Microsoft
®
SQL Server
®
2012
Microsoft
®
SQL Server
®
2012
BIBLE
Adam Jorgensen
Patrick LeBlanc
Jose Chinchilla
Jorge Segarra
Microsoft® SQL Server® 2012 Bible
Published by
John Wiley & Sons, Inc.
10475 Crosspoint Boulevard Indianapolis, IN 46256 www.wiley.com
Copyright © 2012 by John Wiley & Sons, Inc., Indianapolis, Indiana Published simultaneously in Canada
ISBN: 978-1-118-10687-7 ISBN: 978-1-118-28217-5 (ebk) ISBN: 978-1-118-28386-8 (ebk) ISBN: 978-1-118-28682-1 (ebk)
Manufactured in the United States of America 10 9 8 7 6 5 4 3 2 1
No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 646-8600. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 111 River Street, Hoboken, NJ 07030, (201) 748-6011, fax (201) 748-6008, or online at http://www.wiley.com/go/permissions.
LIMIT OF LIABILITY/DISCLAIMER OF WARRANTY: THE PUBLISHER AND THE AUTHOR MAKE NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE ACCURACY OR COMPLETENESS OF THE CONTENTS OF THIS WORK AND SPECIFICALLY DISCLAIM ALL WARRANTIES, INCLUDING WITHOUT LIMITATION WARRANTIES OF FITNESS FOR A PARTICULAR PURPOSE. NO WARRANTY MAY BE CREATED OR EXTENDED BY SALES OR PROMOTIONAL MATERIALS. THE ADVICE AND STRATEGIES CONTAINED HEREIN MAY NOT BE SUITABLE FOR EVERY SITUATION. THIS WORK IS SOLD WITH THE UNDERSTANDING THAT THE PUBLISHER IS NOT ENGAGED IN RENDERING LEGAL, ACCOUNTING, OR OTHER PROFESSIONAL SERVICES. IF PROFESSIONAL ASSISTANCE IS REQUIRED, THE SERVICES OF A COMPETENT PROFESSIONAL PERSON SHOULD BE SOUGHT. NEITHER THE PUBLISHER NOR THE AUTHOR SHALL BE LIABLE FOR DAMAGES ARISING HEREFROM. THE FACT THAT AN ORGANIZATION OR WEB SITE IS REFERRED TO IN THIS WORK AS A CITATION AND/OR A POTENTIAL SOURCE OF FURTHER INFORMATION DOES NOT MEAN THAT THE AUTHOR OR THE PUBLISHER ENDORSES THE INFORMATION THE ORGANIZATION OR WEBSITE MAY PROVIDE OR RECOMMENDATIONS IT MAY MAKE. FURTHER, READERS SHOULD BE AWARE THAT INTERNET WEBSITES LISTED IN THIS WORK MAY HAVE CHANGED OR DISAPPEARED BETWEEN WHEN THIS WORK WAS WRITTEN AND WHEN IT IS READ.
For general information on our other products and services please contact our Customer Care Department within the United States at (877) 762-2974, outside the United States at (317) 572-3993 or fax (317) 572-4002.
Wiley also publishes its books in a variety of electronic formats and by print-on-demand. Not all content that is available in standard print versions of this book may appear or be packaged in all book formats. If you have purchased a version of this book that did not include media that is referenced by or accompanies a standard print version, you may request this media by visiting http://booksupport.wiley.com. For more information about Wiley products, visit us at www.wiley.com.
Library of Congress Control Number: 2012941788
This book is dedicated to my Lord and Savior, Jesus Christ, who has blessed
me with a family and fi ancé, who are always my biggest supporters.
-- Adam Jorgensen
To my precious wife, Madeline, for her unconditional love and support for my
career and passion for SQL Server and Business Intelligence technologies. To
my two princesses, Sofi a and Stephanie, for making me understand everyday
how beautiful and fun life is.
-- Jose Chinchilla
To my wife, Jessica, whose love, patience, and abundant supply of caffeine
helped make this book a reality.
About the Authors
Adam Jorgensen (www.adamjorgensen.com), lead author for this edition of the SQL Server 2012 Bible, is the president of Pragmatic Works Consulting (www.pragmaticworks.com); a director for the Professional Association of SQL Server (PASS) (www.sqlpass.org); a SQL Server MVP; and a well-known speaker, author, and executive mentor. His focus is on helping com-panies realize their full potential by using their data in ways they may not have previously imagined. Adam is involved in the community, delivering more than 75 community sessions per year. He is based in Jacksonville, FL, and has written and contributed to fi ve previous books on SQL Server, analytics, and SharePoint. Adam rewrote or updated the following chapters: 1, 53, 54, and 57.
Jose Chinchilla is a Microsoft Certifi ed Professional with dual MCITP certifi -cations on SQL Server Database Administration and Business Intelligence Development. His career focus has been in Database Modeling, Data Warehouse and ETL Architecture, OLAP Cube Development, Master Data Management, and Data Quality Frameworks. He is the founder and CEO of Agile Bay, Inc., and serves as president of the Tampa Bay Business Intelligence User Group. Jose is a frequent speaker, avid networker, syndicated blogger (www.sqljoe.com), and social networker and can be reached via twitter under the @SQLJoe handle or LinkedIn at www.linkedin.com/in/josechinchilla. He rewrote or updated the following chap-ters: 3, 24, 25, 29, 32, 33, 43, 58, and 59.
Patrick LeBlanc, former SQL Server MVP, is currently a SQL Server and BI Technical Specialist for Microsoft. He has worked as a SQL Server DBA for the past 9 years. His experience includes working in the educational, advertis-ing, mortgage, medical, and fi nancial industries. He is also the founder of TSQLScripts.com, SQLLunch.com, and the president of the Baton Rouge Area SQL Server User Group. Patrick rewrote or updated the following chapters: 6, 7, 8, 10, 11, 12, 28, 48, 49, and 51.
About the Authors
About the Contributors
Tim Chapman is a Dedicated Support Engineer in Premier Field Engineering at Microsoft where he specializes in database architecture and performance tuning. Before coming to Microsoft, Tim Chapman was a database architect for a large fi nancial institution and a consultant for many years. Tim enjoys blogging, teaching and speaking at PASS events, and participated in writ-ing the second SQL Server MVP Deep Dives book. Tim graduated with a bachelor’s degree in Information Systems from Indiana University. Tim rewrote or updated chapters 39, 40, 44, 45, 46, and 47.
Audrey Hammonds is a database developer, blogger, presenter, and writer. Fifteen years ago, she volunteered to join a newly formed database team so that she could stop writing COBOL. (And she never wrote COBOL again.) Audrey is convinced that the world would be a better place if people would stop, relax, enjoy the view, and normalize their data. She’s the wife of Jeremy; mom of Chase and Gavin; and adoptive mother to her cats, Bela,
Elmindreda, and Aviendha. She blogs at http://datachix.com and is based in Atlanta, Georgia. Audrey rewrote or updated the following chapters: 2, 16, 17, and 18.
Scott Klein is a Technical Evangelist for Microsoft, focusing on Windows Azure SQL Database (formerly known as SQL Azure). He has over 20 years working with SQL Server, and he caught the cloud vision when he was intro-duced to the Azure platform. Scott’s background includes co-owning an Azure consulting business and providing consulting services to companies large and small. He speaks frequently at conferences world-wide as well as community events, such as SQL Saturday events and local user groups. Scott has authored a half-dozen books for both Wrox and APress, and co-authored the book Professional SQL Azure (APress, 2010). Scott is also the founder of the South Florida Geek Golf charity golf tournament, which has helped raise thousands of dollars for charities across South Florida, even though he can’t play golf at all. As much as he loves SQL Server and Windows Azure, Scott also enjoys spending time with his family and looks forward to getting back to real camping in the Pacifi c Northwest. Scott rewrote or updated the following chapters: 13, 14, 15, and 31.
David Liebman is a developer specializing in .Net, SQL, and SSRS develop-ment for more than 5 of the 18 years he has spent in the IT industry, work-ing for some big companies in fi nancial, healthcare, and insurance sectors. Dave has written some custom reporting solutions and web applications for large companies in the Tampa Bay area using .NET, SSRS, and SQL. He is cur-rently a senior developer at AgileThought located in Tampa, FL. Dave rewrote or updated the content in the following chapters: 34 and 35.
About the Technical Editors
Kathi Kellenberger is a Senior Consultant with Pragmatic Works. She enjoys speaking and writing about SQL Server and has worked with SQL Server since 1997. In her spare time, Kathi enjoys spending time with friends and family, running, and singing.
Bradley Schact is a consultant at Pragmatic Works in Jacksonville, FL and an author on the book SharePoint 2010 Business Intelligence 24-Hour Trainer
(Wrox, 2012). Bradley has experience on many parts of the Microsoft BI platform. He frequently speaks at events like SQL Saturday, Code Camp, SQL Lunch, and SQL Server User Groups.
Credits
Vice President and Executive Group Publisher
Richard Swadley
Vice President and Executive Publisher
Neil Edde
© Aleksandar Velasevic / iStockPhoto
Cover Designer
Acknowledgments
From Adam Jorgensen:
Thank you to my team at Pragmatic Works, who are always a big part of any project like this and continue to give me the passion to see them through. I would also like to thank my furry children, Lady and Mac, for their “dogged” persistence in keeping me awake for late nights of writing. Thank you especially to the SQL Community; my fellow MVP’s; and all of you who have attended a SQL Saturday, other PASS event, spoke at a user group, or just got involved. You are the reason we have such a vibrant community, the best in technology. Keep it up; your passion and curiosity drives all of us further every day.
I want to thank my incredible author and tech editing teams. This team of community experts and professionals worked very hard to take a great book and re-invent it in the spirit of the changing landscape that we are witnessing. There were so many new features, focuses, messages, and opportunities to change the way we think, do business, and provide insight that we needed an amazing team of folks. They put up with my cat herding and hit “most” of their deadlines. Their passion for the community is tremendous, and it shines throughout this book. Thank you all from the bottom of my heart. You readers are about to see why this book was such a labor of love! A special thanks to Bob and Ami over at Wiley for their support and effort in getting this title completed. What a great team!
From Jose Chinchilla:
Many thanks to the team that put together this book for keeping us in line with our due dates. Thanks to my lovely family for allowing me to borrow precious time from them in order to fulfi ll my writing and community commitments. I also want to thank Nicholas Cain for his expert contribution to the SQL Clustering Chapter and to Michael Wells for his SQL Server deployment automation PowerShell scripts that are part of his Codeplex project named SPADE.
From Aaron Nelson:
Acknowledgments
From Jorge Segarra:
First and foremost I’d like to thank my wife. There’s no way I would’ve been able to get through the long nights and weekends without her. To our amazing editors, Ami Sullivan and Robert Elliott, and the rest of the folks at Wrox/Wiley: Your tireless efforts and ability to herd A.D.D.-affl icted cats is astounding and appreciated. Thanks to Adam Jorgensen for giving me and the rest of this author team the opportunity to write on this title.
To my fellow authoring team, Adam Jorgensen, Patrick LeBlanc, Aaron Nelson, Julie Smith, Jose Chinchilla, Audrey Hammonds, Tim Chapman, and David Liebman: Thank you all for your tireless work and contributions. To the authors of the previous edition: Paul Nielsen, Mary Chipman, Scott Klein, Uttam Parui, Jacob Sebastian, Allen White, and Michael White — this book builds on the foundation you all laid down, so thank you.
One of the greatest things about being involved with SQL Server is the community around it. It really is a like a big family, a SQLFamily! I’d love to name everyone here I’ve met (and haven’t met yet!) at events or online, but I’d run out of room. Special thanks to Pam Shaw for introducing me to the community and giving me my fi rst speaking opportunity.
Introduction . . . xxix
Part I: Laying the Foundations
1
Chapter 1: The World of SQL Server . . . . 3
SQL Server History ... 3
SQL Server in the Database Market ... 4
SQL Server Components ... 5
Editions of SQL Server 2012 ... 12
Notable SQL Server 2012 Enhancements ... 12
Summary ... 14
Chapter 2: Data Architecture . . . . 15
Information Architecture Principle ... 16
Database Objectives ... 17
Smart Database Design ... 22
Summary ... 29
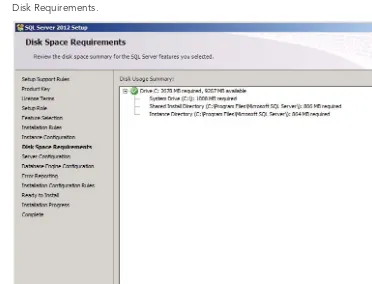
Chapter 3: Installing SQL Server . . . . 31
Preparing the Server ... 32
Selecting the Edition ... 34
The Installation Process ... 42
Summary ... 69
Chapter 4: Client Connectivity . . . . 71
Enabling Server Connectivity ... 72
SQL Server Native Client Features ...74
Summary ... 79
Chapter 5: SQL Server Management and Development Tools . . . . 81
Organizing the Interface ... 82
Registered Servers ... 86
Object Explorer ... 89
Using the Query Editor ... 99
Using the Solution Explorer ...105
Getting a Jumpstart on Code with Templates and Code Snippets ...106
Summary ...106
Introduction . . . .
Contents
Part II: Building Databases and Working with Data
109
Chapter 6: Introducing Basic Query Flow . . . 111
Understanding Query Flow ...112
FROM Clause Data Sources ... 117
WHERE Conditions ...120
(0 row(s) affected)Columns, Stars, Aliases, and Expressions ...129
Ordering the Result Set ...131
Select Distinct ...137
TOP () ...138
Summary ...142
Chapter 7: Relational Database Design and Creating the Physical
Database Schema . . . . 143
Database Basics ...143
Data Design Patterns ...154
Normal Forms ...164
Strategy Considerations ... 170
Summary ... 171
Chapter 8: Data Types, Expressions, and Scalar Functions . . . 173
Data Types ...173
Building Expressions ...177
Scalar Functions ...190
String Functions ...197
Soundex Functions ...203
Data-Type Conversion Functions ...207
Server Environment Information ...210
Summary ...211
Chapter 9: Merging Data with Joins, Subqueries, and CTEs . . . . 213
Using Joins...215
Set Difference Queries ...232
Using Unions ...233
Subqueries ...237
Summary ...247
Chapter 10: Aggregating, Windowing, and Ranking Data . . . . 249
Aggregating Data ...249
Grouping Within a Result Set ...252
Windowing and Ranking ...256
Ranking Functions ...259
Summary ...269
Contents
A Broader Point of View ...279
Locking Down the View ...284
Using SQL Synonyms ...288
Summary ...289
Chapter 12: Modifying Data In SQL Server . . . . 291
Inserting Data ...292
Updating Data ...302
Deleting Data ...310
Merging Data ...313
Returning Modifi ed Data ...318
Summary ...321
Part III: Advanced T-SQL Data Types and Querying
Techniques 323
Chapter 13: Working with Hierarchies . . . . 325
HierarchyID ...326
HierarchyID Methods ...331
Indexing Strategies ...334
Hierarchical Data Alternatives ...334
Summary ...337
Chapter 14: Using XML Data . . . . 339
The XML Data Type ...340
XML Data Type Methods ...353
FOR XML ...355
XQuery and FLWOR Operations ...363
Summary ...365
Chapter 15: Executing Distributed Queries . . . . 367
Distributed Query Overview ...367
Developing Distributed Queries ...377
Performance Consideration ...383
Summary ...386
Part IV: Programming with T-SQL
387
Chapter 16: Programming with T-SQL . . . . 389
Transact-SQL Fundamentals ...390
Working with Variables ...393
Procedural Flow ...399
Examining SQL Server with Code ...403
Temporary Tables and Table Variables ...406
What’s New in T-SQL for 2012 ...409
Contents
Bulk Operations ...424 Summary ...428
Chapter 17: Developing Stored Procedures . . . . 431
Managing Stored Procedures ...432 Passing Data to Stored Procedures ...437 Returning Data from Stored Procedures ... 444 Summary ... 451Chapter 18: Building User-Defi ned Functions . . . . 453
Scalar Functions ...455 Inline Table-Valued Functions ...458 Multistatement Table-Valued Functions ...462 Best Practices with User-Defi ned Functions ...464 Summary ...465Part V: Enterprise Data Management
467
Contents
Import and Export Wizard ...627 Data-Tier Application (DAC) ...630 Summary ...632
Chapter 24: Database Snapshots . . . . 635
How Do Database Snapshots Work? ...636 Using Database Snapshots ...637 Summary ...645Chapter 25: Asynchronous Messaging with Service Broker . . . . 647
Confi guring a Message Queue ...649 Working with Dialogs ... 651 What’s New in Service Broker for SQL Server 2012? ...655 Monitoring and Troubleshooting Service Broker ...656 Summary ...659Chapter 26: Log Shipping . . . . 661
Availability Testing ...662 Warm Standby Availability ...663 Defi ning Log Shipping ...664 Checking Log Shipping Confi guration ...676 Monitoring Log Shipping ...677 Modifying or Removing Log Shipping ...678 Switching Roles ...682 Summary ...683Chapter 27: Database Mirroring . . . . 685
Database Mirroring Overview ...686 Defi ning and Confi guring Database Mirroring ...688 Checking Database Mirroring Confi guration ...701 Monitoring Database Mirroring ...703 Pausing or Removing Database Mirroring ...708 Role Switching ...709 High Availability/AlwaysOn ... 711 Summary ...725Chapter 28: Replicating Data . . . . 727
Moving Data Between Servers ...727 Replication Concepts ...730 Confi guring Replication ...732 Summary ...744Contents
Chapter 30: Confi guring and Managing SQL Server with PowerShell . . . . 769
Why Use PowerShell? ...770 Basic PowerShell ...770 SQL Server PowerShell Extensions ...781 Communicating with SQL Server via SMO ...785 Scripting SQL Server Tasks ...793 Summary ...799Chapter 31: Managing Data in Windows Azure SQL Database . . . . 801
Overview of Azure SQL Database ...801 Managing Windows Azure SQL Database ...802 High Availability and Scalability ...806 Migrating Data to SQL Database...807 Summary ...829Part VI: Securing Your SQL Server
831
Contents
Part VII: Monitoring and Auditing
877
Contents
Removing Change Data Capture ...964 Summary ...965
Chapter 42: SQL Audit . . . . 967
SQL Audit Technology Overview ...967 Creating an Audit...968 Server Audit Specifi cations ...971 Database Audit Specifi cations ...973 Viewing the Audit Trail ... 974 Summary ... 974Chapter 43: Management Data Warehouse . . . . 977
Using the Management Data Warehouse ...977 Confi guring MDW ...978 Setting Up Data Collection ...983 Viewing MDW Reports ...985 Creating Custom Data Collector Sets ...989 Summary ...992Part VIII: Performance Tuning and Optimization
993
Contents
Understanding SQL Server Locking ... 1066 Transaction Isolation Levels ... 1070 Application Locks ... 1087 Application Locking Design ... 1088 Transaction-Log Architecture ... 1089 Transaction Performance Strategies ... 1093 Summary ... 1095
Chapter 48: Data Compression . . . . 1097
Understanding Data Compression ... 1097 Applying Data Compression ... 1103 Summary ... 1108Chapter 49: Partitioning . . . . 1109
Partitioning Strategies ... 1109 Partitioned Views ... 1110 Partitioned Tables and Indexes ... 1117 Summary ... 1129Chapter 50: Resource Governor . . . 1131
Exploring Fundamentals of Resource Governor ... 1132 Performance Monitoring of Resource Governor ... 1138 Views and Limitations ... 1140 Summary ... 1140Part IX: Business Intelligence
1141
Chapter 51: Business Intelligence Database Design . . . . 1143
Data Warehousing ... 1144 Designing a Data Warehouse Using a Star Schema ... 1144 Designing your Data Warehouse using a Snowfl ake Schema ... 1146 Ensuring Consistency within a Data Warehouse ... 1147 Loading Data ... 1147 Summary ... 1153Chapter 52: Building, Deploying, and Managing ETL Workfl ows in Integration
Contents
Building a Database ... 1198 Dimensions ... 1204 Cubes ... 1210 Data Storage ... 1219 Cube Processing ... 1219 Summary ... 1222
Chapter 54: Confi guring and Administering Analysis Services . . . . 1223
Installing Analysis Services ... 1223 Confi guring Basic Analysis Services Settings ... 1227 Advanced SSAS Deployments ... 1230 Reviewing Query Performance with SQL Profi ler ... 1230 Summary ... 1232Chapter 55: Authoring Reports in Reporting Services . . . . 1233
Report Authoring Environments ... 1234 The Basic Elements of a Report ... 1235 Building a Report with the Report Wizard ... 1237 Authoring a Report from Scratch ... 1239 Exploring the Report Designer ... 1240 Using Reporting Services Features to VisualizeYour Data ... 1244 Designing the Report Layout ... 1251 Building Reports with Report Builder ... 1255 Summary ... 1259
Contents
Deploying BI Semantic Models to SharePoint ... 1317 Managing Automatic Data Refresh of PowerPivot Workbooks in SharePoint 2010 ... 1318 Creating BI Semantic Models Using SQL Server Data Tools... 1319 Extending a BI Semantic Model with SQL Server Data Tools ... 1322 Deploying BI Semantic Models to an Analysis Services Instance ... 1324 Summary ... 1326
Chapter 59: Creating and Deploying Power View Reports . . . . 1327
Power View Requirements ... 1327 Creating and Deploying Reports with Power View ... 1328 Deploying Power View Reports ...1344 Summary ... 1345Introduction
W
elcome to the SQL Server 2012 Bible. SQL Server is an incredible database product that offers an excellent mix of performance, reliability, ease of administration, and new architectural options, yet enables the developer or DBA to control minute details. SQL Server is a dream system for a database developer.If there’s a theme to SQL Server 2012, it’s this: enterprise-level excellence. SQL Server 2012 opens several new possibilities to design more scalable and powerful systems. The fi rst goal of this book is to share with you the pleasure of working with SQL Server.
Like all books in the Bible series, you can expect to fi nd both hands-on tutorials and real-world practical applications, as well as reference and background information that provide a context for what you are learning. However, to cover every minute detail of every command of this complex product would consume thousands of pages, so it is the second goal of this book to provide a con-cise yet comprehensive guide to SQL Server 2012. By the time you have completed the SQL Server 2012 Bible, you will be well prepared to develop and manage your SQL Server 2012 database and BI environment.
Some of you are repeat readers of this series (thanks!) and are familiar with the approach from the previous SQL Server Bibles. Even though you might be familiar with this approach, you will fi nd sev-eral new features in this edition, including the following:
■ A What’s New sidebar in most chapters presents a timeline of the features so that you can envision the progression.
■ Expanded chapters on Business Intelligence.
■ The concepts on T-SQL focusing on the best and most useful areas, while making room for more examples.
■ New features such as Always On, performance tuning tools, and items like column store indexing.
■ All the newest features from T-SQL to the engine to BI, which broaden the reach of this title.
Who Should Read This Book
There are fi ve distinct roles in the SQL Server space:
Introduction
■ Database administrator
■ Business Intelligence (BI) developer
■ PTO performance tuning and optimization expert
This book has been carefully planned to address each of these roles.
Whether you are a database developer or a database administrator, whether you are just starting out or have one year of experience or fi ve, this book contains material that will be useful to you.
Although the book is targeted at intermediate-level database professionals, each chapter begins with the assumption that you’ve never seen the topic before and then progresses through the subject, presenting the information that makes a difference.
At the higher end of the spectrum, the book pushes the intermediate professional into cer-tain advanced areas in which it makes the most sense. For example, you can fi nd advanced material on T-SQL queries, index strategies, and data architecture.
How This Book Is Organized
SQL Server is a huge product with dozens of technologies and interrelated features. Just organizing a book of this scope is a daunting task.
A book of this size and scope must also be approachable as both a cover-to-cover read and a reference book. The nine parts of this book are organized by job role, project fl ow, and skills progression:
Part I: Laying the Foundations
Part II: Building Databases and Working with Data
Part III: Advanced T-SQL Data Types and Querying Techniques
Part IV: Programming with T-SQL
Part V: Enterprise Data Management
Part VI: Securing Your SQL Server
Part VII: Monitoring and Auditing
Part VIII: Performance Tuning and Optimization
Introduction
SQL Server Books Online
This book is not a rehash of Books Online and doesn’t pretend to replace Books Online. We avoid listing the complete syntax of every command — there’s little value in reprinting Books Online.
Instead, this book shows you what you need to know to get the most out of SQL Server so that you can learn from the author’s and co-authors’ experience.
You can fi nd each feature explained as if we are friends — you have a new job that requires a specifi c feature you’re unfamiliar with, and you ask us to get you up-to-speed with what matters most.
The chapters contain critical concepts, real-world examples, and best practices.
Conventions and Features
This book contains several different organizational and typographical features designed to help you get the most from the information.
Tips, Notes, Cautions, and Cross-References
Whenever the authors want to bring something important to your attention, the informa-tion appears in a Cauinforma-tion, Tip, or Note.
This information is important and is set off in a separate paragraph. Cautions provide information about things to watch out for, whether simply inconvenient or potentially hazardous to your data or systems.
Tips generally provide information that can make your work simpler — special shortcuts or methods for doing some-thing easier than the norm. You will often fi nd the relevant .sys fi les listed in a tip.
Notes provide additional, ancillary information that is helpful, but somewhat outside of the current presentation of information.
Introduction
What’s New and Best Practice Sidebars
Two sidebar features are specifi c to this book: the What’s New sidebars and the Best Practice sidebars.
What’s New with SQL Server Feature
Whenever possible and practical, a sidebar will be included that highlights the relevant new features covered in the chapter. Often, these sidebars also alert you to which features have been eliminated and which are deprecated. Usually, these sidebars are placed near the beginning of the chapter.
Best Practice
This book is based on the real-life experiences of SQL Server developers and administrators. To enable you to benefi t from all that experience, the best practices have been pulled out in sidebar form wher-ever and whenwher-ever they apply.
Where to Go from Here
There’s a whole world of SQL Server. Dig in. Explore. Play with SQL Server. Try out new ideas, and post questions in the Wrox forums (monitored by the author team) if you have questions or discover something cool. You can fi nd the forums at www.wrox.com.
Come to a conference or user group where the authors are speaking. They would love to meet you in person and sign your book. You can learn where and when on SQLSaturday.com and SQLPASS.org.
Part I
Laying the Foundations
IN THIS PART
Chapter 1
The World of SQL Server
Chapter 2 Data Architecture
Chapter 3
Installing SQL Server
Chapter 4
Client Connectivity
Chapter 5
C H A P T E R
1
The World of SQL Server
IN THIS CHAPTER
Understanding SQL Server History and Overview Understanding SQL Server Components and Tools Understanding Notable Features in SQL 2012 What’s New with SQL Server 2012?
S
QL Server 2012 represents another tremendous accomplishment for the Microsoft data plat-form organization. A number of new features in this release drive perplat-formance and scalability to new heights. A large focus is on speed of data access, ease and fl exibility of integration, and capability of visualization. These are all strategic areas in which Microsoft has focused on to add value since SQL Server 2005.SQL Server History
SQL Server has grown considerably over the past two decades from its early roots with Sybase.
In 1989, Microsoft, Sybase, and Ashton-Tate jointly released SQL Server 1.0. The product was based on Sybase SQL Server 3.0 for UNIX and VMS.
SQL Server 4.2.1 for Windows NT released in 1993. Microsoft began making changes to the code.
SQL Server 6.0 (code named SQL 95) released in 1995. In 1996, the 6.5 upgrade (Hydra) was released in 1996. It included the fi rst version of Enterprise Manager (StarFighter I) and SQL Server Agent (StarFighter II.)
SQL Server 7.0 (Sphinx), released in 1999 and was a full rewrite of the database engine by Microsoft. From a code sense, this was the fi rst Microsoft SQL Server. SQL Server 7 also included English Query (Argo), OLAP Services (Plato), Replication, Database Design and Query tools
Part I: Laying the Foundations
SQL Server 2000 (Shiloh) 32-bit, version 8, introduced SQL Server to the enterprise with clustering, better performance, and OLAP. It supported XML through three different XML add-on packs. It added user-defi ned functions, indexed views, clustering support, OLAP, Distributed Partition Views, and improved Replication. SQL Server 2000 64-bit version for Intel Itanium (Liberty) released in 2003, along with the fi rst version of Reporting Services (Rosetta) and Data Mining tools (Aurum). DTS becomes powerful and gained in popularity. Northwind joined Pubs as the sample database.
SQL Server 2005 (Yukon), version 9, was another rewrite of the database engine and pushed SQL Server further into the enterprise space. In 2005, a ton of new features and technologies were added including Service Broker, Notifi cation Services, CLR, XQuery and XML data types, and SQLOS. T-SQL gained try-catch, and the system tables were replaced with Dynamic Management Views. Management Studio replaced Enterprise Manager and Query Analyzer. DTS was replaced by Integration Services. English Query was removed, and stored procedure debugging was moved from the DBA interface to Visual Studio. AdventureWorks and AdventureWorksDW replaced Northwind and Pubs as the sample data-base. SQL Server 2005 supported 32-bit, 64x, and Itanium CPUs. Steve Ballmer publically vowed to never again make customers wait 5 years between releases and to return to a 2-to-3-year release cycle.
SQL Server 2008 (Katmai), version 10, is a natural evolution of SQL Server adding Policy-Based Management, Data Compression, Resource Governor, and new beyond relational data types. Notifi cation Services went the way of English Query. T-SQL fi nally has date and time data types, table-valued parameters, the debugger returns, and Management Studio gets IntelliSense.
SQL Server 2008R2, version 10.5, is a release mostly focused on new business intelligence features and SharePoint 2010 supportability. The list of major new work and code in the SQL Server 2005 and 2008/R2 releases have been fully covered in previ-ous editions, but the high points would be SQLCLR (this was the integration of another long-term strategy project); XML support; Service Broker; and Integration Services, which is all ground up code. Microsoft formed a new team built on the original members of the DTS team, adding in some C++, hardware, AS and COM+ folks, and Report Builder. Additional features to support SharePoint 2010 functionality and other major releases are also critically important. Now you have SQL 2012; so look at where this new release can carry you forward.
SQL Server in the Database Market
Chapter 1: The World of SQL Server
1
SQL Server’s Competition
SQL Server competes primarily with two other major database platforms, Oracle and IBM’s DB2. Both of these products have existed for longer than SQL Server, but the last four releases of SQL Server have brought them closer together. They are adding features that SQL has had for years and vice versa. Many of the scalability improvements added since SQL 2005 have been directly focused on overtaking the performance and other qualities of these products. Microsoft has succeeded in these releases in besting benchmarks set by many other products both in the relational database platforms as well as in data integra-tion, analytics, and reporting. These improvements, along with the strongest integrated ecosystem, including cloud (Windows Azure SQL Database), portal (SharePoint 2010), and business intelligence make SQL Server the market leader.
Strength of Community
SQL Server has one of the strongest communities of any technology platform. There are many websites, blogs, and community contributors that make up a great ecosystem of sup-port. Some great avenues to get involved with include the following:
■ PASS (Professional Association of SQL Server) SQLPASS.org ■ SQL Saturday events — SQLSaturday.com
■ SQLServerCentral.com
■ BIDN.com
■ MSSQLTips.com
■ SQLServerPedia.com
■ Twitter.com — #SQLHelp
Many of these are started and operated by Microsoft SQL Server MVPs and companies focused on SQL Server, education, and mentoring.
SQL Server Components
SQL Server is composed of the database engine, services, business intelligence tools, and other items including cloud functionality. This section outlines the major components and tools you need to become familiar with as you begin to explore this platform.
Database Engine
Part I: Laying the Foundations
Within the relational engine are several key processes and components, including the following:
■ The Algebrizer checks the syntax and transforms a query to an internal representa-tion used by the following components.
■ SQL Server’s QueryOptimizer determines how to best process the query based on the costs of different types of query-execution operations. The estimated and actual query-execution plans may be viewed graphically, or in XML, using Management Studio or SQL Profi ler.
■ The QueryEngine, or QueryProcessor executes the queries according to the plan generated by the Query Optimizer.
■ The StorageEngine works for the Query Engine and handles the actual reading and writing to and from the disk.
■ The BufferManager analyzes the data pages used and prefetches data from the data fi le(s) into memory, thus reducing the dependency on disk I/O performance.
■ The Checkpoint process writes dirty data pages (modifi ed pages) from memory to the data fi le.
■ The Resource Monitor optimizes the query plan cache by responding to memory pressure and intelligently removing older query plans from the cache.
■ The LockManager dynamically manages the scope of locks to balance the number of required locks with the size of the lock.
■ SQL Server eats resources for lunch, and for this reason it needs direct control of the available resources (memory, threads, I/O request, and so on). Simply leaving the resource management to Windows isn’t sophisticated enough for SQL Server. SQL Server includes its own OS layer, called SQLOS, which manages all its internal resources.
SQL Server 2012 supports installation of many instances of the relational engine on a phys-ical server. Although they share some components, each instance functions as a complete separate installation of SQL Server.
Services
The following components are client processes for SQL Server used to control, or communi-cate with, SQL Server.
SQL Server Agent
Chapter 1: The World of SQL Server
1
Database Mail
The Database Mail component enables SQL Server to send mail to an external mailbox through SMTP. Mail may be generated from multiple sources within SQL Server, including T-SQL code, jobs, alerts, Integration Services, and maintenance plans.
Microsoft Distributed Transaction Coordinator (MSDTC)
The Distributed Transaction Coordinator is a process that handles dual-phase commits for transactions that span multiple SQL Servers. DTC can be started from within Windows’ Computer Administration/Services. If the application regularly uses distributed transac-tions, you should start DTC when the operating system starts.
Business Intelligence
Business intelligence (BI) is the name given to the discipline and tools that enable the management of data for the purpose of analysis, exploration, reporting, mining, and visu-alization. Although aspects of BI appear in many applications, the BI approach and toolset provide a rich and robust environment to understand data and trends.
SQL Server provides a great toolset to build BI applications, which explains Microsoft’s continued gains in the growing BI market. SQL Server includes three services designed for BI: Integration Services (IS, sometimes called SSIS for SQL Server Integration Services), Reporting Services (RS), and Analysis Services (AS). Development for all three services can be done using the new SQL Server Data Tools, which is the new combining of Business Intelligence Development Studio and database development into a new environment in Visual Studio.
SSIS
Integration Services moves data among nearly any types of data sources and is SQL Server’s Extract-Transform-Load (ETL) tool. IS uses a graphical tool to defi ne how data can be moved from one connection to another connection. IS packages have the fl exibility to either copy data column for column or perform complex transformations, lookups, and exception han-dling during the data move. IS is extremely useful during data conversions, collecting data from many dissimilar data sources, or gathering for data warehousing data that can be ana-lyzed using Analysis Services.
Part I: Laying the Foundations
SSAS
The Analysis Services service hosts two key components of the BI toolset: Online Analytical Processing (OLAP) hosts multidimensional databases where data is stored in cubes, whereas Data Mining provides methods to analyze datasets for nonobvious patterns in the data.
OLAP
Building cubes in a multidimensional database provides a fast, pre-interpreted, fl exible analysis environment. Robust calculations can be included in a cube for later query and reporting, going a long way toward the “one version of the truth” that is so elusive in many organizations. Results can be used as the basis for reports, but the most powerful uses involve the interactive data exploration using tools such as Excel pivot tables or similar query and analysis applications. Tables and charts that summarize billions of rows can be generated in seconds, allowing users to understand the data in ways they never thought possible.
Although relational databases in SQL Server are queried using T-SQL, cubes are queried using the Multidimensional Expressions (MDX), a set-based query language tailored to retrieving multidimensional data. (See Figure 1-1.) This enables relatively easy custom application development in addition to standard analysis and reporting tools.
FIGURE 1-1
Chapter 1: The World of SQL Server
1
Data Mining
Viewing data from cubes or even relational queries can reveal the obvious trends and cor-relations in a dataset, but data mining can expose the nonobvious ones. The robust set of mining algorithms enables tasks such as fi nding associations, forecasting, and classify-ing cases into groups. When a model is trained on an existclassify-ing set of data, it can predict new cases that occur, for example, predicting the most profi table customers to spend scarce advertising dollars on or estimating expected component failure rates based on its characteristics.
SSRS
Reporting Services (RS) for SQL Server 2012 is a full-featured, web-based, managed report-ing solution. RS reports can be exported to PDF, Excel, or other formats with a sreport-ingle click and are easy to build and customize.
Reports are defi ned graphically or programmatically and stored as .rdl fi les in the RS data-bases in SQL Server. They can be scheduled to be pre-created and cached for users, e-mailed to users, or generated by users on-the-fl y with parameters. Reporting Services is bundled with SQL Server so there are no end-user licensing issues. It’s essentially free; although most DBAs place it on its own dedicated server for better performance. There is new func-tionality in SSRS 2012 with the addition of Power View. This is a SharePoint integrated fea-ture that provides for rich drag and drop visualization and data exploration. It is one of the hottest new features in SQL 2012.
Tools and Add-Ons
SQL Server 2012 retains most of the UI feel of SQL Server 2008, with a few signifi cant enhancements.
SQL Server Management Studio
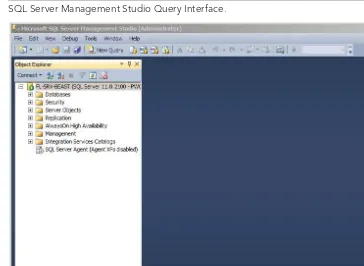
Management Studio is a Visual Studio–esque integrated environment that’s used by data-base administrators and datadata-base developers. At its core is the visual Object Explorer com-plete with fi lters and the capability to browse all the SQL Server servers (database engine, Analysis Services, Reporting Services, and so on). Management Studio’s Query Editor is an excellent way to work with raw T-SQL code, and it’s integrated with the Solution Explorer to manage projects. Although the interface can look crowded (see Figure 1-2), the windows are easily confi gurable and can auto-hide.
SQL Server Configuration Manager
Part I: Laying the Foundations
FIGURE 1-2
SQL Server Management Studio Query Interface.
SQL Profiler/Trace/Extended Events
SQL Server has the capability to expose a trace of selected events and data points. The server-side trace has nearly no load on the server. SQL Profi ler is the UI for viewing traces in real time (with some performance cost) or viewing saved Trace fi les. Profi ler is great for debugging an application or tuning the database. Profi ler is being deprecated in favor of extended events. This will enable a deeper level of tracing with a decreased load on the server overall . This feature is continually enhanced and grown by support for other fea-tures such as Reporting services, Analysis Services, etc.
Performance Monitor
Chapter 1: The World of SQL Server
1
Database Engine Tuning Advisor
The Database Engine Tuning Advisor analyzes a batch of queries (from Profi ler) and mends index and partition modifi cations for performance. The scope of changes it can recom-mend is confi gurable, and the changes may be applied in part or in whole at the time of the analysis or later. The features of DBTA have been signifi cantly enhanced in this newest version.
Command-Line Utilities
You can use various command-line utilities to execute SQL code (sqlcmd) or perform bulk copy program (bcp) from the DOS prompt or a command-line scheduler. Integration Services and SQL Server Agent have rendered these tools somewhat obsolete, but in the spirit of extreme fl exibility, Microsoft still includes them.
Management Studio has a mode that enables you to use the Query Editor as if it were the command-line utility sqlcmd.
Online Resources
The SQL Server documentation team did an excellent job with Books Online (BOL) — SQL Server’s mega help on steroids. The articles tend to be complete and include several exam-ples. The indexing method provides a short list of applicable articles. BOL may be opened from Management Studio or directly from the Start menu.
BOL is well integrated with the primary interfaces. Selecting a keyword within Management Studio’s Query Editor and pressing F1 launches BOL to the selected keyword. The Enterprise Manager help buttons can also launch the correct BOL topic.
Management Studio also includes a dynamic Help window that automatically tracks the cur-sor and presents help for the current keyword.
Searching returns both online and local MSDN articles. In addition, BOL searches the Codezone Community for relevant articles.
The Community Menu and Developer Center both launch web pages that enable users to ask a question or learn more about SQL Server.
CodePlex.com
Part I: Laying the Foundations
Editions of SQL Server 2012
The edition layout of SQL Server has changed again with this release to align closer with the way organizations use the product. Following are three main editions:
■ Enterprise: This edition focused on mission critical applications and data warehousing.
■ Business intelligence: This new edition has premium corporate features and self-service business intelligence features. If your environment is truly mission criti-cal however, this may be missing some key features you might want. The key is to leverage this edition on your BI servers and use Enterprise where needed.
■ Standard: This edition remains to support basic database capabilities including reporting and analytics.
You may wonder about the previous editions and how to move from what you have to the new plan. Following is a breakdown of deprecated editions and where the features now reside.
■ Datacenter: Its features are now available in Enterprise Edition.
■ Workgroup: Standard will become your edition for basic database needs.
■ Standard for small business: Standard becomes your sole edition for basic data-base needs.
Notable SQL Server 2012 Enhancements
SQL 2012 has added many areas to its ecosystem. This includes new appliances, integration with “Big Data,” and connectors that leverage this technology as sources and destinations for analytics. Reference architectures have been improved and are released with improve-ments for SQL 2012. New features that add incredible performance boosts make these archi-tectures a major weapon in return on investment (ROI) for many organizations.
Many of the important features that have been added to SQL Server 2012 fall into several categories, including the following:
■ Availability Enhancements
■ AlwaysOn Failover Cluster instances ■ AlwaysOn Availability Groups ■ Online operations
■ Manageability Enhancements
■ SQL Server Management Studio enhancements ■ Contained databases
Chapter 1: The World of SQL Server
1
■ Windows PowerShell
■ Database Tuning Advisor enhancements ■ New Dynamic Management Views and Functions ■ Programmability Enhancements
■ FileTables
■ Statistical Semantic Search functionality ■ Full-Text Search improvements
■ New and improved Spatial features
■ Metadata discovery and Execute Statement metadata support ■ Sequence Objects
■ THROW statement ■ 14 new T-SQL functions
■ Extended Events enhancements and more ■ Security Enhancements
■ Enhanced Provisioning during setup ■ New permissions levels
■ New role management
■ Signifi cant SQL Audit enhancements ■ Improved Hashing algorithms
■ Scalability and Performance Enhancements
■ ColumnStore Indexes and Velocity
■ Online Index operation support for x(max) columns ■ Partition support increased to 15,000
■ Business Intelligence Features
■ New Data Cleansing Components
■ Improved usability for SSIS and new deployment functionality ■ Master Data functionality has been signifi cantly enhanced ■ New exciting features for Power Pivot
■ Power View data exploration and visualization ■ Tabular Models in SSAS
■ Expanded Extended Events throughout the BI ecosystem
Part I: Laying the Foundations
Summary
C H A P T E R
2
Data Architecture
IN THIS CHAPTER
Understanding Pragmatic Data Architecture Evaluating Six Objectives of Information Architecture Designing a Performance Framework
Using Advanced Scalability Options
Y
ou can tell by looking at a building whether there’s elegance to the architecture, but architecture is more than just good looks. Architecture brings together materials, founda-tions, and standards. In the same way, data architecture is the study to defi ne what a good database is and how you can build a good database. That’s why data architecture is more than just data modeling, more than just server confi guration, and more than just a collection of tips and tricks.Data architecture is the overarching design of the database, how the database should be devel-oped and implemented, and how it interacts with other software. In this sense, data architec-ture can be related to the architecarchitec-ture of a home, a factory, or a skyscraper. Data architecarchitec-ture is defi ned by the Information Architecture Principle and the six attributes by which every database can be measured.
Part I: Laying the Foundations
What’s New with Data Architecture in SQL Server
2012
SQL Server 2012 introduces a couple of new features that the data architect will want to be familiar with and leverage while designing a data storage solution. These include:
■ Columnstore indexes: allows data in the index to be stored in a columnar format rather than traditional rowstore format, which provides the potential for vastly reduced query times for large-scale databases. More information about columnstore indexes can be found in Chapter 45, “Indexing Strategies”.
■ Data Quality Services (DQS): enables you to build a knowledge base that supports data quality analysis, cleansing, and standardization.
Information Architecture Principle
For any complex endeavor, there is value in beginning with a common principle to drive designs, procedures, and decisions. A credible principle is understandable, robust, complete, consistent, and stable. When an overarching principle is agreed upon, confl icting opinions can be objectively measured, and standards can be decided upon that support the principle.
The Information Architecture Principle encompasses the three main areas of information management: database design and development, enterprise data center management, and business intelligence analysis.
Information Architecture Principle: Information is an organizational asset, and, according to its value and scope, must be organized, inventoried, secured, and made readily available in a usable format for daily operations and analysis by individuals, groups, and processes, both today and in the future.
Unpacking this principle reveals several practical implications. There should be a known inventory of information, including its location, source, sensitivity, present and future value, and current owner. Although most organizational information is stored in IT data-bases, uninventoried critical data is often found scattered throughout the organization in desktop databases, spreadsheets, scraps of papers, and Post-it notes, and (the most danger-ous of all) inside the head of key employees.
Chapter 2: Data Architecture
2
If the data is to be made readily available in the future, then current designs must be fl ex-ible enough to avoid locking the data in a rigid, but brittle, database.
Database Objectives
Based on the Information Architecture Principle, every database can be architected or evalu-ated by six interdependent database objectives. Four of these objectives are primarily a func-tion of design, development, and implementafunc-tion: usability, extensibility, data integrity, and
performance. Availability and security are more a function of implementation than design. With suffi cient design effort and a clear goal to meet all six objectives, it is fully possible to design and develop an elegant database that does just that. No database architecture is going to be 100 percent perfect, but with an early focus on design and fundamental prin-ciples, you can go a long way toward creating a database that can grow along with your organization.
You can measure each objective on a continuum. The data architect is responsible to inform the organization about these six objectives, including the cost associated with meeting each objective, the risk of failing to meet the objective, and the recommended level for each objective.
It’s the organization’s privilege to then prioritize the objectives compared with the relative cost.
Usability
The usability of a data store (the architectural term for a database) involves the com-pleteness of meeting the organization’s requirements; the suitability of the design for its intended purpose; the effectiveness of the format of data available to applications; the robustness of the database; and the ease of extracting information (by programmers and power users). The most common reason why a database is less than usable is an overly com-plex or inappropriate design.
Usability is enabled in the design by ensuring the following:
■ A thorough and well-documented understanding of the organizational requirements ■ Life-cycle planning of software features
■ Selecting the correct meta-pattern (for example, transactional and dimensional) for the data store
■ Normalization and correct handling of optional data ■ Simplicity of design
Part I: Laying the Foundations
Extensibility
The Information Architecture Principle states that the information must be readily avail-able today and in the future, which requires the database to be extensible and able to be easily adapted to meet new requirements. The concepts of data integrity, performance, and availability are all mature and well understood by the computer science and IT professions. With enough time and resources, you can design a data architecture that meets the objec-tive of extensibility. The trick is to make sure that your entire organization understands that the resource investment is not only important, but also absolutely necessary to good data architecture. There are many databases that fell victim to the curse of not enough time and too few resources. These are usually the ones that can’t grow and adapt to new business requirements or organizational change well. Extensibility is incorporated into the design as follows:
■ Normalization and correct handling of optional data. ■ Generalization of entities when designing the schema.
■ Data-driven designs that not only model the obvious data (for example, orders and customers), but also enable the organization to store the behavioral patterns, or process fl ow.
■ A well-defi ned abstraction layer that decouples the database from all client access, including client apps, middle tiers, ETL, and reports.
■ Extensibility is also closely related to simplicity. Complexity breeds complexity and inhibits adaptation. Remember, a simple solution is easy to understand and adopt, and ultimately, easy to adjust later.
Data Integrity
The ability to ensure that persisted data can be retrieved without error is central to the Information Architecture Principle, and it was the fi rst major problem tackled by the data-base world. Without data integrity, a query’s answer cannot be guaranteed to be correct; consequently, there’s not much point in availability or performance. Data integrity can be defi ned in multiple ways:
■ Entity integrity: Involves the structure (primary key and its attributes) of the entity. If the primary key is unique and all attributes are scalar and fully depen-dent on the primary key, then the integrity of the entity is good. In the physical schema, the table’s primary key enforces entity integrity.
■ Domain integrity: Ensures that only valid data is permitted in the attribute. A domain is a set of possible values for an attribute, such as integers, bit values, or characters. Nullability (whether a null value is valid for an attribute) is also a part of domain integrity. In the physical schema, the data type and nullability of the row enforce domain integrity.
Chapter 2: Data Architecture
2
domain. In the case of the foreign key, the domain is the list of values in the related primary key. Referential integrity, therefore, is not an issue of the integrity of the primary key but of the foreign key.
■ Transactional integrity: Ensures that every logical unit of work, such as inserting 100 rows or updating 1,000 rows, is executed as a single transaction. The quality of a database product is measured by its transactions’ adherence to the ACID proper-ties: atomic —all or nothing; consistent — the database begins and ends the trans-action in a consistent state; isolated — one transaction does not affect another transaction; and durable — once committed always committed.
In addition to these four generally accepted defi nitions of data integrity, user-defi ned data integrity should be considered as well:
■ User-defi ned integrity means that the data meets the organization’s requirements with simple business rules, such as a restriction to a domain and limiting the list of valid data entries. Check constraints are commonly used to enforce these rules in the physical schema.
■ Complex business rules limit the list of valid data based on some condition. For example, certain tours may require a medical waiver. Implementing these rules in the physical schema generally requires stored procedures or triggers.
■ Some data-integrity concerns can’t be checked by constraints or triggers. Invalid, incomplete, or questionable data may pass all the standard data-integrity checks. For example, an order without any order detail rows is not a valid order, but no SQL constraint or trigger traps such an order. The abstraction layer can assist with this problem, and SQL queries can locate incomplete orders and help to identify other less measurable data-integrity issues, including wrong data, incomplete data, ques-tionable data, and inconsistent data.
Integrity is established in the design by ensuring the following:
■ A thorough and well-documented understanding of the organizational requirements ■ Normalization and correct handling of optional data
■ A well-defi ned abstraction layer
■ Data quality unit testing using a well-defi ned and understood set of test data ■ Metadata and data audit trails documenting the source and veracity of the data,
including updates
Performance/Scalability
Part I: Laying the Foundations
Performance is enabled in the database design and development by ensuring the following:
■ A well-designed schema with normalization and generalization, and correct han-dling of optional data
■ Set-based queries implemented within a well-defi ned abstraction layer
■ A sound indexing strategy, including careful selection of clustered and nonclus-tered indexes
■ Tight, fast transactions that reduce locking and blocking ■ Partitioning, which is useful for advanced scalability
Availability
The availability of information refers to the information’s accessibility when required regarding uptime, locations, and the availability of the data for future analysis. Disaster recovery, redundancy, archiving, and network delivery all affect availability.
Availability is strengthened by the following:
■ Quality, redundant hardware
■ SQL Server’s high-availability features
■ Proper DBA procedures regarding data backup and backup storage ■ Disaster recovery planning
Security
The sixth database objective based on the Information Architecture Principle is security. For any organizational asset, the level of security must be secured depending on its value and sensitivity.
Security is enforced by the following:
■ Physical security and restricted access of the data center ■ Defensively coding against SQL injection
■ Appropriate operating system security
■ Reducing the surface area of SQL Server to only those services and features required ■ Identifying and documenting ownership of the data
■ Granting access according to the principle of least privilege, which is the concept that users should have only the minimum access rights required to perform neces-sary functions within the database
■ Cryptography — data encryption of live databases, backups, and data warehouses ■ Metadata and data audit trails documenting the source and veracity of the data,
Chapter 2: Data Architecture
2
Planning Data Stores
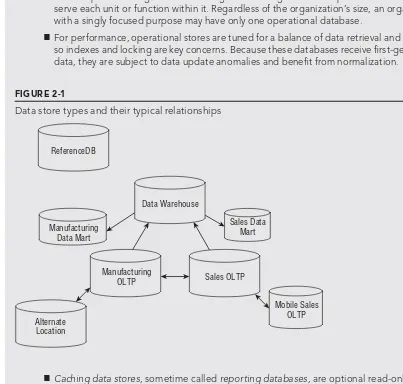
The enterprise data architect helps an organization plan the most effective use of information throughout the organization. An organization’s data store confi guration (see Figure 2-1) includes multiple types of data stores, as illustrated in the following fi gure, each with a specifi c purpose:
■Operational databases, or online transaction processing (OLTP) databases collect fi rst-gen-eration transactional data that is essential to the day-to-day oprst-gen-eration of the organization and unique to the organization. An organization might have an operational data store to serve each unit or function within it. Regardless of the organization’s size, an organization with a singly focused purpose may have only one operational database.
■For performance, operational stores are tuned for a balance of data retrieval and updates, so indexes and locking are key concerns. Because these databases receive fi rst-generation data, they are subject to data update anomalies and benefi t from normalization.
FIGURE 2-1
Data store types and their typical relationships
ReferenceDB
Data Warehouse
Manufacturing Data Mart
Manufacturing
OLTP Sales OLTP
Sales Data Mart
Mobile Sales OLTP Alternate
Location
■Caching data stores, sometime called reporting databases, are optional read-only copies of all or part of an operational database. An organization might have multiple caching data stores to deliver data throughout the organization. Caching data stores might use SQL Server replication or log shipping to populate the database and are tuned for high-performance data retrieval.
Part I: Laying the Foundations
■ Reference data stores are primarily read-only and store generic data required by the organi-zation but which seldom changes — similar to the reference section of the library. Examples of reference data might be unit of measure conversion factors or ISO country codes. A reference data store is tuned for high-performance data retrieval.
■ Data warehouses collect large amounts of data from multiple data stores across the entire enterprise using an extract-transform-load (ETL) process to convert the data from the vari-ous formats and schema into a common format, designed for ease of data retrieval. Data warehouses also serve as the archival location, storing historical data and releasing some of the data load from the operational data stores. The data is also pre-aggregated, mak-ing research and reportmak-ing easier, thereby improvmak-ing the accessibility of information and reducing errors.
■ Because the primary task of a data warehouse is data retrieval and analysis, the data-integ-rity concerns presented with an operational data store don’t apply. Data warehouses are designed for fast retrieval and are not normalized like master data stores. They are generally designed using a basic star schema or snowfl ake design. Locks generally aren’t an issue, and the indexing is applied without adversely affecting inserts or updates.
■ The analysis process usually involves more than just SQL queries and uses data cubes that con-solidate gigabytes of data into dynamic pivot tables. Business intelligence (BI) is the combination of the ETL process, the data warehouse data store, and the acts to create and browse cubes.
■ A common data warehouse is essential to ensure that the entire organization researches the same data set and achieves the same result for the same query — a critical aspect of the Sarbanes-Oxley Act and other regulatory requirements.
■ Data marts are subsets of the data warehouse with preaggregated data organized specifi -cally to serve the needs of one organizational group or one data domain.
■ Master data store, or master data management (MDM), refers to the data warehouse that combines the data from throughout the organization. The primary purpose of the master data store is to provide a single version of the truth for organizations with a complex set of data stores and multiple data warehouses.
■ Data Quality Services (DQS) refers to the SQL Server instance feature that consists of three SQL Server catalogs with data-quality functionality and storage. The purpose of this feature is to enable you to build a knowledge base to support data quality tasks.
Chapter 51, “Business Intelligence Database Design,” discusses star schemas and snowfl ake designs used in data warehousing.