ABSTRAK
AHMAD SUHAIRI. Pembangunan Fuzzy Classifier untuk Data Potensi Desa 2003. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan WISNU ANANTA KUSUMA.
Penelitian ini bertujuan untuk membuat suatu aplikasi data mining menggunakan fuzzy classifier. Konsep himpunan fuzzy dipilih karena lebih baik dalam menangani data numerik dan dapat ”memperhalus” batasan yang tegas. Aplikasi ini diterapkan pada data potensi desa di Indonesia tahun 2003. Data potensi desa 2003 memiliki 750 atribut dan 65536 record. Untuk kebutuhan penelitian diambil 5 atribut numerik (jumlah keluarga prasejahtera sejahtera 1, jumlah pengangguran, jumlah keluarga pengguna listrik PLN, jumlah bangunan permanen, dan jumlah murid SD yang drop-out) dan 10500 record data (7500 record untuk data training dan 3000 data untuk data tes). Aplikasi yang dibuat dapat dimanfaatkan untuk menentukan nilai dan kelas atribut yang belum diketahui berdasarkan aturan-aturan yang ditemukan. Ada beberapa proses yang harus dilakukan antara lain merubah data ke dalam himpunan fuzzy, membangkitkan aturan fuzzy, memprediksi nilai dan kelas data target, mengevaluasi performa akurasi dan rms, terakhir menyajikan informasi dalam bentuk grafik dan tabel.
Setelah dicobakan dari berbagai data training dan data tes yang ada, didapatkan informasi sebagai berikut: Semakin banyak data training yang digunakan, maka jumlah aturan yang terbentuk semakin besar dengan kenaikan terbesar terjadi pada selang 1000 sampai 1500 data training. Semakin banyak antecedent yang ingin dibuat maka jumlah aturan yang terbentuk semakin sedikit. Semakin banyak data training yang digunakan, maka waktu untuk membangkitkan aturan juga semakin besar dengan kenaikannya secara linier. Banyaknya data training yang ada tidak berpengaruh signifikan dengan nilai akurasi dan rmse, yang mempengaruhi adalah nilai bobot dari masing-masing aturan. Persentase akurasi terbesar (80%) didapatkan jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) dengan jumlah data training sebanyak 1000 data. Persentase terkecil (13%) didapatkan jika atribut targetnya C5 (Jumlah murid SD yang DO) untuk setiap jumlah data training yang ada. Evaluasi akurasi dan rmse akan mendapatkan hasil yang baik jika atribut yang dijadikan kelas target berasal dari atribut C3 (jumlah keluarga pengguna listrik PLN) atau C4 (jumlah bangunan permanen) dan digunakan sebagai model yang terbaik untuk memprediksi nilai dan kelas suatu data.
PEMBANGUNAN
FUZZY CLASSIFIER
UNTUK DATA POTENSI DESA 2003
Oleh :
AHMAD SUHAIRI
G64102014
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
1 Pada tahap penyeleksian data hanya mempertimbangkan atribut yang numerik saja, pada penelitian selanjutnya dapat dipakai teknik data mining yang khusus untuk menyeleksi atribut yang relevan untuk dilakukan proses data mining.
2 Aturan yang terbentuk sebenarnya bisa diringkas lagi sehingga didapatkan aturan yang lebih sedikit, diharapkan proses meringkas aturan dapat diakukan pada penelitian selanjutnya.
DAFTAR PUSTAKA
Au, W. H., Chan, K. C. C. 2001. Classification with Degree of Membership: A Fuzzy Approach. Hasil ICDM’01.
Cheney W, Kincaid D. 1994. Numerical Mathematics and Computing. Brooks/Cole Publishing Company, California.
Fayyad, U. M., G. P. Shapiro, P. Smyth dan R Uthurusamy. 1996. Advances Knowledge Discovery and Data mining. American Association for Artificial Intelligence, California.
Han, J. M. Kamber. 2001. Data mining Concepts and mining. Morgan Kaufmann Publiser, USA.
Hoffer, J. A., M. B. Prescott dan F. R. McFadden. 2002. Modern Database Management Sixth Edition. Pearson Education, New Jersey.
Jang, J. S. R., C. T. Sun, E. Mizutani. 1997. Neuro-Fuzzy and Soft Computing. Prentice-Hall Inc., USA.
Kusumadewi, S. 2002. Analisis dan Desain Sistem Fuzzy Menggunakan Tool Box Matlab. Graha Ilmu, Yogyakarta.
Mustika, A. 2006. Pengembangan Aplikasi Data mining Menggunakan Fuzzy Association Rules [skripsi]
Shapiro, G. P. 2006. Machine Learning, Data mining, and Knowledge Discovery. http://www.kdnuggets.com/dmcourse/data_ mining_course
PEMBANGUNAN
FUZZY CLASSIFIER
UNTUK DATA POTENSI DESA 2003
Oleh :
AHMAD SUHAIRI
G64102014
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
ABSTRAK
AHMAD SUHAIRI. Pembangunan Fuzzy Classifier untuk Data Potensi Desa 2003. Dibimbing oleh IMAS SUKAESIH SITANGGANG dan WISNU ANANTA KUSUMA.
Penelitian ini bertujuan untuk membuat suatu aplikasi data mining menggunakan fuzzy classifier. Konsep himpunan fuzzy dipilih karena lebih baik dalam menangani data numerik dan dapat ”memperhalus” batasan yang tegas. Aplikasi ini diterapkan pada data potensi desa di Indonesia tahun 2003. Data potensi desa 2003 memiliki 750 atribut dan 65536 record. Untuk kebutuhan penelitian diambil 5 atribut numerik (jumlah keluarga prasejahtera sejahtera 1, jumlah pengangguran, jumlah keluarga pengguna listrik PLN, jumlah bangunan permanen, dan jumlah murid SD yang drop-out) dan 10500 record data (7500 record untuk data training dan 3000 data untuk data tes). Aplikasi yang dibuat dapat dimanfaatkan untuk menentukan nilai dan kelas atribut yang belum diketahui berdasarkan aturan-aturan yang ditemukan. Ada beberapa proses yang harus dilakukan antara lain merubah data ke dalam himpunan fuzzy, membangkitkan aturan fuzzy, memprediksi nilai dan kelas data target, mengevaluasi performa akurasi dan rms, terakhir menyajikan informasi dalam bentuk grafik dan tabel.
Setelah dicobakan dari berbagai data training dan data tes yang ada, didapatkan informasi sebagai berikut: Semakin banyak data training yang digunakan, maka jumlah aturan yang terbentuk semakin besar dengan kenaikan terbesar terjadi pada selang 1000 sampai 1500 data training. Semakin banyak antecedent yang ingin dibuat maka jumlah aturan yang terbentuk semakin sedikit. Semakin banyak data training yang digunakan, maka waktu untuk membangkitkan aturan juga semakin besar dengan kenaikannya secara linier. Banyaknya data training yang ada tidak berpengaruh signifikan dengan nilai akurasi dan rmse, yang mempengaruhi adalah nilai bobot dari masing-masing aturan. Persentase akurasi terbesar (80%) didapatkan jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) dengan jumlah data training sebanyak 1000 data. Persentase terkecil (13%) didapatkan jika atribut targetnya C5 (Jumlah murid SD yang DO) untuk setiap jumlah data training yang ada. Evaluasi akurasi dan rmse akan mendapatkan hasil yang baik jika atribut yang dijadikan kelas target berasal dari atribut C3 (jumlah keluarga pengguna listrik PLN) atau C4 (jumlah bangunan permanen) dan digunakan sebagai model yang terbaik untuk memprediksi nilai dan kelas suatu data.
PEMBANGUNAN
FUZZY CLASSIFIER
UNTUK DATA POTENSI DESA 2003
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Oleh :
AHMAD SUHAIRI
G64102014
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : Pembangunan
Fuzzy Classifier
untuk Data Potensi Desa 2003
Nama : Ahmad
Suhairi
NIM :
G64102014
Menyetujui:
Pembimbing I,
Imas S.Sitanggang, S.Si., M.Kom.
NIP 132 206 235
Pembimbing II,
Wisnu Ananta Kusuma, S.T, M.T
NIP 132 312 485
Mengetahui:
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Dr. Ir. Yonny Koesmaryono, MS
NIP 131 473 999
PRAKATA
Alhamdulillahi Rabbil ‘alamin, puja dan puji syukur penulis panjatkan kepada Allah SWT atas segala curahan rahmat dan karunia-Nya sehingga penelitian ini berhasil diselesaikan dengan baik. Shalawat dan salam selalu tercurah kepada junjungan dan suri teladan kita Nabi Muhammad SAW.
Topik yang dipilih dalam penelitian tugas akhir ini ialah data mining, dengan judul Pembangunan Fuzzy Cassification untuk Data Potensi Desa 2003.
Penyelesaian penelitian ini tidak terlepas dari bantuan berbagai pihak, karena itu penulis mengucapkan terima kasih sebesar-besarnya kepada:
1. Ayahanda Syahril Anwar dan Ibunda Zar’ah atas do’a dan kasih sayangnya yang tak terhingga selama ini.
2. Ibu Imas S. Sitanggang, S.Si., M.Kom. selaku pembimbing I, Bapak Wisnu Ananta Kusuma, S.T, M.T selaku pembimbing II.
3. Ibu Annisa, S.Kom selaku dosen penguji.
4. Kakakku Huzaemah, Humairoh, Fitriah atas dukungannya kepada penulis baik secara materi maupun moril. Adikku Rosidah, Zainal, dan Zauzi yang selalu membuat penulis merasa nyaman tinggal di rumah.
5. Arsha Mustika atas bantuan bahan penelitiannya kepada penulis.
6. Ibu kost yang baik hati dan murah senyum, terima kasih atas tempat kosannya yang nyaman. 7. Teman-teman sekosanku Firman, Zaki, Adi, Erus, Laode, Tri, Tedi, Ahim, Wisnu, Arif, Joko,
Wicak, dan Reza, segala kenangan indah di kosan tidak akan pernah penulis lupakan.
8. Teman-teman Ilkomerz 39, persahabatan dan persaudaraan kita yang indah selalu terikat dihati penulis.
9. Rekan-rekan DPM 2004, 2005, 2006 atas persaudaraan dan kebersamaannya, 10. Rekan-rekan LDK se-IPB atas perjuangan dan nasihatnya,
11. Seluruh staf dan karyawan Departemen Ilmu Komputer, serta pihak lain yang telah membantu dalam penyelesaian penelitian ini.
Segala kesempurnaan hanya milik Allah SWT, semoga hasil penelitian ini dapat bermanfaat, Amin.
Bogor, Agustus 2007
RIWAYAT HIDUP
Penulis dilahirkan di Jakarta pada tanggal 10 Oktober 1983 dari ayah Syahril Anwar dan ibu Ahmad Suhairi. Penulis merupakan putra ke empat dari tujuh bersaudara. Tahun 2002 penulis lulus dari SMU Negeri 29 Jakarta. Pada tahun yang sama penulis diterima di Program Studi Ilmu Komputer, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur Undangan Seleksi Masuk IPB (USMI).
DAFTAR ISI
Halaman
DAFTAR TABEL ... viii
DAFTAR GAMBAR ... viii
DAFTAR LAMPIRAN ... viii
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Data Mining ... 1
Knowledge Discovery in Database (KDD) ... 2
Himpunan Fuzzy ... 2
Fuzzy C-Means (FCM) ... 3
Pendekatan Fuzzy dalam Data Mining ... 4
Pencarian Aturan yang Menarik dalam Data Fuzzy ... 4
Representasi Ketidakpastian ... 5
Proses Defuzzifikasi ... 5
Integrasi Numerik dengan Metode Trapesium ... 6
Pengukuran Keakuratan Prediksi ... 6
Root Mean Squared Error (RMSE) ... 6
METODE PENELITIAN Proses Dasar Sistem ... 7
Lingkungan Pengembangan Sistem ... 8
HASIL DAN PEMBAHASAN Transformasi Data ... 8
Pembersihan Data ... 8
Seleksi Data ... 8
Data Mining ... 8
Pembentukan Himpunan Fuzzy ... 8
Pembentukan Basis Data ... 9
Pembentukan Aturan ... 9
Prediksi Nilai ... 10
Evaluasi Pola ... 10
KESIMPULAN DAN SARAN Kesimpulan ... 11
Saran ... 11
DAFTAR PUSTAKA ... 12
DAFTAR TABEL
Halaman
1 Atribut PODES 2003 yang telah ditransformasi ke himpunan fuzzy ... 8
2 Nilai minimum dan maksimum untuk masing-masing atribut ... 9
3 Banyaknya aturan orde ke satu (R1) untuk masing-masing data training ... 9
4 Banyaknya aturan orde ke dua, tiga, dan empat untuk masing-masing data training ... 9
5 Jumlah aturan yang terbentuk untuk masing-masing data training ... 9
6 Contoh aturan yang terbentuk dari 500 data training ... 9
7 Contoh perbandingan data prediksi dengan data sebenarnya ... 10
DAFTAR GAMBAR
Halaman 1 Proses KDD (Han & Kamber 2001) ... 22 Derajat record d dengan terminologi linguistik Lφr (Jang et al 1997) ... 4
3 Pendekatan trapesium untuk menghitung integral dari suatu fungsi f(x) (Cheney et al. 1994) ... 6
4 Jumlah aturan yang terbentuk pada jumlah data training yang ada ... 9
5 Grafik hubungan jumlah data training dengan waktu pembangkitan ... 10
6 Grafikhubungan jumlah data training dengan akurasi rata-rata tiap atribut target ... 10
7 Grafikhubungan jumlah data training dengan nilai rmse tiap atribut target ... 11
DAFTAR LAMPIRAN
Halaman 1 Tabel-tabel yang ada di data.mdb ... 142 120 Aturan yang terbentuk dari 500 data training ... 14
3 Performa akurasi untuk masing-masing data training dan data tes yang ada ... 19
PENDAHULUAN
Latar Belakang
Berkembangnya peralatan-peralatan untuk koleksi data dan teknologi basis data dewasa ini telah mendorong organisasi dan perusahaan untuk menyimpan data secara besar-besaran dalam basis data, gudang data, dan media penyimpanan lainnya. Tetapi permasalahan yang ada sekarang adalah melimpahnya data yang dimiliki, tetapi kurang dimanfaatkan untuk mendapatkan informasi dari data yang besar itu.
Untuk mengatasi kesenjangan informasi ini, para ahli mengembangkan konsep data mining yang mengintegrasikan informasi data dari sumber-sumber yang berbeda, dan merancangnya dalam format yang sesuai untuk mengambil informasi-informasi yang tersembunyi sehingga berguna untuk membuat keputusan yang akurat (Hoffer et al. 2002). Salah satu teknik data mining yang digunakan adalah klasifikasi.
Klasifikasi merupakan salah satu metode analisis data yang dapat digunakan untuk memperkirakan nilai beberapa atribut di dalam suatu basis data berdasarkan atribut-atribut lainnya (Au & Chan 2001). Sebagai contoh pihak instansi pemerintah khususnya dari PLN ingin menentukan jumlah keluarga pengguna listrik PLN di suatu desa apakah sedikit atau banyak berdasarkan jumlah keluarga prasejahtera sejahtera I atau berdasarkan jumlah pengangguran di desa tersebut. Ada beberapa konsep dalam mengklasifikasi data, salah satunya dengan konsep himpunan fuzzy.
Konsep himpunan fuzzy dipilih karena dapat lebih dipahami manusia dan lebih baik dalam menangani data numerik. Contoh pengklasifikasian dengan himpunan fuzzy adalah ”Jika jumlah keluarga prasejahtera sejahtera I banyak maka jumlah keluarga pengguna listrik PLN banyak”
Pada penelitian kali ini proses data mining akan diterapkan pada basis data mengenai potensi desa di Indonesia. Di dalam basis data tersebut terdapat 750 atribut dan tiap tahun mengalami update data. Khusus pada tahun 2003 data tersebut memiliki jumlah record sebanyak 65536. Dengan diterapkannya proses data mining ke data potensi desa diharapkan dapat menghasilkan informasi atau pengetahuan yang penting dan berguna sehingga mempunyai nilai guna lebih untuk keperluan di masa mendatang.
Tujuan Penelitian
Tujuan penelitian ini adalah:
1 Menerapkan proses data mining menggunakan klasifikasi fuzzy untuk menganalisis suatu data potensi desa di pulau Jawa tahun 2003.
2 Mendapatkan aturan-aturan yang menarik dari data potensi desa dengan menggunakan pendekatan logika fuzzy.
3 Menentukan nilai dan kelas atribut yang belum diketahui berdasarkan aturan-aturan yang ditemukan.
Ruang Lingkup Penelitian
Penelitian ini hanya dibatasi untuk membuat aplikasi perangkat lunak yang digunakan untuk proses data mining menggunakan metode klasifikasi dengan menggunakan pendekatan logika fuzzy pada 5 atribut pada data PODES 2003 di pulau Jawa. Perangkat lunak tersebut dapat juga menghasilkan aturan-aturan dan yang selanjutnya digunakan untuk menentukan suatu nilai atribut yang belum diketahui nilai dan kelasnya.
Manfaat Penelitian
Penelitian bermanfaat agar data PODES 2003 yang diolah dengan aplikasi data mining, dapat digunakan untuk melihat pola keterkaitan antardata. Aplikasi tersebut juga dapat dimanfaatkan untuk mengisi nilai suatu atribut yang kosong pada data PODES 2003 berdasarkan nilai aribut lain yang telah diketahui dan menentukan kelas data dari nilai yang dicari.
TINJAUAN PUSTAKA
Data Mining
Data mining merupakan kegiatan untuk mengekstrak atau ”menambang” pengetahuan atau pola yang menarik (non-trivial, implisit, sebelumnya tidak dikenal) dari sejumlah data yang besar (Han & Kamber 2001).
Data yang akan diekstrak secara umum memiliki ciri-ciri sebagai berikut (Fayyad et al. 1996):
- Basis data dengan ukuran yang sangat besar. - Memiliki dimensi yang tinggi, ditandai
dengan besarnya jumlah field (atribut dan variabel) yang ada.
- Pendugaan statistik yang signifikan seperti permasalahan mencari banyaknya kemungkinan dari model.
- Permasalahan integrasi dengan sistem-sistem yang berbeda.
Data mining memiliki beberapa teknik yang dapat diterapkan, antara lain (Han & Kamber 2001):
1 Aturan asosiasi, merupakan teknik data mining untuk menemukan aturan asosiatif antara suatu kombinasi item. Penting tidaknya suatu aturan asosiatif dapat diketahui dengan dua parameter, support yaitu persentase kombinasi tersebut dalam basis data, dan confidence, kuatnya hubungan antaritem dalam aturan asosiatif. 2 Klasifikasi merupakan proses menemukan
sekumpulan model (atau fungsi) yang menjelaskan dan membedakan kelas data atau konsep-konsep, dengan tujuan agar mampu menggunakan model tersebut untuk menentukan suatu objek yang label kelasnya belum diketahui.
3 Clustering. Tidak seperti klasifikasi dimana kelas data telah ditentukan terlebih dahulu, clustering melakukan pengelompokan data tanpa diketahui terlebih dahulu label kelasnya. Objek yang dikelompokkan tersebut didasarkan prinsip memaksimalkan kesamaan antar anggota dalam satu kelas dan meminimalkan kesamaan antarkelas.
Knowledge Discovery in Database (KDD)
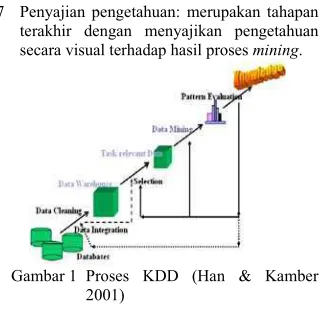
Proses dasar sistem dalam data mining dapat dipandang sebagai proses KDD (Knowledge Discovery in Databases) (Gambar 1) yang memiliki beberapa tahap sebagai berikut (Han & Kamber 2001):
1 Pembersihan data: merupakan tahapan untuk membersihkan data. Pembersihan data mempunyai peran untuk menangani nilai– nilai yang hilang, meminimalkan pengotor data, dan membetulkan data yang tidak konsisten.
2 Pengintegrasian data: merupakan tahapan untuk menggabungkan data dari berbagai macam tipe data dan sumber ke dalam tempat yang terpadu. Sumber yang dimaksud bisa berupa beberapa basis data, kubus data, ataupun sebuah file.
3 Seleksi data: merupakan proses pemilihan data yang relevan untuk proses analisis. 4 Transformasi data: merupakan tahapan
untuk mentransformasi data ke dalam bentuk yang sesuai untuk proses mining. 5 Data mining: merupakan proses inti dari
KDD untuk melakukan analisis dari suatu data tertentu.
6 Evaluasi pola: berguna untuk
mengidentifikasi pola yang benar-benar menarik untuk penyajian pengetahuan.
7 Penyajian pengetahuan: merupakan tahapan terakhir dengan menyajikan pengetahuan secara visual terhadap hasil proses mining.
Gambar1 Proses KDD (Han & Kamber 2001)
Himpunan Fuzzy
Sebuah himpunan fuzzy merupakan himpunan tanpa ada batasan yang tegas (crisp boundary) yaitu dengan memperhalus batasan yang tegas dengan fungsi keanggotaan. Fungsi keanggotaan memberikan himpunan fuzzy fleksibilitas dalam pemodelan yang secara umum menggunakan ekspresi linguistik seperti ”gaji rendah” (Jang et al., 1997).
Jika X adalah sekumpulan objek yang dilambangkan secara umum oleh x, maka himpunan fuzzy A di dalam X didefinisikan sebagai himpunan pasangan sebagai berikut (Jang et al. 1997):
},
|
))
(
,
{(
x
x
x
X
A
=
μ
A∈
dimana μA(x) adalah fungsi keanggotaan untuk himpunan fuzzy A. Fungsi keanggotaan memetakan masing-masing anggota X dengan nilai antara 0 dan 1.
Fuzzy C-Means (FCM)
Fuzzy clustering adalah salah satu teknik untuk menentukan cluster optimal dalam suatu ruang vektor yang didasarkan pada bentuk normal Euclidian untuk jarak antar vektor (Kusumadewi 2002). Ada beberapa algoritma clustering data, salah satu diantaranya adalah Fuzzy C-Means (FCM).
Fuzzy C-Means (FCM) adalah suatu teknik peng-cluster-an data dimana keberadaan tiap-tiap titik data dalam suatu cluster ditentukan oleh derajat keanggotaan. Teknik ini pertama kali diperkenalkan oleh Jim Bezdek pada tahun 1981 (Kusumadewi 2002).
∑
∑
= ==
N k w ik N k k w ik fu
i
v
1 1)
(
)
(
μ
μ
…
…
…
…
∑
∑
= ==
N k w ik N k k w ik fu
i
v
1 1)
(
)
(
μ
μ
…
…
…
…
2 1 1)
(
)
(
c
v
i
P
k fN k c i w ik
t
=
∑∑
−
= =
μ
μ
1 1 =∑
= c i ik μdata memiliki derajat keanggotaan untuk tiap cluster, dengan cara memperbaiki pusat cluster dan derajat keanggotaan tiap-tiap titik secara berulang, maka akan dapat dilihat bahwa pusat cluster akan bergerak menuju ke lokasi yang tepat. Perulangan ini didasarkan pada minimalisasi fungsi obyektif yang menggambarkan jarak dari titik data yang diberikan ke pusat cluster yang berbobot oleh derajat keanggotaan titik data tersebut. Keluaran dari FCM merupakan deretan pusat cluster dan beberapa derajat keanggotaan untuk tiap-tiap titik data.
Apabila terdapat suatu himpunan data sebagai berikut:
U = (u1, u2, u3,..., uN)
derajat keanggotaan suatu titik data ke-k di cluster-i adalah:
μ
ik (uk) ∈ [0,1] dengan (1 ≤ i ≤ c; 1 ≤ k ≤ N) Pada metode FCM, matriks partisi didefinisikan sebagai:μ11[u1] μ21[u1] ... μc1[u1] μ12[u2] μ21[u2] ... μc1[u2]
μ1N[uN] μ2N[un] ... μcN[uN]
dengan
yang berarti bahwa jumlah nilai keanggotaan suatu data pada semua cluster harus sama dengan 1.
Fungsi obyektif iterasi ke-t P(c) pada matriks partisi adalah:
dengan vf i adalah pusat vektor pada cluster fuzzy ke-i,
dan w adalah bobot pada nilai-nilai keanggotaan, μk−vfi adalah bentuk normal
Euclidian yang digunakan sebagai jarak antara uk dan vf i (Kusumadewi 2002).
Algoritma FCM adalah sebagai berikut (Kusumadewi 2002):
1 Tetapkan matriks partisi
μ
f(c) awal sembarang, sebagai berikut:μ11[u1] μ21[u1] ... μc1[u1] μ12[u2] μ21[u2] ... μc1[u2]
μ1N[uN] μ2N[un] ... μcN[uN] 2 Tetapkan nilai w > 1 (misal w = 2), Eps
sangat kecil (misal 10-5), MaxIter (misal 100). Jumlah cluster c > 1, dan t = 0; 3 Tetapkan fungsi obyektif awal: Pt(c) secara
acak;
4 Naikkan nomor iterasi: t = t + 1;
5 Hitung pusat vektor tiap-tiap cluster untuk matriks partisi tersebut sebagai berikut:
6 Modifikasi tiap-tiap nilai keanggotaan sebagai berikut:
- jika yk≠ vf i,
1 ) 1 ( 1 1 2 2 ) ( − − = ⎥ ⎥ ⎥ ⎥ ⎦ ⎤ ⎢ ⎢ ⎢ ⎢ ⎣ ⎡ ⎟ ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎜ ⎝ ⎛ − − =
∑
w c g g k f k k ik i v u i v u yμ
- jika yk = vf i,
μ
ik (yk) = 1, jika i = g;μ
ik (yk) = 0, jika i ≠ g;7 Modifikasi matriks partisi sebagai berikut:
μ11[u1] μ21[u1] ... μc1[u1] μ12[u2] μ21[u2] ... μc1[u2]
μ1N[uN] μ2N[un] ... μcN[uN] 8 Hitung fungsi obyektif:
2
1 1
)
(
)
(
c
y
v
i
P
k fN k c i w ik
t
=
∑∑
−
= =
μ
9 Cek kondisi berhenti, yaitu:
( | Pt(c) – Pt-1(c) | < Eps) atau (t > MaxIter)
Jika memenuhi langkah-9, maka berhenti. Jika tidak, ulangi lagi dari langkah-4.
Pendekatan Fuzzy dalam Data mining
Misalkan diberikan suatu kumpulan record data D yang masing-masing berisi sekumpulan atribut I = {I1, I2, …, In} dimana Iv, v=1, …, n atribut dapat merupakan data kuantitatif atau data kategori. Daerah asal atribut Iv (dom(Iv))
μ
f(c) =μ
f(c) =μ
f(c) =…
merupakan himpunan bagian dari bilangan nyata, dom(Iv)⊆ℜ.
Berdasarkan teori himpunan fuzzy, himpunan terminologi linguistik (Lvr, r = 1, …, sv, dengan sv: banyaknya variabel linguistik) didefinisikan sebagai daerah asal dari suatu atribut dan direpresentasikan dengan himpunan fuzzy
L
vr.
Fungsi keanggotaan(
μ
Lvr)
darisebuah himpunan fuzzy,
L
vr, didefinisikan sebagai berikut (Au & Chan 2001):1] , 0 [ ) (
: v →
Lvr domI μ
dimana fungsi keanggotaan memetakan masing-masing atribut ke dalam suatu nilai keanggotaan antara 0 dan 1.
Sedangkan untuk himpunan fuzzy Lvr
didefinisikan sebagai berikut (Au & Chan, 2001): ⎪ ⎪ ⎩ ⎪⎪ ⎨ ⎧ =
∫
∑
) ( ) ( kontinu jika ) ( diskret jika ) ( v vr vr vr I dom v v v L I dom v v v L vr I i i I i i L μ μJika atribut Iv∈I adalah variabel kategori maka dom(Iv)={iv1 ,...,ivmv}
melambangkan daerah asal dari Iv dengan m kategori. Himpunan fuzzy untuk Atribut Iv didefinisikan sebagai berikut (Au & Chan, 2001):
vr vr
i
L
=
1
dengan r = 1, ..., mv.
Derajat keanggotaan dari suatu nilai di record d ∈ D pada atribut Iv dilambangkan dengan L (d[Iv]).
vr
μ Jika L (d[Iv])
vr
μ = 1, d
secara lengkap dicirikan oleh terminologi Lvr. Jika L
(
d
[
I
v])
vr
μ
= 0, maka d tidak dicirikan oleh terminologi Lvr, sedangkan jika 0<μ
Lvr(d[Iv])<1, maka d dicirikan sebagianoleh terminologi Lvr.
Pada kenyataannya d dapat juga dicirikan oleh lebih dari satu terminologi linguistik. Misalkan φ himpunan dari bilangan integer dengan φ = {v1, ..., vm} dimana v1, ..., vm∈ { 1, ..., n}, v1≠ ... ≠vm, dan |φ| = h ≥1, maka derajat,
(
d
),
r
ϕ
λ
L dimana record d dicirikandengan terminologi Lφr dan didefinisikan sebagai berikut (Au & Chan, 2001):
]) [ ( ..., ]), [ ( min( ) ( 1 1
1r vmrm m
v
r d
μ
L d Ivμ
L d Ivλ
Lϕ =Nilai
r
ϕ
λ
L dapat ilustrasikan seperti padaGambar 2.
Gambar 2 Derajat record d dengan terminologi linguistik Lφr (Jang et al 1997).
Suatu kumpulan record D dapat disajikan oleh himpunan data fuzzy, F, yang dicirikan oleh himpunan atribut linguistik,
}. ,..., {L1 Ln
L= Untuk sembarang atribut
linguistik ,
L
v∈
L,
nilai dariL
vdari sebuahrecord t∈F adalah himpunan pasangan berurutan seperti berikut (Au & Chan, 2001):
)}
,
(
...,
),
,
{(
]
[
v v1 v1 vsv vsvt
L
=
L
μ
L
μ
dengan Lvk dan μvk, k ∈ {1, ..., sv } adalah sebuah terminologi linguistik dan derajat keanggotaannya.
Untuk sembarang record t ∈ F, derajat dimana record t dicirikan oleh
pq
L
danL
ϕk,
p∉ϕ, didefinisikan sebagai berikut (Au & Chan, 2001):) , min( pq k
k pq
oL Lϕ =
μ
Lμ
Lϕ (1)Sedangkan jumlah derajat dimana record-record di F dicirikan oleh
L
pq dan,
k ϕL
diberikan sebagai berikut (Au & Chan, 2001):∑
∈ = F t k pq kpqLϕ oL Lϕ
L
deg (2)
Pencarian Aturan yang Menarik dalam Data fuzzy
Sebuah aturan fuzzy dapat memiliki orde yang berbeda-beda. Aturan fuzzy orde kesatu (R1) merupakan aturan yang memiliki satu
terminologi linguistik pada antecedent. Aturan fuzzy orde kedua (R2) merupakan aturan yang memiliki dua terminologi linguistik, dan seterusnya. Untuk mendapatkan aturan orde kesatu maka perlu membuat pengunaan ukuran kemenarikan sebuah objek.
(3) k pq k k pq record record ϕ ϕ ϕ L L L L L oleh istikkan dikarakter dimana derajat jumlah dan oleh istikkan dikarakter dimana derajat jumlah ) | ( Pr =
memiliki perbedaan yang signifikan dengan (4)
M
record pq
pq
L L ) jumlah derajat dimana dikarakteristikkan oleh (
Pr =
Dengan
∑∑
= = = p i pu s u s i M 1 1 deg ϕ ϕ L
L (5)
Perbedaan yang signifikan (dLpqLϕk) secara
objektif dapat dievaluasi berdasarkan sebuah adjusted residual yang didefinisikan sebagai berikut (Au & Chan 2001):
k pq k pq k pq
z
d
ϕ ϕ ϕγ
L L L L LL
=
(6)dengan
k pq
z
L Lϕ adalah sebuah standardizedresidual yang dirumuskan sebagai berikut (Au & Chan 2001):
k pq k pq k pq k pq
e
e
z
ϕ ϕ ϕ ϕ L L L L L L L L−
=
deg
(7)dimana
k pq
eL Lϕ adalah jumlah derajat suatu
record diharapkan untuk terkarakterisasi oleh pq
L
danL
ϕk,
dan dirumuskan sebagai berikut (Au & Chan 2001):M
e
s i s u p k pu i pq k pq∑
∑
= ==
ϕ ϕ ϕ ϕ 1 1deg
deg
L L L LL
L (8)
dan
k pqϕ
γ
L L merupakan perkiraan maximumlikelihood dari varian
k pq
z
L Lϕ yang dirumuskansebagai berikut (Au & Chan 2001):
(9)
⎟⎟
⎟
⎟
⎟
⎠
⎞
⎜⎜
⎜
⎜
⎜
⎝
⎛
−
⎟⎟
⎟
⎟
⎟
⎠
⎞
⎜⎜
⎜
⎜
⎜
⎝
⎛
−
=
∑
=∑
=M
M
p k pu i pq k pq s u si1 1
deg
1
deg
1
ϕ ϕ ϕ ϕγ
L L L L L LRepresentasi Ketidakpastian
Misalkan diberikan sebuah terminologi linguistik
L
ϕk yang diasosiasikan denganterminologi linguistik yang lain
L
pq,
akan dibentuk aturan fuzzy sebagai berikut (Au & Chan 2001):]
[
k pqw
pq k ϕϕ
L
L LL
⇒
dimana
k pq
wL Lϕ adalah ukuran weight of evidence
dan dirumuskan sebagai berikut (Au & Chan 2001):
U
q i k pq k pq I Iwpq k
≠ −
= ( : ϕ ) ( ( : ϕ ))
ϕ L L L L
L L ) | ( Pr ) | ( Pr log
U
q i pi k pq k ≠ = L L L L ϕϕ (10)
dimana
I
(
L
pq:
L
ϕk)
merupakan informasi yang saling menguntungkan (mutual information) yang mengukur perubahan ketidakpastian dari presenceL
pqdi dalam sebuah record yang diberikan, mengandung antecedentL
ϕk.I
(
L
pq:
L
ϕk)
didefinisikan sebagai berikut (Au & Chan 2001):)
(
Pr
)
|
(
Pr
log
)
:
(
pq k pq k pqI
L
L
L
L
L
ϕ=
ϕ (11)k pq
wL Lϕ dapat diinterpretasikan sebagai secara
intuitif sebagai ukuran perbedaan di dalam perolehan informasi ketika sebuah record dengan
L
ϕk dicirikan olehL
pq dan dicirikan olehL
pi,
i≠q. wLpqLϕkdapat digunakan untuk
mempertimbangkan pentingnya aturan fuzzy.
Aturan fuzzy
[
]
k pq
w
pq
k ϕ
ϕ
L
L LL
⇒
dapatpula dijabarkan sebagai berikut:
]
[
,...,
1
1k vmkm pq
w
pq kv
L
L
L LϕL
⇒
dimana v1,...,vm∈
ϕ
yang mendeskripsikan aturan fuzzy dengan orde yang lebih tinggi.Proses Defuzzifikasi
Proses defuzzifikasi bertujuan untuk menentukan nilai yang belum diketahui menggunakan aturan fuzzy.
Diberikan sebuah record, d∈dom(I1) x ... x dom(Ip) x ... x dom(In), d dicirikan oleh n
, ..., , 1
, p
p p= s
L merupakan terminologi
linguistik yang berkorespondensi dengan atribut Ip, nilai
α
p diberikan dari nilail
pdengan}. ..., , { )
(lp p1 psp
dom = L L Untuk menentukan
nilai lp, maka dicari aturan fuzzy dengan )
( p pq∈domI
L sebagai consequent. Untuk
setiap kombinasi nilai-nilai atribut (
α
ϕ,
,ϕ
∉
p ), nilai
α
ϕ dicirikan oleh terminologi linguistikL
ϕk,
dengan derajat kompatibilitasnya λLϕk(d), untuk setiap}.
...,
,
1
{
s
ϕk
∈
Misalkan diberikan aturanimplikasi, [ ]
k pq
w
pq
k ϕ
ϕ L L L
L ⇒ , maka nilai
evidence untuk
L
ϕk dirumuskan sebagai berikut (Au & Chan 2001):)
(
.
} ..., , 1 {d
w
w
sk pq k k
pq
∑
∈=
ϕ ϕ ϕ ϕλ
α L L L
L (12)
Weight of evidence untuk nilai lp diberikan sebagai berikut (Au & Chan 2001):
∑
==
β α 1 ] [ j qw
pq jw
L (13)dimana
α
[j]={α
i|i∈{1,...,n}−{p}}. Sebagai hasilnya, nilai dariα
p, diberikan oleh)}.
,
(
...,
),
,
(
...,
,
)
,
{(
1 1p
p s
ps q
pq
p
w
L
w
L
w
L
Untuk mendapatkan nilai
α
p secara tegas dilakukan proses defuzzifikasi. Diberikan terminologi linguistik,p
ps
p
L
L
1,
...,
dengan weight of evidence-nya,p
s
w
w
1,
...,
, misalkan) ( 'Lpu ip
μ
merupakan weight of degree dari keanggotaan ip∈dom(lp) untuk himpunan fuzzy}.
...,
,
1
{
,
ppu
u
s
L
∈
'
L(
i
p)
pu
μ
diberikansebagai berikut (Au & Chan 2001):
)
(
.
)
(
'
Li
pw
u Li
p pupu
μ
μ
=
Nilai defuzzifikasi,
U
p s u pu L F 1 1 ), ( =
− yang
digunakan sebagai nilai untuk
α
pdidefinisikan sebagai berikut (Au & Chan, 2001):(14)
U
pp p psp
p p psp
s u
i
dom L L p p
i
dom L L p p p pu
di
i
di
i
i
L
F
1 ) ( ... ) ( ... 1)
(
'
.
)
(
'
)
(
1 1 = ∪ ∪ ∪ ∪ −∫
∫
=
μ
μ
(15) dimana ' max( ' ,..., ' ).1 1 ... psp p psp
p L L L
L
μ
μ
μ
∪ ∪ =Integrasi Numerik dengan Metode Trapesium
Metode trapesium berdasarkan sebuah perkiraan dari daerah di bawah sebuah kurva mengunakan luas trapesium. Gambar 3 menjelaskan pendekatan integrasi numerik menggunakan metode trapesium.
Gambar 3 Pendekatan trapesium untuk menghitung integral dari suatu fungsi f(x) (Cheney et al. 1994) Total dari luas daerah trapesium dirumuskan sebagai berikut (Cheney et al. 1994): (16)
∑
− = + + + − = 1 0 1 1 )[ ( ) ( )] ( 2 1 ) ; ( n i x i ii x f x f x
x P
f T
dengan nilai x0 = a dan nilai xn = b.
Pengukuran Keakuratan Prediksi
Pengukuran keakuratan merupakan suatu evaluasi performa dari suatu model klasifikasi yang berdasarkan penghitungan jumlah prediksi yang benar dan tidak benar dari model data uji yang ada. Performa akurasi dirumuskan sebagai berikut (Han & Kamber 2001):
Root Mean Squared Error (RMSE)
Root mean squared error digunakan untuk mungukur performa dari sebuah nilai perkiraan kuantitatif. Diberikan sebuah record yang akan diuji, r, misalkan n adalah jumlah record di D. untuk setiap record,
r
∈
D
,
misalkanℜ
⊂
]
,
[
l
u
melambangkan daerah asal dari atribut kelas, tr sebagai nilai target dan or sebagai nilai perkiraan. Maka root mean squared error, rmse, didefinisikan sebagai berikut (Au & Chan, 2001):(18)
∑
∈⎟
⎠
⎞
⎜
⎝
⎛
−
−
−
−
−
=
D r r rl
u
o
l
u
t
n
rmse
21
1
1
METODE PENELITIANA.Proses Dasar Sistem
Proses dasar sistem yang digunakan mengacu pada proses KDD sebagai berikut: a.1 Pembersihan data
Pada tahapan ini data yang tidak konsisten, data yang mengandung nilai null, dan data yang mengandung noise akan dihilangkan. Salah satu teknik yang dipakai adalah dengan menghapus record yang mengandung nilai null.
12Pengintegrasiandata
Data-data yang terpisah akan digabungkan dalam tahap ini menjadi satu kesatuan.
23Seleksi data
Karena menggunakan metode fuzzy, pada tahapan ini akan mengambil dari basis data berupa data-data yang numerik.
34Transformasi data
Pada tahapan ini merubah format data yang sesuai dengan perangkat lunak yang digunakan.
45Data mining
Data mining merupakan proses inti untuk melakukan analisis. Metode yang digunakan adalah klasifikasi fuzzy, dengan algoritma fuzzy data mining. Algoritma ini didasarkan atas derajat keanggotaan dari himpunan fuzzy. Beberapa langkah yang dilakukan antara lain: - Membentuk himpunan fuzzy dengan nilai
keanggotaanya menggunakan metode fuzzy c-means.
- Mendapatkan aturan fuzzy orde kesatu dengan menggunakan interestingness measure berdasarkan adjusted
residual
(
)
k pq
d
L Lϕ . Jika nilai dLpqLϕk >1.96(95 persen dari distribusi normal), hubungan antara
L
pqdanL
ϕk dikatakan menarik. - Mendapatkan aturan fuzzy dengan orde yanglebih tinggi menggunakan algoritma fuzzy classification data mining sebagai berikut
(Au & Chan 2001):(referensi???):
U
m m k pq m m k pq k k p pq pq k pq k k p pq pq m m R R Aturan Pembangkit R R Menarik p t , μ t , μ p t , μ t , μ F t C m R r r antecedent m ; |R m R k pq = ∪ = ∉ ∈ ∈ = + ∉ ∈ ∈ ∈ ∈ = + + ≠ = = − − end end then if do forall do forall do forall begin do forall begin do for ); , ( ) , ( ], [ ) ( ], [ ) ( ); , min( deg ], [ ) ( ], [ ) ( di elemen dari tersusun yang } | dari di kondisi masing -masing { C ) ; | 2 ( kesatu}; orde fuzzy aturan { 1 1 1 ϕ ϕ ϕ ϕ ϕ ϕ ϕ ϕ ϕ ϕ μ μ ϕ ϕ φ ϕ L L L L L L L L L L L L L L Penjelasan algoritma:a Aturan fuzzy orde ke satu (R1) digunakan
untuk membangkitkan aturan orde kedua yang disimpan di R2. R2 digunakan untuk
membangkitkan aturan orde ketiga yang disimpan di R3 dan seterusnya sampai orde
yang lebih tinggi tidak ditemukan lagi. b Fungsi Menarik(Lpq, Lφk) menghitung
ukuran secara objektif untuk menentukan apakah hubungan antara Lpq dan Lφk menarik. Jika benar maka menjalankan fungsi PembangkitAturan(Lpq, Lφk).
c Fungsi PembangkitAturan(Lpq, Lφk) digunakan untuk membangkitkan aturan fuzzy. Untuk setiap aturan yang dibangkitkan, fungsi ini juga mengembalikan ukuran ketidakpastian yang diasosiasikan dengan aturan
(
)
k pq
w
L Lϕ.
d Semua aturan fuzzy yang telah dibangkitkan akan disimpan di R.
e Menentukan nilai yang belum diketahui berdasarkan aturan yang telah dibangkitkan dengan proses defuzzifikasi dan menentukan kelas pada atribut yang akan diprediksi kelasnya.
56Evaluasi pola
Pada tahapan ini akan dilakukan pengukuran performa terhadap hasil penelitian proses data
Formatted: I ndent: Left: 0", Hanging: 0.2", Space Before: 6 pt, Numbered + Level: 2 + Numbering Style: 1, 2, 3, … + Start at: 1 + Alignment: Left + Aligned at: 0" + Tab after: 0.2" + I ndent at: 0.2"
mining yang didapat. Adapun yang dievaluasi meliputi:
a Waktu eksekusi untuk pembangkitan aturan dengan jumlah data training yang berbeda-beda yaitu 500, 1000, 1500, 2000, dan 2500 data.
b Akurasi hasil penentuan kelas dengan kelas sebenarnya pada setiap data yang telah ditentukan.
c Nilai root mean squared error (rmse) untuk setiap masing-masing nilai data yang telah ditentukan.
67Penyajian Pengetahuan
Pada tahap ini hasil penelitian dalam proses KDD akan disajikan dalam bentuk tabel dan grafik.
B. Lingkungan Pengembangan Sistem
Sistem dikembangkan menggunakan: Perangkat lunak:
- Microsoft Windows XP Home Edition - Microsoft® Visual Basic 6.0 sebagai bahasa
pemrograman
- DBMS: Microsoft® Access Perangkat keras:
- PC dengan prosesor AMD Sempron 2500+ (1.40 GHz)
- RAM DDR 512 MB - Harddisk 40 GB (7200 rpm) - Mouse dan keyboard - Monitor
HASIL DAN PEMBAHASAN
Transformasi Data
Data PODES 2003 memiliki format data .sd2 sehingga harus dikonversi sesuai dengan format jenis DBMS yang digunakan yaitu .mdb, berhubung proses transformasi data telah dilakukan pada penelitian sebelumnya (Mustika 2006) data PODES 2003 sudah diolah, sehingga pada penelitian ini tinggal menggunakan data yang sudah diolah tersebut.
Pembersihan Data
Tahap pembersihan data tidak dilakukan juga karena tahap pembersihan sudah dilakukan pada penelitian sebelumya (Mustika 2006).
Seleksi Data
Data PODES 2003 memiliki 750 atribut dan baik berupa atribut numerik maupun yang bukan numerik dan memiliki 65536 record yang berasal dari seluruh Indonesia. Pada penelitian sebelumnya (Mustika 2006) diambil
5 atribut yang berupa data numerik dan dipilih 24962 record yang berasal dari desa yang ada di pulau Jawa. Adapun 5 atribut tersebut yaitu : a Jumlah keluarga prasejahtera sejahtera 1 b Jumlah pengangguran
c Jumlah keluarga pengguna listrik PLN d Jumlah bangunan permanen
e jumlah murid SD yang drop-out
Dari hasil seleksi data tersebut diambil sebanyak 10500 record dengan 7500 record untuk data training dan 3000 data untuk data tes. Untuk tujuan penelitian, data training dibagi menjadi 5 bagian yaitu 500, 1000, 1500, 2000, dan 2500 record data training, sedangkan untuk data tes dibagi menjadi 5 bagian yaitu 200, 400, 600, 800, dan 1000 record data tes.
Data mining
Proses data mining menggunakan algoritma yang diajukan oleh Wai-Hou Au dan Keith C.C. Chan pada tahun 2001. Secara garis besar ada tiga tahap yang dilakukan yaitu membentuk himpunan fuzzy, membangkitkan aturan yang menarik, dan menentukan nilai dan kelas suatu data yang belum diketahui.
Pembentukkan Himpunan Fuzzy
Tahap pembentukkan himpunan fuzzy ini melakukan transformasi data ke dalam himpunan fuzzy. Untuk penelitian ini digunakan 10500 record data dari hasil transformasi yang dilakukan oleh Arsha Mustika pada hasil penelitiannya tahun 2006. Berdasarkan penelitiannya, masing-masing atribut terbagi menjadi 2 kelas sehingga jumlah atribut menjadi 10 buah. Penjelasan mengenai atribut tersebut dapat dilihat pada Tabel 1 dan Tabel 2. Tabel 1 Atribut PODES 2003 yang telah
ditransformasi ke himpunan fuzzy
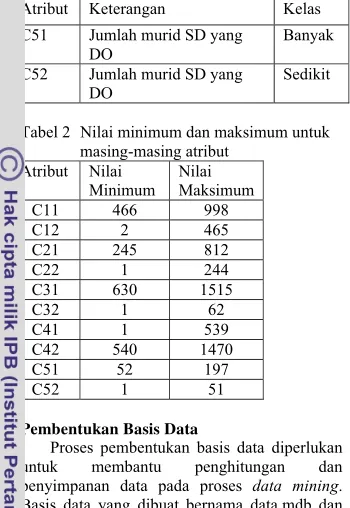
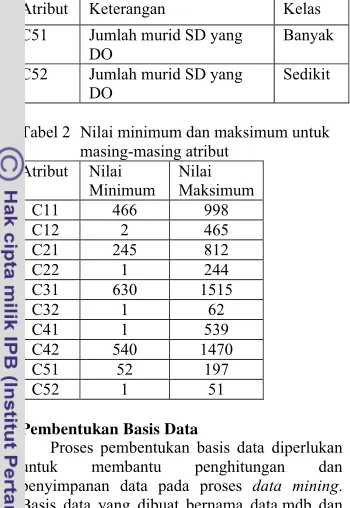
Atribut Keterangan Kelas
C11 Jumlah keluarga prasejahtera sejahtera I
Banyak C12 Jumlah keluarga
prasejahtera sejahtera I
Sedikit C21 Jumlah pengangguran Banyak C22 Jumlah pengangguran Sedikit C31 Jumlah keluarga
pengguna listrik PLN
Banyak C32 Jumlah keluarga
pengguna listrik PLN
Sedikit C41 Jumlah bangunan
permanen
Sedikit C42 Jumlah bangunan
permanen
Atribut Keterangan Kelas C51 Jumlah murid SD yang
DO
Banyak C52 Jumlah murid SD yang
DO
Sedikit
Tabel 2 Nilai minimum dan maksimum untuk masing-masing atribut
Atribut Nilai Minimum
Nilai Maksimum C11 466 998 C12 2 465 C21 245 812 C22 1 244 C31 630 1515
C32 1 62
C41 1 539 C42 540 1470 C51 52 197
C52 1 51
Pembentukan Basis Data
Proses pembentukan basis data diperlukan untuk membantu penghitungan dan penyimpanan data pada proses data mining. Basis data yang dibuat bernama data.mdb dan berisi 27 tabel. Perincian menggenai tabel yang ada di dalam basis data dapat dilihat pada Lampiran 1.
Pembentukan Aturan
Pembentukan aturan dimulai terlebih dahulu dengan membentuk aturan orde ke satu (R1). Dari hasil percobaan didapat jumlah aturan orde ke satu yang terbentuk dari beberapa data tes yang ada sebagai berikut ( Tabel 3) :
Tabel 3 Banyaknya aturan orde ke satu (R1) untuk masing-masing data training Jumlah data training Banyaknya R1 500 20 1000 24 1500 40 2000 36 2500 32 Setelah aturan orde ke satu didapat, kemudian dibentuk aturan untuk orde yang lebih tinggi. Karena data awalnya yang diambil sebanyak 5 atribut maka maksimum aturan-aturan yang dapat dibentuk sampai orde ke empat. Banyaknya aturan yang didapat untuk masing-masing orde dapat dilihat pada Tabel 4.
Dari Tabel 4 dapat dilihat bahwa secara umum dengan pembangkitan aturan yang lebih
tinggi (antecedent makin banyak) maka jumlah aturan yang terbentuk semakin sedikit.
Tabel 4 Banyaknya aturan orde ke dua, tiga, dan empat untuk masing-masing data training
Jumlah data training
Banyak aturan yang terbentuk R2 R3 R4 500 50 41 9
1000 52 48 15
1500 90 89 25
2000 94 98 32
2500 98 102 39
Secara keseluruhan hubungan antara jumlah data training yang ada dengan jumlah aturan yang tebentuk dapat dilihat pada Tabel 5. Tabel 5 Jumlah aturan yang terbentuk untuk
masing-masing data training Jumlah data training Jumlah aturan 500 120 1000 139 1500 244 2000 260 2500 271 Secara umum dari seluruh percobaan yang dibuat jika jumlah data trainingnya semakin banyak maka jumlah aturannya juga semakin banyak dengan kenaikan terbesar terjadi pada selang 1000 sampai 1500 data training. Jumlah aturan terbesar yang dapat dibangkitkan sebanyak 271 aturan dengan jumlah data training 2500 data. Hal ini dapat dilihat pada Gambar 4.
120 139
244 260 271
0 50 100 150 200 250 300
500 1000 1500 2000 2500
jumlah data training
jm
lah
at
u
ran
t
er
b
en
tu
k
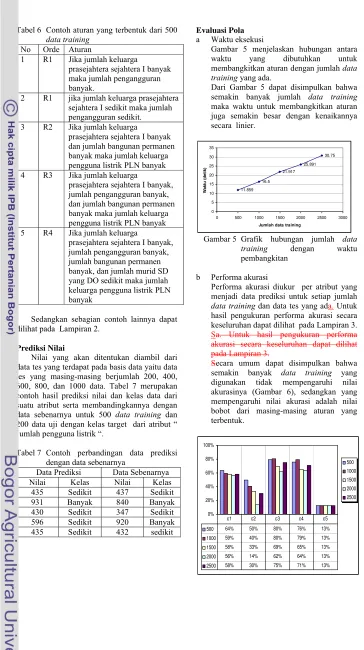
Tabel 6 Contoh aturan yang terbentuk dari 500 data training
No Orde Aturan
1 R1 Jika jumlah keluarga prasejahtera sejahtera I banyak maka jumlah pengangguran banyak.
2 R1 jika jumlah keluarga prasejahtera sejahtera I sedikit maka jumlah pengangguran sedikit. 3 R2 Jika jumlah keluarga
prasejahtera sejahtera I banyak dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak 4 R3 Jika jumlah keluarga
prasejahtera sejahtera I banyak, jumlah pengangguran banyak, dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak 5 R4 Jika jumlah keluarga
prasejahtera sejahtera I banyak, jumlah pengangguran banyak, jumlah bangunan permanen banyak, dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN banyak
Sedangkan sebagian contoh lainnya dapat dilihat pada Lampiran 2.
Prediksi Nilai
Nilai yang akan ditentukan diambil dari data tes yang terdapat pada basis data yaitu data tes yang masing-masing berjumlah 200, 400, 600, 800, dan 1000 data. Tabel 7 merupakan contoh hasil prediksi nilai dan kelas data dari suatu atribut serta membandingkannya dengan data sebenarnya untuk 500 data training dan 200 data uji dengan kelas target dari atribut “ Jumlah pengguna listrik “.
Tabel 7 Contoh perbandingan data prediksi dengan data sebenarnya
Data Prediksi Data Sebenarnya Nilai Kelas Nilai Kelas
435 Sedikit 437 Sedikit 931 Banyak 840 Banyak 430 Sedikit 347 Sedikit
596 Sedikit 920 Banyak
435 Sedikit 432 sedikit
Evaluasi Pola
a Waktu eksekusi
Gambar 5 menjelaskan hubungan antara waktu yang dibutuhkan untuk membangkitkan aturan dengan jumlah data training yang ada.
Dari Gambar 5 dapat disimpulkan bahwa semakin banyak jumlah data training maka waktu untuk membangkitkan aturan juga semakin besar dengan kenaikannya secara linier.
11.859 16.5
21.917 25.891
30.75
0 5 10 15 20 25 30 35
0 500 1000 1500 2000 2500 3000
Jumlah data training
Wakt
u
(
d
e
ti
k
)
Gambar 5 Grafik hubungan jumlah data training dengan waktu pembangkitan
b Performa akurasi
Performa akurasi diukur per atribut yang menjadi data prediksi untuk setiap jumlah data training dan data tes yang ada. Untuk hasil pengukuran performa akurasi secara keseluruhan dapat dilihat pada Lampiran 3.
Sa. Untuk hasil pengukuran performa akurasi secara keseluruhan dapat dilihat pada Lampiran 3.
Secara umum dapat disimpulkan bahwa semakin banyak data training yang digunakan tidak mempengaruhi nilai akurasinya (Gambar 6), sedangkan yang mempengaruhi nilai akurasi adalah nilai bobot dari masing-masing aturan yang terbentuk.
0% 20% 40% 60% 80% 100%
500 1000 1500 2000 2500
Gambar 6 Grafik hubungan jumlah data training dengan akurasi rata-rata tiap atribut target
Pada Gambar 6 juga terlihat bahwa nilai akurasi yang tinggi jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) atau C4 (jumlah bangunan permanen) dan akurasi terendah jika atributnya C5 (Jumlah murid SD yang DO). Untuk nilai akurasi tertinggi (80%) didapatkan jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) dengan jumlah data training sebanyak 1000 data. Nilai akurasi terendah (13%) didapatkan jika atribut targetnya C5 (Jumlah murid SD yang DO) untuk setiap jumlah data training yang ada.
c Nilai root mean squared error (rmse) Nilai rmse diukur per atribut yang menjadi data prediksi untuk setiap jumlah data training dan data tes yang ada. Untuk hasil pengukuran nilai rmse secara keseluruhan dapat dilihat pada Lampiran 4.
0 0.1 0.2 0.3 0.4 0.5 0.6
500 1000 1500 2000 2500
500 0.24778 0.28696 0.17862 0.20114 0.29306 1000 0.2542 0.3379 0.17904 0.19498 0.39054 1500 0.2578 0.3528 0.2086 0.23254 0.39754 2000 0.26846 0.43432 0.2271 0.24128 0.4657 2500 0.25952 0.36704 0.19358 0.22154 0.50804 c1 c2 c3 c4 c5
Gambar 7 Grafik hubungan jumlah data training dengan nilai rmse tiap atribut target
Pada Gambar 7 juga terlihat nilai rmse yang terkecil (0.17862) didapat jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) dengan jumlah data training sebanyak 500 data. Nilai rmse yang terbesar (0.50804) didapat jika atribut targetnya C5 (Jumlah murid SD yang DO) dengan jumlah data training sebanyak 2500 data.
Dari percobaan penghitungan nilai akurasi didapatkan model yang terbaik untuk memprediksi nilai dan kelas suatu data adalah jika data training yang digunakan sebanyak 1000 data dengan kelas targetnya dari atribut C3 (jumlah keluarga pengguna listrik PLN) atau C4 (jumlah bangunan permanen) dengan nilai akurasi masing-masing atribut tersebut sebesar 80% dan 79%.
KESIMPULAN DAN SARAN
Kesimpulan
Dari berbagai percobaan yang dilakukan terhadap data PODES 2003 didapat kesimpulan sebagai berikut:
1 Semakin banyak data training yang digunakan, maka jumlah aturan yang terbentuk semakin besar dengan kenaikan terbesar terjadi pada selang 1000 sampai 1500 data training. Jumlah aturan terbesar yang dapat dibangkitkan sebanyak 271 aturan dengan jumlah data training 2500 data.
2 Semakin banyak antecedent yang ingin dibuat maka jumlah aturan yang terbentuk semakin sedikit.
23 Semakin banyak data training yang digunakan, maka waktu untuk membangkitkan aturan juga semakin besar dengan kenaikannya secara linier.
34 Banyaknya data training yang ada tidak berpengaruh signifikan dengan nilai akurasi dan rmse, yang mempengaruhi adalah nilai bobot dari masing-masing aturan.
45 Evaluasi akurasi semakin baik jika nilai persentasenya semakin besar. Persentase terbesar (80%) didapatkan jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) dengan jumlah data training sebanyak 1000 data. Persentase terkecil (13%) didapatkan jika atribut targetnya C5 (Jumlah murid SD yang DO) untuk setiap jumlah data training yang ada.
56 Evaluasi rmse semakin baik jika nilainya semakin mendekati nol. Nilai rmse yang terkecil (0.17862) didapat jika atribut targetnya C3 (jumlah keluarga pengguna listrik PLN) dengan jumlah data training sebanyak 500 data. Nilai rmse yang terbesar (0.50804) didapat jika atribut targetnya C5 (Jumlah murid SD yang DO) dengan jumlah data training sebanyak 2500 data.
67 Evaluasi akurasi dan rmse akan mendapatkan hasil yang baik jika atribut yang dijadikan kelas target berasal dari atribut C3 (jumlah keluarga pengguna listrik PLN) atau C4 (jumlah bangunan permanen) dan digunakan sebagai model yang terbaik untuk memprediksi nilai dan kelas suatu data.
Saran
1 Pada tahap penyeleksian data hanya mempertimbangkan atribut yang numerik saja, pada penelitian selanjutnya dapat dipakai teknik data mining yang khusus untuk menyeleksi atribut yang relevan untuk dilakukan proses data mining.
2 Aturan yang terbentuk sebenarnya bisa diringkas lagi sehingga didapatkan aturan yang lebih sedikit, diharapkan proses meringkas aturan dapat diakukan pada penelitian selanjutnya.
DAFTAR PUSTAKA
Au, W. H., Chan, K. C. C. 2001. Classification with Degree of Membership: A Fuzzy Approach. Hasil ICDM’01.
Cheney W, Kincaid D. 1994. Numerical Mathematics and Computing. Brooks/Cole Publishing Company, California.
Fayyad, U. M., G. P. Shapiro, P. Smyth dan R Uthurusamy. 1996. Advances Knowledge Discovery and Data mining. American Association for Artificial Intelligence, California.
Han, J. M. Kamber. 2001. Data mining Concepts and mining. Morgan Kaufmann Publiser, USA.
Hoffer, J. A., M. B. Prescott dan F. R. McFadden. 2002. Modern Database Management Sixth Edition. Pearson Education, New Jersey.
Jang, J. S. R., C. T. Sun, E. Mizutani. 1997. Neuro-Fuzzy and Soft Computing. Prentice-Hall Inc., USA.
Kusumadewi, S. 2002. Analisis dan Desain Sistem Fuzzy Menggunakan Tool Box Matlab. Graha Ilmu, Yogyakarta.
Mustika, A. 2006. Pengembangan Aplikasi Data mining Menggunakan Fuzzy Association Rules [skripsi]
Shapiro, G. P. 2006. Machine Learning, Data mining, and Knowledge Discovery. http://www.kdnuggets.com/dmcourse/data_ mining_course
Lampiran 1 Tabel-tabel yang ada di data.mdb Tabel Keterangan DataUji1000 Seribu data yang akan dites DataUji200 Dua ratus data yang akan dites DataUji400 Empat ratus data yang akan dites DataUji600 Enam ratus data yang akan dites DataUji800 Delapan ratus data yang akan dites Deg1 Sum of degree dari aturan orde ke satu Deg2 Sum of degree dari aturan orde ke dua Deg3 Sum of degree dari aturan orde ke tiga Deg4 Sum of degree dari aturan orde ke empat Domain Daerah asal untuk masing-masing atribut Linguistik Keterangan untuk kode kelas
MF Nilai dari fungsi keanggotaan setiap kelas MFTes1000 Fungsi Keanggotaan untuk 1000 data tes MFTes200 Fungsi keanggotaan untuk 200 data tes MFTes400 Fungsi keanggotaan untuk 400 data tes MFTes600 Fungsi keanggotaan untuk 600 data tes MFTes800 Fungsi keanggotaan untuk 800 data tes MFTrain1000 Fungsi keanggotaan untuk 1000 data training MFTrain200 Fungsi keanggotaan untuk 200 data training MFTrain400 Fungsi keanggotaan untuk 400 data training MFTrain600 Fungsi keanggotaan untuk 600 data training MFTrain800 Fungsi keanggotaan untuk 800 data training Rule1 Aturan orde ke satu
Rule2 Aturan orde ke dua Rule3 Aturan orde ke tiga Rule4 Aturan orde ke empat
Lampiran 2 120 Aturan yang terbentuk dari 500 data training
no Aturan
1 Jika jumlah keluarga prasejahtera sejahtera I banyak maka jumlah pengangguran banyak 2
Jika jumlah keluarga prasejahtera sejahtera I banyak maka jumlah keluarga pengguna listrik PLN banyak
3 Jika jumlah keluarga prasejahtera sejahtera I sedikit maka jumlah pengangguran sedikit 4
Jika jumlah keluarga prasejahtera sejahtera I sedikit maka jumlah keluarga pengguna listrik PLN sedikit
5 Jika jumlah pengangguran banyak maka jumlah keluarga prasejahtera sejahtera I banyak 6 Jika jumlah pengangguran banyak maka jumlah keluarga pengguna listrik PLN banyak 7 Jika jumlah pengangguran sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit 8 Jika jumlah pengangguran sedikit maka jumlah keluarga pengguna listrik PLN sedikit 9
Jika jumlah keluarga pengguna listrik PLN banyak maka jumlah keluarga prasejahtera sejahtera I banyak
10 Jika jumlah keluarga pengguna listrik PLN banyak maka jumlah pengangguran banyak 11
Jika jumlah keluarga pengguna listrik PLN banyak maka jumlah bangunan permanen banyak
12
Jika jumlah keluarga pengguna listrik PLN sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
Lampiran 2 Lanjutan
No Aturan
14 Jika jumlah keluarga pengguna listrik PLN sedikit maka jumlah bangunan permanen sedikit 15 Jika jumlah bangunan permanen sedikit maka jumlah keluarga pengguna listrik PLN sedikit 16 Jika jumlah bangunan permanen sedikit maka jumlah murid SD yang DO sedikit
17
Jika jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak
18 Jika jumlah bangunan permanen banyak maka jumlah murid SD yang DO banyak 19 Jika jumlah murid SD yang DO banyak maka jumlah bangunan permanen banyak 20 Jika jumlah murid SD yang DO sedikit maka jumlah bangunan permanen sedikit 21
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah pengangguran banyak maka jumlah keluarga pengguna listrik PLN banyak
22
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah keluarga pengguna listrik PLN banyak maka jumlah pengangguran banyak
23
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah keluarga pengguna listrik PLN banyak maka jumlah bangunan permanen banyak
24
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah bangunan permanen sedikit
25
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak
26
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah murid SD yang DO sedikit maka jumlah pengangguran banyak
27
Jika jumlah keluarga prasejahtera sejahtera I banyak dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN banyak
28
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah pengangguran sedikit maka jumlah keluarga pengguna listrik PLN sedikit
29
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah pengangguran sedikit maka jumlah murid SD yang DO sedikit
30
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah keluarga pengguna listrik PLN banyak maka jumlah bangunan permanen banyak
31
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah pengangguran sedikit
32
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah bangunan permanen sedikit
33
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah murid SD yang DO sedikit
34
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah bangunan permanen sedikit maka jumlah keluarga pengguna listrik PLN sedikit
35
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah bangunan permanen sedikit maka jumlah murid SD yang DO sedikit
36
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak
37
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah murid SD yang DO sedikit maka jumlah pengangguran sedikit
38
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN sedikit
39
Jika jumlah keluarga prasejahtera sejahtera I sedikit dan jumlah murid SD yang DO sedikit maka jumlah bangunan permanen sedikit
40
Jika jumlah pengangguran banyak dan jumlah keluarga pengguna listrik PLN banyak maka jumlah keluarga prasejahtera sejahtera I banyak
41
Jika jumlah pengangguran banyak dan jumlah keluarga pengguna listrik PLN banyak maka jumlah bangunan permanen banyak
42
Lampiran 2 Lanjutan
No Aturan
43
Jika jumlah pengangguran banyak dan jumlah bangunan permanen banyak maka jumlah keluarga prasejahtera sejahtera I banyak
44
Jika jumlah pengangguran banyak dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak
45
Jika jumlah pengangguran banyak dan jumlah murid SD yang DO sedikit maka jumlah keluarga prasejahtera sejahtera I banyak
46
Jika jumlah pengangguran banyak dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN banyak
47
Jika jumlah pengangguran sedikit dan jumlah keluarga pengguna listrik PLN banyak maka jumlah bangunan permanen banyak
48
Jika jumlah pengangguran sedikit dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
49
Jika jumlah pengangguran sedikit dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah bangunan permanen sedikit
50
Jika jumlah pengangguran sedikit dan jumlah keluarga pengguna listrik PLN sedikit maka jumlah murid SD yang DO sedikit
51
Jika jumlah pengangguran sedikit dan jumlah bangunan permanen sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
52
Jika jumlah pengangguran sedikit dan jumlah bangunan permanen sedikit maka jumlah keluarga pengguna listrik PLN sedikit
53
Jika jumlah pengangguran sedikit dan jumlah bangunan permanen sedikit maka jumlah murid SD yang DO sedikit
54
Jika jumlah pengangguran sedikit dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak
55
Jika jumlah pengangguran sedikit dan jumlah murid SD yang DO banyak maka jumlah bangunan permanen banyak
56
Jika jumlah pengangguran sedikit dan jumlah murid SD yang DO sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
57
Jika jumlah pengangguran sedikit dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN sedikit
58
Jika jumlah keluarga pengguna listrik PLN banyak dan jumlah bangunan permanen sedikit maka jumlah pengangguran banyak
59
Jika jumlah keluarga pengguna listrik PLN banyak dan jumlah murid SD yang DO banyak maka jumlah bangunan permanen banyak
60
Jika jumlah keluarga pengguna listrik PLN banyak dan jumlah murid SD yang DO sedikit maka jumlah pengangguran banyak
61
Jika jumlah keluarga pengguna listrik PLN banyak dan jumlah murid SD yang DO sedikit maka jumlah bangunan permanen banyak
62
Jika jumlah keluarga pengguna listrik PLN sedikit dan jumlah bangunan permanen sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
63
Jika jumlah keluarga pengguna listrik PLN sedikit dan jumlah bangunan permanen sedikit maka jumlah pengangguran sedikit
64
Jika jumlah keluarga pengguna listrik PLN sedikit dan jumlah murid SD yang DO sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
65
Jika jumlah keluarga pengguna listrik PLN sedikit dan jumlah murid SD yang DO sedikit maka jumlah pengangguran sedikit
66
Jika jumlah keluarga pengguna listrik PLN sedikit dan jumlah murid SD yang DO sedikit maka jumlah bangunan permanen sedikit
67
Jika jumlah bangunan permanen sedikit dan jumlah murid SD yang DO sedikit maka jumlah keluarga prasejahtera sejahtera I sedikit
68
Jika jumlah bangunan permanen sedikit dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN sedikit
69
Lampiran 2 Lanjutan
No Aturan
70
Jika jumlah bangunan permanen banyak dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN banyak
71
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah pengangguran banyak ,dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak 72
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah pengangguran banyak ,dan jumlah murid SD yang DO sedikit maka jumlah keluarga pengguna listrik PLN banyak 73
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah pengangguran sedikit ,dan jumlah keluarga pengguna listrik PLN banyak maka jumlah bangunan permanen banyak 74
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah pengangguran sedikit ,dan jumlah bangunan permanen banyak maka jumlah keluarga pengguna listrik PLN banyak 75
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah keluarga pengguna listrik PLN banyak ,dan jumlah bangunan permanen sedikit maka jumlah pengangguran banyak
76
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah keluarga pengguna listrik PLN banyak ,dan jumlah murid SD yang DO banyak maka jumlah bangunan permanen banyak
77
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah keluarga pengguna listrik PLN banyak ,dan jumlah murid SD yang DO sedikit maka jumlah pengangguran banyak
78
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah keluarga pengguna listrik PLN banyak ,dan jumlah murid SD yang DO sedikit maka jumlah bangunan permanen banyak
79
Jika jumlah keluarga prasejahtera sejahtera I banyak , jumlah keluarga pen