Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 559
Algoritma AdaBoost
Dalam
Pengklasifikasian
Zulhanif
St af Pengajar Jurusan St at ist ika FM IPA, Unpad Bandung Em ail : [email protected]
ABSTRAK
M et ode AdaBoost m erupakan salah sat u algoritm a supervised pada dat a mining yang dit erapakan secara luas unt uk mem buat m odel klasifikasi. AdaBoost sendiri pert ama kali diperkenalkan oleh Yoav Freund dan Robert Schapire(1995). Walaupun pada aw alnya algoritm a ini dit erapkan pada m odel regresi, seiring dengan perkem bangan t eknologi kom put er yang cepat , m et ode ini juga dapat dit erapkan pada m odel st at ist ik lainnnya. M et ode adaBoost m erupakan salah sat u t eknik ensam ble dengan m enggunakan loss function fungsi exponent ial unt uk memperbaiki t ingkat akurasi dari prediksi yang dibuat. Pada m akalah ini akan akan dijelaskan penerapan m et ode AdaBoost dalam m asalah pengklasifikasian dengan t ujuan unt uk memperbaiki tingkat akurasi m odel yang dibent uk.
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 560
1. PENDAHULUAN
Ada dua budaya dalam penggunaan pemodelan statistik untuk mencapai kesimpulan dari data.
Budaya pertama merupakan budaya pertama adalah The Data Modeling Culture yang merupakan
budaya sebagian besar ahli statistik saat ini, pada kelompok Data Modelling Culture statistikawan
mengasumsikan model stokastik tertentu untuk menjelaskan mekanisme suatu data, sedangkan
budaya kedua yang merupakan kelompok Algorithmic Modeling Culturemerupakan kelompok
statistikawan yang menggunakan model algoritma untuk menjelaskan mekanisme suatu data.
Sebagai ilustrasi bahwa seorangEkonom dalam komunitas data mining akan berbeda dalam
pendekatan mereka untukanalisis regresi. Para ekonom diluar komunitas data mining akan
membangun sebuah model regresi dari teori dan kemudian menggunakan model tersebut untuk
menjelaskan bentuk hubungan yang tejadi, hal ini berbeda untuk ekonom pada komunitas data
mining, pada kominitas ini ekonom akan menggunakan prinsip “kitchen sink” yang mana suatu
pendekatan yang menggunakansebagian besar regressor atau x-variabel yang tersedia akan
dipergunakan dalam model regresi. Karena pemilihan x-variabel tidak didukung olehteori, validasi
model regresi menjadi hal yang sangat penting. Pendekatan standar untukmemvalidasi model
regresi pada data mining adalah dengan cara membagi data ke dalam data pelatihan dan
datapengujian.Konsep dataset pelatihan versus dataset pengujian merupakan inti dari algoritma
supervised pada data mining. Pada prinsipnya model yang dibentuk pada data pelatihan akan
dipergunakan untuk membuat membuat prediksi pada data pengujin. Tujuan dari proses ini adalah
agar model tidak overfitted serta dapat digeneralisasi. Pada makalah ini akan dijelaskan model
boosting dalam pengklasifikasian berdasarakan algoritma AdaBoost yang dikembangkan oleh
Yoav Freund dan Robert Schapire [3].
2. M ETODE PENELITIAN
Algoritma AdaBoost sendiri merupakan akronim dari Adaptive Boosting, algoritma ini diterapkan
secara luas pada model prediksi dalam data mining. Inti dari algoritma AdaBoost adalah
memberikan suatu bobot lebih pada observasi yang tidak tepat (weak classification). Boosting
sendiri pada dasarnya adalah m buah kombinasi liniear dari m
k
m(
x
i)
classifierdengan
fungsi classifier dimisalkan
k
m(
x
i)
{
1
,
1
}
,
sehingga kombinasi linear dari
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 561
)
(
)
(
)
(
)
(
1 1 2 2 1 1) 1
(m
x
ik
x
ik
x
i mk
mx
iC
(2.1)
Dalam bentuk yang lebih umum dapat dinyatakan dalam persamaan sbb:
)
(
)
(
)
(
i (m1) i m m im
x
C
x
k
x
C
(2.2)
Pada
algoritma
AdaBoost
didefinisikantotalcost,
atau
totalerror,
dariclassifiersebagai fungsieksponensial sbb:
)
)
(
)
(
(
exp(
1 ) 1 (
N i i m m i mi
C
x
k
x
y
E
(2.3)
Persamaan 3 dapat ditulis juga dalam sebuah persamaan sbb:
)
)
(
)
(
(
exp(
1 ) 1 ( ) (
N i i m m i m i mi
y
C
x
k
x
w
E
(2.4)
Dengan
))
(
(
exp(
( 1) ) ( i m i mi
y
C
x
w
Persamaan 4 sendiri dapat dinyatakan dalam dua persamaan sbb:
) ( ) ( ) ( ) ()
exp(
)
exp(
i m i i mi y k x
m m i x k y m m i
w
w
E
(2.5)
Jika persamaan pertama untuk kasus individu diklasifikasikan dengan benar dinyatakan
)
exp(
mc
W
sebagai dan yang tidak benar dinyatakan dnegan
W
eexp(
m)
maka persamaan 4
dapat ditulis sbb
)
exp(
)
exp(
m e mc
W
W
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 562
Dari persamaan 6 terihat bahwa untuk meminimumkan fungsi E akan dicari nilai
bobot
myang optimum yang dihitung dengan cara sbb:
)
exp(
)
exp(
m e mc m
W
W
d
dE
(2.7)
0
)
2
exp(
W
cW
e
m)
ln(
2
1
e c mW
W
)
1
ln(
2
1
)
ln(
2
1
m m e e me
e
W
W
W
dengan
W
W
e
eProsiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 563
Perumusan algoritma AdaBoost secara lengkap dapat dijabarkan sbb:
Untuk m=1 to M
1.
Minimumkan fungsi error
) ( ) ()
exp(
i mi k x
y m m i e
w
W
2.
Set
ln(
1
)
2
1
m m me
e
yang mana
W
W
e
em
3.
Update nilai
m m m i m m i m i
e
e
w
w
w
( 1)
( )exp(
)
( )1
jika pengamatan itu
missclasisfication dan
m m m i m m i m i
e
e
w
w
w
1
)
exp(
( ) ) ( ) 1 (
untuk lainnnya
3. HASIL DAN PEM BAHASAN
Sebagai ilustrasi dalam penggunaan algoritma Adaboost dengan fungsi classifierregression treeini
akan dipergunakan data penelitian Database kanker payudara ini diperoleh dariRumah SakitUniversity
of Wisconsin , Madison dari Dr. William H. Wolberg . Ia menilai biopsi tumor payudara untuk 699
pasien hingga 15 Juli 1992 ; masing-masing sembilan atribut telah dinilai pada skala 1 sampai 10 ,
sehingga terdapat 699 pengatamat celss dengan 9atribut
,
selanjutnayatahapan analisis dalam membuat
model klasifikasinya adalah sbb :
1. M em bagi dat a yang dipergunakan m enjadi dua bagian yang t erdiri at as data training dan dat a t est ing dengan perbandingan 80% dan 20%
2. M engevaluasi besarnya kesalahan klasifikasi dari dat a t raining dan dat a t est ing 3. M em buat m odel prediksi
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 564
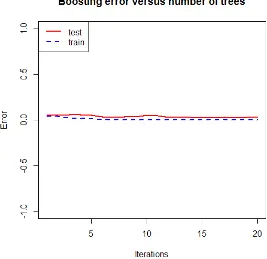
3.1.1)Jum lah Boost ing Opt im al
Tabel 1 Tingkat Kepentingan Variabel Predikt or
Variabel Prediktor Impotance
Cell.size 20.923363
Bare.nuclei 20.239509
Norm al.nucleoli 18.733969
Cl.t hickness 10.158718
Bl.crom at in 9.387055
M arg.adhesion 8.721022
Epit h.c.size 5.535636
Cell.shape 3.174272
M it oses 3.126455
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 565
Gambar 1 Jum lah Optim al Boost ing
3.2.1) Tingkat Akurasi Klasifikasi t anpa Boost ing
Tingkat akurasi klasifikasi dit injau dari dat a t raining dan dat a t est ing sbb:
3.2.1.1 Dat a Training
Tabel 2 Tabel Klasifikasi Dat a Training
Benign M alignant Total
Benign 360 4 364
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 566
Total 377 183 560
Dari dat a t raining pada t abel 2 dapat dilihat tingkat m isklasifikasi sebesar 3.75%
3.2.1.2 Dat a Test ing
Tabel 2 Tabel Klasifikasi Dat a Test ing
Benign M alignant Total
Benign 75 1 76
M alignant 6 57 63
Total 81 58 139
Dari dat a t raining pada t abel1 dapat dilihat t ingkat misklasifikasi sebesar 5.04%
3.3.1 Tingkat Akurasi Klasifikasi dengan Boost ing
Tingkat akurasi klasifikasi dit injau dari dat a t raining dan dat a t est ing sbb:
3.3.1.1 Dat a Training
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 567
Benign M alignant Total
Benign 377 0 377
M alignant 0 183 183
Total 377 183 560
Dari dat a t raining pada t abel 3 dapat dilihat tingkat m isklasifikasi sebesar 0%
3.2.1.2 Dat a Test ing
Tabel 4 Tabel Klasifikasi Dat a Test ing
Benign M alignant Total
Benign 77 0 77
M alignant 4 58 62
Total 81 58 139
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 568
3.4 M odel Boost ing
Prosiding Seminar Nasional Matematika dan Pendidikan Matematika UMS 2015 569
Hasil analisis m enunjukkan adanya kekurang akurat an hasil klasifikasi pada dat a test ing yang berpot ensi m eyebabkan over fiitng dari m odel klasifikasi yang dibent uk.Pem odelan klasifikasi dengan m et ode ini perlu diuji lagi berkenaan dengan m em pertim bangkan m enggunakan loss function selain fungsi exponential.Pereduksian jum lah varabel predikt or m enjadi hal yang dapat dipert im bangkan unt uk m egurangi kesalahan dari m odel kalaifikasi yang dibuat .
5.DAFTAR PUSTAKA
[1] Bauer, E. and R. Kohavi. 1999. An em pirical com parison of vot ing classificat ion algo- rit hm s: Bagging, boosting, and variant s. M achine Learning 36: 105–139.
[2] Breim an, L., J. Friedm an, R. Olshen, and C. St one. 1984. Classificat ion and Regression Trees. Belm ont , CA: Wadsw ort h.
[3] Freund, Y. and R. E. Schapire. 1997. A decision-t heoret ic generalization of online learning and an application t o boost ing. Journal of Com put er and Syst em Sciences 55(1): 119–139. [4] Friedm an, J. 2001. Greedy function approxim at ion: a gradient boost ing m achine. An-nals of
St at ist ics 29: 1189–1232.
[5] Friedm an, J., T. Hast ie, and R. Tibshirani. 2000. Additive logist ic regression: a st at is-t ical view of boost ing. Annals of St at ist ics 28: 337–407.
[6] Hast ie, T., R. Tibshirani, and J. Friedm an. 2001. The Element s of St at ist ical Learning New York: Springer.
[7] Long, J. S. and J. Freese. 2003. Regression M odels for Cat egorical Dependent Variables Using St at a. rev. ed. College St at ion, TX: St at a Press.