waktu selama 29 131 detik atau delapan jam. Penelitian ini mencoba mengurangi waktu komputasi tersebut. Kedua model perancangan dijalankan dalam sebuah komputer cluster. Komputer cluster (Gambar 19) terdiri atas sejumlah komputer yang terkoneksi dalam Local Area Network (LAN) yang saling bekerja secara paralel. Komputer cluster pada penelitian ini menggunakan 8 unit komputer (prosesor) yang dihubungkan melalui kabel LAN 100Mbps.
Gambar 19 Komputer cluster menggunakan 8 unit komputer
Delapan unit komputer yang digunakan pada komputer cluster memiliki spesifikasi yang sama yaitu, ProcessorIntel Core i3-2100 CPU 3.10 Ghz, memori RAM 4 GB dan harddisk 500 GB. Pada penelitian ini salah satu komputer cluster dijadikan prosesor master. Prosesor master memberikan perintah kepada prosesor slave untuk dikerjakan secara paralel. Prosesor master dan slave terhubung melalui kabel LAN dan satu unit switch. Komunikasi dalam topologi LAN hanya terjadi pada prosesor yang tergabung didalamnya tanpa ada komunikasi dari topologi jaringan lain. Oleh karena itu, nilai latency yang dihasilkan sangat baik yaitu 0.113 miliseconds. Semakin kecil nilai latency dari suatu model perancangan cluster, maka semakin baik performa dari model perancangan tersebut. Pencatatan waktu ekstraksi fitur citra daun tumbuhan obat secara paralel dilakukan oleh prosesor master. Pengerjaan paralel pada sistem identifikasi tumbuhan obat hanya pada saat ekstraksi fitur citra daun. Setelah prosesor master menerima hasil ekstraksi fitur dari prosesor slave, prosesor master akan memroses hasil ekstraksi fitur tersebut untuk mendapatkan model PNN. Proses klasifikasi menggunakan PNN dikerjakan di dalam satu komputer yaitu komputer master.
Model 1
Partisi
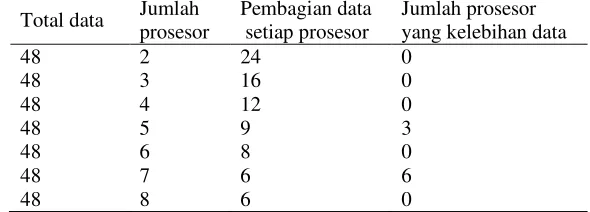
Partisi dapat dilakukan dengan membagi citra ke beberapa prosesor kemudian dilakukan ekstraksi fitur di masing-masing prosesor. Tabel 2 menunjukkan proses pembagian data untuk setiap prosesor. Pembagian data citra dilakukan pada setiap spesies yang akan diekstraksi. Partisi yang ideal adalah saat setiap prosesor mendapatkan jumlah data yang sama.
Tabel 2 Pembagian data citra setiap spesies untuk setiap prosesor
Total data Jumlah prosesor
Pembagian data setiap prosesor
Jumlah prosesor yang kelebihan data
48 2 24 0
48 3 16 0
48 4 12 0
48 5 9 3
48 6 8 0
48 7 6 6
48 8 6 0
Tabel 2 menunjukkan bahwa terdapat kondisi tidak ideal di dalam pembagian data citra ke setiap prosesor. Penggunaan 5 buah prosesor terjadi kondisi tidak ideal tersebut. Terdapat 3 buah prosesor yang mengolah data lebih banyak. 3 buah prosesor masing-masing mengolah 10 data citra dan 2 prosesor lainnya mengolah sebanyak 9 data citra untuk setiap spesiesnya.
Kondisi tidak ideal juga terjadi pada penggunaan 7 buah prosesor. Kondisi ini terjadi karena terdapat 6 buah prosesor mengolah 7 data citra sedangkan 1 buah prosesor hanya mengolah 6 data citra. Hanya satu prosesor yang mengolah sebanyak 6 data citra setiap spesiesnya.
Komunikasi
Komunikasi yang digunakan pada model 1 adalah MPI_Scatterv (Gambar 20). MPI_Scatterv merupakan komunikasi yang disediakan oleh Library MPI untuk mendistribusikan jumlah data yang berbeda untuk setiap prosesor. Model 1 terdapat beberapa prosesor yang mengolah data tidak dalam jumlah yang sama.
Gambar 20 Proses komunikasi menggunakan MPI_Scatterv dan MPI_Gatherv
29
citra daun tumbuhan obat. Proses pengumpulan histogram terjadi dari prosesor slave ke prosesor master. Proses komunikasi yang terjadi pada model 1 cukup sederhana sehingga tidak menggunakan tahapan proses aglomerasi dan mapping. Hasil pengumpulan histogram FLBP selanjutnya menjadi input untuk proses PNN.
Evaluasi kinerja paralel model 1
Hasil evaluasi percepatan dan efisiensi seperti ditunjukkan pada Tabel 3. Penerapan proses paralel mampu meningkatkan percepatan pemrosesan ekstraksi fitur citra menggunakan FLBP. Peningkatan ini didapatkan dari perbandingan waktu paralel dengan waktu sekuensial.
Tabel 3 Hasil evaluasi percepatan dan efisiensi model 1
Jumlah processor( ) Waktu paralel …W-†
(detik) Percepatan(S) Efisiensi (\)
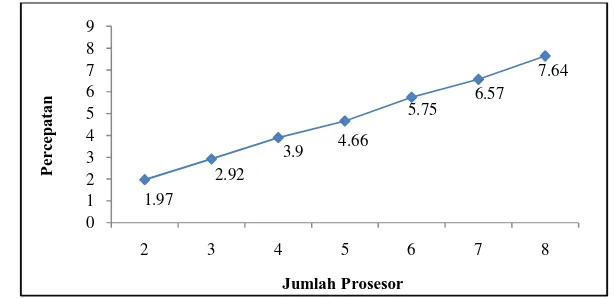
2 14 742 1.97 0.97
Pengukuran kinerja model perancangan paralel yang pertama adalah percepatan. Percepatan merupakan hasil perbandingan antara waktu sekuensial dengan waktu paralel. Waktu sekuensial merupakan waktu proses ekstraksi fitur citra daun tumbuhan obat menggunakan satu prosesor sedangkan waktu paralel merupakan waktu ekstraksi fitur citra daun tumbuhan obat menggunakan multi-processor. Hasil evaluasi percepatan menggunakan beberapa prosesor (Gambar 21) menunjukkan peningkatan percepatan kinerja pada saat ekstraksi fitur.
Gambar 21 Percepatan model 1
Berdasarkan grafik pada Gambar 21, penggunaan multi-processor untuk melakukan ekstraksi fitur citra daun tumbuhan dapat mengurangi waktu komputasi. Percobaan dilakukan dengan menggunakan 2 prosesor untuk ekstraksi fitur memerlukan waktu selama 14 742 detik dengan percepatan mencapai 1.97 kali lebih cepat dari waktu sekuensial. Percobaan dilakukan sampai dengan menggunakan 8 prosesor memerlukan waktu selama 3 812 detik dengan percepatan mencapai 7.64 kali lebih cepat dari waktu sekuensial.
Menurut Grama et al. (2003) percepatan yang ideal adalah nilai percepatan yang dihasilkan sama dengan jumlah prosesor yang digunakan. Namun pada banyak percobaan seringkali tidak mencapai kondisi ideal tersebut. Hal ini disebabkan oleh faktor komunikasi yang terjadi selama proses paralel dan terdapat prosesor yang idle atau tidak berkerja. Percepatan yang dihasilkan dari semua percobaan mendekati kondisi ideal. Setiap percobaan menghasilkan nilai percepatan (S) yang mendekati jumlah prosesor yang digunakan ( ).
Efisiensi
Efisiensi merupakan perbandingan antara percepatan dengan jumlah prosesor yang digunakan (p). Efisiensi mengukur seberapa efisien penggunaan sejumlah prosesor di dalam model perancangan paralel yang dibangun. Dalam model perancangan paralel yang ideal, efisiensi mencapai nilai satu. Penelitian ini mengukur nilai efisiensi (Gambar 22) pada model perancangan yang dibangun. Pengukuran efisiensi dilakukan untuk melihat seberapa maksimum prosesor yang bekerja di dalam model perancangan yang dibangun.
Gambar 22 Efisiensi model 1
Nilai efisiensi yang dihasilkan pada model perancangan paralel pembagian data mendekati nilai ideal. Nilai efisiensi tertinggi adalah 0.97 pada saat penggunaan 2, 3, dan 4 prosesor. Penggunaan 5 prosesor terjadi penurunan nilai efisiensi menjadi 0.93. Penurunan nilai efisiensi ini disebabkan oleh hasil proses pembagian data yang tidak ideal. Untuk pengolahan 48 data citra setiap spesiesnya terdapat 3 prosesor mengolah 10 data citra, sedangkan 2 prosesor mengolah 9 data citra. Pembagian data citra yang tidak ideal ini menyebabkan 2 prosesor dalam kondisi idle pada saat 3 prosesor lainnya masih mengolah data citra. Kondisi idle ini mempengaruhi nilai efisiensi pada pemrosesan paralel.
31
Namun, penurunan nilai efisiensi tidak secara signifikan. Penggunaan multiprocessor untuk mengekstraksi fitur sebanyak 1 440 citra daun tumbuhan obat cukup ideal.
Isoefisiensi
Skalabilitas (isoefisiensi) merupakan kemampuan model perancangan paralel untuk mempertahankan nilai efisiensi dengan bertambahnya jumlah data dan prosesor. Jumlah prosesor pada model perancangan program paralel sangat diperhitungkan. Penggunaan sejumlah prosesor berhubungan dengan biaya komunikasi. Penggunaan prosesor yang efektif mampu mengurangi biaya komunikasi yang dikeluarkan oleh model perancangan paralel. Pengukuran isoefisiensi ditunjukkan pada Tabel 4.
Tabel 4 Hasil evaluasi isoefisiensi model 1
R = 2 = 3 = 4 = 5 = 6 = 7 = 8
540 0.97 0.97 0.88 0.87 0.95 0.82 0.72
600 0.99 0.94 0.97 0.97 0.83 0.90 0.80
720 0.98 0.97 0.96 0.92 0.95 0.82 0.83
840 0.97 0.93 0.97 0.90 0.89 0.94 0.83
900 0.99 0.99 0.92 0.97 0.96 0.84 0.90
1 020 0.99 0.94 0.93 0.95 0.92 0.80 0.84
1 140 1.00 0.96 0.93 0.93 0.88 0.88 0.90
1 200 1.00 0.94 0.98 0.97 0.92 0.92 0.96
1 320 0.89 0.97 0.99 0.96 0.90 0.88 0.89
1 440 0.99 0.98 0.98 0.93 0.96 0.94 0.96
Berdasarkan perhitungan performance metric didapatkan bahwa untuk mempertahankan nilai efisiensi pada model 1 dengan menambahkan data citra sebesar 2 (}`A/ ). Tabel 4 menunjukkan penambahan prosesor dari berjumlah 2 menjadi 3 dengan penambahan data sebesar 2 (}`A/ ) mempertahankan efisiensi sebesar 0.98.
Model 1 untuk citra kueri
Model 1 didesain juga untuk ekstraksi citra kueri. Sistem identifikasi yang dikembangkan dirancang untuk menerima citra input dari user. Citra kueri atau citra input ini akan diekstraksi fitur dan hasil ekstraksi berupa histogram FLBP. Proses ekstraksi fitur citra kueri akan diproses menggunakan model perancangan paralel.
dan threshold FLBP ke setiap prosesor slave. Prosesor slave mengekstrasi fitur citra kueri dengan kombinasi yang diberikan oleh prosesor master. Hasil ekstraksi fitur menggunakan kombinasi operator LBP dan threshold FLBP berupa vektor histogram FLBP. Prosesor slave mengirimkan kembali histogram FLBP ke prosesor master.
Evaluasi kinerja paralel untuk citra kueri
Pengukuran kinerja paralel pada ekstraksi citra kueri menggunakan percepatan dan efisiensi. Pengukuran percepatan dengan membandingkan waktu sekuensial dengan waktu paralel ekstraksi citra kueri. Waktu sekuensial ekstraksi citra kueri adalah 24.9 detik. Tabel 5 menunjukkan waktu paralel yang dibutuhkan untuk ekstraksi citra kueri. Jumlah prosesor yang digunakan adalah sebanyak 2 prosesor sampai 8 prosesor.
Tabel 5 Hasil evaluasi percepatan dan efisiensi model 1 untuk citra kueri
Jumlah processor( ) Waktu paralel …W-†
(detik) Percepatan(S) Efisiensi (\)
2 12.1 2.06 1 ekstraksi fitur citra kueri memperlihatkan tercapainya kondisi ideal. Penggunaan prosesor sampai dengan 5 buah prosesor efisiensi tercapai nilai satu dan nilai percepatan yang sama dengan jumlah prosesor.
Gambar 23 Percepatan model 1 untuk citra kueri
33
Grafik percepatan (Gambar 23) menunjukkan bahwa pemrosesan paralel untuk ekstraksi fitur citra kueri dapat meningkatkan percepatan proses ekstraksi fitur. Pengukuran percepatan mencapai kondisi ideal pada saat penggunaan prosesor sebanyak 2 sampai dengan 5 buah prosesor. Percobaan dengan menggunakan 2 prosesor, peningkatan percepatan sampai dengan 2.05 kali lebih cepat dari waktu sekuensial. Percobaan dengan 3, 4 dan 5 prosesor, peningkatan percepatan sama dengan jumlah prosesor yang digunakan. Percobaan dengan menggunakan 6 dan 8 prosesor memiliki nilai percepatan yang jauh dari kondisi ideal.
Pengukuran efisiensi pada saat ekstraksi fitur citra kueri mencapai kondisi ideal (Gambar 24) pada saat penggunaan 3, 4 dan 5 prosesor. Percobaan menggunakan 6 prosesor, nilai efisiensi yang dihasilkan menurun, begitu juga dengan menggunakan 8 prosesor. Hal ini terjadi disebabkan oleh adanya prosesor yang dalam kondisi idle pada saat proses paralel berlangsung.
Gambar 24 Efisiensi model 1 untuk citra kueri
Klasifikasi dan Evaluasi
Hasil ekstraksi fitur dari model 1 dibagi menjadi data latih dan uji dengan persentase masing-masing 80% dan 20%. Data latih sebanyak 1 140 citra dan 300 citra menjadi data uji. Bias yang digunakan adalah 40. Hasil klasifikasi menggunakan classifier PNN menunjukkan jumlah citra yang berhasil diidentifikasi sebanyak 206 citra dari seluruh data uji sehingga diperoleh akurasi sebesar 68.89%. Perhitungan akurasi dapat dilihat sebagai berikut:
spqrs_ = 206300 × 100% = 68.89%
Gambar 25 Perbandingan akurasi per kelas model 1
Grafik pada Gambar 25 menunjukkan bahwa kelas 2 (Jarak Pagar), 6 (Daruju), 7 (Pegagan), 21 (Nanas Kerang) dan 26 (Cincau Hitam) merupakan kelas yang berhasil diidentifikasi dengan tingkat akurasi 100%, sedangkan kelas 5 (Akar Kuning) memiliki tingkat akurasi 0% yang berarti tidak pernah teridentifikasi benar. Adapun contoh citra latih dan citra uji kelas 7 dapat dilihat pada Gambar 26 dan kelas 5 dapat dilihat pada Gambar 27.
Data Latih Data Uji
Gambar 26 Contoh citra data latih dan data uji kelas 7 (Pegagan)
Data Latih Data Uji
Gambar 27 Contoh citra data latih dan data uji kelas 5 (Akar Kuning)
Model 2
Model 2 didesain untuk memparalelkan proses ekstraksi fitur menggunakan FLBP. Langkah-langkah perancangan model 2 menggunakan metode Foster seperti pada perancangan model 1. Metode Foster terdiri atas partisi, efisiensi, aglomerasi dan mapping.
0 10 20 30 40 50 60 70 80 90 100
1 2 3 4 5 6 7 8 9 10 11121314 15 16 17 18192021 22 23 24 25262728 29 30
A
k
u
ra
si
%
35
Partisi
Proses partisi pada model 2 terbagi menjadi dua bagian yaitu pembagian data citra dan pembagian area citra. Pembagian data citra pada model 2 mengikuti model perancangan satu seperti terlihat pada Tabel 2. Partisi dilakukan dengan membagi citra ke beberapa prosesor kemudian dilakukan ekstraksi fitur di masing-masing prosesor. Pembagian area citra (Gambar 28) dilakukan saat prosesor mengekstraksi hasil pembagian data citra. Proses ekstraksi FLBP merupakan proses yang independent sehingga dapat dilakukan proses paralel pada area citra yang berbeda.
Gambar 28 Proses pembagian area citra daun
Proses ekstraksi fitur FLBP dilakukan pada area citra (Gambar 29). Area citra akan diekstraksi menggunakan prosesor yang berbeda. Hasil ekstraksi dari masing-masing area citra dijumlahkan untuk mendapatkan histogram FLBP hasil ekstraksi citra tersebut.
+
Gambar 29 Proses ekstraksi fitur FLBP pada area citra daun
Komunikasi