PENETAPAN STRATEGI PEMASARAN DENGAN PENDEKATAN
MODEL ATURAN POHON KEPUTUSAN MENGGUNAKAN
ALGORITMA ITERATIVE DICHOTOMIZES 3 (ID3)
DI PERGURUAN TINGGI SWASTA
TESIS
Oleh
M. S A F I I
097038008 / TIF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PENETAPAN STRATEGI PEMASARAN DENGAN PENDEKATAN
MODEL ATURAN POHON KEPUTUSAN MENGGUNAKAN
ALGORITMA ITERATIVE DICHOTOMIZES 3 (ID3)
DI PERGURUAN TINGGI SWASTA
TESIS
Diajukan sebagai salah satu syarat untuk memperoleh gelar
Magister Komputer dalam Program Studi Magister
Teknik Informatika pada Program Pascasarjana
Fakultas MIPA Universitas Sumatera Utara
Oleh
M. S A F I I
097038008 / TIF
PROGRAM STUDI MAGISTER (S2) TEKNIK INFORMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS SUMATERA UTARA
M E D A N
PENGESAHAN TESIS
Judul Tesis : Penetapan Strategi Pemasaran Dengan
Pendekatan Model Pohon Keputusan Menggunakan Algoritma Iterative
Dichotomizes (ID3) di Perguruan Tinggi Swasta
Nama Mahasiswa : M. SAFII
Nomor Induk Mahasiswa : 097038008
Program Studi : Magister Teknik Informatika
Fakultas : Matematika dan Ilmu Pengetahuan Alam
Universitas Sumatera Utara
Menyetujui Komisi Pembimbing
M. Andri Budiman, ST, M.Comp, Sc.MEM Prof. Dr. Herman Mawengkang
Anggota Ketua
Ketua Program Studi,
PERNYATAAN ORISINALITAS
PENETAPAN STRATEGI PEMASARAN DENGAN PENDEKATAN
MODEL ATURAN POHON KEPUTUSAN MENGGUNAKAN
ALGORITMA ITERATIVE DICHOTOMIZES 3 (ID3)
DI PERGURUAN TINGGI SWASTA
TESIS
Dengan ini saya nyatakan bahwa saya mengakui semua karya tesis/disertai ini adalah hasil kerja saya sendiri kecuali kutipan dan ringkasan yang tiap satunya telah di jelaskan sumbernya dengan benar.
Medan, April 2011
M. S A F I I
PERNYATAAN PERSETUJUAN PUBLIKASI KARYA ILMIAH UNTUK KEPENTINGAN
AKADEMIS
Sebagai sivitas akademika Universitas Sumatera Utara, saya yang bertanda tangan
di bawah ini:
Nama : M. S A F I I
NIM : 097038008
Program Studi : Magister Teknik Informatika
Jenis Karya Ilmiah : TESIS
Demi pengembangan ilmu pengetahuan, menyetujui untuk memberikan kepada
Universitas Sumatera Utara Hak Bebas Royalti Non-Eksklusif (Non-Exclusive
Royalty free Right) atas Tesis saya yang berjudul:
PENETAPAN STRATEGI PEMASARAN DENGAN PENDEKATAN
MODEL ATURAN POHON KEPUTUSAN MENGGUNAKAN
ALGORITMA ITERATIVE DICHOTOMIZER 3 (ID3)
DI PERGURUAN TINGGI SWASTA
Beserta perangkat yang ada (jika diperlukan). Dengan Hak Bebas Royalti
Non-Eksklusif ini, Universitas Sumatera Utara berhak menyimpan, mengalih media,
memformat, mengelola dalam bentuk data_base, merawat dan mempublikasikan
Tesis/Disertasi saya tanpa meminta izin dari saya selama tetap mencantumkan
nama saya sebagai penulis dan sebagai pemegang dan atau sebagai pemilik hak
cipta.
Demikian pernyataan ini dibuat dengan sebenarnya.
Medan, April 2011
M. S A F I I
Telah diuji pada
Tanggal : Tanggal Bulan April Tahun 2011
PANITIA PENGUJI TESIS
Ketua : Prof. Dr. Herman Mawengkang
Anggota : 1. Prof. Dr. Muhammad Zarlis
2. M. Andri Budiman, ST, M.Comp.Sc, MEM
3. Ade Candra, ST, M.Kom
RIWAYAT HIDUP
DATA PRIBADI
Nama lengkap berikut gelar : M. Safii, S.Kom
Tempat dan Tanggal Lahir : Pematangsiantar, 10 Juni 1980
Alamat Rumah : Perumahan Sibatu-batu Indah Blok G
No. 11 Pematangsiantar
Telepon/Faks/HP : +6262222431 / +6281361242311
Email : [email protected]
Instansi Tempat Bekerja : AMIK Tunas Bangsa Pematangsiantar
Alamat Kantor : Jl. Jend. Sudirman Blok A No.1,2 & 3
Pematangsiantar
Telepon/Faks/HP : +6262222431 / +6227436800
DATA PENDIDIKAN
SD : Negeri No.423195 Tamat : 1992
SMP : Muhammadiyah-19 Tamat : 1995
SMA : Yayasan Perguruan Keluarga Tamat : 1998
STRATA-1 : STMIK Multimedia Prima Tamat : 2005
KATA PENGANTAR
Alhamdulillah, puji syukur senantiasa kita panjatkan ke hadirat Allah
SWT atas segala limpahan karunia-Nya kepada kita sehingga Tesis ini dapat
diselesaikan. Kami mengucapkan terima kasih yang sebesar-besarnya kepada:
Ketua Yayasan Muhammad Nasir AMIK Tunas Bangsa Pematangsiantar
H.M.Ahmad Ridwan Syah yang telah memberikan ijin, bantuan moril dan materil
dan kesempatan kepada penulis untuk mengikuti pendidikan pada program
pascasarjana FMIPA USU.
Rektor Universitas Sumatera Utara, Prof. Dr. dr. Syahril Pasaribu,
D.T.M.&H, M.Sc.(CTM), Sp.A.(K) atas kesempatan yang diberikan kepada kami
untuk mengikuti dan menyelesaikan pendidikan Program Magister.
Dekan Fakultas MIPA Universitas Sumatera Utara, Dr. Sutarman, M.Sc.
atas kesempatan yang diberikan kepada kami menjadi mahasiswa Program
Magister pada Program Pascasarjana FMIPA Universitas Sumatera Utara.
Ketua Program Studi Magister (S2) Teknik Informatika, Prof. Dr.
Muhammad Zarlis, Sekretaris Program Studi Magister (S2) Teknik Informatika
Mohammad Andri Budiman, ST, M.Comp.Sc, M.E.M beserta seluruh Staff
Pengajar pada Program Studi Magister (S2) Teknik Informatika Program
Pascasarjana Fakultas MIPA Universitas Sumatera Utara.
Terimakasih yang tak terhingga dan penghargaan setinggi-tingginya kami
ucapkan kepada Prof. Dr. Herman Mawengkang selaku Pembimbing Utama yang
dengan penuh perhatian dan telah memberikan dorongan, bimbingan dan arahan,
demikian juga kepada Mohammad Andri Budiman, ST, M.Comp.Sc, M.E.M
selaku Pembimbing Anggota yang dengan penuh kesabaran menuntun dan
membimbing kami hingga selesainya penelitian ini.
Seluruh Staf Pengajar dan Administrasi, Program Studi Magister (S2)
Teknik Informatika Program Pascasarjana Fakultas MIPA Universitas Sumatera
Utara yang telah memberikan bantuan dan pelayanan yang baik kepada penulis
Kepada Ayahanda Surdi , Ibunda Asri, Bapak / Ibu Mertua dan isteri
tersayang Widya Astuti beserta kedua anak tercinta Sasha Aiko Leana dan Akilah
Aish, terimakasih atas segala pengorbanan berupa moril maupun materil, budi
baik ini tidak dapat dibalas hanya diserahkan kepada Allah SWT, Tuhan Yang
maha Esa.
Seluruh Mahasiswa Angkatan Pertama Program Studi Magister (S2)
Teknik Informatika Komputer FMIPA Universitas Sumatera Utara dan Rekan
Sejawat di AMIK Tunas Bangsa Pematangsiantar yang telah banyak membantu
penulis selama mengikuti perkuliahan.
Kepada semua pihak yang tidak dapat penulis sebutkan satu persatu dalam
tesis ini, terima kasih atas segala bantuan yang diberikan. Sekecil apapun yang
Anda berikan untuk penulis turut menghantarkan penulis untuk menyelesaikan
pendidikan yang ditempuh selama ini. Dengan segala kekurangan dan kerendahan
hati, semoga kiranya Allah SWT Tuhan Yang Maha Kuasa membalas segala
bantuan, kebaikan yang telah diberikan.
Semoga karya ilmiah yang kami susun dapat memberikan manfaat bagi
banyak pihak, sekaligus dicatat sebagai bagian dari amal kebajikan kita, Amien.
Medan, April 2011 Penulis,
PENETAPAN STRATEGI PEMASARAN DENGAN PENDEKATAN MODEL ATURAN POHON KEPUTUSAN MENGGUNAKAN
ALGORITMA ITERATIVE DICHOTOMIZES 3 (ID3) DI PERGURUAN TINGGI SWASTA
ABSTRAK
Pencapaian target jumlah mahasiswa baru pada perguruan tinggi swasta adalah hal yang prioritas disebabkan banyaknya perguruan tinggi swasta di Indonesia. Sesuai dengan data dikti.go.id keberadaan perguruan tinggi swasta saat ini adalah 2.913 PTS di seluruh Indonesia dan 234 di Sumatera Utara. Dengan jumlah tersebut maka pihak perguruan tinggi harus bisa mempertahankan pasar dan menciptakan
brand image dimasyarakat. Konsep pohon merupakan salah satu konsep teori graf yang paling penting. Pemanfaatan struktur pohon dalam kehidupan sehari-hari adalah untuk menggambarkan hierarki dan memodelkan persoalan, contohnya pohon keputusan (decision tree). Algoritma Iterative dichotomizes 3 ( ID3 )
merupakan suatu metode dalam learning yang akan membangun sebuah pohon keputusan untuk pemodelan dalam mencari solusi dari persoalan. Kegiatan analisis kemahasiswaan diperlukan untuk mendapatkan keputusan yang bersifat menguntungkan demi maju dan berkembangnya suatu perguruan tinggi dan analisis penerimaan mahasiswa baru tersebut dapat dilakukan melalui berbagai metode, salah satunya dengan decision tree menggunakan algoritma ID3 (Iterative Dichotomizes 3) yang akan memperlihatkan pemakaian pohon keputusan untuk memudahkan pengambilan keputusan penerimaan mahasiswa baru pada perguruan tinggi. Dari beberapa metode teknik pemasaran yang diimplementasikan akan diperoleh penetapan strategi yang paling efektif.
DETERMINING MARKETING STRATEGIES WITH RULES MODEL APPROACH OF DECISION TREE USING ALGORITHM
ITERATIVE DICHOTOMIZES (ID3) AT PRIVATE UNIVERSITIES
ABSTRACT
Achieving the target number of new students in private colleges is a priority because there are many private universities in Indonesia. In accordance with the data issued from dikti.go.id, the availability of private universities today is 2.913 throughout Indonesia and 234 in North Sumatra. With this number the university should be able to sustain the market and create a brand image in the community. The Tree concept of is one of the most important concept of graph theory. The utilization of tree structure in everyday life is to describe hierarchy and to model problem, for example, decision tree. Iterative algorithms dichotomizes 3 (ID3) is a method of learning that will build a decision tree for modeling in finding solutions to problems. Student analysis activity is required to obtain a beneficial decision for the advance and development of a college can be carried out through various methods, one of which is with decision tree algorithm ID3 (Iterative Dichotomizes 3) which will demonstrate the use of decision trees to facilitate decision making for new student admission at universities. Of several methods marketing techniques implemented will be obtained the most effective determining strategy.
DAFTAR ISI
Halaman
KATA PENGANTAR i
ABSTRAK iii
DAFTAR ISI iv
DAFTAR TABEL vi
DAFTAR GAMBAR vii
DAFTAR LAMPIRAN viii
BAB I PENDAHULUAN 1
1.1. Latar Belakang Masalah 1
1.2. Rumusan Masalah 3
1.3. Batasan Masalah 4
1.4. Tujuan 4
1.5. Manfaat 4
BAB II TINJAUAN PUSTAKA 6
2.1. Data Mining 6
2.2. Teknik Data Mining 9
2.3. Pohon Keputusan 10
2.4. Algoritma Iterative Dichotomizes Versi 3 (ID3) 13
2.5. Entropy 14
2.6. Information Gain 16
2.7. Riset-riset Terkait 17
BAB III METODOLOGI PENELITIAN 19
3.1. Lokasi dan Waktu Penelitian 19
3.2. Rancangan Penelitian 20
3.3. Prosedur Pengumpulan Data 21
3.4. Alat Analisis Data 21
3.5. Instrumen Penelitian 22
3.7. Perancangan Model 23
3.8. Model Text 23
BAB IV. ANALISIS DAN HASIL 24
4.1. Analisis 24
4.2. Hasil Percobaan 24
4.2.1. Hasil Percobaan Training Data 27
4.2.2. Hasil Percobaan Testing Data 28
4.2.3. Signifikansi 31
4.2.4. Multicollinearity 32
4.2.5. Implementasi ID3 33
4.2.6. Hasil Percobaan Decision Tree 35
BAB V. KESIMPULAN DAN SARAN 41
5.1. Kesimpulan 41
5.2. Saran 42
Daftar Pustaka 43
DAFTAR TABEL
Nomor J u d u l Halaman
4.1. Kuesioner Fasilitas Kampus ... 25
4.2. Statistic Reliabilitas data... 30
4.3. Korelasi Signifikan ... 31
4.4. Signifikan Variabel Prediktor Minat ... 32
4.5. Multocollinearity Diagnostik ... 32
4.6. Pengukuran Terhadap Minat ... 33
DAFTAR GAMBAR
Nomor J u d u l Halaman
2.1. Tahap-tahap KDD didalam Database ... 8
2.2. Model Pohon Keputusan ... 12
2.3. Algoritma ID3 ... 14
3.1. Program Sistem Informasi PMB ... 20
3.2. Aturan (Rule) Penerimaan Mahasiswa Baru ... 20
3.3. Alur Kerangka Kerja Penelitian ... 22
3.4. Graph View Data ... 23
3.5. Model Text ... 23
4.1. Formula Cronbach Alpha ... 24
4.2. Nilai Uji Reliabilitas ... 26
4.3. Reliability Statistics Fasilitas Kampus... 27
4.4. Reliability Statistics Dukungan Pihak Sekolah ... 27
4.5. Reliability Statistics Dukungan Keluarga ... 28
4.6. Reliability Statistics Dukungan Minat ... 28
4.7. Reliability Statistics Fasilitas Kampus ... 29
4.8. Reliability Statistics Dukungan Pihak Sekolah... 29
4.9. Reliability Statistics Dukungan Keluarga ... 30
4.10. Reliability Statistics Dukungan Minat ... 30
4.11. Manual Decision Tree ... 34
4.12. Grafik Decision Tree ... 35
4.13. Model Aturan Teks Decision Tree Terhadap Minat... 36
4.14. Model Aturan Induction rule Terhadap Minat ... 37
4.15. Grafik Decision Tree Media Publikasi ... 37
4.16. Model Aturan Teks Media Publikasi... 39
DAFTAR LAMPIRAN
Nomor J u d u l Halaman
A Contoh Formulir Penerimaan Mahasiswa Baru L- 1
B Contoh Kuesioner L- 2
C Hasil Percobaan Training Data L- 4
D Hasil Percobaan Testing Data L-14
PENETAPAN STRATEGI PEMASARAN DENGAN PENDEKATAN MODEL ATURAN POHON KEPUTUSAN MENGGUNAKAN
ALGORITMA ITERATIVE DICHOTOMIZES 3 (ID3) DI PERGURUAN TINGGI SWASTA
ABSTRAK
Pencapaian target jumlah mahasiswa baru pada perguruan tinggi swasta adalah hal yang prioritas disebabkan banyaknya perguruan tinggi swasta di Indonesia. Sesuai dengan data dikti.go.id keberadaan perguruan tinggi swasta saat ini adalah 2.913 PTS di seluruh Indonesia dan 234 di Sumatera Utara. Dengan jumlah tersebut maka pihak perguruan tinggi harus bisa mempertahankan pasar dan menciptakan
brand image dimasyarakat. Konsep pohon merupakan salah satu konsep teori graf yang paling penting. Pemanfaatan struktur pohon dalam kehidupan sehari-hari adalah untuk menggambarkan hierarki dan memodelkan persoalan, contohnya pohon keputusan (decision tree). Algoritma Iterative dichotomizes 3 ( ID3 )
merupakan suatu metode dalam learning yang akan membangun sebuah pohon keputusan untuk pemodelan dalam mencari solusi dari persoalan. Kegiatan analisis kemahasiswaan diperlukan untuk mendapatkan keputusan yang bersifat menguntungkan demi maju dan berkembangnya suatu perguruan tinggi dan analisis penerimaan mahasiswa baru tersebut dapat dilakukan melalui berbagai metode, salah satunya dengan decision tree menggunakan algoritma ID3 (Iterative Dichotomizes 3) yang akan memperlihatkan pemakaian pohon keputusan untuk memudahkan pengambilan keputusan penerimaan mahasiswa baru pada perguruan tinggi. Dari beberapa metode teknik pemasaran yang diimplementasikan akan diperoleh penetapan strategi yang paling efektif.
DETERMINING MARKETING STRATEGIES WITH RULES MODEL APPROACH OF DECISION TREE USING ALGORITHM
ITERATIVE DICHOTOMIZES (ID3) AT PRIVATE UNIVERSITIES
ABSTRACT
Achieving the target number of new students in private colleges is a priority because there are many private universities in Indonesia. In accordance with the data issued from dikti.go.id, the availability of private universities today is 2.913 throughout Indonesia and 234 in North Sumatra. With this number the university should be able to sustain the market and create a brand image in the community. The Tree concept of is one of the most important concept of graph theory. The utilization of tree structure in everyday life is to describe hierarchy and to model problem, for example, decision tree. Iterative algorithms dichotomizes 3 (ID3) is a method of learning that will build a decision tree for modeling in finding solutions to problems. Student analysis activity is required to obtain a beneficial decision for the advance and development of a college can be carried out through various methods, one of which is with decision tree algorithm ID3 (Iterative Dichotomizes 3) which will demonstrate the use of decision trees to facilitate decision making for new student admission at universities. Of several methods marketing techniques implemented will be obtained the most effective determining strategy.
BAB 1
PENDAHULUAN
1.1. Latar Belakang Masalah
Akademi Manajemen Informatika Komputer Tunas Bangsa atau disingkat dengan
AMIK Tunas Bangsa adalah salah satu perguruan tinggi swasta di Sumatera Utara
yang menyelenggarakan perkuliahan jenjang Diploma 3 dengan program studi
manajemen informatika dan komputerisasi akuntansi. Sejak berdiri tahun 2003
sampai saat ini jumlah mahasiswa/I kedua program sudi tersebut telah mencapai
±1.400 orang (EPSBED,2010). Dalam mempertahankan dan meningkatkan
jumlah mahasiswa perlu dibuat sebuah metode dalam proses penerimaan
mahasiswa baru setiap tahunnya. Tanpa adanya jumlah mahasiswa yang memadai
maka mustahil bagi perguruan tinggi swasta dapat menjalankan manajemennya.
Saat ini keberadaan perguruan tinggi swasta adalah 2.913 PTS di seluruh
Indonesia dan 234 di Sumatera Utara (sumber: www.dikti.go.id).
Proses penerimaan mahasiswa baru (PMB) di Akademi Manajeman
Informatika Komputer (AMIK) Tunas Bangsa terdiri dari 3 (tiga) proses yaitu
Informasi, Daftar dan Registrasi. Proses Informasi adalah apabila calon
mahasiswa tersebut berkunjung ke kampus dan mengisi formulir biodata tanpa
melakukan pembayaran apapun. Peran presenter disini sangat menentukan apakah
calon tersebut akan melakukan proses daftar atau registrasi. Proses Daftar adalah
apabila calon mahasiswa berkunjung ke kampus dan mengisi biodata serta
melakukan pembayaran yaitu biaya daftar. Pada kondisi ini calon mahasiswa
belum bisa dimasukan kedalam kelompok kelas. Proses registrasi adalah apabila
calon mahasiswa berkunjung ke kampus dan mengisi biodata serta melakukan
pembayaran biaya daftar, uang kuliah, dan biaya lainnya. Dan pada posisi ini
kelas. Kelompok kelas adalah penempatan calon mahasiswa kedalam kelas
tertentu yang merupakan bagian didalam kelompok belajar.
Pada tahap pengisian biodata, calon mahasiswa harus mengisi data seperti
asal sekolah, alamat, penghasilan orang tua, dan sumber informasi. Dari kondisi
tersebut maka bisa dilakukan pengelompokan sumber data sehingga dapat dibuat
suatu metode yang tepat untuk mempercepat pencapaian target. Sedangkan data
pedukungnya adalah kuisioner yang terdiri dari 4 (empat) kelompok pertanyaan
yaitu fasilitas kampus, dukungan sekolah, dukungan keluarga dan minat calon
mahasiswa.
Untuk mengelola data tersebut dibutuhkan sebuah metode yang bisa
digunakan untuk menggali informasi tersembunyi dari data tersebut. Metode
tersebut dikenal dengan data mining. Dengan bantuan perangkat lunak, data
mining akan melakukan proses analisis data untuk menemukan pola atau aturan
tersembunyi dalam lingkup himpunan data tersebut. Pada studi kasus ini, analisis
data mining dilakukan dengan metode pohon keputusan yang mengunakan
algoritma ID3.
Konsep pohon merupakan salah satu konsep teori graf yang paling
penting. Pemanfaatan struktur pohon dalam kehidupan sehari-hari adalah untuk
menggambarkan hierarki dan memodelkan persoalan, contohnya pohon keputusan
(decision tree). Algoritma Iterative dichotomizes 3 ( ID3 ) merupakan suatu
metode dalam learning yang akan membangun sebuah pohon keputusan untuk
pemodelan dalam mencari solusi dari persoalan. Kegiatan analisis kemahasiswaan
diperlukan untuk mendapatkan keputusan yang bersifat menguntungkan demi
maju dan berkembangnya suatu perguruan tinggi dan analisis penerimaan
mahasiswa baru tersebut dapat dilakukan melalui berbagai metode, salah satunya
dengan decision tree menggunakan algoritma ID3 (Iterative Dichotomizes 3).
Salah satu solusi memprediksi validitas alamat adalah dengan membuat
suatu sistem yang dianggap mampu melakukan prediksi suatu alamat secara tepat.
Metode decision tree dengan algoritma ID3 merupakan salah satu metode dari
data mining yang digunakan untuk mengklasifikasikan data sampel ke dalam
dilakukan penelitian untuk menganalisis keefektifitasan metode ini dalam
melakukan prediksi alamat menggunakan kelas yang terbentuk dari metode ini.
Bentuk penelitian yang dilakukan adalah dengan melihat tingkat kebenaran yang
dihasilkan oleh metode ini dalam melakukan validitas prediksi suatu alamat pada
sekumpulan data uji yang diteliti (Nugroho,2007).
Salah satu metode yang paling banyak digunakan untuk inferensi induksi
adalah Decision Tree Learning, merupakan metode untuk menganalisa fungsi
target yang bernilai diskrit, dimana fungsi pembelajarannya direpresentasikan
dalam bentuk pohon keputusan. Algoritma ID3 (Iterative Dichotomizes versi 3)
adalah algoritma yang paling banyak digunakan untuk men-generate pohon
keputusan. Algoritma ini dikenalkan oleh Ross Quinlan, menggunakan teori
informasi untuk menentukan atribut yang paling informatif. Kelemahan dari
algoritma ID3 adalah ketidakstabilannya dalam melakukan klasifikasi data apabila
terjadi sedikit perubahan pada data training (Setiawan,2007).
Berdasarkan latar belakang masalah diatas, maka penulis tertarik untuk
meneliti bidang ini dengan mengambil judul “Penetapan Strategi Pemasaran
Dengan Pendekatan Model Pohon Keputusan Algoritma Iterative
Dichotomizes 3 (ID3) di Perguruan Tinggi Swasta”.
1.2. Perumusan Masalah
Dalam kegiatan penerimaan mahasiswa baru pencapaian jumlah mahasiswa
adalah hal yang prioritas bagi perguruan tinggi swasta. Untuk peningkatan dan
pencapaian target perlu dilakukan teknik dan menetapkan metode yang sesuai
didalam mempertahankan minat calon mahasiswa. Dalam hal tersebut PTS
mengalami permasalahan yang menyangkut kebutuhan data dan informasi tentang
calon Mahasiswa, sehingga sulit untuk melakukan kegiatan-kegiatan promosi.
Permasalahan yang diangkat adalah bagaimana menetapkan metode pemasaran
dengan mengidentifikasi minat data calon mahasiswa baru yang akan diterima
pada perguruan tinggi swasta dalam hal ini penerapan media publikasi terhadap
Metode solusi yang digunakan adalah membentuk pohon keputusan dengan
algoritma Iterative Dichotomizes versi 3 (ID3).
1.3. Batasan Masalah
Untuk menghindari salah pengertian dalam penulisan tesis ini dan untuk lebih
menfokuskan terhadap permasalahan, maka fokus permasalahan dititik beratkan
pada pemanfaatan data mining dengan pendekatan model pohon keputusan
menggunakan algoritma ID3 untuk penetapan strategi pemasaran pada perguruan
tinggi swasta, meliputi:
1. Data yang akan digunakan dalam studi kasus ini adalah data calon
mahasiswa baru yang kemudian akan diolah berdasarkan proses-proses
yang ada dalam data mining.
2. Mengklasifikasikan penetapan metode pemasaran berdasakan sarana
publikasi kampus terhadap fasilitas kampus, dukungan pihak sekolah
dan dukungan keluarga.
3. Membangun sebuah pohon keputusan untuk pemodelan dalam mencari
solusi dari persoalan penerimaan mahasiswa baru.
4. Sebagai prototype sistem, studi kasus dilakukan di AMIK Tunas
Bangsa Pematangsiantar.
5. Analisis penerimaan mahasiswa baru tersebut dilakukan dengan
decision tree menggunakan algoritma Iterative Dichotomizes v.3 (ID3).
1.4. Tujuan
Tujuan penelitian ini adalah :
1. Menganalisis data calon mahasiswa dengan decision tree
menggunakan algoritma ID3 (Iterative Dichotomizes v.3).
2. Memberikan keputusan penetapan strategi pemasaran yang paling
efektif digunakan untuk pencapaian target jumlah mahasiswa baru.
1.5. Manfaat
Kegunaan penelitian ini sangat bermanfaat dan berguna, baik secara teoritis
1. Manfaat Teoritis
Sebagai sumbangan penting dan memperluas bagi kajian ilmu
komputer dalam bidang data mining sehingga dapat dijadikan rujukan
untuk membangun dalam kasus yang berbeda dimasa yang akan
datang.
2. Manfaat Praktis
a. Hasil penelitian ini menghasilkan suatu keputusan didalam
penetapan strategi pemasaran dalam penerimaan mahasiswa baru di
perguruan tinggi swasta.
b. Penelitian ini dapat menghasilkan keterhubungan antara fasilitas
perguruan tinggi dengan dukungan pihak sekolah dan keluarga
terhadap minat calom mahasiswa pada penerimaan mahasiswa
baru.
c. Hasil penelitian ini dapat digunakan sebagai tolak ukur kinerja dari
komputer untuk melakukan pencapaian target mahasiswa.
d. Hasil penelitian ini dapat meningkatkan perkembangan dunia
BAB II
TINJAUAN PUSTAKA
2.1. Data Mining
Dengan perkembangan pesat teknologi informasi termasuk diantaranya teknologi
pengelolaan data, penyimpanan data, pengambilan data disertai kebutuhan
pengambilan keputusan yang komprehensif, cepat, dan akurat menjadikan data
ada dimana-mana disekitar kita. Data terstruktur dikelola oleh database, termasuk
bagaimana me-retrieve datanya. Query yang kompleks yang dibutuhkan analis,
dan pengambilan keputusan ditangani oleh OLAP (Online Analytical Processing)
dengan didukung data warehouse.
Data mining merupakan sebuah analisis dari observasi data dalam jumlah
besar untuk menemukan hubungan yang tidak diketahui sebelumnya dan metode
baru untuk meringkas data agar mudah dipahami serta kegunaannya untuk
pemilik data (Hand,2001). Dengan kecanggihan teknologi yang semakin
meningkat, kini database mampu untuk menyimpan data berkapasitas terabytes.
Dalam kumpulan data yang sangat banyak ini, tersimpan informasi tersembunyi
yang merupakan strategi penting.
Data mining sesunggunghnya merupakan salah satu rangkaian dari proses
pencarian pengetahuan pada database (Knowledge Discovery in Database/KDD).
KDD berhubungan dengan teknik integrasi dan penemuan ilmiah, interprestasi
dan visualisasi dari pola-pola sejumlah kumpulan data. KDD adalah keseluruhan
proses non-trivial untuk mencari dan mengidentifikasi pola (pattern) dalam data,
dimana pola yang ditemukan bersifat sah, baru, dapat bermanfaat dan dapat
dimengerti. Serangkaian proses tersebut yang memiliki tahap sebagai berikut
1. Pembersihan data dan integrasi data (cleaning and integration)
Proses ini digunakan untuk membuang data yang tidak konsisten dan
bersifat noise dari data yang terdapat diberbagai basisdata yang mungkin
berbeda format maupun platform yang kemudian diintegrasikan dalam
satu database data warehouse.
2. Seleksi dan transformasi data (selection and transformation)
Data yang terdapat dalam database data warehouse kemudian direduksi
dengan berbagai teknik. Proses reduksi diperlukan untuk mendapatkan
hasil yang lebih akurat dan mengurangi waktu komputasi terutama untuk
masalah dengan skala besar (large scale problem). Beberapa cara seleksi,
antara lain:
a. Sampling, adalah seleksi subset representatif dari populasi data yang
besar.
b. Denoising, adalah proses menghilangkan noise dari data yang akan
ditransformasikan
c. Feature extraction, adalah proses membuka spesifikasi data yang
signifikan dalam konteks tertentu.
Transformasi data diperlukan sebagai tahap pre-procecing, dimana data
yang diolah siap untuk ditambang. Beberapa cara transformasi, antara lain
(Santosa,2007):
1. Centering, mengurangi setiap data dengan rata-rata dari setiap
atribut yang ada.
2. Normalization, membagi setiap data yang dicentering dengan
standar deviasi dari atribut bersangkutan.
Gambar 2.1: Tahap-tahap Knowledge Discovery in Database
3. Penambangan data (data mining)
Data yang telah diseleksi dan ditransformasi ditambang dengan berbagai
teknik. Proses data mining adalah proses mencari pola atau informasi
menarik dalam data terpilih dengan menggunakan fungsi-fungsi tertentu.
Fungsi atau algoritma dalam data mining sangat bervariasi. Pemilihan
fungsi atau algoritma yang tepat sangat bergantung pada tujuan dan proses
pencarian pengetahuan secara keseluruhan. 4. Evaluasi pola dan presentasi pengetahuan
Tahap ini merupakan bagian dari proses pencarian pengetahuan yang
mencakup pemeriksaan apakah pola atau informasi yang ditemukan
bertentangan dengan fakta atau hipotesa yang ada sebelumnya. Langkah
terakhir KDD adalah mempresentasikan pengetahuan dalam bentuk yang
2.2. Teknik Data Mining
Beberapa teknik Data Mining yang sering digunakan antara lain (Dunham,2002) :
1. Clustering
Analisis cluster merupakan salah satu teknik data mining yang
bertujuan untuk mengidentifikasi sekelompok obyek yang mempunyai
kemiripan karakteristik tertentu yang dapat dipisahkan dengan
kelompok obyek lainnya, sehingga obyek yang berada dalam
kelompok yang sama relatif lebih homogen daripada obyek yang
berada pada kelompok yang berbeda. Clustering adalah salah satu
teknik unsupervised learning dimana kita tidak perlu melatih metode
tersebut atau dengan kata lain, tidak ada fase learning. Tujuan dari
metode clustering adalah untuk mengelompokkan sejumlah data atau
objek kedalam klaster sehingga setiap klaster akan terisi data yang
semirip mungkin (Santosa,2007).
2. Association Rule (Market Basket Analysis)
Association Rule adalah teknik data mining yang digunakan untuk
menemukan aturan associative antara suatu kombinasi item. Salah satu
contoh penerapan Association Rule adalah Market Basket Analysis.
3. Classification
Klasifikasi merupakan proses untuk menemukan sekumpulan model
yang menjelaskan dan membedakan kelas-kelas data, sehingga model
tersebut dapat digunakan untuk memprediksi nilai suatu kelas yang
belum diketahui pada sebuah objek.
4. Regression (Predictive)
Analisis regresi merupakan teknik untuk membantu menganalisis
hubungan antara suatu peristiwa atau keadaan yang terjadi akibat
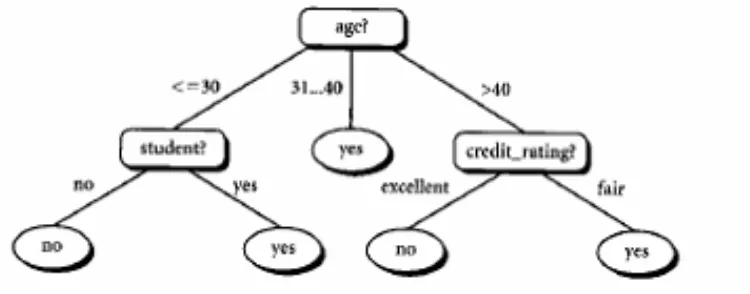
2.3. Pohon Keputusan
Pohon Keputusan (Decision tree) adalah salah satu metode yang sangat populer
dan banyak digunakan secara praktis. Metode ini merupakan metode yang
berusaha menemukan fungsi-fungsi pendekatan yang bernilai diskrit dan tahan
terhadap data yang terdapat kesalahan (noisy data) serta mampu mempelajari
ekspresi-ekspresi disjunctive (ekspresi OR).
Decision tree adalah struktur flowchart yang mempunyai tree (pohon),
dimana setiap simpul internal menandakan suatu tes atribut, setiap cabang
merepresentasikan hasil tes, dan simpul daun merepresentasikan kelas atau
distribusi kelas (Neymark,2007).
Decision tree (pohon keputusan) adalah sebuah diagram alir yang mirip
dengan struktur pohon, dimana setiap internal node menotasikan atribut yang
diuji, setiap cabangnya mempresentasikan hasil dari atribut tes tersebut dan leaf
node mepresentasikan kelas-kelas tertentu atau distribusi dari kelas-kelas
(Han,2001).
Alur pada decision tree ditelusuri dari simpul ke akar ke simpul daun yang
memegang prediksi kelas untuk contoh tersebut. decision tree mudah untuk
dikonversi ke aturan klasifikasi (classification rule). Konsep data dalam decision
tree dinyatakan dalam bentuk tabel dengan atribut dan record.
Manfaat utama dari penggunaan pohon keputusan adalah kemampuannya
untuk mem-break down proses pengambilan keputusan yang kompleks menjadi
lebih simpel sehingga pengambil keputusan akan lebih menginterpretasikan solusi
dari permasalahan. Pohon Keputusan juga berguna untuk mengeksplorasi data,
menemukan hubungan tersembunyi antara sejumlah calon variabel input dengan
sebuah variabel target. Pohon keputusan memadukan antara eksplorasi data dan
pemodelan, sehingga sangat bagus sebagai langkah awal dalam proses pemodelan
bahkan ketika dijadikan sebagai model akhir dari beberapa teknik lain. Sering
terjadi tawar menawar antara keakuratan model dengan transparansi model.
Dalam beberapa aplikasi, akurasi dari sebuah klasifikasi atau prediksi adalah
satu-satunya hal yang ditonjolkan, misalnya sebuah perusahaan direct mail membuat
untuk merespon permintaan, tanpa memperhatikan bagaimana atau mengapa
model tersebut bekerja.
Kelebihan dari metode pohon keputusan adalah:
1. Daerah pengambilan keputusan yang sebelumnya kompleks dan sangat global, dapat diubah menjadi lebih simpel dan spesifik.
2. Eliminasi perhitungan-perhitungan yang tidak diperlukan, karena ketika menggunakan metode pohon keputusan maka sample diuji hanya
berdasarkan kriteria atau kelas tertentu.
3. Fleksibel untuk memilih fitur dari internal node yang berbeda, fitur yang terpilih akan membedakan suatu kriteria dibandingkan kriteria yang lain
dalam node yang sama. Kefleksibelan metode pohon keputusan ini
meningkatkan kualitas keputusan yang dihasilkan jika dibandingkan ketika
menggunakan metode penghitungan satu tahap yang lebih konvensional
4. Dalam analisis multivariant, dengan kriteria dan kelas yang jumlahnya sangat banyak, seorang penguji biasanya perlu untuk mengestimasikan
baik itu distribusi dimensi tinggi ataupun parameter tertentu dari distribusi
kelas tersebut. Metode pohon keputusan dapat menghindari munculnya
permasalahan ini dengan menggunakan kriteria yang jumlahnya lebih
sedikit pada setiap node internal tanpa banyak mengurangi kualitas
keputusan yang dihasilkan.
Sedangkan kekurangan dari pohon keputusan adalah :
1. Terjadi overlap terutama ketika kelas-kelas dan kriteria yang digunakan jumlahnya sangat banyak. Hal tersebut juga dapat menyebabkan
meningkatnya waktu pengambilan keputusan dan jumlah memori yang
diperlukan.
2. Pengakumulasian jumlah error dari setiap tingkat dalam sebuah pohon keputusan yang besar.
3. Kesulitan dalam mendesain pohon keputusan yang optimal.
4. Hasil kualitas keputusan yang didapatkan dari metode pohon keputusan
Bagian awal dari pohon keputusan ini adalah titik akar (root), sedangkan
setiap cabang dari decision tree merupakan pembagian berdasarkan hasil uji, dan
titik akhir (leaf) merupakan pembagian kelas yang dihasilkan. Pada umumnya
proses dari sistem decision tree adalah mengadopsi strategi pencarian top-down
untuk solusi ruang pencariannya. Pada proses mengklasifikasikan sampel yang
tidak diketahui, nilai atribut akan diuji pada decision tree dengan cara melacak
jalur dari titik akar sampai titik akhir, kemudian akan diprediksikan kelas yang
ditempati sampel baru tersebut. Decision tree mempunyai 3 tipe simpul yaitu: 1. Simpul akar dimana tidak memiliki cabang yang masuk dan memiliki
cabang lebih dari satu, terkadang tidak memiliki cabang sama sekali.
2. Simpul internal dimana hanya memiliki 1 cabang yang masuk, dan
memiliki lebih dari 1 cabang yang keluar.
3. Simpul daun atau simpul akhir dimana hanya memiliki 1 cabang yang
masuk, dan tidak memiliki cabang sama sekali dan menandai bahwa
simpul tersebut merupakan label kelas.
Gambar 2.2: Model Pohon Keputusan
Disini setiap percabangan menyatakan kondisi yang harus dipenuhi dan
tiap ujung pohon menyatakan kelas data. Setelah sebuah pohon keputusan
dibangun maka dapat digunakan untuk mengklasifikasikan record yang belum ada
kelasnya. Dimulai dari node root, menggunakan tes terhadap atribut dari record
dari tes tersebut, yang akan membawa kepada internal node (node yang memiliki
satu cabang masuk dan dua atau lebih cabang yang keluar), dengan cara harus
melakukan tes lagi terhadap atribut atau node daun. Record yang kelasnya tidak
diketahui kemudian diberikan kelas yang sesuai dengan kelas yang ada pada node
daun. Pada pohon keputusan setiap simpul daun menandai label kelas. Proses
dalam pohon keputusan yaitu mengubah bentuk data (tabel) menjadi model pohon
(tree) kemudian mengubah model pohon tersebut menjadi aturan (rule).
2.4. Algoritma Iterative Dichotomizes versi 3 (ID3)
Iterative Dichotomizes 3 (ID3) adalah algoritma decision tree learning (algoritma
pembelajaran pohon keputusan) yang paling dasar. Algoritma ini melakukan
pencarian secara rakus /menyeluruh (greedy) pada semua kemungkinan pohon
keputusan. Salah satu algoritma induksi pohon keputusan yaitu ID3 (Iterative
Dichotomizes 3). ID3 dikembangkan oleh J. Ross Quinlan. Algoritma ID3 dapat
diimplementasikan menggunakan fungsi rekursif (fungsi yang memanggil dirinya
sendiri). Algoritma ID3 berusaha membangun decision tree (pohon keputusan)
secara top-down (dari atas ke bawah), mulai dengan pertanyaan : “atribut mana
yang pertama kali harus dicek dan diletakkan pada root?” pertanyaan ini dijawab
dengan mengevaluasi semua atribut yang ada dengan menggunakan suatu ukuran
statistic (yang banyak digunakan adalah information gain) untuk mengukur
efektivitas suatu atribut dalam mengklasifikasikan kumpulan sampel data
(David,2004)
Decision Tree adalah sebuah struktur pohon, dimana setiap node pohon
merepresentasikan atribut yang telah diuji, setiap cabang merupakan suatu
pembagian hasil uji, dan node daun (leaf) merepresentasikan kelompok kelas
tertentu. Level node teratas dari sebuah decision tree adalah node akar (root) yang
biasanya berupa atribut yang paling memiliki pengaruh terbesar pada suatu kelas
Function ID3 (kumpulanSampel, AtributTarget, KumpulanAtribut)
1. Buat simpul root
2. If semua sampel adalah kelas I, maka return pohon satu simpul
root dengan label i
3. If kumpulanAtribut = = 0, return pohon satu simpul Root
dengan label = nilai atribut target yang paling sering muncul
Else
Hitung Information gain tiap atribut
A adalah Information gain terbesar. Jadikan A sebagai
Root
For Vi (setiap nilai pada atribut A)
- Tambahkan cabang untuk tiap nilai Vi
- Buat suatu variabel, misal sampel Vi, Sebagai
himpunan bagian dari kumpulan sampel yang bernilai Vi pada atribut A
- If sampel Vi kosong, maka tambahkan simpul daun
dengan label = nilai atribut yang paling sering muncul.
Else
Dibawah cabang tambahkan subtree dengan memanggil fungsi ID3 (SampelVi, AtributTarget,
Atribut-[A]) Rekursif. End
End End
4. Return Root
Gambar 2.3: Algoritma ID3
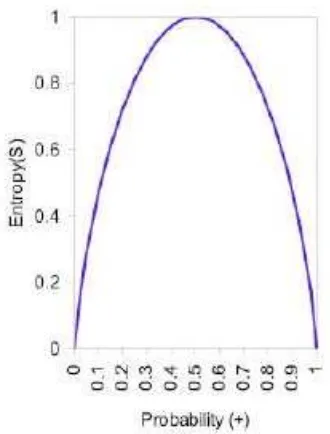
2.5. Entropy
Sebuah obyek yang diklasifikasikan dalam pohon harus dites nilai entropy-nya.
Entropy adalah ukuran dari teori informasi yang dapat mengetahui karakteristik
dari impurity dan homogeneity dari kumpulan data. Dari nilai entropy tersebut
kemudian dihitung nilai information gain (IG) masing-masing
Gambar 2.4: Entropy
Entropy(S) = - P+2 logP + -P-2logP- dimana :
S adalah ruang (data) sample yang digunakan untuk training.
P+ adalah jumlah yang bersolusi positif (mendukung) pada data
sample untuk kriteria tertentu.
P+ adalah jumlah yang bersolusi negatif (tidak mendukung) pada data sample untuk kriteria tertentu.
Dari rumus entropy diatas dapat disimpulkan bahwa definisi entropy (S) adalah
jumlah bit yang diperkirakan dibutuhkan untuk dapat mengekstrak suatu kelas (+
atau -) dari sejumlah data acak pada suatu ruang sampel S.
Entropy bisa dikatakan sebagai kebutuhan bit untuk menyatakan suatu
kelas. Semakin kecil nilai entropy maka semakin baik digunakan dalam
mengekstraksi suatu kelas. Panjang kode untuk menyatakan informasi secara
optimal adalah –2logP bits untuk messages yang mempunyai probabilitas P. Sehingga jumlah bit yang diperkirakan untuk mengekstraksi S ke dalam kelas
2.6. Information Gain
Setelah mendapat nilai entropy untuk suatu kumpulan data, maka kita dapat
mengukur efektivitas suatu atribut dalam mengklasifikasikan data. Ukuran
efektifitas ini disebut information gain. Secara matematis, information gain dari
suatu atribut A, dituliskan sebagai berikut: (Gambetta,2003)
Gain (S,A)=Entropy(S) - Entropy(Sv) vValues (A)
| Sv |
| S |
dimana :
A : atribut
V : suatu nilai yang mungkin untuk atribut A
Values (A) : himpunan yang mungkin untuk atribut A
|Sv| : jumlah sampel untuk nilai v
|S| : jumlah seluruh sampel data
2.7. Riset-riset Terkait
Terdapat beberapa riset yang telah dilakukan oleh banyak peneliti berkaitan
dengan Decision Tree dengan Algoritma ID3 seperti yang akan dijelaskan di
bawah ini.
Nugroho (2007), dalam risetnya menjelaskan bahwa untuk suatu
perusahaan yang secara khusus yang bergerak dibidang jasa, permasalahan yang
dihadapi adalah ketika pihak perusahaan mengirimkan barang dengan tujuan
alamat yang diperoleh dari pihak pelanggan, seringkali pihak pelanggan tidak
memberikan alamat pengiriman secara tepat sehingga pihak perusahaan harus
memprediksi alamat tersebut secara manual. Dalam melakukan hal ini,
membutuhkan waktu yang tidak sedikit sehingga mengurangi kualitas pelayanan
terhadap pelanggan. Dari permasalahan ini, diperlukan suatu solusi yang dapat
membantu perusahaan dalam melakukan prediksi suatu alamat yang benar. Salah
satu solusi memprediksi validitas alamat adalah dengan membuat suatu sistem
yang dianggap mampu melakukan prediksi suatu alamat secara tepat. Metode
decision tree dengan algoritma ID3 merupakan salah satu metode dari data mining
yang digunakan untuk mengklasifikasikan data sampel kedalam kelas-kelas
tertentu. Berdasarkan kemampuan dari metode ini, kemudian dilakukan penelitian
untuk menganalisis keefektifitasan metode ini dalam melakukan prediksi alamat
menggunakan kelas yang terbentuk dari metode ini. Bentuk penelitian yang
dilakukan adalah dengan melihat tingkat kebenaran yang dihasilkan oleh metode
ini dalam melakukan validitas prediksi suatu alamat pada sekumpulan data uji
yang diteliti.
Wahyudin (2009) dalam risetnya juga menjelaskan Konsep pohon
merupakan salah satu konsep teori graf yang paling penting. Pemanfaatan struktur
pohon dalam kehidupan sehari-hari adalah untuk menggambarkan hierarki dan
memodelkan persoalan, contohnya pohon keputusan (decision tree). Iterative
dichotomizes 3 ( ID3 ) merupakan suatu metode dalam learning yang akan membangun sebuah pohon keputusan untuk pemodelan dalam mencari solusi dari
persoalan. Dalam jurnal ini akan dibahas pemakaian pohon keputusan dalam
analisis kemahasiswaan diperlukan untuk mendapatkan keputusan yang bersifat
menguntungkan demi maju dan berkembangnya suatu universitas dan analisis
penerimaan mahasiswa baru tersebut dapat dilakukan melalui berbagai metode,
salah satunya dengan decision tree menggunakan ID3 (Iterative Dichotomizes 3).
Sofi Defiyanti dan D. L. Crispina Pardede (2009) dalam risetnya
menyampaikan tentang klasifikasi spam mail digunakan untuk memisahkan
spam-mail dari non spam mail (legitimate mail). Klasifikasi spam mail berguna untuk
menghemat waktu dan biaya yang digunakan untuk menghapus spam mail dari
inbox. Untuk itu diperlukan metode yang paling baik untuk melakukan klasifikasi
spam mail. Algoritma decision tree merupakan salah satu metode untuk
klasifikasi spam mail. Algoritma decision tree telah banyak mengalami
pengembangan. Algoritma ID3 dan C4.5 adalah salah satu pengembangan dari
algoritma decision tree. Penelitian ini membandingkan kinerja dari dua algoritma
tersebut dalam melakukan klasifikasi spam mail. Pengukuran dilakukan
menggunakan sekelompok data uji untuk mengetahui persentase precision, recall
dan accuracy. Hasil pengukuran menunjukkan algoritma ID3 memiliki kinerja
BAB III
METODOLOGI PENELITIAN
Data merupakan bahan baku informasi untuk memberikan gambaran spesifik
mengenai obyek penelitian. Berdasarkan sumbernya, data penelitian dapat
dikelompokkan dalam dua jenis yaitu data primer dan data sekunder.
a. Data Primer adalah data yang diperoleh atau dikumpulkan secara langsung
dari sumber datanya. Data primer disebut juga sebagai data asli atau data
baru yang memiliki sifat up to date. Teknik yang dapat digunakan untuk
mengumpulkan data primer antara lain observasi, wawancara, diskusi
terfokus (focus group discussion - FGD) dan penyebaran kuesioner.
b. Data Sekunder adalah data yang diperoleh atau dikumpulkan dari berbagai
sumber yang telah ada. Data sekunder dapat diperoleh dari berbagai sumber
seperti buku, laporan, jurnal, dan lain-lain.
Tujuan dari usulan tesis ini adalah untuk membuat model dengan pohon
keputusan menggunakan algoritma Iterative Dichotomizes Versi 3 (ID3) dalam
pembuatan keputusan untuk penetapan strategi pemasaran pada perguruan tinggi
swasta dalam tesis ini mengambil kasus di AMIK Tunas Bangsa.
3.1. Lokasi dan Waktu Penelitian
Penelitian dilakukan di Kampus AMIK Tunas Bangsa Jl. Jend. Sudirman
Blok A No.1,2 & 3 Pematangsiantar-Sumatera Utara. Lamanya waktu yang
dibutuhkan untuk menyelesaikan penelitian ini yaitu selama 6 (Enam) bulan yang
3.2. Rancangan Penelitian
Rancangan penelitian ini pertama kali dilakukan dengan melakukan
pengamatan (observasi) untuk mempelajari data calon mahasiswa baru. Hasil
pengamatan kemudian dibuat skenario-skenario yang mendukung, selanjutnya
dilakukan eksperimen data dengan menggunakan software rapid miner untuk
menguji data yang diambil dari database program sistem penerimaan mahasiswa
baru di AMIK Tunas Bangsa.
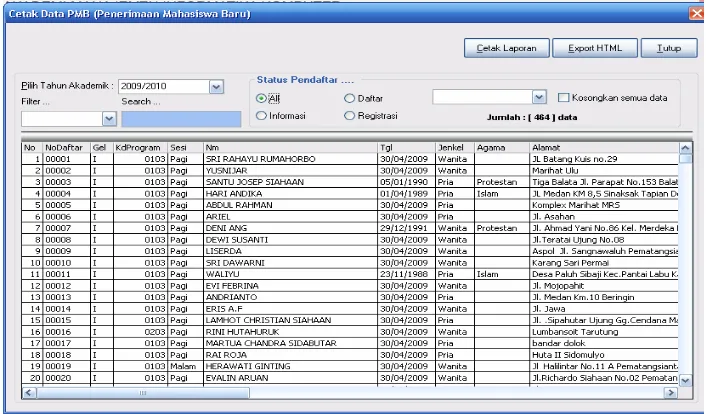
Tahapan untuk melakukan klasifikasi data dari database antara lain :
1. Mengambil data dari database program sistem penerimaan mahasiswa baru
Gambar 3.1 : Program Sistem Informasi PMB
2. Meng‐export data dari database ke Microsoft excel
3. Membuat aturan (rule) dengan menggunakan software rapid miner
3.3. Prosedur Pengumpulan Data
Dalam studi kasus ini, data dibagi menjadi 2 (dua) dataset. Dataset yang
pertama berasal dari database penerimaan mahasiswa baru dengan jumlah sampel
data 1.200 data. Sedangkan dataset yang kedua diambil dari data kuesioner
dengan sampel sebanyak 1.200 sampel data. Dataset kedua ini untuk mengukur
korelasi antara jenis publikasi yang diterapkan terhadap minat calon mahasiswa
dengan fasilitas kampus, dukungan pihak sekolah dan dukungan keluarga. Dari
keempat kategori pertanyaan tersebut koresponden menjawab 20 (dua puluh)
pertanyaan.
3.4. Alat Analisis Data
Dalam studi kasus ini penulis menggunakan software-software untuk
mengalisis data, antara lain: 1. Paket statistik ilmu sosial
Software yang digunakan adalah SPSS Versi 16.0 untuk menampilkan
analisis regresi pada data mahasiswa baru yang penulis teliti. SPSS adalah
aplikasi untuk mempermudah perhitungan statistik.
2. Rapid Miner
Rapid Miner 5.0 digunakan pada studi ini untuk menampilkan kelompok
calon mahasiswa pada kumpulan data dan memperlihatkan matriks
presentasi yang tersebar dari kelompok-kelompok. Rapid Miner
membuktikan lebih dari 400 operator dari segala aspek data mining.
Operator Meta secara otomatis mengoptimalkan desain eksperimen dan
pengguna tidak memerlukan waktu yang panjang untuk menentukan
langkah dan parameter yang lebih panjang. Sejumlah besar teknik
visualisasi dan kemungkinan untuk meletakkan breakpoints setelah
masing masing operator memberikan pandangan tentang keberhasilan
desain bahkan untuk menjalankan percobaan
3.5. Instrumen Penelitian
Instrumen atau alat ukur yang digunakan dalam penelitian ini adalah
dengan melakukan beberapa dataset file spreadsheet transformasi dari bentuk
aslinya (xls) divalidasi menggunakan software SPSS yang kemudian diolah
dengan menggunakan rapid miner untuk membuat pohon keputusan dan rule
dengan algoritma ID3.
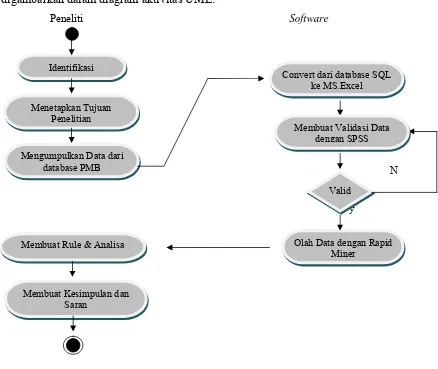
3.6. Kerangka Kerja
Berikut ini alur kerja yang akan dilakukan pada penelitian ini yang
digambarkan dalam diagram aktivitas UML:
Peneliti Software
N
y
Identifikasi
Menetapkan Tujuan Penelitian
Mengumpulkan Data dari database PMB
Convert dari database SQL ke MS.Excel
Valid
Membuat Validasi Data dengan SPSS
Olah Data dengan Rapid Miner
Membuat Rule & Analisa
Membuat Kesimpulan dan Saran
3.7. Peracangan Model
Perancangan model yang dibuat adalah dengan model decision tree dengan
hasil sebagai berikut:
Gambar 3.4. Graph view data
3.8. Model Text
Perancangan model text dengan hasil sebagai berikut:
FASILITAS KAMPUS = 16 | DUKUNGAN SEKOLAH = 16
| | DUKUNGAN KELUARGA = 13: Tidak Berminat {Sangat Berminat=8, Berminat=1, Tidak Berminat=12}
FASILITAS KAMPUS = 17 | DUKUNGAN KELUARGA = 13
| | DUKUNGAN SEKOLAH = 17: Sangat Berminat {Sangat Berminat=4, Berminat=1, Tidak Berminat=2}
| DUKUNGAN KELUARGA = 14
| | DUKUNGAN SEKOLAH = 17: Tidak Berminat {Sangat Berminat=2, Berminat=1, Tidak Berminat=9}
FASILITAS KAMPUS = 18 | DUKUNGAN KELUARGA = 14
| | DUKUNGAN SEKOLAH = 18: Tidak Berminat {Sangat Berminat=5, Berminat=0, Tidak Berminat=12}
| DUKUNGAN KELUARGA = 15: Sangat Berminat {Sangat Berminat=2, Berminat=0, Tidak Berminat=0}
FASILITAS KAMPUS = 19
| DUKUNGAN SEKOLAH = 18: Sangat Berminat {Sangat Berminat=1, Berminat=0, Tidak Berminat=0}
| DUKUNGAN SEKOLAH = 19
| | DUKUNGAN KELUARGA = 15: Berminat {Sangat Berminat=22, Berminat=54, Tidak Berminat=10}
FASILITAS KAMPUS = 20 | DUKUNGAN SEKOLAH = 19
| | DUKUNGAN KELUARGA = 15: Berminat {Sangat Berminat=1, Berminat=11, Tidak Berminat=1}
| DUKUNGAN SEKOLAH = 20
| | DUKUNGAN KELUARGA = 15: Berminat {Sangat Berminat=1, Berminat=2, Tidak Berminat=0}
| | DUKUNGAN KELUARGA = 16: Berminat {Sangat Berminat=33, Berminat=35, Tidak Berminat=5}
FASILITAS KAMPUS = 21 | DUKUNGAN SEKOLAH = 20
| | DUKUNGAN KELUARGA = 16: Sangat Berminat {Sangat Berminat=11, Berminat=1 Tidak Berminat=1}
BAB IV
HASIL DAN PEMBAHASAN
4.1. Analisis
Analisis sistem adalah penguraian dari suatu sistem perangkat lunak yang utuh
kedalam bagian komponen-komponennya dengan tujuan untuk
mengidentifikasikan dan mengevaluasi permasalahan, hambatan dan kebutuhan
yang diharapkan dalam penetapan strategi pemasaran dengan pendekatan model
pohon keputusan menggunakan algoritma Iterative Dichotomizes versi 3 (ID3).
Bab ini menyajikan hasil penelitian yang penulis lakukan dengan
mengolah dua dataset yaitu dataset yang berasal dari database penerimaan
mahasiswa baru dan dataset kedua adalah kuesioner yang terdiri dari empat
kategori pertanyaan yaitu fasilitas kampus, dukungan sekolah, dukungan keluarga
dan dukungan minat. Dalam percobaan ini dibuat model aturan pohon keputusan
dengan algoritma ID3 menggunakan software Rapid Miner. Untuk validasi dan
korelasi data penulis membuat analisa dengan software SPSS.
4.2. Hasil Percobaan
Dalam percobaan ini penulis menguji reliabilitas data hasil kuesioner yang
dijawab oleh calon mahasiswa dengan menggunakan metode Cronbach's Alpha
untuk data training yang terdiri dari 300 data, sedangkan untuk keseluruhan data
sebagai data testing penulis menggunakan sebanyak 1.200 data. Rumus untuk
menghitung koefisien reliabilitas instrument dengan menggunakan Cronbach
Gambar 4.1. Formula Crobach Alpha
Keterangan:
r = koefisien reliabilitas instrument (cronbach alpha)
k = banyaknya butir pertanyaan atau banyaknya soal
∑2
= total varians butir
t 2
= total varians
Adapun hasil percobaan training dan testing data secara manual dapat dilihat pada
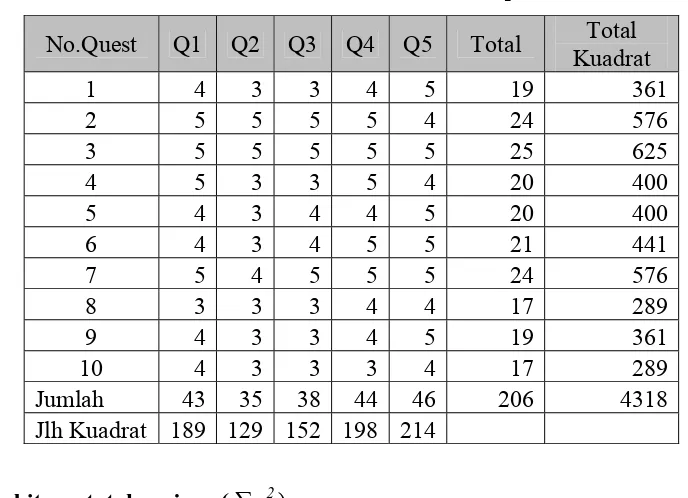
contoh dibawah ini : Kuesioner untuk fasilitas kampus
Tabel 4.1. Kuesioner Fasilitas Kampus
No.Quest Q1 Q2 Q3 Q4 Q5 Total Total
Varians butir ke-2 sampai ke-5 sama seperti diatas, sehingga total varians butir
b
t
( ∑2= 0,41 + 0,65 + 0,76 + 0,44 + 0,24)
= 2,5
Menghitung total varians (2 )
2062 4318- =
10
= 7,44
Menghitung Koefisien Cronbach Alpha
r = [ ][ ] 2,5 1- 7 44 5
(5-1)
= 0,829
Keterangan:
1. Nilai-nilai untuk pengujian reliabilitas berasal dari skor-skor item angket yang
valid. Item yang tidak valid tidak dilibatkan dalam pengujian reliabilitas. 2. Instrumen memiliki tingkat reliabilitas yang tinggi jika nilai koefisien yang
diperoleh >0,60. Ada pendapat lain yang mengemukakan baik/ buruknya
reliabilitas instrument dapat dikonsultasikan dengan nilai r tabel.
3. Interpretasi reliabilitas bisa juga menggunakan pertimbangan gambar di
bawah ini:
________________________________________________________
0 Reliabilitas Rendah 0,5 Reliabilitas Tinggi 1
/buruk /baik
4.2.1. Hasil Percobaan Training Data
Dalam pengujian data training yang terdiri dari 300 data dapat dilihat pada
gambar dibawah ini :
Reliability Statistics
Cronbach's
Alpha Based on
Standardized
Items Cronbach's
Alpha N of Items
,769 ,768 5
Gambar 4.3. Reliability Statistics Fasilitas Kampus
Dari Gambar 4.3. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics fasilitas kampus dengan 300 sampel data yang dihasilkan adalah 0,769.
Reliability Statistics
Cronbach's
Alpha
Cronbach's
Alpha Based on
Standardized
Items N of Items
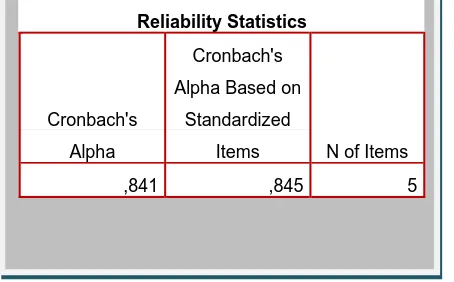
,841 ,845 5
Gambar 4.4. Reliability Statistics Dukungan Pihak Sekolah
Dari Gambar 4.4. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics dukungan sekolah dengan 300 sampel data yang dihasilkan adalah
Gambar 4.5. Reliability Statistics Dukungan Keluarga
Reliability Statistics
Cronbach's
Alpha
Cronbach's
Alpha Based on
Standardized
Items N of Items
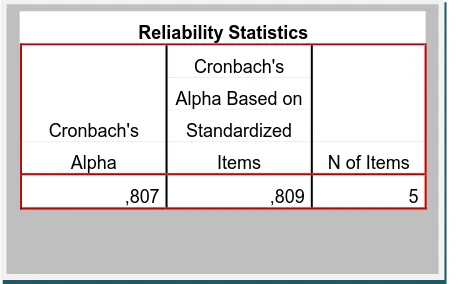
,806 ,807 5
Dari Gambar 4.5. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics dukungan keluarga dengan 300 sampel data yang dihasilkan adalah
0,806.
Reliability Statistics
Cronbach's
Alpha
Cronbach's
Alpha Based on
Standardized
Items N of Items
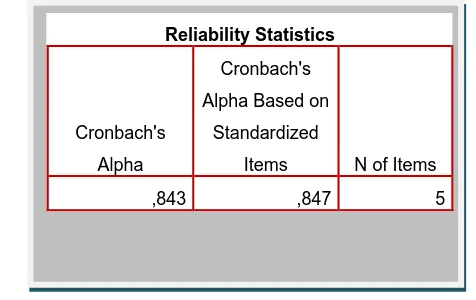
,843 ,847 5
Gambar 4.6. Reliability Statistics terhadap Minat
Dari Gambar 4.6. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics terhadap minat dengan 300 sampel data yang dihasilkan adalah 0,843.
4.2.2. Hasil Percobaan Testing Data
Dalam pengujian Testing data digunakan data keseluruhan setelah
dilakukan cleaning data dengan cara menghilangkan data yang inconsistent, data
testing menggunakan data sebanyak 1.200 data, hasil pengujiannya dapat dilihat
Reliability Statistics
Gambar 4.7. Reliability Statistics Fasilitas Kampus
Dari Gambar 4.7. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics fasilitas kampus yang dihasilkan adalah 0,764.
Gambar 4.8. Reliability Statistics Dukungan Pihak Sekolah
Dari Gambar 4.8. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics dukungan sekolah yang dihasilkan adalah 0,843.
Reliability Statistics
Gambar 4.9. Reliability Statistics Dukungan Keluarga
Dari gambar 4.9. menunjukan bahwa cronbach’s Alpha dari Reliability
Reliability Statistics
Cronbach's
Alpha
Cronbach's
Alpha Based on
Standardized
Items N of Items
,843 ,847 5
Gambar 4.10. Reliability Statistics Terhadap Minat
Dari Gambar 4.10. menunjukan bahwa cronbach’s Alpha dari Reliability
Statistics terhadap minat yang dihasilkan adalah 0,843.
Dari perbedaan data training dan testing dapat dilihat pada tabel di bawah ini :
Tabel 4.2. Statistik Reliabilitas data
No Variabel dalam skala
Cronbach's alpha Data Training
300 Data
Cronbach's alpha Data Testing
1200 Data
1 Fasilitas Kampus ,769 ,764
2 Dukungan Sekolah ,841 ,843
3 Dukungan Keluarga ,806 ,803
4 Dukungan Minat ,843 ,843
Dari Tabel 4.2. diatas dapat dijelaskan bahwa Statistik Signifikan dan
Reliabilitas data training memiliki nilai diatas >0,60. Cronbach's alpha diberikan
survei untuk mengukur konsistensi internal. Menurut Mitchell dan Jolley (1999),
Cronbach's alpha di atas 0,60 dapat diterima sebagai bukti reliabilitas internal.
Dari hasil training dan testing dapat disimpulkan bahwa data yang penulis
4.2.3. Signifikansi
Untuk menguji korelasi dari tiga predictor variabel (fasilitas kampus,
dukungan sekolah dan dukungan keluarga) terhadap dependent variabel (daerah)
untuk penetapan strategi pemasaran penerimaan mahasiswa baru penulis
menggunakan metode analisis regresi berganda dengan model fit. Dari metode ini
akan diketahui variabel yang paling memberikan kontribusi. Seperti terlihat pada
tabel 4.3. dibawah ini :
Tabel 4.3. Korelasi signifikan dari tiga prediktor
Change Statistics
a. Predictors: (Constant), FASILITAS KAMPUS
b. Predictors: (Constant), FASILITAS KAMPUS, DUKUNGAN SEKOLAH
c. Predictors: (Constant), FASILITAS KAMPUS, DUKUNGAN SEKOLAH, DUKUNGAN KELUARGA
d. Dependent Variable: MINAT
Dari Tabel 4.3. kita dapat melihat bahwa variable terbaik dari predictor R1 atau Fasilitas Kampus yang memberikan kontribusi 80,7% (R Square change).
Keempat variabel memberikan kontribusi yang signifikan R2 = 0,828. Dengan demikian, kita dapat menyimpulkan bahwa tiga variabel tersebut di atas dapat
dijadikan sebagai penaksir model aturan untuk penetapan staretgi pemasaran pada
penerimaan mahasiswa baru seperti yang terdapat pada tabel 4.4. dibawah ini:
Tabel 4.4. Signifikan Dari Tiga Variabel Prediktor Predikat
Change Statistics
Tabel 4.4. Signifikan Dari Tiga Variabel Prediktor Predikat
Change Statistics Model
R Std. Error R Sig. F
Squar Adjusted of the Square F Chang
Durbin-R e R Square Estimate Change Change df1 df2 e Watson
,915a
1 ,838 ,838 ,331 ,838 2062,768 3 1196 ,000 1,828 dimension0
a. Predictors: (Constant), DUKUNGAN KELUARGA, FASILITAS KAMPUS, DUKUNGAN SEKOLAH
b. Dependent Variable: MINAT
4.2.4. Multicollinearity
Multikolinearitas adalah masalah umum dalam analisis korelasi banyak,
terjadi ketika variabel yang berlebihan dan dapat mengganggu penafsiran yang
tepat dari hasil regresi berganda. Cara sederhana untuk mengidentifikasi
collinearity adalah Toleransi dan Varian Inflation Factor (VIF). Toleransi adalah
jumlah variabilitas variabel independen yang dipilih. Toleransi nilai mendekati
0.00 menunjukkan variabel sangat collinear dengan variabel prediktor lainnya.
Faktor inflasi varian berbanding terbalik dengan nilai toleransi. Sebuah nilai VIF
yang besar, (biasanya ambang 10,0) menunjukkan tingkat tinggi collinearity atau
multikolinieritas antar variabel independent, seperti pada tabel 4.5.
Collinearity Statistics
Model
Beta In
t Sig. Partial Correlation
Tabel 4.5. Multikolinearity Diagnostik
Tolerance VIF Minimum Tolerance
a. Predictors in the Model: (Constant), FASILITAS KAMPUS
b. Predictors in the Model: (Constant), FASILITAS KAMPUS, DUKUNGAN SEKOLAH
4.2.5. Implementasi ID3
Contoh dari manual implementasi ID3 terhadap pengukuran minat adalah
sebagai berikut:
Tabel 4.6. Pengukuran Terhadap Minat
Calon
C11 Buruk Rendah Tinggi Minat
Dari data diatas disimpulkan:
a. Jumlah class target (apakah minat?) = 2 (“Minat” dan “Tidak”)
b. Jumlah sampel untuk kelas 1 (“minat”) = 8 P1
Information Gain berdasarkan Fasilitas Kampus (FK):
Gain (S,FK)=Entropy(S)- | Sv | Entropy(Sv)=
| S |
v{Baik,Cukup,buruk}
Entropy(S) – (4/11) Entropy-(Sbaik) – (4/11)Entropy(Scukup)-(3/11)Entropy(Sburuk)
= 0.8454 - (4/11)0.8113 - (4/11)0.8113 – (3/11)0.9183 = 0.0049
Begitu juga dengan perhitungan gain untuk Dukungan Sekolah dan Dukungan
Keluarga, sehingga diperoleh hasil sebagai berikut:
Gain (S,FK) = 0.0049
Gain (S,DS) = 0.2668
Gain (S,DK) = 0.4040
Dari perolehan information gain diperoleh tree sebagai berikut:
tinggi rendah
minat
tinggi rendah
Dukungan Sekolah Dukungan Keluarga
tidak minat sedang tidak minat Fasilitas Kampus
baik buruk
minat cukup tidak minat
minat
Gambar 4.11. Manual Decision Tree Terhadap Minat (DK=tinggi) V
((DK=rendah)^(DS=sedang)^(FK=baik)) V
((DK=rendah)^(DS=sedang)^(FK=cukup)) dukungan minat = minat
Berdasarkan implementasi manual dari algoritma ID3 tersebut diatas diperoleh
rule sebagai berikut:
Jika DK ’tinggi’ atau
Jika DK ‘rendah’ dan DS ‘sedang’ dan FK ‘baik’ atau
Jika DK ‘rendah’ dan DS ’sedang’ dan FK ‘cukup’ maka dukungan minat adalah
4.2.6. Hasil Percobaan Decision Tree
Model Decision Tree dengan Model Grafik yang akan digunakan
digambarkan sebagai berikut:
Gambar 4.12. Grafik Decision Tree
Dari grafik diatas dapat dijelaskan bahwa fasilitas kampus memiliki pengaruh
paling besar terhadap minat. Untuk lebih jelasnya dapat dilihat pada model aturan
berbentuk text seperti pada gambar 4.13.
FASILITAS KAMPUS = 13 | DUKUNGAN SEKOLAH = 16 | | DUKUNGAN KELUARGA = 16
| | | Asal Sekolah = Pematangsiantar: Sangat Berminat {Sangat Berminat=10, Berminat=1, Tidak Berminat=9}
| | Asal Sekolah = Simalungun: Sangat Berminat {Sangat Berminat=5, Berminat=0, Tidak Berminat=0}
FASILITAS KAMPUS = 14 | DUKUNGAN SEKOLAH = 17 | | DUKUNGAN KELUARGA = 17
| | | Asal Sekolah = Pematangsiantar: Tidak Berminat {Sangat Berminat=4, Berminat=2, Tidak Berminat=8}
FASILITAS KAMPUS = 15 | DUKUNGAN SEKOLAH = 18 | | DUKUNGAN KELUARGA = 18
| | | Asal Sekolah = Pematangsiantar: Sangat Berminat {Sangat Berminat=2, Berminat=0, Tidak Berminat=1}
| | DUKUNGAN KELUARGA = 19: Sangat Berminat {Sangat Berminat=1, Berminat=0, Tidak Berminat=0}
| DUKUNGAN SEKOLAH = 19 | | DUKUNGAN KELUARGA = 19