p-ISSN 2087-1716 e-ISSN 2548-7779
ILKOM Jurnal Ilmiah Volume 10 Nomor 3 Desember 2018
Copyright © 2018 ² ILKOM Jurnal Ilmiah -- All rights reserved | 251
OPTIMASI
K-MEANS CLUSTERING
UNTUK IDENTIFIKASI DAERAH
ENDEMIK PENYAKIT MENULAR DENGAN
ALGORITMA PARTICLE
SWARM OPTIMIZATION
DI KOTA SEMARANG
Suhardi Rustam1, Heru Agus Santoso 2, Catur Supriyanto 3
1[email protected], 2[email protected], 3[email protected]
1Universitas Ichsan Gorontalo,2,3Universitas Dian Nuswantoro
Abstrak
Wilayah tropik merupakan kawasan endemik berbagai penyakit menular. Sekaligus merupakan kawasan yang berpotensi tinggi untuk hadirnya penyakit infeksi baru. Penyakit menular masih merupakan masalah utama kesehatan masyarakat Indonesia. Indentifikasi daerah endemik penyakit menular merupakan persoalan penting dibidang kesehatan, rata-rata tingkat penderita cacat fisik dan kematian bersumber dari penyakit menular. Data Mining dalam perkembangannya menjadi salah satu tren utama dalam pengolahan data. Data Mining secara efektif bisa mengidentifikasi wilayah endemik dari hubunngan antar variable. Algoritma k-means klustering digunakan dengan tujuan mengelompokkan daerah endemik sehingga pengidentifikasian endemik penyakit menular bisa tercapai dengan tingkat validasi yang maksimal dalam klastering. Penggunaan optimasi dalam mengidentifikasi daerah endemik penyakit menular menggabungkan algoritma k-means clustering dengan optimasi particle swarm optimization ( PSO ). hasil eksperimen endemik untuk algoritma k-means dengan iterasi =10, K-Fold =2 memiliki Indek davies bauldin = 0.169 dan algoritma k-means dengan PSO, iterasi = 10, K-Fold = 5, memiliki index davies bouldin = 0.113. k-fold = 5 memiliki performance yang lebih baik. Kata Kunci: Endemik Penyakit menular, Data Mining, Klustering, K-Means, Particle Swarm
Optimization
Abstract
Tropical regions is a region endemic to various infectious diseases. At the same time an area of high potential for the presence of infectious diseases. Infectious diseases still a major public health problem in Indonesia. Identification of endemic areas of infectious diseases is an important issue in the field of health, the average level of patients with physical disabilities and death are sourced from infectious diseases. Data Mining in its development into one of the main trends in the processing of the data. Data Mining could effectively identify the endemic regions of hubunngan between variables. K-means algorithm klustering used to classify the endemic areas so that the identification of endemic infectious diseases can be achieved with the level of validation that the maximum in the clustering. The use of optimization to identify the endemic areas of infectious diseases combines k-means clustering algorithm with optimization particle swarm optimization ( PSO ). the results of the experiment are endemic to the k-means algorithm with iteration =10, the K-Fold =2 has Index davies bauldin = 0.169 and k-means algorithm with PSO, iteration = 10, the K-Fold = 5, index davies bouldin = 0.113. k-fold = 5 has better performance.
Keywords: Endemic infectious Disease, Data Mining, Clustring, K-Means, Particle Swarm Optimization
1. Pendahuluan
wilayah tropik dan wilayah dinamik secara sosial ekonomi, merupakan kawasan endemik berbagai penyakit menular. Sekaligus merupakan kawasan yang berpotensi tinggi untuk hadirnya penyakit infeksi baru. Penyakit menular masih merupakan masalah utama kesehatan masyarakat Indonesia. Penyakit menular tidak mengenal batas-batas daerah administratif, misalnya antar propinsi, Kabupaten/kota bahkan antar negara. menghilangkan sumber penyakit dengan cara menemukan dan mencari kasus secara proaktif dan mengurangi Intervensi faktor resiko, misalnya lingkungan dan intervensi terhadap perilaku. Endemik ditandai dengan adanya kondisi/keadaan dimana penyakit secara menetap berada dalam masyarakat pada suatu tempat/populasi tertentu, suatu infeksi penyakit disebut sebagai endemik jika kondisi/keadaan setiap orang yang terinfeksi penyakit menularkannya kepada setiap orang dalam kondisi rata-rata[1]. Variabel-variabel endemik secara umum seperti Nama Penyakit, Agen/Pembawa, tubuh pasien, kondisi lingkungan dan kepadatan penduduk.
Beberapa penyakit menular, menjadi perhatian pemerintah untuk ditangani secara komputasi. Teknologi komputasi yang telah berkembang dengan kemampuan yang dimiliki memberikan beberapa solusi untuk menganalisis permasalahan-permasalahan yang muncul dalam melihat kesehatan
masyarakat. Teknologi komputasi mampu memberikan analisa pandangan dengan bentuk persentase angka dengan perhitungan tersendiri berdasarkan metode yang digunakan. Teknologi komputasi memberikan cara menganalisa akurasi terhadap jenis data, pengelompokkan data, mengatur variable dan pengaruh terhadap setiap variable. Terdapatnya daerah penyakit menular dituntut untuk mengelompokkan penyakit menular berdasarkan daerah endemik.
Secara komputasi, dalam pengolahan data komputasi memenggunakan beberapa metode seperti klustering, Analisis kluster merupakan suatu teknik klasifikasi tanpa pengawasan, menurut kriteria kesamaan tertentu untuk mengklasifikasikan dataset, sehingga objek dari kelas yang mungkin sama, tapi itu adalah keragaman mungkin antara objek yang berbeda, k-means adalah algoritma klustering klasik berdasarkan partisi, algoritma k-means memiliki banyak keuntungan mudah dimengerti, sederhana, konvergensi cepat dan sebagainya, tetapi memiliki kekurangan: sensitif untuk memilih pusat pengelompokan awal dan mudah konvergen untuk optimasi local[2]. Fungsi yang paling penting dari algoritma klustering mengukur kesamaan untuk menentukan bagaimana menutup dua pola data ke satu sama lain. Lebih dari ribuan algoritma pengelompokan dirumuskan dalam berbagai makalah penelitian termasuk metode pengelompokan tradisional dan teknik optimasi yang berbeda [3].
k-means klustering belum optimal sehingga perlu menerapkan metode particle swarm
optimization (PSO). particle swarm optimization (PSO) adalah teknik pencarian dan optimasi [3]. Hal ini
efisien untuk memecahkan masalah optimasi. Partisi klustering dapat dianggap sebagai masalah optimasi, karena kita perlu mengoptimalkan nilai jarak antar dan antar kluster. PSO dapat dikombinasikan dengan partisi pengelompokan untuk mengatasi keterbatasan partisi klustering, dan kombinasi ini dapat menghasilkan kluster yang berkualitas tinggi. Optimasi ini terpercaya juga dalam
memastikan pusat kluster baru berdasarkan total kluster yang tertentukan[4]. Algoritma ini akan
dimaksimalkan dengan metode k-means klustering dalam kelompok awal, selanjutnya PSO memperbaiki kelompok data dari hasil bentukan k-means clustering.
Penelitian ini akan dilihat bagaimana Mengidentifikasi daerah endemik penyakit menular
berdasarkan asal pasien dengan k-means klustering yang memungkinkan untuk mengoptimasi k-means dengan PSO sehingga dihasilkan informasi yang lebih bermutu
2. Metode
Penelitian ini, mempergunakan cara penelitian eksperimen, untuk tahap penelitian dimulai dari pengumpulan data sampai dengan mendapatkan hasil evaluasi dan hasil untuk mendapatkan tujuan yang akan dicapai[5], adapun tahapannya adalah, di mulai dari penyiapan dataset kemudian dilakukan langkah prepossessing terhadap data untuk menghilangkan outliernya, selanjutnya adalah menormalisasikan data kemudian menggunakan tool rapidminer untuk mengelola data tersebut dengan
menggunakan metode PSO-k-means clustering.
2.1 Pengumpulan Data
Pada penelitian tersebut, yang data digunakan ini, juga diperoleh dari penelitian yang dilakuan pada Rumah Sakit/Puskesmas di kota semarang propinsi jawa tengah. Data diperoleh dari sistem rekam medis Rumah Sakit Umum Daerah (RSUD) kota Semarang. Sebagai data sekunder dengan mengajukan surat penelitian dari instansi untuk pengambilan data rekam medis pasien yang berkaitan dengan penyakit menular. Beberapa variabel yang terdapat dalam dataset tersebut adalah:
1. Variabel Kecamatan, terdiri dari a. Id Kecamatan
b. Nama Kecamatan c. Luas Kecamatan d. Jumlah Penduduk 2. Variabel Endemik, terdiri dari
a. Id Penyakit b. Nama Penyakit c. Jumlah Pasien
p-ISSN 2087-1716 e-ISSN 2548-7779
ILKOM Jurnal Ilmiah Volume 10 Nomor 3 Desember 2018
Copyright © 2018 ² ILKOM Jurnal Ilmiah -- All rights reserved | 253 Gambar 1. Tabel Penyakit Endemik
Gambar 2.Tabel icd Penyakit Endemik
2.2 Pengolahan Data Awal
Penelitian ini dibatasi hanya pada tahapan ini melakukan preprocessing terhadap data untuk
menghilangkan outlier, merapikan setiap variable yang terkait sehingga siap untuk ke tahap penggunaan selanjutnya
2.3 Eksperimen
Ekperimen pada tahan ini adalah menjalankan seluruh prosedur yang telah ditentukan/disusun dalam sebuah kerangka pemikirian untuk menyelesaikan masalah, adapun tahapannya adalah sebagai berikut.:
Tahap 1, Preprosessing Tahap 2, Algoritma k-means [6]
Setiap tahapan dalam melakukan clustering dengan algoritma K-Means yaitu :
a. Awali dengan memilih jumlah cluster k
b. Berikan Inisialisasi k pusat cluster tersebut maka akan dilakukan dengan berbagai cara. tetapi
paling sering dilakukan adalah dengan cara random. Pusat-pusat cluster diberi nilai awal dengan angka-angka random,
c. Juga alokasikan semua data/objek ke cluster terdekat. Kedekatan dua objek ditentukan
berdasarkan jarak kedua objek tersebut.halnya juga kedekatan suatu data ke cluster tertentu
ditentukan jarak antara data dengan pusat cluster. tahap ini juga perlu dihitung jarak tiap data
ke tiap pusat cluster. jarak paling dekat antara satu data dengan satu cluster tertentu akan
menentukan suatu data masuk dalam cluster mana dengan menggunakan teori jarak Euclidean.
d. Juga Hitung kembali pusat cluster dengan keanggotaan cluster yang terkini. Pusat cluster
merupakan rata-rata dari semua data/objek dalam cluster tersebut. Jika dikehendaki bisa juga
digunakan median dari cluster tersebut. Jadi rata-rata(mean) bukan satu-satunya ukuran yang
e. Akhirnya tugaskan lagi setiap objek memakai pusat cluster yang baru. Jika pusat cluster tidak
berubah lagi maka proses clustering selesai. Atau, kembali ke langkah nomor 3 sampai pusat
cluster tidak berubah lagi Tahap 3, optimasi dengan PSO [7]
Langkah-langkah dalam Algoritma PSO untuk klastering Langkah 1 : Pendefinisian pusat klaster awal.
Pada langkah ini, ditentukan posisi titik awal sebagai pusat klaster data sebanyak k titik data
secara random.
Langkah 2 : Pengelompokan data ke dalam klaster
Pada langkah ini, data dimasukkan ke dalam salah satu klaster yang mempunyai pusat klaster terdekat dengan data tersebut. Besar kecilnya nilai jarak sangat menentukan letak data tersebut akan
dimasukkan dalam klaster mana. Dalam menghitung jarak antara data ke pusat cluster, dapat
digunakan rumus jarak Euclidean. Perhitungan jarak pada algoritma ini dilakukan untuk masing-masing
data ke setiap pusat cluster. sehingga jika terdapat N data dan k pusat cluster maka akan dihasilkan
sebanyak (N x k) perhitungan jarak. Selanjutnya, dari hasil perhitungan jarak data dengan pusat cluster
akan dicari nilai minimun untuk masing-masing data. Nilai minimun menunjukkan bahwa data lebih dekat dengan pusat klaster tersebut, sehingga data akan lebih tepat ditempatkan kedalam klaster tersebut.
Langkah 3 : Perhitungan nilai sum of squared error (SSE)
Dalam penelitian ini, SSE merupakan fitness function yang akan dicari nilainya dalam algoritma
clustering. SSE inilah yang akan dicari nilai optimalnya (minimun) dengan menggunakan algoritma PSO
Langkah 4 : Optimasi cluastering dengan PSO
Dalam algoritma PSO clustering pada penelitian ini, pusat cluster mewakili partikel. Set solusi
yang diperoleh nantinya adalah pusat cluster yang baru, yang diharapkan akan menghasilkan
perhitungan SSE yang lebih kecil daripada SSE sebelumnya. Sebelum memulai optimasi klastering
untuk iterasi awal perlu didefenisikan terlebih dahulu kecepatan awal partikel (V0), dengan
memperhatikan batas kecepatan. Jika nilai V0 lebih besar dari batas maksimun atau lebih kecil dari
batas minimun, nilai kecepatan ditetapkan sama dengan batas. Dalam algoritma klastering pada penelitian ini, nilai rata-rata yang digunakan adalah nilai rata-rata terbaik dari semua solusi, pada penelitian ini adalah pencarian nilai optimal pada pengelompokkan data ke tiap klaster dengan
memperhitungkan nilai terbaik dari semua data. Langkah selanjutnya adalah meng-update posisi pusat
cluster, dengan cara menjumlahkannya dengan nilai kecepatan. Setelah pusat klaster secara random
di-update, maka akan diperoleh k titik pusat cluster dilakukan tahapan dalam langkah 2 dan langkah 3,
sehingga diperoleh nilai SSE dan cluster terbaik untuk tiap-tiap data.
Langkah 5: Meng-update nilai SSE
Nilai SSE yang diperoleh paling akhir kemudian dibandingkan dengan nilai SSE sebelumnya,
jika nilai SSE tersebut lebih kecil dari nilai SSE sebelumnya, maka pusat cluster yang dihasilkan akan
menjadi pusat cluster yang baru.
Langkah 6: Kembali ke langkah 4
Pengulangan dilakukan sampai terjadi stopping condition, yaitu setelah beberapa kali iterasi sesuai yang telah ditentukan sebelumnya.
Berikut ini adalah Pseudo-Code untuk algoritma PSO clustering :
1. Mulai
2. Mendefenisikan populasi data yang akan diklasterkan, jumlah klaster (k), serta jumlah iterasi
maksimum (maxiter).
3. Memilih sebanyak k data secara random dari populasi sebagai pusat cluster.
4. Mengelompokkan data berdasarkan jarak terdekat data ke pusat klaster. Perhitungan jarak menggunakan rumus jarak Euclidean
5. Menghitung nilai sum of squared error (SSE) klaster menggunakan persamaan SSE
6. Inisialisasi parameter PSO, me-generate nilai kecepatan awal (V0) dengan memperhatikan
batas kecepatan yang telah ditentukan 7. Iterasi mulai dilakukan
8. Untuk i = 1 sampai k, lakukan proses update kecepatan;
a. Mencari Xgi, yaitu nilai rata-rata data dari semua solusi
b. Jika clusteri tidak memiliki anggota, kecepatan = 0, sebaliknya jika clusteri memiliki
anggota, dilakukan proses update kecepatan dengan memperhatikan batas kecepatan.
c. Meng-Update posisi pusat cluster
9. Selesai loopingi, diperoleh pusat cluster baru
10. Mengulangi langkah 4 dan 5 untuk pusat cluster baru.
p-ISSN 2087-1716 e-ISSN 2548-7779
ILKOM Jurnal Ilmiah Volume 10 Nomor 3 Desember 2018
Copyright © 2018 ² ILKOM Jurnal Ilmiah -- All rights reserved | 255
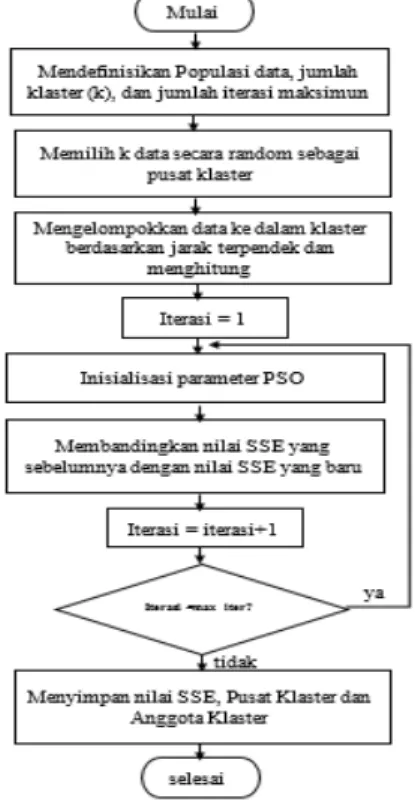
Pseudo-code diatas dapat digambarkan dalam bentuk sebagai berikut :
Gambar 3. Flowchart Algoritma PSO Clustering
2.4 Evaluasi
Pengujian eksperimen yang dilakukan berupa berbandingan Perbandingan dengan cosine similarity
dalam kluster serta menampilakan uraian analisi daerah endemik dengan validasi davis bouldin index (IDB).
3. Hasil dan Pembahasan 3.1 Hasil Pengumpulan Data
Pengumpulan data dilakukan dengan mendapatkan variabel yang sesuai dari dataset endemik, dengan variabel. Data yang digunakan pada penelitian ini dikumpulkan berdasarkan data Penderita Penyakit di kota Semarang RS.Karyadi sebagai Rumah Sakit umum dan rujukan di kota Semarang Jawa Tengah.
Tabel 1. Data Endemik (Contoh)
No Kd_Endemik nm_endemik kd_ jnsKlmin jns_klamin kd_wilyh nm_wilyah Luas_wil jml_pnddk Kpdtn_Pndduk nm_penyakit jml_pasien
1 3 Cinkunya N Laki-laki 1 Banyumanik 25.69 130494 5079 Cholera 1
2 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Cholera due to Vibrio cholerae 01, biovar cholerae 1
3 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Cholera due to Vibrio cholerae 01, biovar eltor 1
4 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Cholera, unspecified 1
5 3 Cinkunya N Laki-laki 1 Banyumanik 25.69 130494 5079 Typhoid and paratyphoid fevers 2
6 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Typhoid fever 2
7 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Paratyphoid fever A 2
8 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Paratyphoid fever B 2
9 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Paratyphoid fever C 2
10 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Paratyphoid fever, unspecified 2
11 3 Cinkunya N Laki-laki 1 Banyumanik 25.69 130494 5079 Other salmonella infections 6
12 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Salmonella enteritis 6
13 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Salmonella sepsis 6
14 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Localized salmonella infections 6
15 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Other specified salmonella infections 6
16 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Salmonella infection, unspecified 6
17 3 Cinkunya N Laki-laki 1 Banyumanik 25.69 130494 5079 Shigellosis 3
18 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Shigellosis due to Shigella dysenteriae 3
19 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Shigellosis due to Shigella flexneri 3
20 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Shigellosis due to Shigella boydii 3
21 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Shigellosis due to Shigella sonnei 3
22 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Other shigellosis 3
23 4 Malariya T Perempuan 1 Banyumanik 25.69 130494 5079 Shigellosis, unspecified 3
24 3 Cinkunya N Laki-laki 1 Banyumanik 25.69 130494 5079 Other bacterial intestinal infections 6
3.2 Preprocessing
Preprosessing dataset endemik dengan menggunakan fitur Replace Missing Value, fitur ini
menghasilkan data yang telah siap diujikan, adapun hasilnya adalah sebagai berikut : Tabel 2. Data Endemik tahap Preprocessing
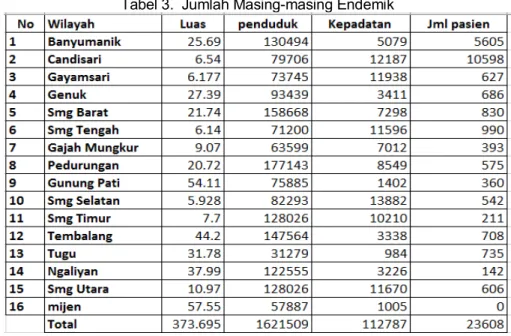
Pemilihan atribut dengan memilih variabel yang saling berkaitan yaitu, variabel nama endemik, luas wilayah, jumlah penduduk, kepadatan penduduk dan jumlah penderita/pasien. Dalam pemilihan nama endemik yang memiliki kesamaan rata-rata disetiap wilayah yaitu endemik cinkunya dan malaria sehingga nama endemik yang difokuskan adalah cinkunya.
Tabel 3. Jumlah Masing-masing Endemik
Pada eksperimen ini algoritma klustering k-means dengan optimasi PSO (particle swarm optimization ) digunakan sebagai pembanding dalam pengelompokkan daerah endemik
cinkunya, pengujian menggunakan model Cluster Number index (keseluruhan nilainya memiliki
kesaman) dan davies bouldin index (IDB). Dengan bobot awal w = 0.36 yang di set denga K=2
dengan pertimbangan nilai validasi ini perbandingakan dengan IDB means dan IDB k-means+PSO dengan Lbest 1.0 dan Gbest 1.0 menghasilkan IDB 0.165. dengan nilai tersebut menjadi nilai terukur yang bermutu, adapun tabel kedua perbandingan validasi adalah sebagai berikut
Tabel 4 Evaluasi K-Means, K-Means dengan PSO
Metode Lbest Gbest K-Fold IDB
K-Means 0.25 0.25 5 0.136
0.25 0.5 5 0.174
1.0 1.0 5 0.165
p-ISSN 2087-1716 e-ISSN 2548-7779
ILKOM Jurnal Ilmiah Volume 10 Nomor 3 Desember 2018
Copyright © 2018 ² ILKOM Jurnal Ilmiah -- All rights reserved | 257 Tabel 5. Evaluasi Hasil K-Means, K-Means dengan PSO
Validasi Iterasi K-Means K-Means dengan PSO
Davie Bouldin Index 10 0. 168 0.136
0.180 0.174
- 0.165
Tabel 6. Hasil Eksperimen Data Endemik
Dataset Metode Iterasi K-Fold Index Davies Bouldin
Endemik (Cikunya) K-Means 10 2 0.169 K-Means+PSO Lbest = 1.0 Gbest = 1.0 10 5 0.113
Dari tabel 6 menunjukkan hasil eksperimen endemik untuk algoritma k-means dengan iterasi =10, k-fold =2 memiliki indek davies baouldin = 0.169 dan algoritma k-means dengan PSO, iterasi = 10, k-fold = 5, memiliki index davies bouldin = 0.113, hasil ini memberikan perbedaan k-mean dalam pemilihan kluster adalah random dan k-means dengan PSO memberikan nilai pada hasil sum of square pada hasil random acak, dengan k-fold = 2, memiliki IDB = 0.169 dan k-fold = 5, memiliki IDB 0.113. maka k-fold = 5 memiliki performansi yang lebih baik.
Gambar 4. K-Means Klustering
Gambar 4 menunjukkan wilayah-wilayah endemik dengan jumlah pasien dengan menggunakan algoritma K-means klustering.
Gambar 5. menunjukan wilayah-wilayah endemik dengan didasarkan pada bobot, untuk algoritma k-means dengan optimasi PSO.
4. Kesimpulan dan Saran
Berdasarkan hasil eksperimen dan pembahasan, maka dengan ini dapat simpulkan bahwa Dalam penelitian ini dilakukan pengujian model dengan menggunakan algoritma k-means dengan optimasi PSO (particle swarm optimization) untuk data endemik. Model yang dihasilkan diuji untuk mendapat nilai SSE (sum of square error) dan dari nilai ini digunakan sebagai bobot awal optimasi untuk mendapatkan Nilai IDB (davies bouldin index) sebagai nilai ukur terhadap validasi data endemik. Untuk selanjutnya nilai IDB k-means dengan optimasi PSO dibandingkang dengan k-mean klustering. Maka dapat disimpulkan pengujian model daerah sebaran endemik dengan menggunakan k-means dengn optimasi PSO (particle swarm optimization) Lebih baik dari pada K-Means sendiri, bahwa K-Means
dengan optimasi PSO (particle swarm optimization) memberikan pemecahan untuk permasalahan
identifikasi daerah endemic penyakit menular yang lebih akurat dan bermutu saran yaitu Penambahan variabel yang lebih banyak dan saling berkaitan dalam mengidentifikasi daerah endemik penyakit menular sangat dibutuhkan, sehingga dapat menghasilkan pola klustering daerah endemik dengan tingkat validasi yang lebih akurat.
5. Terima Kasih
Saya dengan ini mengucapkan banyak terima kasih atas sharing ide ilmu dari rekan sesama dosen dan peneliti di fakultas ilmu komputer universitas ichsan gorontalo, semoga di bidang ilmu komputer selalu dikembangkan dan diteliti terus-menerus
Daftar Pustaka
[1] Achmadi UF,2009. Manajemen Penyakit berbasis wilayah. Jurnal Kesehatan Masyarakat Nasional Vol. 3,No.4
[2] Van der Merwe DW, Engelbrecht AP. 2003. Data Clustering using Practicle Swarm Optimization, University of Pretoria, IEEE 0-7803-7804-0/03, hlm 215-220.
[3] Fan Y. 'R ³VPDUW´ SODFHV KDYH OHVV XUEDQ KHDOWK SHQDOW\".2009. 47th International Making Cities
Livable Conference; Portland, Oregon
[4] Han Jiawei, 2006. Kamber M.Data mining: Concepts and techniques.2nd ed.Beijing: China Machine
Press
[5] Hasibuan, A Zaenal .2007. Metodelogi Penelitian Pada Bidang Ilmu Komputer dan Teknologi Informasi. 20 Juli 2018
[6] Agusta, Y.2007, K-means-Penerapan, Permasalahan dan Metode Terkait. Jurnal Sistem dan
Informatika Vol.3 (Februari):47-60
[7] Utami Nanik. Dkk,. Aplikasi Metode Particle Swarm Optimization(PSO) dalam Clustering. ITS