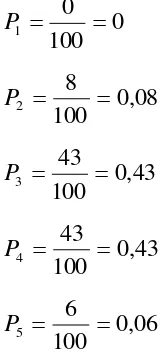PENERAPAN ANALISIS REGRESI LOGISTIK TERHADAP TINGKAT KEPUASAN MASYARAKAT DALAM PELAYANAN
PEMBUATAN KARTU KELUARGA
(STUDI KASUS: DI KECAMATAN MEDAN BELAWAN)
SKRIPSI
PENERAPAN ANALISIS REGRESI LOGISTIK TERHADAP TINGKAT KEPUASAN MASYARAKAT DALAM PELAYANAN
PEMBUATAN KARTU KELUARGA
(STUDI KASUS: DI KECAMATAN MEDAN BELAWAN)
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
CHAIRUNNISA 120823008
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PERSETUJUAN
Judul : Penerapan Analisis Regresi Logistik
terhadap Tingkat Kepuasan Masyarakat dalam Pelayanan Pembuatan Kartu Keluarga (Studi Kasus: di Kecamatan Medan Belawan)
Kategori : Skripsi
Nama : Chairunnisa
Nomor induk mahasiswa : 120823008
Program studi : Sarjana (S1) Matematika
Departemen : Matematika
Fakultas : Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara
Diluluskan di Medan, Oktober 2014
Komisi pembimbing:
Pembimbing 2, Pembimbing 1,
Drs. Marihat Situmorang, M.Kom Prof. Dr. Tulus, M.Si
PERNYATAAN
PENERAPAN ANALISIS REGRESI LOGISTIK TERHADAP TINGKAT KEPUASAN MASYARAKAT DALAM PELAYANAN
PEMBUATAN KARTU KELUARGA
(STUDI KASUS: DI KECAMATAN MEDAN BELAWAN)
SKRIPSI
Saya mengakui bahwa skripsi ini adalah hasil karya sendiri. Kecuali beberapa kutipan dan ringkasan yang masing-masing disebutkan sumbernya.
Medan, Oktober 2014
PENGHARGAAN
Puji dan syukur penulis panjatkan kepada Allah SWT atas segala berkah, rahmat dan karunia yang dilimpahkan-Nya sehingga penulis dapat menyelesaikan penyusunan skripsi ini dengan judul Penerapan Analisis Regresi Logistik terhadap Tingkat Kepuasan Masyarakat dalam Pelayanan Pembuatan Kartu Keluarga (Studi Kasus: di Kecamatan Medan Belawan).
Terimakasih penulis sampaikan kepada Bapak Prof. Dr. Tulus, M.Si selaku pembimbing 1 dan sekaligus sebagai Ketua Departemen Matematika FMIPA USU dan Bapak Drs. Marihat Situmorang, M.Kom selaku pembimbing 2 yang telah meluangkan waktunya selama penyusunan skripsi ini. Terimakasih kepada Bapak Dr. Pasukat Sembiring, M.Si dan Bapak Dr. Faigiziduhu Bu’ulolo, M.Si sebagai dosen penguji atas setiap bimbingan dan saran dalam pengerjaan skripsi ini. Terimakasih kepada Ibu Dr. Mardiningsih, M.Si selaku Sekertaris Departemen Matematika FMIPA USU, Dekan dan Pembantu Dekan FMIPA USU, seluruh Staff dan Dosen Matematika FMIPA USU, pegawai FMIPA USU. Akhirnya tidak terlupakan kepada Ayahanda Edi Budi Purwanto dan Ibunda Suharni (Almh) tercinta dan rekan-rekan kuliah yang selama ini memberikan bantuan dan dorongan yang diperlukan. Semoga Allah SWT membalasnya.
Penulis,
Chairunnisa
PENERAPAN ANALISIS REGRESI LOGISTIK TERHADAP TINGKAT KEPUASAN MASYARAKAT DALAM PELAYANAN
PEMBUATAN KARTU KELUARGA
(STUDI KASUS: DI KECAMATAN MEDAN BELAWAN)
ABSTRAK
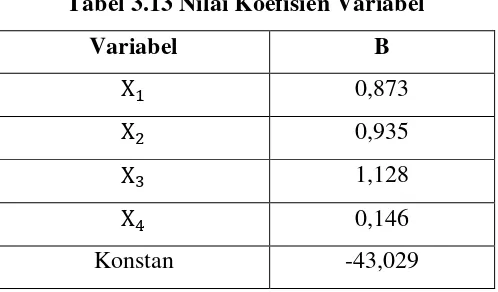
Bentuk pelayanan yang diberikan oleh Pemerintah Daerah kepada masyarakat antara lain adalah pelayanan administrasi kependudukan yaitu pembuatan Kartu Keluarga. Dalam penelitian ini penerapan Model Regresi Logistik digunakan untuk mengidentifikasi faktor-faktor yang mempengaruhi tingkat kepuasan masyarakat dalam pelayanan pembuatan Kartu Keluarga di Kecamatan Medan Belawan dengan variabel dependennya berupa data kategorik. Model Regresi Logistik yang terbentuk adalah sebagai berikut:
) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( ) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( 4 3 2 1 4 3 2 1
1
)
(
X X X XX X X X i
e
e
x
p
Dari persamaan dapat dilihat besar masing-masing koefisien variabel independen persamaan logistik tersebut, maka hasil interpretasinya jika semua nilai variabel independen meningkat maka probabilitasnya juga akan bertambah di mana nilai probabilitasnya tidak lebih dari satu.
THE APPLICATION OF REGRESSION ANALYSIS LOGISTICS ON THE PUBLIC SATISFACTION IN THE SERVICE OF MAKING FAMILY
CARD (CASE STUDY: IN MEDAN BELAWAN SUB-DISTRICT )
ABSTRACT
The services provided by local government to the public among others are administration service that is making the family card.In this research application of model regression logistics used to identifies factors affecting level public satisfaction in the service card family in sub-district medan belawan with variable dependent form of data categorik. Model regression logistics formed is as follows:
) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( ) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( 4 3 2 1 4 3 2 1
1
)
(
X X X XX X X X i
e
e
x
p
The equation on top can see big each coefficient in the equation of logistics is, the independent variable, Then her interpretation of the results if all the value of the independent variable Up and probabilities will also increase the value at which the probability of no more than one.
DAFTAR ISI
Halaman
PERSETUJUAN ii
PERNYATAAN iii
PENGHARGAAN iv
ABSTRAK v
ABSTRACT vi
DAFTAR ISI vii
DAFTAR TABEL ix
BAB 1 PENDAHULUAN 1
1.1 Latar Belakang 1
1.2 Perumusan Masalah 3
1.3 Batasan Masalah 3
1.4 Tujuan Penelitian 4
1.5 Manfaat Penelitian 4
1.6 Tinjauan Pustaka 4
1.7 Metode Penelitian 8
1.7.1 Metode Pengambilan Sampel 8
1.7.2 Teknik Pengumpulan Data 9
1.7.3 Skala untuk Instrumen (Model Skala Sikap) 9
1.7.4 Teknik Pengolahan Data 10
BAB 2 LANDASAN TEORI 11 2.1 Pengertian Pelayanan 11 2.2 Pengertian Kepuasan Masyarakat 12
2.3 Data 13 2.3.1 Data Menurut Sifatnya 14
2.3.2 Data Menurut Cara Memperolehnya 14
2.4 Skala Pengukuran Data 15
2.5 Skala untuk Instrumen (Model Skala Sikap) 16
2.6 Definisi Operasional Variabel Penelitian 18 2.7 Tahapan Penelitian 22 2.8 Uji dalam Pengolahan Data 23 2.8.1 Uji Validitas 23 2.8.2 Uji Reliabilitas 26
2.9 Transformasi Data Ordinal ke Data Interval dengan MSI 28 2.10 Analisis Regresi Logistik 30 2.10.1Model Regresi Logistik 31
2.10.2Uji Signifikansi parameter 32
2.10.3Uji Kecocokan Model 33
BAB 3 PEMBAHASAN 36
3.1 Pengolahan Data 36
3.1.1 Tabulasi Hasil Kuisioner 36
3.1.2 Nilai Total Skor Variabel Hasil Penelitian 36
3.1.3 Uji Instrumen Kuesioner Menggunakan Uji validitas 36
3.1.4 Uji Instrumen Kuesioner Menggunakan Uji Reliabilitas 42
3.2 Transformasi Data Ordinal ke Data Interval dengan MSI 45
3.3 Analisis Data 52
3.3.1 Tipe Data 52
3.4 Menjelaskan Hasil Analisis Data Menggunakan SPSS 16.0 52
3.4.1 Model Regresi Logistik 52
3.4.2 Uji Signifikansi Parameter Model Awal 55
3.4.3 Uji Kecocokan Model 59
3.5 Interpretasi Model Menggunakan Odds Rasio 61
3.6 Mencari Persamaan Regresi Logistik dengan Perhitungan Manual 62
BAB 4 KESIMPULAN DAN SARAN 71 4.1 Kesimpulan 71 4.2 Saran 72
DAFTAR TABEL
Halaman
1. Tabel 2.1 Definisi Operasional Variabel Penelitian 19
2. Tabel 3.1 Uji Validitas Cara Pelayanan 39
3. Tabel 3.2 Uji Validitas Jalur Birokrasi 40
4. Tabel 3.3 Uji Validitas Besar Biaya Pengurusan 41
5. Tabel 3.4 Uji Validitas Informasi Pengurusan 41
6. Tabel 3.5 Uji Reliabilitas Cara Pelayanan 44
7. Tabel 3.6 Uji Reliabilitas Jalur Birokrasi 44
8. Tabel 3.7 Uji Reliabilitas Besar Biaya Pengurusan 44
9. Tabel 3.8 Uji Reliabilitas Informasi Pengurusan 45
10.Tabel 3.9 Skor Jawaban Ordinal 45
11.Tabel 3.10 Proporsi Kumulatif 49
12.Tabel 3.11 Nilai Proporsi Kumulatif dan Dentitas 50
13.Tabel 3.12 Rincian Hasil Perhitungan dengan MSI 52
14.Tabel 3.13 Nilai Koefisien Variabel 53
15.Tabel 3.14 Model Ringkasan 56
16.Tabel 3.15 Klasifikasi 56
17.Tabel 3.16 Variabel dalam Persamaan 58
18.Tabel 3.17 Tabel Kontingensi untuk Uji Hosmer dan Lemeshow 60
19.Tabel 3.18 Tabel Kontingensi 60
20.Tabel 3.19 Kontibusi Variabel X terhadap Variabel Y 61
21.Tabel 3.20 Data Variabel X dan Y 63
22.Tabel 3.21 Kontingensi 64
23.Tabel 3.22 Nilai Peluang 65
24.Tabel 3.23 Nilai Y 65
PENERAPAN ANALISIS REGRESI LOGISTIK TERHADAP TINGKAT KEPUASAN MASYARAKAT DALAM PELAYANAN
PEMBUATAN KARTU KELUARGA
(STUDI KASUS: DI KECAMATAN MEDAN BELAWAN)
ABSTRAK
Bentuk pelayanan yang diberikan oleh Pemerintah Daerah kepada masyarakat antara lain adalah pelayanan administrasi kependudukan yaitu pembuatan Kartu Keluarga. Dalam penelitian ini penerapan Model Regresi Logistik digunakan untuk mengidentifikasi faktor-faktor yang mempengaruhi tingkat kepuasan masyarakat dalam pelayanan pembuatan Kartu Keluarga di Kecamatan Medan Belawan dengan variabel dependennya berupa data kategorik. Model Regresi Logistik yang terbentuk adalah sebagai berikut:
) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( ) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( 4 3 2 1 4 3 2 1
1
)
(
X X X XX X X X i
e
e
x
p
Dari persamaan dapat dilihat besar masing-masing koefisien variabel independen persamaan logistik tersebut, maka hasil interpretasinya jika semua nilai variabel independen meningkat maka probabilitasnya juga akan bertambah di mana nilai probabilitasnya tidak lebih dari satu.
THE APPLICATION OF REGRESSION ANALYSIS LOGISTICS ON THE PUBLIC SATISFACTION IN THE SERVICE OF MAKING FAMILY
CARD (CASE STUDY: IN MEDAN BELAWAN SUB-DISTRICT )
ABSTRACT
The services provided by local government to the public among others are administration service that is making the family card.In this research application of model regression logistics used to identifies factors affecting level public satisfaction in the service card family in sub-district medan belawan with variable dependent form of data categorik. Model regression logistics formed is as follows:
) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( ) 146 , 0 128 , 1 935 , 0 873 , 0 029 , 43 ( 4 3 2 1 4 3 2 1
1
)
(
X X X XX X X X i
e
e
x
p
The equation on top can see big each coefficient in the equation of logistics is, the independent variable, Then her interpretation of the results if all the value of the independent variable Up and probabilities will also increase the value at which the probability of no more than one.
BAB 1
PENDAHULUAN
1.1 Latar Belakang
Menghadapi era globalisasi yang penuh tantangan, aparatur negara dituntut untuk dapat memberikan pelayanan yang berorientasi pada kebutuhan masyarakat dalam pemberian pelayanan publik yang baik. Kata perubahan menjadi kata yang sering disuarakan, baik untuk individu ataupun kelompok masyarakat.
Suatu organisasi yang bergerak dalam bidang jasa, kunci keberhasilan terletak pada pelayanan yang diberikan kepada masyarakat atau pengguna jasa, harus disadari bahwa pelayanan dan kepuasan masyarakat sebagai pengguna jasa merupakan suatu aspek vital dalam rangka mempertahankan eksistensi suatu organisasi. Meskipun demikian untuk mewujudkan kepuasan secara menyeluruh tidaklah mudah, apalagi masyarakat sekarang lebih kritis dan betul-betul telah memahami haknya. Masyarakat akan selalu memperhatikan semua haknya dan dengan semaksimal mungkin akan menggunakannya untuk mendapatkan kepuasan kebutuhan.
dalam pelaksanaan kerja maupun pengetahuan pegawai terhadap pekerjaan yang dilakukan.
Berdasarkan pengamatan terkait dengan tingkat kepuasan masyarakat dalam Pembuatan KK pada Kantor Kecamatan Medan Belawan, ditemukan adanya beberapa gejala-gejala di antaranya dalam pengurusan pembuatan KK. Beberapa pegawai belum dapat memberikan pelayanan yang baik hal ini dapat menghambat pemberian pelayanan yang berkualitas di Kantor Kecamatan Medan Belawan, yaitu masih adanya kesalahan kerja seperti pengetikan nama, tanggal lahir, penomoran dan dalam penyimpanan berkas permohonan masyarakat, serta masih kurangnya informasi kelengkapan berkas untuk kepengurusan KK sehingga warga harus sering berulang-ulang kembali ke kantor camat yang membuang waktu dan tenaga. Hal ini tentu berdampak terhadap kurangnya kepuasan masyarat terhadap kinerja pegawai. Selain itu masih adanya keterlambatan pengurusan KK yang mana masyarakat masih harus menunggu waktu berminggu-minggu untuk mendapatkan KK tersebut dan untuk biaya pengurusan juga masih menjadi kendala bagi masyarakat.
Pelayanan pembuatan KK adalah salah satu bentuk pelayanan publik yang dilakukan oleh pemerintah. Kartu Keluarga merupakan kartu identitas keluarga yang memuat data tentang nama, susunan hubungan dalam keluarga. Kegunaan dari KK adalah menjadi bukti yang sah dan kuat atas status identitas keluarga dan anggota keluarga akan kedudukan keberadaan kependudukan seseorang, menjadi dasar proses penerbitan Kartu Tanda Penduduk dan pelayanan kependudukan lainnya (http://id.wikipedia.org/wiki/Kartu keluarga).
diterapkan pada saat variabel dependennya bersifat kualitatif adalah model regresi logistik. Model regresi logistik merupakan salah satu pendekatan model matematis yang digunakan untuk menganalisis hubungan satu atau beberapa variabel dependen kategorik (Hastono, 2008).
Berdasarkan penjelasan di atas, penulis ingin menggunakan analisis regresi logistik untuk mengidentifikasi faktor-faktor yang berpengaruh terhadap tingkat kepuasan masyarakat dalam proses pembuatan KK. Maka penulis memilih judul “Penerapan Analisis Regresi Logistik terhadap Tingkat Kepuasan Masyarakat dalam Pelayanan Pembuatan Kartu Keluarga (Studi Kasus: di
Kecamatan Medan Belawan)”.
1.2 Perumusan Masalah
Berdasarkan latar belakang tersebut, maka permasalahan dalam penelitian ini adalah pelayanan pembuatan Kartu Keluarga di Kantor Kecamatan Medan Belawan yang dianggap tidak memuaskan berpengaruh terhadap kepuasan masyarakat di daerah setempat. Masalah kepuasan masyarakat adalah masalah yang variabel dependennya bersifat kualitatif yang mempunyai dua nilai variasi. Regresi logistik merupakan model regresi yang digunakan untuk menganalisis hubungan antara satu atau beberapa variabel independen dengan sebuah variabel dependen kategorik yang bersifat biner dan kualitatif. Oleh karena itu, regresi logistik merupakan metode yang sesuai untuk digunakan dalam penelitian kepuasan masyarakat.
1.4 Tujuan Penelitian
Penelitian ini bertujuan untuk mengetahui apakah pelayanan pembuatan Kartu Keluarga yang dianggap tidak memuaskan dapat berpengaruh terhadap kepuasan masyarakat di Kantor Kecamatan Medan Belawan dengan menerapkan metode regresi logistik.
1.5 Manfaat Penelitian
Hasil penelitian ini diharapkan dapat memberikan manfaat sebagai berikut:
1. Sebagai masukan bagi Pimpinan Kantor Kecamatan Medan Belawan dan menjadi bahan pertimbangan dalam hal pelayanan publik.
2. Menambah pengetahuan dan pemahaman tentang metode regresi logistik dan sebagai referensi bagi peneliti selanjutnya yang akan melakukan penelitian sama di masa mendatang.
1.6 Tinjauan Pustaka
Metode regresi logistik adalah suatu metode analisis statistika yang mendeskripsikan hubungan antara variabel dependen yang memiliki dua kategori atau lebih dengan satu atau lebih variabel independen berskala kategorik atau interval (Hosmer dan Lemeshow, 1989). Menurut David (1989) uji regresi logistik adalah metode statistik yang mempelajari tentang pola hubungan secara matematis antara satu variabel dependen dengan satu atau lebih variabel independen.
Untuk model logistik dikotomus, dengan metode maximum likelihood dapat diperoleh penduga dari suatu model regresi dengan variabel dependen biner, di mana antar amatan diasumsikan bebas dan nilai harapan variabel dependennya tidak linier terhadap parameter. Parameter yang didapat dilakukan pengujian untuk mengetahui tingkat signifikan parameter yang telah diperoleh. Kemudian model diuji kesesuaiannya untuk mengetahui variabel-variabel independen yang terdapat dalam model tersebut memiliki hubungan yang nyata dengan variabel dependennya.
Bentuk persamaan regresi logistik yaitu:
k
i i i k
i i i
x x
i
e
e
x
p
1 0
1 0
) (
) (
1
)
(
1.1
Keterangan:
) (xi
p : Peluang terjadinya tingkat kepuasan masyarakat.
e : Bilangan natural (2,7183).
i : 1, 2, . . ., k.
0
: intersep
i
: Koefisien regresi pada model logistik.
i
x : Variabel independen ke-i dari sejumlah k variabel independen.
Model pada persamaan (1.1) merupakan model peluang suatu kejadian
k i i i i ix
x
p
x
p
1 0)
(
1
)
(
ln
1.2
Keterangan:
) (xi
p : Peluang terjadinya tingkat kepuasan masyarakat.
i : 1, 2, . . ., k.
0
: intersep
i
: Koefisien regresi pada model logistik.
i
x : Variabel independen ke-i dari sejumlah k variabel independen.
Sebelum membentuk model regresi logistik terlebih dahulu dilakukan uji signifikansi parameter. Uji yang pertama kali dilakukan adalah pengujian peranan parameter di dalam model secara keseluruhan atau uji signifikansi secara overall. Menurut Hosmer dan Lemeshow (1989) suatu statistik uji rasio likelihood G adalah fungsi dari dan yang berdistribusi (Chi-square) dengan derajat bebas yang didefenisikan sebagai berikut:
log( ) log( )
2( ) 2log
2 0 1 0 1
1
0 l l L L
l l
G
1.3 Keterangan: 0
l : Nilai maksimum fungsi likelihood tanpa variabel independen.
1
l : Nilai maksimum fungsi likelihood dengan variabel independen.
0
L : Nilai maksimum fungsi log-likelihood tanpa variabel independen.
1
L : Nilai maksimum fungsi log-likelihood dengan variabel independen.
2 ) ˆ ( ˆ i i i SE W
dengan i1,2,...,k
1.4
Keterangan: i
ˆ : Nilai dari estimasi parameter regresi untuk variabel ke-i.
) ˆ ( i
SE : Nilai standard error untuk variabel ke-i.
: taraf nyata.
Untuk menguji hipotesis digunakan model Hosmer and Lemeshow’s goodness of fit test. Uji ini digunakan untuk mengetahui apakah model regresi logistik sudah sesuai dengan data observasi yang diperoleh. Untuk menilai kecocokan model regresi logistik dalam penelitian ini di ukur dengan nilai chi-square dengan uji Hosmer dan Lemeshow. Pengujian ini akan melihat nilai goodness of fit test yang di ukur dengan nilai chi-square pada tingkat signifikansi, di mana tingkat signifikansi pada penelitian ini adalah 5%. Statistik Hosmer dan Lemeshow mengikuti distribusi chi-square dengan df g2 di mana gadalah
banyaknya kelompok. Dengan rumus sebagai berikut:
gi i i i
i i i HL
N
N
O
1 2 2)
1
(
)
(
(
1.5 Keterangan: iN :Total jumlah sampel kelompok ke-i.
i
Regresi logistik juga menghasilkan rasio peluang (odds ratio) terkait dengan nilai setiap variabel independen. Peluang (odds) dari suatu kejadian diartikan sebagai probabilitas hasil yang muncul yang dibagi dengan probabilitas suatu kejadian tidak terjadi. Odds ratio didefinisikan sebagai perbandingan dari nilai variabel sukses terhadap variabel bernilai gagal. Dengan kata lain odds ratio menjelaskan seberapa besar pengaruh variabel sukses dibanding variabel gagal terhadap suatu eksperimen atau observasi. Untuk menentukan odds ratio rumusnya sebagai berikut:
) ( 1
) (
i i
x p
x p
1.6
Keterangan:
) (xi
p : Rasio peluang kejadian puas.
) (
1p xi : Rasio peluang kejadian tidak puas.
1.7 Metodologi Penelitian
1.7.1 Metode Pengambilan Sampel
Metode penarikan sampel secara tidak acak (Nonprobability Sampling) yaitu menggunakan sampling kemudahan (Convenience Sampling), dengan responden yang terpilih adalah yang sesuai dengan teori penelitian dan dianggap cocok sebagai sumber data.
1.7.2 Teknik Pengumpulan Data
Teknik pengumpulan data yang digunakan pada penelitian ini adalah menggunakan daftar pertanyaan (questionnaire). Teknik ini dilakukan dengan cara penyebaran daftar pertanyaan kepada seluruh responden yang dalam hal ini adalah masyarakat yang ingin mengurus KK yang berisi pertanyaan-pertanyaan mengenai data pribadi responden, cara pelayanan , jalur birokrasi , biaya pengurusan , informasi pengurusan dan kepuasan masyarakat
1.7.3 Skala untuk Instrumen (Model Skala Sikap)
Pada penelitian ini teknik skala yang dipakai dalam pengumpulan data yaitu menggunakan skala likert. Skala likert ini digunakan untuk mengukur sikap, pendapat dan persepsi seseorang atau sekelompok terhadap kepuasan dalam pelayanan pembuatan Kartu Keluarga di Kecamatan Medan Belawan.
Dengan menggunakan skala likert, maka variabel yang akan diukur dijabarkan menjadi dimensi, yang dijabarkan menjadi sub variabel, kemudian sub variabel dijabarkan menjadi indikator-indikator yang dapat diukur. Artinya indikator ini dapat dijadikan titik tolak untuk membuat item instrument yang berupa pertanyaan yang dapat dijawab oleh responden. Setiap jawaban dihubungkan dengan bentuk pertanyaan yang diungkapkan dengan kata-kata, pada penelitian ini menggunakan pernyataan positif, yaitu sebagai berikut:
Sangat puas = 5
Puas = 4
1.7.4 Teknik Pengolahan Data
Untuk mengolah data penulis menggunakan bantuan SPSS 16.0 (Statistic Product and Service Solution 16.0). Selanjutnya dilakukan langkah-langkah pengolahan data sebagai berikut:
1. Mentabulasi data hasil kuesioner penelitian.
2. Uji Validitas dan Reliabilitas setiap item pertanyaan pada kuesioner dengan menggunakan bantuan SPSS 16.0.
3. Transformasi Data Ordinal ke Data Interval dengan Methodof Successive Interval (MSI)
4. Menganalisis Regresi Logistik, yaitu:
a. Menguji signifikansi parameter model secara keseluruhan dan individual yaitu dengan uji rasio likelihood G dan uji Wald.
b. Menerapkan uji kecocokan model regresi logistik dengan uji Hosmer dan Lemeshow.
BAB 2
LANDASAN TEORI
2.1 Pengertian Pelayanan
Pelayanan adalah kegiatan yang dilakukan oleh seseorang atau sekelompok orang dengan landasan faktor material melalui sistim, prosedur dan metode tertentu dalam rangka usaha memenuhi kepentingan orang lain sesuai haknya (Moenir, 2006).
Pelayanan umum adalah segala bentuk barang atau jasa, baik dalam rangka upaya kebutuhan masyarakat maupun dalam rangka pelaksanaan ketentuan perundang-undangan. Jasa atau pelayanan merupakan suatu kinerja penampilan, tidak terwujud dan cepat hilang, lebih dapat dirasakan dari pada dimiliki, serta pelanggan lebih dapat berperan aktif dalam proses mengkonsumsi jasa tersebut. Pelayanan adalah kegiatan atau kinerja untuk menciptakan keuntungan pelanggan dengan memberikan perubahan yang bisa diterima oleh pelanggan sedangkan untuk memperoleh hal tersebut pelayanan pelanggan adalah pelayanan yang dimunculkan untuk mendukung inti produk perusahaan.
2.2 Pengertian Kepuasan Masyarakat
Banyak pakar memberikan definisi mengenai kepuasan pelanggan. Day (Tse dan Wilton, 1998) menyatakan, bahwa kepuasan dan ketidakpuasan pelanggan adalah respon pelanggan terhadap evaluasi ketidaksesuaian yang dirasakan antara harapan sebelumnya (norma kinerja lainnya) dan kinerja aktual produk yang dirasakan setelah pemakaiannya.
Engel et al. (1990) berpendapat bahwa kepuasan pelanggan adalah evaluasi purna beli di mana banyak pilihan alternatif yang dipilih oleh konsumen dapat sama atau melebihi harapan para pelanggan dalam arti pelanggan sangat puas. Kotler et al.(1994) berpendapat bahwa kepuasan pelanggan adalah tingkat perasaan seseorang setelah membandingkan kinerja atau hasil yang dirasakan selama memakai produk dibandingkan dengan segi harapannya.
(http:/mediapusat.com/2013/10/pengertian-kepuasan-pelanggan-menurut.html).
2.3 Data
Pengertian data menurut Webster New World Dictionary, Data adalah things known or assumed, yang berarti bahwa data itu sesuatu yang diketahui atau dianggap. Diketahui artinya yang sudah terjadi merupakan fakta (bukti). Data dapat memberikan gambaran tentang suatu keadaan atau persoalan (Situmorang et al. 2010).
Data yang baik adalah data yang bisa dipercaya kebenarannya (reliable), tepat waktu dan mencakup ruang lingkup yang luas atau bisa memberikan gambaran tentang suatu masalah secara menyeluruh merupakan data relevan. Ada tiga peringkat data yaitu data mentah, hasil pengumpulan, data hasil pengolahan berupa jumlah, rata-rata, dan data hasil analisis berupa kesimpulan, yang terakhir ini mempunyai peringkat tertinggi sebab langsung dapat dipergunakan untuk menyusun saran atau usul untuk dapat keputusan (Situmorang et al. 2010).
2.3.1 Data Menurut Sifatnya
Menurut sifatnya data terbagi atas dua bagian, yaitu:
1. Data kualitatif yaitu data yang bukan berbentuk angka seperti atribut/kategorik, misalnya: kuesioner pertanyaan tentang suasana kerja, kualitas pelayanan sebuah restoran atau gaya kepemimpinan, dan sebagainya.
Catatan: Data kategorik (dengan skala nominal maupun ordinal) dapat dianalisis dengan menggunakan rumus-rumus matematika/statistika setelah diberi kode (coding) berupa angka.
2. Data kuantitatif yaitu data yang berbentuk angka/numerik (dengan skala ordinal, interval ataupun rasio), misalnya: harga saham, besarnya pendapatan dan sebagainya.
2.3.2 Data Menurut Cara Memperolehnya
maupun di laboratorium. Pelaksanaanya dapat berupa survei atau percobaan/eksperimen.
2. Data sekunder
Data sekunder adalah data primer yang diperoleh dari pihak lain atau data primer yang telah diolah lebih lanjut dan disajikan. Data sekunder pada umumnya digunakan oleh peneliti untuk memberikan gambaran tambahan, gambaran pelengkap atau diproses lebih lanjut. Data sekunder didapat dari hasil penelitian dari beberapa sumber seperti Badan Pusat Statistika, Media Masa, Lembaga Pemerintah atau Swasta dan sebagainya.
2.4 Skala Pengukuran Data
Skala merupakan suatu prosedur pemberian angka atau simbol lain kepada sejumlah ciri dari suatu objek agar dapat menyatakan karakteristik angka pada ciri tersebut. Skala pengukuran dibagi atas 4 bagian yaitu:
1. Skala Nominal
Skala nominal tingkatan pengukuran yang paling sederhana. Dasar penggolongan ini agar kategori yang tidak tumpang tindih (mutually exclutive) dan tuntas (exhaustive). Angka yang ditunjuk untuk suatu kategori tidak mereflesikan bagaimana kedudukan kategori tersebut terhadap kategori lainnya, tetapi hanya sekedar label atau kode sehingga skala yang diterapkan pada data yang hanya dibagi ke dalam kelompok-kelompok tertentu dan pengelompokan tersebut hanya dilakukan untuk tujuan identifikasi.
2. Skala Ordinal
Skala ini memungkinkan peneliti untuk mengurutkan respondennya dari tingkatan paling rendah ke tingkatan paling tinggi menurut atribut tertentu. Skala yang diterapkan pada data yang dapat dibagi dalam berbagai kelompok dan bisa dibuat peringkat di antara kelompok tersebut.
Contoh: sebuah produk yang diproduksi sebuah pabrik dapat dikategorikan ke dalam skala sangat bagus, bagus dan kurang bagus.
3. Skala Interval
Seperti hal ukuran ordinal, ukuran interval adalah mengurutkan orang atau objek berdasarkan suatu atribut. Interval atau jarak yang sama pada skala interval dipandang sebagai mewakili interval atau jarak yang sama pula pada objek yang diukur. Skala yang diterapkan pada data yang dapat dirangking dan dengan peringkat tersebut bisa mengetahui perbedaan di antara peringkat-peringkat dan bisa menghitung besarnya perbedaan, namun harus diperhatikan bahwa dalam skala ini perbandingan rasio yang ada tidak diperhitungkan.
Contoh: nilai mahasiswa A mempunyai IP 4,00; B 3,50; C 3,00; D 2,50; E 2,00, maka interval mahasiswa A dan C (4 – 3 = 1) adalah sama dengan interval antara mahasiswa C dan E (3 – 2 = 1).
4. Skala Rasio
Skala pengukuran yang mempunyai nilai nol mutlak dan mempunyai jarak yang sama.
2.5 Skala untuk Instrumen (Skala Sikap)
Menurut Riduwan et al. (2010) bentuk-bentuk model skala sikap yang sering digunakan dalam penelitian ada 5 macam, yaitu:
1. Skala Likert
Skala Likert digunakan untuk mengatur sikap, pendapatan dan persepsi seseorang atau sekelompok tentang kejadian atau gejala sosial. Dalam penelitian gejala sosial ini telah ditetapkan secara spesifik oleh peneliti, yang selanjutnya disebut sebagai variabel penelitian. Pada skala Likert variabel yang akan diukur dijabarkan menjadi dimensi, dimensi dijabarkan menjadi sub variabel. Kemudian sub variabel dijabarkan lagi menjadi indikator-indikator yang dapat diukur. Akhirnya indikator-indikator yang terukur ini dapat dijadikan titik tolak untuk membuat item instrumen yang berupa pertanyaan atau pernyataan yang perlu dijawab oleh responden. Setiap jawaban dihubungkan dengan bentuk pernyataan atau dukungan sikap yang diungkapkan dengan kata-kata sebagai berikut:
Pernyataan positif:
Sangat Setuju : 5
Setuju : 4
Cukup Setuju : 3
Tidak Setuju : 2
Sangat Tidak Setuju : 1
2. Skala Guttman
Skala Guttman merupakan skala kumulatif. Skala Guttman mengukur suatu dimensi saja dari suatu variabel multidimensi. Skala Guttman adalah skala yang digunakan untuk jawaban yang bersifat jelas (tegas) dan konsisten.
3. Skala Diferensial Semantik
Skala Diferensial Semantik atau skala perbedaan semantik berisikan serangkaian bipolar (dua kutub). Responden diminta untuk menilai suatu objek atau konsep pada suatu skala yang mempunyai 2 ajektif yang bertentangan.
Contoh: panas-dingin, populer-tidak populer, bagus-buruk dan sebagainya.
4. Rating Scale
Berdasarkan ketiga skala pengukuran yaitu: skala Likert, Guttman dan Diferensial Semantik, data yang diperoleh adalah data kualitatif yang dikuantitatifkan, sedangkan rating scale adalah data mentah yang dapat berupa angka kemudian ditafsirkan dalam pengertian kualitatif.
Contoh responden menjawab: ketat–longgar, lemah–kuat, aktif-pasif, sering dilakukan-tidak pernah dilakukan ini semua adalah contoh data kualitatif.
5. Skala Thurstone
Skala Thurstone meminta responden untuk memilih jawaban pertanyaan yang disetujui dari beberapa pertanyaan yang menyajikan pandangan-pandangan berbeda. Pada umumnya setiap item mempunyai asosiasi antara 1 sampai 10 tetapi nilainya tidak diketahui oleh responden.
2.6 Definisi Operasional Variabel Penelitian
Untuk memberikan gambaran yang jelas dan memudahkan pelaksanaan penelitian, maka variabel-variabel yang akan diteliti sebagai berikut:
a. Variabel independen adalah variabel yang mempengaruhi atau menjadi sebab timbulnya perubahan variabel dependen. Dalam penelitian ini yang menjadi variabel independen adalah cara pelayanan , jalur birokrasi
, biaya pengurusan dan informasi pengurusan .
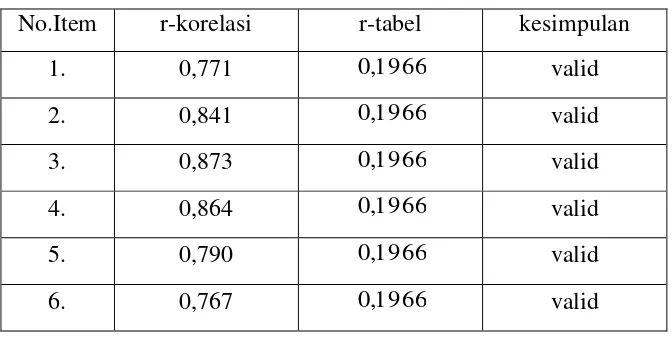
[image:30.595.114.510.436.731.2]b. Variabel dependen adalah variabel yang dipengaruhi atau menjadi akibat karena adanya perubahan variabel independen. Dalam penelitian ini variabel dependen kategorik yang bersifat dikotomus/biner yaitu diberi kode 0 jika tidak puas, diberi kode 1 jika puas dan yang menjadi variabel terikat adalah kepuasan masyarakat .
Tabel 2.1 Definisi Operasional Variabel Penelitian
No. Variabel Definisi
Operasional Indikator Pengukuran
1 Cara Pelayanan (X1)
Pelayanan adalah cara melayani, membantu menyiapkan atau mengurus
keperluan seseorang atau kelompok orang.
1. Kebersihan ruang tunggu
2. Kecepatan petugas
3. Kesopanan dan keramahan petugas
4. Kedisiplinan petugas
5. Kepastian petugas memberikan pelayanan
6. Tanggung jawab petugas
Sambungan Tabel 2.1 No. Variabel Definisi
Operasional Indikator Pengukuran
2. Jalur Birokrasi (X2)
Birokrasi sebagai suatu istilah kolektif bagi suatu badan yang terdiri atas pejabat-pejabat atau sekelompok yang pasti dan jelas pekerjaannya serta pengaruhnya dapat dilihat pada semua macam organisasi.
1. Kemudahan prosedur pelayanan
2. Kesesuaian persyaratan pelayanan kepatuhan terhadap tata tertib
3. Keadilan untuk mendapatkan pelayanan
4. Ketepatan pelaksanaan
5. Pembenahan sistim dan prosedur birokrasi pelayanan
6.Cara pelayanan yang diberikan petugas
pelayanan
Skala Likert
3. Biaya Pengurusan (X3)
Biaya adalah harga perolehan yang dikorbankan atau digunakan dalam rangka memperoleh penghasilan
1. Kewajaran biaya pengurusan
2. Kesesuaian antara biaya
Sambungan Tabel 2.1 No. Variabel Definisi
Operasional Indikator Pengukuran
5. Biaya yang
mengalami perubahan dari waktu ke waktu
6. Biaya pengurusan KK yang masih perlu ditinjau
4. Informasi Pengurusan (X4)
Informasi adalah data yang telah diproses/diolah ke dalam bentuk yang sangat berarti untuk
penerimanya dan
merupakan nilai yang sesungguhnya atau dipahami dalam
tindakan atau keputusan yang sekarang atau nantinya
1. Informasi pengurusan KK
2. Penyampaian
informasi pengurusan KK
3. Sosialisasi tentang informasi pengurusan KK
4. Kesesuaian informasi yang diterima dengan kenyataan dilapangan
5. Penyediaan informasi ”mading” tentang tata cara pengurusan KK
6. Tanpa bantuan petugas masyarakat kesulitan atau tidak dalam menangani pengurusan KK
Skala Likert
5. Kepuasan Masyarakat (Y)
Ukuran akseptasi dari pelayanan publik adalah kepuasan masyarakat
1. Puas
2. Tidak puas
2.7 Tahapan Penelitian
Studi Pendahuluan: - Identifikasi/penentuan lokasi studi - Identifikasi data
- Identifikasi pustaka
- Identifikasi alat bantu (perangkat lunak)
Latar Belakang dan Rumusan Masalah
Tujuan Penelitian
Pengumpulan Data dengan Menggunakan Kuesioner
Tabulasi Data
Uji Validitas dan Reliabilitas
Transformasi Data Ordinal ke Data Interval
Uji Statistika dengan Menggunakan Model Regresi Logistik
2.8 Uji dalam Pengolahan Data 2.8.1 Uji Validitas
Validitas menunjukkan sejauh mana suatu alat pengukur itu mengukur apa yang ingin diukur. Seandainya peneliti ingin mengukur kuesioner di dalam pengumpulan data penelitian, maka kuesioner yang disusunnya harus mengukur apa yang ingin diukurnya.
Untuk menguji validitas alat ukur, terlebih dahulu dicari harga korelasi antara bagian alat ukur secara keseluruhan dengan cara mengkorelasikan setiap butir alat ukur dengan skor total yang merupakan jumlah tiap skor butir. Untuk menghitung validitas menggunakan teknik Korelasi Pearson Product Moment. Rumusnya adalah sebagai berikut:
2 2
2 2
Y Y
n X X
n
Y X XY
n rxy
2.1
Keterangan:
xy
r : Koefisien korelasi pearson antara variabel X dan variabel Y.
n : Banyaknya responden.
X : Skor yang yang diperoleh subjek dari seluruh item.
Y : Skor total yang diperoleh dari seluruh item.
X : Jumlah skor dalam distribusi X.
Y : Jumlah skor dalam distribusi Y.
2X : Jumlah kuadrat dalam skor distribusi X.
2
Y : Jumlah kuadrat dalam skor distribusi Y.1. Bila
r
hit (nilai Correlation Item-total Correlation) bernilai positif danlebih besar dari pada
r
tab(r
hit
r
tab), maka butir atau variabel tersebut adalah valid.2. Bila
r
hit (nilai Correlation Item-total Correlation) bernilai negatif danlebih kecil dari pada
r
tab(r
hit
r
tab), maka butir atau variabel tersebut adalah tidak valid.Untuk melakukan uji validitas secara manual dalam penelitian ini
menggunakan tabel t-student untuk menghitung
r
tabdengan menggunakan nilai. 05 , 0
Dalam penelitian ini diperoleh dari rumus:
2
tabel tabel tabel
t
db
t
r
2.2
Keterangan:
tabel
r : Nilai r tabel.
tabel
t : Nilai t yang terdapat dalam tabel t.
2
n
ttab ; Jumlah responden.
db : Derajat bebas
2
n
2.8.2 Uji Reliabilitas
Reliabilitas adalah indeks yang menunjukkan sejauh mana suatu alat pengukur dapat dipercaya atau diandalkan. Bila suatu alat pengukur dipakai dua kali untuk mengukur gejala yang sama dan hasil pengukuran diperoleh relatif koefisien, maka alat pengukur tersebut reliabel. Suatu variabel dikatakan reliabel jika memberikan nilai cronbach alpha > 0,60 atau nilai cronbach alpha > 0,80 (Ghozali, 2005). Langkah-langkah mencari nilai reliabilitas dengan metode alpha cronbach sebagai berikut:
Langkah 1: Menghitung varians skor tiap-tiap item dengan rumus:
N N
X X
S
i i
i
2
2
2.3
Keterangan:
i
S
: Varians skor tiap-tiap item pertanyaan.
2i
X
: Jumlah kuadrat itemXi.
2
Xi : Jumlah item Xi dikuadratkan.N
: Jumlah responden.Langkah 2: Menjumlahkan varians semua item dengan rumus:
n
i S S S S
S
1 2 3 ...2.4
Keterangan:
S
i : Jumlah varians semua item pertanyaan. nS S
S
Langkah 3: Menghitung varians total dengan rumus:
N N
X X
S
t t
t
2
2
2.5
Keterangan:
t
S
: Varians total.
2t
X
: Jumlah kuadrat X total.
2
Xt : Jumlah X totaldikuadratkan. N : Jumlah responden.Langkah 4: Masukkan nilai Alpha dengan rumus:
t i
S S
k k
r 1
1 2.6
Keterangan:
r
: Nilai reliabilitas (cronbach alpha).k
: Jumlah item pertanyaan yang di uji.
Si : Jumlah varians skor tiap-tiap item pertanyaan.t
2.9 Transformasi Data Ordinal ke Data Interval dengan Method of Successive Interval (MSI)
Metode interval suksesif (Method of Successive Interval/MSI) adalah proses mengubah data ordinal menjadi data interval. Mengapa data ordinal harus diubah ke dalam bentuk interval? Data ordinal sebenarnya adalah data kualitatif atau bukan angka sebenarnya. Data ordinal menggunakan angka sebagai simbol data kualitatif. Contoh:
1. Angka 1 mewakili “sangat tidak setuju” 2. Angka 2 mewakili “tidak setuju” 3. Angka 3 mewakili “cukup setuju” 4. Angka 4 mewakili “setuju”
5. Angka 5 mewakili “sangat setuju”
Prosedur-prosedur statistik seperti regresi, korelasi, uji t dan lain sebagainya mengharuskan data berskala interval. Pada penelitian ini digunakan instrumen berupa kuesioner yang memiliki jawaban skala likert yaitu data ordinal. Data ordinal harus diubah dalam bentuk interval, sebab data ordinal adalah data kualitatif atau bukan angka sebenarnya. Oleh karena itu data ordinal harus ditransformasikan menjadi data interval untuk memenuhi persyaratan prosedur-prosedur tersebut (Sarwono, 2013).
Proses untuk mengubah data berskala ordinal menjadi data berskala interval ada beberapa tahapan yang harus dilakukan, yaitu:
1. Menghitung frekuensi. 2. Menghitung proporsi.
3. Menghitung proporsi kumulatif. 4. Menghitung nilai z.
5. Menghitung nilai dentitas fungsi z. 6. Menghitung scale value.
2.10 Analisis Regresi Logistik
Regresi logistik merupakan model regresi yang digunakan bila variabel dependennya bersifat kualitatif (Hosmer dan Lemeshow, 1989). Model regresi logistik sederhana yaitu model regresi logistik yang digunakan untuk mempelajari hubungan antara satu atau beberapa variabel independen dengan satu variabel dependen yang bersifat dikotomus/biner. Variabel yang bersifat biner adalah variabel yang hanya mempunyai dua kategori saja, yaitu kategori yang menyatakan kejadian puas dan kategori yang menyatakan kejadian tidak puas . Oleh karena itu, model regresi dependen kualitatif sering disebut juga sebagai model probabilitas (Gujarati et al. 2012).
Regresi logistik berbeda dengan regresi linier pada penggunaan jenis variabel dependennya. Pada regresi linier menggunakan variabel dependen numerik sedangkan pada regresi logistik menggunakan variabel dependen kategorik. Tujuan dari analisis regresi logistik adalah untuk mendapatkan model yang paling baik (fit) dan sederhana (parsinomy) yang dapat menggambarkan hubungan antara variabel dependen dan independen (Yasril et al. 2008).
individual ini akan menunjukkan kelayakan suatu variabel prediktor untuk masuk dalam model.
2.10.1 Model Regresi logistik
Bentuk persamaan regresi logistik adalah:
k i i i k i i i x x ie
e
x
p
1 0 1 0 ) ( ) (1
)
(
2.7 Keterangan: ) (xip : Peluang terjadinya tingkat kepuasan masyarakat.
e : Bilangan natural (2,7183).
i : 1, 2, . . ., k.
0
: Intersep
i
: Koefisien regresi pada model logistik.
i
x : Variabel independen ke-i dari sejumlah k variabel independen.
Apabila model pada persamaan 2.7 ditransformasi dengan transformasi logit, akan diperoleh bentuk logit sebagai berikut:
k i i i i ix
x
p
x
p
1 0)
(
1
)
(
ln
2.8
Keterangan:
) (xi
p : Peluang terjadinya tingkat kepuasan masyarakat.
i : 1, 2, . . ., k.
0
: Intersep
i
: Koefisien regresi pada model logistik.
i
2.10.2 Uji Signifikansi Parameter
Sebelum membentuk model regresi logistik terlebih dahulu dilakukan uji signifikansi parameter. Uji yang pertama kali dilakukan adalah pengujian peranan parameter di dalam model secara keseluruhan atau uji signifikansi secara overall yang dapat dilakukan dengan Uji Rasio Kemungkinan dengan hipotesis sebagai berikut:
Hipotesis:
,
0
:
0 i
H
dengan i1,2,...,k. (Tidak ada pengaruh antara variabelindependen terhadap variabel dependen).
:
1
H Paling sedikit ada satu i 0 (Ada pengaruh antara variabel independen
terhadap variabel dependen).
Statistik Uji:
Statistik uji yang digunakan adalah G likelihood ratio:
log( ) log( )
2( ) 2log
2 0 1 0 1
1
0 l l L L
l l
G
2.9
Keterangan:
0
l : Nilai maksimum fungsi likelihood tanpa variabel independen.
1
l : Nilai maksimum fungsi likelihood dengan variabel independen.
0
L : Nilai maksimum fungsi log-likelihood tanpa variabel independen.
1
Uji signifikansi parameter secara individual dilakukan dengan menggunakan Wald test dengan rumusan hipotesis sebagai berikut:
Hipotesis:
,
0
:
0 i
H
dengan i1,2,...,k. (Tidak ada pengaruh antara masing-masingvariabel independen terhadap variabel dependen).
,
0
:
1 i
H
dengan i1,2,...,k. (Ada pengaruh antara masing-masingvariabel independen terhadap variabel dependen).
Statistik Uji: 2
) ˆ ( ˆ
i i i
SE W
dengan i1,2,...,k
2.10
Keterangan: i
ˆ : Nilai dari estimasi parameter regresi untuk variabel ke-i.
) ˆ ( i
SE : Nilai standard error untuk variabel ke-i.
: taraf nyata.
Statistik Wald mengikuti distribusi normal sehingga untuk memperoleh
keputusan pengujian, dibandingkan nilai W dengan nilai
2
Z (H0 ditolak jika
nilai
2
Z
W atau p-value < α).
2.10.3 Uji Kecocokan Model
Chi-Square pada tingkat signifikansi 5%. Langkah pengujiannya adalah sebagai berikut: Hipotesis: ) ... ( ) ... ( 0 2 2 1 1 0 2 2 1 1 0
1
k kk k x x x x x x
e
e
H
) ... ( ) ... (1 0 11 2 2
2 2 1 1 0
1
k kk k x x x x x x
e
e
H
atau 0H : Data empiris cocok atau sesuai dengan model (tidak ada perbedaan
antara model dengan data sehingga model dapat dikatakan fit).
1
H : Data empiris tidak cocok atau tidak sesuai dengan model (ada perbedaan
antara model dengan data sehingga model dapat dikatakan fit).
Statistik Uji:
Statistik uji yang digunakan adalah Uji Hosmer dan Lemeshow:
gi i i i
i i i HL
N
N
O
1 2 2)
1
(
)
(
(
2.11 Keterangan: iN :Total jumlah sampel kelompok ke-i.
i
O :Jumlah sampel pengamatan kelompok ke-i.
i
2.10.4 Odds Ratio
Secara umum rasio peluang merupakan sekumpulan peluang yang dibagi oleh peluang lainnya. Rasio peluang bagi independen diartikan sebagai jumlah relatif di mana peluang hasil meningkat (rasio peluang>1) atau turun (rasio peluang<1) ketika nilai variabel independen meningkat sebesar 1 unit. Untuk menentukan odds ratio rumusnya sebagai berikut:
) ( 1
) (
i i
x p
x p
2.12
Keterangan:
) (xi
p : Rasio peluang kejadian puas.
) (
1p xi : Rasio peluang kejadian tidak puas.
Odds ratio didefinisikan sebagai perbandingan dari nilai variabel sukses terhadap variabel bernilai gagal. Dengan kata lain odds ratio menjelaskan seberapa besar pengaruh variabel sukses dibanding variabel gagal terhadap suatu eksperimen atau observasi. Pada kasus penelitian dengan regresi logistik, nilai ini
dapat dilihat dari nilai Exp(B) pada hasil analisis data atau (ei)dengan
i
adalah
BAB 3
PEMBAHASAN
3.1 Pengolahan Data
3.1.1 Tabulasi Hasil Kuisioner
Untuk melakukan analisis pada penelitian ini data pengamatan hasil survei terhadap masing-masing variabel independen yaitu cara pelayanan , jalur birokrasi , biaya pengurusan , informasi pengurusan dan variabel dependen yaitu kepuasan masyarakat ditabulasi dengan menggunakan skala likert. Pemberian skor dari setiap item pertanyaan dilakukan dengan cara sangat setuju diberi skor 5, setuju diberi skor 4, cukup setuju diberi skor 3, tidak setuju diberi skor 2, dan sangat tidak setuju diberi skor 1. Hasil tabulasi kuisioner dapat dilihat pada Lampiran 1.
3.1.2 Nilai Total Skor Variabel Hasil Penelitian
Setelah data pengamatan hasil survei ditabulasi, langkah selanjutnya adalah mengumpulkan data yang sudah ditabulasi dalam bentuk nilai total skor masing-masing variabel bebas , , , dan variabel terikat . Bentuk total nilai skor
tersebut dapat dilihat pada Lampiran 1.
2 2 2 2 Y Y n X X n Y X XY n rxy 3.1 Keterangan: xyr : Koefisien korelasi pearson antara variabel X dan variabel Y.
n : Banyaknya responden.
X : Skor yang yang diperoleh subjek dari seluruh item.
Y : Skor total yang diperoleh dari seluruh item.
X
: Jumlah skor dalam distribusi X.
Y
: Jumlah skor dalam distribusi Y.
2 X
: Jumlah kuadrat dalam skor distribusi X.
2 Y
: Jumlah kuadrat dalam skor distribusi Y.
Contoh:
Mencari nilai
r
korelasi hitung dengan cara manual untuk pertanyaan pertamapada variabel (X1)cara pelayanan, pengujian dilakukan pada 100 responden. Data
dapat dilihat pada Lampiran 4.
2 2 2 2 1 Y Y n X X n Y X XY n rxy
2
2
) 139 . 2 ( ) 47.193 ( 100 ) 347 ( ) 257 . 1 ( 100 ) 139 . 2 )( 347 ( ) 7.635 ( 100 1 y x r
125.700 120.409
4.719.300 4.575.321
742.233
-763.500
1y
x r
3.979) (5.291)(14
21.267
1y
x r
9 761.792.88
21.267
1y
x r
27.600,596 21.267
1y
x r
0,771 0,7705268
1y
Selanjutnya untuk lebih mempermudah melakukan uji validitas dalam penelitian ini dapat dilakukan dengan bantuan program SPSS 16.0. dapat dilihat pada Lampiran 3.
Rumus untuk mencari
r
tabel adalah sebagai berikut:2 tabel tabel tabel
t
db
t
r
3.2 Keterangan: tabelr : Nilai r tabel
tabel
t : Nilai t yang terdapat dalam tabel t
2
n
ttab ; Jumlah responden
db : Derajat bebas
2
n
db ; Jumlah responden
Nilai
r
tabel untuk semua item pertanyaan yang dilakukan kepada 100 responden dengan tingkat signifikansi untuk uji satu arah 0,025 atau tingkatsignifikansi uji dua arah 0,05.
Untuk lebih mudah dapat dilihat langsung tabel
r
pada Lampiran 5dengan df n2 jumlah responden) dengan tingkat signifikansi untuk uji
satu arah 0,025atau tingkat signifikansi uji dua arah 0,05.
Berikut adalah hasil perhitungan nilai
r
korelasi dari variabel-variabel independen berdasarkan item-item pertanyaan dapat dilihat pada Lampiran 3, perhitungan dilakukan dengan bantuan program SPSS 16.0 yang diberikan kepada 100 responden. Adapun langkah-langkah untuk menghitung uji validitas dengan SPSS 16.0 adalah sebagai berikut:1. Buka program SPSS 16.0.
2. Masukkan data yang telah di tabulasi ke data view. 3. Pilih menu analyze, correlate, pilih bivariate. 4. Pindahkan data (item 1-item 6) ke kotak variables. 5. Pada correlation coefficients pilih pearson.
6. Pada test of significance pilih two-tailed dan centang flag significant correlations.
7. Setelah itu pilih Ok.
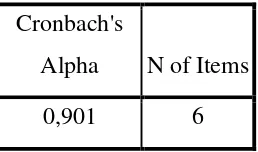
[image:48.595.145.481.521.690.2]a. Variabel Cara Pelayanan
Tabel 3.1 Uji Validitas Cara Pelayanan
No.Item r-korelasi r-tabel kesimpulan
1. 0,771 0,1966 valid
2. 0,841 0,1966 valid
3. 0,873 0,1966 valid
4. 0,864 0,1966 valid
5. 0,790 0,1966 valid
Berdasarkan Tabel 3.1 terlihat bahwa seluruh item pertanyaan dinyatakan valid, karena nilai
r
hitung lebih besar darir
tabel (0,1966). Selanjutnya dapat dilakukan uji reliabilitas.b. Variabel Jalur Birokrasi
Tabel 3.2 Uji Validitas Jalur Birokrasi
No.Item r-korelasi r-tabel Kesimpulan
1. 0,823 0,1966 Valid
2. 0,816 0,1966 Valid
3. 0,821 0,1966 Valid
4. 0,833 0,1966 Valid
5. 0,847 0,1966 Valid
6. 0,821 0,1966 Valid
Berdasarkan Tabel 3.2 terlihat bahwa seluruh item pertanyaan dinyatakan valid, karena nilai
r
hitung lebih besar darir
tabel (0,1966). Selanjutnya dapat dilakukan uji reliabilitas.c. Variabel Biaya Pengurusan
Tabel 3.3 Uji Validitas Besar Biaya Pengurusan
No.Item r-korelasi r-tabel Kesimpulan
1. 0,552 0,1966 Valid
2. 0,722 0,1966 Valid
3. 0,728 0,1966 Valid
4. 0,895 0,1966 Valid
5. 0,749 0,1966 Valid
d. Variabel Informasi Pengurusan
Tabel 3.4 Uji Validitas Informasi Pengurusan
No.Item r-korelasi r-tabel Kesimpulan
1. 0,847 0,1966 Valid
2. 0,848 0,1966 Valid
3. 0,644 0,1966 Valid
3. 0,859 0,1966 Valid
4. 0,861 0,1966 Valid
5. 0,782 0,1966 Valid
Berdasarkan Tabel 3.4 terlihat bahwa seluruh item pertanyaan dinyatakan valid, karena nilai
r
hitung lebih besar darir
tabel (0,1966). Selanjutnya dapat dilakukan uji reliabilitas.3.1.4 Uji Instrumen Kuesioner Menggunakan Uji Reliabilitas
Uji reliabilitas adalah uji yang dilakukan untuk mengetahui apakah sebuah pertanyaan atau pernyataan sudah reliabel atau belum. Menurut Ghozali (2005), suatu variabel dikatakan reliabel jika memberikan nilai alpha cronbach lebih besar dari 0,80. Rumus yang digunakan untuk menghitung nilai alpha cronbabach adalah sebagai berikut:
t i
S S
k k
r 1
1 3.3
Keterangan:
r
: Nilai reliabilitas (cronbach alpha)k
: Jumlah item pertanyaan yang di uji
Si : Jumlah varians skor tiap- tiap item pertanyaant
Contoh:
Mencari nilai Alpha Cronbach dengan cara manual untuk pertanyaan pertama
pada variabel (X1)cara pelayanan, pengujian dilakukan pada 100 responden. Data
dapat dilihat pada Lampiran 4.
5291 , 0 100 91 , 52 100 100 ) 347 ( 257 . 1 2
1
S 5675 , 0 100 75 , 56 100 100 ) 345 ( 247 . 1 2
2
S 6504 , 0 100 04 , 65 100 100 ) 364 ( 390 . 1 2
3
S 6539 , 0 100 39 , 65 100 100 ) 369 ( 427 . 1 2
4
S 6296 , 0 100 96 , 62 100 100 ) 352 ( 302 . 1 2
5
S 5556 , 0 100 56 , 55 100 100 ) 362 ( 366 . 1 2
6
S 5861 , 3 5556 , 0 6296 , 0 6539 , 0 6504 , 0 5675 , 0 5291 ,
0
Si14,3979 100 1439,79 100 100 ) 139 . 2 ( 47.193 2
StBerikut adalah hasil perhitungan alpha cronbach dari variabel-variabel independen berdasarkan item-item pertanyaan dapat dilihat pada Lampiran 3, perhitungan dilakukan dengan bantuan program SPSS 16.0 yang diberikan kepada 100 responden. Adapun langkah-langkah untuk menghitung uji Reliabilitas dengan SPSS 16.0 adalah sebagai berikut :
1. Buka program SPSS 16.0.
2. Isikan data ke dalam SPSS kemudian klik analyze, pilih scale dan reliability analysis.
3. Kemudian muncul reliability analisis, pindahkan data (item 1-item 6) ke dalam item dan klik statistik.
4. Muncul kotak reliability analysis: statistics, pilih descriptives for (item, scale dan scale if item deleted), kemudian klik continue dan ok.
[image:52.595.249.378.415.491.2]a. Variabel Cara Pelayanan
Tabel 3.5 Uji Reliabilitas Cara Pelayanan Cronbach's
Alpha N of Items
0,901 6
Berdasarkan Tabel 3.5 terlihat bahwa seluruh item pertanyaan reliabel karena memberikan nilai alpha cronbach > 0,80. Jadi dapat disimpulkan bahwa pertanyaan pada kuesioner cara pelayanan adalah reliabel.
b. Variabel Jalur Birokrasi
Tabel 3.6 Uji Reliabilitas Jalur Birokrasi Cronbach's
Alpha N of Items
Berdasarkan Tabel 3.6 terlihat bahwa seluruh item pertanyaan reliabel karena memberikan nilai alpha cronbach > 0,80. Jadi dapat disimpulkan bahwa pertanyaan pada kuesioner jalur birokrasi adalah reliabel.
c. Variabel Besar Biaya Pengurusan
Tabel 3.7 Uji Reliabilitas Biaya Pengurusan Cronbach's
Alpha N of Items
0,858 6
Berdasarkan Tabel 3.7 terlihat bahwa seluruh item pertanyaan reliabel karena memberikan nilai alpha cronbach > 0,80. Jadi dapat disimpulkan bahwa pertanyaan pada kuesioner biaya pengurusan adalah reliabel.
d. Variabel Informasi Pengurusan
Tabel 3.8 Uji Reliabilitas Informasi Pengurusan Cronbach's
Alpha N of Items
0,888 6
Berdasarkan Tabel 3.8 terlihat bahwa seluruh item pertanyaan reliabel karena memberikan nilai alpha cronbach > 0,80. Jadi dapat disimpulkan bahwa pertanyaan pada kuesioner Informasi Pengurusan adalah reliabel.
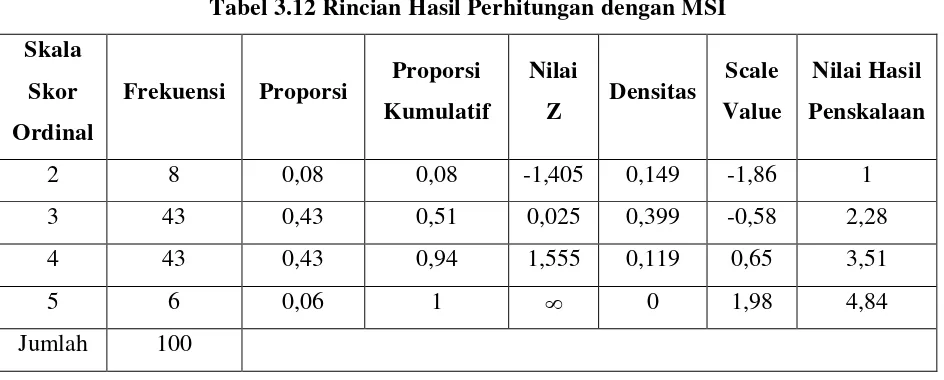
Successive Interval). Perhitungan manual Method of Succesive Interval untuk variabel cara pelayanan pada butir soal/item pertama.
1. Menghitung Frekuensi
[image:54.595.130.494.257.444.2] [image:54.595.132.212.548.725.2]Frekuensi merupakan banyaknya tanggapan responden dalam memilih skala ordinal 1 s/d 5 dengan jumlah responden 100. Skor jawaban dapat dilihat pada Tabel 3.9
Tabel 3.9 Skor Jawaban Ordinal Variabel
Cara pelayanan
Kategori Skor Jawaban
Ordinal Frekuensi
Butir soal/item 1
1 0
2 8
3 43
4 43
5 6
Jumlah 100
2. Menghitung Proporsi
Proporsi diperoleh dari hasil perbandingan antara jumlah frekuensi perpoin dengan total frekuensi, sehingga diperoleh proporsi sebagai berikut:
0 100
0
1
P
08 , 0 100
8
2
P
43 , 0 100
43
3
P
43 , 0 100
43
4
P
06 , 0 100
6
5
3. Menghitung Proprosi Kumulatif (PK)
Proporsi kumulatif dihitung dengan menjumlahkan proporsi secara berurutan untuk setiap nilai, sehingga nilai diperoleh sebagai berikut:
0 0 0
1
k
P
08 , 0 08 , 0 0
2
k
P
51 , 0 43 , 0 08 , 0
3
k
P
94 , 0 43 , 0 51 , 0
4
k
P
1 06 , 0 94 , 0
5
k
P
4. Mencari Nilai Z
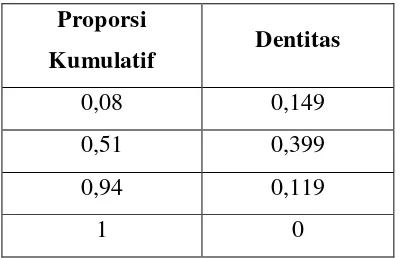
Nilai Z diperoleh dari tabel distribusi normal baku (critical Value of Z), dengan asumsi bahwa proporsi kumulatif berdistribusi normal baku.
Contoh untuk proporsi kumulatif 2 adalah Pk2 0,08. Nilai p yang akan dihitung
[image:55.595.199.427.503.609.2]adalah 0,5 – 0,08 = 0,42.
Tabel Z yang mempunyai daerah dengan proporsi 0,42
Z …… 0.00 0,01
. . .
Cari nilai X sebagai pembagi interpolasi.
999 , 1 42 , 0
8399 , 0
X
Keterangan:
0,8399 = jumlah antara dua nilai yang mendekati 0,3889 dari tabel z. 0,42 = nilai yang diinginkan sebenarnya.
2,42 = nilai yang digunakan sebagai pembagi dalam interpolasi.
Nilai z hasil interpolasi adalah:
405 , 1 999 , 1
41 , 1 40 , 1
Karena Z ada disebelah kiri nol, maka Z bernilai negatif. Dengan demikian untuk
08 , 0 2
k
P nilai Z1 adalah -1,405.
Contoh untuk proporsi kumulatif 3 adalah Pk3 0,51. Nilai p yang akan dihitung
[image:56.595.211.418.544.652.2]adalah 0,51 – 0,5 = 0,01
Tabel Z yang mempunyai daerah dengan proporsi 0,01
Z …… 0,02 0,03
. . .
0,00 ….. 0,0080 0,0120
Lihat Tabel Z pada Lampiran 5 yang mempunyai luas 0,42 terletak diantara nilai Z (0,02 dan 0,03). Oleh karena itu, nilai Z untuk daerah dengan proporsi 0,01 diperoleh dengan cara interpolasi:
Cari nilai X sebagai pembagi interpolasi.
2 01 , 0
02 , 0
X
Keterangan:
0,02 = jumlah antara dua nilai yang mendekati 0,3889 dari tabel z. 0,01 = nilai yang diinginkan sebenarnya.
2,01 = nilai yang digunakan sebagai pembagi dalam interpolasi.
Nilai z hasil interpolasi adalah:
025 , 0 2
03 , 0 02 ,
0
Karena Z ada disebelah kanan nol, maka z bernilai positif. Dengan demikian untuk Pk3 0,51 nilai Z