IMPLEME
BAHAS
FAKUL
ENTASI
QU
SA INDONE
DE
LTAS MAT
IN
UESTION A
ESIA DENG
AGU
EPARTEME
TEMATIKA
NSTITUT P
ANSWERIN
GAN PERT
US UMRIA
EN ILMU K
A DAN ILM
PERTANIA
BOGOR
2011
NG SYSTEM
TANYAAN
ADI
KOMPUTE
MU PENGET
AN BOGOR
M
PADA DO
BERSIFAT
R
TAHUAN A
R
OKUMEN
T
LIST
ABSTRACT
AGUS UMRIADI. Implementation of Question Answering System for Document in Bahasa Indonesia with List Question.Under direction of JULIO ADISANTOSO.
In the last few years, many studies of Question Answering System (QAS) have been conducted by a number of research groups around the world. Lately, a question is not only presented in the form of factoid questions, but also as a list questions where a question requires more than a single-entity of answer. However, recent development on QAS can only accommodate factoid questions which only require a single-entity's answer. To address this issue, the purpose of this research is to implement QAS for list questions. In order to obtain candidate of answers, heuristic weighting is performed in the passage which is contained on the top n documents. One thousand documents and 40 queries are used in the experiment. The best results of experiment show correctness of 26%, 39%, 36.33% and 70 % for “who”, “how many/much”, “where” and “when” list questions, respectively.
IMPLEMENTASI
QUESTION ANSWERING SYSTEM
PADA DOKUMEN
BAHASA INDONESIA DENGAN PERTANYAAN BERSIFAT
LIST
AGUS UMRIADI
Skripsi
Sebagai salah satu syarat untuk memperoleh
gelar Sarjana Komputer pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul Penelitian : Implementasi Question Answering System pada Dokumen Bahasa Indonesia dengan Pertanyaan Bersifat List
Nama : Agus Umriadi
NRP :G64070125
Menyetujui:
Pembimbing
Ir. Julio Adisantoso, M.Kom NIP 19620714 198601 1 002
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP 19601126 198601 2 001
KATA PENGANTAR
Alhamdulilahirobbil’alamin, segala puji syukur penulis panjatkan kehadirat Allah SWT atas segala karunia-Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul Implementasi
Question Answering System pada Dokumen Bahasa Indonesia dengan Pertanyaan Bersifat List. Penulis menyadari bahwa tugas akhir ini tidak akan terselesaikan tanpa bantuan dari berbagai pihak. Pada kesempatan ini penulis ingin mengucapkan terima kasih kepada:
1. Orang tua tercinta, bapak Masud dan ibu Umiati, kakak saya Muslihah serta kedua adik yang saya sayangi Ichwanudin dan Ilham Mahfudi, yang selalu memberikan doa, nasihat, semangat, dukungan dan kasih sayang yang luar biasa kepada penulis sehingga dapat menyelesaikan tugas akhir ini.
2. Bapak Ir. Julio Adisantoso, M.Kom selaku dosen pembimbing tugas akhir. Terima kasih atas kesabaran, bimbingan serta dukungan dalam penyelesaian tugas akhir ini.
3. Bapak Ahmad Ridha, S.Kom, M.Si selaku dosen pembimbing akademik. Terima kasih atas bimbinganyang telah diberikan selama penulis melakukan kegiatan perkuliahan.
4. Teman-teman satu bimbingan Aprilia Ramadhina, Devi Dian P, Fandi Rahmawan, Woro Indriani, Isna Mariam, Nova Maulizar, Nutri Rahayuni dan Ilkomerz 44 terima kasih atas kebersamaan dan semangatnya dalam menyelesaikan tugas akhir ini.
5. Sutanto Ningsih, Fani Wulandari, Teguh Cipta Pramudia, Arizal Noviansah, Yoga Herawan danMedria Hardhienata terima kasih untuk dukungan dan bantuannya selama penyelesaikan tugas akhir ini.
6. Wenti Ismayulia yang senantiasa memberikan semangat dan doa kepada penulis.
7. Seluruh staf Departemen Ilmu Komputer IPB yang telah banyak membantu baik selama penelitian maupun selama perkuliahan.
Penulis menyadari bahwa dalam penulisan tugas akhir ini masih terdapat banyak kekurangan dan kelemahan dalam berbagai hal karena keterbatasan kemampuan penulis.Penulis berharap adanya masukan berupa saran atau kritik yang bersifat membangun dari pembaca demi kesempurnaan tugas akhir ini.Semoga tugas akhir ini bermanfaat.
Bogor, Agustus 2011
RIWAYAT HIDUP
Agus Umriadi dilahirkan di kota Serang, Banten, pada tanggal 29 Agustus 1989 dari pasangan Ibu Umiati dan Bapak Mas’ud. Pada tahun 2007 penulis lulus dari Sekolah Menengah Atas (SMA) Negeri 1 Cilegon.
DAFTAR ISI
Halaman
DAFTAR GAMBAR ... viii
DAFTAR TABEL ... viii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN ... 1
Latar Belakang ... 1
Tujuan ... 1
Ruang Lingkup ... 1
TINJAUAN PUSTAKA ... 1
Temu Kembali Informasi ... 1
Question Answering ... 1
Faktor Heuristic ... 2
METODE PENELITIAN ... 3
Gambaran Umum Sistem ... 3
Evaluasi ... 4
Lingkungan Implementasi ... 5
HASIL DAN PEMBAHASAN ... 5
Koleksi Dokumen Pengujian ... 5
Pemrosesan Query ... 6
Pemrosesan Dokumen ... 6
Perolehan Top Document ... 7
Pembentukan Kalimat ... 8
Pembentukan Passages ... 8
Pemrosesan Passages ... 9
Perolehan Kandidat Jawaban ... 9
Evaluasi Question Answering System ... 10
Kelebihan dan Kelemahan Sistem ... 12
KESIMPULAN DAN SARAN ... 13
Kesimpulan ... 12
Saran ... 12
DAFTAR PUSTAKA ... 13
DAFTAR GAMBAR
Halaman
1Arsitektur umum Question Answering System (Molla 2003) ... 2
2Diagram gambaran umum QAS ... 4
3 Kalimat yang sudah dilakukan ... 5
4 Format dokumen dengan struktur ... 6
5 Format dokumen setelah mengalami perubahan struktur tag ... 6
6 Implementasi pemrosesan query ... 6
7Konfigurasi SPHINX ... 7
8 Cuplikan implementasi untuk mengambil sepuluh dokumen teratas ... 7
9 Dokumen teratas ... 8
10 Fungsi pembentuk kalimat ... 8
11 Hasil pembentukan kalimat ... 8
12 Fungsi pembentuk passage ... 8
13 Pembentukan passage ... 8
14 Contoh passage teratas ... 9
15 Kandidat jawaban pada n passage teratas ... 10
16 Implementasi perhitungan bobot jarak ... 11
17 Bobot jarak entitas jawaban ... 12
DAFTAR TABEL Halaman 1 Daftar pasangan kata tanya dan ... 6
2 Perolehan indeks kandidat jawaban ... 10
3 Perolehan indeks hasil wordmatch ... 10
4 Bobot jarak kandidat jawaban... 10
5 Persentase perbandingan nilai right, wrong dan null untuk 20 pertanyaan dan perbandingan sumber dokumen dari entitas jawaban yang ditemukembalikan ... 11
6 Persentase perolehan jawaban query factoid ... 11
7 Contoh dokumentasi pertanyaan dengan menggunakan 10 top passages dan threshold 25% ... 13
DAFTAR LAMPIRAN Halaman 1 Hasil pengujian kata tanya SIAPA ... 16
2 Hasil pengujian kata tanya DIMANA ... 17
3 Hasil pengujian kata tanya KAPAN ... 18
4 Hasil pengujian kata tanya BERAPA ... 19
PENDAHULUAN Latar Belakang
Sistem temu kembali informasi memiliki kaitan yang sangat erat dengan sistem pencarian(searchengine).Untuk memperoleh suatu informasi sistem pencarian membutuhkan masukan yang dikenal dengan
query yang biasanya berbentuk kata kunci. Saat ini sudah dikembangkan sistem pencarian menggunakan pertanyaan sebagai
query yang dikenal dengan Question Answering System(QAS). Dengan menggunakan pertanyaan sebagai query
diharapkan informasi yang diperoleh oleh pengguna selain relevan juga lebih spesifik.
Ballesteros dan Xiayoan-Li (2007) mengimplementasikan Question Answering
yang digunakan untuk monolingual English
dan Chinesse. Dalam mengembalikan kalimat jawaban atau informasi yang relevan, pemberian skor pada koleksi dokumen secara
heuristic dan bergantung pada syntactic factor yang didefinisikan sebagai aturan-aturan untuk mengidentifikasi kandidat kalimat relevan atau kalimat jawaban.
Hui Yang dan Tat-Seng Chua (2004) mengimplementasikan Web-Based List Question Answeringdimana kandidat jawaban diperoleh dari dua sumber utama yaitu
collection pages dandistinct
topic.Ikhsani(2006) telah
mengimplementasikan QAS untuk menemukan jawaban dari query pertanyaan hanya dengan menggunakan satu dokumen bacaan yang menggunakan kalimat baku.
Anggraeini (2007) menyusun QAS untuk surat Al-Baqarah yang terdiri atas beberapa ayat sebagai dokumen. Sianturi (2008) menyempurnakan penelitian Ikhsani (2006) dengan menggunakan metode Rule-Based
pada banyak dokumen bahasa
Indonesia.Selanjutnya, Cidhy (2009)mengimplementasikan Question
Answering System dengan pembobotan
heuristic dan Panggudi (2009) membuatNamed Entity Taggeruntuk dokumen bahasa Indonesia menggunakan metode berbasis aturan. Kartina (2010) menganalisis pertanyaan untukQuestion Answering System pada dokumen bahasa Indonesia dan Herdi (2010) menggunakan
framework INDRI untuk melakukan pembobotan dalam proses pengindeksandokumen bahasa Indonesia.
Semua QAS yang telah dikembangkan hanya dapat mengakomodasi pertanyaan bersifat factoid.Pertanyaan ini hanya membutuhkan satu entitas jawaban.Penelitian ini mengimplementasikan QAS dengan jenis pertanyaan bersifatlistyang dapat menghasilkan banyak jawaban.
Tujuan
Tujuan dari penelitian ini adalah mengimplementasikan sistem temu kembali informasi (Question Answering System) menggunakan query pertanyaan bersifat list
untuk dokumen bahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah :
1. Korpus dokumen bahasa Indonesia dan kata tanya yaitu siapa, dimana, kapan, dan berapa.
2. Pasangan pertanyaan dan jawaban sudah ditentukan oleh penulis dari koleksi dokumen yang ada.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi berkaitan dengan merepresentasi, menyimpan, mengorganisasi, dan mengakses informasi.Merepresentasi dan mengorganisasi suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya.Dalam pencarian suatu informasi pengguna harus menerjemahkan kebutuhan informasinya dalam bentuk query. Berdasarkan query tersebut, sistem temu kembali informasi akan mengembalikan informasi yang relevan dengan query yang diberikan oleh pengguna (Baeza-Yates & Ribeiro-Neto 1999).
Question Answering
Question Answering system merupakan aplikasi yang menggabungkan konsepInformation Retrieval (IR) dengan
keluaran yang dihasilkan adalah dokumen yang dianggap relevan oleh sistem. Sedangkan pada QA, query berupa kalimat tanya dan keluarannya berupa jawaban (entitas) yang dianggap sesuai oleh sistem sehingga memungkinkan sistem tidak mengembalikan jawaban apapun (Strzalkowski & Harabagiu 2008).QA memiliki ide dasar sebagai berikut (Lin 2004) :
Menentukan tipe semantik dari jawaban yang diharapkan.
Menentukan dokumen-dokumen yang mengandung kata-kata yang terdapat dalam pertanyaan (query).
Mencari entitas jawaban dengan tipe yang sesuai dengan pertanyaan, dan memiliki kedekatan yang tinggi dengan query.
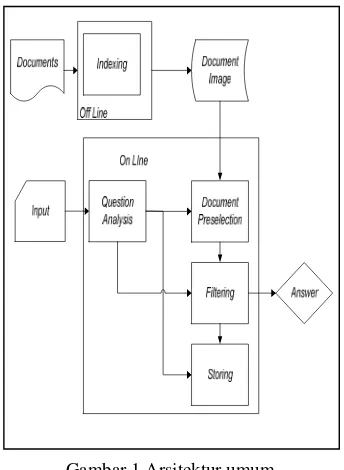
Gambar 1 menunjukkan proses pada
Question Answering System (QAS). Dalam tahapan offline atau indexing dilakukan analisis terhadap teks dokumen. Teks dokumen yang digunakan sudah memiliki
named entity tag didalamnya. Hasil dari proses indexing digunakan untuk tahapan QAS selanjutnya, yaitu tahapan online yang terdiri atas analisis pertanyaan, document preselection, seleksi, dan pembobotan.
Modul analisis pertanyaan mengklasifikasi pertanyaan dan menentukan tipe dari jawaban yang diharapkan. Hasil dari modul ini terdiri atas kata tanya dan kata-kata yang akan digunakan dalam pembobotan
heuristic (scoring). Kata-kata yang digunakan untuk pembobotan heuristic juga digunakan dalam document preselection.
Document preselection menghasilkann dokumen tertinggi. Kata tanya digunakan untuk mengidentifikasi tipe named entity dari pertanyaan. Perolehan named entity digunakan untuk menyeleksinpassages
yang mengandung kandidat jawaban. Contohnya adalah kata tanya “Dimana”mengidentifikasi keterangan tempat, yang diwakili oleh named entity tag LOCATION. Perolehan entitas kandidat jawaban dilakukan pada npassages dengan bobot tertinggi (Molla 2003).
Faktor Heuristic
QAS memiliki tiga modul utama yaitu modul pemrosesan query, modul sistem pencarian, dan modul ekstraksi jawaban (Ballesteros & Xiaoyan-Li 2007).
Gambar 1 Arsitektur umum
QuestionAnswering System(Molla 2003)
1. Pemrosesan Query
Langkah-langkah dalam pemrosesan
query adalah sebagai berikut :
a. Sebagai langkah awal dilakukan pendefinisian kembali tipe pertanyaan yang memiliki hubungan dengan NE (named entity) yang baku. Mengacu pada penelitian (Ballesteros &Xiaoyan-Li 2007), ada tujuh tipe pertanyaan yang terdiri atas NAME, LOCATION, ORGANIZATION, DATE, TIME, CURRENCY dan NUMBER. Dalam bahasa Indonesia akan diwakili dengan SIAPA, DIMANA, KAPAN, dan BERAPA. Setiap pertanyaan akan mengalami proses parsing terlebih dahulu.
b. Kata tanya seperti “APAKAH” dan “APA” tidak diperhitungkan karena hanya akan menambahkan informasi yang tidak berguna.
c. Stopwordsdihilangkan.
Setelah dilakukan pemrosesan, query
2. RetrievalEngine
Banyak fungsi kesamaan yang digunakan padaretrieval engine untuk melakukan pemeringkatan dokumen yang mengadung informasi yang berkaitan dengan
query.Fungsi yang sering digunakan untukmengukur kesamaan antara query dan dokumen yaitu denganmenggunakan kesamaan cosine (Manning 2008). Terdapat juga Pembobotan BM25 yang dikenal denganpembobotan Okapi.Pembobotan BM25 menggabungkan bobot idf dengan koleksi pengskalaan khusus untuk dokumen dan query(Kontostathis 2008 dalam Herdi 2010). Dokumen yang ditemukembalikan akan digunakan dalam proses ekstraksi jawaban.
3. Modul Ekstraksi Jawaban
Pada tahap ini dilakukan identifikasi terhadap jawaban. Setiap n dokumen teratas yang terambil dianalisis kembali untuk mengidentifikasi kandidat jawaban dengan cara sebagai berikut (Ballesteros & Xiaoyan-Li 2007):
1. Dilakukan identifikasi named entity yang terdiri atas orang, organisasi, lokasi, ekspresi waktu, tanggal, ekspresi numerik dan uang.
2. Dokumen dibagi menjadi passage.
Passage terdiri atas beberapa kalimat yang berdampingan. Antarpassage memiliki kalimat yang overlap.
3. Dilakukan pembobotan heuristic pada setiap passage. Pertama-tama didefinisikan count_query adalah jumlah kata yang terdapat pada query (kalimat tanya), count_match adalah jumlah hasil pencocokan antara kata yang terdapat pada query dan passage (wordmatch) dan
score adalah bobot dari passage. Proses pembobotan adalah sebagai berikut:
i. Jika tidak ada named entity yang ditampilkan,passage menerima nilai 0. Jika named entity ditampilkan pada
passage namun tidak memilki tipe yang sama dengan pertanyaan, named entity diabaikan.
ii. Dilakukan pencocokan kata-kata pada
query dengan kata-kata pada passage
(proses wordmatch). Jika nilai
count_match kurang dari threshold (t),
score = 0. Selain itu, score =
count_match. Nilai threshold(t), didefinisikan dengan cara sebagai berikut:
a. Jika count_query kurang dari 4, t = count_query. Dengan kata lain, paragraf apapun yang tidak mengandung kata-kata yang terdapat pada query tidak diperhitungkan.
b. Jika count_query antara 4 dan 8, t = (count_query/2.0 ) + 1.0.
c. Jika lebih besar dari 8, t = (count_query/3.0) + 2.0.
iii. Kata yang berdekatan memiliki hubungan keterkaitan informasi yang lebih tinggi. Jika seluruh kata yang cocok dengan query terdapat pada satu kalimat Sm = 1, selainituSm= 0. Maka
score = score + (Sm*0.5).
iv.Seperti diketahui urutan kata dapat mempengaruhi arti. Maka diberikan bobot yang lebih tinggi (Ord = 1) terhadap passage jika kata-kata yang cocok dengan query memiliki urutan yang sama seperti pada pertanyaan. Selain itu Ord = 0. Maka score = score
+ ( Ord*0.5).
v. Score = score + (count_match/W),
dimana Wadalah panjang
passagedengan
nilaicount_matchterbesar.
4. Pembobotan terakhir yaitu menghitung total perolehan nilai. Heuristic_score =
count_match + 0.5*Sm + 0.5*Ord +
count_match/W. Dilakukan pengurutan terhadap seluruh passage dari setiap 10 dokumen teratas. Pengurutan dilakukan berdasarkan bobot yang dimiliki oleh setiap passage.
5. Ekstraksi kandidat jawaban daripassage
peringkat teratas. Jarak antara kandidat jawaban dan posisi dari setiap query yang cocok dalam passage dihitung.Kandidat jawaban yang memiliki jarak kurang dari
threshold dipilih menjadi entitas jawaban terakhir.
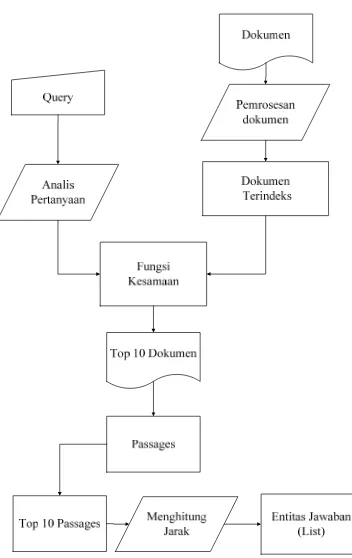
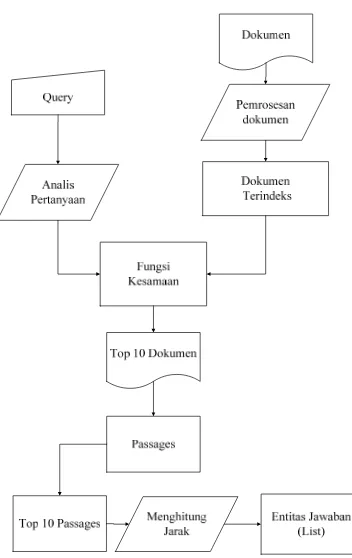
METODE PENELITIAN Gambaran Umum Sistem
kalimat pertanyaan dimasukan secara manual oleh pengguna. Kemudian dilakukananalisis untuk mengidentifikasi tipe dari pertanyaan tersebut sehingga dapat ditentukan named entity yang akan dicari untuk dapat menemukan kandidat jawaban. Langkah selanjutnya adalah querytanpa kata tanyadigunakan untuk memperoleh n
dokumen teratas. Kemudian pada n dokumen teratas dilakukan pemisahan dua kalimat yang saling berdampingan yang disebut passage. Jumlah dokumen teratas yang digunakan dalam proses pembobotan paling banyakadalah 10 dan 20. Dokumen uji yang digunakan terdiri dari 1000 dokumen bahasa Indonesia berformat .xml yang diambil dari media koran, majalah dan jurnal penelitian.
Langkah selanjutnya adalah proses ekstraksi jawaban. Dilakukan pencarian entitas dengan tipe yang sesuai dengan pertanyaan.Pembobotan terhadap passage
menggunakan faktor heuristic seperti yang telah dijelaskan oleh (Xiaoyan-Li & Ballestros 2007).
Setiap diperolehnpassages teratas dilakukan perhitungan jarak kata pada masing-masing passage.Kata yang menjadi kandidat jawaban dan memiliki jarak kurang dari thresholdakan menjadi entitas jawaban (list).
Evaluasi
Evaluasi Question Answering System
(QAS) ini dilakukan dengan melihat banyaknya kalimat jawaban yang ditemukembalikan dan banyaknya hasil yang benar maupun yang salah. Semakin banyak hasil yang benar, tentu kinerja sistem semakin tinggi. Setiap query bisa memiliki satu atau lebih kalimat jawaban.Evaluasi dilakukan menurut persepsi manusia.
Penilaian untuk querylist dan factoid
memiliki perbedaan. Pada query factoid
terdapat 4 jenis penilaian, yaitu:
1. Right : jawaban dan dokumen benar 2. Wrong : jawaban salah
3. Unsupported : jawaban benar tapi dokumen tidak mendukung
4. Inexact : jawaban dan dokumen benar tapi terlalu panjang.
Gambar 2 Diagram gambaran umum QAS
Sedangkan penilaian untuk querylist hanya terdapat tiga jenis, yaitu :
1. Right : Jawaban yang diperoleh sistem sama dengan jawaban yang ditentukan penulis sebelumnya.
2. Wrong: Jawaban yang ditemukembalikan tidak ada yang sesuaidengan jawaban yang ditentukan sebelumnya.
3. Null : Sistem tidak mengembalikan jawaban apapun.
Nilai “Right” mempunyai dua sumber dokumen yang digunakan untuk mengembalikan dokumen yaitu (Yang &Chua 2004):
1. Collection Page : Entitas jawaban berasal dari dokumen yang sama.
Mengukur nilai Right untuk setiap jenis kata tanya menggunakan formula berikut :
Right :
- 0.1x∑
Keterangan :
B= Banyaknya jawaban benar yang ditemukembalikan
J= Banyaknya jawaban yang dianggap benar
S = Banyaknya jawaban tidak relevan yang ditemukembalikan
Untuk menghitung nilai rata-rata untuk setiap jenis kata tanya menggunakan formula berikut :
Avg Right:
∑Keterangan :
N = Banyaknya pertanyaan yang diujikan pada setiap jenis kata tanya
Asumsi
Asumsi-asumsi yang digunakan dalam pengembangan sistem ini adalah:
1. Tidak ada kesalahan dalam pengetikan
query.
2.Setiap kata pada query dipisahkan oleh
whitespace atau spasi.
3. Setiap query diawali oleh kata tanya. 4. Query berkaitan dengan koleksi dokumen.
Lingkungan Implementasi
Lingkungan implementasi yang digunakan adalah sebagai berikut :
Perangkat Lunak :
Sistem operasi Windows 7 professional
PHP SPHINX
Named Entity Tagger bahasa Indonesia
PerangkatKeras :
Processor intel Pentium dualcore, 1.86 GHz
RAM 1 GB
Harddisk dengan kapasitas 160 GB
HASIL DAN PEMBAHASAN 1. Koleksi Dokumen Pengujian
Dokumen uji yang digunakan memiliki ukuran terkecil 1 KB dan ukuran terbesar 53 KB. Setiap dokumen memiliki struktur XML yang sama.Cuplikan dokumen dapat dilihat pada Gambar 4. Dokumen memiliki tag
dengan fungsi yang berbeda-beda. Pada baris pertama terdapat tag<DOC> yang berfungsi membedakan satu dokumen dengan dokumen lainnya. Tag<DOCNO> menunjukkan nama dokumen, tag<TITLE> menunjukkan judul dari dokumen,
tag<AUTHOR> menunjukkan penulis dari dokumen dan tag<TEXT> yang menunjukkan isi dari dokumen.
Pada dokumen uji yang digunakan, pertama-tama dilakukan penamaan entitas (named entity) yang disebut tagging pada dokumen dengan menggunakan Named Entity Tagger bahasa Indonesia yang merupakan aplikasi hasil penelitian dari (Citraningputra 2009). Penamaan entitas dilakukan untuk proses perolehan kandidat jawaban sesuai dengan jenis pertanyaan. Named entity yang digunakan terdiri dari NAME, ORGANIZATION, LOCATION, CURRENCY, DATE, TIME dan NUMBER. Gambar 3 adalah contoh kalimat yang terdapat pada indosiar010504.txt yang sudah dilakukan proses tagging.
Ratusan hektar tanaman bawang merah di [LOCATION]Tegal Jawa Tengah[/LOCATION],gagal panen karena rusak di serang hama ulat.
Gambar 3 Kalimat yang sudah dilakukan
tagging
<DOC> <DOCNO>jurnal000000</DOCNO> <TITLE> PEMBANGUNAN</TITLE> <AUTHOR>Triharso</AUTHOR> <TEXT> …… <P>Penyiangan jalur…..…</P> </TEXT> </DOC>
Gambar 4 Format dokumen dengan struktur
tagXML <sphinx:document id="1"> <docno>suarapem.txt</docno> <author>AP/AFP/H-12/N-</author> <title>Gelombang Protes</title> <content>
JAKARTA -Agenda-agenda yang dibahas dalam Konferensi Tingkat
Menteri(KTM)[ORGANIZATION]Organ isasi)[/ORGANIZATION]………… </content>
Gambar 5 Format dokumen setelah
mengalami perubahan struktur tag
2. Pemrosesan Query
Query yang digunakan dalam penelitian ini berupa bahasa alami berbentuk kalimat tanya. Kalimat ini diawali kata tanya dan diakhiri dengan tanda (?).
Dalam pemrosesan query yang pertama dilakukan adalah melakukan parsing terhadap kalimat tanya dengan pemisah yang tersimpan dalam variabel pemisahkata yang dapat dilihat pada Gambar 6.
Var $pemisahkata = "/[\s\+\/%,.\"\];()\' :=`?\[!@>]+/”; function setQuery($query) {$question=preg_split($this->pemisahkata, strtolower($query)); $this->question_word= $question[0]; foreach($question as $word){ if((!in_array($word,$this-> getStopWords()))&&(!in_array($word, $this->arrayKataTanya))&& (strlen($word) !=null)) $this->wordQuestion[]= $word; }
Gambar 6Implementasi pemrosesan query
Parsing pada query dilakukan setelah proses case folding. Case folding adalah membuat huruf pada teks menjadi kecil. Pada proses ini kata-kata pada queryyang termasuk
stopwords dihilangkan. Mengacu pada Gambar 6 hasil dari proses parsing disimpan dalam variabel arrayquestion. Pada indeks ke-0 atau question[0] dapat diidentifikasi kata tanya yang disimpan dalam variabel
question_word. Kata tanya ini digunakan untuk menentukan tipe jawaban yang ditemukembalikan oleh sistem. Tipe jawaban dicirikan dengan tag named entity yang terdapat pada dokumen.
Pada penelitian kali ini kata tanya yang digunakan dibatasi dalam empat jenis, yaitu siapa, kapan, dimana dan berapa. Tabel 1 menunjukkan daftar pasangan jenis kata tanya dan named entity yang menjadi penciri dari jawaban yang akan ditemukembalikan.
Tabel 1 Daftar pasangan kata tanya dan
named entity
No Kata
Tanya Tag Named Entity 1 Siapa NAME, ORGANIZATION
2 Kapan DATE,TIME
3 Dimana LOCATION
4 Berapa NUMBER,CURRENCY
Untuk nilai question selain kata tanya pada indeks 0 atau question[0], yaitu
question[1] sampai question[n] disimpan dalam variabel wordQuestion. Variabel ini digunakan dalam proses perolehan n
dokumen teratas dengan menggunakan SPHINX, pembobotan heuristic dan perolehan jawaban.
3. Pemrosesan Dokumen
Penjelasan untuk konfigurasi yang digunakan pada Sphinx search,yaitu:
source = srcxml, konfigurasi untuk
menandakan bahwa sumber yang digunakan atau file yang akan diindeks berupa file dengan format XML.
xmlpipe_field, konfigurasi untuk
menyebutkan atribut apa saja yang ingin diproses pada SPHINX.
path=c:/sphinx/data/qas,
konfigurasi untuk mengatur dimana file hasil indexing disimpan, pada dokumen pertanian disimpan pada folder data dengan nama file qas.
docinfo = extern, konfigurasi
untuk penyimpanan dokumen hasil
indexing. Dalam hal ini konfigurasi externmenunjukkan bahwa hasil
indexingakan disimpan dalam file terpisah dengan nama file yang sama.
morphology= stem_en, konfigurasi
untuk stemmer, stem_enmenunjukkan bahwa stemmer yang digunakan yaitu
english stemmer.
min_word_len = 3, konfigurasi ini
menjelaskan panjang minimal kata yang diindeks yaitu minimal 3 karakter.
charset_type = utf-8, konfigurasi
ini menunjukkan tipe karakter yang digunakan yaitu utf-8.
enable_star = 0, konfigurasi untuk
pengindeksan prefiks. Digunakan nilai 0 yang menunjukkan bahwa tidak dilakukan pengindeksan untuk prefiks.
html_strip = 0, konfigurasi untuk
menghilangkan tag. Digunakan nilai 0 yang berarti tidak menghilangkan tag.
Stopwords=c:/sphinx/data/Sto
pWords.txt, konfigurasi untuk eliminasi kata buangan.
4. Perolehan Top Document
Tahapan ini dilakukan untuk mendapatkanndokumen teratas yang akan digunakan untuk membentuk kalimat dan
passage pada tahap selanjutnya. Dokumen yang digunakan pada penelitian ini paling banyak 10 dokumen dan 20 dokumen.Query
dimasukkan secara manual kemudian dilakukan pembobotan oleh SPHINX dengan pembobotan BM25.
Kata pada query kecuali kata tanya akan dicocokkan dengan dokumen yang ada. Semua dokumen yang relevan dengan query
akan ditemukembalikan dari dokumen dengan bobot tertinggi sampai dengan bobot terendah.Namun pada penelitian ini hanya 10 atau 20 dokumen yang dgunakan. Hal ini dilakukan untuk mempermudah proses pembentukan kalimat dan passage.
source srcxml {
Type = xmlpipe
xmlpipe_command = type C:\sphinx\corpus\korpusqas.xml xmlpipe_field = docno
xmlpipe_field = author xmlpipe_field = title xmlpipe_field = content } index qas { source= srcxml path= c:/sphinx/data/qas docinfo= extern morphology= stem_en min_word_len = 3 charset_type = utf-8 enable_star = 0 html_strip = 0
stopwords =
c:/sphinx/data/stopwords.txt }
Gambar 7Konfigurasi SPHINX
$tempcontent=array(); $n = $res['total']; if($res['matches'])
$temp2=array_slice ($res['matches'],0,10); if($temp2)foreach ($temp2 as $data) { $tempcontent[$data['attrs'] ['docno']] = $data['attrs']['content']; } }}
Hasil dari perolehan n dokumen teratas
disimpan dalam
arraytempcontent[$data['attrs']['docno']].Cu plikan implementasi untuk mengambil 10 dokumen teratas dapat dilihat pada Gambar 8.Gambar 9 adalah contoh dari dokumen teratas dengan query, “Siapa saja pejabat yang menjadi tersangka kasus ilegal logging?”
[suarakarya000000-016.txt] => Maraknya praktek illegal logging (penebangan liar) di
wilayah provinsi [LOCATION]Kalimantan
Tengah[/LOCATION] yang terkenal dengan emas hijau hingga kini terus berlangsung, bahkan sampai merambah kawasan Taman Nasional [LOCATION]Tanjung Puting[/LOCATION]
([LOCATION]TNTP[/LOCATION])
yang merupakan pusat rehabilitasi orangutan.
………
Gambar 9 Dokumen teratas
5. Pembentukan Kalimat
Sepuluh dokumen teratas yang ditemukembalikan oleh SPHINX kemudian diproses menjadi kalimat. Dalam wujud tulisan Latin, kalimat dimulai dengan huruf kapital dan diakhiri dengan tanda (.), tanda tanya(?), atau tanda seru (!).
Kalimat disimpan dalam variabel
arraykalimat.Cuplikan kalimat dapat dilihat pada Gambar 11 sedangkan fungsi yang digunakan dalam pembentukan kalimat dapat dilihat pada Gambar 10.
Function pemisahkalimat ($paragraf){
$tempkalimat = preg_split ("/[.?!]+[\s]+/",$paragraf);
return $tempkalimat;
}
Gambar 10 Fungsi pembentuk kalimat
Array (
[suarakarya.txt] => Array
(
[0] =>Maraknya praktek illegal.. [1] => Kerusakan hutan yang semakin parah dan..
[2] => Bahkan tekanan untuk menyelamatkan hutan.. …………
Gambar 11 Hasil pembentukan kalimat
6. Pembentukan Passages
Pembentukan passages dilakukan dengan cara menggabungkan dua kalimat dari masing-masing dokumen, yaitu kalimat pada indeks sebelumnya dengan kalimat pada indeks sesudahnya. Dengan demikian, satu kalimat akan terdapat pada dua passages (hal ini tidak berlaku pada kalimat pertama dan terakhir). Fungsi yang digunakan untuk membentuk passage dapat dilihat pada Gambar 12.
function createpassage ($arraykalimat){
$total= count($arraykalimat); $arrayhasil=array();
for($indeks=0;$indeks<$total-1; $indeks++){
$arrayhasil[]=$arraykalimat[$ind eks].".
".$arraykalimat[$indeks+1].".";} return $arrayhasil;}
Gambar 12 Fungsi pembentuk passage
Hasil pembentukan passages disimpan dalam arrayarraypassagesdengan indeks asosiatif berupa nama dokumen. Ilustrasi pembentukan passages ditunjukkan oleh Gambar 13.
Array (
[doc1] => Array (
[0] => kalimat 1. kalimat 2 [1] => kalimat 2.kalimat 3 )).
7. Pemrosesan Passages
Tidak semua passages dalam dokumen digunakan dalam proses pembobotan
passages, namun hanya passages yang mengandung tag name entity yang sesuai dengan kata tanya. Tag yang sesuai tersebut disimpan dalam arrayarrayTag, misalkan kata tanya “Siapa” maka tag yang disimpan didalam arrayTag adalah ORGANIZATION
dan PERSON.
Sebagai contoh dengan menggunakan
query “Siapa saja pejabat yang menjadi tersangka kasus ilegal logging?” dari 1 dokumen teratas diperoleh passagessebanyak 30. Kemudian dilakukan seleksi berdasarkan
named entity sesuai kata tanya. Dalam contoh queryini passages diseleksi dengan
tag ORGANIZATON dan PERSON, sehingga diperoleh passages sebanyak 14passages.
8. Pembobotan Passages
Pada tahapan ini dilakukan pembobotan terhadap passagesyang diseleksi berdasarkan
named entity yang dibutuhkan. Pembobotan dilakukan dengan mengikuti tahapan yang terdapat pada jurnal Ballesteros & Xiaoyan-Li (2007) yang dijadikan acuan dalam penelitian ini, pembobotan passages terdiri dari:
1. Pembobotan passages dari proses
wordmatch sesuai threshold disimpan dalam variabel sThreshold.
2. Pembobotan passages berdasarkan urutan nilai dari wordQuestion dalam
passages. Hasilnya disimpan dalam variabel sInordered.
3. Pembobotan passages berdasarkan jumlah nilai dari wordQuestion dalam
passages. Hasilnya disimpan dalam variabel sInSentence.
4. Pembobotan berdasarkan hasil dari
arrayWordMatch dibagi dengan jumlah kata dari passage dengan bobot
arrayWordMatchtertinggi disimpan dalam variabel sWindow.
Fungsi yang digunakan dalam pembobotan passages dapat dilihat pada Lampiran 5. Implementasi pembobotan dalam penelitian ini menggunakan fungsi yang telah dikembangkan oleh (Chidy 2009), namun penulis melakukan perubahan pada pembobotan sWindow yaitu pada bagian
Score = score +
(count_match/W), pada penelitian
(Cidhy 2009) W merupakan banyaknya kata pada tiap passage yang dihitung bobotnya, sedangkan pada penelitian ini W adalah banyaknya kata pada passage yang memiliki nilai countmatch terbesar antara query dengan kata pada passageyang berada pada n passage
teratas.
Setelah diperoleh empat score dari masing-masing passage kemudian dilakukan penjumlahan secara linear
Heuristic_score = sThreshold + sInordered + sInSentence + sWindow.
Tujuan dari pembobotan passages adalah memperoleh passages dengan bobot tertinggi yang disimpan dalam variabel
scorePassageDoc.Banyaknya top passage
yang digunakan dalam penelitian ini maksimal adalah 10 passage atau 20 passage. Dari n passage teratas, kandidat jawaban dan penemu kembalian jawaban akan diterapkan.
Cuplikan n passage teratasdapat dilihat pada Gambar 14. Cuplikann passage teratas ini menggunakan query “Siapa saja pejabat yang menjadi tersangka kasus ilegal logging?”.
[docno] => suarakarya.txt [selected_passage] => Hasil operasi penertiban/pengamanan hutan oleh Tim Gabungan yang digelar …………
[score_passage] => 8.113
Gambar 14 Contoh passageteratas
Dengan perolehan nilai untuk masing-masing jenis pembobotan yaitu 7, 0.5, 0.5 dan 0.113. .
9. Perolehan Kandidat Jawaban
Kandidat jawaban yang dipilih adalah kata yang memilki tag named entity yang sesuai dengan kata tanya yang diperoleh dari
Array (
[0] => Array (
[27]=>[NAME]Ir.H.Badaruddin[/NAME] [32]=>[NAME]Thamrin Nor[/NAME] )
[1] => Array ( [0]=>[ORGANIZATION]Pemprov Kalteng[/ORGANIZATION] [33]=>[ORGANIZATION]Pemkab Kobar[/ORGANIZATION] [68]=>[NAME]Ir.H.Badaruddin[/NAME] [73]=>[NAME]ThamrinNor[/NAME] ) ………
Gambar 15 Kandidat jawaban padan passageteratas
10. Perolehan Entitas Jawaban
Untuk mendapatkan entitas jawaban dilakukan perhitungan terhadap jarak antara kata pada npassage teratas yang sesuai dengan query dengan kata yang merupakan kandidat jawaban. Setelah diperoleh bobot atau jarak dari masing-masing kandidat pada setiap passage, diambil kandidat-kandidat jawaban dengan jarak yang memiliki bobot kurang dari threshold yang sudah ditetapkan.
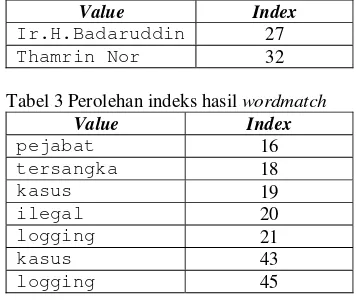
Berikut contoh perhitungan jarak kandidat jawaban pada passage yang berada pada urutan pertama untuk query“Siapa saja pejabat yang menjadi tersangka kasus ilegal logging? ”.
Tabel 2menunjukkan indeks kandidat jawaban dalam passageyang disimpan dalam variabel arrayCandidatKey sementara pada Tabel 3 menunjukkan perolehan indeks hasil
wordmatch antara kata-kata pada passage
dengan kata-kata pada queryyang disimpan dalam variabelarrayKey,.Pada tabel 4 berisi perolehan nilai atau bobot jarak untuk masing-masing kandidat jawaban yang disimpan dalam variabel avrg.Implementasi perhitungan jarak dapat dilihat pada Gambar 16.
Bobot jarak yang kurang dari
thresholdakan menjadi entitas jawaban terakhir. Threshold yang digunakan dalam penelitian ini adalah 25% dan 50% dari
passage yang berada pada n passage teratas dan memiliki panjang terbesar.
Tabel 2 Perolehan indeks kandidat jawaban
Value Index
Ir.H.Badaruddin 27
Thamrin Nor 32
Tabel 3 Perolehan indeks hasil wordmatch
Value Index
pejabat 16
tersangka 18 kasus 19 ilegal 20 logging 21 kasus 43 logging 45
Tabel 4 Bobot jarak kandidat jawaban
Value Index
Ir.H.Badaruddin 15
Thamrin Nor 18
11. Evaluasi Question Answering System Dalam tahapan evaluasi digunakan 40
query berupa kalimat tanya. Query dibuat secara manual oleh penulis. Query tersebut mewakili tipe pertanyaan siapa, kapan, dimana dan berapa. Evaluasi sistem pada penelitian ini dialokasikan 20 query bersifat
list dan 20 query bersifat factoid.
Pada Tabel 6 dan Tabel 8 dapat dilihat persentase perolehan untuk masing-masing jenis pertanyaan baik yang bersifat factoid
maupun pertanyaan yang bersifat list.Nilai terbesar untuk masing-masing pertanyaan yaitu kata tanya “Siapa” memperoleh nilai benar 26%, “Dimana” memperoleh nilai 36.33%, “Kapan” memperoleh nilai 70% dan “Berapa” memperoleh nilai 41%. Nilai terbesar untuk setiap pertanyaan diperoleh dari 10 passage teratas dengan threshold
for($i=0;$i<$top_passages;$i++ ){
if((array_key_exists($i,
$arrayCandidatKey)) && (array_key_exists($i,
$arrayKey))){
foreach($arrayCandidatKey[$i] as $key=>$value){foreach ($arrayKey[$i]as
$key2=>$value2){$distance[$i][ $value][$value2]=abs($key-$key2);
$totdis[$i][$value]+=$distance [$i][$value][$value2];
$avrg[$i][$value]=
($totdis[$i][$value])/(count($ query));
} }
}
Gambar 16 Implementasi perhitungan bobot jarak
Perbandingan dokumen yang ditemukembalikan dapat dilihat pada Tabel 5. Perbandingan Collection Page untuk semua jumlah n passages teratas dan threshold
selalu lebih besar dari Topic Page. Hal inimenunjukkan bahwa entitas jawaban yang ditemukembalikan dari dokumen yang sama lebih mudah dibandingkan mendapatkan entitas jawaban dari dokumen yang berbeda-beda. Mengacu pada tabel yang sama, sistem QA banyak mengembalikan entitas yang tidak relevan pada saat passages teratas yang diambil paling banyak 20 dan threshold 50% yaitu 50% dari 20 pertanyaan mendapat nilai
wrong.
Tabel 7 merupakan contoh dari dokumentasi dan penilaian yang mewakili tiap kasus pada proses penemukembalian entitas jawaban, sedangkan untuk dokumentasi lengkap dapat dilihat pada Lampiran 1 sampai dengan Lampiran 4 untuk tiap-tiap jenis pertanyaan.
Tabel 5 Persentase perbandingan nilai right, wrong dan null untuk 20 pertanyaan dan perbandingan sumber dokumen dari entitas jawaban yang ditemukembalikan
Passages /Threshold
Right
Wrong Null Collection Page Topic Page
20/50% 35% 15% 50% -
20/25% 35% 20% 40% 5%
10/50% 55% 25% 20% -
10/25% 50% 20% 25% 5%
Tabel 6 Persentase perolehan jawaban query factoid
Kata Tanya
Right Unsupported Wrong
Siapa 80% 0% 20%
Berapa 60% 0% 40%
Dimana 80% 0% 20%
Kapan 100% 0% 0%
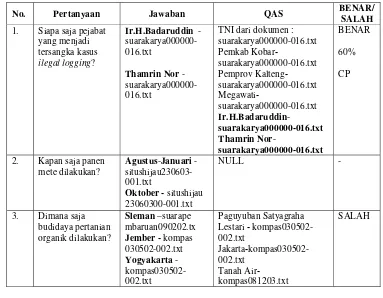
Mengacu pada Tabel 7 pertanyaan nomor 1 memperoleh nilai benar karena jawaban yang ditemukembalikan oleh sistem QAsama seperti jawaban yang ditentukan penulis sebelumnya. Untuk pertanyaan nomor 2 sistem memperoleh nilai NULL karena QA tidak mengembalikan entitas jawaban apapun.Hal ini terjadi karena semua kandidat jawaban mendapat bobot jarak melebihi
Contoh kasus terakhir, pertanyaan memperoleh nilai salah. Sistem QA pada kasus ini mengembalikan jawaban, namun tidak ada jawaban yang tepat dengan jawaban yang telah ditentukan sebelumnya.
12. Kelebihan dan Kelemahan Sistem Kelebihan dari Question Answering System yang telah dibangun adalah sistem dapat menemukembalikan jawaban dalam bentuk list.
Sistem ini memiliki kelemahan berikut :
Pemberian tag pada kandidat jawaban menggunakan aplikasi tagging, sehingga
tag pada dokumen tidak sempurna yang mengakibatkan entitas jawaban yang ditemukembalikan tidak sempurna.
Banyak entitas jawaban yang ditemukembalikan namun tidak relevan sehingga entitas jawaban benar mendapat pengurangan nilai.
Tidak dilakukan pengkajian semantic
dalam penelitian ini. Contohnya adalah makna yang terdapat dalam hubungan antar kata dan struktur kalimat dalam suatu passage.
Jawaban yang diperoleh bukan informasi terkini karena tidak ada waktu yang menunjukkan kapan informasi atau berita dibuat.
KESIMPULAN DAN SARAN Kesimpulan
Kesimpulan dari penelitian ini adalah :
1. Pembobotan yang paling berpengaruh pada penelitian ini adalah pembobotan berdasarkan hasil pencocokan kata antara
passage dengan kata-kata query.
2. Nilai terbesar untuk pertanyaan “Siapa”, “Dimana” dan “Kapan” menggunakan
passage teratas paling banyak 10 dan
threshold sebesar50% .
3. Entitas jawaban bersifat list dapat berasal dari dokumen yang sama atau kumpulan entitas jawaban dari dokumen yang berbeda-beda.
4. Collection page merupakan sumber dokumen yang lebih baik digunakan daripada distinct topic page.
Array (
[0] => Array (
[docno] => situshijau.txt [text] => Oktober
[score] => 21.5 ) [1] => Array (
[docno] => situshijau.txt [text] => Agustus-Januari [score] => 21.5
) [2] => Array (
[docno] => suarapembar.txt [text] => E-2001
[score] => 33.5 ) )
Gambar 17 Bobot jarak entitas jawaban
Saran
Penelitian ini perlu disempurnakan dengan :
1. Melakukan pengkajian semanticuntuk melengkapi pembobotan heuristic
dengan pembobotan syntactic.
2. Menambahkan atributtimestamp
sehingga entitas jawaban yang ditemukembalikan merupakan informasiterkini.
3. Melakukan analisisthreshold dan menentukan banyaknya kandidat jawaban yang akan dijadikan entitas jawaban akhir.
Tabel 7 Contoh dokumentasi pertanyaan dengan menggunakan 10 top passages dan threshold
25%
No. Pertanyaan Jawaban QAS BENAR/
SALAH 1. Siapa saja pejabat
yang menjadi tersangka kasus
ilegal logging?
Ir.H.Badaruddin - suarakarya000000-016.txt
Thamrin Nor - suarakarya000000-016.txt
TNI dari dokumen : suarakarya000000-016.txt Pemkab
Kobar-suarakarya000000-016.txt Pemprov Kalteng-suarakarya000000-016.txt
Megawati-suarakarya000000-016.txt Ir.H.Badaruddin-
suarakarya000000-016.txt Thamrin
Nor-suarakarya000000-016.txt
BENAR
60%
CP
2. Kapan saja panen mete dilakukan?
Agustus-Januari - situshijau230603-001.txt
Oktober - situshijau 23060300-001.txt
NULL -
3. Dimana saja budidaya pertanian organik dilakukan?
Sleman –suarape mbaruan090202.tx Jember - kompas 030502-002.txt Yogyakarta - kompas030502-002.txt
Paguyuban Satyagraha Lestari - kompas030502-002.txt
Jakarta-kompas030502-002.txt
Tanah Air-kompas081203.txt
SALAH
Tabel 8 Perolehan rata-rata untuk pertanyaan yang bernilaibenar untuk setiap jenis kata tanyalist
Kata Tanya 20 Top Passages 10 Top Passages
50% Threshold 25% Threshold 50% Threshold 25% Threshold
Siapa 26.00% 22.00 % 26.00 % 22.00 %
Dimana 29.00 % 16.33 % 36.33 % 20.33 %
Kapan 28.00 % 16.00 % 70.00 % 45.33 %
Berapa 10.00 % 16.00 % 30.00 % 39.00 %
DAFTAR PUSTAKA
Anggraeni M. 2007. Implementasi Question Answering System dengan Metode Rule-Based Pada Terjemahan Al-Qurr’an Surat Al-baqarah [skripsi]. Bogor. Fakultas Matematika dan Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
Baeza-Yates R, Ribeiro-Neto B.
1999.Modern Information
Retrieval.Addison-Wesley.
Ballessteros, L. A dan Xiaoyan-Li. 2007.Heuristic and Syantatic for Cross-Languange Question Answering.
Cidhy. 2009. . Implementasi Question Answering System dengan Pemboobtan Heuristic. [skripsi]. Bogor. Fakultas Matematika dan Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
Citraningputra. 2009. Named Entity Tagging untuk Dokumen Berbahasa Indonesia Menggunakan Metode Berbabsis Aturan
Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
Harabagiu.M. dan Marius A. Pasca. 2000.
Experiment whit Open-Domain Textual Question Answering.
Herdi. 2010 Pembobotan Dalam Proses Pengindeksan Dokumen Bahasa Indonesia Menggunakan Framework Indri [skripsi]. Bogor.Fakultas Matematika dan Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
Ikhsani N. 2006. Implementasi Question Answering System dengan Metode Rule-Based untuk Temu Kembali Informasi Dokumen Berbahasa Indonesia [skripsi]. Bogor. Fakultas Matematika dan Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
Kartina. 2010. Analisis Pertanyaan untuk Question Answering System pada Dokumen Berbahasa Indonesia . [skripsi]. Bogor. Fakultas Matematika dan Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
Lin J. 2004. Introduction to Information Retrieval and Question Answering. College of Information Studies University of Maryland.
Molla. 2003. Towards Semantic-Based Overlap Measures for Question Answering.
Sianturi R. 2008. Implementasi Question Answering System dengan Metode Rule-Based untuk Temu Kembali Informasi pada Bnayak Dokumen Berbahasa Indonesia
[skripsi]. Bogor. Fakultas Matematika dan Ilmu Pengetahuan Alam.Institut Pertanian Bogor.
16
Lampiran 1Hasil pengujian kata tanyaSIAPA
No. Pertanyaan Jawaban
20 Top Passages 10 Top Passages 50%
Threshold
25% Threshold
50% Threshold
25% Threshold 1 Siapa saja pejabat yang menjadi tersangka
kasus ilegal logging?
Ir.H.Badaruddin - suarakarya000000-016.txt
Thamrin Nor -suarakarya000000-016.txt
60% 60% 60% 60%
2 Siapa saja pihak yang mengawasi pemasukan bahan asal hewan impor?
Bea Cukai - suarakarya000000-004.txt Badan POM- suarakarya000000-004.txt
30% 10% 30% 10%
3 Siapa saja anggota dari kelompok kerja penyidik penyakit unggas nasional?
Balai Penelitian Veteriner Bogor - gatra300104.txt
Balai Pengujian Mutu dan Sertifikasi Obat Hewan -gatra300104.txt Fakultas Kedokteran Hewan UGM -
gatra300104.txt
Institut Pertanian Bogor - gatra300104.txt
Universitas Airlangga - gatra300104.txt
40% 40% 40% 40%
4 Siapa saja pengamat pertanian di Indonesia? Tejo Pramono-
suarapembaruan010903.txt, Bayu Krisnamurti -
mediaindonesia180504.txt
SALAH SALAH SALAH SALAH
5 Siapa saja pihak yang impor gula kristal? PT Perkebunan Negara - republika150604-002.txt
PT Rajawali Nusantara Indonesia - republika150604-002.txt
Perusahaan Perdagangan Indonesia - republika150604-002.txt
PTPN X - republika150604-002.txt PTPN XI - republika150604-002.txt PTPN - republika150604-002.txt
SALAH SALAH SALAH SALAH
17
Lampiran 2 Hasil pengujiankata tanya DIMANA
No. Pertanyaan Jawaban
20 Top Passages 10 Top Passages 50%
Threshold
25% Threshold
50% Threshold
25% Threshold
1 Dimana saja praktek illegal logging sering terjadi?
Kalimantan Tengah - suarakarya000000-016.txt
Tanjung Putting - suarakarya000000-016.txt
TNTP - suarakarya000000-016.txt
70% 36.67% 70% 36.67%
2 Dimana saja budidaya pertanian organik dilakukan?
Sleman - suarapembaruan090202.tx Jember - kompas030502-002.txt Yogyakarta - kompas030502-002.txt
SALAH SALAH 16.67% SALAH
3 Dimana saja kota yang menjadi industri kulit? Kabupaten Garut -suarapembaruan111202.tx
Sukaregang -suarapembaruan111202.txt Magetan - situshijau290403-004.txt Yogyakarta - situshijau290403-004.txt
SALAH SALAH SALAH SALAH
4 Dimana saja terminal agrobisnis? Jakarta - suarakarya000000-003.txt Tangerang - suarakarya000000-003.txt Depok - suarakarya000000-003.txt Bekasi- suarakarya000000-003.txt Bandungan - suaramerdeka240204.txt
70% 10% 70% 10%
5 Dimana saja varietas kapas kanesia berada? Nusa Tenggara Barat - situshijau270703-004.txt Sulawesi Selatan -
suarapembaruan290802-001.txt Malang - situshijau270703-004.txt Lamongan -
suarapembaruan290802-001.txt
5% 35% 25% 55%
18
Lampiran 3 Hasil pengujian kata tanya KAPAN
No. Pertanyaan Jawaban
20 Top Passages 10 Top Passages 50%
Threshold
25% Threshold
50% Threshold
25% Threshold
1 Kapan saja musim hujan di Indonesia dimulai?
Oktober - republika231202-001.txt Januari - republika231202-001.txt Desember - suarapembaruan150903.txt
20% 30% 50% 46.67%
2 Kapan saja panen mete dilakukan? Agustus-Januari - situshijau230603-001.txt
Oktober - situshijau230603-001.txt
100% NULL 100% NULL
3 Kapan saja musim panen besar kopi? Mei - pikiranrakyat240404.txt juli - pikiranrakyat240404.txt September -
wartapenelitian000000-004.txt
oktober -pikiranrakyat240404.txt
SALAH SALAH 40% 40%
4 Kapan saja sensus pertanian yang sudah dilakukan?
1963 - kompas020803.txt 1983 - kompas220399.txt 1993 - republika030304.txt 2003 - kompas020803.txt
20% 30% 90% 50%
5 Kapan saja impor komoditas pertanian naik?
2002 - kompas311203.txt 2003 - kompas311203.txt
SALAH 20% 70% 90%
19
Lampiran 4 Hasil pengujian kata tanya BERAPA
No. Pertanyaan Jawaban
20 Top Passages 10 Top Passages 50%
Threshold
25% Threshold
50% Threshold
25% Threshold
1 Berapa saja harga gabah kering giling? Rp 1.700 - republika060804-003.txt Rp 1.200 - republika060804-003.txt Rp 1.230 -suarakarya000000-007.txt Rp 1.275 - situshijau280404-002.txt Rp 1.900 - kompas170402.txt
SALAH SALAH 30% 40%
2 Berapa saja harga buah merah? Rp 2.000/kg - situshijau270703-002.txt 3000 - situshijau270703-002.txt Rp25.000/kg - situshijau130203-002.txt Rp 75.000 - situshijau130203-002.txt
SALAH 30% 50% 55%
3 Berapa saja harga jual kopi per kg? Rp 1.100 - kompas140802.txt Rp 1.200,00 - pikiranrakyat240404.txt Rp 1.000 -kompas140802.txt
SALAH SALAH SALAH SALAH
4 Berapa saja harga bawangmerah pada musim kemarau?
Rp 6.000 - situshijau180603-001.txt Rp 7.000 - situshijau180603-001.txt Rp 4.000 - situshijau180603-001.txt Rp 4.500 - situshijau180603-001.txt
50% 50% 50% 60%
5 Berapa saja harga urea di tingkat kecamatan? Rp 1.140/kg - suaramerdeka161101.txt Rp 1.120/kg - suaramerdeka161101.txt Rp 1.500/kg- suaramerdeka161101.txt Rp 1.070/kg - suaramerdeka161101.txt Rp 1.080/kg - suaramerdeka161101.txt
SALAH SALAH 20% 40%
Lampiran 5 Fungsi pembobotan passage
function scoreThreshold($arrayAllPassage){
$threshold = $this->getThreshold();
$wordQuestion = $this->getWordQuestion(); $arrayWordMatch = array();
$index = 0;
if($arrayAllPassage){
foreach($arrayAllPassage as $allPassages){ $count = 0;
foreach($allPassages as $wordPassage){
if(in_array(strtolower($wordPassage),$wordQuestion)){
$count++;
}
}
$arrayWordMatch[$index] = $count; $index++;
}
}
$this->arrayCountMatch=$arrayWordMatch; $n = sizeof($arrayWordMatch);
$index = 0;
for($index = 0; $index<$n; $index++){
if($arrayWordMatch[$index] >= $threshold){
//do nothing
}
else
$arrayWordMatch[$index] = 0;
}
return $arrayWordMatch;
Lanjutan Lampiran 6 Fungsi pembobotan passage
function scoreInSentence($arrayAllPassage){ $wordQuestion = $this->getWordQuestion(); $index = 0;
$arrayInSentence = array(); if($arrayAllPassage){
foreach($arrayAllPassage as $passage){
$duaKalimat=preg_split("/[.?!]+[\s]+/",strtolower
($this->myStripTag($passage))); $score = 1;
$score_1=1;
$kalimatPertama=preg_split("/[\"!.,?()<>*\s]/", strtolower($duaKalimat[0]));
foreach($wordQuestion as $word){
if(!in_array($word, $kalimatPertama))
$score_1 = $score_1*0;
}
if($score_1==0){
$kalimatKedua=preg_split("/[\"!.,?()<>*\s]/", strtolower($duaKalimat[1]));
foreach($wordQuestion as $word){
if(!in_array($word, $kalimatKedua))
$score = $score*0;
}
}
$arrayInSentence[$index++] = $score;
}
}
$n = sizeof($arrayInSentence); $i = 0;
for($i=0; $i<$n; $i++){
if($arrayInSentence[$i] != 0)
$arrayInSentence[$i] = $arrayInSentence[$i]*0.5;
}
return $arrayInSentence;
LanjutanLampiran 7 Fungsi pembobotan passage
function ScoreInOrdered($arrayAllPassage){
$arrayScoreOrder = array();
$index = 0;
//echo "<pre>"; print_r($arrayAllPassage); exit();
if($arrayAllPassage){
foreach($arrayAllPassage as $passage){
//echo $passage."<hr />";
$arrayScoreOrder[$index++] =
$this->countScoreOrder($passage, $this->question);
}
}
return $arrayScoreOrder; }
function scoreWindow2(){ $this->SCORE_WINDOW=array(); $max=max($this->arrayCountMatch); $pembagi=$this->PembagiWindow($max); foreach($this->arrayCountMatch as $value){
$this->SCORE_WINDOW[]=($value/$pembagi);
ABSTRACT
AGUS UMRIADI. Implementation of Question Answering System for Document in Bahasa Indonesia with List Question.Under direction of JULIO ADISANTOSO.
In the last few years, many studies of Question Answering System (QAS) have been conducted by a number of research groups around the world. Lately, a question is not only presented in the form of factoid questions, but also as a list questions where a question requires more than a single-entity of answer. However, recent development on QAS can only accommodate factoid questions which only require a single-entity's answer. To address this issue, the purpose of this research is to implement QAS for list questions. In order to obtain candidate of answers, heuristic weighting is performed in the passage which is contained on the top n documents. One thousand documents and 40 queries are used in the experiment. The best results of experiment show correctness of 26%, 39%, 36.33% and 70 % for “who”, “how many/much”, “where” and “when” list questions, respectively.
PENDAHULUAN Latar Belakang
Sistem temu kembali informasi memiliki kaitan yang sangat erat dengan sistem pencarian(searchengine).Untuk memperoleh suatu informasi sistem pencarian membutuhkan masukan yang dikenal dengan
query yang biasanya berbentuk kata kunci. Saat ini sudah dikembangkan sistem pencarian menggunakan pertanyaan sebagai
query yang dikenal dengan Question Answering System(QAS). Dengan menggunakan pertanyaan sebagai query
diharapkan informasi yang diperoleh oleh pengguna selain relevan juga lebih spesifik.
Ballesteros dan Xiayoan-Li (2007) mengimplementasikan Question Answering
yang digunakan untuk monolingual English
dan Chinesse. Dalam mengembalikan kalimat jawaban atau informasi yang relevan, pemberian skor pada koleksi dokumen secara
heuristic dan bergantung pada syntactic factor yang didefinisikan sebagai aturan-aturan untuk mengidentifikasi kandidat kalimat relevan atau kalimat jawaban.
Hui Yang dan Tat-Seng Chua (2004) mengimplementasikan Web-Based List Question Answeringdimana kandidat jawaban diperoleh dari dua sumber utama yaitu
collection pages dandistinct
topic.Ikhsani(2006) telah
mengimplementasikan QAS untuk menemukan jawaban dari query pertanyaan hanya dengan menggunakan satu dokumen bacaan yang menggunakan kalimat baku.
Anggraeini (2007) menyusun QAS untuk surat Al-Baqarah yang terdiri atas beberapa ayat sebagai dokumen. Sianturi (2008) menyempurnakan penelitian Ikhsani (2006) dengan menggunakan metode Rule-Based
pada banyak dokumen bahasa
Indonesia.Selanjutnya, Cidhy (2009)mengimplementasikan Question
Answering System dengan pembobotan
heuristic dan Panggudi (2009) membuatNamed Entity Taggeruntuk dokumen bahasa Indonesia menggunakan metode berbasis aturan. Kartina (2010) menganalisis pertanyaan untukQuestion Answering System pada dokumen bahasa Indonesia dan Herdi (2010) menggunakan
framework INDRI untuk melakukan pembobotan dalam proses pengindeksandokumen bahasa Indonesia.
Semua QAS yang telah dikembangkan hanya dapat mengakomodasi pertanyaan bersifat factoid.Pertanyaan ini hanya membutuhkan satu entitas jawaban.Penelitian ini mengimplementasikan QAS dengan jenis pertanyaan bersifatlistyang dapat menghasilkan banyak jawaban.
Tujuan
Tujuan dari penelitian ini adalah mengimplementasikan sistem temu kembali informasi (Question Answering System) menggunakan query pertanyaan bersifat list
untuk dokumen bahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah :
1. Korpus dokumen bahasa Indonesia dan kata tanya yaitu siapa, dimana, kapan, dan berapa.
2. Pasangan pertanyaan dan jawaban sudah ditentukan oleh penulis dari koleksi dokumen yang ada.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi berkaitan dengan merepresentasi, menyimpan, mengorganisasi, dan mengakses informasi.Merepresentasi dan mengorganisasi suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya.Dalam pencarian suatu informasi pengguna harus menerjemahkan kebutuhan informasinya dalam bentuk query. Berdasarkan query tersebut, sistem temu kembali informasi akan mengembalikan informasi yang relevan dengan query yang diberikan oleh pengguna (Baeza-Yates & Ribeiro-Neto 1999).
Question Answering
Question Answering system merupakan aplikasi yang menggabungkan konsepInformation Retrieval (IR) dengan
PENDAHULUAN Latar Belakang
Sistem temu kembali informasi memiliki kaitan yang sangat erat dengan sistem pencarian(searchengine).Untuk memperoleh suatu informasi sistem pencarian membutuhkan masukan yang dikenal dengan
query yang biasanya berbentuk kata kunci. Saat ini sudah dikembangkan sistem pencarian menggunakan pertanyaan sebagai
query yang dikenal dengan Question Answering System(QAS). Dengan menggunakan pertanyaan sebagai query
diharapkan informasi yang diperoleh oleh pengguna selain relevan juga lebih spesifik.
Ballesteros dan Xiayoan-Li (2007) mengimplementasikan Question Answering
yang digunakan untuk monolingual English
dan Chinesse. Dalam mengembalikan kalimat jawaban atau informasi yang relevan, pemberian skor pada koleksi dokumen secara
heuristic dan bergantung pada syntactic factor yang didefinisikan sebagai aturan-aturan untuk mengidentifikasi kandidat kalimat relevan atau kalimat jawaban.
Hui Yang dan Tat-Seng Chua (2004) mengimplementasikan Web-Based List Question Answeringdimana kandidat jawaban diperoleh dari dua sumber utama yaitu
collection pages dandistinct
topic.Ikhsani(2006) telah
mengimplementasikan QAS untuk menemukan jawaban dari query pertanyaan hanya dengan menggunakan satu dokumen bacaan yang menggunakan kalimat baku.
Anggraeini (2007) menyusun QAS untuk surat Al-Baqarah yang terdiri atas beberapa ayat sebagai dokumen. Sianturi (2008) menyempurnakan penelitian Ikhsani (2006) dengan menggunakan metode Rule-Based
pada banyak dokumen bahasa
Indonesia.Selanjutnya, Cidhy (2009)mengimplementasikan Question
Answering System dengan pembobotan
heuristic dan Panggudi (2009) membuatNamed Entity Taggeruntuk dokumen bahasa Indonesia menggunakan metode berbasis aturan. Kartina (2010) menganalisis pertanyaan untukQuestion Answering System pada dokumen bahasa Indonesia dan Herdi (2010) menggunakan
framework INDRI untuk melakukan pembobotan dalam proses pengindeksandokumen bahasa Indonesia.
Semua QAS yang telah dikembangkan hanya dapat mengakomodasi pertanyaan bersifat factoid.Pertanyaan ini hanya membutuhkan satu entitas jawaban.Penelitian ini mengimplementasikan QAS dengan jenis pertanyaan bersifatlistyang dapat menghasilkan banyak jawaban.
Tujuan
Tujuan dari penelitian ini adalah mengimplementasikan sistem temu kembali informasi (Question Answering System) menggunakan query pertanyaan bersifat list
untuk dokumen bahasa Indonesia.
Ruang Lingkup
Ruang lingkup penelitian ini adalah :
1. Korpus dokumen bahasa Indonesia dan kata tanya yaitu siapa, dimana, kapan, dan berapa.
2. Pasangan pertanyaan dan jawaban sudah ditentukan oleh penulis dari koleksi dokumen yang ada.
TINJAUAN PUSTAKA Temu Kembali Informasi
Temu kembali informasi berkaitan dengan merepresentasi, menyimpan, mengorganisasi, dan mengakses informasi.Merepresentasi dan mengorganisasi suatu informasi harus membuat pengguna lebih mudah dalam mengakses informasi yang diinginkannya.Dalam pencarian suatu informasi pengguna harus menerjemahkan kebutuhan informasinya dalam bentuk query. Berdasarkan query tersebut, sistem temu kembali informasi akan mengembalikan informasi yang relevan dengan query yang diberikan oleh pengguna (Baeza-Yates & Ribeiro-Neto 1999).
Question Answering
Question Answering system merupakan aplikasi yang menggabungkan konsepInformation Retrieval (IR) dengan
keluaran yang dihasilkan adalah dokumen yang dianggap relevan oleh sistem. Sedangkan pada QA, query berupa kalimat tanya dan keluarannya berupa jawaban (entitas) yang dianggap sesuai oleh sistem sehingga memungkinkan sistem tidak mengembalikan jawaban apapun (Strzalkowski & Harabagiu 2008).QA memiliki ide dasar sebagai berikut (Lin 2004) :
Menentukan tipe semantik dari jawaban yang diharapkan.
Menentukan dokumen-dokumen yang mengandung kata-kata yang terdapat dalam pertanyaan (query).
Mencari entitas jawaban dengan tipe yang sesuai dengan pertanyaan, dan memiliki kedekatan yang tinggi dengan query.
Gambar 1 menunjukkan proses pada
Question Answering System (QAS). Dalam tahapan offline atau indexing dilakukan analisis terhadap teks dokumen. Teks dokumen yang digunakan sudah memiliki
named entity tag didalamnya. Hasil dari proses indexing digunakan untuk tahapan QAS selanjutnya, yaitu tahapan online yang terdiri atas analisis pertanyaan, document preselection, seleksi, dan pembobotan.
Modul analisis pertanyaan mengklasifikasi pertanyaan dan menentukan tipe dari jawaban yang diharapkan. Hasil dari modul ini terdiri atas kata tanya dan kata-kata yang akan digunakan dalam pembobotan
heuristic (scoring). Kata-kata yang digunakan untuk pembobotan heuristic juga digunakan dalam document preselection.
Document preselection menghasilkann dokumen tertinggi. Kata tanya digunakan untuk mengidentifikasi tipe named entity dari pertanyaan. Perolehan named entity digunakan untuk menyeleksinpassages
yang mengandung kandidat jawaban. Contohnya adalah kata tanya “Dimana”mengidentifikasi keterangan tempat, yang diwakili oleh named entity tag LOCATION. Perolehan entitas kandidat jawaban dilakukan pada npassages dengan bobot tertinggi (Molla 2003).
Faktor Heuristic
[image:35.612.334.506.104.339.2]QAS memiliki tiga modul utama yaitu modul pemrosesan query, modul sistem pencarian, dan modul ekstraksi jawaban (Ballesteros & Xiaoyan-Li 2007).
Gambar 1 Arsitektur umum
QuestionAnswering System(Molla 2003)
1. Pemrosesan Query
Langkah-langkah dalam pemrosesan
query adalah sebagai berikut :
a. Sebagai langkah awal dilakukan pendefinisian kembali tipe pertanyaan yang memiliki hubungan dengan NE (named entity) yang baku. Mengacu pada penelitian (Ballesteros &Xiaoyan-Li 2007), ada tujuh tipe pertanyaan yang terdiri atas NAME, LOCATION, ORGANIZATION, DATE, TIME, CURRENCY dan NUMBER. Dalam bahasa Indonesia akan diwakili dengan SIAPA, DIMANA, KAPAN, dan BERAPA. Setiap pertanyaan akan mengalami proses parsing terlebih dahulu.
b. Kata tanya seperti “APAKAH” dan “APA” tidak diperhitungkan karena hanya akan menambahkan informasi yang tidak berguna.
c. Stopwordsdihilangkan.
Setelah dilakukan pemrosesan, query
2. RetrievalEngine
Banyak fungsi kesamaan yang digunakan padaretrieval engine untuk melakukan pemeringkatan dokumen yang mengadung informasi yang berkaitan dengan
query.Fungsi yang sering digunakan untukmengukur kesamaan antara query dan dokumen yaitu denganmenggunakan kesamaan cosine (Manning 2008). Terdapat juga Pembobotan BM25 yang dikenal denganpembobotan Okapi.Pembobotan BM25 menggabungkan bobot idf dengan koleksi pengskalaan khusus untuk dokumen dan query(Kontostathis 2008 dalam Herdi 2010). Dokumen yang ditemukembalikan akan digunakan dalam proses ekstraksi jawaban.
3. Modul Ekstraksi Jawaban
Pada tahap ini dilakukan identifikasi terhadap jawaban. Setiap n dokumen teratas yang terambil dianalisis kembali untuk mengidentifikasi kandidat jawaban dengan cara sebagai berikut (Ballesteros & Xiaoyan-Li 2007):
1. Dilakukan identifikasi named entity yang terdiri atas orang, organisasi, lokasi, ekspresi waktu, tanggal, ekspresi numerik dan uang.
2. Dokumen dibagi menjadi passage.
Passage terdiri atas beberapa kalimat yang berdampingan. Antarpassage memiliki kalimat yang overlap.
3. Dilakukan pembobotan heuristic pada setiap passage. Pertama-tama didefinisikan count_query adalah jumlah kata yang terdapat pada query (kalimat tanya), count_match adalah jumlah hasil pencocokan antara kata yang terdapat pada query dan passage (wordmatch) dan
score adalah bobot dari passage. Proses pembobotan adalah sebagai berikut:
i. Jika tidak ada named entity yang ditampilkan,passage menerima nilai 0. Jika named entity ditampilkan pada
passage namun tidak memilki tipe yang sama dengan pertanyaan, named entity diabaikan.
ii. Dilakukan pencocokan kata-kata pada
query dengan kata-kata pada passage
(proses wordmatch). Jika nilai
count_match kurang dari threshold (t),
score = 0. Selain itu, score =
count_match. Nilai threshold(t), didefinisikan dengan cara sebagai berikut:
a. Jika count_query kurang dari 4, t = count_query. Dengan kata lain, paragraf apapun yang tidak mengandung kata-kata yang terdapat pada query tidak diperhitungkan.
b. Jika count_query antara 4 dan 8, t = (count_query/2.0 ) + 1.0.
c. Jika lebih besar dari 8, t = (count_query/3.0) + 2.0.
iii. Kata yang berdekatan memiliki hubungan keterkaitan informasi yang lebih tinggi. Jika seluruh kata yang cocok dengan query terdapat pada satu kalimat Sm = 1, selainituSm= 0. Maka
score = score + (Sm*0.5).
iv.Seperti diketahui urutan kata dapat mempengaruhi art