ARISTI IMKA APNIASARI
G64103027
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh:
ARISTI IMKA APNIASARI
G64103027
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ARISTI IMKA APNIASARI. Diagnosis Penyakit Demam Berdarah Dengue Menggunakan Voting Feature Intervals 5. Dibimbing oleh AZIZ KUSTIYO dan IRMAN HERMADI.
Penyakit Demam Berdarah Dengue (DBD) atau Dengue Hemorrhagic Fever ialah penyakit yang disebabkan oleh virus dengue yang ditularkan melalui gigitan nyamuk Aedes aegypti dan Aedes albopictus. Tingkat kematian akibat penyakit Demam Berdarah Dengue relatif masih tinggi. Salah satu penyebab tingginya tingkat kematian tersebut adalah keterlambatan diagnosis. Semakin cepat diagnosis dapat dilakukan, semakin cepat pula pertolongan bisa diberikan sehingga dapat mengurangi angka kematian tersebut. Penelitian ini akan menerapkan algoritma Voting Feature Intervals 5 (VFI5) untuk mendiagnosa penyakit DBD.
Data yang digunakan adalah data sekunder penyakit DBD pada penelitian yang telah dilakukan oleh Syafii pada tahun 2006. Sampel terdiri dari data pasien yang menderita penyakit DBD dan demam dengue (DD) yang terdiri dari 32 kasus DBD dan 32 kasus DD. Pada penelitian ini digunakan 4 gejala klinis objektif yaitu demam, bercak, pendarahan spontan dan hasil uji tornikuet untuk menetapkan diagnosa DBD secara klinis. Empat gejala klinis tersebut selanjutnya dijadikan sebagai fitur pada algoritma VFI5. Berdasarkan kesimpulan klinis yang telah ditentukan, selanjutnya dilakukan validasi data. Semua data yang nilainya dianggap tidak konsisten dengan kelasnya akan dihilangkan. Dari validasi data dihasilkan 42 kasus, terdiri dari 23 kasus DBD dan 19 kasus DD.
Pada penelitian ini dilakukan 4 tahap pengujian. Tahap pertama adalah pengujian untuk data sebelum validasi, tahap kedua adalah pengujian untuk data setelah validasi tanpa persebaran, tahap ketiga adalah pengujian untuk data setelah validasi dengan persebaran dan tahap keempat adalah pengujian data dengan pembagian data latih dan data uji seperti pada penelitian yang telah dilakukan oleh Syafii pada tahun 2006. Rata-rata akurasi yang dihasilkan pada pengujian tahap pertama terhadap data sebelum validasi adalah 65,66%. Pada pengujian tahap kedua untuk data setelah validasi tanpa persebaran ditemukan 3 instances yang kelas prediksinya tidak sesuai dengan kelas sebenarnya. Masing-masing instances tersebut memiliki peluang yang hampir sama untuk menjadi kelas DBD maupun kelas DD. Rata-rata akurasi pada pengujian tahap kedua ini adalah 92,86%. Selanjutnya pada pengujian tahap ketiga yang dilakukan pada data setelah validasi, tiga instances yang salah diklasifikasi pada tahap kedua disebar pada tiga data pengujian yang berbeda. Hasilnya terdapat 1 instances yang kelas prediksinya tidak sesuai dengan kelas sebenarnya. Instances tersebut memiliki peluang yang hampir sama untuk setiap kelasnya. Rata-rata akurasi yang dihasilkan pada pengujian tahap ketiga ini mencapai 97,62%. Selanjutnya, pada pengujian tahap keempat akurasi yang dihasilkan untuk data setelah validasi adalah 100%. Akurasi tersebut jauh lebih tinggi bila dibandingkan dengan penelitian yang telah dilakukan oleh Syafii pada tahun 2006 dengan menggunakan model ANFIS yang hanya mencapai 86,67%.
NRP
: G64103027
Menyetujui:
Pembimbing I,
Aziz Kustiyo, S.Si., M.Kom.
NIP. 132 206 241
Pembimbing II,
Irman Hermadi, S.Kom., MS.
NIP. 132 321 422
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS.
NIP. 131 473 999
Penulis lahir di Pati pada tanggal 12 April 1985, anak dari pasangan Ali Imron dan Kartika Rini. Penulis merupakan putri pertama dari tiga bersaudara.
Puji dan syukur penulis panjatkan kepada Allah SWT karena hanya dengan rahmat dan karunia-Nya, penulis dapat menyelesaikan tugas akhir ini yang merupakan salah satu persyaratan kelulusan pada Program Sarjana Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Tugas akhir ini mengambil judul Diagnosis Penyakit Demam Berdarah Dengue Menggunakan Voting Feature Intervals 5.
Penulis menyampaikan terima kasih kepada semua pihak yang telah membantu dalam penulisan karya ilmiah ini khususnya kepada Bapak Aziz Kustiyo, S.Si, M.Kom dan Bapak Irman Hermadi, S.Kom, MS yang telah membimbing dengan penuh ketekunan dan kesabaran hingga selesainya penulisan karya ilmiah ini. Selanjutnya, penulis juga ingin mengucapkan terima kasih kepada :
1 Papa, Ibu, beserta kedua adikku atas motivasi, kasih sayang dan doanya selama ini.
2 Bapak Arief Ramadhan S.Kom atas kesediaannya menjadi moderator pada seminar tugas akhir dan penguji pada sidang tugas akhir.
3 Tatak T Setiana atas pengertian, motivasi dan doa yang diberikan kepada penulis.
4 Dr. M. Syafii, M.Si atas informasi yang diberikan kepada penulis.
5 Dian, Aulia, Charolina, Dessy dan Tri Puji atas motivasi dan keakraban yang terjalin selama ini.
6 Staf pengajar dan karyawan Departemen Ilmu Komputer, atas bantuannya selama penyelenggaraan seminar dan sidang tugas akhir.
7 Teman-teman seperjuangan Program Studi Ilmu Komputer angkatan 40 atas pengalaman dan kenangan yang tak ternilai.
8 Kepada semua pihak yang telah memberikan bantuan selama pengerjaan penelitian ini namun tidak dapat penulis sebutkan satu persatu.
Akhir kata, penulis berharap semoga karya ilmiah ini dapat bermanfaat bagi semua pihak termasuk penulis pribadi.
Bogor, Mei 2007
Penulis
Halaman
DAFTAR TABEL ... vi
DAFTAR LAMPIRAN... vii
PENDAHULUAN Latar Belakang... 1
Tujuan... 1
Ruang Lingkup ... 1
Manfaat... 1
TINJAUAN PUSTAKA Demam Berdarah Dengue (DBD)... 1
Validasi Data ... 3
Metode k-Fold Cross Validation... 3
Algoritma Voting Feature Intervals 5 (VFI5) ... 3
METODE PENELITIAN Data ... 4
Seleksi Data ... 5
Data Latih dan Data Uji... 5
Algoritma VFI5 ... 5
Analisis ... 5
Spesifikasi Aplikasi ... 5
HASIL DAN PEMBAHASAN Pengujian Tahap Pertama ... 6
Pengujian Tahap Kedua... 9
Pengujian Tahap Ketiga... 12
Pengujian Tahap Keempat ... 15
KESIMPULAN DAN SARAN Kesimpulan... 17
Saran ... 17
DAFTAR PUSTAKA ... 17
DAFTAR TABEL
Halaman
1 Jumlah kasus penyakit DBD... 3
2 Sebaran data sebelum dan setelah validasi ... 6
3 Hasil pembagian data tahap pertama ... 6
4 Susunan data pelatihan dan data pengujian tahap pertama ... 6
5 Akurasi dari setiap iterasi tahap pertama ... 7
6 Komposisi jumlah instances tahap pertama iterasi pertama ... 7
7 Komposisi jumlah instances tahap pertama iterasi kedua ... 8
8 Komposisi jumlah instances tahap pertama iterasi ketiga ... 8
9 Hasil pembagian data tahap kedua... 9
10 Susunan data pelatihan dan data pengujian tahap kedua ... 9
11 Akurasi dari setiap iterasi tahap kedua ... 10
12 Komposisi jumlah instances tahap kedua iterasi pertama ... 10
13 Komposisi jumlah instances tahap kedua iterasi kedua... 11
14 Normalisasi tiga instances pengujian ... 11
15 Komposisi jumlah instances tahap kedua iterasi ketiga... 12
16 Hasil pembagian data tahap ketiga ... 12
17 Susunan data pelatihan dan data pengujian tahap ketiga ... 13
18 Akurasi dari setiap iterasi tahap ketiga ... 13
19 Komposisi jumlah instances tahap ketiga iterasi pertama ... 13
20 Hasil pengujian instances salah klasifikasi tahap ketiga... 14
21 Normalisasi instances pengujian salah klasifikasi ... 14
22 Komposisi jumlah instances tahap ketiga iterasi kedua... 14
23 Komposisi jumlah instances tahap ketiga iterasi ketiga ... 15
24 Susunan data pelatihan dan data pengujian tahap keempat ... 15
25 Komposisi jumlah instances tahap keempat pada data sebelum validasi ... 16
DAFTAR LAMPIRAN
Halaman
1 Algoritma pelatihan VFI5... 20
2 Algoritma klasifikasi VFI5 ... 20
3 Jenis fitur dan nilainya... 20
4 Data sebelum validasi ... 21
5 Data setelah validasi tanpa persebaran ... 22
6 Hasil pengujian tahap pertama... 23
7 Nilai interval_class_vote hasil pelatihan data tahap pertama iterasi pertama... 25
8 Nilai interval_class_vote hasil pelatihan data tahap pertama iterasi kedua ... 25
9 Nilai interval_class_vote hasil pelatihan data tahap pertama iterasi ketiga... 25
10 Hasil pengujian tahap kedua ... 26
11 Nilai interval_class_vote hasil pelatihan data tahap kedua iterasi pertama ... 27
12 Nilai interval_class_vote hasil pelatihan data tahap kedua iterasi kedua ... 27
13 Hasil pengujian 3 instances salah klasifikasi pada tahap kedua ... 28
14 Nilai interval_class_vote hasil pelatihan data tahap kedua iterasi ketiga ... 28
15 Data setelah validasi dengan persebaran... 28
16 Hasil pengujian tahap ketiga... 29
17 Nilai interval_class_vote hasil pelatihan data tahap ketiga iterasi pertama... 30
18 Nilai interval_class_vote hasil pelatihan data tahap ketiga iterasi kedua ... 31
19 Nilai interval_class_vote hasil pelatihan data tahap ketiga iterasi ketiga ... 31
20 Data pelatihan sebelum validasi tahap keempat ... 32
21 Data pengujian sebelum validasi tahap keempat ... 33
22 Nilai interval_class_vote hasil pelatihan data sebelum validasi pada tahap keempat... 33
23 Hasil pengujian tahap keempat pada data sebelum validasi ... 34
24 Data pelatihan setelah validasi tahap keempat... 34
25 Data pengujian setelah validasi tahap keempat ... 35
PENDAHULUAN
Latar Belakang
Penyakit Demam Berdarah Dengue (DBD) atau Dengue Hemorrhagic Fever ialah penyakit yang disebabkan oleh virus dengue yang ditularkan melalui gigitan nyamuk Aedes aegypti dan Aedes albopictus. Kedua jenis nyamuk ini terdapat hampir di seluruh pelosok Indonesia, kecuali di tempat-tempat dengan ketinggian lebih dari 1000 meter di atas permukaan air laut (Kristina et al, 2004).
Tingkat kematian akibat penyakit Demam Berdarah Dengue relatif masih tinggi. Sejak Januari sampai dengan 5 Maret tahun 2004 total kasus DBD di seluruh propinsi di Indonesia sudah mencapai 26.015, dengan jumlah kematian sebanyak 389 jiwa atau case fatality rate (CFR) sebesar 1,53% (Kristina et al, 2004).
Salah satu penyebab tingginya tingkat kematian tersebut adalah keterlambatan diagnosis (Sutaryo 2004 diacu dalam Syafii 2006). Semakin cepat diagnosis dapat dilakukan, semakin cepat pula pertolongan bisa diberikan sehingga dapat mengurangi angka kematian tersebut. Penyakit DBD juga sering salah didiagnosis dengan penyakit lain seperti flu atau tipus. Hal ini disebabkan karena infeksi virus dengue yang menyebabkan DBD bisa bersifat asimtomatik atau tidak jelas gejalanya (Kristina et al, 2004).
Diagnosis penyakit DBD berdasarkan hasil pemeriksaan klinis antara lain dilakukan oleh Syafii (2006) dengan menggunakan Adaptive Neuro Fuzzy Inference System (ANFIS). Akurasi model ANFIS yang dikembangkan Syafii (2006) mencapai 86,67%. Akurasi ini belum maksimal karena data yang digunakan pada penelitian Syafii (2006) lebih banyak berupa data nominal. Sementara itu salah satu syarat agar model ANFIS bisa digunakan secara efektif adalah data yang digunakan harus memiliki selang atau grade. Oleh karena itu pada penelitian ini digunakan algoritma klasifikasi Voting Feature Intervals (VFI5), karena algoritma ini bisa menangani data ordinal maupun data nominal dengan baik. Seperti pada penelitian yang dilakukan oleh Iqbal (2007) dalam mengklasifikasi pasien Suspect Parvo dan Distemper. Dari 49 fitur yang digunakan, 47 fitur diantaranya berupa data nominal. Hasil akurasi yang diperoleh dalam pengklasifikasian pasien Suspect Parvo dan Distemper dengan menggunakan algoritma VFI5 adalah 90%. Demikian pula dengan penelitian yang telah dilakukan oleh HA
Güvenir, G Demiröz dan N Ilter (1998) dalam memprediksi penyakit erythemato-squamous. Akurasi yang dihasilkan dengan menggunakan algoritma VFI5 mencapai 96,2%. Dengan demikian terbukti bahwa algoritma VFI5 mampu memprediksi suatu penyakit dengan akurasi yang cukup tinggi.
Tujuan
Tujuan dari penelitian ini adalah untuk menerapkan algoritma klasifikasi VFI5 dalam diagnosa penyakit DBD.
Ruang Lingkup
Pada penelitian ini dilakukan pembatasan masalah pada :
1 Data yang digunakan adalah data sekunder penyakit DBD pada penelitian Syafii (2006).
2 Bobot (weight) setiap feature pada data diasumsikan sama.
Manfaat
Penelitian ini diharapkan dapat membantu semua pihak dalam deteksi dini penyakit DBD menggunakan algoritma VFI5.
TINJAUAN PUSTAKA
Demam Berdarah Dengue (DBD)
Penyakit DBD pertama kali di Indonesia ditemukan di Surabaya pada tahun 1968, akan tetapi konfirmasi virologis baru didapat pada tahun 1972. Sejak itu penyakit DBD menyebar ke berbagai daerah, sehingga sampai tahun 1980 seluruh propinsi di Indonesia telah terjangkit penyakit ini (Kristina et al, 2004).
DBD adalah penyakit febril akut yang disebabkan oleh virus Dengue. Virus ini terdiri dari empat serotipe dan disebarkan oleh nyamuk Aedes aegypti dan Aedes albopictus (Ibrahim et al, 2005).
Keempat tipe virus Dengue yaitu DEN 1, DEN 2, DEN 3 dan DEN 4 telah ditemukan di berbagai daerah di Indonesia antara lain Jakarta dan Yogyakarta. Virus yang banyak berkembang di masyarakat adalah virus dengue dengan tipe satu dan tiga (Kristina et al, 2004).
Gejala
menyebabkan DBD bisa bersifat asimtomatik atau tidak jelas gejalanya. Beberapa pasien DBD sering menunjukkan gejala batuk, pilek, mual, muntah maupun diare. Masalah bisa bertambah karena virus tersebut dapat masuk bersamaan dengan infeksi penyakit lain seperti flu atau tipus (Kristina et al, 2004).
Kriteria klinis untuk diagnosa DBD antara lain (Kristina et al, 2004) :
a Demam tinggi yang mendadak dan terus menerus selama 2-7 hari (38 °C- 40 °C)
b Manifestasi pendarahan, dengan bentuk : uji tornikuet positif dan terdapat salah satu bentuk pendarahan yaitu pandarahan pada kulit (petekia, purpura), pendarahan hidung (epitaksis), pendarahan gusi, muntah berdarah (hematemesis) dan berak berdarah (melena).
c Hepatomegali (pembesaran hati).
dShock yang ditandai dengan nadi lemah, cepat, tekanan nadi menurun menjadi 20 mmHg atau kurang dan tekanan sistolik sampai 80 mmHg atau lebih rendah.
e Trombositopenia, pada hari ke 3-7 ditemukan penurunan trombosit sampai 100.000/mm3.
f Hemokonsentrasi, meningkatnya nilai hematokrit.
gGejala-gejala klinis lainnya yang dapat menyertai : anoreksia (hilangnya nafsu makan), lemah, mual, muntah, sakit perut, diare, kejang dan sakit kepala.
hRasa sakit pada otot dan persendian.
Berdasarkan kriteria klinis tersebut, maka WHO membagi derajat penyakit DBD dalam empat kategori yaitu (Hasan 1985 diacu dalam Syafii 2006) :
- Kategori (1) : dijumpai demam disertai gejala tidak khas dan satu-satunya manifestasi pendarahan adalah uji tornikuet positif.
- Kategori (2) : kategori 1 disertai pendarahan spontan seperti petekia di kulit, epitaksis atau pendarahan lainnya.
- Kategori (3) : kategori 2 disertai kegagalan sirkulasi yaitu nadi lemah, cepat, tekanan darah menurun disertai kulit dingin, lembab dan penderita gelisah.
- Kategori (4) : kategori 3 disertai shock berat dengan nadi tidak dapat diraba dan tekanan darah tidak dapat diukur.
Secara alamiah penyakit DBD mengalami perjalanan empat tahap yaitu (Sutaryo 2004 diacu dalam Syafii 2006) :
1 masa inkubasi selama 5-9 hari, pada masa ini tidak dijumpai gejala.
2 masa akut selama 1-3 hari, pada masa ini akan muncul gejala subjektif (lemah, mual, muntah, nyeri kepala dan lain-lain) serta gejala objektif (demam, bercak merah, pendarahan spontan hidung, gusi, pencernaan, pembesaran hati)
3 masa kritis selama 1-3 hari, pada masa ini diikuti gejala shock, kesadaran menurun, ekstremitas dingin, kulit lembab dan tekanan darah turun.
4 masa penyembuhan selama 1-2 hari, pada masa ini cepat sekali membaik dan gejala hilang tetapi terkadang muncul bercak merah yang disebut rash rekovalesen.
Pemeriksaan uji tornikuet adalah menguji ketahanan kapiler darah dengan cara membendung pembuluh darah lengan atas dengan tekanan alat tensimeter yang dipompa sampai tekanan 100mmHg dan dipertahankan selama 10 menit kemudian dilepas (Gandasoebrata 1985 diacu dalam Syafii 2006). Setelah itu dicari adanya bercak-bercak merah kecil yang disebut petekia yang timbul dalam lingkaran bergaris 5 cm, kira-kira 4 cm di bawah lipatan dalam lengan (fossa cubiti). Uji tornikuet dinyatakan positif apabila ditemukan 10 petekia atau lebih dalam lingkaran (Syafii 2006).
Penularan
Penularan DBD terjadi melalui gigitan nyamuk Aedes Aegypti dan Aedes albopictus betina yang sebelumnya telah membawa virus dalam tubuhnya dari penderita demam berdarah lain. Nyamuk Aedes aegypti berasal dari Brazil dan Ethiopia dan sering menggigit manusia pada waktu pagi dan siang.
Orang yang beresiko terserang DBD adalah anak-anak yang berusia di bawah 15 tahun dan sebagian besar tinggal di lingkungan lembab serta daerah kumuh. Penyakit DBD sering terjadi di daerah tropis dan muncul pada musim penghujan (Kristina et al, 2004).
Penyebaran
kemudian penyakit ini menyebar ke beberapa propinsi di Indonesia, dengan jumlah kasus sebagai berikut (Kristina et al, 2004).
Tabel 1 Jumlah kasus penyakit DBD
Tahun Jumlah kasus Jumlah kematian 1996 45.548 orang 1.234 orang 1998 72.133 orang 1.414 orang
1999 21.134 orang -
2000 33.443 orang -
2001 45.904 orang -
2002 40.377 orang -
2003 50.131 orang -
2004 (sampai
5 Maret) 26.015 orang 389 orang
Validasi Data
Validasi adalah meneliti kebenaran data dalam kondisi khusus. Dalam hal ini kondisi khusus tersebut adalah aturan (rule base) yang diperoleh dari pakar. Validasi dilakukan dengan cara meneliti konsistensi data terhadap aturan tersebut. Menurut pendapat pakar dijumpai demam tinggi yang mendadak disertai salah satu manifestasi pendarahan dapat dijadikan kesimpulan klinis penyakit DBD (Syafii 2006).
Metode k-Fold Cross Validation
Validasi silang (cross-validation) merupakan metode untuk memperkirakan eror generalisasi berdasarkan “resampling” (Weiss & Kulikowski 1991; Efron & Tibshirani 1993; Hjorth 1994; Plutowski et al. 1994; Shao & Tu 1995, diacu dalam Sarle 2004). Dalam k-fold cross validation, data dibagi secara acak menjadi k himpunan bagian yang ukurannya hampir sama satu sama lain. Himpunan bagian yang dihasilkan yaitu S1,S2,...,Sk digunakan
sebagai pelatihan dan pengujian.
Pengulangan dilakukan sebanyak k kali dan pada setiap ulangan disisakan satu subset untuk pengujian dan subset lainnya untuk pelatihan. Pada iterasi ke-i, subset Si diperlakukan sebagai
data pengujian, dan subset lainnya diperlakukan sebagai data pelatihan. Pada iterasi pertama S2,...Sk menjadi data pelatihan dan S1 menjadi
data pengujian. Selanjutnya pada iterasi kedua S1,S3,...,Sk menjadi data pelatihan dan S2
menjadi data pengujian, dan seterusnya.
Algoritma Voting Feature Intervals 5 (VFI5)
Salah satu algoritma yang digunakan untuk mengklasifikasikan data adalah Voting Feature Intervals. Algoritma ini dikembangkan oleh Gülşen Demiröz dan H. Altay Güvenir pada tahun 1997 (Demiröz dan Güvenir 1997).
Algoritma klasifikasi Voting Feature Intervals 5 (VFI5) merepresentasikan deskripsi sebuah konsep oleh sekumpulan interval nilai-nilai feature atau atribut. Pengklasifikasian instances baru didasarkan pada voting pada klasifikasi yang dibuat oleh nilai tiap-tiap feature secara terpisah. Algoritma tersebut termasuk dalam algoritma yang supervised, artinya memiliki target yang dalam hal ini adalah kelas-kelas data dari kasus yang ada. Selain itu juga bersifat non-incremental yang berarti semua instances pelatihan diproses secara bersamaan (Demiroz dan Güvenir 1997). Dari semua instances pelatihan tersebut, algoritma VFI5 membuat interval untuk setiap feature. Interval-interval yang dibuat dapat berupa range interval maupun point interval. Range interval terdiri atas nilai-nilai antara dua end point yang berdekatan tetapi tidak termasuk kedua nilai end point itu sendiri. Point interval terdiri atas seluruh end point secara berturut-turut.
Untuk setiap interval, nilai vote untuk setiap kelas pada interval tersebut akan disimpan. Dengan demikian, sebuah interval dapat merepresentasikan beberapa kelas dengan menyimpan nilai vote yang dimiliki setiap kelas. Oleh karena itu, algoritma VFI dikatakan sebagai multi-class feature projection based algorithms.
Keunggulan algoritma VFI5 adalah algoritma ini cukup kokoh (robust) terhadap feature yang tidak relevan namun mampu memberikan hasil yang baik pada real-world datasets yang ada. VFI5 mampu menghilangkan pengaruh yang kurang menguntungkan dari feature yang tidak relevan tersebut dengan mekanisme voting-nya (Güvenir 1998).
Algoritma VFI5 dikembangkan menjadi dua tahap yaitu pelatihan dan klasifikasi.
1 Pelatihan
yang ada pada feature kelas yang sedang diamati.
Setelah nilai end point untuk setiap feature linier didapatkan maka langkah selanjutnya adalah mengurutkan nilai-nilai end point tersebut. Hasil pengurutan tersebut akan membentuk suatu interval bagi feature f. Jika feature tersebut merupakan feature linier yang memiliki nilai kontinu maka akan dibentuk dua interval yaitu point interval dan range interval. Jika suatu feature merupakan feature nominal maka hanya akan dibentuk point interval.
Batas bawah pada range interval (ujung paling kiri) adalah -∞ sedangkan batas atas range interval (ujung paling kanan) adalah +∞. Jumlah maksimum end point pada feature linier adalah 2k, sedangkan jumlah maksimum intervalnya adalah 4k+1, dengan k adalah jumlah kelas yang diamati.
Langkah selanjutnya adalah menghitung jumlah instances pelatihan setiap kelas c dengan feature f yang nilainya jatuh pada interval i dan direpresentasikan sebagai interval_class_count [f,i,c]. Untuk setiap instance pelatihan, dicari interval i dimana nilai feature f dari instance pelatihan e (ef) tersebut jatuh. Jika interval i
merupakan point interval dan nilai ef sama
dengan nilai pada batas bawah atau batas atas maka jumlah kelas instances tersebut (ef) pada
interval i ditambah 1. Jika interval i merupakan range interval dan nilai ef jatuh pada interval
tersebut maka jumlah kelas instances ef pada
interval i ditambah 1. Hasil dari proses tersebut merupakan jumlah vote kelas c pada interval i.
Untuk menghilangkan efek perbedaan distribusi setiap kelas, maka jumlah vote kelas c untuk feature f pada interval i dinormalisasi dengan cara membagi vote tersebut dengan jumlah instances kelas c yang direpresentasikan dengan class_count[c]. Hasil normalisasi ini dinotasikan sebagai interval_class_vote[f,i,c]. Kemudian nilai-nilai interval_class_vote[f,i,c] dinormalisasi sehingga jumlah vote dari beberapa kelas pada setiap feature f sama dengan 1. Normalisasi ini bertujuan agar setiap feature memiliki kekuatan voting yang sama pada proses klasifikasi yang tidak dipengaruhi oleh ukurannya.
2 Prediksi (klasifikasi)
Tahap klasifikasi pada algoritma VFI5 diawali dengan proses inisialisasi awal nilai vote masing-masing kelas dengan nilai 0. Untuk setiap feature f, dicari interval i dimana nilai ef
jatuh, dengan ef merupakan nilai feature f dari
instances tes e. Jika ef tidak diketahui (hilang),
maka feature tersebut tidak diikutsertakan dalam voting (memberi vote 0 untuk masing-masing kelas). Oleh karena itu, feature yang memiliki nilai tidak diketahui diabaikan.
Jika ef diketahui maka interval tersebut
dapat ditemukan. Interval tersebut dapat menyimpan instances pelatihan dari beberapa kelas. Kelas-kelas dalam sebuah interval direpresentasikan oleh vote kelas-kelas tersebut pada interval itu. Untuk setiap kelas c, feature f memberikan vote yang sama dengan interval_class_vote[f,i,c]. Notasi tersebut merepresentasikan vote feature f yang diberikan untuk kelas c.
Setiap feature f mengumpulkan vote-votenya dalam sebuah vektor
(feature_vote[f,C1],..., feature_vote[f,Cj], ...,
feature_vote[f,Ck]), dimana feature_vote[f,Cj]
merupakan vote feature f untuk kelas Cj dan k
adalah jumlah kelas. Kemudian d vektor vote, dimana d merupakan jumlah feature, dijumlahkan untuk memperoleh total vektor vote (vote[C1], ..., vote[Ck]). Kelas dengan
jumlah vote terbesar diprediksi sebagai kelas dari instances tes e. Pseudocode algoritma pelatihan dan klasifikasi VFI5 dapat dilihat pada Lampiran 1 dan Lampiran 2.
METODE PENELITIAN
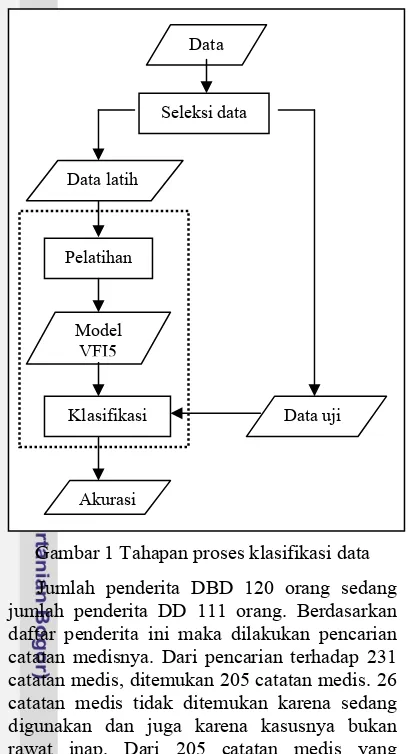
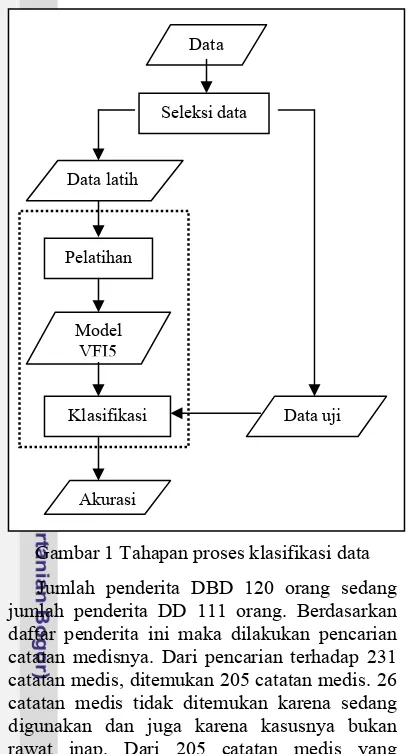
Penelitian ini melalui beberapa tahapan proses untuk mengetahui akurasi yang diperoleh algoritma VFI5 dalam mendiagnosa penyakit Demam Berdarah Dengue (DBD). Tahapan-tahapan proses tersebut dapat dilihat pada Gambar 1.
Data
Data yang digunakan dalam penelitian ini adalah data penyakit Demam Berdarah Dengue (DBD) pada penelitian Syafii (2006). Sampel terdiri dari data pasien yang menderita penyakit DBD dan Demam Dengue (DD). Menurut International Classification of Deseases tenth revision (ICD 10) penyakit DBD diberi kode A.91 dan penyakit DD dengan kode A.90.
pertimbangan adanya catatan 4 kriteria klinis dan 1 kriteria laboratoris (Syafii 2006).
Gambar 1 Tahapan proses klasifikasi data
Jumlah penderita DBD 120 orang sedang jumlah penderita DD 111 orang. Berdasarkan daftar penderita ini maka dilakukan pencarian catatan medisnya. Dari pencarian terhadap 231 catatan medis, ditemukan 205 catatan medis. 26 catatan medis tidak ditemukan karena sedang digunakan dan juga karena kasusnya bukan rawat inap. Dari 205 catatan medis yang ditemukan, catatan medis yang memenuhi persyaratan hanya 64, yang terdiri dari 32 kasus DBD dan 32 kasus DD (Syafii 2006).
Seleksi Data
Pada penelitian ini akan dilakukan seleksi terhadap keseluruhan data baik sebelum maupun setelah validasi. Seleksi ini dilakukan untuk menentukan data mana yang digunakan sebagai data latih dan data uji.
Data Latih dan Data Uji
Dengan metode 3-fold cross validation, seluruh data dibagi menjadi beberapa subset. Masing-masing subset memiliki ukuran contoh yang hampir sama. Subset-subset tersebut akan digunakan sebagai data pelatihan dan data pengujian. Masing-masing data memuat informasi tentang data input berupa demam, bercak, pendarahan, hasil uji tornikuet dan data output berupa diagnosa (DBD atau DD).
Algoritma VFI5
Pada penelitian ini digunakan algoritma klasifikasi VFI5 dengan bobot setiap feature diasumsikan sama, yaitu satu. Tahapan ini terdiri dari dua proses yaitu pelatihan dan prediksi (klasifikasi) kelas instances baru. Data
Pada tahap pelatihan, data yang telah dibagi-bagi menjadi beberapa subset menjadi input algoritma klasifikasi VFI5. Selanjutnya akan ditentukan nilai end point untuk setiap fitur. Dari nilai end point tersebut akan dibentuk interval-interval dari setiap fitur yang ada. Setelah semua interval terbentuk, langkah selanjutnya adalah menghitung jumlah instances setiap kelas yang berada pada setiap interval tersebut dan dilakukan normalisasi. Hasil dari tahap pelatihan berupa interval setiap fitur merupakan suatu model dari VFI5.
Seleksi data
Pada tahap klasifikasi, setiap nilai feature dari suatu instances baru diperiksa letak interval nilai feature tersebut. Vote-vote setiap kelas untuk setiap feature pada setiap interval yang bersesuaian diambil dan kemudian dijumlahkan. Kelas dengan nilai total vote tertinggi akan menjadi kelas prediksi instances baru tersebut.
Analisis
Pada tahapan ini dilakukan proses penghitungan akurasi. Akurasi diperoleh dengan perhitungan :
Selain itu juga dilakukan pengamatan terhadap hasil diagnosa penyakit DBD dengan menggunakan VFI5. Hasil diagnosa diperoleh dari kelas dengan jumlah vote terbesar.
Spesifikasi Aplikasi
Aplikasi dirancang dan dibangun dengan hardware dan software sebagai berikut :
Hardware berupa komputer personal dengan spesifikasi :
1 Prosesor Intel Pentium 4
2 Memori 512 MB
3 Harddisk 80 GB
4 Monitor 15”
5 Alat input mouse dan keyboard
Software :
1. Sistem Operasi : Microsoft Windows XP
2. Microsoft Visual Basic 6.0 ∑ ∑ =
uji data total
asi diklasifik benar
uji data akurasi
Data uji Klasifikasi
Pelatihan Data latih
Model VFI5
HASIL DAN PEMBAHASAN
Sesuai dengan penelitian Syafii (2006) maka pada penelitian ini digunakan 4 gejala klinis objektif yaitu demam, bercak, pendarahan spontan dan hasil uji tornikuet untuk menetapkan diagnosa DBD secara klinis. Demam tinggi yang mendadak disertai salah satu manifestasi pendarahan dapat dijadikan kesimpulan klinis penyakit DBD. Empat gejala klinis tersebut selanjutnya dijadikan sebagai fitur.
Fitur-fitur yang ada dibedakan menjadi fitur linier dan fitur nominal. Suhu badan merupakan fitur linier sedangkan tiga gejala klinis lainnya merupakan fitur nominal. Nilai untuk fitur nominal ditentukan sebagai berikut :
• Nilai 1 diberikan untuk fitur nominal tertentu pada instances yang memiliki gejala penyakit yang dilambangkan fitur nominal tersebut.
• Nilai 0 diberikan untuk fitur nominal tertentu pada instances yang tidak memiliki gejala penyakit yang dilambangkan fitur nominal tersebut.
Nama-nama fitur beserta keterangan nilainya dapat dilihat pada tabel yang disajikan pada Lampiran 3.
Berdasarkan kesimpulan klinis yang telah ditentukan, selanjutnya dilakukan validasi data. Semua data yang nilainya dianggap tidak konsisten dengan kelasnya akan dihilangkan.
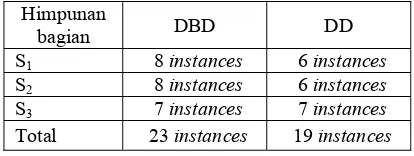
Data sebelum dan setelah validasi dapat dilihat pada Lampiran 4 dan Lampiran 5. Sebaran data sebelum dan setelah validasi dapat dilihat pada Tabel 2.
Tabel 2 Sebaran data sebelum dan setelah validasi
Kasus Sebelum
validasi
Setelah validasi
DBD 32 23
DD 32 19
Jumlah 64 42
Keseluruhan data baik sebelum maupun setelah validasi terlebih dahulu dibagi secara acak menjadi 3 himpunan bagian (subset) yang akan digunakan dalam metode validasi silang, yaitu metode 3-fold cross validation. Setiap himpunan bagian memiliki ukuran yang hampir sama satu sama lain. Pembagian data keseluruhan secara acak menghasilkan himpunan bagian yang disebut sebagai
himpunan bagian S1, himpunan bagian S2 dan
himpunan bagian S3.
Pada penelitian ini dilakukan 4 tahap pengujian. Tahap pertama adalah pengujian untuk data sebelum validasi, tahap kedua adalah pengujian untuk data setelah validasi tanpa persebaran, tahap ketiga adalah pengujian untuk data setelah validasi dengan persebaran dan tahap keempat adalah pengujian data dengan pembagian data latih dan data uji seperti pada penelitian Syafii (2006).
Pengujian Tahap Pertama
Pada tahap ini dilakukan pengujian untuk keseluruhan data sebelum validasi. Pembagian data secara acak menghasilkan subset-subset yang masing-masing memiliki jumlah instances yang hampir sama. Hasil pembagian data tahap pertama disajikan pada Tabel 3.
Tabel 3 Hasil pembagian data tahap pertama Himpunan
bagian DBD DD
S1 11 instances 10 instances
S2 10 instances 11 instances
S3 11 instances 11 instances
Total 32 instances 32 instances
Pada Lampiran 4, himpunan bagian S1 untuk
kasus DBD adalah data dari nomor 1 sampai 11, sedangkan untuk kasus DD adalah data dari nomor 33 sampai 42. Himpunan bagian S2
terdiri dari data kasus DBD dari nomor 12 sampai 21 dan kasus DD dari nomor 43 sampai 53. Himpunan bagian S3 terdiri dari data kasus
DBD dari nomor 22 sampai 32 dan kasus DD dari nomor 54 sampai 64.
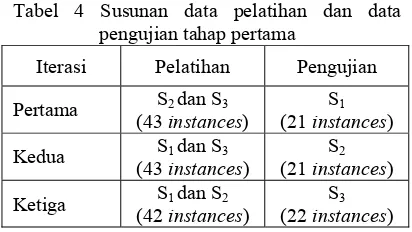
Pada penelitian ini pelatihan dan pengujian data dilakukan sebanyak 3 kali. Susunan data yang digunakan sebagai data pelatihan dan data pengujian pada setiap iterasi disajikan pada Tabel 4.
Tabel 4 Susunan data pelatihan dan data pengujian tahap pertama
Iterasi Pelatihan Pengujian
Pertama S2 dan S3 (43 instances)
S1
(21 instances)
Kedua S1 dan S3 (43 instances)
S2
(21 instances)
Ketiga S1 dan S2
(42 instances)
S3
(22 instances)
sebelum validasi yaitu sebanyak 64 instances, ditemukan 42 instances sebagai data yang diklasifikasi benar. Rata-rata akurasi yang dihasilkan pada pengujian tahap pertama ini dapat dilihat pada Tabel 5.
Tabel 5 Akurasi dari setiap iterasi tahap pertama Iterasi Akurasi Pertama 66,67% Kedua 66,67% Ketiga 63,64% Rata-rata 65,66%
Pada tahap pertama ini, baik pada iterasi pertama, kedua maupun ketiga, kecenderungan yang terlihat pada setiap fitur untuk menjadi ciri khas gejala DBD dan DD hampir sama, dengan perbandingan nilai yang kurang signifikan. Bahkan terdapat kecenderungan yang tidak tepat pada fitur pendarahan untuk menjadi ciri khas gejala DBD dan DD.
Iterasi Pertama
Pada iterasi pertama, himpunan bagian S2
dan S3 digunakan sebagai data pelatihan
sedangkan himpunan bagian S1 digunakan
sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian iterasi pertama disajikan pada Tabel 6.
Tabel 6 Komposisi jumlah instances tahap pertama iterasi pertama
Kelas Pelatihan Pengujian
DBD 21 instances 11 instances
DD 22 instances 10 instances
Pada Lampiran 4, data yang digunakan untuk pelatihan pada tahap pertama iterasi pertama ini adalah gabungan dari himpunan bagian S2 dan S3 dengan kasus DBD dari nomor
12 sampai 32 dan kasus DD dari nomor 43 sampai 64. Data pengujiannya adalah himpunan bagian S1 yaitu data dari nomor 1 sampai 11
untuk kasus DBD dan nomor 33 sampai 42 untuk kasus DD.
Proses pelatihan pada iterasi pertama akan menghasilkan selang-selang fitur. Setiap selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 7.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan 36 ºC dan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu 36,4 ºC sampai 39 ºC merujuk pada kelas DBD. Tetapi dari
hasil tersebut tidak dapat disimpulkan bahwa pada suhu rendah dan suhu tinggi penderita terserang DD dan pada suhu sedang penderita positif DBD. Hal ini disebabkan karena peran fitur-fitur lain dalam pengklasifikasian kelas sangat mempengaruhi. Antara fitur yang satu dengan fitur yang lain memiliki keterkaitan yang sangat erat.
Selain itu, kecenderungan yang muncul tersebut bisa dijelaskan dari segi tahapan perjalanan siklus DBD. Seperti yang sudah disebutkan sebelumnya bahwa DBD mengalami perjalanan empat tahap. Pada masa inkubasi hampir tidak ditemukan gejala. Kemudian pada masa akut mulai dijumpai beberapa gejala yang salah satunya adalah suhu badan naik. Adanya fenomena bahwa pada suhu tinggi penderita justru negatif DBD, bisa jadi disebabkan karena penderita memeriksakan dirinya ke dokter pada masa akut ini, yaitu saat gejala demam mulai muncul, sehingga kemungkinan terjadi kesalahan diagnosis sebagai penyakit flu atau tipus, bukan DBD.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai yang cukup signifikan yaitu 0,840 untuk kelas DBD dan 0,160 untuk kelas DD. Sementara itu kecenderungan penderita DD kurang terlihat dengan perbandingan nilai yang kurang signifikan, yaitu 0,556 untuk kelas DD dan 0,444 untuk kelas DBD.
Pada fitur pendarahan, kecenderungan yang muncul untuk menjadi ciri khas kelas DBD bisa dikatakan tidak tepat karena nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita terserang DD apabila terjadi pendarahan dengan perbandingan nilai 0,656 untuk kelas DD dan 0,344 untuk kelas DBD. Begitu juga sebaliknya untuk kecenderungan penderita positif DBD justru terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,512 untuk kelas DBD dan 0,488 untuk kelas DD.
Pengujian yang dilakukan pada iterasi pertama sebagai klasifikasi pada data pengujian S1 menghasilkan akurasi sebesar 66,67%. Dari
keseluruhan jumlah data pengujian S1 sebanyak
21 instances, ditemukan 14 instances sebagai data yang diklasifikasi benar.
Iterasi Kedua
Pada iterasi kedua, himpunan bagian S1 dan
himpunan bagian S3 digunakan sebagai data
pelatihan sedangkan himpunan bagian S2
digunakan sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian iterasi kedua disajikan pada Tabel 7.
Tabel 7 Komposisi jumlah instances tahap pertama iterasi kedua
Kelas Pelatihan Pengujian
DBD 22 instances 10 instances DD 21 instances 11 instances
Pada Lampiran 4, data yang digunakan untuk pelatihan pada tahap pertama iterasi kedua adalah gabungan dari himpunan bagian S1 dan S3, yaitu data dari nomor 1 sampai 11
serta 22 sampai 32 untuk kasus DBD dan data dari nomor 33 sampai 42 serta 54 sampai 64 untuk kasus DD. Data pengujiannya adalah himpunan bagian S2 yaitu data dari nomor 12
sampai 21 untuk kasus DBD dan nomor 43 sampai 53 untuk kasus DD.
Seperti pada iterasi pertama, proses pelatihan pada iterasi ini menghasilkan selang-selang fitur. Setiap selang-selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 8.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan kurang dari 36 ºC dan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu antara 36,4 ºC sampai 39 ºC merujuk pada kelas DBD. Kecenderungan yang muncul untuk fitur demam pada iterasi kedua ini sama seperti kecenderungan yang terlihat pada iterasi pertama, yaitu bahwa pada suhu rendah dan suhu tinggi penderita terserang DD dan pada suhu sedang penderita positif DBD, demikian pula dengan penyebab munculnya kecenderungan ini.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai yang cukup signifikan yaitu
0,827 untuk kelas DBD dan 0,173 untuk kelas DD. Sementara itu kecenderungan penderita DD kurang terlihat dengan perbandingan nilai yang kurang signifikan, yaitu 0,552 untuk kelas DD dan 0,448 untuk kelas DBD.
Seperti pada iterasi pertama, untuk fitur pendarahan kecenderungan yang muncul bisa dikatakan tidak tepat karena nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita terserang DD apabila terjadi pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,512 untuk kelas DD dan 0,488 untuk kelas DBD. Begitu juga sebaliknya untuk kecenderungan penderita positif DBD justru terjadi bila tidak ada pendarahan dengan perbandingan nilai 0,501 untuk kelas DBD dan 0,499 untuk kelas DD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 0,672 untuk kelas DBD dan 0,328 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai pada selang adalah 0,677 untuk kelas DD dan 0,323 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi kedua sebagai klasifikasi pada data pengujian S2
menghasilkan akurasi sebesar 66,67%. Dari keseluruhan jumlah data pengujian S2 sebanyak
21 instances, ditemukan 14 instances sebagai data yang diklasifikasi benar.
Iterasi Ketiga
Pada iterasi ketiga, himpunan bagian S1 dan
himpunan bagian S2 digunakan sebagai data
pelatihan sedangkan himpunan bagian S3
digunakan sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian pada iterasi ini disajikan pada Tabel 8.
Tabel 8 Komposisi jumlah instances tahap pertama iterasi ketiga
Kelas Pelatihan Pengujian
DBD 21 instances 11 instances
DD 21 instances 11 instances
Pada Lampiran 4, data yang digunakan untuk pelatihan pada tahap pertama iterasi ketiga ini adalah gabungan dari himpunan bagian S1 dan S2 dengan kasus DBD dari nomor
untuk kasus DBD dan nomor 54 sampai 64 untuk kasus DD.
Proses pelatihan menghasilkan selang-selang fitur. Seperti pada iterasi pertama dan iterasi kedua, setiap selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 9.
Hampir sama dengan hasil yang didapat pada iterasi pertama dan iterasi kedua, nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan kurang dari 36,5 ºC dan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu 36,5 ºC sampai 39 ºC merujuk pada kelas DBD. Penyebab munculnya kecenderungan ini sama seperti yang sudah dijelaskan pada iterasi pertama dan iterasi kedua.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang tidak ada yang mencerminkan kecenderungan fitur ini untuk menjadi ciri khas dari kelas DBD dan kelas DD. Nilai yang dihasilkan setiap interval baik pada kelas DBD maupun kelas DD adalah 0,5.
Seperti pada iterasi pertama dan iterasi kedua, kecenderungan yang muncul pada fitur pendarahan bisa dikatakan tidak tepat karena nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita terserang DD apabila terjadi pendarahan dengan perbandingan nilai 0,6 untuk kelas DD dan 0,4 untuk kelas DBD. Kecenderungan penderita positif DBD justru terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,514 untuk kelas DBD dan 0,486 untuk kelas DD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 0,593 untuk kelas DBD dan 0,407 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0,667 untuk kelas DD dan 0,333 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi ketiga sebagai klasifikasi pada data pengujian S3
menghasilkan akurasi sebesar 63,64%. Dari keseluruhan jumlah data pengujian S3 sebanyak
22 instances, ditemukan 14 instances sebagai data yang diklasifikasi benar.
Pengujian Tahap Kedua
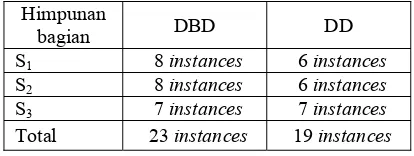
Pada tahap ini akan dilakukan pengujian terhadap data setelah validasi. Pembagian data keseluruhan secara acak menghasilkan subset-subset yang masing-masing memiliki jumlah instances yang hampir sama. Hasil pembagian data tahap kedua disajikan pada Tabel 9.
Tabel 9 Hasil pembagian data tahap kedua Himpunan
bagian DBD DD
S1 8 instances 6 instances
S2 8 instances 6 instances
S3 7 instances 7 instances
Total 23 instances 19 instances
Pada Lampiran 5, himpunan bagian S1 untuk
kasus DBD adalah data dari nomor 1 sampai 8, sedangkan untuk kasus DD adalah data dari nomor 24 sampai 29. Himpunan bagian S2
terdiri dari data kasus DBD dari nomor 9 sampai 16 dan kasus DD dari nomor 30 sampai 35. Himpunan bagian S3 terdiri dari data kasus
DBD dari nomor 17 sampai 23 dan kasus DD dari nomor 36 sampai 42.
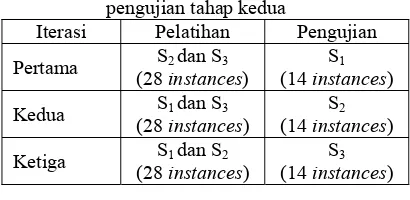
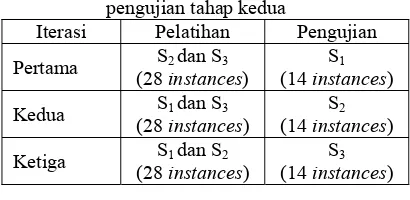
Seperti pengujian tahap pertama, pada pengujian tahap kedua ini pelatihan dan pengujian data dilakukan sebanyak 3 kali. Susunan data yang digunakan sebagai data pelatihan dan data pengujian padasetiap iterasi disajikan pada Tabel 10.
Tabel 10 Susunan data pelatihan dan data pengujian tahap kedua
Iterasi Pelatihan Pengujian
Pertama S2 dan S3 (28 instances)
S1
(14 instances)
Kedua S1 dan S3 (28 instances)
S2
(14 instances)
Ketiga S1 dan S2 (28 instances)
S3
(14 instances)
Nilai-nilai distribusi yang dihasilkan setiap fitur pada selang baik pada iterasi pertama, kedua maupun ketiga jauh lebih baik dan lebih jelas terlihat kecenderungannya daripada pengujian tahap pertama. Hal ini disebabkan karena adanya validasi data dimana data dengan nilai yang tidak konsisten dengan kelasnya dihilangkan.
pendarahan bisa dijadikan kesimpulan klinis untuk menjadi ciri khas gejala DBD.
Hasil pengujian keseluruhan data setelah validasi tanpa adanya persebaran 3 instances yang salah diklasifikasi baik dari iterasi pertama, kedua maupun ketiga dapat dilihat pada Lampiran 10. Dari keseluruhan jumlah data setelah validasi yaitu sebanyak 42 instances, ditemukan 39 instances sebagai data yang diklasifikasi benar. Rata-rata akurasi yang dihasilkan pada pengujian tahap kedua ini dapat dilihat pada Tabel 11.
Tabel 11 Akurasi dari setiap iterasi tahap kedua
Iterasi Akurasi Pertama 100%
Kedua 78,57 %
Ketiga 100% Rata-rata 92,86%
Iterasi Pertama
Pada iterasi pertama, himpunan bagian S2
dan himpunan bagian S3 digunakan sebagai data
pelatihan sedangkan himpunan bagian S1
digunakan sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian pada iterasi ini disajikan pada Tabel 12.
Tabel 12 Komposisi jumlah instances tahap kedua iterasi pertama
Kelas Pelatihan Pengujian
DBD 15 instances 8 instances DD 13 instances 6 instances
Pada Lampiran 5, data yang digunakan untuk pelatihan pada tahap kedua iterasi pertama ini adalah gabungan dari himpunan bagian S2 dan S3 dengan kasus DBD dari nomor
9 sampai 23 dan kasus DD dari nomor 30 sampai 42. Data pengujiannya adalah himpunan bagian S1 yaitu data dari nomor 1 sampai 8
untuk kasus DBD dan nomor 24 sampai 29 untuk kasus DD.
Proses pelatihan pada iterasi pertama menghasilkan selang-selang fitur. Setiap selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 11.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu antara 36,4 ºC sampai 39 ºC merujuk pada kelas DBD. Kecenderungan yang muncul untuk fitur demam pada tahap
kedua iterasi pertama ini sama seperti kecenderungan yang terlihat pada pengujian tahap pertama, yaitu bahwa pada suhu rendah dan suhu tinggi penderita terserang DD dan pada suhu sedang penderita positif DBD. Faktor-faktor yang menyebabkan kecenderungan ini sama seperti yang sudah dijabarkan sebelumnya pada pengujian tahap pertama.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, penderita cenderung DD bila tidak ditemukan bercak di tubuhnya dengan perbandingan nilai yang kurang signifikan, yaitu 0,6 untuk kelas DD dan 0,4 untuk kelas DBD.
Bila pada pengujian tahap pertama kecenderungan yang dihasilkan oleh fitur pendarahan kurang tepat, maka pada pengujian tahap kedua ini, kecenderungan yang muncul pada fitur pendarahan bisa dijadikan kesimpulan klinis untuk menjadi ciri khas gejala DBD. Nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD apabila terjadi pendarahan dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Begitu juga sebaliknya, kecenderungan penderita DD terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,517 untuk kelas DD dan 0,483 untuk kelas DBD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0 untuk kelas DD dan 1 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi pertama sebagai klasifikasi pada data pengujian S1 menghasilkan akurasi sebesar 100%. Hal ini
berarti prediksi kelas sebagai hasil klasifikasi yang dilakukan oleh algoritma VFI5 sama dengan kelas sebenarnya untuk seluruh data pengujian S1.
Iterasi Kedua
Pada iterasi kedua, himpunan bagian S1 dan
himpunan bagian S3 digunakan sebagai data
pelatihan sedangkan himpunan bagian S2
jumlah instances per kelas pada data pelatihan dan data pengujian pada iterasi ini disajikan pada Tabel 13.
Tabel 13 Komposisi jumlah instances tahap kedua iterasi kedua
Kelas Pelatihan Pengujian
DBD 15 instances 8 instances DD 13 instances 6 instances
Pada Lampiran 5, data yang digunakan untuk pelatihan pada tahap kedua iterasi kedua adalah gabungan dari himpunan bagian S1 dan
S3, yaitu data dari nomor 1 sampai 8 serta 17
sampai 23 untuk kasus DBD dan data dari nomor 24 sampai 29 serta 36 sampai 42 untuk kasus DD. Data pengujiannya adalah himpunan bagian S2 yaitu data dari nomor 9 sampai 16
untuk kasus DBD dan nomor 30 sampai 35 untuk kasus DD.
Seperti pada iterasi pertama, proses pelatihan pada iterasi ini menghasilkan selang-selang fitur. Setiap selang-selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 12.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan 36,2 ºC dan lebih dari 38,2 ºC merujuk pada kelas DD, sedangkan pada suhu antara 36,4 ºC sampai 38,2 ºC merujuk pada kelas DBD. Kecenderungan ini sama seperti kecenderungan yang terlihat pada proses pengujian sebelumnya yaitu pada suhu rendah dan suhu tinggi penderita terserang DD, sedangkan pada suhu sedang penderita positif DBD, demikian pula dengan penyebab munculnya kecenderungan ini.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, penderita cenderung DD bila tidak ditemukan bercak di tubuhnya dengan perbandingan nilai yang kurang signifikan, yaitu 0,6 untuk kelas DD dan 0,4 untuk kelas DBD.
Nilai-nilai distribusi fitur pendarahan pada selang mencerminkan kecenderungan bahwa penderita positif DBD apabila terjadi pendarahan dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Begitu juga sebaliknya untuk kecenderungan penderita DD terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu
0,517 untuk kelas DD dan 0,483 untuk kelas DBD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0 untuk kelas DD dan 1 untuk kelas DBD.
Akurasi yang dihasilkan pada pengujian tahap kedua iterasi kedua ini adalah sebesar 78,57%. Dari 14 instances, ditemukan 11 instances sebagai data yang diklasifikasi benar. Tiga instances yang kelas prediksinya tidak sesuai dengan kelas sebenarnya dapat dilihat pada Lampiran 10. Hasil pengujian algoritma VFI5 untuk 3 instances yang salah diklasifikasi tersebut disajikan pada Lampiran 13.
Ketiga instances yang salah diklasifikasi oleh algoritma VFI5 tersebut termasuk ke dalam kelas DD, sedangkan kelas sebenarnya dari instances tersebut adalah kelas DBD. Normalisasi tiga instances pengujian ini disajikan pada Tabel 14.
Tabel 14 Normalisasi tiga instances pengujian Fitur instances
1 2 3 4 DBD DD
39.0 0 0 1 0,47 0,53 38.5 0 0 1 0,47 0,53 38.7 0 0 1 0,47 0,53 Keterangan fitur :
1 = demam 3 = pendarahan 2 = bercak 4 = uji tornikuet
Dari Tabel 14 dapat dilihat bahwa nilai normalisasi ketiga instances mendekati 0,5. Ini berarti ketiga instances tersebut mempunyai peluang yang hampir sama untuk menjadi kelas DBD maupun kelas DD.
Tiga instances tersebut berada pada satu data pengujian yaitu S2. Ternyata akurasi yang
dihasilkan apabila ketiga instances yang salah diklasifikasi tersebut berada pada satu data pengujian hanya mencapai 78,57%. Oleh karena itu pada tahap pengujian selanjutnya, ketiga instances salah klasifikasi tersebut akan disebar pada 3 data pengujian yang berbeda.
Iterasi Ketiga
Pada iterasi ketiga, himpunan bagian S1 dan
himpunan bagian S2 digunakan sebagai data
pelatihan sedangkan himpunan bagian S3
dan data pengujian pada iterasi ini disajikan pada Tabel 15.
Tabel 15 Komposisi jumlah instances tahap kedua iterasi ketiga
Kelas Pelatihan Pengujian
DBD 16 instances 7 instances DD 14 instances 7 instances
Pada Lampiran 5, data yang digunakan untuk pelatihan pada tahap kedua iterasi ketiga ini adalah gabungan dari himpunan bagian S1
dan S2 dengan kasus DBD dari nomor 1 sampai
16 dan kasus DD dari nomor 24 sampai 35. Data pengujiannya adalah himpunan bagian S3
yaitu data dari nomor 17 sampai 23 untuk kasus DBD dan nomor 36 sampai 42 untuk kasus DD.
Proses pelatihan pada iterasi ini menghasilkan selang-selang fitur. Seperti pada iterasi pertama dan iterasi kedua, setiap selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 14.
Hampir sama dengan hasil yang didapat pada iterasi pertama dan iterasi kedua, nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan 36,2 ºC dan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu 36,5 ºC sampai pada suhu badan kurang dari 39 ºC merujuk pada kelas DBD. Penyebab munculnya kecenderungan ini sama seperti yang sudah dijelaskan pada iterasi pertama dan iterasi kedua.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, penderita cenderung DD bila tidak ditemukan bercak di tubuhnya dengan perbandingan nilai yang kurang signifikan, yaitu 0,533 untuk kelas DD dan 0,467 untuk kelas DBD.
Nilai-nilai distribusi fitur pendarahan pada selang mencerminkan kecenderungan bahwa penderita positif DBD apabila terjadi pendarahan dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Kecenderungan penderita DD terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,533 untuk kelas DD dan 0,467 untuk kelas DBD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang
mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0 untuk kelas DD dan 1 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi ketiga sebagai klasifikasi pada data pengujian S3
menghasilkan akurasi sebesar 100%. Hal ini berarti prediksi kelas sebagai hasil klasifikasi yang dilakukan oleh algoritma VFI5 sama dengan kelas sebenarnya untuk seluruh data pengujian S3.
Pengujian Tahap Ketiga
Dari hasil pengujian tahap kedua, ditemukan 3 instances yang salah diklasifikasi dimana ketiga instances tersebut berada pada satu data pengujian yang sama. Pada tahap ini, ketiga instances tersebut akan disebar pada 3 data pengujian yang berbeda, sehingga masing-masing data pengujian mengandung satu instances yang salah diklasifikasi.
Pembagian data keseluruhan setelah validasi dengan persebaran menghasilkan subset-subset yang masing-masing memiliki jumlah instances yang hampir sama. Hasil pembagian data tahap ketiga disajikan pada Tabel 16.
Tabel 16 Hasil pembagian data tahap ketiga Himpunan
bagian DBD DD
S1 8 instances 6 instances
S2 8 instances 6 instances
S3 7 instances 7 instances
Total 23 instances 19 instances
Pada Lampiran 15, himpunan bagian S1
untuk kasus DBD adalah data dari nomor 1 sampai 8, sedangkan untuk kasus DD adalah data dari nomor 24 sampai 29. Himpunan bagian S2 terdiri dari data kasus DBD dari
nomor 9 sampai 16 dan kasus DD dari nomor 30 sampai 35. Himpunan bagian S3 terdiri dari
data kasus DBD dari nomor 17 sampai 23 dan kasus DD dari nomor 36 sampai 42.
Seperti pada proses pengujian sebelumnya, pada penelitian ini pelatihan dan pengujian data dilakukan sebanyak 3 kali. Susunan data yang digunakan sebagai data pelatihan dan data pengujian pada setiap iterasi disajikan pada Tabel 17.
diklasifikasi pada tahap kedua tidak semuanya diklasifikasi salah pada pengujian tahap ketiga.
Tabel 17 Susunan data pelatihan dan data pengujian tahap ketiga
Iterasi Pelatihan Pengujian
Pertama S2 dan S3
(28 instances)
S1
(14 instances)
Kedua S1 dan S3 (28 instances)
S2
(14 instances)
Ketiga S1 dan S2 (28 instances)
S3
(14 instances)
Dari keseluruhan jumlah data setelah validasi yaitu sebanyak 42 instances, ditemukan 41 instances sebagai data yang diklasifikasi benar dengan akurasi 97,62%. Akurasi yang dihasilkan ketika ketiga instances yang salah diklasifikasi tersebut disebar pada data pengujian yang berbeda jauh lebih baik daripada bila ketiga instances tersebut berada pada satu data pengujian yang sama. Akurasi yang dihasilkan pada proses pengujian tahap ketiga disajikan pada Tabel 18.
Tabel 18 Akurasi dari setiap iterasi tahap ketiga
Iterasi Akurasi Pertama 92,86%
Kedua 100 %
Ketiga 100% Rata-rata 97,62%
Iterasi Pertama
Pada iterasi ini, himpunan bagian S2 dan
himpunan bagian S3 digunakan sebagai data
pelatihan sedangkan himpunan bagian S1
digunakan sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian iterasi pertama disajikan pada Tabel 19.
Tabel 19 Komposisi jumlah instances tahap ketiga iterasi pertama
Kelas Pelatihan Pengujian
DBD 15 instances 8 instances DD 13 instances 6 instances
Pada Lampiran 15, data yang digunakan untuk pelatihan pada tahap ketiga iterasi pertama ini adalah gabungan dari himpunan bagian S2 dan S3 dengan kasus DBD dari nomor
9 sampai 23 dan kasus DD dari nomor 30 sampai 42. Data pengujiannya adalah himpunan bagian S1 yaitu data dari nomor 1 sampai 8
untuk kasus DBD dan nomor 24 sampai 29 untuk kasus DD.
Proses pelatihan pada iterasi pertama menghasilkan selang-selang fitur. Setiap selang suatu fitur tertentu memiliki nilai-nilai yang
didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 17.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan lebih dari 38,7 ºC merujuk pada kelas DD, sedangkan pada suhu antara 36,4 ºC sampai 38,7 ºC merujuk pada kelas DBD. Hasil ini hampir sama dengan kecenderungan yang dihasilkan pada proses pengujian sebelumnya, begitu juga dengan penyebab munculnya kecenderungan ini.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, penderita cenderung DD bila tidak ditemukan bercak di tubuhnya dengan perbandingan nilai 0,625 untuk kelas DD dan 0,375 untuk kelas DBD.
Untuk fitur pendarahan, kecenderungan yang muncul sama seperti kecenderungan yang dihasilkan pada pengujian tahap kedua. Nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD apabila terjadi pendarahan dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Begitu juga sebaliknya untuk kecenderungan penderita DD terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,517 untuk kelas DD dan 0,483 untuk kelas DBD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0 untuk kelas DD dan 1 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi pertama sebagai klasifikasi pada data pengujian S1 menghasilkan akurasi sebesar 92,86%. Dari
keseluruhan jumlah data pengujian S1 sebanyak
14 instances, ditemukan 13 instances sebagai data yang diklasifikasi benar. Satu instance yang diklasifikasi salah dapat dilihat pada Lampiran 16. Hasil pengujian instances tersebut disajikan pada Tabel 20.
diklasifikasi tersebut termasuk ke dalam kelas DD, sedangkan kelas sebenarnya adalah kelas DBD. Hal ini disebabkan karena nilai fitur demam instances tersebut merujuk pada kelas DD.
Tabel 20 Hasil pengujian instances salah klasifikasi tahap ketiga
Instances (39; 0; 0; 1) Fitur
DBD DD Demam 0 1
Bercak 0,375 0,625
Pendarahan 0,483 0,517
Uji tornikuet 1 0 Total vote 1,858 2,142
Normalisasi instances pengujian tersebut disajikan pada Tabel 21.
Tabel 21 Normalisasi instances pengujian salah klasifikasi
Fitur instances
1 2 3 4 DBD DD
39.0 0 0 1 0,46 0,54 Keterangan fitur :
1 = demam 3 = pendarahan 2 = bercak 4 = uji tornikuet
Dari Tabel 21 dapat dilihat bahwa instances pengujian yang salah diklasifikasi ini memiliki nilai normalisasi yang mendekati 0.5 untuk setiap kelasnya. Ini berarti instances tersebut mempunyai peluang yang hampir sama untuk menjadi kelas DBD maupun kelas DD.
Iterasi Kedua
Pada iterasi kedua, himpunan bagian S1 dan
himpunan bagian S3 digunakan sebagai data
pelatihan sedangkan himpunan bagian S2
digunakan sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian pada iterasi ini disajikan pada Tabel 22.
Tabel 22 Komposisi jumlah instances tahap ketiga iterasi kedua
Kelas Pelatihan Pengujian
DBD 15 instances 8 instances
DD 13 instances 6 instances
Pada Lampiran 15, data yang digunakan untuk pelatihan pada tahap ketiga iterasi kedua adalah gabungan dari himpunan bagian S1 dan
S3, yaitu data dari nomor 1 sampai 8 serta 17
sampai 23 untuk kasus DBD dan data dari nomor 24 sampai 29 serta 36 sampai 42 untuk kasus DD. Data pengujiannya adalah himpunan bagian S2 yaitu data dari nomor 9 sampai 16
untuk kasus DBD dan nomor 30 sampai 35 untuk kasus DD.
Seperti pada iterasi pertama, proses pelatihan pada iterasi ini menghasilkan selang-selang fitur. Setiap selang-selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 18.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan kurang dari 36,5 ºC, 39 ºC dan 39,7 ºC merujuk pada kelas DD, sedangkan pada suhu antara 36,5 ºC sampai 39 ºC merujuk pada kelas DBD. Kecenderungan ini sama seperti kecenderungan yang terlihat pada pengujian data sebelumnya yaitu pada suhu rendah dan suhu tinggi penderita cenderung DD sedangkan pada suhu sedang penderita cenderung DBD, demikian pula dengan penyebab munculnya kecenderungan ini.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, penderita cenderung DD bila tidak ditemukan bercak di tubuhnya dengan perbandingan nilai yang kurang signifikan yaitu 0,556 untuk kelas DD dan 0,444 untuk kelas DBD.
Pada fitur pendarahan, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD apabila terjadi pendarahan dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Begitu juga sebaliknya kecenderungan penderita DD terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,517 untuk kelas DD dan 0,483 untuk kelas DBD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0 untuk kelas DD dan 1 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi kedua sebagai klasifikasi pada data pengujian S2
menghasilkan akurasi sebesar 100%. Satu instances salah klasifikasi yang telah dimasukkan pada data pengujian S2, ternyata
berarti prediksi kelas sebagai hasil klasifikasi yang dilakukan oleh algoritma VFI5 sama dengan kelas sebenarnya untuk seluruh data pengujian S2.
Iterasi Ketiga
Pada iterasi ketiga, himpunan bagian S1 dan
himpunan bagian S2 digunakan sebagai data
pelatihan sedangkan himpunan bagian S3
digunakan sebagai data pengujian. Komposisi jumlah instances per kelas pada data pelatihan dan data pengujian pada iterasi ini disajikan pada Tabel 23.
Tabel 23 Komposisi jumlah instances tahap ketiga iterasi ketiga
Kelas Pelatihan Pengujian
DBD 16 instances 7 instances DD 14 instances 7 instances
Pada Lampiran 15, data yang digunakan untuk pelatihan pada tahap ketiga iterasi ketiga ini adalah gabungan dari himpunan bagian S1
dan S2 dengan kasus DBD dari nomor 1 sampai
16 dan kasus DD dari nomor 24 sampai 35. Data pengujiannya adalah himpunan bagian S3
yaitu data dari nomor 17 sampai 23 untuk kasus DBD dan nomor 36 sampai 42 untuk kasus DD.
Proses pelatihan pada iterasi ini menghasilkan selang-selang fitur. Seperti pada iterasi pertama dan iterasi kedua, setiap selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 19.
Hampir sama dengan hasil yang didapat pada iterasi pertama dan iterasi kedua, nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan 36,2 ºC dan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu 36,4 ºC sampai pada suhu badan kurang dari 39 ºC merujuk pada kelas DBD. Penyebab munculnya kecenderungan ini sama seperti yang sudah dijelaskan pada proses pengujian sebelumnya.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, penderita cenderung DD bila tidak ditemukan bercak di tubuhnya dengan perbandingan nilai yang kurang signifikan yaitu 0,552 untuk kelas DD dan 0,448 untuk kelas DBD.
Pada fitur pendarahan, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD apabila terjadi pendarahan dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Begitu juga sebaliknya kecenderungan penderita DD terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,533 untuk kelas DD dan 0,467 untuk kelas DBD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 1 untuk kelas DBD dan 0 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan nilai 0 untuk kelas DD dan 1 untuk kelas DBD.
Pengujian yang dilakukan pada iterasi ketiga sebagai klasifikasi pada data pengujian S3
menghasilkan akurasi sebesar 100%. Sama seperti yang telah dihasilkan pada iterasi kedua, satu instances salah klasifikasi yang telah dimasukkan pada data pengujian S3, ternyata
pada pengujian iterasi ketiga ini, instances tersebut bisa diklasifikasi dengan benar. Hal ini berarti prediksi kelas sebagai hasil klasifikasi yang dilakukan oleh algoritma VFI5 sama dengan kelas sebenarnya untuk seluruh data pengujian S3.
Pengujian Tahap Keempat
Pada tahap ini dilakukan pengujian terhadap data baik sebelum validasi maupun setelah validasi dengan pembagian data latih dan data uji seperti pada penelitian Syafii (2006). Susunan data yang digunakan sebagai data pelatihan dan data pengujian disajikan pada Tabel 24.
Tabel 24 Susunan data pelatihan dan data pengujian tahap keempat
Data Sebelum
validasi
Setelah validasi Pelatihan 44 instances 27 instances Pengujian 20 instances 15 instances Jumlah 64 instances 42 instances
Sebelum validasi
Tabel 25 Komposisi jumlah instances tahap keempat pada data sebelum validasi
Kelas Pelatihan Pengujian
DBD 22 instances 10 instances
DD 22 instances 10 instances
Proses pelatihan pada data sebelum validasi akan menghasilkan selang-selang fitur. Setiap selang suatu fitur tertentu memiliki nilai-nilai yang didistribusikan fitur tersebut untuk kelas DBD dan kelas DD. Selang-selang tersebut beserta nilai setiap kelasnya disajikan pada Lampiran 22.
Nilai distribusi pada fitur demam menunjukkan kecenderungan bahwa pada suhu badan kurang dari 36,4 ºC dan lebih dari 39 ºC merujuk pada kelas DD, sedangkan pada suhu 36,4 ºC sampai 39 ºC merujuk pada kelas DBD. Kecenderungan ini sama seperti kecenderungan yang terlihat pada pengujian data sebelumnya yaitu pada suhu rendah dan suhu tinggi penderita cenderung DD sedangkan pada suhu sedang penderita cenderung DBD, demikian pula dengan penyebab munculnya kecenderungan ini.
Pada fitur bercak, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila ditemukan adanya bercak dengan perbandingan nilai yang kurang signifikan yaitu 0,6 untuk kelas DBD dan 0,4 untuk kelas DD. Demikian pula dengan kecenderungan penderita DD, perbandingan nilainya adalah 0,513 untuk kelas DD dan 0,487 untuk kelas DBD.
Sama seperti hasil pengujian tahap pertama, kecenderungan yang muncul pada fitur pendarahan untuk menjadi ciri khas kelas DBD bisa dikatakan tidak tepat karena nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita terserang DD apabila terjadi pendarahan dengan perbandingan nilai 0,6 untuk kelas DD dan 0,4 untuk kelas DBD. Begitu juga sebaliknya, kecenderungan penderita positif DBD justru terjadi bila tidak ada pendarahan dengan perbandingan nilai yang kurang signifikan yaitu 0,513 untuk kelas DBD dan 0,487 untuk kelas DD.
Untuk fitur uji tornikuet, nilai-nilai distribusi fitur tersebut pada selang mencerminkan kecenderungan bahwa penderita positif DBD bila hasil uji tornikuetnya positif dengan perbandingan nilai 0,586 untuk kelas DBD dan 0,414 untuk kelas DD. Sebaliknya, kecenderungan penderita DD terjadi bila hasil uji tornikuetnya negatif dengan perbandingan
nilai 0,667 untuk kelas DD dan 0,333 untuk kelas DBD.
Dari keseluruhan jumlah data pengujian sebanyak 20 instances, ditemukan 14 instances sebagai data yang diklasifikasi benar. Hasil pengujian tahap keempat untuk keseluruhan data sebelum validasi dapat dilihat pada Lampiran 23. Akurasi yang dihasilkan pada pengujian ini adalah 70%.
Setelah validasi
Data setelah validasi yang digunakan untuk pelatihan tahap