I. Pendahuluan
Bab ini memperkenalkan latar belakang penelitian, perumusan masalah, batasan masalah, tujuan penelitian, dan manfaat penelitian. Latar belakang menjelaskan pentingnya akurasi prediksi dan bagaimana metode backpropagation, khususnya dengan inisialisasi bobot menggunakan metode Nguyen-Widrow, dapat meningkatkannya. Perumusan masalah menggariskan fokus penelitian pada pengaruh metode Nguyen-Widrow terhadap akurasi prediksi menggunakan backpropagation. Batasan masalah menjelaskan parameter-parameter yang digunakan dalam penelitian, seperti fungsi aktivasi sigmoid biner, batas toleransi error, dan data yang digunakan. Tujuan penelitian secara spesifik menyatakan kehendak untuk merancang bobot dan bias dalam backpropagation dengan metode Nguyen-Widrow untuk mencapai akurasi yang lebih tinggi. Manfaat penelitian menyoroti kontribusi praktis dan teoritis, termasuk pemahaman pengaruh bobot dan bias serta aplikasi metode ini dalam bidang peramalan.
1.1 Latar Belakang Masalah
Bagian ini membahas isu ketidakakuratan prediksi dan perlunya metode yang lebih baik. Di sini, penelitian-penelitian sebelumnya yang menggunakan backpropagation, seperti oleh Halim dan Wibisono (2000) dan Andrijasa dan Mistianingsih (2010), dikaji untuk menunjukkan kelemahan inisialisasi bobot secara random. Penelitian ini berargumen bahwa metode Nguyen-Widrow menawarkan solusi yang lebih baik dengan menyesuaikan bobot dan bias awal, sehingga meningkatkan kemampuan lapisan tersembunyi dalam proses pembelajaran dan mempercepat konvergensi. Diskusi juga mencakup parameter backpropagation seperti bobot, bias, learning rate, dan momentum, serta peranan fungsi aktivasi sigmoid biner dalam mencapai output antara 0 dan 1. Kaitan antara pemilihan parameter dan peningkatan akurasi ditekankan sebagai fokus utama penelitian.
1.2 Perumusan Masalah
Fokus utama penelitian ini adalah menyelidiki pengaruh penggunaan metode Nguyen-Widrow dalam inisialisasi bobot pada algoritma backpropagation untuk prediksi. Perumusan masalah ini secara ringkas merangkum pertanyaan penelitian: Bagaimana pengaruh metode Nguyen-Widrow dalam meningkatkan akurasi prediksi dibandingkan dengan metode inisialisasi bobot secara random? Perumusan masalah ini berfungsi sebagai panduan dalam penelitian dan membatasi skop penelitian hanya pada variabel-variabel yang relevan, seperti metode inisialisasi bobot dan metrik evaluasi akurasi prediksi.
1.3 Batasan Masalah
Bagian ini menjelaskan batasan-batasan yang ditetapkan dalam penelitian untuk menjaga fokus dan kelayakan penelitian. Batasan-batasan tersebut mencakup penggunaan fungsi aktivasi sigmoid biner, batas toleransi error (0.01), jenis data yang digunakan (data cuaca dari BBMKG Wilayah I Medan selama 15 tahun), dan parameter-parameter backpropagation yang tetap. Pembatasan ini memastikan bahwa penelitian terfokus pada pengaruh metode Nguyen-Widrow tanpa terpengaruh oleh variabel-variabel lain yang dapat mempengaruhi hasil. Ini juga meningkatkan kendali eksperimen dan interpretasi hasil.
1.4 Tujuan Penelitian
Tujuan penelitian ini adalah untuk merancang dan mengimplementasikan metode inisialisasi bobot dan bias menggunakan metode Nguyen-Widrow dalam algoritma backpropagation untuk prediksi. Tujuannya adalah untuk menguji apakah metode ini dapat menghasilkan bobot dan bias yang lebih optimal dibandingkan dengan inisialisasi secara random, sehingga meningkatkan akurasi prediksi. Tujuan ini diukur dengan membandingkan kinerja model yang menggunakan metode Nguyen-Widrow dengan model yang menggunakan inisialisasi bobot secara random, dengan menggunakan metrik evaluasi yang relevan.
1.5 Manfaat Penelitian
Manfaat penelitian dijelaskan dari dua perspektif: Manfaat teoritis berupa pemahaman yang lebih dalam tentang pengaruh metode inisialisasi bobot pada kinerja backpropagation, khususnya dalam konteks prediksi. Manfaat praktis terletak pada potensi aplikasi metode ini dalam berbagai bidang yang memerlukan prediksi akurat, seperti peramalan cuaca. Penelitian ini diharapkan dapat memberikan kontribusi pada pengembangan metode prediksi yang lebih akurat dan efisien. Hasil penelitian juga dapat digunakan sebagai rujukan bagi penelitian selanjutnya dalam meningkatkan kinerja backpropagation.
II. Tinjauan Pustaka
Bab ini memberikan landasan teori yang mendasari penelitian. Tinjauan ini mencakup jaringan saraf biologis, jaringan saraf tiruan (JST), metode backpropagation, metode Nguyen-Widrow, dan normalisasi data. Penjelasan komprehensif tentang konsep-konsep ini memberikan konteks teoritis yang kuat untuk penelitian, serta mengkaji penelitian-penelitian terdahulu yang relevan untuk memberikan perspektif yang lebih luas.
2.1 Jaringan Saraf Secara Biologis
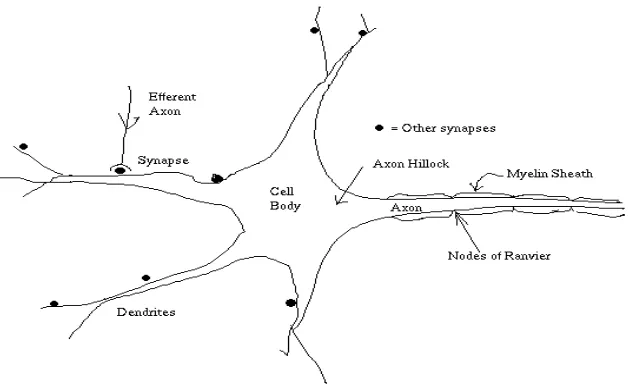
Bagian ini memberikan gambaran umum tentang struktur dan fungsi jaringan saraf biologis sebagai dasar pemahaman jaringan saraf tiruan. Penjelasan tentang neuron, dendrit, akson, dan ambang batas memberikan konteks biologis untuk model komputasional yang digunakan dalam penelitian. Perbandingan antara fungsi jaringan saraf biologis dan jaringan saraf tiruan memberikan pemahaman tentang bagaimana model komputasional meniru aspek-aspek tertentu dari sistem biologis. Ini juga menjelaskan bagaimana model komputasional ini dapat diadaptasi untuk memecahkan masalah prediksi.
2.2 Jaringan Saraf Tiruan (JST)
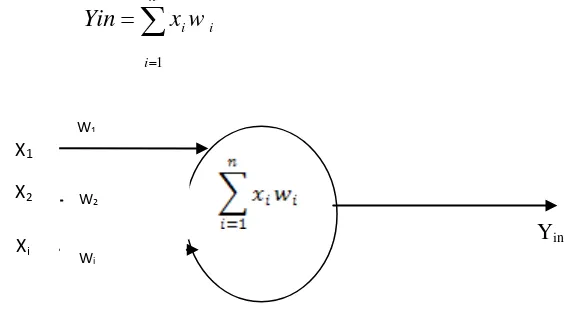
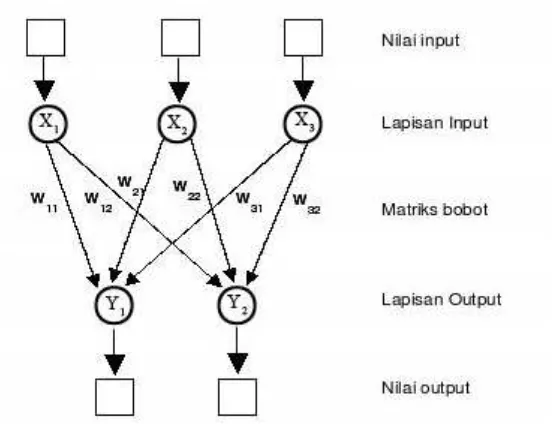
Bagian ini menjelaskan karakteristik, struktur, dan komponen JST, termasuk lapisan masukan, lapisan tersembunyi, dan lapisan keluaran. Penjelasan tentang pemrosesan informasi dalam JST, fungsi aktivasi (termasuk sigmoid biner), dan arsitektur jaringan (single layer dan multi-layer) memberikan dasar yang kuat untuk memahami algoritma backpropagation. Diskusi tentang proses pembelajaran terawasi dan tidak terawasi memberikan konteks yang lebih luas tentang berbagai pendekatan pembelajaran mesin.
2.3 Metode Backpropagation
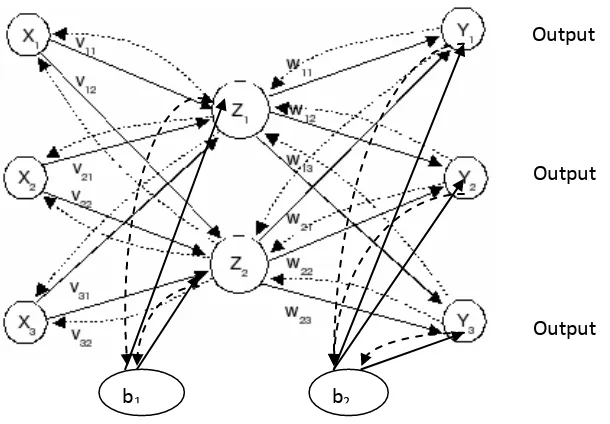
Penjelasan terperinci tentang algoritma backpropagation, termasuk inisialisasi bobot, propagasi maju, propagasi mundur, dan penyesuaian bobot. Diskusi tentang cara meningkatkan hasil metode backpropagation, seperti pemilihan bobot dan bias awal, jumlah unit tersembunyi, waktu iterasi, dan penambahan momentum, memberikan wawasan yang penting untuk penelitian. Bagian ini juga mencakup pengujian (testing) pada metode backpropagation, yaitu perbandingan antara hasil prediksi dengan hasil aktual.
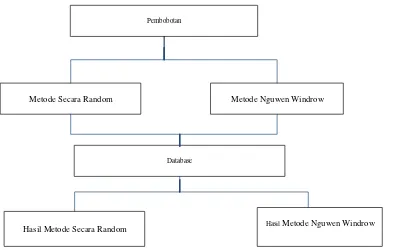
2.4 Metode Nguyen Widrow
Bagian ini menjelaskan metode Nguyen-Widrow sebagai teknik inisialisasi bobot dan bias. Penjelasan algoritma dan rasionalisasi penggunaan faktor skala β = 0.7 dalam metode ini diberikan. Perbandingan antara metode Nguyen-Widrow dengan inisialisasi bobot secara random ditekankan sebagai inti dari penelitian. Pentingnya metode ini dalam mempercepat konvergensi dan meningkatkan akurasi prediksi dijelaskan secara detail.
2.5 Normalisasi Data
Bagian ini membahas pentingnya normalisasi data untuk memastikan bahwa data input berada dalam range yang sesuai dengan fungsi aktivasi sigmoid biner yang digunakan. Rumus normalisasi data dijelaskan, dan alasan mengapa normalisasi data penting untuk kinerja algoritma backpropagation dijelaskan secara detail. Hal ini penting untuk memastikan ketepatan dan reliabilitas hasil penelitian.
2.6 Penelitian Terkait
Tinjauan pustaka ini meneliti studi-studi sebelumnya yang berkaitan dengan topik ini. Ia menganalisis kesamaan dan perbedaan antara penelitian sebelumnya dengan penelitian yang sedang dilakukan. Ini memberikan gambaran umum tentang literatur yang relevan, menunjukkan jurang pengetahuan yang perlu diisi oleh penelitian ini, dan menyoroti kontribusi unik dari penelitian saat ini terhadap literatur yang sudah ada.
III. Metodologi Penelitian
Bab ini menjelaskan secara detail metodologi yang digunakan dalam penelitian, termasuk desain penelitian, data yang digunakan, dan prosedur analisis data. Metodologi menjelaskan bagaimana data dikumpulkan, diolah, dan dianalisis untuk menjawab pertanyaan penelitian. Deskripsi yang jelas tentang langkah-langkah penelitian ini memungkinkan replikasi penelitian dan memastikan transparansi dalam proses penelitian.
3.1 Pendahuluan
Pendahuluan ini memberikan gambaran singkat tentang metodologi penelitian yang akan dijelaskan dalam bab ini. Ia menyoroti pendekatan yang digunakan untuk analisis sistem prediksi cuaca menggunakan backpropagation dengan inisialisasi bobot menggunakan metode Nguyen-Widrow dan metode random. Ia juga menyoroti proses pelatihan dan pengujian sistem untuk menilai kinerja dan akurasi prediksi.
3.2 Perbedaan dan Persamaan dengan Penelitian Lain
Bagian ini membandingkan dan membedakan penelitian ini dengan penelitian sebelumnya yang terkait. Ia mengidentifikasi kesamaan, seperti penggunaan metode backpropagation, dan perbedaan, seperti penggunaan metode Nguyen-Widrow untuk inisialisasi bobot. Ia juga menjelaskan kontribusi unik dari penelitian ini terhadap literatur yang sudah ada, yaitu penggunaan metode Nguyen-Widrow untuk meningkatkan akurasi prediksi dengan metode backpropagation.
3.3 Data Yang Digunakan
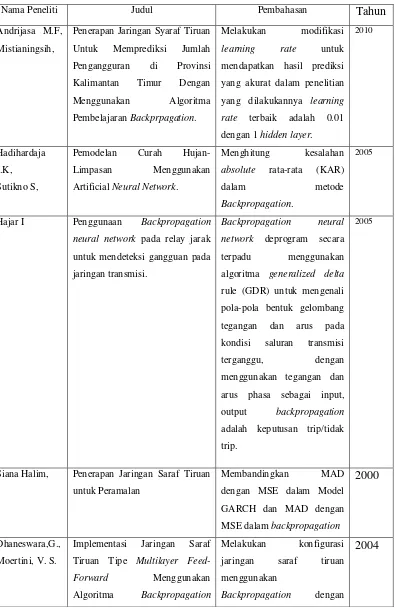
Bagian ini menjelaskan secara rinci data yang digunakan dalam penelitian ini, yaitu data cuaca dari BBMKG Wilayah I Medan selama 15 tahun (1997-2011). Ia juga menjelaskan proses normalisasi data untuk memastikan bahwa data input berada dalam range yang sesuai dengan fungsi aktivasi sigmoid biner. Ia juga menjelaskan bagaimana data dibagi menjadi data pelatihan dan data pengujian. Deskripsi yang jelas tentang data ini penting untuk memahami konteks penelitian dan interpretasi hasil.
3.4 Perancangan
Bagian ini menjelaskan perancangan arsitektur jaringan dan skema sistem yang digunakan dalam penelitian ini. Ia menjelaskan bagaimana arsitektur jaringan backpropagation dirancang, termasuk jumlah node pada lapisan masukan, lapisan tersembunyi, dan lapisan keluaran. Ia juga menjelaskan bagaimana skema sistem dirancang untuk mengolah data, melatih model, dan melakukan prediksi. Diagram atau gambar yang menggambarkan arsitektur dan skema sistem akan membantu pembaca memahami desain penelitian.
3.5 Diagram Tahapan Proses Pelatihan
Bagian ini memberikan gambaran visual dari tahapan proses pelatihan model backpropagation. Diagram alur yang jelas akan menggambarkan langkah-langkah yang terlibat dalam proses pelatihan, termasuk inisialisasi bobot, propagasi maju, propagasi mundur, dan penyesuaian bobot. Ini membantu pembaca memahami alur kerja penelitian dan bagaimana hasil penelitian dicapai.
IV. Hasil dan Pembahasan
Bab ini menyajikan hasil penelitian dan pembahasan yang komprehensif. Hasil penelitian mencakup data empiris yang diperoleh dari eksperimen, termasuk analisis statistik yang relevan. Pembahasan menafsirkan hasil penelitian dalam konteks teori yang telah dijelaskan sebelumnya, dan menjelaskan implikasi dari temuan penelitian. Pembahasan juga membandingkan hasil penelitian dengan penelitian sebelumnya.
4.1 Hasil
Bagian ini menyajikan hasil eksperimen secara sistematis. Ini mencakup data tentang inisialisasi bobot dan bias, proses pelatihan data, hasil pengujian, dan prediksi. Data yang disajikan akan mencakup metrik evaluasi yang relevan, seperti tingkat akurasi, error, dan waktu pelatihan. Tabel dan grafik akan digunakan untuk menyajikan data dengan cara yang jelas dan ringkas.
4.2 Pembahasan
Bagian ini memberikan interpretasi dan analisis yang mendalam terhadap hasil penelitian. Ia membahas pengaruh bobot, bias, dan momentum pada akurasi prediksi. Ia juga menganalisis hasil pengujian dan perbandingan antara metode Nguyen-Widrow dan metode inisialisasi bobot secara random. Pembahasan juga membahas keterbatasan penelitian dan implikasi dari temuan penelitian.
V. Kesimpulan dan Saran
Bab ini merangkum temuan utama penelitian dan memberikan saran untuk penelitian selanjutnya. Kesimpulan menggarisbawahi hasil utama yang mendukung atau menolak hipotesis penelitian. Saran memberikan rekomendasi untuk pengembangan dan perbaikan penelitian di masa mendatang.
5.1 Kesimpulan
Kesimpulan penelitian merangkum temuan utama tentang pengaruh metode Nguyen-Widrow terhadap akurasi prediksi menggunakan backpropagation. Kesimpulan ini didasarkan pada data empiris yang telah dianalisis dan dibahas sebelumnya. Kesimpulan harus jelas, ringkas, dan mendukung oleh data yang ada.
5.2 Saran
Bagian ini memberikan saran untuk penelitian selanjutnya berdasarkan keterbatasan dan implikasi dari penelitian ini. Saran-saran ini dapat mencakup penggunaan dataset yang lebih besar, eksplorasi metode inisialisasi bobot yang lain, atau penerapan metode ini pada domain prediksi yang berbeda. Saran-saran ini bertujuan untuk meningkatkan dan memperluas penelitian di masa mendatang.