Pembuatan Prototype Speaker Diarization
Samuel Enrico WijayaProgram Studi Teknik Informatika Institut Teknologi Bandung
Bandung, Indonesia 13509059@std.stei.itb.ac.id
Nur Ulfa Maulidevi Program Studi Teknik Informatika
Institut Teknologi Bandung Bandung, Indonesia
ulfa@stei.itb.ac.id
Dessi Puji Lestari Program Studi Teknik Informatika
Institut Teknologi Bandung Bandung, Indonesia dessipuji@gmail.com
Abstrak - File suara mengandung banyak informasi di dalamnya seperti identitas pembicara dan pembicaraannya. Akan tetapi sulit menarik informasi dari file suara dengan banyak informasi di dalamnya. Semisal ada suatu file suara yang didalamnya terdapat banyak pembicara. Butuh waktu dan tenaga yang besar untuk memisahkan atau mengetahui bagian pembicaraan yang diucapkan oleh pembicara tertentu. Untuk mengatasi hal itu speaker diarization adalah salah satu solusinya. Speaker diarization adalah suatu metode pengolahan file suara untuk mengelompokan file suara tersebut berdasar pembicara dan waktu berbicaranya. Dengan metode ini maka penyimpanan maupun pengolahan file suara menjadi lebih efisien.
Kata kunci: suara, informasi, speaker diarization.
I. LATARBELAKANG
Media suara adalah salah satu media penyimpanan file yang banyak digunakan manusia. Media ini sering ditemui sebagai media pencatatan wawancara, pencatatan rapat, dan lain-lain [1]. Media ini memiliki keunggulan dibanding media lain. Bila dibandingkan dengan media tulisan, media ini lebih gampang untuk dibuat dan mengandung informasi yang akurat. Bila dibandingkan dengan media video, ukuran file suara relatif lebih kecil [2].
Namun file suara juga memiliki kekurangan, salah satunya adalah banyaknya informasi yang terkandung di dalam file tersebut. Dengan adanya banyak informasi tersebut, proses pencarian suatu informasi dari file suara tersebut pun menjadi sulit. Semisal ada file suara berisi empat orang sedang berbicara di dalamnya, bila dicari data hanya dari satu pembicara saja, dicari secara manual dimana orang terebut berbicara, atau bahkan harus mendengar seluruh isi dari file suara tersebut. Untuk mengatasi hal itu, ada sebuah metode yang dinamakan speaker diarization.
Speaker diarization adalah metode untuk menentukan siapa
berbicara pada waktu yang mana pada suatu file suara [3]. File suara yang tadinya merupakan gabungan dari banyak pembicara, dapat dipisahkan berdasarkan pembicara dan waktu berbicaranya dengan memanfaatkan metode ini. Dengan adanya metode ini, pencarian data dari file suara pun dapat dipermudah. Selain itu ukuran dari file suara yang disimpan pun dapat dikurangi dengan menghapus pembicara yang dianggap tidak penting dan tidak ingin disimpan.
Disamping fungsinya tersebut, speaker diarization bisa juga digunakan sebagai preprocessing dalam pemrosesan lain
file suara seperti speech recognition. Tahap speaker diarization
dianggap dapat membantu meningkatkan performa dari speech
recognition [4]. Karenanya proses speaker diarization
memiliki peran yang cukup penting dalam pemrosesan suara. Akurasi dan performa dari speaker diarization mempengaruhi akurasi dan performa dari tahap selanjutnya dalam pemrosesan
file suara.
II. SPEAKER DIARIZATION
Telah banyak penelitian terkait dengan speaker diarization. Berikut adalah beberapa contoh penelitian terkait dengan
speaker diarization:
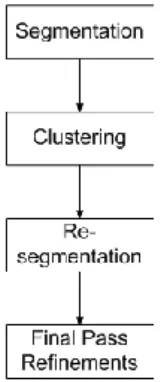
A. On the Use of Spectral and Iterative Methods for Speaker Diarization
Dalam makalahnya, Shum [5] membagi speaker diarization menjadi tahapan-tahapan seperti Gambar 1 berikut:
Gambar 1 Tahapan Speaker Diarization menurut Shum
Pada tahap segmentasi, file suara dibagi menjadi segmen-segmen kecil. Segmen-segmen-segmen ini memiliki durasi bervariasi, dengan maksimal durasi adalah satu detik. Pemotongan ini dapat dibilang kasar, karenanya segmen awal ini dapat memiliki pembicaraan dari beberapa pembicara.
Tahap kedua adalah clustering. Pada tahap ini, ada dua metode yang digunakan. Metode pertama adalah k-means dengan dasar cosine distance dan yang kedua adalah spectral
clustering. Hasil dari eksperimen tersebut dapat dilihat pada
gambar. Gambar 2 merupakan hasil eksperimen dengan jumlah pembicara diketahui, dan Gambar 3 merupakan hasil eksperimen dengan jumlah pembicara yang belum diketahui.
Gambar 2 Hasil eksperimen oleh Shum [5]
Gambar 3 Hasil eksperimen oleh Shum [5]
B. Approaches and Applications of Audio Diarization
Dalam makalahnya, Reynold [6] membagi speaker
diarization menjadi tahapan-tahapan seperti Gambar 4 berikut:
Gambar 4Komponen kunci Speaker Diarization [6]
Tahap speech detection menghilangkan bagian non speech pada file suara. File suara yang sudah dihilangkan bagian non
speech nya selanjutnya masuk ke tahap change detection. Pada
tahap ini, dicari titik-titik pada file suara yang dianggap merupakan titik pergantian antara pembicara.
Sex/ Bandwidth Classification bertujuan mengelompokkan
segmen-segmen kedalam kelompok yang berdasar jenis kelamin (pria / perempuan) dan berdasar bandwidth (tinggi, seperti studio atau rendah, seperti telepon). Setelah itu segmen-segmen tersebut dimasukkan ke tahap clustering. Idealnya, tahap ini menghasilkan satu cluster untuk satu pembicara.
Tahap ini menggunakan Bayesian Information Criterion sebagai dasarnya. Hasil eksperimen ini dapat dilihat pada Gambar 5 dan Gambar 6 berikut:
Gambar 5 Hasil Eksperimen 1 oleh Reynolds [6]
Gambar 6 Hasil Eksperimen 2 oleh Reynolds [6]
Pada Gambar 6 , label LIMSI adalah eksperimen dengan mengaplikasikan cluster recombination. Label MITLL menggunakan model dari suara penyiar untuk clustering. ICSI-SRI menggunakan batasan sebagai stopping criterion. CUED menggunakan top-down clustering dan AHS distance. Gambar II.7 adalah penjabaran dari MITLL.
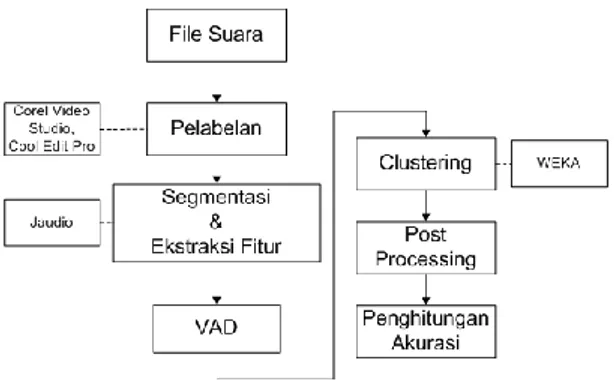
III. PEMBUATAN PROTOTYPE
Alur kerja prototype terdiri dari 4 langkah utama,yaitu Segmentasi dan Ekstraksi Fitur, Voice Activity Detection,
Clustering, dan Post Processing. Sedangkan alur eksperimen
pada tugas akhir adalah alur dari pengujian prototype yang dibuat, sehingga ada dua tahap tambahan yaitu Pelabelan dan Penghitungan Akurasi. Dua tahap ini bertujuan untuk menghitung akurasi dari prototype yang telah dibuat. Untuk lebih jelasnya, alur kerja eksperimen dapat dilihat pada Gambar 7 berikut:
Dalam kegiatan pemrosesan suara dan pembelajaran mesin, ada beberapa tools yang dapat digunakan. Dengan adanya tools tersebut, pengerjaan dari pemrosesan suara dan pembelajaran mesin menjadi lebih mudah. Beberapa tools tersebut antara lain adalah Corel Video Studio X2, Cool Edit Pro, Jaudio, dan WEKA. Peran dari masing-masing tools tersebut dapat dilihat pada Gambar 8 berikut:
Gambar 8 Penggunaan tools pada alur eksperimen
A. Pelabelan
Pelabelan data ini dibagi menjadi dua langkah utama. Langkah pertama adalah mendengarkan file berbentuk video untuk diambil waktu perkiraan pergantian pembicara, serta untuk mengetahui siapa pembicaranya. Pada tahap ini Corel Video Studio digunakan untuk membuka file video serta menghapus overlapping yang dianggap mengganggu. Langkah kedua adalah dengan menggunakan aplikasi Cool Edit Pro. Dengan menggunakan aplikasi ini, pergantian pembicara kadang dapat terlihat cukup jelas pada spektrum suara. Selain itu dengan menggunakan aplikasi ini, didapatkan label yang mencapai satuan milisecond sehingga dapat mengurangi tingkat kesalahan. Waktu pergantian tersebut lalu dicatat dalam sebuah
file yang nantinya menjadi kunci untuk menguji akurasi prototype yang dibuat. Contoh file tersebut dapat dilihat pada
Tabel 1 berikut:
Tabel 1 Label yang disimpan pada file Waktu Mulai Waktu Selesai Speaker
14.36.231 16.53.636 a 16.57.327 17.53.815 b 17.54.362 18.29.908 d 18.30.316 21.15.601 b 21.15.663 21.20.038 c 21.20.264 21.57.387 b 21.58.826 22.17.516 a 22.18.230 27.16.571 c
Pada Tabel 1, kolom pertama menunjukan waktu mulai, kolom kedua menujukkan waktu selesai, dan kolom ketiga menunjukkan nomor pembicara. Pada baris pertama, terlihat bahwa pembicara 1 berbicara pada menit ke 14 detik ke 36
milisecond ke 231 sampai ke menit ke 16 detik ke 53 milisecond ke 636.
B. Segmentasi dan Ekstraksi Fitur
Pada prototype yang dibuat, tahap segmentasi dan pengambilan fitur dilakukan secara bersamaan. Karena gelombang suara selalu berubah setiap waktu, maka diperlukan tahap segmentasi ini. File suara yang tadinya berupa suatu file panjang diubah menjadi potongan-potongan kecil. Durasi dari segmen ini dapat bervariasi, tetapi biasanya digunakan durasi sekitar 20-40ms [7], hal ini dikarenakan durasi tersebut dianggap tidak terlalu pendek sehingga data yang didapat dianggap mewakili, dan tidak terlalu panjang sehingga data dianggap belum mengalami perubahan yang signifikan.
Prototype ini menggunakan segmen sebesar 32ms. Durasi
tersebut diambil karena durasi tersebut dianggap titik tengah dari 20-40ms.
Pada setiap segmen dilakukan pengekstrakan fitur. Ada dua jenis fitur yang diambil dalam prototype ini, yaitu energi dan MFCC. Energi berguna untuk menandai voice activity yang terdapat di dalam suatu file suara. Untuk MFCC, ada 26 fitur yang diambil,yaitu 13 buah MFCC dan 13 turunannya. Hal ini dilakukan karena fitur tersebut dianggap yang paling mewakili karakteristik tiap pembicara sehingga dapat didapatkan perbedaan antara tiap pembicara.
Segmentasi dan pengambilan fitur dilakukan dengan menggunakan Jaudio. Hasil dari ekstraksi fitur menggunakan Jaudio ini berupa sebuah file ARFF. File ini akan menjadi masukan ke tahap berikutnya.
C. Voice Activity Detection
Voice activity detection bertujuan membedakan bagian
mana pada suatu file suara yang merupakan bagian pembicaraan dan mana yang bukan. Voice activity detection menggunakan fitur-fitur suara seperti energi sebagai alat bantunya. Dalam pemrosesannya, voice activity detection dapat menggunakan heuristic model, maupun statistical model seperti supervised learning atau unsupervised learning [8].
Pada prototype yang dibuat, ada dua macam voice activity
detection yang dilakukan. Yang pertama adalah voice activity detection dengan menggunakan dua kali clustering dan yang
kedua adalah menggunakan clustering dengan jumlah cluster +1. Pada dua kali clustering, pertama-tama data dikelompokkan dengan menggunakan fitur energi sebagai acuannya. Pengelompokan itu menghasilkan dua cluster, dimana satu cluster merupakan voice activity dan 1 cluster merupakan non voice. Setelah itu barulah dilakukan clustering dengan menggunakan fitur MFCC sebagai acuan. Pada
clustering dengan jumlah cluster +1, tambahan 1 cluster
mewakili bagian non voice pada file suara.
D. Clustering
Clustering dilakukan dengan menggunakan bantuan
WEKA. Fitur-fitur yang didapatkan dari tiap segmen tersebut dijadikan file ARFF lalu dimasukkan ke WEKA. Algoritma
clustering yang digunakan adalah k-means. Pada tahap inilah
pengelompokan file suara menjadi masing-masing pembicaranya dilakukan. Dengan menggunakan fitur MFCC yang telah diekstrak sebelumnya, tiap cluster dianggap mewakili masing-masing pembicara yang ada.
E. Post Processing
Setelah melalui tahap clustering, segmen-segmen terkumpul menjadi beberapa cluster bergantung pada nilai atributnya. Akan tetapi, masing-masing cluster tersebut dapat memiliki data pencilan. Data pencilan yang ada merupakan segmen yang dianggap salah dikelompokkan. Hal ini dapat dilihat dari adanya kehomogenan data berurutan dengan jumlah yang sedikit.
Tabel 2 Contoh hasil clustering Segmen# Cluster 1 3 2 3 3 3 4 3 5 3 6 3 7 3 8 2 9 2 10 3 11 3 12 3 13 3 14 3
Semisal Tabel 2 merupakan hasil dari clustering. Segmen 8 dan segmen 9 dianggap data pencilan, karena hanya merupakan 2 data homogen berurutan. Karena 1 buah segmen memiliki durasi 32ms, 2 segmen memiliki durasi 64ms. Durasi terebut dirasa terlalu pendek bagi seseorang untuk melakukan pembicaraan. Karena itu segmen 8 dan segmen 9 diganti nilainya dengan nilai lain yang dianggap merupakan kelompok sebenarnya dari segmen tersebut.
Saat pelabelan manual, terkadang didapatkan durasi pembicaraan yang cukup pendek. Nilai itu lalu dijadikan batasan durasi paling pendek dari kehomogenan kumpulan segmen. Nilai yang diambil adalah 17 segmen atau 544
milisecond. Bila ada kumpulan segmen homogen dengan
panjang kurang dari 17 segmen, kumpulan tersebut diganti nilainya dengan nilai lain. Nilai pengganti tersebut adalah modus dari 16 segmen sebelum kumpulan dan 16 segmen setelah kumpulan. Pada tahap ini, dibuat sebuah program sederhana dalam bahasa java untuk menjalankan proses post
processing.
F. Penghitungan Akurasi
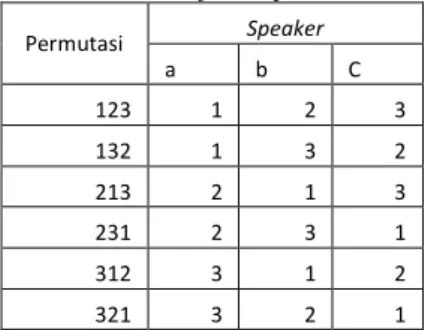
Penghitungan akurasi pada tugas akhir ini dilakukan dengan cara membandingkan hasil clustering dengan label yang diberikan manual pada tahap awal.. Selain itu, penghitungan ini juga dilakukan dengan cara permutasi. Permutasi dilakukan karena adanya ambiguitas pada label
cluster hasil clustering pada WEKA. Permutasi merupakan
semua kemungkinan yang ada dari data yang ada dengan tidak
adanya data kembar. Jika diberikan data 123, hasil permutasinya adalah 123, 132, 213, 231, 312, dan 321.
Tabel 3 Penjelasan permutasi Permutasi Speaker a b C 123 1 2 3 132 1 3 2 213 2 1 3 231 2 3 1 312 3 1 2 321 3 2 1
Tabel 3 menggambarkan bagaimana permutasi digunakan dalam tugas akhir ini. Label a, b, dan c merupakan label yang didapat dari pemberian label secara manual. Label 1, 2, dan 3 merupakan label yang didapat dari hasil clustering. Pada permutasi 213, cluster 2 diartikan speaker a, cluster 1 diartikan speaker b, cluster 3 diartikan speaker c.
IV. HASIL EKSPERIMEN
Pada eksperimen ini, ada 6 buah skenario yang dilakukan. Masing-masing skenario tersebut dijalankan pada 3 macam fitur. Fitur pertama adalah 13 MFCC beserta 13 turunannya, yang kedua adalah 4 buah MFCC, dan yang terakhir adalah 1 buah MFCC. Skenario tersebut dapat dilihat pada Tabel 4 berikut:
Tabel 4 Skenario eksperimen
Skenario VAD Post Processing
1 Tidak Tidak
2 Tidak Ya
3 Cluster +1 Tidak
4 Cluster +1 Ya
5 Dua kali clustering Tidak 6 Dua kali clustering Ya
Untuk skenario 1, tidak ada proses Voice Activity Detection dan Post Processing yang dilakukan. Skenario ini merupakan skenario dasar untuk melihat seberapa besar pengaruh metode yang lain terhadap akurasi yang didapat. Skenario 2 merupakan skenario tanpa menggunakan VAD tetapi menggunakan Post Processing.
Skenario 3 dan 4 merupakan skenario dengan metode penambahan 1 cluster pada VAD. Pada model ini ada penambahan cluster dengan nilai 1. Cluster tersebut dianggap mewakili non voice yang terdapat dalam file suara. Setelah dilakukan clustering, cluster dengan anggota terendah dihilangkan karena cluster itu dianggap mewakili non voice pada file suara. Perbedaan dari skenario 3 dan 4 adalah pada skenario 3 tidak dilakukan post processing, sedangkan pada skenario 4 dilakukan post processing.
Skenario 5 dan 6 merupakan skenario dengan metode dua kali clustering pada VAD. Pada skenario ini, ada dua tahap
clustering, yaitu dengan menggunakan energi sebagai
acuannya dan dengan MFCC. Clustering tahap pertama dilakukan untuk mengetahui segmen mana saja yang merupakan voice activity dan mana yang bukan. Segmen yang merupakan non voice activity, tidak diikutkan ke dalam penghitungan akurasi karena dianggap sebagai non voice
activity. Sedangkan segmen yang merupakan voice activity
diteruskan ke tahap berikutnya. Pembedaan mana yang merupakan non voice activity dan yang bukan didapat dari jumlah anggota cluster. Jumlah yang lebih sedikit dianggap
non voice activity.
Tabel 5 Akurasi Pada Semua Fitur
Fitur Akurasi Maksimal
1 2 3 4 5 6
13MFCC 31.7172 36.4268 27.5241 48.8204 26.2329 29.7896 4MFCC 32.1970 37.1549 30.3347 43.6788 26.5423 30.7003 1MFCC 33.9983 38.1271 34.2879 40.8544 27.8159 31.4447 Pada Tabel 5, dapat terlihat bahwa akurasi paling besar didapat pada skenario 4 dengan fitur 13 MFCC dan 13 turunannya. Akurasi yang didapat mencapai 48.8%. VAD dan
post processing memberikan perubahan pada akurasi yang
didapat. Ada peningkatan dan pengurangan akurasi, bergantung pada metode yang digunakan.
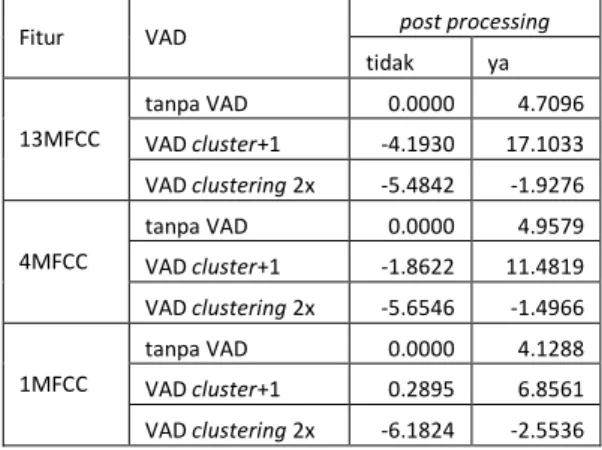
Tabel 6 Perbedaan akurasi masing-masing skenario Fitur VAD post processing
tidak ya 13MFCC tanpa VAD 0.0000 4.7096 VAD cluster+1 -4.1930 17.1033 VAD clustering 2x -5.4842 -1.9276 4MFCC tanpa VAD 0.0000 4.9579 VAD cluster+1 -1.8622 11.4819 VAD clustering 2x -5.6546 -1.4966 1MFCC tanpa VAD 0.0000 4.1288 VAD cluster+1 0.2895 6.8561 VAD clustering 2x -6.1824 -2.5536 Tabel 6 merupakan perbedaan (delta) dari akurasi yang didapat, dibandingkan dengan skenario 1 (tanpa VAD tanpa
post processing). Perbedaan paling besar didapat pada metode
VAD dengan cluster+1 dan menggunakan post processing. Secara keseluruhan, post processing berhasil meningkatkan akurasi yang didapat, dibanding bila tidak menggunakannya.
Hal ini dikarenakan adanya data pencilan yang jumlahnya tidak sedikit pada hasil clustering. Karenanya dengan mengganti nilai dari data pencilan tersebut, akurasi yang didapatkan cenderung meningkat.
V. PENUTUP
Pada eksperimen ini, fitur yang menghasilkan akurasi paling besar adalah fitur 13 MFCC dan 13 turunannya. Skenario yang menghasilkan akurasi terbaik adalah dengan menggunakan VAD metode cluster +1 yaitu penambahan jumlah cluster dengan nilai 1. Tambahan nilai tersebut akan mewakili non voice yang terdapat pada file. Selain itu, metode post processing juga dilakukan pada skenario ini. Akurasi yang didapat mencapai 48.8%. Mungkin akurasi ini dapat meningkat dengan menggunakan fitur-fitur suara lain sebagai acuan clustering, seperti Linear Frequency Cepstral Coefficients (LFCC), Perceptual Linear Predictors (PLP), dan Linear Predictive Coding (LPC).
Tahap post processing diperlukan karena pada hasil
clustering, kadang ditemukan data pencilan yang dapat
mengurangi akurasi yang didapat. Pada eksperimen ini tahap ini berhasil meningkatkan akurasi sampai dengan 17%.
REFERENSI
[1] Stolcke, A., Shriberg, E., Vergyri, D., & Tur, G. (n.d.). Meeting Recognition and Understanding. Retrieved August 12, 2015, from http://www.speech.sri.com/projects/meetings/
[2] Johnson, M. (2000). Interactive Design 1. Columbia University - School of the Arts.
[3] Miro, X. A., Bozonnet, S., Evans, N., Fredouille, C., Friedland, G., dan Vinyals, O. (2012). Speaker diarization: A Review of Recent Research. IEEE Transactions On Audio, Speech, And Language Processing Vol20, 356-370.
[4] Fu, R. (2009). Robust Speaker diarization for Single Channel Recorded Meetings. PhD thesis, University of York: UK.
[5] Shum, S., Dehak, N., & Glass, J. (2012). On the use of spectral and iterative methods for speaker diarization. System, 1(w2), 2.
[6] Reynolds, D. A., dan Torres-Carrasquillo,P.(2005) Approaches and Applications of Audio Diarization. IEEE International Conference on Acoustics, Speech, and Signal Processing Vol5, 953-956.
[7] Lyons, J. (n.d.). Guide mel frequency cepstral coefficients mfccs. Retrieved August 12, 2015, from http://www.practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/
[8] Kola, J., Wilson, C. E., dan Pruthi, T. 2011. Voice activity Detection. Maryland Engineering Research Internship Teams. Biosystems Internships for Engineers. University of Maryland.
![Gambar 5 Hasil Eksperimen 1 oleh Reynolds [6]](https://thumb-ap.123doks.com/thumbv2/123dok/4438324.3224603/2.893.486.698.807.1035/gambar-hasil-eksperimen-oleh-reynolds.webp)