Beberapa tes lab harus dilakukan untuk mengetahui kondisi seseorang didiagnosis menderita penyakit diabetes, US National Institute of Diabetes telah melakukan uji untuk penyakit diabetes sesuai dengan kriteria Organisasi Kesehatan Dunia yang dilakukan pada sejumlah perempuan yang berusia 21 tahun, dari warisan Pima India dan tinggal di dekat Phoenix, Arizona sebanyak 768 objek. . Dengan metode uji coba 3-fold cross validation dari data tersebut dikembangkan untuk analisa data mining penyebab penyakit diabetes yaitu klasifikasi terhadap data diabete yang menggunakan 256 data testing dan sisanya yaitu 512 digunakan sebagai data training. Penerapkan teknik data mining pada data diabetes ini diharapkan dapat ditemukan aturan klasifikasi yang dapat digunakan untuk memprediksi potensi seseorang terserang diabetes, tanpa harus melawan diagnosis penyakit secara langsung dengan diagnosis dini. Rancangan klasifikasi decision tree, menganalisa dan melakukan ujicoba metode klasifikasi fuzzy decision tree pada data diabetes dengan input 9 variabel ujicoba, 768 objek sehingga diharapkan dapat Menemukan aturan klasifikasi pada data diabetes agar dapat digunakan untuk memprediksi gejala seseorang pasien terserang penyakit diabetes, sehingga terjadinya penyakit ini pada seseorang dapat diprediksi sedini mungkin dan dapat dilakukan tindakan antisipasi. Pengolahan klasifikasi fuzzy decision tree ini menggunakan teknik pruning agar rule yang dihasilkan lebih signifikan atau rule yang dihasilkan dapat meningkatkan akurasi yang lebih tinggi lagi. Dengan pruning dihasilkan tingkat akurasi yang lebih tinggi dari pada tidak memakai pruning, dari 69,14% ke 78,91%. Pembagian data himpunan fuzzy dengan menggunakan referensi data standart dengan pruning memiliki tingkat akurasi lebih tinggi 78,91% dibandingkan dengan referensi data kuartil 76,95%. Semakin tinggi θr dan θn, semakin tinggi tingkat akurasi. Dari hasil uji coba 3-fold cross validation didapatkan θn 10 % dan θt 98 % mempunyai tingkat akurasi yang paling tinggi yaitu sebesar 78,91 %. Untuk proses kedepannya pembentukan fungsi fuzzy yang lain selain menggunkan model trapezoidal, seperti model segitiga, kurva S, dan kurva PI agar dapat diketahui pengaruh fungsi keanggotaan fuzzy terhadap akurasi..
Kata kunci: Klasifikasi, fuzzy, data diabetes, entropi, gain, rule, algoritma C4.5.
I. PENDAHULUAN
Penyakit diabetes adalah golongan penyakit kronis yang ditandai dengan peningkatan kadar gula dalam darah sebagai akibat adanya gangguan sistem metabolisme dalam tubuh, dimana organ pankreas tidak mampu memproduksi hormon insulin sesuai kebutuhan tubuh [1]. Badan Kesehatan Dunia (WHO) memperkirakan, setiap 10 detik ada satu orang pasien diabetes yang meninggal karena penyakit itu dan memperkirakan bahwa 177 juta penduduk dunia mengidap penyakit diabetes mellitus atau biasa
disingkat diabetes. Lebih memprihatinkan untuk seorang ibu yang sedang hamil dan menderita penyakit diabetes, hal itu sangat membahayakan untuk janin yang dikandung. Untuk itu diagnosis dini sangat diperlukan untuk penderita diabetes agar bisa mengurangi angka kematian pada penderita diabetes.
Sejumlah rumah sakit sudah menggunakan basis data untuk mengumpulkan dan menyimpan data, namun data yang terkumpul belum dapat dimanfaatkan secara maksimal.
Beberapa tes lab harus dilakukan untuk mengetahui kondisi orang itu didiagnosis menderita penyakit diabetes,
US National Institute of Diabetes telah melakukan uji untuk
penyakit diabetes sesuai dengan kriteria Organisasi Kesehatan Dunia yang dilakukan pada sejumlah perempuan yang berusia 21 tahun, dari warisan Pima India dan tinggal di dekat Phoenix, Arizona sebanyak 768 objek. Dari data
tersebut dikembangkan untuk analisa data mining penyebab
penyakit diabetes.
Data mining merupakan proses ekstraksi informasi
atau pola penting dalam basis data berukuran besar [2].
Penelitian ini menggunakan suatu teknik dalam data mining
yaitu klasifikasi terhadap data diabetes. Dengan
menggunakan 9 variabel yaitu number of times
pregnant(time), plasma glucose concentration a 2 hours in an oral glucose tolerance test (OGTT), diastolic blood pressure(D), triceps skin fold thickness (T), 2-Hour serum insulin (IPOST), body mass index (BMI), diabetes pedigree function(F), Age (T), dan Class variable(Diagnosa).
Metode yang digunakan dalam penelitian ini adalah fuzzy decision tree. Penggunaan teknik fuzzy memungkinkan
melakukan prediksi suatu objek yang dimiliki lebih dari satu kelas. Dengan menerapkan teknik data mining pada diabetes
ini diharapkan dapat ditemukan aturan klasifikasi yang dapat digunakan untuk memprediksi potensi seseorang terserang diabetes, tanpa harus melawan diagnosis penyakit secara langsung dengan diagnosis dini.
Database diabetes Pima India, disumbangkan oleh Vincent Sigillito. Data Diabetes India Pima adalah kumpulan laporan diagnostik medis dari 768 contoh-contoh dari populasi yang tinggal di dekat Phoenix, Arizona, Amerika Serikat. Penelitian sebelumnnya dengan data ini menggunakan pembelajaran adaptif yang menghasilkan dan menjalankan perangkat analog digital perceptron seperti
yang disebut ADAP. Mereka membagi 2 dataset yaitu dataset untuk training dan dataset untuk testing. Mereka
menggunakan 512 training dan 256 data testing dengan
menggunakan algoritma LogDisc dan memperoleh akurasi
tertinggi 76,95% [4].
Fuzzy Decision Tree dengan Algoritma C4.5
pada Data Diabetes Indian Pima
(Januari 2011)
Dataset Pima India ini di dapatkan dari
http://archive.ics.uci.edu . yang bersumber dari pemilik yang asli yaitu National Institute of Diabetes and Digestive and Kidney Diseases yang diambil juga dari Vincent Sigillito (vgs '@' aplcen.apl.jhu.edu), Research Center, RMI Group Leader, Applied Physics Laboratory, The Johns Hopkins University, Johns Hopkins Road, Laurel, MD 20707 [3].
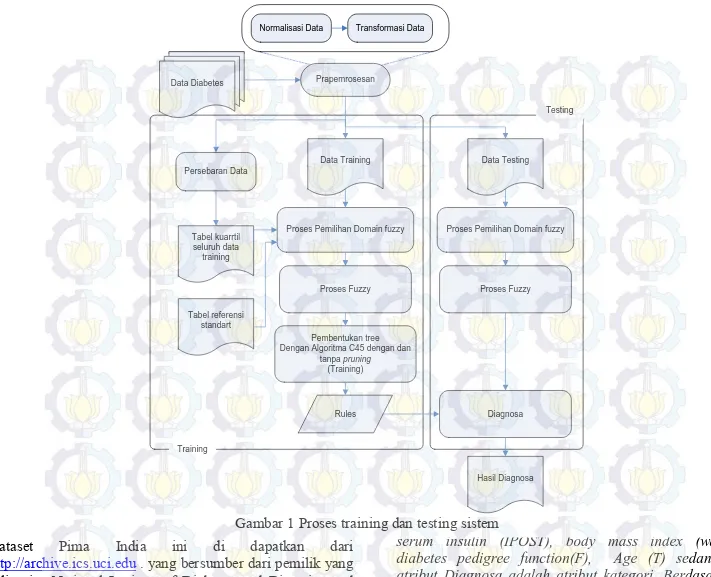
Tahap-tahap proses fuzzy decision tree dengan algoritma C45 seperti pada gambar 1.
II. FUZZY DECISION TREE DENGAN ALGORITMA C45
Fuzzy secara bahasa diartikan sebagai kabur atau
samar-samar. Suatu nilai dapat bernilai besar atau salah secara bersamaan. Dalam fuzzy dikenal derajat keanggotaan
yang memiliki rentang nilai 0 (nol) hingga 1(satu). Berbeda dengan himpunan tegas yang memiliki nilai 1 atau 0 (ya atau tidak).
Logika Fuzzy merupakan sesuatu logika yang memiliki
nilai kekaburan atau kesamaran (fuzziness) antara benar atau
salah. Dalam teori logika fuzzy suatu nilai bias bernilai benar
atau salah secara bersama. Namun berapa besar keberadaan dan kesalahan suatu tergantung pada bobot keanggotaan
yang dimilikinya. Logika fuzzy memiliki derajat
keanggotaan dalam rentang 0 hingga 1. Berbeda dengan logika digital yang hanya memiliki dua nilai 1 atau 0.
Logika fuzzy digunakan untuk menterjemahkan suatu
besaran yang diekspresikan menggunakan bahasa (linguistic). Misalkan tingginya nilai IPOST (2-Hour serum insulin) yang digolongkan ke dalam nilai rendah, normal,
dan tinggi. Dan logika fuzzy menunjukkan sejauh mana
suatu nilai itu benar dan sejauh mana suatu nilai itu salah. Tidak seperti logika klasik (scrip)/tegas, suatu nilai hanya
mempunyai 2 kemungkinan yaitu merupakan suatu anggota himpunan atau tidak. Derajat keanggotaan 0 (nol) artinya nilai bukan merupakan anggota himpunan dan 1 (satu) berarti nilai tersebut adalah anggota himpunan.
Fuzzifikasi merupakan suatu proses untuk mengubah suatu peubah masukan dari bentuk tegas (crisp) menjadi
peubah fuzzy (variable linguistik) yang biasanya disajikan
dalam bentuk himpunan-himpunan fuzzy dengan fungsi
keanggotaannya.
Evaluasi aturan merupakan proses pengambilan keputusan (inference) yang berdasarkan aturan-aturan yang
ditetapkan pada basis aturan (rules base) untuk
menghubungkan antar peubah-peubah fuzzy masukan dan
peubah fuzzy keluaran. Aturan-aturan ini berbentuk jika
maka (IF -THEN).
Teknik pengambilan keputusan yang digunakan adalah metode max-min. Pada metode max-min, pengambilan keputusan didasarkan pada aturan operasi menurut trapezium dan kurva Pi.
Defuzzifikasi merupakan proses pengubahan besaran
fuzzy yang disajikan dalam bentuk himpunanhimpunan fuzzy
keluaran dengan fungsi keanggotaannya untuk mendapatkan kembali bentuk tegasnya.
Ada beberapa hal yang perlu diketahui dalam memahami sistem fuzzy, yaitu:
a. Variabel fuzzy
Variabel fuzzy merupakan variabel yang hendak dibahas
dalam suatu sistem fuzzy. Contoh: number of times pregnant(time), plasma glucose concentration a 2 hours in an oral glucose tolerance test (OGTT), diastolic blood pressure (D), triceps skin fold thickness (T), 2-Hour serum insulin (IPOST), body mass index (waist), diabetes pedigree function(F), Age (T) sedangkan atribut Diagnosa adalah atribut kategori. Berdasarkan referensi hasil laboratorium, range normal untuk atribut number of times pregnant(time), plasma glucose concentration a 2 hours in an oral glucose tolerance test (OGTT), diastolic blood pressure (D), triceps skin fold thickness (T), 2-Hour serum insulin (IPOST), body mass index (BMI), diabetes pedigree function(F), dan Age (T).
b. Himpunan fuzzy
Himpunan fuzzy merupakan suatu grup yang mewakili
suatu kondisi atau keadaan tertentu dalam suatu variabel
fuzzy.
Contoh:
Variabel number of times pregnant(time), terbagi
menjadi 3 himpunan fuzzy, yaitu: rendah, normal
dan tinggi.
c. Semesta Pembicaraan
Semesta pembicaraan adalah keseluruhan nilai yang diperbolehkan untuk dioperasikan dalam suatu variabel
fuzzy. Semesta pembicaraan merupakan himpunan
bilangan real yang senantiasa naik (bertambah) secara monoton dari kiri ke kanan. Nilai semesta pembicaraan dapat berupa bilangan positif maupun negatif. Adakalanya nilai semesta pembicaraan ini tidak dibatasi batas atasnya.
Contoh:
Semesta pembicaraan untuk variabel time: [0 20]
Semesta pembicaraan untuk variabel Age : [0 100]
d. Domain
Domain himpunan fuzzy adalah keseluruhan nilai yang
diijinkan dalam semesta pembicaraan dan boleh
Data Diabetes
Data Training Data Testing
Prapemrosesan
Persebaran Data
Tabel kuarrtil seluruh data
training
Proses Pemilihan Domain fuzzy
Tabel referensi standart
Proses Fuzzy
Rules Pembentukan tree Dengan Algoritma C45 dengan dan
tanpa pruning
(Training)
Diagnosa Proses Pemilihan Domain fuzzy
Proses Fuzzy
Hasil Diagnosa Testing
Training
Normalisasi Data Transformasi Data
dioperasikan dalam suatu himpunan fuzzy. Seperti halnya
semesta pembicaraan, domain merupakan himpunan bilangan real yang senantiasa naik (bertambah) secara monoton dari kiri ke kanan. Nilai domain dapat berupa bilangan positif maupun negatif.
Contoh :
Untuk Variabel time RENDAH = [0 2] PABOBAYA = [2 5] TUA = [5 +∞)
A. Decision Tree
Decision tree merupakan suatu pendekatan yang sangat
populer dan praktis dalam machine learning untuk
menyelesaikan permasalahan klasifikasi. Pada decision tree terdapat 3 jenis node, yaitu:
a. Root Node, merupakan node paling atas, pada node ini
tidak ada input dan bisa tidak mempunyai output atau mempunyai output lebih dari satu.
b. Internal Node, merupakan node percabangan, pada node
ini hanya terdapat satu input dan mempunyai output minimal dua.
c. Leaf node atau terminal node, merupakan node akhir,
pada node ini hanya terdapat satu input dan tidak mempunyai output.
Konsep Decision tree adalah mengubah data menjadi
pohon keputusan (decision tree) dan aturan-aturan
keputusan (rule).
Decision tree membuat aturan rule yang dapat
digunakan untuk menentukan apakah seseorang mempunyai potensi untuk menderita diabetes atau tidak berdasarkan
number of times pregnant(time), plasma glucose concentration a 2 hours in an oral glucose tolerance test (OGTT), diastolic blood pressure (D), triceps skin fold thickness (T), 2-Hour serum insulin (IPOST), body mass index (waist), diabetes pedigree function(F), Age (T)
sedangkan atribut Diagnosa adalah atribut kategorik. Berdasarkan referensi hasil laboratorium, range normal untuk atribut number of times pregnant(time), plasma glucose concentration a 2 hours in an oral glucose tolerance test (OGTT), diastolic blood pressure (D), triceps skin fold thickness (T), 2-Hour serum insulin (IPOST), body mass index (BMI), diabetes pedigree function(F), dan Age (T).
Metode decision tree digunakan untuk memperkirakan
nilai diskret dari fungsi target, yang mana fungsi pembelajaran direpresentasikan oleh sebuah decision tree
[6]. Decision tree merupakan himpunan aturan IF…THEN.
Setiap path dalam tree dihubungkan dengan sebuah aturan,
di mana premis terdiri atas sekumpulan node-node yang
ditemui, dan kesimpulan dari aturan terdiri atas kelas yang terhubung dengan leaf dari path [7].
Dalam pohon keputusan, leaf node diberikan sebuah
label kelas. Non-terminal node, yang terdiri atas root dan internal node lainnya, mengandung kondisi-kondisi uji
atribut untuk memisahkan record yang memiliki
karakteristik yang berbeda. Edge-edge dapat dilabelkan
dengan nilai-nilai numeric-symbolic. Sebuah atribut
numeric-symbolic adalah sebuah atribut yang dapat bernilai numeric ataupun symbolic yang dihubungkan dengan sebuah
variabel kuantitatif. Sebagai contoh, ukuran seseorang dapat dituliskan sebagai atribut numeric-symbolic: dengan nilai
kuantitatif, dituliskan dengan “1,72 meter”, ataupun sebagai nilai numeric-symbolic seperti “tinggi” yang berkaitan
dengan suatu ukuran (size). Nilai-nilai seperti inilah yang
menyebabkan perluasan dari decision tree menjadi fuzzy decision tree [7]. Penggunaan teknik fuzzy memungkinkan
melakukan prediksi suatu objek yang dimiliki oleh lebih dari satu kelas.
Fuzzy decision tree memungkinkan untuk
menggunakan nilai-nilai numeric-symbolic selama
konstruksi atau saat mengklasifikasikan kasus-kasus baru. Manfaat dari teori himpunan fuzzy dalam decision tree ialah
meningkatkan kemampuan dalam memahami decision tree
ketika menggunakan atribut-atribut kuantitatif. Bahkan,
dengan menggunakan teknik fuzzy dapat meningkatkan
ketahanan saat melakukan klasifikasi kasus-kasus baru [8].
B. Algoritma C4.5
Algoritma C4.5 yaitu sebuah algoritma yang
digunakan untuk membangun decision tree (pengambilan
keputusan) . Algoritma C.45 adalah salah satu algoritma
induksi pohon keputusan yaitu ID3 (Iterative Dichotomiser
3). ID3 dikembangkan oleh J. Ross Quinlan. Dalam prosedur algoritma ID3, input berupa sampel training, label training dan atribut. Algoritma C4.5 merupakan
pengembangan dari ID3.
Pohon dibangun dengan cara membagi data secara rekursif hingga tiap bagian terdiri dari data yang berasal dari
kelas yang sama. Bentuk pemecahan (split) yang digunakan
untuk membagi data tergantung dari jenis atribut yang digunakan dalam split. Algoritma C4.5 dapat menangani
data numerik (kontinyu) dan diskret. Split untuk atribut
numerik yaitu mengurutkan contoh berdasarkan atribut kontiyu A, kemudian membentuk minimum permulaan
(threshold) M dari contoh-contoh yang ada dari kelas
mayoritas pada setiap partisi yang bersebelahan, lalu menggabungkan partisi-partisi yang bersebelahan tersebut dengan kelas mayoritas yang sama. Split untuk atribut
diskret A mempunyai bentuk value (A) ε X dimana X ⊂ domain(A).
. Secara singkat logika algoritma C4.5 yang digunakan adalah sebagai berikut:
a.
Pilih atribut sebagai akar
b.
Buat cabang untuk masing-masing nilai
c.
Bagi kasus dalam cabang
d.
Ulangi proses untuk masing-masing
cabang sampai semua kasus pada cabang
memiliki kelas yang sama.
Untuk memilih atribut sebagai akar, didasarkan pada nilai gain tertinggi dari atribut-atribut yang ada. Untuk menghitung gain digunakan rumus seperti tertera dalam Rumus 1. (1) Keterangan S : Himpunan kasus A : Atribut n : jumlah partisi A
|Si| : Jumlah kasus pada partisi ke i
Sedangkan penhitungan nilai entropy dapat dilihat pada rumus 2 berikut:
(2) Keterangan : S : Himpunan kasus n : jumlah partisi S pi : Proporsi Si terhadap S C. Pruning
Teknik pruning yaitu teknik untuk memotong rule
pada decision tree, jika rule yang dihasilkan sudah tidak
signifikan. Yaitu dengan cara serupa dengan pasca-keputusan pemangkasan pohon, mengurangi kesalahan pemangkasan dengan cara menghapus salah satu dalam aturan kemudian bandingkan tingkat kesalahan pada set validasi sebelum dan setelah pemangkasan, jika memperbaiki kesalahan, lakukan proses prune. Pada tugas
akhir ini dilakukan proses pruning dengan menggunakan
Threshold dalam Fuzzy Decision Tree (FDT) . Jika pada
proses pembelajaran dari FDT dihentikan sampai semua
data contoh pada masing-masing leaf-node menjadi anggota
sebuah kelas, akan dihasilkan akurasi yang rendah. Oleh
karena itu untuk meningkatkan akurasinya, proses learning
harus dihentikan lebih awal atau melakukan pemotongan
tree secara umum. Untuk itu diberikan 2 (dua) threshold
yang harus terpenuhi jika tree akan diekspansi, yaitu [9,10] : Fuzziness control threshold (FCT) / θr
Jika proporsi dari himpunan data dari kelas Ck lebih
besar atau sama dengan nilai threshold θr, maka
hentikan ekspansi tree. Sebagai contoh: jika pada
sebuah sub-dataset rasio dari kelas 1 adalah 90%, kelas 2 adalah 10% dan θr adalah 85%, maka hentikan ekspansi tree.
Leaf decision threshold (LDT) / θn
Jika banyaknya anggota himpunan data pada suatu node lebih kecil dari threshold θn, hentikan ekspansi
tree. Sebagai contoh: sebuah himpunan data memiliki
600 contoh dengan θn adalah 2%. Jika jumlah data contoh pada sebuah node lebih kecil dari 12 (2% dari 600), maka hentikan ekspansi
tree
.
D. Akurasi
Akurasi adalah nilai derajat kedekatan dari pengukuran kuantitas untuk nilai sebenarnya (true). Nilai akurasi
didapatkan dari hasil rule yang dihasikan dari perhitungan
decision tree kemudian di uji coba kan pada data testing dan menghasilkan derajat keakuratan dari rule tersebut setelah di
uji coba kan pada data testing. Berikut ini rumus dari nilai
accuracy : Rumus accuracy : (3) Dimana: TP : True Positive TN : True Negative FP : False positive FN : False Negative
Yang dimaksud dengan True Positive adalah jumlah data hasil bentukan rule yang terkena diabetes yang sama dengan data testing yang juga terkena diabetes. Disini ditandai dengan nilai 1. Jadi pada data testing hasil diagnosanya 1 dan pada data diagnose hasi pembentukan rule juga bernilai 1. Yang dimaksud dengan True Negative adalah jumlah data hasil bentukan rule yang tidak terkena tidak diabetes yang sama dengan data testing yang juga tidak terkena diabetes. Disini ditandai dengan nilai 0. Jadi pada data testing hasil diagnosanya 0 dan pada data diagnose hasil pembentukan rule juga bernilai 0. Jadi nilai true positive dan true negative adalah data pada pembentukan rule sama dengan data testing yang diujikan.
Kemudian yang dimaksud dengan False Positive adalah jumlah data hasil bentukan rule yang terkena diabetes dan data testing yang tidak terkena diabetes. Dan False Negative adalah jumlah data hasil bentukan rule yang tidak terkena diabetes dengan data testing yang terkena diabetes.
III. UJICOBA
Perancangan data yang telah dibuat dan diimplementasikan kedalam sebuah perangkat perlu dilakukan uji coba. Uji coba pada klasifikasi decision tree
ini mencakup uji coba proses pembentukan himpunan fuzzy,
pembentukan tree, pembentukan hasil testing dan
perhitungan akurasi. Uji coba ini akan melakukan evaluasi tingkat akurasi kebenaran rule nya. Pada uji coba ini akan dilakukan uji coba data sample dengan proporsi data testing sebesar 256 objek dan 512 objek data training, dengan
menggunakan 3-fold cross validation. Dari data yang
tersedia akan dilakukan uji coba untuk mengetahui pengaruh
proses pembentukan fuzzy, pruning, nilai Fuzziness control
threshold (FCT) atau θr dan Leaf decision threshold (LDT)
atau θn terhadap besarnya akurasi. Dan uji coba tersebut dimulai dari pembagian himpunan fuzzy menurut referensi standart dan kuartl, kemudian dilakukan proses pruning atau tidak. Jika akan dilakukan proses pruning makan harus memasukkan nilai Fuzzinesscontrolthreshold (FCT) atau θr
dan Leaf decision threshold (LDT) atau θn . Dengan
menguji nilai dari Fuzzinesscontrolthreshold (FCT) atau θr
sebanyak 6 yaitu 75%, 80%, 85%, 90%, 95%, dan 98%, dan memasukkan nilai Leaf decision threshold (LDT) atau θn
A. Uji Coba Tanpa Pruning dengan referensi standard
Uji coba pada data training 512 data sample dan 256
data sample untuk testing dan pembentukan fuzzy menurut
referensi standard. Hasil uji coba pada tabel 1.
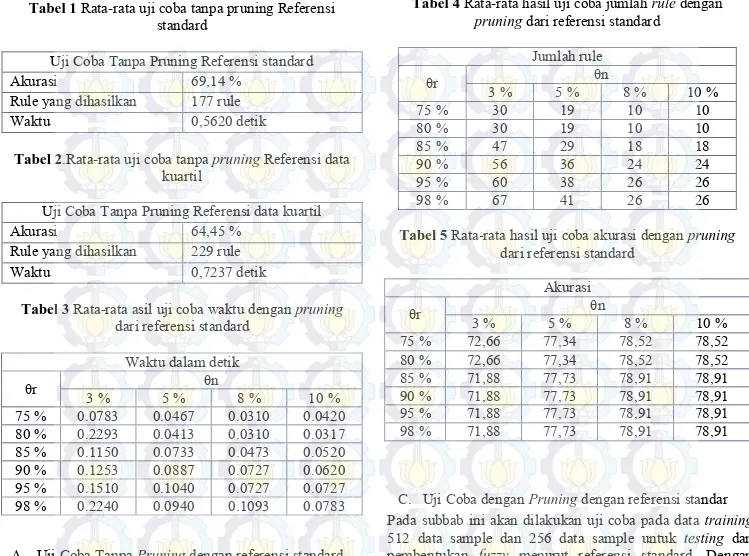
Dari hasil uji coba yang dilakukan tanpa pruning
dengan menggunakan referensi data kuartil menghasilkan
rule dengan kedalaman yang paling dalam adalah 8 node
dan memiliki leaf sebanyak 177 leaf. Dari hasil yang
dilakukan membutuhkan waktu 0,6560 detik dengan tingkat akurasi 69,14 %. Salah satu rule yang dihasilkan yaitu pada rule yang pertama adalah IF OGTT rendah AND IPOST rendah AND TIME rendah AND D rendah AND T rendah THEN TIDAK DIABETES.
B. Uji Coba Tanpa Pruning dengan referensi data kuartil
Uji coba pada data training 512 data sample dan 256 data
sample untuk testing dan pembentukan fuzzy menurut
referensi data kuartil. Hasil uji coba pada tabel 2.
Dari hasil uji coba yang dilakukan tanpa pruning dengan
menggunakan referensi data kuartil dihasilkan rule dengan
kedalaman yang paling dalam adalah 8 node dan memiliki
leaf sebanyak 229 leaf. Dari hasil yang dilakukan
membutuhkan waktu 0,7030 detik dengan tingkat akurasi 64,45 %. Salah satu rule yang dihasilkan yaitu pada rule
yang pertama adalah IF OGTT rendah AND AGE rendah AND BMI rendah THEN TIDAK DIABETES. Dari uji coba yang kedua mengalami penurunan tingkat akurasi, jumlah
rule yang dihasilkan semakin banyak sehingga waktu yang
digunakan juga semakin tinggi. Maka percobaan pertama lebih baik dari hasil uji coba yang kedua.
C. Uji Coba dengan Pruning dengan referensi standar
Pada subbab ini akan dilakukan uji coba pada data training
512 data sample dan 256 data sample untuk testing dan
pembentukan fuzzy menurut referensi standard. Dengan
menggunakan besarnya Fuzziness control threshold (FCT) /
θr : 75%, 80%, 85%, 90%, 95%, dan 98%. Sedangkan untuk nilai Leaf decision threshold (LDT) / θn : 3%, 5%, 8%, dan
10%.
Dari hasil uji coba yang dilakukan dengan pruning dengan menggunakan referensi data standard dihasilkan rule dengan kedalaman yang paling dalam adalah 8 node dan memiliki leaf menurut tabel 4. Dari hasil yang dilakukan membutuhkan waktu pada tabel 3 dengan tingkat akurasi pada tabel 4. Salah satu rule yang dihasilkan yaitu pada θr : 98 dan θn : 10 pada rule yang pertama adalah IF OGTT rendah AND T rendah AND TIME rendah AND D rendah THEN TIDAK DIABETES. Dari uji coba yang ketiga akurasi tertinggi mencapai 78,91 % berarti pada uji coba ketiga ini mengalami peningkatan tingkat akurasi, jumlah rule yang dihasilkan semakin sedikit sehingga waktu yang digunakan juga semakin sedikit. Maka percobaan ketiga lebih baik dari hasil uji coba yang pertama dan yang kedua.
D. Uji Coba dengan Pruning dengan referensi data
kuartil
uji coba pada data training 512 data sample dan 256 data sample untuk testing dan pembentukan fuzzy menurut referensi data kuartil. Dengan menggunakan besarnya Fuzziness control threshold (FCT) / θr : 75%, 80%, 85%, 90%, 95%, dan 98%. Sedangkan untuk nilai Leaf decision threshold (LDT) / θn : 3%, 5%, 8%, dan 10%.
Tabel 1 Rata-rata uji coba tanpa pruning Referensi standard
Uji Coba Tanpa Pruning Referensi standard
Akurasi 69,14 %
Rule yang dihasilkan 177 rule
Waktu 0,5620 detik
Tabel 2.Rata-rata uji coba tanpa pruning Referensi data
kuartil
Uji Coba Tanpa Pruning Referensi data kuartil
Akurasi 64,45 %
Rule yang dihasilkan 229 rule
Waktu 0,7237 detik
Tabel 3 Rata-rata asil uji coba waktu dengan pruning
dari referensi standard Waktu dalam detik
θr 3 % 5 % θn 8 % 10 % 75 % 0.0783 0.0467 0.0310 0.0420 80 % 0.2293 0.0413 0.0310 0.0317 85 % 0.1150 0.0733 0.0473 0.0520 90 % 0.1253 0.0887 0.0727 0.0620 95 % 0.1510 0.1040 0.0727 0.0727 98 % 0.2240 0.0940 0.1093 0.0783
Tabel 4 Rata-rata hasil uji coba jumlah rule dengan pruning dari referensi standard
Jumlah rule θr 3 % 5 % θn 8 % 10 % 75 % 30 19 10 10 80 % 30 19 10 10 85 % 47 29 18 18 90 % 56 36 24 24 95 % 60 38 26 26 98 % 67 41 26 26
Tabel 5 Rata-rata hasil uji coba akurasi dengan pruning
dari referensi standard Akurasi θr 3 % 5 % θn 8 % 10 % 75 % 72,66 77,34 78,52 78,52 80 % 72,66 77,34 78,52 78,52 85 % 71,88 77,73 78,91 78,91 90 % 71,88 77,73 78,91 78,91 95 % 71,88 77,73 78,91 78,91 98 % 71,88 77,73 78,91 78,91
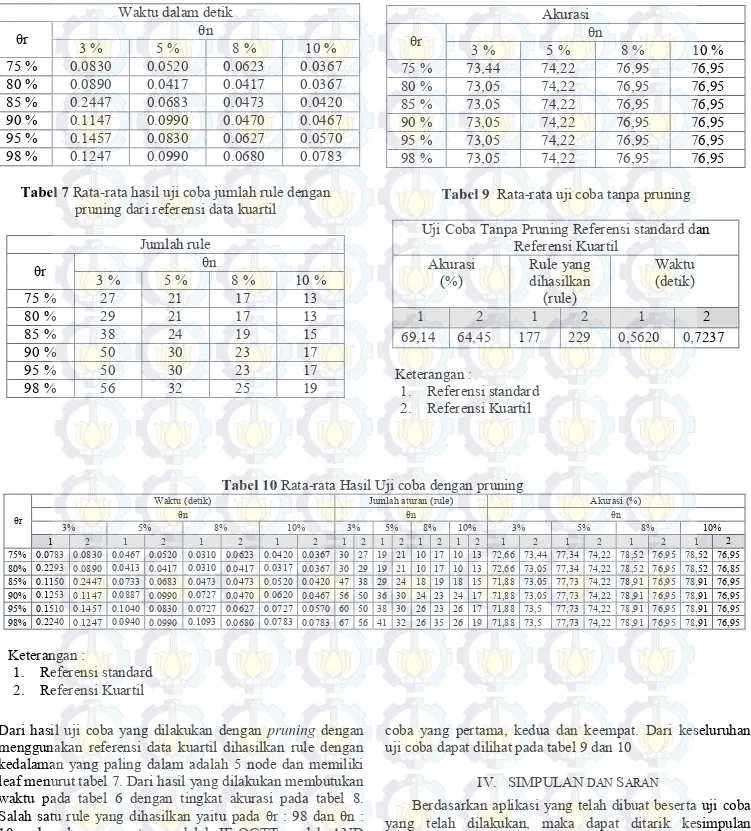
Dari hasil uji coba yang dilakukan dengan pruning dengan
menggunakan referensi data kuartil dihasilkan rule dengan kedalaman yang paling dalam adalah 5 node dan memiliki leaf menurut tabel 7. Dari hasil yang dilakukan membutukan waktu pada tabel 6 dengan tingkat akurasi pada tabel 8. Salah satu rule yang dihasilkan yaitu pada θr : 98 dan θn : 10 pada rule yang pertama adalah IF OGTT rendah AND AGE rendah AND BMI rendah THEN TIDAK DIABETES. Dari uji coba yang ketiga akurasi tertingi mencapai 76,95 %, hasil yang sama yang didapatkan pada uji coba yang pernah dilakukan oleh vi Vincent Sigillito.
Dari keseluruhan hasil uji coba, nilai θr dan θn sangat berpengaruh terhadap jumlah aturan yang dihasilkan, nilai θr yang terlalu tinggi akan menyebabkan turunnya nilai akurasi. Di lain pihak, nilai θn yang terlalu rendah juga dapat menyebabkan akurasi menurun. Pada keseluruhan uji coba nilai akurasi tertinggi pada percoban ketiga yaitu 78,91% . Maka percobaan ketiga lebih baik dari hasil uji
coba yang pertama, kedua dan keempat. Dari keseluruhan uji coba dapat dilihat pada tabel 9 dan 10
IV. SIMPULAN DAN SARAN
Berdasarkan aplikasi yang telah dibuat beserta uji coba yang telah dilakukan, maka dapat ditarik kesimpulan sebagai berikut :
a. Dengan pruning dihasilkan tingkat akurasi yang
lebih tinggi dari pada tidak memakai pruning, dari 69,14% ke 78,91%.
b. Pembagian data himpunan fuzzy dengan
menggunakan referensi data standart dengan pruning memiliki tingkat akurasi lebih tinggi 78,91% dibandingkan dengan referensi data kuartil 76,95%.
c. Semakin tinggi θr dan θn, semakin tinggi tingkat akurasi.
Tabel 6 Rata-rata hasil uji coba waktu dengan pruning dari referensi data kuartil
Waktu dalam detik
θr 3 % 5 % θn 8 % 10 % 75 % 0.0830 0.0520 0.0623 0.0367 80 % 0.0890 0.0417 0.0417 0.0367 85 % 0.2447 0.0683 0.0473 0.0420 90 % 0.1147 0.0990 0.0470 0.0467 95 % 0.1457 0.0830 0.0627 0.0570 98 % 0.1247 0.0990 0.0680 0.0783
Tabel 7 Rata-rata hasil uji coba jumlah rule dengan pruning dari referensi data kuartil
Jumlah rule θr 3 % 5 % θn 8 % 10 % 75 % 27 21 17 13 80 % 29 21 17 13 85 % 38 24 19 15 90 % 50 30 23 17 95 % 50 30 23 17 98 % 56 32 25 19
Tabel 8 Rata-rata hasil uji coba akurasi dengan pruning dari referensi kuartil
Akurasi θr 3 % 5 % θn 8 % 10 % 75 % 73,44 74,22 76,95 76,95 80 % 73,05 74,22 76,95 76,95 85 % 73,05 74,22 76,95 76,95 90 % 73,05 74,22 76,95 76,95 95 % 73,05 74,22 76,95 76,95 98 % 73,05 74,22 76,95 76,95
Tabel 9 Rata-rata uji coba tanpa pruning Uji Coba Tanpa Pruning Referensi standard dan
Referensi Kuartil Akurasi
(%) Rule yang dihasilkan (rule) Waktu (detik) 1 2 1 2 1 2 69,14 64,45 177 229 0,5620 0,7237 Keterangan : 1. Referensi standard 2. Referensi Kuartil
Tabel 10 Rata-rata Hasil Uji coba dengan pruning
θr
Waktu (detik) Jumlah aturan (rule) Akurasi (%)
θn θn θn 3% 5% 8% 10% 3% 5% 8% 10% 3% 5% 8% 10% 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 1 2 75% 0.0783 0.0830 0.0467 0.0520 0.0310 0.0623 0.0420 0.0367 30 27 19 21 10 17 10 13 72,66 73,44 77,34 74,22 78,52 76,95 78,52 76,95 80% 0.2293 0.0890 0.0413 0.0417 0.0310 0.0417 0.0317 0.0367 30 29 19 21 10 17 10 13 72,66 73,05 77,34 74,22 78,52 76,95 78,52 76,85 85% 0.1150 0.2447 0.0733 0.0683 0.0473 0.0473 0.0520 0.0420 47 38 29 24 18 19 18 15 71,88 73,05 77,73 74,22 78,91 76,95 78,91 76,95 90% 0.1253 0.1147 0.0887 0.0990 0.0727 0.0470 0.0620 0.0467 56 50 36 30 24 23 24 17 71,88 73,05 77,73 74,22 78,91 76,95 78,91 76,95 95% 0.1510 0.1457 0.1040 0.0830 0.0727 0.0627 0.0727 0.0570 60 50 38 30 26 23 26 17 71,88 73,5 77,73 74,22 78,91 76,95 78,91 76,95 98% 0.2240 0.1247 0.0940 0.0990 0.1093 0.0680 0.0783 0.0783 67 56 41 32 26 35 26 19 71,88 73,5 77,73 74,22 78,91 76,95 78,91 76,95 Keterangan : 1. Referensi standard 2. Referensi Kuartil
Perlu dibuat proses pembentukan fungsi fuzzy yang lain selain menggunkan model trapezoidal, seperti model segitiga, kurva S, dan kurva PI agar dapat diketahui pengaruh fungsi keanggotaan fuzzy terhadap akurasi.
REFERENSI
[1] http://www.infopenyakit.com/2008/03/penyakit-diabetes-mellitus-dm.html. Diakses tanggal 18 Maret 2010
[2] J. Han and M. Kamber. Data Mining Concepts and
Techniques. Simon Fraser University. USA: Morgan
Kaufman, 2006.
[3] Sigillito,Vincent. Pima Indians Diabetes Data
Set.www.archive.ics.uci.edu/ml/datasets. Diakses
tanggal 3 Maret 2010.
[4] The Inter-University Centre for Astronomy and
Astrophysics, Pune, India .Pima Indians Diabetes Database.http://meghnad.iucaa.ernet.in/~nspp/DBNN_ html/node8.html . Diakses tanggal 12 Nopember 2010
[5] Pang-Ning Tan, M. Steinbach, V. Kumjar,
Introduction to Data Mining, Pearson Education, Inc.,
Boston, 2006.
[6] E Cox. Fuzzy Modeling and Algorithms for Data
mining and Exploration. USA: Academic Press. 2005.
[7] Y. Yuan dan Shaw M J. Induction of fuzzy decision trees, Fuzzy Sets and Systems Vol. 69. 1995.
[8] G. Liang. A Comparative Study of Three Decision Tree
algorithms: ID3, Fuzzy ID3 and Probabilistic Fuzzy ID3. Informatics & Economics Erasmus University
Rotterdam Rotterdam, the Netherlands, 2005.
[9] Romansyah.F, I. S. Sitanggang, S. Nurdiati.Fuzzy
Decision Tree dengan Algoritme ID3 pada Data Diabetes .Internetworking Indonesia Journal.2009.
[10] I-Jen Chianga and Jane Yung-jen Hsu. Fuzzy
classification trees for data analysis. Department of
Computer Science and Information Engineering, National Taiwan University, Taipei, Taiwan, 2001.
[11] Stoppler.Melissa Conrad, MD. Low Blood Pressure
and Stress.
http://www.medicinenet.com/low_blood_pressure/artic le.htm . Diakses tanggal 18 Maret 2010
[12] Fu L. 1994. Neural Network In Computer Intelligence.