PERBANDINGAN UKURAN JARAK
LOG-LIKELIHOOD DAN EUCLIDEAN
PADA PEMBENTUKAN GEROMBOL
DENGAN MENGGUNAKAN ANALISIS
TWO STEP CLUSTER
NUR MILA SARI
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Life is more
about the j ourney
than it’s actual destination
ABSTRAK
NUR MILA SARI. Perbandingan Ukuran Jarak Log-Likelihood dan Euclidean pada Pembentukan Gerombol dengan Menggunakan Analisis Two Step Cluster. Dibimbing oleh BAMBANG SUMANTRI dan SATRIO WISENO.
Analisis Two Step Cluster dapat diterapkan pada data dengan skala pengukuran berbeda, yaitu numerik dan kategorik. Berbeda dengan analisis gerombol klasik, jumlah gerombol yang terbentuk pada analisis Two Step Cluster ditentukan secara objektif. Analisis Two Step Cluster terdiri atas dua tahap, tahap pertama dinamakan tahap pembentukan gerombol awal, sedangkan tahap kedua dinamakan tahap pembentukan gerombol akhir. Pada analisis Two Step Cluster terdapat dua konsep jarak yang digunakan yaitu ukuran jarak Log-Likelihood yang dapat digunakan untuk data numerik dan kategorik dan ukuran jarak Euclidean yang hanya dapat digunakan untuk data numerik.
PERBANDINGAN UKURAN JARAK
LOG-LIKELIHOOD DAN EUCLIDEAN
PADA PEMBENTUKAN GEROMBOL
DENGAN MENGGUNAKAN ANALISIS
TWO STEP CLUSTER
Oleh :
Nur Mila Sari
G14102003
Skripsi
Sebagai salah satu syarat untuk memperoleh gelar Sarjana Sains
pada Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
INSTITUT PERTANIAN BOGOR
Judul : PERBANDINGAN UKURAN JARAK LOG-LIKELIHOOD
DAN EUCLIDEAN PADA PEMBENTUKAN GEROMBOL
DENGAN MENGGUNAKAN
ANALISIS
TWO STEP
CLUSTER
Nama : Nur Mila Sari
NRP : G14102003
Menyetujui :
Pembimbing I
Pembimbing II
Ir. Bambang Sumantri Ir. Satrio Wiseno, MPhil, MM
NIP. 130891511
Mengetahui :
Dekan Fakultas Matematika dan Ilmu Pengetahuan Alam
Institut Pertanian Bogor
Prof. Dr. Ir. Yonny Koesmaryono, MS
NIP. 131473999
PRAKATA
Dengan mengucapkan puji syukur kehadirat Allah SWT atas segala limpahan rahmat, nikmat dan kasih sayang-Nya sehingga karya ilmiah ini dapat diselesaikan. Shalawat serta salam senantiasa dilimpahkan kepada tauladan umat Rasulullah Muhammad SAW, kepada keluarga, sahabat dan pengikutnya.
Banyak ilmu dan pelajaran yang sangat dirasakan oleh penulis dalam proses pembuatan karya ilmiah ini, sehingga pada kesempatan kali ini penulis ingin mengucapkan banyak terimakasih, diantaranya kepada :
1. Bapak Ir. Bambang Sumantri beserta keluarga dan Bapak Ir. Satrio Wiseno , M Phil, MM beserta keluarga atas bimbingannya, pelajarannya, waktunya dan sarannya yang sangat berarti kepada penulis.
2. Seluruh dosen Dep artemen Statistika atas ilmu yang sangat bermanfaat.
3. Teristimewa kupersembahkan karya kecil ini untuk kedua orangtuaku, Bapak Ir. H. Taane LaOla, MP dan Ibu Hj. Halis Wiati, SE, terimakasih banyak atas motivasi dan doanya yang tidak pernah putus. I love you both.
4. My lovely sisters, Kak Yanthi beserta suami (Kak Im) dan Dek Anna atas canda tawa dan bantuannya selama karya ilmiah ini dikerjakan.
5. Ade Kurnia Sulistianto, atas pengertian dan dukungannya.
6. All of the Stakers 39, thanx sudah membuat hari-hariku selama 4 tahun di IPB penuh dengan warna. Especially for my close friends (Eka, Niken, Riana & Puput ), Ibenk, Heri, Agung, Anggi, Ditya dan Angga , thanx buat bantuannya, humornya, dan curhatnya. Ternyata kita harus pisah juga akhirnya. I’m gonna miss you guys..
7. The Crew of GRP, Mba Maria, Mba Salma, Mba Lia, Mba Devi, Mba Dea, Mba Yesi, Mas Donny, Mas Koko, Mas Arif, Mas No, Pa’ijo, Mas Nur, terimakasih atas semuanya yah.
8. Staf Statistika IPB, Bu Marqonah, Bu Sulis, Bu Dedeh, Kak Pika, Pak Iyan, Bang Sudin, Gusdur, dan Mang Herman.
9. Teman SMU ku yang seperjuangan di IPB, Yuyun (atas humornya selama di kosan), Irham (tintanya sangat membantu lho!), Danto (makasih yah atas pinjaman printernya).
10. Anak-anak Mega Kost, yang selalu rame, yang selalu memberi dukungan..Thanks.. 11. Jamiro, tengkyu yah dah selalu mengantar kemana ajah..
Bogor, Agustus 2006
RIWAYAT HIDUP
Penulis dilahirkan di kota Kend ari pada tanggal 7 Januari 1985, sebagai anak kedua dari tiga bersaudara, anak dari pasangan Ir. H. Taane LaOla, M P dan Hj.Halis Wiati, SE.
Tahun 1996 penulis lulus dari SD Unhalu Kendari, tahun 1999 penulis lulus dari SMP Negeri 1 Kendari, tahun 2002 penulis lulus dari SMU Negeri 1 Kendari, dan pada tahun yang sama penulis lulus seleksi melalui jalur Undangan Seleksi Masuk IPB. Penulis diterima pada Departemen Statistika, Fakultas M atematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor. Selama berkuliah, penulis mengambil mata kuliah penunjang Komputasi.
DAFTAR ISI
Halaman
DAFTAR GAMBAR. ... vi
DAFTAR TABEL... vi
DAFTAR LAMPIRAN ... vi
PENDAHULUAN Latar Belakang ... 1
Tujuan ... 1
TINJAUAN PUSTAKA Analisis Gerombol. ... 1
SPSS Two Step Cluster ... 1
Penentuan Jumlah Gerombol ... 3
Ukuran Jarak ... 3
Pengujian Selisih Antara Dua Proporsi ... 4
BAHAN DAN METODE Bahan ... 5
Metode ... 5
HASIL DAN PEMBAHASAN Jumlah Gerombol Akhir ... 6
Profil Gerombol Akhir ... 7
AIC Versus BIC ... 7
Ukuran Data ... 7
Outlier Treatment ... 7
Urutan Data ... 8
KESIMPULAN DAN SARAN Kesimpulan . ... 8
Saran ... 8
DAFTAR PUSTAKA ... 8
DAFTAR GAMBAR
1. Gambaran Pola Populasi A1 ... 5
2. Gambaran Pola Populasi A2 ... 5
DAFTAR TABEL
1. Kombinasi Data Simulasi ... 52. Persentase hasil penggerombolan yang benar dengan ukuran jarak Log-Likelihood bila digunakan kriteria penentuan gerombol AIC ... 10
3. Persentase hasil penggerombolan yang benar dengan ukuran jarak Log-Likelihood bila digunakan kriteria penentuan gerombol BIC ... 10
4. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Euclidean bila digunakan kriteria penentuan gerombol AIC... ... 11
5. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Euclidean bila digunakan kriteria penentuan gerombol BIC... ... 11
6. Persentase hasil penggerombolan yang benar dengan ukuran jarak Log-Likelihood ... ... 12
7. Persentase hasil penggerombolan yang benar dengan ukuran jarak Euclidean... 12
8. Profil gerombol terbentuk dengan tipe p opulasi A1 ... 13
9. Profil gerombol terbentuk dengan tipe p opulasi A2 ... 13
10. Persentase hasil p enggerombolan yang benar dengan kriteria penentuan gerombol AIC ... 14
11.Persentase hasil p enggerombolan yang benar dengan kriteria penentuan gerombol BIC ... 14
12. Perbandingan tanpa maupun dengan Options “Outlier Treatment” pada ukuran jarak Log-Likelihood ... ... 16
13. Perbandingan tanpa maupun dengan Options “Outlier Treatment” pada ukuran jarak Euclidea
n
... ... 1614. Perbandingan tanpa maupun dengan Options “Outlier Treatment” sebesar 1, 5, 10, 15, 20 dan 25 pada ukuran jarak Log-Likelihood... 18
15. Perbandingan tanpa maupun dengan Options “Outlier Treatment” sebesar 1, 5, 10, 15, 20 dan 25 pada ukuran jarak Euclidean...18
DAFTAR LAMPIRAN
1. Tabel lengkap persentase hasil penggerombolan yang benar dengan analisis Two Step Cluster pada s eluruh kombinasi data simulasi 100 u langan...102. Tabel ukuran jarak Log-Likelihood dan Euclidean mengenai persentase hasil penggerombolan yang benar t erbentuk s etelah m enggunakan analisis Two Step Cluster...12
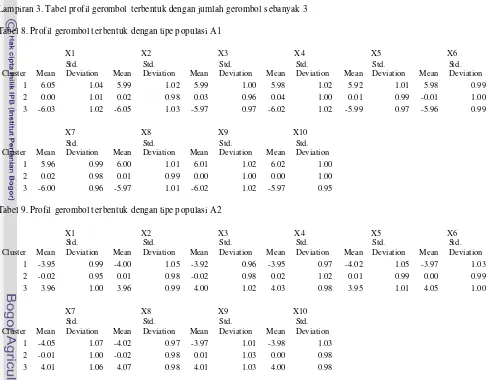
3. Tabel profil gerombol terbentuk dengan jumlah gerombol sebanyak 3. ... 13
4. Tabel persentase hasil penggerombolan yang benar terbentuk setelah menggunakan analisis Two Step Cluster dengan kriteria AIC dan BIC... 14
5. Tabel hasil uji hipotesis dua proporsi dengan perbandingan antara penentuan jumlah gerombol AIC dan BIC... ... 15
6. Tabel p erbandingan tanpa maupun dengan Options “Outlier Treatment” bai k pada ukuran jarak Log-Likelihood maupun Euclidean...16
7. Tabel hasil uji hipotesis dua proporsi dengan perbandingan antara tanpa maupun dengan Options “Outlier Treatment” pada ukuran jarak Log-Likelihood dan Euclidean . ...17
8. Tabel perbandingan tanpa maupun dengan Options “Outlier Treatment” s ebesar 1, 5, 10, 15, 20 dan 25 baik pada ukuran jarak Log-Likelihood maupun Euclidean...18
1
PENDAHULUAN
Latar Belakang
Terdapat dua metode dalam analisis gerombol klasik yaitu metode penggerombolan berhirarki dan tak berhirarki. Penentuan jumlah gerombol yang terbentuk untuk dua metode ini dilakukan secara subjektif. Pada metode pen ggerombolan berhirarki, penentuan besarnya pemotongan (cut off) pada dendogram masih ditentukan oleh peneliti (Hair et. al, 1998). Sedangkan pada metode penggerombolan non hirarki, penentuan banyaknya jumlah gerombol akhir ditentukan oleh pengetahuan dan pengalaman peneliti (Hair et. al, 1998).
Pada saat ini, umumnya data yang ada tidak hanya menggunakan tipe kontinu (numerik), tetapi juga menggunakan tipe data kategorik, contohnya data-data pada marketing riset. Oleh karena itu, SPSS mengembangkan algoritma yang memungkinkan untuk mengolah data dengan tipe numerik dan kategorik, serta dapat menentukan jumlah gerombol secara objektif. Algoritma tersebut diimplementasikan pada SPSS dengan nama Two Step Cluster.
Two Step Cluster menggunakan dua ukuran jarak yaitu Log-Likelihood dan Euclidean. Kedua ukuran jarak tersebut dapat digunakan secara bersamaan pada analisis
Two Step Cluster apabila data yang digunakan bertipe numerik.
Tujuan
Tujuan penelitian ini adalah membandingkan pengaruh ukuran jarak Log-Likelihood dan Euclidean terhadap pembentukan gerombol pada analisis Two Step Custer dengan menggunakan data simulasi.
TINJAUAN PUSTAKA
Analisis Gerombol
Analisis gerombol merupakan salah satu dari grup teknik peubah ganda (multivariate) yang tujuan utamanya adalah mengelompokkan objek berdasarkan atas kriteria yang dimiliki. Analisis gerombol mengklasifikasi objek, sehingga antara satu objek dengan objek lainnya yang terletak dalam satu gerombol akan memiliki kesamaan tinggi yang sesuai dengan kriteria pemilihan
yang ditentukan. Hasil dari penggerombolan harus memperlihatkan keragaman yang homogen di dalam gerombol dan keragaman yang heterogen antargerombol yang terbentuk.
Ada dua metode dalam analisis gerombol satu tahap, yaitu :
1. Metode berhirarki
Metode penggerombolan berhirarki ditujukan untuk ukuran contoh kecil. Penggerombolan berhirarki menghasilkan seluruh kemungkinan terbentuknya gerombol. Metode penggerombolan berhirarki digunakan apabila banyak gerombol yang akan dibentuk belum diketahui sebelumnya. Pada dasarnya, terdapat dua prosedur pada penggerombolan berhirarki, yaitu prosedur penggabungan (agglomerative) dan prosedur pembagian (divisive). Dalam metode berhirarki terdapat beberapa ukuran jarak antargerombol, antara lain metode pautan tunggal (single linkage), pautan lengkap (complete linkage), pautan rataan (average linkage), metode Ward, dan metode centroid.
2. Metode tak berhirarki
Pada metode penggerombolan tak berhirarki, peneliti harus terlebih dahulu menentukan jumlah gerombol yang diinginkan. Salah satu contoh dari metode ini adalah metode K-means. Analisis gerombol
K-means menggunakan ukuran jarak Euclidean. Penentuan pusat gerombol merupakan langkah awal pada metode ini. Langkah selanjutnya adalah menentukan gerombol dari tiap objek, yaitu berdasarkan atas kedekatan ukuran jarak Euclidean terhadap mean dari masing-masing gerombol.
SPSS Two Step Cluster
SPSS Two Step Cluster merupakan analisis penggerombolan yang dirancang untuk menangani data dengan jumlah yang sangat besar. Analisis ini dapat menangani masalah pengukuran dengan tipe data yang berbeda yaitu untuk tipe data numerik dan kategorik (SPSS Two Step Cluster Analysis, 2004). Terdapat dua tahap pada metode ini yaitu :
• Tahap pertama : Pembentukan gerombol awal
2
diimplementasikan dengan membangun modifikasi Cluster Feature (CF) Tree. CF Tree terdiri dari tingkatan cabang (depth) dan masing-masing cabang berisikan dari angka yang dientrikan. Apabila dimisalkan sebuah pohon, maka tingkatan cabang tersebut terdiri dari batang pohon, dahan dan daun. Dalam
CF tree tingkatan daun dikenal dengan nama daun entri (entrian pada cabang daun) dimana pada tingkatan ini merepresentasikan hasil akhir anak gerombol. Algoritma pertama pada
CF Tree adalah memasukkan data satu per satu. Data yang masuk dihitung jaraknya pada daun entri yang telah ada dengan menggunakan ukuran jarak yang telah ditentukan. Apabila jarak tersebut kurang dari kriteria ukuran penerimaan (threshold distance) maka data tersebut masuk ke dalam daun entri yang telah ada, tetapi jika sebaliknya maka data membentuk daun entri baru.
Jika tidak ada lagi tempat dalam cabang daun untuk menciptakan daun entri baru (node
telah melewati batas maksimum), maka cabang daun akan terbagi menjadi dua. Apabila dimisalkan pada sebuah pohon, dari satu dahan kemudian membelah menjadi dua dahan. Entrian pada cabang daun yang asli akan dibagi ke dalam dua grup (dahan) dengan menggunakan pasangan daun terjauh sebagai penempatan, dan membagi-bagikan kembali sisa entrian berdasarkan atas kriteria kedekatan.
Jika tidak tersedia tempat dalam cabang dahan untuk menciptakan daun entri baru, maka cabang dahan yang telah melewati maksimum node akan terbagi menjadi dua. Apabila dimisalkan pada sebuah pohon, dari satu pohon kemudian membelah menjadi dua pohon . Entrian pada cabang dahan yang asli akan dibagi ke dalam dua grup (pohon ) dengan menggunakan pasangan dahan terjauh sebagai penempatan, dan membagi-bagikan
kembali sisa entrian berdasarkan atas kriteria kedekatan yang telah ditetapkan.
Proses ini berlanjut sampai semua data selesai dimasukkan. Jika CF Tree berkembang melewati batas ukuran maksimum yang telah ditetapkan, maka CF Tree yang telah ada akan dibangun ulang dengan cara meningkatkan kriteria ukuran penerimaan.
CF Tree yang melewati batas biasanya dikarenakan pada saat proses algoritma CF Tree ini dijalankan, terbentuk daun entri yang beranggotakan outlier . Outlier pada analisis
Two Step Cluster adalah data yang tidak dapat dimasukkan pada gerombol manapun. Pada saat CF Tree akan dibangun ulang, maka akan diperiksa daun entri yang berpotensi sebagai
outlier. Daun entri yang anggotanya berpotensi sebagai outlier merupakan daun entri yang jumlah anggotanya kurang dari fraksi ukuran gerombol yang memiliki jumlah paling besar yang telah ditetapkan (SPSS
Technical Support, 2001). Pada saat pembangunan ulang, daun entri yang berpotensi sebagai outlier disimpan. Setelah
CF Tree dibangun ulang, maka satu per satu data dalam daun entri yang berpotensi sebagai pencilan dimasukkan ke dalam CF Tree yang baru tanpa mengubah ukuran CF Tree
tersebut. Jika masih ada data yang tidak masuk ke dalam daun entri manapun, maka data tersebut dikatakan sebagai outlier. Dan data-data yang dideteksi sebagai outlier
dimasukkan ke dalam satu gerombol. Besarnya nilai fraksi dimasukkan ke dalam
Options “Outlier Treatment” pada SPSS. Pada gambar algoritma CF Tree di atas dan pada penelitian ini, maksimum depth dan maksimum node yang digunakan mengikuti
default dari SPSS yaitu sebesar 3 dan 8. Sehingga maksimum daun entri (anak gerombol) yang terbentuk adalah sebanyak 512 anak gerombol.
• Tahap kedua : Pembentukan gerombol akhir
3
dalam satu gerombol. Pada tahapan ini, hasil dar i tahap pertama yaitu daun entri (anak gerombol) dari Cluster Feature (CF) Tree
digerombolkan menggunakan metode gerombol berhirarki dengan prosedur penggabungan (agglomerative). Tiap-tiap daun entri akhir yang terbentuk pada tahap pertama akan digabungkan satu per satu sesuai dengan ukuran jarak yang telah ditetapkan. Prosedur ini berakhir sampai seluruh daun entri menjadi satu gerombol. Apabila pada tahap pertama terdeteksi daun entri yang beranggotakan outlier, maka daun entri tersebut tidak diikutsertakan pada tahap kedua.
Penentuan Jumlah Gerombol
Dalam penentuan jumlah gerombol optimal, ada dua langkah yang harus dilakukan. Langkah pertama yaitu menghitung
BIC (Bayesian Information Criterion) atau
AIC (Akaike’s Information Criterion) saat semua daun entri (hasil akhir pada tahap satu) menjadi anggota dalam 1, 2, 3,... gerombol.
Rumus BIC dan AIC untuk jumlah gerombol sebanyak J adalah sebagai berikut :
( )
∑( )
= + − = J j N j m j J BIC 1 log 2 ζ( )
∑
= + − = J j j j m J AIC 1 2 ζ dimana : ∑ = − + = B K k k L A K J j m 1 ) 1 ( 2 AK = jumlah total peubah numerik
B
K = jumlah total peubah kategorik
k
L = jumlah kategori untuk peubah kategorik ke-k
N= jumlah total data
Kemudian hasil perhitungan tersebut digunakan untuk menduga jumlah gerombol. Langkah yang kedua yaitu mencari peningkatan jarak terbesar antara dua gerombol terdekat pada masing-masing tahapan penggerombolan. Solusi gerombol yang terbaik memiliki BIC terkecil, tetapi ada beberapa kasus dalam penggerombolan dimana BIC akan terus menurun nilainya bila jumlah gerombol semakin meningkat. Maka dalam situasi tersebut, ratio BIC Changes
(rasio perubahan BIC) dan ratio of Distance Measure Changes (rasio perubahan jarak) mengidentifikasi solusi gerombol terbaik.
M enurut Chiu et. al (2001: 266) BICk
atau AICk menghasilkan penduga awal yang
baik bagi jumlah gerombol maksimum. Jumlah gerombol maksimum adalah banyaknya gerombol yang memiliki rasio
BICk/BIC1 yang pertama kali lebih kecil dari
c1 (SPSS menetapkan c1 = 0. 04 yang didasarkan atas studi simulasi) (SPSS
Technical Support, 2001).
Jumlah gerombol yang terbentuk dapat diketahui dengan menggunakan perbandingan antar jarak untuk k gerombol, dengan rumus perbandingannya sebagai berikut :
( )
k d k d kR = −1
k l k l k
d = −1−
dimana :
2 log v v v BIC n r
l = − atau
2 2 v v v
AIC r
l = −
1 , −
=k k v
1
−
k
d = jarak jika k gerombol digabungkan dengan k -1 gerombol
Jumlah gerombol diperoleh berdasarkan ketentuan ditemukannya perbedaan yang nyata pada rasio perubahan gerombol. Rasio perubahan gerombol dihitung sebagai berikut :
( )
( )
2 1 k R k R untuk dua nilai terbesar dari R(k)(k=1,2,…,kmax; kmax didapatkan dari langkah pertama).
Jika rasio perubahan lebih besar daripada nilai batas c2 (SPSS menetapkan nilai c2 = 1.15 berdasarkan studi simulasi) jumlah gerombol ditetapkan sama dengan k1, selainnya jumlah gerombol sama dengan maksimum {k1,k2}.
Ukuran Jarak
Ukuran kemiripan dan ketakmiripan yang digunakan dalam analisis gerombol adalah jarak antarobjek dan jarak antargerombol.
4
1. Jarak Euclidean
Jarak Euclidean paling sering digunakan diberbagai metode dalam analisis gerombol, tetapi ukuran jarak ini hanya dapat digunakan apabila semua peubah yang digunakan bertipe kontinu (numerik) .
Jarak Euclidean antara gerombol ke-i dan gerombol ke-j dari p peubah didefinisikan :
( )
21 1 2 , ∑ = − = p i i X j X j i d dimana :
( )
i jd , = jarak antara objek i ke objek j
i
X = nilai tengah pada gerombol ke-i
j
X = nilai tengah pada gerombol ke-j
p= banyaknya peubah yang diamati
Untuk mendeteksi adanya outlier, dilakukan dengan cara mengukur jarak Euclidean antargerombol. Dikatakan outlier
jika jarak Euclidean terbesar antara gerombol tersebut lebih besar dari titik kritis C, dengan rumus C sebagai berikut :
2 1 1 2 ˆ 2 ∑ = = A K
i KA
k l
C σ
dimana :
k
R = range dari peubah kontinu ke-k
A
K = jumlah total peubah kontinu 2
ˆkl
σ = ragam dugaan untuk peubah kontinu ke-l dalam gerombol k
2. Jarak Log-Likelihood
Jarak Log-Likelihood dapat digunakan untuk peubah bertipe kontinu (numerik) maupun kategorik. Jarak antara gerombol j
dan s didefinisikan sebagai berikut:
> < − +
= j s js s
j
d( , ) ξ ξ ξ , dimana : ∑ = + ∑= + − = A K k B K k vk E vk k v N v 1 1 ˆ 2 ˆ 2 ˆ log 2
1 σ σ
ξ
∑ = − = Lk
l Nv vkl N v N vkl N jk E 1 log ˆ
N = jumlah total data
jkl
N = jumlah data di gerombol j untuk peubah kategorik ke-k dengan kategori ke-l
2 ˆjk
σ = ragam dugaan untuk peubah kontinu
ke-k dalam gerombol j
A
K = jumlah total peubah numerik
B
K = jumlah total peubah kategorik
k
L = jumlah kategori untuk peubah kategorik ke-k
( )
j sd , = jarak antara gerombol j dan s
s
j, = indeks kombinasi gerombol j dan s
Setelah dilakukan penghitungan jarak, juga dapat dideteksi adanya outlier. Gerombol yang memiliki jarak terbesar dikatakan outlier
jika jarak antara gerombol tersebut lebih besar dari titik kritis C, dengan rumus sebagai berikut :
( )
V C=logdimana : m L m k R k
V =∏ ∏
k
R = range dari peubah kontinu ke-k
m
L = jumlah kategori untuk peubah kategori ke-m
Pengujian Selisih Antara Dua Proporsi
Data contoh yang diambil dari suatu populasi dapat digunakan untuk mengkaji karakteristik dari populasi asal. Salah satu karakteristik antara dua populasi yang menarik dikaji adalah proporsi. Salah satu bentuk hipotesa untuk proporsi dua populasi adalah :
Ho : p1 = p2
H1 : p1 ? p2
Langkah-langkah penting untuk melakukan uji hipotesis dengan hipotesa di atas adalah :
1. Menentukan taraf nyata a. 2. Menghitung statistik uji.
5
dimana :
2 1
2 ˆ 2 1 ˆ 1 ˆ
n n
p n p n p
+ + =
p qˆ=1−ˆ
3. Keputusan : Tolak Ho bila z jatuh ke
dalam wilayah kritis ; dan terima Ho bila z
jatuh ke dalam w ilayah penerimaan. Dimana wilayah kritis untuk hipotesa yang akan diuji :
hitung z > za/2
BAHAN DAN METODE
Bahan
Bahan yang digunakan dalam penelitian ini adalah data simulasi berupa data bangkitan sebaran Normal (µ,1), yang dibedakan atas dua macam model populasi yaitu :
A1 : satu populasi yang beranggotakan tiga gerombol yang berpisah secara tegas (jarak antar gerombol relatif besar).
Gambar 1. Gambaran pola populasi A1
Gerombol 1 : µ(x1i) = -6.00; i=1,2,3,..., n1 (note:n1=N/4)
Gerombol 2 : µ(x2i) = 0.00; i=1,2,3,..., n2 (note:n2=N/2)
Gerombol 3 : µ(x3i) = +6.00; i=1,2,3,..., n3 (note:n3=N/4)
A2 : satu populasi yang beranggotakan tiga gerombol yang saling tumpang tindih (overlap) satu sama lain (pemisahan antar gerombol tidak tegas).
Gambar 2. Gambaran pola populasi A2
Gerombol 1 : µ(x1i) = -4.00; i=1,2,3,..., n1 (note:n1=N/4)
Gerombol 2 : µ(x2i) = 0.00; i=1,2,3,..., n2 (note:n2=N/2)
Gerombol 3 : µ(x3i) = +4.00; i=1,2,3,..., n3 (note:n3=N/4)
Model komposisi peubah yang digunakan yaitu seluruh peubah bertipe numerik (B1). Pada penelitian ini akan dievaluasi kemungkinan ukuran data (N) kecil (500), sedang (2000), dan besar (5000). Dari masing-masing kombinasi, akan diulang sebanyak 100 kali. Kombinasi data simulasi pada penelitian ini adalah:
Tabel 1. Kombinasi Data Simulasi
Model Populasi
Model Kompisisi
Peubah
Ukuran Data (N) 500 A1 B1 2000
5000 500 A2 B1 2000
5000
Perangkat lunak yang digunakan adalah
SPSS 11.5 for Windows, MINITAB 14 dan Ms Excel.
Metode
Penelitian ini dilakukan dengan langkah-langkah :
1. Studi literatur.
6
bantuan software MINITAB 14. Entri data akhir menggunakan bantuan Ms Excel.
3. Pembandingan ukuran jarak Log-Likelihood dan Euclidean pada SPSS
Two Step Cluster. Setiap gugus data simulasi akan digerombolkan dengan menggunakan SPSS Two Step Cluster. Masing-masing gugus data simulasi dikerjakan dengan tahap : a.Pada menu utama dilaku kan
pemilihan :
Distance Measure : Log-Likelihood kemudian dicobakan juga Euclidean.
Determine automatically : Maximum 30.
Clustering Criterion : BIC
kemudian dicobakan juga AIC. b.Pada menu Options, akan
dilakukan pilihan pada kotak ”Outlier Treatment” dengan memberi check pada kotak ”Use noise handling” dan mengisi pada kotak ”Percentage” dengan angka yang berbeda-beda, yaitu 1, 5, 10, 15, 20 dan 25. Ukuran penentuan gerombol optimal yang digunakan yaitu BIC dan AIC. K emudian tidak dilakukan pilihan pada kotak ”Outlier Treatment” pada menu
Options. Hasil yang didapat pada tahap ini dan tahap sebelumnya yaitu tanpa ”Outlier Treatment” dan menggunakan ”Outlier Treatment” akan dilihat hasilnya yaitu masing-masing hasil output
diperiksa, dilihat input angka ”Outlier Treatment” yang menghasilkan gerombol yang sesuai dengan gerombol sebenarnya. Kemudian dilakukan pengujian dua proporsi sebagai alat penegas untuk informasi yang diambil secara eksplorasi.
c.Setelah mendapat gerombol akhir yang sesuai dengan gerombol sebenarnya, dilakukan penggerombolan lagi pada data dengan menggu nakan angka ”Outlier Treatment” yang menghasilkan gerombol optimal, tetapi dilakukan pengurutan data terlebih dahulu. Pengurutan data pertama dilakukan pada peubah X1, kedua pada peubah X5 dan terakhir pada peubah X9.
HASIL DAN PEMBAHASAN
Hal yang menjad i dasar kebaikan pembentukan gerombol akhir dengan menggunakan analisis Two Step Cluster pada penelitian ini adalah banyaknya jumlah gerombol akhir yang terbentuk, dimana jumlah gerombol yang dianggap memenuhi kriteria adalah jumlah gerombol akhir yang ter bentuk sama dengan jumlah gerombol sebenarnya yaitu sebanyak tiga. Profil gerombol juga merupakan kriteria yang diperiksa, dimana profil gerombol yang baik adalah profil gerombol terbentuk sama dengan gerombol sebenarnya.
Jumlah Gerombol Akhir
Dari Lampiran 2, dapat dilihat bahwa jumlah gerombol yang dihasilkan dengan menggunakan ukuran jarak Log-Likelihood secara garis besar telah sesuai dengan banyaknya jumlah gerombol sebenarnya. Persentase hasil penggerombolan yang benar, terbentuk menggunakan analisis Two Step Cluster dengan rata-rata hampir 100%. Berbeda pada ukuran jarak Euclidean, dapat dilihat pada Lampiran 2 T abel 7, dengan penggunaan Options “Outlier Treatment”, persentase hasil penggerombolan yang benar yang terbentuk sangat kecil. Terdapat beberapa persentase hasil penggerombolan yang benar sebesar 0%, yang berarti dari 100 ulangan, tidak ada satupun jumlah gerombol yang terbentuk sama dengan jumlah gerombol sebenarnya. Apabila dibandingkan dengan ukuran jarak Log-Likelihood, dapat dilihat pada salah satu persentase hasil penggerombolan yang benar yaitu pada Tabel 6 dengan ukuran data kecil (500) bahwa dengan nilai Options “Outlier Treatment”
7
Profil Gerombol Akhir
Dari hasil penggerombolan yang terbentuk dengan ataupun tanp a menggunakan
Options “Outlier Treatment” yang jumlah gerombol akhir terbentuk nya sebesar tiga, profil yang dihasilkan telah sesuai dengan gerombol sebenarnya. Dimana nilai tengah dan ragam telah sesuai dengan nilai tengah (µ) dan ragam (s2) data bangkitan simulasi (Lampiran 3).
AIC Versus BIC
Dari hasil yang didapatkan, dengan membandingkan hasil penggerombolan yang dilakukan dengan analisis Two Step Cluster, dapat dilihat bahwa hasil penentuan jumlah gerombol yang diberikan dengan menggunakan BIC dan AIC tidak terlalu berbeda (Lampiran 4). Untuk membandingkan antara dua kriteria penentuan gerombol ini diperlukan pengujian antara dua proporsi. Dari keseluruhan pengujian, hanya diperoleh tiga statistik uji yang jatuh di dalam wilayah kritis dengan taraf nyata sebesar 0.05, yang berarti bahwa proporsi benar penggerombolan dengan AIC tidak sama dengan proporsi benar penggerombolan dengan menggunakan BIC
(Lampiran 5). Dari proporsi yang diuji yang menghasilkan penolakan Ho, terlihat bahwa proporsi benar penggerombolan dengan menggunakan AIC menunjukkan angka yang lebih besar dibandingkan dengan menggunakan kriteria BIC (Lampiran 5). Sehingga dapat diinformasikan bahwa AIC
lebih baik digunakan pada saat menentukan jumlah gerombol yang terbentuk dibandingkan s aat ukuran penentuan gerombol BIC digunakan .
Ukuran Data
Untuk ukuran data kecil, dapat dilihat bahwa penggerombolan dengan menggunakan analisis Two Step Cluster memberikan hasil yang lebih baik dibandingkan dengan ukuran data sedang dan besar. Hal ini dapat dilihat dari besarnya nilai persentase hasil penggerombolan yang benar yang ditampilkan pada Lampiran 2. Untuk masing-masing ukuran jarak, baik Log-Likelihood maupun Euclidean, menunjukkan analisis Two Step Cluster baik pada ukuran data kecil. Dibandingkan dengan ukuran data sedang dan besar, banyak gerombol yang terbentuk tidak sesuai dengan gerombol sebenarnya. Hal ini dapat terlihat pada Lampiran 2, khususnya
pada saat ukuran jarak Euclidean digunakan, yang salah satunya dapat dilihat pada Tabel 7. Pada “Outlier Treatment” sebesar 10, persentase hasil penggerombolan yang benar hanya sebesar 9.75% , sedangkan pada ukuran data kecil dengan “Outlier Treatment” yang sama, terlihat bahwa persentase hasil penggerombolan yang benar jauh lebih besar yaitu 70.25%.
Outlier Treatment
Dari hasil output analisis Two Step Cluster yang diperoleh , dapat ditentukan nilai optimal ”Outlier Treatment” yang digunakan. Optimal disini yaitu nilai yang dimasukkan akan mengeluarkan hasil penggerombolan yang sesuai dengan gerombol sebenarnya. Dilihat secara keseluruhan, hasil penggerombolan yang diberikan tanpa
Options “Outlier Treatment” memberikan hasil yang jauh lebih baik daripada menggunakan Options “Outlier Treatment”, dapat dilihat pada Lampiran 6. Dengan pengujian antara dua proporsi, diperoleh bahwa proporsi hasil penggerombolan yang benar tanpa Options “Outlier Treatment”
tidak sama dengan proporsi hasil penggerombolan yang benar dengan Options
“Outlier Treatment” pada taraf nyata 0.05. Pada Lampiran 7 dapat dilihat bahwa proporsi hasil penggerombolan yang benar tanpa
Options “Outlier Treatment” menunjukkan angka yang jauh lebih baik daripada proporsi hasil penggerombolan yang benar dengan
Options “Outlier Treatment”. Tetapi apabila
Options “Outlier Treatment” akan digunakan, maka baik itu untuk tipe populasi A1 maupun A2, ukuran jarak Log-Likelihood maupun Euclidean, dan ukuran data kecil, sedang dan besar, nilai ”Outlier Treatment” sebesar 5 merupakan nilai optimal yang dapat dimasukkan (Tabel 13). Sedangkan untuk ukuran jarak Euclidean, apabila Options
“Outlier Treatment” akan digunakan, maka sebaiknya angka yang dimasukkan sebesar 1 (T abel 14). Semakin besar nilai “Outlier Treatment” dimasukkan, terjadi penurunan persentase hasil penggerombolan yang benar. Hal ini terlihat pada “Outlier Treatment”
8
Urutan Data
Dari output yang dikeluarkan pada analisis Two Step Cluster, terlihat bahwa untuk ukuran jarak Log-Likelihood tidak ada perbedaan jumlah gerombol akhir apabila terjadi pengurutan data pada salah satu peubah yang terpilih. Lain halnya pada ukuran jarak Euclidean , dapat terlihat bahwa data masuk yang terurut pada saat penggunaan analisis
Two Step Cluster, menyebabkan hasil akhir yang berbeda. Sehingga dapat diinformasikan bahwa ukuran jarak Euclidean sensitif terhadap urutan data dibandingkan dengan ukuran jarak Log-Likelihood (Lampiran 9). Hal ini juga memberikan informasi secara umum bahwa hasil akhir dari analisis Two Step Cluster berpengaruh pada urutan data.
KESIMPULAN DAN SARAN
Kesimpulan
Two Step Cluster merupakan analisis gerombol dua tahap yang baik digunakan untuk ukuran data yang besar, dengan tipe data yang berbeda yaitu kontinu (numerik) dan kategorik. Pada penelitian ini diperoleh beberapa hal-hal menarik yang dapat dijadikan sebagai informasi kepada pengguna analisis Two Step Cluster, khususnya pada peubah yang keseluruhan bertipe numerik. Dari hasil simulasi didapatkan bahwa ukuran jarak Log-Likelihood lebih baik digunakan daripada ukuran jarak Euclidean. Ini dilihat dari hasil output akhir penggerombolan yang terbentuk, dimana secara keseluruhan ukuran jarak Log-Likelihood menghasilkan penggerombolan akhir yang sangat baik, yaitu sesuai dengan gerombol sebenarnya. Dari profil gerombol yang jumlah gerombol akhirnya telah sesuai dengan jumlah gerombol sebenarnya juga telah memperlihatkan kesesuaian dengan profil gerombol sebenarnya. Kriteria AIC lebih baik digunakan pada saat penentuan jumlah gerombol dibandingkan dengan kriteria BIC, dimana informasi ini juga didukung oleh keputusan dari pengujian proporsi antara dua proporsi yang dilakukan. Tanpa penggunaan Options
”Outlier Treatment” menghasilkan penggerombolan yang lebih baik dibandingkan dengan menggunakan Options
”Outlier Treatment”. Untuk penggunaan
Options ”Outlier Treatment”, maka nilai sebesar 5 merupakan nilai yang baik digunakan untuk mendapatkan hasil penggerombolan optimal untuk ukuran jarak
Log-Likelihood sedangkan untuk ukuran jarak Euclidean nilai yang baik digunakan sebesar 1.
Untuk urutan data, dari output diperoleh bahwa ukuran jarak Euclidean sensitif terhadap urutan data dibandingk an dengan ukuran jarak Log-Likelihood. Sehingga para pengguna analisis Two Step Cluster
disarankan agar data yang akan dimasukkan dalam keadaan teracak (sesuai dengan saran SPSS).
Saran
Karena pada tahap kedua pada Two Step Cluster memakai algoritma Cluster Hierarchichal, ada baiknya penelitian selanjutnya untuk melihat secara lebih jelas apa saja perbedaan dari kedua metode analisis gerombol tersebut.
DAFTAR PUSTAKA
Chiu, T., Fang,D., Chen,J., Wang,Y., and Jeris,C. (2001). A Robust and Scalable Clustering Algorithm for mixed Type Attributes in Large Database Environment.
In Proceedings of the 7th ACM SIGKDD International Confererence on Knowledge Discovery and Data Mining 2001.
Hair, J.F.Jr, R. E, Anderson, R. L. Tatham, & W. C. Black. 1998. Applied Multivariate Statistical Analysis. Ed ke-5. New Jersey: Prentice-Hall.
SPSS Inc. (2001). The SPSS TwoStep Cluster component . A scalable component to segment your customers more effectively. White paper – technical report, Chicago. [terhubung berkala]. http://www.spss.ch/upload/1122644952_Th e%20SPSS%20TwoStep%20Cluster%20Co mponent.pdf. [8 Juni 2006].
SPSS Inc. (2004). Cluster Analys is. Technical report, Chicago. [terhubung berkala].
http://www2.chass.ncsu.edu/garson/PA765/ cluster.htm. [8 Juni 2006].
SPSS Inc. (2004). TwoStep Cluster Analysis. Technical report, Chicago. [terhubung berkala]. http://www1.uni-hamburg.de/RRZ/Software/SPSS/Algorith.1 20/twostep_cluster.pdf. [8 Juni 2006]. Theodoridis, Koutroumbas. 1999. Di dalam:
10
Lampiran 1. Tabel lengkap persentase hasil p enggerombolan yang benar dengan analisis Two Step Cluster pada seluruh kombinasi data s imulasi 100 ulangan
Tabel 2. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Log-Likelihood bila digunakan kriteria penentuan gerombol AIC
Populasi Ukuran Data
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
A 1
500 100% 100% 100% 100% 100% 100% 100% 2000 100% 100% 100% 100% 100% 100% 100% 5000 100% 100% 100% 98% 97% 98% 100%
A 2
500 100% 100% 100% 100% 100% 100% 100% 2000 100% 100% 100% 100% 100% 100% 100% 5000 100% 100% 100% 100% 100% 100% 90%
Tabel 3. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Log-Likelihood bila digunakan kriteria penentuan gerombol BIC
Populasi Ukuran Data
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
A 1
500 100% 100% 100% 100% 100% 100% 100% 2000 100% 100% 100% 100% 100% 100% 100% 5000 100% 100% 100% 97% 96% 98% 90%
A 2
11
Tabel 4. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Euclidean bila digunakan kriteria penentuan gerombol AIC
Populasi Ukuran Data
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
A 1
500 100% 100% 100% 77% 49% 51% 30% 2000 100% 100% 37% 8% 0% 0% 0% 5000 100% 100% 15% 0% 0% 0% 0%
A 2
500 100% 95% 80% 76% 53% 47% 34% 2000 100% 89% 32% 10% 0% 0% 0% 5000 100% 70% 0% 0% 0% 0% 0%
Tabel 5. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Euclidean bila digunakan kriteria penentuan gerombol AIC
Populasi Ukuran Data
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
A 1
500 100% 100% 100% 68% 44% 41% 25% 2000 100% 100% 36% 8% 0% 0% 0% 5000 100% 100% 15% 0% 0% 0% 0%
A 2
12
Lampiran 2. Tabel u kuran jarak Log Likelihood dan Euclidean mengenai persentase hasil penggerombolan yang benar terbentuk setelah menggunakan a nalisis Two Step Cluster
Tabel 6. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Log-Likelihood
Ukuran Data
Without Outlier
Treatment Outlier Treatment
1 5 10 15 20 25
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang
benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
500 100% 100% 100% 100% 100% 100% 100% 2000 100% 100% 100% 100% 100% 100% 100% 5000 100% 100% 100% 98.5% 98.25% 99% 92.5%
Tabel 7. Persentase hasil p enggerombolan yang benar dengan ukuran jarak Euclidean
Ukuran Data
Without Outlier
Treatment Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
13
Lampiran 3. Tabel profil gerombol terbentuk dengan jumlah gerombol sebanyak 3
Tabel 8. Profil gerombol t erbentuk dengan tipe populasi A1
Cluster
X1 X2 X 3 X 4 X5 X6 Mean
Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std. Deviation 1 6.05 1.04 5.99 1.02 5.99 1.00 5.98 1.02 5.92 1.01 5.98 0.99 2 0.00 1.01 0.02 0.98 0.03 0.96 0.04 1.00 0.01 0.99 -0.01 1.00 3 -6.03 1.02 -6.05 1.03 -5.97 0.97 -6.02 1.02 -5.99 0.97 -5.96 0.99
Cluster
X7 X8 X 9 X10
Mean Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std. Deviation 1 5.96 0.99 6.00 1.01 6.01 1.02 6.02 1.00 2 0.02 0.98 0.01 0.99 0.00 1.00 0.00 1.00 3 -6.00 0.96 -5.97 1.01 -6.02 1.02 -5.97 0.95
Tabel 9. Profil gerombol t erbentuk dengan tipe populasi A2
Cluster
X1 X2 X 3 X 4 X5 X6 Mean
Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std.
Deviation Mean Std. Deviation 1 -3.95 0.99 -4.00 1.05 -3.92 0.96 -3.95 0.97 -4.02 1.05 -3.97 1.03 2 -0.02 0.95 0.01 0.98 -0.02 0.98 0.02 1.02 0.01 0.99 0.00 0.99 3 3.96 1.00 3.96 0.99 4.00 1.02 4.03 0.98 3.95 1.01 4.05 1.00
Cluster
X7 X8 X 9 X10 Mean
Std.
Deviation Mean Std.
Deviation Mean Std.
14
Lampiran 4. Tabel p ersentase hasil penggerombolan yang benar terbentuk setelah menggunakan a nalisis Two Step Cluster dengan kriteria AIC dan BIC
Tabel 10. Persentase hasil penggerombolan yang benar dengan kriteria penentuan gerombol AIC
Ukuran Data
Without Outlier
Treatment Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan yang
benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar 500 100% 99% 95% 88.25% 75% 74.5% 66% 2000 100% 97.5% 67.25% 54.5% 50% 50% 50% 5000 100% 95.2% 53.75% 49.5% 49.25% 49.5% 47.5%
Tabel 11. Persentase hasil penggerombolan yang benar dengan kriteria penentuan gerombol BIC
Ukuran Data
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan yang
benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
15
Lampiran 5. Tabel hasil uji hipotesis dua proporsi dengan p erbandingan antara penentuan jumlah gerombol AIC dan BIC
Ukuran Data Outlier Treatment Proporsi hasil penggerombolan yang benar dengan
AIC
Proporsi hasil penggerombolan yang benar dengan
BIC | zhit |
500
1 0.9900 0.9875 0.3748 5 0.9500 0.9525 0.1836 10 0.8825 0.8200 2.7765*
15 0.7500 0.7250 0.8983 20 0.7450 0.7000 1.5889 25 0.6600 0.6300 0.9914
2000
1 0.9750 0.9675 1.4193 5 0.6725 0.6750 0.1686 10 0.5450 0.5525 0.4765
15 0.5000 0.5000 ^
20 0.5000 0.5000 ^
25 0.5000 0.5000 ^
5000
1 0.9520 0.9250 5.6193*
5 0.5375 0.5375 ^
10 0.4950 0.4900 0.5001 15 0.4925 0.4900 0.2500
20 0.4950 0.4950 ^
25 0.4750 0.4500 2.5071* * Signifikan pada a sebesar 0.05
16
Lampiran 6. Tabel perbandingan tanpa maupun dengan Options “Outlier Treatment” baik p ada ukuran jarak Log-Likelihood maupun Euclidean Tabel 12. Perbandingan tanpa maupun dengan Options “Outlier Treatment” pada ukuran jarak Log-Likelihood
Ukuran Data
Without Outlier
Treatment With Outlier Treatment
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang
benar 500 100% 100% 2000 100% 100% 5000 100% 98%
Tabel 13. Perbandingan tanpa maupun dengan Options “Outlier Treatment” p ada ukuran jarak Euclidean
Ukuran Data
Without Outlier Treatment
With Outlier Treatment
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
17
Lampiran 7. Tabel hasil uji hipotesis dua proporsi dengan p erbandingan antara t anpa dan dengan “Outlier Treatment” p ada ukuran jarak Log-Likelihood dan Euclidean
Ukuran Jarak Ukuran Data Proporsi hasil penggerombolan yang benar Tanpa "Outlier Treatment"
Proporsi hasil penggerombolan yang benar Dengan
"Outlier Treatment" | zhit |
Log-Likelihood
500 1.0000 1.0000 ^
2000 1.0000 1.0000 ^
5000 1.0000 0.9800 10.0500*
Eucliden
500 1.0000 0.6329 15.2187*
2000 1.0000 0.2313 49.9708* 5000 1.0000 0.1542 85.6040* * Signifikan pada a sebesar 0.05
18
Lampiran 8. Tabel perbandingan tanpa maupun dengan Options “Outlier Treatment” s ebesar 1, 5, 10, 15, 20 dan 25 baik p ada ukuran jarak Log-Likelihood maupun Euclidean.
Tabel 14. Perbandingan tanpa maupun dengan Options “Outlier Treatment” s ebesar 1, 5, 10, 15, 20 dan 25 pada ukuran jarak Log-Likelihood
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan yang
benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar 100% 100% 100% 99.5% 99.42% 99.67% 97.5%
Tabel 15. Perbandingan tanpa maupun dengan Options “Outlier Treatment” s ebesar 1, 5, 10, 15, 20 dan 25 pada ukuran jarak Euclidean
Without Outlier Treatment
Outlier Treatment
1 5 10 15 20 25 Persentase hasil
penggerombolan yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan yang benar
Persentase hasil penggerombolan
yang benar
Persentase hasil penggerombolan
19
Lampiran 9. Data output analisis Two Step Cluster mengenai sifat urutan d ata
Ukuran data (N)
Sort case by
A 1
Jumlah gerombol sebenarnya Log-Likelihood Euclidean
AIC
Jumlah gerombol BIC
Jumlah gerombol AIC
Jumlah gerombol BIC
Jumlah gerombol
500
X 1 142.049 3 142.049 3 37.920 3 37.920 3 3 X 5 164.468 3 164.468 3 24.688 3 24.688 3 3 X 9 151.973 3 151.973 3 39.741 3 39.741 3 3
2000 X 1 250.347 3 250.347 3 1.672
2,outlier ->3 1.672
2,outlier
->3 3 X 5 237.514 3 237.514 3 88.504 3 88.504 3 3 X 9 272.082 3 272.082 3 73.526 3 73.526 3 3
5000
X 1 253.493 3 253.493 3 61.021 3 61.021 3 3 X 5 251.976 3 251.976 3 68.095 3 68.095 3 3 X 9 345.046 3 345.046 3 72.788 3 72.788 3 3
Ukuran data (N)
Sort case by
A 2
Jumlah gerombol sebenarnya Log-Likelihood Euclidean
AIC
Jumlah gerombol BIC
Jumlah gerombol AIC
Jumlah gerombol BIC
Jumlah gerombol
500
X 1 64.456 3 64.456 3 16.623 3 16.623 3 3 X 5 58.271 3 58.271 3 9.339 3 9.339 3 3 X 9 66.125 3 66.125 3 11.435 3 11.435 3 3
2000
X 1 115.291 3 115.291 3 25.020 3 25.020 3 3
X 5 123.856 3 123.856 3 1.177
2,outlier ->3 1.177
2,outlier
->3 3
X 9 115.001 3 115.001 3 1.201
2,outlier ->3 1.201
2,outlier
->3 3
5000
X 1 127.794 3 127.794 3 47.673 3 47.673 3 3
X 5 126.686 3 126.686 3 31.094
3,outlier ->4 31.094
3,outlier