Pembobotan TF-IDF pada Judul Penelitian Dosen Sebagai Dasar
Klasifikasi Menggunakan Algoritma K-NN
(Studi Kasus: Universitas Siliwangi)
Agus Supriatman
Program Studi Pascasarjana Magister Sistem Informasi, STMIK LIKMI, Bandung Koresponden email: [email protected]
Diterima: 1 Desember 2020 Disetujui: 23 Desember 2020
Abstract
The rapid and inexpensive development of digital storage media technology has led to an increase in the number of electronic documents stored on storage systems such as those in universities. Various academic scientific works, such as articles , research reports, etc., are available in digitally . In addition to teaching activities, lecturers are also required to research to deepen their knowledge. With so much research, of course, the resulting research will be very diverse, which is why it is deemed necessary to have groupings related to the title or topic of the research carried out so that it can support the management of Siliwangi University in achieving its goals. Using TF-IDF weighting in text mining on a research title data set, it is known that the optimal number of k in this study is k = 4 with an accuracy rate of 90.7% and the resulting number of each group is 115 scientific titles, 142 social titles, and 98 educational titles for a total of 355 research titles.
Keywords: research, classification, K-NN, TF-IDF, text mining
Abstrak
Perkembangan teknologi media penyimpanan digital yang pesat dan murah telah menyebabkan lonjakan jumlah dokumen elektronik yang disimpan di pada sistem penyimpanan seperti yang ada di universitas. Berbagai karya ilmiah dari kalangan akademisi, seperti makalah, laporan penelitian, dan lain-lain tersedia dalam bentuk digital. Selain kegiatan mengajar, dosen dituntut juga untuk melakukan penelitian guna memperdalam ilmunya. Dengan banyaknya penelitian, tentunya penelitian yang dihasilkan akan sangat beragam, oleh karena itu dipandang perlu adanya pengelompokan terkait dengan judul atau topik penelitian yang dilakukan sehingga dapat menunjang pihak pengelola Universitas Siliwangi dalam mencapai tujuannya. Penggunaan pembobotan TF-IDF pada text mining pada sekumpulan data judul penelitian maka diketahui jumlah k optimal pada penelitian ini adalah k=4 dengan tingkat akurasi 90,7% dan menghasilkan jumlah dari setiap kelompok sebesar 115 judul untuk science, 142 judul untuk social, dan 98 judul untuk education dari total keseluruhan 355 judul penelitian.
Kata Kunci: penelitian, klasifikasi, K-NN, TF-IDF, text mining
1. Pendahuluan
Pada setiap sudut kehidupan kita dapat menjumpai banyak sekali data yang bisa kita gali untuk bisa dijadikan sebuah informasi yang dibutuhkan, mulai dari bidang kesehatan, pertanian, ekonomi, pendidikan, dan masih banyak lagi bidang lain yang seluruhnya dipastikan memiliki data yang dapat diolah. Pencarian sebuah informasi dari data yang ada bisa dilakukan secara langsung jika data tersebut masih dalam ukuran kecil sehingga informasi bisa didapatkan dengan mudah. Namun tidak demikian bila data yang akan diolah tersebut mempunyai ukuran yang besar, sehingga informasi yang dihasilkan sulit untuk didapatkan dengan cara-cara yang sederhana. Untuk mempermudah hal tersebut maka digunakanlah sebuah alat yang dinamakan data mining.
Menurut [1], data mining adalah proses mengekstraksi informasi dari sekumpulan data yang berukuran besar data tersebut diolah dengan menggunakan algoritma dan teknik menggambar statistik,
machine learning serta sistem pengelolaan basis data. Sebagai proses pencarian informasi dari
sekumpulan data yang akan dijadikan sebagai pengetahuan baru yang dapat dimanfaatkan maka dari itu data mining juga seringkali dikenal dengan sebutan Knowledge Discovery in Database (KDD). [2] Tahapan KDD terdiri dari seleksi, per-processing, transformasi, data mining, dan interpretasi. [3] fungsi
Text mining merupakan salah satu metode pencarian informasi dari sekumpulan data teks [4]. Tahapan pada text mining umumnya adalah text preprocessing dan feature selection [5], kata yang terdapat pada data teks yang akan di mining akan dirubah bentuk akhirnya kedalam sebuah kata dasar [6]. Berdasarkan penelitian terkait, terdapat beberapa algoritma stemming yang bisa digunakan untuk stemming pada kata yang berbahasa Indonesia diantaranya seperti algoritma Porter stemmer bahasa Indonesia, Confix-Stripping, algoritma Arifin dan Sutiono, dan algorima Idris. Algoritma
Confix-Stripping adalah suatu algoritma atau metode yang akurat dalam proses stemming bahasa Indonesia [7].
Pada dasarnya, proses text mining menggunakan banyak penelitian data mining, namun perbedaannya adalah pola yang dipilih dalam text mining diekstrak dari kumpulan bahasa natural. Format bahasa natural ini tidak terstruktur, sedangkan dalam data mining, pola yang digunakan berasal dari database terstruktur [8].
K-Nearest Neighbor adalah metode yang umum digunakan dalam klasifikasi data. Metode ini
digunakan untuk mengklasifikasikan objek berdasarkan data pembelajaran. Pada metode ini klasifikasi dilakukan dengan cara melihat kedekatan jarak satu data dengan data yang lainnya [9]. Algoritma TF-IDF bisa digunakan pada tahap pembobotan kata pada judul terhadap query [10]. Dari sisi data latih yang jumlahnya besar, KNN memiliki keunggulan tersendiri. Karena metode ini merupakan salah satu metode klasifikasi data yang paling umum digunakan, khususnya data teks, yang akan dibandingkan untuk menentukan akurasi klasifikasi yang terbaik [11].
Untuk menentukan jarak pada algoritma K-Nearest Neighbor ini dapat mengikuti langkah sebagai berikut [12]:
1. Melakukan pemilihan parameter k (jumlah tetangga paling dekat) 2. Menentukan kuadrat jarak terhadap data training yang diberikan 3. Hasil diurutkan secara ascending atau naik
4. Memilih sesuai kategori y (klasifikasi Nearest Neighbor berdasarkan nilai k)
5. Dengan menggunakan kategori Nearest Neighbor yang paling banyak maka dapat diprediksikan kategori objek
Berikut beberapa formula yang digunakan dalam algoritma K-NN [13]:
1. EuclideanDistance ... (1) 2. ChebychevDistance ... (2) 3. Manhattan Distance ... (3) 4. Minkowski Distance ... (4)
5. Cosinus Similarity Distance
... (5) Kelebihan algoritma KNN adalah sebagai berikut [14] :
1. Pelatihan sangat cepat
2. Sederhana dan mudah dipelajari
3. Tahan terhadap data pelatihan yang memiliki derau 4. Efektif jika data pelatihan besar
Selain kelebihannya KNN juga mempunyai kekurangan seperti dibawah ini [15]: 1. Nilai k menjadi bias
2. Komputasi yang kompleks 3. Keterbatasan memori
4. Mudah tertipu dengan atribut yang tidak relevan
2. Metodologi Penelitian
Alur Penelitian
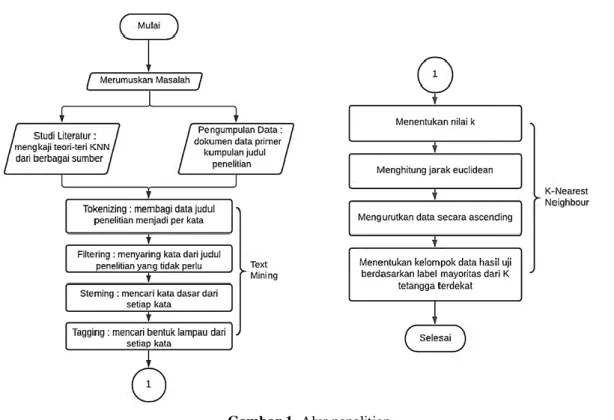
Dalam melakukan sebuah penelitian tahapan-tahapan yang disusun secara sistematis dan baik sangat diperlukan untuk mendapatkan hasil dari penelitian yang sesuai dan tepat dalam mencapai tujuan penelitian yang diharapkan. Maka dari itu alur penelitian tersebut dapat dilihat pada Gambar 1.
Gambar 1. Alur penelitian Sumber: Data penelitian, 2020
Data yang akan diolah pada penelitian ini bersumber langsung dari pengelola kegiatan penelitian di Universitas Siliwangi yaitu Lembaga Penelitian, Pengabdian Kepada Masyarakat dan Penjaminan Mutu Pendidikan (LPPM-PMP). Dengan contoh data tersaji pada Tabel 1.
Tabel 1. Jumlah penelitian tahun 2017 – tahun 2019
No Judul Kelompok
Angin Secara Spasial
3. Analisa Pengaruh Mobile Banking Terhadap Kinerja Perusahaan Sektor Perbankan yang tercatat di Bursa Efek Indonesia
SOSHUM 4. Penerapan Model Pembelajaran Transformasi Teks Cerita Rakyat Ke Dalam Bentuk
Cerita Bergambar (Komik) Dalam Pembelajaran Membaca Apresiatif (Kajian Nilai-Nilai Dalam Cerita Rakyat Pada Siswa Sekolah Menengah Kejuruan Tasikmalaya Tahun 2015-2016)
PENDIDIKAN
5. Implementasi Kompetensi Pedagogik Tutor PAUD Nonformal Dalam Mengevaluasi Pembelajaran Anak Usia Dini (Studi Pada Kelompok Bermain Nurul Anwar Kecamatan Tawang Kota Tasikmalaya)
PENDIDIKAN
3. Hasil dan Pembahasan
Data teks yang ada terlebih dahulu akan dilakukan case folding yang kemudian dilanjutkan dengan tahapan dibawah ini:
Tokenizing
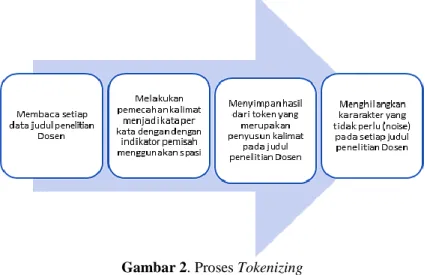
Pada tahap ini data yang sebelumnya sudah diproses dari setiap judul penelitian yang ada akan dilakukan pemotongan kalimat menjadi kata per kata yang disebut dengan istilah token, kemudian dilakukan penghilangan karakter atau tanda baca karena dianggap tidak perlu untuk dilakukan pengolahan.
Gambar 2. Proses Tokenizing Sumber: Data penelitian, 2020 Filtering
Setelah dilakukan proses tokenisasi maka akan dilakukan proses pemilihan atau penyaring kata yang dianggap tidak dibutuhkan karena dianggap tidak memiliki arti yang penting.
Gambar 3. Proses Filtering Sumber: Data penelitian, 2020
Stemming
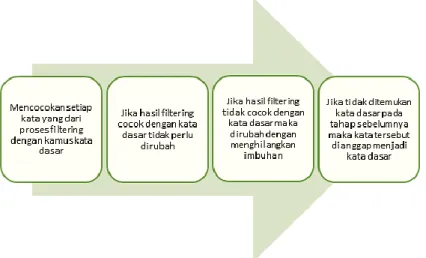
Pada tahapan ini hasil dari filtering akan dilakukan pencarian kata dasar (root word) dari setiap kata yang telah dipisahkan.
Gambar 4. Proses Stemming Sumber: Data penelitian, 2020
Pembobotan TF-IDF
Setelah dilakukan pre-processing maka tahap selanjutnya adalah melakukan pembobotan menggunakan TF-IDF, pada tahap ini dilakukan perhitungan bobot dari setiap judul penelitian dosen
(Term Frequency) dari setiap kata penyusun judul tersebut dikalikan dengan IDF. Berikut adalah langkah
pembobotan yang dilakukan:
1. Menghitung Document Frequency 2. Menghitung Invers Document Frequency
3. Menghitung Bobot = Document Frequency x Invers Document Frequency
Kemudian setelah didapatkan bobot dari setiap term, maka langkah selanjutnya adalah memasukan bobot tersebut pada tahapan K-NN.
Secara umum tahapan diatas dapat dilakukan dengan aplikasi Rapidminer dengan menggunakan desain model tahapan pada Rapidminer sebagai berikut :
Gambar 5. Desain model tahapan pada Rapidminer Sumber: Data penelitian, 2020
Dengan menggunakan nilai k=4 maka dihasilkan nilai performa dari 1577lgoritme K-NN sebesar 90,70%, artinya 90,70% data sebelumnya yang sudah diklasifikasikan secara manual hasilnya sudah sesuai dengan perhitungan 1577lgoritme K-NN yang dilakukan dan sebesar 9.30% tidak sesuai, sehingga data klasifikasi yang tidak sesuai dapat dihitung dari 9,30% x 355 = 33,015 dibulatkan menjadi 33 data
Tabel 2. Performa hasil algoritma K-NN dengan k=4
Nilai k Hasil Pengujian
k = 4 Performance Vector: Accuracy: 90.70% Confusion Matrix:
True: Science Social Education
Science: 107 4 2
Social: 6 131 12
Education: 2 7 84
Sumber:Data penelitian, 2020
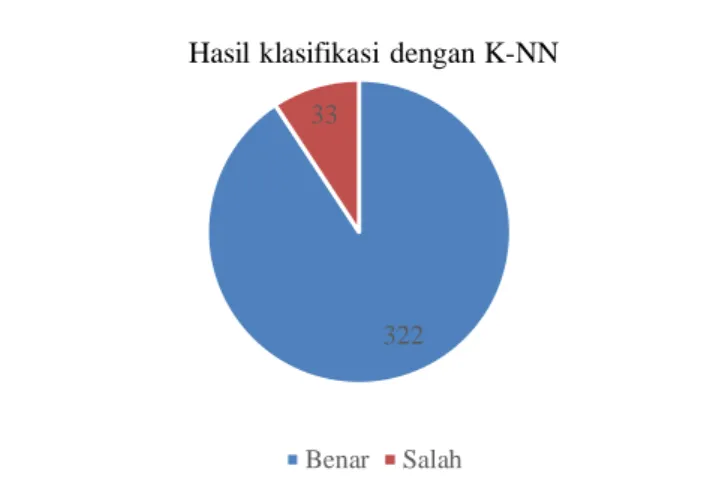
Dari proses diatas maka akan dihasilkan data berupa prediksi kelompok baru dan performa algoritma K-NN dengan pembobotan nilai TF-IDF yang dapat dilihat pada Gambar 6.
Gambar 6. Grafik perbandingan hasil prediksi dengan K-NN
4. Kesimpulan
Penggalian informasi dari sebuah data teks dapat dilakukan dengan menggunakan metode data mining yang disebut text mining. Langkah awal untuk tahapan text mining yang dilakukan adalah dengan terlebih dahulu melakukan case folding pada data teks yang ada yang kemudian dilanjutkan dengan tahapan preprocessing data meliputi tokenizing, filtering, stemming, selanjutnya dilakukan dengan mencari nilai dari Term Frequency dan Invers Document Frequency. Setelah didapatkan bobot dari setiap term maka langkah setelah itu adalah dengan menggunakan bobot tersebut sebagai dasar dari penggunaan algoritma K-NN. Jumlah dari hasil penggunaan K-Nearest Neighbor pada data judul penelitian Dosen di Universitas Siliwangi dari setiap kelompok klasifikasinya adalah 115 judul untuk hasil klasifikasi Sains dan Teknologi (Science), 142 judul untuk hasil klasifikasi Sosial dan Humaniora (Social), dan 98 judul untuk hasil klasifikasi Pendidikan (Education) dari total keseluruhan 355 judul penelitian
5. Singkatan
KNN K-Nearest Neighbor
TF Term Frequency
IDF Invers Document Frequency
6. Referensi
[1] Aziz, Fajar, N. R. Fauzan, J. “Implementasi Algoritma K-Neans untuk Klasterisasi Kinerja Akademik Mahasiswa,” J. Pengembangan Teknologi Informasi dan Ilmu Komputer, 2(6), 2243-2251, 2018.
[2] Hamza, Amir. “Klasifikasi Teks Dengan Naïve Bayes Classifier (NBC) Untuk Pengelompokan Teks Berita Dan Abstract Akademis” Prosiding Seminar Nasional Aplikasi Sains & Teknologi (SNAST) Periode III, 2012.
[3] Susanto, Sani, Dedy S. Pengantar Data Mining, ANDI, Yogyakarta, 2010.
322 33
Hasil klasifikasi dengan K-NN
[4] Buana, P. W., & Putra, I. K.G.D. Combination of K-Nearest Neighbor and K-Means based on Term Re-weighting for Classify Indonesian News. International Journal of Computer Applications 11(50).0975-8887, 2012.
[5] Rustiana, Deden, “Analisis Sentimen Pasar Otomotif Mobil: Tweet Twitter Menggunakan Naïve Bayes,” J. Simetris, 8(1), 113-120, 2017.
[6] A. Rohman, “Model Algoritma K-Nearest Neighbor (K-NN) Untuk Prediksi Kelulusan Mahasiswa,” Neo Tek., vol. 1, no. 1, 2015.
[7] Prilianti, K. R., & Wijaya, H. “Aplikasi Text Mining untuk Automasi Penentuan Tren Topik Skripsi dengan Metode K-Means Clustering”. Jurnal Cybermatika, 2(1), 2014.
[8] S. Zhang, X. Li, M. Zong, X. Zhu, and D. Cheng, “Learning k for kNN Classification,” ACM Trans. Intell. Syst. Technol., vol. 8, no. 3, pp. 1–19, 2017.
[9] Larasati, Kinanti D. 2019, Klasifikasi dengan KNN (K-Nearest Neighbor) Menggunakan Iris
Dataset pada R. Diakses Tanggal 7 Oktober 2020 di
https://medium.com/@dhea.larasati326/klasifikasi-dengan-knn-k-nearest-neighbor-menggunakan-iris-dataset-pada-r-e9cc5ca23fd1
[10] Aini, Bariroh I.N. “Identifikasi Kemiripan Judul Tugas Akhir PSTI Dan PSMI Di Politeknik Negeri Malang,” J. Informatika Polinema, 1(4), 62-67, 2015.
[11] Asiyah, Siti N. Klasifikasi Berita Online Menggunakan Metode Support Vector Machine dan K- Nearest Neighbor,” J. Sains dan Seni ITS, 5(2), 317-322, 2016.
[12] Nafi, Nihru, “Penerapan Metode K–Nearest Neighbor (KNN) dan Metode Weighted Product (WP) Dalam Penerimaan Calon Guru Dan Karyawan Tata Usaha Baru Berwawasan Teknologi (Studi Kasus : Sekolah Menengah Kejuruan Muhammadiyah 2 Kediri),” J. Pengembangan Teknologi
Informasi dan Ilmu Komputer, 1(5), 378-385, 2017.
[13] Lazwardi, Riad, T. 2018. 4 Cara Menghitung Jarak Dan Algoritma KNN, Diakses tanggal 20 September 2020 di https://belajarkalkulus.com/clustering-part-iii/
[14] Bhatia N, Vandana, “Survey of Nearest Neighbor Techniques. International,” J. of Computer
Science and Information Security, 8(2), 302-305, 2010.
[15] Sinuhaji, Br. Imelia, R. “Implementasi Algoritma K-Nearest Neighbor Untuk Menentukan Mahasiswa Berprestasi Di STMIK Kristen Neumann Indonesia,” Publikasi Ilmiah Teknologi