BAB 2
LANDASAN TEORI
2.1. ArtificialNeuralNetwork
Artificial neural network (ANN) / jaringan saraf tiruan adalah konsep yang merefleksikan cara kerja dari jaringan saraf biologi kedalam bentuk artificial atau buatan. Tujuan dari ANN adalah untuk meniru kemampuan jaringan saraf biologi asli yaitu dalam hal pembelajaran, seperti jaringan saraf biologi salah satunya jaringan saraf manusia yang dapat belajar terhadap lingkungan sehingga dapat mengelola lingkungan berdasarkan pada pengalaman yang didapat. Tujuan dikembangkan ANN adalah mengambil kemampuan dalam melakukan pembelajaran berdasarkan pada data yang didapat dan jika diberikan data dengan kasus / lingkungan yang sama, maka jaringan saraf dapat melakukan klasifikasi yang akurat terhadap data tersebut.
2.2. Backpropagation
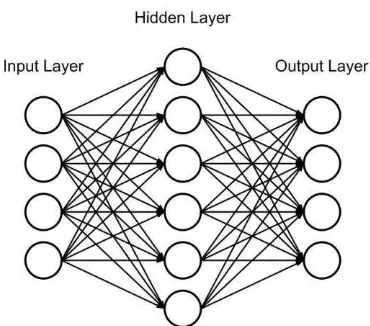
Gambar 2. 1 Neuralnetworkbackpropagation
Algoritma backpropagation memiliki 3 layer yaitu input layer, hidden layer, output layer, masing – masing layer terdapat neuron / node. Pada input layer tujuan node / neuron ini adalah menerima input seusai dengan banyak variabel nilai yang diinputkan. Hidden layer neuron berfungsi untuk menerima nilai dari inputlayer yang telah dikalikan dengan nilai weight. Pada hiddenlayer maka nilai input diubah menjadi nilai hidden layer dengan menggunakan function, setelah itu nilai tersebut diteruskan ke output layer. Output layer menerima nilai pada hidden layer yang telah dikalkulasikan dengan nilai weight. Pada output layer berfungsi untuk mendapatkan nilai output. Setelah mendapatkan nilai output maka dicari nilai error dengan cara membandingkan dengan nilai target. Jika nilai ouput sama dengan nilai target maka pembelajaran sudah selesai, jika tidak mendekati target maka pembelajaran akan dilanjutkan dengan melakukan teknik backward yaitu pembelajaran dari output kembali ke input dengan melakukan update weight. Setelah selesai update weight maka dilanjutkan kembali pembelajaran sampai konvergen dengan nilai target.
Langkah – langkah perhitungan dalam pelatihan backpropagation dijabarkan sebagai berikut (Prasetyo, 2014):
1. Inisialisasi bobot / weight
Pertama kali yang dilakukan adalah penentuan bobot / weight secara acak pada setiap node yang berada pada inputlayer, hiddenlayer, dan outputlayer. 2. Aktivasi hiddenlayer
ℎ
= ∑
×
ℎSetelah mendapatkan nilai total masukan pada setiap hidden layer, maka dilakukan perhitungan fungsi aktivasi pada setiap neuron di hiddenlayer.
ℎ
=
+
− ℎℎ : nilai aktivasi hidden neuron. 3. Aktivasi outputlayer
Menghitung total nilai yang masuk ke output neuron
= ∑
ℎ×
ℎℎ=
: nilai total bobot yang masuk ke output neuron
ℎ : nilai aktivasi dari neuron hiddenlayer ℎ : nilai weight yang menuju ke outputlayer
: Jumlah neuron yang ada pada hiddenlayer
Setelah mendapatkan nilai total masukan ke neuron output layer, maka dilakukan perhitungan fungsi aktivasi pada setiap neuron di outputlayer
=
+
− �: nilai aktivasi output neuron 4. Gradien errorlayer output
Menghitung nilai error pada setiap neuron outputlayer
=
−
: nilai error dari neuron outputlayer : nilai target neuron pada outputlayer : nilai aktivasi neuron pada outputlayer
2.1
2.2
2.3
2.4
Setelah mendapatkan nilai error neuron dari output layer, lalu dicari nilai gradien error dari neuron tersebut
�
=
× [ −
] ×
� : nilai gradien error
: nilai aktivasi output neuron : nilai error dari neuron outputlayer
5. Perhitungan updateweighthiddenlayer ke outputlayer Menghitung delta bobot
∆
ℎ= � ×
ℎ× �
∆ ℎ : nilai delta bobot � : learningrate
ℎ : nilai aktivasi neuron hiddenlayer � : nilai gradien error
Setelah didapat delta bobot kemudian melakukan update bobot weight dari hiddenlayer menuju ke outputlayer.
ℎ
+
=
ℎ+ ∆
ℎℎ + : weight baru dari neuron hiddenlayer ke neuron outputlayer ℎ : weight lama dari neuron hiddenlayer ke neuron outputlayer ∆ ℎ : nilai delta bobot
6. Perhitungan updateweightinputlayer ke hiddenlayer Menghitung gradien error pada hiddenlayer
�
ℎ=
ℎ× [ −
ℎ] × ∑ �
.
=
ℎ
�ℎ : nilai gradien error dari neuron hiddenlayer
ℎ : nilai aktivasi pada hiddenlayer
: banyak neuron outputlayer yang terhubung ke neuron hiddenlayer � : nilai gradien error neuron outputlayer
ℎ : nilai weight lama neuron hiddenlayer ke neuron outputlayer Menghitung delta bobot dari inputlayer ke hiddenlayer
� : learningrate : nilai input
�ℎ : nilai gradien error neuron pada hiddenlayer Mengupdate nilai weightinputlayer ke hiddenlayer
ℎ
+
=
ℎ+ ∆
ℎℎ + : weight baru dari inputlayer ke hiddenlayer ℎ : nilai weight lama
∆ ℎ : delta bobot dari hiddenlayer ke inputlayer
7. Nilai iterasi dinaikan sebanyak 1 dan diulangi prosesnya dari langkah 2 sampai nilai error tercapai.
2.3. ResilientBackpropagation
Resilient backpropagation (RPROP) adalah algortima neural network yang bersifat supervised dan adaptive learning. RPROP merupakan perkembangan dari backpropagation. Pada resilient backpropagation parameter sudah ditetapkan jadi tidak diperlukan penentuan learning rate lagi. Kemampuan RPROP adalah untuk menghidari perubahan nilai gradien yang terlalu kecil ini bertujuan agar mempercepat laju pembelajaran RPROP dibandingkan dengan backpropagation, ini ditunjukan pada jaringan RPROP memiliki sebuah nilai delta yang mengikuti perubahan nilai weight. Jika perubahan nilai weight kecil maka nilai delta membesar, sebaliknya ketika perubahan weight aktif maka nilai delta mengecil.
RPROP memiliki langkah yang sama dengan backpropagation yang membedakannya adalah pada waktu backwardnya yaitu pada bagian update weight. Untuk melakukan updateweight harus dilakukan pemilihan berdasarkan gradien error yang dihasilkan, lalu penentuan learning rate yang dipakai untuk melakukan update weight.
Pelatihan feedforward pada algoritma resilient propagation sama dengan pelatihan feedforward pada algoritma backpropagation, yang membedakan pada waktu melakukan updateweight dengan learningrate pada pelatihan backward. Perhitungan learning rate akan dijabarkan pada langkah – langkah sebagai berikut (Riedmiller, 1994):
1. Perhitungan nilai ∆�
Untuk menentukan nilai ∆ � ada beberapa aturan yang harus dipenuhi untuk
mendapat nilai delta tersebut yaitu :
∆
�=
∆ = . nilai pada delta 0 dapat saja ditetapkan lebih besar atau lebih kecil dari 0.1, karena nilai delta 0 tidak memiliki pengaruh besar terhadap laju proses pembelajarannya (Martin Riedmiller, 1994). Untuk pembelajaran berikutnya maka ∆ yang terdahulu akan dikalikan dengan learning rate. Pada perkalian∆
�− dengan learningrate ada aturan yang harus dicapai yaitu error gradienpada hasil terdahulu �� �−1
� dikalikan dengan error gradien �� �
� . Dari hasil
perkalian error tersebut maka didapatkan hasil jika hasil lebih besar dari 0 maka
∆
�− dikalikan dengan �+, dan jika hasil lebih kecil dari 0 maka∆
�−dikalikan dengan �− . Nilai �+ dan �− merupakan learning rate yang membedakan adalah pada �+ memiliki nilai yang lebih besar daripada �−. Marthin Riedmiller (1994) menetapkan nilai standar pada �+ = . sedangkan �− = . untuk algoritma resilient propagation.
2.
Penentuan nilai∆
�Setelah ditentukan
∆
� maka akan dilanjutkan ke dalam aturan untuk menentukan fungsi operator yang akan dipakai untuk melakukan updateweight dengan aturan sebagai berikut:∆
�=
digunakan apakah akan dikurangi atau ditambah atau tidak terjadi perubahanbobot. Untuk menentukan fungsi operator yang dipakai pada
∆
� maka dibandingkan nilai error gradien terhadap nol. Jika nilai error gradien lebihbesar daripada nol maka
∆
� akan menerima nilai− ∆
� , dan jika nilaierror gradien lebih kecil daripada 0 maka
∆
� akan menerima+ ∆
� . Setelah mendapatkan nilai delta w maka dilanjutkan ke updateweightnya secara langsung.Pada aturan pertama untuk penentuan learning rate memiliki masalah pada aturan kedua yaitu terjadi peningkatan pembelajaran yang melebih batas minimum maka dilakukan pengurangan weight secara langsung dengan weight terdahulunya.
∆
�= −∆
�−,
��
�
�−∗
��
�
�<
Untuk menghindari terjadi keadaan tersebut untuk terjadi kedua kalinya maka
pada �� �
�
= .
2.4. ParallelProcessing
Parallel processing adalah sebuah kegiatan menjalankan beberapa proses sekaligus dalam waktu yang bersamaan. Teknik parallel processing ada 2 macam yaitu SIMD (Single Instruction Multiple Data streams) dan MIMD (Multiple Instruction Multiple Data streams).
2.13
SIMD (Single Instruction Multiple Data streams) adalah teknik parallel yang menggunakan sebuah control unit dan processor melakukan eksekusi terhadap instruksi yang sama ini ditunjukan pada Gambar 2.2.
Gambar 2. 2 Single Instruction Multiple Data streams (Sumber : El-Rewini & Abd-El-Barr, 2005)
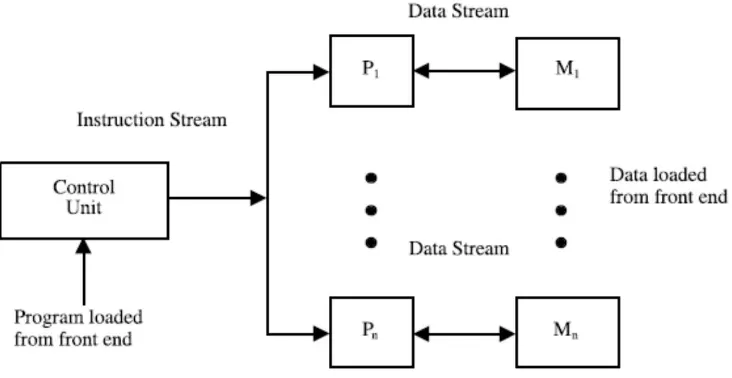
MIMD (Multiple Instruction Multiple Data streams) adalah teknik parallel yang menggunakan multiple processor dan multiple memory yang tergabung dalam sebuah koneksi. Pada MIMD setiap processor memiliki control unit sendiri yang dapat memberikan instruksi yang berbeda. Arsitektur dari MIMD akan ditunjukan pada Gambar 2.3.
Implementasi parallel processing maka digunakan multithreading untuk mengimplementasikan parallel processing tersebut.
2.4.1. Thread & Multithreading
Thread adalah sebuah proses yang berukuran kecil yang dibuat oleh sebuah program untuk dijalankan bersamaan dengan thread–thread lainnya. Tujuan thread ini adalah agar proses – proses yang dapat dikerjakan bersamaan dapat dijalankan secara bersamaan tanpa memerlukan waktu tunggu untuk proses berikutnya. Ini dapat dicontohkan dari perangkat lunak pengolah kata yang membentuk beberapa thread untuk melakukan fungsi tampilan, proses pengetikan, dan proses pemeriksaan jumlah kata, dengan pembagian fungsi tersebut kedalam thread maka semua proses tersebut dapat dijalankan secara bersamaan tanpa terjadinya delay, sehingga dapat disebut berjalan secara parallel.
Multithreading adalah kumpulan beberapa thread yang dijalankan bersamaan pada sebuah processor. Pada multithreading ini merupakan proses eksekusi dari kumpulan thread dimana kumpulan thread tersebut diproses secara berulang – ulang dengan perpindahan dalam waktu nanosecond.
2.4.2. Parallel Arsitektur Neural Network
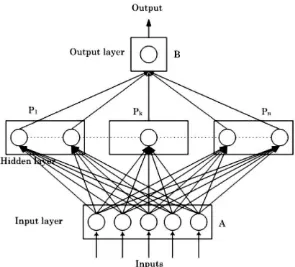
Gambar 2. 4 Arsitektur NeuralNetwork dengan parallel (Ganeshamoorthy & Ranasinghe, 2008)
Gambar 2.4 adalah sebuah teknik parallel yang bernama hybrid partition yaitu membagi arsitektur proses pada neural network menjadi subproses – subproses. Subproses tersebut dikerjakan pada waktu yang bersamaan dengan menggunakan teknik multithreading. Proses yang akan dilakukan adalah dari input layer (A) akan mengirimkan data input yang telah dikalikan dengan weight ke neuron (P1) dan nilai tersebut akan dihasilkan nilai function yang akan diteruskan ke output (B). Proses di hiddenlayer yaitu P1, Pk, dan Pn dijalankan bersamaan dengan memproses nilai dari A dan diteruskan ke B.
2.5. Penelitian Terdahulu
menggunakan program MPI dan virtual shared memory implementation menggunakan program C/Linda. Hasil penelitian yang didapatkan kecepatan pembelajaran hybrid partition dengan batch backpropagation meningkat dengan seiring penambahan processor sedangkan untuk hybrid partition dengan backpropagation dan fast parallel matrix multiplication dengan batch backpropagation menunjukan dengan penambahan processor kecepatan pembelajaran berangsur – angsur meningkat tapi fast parallel matrix multiplication dengan batch backpropagation lebih unggul dibandingkan dengan hybrid partition dengan backpropagation.
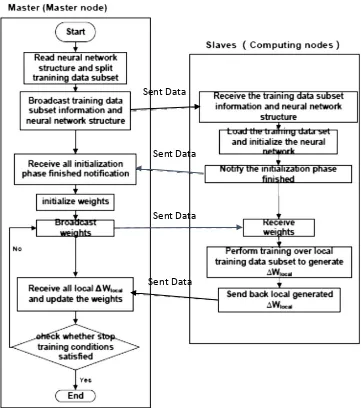
Gambar 2. 5 Framework cNeuralparallel computation pada algoritma neuralnetwork (Gu, Shen, & Huang, 2013)
Framework cNeural membagi dataset menjadi beberapa sub - dataset. Sub - dataset tersebut dikirim ke computer pembantu berserta dengan arsitektur neuralnetwork untuk diolah mendapatkan weight update, setelah itu delta weight yang dihasilkan dari komputer pembantu dikirim ke komputer utama untuk digabungkan dengan beberapa delta weight yang dihasilkan dari komputer pembantu lain. Proses tersebut diulangi sampai jaringan neural network dapat mengenali lingkungannya. Hasil penelitian adalah dengan menggunakan framework cNeural membantu untuk meningkatkan proses pembelajaran seiring dengan penambahan komputer pembantu untuk membantu memproses dalam pembelajaran.
Sent Data
Sent Data
Sent Data
Penelitian Riedmiller & Braun (1993) pada jurnal penelitian memperkenalkan sebuah algoritma neural network yaitu Resilient Backpropagation yang memiliki kemampuan dalam adaptive learning rate, adaptive learning rate adalah sebuah kemampuan dalam mengubah learningrate berdasarkan pada nilai error gradien yang dihasilkan. Algoritma adaptive learning rate pada resilientbackpropagation dijelaskan pseudocode sebagai berikut:
1. Berikan nilai awal pada semua nilai delta = 0.1 dan nilai awal gradien error = 0. 2. Lakukan perhitungan feedforward untuk mendapatkan nilai gradien error. 3. Nilai gradien error yang telah didapatkan dikalikan dengan nilai gradien
terdahulu.
4. Nilai gradien error yang telah didapat akan dibadingkan dengan beberapa rule sebagai berikut:
Jika nilai gradien error lebih besar dari nilai 0 dilakukan hal berikut: i. Nilai delta didapatkan dari nilai minimum antara dua nilai yaitu
nilai delta terdahulu dikalikan learning rate max dengan delta max = 50.0.
ii. Setelah mendapatkan nilai delta maka dilanjutkan ke delta weight. Pada delta weight akan menentukan nilai delta tersebut akan berbentuk sebagai nilai minus atau positif, yang berdasarkan dari nilai error gradiennya. Jika nilai error gradien lebih besar dari 0 maka nilai delta weight akan bernilai negatif sedangkan nilai gradien error lebih kecil dari 0 maka nilai delta weight bernilai positif.
iii. Setelah didapatkan nilai delta weight dilajutkan dengan melakukan udapte weight yaitu weight terdahulu dijumlah dengan delta weight.
iv. Terakhir adalah menyimpan nilai gradien error.
Jika nilai gradien error lebih kecil dari 0 dilakukan hal berikut:
i. Nilai delta didapatkan dari nilai maksimum dari dua nilai yaitu nilai delta terdahulu dikalikan learning rate min dengan delta min = 1e-6.
iii. Nilai gradien error menyimpan nilai 0
Jika nilai gradien error sama dengan 0 dilakukan sebagai berikut: i. Nilai delta weight menentukan nilai delta apakah nilai tersebut
menjadi minus atau positif.
ii. Updateweight yaitu nilai weight ditambah dengan delta weight. 5. Setiap weight akan mengalami proses pada aturan keempat
6. Melakukan pembelajaran lagi dimulai dari aturan kedua sampai nilai error mendekati 0.
Pada setiap weight yang digunakan pada neural network dilakukan update weight berdasarkan nilai gradien error yang dihasilkan pada setiap neuron. Resilient backpropagation menetapkan beberapa parameter awal yaitu ∆ = . ini merupakan nilai penetapan awal yang diberikan pada setiap nilai delta weight awal, nilai ∆ � =
. dan ∆ = − yang bertujuan untuk menghindari masalah overflow / underflow pada variabel floating, dan nilai learningrate�+ = . dan �− = . . Hasil penelitian jurnal tersebut menunjukan resilient backpropagation hanya memerlukan pembelajaran / epoch yang lebih sedikit dibandingkan dengan algoritma Backpropagation, SuperSAB, dan Quickprop.
Gambar 2. 6 Pengaruh tingkat akurasi jumlah neuron pada hiddenlayer pada algoritma ResilientBackpropagation (Prasad, Singh, & Lal, 2013)
Ringkasan dari penelitian terdahulu dapat dilihat pada Tabel 2.1
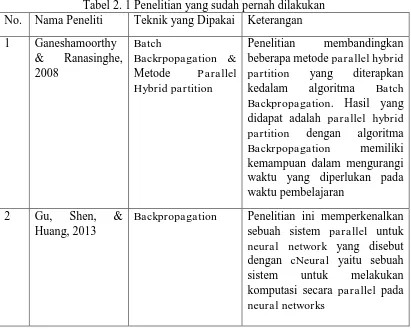
Tabel 2. 1 Penelitian yang sudah pernah dilakukan No. Nama Peneliti Teknik yang Dipakai Keterangan
1 Ganeshamoorthy Backpropagation. Hasil yang didapat adalah parallel hybrid partition dengan algoritma
Backpropagation Penelitian ini memperkenalkan sebuah sistem parallel untuk neural network yang disebut dengan cNeural yaitu sebuah
sistem untuk melakukan
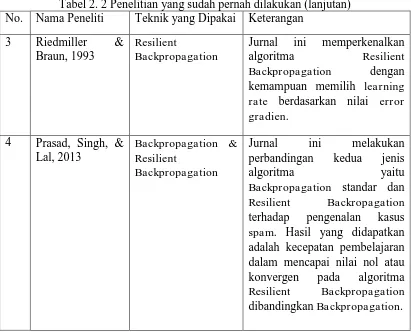
Tabel 2. 2 Penelitian yang sudah pernah dilakukan (lanjutan) No. Nama Peneliti Teknik yang Dipakai Keterangan
3 Riedmiller &
Backpropagation standar dan Resilient Backropagation
2.6. Perbedaan Penelitian Sekarang Dengan Penelitian Terdahulu
hasil delta weight yang dihasilkan dari masing – masing processor pembantu akan dikumpulkan untuk dijumlah semua terlebih dahulu dan dilakukan update weight, sedangkan penelian yang akan dilakukan menggunakan teknik parallelhybrid partition adalah membagi kerja komputasi yang terletak pada bagian hidden layer agar dapat dikerjakan pada waktu yang bersamaan. Jurnal penelitian lain yaitu Riedmiller & Braun (1993) dan Prasad, Singh, & Lal (2013) adalah sebagai jurnal tambahan yang menunjukan kemampuan kecepatan pembelajaran pada algoritma resilient backpropagation.