U]IIUERSITIS
IRIT|IGI
Telmouen0ur
lbla[orasl
danl(emandlilan
SINATTT'Cls
Itlo- $2*ftjni},TriheiJkodi.r#3rg/5e/ft ryzoil}
fryb
Prqram Studi tvlanaprnen{S-t}UnirersitasTriQp menugadcan kepda dosen herilaltini: FairCr S1ilraD, S.E-tSG-Frr-UnU* melatsanahn pemhratan &rhr AFr
rmtr
kulbh Afli*asi f,ornprer BfonirAdapun ruarg lirgkup pemgasan
ndipti
7,1"
ilhmhuat buku aiar sesuai dengan topik Ersehut di atas2- ilifiembedlun
buku aiar hesertasj@lnrrya
kepada prognam sudi.Xffi*
berharap Sapakflto dapat rrehtsamkantlgas
in{ dengan*baik{aikrm
sesuai derganke&nbran yarg berhku di Uniuersitas Trilogi- Aras perharian dan keriasarnarya diucapftan Erftna
ke$h-Jakarta, CS f€bruari
z0fil
A
uv
Eufi Surusuari S.E.,
tllH.
l(eftra Program Studi fiihnaiermem
(FIl
TenrtusanYth.,
r
I l(epah BiroSDM, Efika dan HukumKampus Universitas Trilogi
Jl. TMP. Kalibata No. 1 Jakarta Selatan 12760 Telp. 021 798 0011 (Hunting), Fax. O21 7981352
Website : www.trilogi.ac.id
@lppni
SI]RAT
KETERANGAI\I
No. 74lLP PM / KET I txl zCILga
Yang bertanda tangan
di
bawahini
Kepala Lembaga Penelitiandan
Pengabdian Masyarakat (LPPM ) UniversitasTrilogi,
menerangkan bahwa :Noma N'DN Progru
n
Stttdi/Fo kutta s Teloh menyelesaikan penelitian yangberjudul
Terbitpodo
LPPM UNIVERSITAS TRILOGI
Gedung Rektorat Lantai 4 UniversitasTrilogi
Jl.TMP. Kalibata No. 1 Jakarta Selatan 12760 Telp. 021 798 001 1 ext.429 Fax. 02 l 798 1352 Website : www.trilogi.ac.id, E-mail : [email protected]
Faizah Syihab, S.E., M.Sc.Fin., C.R.Po 0309088402
Manaiemen
"Aplikasi Komputer Bisnis" 25 April2019
Demikianlah Surat Keterangan
inidibuat
untuk dipergunakan sebagaimana mestinya.Tembusan, Yth.:
. Wakil Rektor
o Ketua Prodi
@lppffi
SI]RAT
KETERANGAI\TPUBLIKASI KARYA TULIS
HASIL
PEI{ELITAN
I}AI{
PENGABDIAN KUPADA
MASYARAKAT
Nomor : 7 4lPUBlLPPMfixlzALg
Berdasarkan
Persyaratan:
i
1.
SuratTugas Penelitian Dari Program Studi2.
Proposal Penelitian3.
Laporan Hasil Penelitian4.
Surat Keterangan Telah Melaksanakan Penelitian dari LPPM Menerangkan bahwa iurnal/prosiding dengan :tudul
:
"Aplikasi Komputer Bisnis"Penulis
:
Faizah Syihab, 5.E., M.Sc.Fin., C.R.P0Sebagai publikasi karya tulis hasil penelitian dan pengabdian kepada masyarakat berupa : Buku/Keran/n*qialilh Tingkat Nasional {referensi/raoaograf}
Buku/Koran/Majalah Tingkat lnternasional {referensi/monograf}
Sudah memenuhi perryaratan untuk mendapatkan insentif publikasi atau penulisan karya tulis.
LPPM UNIVERSITAS TRILOGI
Gedung Rektorat Lantai 4 UniversitasTrilogi Jl. TMP. Kalibata No. 1 Jakarta Selatan 12760 Telp.021 798 001 1 ext.429 Fax.021 798 1352 Website : www.trilogi.ac.id, E-mail : [email protected]
@lppffi
Yang bertanda tangan di bawah ini
Nomo Nim Prcgram Studi/Fakuttas
ludul
Valume/Tohun E-tssN/rsBN Nomolurnol/Prosiding
LPPM UNIVERSITAS TRILOGIGedung Rektorat Lantai 4 UniversitasTrilogi
Jl.TMP. Kalibata No. 1 Jakarta Selatan 12760
Telp. 021 798 001 1 ext. 429 Fax. 021 798 1352 Website : www.trilogi.ac.id, E-mail : [email protected]
Menyatakan bersedia untuk memberikan jurnal yang telah dipublikasi kepada :
o
Perpustakaan sebagai bahanbaaanfiiterafure
rnahasiswa/dosen (1eksernplar asli)r
LPPM sebagai arsip/dokumen Universitas{l
eksemplar fotocopy}Demikian
pernyataan
ini
saya
buat
sebenar-hnarnya
agar
supaya
dapat
digunakansebagaimana mestinya.
Ja,karta, 3O September 2019 Yang menyatakan,
-1
SI'RAT
PERIANJIAN
No. T4lLPPMIurna l-Prosiding/1X12019
Faizah Syihab, S.8., M.Sc.Fin., C.R.Po 0309088402
Manajemen
"Aplikasi Kornputer Bisnis"
-
I
25 April 201.9-
1978-623-91313-19 Aplikasi Kornputer Bisnis (BUKU){raizah
r-r.
J'.4".
Fin., c.R.Po} Meng6tahui,Kepala Perpustakaan
ffi
t
Universitas Trilogi 2019
Kata Pengantar
Aplikasi Komputer BisnisAnggota APPTI : 001.009.1.06.2017 Universitas Trilogi
Copyrights © Universitas Trilogi, 2019 Hak cipta dilindungi undang-undang
All Right Reserved Penulis:
Faizah Syihab, S.E.,M.Sc.Fin., C.R.P
®.
Diterbitkan oleh Universitas Trilogi Jl. Taman Makam Pahlawan No.1, Kalibata,Jakarta – Selatan Telp. 021-7981352 www.universitas-trilogi.ac.id email : [email protected] 15 x 23 cm; viii + 96 ISBN; 978-623-91313-1-9 Cetakan Pertama Agustus 2019
Dicetak di Rajawali Printing
v
Daftar Isi
Segala puji syukur ke khadirat Allah Swt., atas berkat dan karunia-Nya, sehingga buku ini dapat terselesaikan dengan baik. Penulis berharap buku ini dapat memberikan sumbangan bagi dunia ilmu pengetahuan khususnya bagi para pemula yang ingin melakukan penelitian mandiri. Buku ini berisi uraian mengenai: penggunaan dan penguasaan dasar SPSS yang disertai dengan beberapa contoh ilustrasi dengan menggunakan bahasa yang ringan sehingga dapat lebih mudah untuk dipahami pembaca. Pembaca diharapkan dapat memahami software SPSS yang ada di mana berbagai menu yang ada di dalamnya untuk penyuntingan dan pengolahan data, serta berguna untuk meningkatkan
softskills, membantu dalam pembuatan penelitian dan juga sebagai penunjang dalam bisnis aplikasi.
Penulis menyadari penyusunan buku ini masih belum sempurna, oleh karena itu saran dan kritik dari para pembaca tentunya penulis tunggu dalam rangka perbaikan buku ini kedepannya.
Jakarta, 25 April 2019
Penulis
Faizah Syihab, S.E., M.Sc.Fin., C.R.P
®.
Daftar Isi
vii
Daftar Isi
KATA PENGANTAR v
DAFTAR ISI vii
BAB 1 SEKILAS SPSS DAN MEMBANGUN DATA 1
A. Memulai SPSS 1 B. Membangun Data 6 C. Input Data pada Worksheet 6 D. Membuka/Mengimpor Data (Dari Excel Ke SPSS) 7 E. Menyimpan Data 7 F. Memodifikasi Data 8
BAB 2 GRAFIK 9
A. Pembuatan Grafik Jenis Batang (Bar Graph) 9 B. Pembuatan Grafik Jenis Lingkaran (Pie Graph) 14 C. Pembuatan Grafik Jenis Garis (Line Graph) 15
BAB 3 DATA PREMIER
ANGKET KUESIONER 17
A. Uji Validitas 18 B. Uji Realibilitas 23
Daftar Isi
viii Aplikasi Komputer Bisnis
BAB 4 DATA SEKUNDER (KUANTITATIF) 25
A. Ekstrak Data Sekunder 25 B. Statistik Deskriptif 29
BAB 5 DISTRIBUSI DATA (NORMALITAS) 33
A. Pendahuluan 33 B. Uji Normalitas (Kolmogorov-Smirnov) 34
BAB 6 ANALISA KORELASI 39
A. Pendahuluan 39 B. Koefisien Korelasi (r) 39 C. Multikolinearitas (Multicollinearity) 43
BAB 7 ANALISA REGRESI 47
A. Pendahuluan 47 B. Tata Cara Pengerjaan 48 C. Koefisien Determinasi (R2) 49
D. Uji Simultan 51 E. Uji Parsial 52 F. Interpretasi pada Model Regresi 53 G. Jenis-jenis Model Regresi 53
BAB 8 REGRESI LOGISTIK 55
A. Contoh Soal 56 B. Uji Goodness of fit 58 C. Uji Serentak Signifikan 61 D. Uji Signifikansi Parsial 63 E. Penafsiran Koefisien Odds Ratio 65
DAFTAR PUSTAKA 67
LAMPIRAN: BUKU KERJA 69
1
Bab 1 | Sekilas SPSS dan Membangun Data
SPSS (Statistical Product and Service Solutions) adalah Program Aplikasi yang memiliki kemampuan analisis statistik cukup tinggi, dengan berbagai fasilitas memproses data statistik, uji data, analisis sampai dengan penyajian data yang dikehendaki oleh para pengambil keputusan. Buku ini bertujuan untuk menjelaskan lingkungan dan sifat aplikasi program SPSS.
A. Memulai SPSS
Langkah memulai SPSS adalah: Menu Start IBM SPSS Statistic 22. Pada saat membuka SPSS pertama kali akan muncul kotak dialog, yang kemudian akan dicancel (klik Esc).
Pada SPSS menggunakan 2 windows (jendela) yaitu: The Data Editor windows (Jendela Data Editor) dan The Output Windows (Jendela Viewer).
Bab 1
2 Aplikasi Komputer Bisnis
The Command window
Pada bagian atas dari SPSS (command window) akan ada berbagai pilihan menu yang dapat digunakan untuk mengoperasikan SPSS. Command Window untuk Data Editor dan Output Windows adalah sebagai berikut.
1.
The Data Editor Window
Fasilitas-fasilitas SPSS sebagai berikut.
a. Data View adalah spreadsheet di mana terdapat Data Editor, jendela untuk melakukan penginputan data, pengeditan data, dan untuk menampilkan nilai data aktual.
b. Variable view adalah spreadsheet di mana memudahkan pengguna untuk memproses, mengakses, pengelompokan, penamaan, pendefinisian suatu variabel. Menampilkan informasi definisi suatu variabel, seperti tipe data (numeric, string), jenis pengukuran data (nominal, ordinal ataupun skala/scale).
3
Bab 1 | Sekilas SPSS dan Membangun Data a. Menu (Command Window) pada Data View:
1) File
Menu dasar yang berfungsi untuk menyimpan, membuka, membuat baru suatu file data editor atau output.
2) Edit
Menu dasar yang berfungsi untuk merubah, memperbaiki atau menyalin (copy) data.
3) View
Berfungsi untuk merubah tampilan pada toolbar. 4) Data
Digunakan untuk mengklasifikasi, mendefinisikan dan mengatur data serta variabel.
5) Transform
Digunakan untuk mentransformasi data, seperti menghitung variabel, mengganti data (missingvalues), dan lain-lain.
6) Analyze
Menu ini digunakan dalam pengolahan dan analisa data seperti statistic deskriptif, uji statistik (uji beda rata-rata, uji kuesioner/ angket), korelasi, regresi, nonparametrik tes, peramalan, dan lain-lain.
7) Graphs
Digunakan untuk menampilkan data dalam bentuk grafik dan chart, memvisualisasikan data.
8) Utilities, Add-ons, Windows 9) Help
Tentang topik-topik SPSS dan Tutorial panduan.
b. Kolom pada Variable View:
Isikan data pada SPSS sesuai dengan ketentuan berikut ini. 1) Name
Pengisian nama variabel sesuai dengan data yang ada.
4 Aplikasi Komputer Bisnis
2) Type
Pemilihan jenis data yang sesuai sebagai berikut. 3) Width
Menentukan batas pengisian karakter data. Bata pengisian maksimum adalah 1-255 digit.
4) Decimal
Kolom ini untuk menentukan jumlah angka desimal di belakang koma.
5) Label
Digunakan untuk memberikan penjelasan karakter suatu variabel nama.
6) Values
Dapat menerapkan nilai label untuk tiap variabel. Seperti untuk mengkategorikan data non-numerik, misal angka 1 dan 2 untuk lelaki dan wanita.
7) Missing Values
Menandakan nilai-nilai yang hilang namun tidak disertakan dalam pengolahan data.
8) Columns
Penyesuaian lebar kolom. 9) Align
Merubah display dari data (rata kiri, rata kanan, tengah). 10) Measure
Menentukan jenis data yang digunakan. Jenis data terdiri dari nominal, ordinal dan skala/scale. Jenis data non numeric adalah data string = nominal dan ordinal.
5
Bab 1 | Sekilas SPSS dan Membangun Data
Skala ratio memiliki angka "0" dan perbandingan dua nilai mempunyai arti
Interval Data Ordinal Data Nominal Data Ratio Data Contoh: Jenis Kelamin Contoh: kuesioner, tingkat pendidikan (SD, SMP, SMA) Contoh: Temperature. Contoh: 0-100 pengangguran Sifatnya hanya membedakan antar kelompok (klasifikasi data) Selain memiliki sifat nominal, juga menunjukkan peringkat. memiliki nomor pengukuran. "0" tidak memiliki makna
Data Menurut Skala Pengukuran
11) Role
Pada menu ini, pemilihan “Input” adalah bentuk defaultnya.
c. Jenis Data Data Qualitative (Categorical) Contoh: Status Pernikahan Merk Komputer Warna Rambut Continuos Quantitative (Numerical)
Jenis Data (Menurut Sifat)
Contoh:
Jumlah anak
Jumlah barang yang cacat tiap bulannya
Contoh:
jumlah pajak penghasilan yang harus dibayarkan
Berapa menit tersisa di dalam kelas Skala Pengukuran: Nominal Ordinal Skala Pengukuran: Interval Ratio
2.
The Output Window
Hasil-hasil pengolahan dan analisis pada SPSS akan dituangkan dalam Output window. Jumlah output dapat disesuaikan berdasarkan kegunaan. Misal, 1 Data Editor Window dapat memiliki beberapa Output Window, dan juga beberapa Data Editor Window dapat memiliki hanya 1 Output Window untuk meringkas hasil pengolahan data.
6 Aplikasi Komputer Bisnis
B. Membangun Data
Dalam membangun data di SPSS, ada dua cara yang dapat dilakukan, yaitu:
1. Menginput data pada worksheet.
2. Membuka/mengimpor data ke SPSS (misal dari Microsoft Excel ke SPSS).
C. Input Data pada Worksheet
Langkah-langkahnya adalah sebagai berikut.
File New Data Muncullah Data Editor Window
Untuk memulainya, pilihlah spreadsheet (bagian bawah) VariableView,
dengan pilihan menu seperti yang sudah dijelaskan pada subbab 1 bagian b (hlm 3). Kemudian, inputlah data ke dalam kolom-kolom yang sesuai.
1. Contoh Soal 1
No. Nama Jenis Kelamin Umur Nilai UTS Nilai UAS
1. Haris Baginda Lelaki 19 85.50 60.50
2. Andika Akbar Lelaki 20 72.50 60.00
3. Dwi Guna Lelaki 19 90.00 80.00
4. Indah Dina Maritha Perempuan 17 82.50 70.50
5. Rista Elvira Perempuan 23 50.50 80.00
6. Riri Suherman Perempuan 22 70.50 90.00
7. Wibisono Lelaki 25 50.00 62.50
2. Tata Cara Pengerjaan pada Variable View
Lakukanlah perubahan data pada Width dan Columns, apakah perbedaan pada Data View?
7
Bab 1 | Sekilas SPSS dan Membangun Data
D. Membuka/Mengimpor Data (Dari Excel Ke SPSS)
Langkah-langkahnya adalah sebagai berikut.
Block data yang ada di Excel CTRL C Buka SPSS (Data View), letakkan kursor di paling atas sisi kanan CTRL V. Lakukan pengolahan data sesuai dengan poin C.2.
Atau:
Pada worksheet SPSS, klik File Open Data Pilih direktori file excel berada Rubah “files of type” dengan “Excel (*.xls, *xlsx, *xlsm) Pilih file yang diinginkan Open Pilih worksheet yang diinginkan (lihat gambar 3) OK.
Lakukan pengolahan data sesuai dengan poin C.2.
E. Menyimpan Data
1. Penyimpanan Data untuk Data Editor Window
Langkah-langkahnya adalah:
Pilih File Save As Pilih direktori penyimpanan yang diinginkan
Isikan File Name yang sesuai “Save as type” yang dipilih adalah SPSS Statistics (*.sav) Save
8 Aplikasi Komputer Bisnis
Data yang tersimpan akan berekstensi .sav
2. Penyimpanan Data untuk Output Window
Pilih File Save As Pilih direktori penyimpanan yang diinginkan
Isikan File Name yang sesuai “Save as type” yang dipilih adalah Viewer Files (*.spv) Save.
Data yang tersimpan akan berekstensi .spv
F. Memodifikasi Data
Untuk memodifikasi data dapat dilakukan dengan berbagai cara seperti menyisipkan data (Data Insert Case), menyisipkan variabel (Data
Insert variabel), menghapus data (Del), menyorotkan data (Data
9
Bab 2 | Grafik
Data yang sudah diolah, kemudian disajikan dalam bentuk ilustrasi (grafik) untuk memudahkan dalam analisa, dan dapat memahami kandungan dari data/informasi yang disajikan. Suatu grafik hendaknya membantu pembacanya untuk memahami, bukannya malah membingungkan.
SPSS menyediakan beberapa menu untuk pembuatan berbagai grafik (Charts Legacy Dialogs ataupun Graphs Chart Builder). Di dalam buku ini, saya akan menjelaskan salah satu cara dalam membuat grafik, yang bertujuan untuk mengenalkan dan memfamiliarkan fungsi-fungsi menu SPSS pada mahasiswa.
Dalam pembuatan grafik, tentukan terlebih dahulu, informasi apa yang ingin disampaikan. Buatlah label-label yang diperlukan, namun jangan dipenuhi oleh banyak kata-kata/kalimat, karena tujuan dari grafik adalah memvisualisasikan informasi.
A. Pembuatan Grafik Jenis Batang (Bar Graph)
Jenis grafik yang pertama adalah grafik batang. Gunakan Graphs
Chart Builder.
Bab 2
10 Aplikasi Komputer Bisnis
1. Contoh Soal 2
Minggu Penjualan Promosi Penjual Harga
1 85.00 775.00 5 105.0 2 75.00 650.75 4 110.5 3 85.75 825.5 6 115.0 4 91.25 950.00 7 116.0 5 102.5 1,100.00 8 126.0 6 94.00 975.00 7 130.0 7 120.00 1,155.50 10 135.0 8 156.75 1,555.00 12 136.0 9 150.00 1,400.00 13 145.0 10 165.00 1,600.00 14 150.5
2. Tata Cara Pengerjaan
a. Salinlah data di atas dengan ketentuan di Variable View sebagai berikut:
11
Bab 2 | Grafik
c. Buatlah Bar graph dari variabel-variabel penjualan, promosi, harga dan penjual dalam satu gambar. Dengan ketentuan sebagai berikut. - Sumbu Y: Variabel Penjualan, menggunakan fungsi statistik
(jumlah/Sum).
- Sumbu Y: Variabel Promosi, menggunakan fungsi statistik (rata-rata/Mean).
- Sumbu Y: Variabel Harga menggunakan fungsi statistik (simpangan baku/Standard Deviation).
- Sumbu Y: Variabel Penjual menggunakan fungsi statistik (varians/Variance).
- Sumbu X: waktu (minggu).
- Berikan keterangan (legend, seperti penamaan pada judul, sumbu Y, sumbu X, dll) sesuai dengan ketentuan di soal. - Berikan warna pada grafik tersebut.
12 Aplikasi Komputer Bisnis
d. Sesuaikan fungsi statistik pada variables sesuai dengan ketentuan soal di atas:
13
Bab 2 | Grafik
e. Kemudian, berikanlah judul, subjudul pada Tab Titles/Footnotes
OK
f. Hasil Grafik (sebelum diwarnai)
APLIKOM CONTOH SOAL 2
14 Aplikasi Komputer Bisnis
g. Hasil Grafik (sesudah pewarnaan). Double Click untuk mengedit Grafik. Untuk menampilkan informasi data: Element Show Data Label
B. Pembuatan Grafik Jenis Lingkaran (Pie Graph)
Lakukan prosedur yang sama namun dengan menggunakan Grafik Lingkaran (Pie). Buatlah grafik sebagai berikut (fungsi statistik untuk semua variabel adalah SUM).
15
Bab 2 | Grafik
C. Pembuatan Grafik Jenis Garis (Line Graph)
Lakukan prosedur yang sama namun dengan menggunakan Grafik Garis (Line). Buatlah grafik sebagai berikut (fungsi statistic untuk semua variabel adalah MEAN).
17
Bab 3 | Data Premier (Kualitatif)
Salah satu elemen penting dalam melakukan penelitian adalah pencarian data. Sumber data dapat berupa data primer dan sekunder. Data primer adalah data yang dikumpulkan peneliti secara langsung, contohnya adalah kuesioner, wawancara. Sedangkan, data sekunder adalah data yang diambil dari sumber yang tersedia.
Variabel kualitatif adalah variabel yang mempunyai data nonmetrik
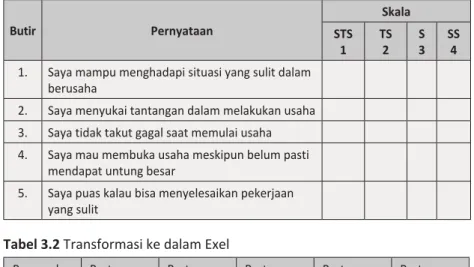
(tidak dalam bentuk angka). Contoh variabel kualitatif dapat digambarkan di dalam pengambilan data berupa angket/kuesioner yang jawabannya berupa data ordinal, yaitu data yang memiliki susunan tertentu. Contohnya pada tabel 3.1 di bawah.
Sebelum suatu kuesioner/angket disebar pada sampel terpilih, hendaknya lakukan pilot studi terlebih dahulu, untuk menguji apakah kuesioner yang akan disebar untuk penelitian, sudah valid dan andal. Untuk hal tersebut, ada dua uji yang perlu dilakukan pada suatu kuesioner. Berikut adalah contoh pertanyaan dari kuesioner yang ingin mengetahui bagaimana profil usaha UMKM (tabel 3.1). Hasil dari kuesioner tersebut kemudian disesuaikan seperti pada tabel 3.2.
Bab 3
18 Aplikasi Komputer Bisnis
Tabel 3.1 Karakteristik Kewirausahaan
Butir Pernyataan STS Skala 1 TS2 S3 SS4
1. Saya mampu menghadapi situasi yang sulit dalam berusaha
2. Saya menyukai tantangan dalam melakukan usaha
3. Saya tidak takut gagal saat memulai usaha
4. Saya mau membuka usaha meskipun belum pasti
mendapat untung besar
5. Saya puas kalau bisa menyelesaikan pekerjaan yang sulit
Tabel 3.2 Transformasi ke dalam Exel
Responden
ke- Pertanyaan 1 Pertanyaan 2 Pertanyaan 3 Pertanyaan 4 Pertanyaan 5 1
... 30
A. Uji Validitas
Uji validitas digunakan untuk mengetahui kelayakan/kevalidan dari tiap pertanyaan dari angket.
Aturan dalam Uji Validitas adalah:
• Valid Jika r-hitung > r-tabel ; r-tabel dengan df= n-k (sampel – jumlah pertanyaan)
• Tidak Valid Jika: r-hitung < r-tabel
Langkah-langkahnya adalah sebagai berikut. Pilih Analyze Scale Reability Analysis.
19
Bab 3 | Data Premier (Kualitatif)
Tabel 3.3 Nilai-nilai r Poduct Moment (Tabel r)
N Taraf Signifikan N Taraf Signifikan N Taraf Signifikan
5% 1% 5% 1% 5% 1% 3 0.997 0.999 27 0.381 0.487 55 0.266 0.345 4 0.95 0.99 28 0.374 0.478 60 0.254 0.33 5 0.878 0.959 29 0.367 0.47 65 0.244 0.317 6 0.811 0.917 30 0.361 0.463 70 0.235 0.306 7 0.754 0.874 31 0.355 0.456 75 0.227 0.296 8 0.707 0.834 32 0.349 0.449 80 0.22 0.286 9 0.666 0.798 33 0.344 0.442 85 0.213 0.278 10 0.632 0.765 34 0.339 0.436 90 0.207 0.27 11 0.602 0.735 35 0.334 0.43 95 0.202 0.263 12 0.576 0.708 36 0.329 0.424 100 0.195 0.256 13 0.553 0.684 37 0.325 0.418 125 0.176 0.23 14 0.532 0.661 38 0.32 0.413 150 0.159 0.21 15 0.514 0.641 39 0.316 0.408 175 0.148 0.194 16 0.497 0.623 40 0.312 0.403 200 0.138 0.181 17 0.482 0.606 41 0.308 0.398 300 0.113 0.148 18 0.468 0.59 42 0.304 0.393 400 0.098 0.128 19 0.456 0.575 43 0.301 0.389 500 0.088 0.115 20 0.444 0.561 44 0.297 0.384 600 0.08 0.105 21 0.433 0.549 45 0.294 0.38 700 0.074 0.097 22 0.423 0.537 46 0.291 0.376 800 0.07 0.091 23 0.413 0.526 47 0.288 0.372 900 0.065 0.086 24 0.404 0.515 48 0.284 0.368 1000 0.062 0.081 25 0.396 0.505 49 0.281 0.364 26 0.388 0.496 50 0.279 0.361
1. Tata Cara Pengerjaan
Salinlah data kuesioner berikut, Ujilah Validitas dari data kuesioner tersebut, dengan menjawab:
a. Berapakah r-tabel dan r-hitung?
20 Aplikasi Komputer Bisnis Responden P1 P2 P3 P4 P5 Responden P1 P2 P3 P4 P5 1 4 4 4 4 4 17 3 3 3 3 3 2 3 4 3 3 3 18 3 3 4 4 3 3 3 2 2 3 3 19 3 3 3 3 3 4 3 3 3 3 3 20 4 4 4 3 3 5 3 3 3 3 3 21 3 2 3 3 3 6 3 2 3 3 3 22 3 3 3 3 3 7 3 3 3 3 3 23 3 2 3 4 4 8 3 3 4 3 4 24 3 2 3 3 2 9 3 3 3 3 3 25 3 2 3 3 3 10 3 3 3 3 3 26 3 3 3 3 3 11 3 3 3 3 3 27 3 3 4 4 3 12 3 3 3 3 3 28 3 3 3 3 3 13 3 3 3 3 3 29 3 3 3 3 2 14 3 2 3 3 3 30 3 3 3 3 3 15 3 2 3 3 3 31 3 3 3 2 3 16 3 4 3 3 3
a. Masukkan data kuesioner di atas dengan ketentuan pada Variabel View sebagai berikut.
b. Pilih Analyze Scale Realibility Analysis; Masukkan Pertanyaan yang akan diuji;
Padaikon Statistics tick Item, Scale, Scale if item deleted, Correlations Pilih OK.
21
Bab 3 | Data Premier (Kualitatif)
c. Untuk Uji Validitas dapat dilihat dari tabel Item-Total Statistics
pada kolom Corrected Item-Total Correction.
Item-Total Statistic Scale Mean if Item Deleted Scale Variance if Item Deleted Corected Item-Total correlation Squared Multiple Correlation Cronbach's Alpha if Item Deleted P1 12.13 1.649 .597 .387 .615 P2 12.32 1.226 .355 .323 .716 P3 12.06 1.262 .676 .504 .522 P4 12.10 1.557 .385 .352 .654 P5 12.16 1.540 .385 .206 .654
22 Aplikasi Komputer Bisnis
d. Uji Hipotesis dengan mengeluarkan semua butir yang tidak valid.
Butir r-hitung tanda r-tabel Keterangan
Pertanyaan 1 0.597 > 0.388 Valid
Pertanyaan 2 0.355 < 0.388 Tidak Valid
Pertanyaan 3 0.676 > 0.388 Valid
Pertanyaan 4 0.385 < 0.388 Tidak Valid
Pertanyaan 5 0.385 < 0.388 Tidak Valid
* df = 31 – 5 = 26 ; = 0.05 r-tabel = 0.388
Dari hasil Uji Validitas tersebut menunjukkan bahwa butir pertanyaan 2, 4 dan 5 tidak valid (karena r-hitung < r-tabel), sehingga ketiga butir pertanyaan tersebut hendaknya dihilangkan dari item yang diuji dan dilakukan tes kembali untuk pertanyaan 1 dan 3. Berikut adalah cara untuk mengeluarkan butir pertanyaan pada SPSS dengan mengulangi kembali langkah-langkah pada poin b (hlm 20). Lakukan penyesuaian pada item (masukkan butir pertanyaan yang valid saja).
e. Hasil Uji Validitas dengan semua butir yang Valid
Item-Total Statistics Scale Mean if Item Deleted Scale Variance if Item Deleted Corected Item-Total correlation Squared Multiple Correlation Cronbach's Alpha if Item Deleted P1 3.13 .183 .544 .296 . P2 3.06 .062 .544 .296 .
23
Bab 3 | Data Premier (Kualitatif)
Uji hipotesa:
Butir r-hitung Tanda r-tabel Keterangan
Pertanyaan 1 0.544 > 0.367 Valid
Pertanyaan 3 0.544 > 0.367 Valid
* df = 31 – 2 = 29 ; = 0.05 r-tabel = 0.367
Dari hasil uji tersebut, menunjukkan semua r-hitung > r-tabel, sehingga butir pertanyaan 1 dan 3 memenuhi persyaratan validitas. Untuk melakukan uji Realibilitas, semua butir pertanyaan harus memenuhi Uji Validitas terlebih dahulu.
B. Uji Reliabilitas
Uji reliabilitas digunakan untuk mengetahui kekonsistensian dari tiap responden dalam menjawab kuesioner. Dikatakan baik jika nilai Cronbach Alpha > 0.6. langkah-langkah dalam melakukan Uji Reliabilitas sama dengan poin b (hlm 20). Uji Reabilitas dapat dilihat dari tabel Raliability Statistics pada kolom Cronbach’s Alpha.
Cronbach's Alpha Based on Standardized Cronbach's Alpha
Items N of Items
.643 .705 2
Dari hasil uji tersebut, menunjukkan nilai dari Cronbach’s Alpha > 0.6, maka dapat disimpulkan bahwa data tersebut realibel (Nugroho, 2005).
25
Bab 4 | Data Sekunder (Kuantitatif)
A. Ekstrak Data Sekunder
1. Pendahuluan
Salah satu elemen penting dalam melakukan penelitian adalah pencarian data. Data sekunder adalah data yang diambil dari sumber yang tersedia.
Contoh data sekunder adalah data yang tersedia di website Badan Pusat Statistik/BPS (www.bps.go.id), Worldbank (www.worldbank. org), bursa efek Indonesia (www.idx.co.id) ataupun merujuk ke database tertentu seperti Bloomberg, Thomson Reuter Datastream. Namun untuk pengoperasian dan mengekstrak data menjadi data yang dapat digunakan, membutuhkan pembelajaran penggunaan dari database atau website tersebut. Pada buku ini akan membahas, bagaimana mengekstrak data sekunder yang ada pada website World Bank. Mahasiswa diharapkan memiliki kemampuan untuk mengunggah data secara sekaligus dan tepat sasaran penelitian yang dilakukan.
2. Mengunggah (Mendownload) Database/Variabel
1) Pilih bahasa yang diinginkan (English). Buka link berikut:
http://databank.worldbank.org/data/databases.aspx (untuk mengganti database/variabel yang diinginkan)
Data Sekunder (Kuantitatif)
Bab 4
26 Aplikasi Komputer Bisnis
Pilih DataPilih DatabasePilih salah satu Indicator Variable seperti “World Development Indicators”
2) Tampilan akan menjadi sebagai berikut.
3) Sesuaikan variabel yang diinginkan (sebagai berikut) Apply Changes
i. Database adalah menu dalam menentukan variabel yang diinginkan (metadata), yang mengandung berbagai variabel yang spesifik. Pada tiap metadata, ada icon yang akan menjelaskan variabel metadata tersebut.
Dalam hal ini, pilihlah World Development Indicators.
ii. Country adalah menu untuk memilih Negara yang diinginkan.
Pilihlah: Indonesia, Malaysia, China, Macao China, Hongkong China.
27
Bab 4 | Data Sekunder (Kuantitatif)
iii. Series adalah Jenis Variabel yang disediakan oleh Indikator yang kita sudah pilih (World Development Indicator).
PIlihlah variabel berikut: GDP per capita growth (annual %), GDP per capita, PPP (current international $), Final consumption expenditure (% of GDP), Foreign direct investment, net inflows (% of GDP), Gross national expenditure (%of GDP), Exports of goods and services (% of GDP), Imports of goods and services (annual % growth).
iv. Time adalah pilihan range waktu data yang ingin diunggah (download).
Pilihlah tahun 1993 sampai dengan 2017.
4) Posisi tata letak (layout) dari File Unggah (download file) dapat dirubah sesuai keperluan, dengan memilih Layout.
28 Aplikasi Komputer Bisnis
5) Untuk penyesuaian tampilan, menu lain yang dapat juga dipilih adalah Layout Custom.
Keterangan:
Menu Column digunakan jika ingin menampilkan variabel dalam bentuk vertikal.
Menu Row digunakan jika ingin menampilkan variabel dalam bentuk horizontal.
Menu Page untuk menentukan pilihan yang diutamakan tampilan variabelnya.
6) Pilihan Download ada beberapa jenis output yang dapat dipilih yaitu Excel, CSV, Tabbed TXT.
7) Hasil Ekstrak
Dari data-data diatas, buatlah hasil ekstrak excel dengan hasil unggahan (download) sebagai berikut.
29
Bab 4 | Data Sekunder (Kuantitatif)
B. Statistik Deskriptif
1. Pendahuluan
Statistika adalah ilmu dalam mengumpulkan, mengorganisasikan, mempresentasikan, menganalisa dan menginterpretasikan data-data numerik untuk mempermudah dalam pengambilan keputusan. Statistik deskriptif adalah metode dalam mengumpulkan, mengorganisasikan, menyimpulkan dan mendeskripsikan suatu data dengan penyampaian yang informatif.
Statistik deskriptif meliputi beberapa bahasan seperti ukuran tendensi sentral, dispersi, dan distribusi data. Ukuran yang digunakan untuk tendensi sentral adalah Mean, Median, Modus. Ukuran umum untuk melihat penyebaran suatu data (disperse) digunakan Standar Deviasi, Varian, dan Standar Error Mean (S.E Mean). Sedangkan, untuk mengukur distribusi data, ukuran yang digunakan adalah Skewness dan Kurtosis. Pada SPSS, untuk men-run Statistik Deskriptif, kita dapat memilih submenu (Menu Utama: Descriptive Statistics) pada analisis Frequencies, Descriptive, Explore, Crosstabs, TRUF Analysis, Ratio, dan Plots. Adapun pilihan dari menu-menu tadi, memiliki kegunaan dan kelebihan tersendiri. Pada buku ini, saya akan membatasi pada submenu Descriptive.
2. Penyajian Statistik Deskriptif
Untuk menampilkan nilai-nilai pada Statistik Deskriptif seperti Mean, Median, Modus, Standar Deviasi, Varian, Range, Minimum dan Maksimum, submenu yang digunakan adalah Descriptive. Dalam
30 Aplikasi Komputer Bisnis
menampilkan data penelitian, disesuaikan dengan tujuan penelitian itu sendiri, sehingga tidak semua nilai-nilai pada Statistik deskriptif perlu ditampilkan.
a. Contoh Soal
Berdasarkan data pada halaman 29, tentukanlah:
a. Berapakah nilai tertinggi dan terendah variabel GDP per capita growth (annual %), GDP per capita, PPP (current international $), dan Final consumption expenditure (% of GDP.
b. Berapakah nilai range, variance, minimum, maksimum, rata-rata dan simpangan baku dari variabel Exports of goods and services (% of GDP), dan Imports of goods and services (annual % growth).
b. Tata Cara Pengerjaan
Langkah-langkahnya adalah sebagai berikut.
1) Untuk memulai langkah awal adalah meng-Import data worldbank ke dalam SPSS (tata cara ada di halaman 7). Berikut adalah penyesuaian yang perlu dilakukan: Pada variabel view, Lakukan pengecekan kembali sub-menu “Measure” pada masing-masing variabel yang ada.
31
Bab 4 | Data Sekunder (Kuantitatif)
3) Pindahkan variabel yang diminta soal a) Option Pilih Ukuran Statistika (sesuai soal yaitu minimum dan maksimum)
ContinueOK.
4) Berikut adalah tampilan Output soal a).
5) Berikut adalah Output untuk soal b).
6) Penjelasan Kolom
Keterangannya adalah sebagai berikut.
32 Aplikasi Komputer Bisnis
- N adalah jumlah data yang diolah. - Minimum adalah nilai terendah dari data. - Maksimum adalah nilai tertinggi dari data. - Mean adalah nilai rata-rata dari suatu data.
- Range adalah jarak dari suatu kumpulan data (Data tertinggi dikurangi Data terendah).
- Standard Deviation adalah besaran simpangan dari suatu data terhadap Mean. Makin kecil nilai Std. Deviasi maka data-data tersebut makin terkumpul mendekati Mean.
- Median adalah nilai tengah dari suatu deretan data yang disusun mulai dari nilai terkecil hingga terbesar.
33
Bab 5 | Distribusi Data (Normalitas)
A. Pendahuluan
Sebelum mengolah data kuantitatif, uji asumsi klasik perlu dilakukan. Pada bab ini akan terfokus pada uji normalitas perlu dilakukan, yang bertujuan untuk mengetahui bagaimana penyebaran distribusi data yang akan digunakan dalam penelitian. Untuk menguji normalitas suatu data dapat dilakukan dengan beberapa cara. Dengan berdasarkan Teorema Nilai Pusat (The Central Limit Theorem), jika banyaknya data
lebih dari 30 (n ≥ 30), maka dapat disimpulkan bahwa data tersebut
terdistribusi normal. Namun untuk memberikan suatu kesimpulan yang lebih konkrit, uji normalitas dapat juga dilakukan dengan SPSS.
Data yang terdistribusi secara normal, dan makin mendekati mean, maka dapat diasumsikan bahwa sampel yang diambil dapat mewakili populasi. Jika suatu data tidak terdistribusi secara normal, beberapa hal yang dapat kita lakukan adalah menambah jumlah sampel (n), membuang nilai ekstrem (outliers), mentransformasi data atau mengganti metode penelitian yang tidak memerlukan asumsi normalitas data. Pada buku ini, akan dijelaskan caraa untuk melakukan uji normalitas pada suatu data yaitu dengan Kolmogorov-Smirnov.
Distribusi Data (Normalitas)
Bab 5
34 Aplikasi Komputer Bisnis
B. Uji Normalitas (Kolmogorov-Smirnov)
Gunakanlah kembali data-data hasil download dari World Bank Database (lihat kembali halaman 29). Berikut adalah langkah-langkahnya: 1) Sesuaikan data hasil unggahan (download) dari World Bank Database
yang berupa excel sebagai berikut.
- Gunakan logaritma (log) pada variabel yang berdata besar, seperti GDP (current US$), Final consumption expenditure (constant 2010 US$) dan Foreign direct investment, net inflows (BoP, current US$).
Penerapan log TIDAK pada data yang berjenis Index, Presentase, growth, rate.
- Hanya gunakan Negara Indonesia, hapuslah Negara-negara lainnya.
- Hapuslah data Indonesia dari tahun 1968-1980. Hal ini dikarenakan nilai FDI di tahun 1968-1980 tidak ada.
2) Data penelitian tidak boleh ada data yang hilang (missing value = #NUM!), karena itu data Indonesia hanya bisa menggunakan data dari tahun 2004-2017.
35
Bab 5 | Distribusi Data (Normalitas)
3) Berikut adalah hasil Variable View di SPSS:
4) Pilihlah AnalyzeDescriptive StatisticsExplore.
Explore Masukkan Variabel yang akan diuji (Dependent List)
Plots.
36 Aplikasi Komputer Bisnis
5) Berikut adalah hasil Outputnya
6) Hipotesa nol (H0) dan Hipotesa Alternatif (H1)
Hipotesa nol dan hipotesa alternatif dalam uji normalitas ini adalah: H01: Variabel logGDP berdistribusi normal.
H11: Variabel logGDP tidak berdistribusi normal.
H02: Variabel GDP growth (annual %) berdistribusi normal. H12: Variabel GDP growth (annual %) tidak berdistribusi normal. H03: Variabel logFINALCONS berdistribusi normal.
H13: Variabel logFINALCONS tidak berdistribusi normal. H04: Variabel logFDI berdistribusi normal.
H14: Variabel logFDI tidak berdistribusi normal.
H05: Variabel Gross national expenditure deflator (base year varies by country) berdistribusi normal.
H15: Variabel Gross national expenditure deflator (base year varies by country) tidak berdistribusi normal.
H06: Variabel Exports of goods and services (% of GDP) berdistribusi normal.
H16: Variabel Exports of goods and services (% of GDP) tidak berdistribusi normal.
37
Bab 5 | Distribusi Data (Normalitas)
H07: Variabel Imports of goods and services (% of GDP) berdistribusi normal.
H17: Variabel Imports of goods and services (% of GDP) tidak berdistribusi normal.
Aturan penolakannya adalah:
• H0 diterima jika p-value pada kolom sig. > level of significance (α).
• H0 ditolak jika p-value pada kolom sig. < level of significance (α).
Jadi, H0 diterima karena p-value (0.200) > α (0.05). Kesimpulannya, variabel logFDI, GDP growth (annual %), logFINALCONS, Exports of goods and services (% of GDP) dan Imports of goods and services (% of GDP) berdistribusi normal.
Adapun variabel logFDI dan Gross national expenditure deflator (base year varies by country) tidak terdistribusi secara normal karena H0 ditolak (p-value 0.000 < α0.05).
Sehingga keseluruhan jumlah data perlu ditambahkan, sampai dengan seluruh variabel-variabel terdistribusi secara normal. Atau jika ingin tetap menggunakan data-data tersebut (Indonesia 2004-2017), maka variabel logGDP dan Imports of goods and services (% of GDP) tidak perlu digunakan di dalam penelitian. Seperti hasil output di bawah ini.
39
Bab 6 | Analisa Korelasi
A. Pendahuluan
Analisa korelasi digunakan untuk mengetahui hubungan antara dua variabel. Hubungan antara dua variabel dinyatakan dalam bentuk koefisien korelasi (r). Ada beberapa analisa korelasi yang dapat digunakan sesuai dengan jenis data penelitian, yaitu Pearson, Spearman dan Kendall. Korelasi Pearson digunakan jika data terdistribusi normal dan data sekunder, sedangkan untuk korelasi Spearman dan Kendall digunakan jika data tidak terdistribusi normal dan data kualitatif. Dalam buku ini akan dibatasi dengan Uji Korelasi Pearson saja.
B. Koefisien Korelasi (r)
Nilai korelasi berkisar antara -1 sampai dengan 1. Tanda positif menunjukkan arah hubungan yang positif/searah antardua variabel, dan tanda negatif menunjukkan arah hubungan yang negatif/berlawanan arah. Tanda berlawanan arah berarti jika satu variabel naik, maka variabel lain akan turun, begitu pula sebaliknya jika tandanya searah, apabila satu variabel naik maka variabel lainnya akan naik juga.
Keeratan hubungan antara dua variabel dinyatakan dari nilai korelasi tersebut. Nilai korelasi yang makin mendekati 1 ataupun -1, maka hubungan antara kedua variabel tersebut sangat kuat sekali. Nilai
Analisa Korelasi
Bab 6
40 Aplikasi Komputer Bisnis
yang makin mendekati 0.0 mengindikasikan hubungan yang lemah. Berikut adalah bagan hubungan keeratan pada korelasi.
(Sumber: Anderson, 2014)
1. Tata Cara Pengerjaan
Gunakan kembali data pada Uji Normalitas (hlm 34 data Indonesia 2004-2017). Pada data tersebut, Bapak Ahmad akan meneliti hubungan antara:
i) logGDP dengan logFDI,
ii) GDP growth (annual %) dengan logFDI, iii) logFINALCONS dengan logFDI,
iv) Exports of goods and services (% of GDP) dengan logFDI, v) Imports of goods and services (% of GDP) dengan logFDI.
Bantulah Bapak Ahmad untuk menentukan hubungan antara variabel tersebut.
1) Data Indonesia 2004-2017 adalah sebagai berikut.
2) Langkah-langkahnya adalah sebagai berikut. Pilih Analyze Correlate Bivariate.
3) Pilihlah menu command (Analyze) Masukkan variabel yang ingin dilakukan uji korelasi Pilih uji korelasi yang sesuai (tick Pearson) OK.
41
Bab 6 | Analisa Korelasi
4) Hipotesa nol (H0) dan Hipotesa Alternatif (H1)
Hipotesa nol dan hipotesa alternatif dalam uji korelasi ini adalah: H01: Variabel GDP growth (annual %) tidak berkorelasi dengan
Variabel logFDI.
H11: Variabel GDP growth (annual %) berkorelasi dengan Variabel logFDI.
H02: Variabel logFINALCONS tidak berkorelasi dengan Variabel logFDI.
H12: Variabel logFINALCONS berkorelasi dengan Variabel logFDI. H03: Variabel Exports of goods and services (% of GDP) tidak
berkorelasi dengan Variabel logFDI.
H13: Variabel Exports of goods and services (% of GDP) berkorelasi dengan Variabel logFDI.
H04: Variabel Imports of goods and services (% of GDP) tidak berkorelasi dengan Variabel logFDI.
H14: Variabel Imports of goods and services (% of GDP) berkorelasi dengan Variabel logFDI.
Hipotesa secara umum:
H0: ρ = 0 (no correlation, tidak ada hubungan/korelasi Antara variabel X dan Y)
H1: ρ≠ 0 (correlation exists, Ada hubungan/korelasi Antara
variabel X dan Y) Aturan penolakannya adalah:
• H0 diterima jika p-value pada kolom sig. > level of significance (α).
• H0 ditolak jika p-value pada kolom sig. < level of significance (α).
42 Aplikasi Komputer Bisnis
5) Hasil output SPSS untuk korelasi kedua variabel sebagai berikut.
6) Analisa korelasinya:
i. GDP growth (annual %) dengan logFDI,
H0 diterima (p-value 0.425 > α0.05). Artinya tidak ada hubungan antara GDP growth (annual %) dan logFDI. Jadi, perubahan nilai GDP growth (annual %), tidak akan memengaruhi perilaku investor dalam menanamkan modal di Indonesia.
ii. logFINALCONS dengan logFDI,
H0 ditolak (p-value 0.016 < α0.05). Artinya ada hubungan antara logFINALCONS dan logFDI yang menunjukkan hubungan yang sedang, erat dan searah (r=0.627). Jadi, jika nilai konsumsi di Indonesia meningkat, maka kecenderungan investor menanamkan modal di Negara tersebut (Indonesia) juga akan mengalami peningkatan.
iii. Exports of goods and services (% of GDP) dengan logFDI,
H0 diterima (p-value 0.08 > α0.05). Artinya tidak ada hubungan antara Exports of goods and services (% of GDP) dan logFDI. Jadi, perubahan nilai Exports barang tidak akan memengaruhi perilaku investor dalam menanamkan modal di Indonesia. iv. Imports of goods and services (% of GDP) dengan logFDI.
H0 diterima (p-value 0.460 > α 0.05). Artinya tidak ada hubungan antara Imports of goods and services (% of GDP) dan logFDI. Jadi, perubahan nilai Imports barang tidak akan memengaruhi perilaku investor dalam menanamkan modal di Indonesia.
43
Bab 6 | Analisa Korelasi
C. Multikolinearitas (Multicollinearity)
Multikolinearitas adalah suatu keadaan di mana variabel-variabel independent memiliki hubungan korelasi yang perfect (r mendekati atau sama dengan 1). Variabel independent saling memengaruhi yang akan menyebabkan nilai koefisien regresi akan cenderung menjadi bias. Multikolinearitas pada umumnya terjadi pada data time-series.
Menurut Gujarati (2003), jika korelasi antara kedua variabel independen melebihi 0,8 maka terdapat masalah multikolineritas. Jika suatu data terdapat masalah multikolineritas, adapun hal yang dapat kita lakukan adalah mengganti variabel independennya dengan variabel lain atau menghapus salah satu variabel independen yang berkorelasi tinggi.
1. Tata Cara Pengerjaan
Lakukan tahapan seperti pada uji korelasi Pearson (poin 1 halaman 40) dan gunakan kembali data tersebut, ujilah apakah ada masalah multikolinearitas pada variabel-variabel independentnya. Variabel dependent (Y) adalah logaritma dari Foreign Direct Investment (logFDI). Variabel-variabel bebas yang memengaruhi variabel dependen adalah variabel GDP growth (annual %), logFINALCONS, Exports of goods and services (% of GDP) dan Imports of goods and services (% of GDP).
44 Aplikasi Komputer Bisnis
2) Hasil Pengamatan:
Pada data di atas terdapat multikolinearitas antara Export of Goods and Services (%) dan logFINALCONS (r > 0,80 yaitu 0,938). 3) Pembersihan data pertama:
Untuk mengatasi masalah Multikolinearitas adalah Salah satu variabel dibuang (Export of Goods and Services (%) atau logFINALCONS) atau diganti dengan variabel lainnya.
3.a Berikut adalah output korelasi, Jika variabel Export of Goods and Services (%) dihilangkan.
3.b Berikut adalah hasil output korelasi, Jika variabel
logFINALCONS dihilangkan. 4) Pembersihan data kedua:
Pembersihan data pertama, lihatlah variabel signifikan mana yang memiliki korelasi lebih tinggi. Dalam hal ini yang signifikan adalah antara logFDI – logFINALCONS (poin 3.a.) dan antara logFDI – Export (poin 3.b).
45
Bab 6 | Analisa Korelasi
Korelasi antara logFDI – logFINALCONS lebih tinggi (0,627) dibandingkan logFDI-Export (-0,483). Dengan demikian sebaiknya variabel yang didelete adalah Export of Goods and Services (%). Walaupun acuan di atas, tidak bisa diterapkan oleh setiap kasus penelitian, namun hal utama yang perlu diperhatikan apakah setelah pembersihan data kedua, data sudah bersih dari masalah multikolinearitas. Dalam poin 5 dapat dilihat selain korelasi lebih lemah dan masih terdapatnya masalah multikolinearitas, jadi variabel Export of Goods and Services (%) sebaiknya dihilangkan. 5) Jadi, antara variabel X sudah tidak terdapat masalah multikolinearitas jika menghilangkan variabel (poin 3.b di atas), Export of Goods and Services (%).
47
Bab 7 | Analisa Regresi
A. Pendahuluan
Analisa regresi adalah proses di dalam statistika untuk mengestimasikan hubungan antara variabel, lebih tepatnya analisa regresi membantu mengestimasikan besarnya nilai variabel dependen (Y) dari perubahan nilai-nilai variabel independennya (Xi). Analisa regresi menunjukkan hubungan sebab akibat, independen variabel berperan sebagai eksperimen variabel yang mempunyai pengaruh akan nilai dari variabel dependen. Persamaan regresi (populasi) adalah sebagai berikut.
Persamaan estimasi regresi bertujuan untuk melakukan estimasi (perkiraan) akan nilai dari populasi. Berikut adalah persamaan estimasi regresi untuk 1 variabel independen (disebut dengan Regresi Sederhana/Simple Regression):
Analisa Regresi
Bab 7
48 Aplikasi Komputer Bisnis
Sedangkan regresi yang memiliki lebih dari 1 variabel independen disebut dengan regresi berganda/Multiple Regression, persamaannya adalah:
Suatu persamaan regresi dikatakan model yang baik apabila model tersebut terbebas dari masalah-masalah (Uji Klasik) seperti multikolinearitas, autokorelasi, heteroskesdastisitas, serta terdistribusi normal (terbebas dari masalah asumsi klasik). Adapun pada buku ini, terbatas untuk membahas beberapa asumsi klasik seperti multikolinearitas, dan normalitas data.
B. Tata Cara Pengerjaan
Pada buku ini, persamaan regresi yang akan dijelaskan adalah Regresi Berganda yang Linier (Linear Multiple Regression). Variabel dependen adalah variabel yang ingin kita jelaskan, sedangkan variabel independen adalah variabel yang digunakan untuk menjelaskan variabel dependen tersebut.
Gunakanlah kembali data-data hasil download dari World Bank Database data Indonesia 2004-2017 (lihat kembali halaman
40). Gunakan data yang sudah bersih dari masalah Normalitas dan Multikolinearitas, maka data yang akan digunakan adalah:
- Variabel dependent (Y) adalah logaritma dari Foreign Direct Investment (logFDI).
- Variabel-variabel bebas (X) yang memengaruhi variabel dependen adalah variabel GDP growth (annual %), logFINALCONS dan Imports of goods and services (% of GDP).
49
Bab 7 | Analisa Regresi
Pada data tersebut, Bapak Aziz akan meneliti hubungan antara GDP growth (annual %), logFINALCONS dan Imports of goods and services (% of GDP) yang memengaruhi Foreign Direct Investment. Bantulah bapak Aziz untuk menentukan persamaan estimasi regresinya.
1) Pilihlah Analyze
Regression Linear.
2) Masukkan Variabel Penjualan pada kotak Dependent Masukkan Variabel Promosi, Penjual, Harga pada kotak Independent(s)
Klik pada Statistics Tick pada bagian Estimates, Model Fit, Collinearity diagnostics dan Durbin-Watson Continus
OK.
Hasil Output dari Regresi akan dijelaskan pada poin-poin berikut.
C. Koefisien Determinasi (R
2)
Koefisien determinasi bertujuan untuk mengetahui seberapa besar porsi dari variabel dependen yang dapat dijelaskan oleh variabel-variabel independen. Koefisien determinasi disebut juga dengan R-Squared
50 Aplikasi Komputer Bisnis
Koefisien determinasi dapat dilihat dari tabel Model Summary. Nilai R2sebesar 72%, artinya 72% dari variabel dependen Y dijelaskan
oleh variabel x1, x2, …, dan xi. Sisanya sebesar 18% (100%-72%), artinya variabel dependent (Y) dijelaskan oleh variabel independent lainnya (variabel lain yang tidak digunakan di dalam persamaan).
Nilai minimal R2 bervariasi tergantung dari penelitian yang dilakukan.
Jika data-data penelitian adalah data makro seperti data Indonesia (FDI, GDP Growth, Export, dll) angka minimal setidaknya 80%. Jika dilihat nilai di atas masih kurang, artinya perlu dilakukan penambahan variabel X baru di luar variabel X yang sudah digunakan.
Jadi, nilai R2 yang tidak cukup besar, sehingga dapat disimpulkan
bahwa model regresi berganda yang dipakai untuk mengestimasikan nilai variabel dependen, kurang baik/layak digunakan untuk penelitian.
Artinya nilai R2 diatas: hanya 72% dari variabel dependen FDI (Y)
yang dapat dijelaskan oleh variabel GDP growth, logFINALCONS dan Import (x1, x2, x3). Sisanya sebesar 18%, artinya variabel FDI dijelaskan oleh variabel X di luar persamaan.
51
Bab 7 | Analisa Regresi
D. Uji Simultan
Uji simultan menggunakan F-test bertujuan untuk menguji persamaan estimasi regresi secara keseluruhan, untuk mengetahui apakah seluruh variabel independen berpengaruh pada variabel dependen. Hasil dari F-tes dapat dilihat dari tabel ANOVA.
Hipotesa secara umum:
H0: ρ2 = 0 (Variabel independen secara bersama-sama tidak
dapat menjelaskan/tidak berpengaruh terhadap nilai dari variabel dependen).
H1: ρ2 ≠ 0 (Variabel independen secara bersama-sama dapat
menjelaskan/berpengaruh terhadap nilai dari variabel dependen). Aturan penolakannya adalah:
• H0 diterima jika p-value pada kolom sig. > level of significance (α).
• H0 ditolak jika p-value pada kolom sig. < level of significance (α). 1) Hipotesa nol dan hipotesa alternatif dalam Analisa Regresi ini
adalah:
H0: Variabel GDP growth (annual %), logFINALCONS, dan Import of Good and Services (%) tidak berpengaruh dengan Variabel logFDI.
H1: Variabel GDP growth (annual %), logFINALCONS, dan Import of Good and Services (%) berpengaruh dengan Variabel logFDI. 2) Hasil Output Regresi (table ANOVA) sebagai berikut.
Analisa regresinya:
H0 ditolak (p-value 0.004 < α0.05). Artinya Variabel GDP growth (annual %), logFINALCONS, dan Import of Good and Services (%) secara bersama-sama berpengaruh terhadap Variabel logFDI.
52 Aplikasi Komputer Bisnis
E. Uji Parsial
Uji parsial menggunakan uji t (t-test) yang bertujuan untuk menguji pengaruh dari masing-masing variabel independen (secara individual) terhadap variabel dependen. Hasil dari uji t (t-test) dapat dilihat dari tabel Coefficients.
Hipotesa secara umum:
H0: β1 = 0 (no linear relationship). H1: β1 ≠ 0 (linear relationship exist).
Aturan penolakannya adalah:
• H0 diterima jika p-value pada kolom sig. > level of significance (α).
• H0 ditolak jika p-value pada kolom sig. < level of significance (α). 1) Hipotesa nol dan hipotesa alternatif dalam analisa regresi ini adalah: H01: Variabel GDP growth (annual %) tidak berpengaruh dengan
Variabel logFDI.
H11: Variabel GDP growth (annual %) berpengaruh dengan Variabel logFDI.
H02: Variabel logFINALCONS tidak berpengaruh dengan Variabel logFDI.
H12: Variabel logFINALCONS berpengaruh dengan Variabel logFDI. H03: Variabel Imports of goods and services (% of GDP) tidak
berpengaruh dengan Variabel logFDI.
H13: Variabel Imports of goods and services (% of GDP) berpengaruh dengan Variabel logFDI.
53
Bab 7 | Analisa Regresi
Artinya:
Variabel GDP growth (annual %) tidak berpengaruh terhadap Variabel logFDI
Variabel logFINALCONS berpengaruh terhadap Variabel logFDI. Variabel Imports of goods and services (% of GDP) tidak berpengaruh terhadap Variabel logFDI.
Persamaan Estimasi Regresinya menjadi:
logFDI = -51,589 + 5,033logFINALCONS
F. Interpretasi pada Model Regresi
Interpretasi dari model regresi pada contoh di atas adalah: Jika jumlah konsumsi meningkat sebanyak 1%, maka nilai Foreign Direct Investment (Investasi Asing) juga akan meningkat sebesar 5,033% (variabel lain dianggap konstan).
G. Jenis-jenis Model Regresi
Interpretasi pada model regresi akan berbeda-beda, tergantung dari jenis model regresi yang digunakan. Jenis-jenis model regresi akan dijabarkan sebagai berikut.
1. Model Linear
Import = 47,468 -1,37 Nilai Tukar
Y (nilai impor dalam US$ juta); X (nilai tukar dalam Rp/US$) kedua data nilai besar, maka tidak perlu di-log-kan.
Interpretasi:
47,648 = Artinya walaupun tidak dilakukan penukaran uang, maka volume impor tetap akan meningkat sebesar 47,648 juta US$.
- 1,37 = Apabila nilai tukar melemah 1 rupiah/US$, maka volume impor akan turun sebesar 1,37 juta US$ (ceteris paribus)
2. Model Logaritma-Logaritma (Log-Log)
LDemand = 2.34 – 2.65LPrice
Interpretasi:
-β1= Apabila harga komoditas naik sebesar 1%, maka permintaan terhadap komoditas tersebut akan turun sebesar 2.65% (β1%).
54 Aplikasi Komputer Bisnis
3. Model Semi Logaritma (Semi Log)
LDemand = 2.34 – 2.65Price
Interpretasi:
-β1= Apabila harga komoditas naik sebesar 1Rp, maka permintaan terhadap komoditas tersebut akan turun sebesar 2.65% (β1%).
4. Model Dummy (Binary)
Variabel dummy digunakan saat klasifikasi variabel dikategorikan menjadi beberapa tingkatan. Misal, variabel jenis kelamin dikategorikan menjadi 2, yaitu lelaki dan perempuan. Klasifikasi yang dilakukan adalah menginput angka 1 pada Excel (jika data tersebut berjenis kelamin lelaki) dan menginput angka 0 pada Excel (jika data tersebut berjenis kelamin perempuan).
Contoh: Gaji = 128,859 + 30,016 Gender + 28, 629 didik + 1,396 usia
Bagaimanakah estimasi gaji yang diterima seorang laki-laki (kode 1), yang berusia 42 tahun, dengan pendidikan terakhir adalah Sarjana
(kode 1)?
Penyelesaian: Gaji = 128.859 + 30.016 (1) + 28.629 (1) + 1.396 (42) = Rp246.136
Sebaliknya jika wanita (kode 0), pendidikan Sarjana dan berusia 35 tahun, berapa estimasi Gaji yang diterimanya?
Penyelesaian: Gaji = 128.859 + 30.016 (0) + 28.629 (1) + 1.396 (35) = Rp206.348
Melalui estimasi di atas, berdasarkan Gender, gaji karyawan lelaki lebih besar dibandingkan dengan gaji karyawan wanita.
55
Bab 8 | Regresi Logistik
Regresi Logistik adalah sebuah pendekatan untuk membuat model prediksi seperti halnya regresi linear atau yang biasa disebut dengan istilah Ordinary Least Squares (OLS) regression. Perbedaannya adalah pada regresi logistik adalah prediksi variabel terikat (Y) bersifat kualitatif yang berskala dikotomi. Skala dikotomi yang dimaksud adalah skala data nominal dengan dua kategori, misalnya: Ya dan Tidak, Baik dan Buruk atau Tinggi dan Rendah. Pada regresi logistik, dimungkinkan data tidak terdistribusi secara normal.
Dalam hal ini, penulis akan membatasi topik dengan menggunakan
model logit. Model logit adalah model regresi non-linear yang menghasilkan sebuah persamaan di mana variabel dependen bersifat kategorikal. Kategori paling dasar dari model tersebut menghasilkan binary values seperti angka 0 dan 1. Angka yang dihasilkan mewakilkan suatu kategori tertentu yang dihasilkan dari perhitungan probabilitas terjadinya kategori tersebut. Gujarati (2003) menjelaskan bahwa penggunaan model logit seringkali digunakan dalam data klasifikasi.
Regresi Logistik
Bab 8
56 Aplikasi Komputer Bisnis
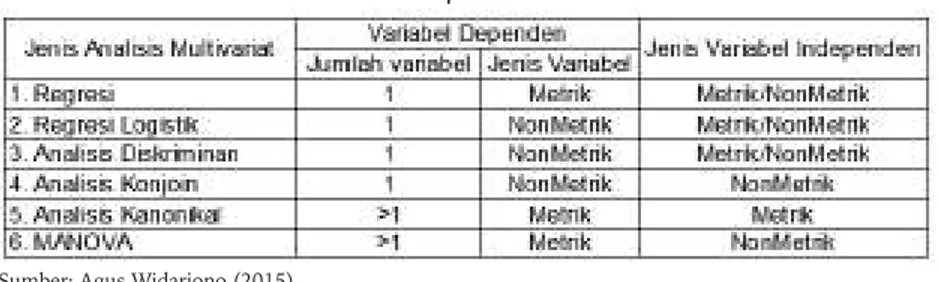
Tabel 8.1 Jenis Teknik Multivariat Dependen
Sumber: Agus Widarjono (2015)
Tabel 8.2 Perbandingan Pengujian OLS dengan Logit Model
OLS Logit Model Goodness of fit R Square Count R-Square
Uji Simultan F-stat Likelihood Ratio
Uji Parsial t-stat Z-Stat
Uji-uji yang akan dilakukan pada regresi Logistik ini adalah Uji Goodness of Fit (R2), Uji Serentak (Overall Model Fit), Uji Parsial,
dan Odds Ratio.
A. Contoh Soal
Ibu Farah ingin melakukan penelitian terhadap Rating Perusahaan (Credit Rating), di mana binary valuenya akan diklasifikasikan menjadi nilai 1 untuk perusahaan yang memiliki peringkat perusahaan BAIK
dengan kategori A, A-, A+, AA, AA-, AA+, AAA dan nilai 0 untuk perusahaan yang memiliki peringkat perusahaan KURANG BAIK
dengan kategori BB, BBB, BBB+. Variabel-variabel independen yang digunakan adalah: Debt Ratio (X1), Cash to Current Liabilities (X2), Debt to EBITDA (X3), Return on Asset (X4), Total Asset_Log (X5), Growth (X6). Berikut adalah data dari 12 perusahaan dari tahun 2014-2017:
57
58 Aplikasi Komputer Bisnis
Dari data di atas, cari pengaruh variabel-variabel independen (Debt Ratio X1, Cash to Current Liabilities X2, Debt to EBITDA X3, Return on Asset X4, Total Asset_Log X5, Growth X6 terhadap variabel dependennya (Rating Perusahaan Y).
B. Uji
Goodness of fit
Uji Goodness of Fit dilakukan untuk melihat seberapa baik suatu model dapat menjelaskan hubungan antara variabel dependen dengan independennya. Atau, seberapa besar variabel dari variabel dependen dapat dijelaskan oleh model.
59
Bab 8 | Regresi Logistik
Pada regresi logistik, parameter yang dilihat pada Uji Goodness of Fit
adalah Pseudo R2 yaitu R Square. Pseudo R-square adalah tiduran R-square
yang digunakan untuk menggantikan R-square biasa. Hal ini dilakukan karena tidak adanya padanan tepat yang dapat menggantikan R-square
biasa (University of CaliforniaAcademic Technology Services, 2007, Dalam Kharisma, 2007). Nilai Pseudo R-square akan menghasilkan nilai yang lebih rendah dibandingkan nilai R-square pada regresi OLS biasa. Oleh karena itu, nilai Pseudo R-square yang berada diantara 0,2 hingga 0,4 dianggap sebagai nilai yang paling baik.
1. Tata Cara Pengerjaan
1) Input data pada SPSS dan sesuaikan worksheet “Data View” dan “Variabel View” sebagai berikut.
60 Aplikasi Komputer Bisnis
2) Pilihlah AnalyzeRegressionBinary Logistic.
3) Masukkan variabel Credit Rating Y pada sub-menu “Dependent” dan variabel independent (x1 – x6) pada sub-menu “Covariates”. Lalu pilih “Options”.
61
Bab 8 | Regresi Logistik
5) Tampilan Output akan menjadi sebagai berikut.
Artinya nilai R2 diatas: hanya 28,1% dari variabel dependen Rating
Perusahaan (Y) yang dapat dijelaskan oleh variabel Debt Ratio X1, Cash to Current Liabilities X2, Debt to EBITDA X3, Return on Asset X4, Total Asset_Log X5, Growth X6.
Sisanya sebesar 71,9%, artinya variabel Rating Perusahaan dijelaskan oleh variabel X lainnya di luar persamaan.
C. Uji Serentak Signifikan
LR (Likelihood Ratio) merupakan pengganti F-stat yang berfungsi untuk menguji apakah semua slope koefisien regresi variabel independen secara bersama-sama memengaruhi variabel dependen.
Dengan hipotesa sebagai berikut.
H0: Semua variabel independen secara bersama-sama tidak memengaruhi variabel dependen yang diuji.
H1: Semua variabel independen secara bersama-sama memengaruhi variabel dependen yang diuji.
Aturan penolakannya adalah:
• H0 diterima jika p-value pada kolom sig. > level of significance (α).
62 Aplikasi Komputer Bisnis
1) Kembali pada Output SPPS
2) Hipotesa nol dan hipotesa alternatif dalam Analisa Regresi ini adalah:
H0: Variabel Debt Ratio X1, Cash to Current Liabilities X2, Debt to EBITDA X3, Return on Asset X4, Total Asset_Log X5, Growth X6 tidak berpengaruh dengan Variabel Rating Perusahaan. H1: Variabel Debt Ratio X1, Cash to Current Liabilities X2, Debt to
EBITDA X3, Return on Asset X4, Total Asset_Log X5, Growth X6 berpengaruh dengan Variabel Rating Perusahaan.
3) Hasil Output Regresi sebagai berikut.
4) Analisanya:
H0 ditolak (p-value 0.028 < α 0.05). Artinya Debt Ratio X1, Cash to Current Liabilities X2, Debt to EBITDA X3, Return on Asset X4, Total Asset_Log X5, Growth X6secara bersama-sama berpengaruh terhadap Variabel Rating Perusahaan.
63
Bab 8 | Regresi Logistik
D. Uji Signifikansi Parsial
Uji Signifikansi parsial untuk melihat secara individual apakah suatu variabel independen berpengaruh terhadap signifikan terhadap variabel dependen dalam regresi.
Hipotesa secara umum:
H0: Variabel independen (x) tidak memengaruhi variabel dependen (Y) H1: Variabel independen (x) memengaruhi variabel dependen (Y)
Aturan penolakannya adalah:
• H0 diterima jika p-value pada kolom sig. > level of significance (α).
• H0 ditolak jika p-value pada kolom sig. < level of significance (α). 1) Hipotesa nol dan hipotesa alternatif dalam analisa regresi ini adalah: H01: Variabel Debt Ratio tidak berpengaruh dengan Variabel Rating
Perusahaan.
H11: Variabel Debt Ratio berpengaruh dengan Variabel Rating Perusahaan.
H02: Variabel Cash to CL tidak berpengaruh dengan Variabel Rating Perusahaan.
H12: Variabel Cash to CL berpengaruh dengan Variabel Rating Perusahaan.
H03: Variabel Debt to EBITDA tidak berpengaruh dengan Variabel Rating Perusahaan.
H13: Variabel Debt to EBITDA berpengaruh dengan Variabel Rating Perusahaan.
H04: Variabel ROA tidak berpengaruh dengan Variabel Rating Perusahaan.
H14: Variabel ROA berpengaruh dengan Variabel Rating Perusahaan. H05: Variabel logTA tidak berpengaruh dengan Variabel Rating
Perusahaan.
H15: Variabel logTA berpengaruh dengan Variabel Rating Perusahaan.
H06: Variabel Growth tidak berpengaruh dengan Variabel Rating Perusahaan.
H16: Variabel Growth berpengaruh dengan Variabel Rating Perusahaan.
64 Aplikasi Komputer Bisnis
2) Kembali pada Output SPPS
3) Hasil Output Regresi (Variabel in the Equation) sebagai berikut.
Artinya:
Variabel Debt Ratio tidak berpengaruh terhadap Variabel Rating Perusahaan.
Variabel Cash to CL tidak berpengaruh terhadap Variabel Rating Perusahaan.
Variabel Debt to EBITDA tidak berpengaruh terhadap Variabel Rating Perusahaan.
Variabel ROA berpengaruh terhadap Variabel Rating Perusahaan. Variabel logTA tidak berpengaruh terhadap Variabel Rating Perusahaan.
Variabel Growth tidak berpengaruh terhadap Variabel Rating Perusahaan.