KATA PENGANTAR
Puji dan syukur kehadirat Tuhan Yang Maha Esa atas segala berkat dan lindunganNya sehingga buku yang berjudul 15 Metode Menyelesaikan Data
Mining, Sistem Pakar dan Sistem Pendukung Keputusan ini dapat saya
selesaikan dengan tuntas setelah melewati masa-masa yang cukup melelahkan kurang lebih 14 bulan dengan menelusuri beberapa referensi dari jurnal, internet, buku dan artikel-artikel lainnya.
Buku 15 Metode Menyelesaikan Data Mining, Sistem Pakar dan Sistem
Pendukung Keputusan ini ditujukan khusus untuk mahasiswa dan tidak tertutup
kemungkinan juga para masyarakat awam yang ingin memahami cara membangun system berbasis artificial intelligence. Karena memang sengaja disusun lengkap dengan contoh-contoh dan latihan sehingga benar-benar para pembaca mudah memahami dan mampu mengimplementasikannya.
Kalangan mahasiswa sering terkendala dengan metode-metode yang berhubungan dengan Data Mining, Sistem Pakar dan Sistem Pendukung Keputusan, dalam buku ini penulis membahas 15 metode sehingga antar metode dapat diimplementasikan ke dalam Data Mining, Sistem Pakar dan Sistem Pendukung Keputusan.
Melalui kata pengantar ini, penulis ingin mengucapkan trimakasih yang sebesar-besarnya kepada Yayasan Teknologi Informasi Mutiara dan STMIK Kaputama serta seluruh civitas akademika STMIK KAPUTAMA Binjai yang turut serta membantu dari segi doa dan motivasi hingga selesainya buku ini, dan persembahan khusus buku ini kepada Triple-R Buaton Junior (Randhy, Richard, Rachel) dan istri tercinta Dewi Sartika. Akhir kata semoga buku ini bermanfaat bagi kita semua
Penulis
DAFTAR ISI Kata Pengantar
Daftar Isi
BAB 1 : Pendahuluan BAB 2 : DATA MINING
2.1. Pengertian Data Mining 2.2.1. Data Warehouse 2.2.2. Proses Data Mining 2.2.3. Teknik Data Mining 2.2. Metode Rough Set
2.2.1. Pengantar Rough Set 2.2.2. Discernibility Matrix
2.2.3. Discernibility Matrix Modulo D 2.2.4. Reduct
2.2.5. Generating Rules 2.3. Metode Association Rules
2.3.1. Pengantar Association Rules 2.3.2. Terminologi Association Rule
2.3.3. Langkah-Langkah Algoritma PadaAssociation Rule 2.4.Metode Clustering
2.4.1. Pengantar Clustering 2.4.2. Algoritma K-Means 2.5. Artificial Neural Networ(ANN)
2.5.1. Pengantar Jaringan syaraf Tiruan 2.5.2. Perceptron
2.5.3. BACK PROPAGATION(Perambatan Galat Mundur) 2.5.3.1. Pengantar Back Propagation
2.6. Decision Tree(Pohon Keputusan) 2.6.1. Pengantar Decision Tree 2.6.2. AlgoritmaID3
BAB 3 : SISTEM PAKAR
3.1. Sekilar Tentang Artificial Inteligence 3.1.1. Pengertian Sistem Pakar 3.1.2. Konsep Dasar Sistem Pakar 3.1.3. Ciri-Ciri Sistem Pakar 3.1.4. Struktur Sistem Pakar 3.1.5. Keuntungan Sistem Pakar 3.1.6. Representasi pengetahuan
3.1.7. Model Representasi Pengetahuan 3.1.8. Inferensi
3.2.1. Prior 3.2.1. Posterior
3.2.3. Penerapan Metode Bayes 3.3. Fuzzy Sistem
3.3.1 Fuzziness dan Probabilitas 3.3.2 Fuzzy Set
3.3.3 Fuzzy logic 3.4. Certainty Factor
3.4.1. Pengertian Faktor Kepastian ( Certainty Factor ) 3.4.2. Perhitungan Certainty Factor
BAB 4: SISTEM PENDUKUNG KEPUTUSAN
4.1. Fuzzy Multiple Attribute Decision Making (FMADM) 4.1.1. Sistem Pendukung Keputusan
4.1.2. Ciri-ciri Decision Support System (DSS)
4.1.3. Karakteristik, Kemampuan dan Keterbatasan SPK 4.1.4. Komponen - Komponen Sistem Pendukung Keputusan 4.1.5. Tahapan Proses Pengambilan Keputusan
4.2. Metode Analytical Hierarchy Process (AHP) 4.2.1 Kelebihan AHP
4.2.2 Prinsip - Prinsip Analytical Hierarchy Process 4.2.3 Langkah-Langkah Analytical Hierarchy Process 4.2.4. Contoh Kasus Dengan Metode AHP
4.3.Metode TOPSIS( Technique For Order Preference by Similarity to 4.3.1. Langkah-langkah metode TOPSIS
4.3.2. Contoh Penerapan Metode Topsis 4.4.Metode Weighted Product (WP)
4.4.1. Contoh Kasus Dengan Metode WP 4.5. Metode Simple Additive Weighting (SAW)
4.5.1. Analisis Pemecahan Masalah dengan Metode SAW 4.5.2. Studi Kasus
MOTTO
Tentang Penulis
Relita Buaton, ST, M. Kom, lahir pada tahun 1979 yang selalu mendapat prestasi baik sejak SD, SMP, SMA hingg jenjang Perguruan Tinggi. Gelar ST diraih di ISTP(Institut Sains dan Teknologi TD. Pardede) pada tahun 2004 di Medan, Gelar M. Kom diraih di UPI (Universitas Putra Indonesia) di Padang tahun 2010. Berbagai pengalaman dan pekerjaan telah didapat sebagai EDP Staff, IT Manager di beberapa perusahaan swasta di Kota Medan, Sejak tahun 2006 mengabdi sebagai dosen di beberapa PTS Medan, dan tahun 2009 sebagai dosen tetap di STMIK Kaputama Binjai sampai saat ini
Penulis gemar pada beberapa cabang ilmu computer diantaranya, pemrograman(desktop maupun web base), Artificial Inteligence, Expert System dan Data Mining. Kontak dengan penulis dapat melalui [email protected]
BAB I PENGANTAR
Buku ini terdiri dari 4 bab, yang terdiri dari Data Mining, Sistem Pakar dan Sistem Pendukung Keputusan, berikut akan dijelaskan gambaran bab demi bab
Bab I pengantar
Bab II tentang data mining mencakup a. Konsep data mining b. Metode Rough Set c. Apriori
d. Clustering e. Perceptro
f. Back Propagation g. Decision Tree
Data mining merupakan serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Defenisi lain data mining adalah sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data mining juga diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. Istilah data mining kadang disebut juga knowledge discovery. Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda,
tetapi berkaitan satu sama lain. KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data yang berukuran besar
Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan. Karakteristik data mining sebagai berikut
1. Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
2. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
3. Association rule mining adalah teknik mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Contoh dari aturan assosiatif dari analisa pembelian di suatu pasar swalayan adalah bisa diketahui berapa besar kemungkinan seorang pelanggan membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut, pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang kampanye pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support yaitu persentase kombinasi item tersebut dalam database dan confidence yaitu kuatnya hubungan antar item dalam aturan assosiatif. 4. Classification adalah proses untuk menemukan model atau fungsi yang
menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui.
5. Decision tree adalah salah satu metode classification yang paling populer karena mudah untuk diinterpretasi oleh manusia. Setiap percabangan menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon menyatakan kelas data. Algoritma decision tree yang paling terkenal adalah C4.5, tetapi akhir-akhir ini telah dikembangkan algoritma yang
mampu menangani data skala besar yang tidak dapat ditampung di main memory seperti RainForest.
6. Clustering
Berbeda dengan association rule dan classification dimana kelas data telah ditentukan sebelumnya, clustering melakukan pengelompokan data tanpa berdasarkan kelas data tertentu. Bahkan clustering dapat dipakai untuk memberikan label pada kelas data yang belum diketahui itu. Karena itu clustering sering digolongkan sebagai metode unsupervised learning. Prinsip clustering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar kelas/cluster. Clustering dapat dilakukan pada data yang memiliki beberapa atribut yang dipetakan sebagai ruang multidimensi.
7. Neural Network
Merupakan pendekatan perhitungan yang melibatkan pengembangan struktur secara matematis dengan kemampuan untukbelajar dan mampu menurunkan pengertian dari data yang kompleks dan tidak jelas dan dapat digunakan pula untuk mengekstrak pola dan mendeteksi trend-trend yang sangat kompleks untuk dibicarakan baik oleh manusia maupun teknik komputer lainnya. Jaringan syaraf buatan yang terlatih dapat dianggap sebagai pakar dalam kategori informasi yang akan dianalisis. Pakar ini dapatbdigunakan untuk memproyeksi situasi baru dari ketertarikan informasi
Dengan memahami bab 2, maka dapat memecahkah masalah yang berhubungan dengan tumpukan data, sehingga mampu mendapatkan informasi atau pengetahuan baru sekumpulan atau tumpukan data. Untuk memahami metode-metode yang terdapat dalam data mining, penulis membuat beberapa contoh untuk memahami perhitungan secara matematis
Kalangan mahasiswa terkadang mengalami kesulitan dalam memilihi metode untuk penelitian, pada bab 2 penulis juga menjelaskan saat kapan metode terdebut digunakan sesuai data.
Bab III tentang Sistem pakar, mencakup a. Konsep system pakar
b. Backward Chaining c. Forward Chaining d. Metode Fuzzy Logic e. Certainty factor f. Metode Bayes
Sistem Pakar ( Expert System ) adalah sistem yang berusaha mengadopsi pengetahuan manusia ke komputer, agar komputer dapat menyelesaikan masalah seperti biasa yang dilakukan para ahli Sistem pakar (expert system) mulai dikembangkan pada pertengahan tahun 1960-an oleh Artificial Intelligence Corporation. Sistem pakar yang muncul pertama kali adalah General-purpose Problem Solver (GPS) yang merupakan sebuah predecessor untuk menyusun langkah-langkah yang dibutuhkan untuk mengubah situasi awal menjadi state tujuan yang telah ditentukan sebelumnya dengan menggunakan domain masalah yang kompleks. Sistem pakar dapat diterapkan untuk persoalan di bidang industri, pertanian, bisni, kedokteran, militer, komunikasi dan transportasi, pariwisata, pendidikan, dan lain sebagainya. Permasalahan tersebut bersifat cukup kompleks dan terkadang tidak memiliki algoritma yang jelas di dalam pemecahannya, sehingga dibutuhkan kemampuan seorang atau beberapa ahli untuk mencari sistematika penyelesaiannya secara evolutif.
Sistem pakar disusun oleh dua bagian utama, yaitu: lingkungan pengembangan (development environment) dan lingkungan konsultasi (consultation environment) (Muhammad Arhami, 2005). Lingkungan pengembangan sistem pakar digunakan untuk memasukkan pengetahuan pakar kedalam lingkungan sistem pakar, sedangkan lingkungan konsultasi digunakan oleh pengguna yang bukan pakar guna memperoleh pengetahuan pakar.
Komponen-komponen yang terdapat dalam sistem pakar antara lain adalah sebagai berikut :
1. Antarmuka pengguna (user interface)
User interface merupakan mekanisme yang digunakan oleh pengguna dan sistem pakr untuk berkomunikasi. Antarmuka menerima informasi dari pemakai dan mengubahnya kedalam bentuk yang dapat diterima oleh sistem. Pada bagian ini terjadi dialog antara program dan pemakai, yang memungkinkan sistem pakar menerima instruksi dan informasi (input) dari pemakai, juga memberikan informasi (output) kepada pemakai.
1. Basis Pengetahuan
Basis pengetahuan berisi pengetahuan-pengetahuan dalam penyelesaian masalah dalam domain tertentu.Ada dua bentuk pendekatan basis pengetahuan yang sangat umum digunakan, yaitu :
a) Penalaran berbasis aturan (Rule-Based Reasoning)
Pengetahuan direpresentasikan dengan menggunakan aturan berbentuk : IF-THEN. Bentuk ini digunakan apabila memiliki sejumlah pengetahuan pakar pada suatu permasalahan tertentu, dan pakar dapat menyelesaikan masalah tersebut secara berurutan.
b) Penalaran berbasis kasus (Case-Based Reasoning)
Basis pengetahuan berisi solusi-solusi yang telah dicapai sebelumnya, kemudian akan diturunkan suatu solusi untuk keadaan yang terjadi sekarang. 3. Akuisisi Pengetahuan (knowledge acquisition)
Akuisisi pengetahuan adalah akumulasi, transfer, dan transformasi keahlian dalam menyelesaikan masalah dari sumber pengetahuan kedalam program komputer. Dalam tahap ini knowledge engineer berusaha menyerap pengetahuan untuk selanjutnya di transfer ke dalam basis pengetahuan.Terdapat empat metode utama dalam akuisisi pengetahuan, yaitu: wawancara, analisis protocol, observasi pada pekerjaan pakar dan induksi aturan dari contoh.
4. Mesin inferensi
Mesin inferensi merupakan perangkat lunak yang melakukan penalaran dengan menggunakan pengetahuan yang ada untuk menghasilkan suatu kesimpulan atau hasil akhir. Dalam komponen ini dilakukan permodelan proses berfikir manusia.
5. Workplace
Workplace merupakan area dari sekumpulan memori kerja yang digunakan untuk merekam hasil-hasil dan kesimpulan yang dicapai. Ada tiga tipe keputusan yang direkam, yaitu :
a) Rencana : Bagaimana menghadapi masalah.
b) Agenda : Aksi-aksi yang potensial yang sedang menunggu untuk eksekusi. c) Solusi : calon aksi yang akan dibangkitkan.
6. Fasilitas penjelasan
Fasilitas penjelasan adalah komponen tambahan yang akan meningkatkan kemampuan sistem pakar. Komponen ini menggambarkan penalaran sistem kepada pemakai dengan cara menjawab pertanyaan-pertanyaan.
7. Perbaikan pengetahuan
Pakar memiliki kemampuan untuk menganalisis dan meningkatkan kinerjanya serta kemampuan untuk belajar dan kinerjanya
Sistem pakar merupakan program yang dapat menggantikan keberadaan seorang pakar. Alasan mendasar mengapa sistem pakar dikembangkan menggantikan seorang pakar adalah sebagai berikut :
1. Dapat menyediakan kepakaran setiap waktu dan di berbagai lokasi. 2. Secara otomatis mengerjakan tugas-tugas rutin yang membutuhkan
seorang pakar.
3. Seorang pakar akan pensiun atau pergi.
4. Menghadirkan atau menggunkan jasa seorang pakar memerlukan biaya yang mahal.
5. Kepakaran dibutuhkan juga pada lingkungan yang tidak bersahabat (hostile environment).
Dengan memahami bab 3 yaitu tentang system pakar, para pembaca diharapkan mampu menerapkan metode-metode tersebut untuk membangun system pakar maupun memahami perhitungan secara matematis
Bab IV tentang Sistem Pendukung Keputusan, mencakup a. Konsep system pendukung keputusan
b. MADM c. AHP d. SAW e. WP f. TOPSIS
Fuzzy Multiple Attribute Decision Making (FMADM) adalah suatu metode yang digunakan untuk mencari alternatif optimal dari sejumlah alternatif dengan kriteria tertentu. Inti dari FMADM adalah menentukan nilai bobot untuk setiap atribut, kemudian dilanjutkan dengan proses perankingan yang akan menyeleksi alternatif yang sudah diberikan. Pada dasarnya, ada tiga pendekatan untuk mencari nilai bobot atribut, yaitu pendekatan subyektif, pendekatan obyektif dan pendekatan integrasi antara subyektif & obyektif. Masing-masing pendekatan memiliki kelebihan dan kelemahan. Pada pendekatan subyektif, nilai bobot ditentukan berdasarkan subyektifitas dari para pengambil keputusan, sehingga beberapa faktor dalam proses perankingan alternatif bisa ditentukan secara bebas. Sedangkan pada pendekatan obyektif, nilai bobot dihitung secara matematis sehingga mengabaikan subyektifitas dari pengambil keputusan
Sistem Pendukung Keputusan adalah suatu sistem informasi bebasis komputer yang menghasilkan berbagai alternatif keputusan untuk membantu manajemen dalam menangani berbagai permasalahan yang terstruktur ataupun tidak terstruktur dengan menggunakan data dan model. Kata berbasis komputer merupakan kata kunci, karena hampir tidak mungkin membangun SPK tanpa
memanfaatkan komputer sebagai alat bantu, terutama untuk menyimpan data serta mengelola model
a. Karakteristik DSS
1. Mendukung seluruh kegiatan organisasi
2. Mendukung beberapa keputusan yang saling berinteraksi 3. Dapat digunakan berulang kali dan bersifat konstan 4. Terdapat dua komponen utama, yaitu data dan model 5. Menggunakan baik data eksternal dan internal
6. Memiliki kemampuan what-if analysis dan goal seeking analysis 7. Menggunakan beberapa model kuantitatif
b. Kemampuan DSS
1. Menunjang pembuatan keputusan manajemen dalam menangani masalah semi terstruktur dan tidak terstruktur
2. Membantu manajer pada berbagai tingkatan manajemen, mulai dari manajemen tingkat atas sampai manajemen tingkat bawah
3. Menunjang pembuatan keputusan secara kelompok maupun perorangan 4. Menunjang pembuatan keputusan yang saling bergantung dan berurutan 5. Menunjang tahap-tahap pembuatan keputusan antara lain intelligensi,
desain, choice, dan implementation
6. Menunjang berbagai bentuk proses pembuatan keputusan dan jenis keputusan
7. Kemampuan untuk melakukan adaptasi setiap saat dan bersifat fleksibel 8. Kemudahan melakukan interaksi system
9. Meningkatkan efektivitas dalam pembuatan keputusan daripada efisiensi 10. Mudah dikembangkan oleh pemakai akhi
11. Kemampuan pemodelan dan analisis pembuatan keputusan
12. Kemudahan melakukan pengaksesan berbagai sumber dan format data Di samping berbagai Karakteristik dan Kemampuan seperti dikemukakan di atas, SPK juga memiliki beberapa keterbatasan, diantaranya adalah
1. Ada beberapa kemampuan manajemen dan bakat manusia yang tidak dapat dimodelkan, sehingga model yang ada dalam sistem tidak semuanya mencerminkan persoalan sebenarnya.
2. Kemampuan suatu SPK terbatas pada pembendaharaan pengetahuan yang dimilikinya (pengetahuan dasar serta model dasar).
3. Proses-proses yang dapat dilakukan oleh SPK biasanya tergantung juga pada kemampuan perangkat lunak yang digunakannya.
4. SPK tidak memiliki kemampuan intuisi seperti yang dimiliki oleh manusia. Karena walau bagaimana pun canggihnya suatu SPK, hanyalah sautu kumpulan perangkat keras, perangakat lunak dan sistem operasi yang tidak dilengkapi dengan kemampuan berpikir.
Dengan membaca bab 4 yakni tentang system pendukung keputusan, pembaca mampu membangun system pendukung keputusan, yan tentu konsepnya berbeda dengan data mining dan system pendukung keputusan
Buku ini juga disertai dengan beberapa contoh kasus, dimana kasus tersebut diambil dari pengalaman penulis dalam beberap jurnal yang penulis buat dan sedang proses penerbitan
BAB II DATA MINING
2.1. Pengertian Data Mining
Sebelum membahas lebih jauh tentang data mining, mari kita simak terlebih dahulu pengalaman 2 orang mahasiswa pasca sarjana di Curtin University of Tecnology berikut ini(Yudho, 2003)
”Ketika saya mengikuti program orientasi mahasiswa baru pasca sarjana di Curtin University of Technology, saya berkenalan dengan seorang mahasiswi asal Australia. Dia mengambil program Master di bidang Jaringan Komputer dan telah menyandang gelar MCSE (Microsoft Certified Systems Engineer), lalu dia bertanya pada saya, “Apa topik penelitian Anda?”, saya menjawab “Data Mining”. Dia kemudian memberi komentar kepada saya, “Oh…. itu bagus sekali…. Anda tepat sekali mengambil topik itu disini, karena kita punya pertambangan emas yang besar sekali di Kalgoorlie (Kalgoorlie berada 600 km di sebelah timur Perth dan Curtin University mempunyai cabang kampus disana)”. Data Mining memang salah satu cabang ilmu komputer yang relatif baru. Dan sampai sekarang orang masih memperdebatkan untuk menempatkan data mining di bidang ilmu mana, karena data mining menyangkut database, kecerdasan buatan (artificial intelligence), statistik, dsb. Ada pihak yang berpendapat bahwa data mining tidak lebih dari machine learning atau analisa statistik yang berjalan di atas database. Namun pihak lain berpendapat bahwa database berperanan penting di data mining karena data mining mengakses data yang ukurannya besar (bisa sampai terabyte) dan disini terlihat peran penting database terutama dalam optimisasi query-nya. Lalu apakah data mining itu? Apakah memang berhubungan erat
dengan dunia pertambangan, tambang emas, tambang timah, dsb. Definisi sederhana dari data mining adalah ekstraksi informasi atau pola yang penting atau menarik dari data yang ada di database yang besar. Dalam jurnal ilmiah, data mining juga dikenal dengan nama Knowledge Discovery in Databases (KDD)”
Kutipan di atas menceritakan 2 orang mahasiswa yang memiliki perbedaan persfektif dan pemahaman terkait dengan data mining, ketika dia mengatakan topik penelitiannya tentang data mining, dan temannya beranggapan bahwa data mining itu berarti penggalian atau penambangan(emas, timah, dll), sehingga dia mengatakan , oh itu bagus sekali karena kita punya pertambangan emas yang besar sekali di Kalgoorlie, mungkin kata “mining” diasumsikan sama dengan penambangan atau penggalian emas atau timah.
Setiap hari, bulan atau tahun data transaksi di perusahaan, perguruan tinggi, swalayan atau instansi lainnya terakumulasi dalam jumlah yang besar. Jika dalam satu hari ada 200 transaksi, maka dalam setahun kurang lebih sekitar 72.000 transaksi. Kemudian berapa transaksi jika data itu diakumulasikan untuk 10 tahun. Pertanyaannya setelah data itu selesai digunakan setiap bulannya,
untuk apa data itu disimpan?
apakah dibuang, atau disimpan begitu saja hingga menjadi gunung data? Kalau disimpan terus menerus tentu membutuhkan biaya untuk penambahan kapasitas memori penyimpanan dan biaya perawatan. Solusi terbaik adalah dengan membuang data, tetapi sebelum data itu dimusnahkan maka data tersebut digali terlebih dahulu untuk mendapatkan pengetahuan baru, informasi baru yang sangat berarti dengan menggunakan teknik data mining.
Data mining merupakan serangkaian proses untuk menggali nilai tambah dari suatu kumpulan data berupa pengetahuan yang selama ini tidak diketahui secara manual dari suatu kumpulan data. Defenisi lain data mining adalah sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data mining juga diartikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan
keputusan. Istilah data mining kadang disebut juga knowledge discovery (Eko Prasetyo, 2012). Istilah data mining dan Knowledge Discovery in Database (KDD) sering kali digunakan secara bergantian untuk menjelaskan proses penggalian informasi tersembunyi dalam suatu basis data yang besar. Sebenarnya kedua istilah tersebut memiliki konsep yang berbeda, tetapi berkaitan satu sama lain. KDD adalah kegiatan yang meliputi pengumpulan, pemakaian data, historis untuk menemukan keteraturan, pola atau hubungan dalam set data yang berukuran besar (Budi Santoso , 2007a).
Data mining didefinisikan sebagai proses menemukan pola-pola dalam data. Pola yang ditemukan harus penuh arti dan pola tersebut memberikan keuntungan. Karakteristik data mining sebagai berikut
8. Data mining berhubungan dengan penemuan sesuatu yang tersembunyi dan pola data tertentu yang tidak diketahui sebelumnya.
9. Data mining biasa menggunakan data yang sangat besar. Biasanya data yang besar digunakan untuk membuat hasil lebih dipercaya.
Data mining berguna untuk membuat keputusan yang kritis, terutama dalam strategi (Davies, 2004), juga dapat digunakan untuk pengambilan keputusan di masa depan berdasarkan informasi yang diperoleh dari data masa lalu. Tergantung pada aplikasinya, data bisa berupa data mahasiswa, data pasien, data nasabah atau penjualan. Banyak kasus dalam kehidupan sehari-hari yang tanpa disadari bisa diselesaikan dengan data mining, diantaranya adalah
1. Memprediksi harga saham dalam beberapa bulan ke depan berdasarkan performansi perusahaan dan data-data ekonomi
2. Memprediksi berapa jumlah mahasiswa baru di perguruan tinggi berdasarkan data pendaftar pada tahun-tahun sebelumnya
3. Memprediksi nilai indeks prestasi mahasiswa berdasarkan nilai IP setiap semester sebelumnya
4. Produk apa yang akan dibeli pelanggan secara bersamaan jika membeli produk di swalayan
5. Bagaimana mengetahui karakteristik nasabah yang kredit lancar atau macet dalam suatu perbankan atau finance
6. Mengelompokan customer berdasarkan minat, atau pola kebiasaan sehingga mempermudah menentukan target pemasaran
7. Dll.
Tentu masih banyak lagi contoh-contoh dalam bidang lain atau kasus lain yang kaitannnya dengan penggalian data sehingga bisa menghasilkan pengetahuan baru dan informasi baru menjadi strategi dalam mengembangkan suatu bidang uasaha.
9.1.1. Data Warehouse
Data warehouse merupakan kumpulan data dari berbagai sumber yang disimpan dalam suatu gudang data (repository) dalam kapasitas besar dan digunakan untuk proses pengambilan keputusan (Prabhu, 2007). Data warehouse menyatukan dan menggabungkan data dalam bentuk multidimensi. Pembangunan data warehouse meliputi pembersihan data, penyatuan data dan transformasi data dan dapat dilihat sebagai praproses yang penting untuk digunakan dalam data mining. Selain itu data warehouse mendukung On-line Analitycal Processing (OLAP), sebuah kakas yang digunakan untuk menganalisis secara interaktif dari bentuk multidimensi yang mempunyai data yang rinci. Sehingga dapat memfasilitasi secara efektif data generalization dan data mining. Banyak metode-metode data mining yang lain seperti asosiasi, klasifikasi, prediksi, dan clustering, dapat diintegrasikan dengan operasi OLAP untuk meningkatkan proses mining yang interaktif dari beberapa level dari abstraksi. Oleh karena itu data warehouse menjadi platform yang penting untuk data analisis dan OLAP untuk dapat menyediakan platform yang efektif untuk proses data mining.
Menurut William Inmon, karakteristik dari data warehouse adalah sebagai berikut :
Pada sistem operasional, data disimpan berdasarkan aplikasi. Set data hanya terdiri dari data yang dibutuhkan oleh fungsi yang terkait dan aplikasinya. Sedangkan pada data warehouse, data disimpan bukan berdasarkan aplikasi, melainkan berdasarkan subjeknya. Misalnya untuk sebuah perusahaan manufaktur subjek bisnis yang penting, yaitu penjualan, pengangkutan, dan penyimpanan barang.
2. Integrated.
Data yang tersimpan dalam data warehouse terdiri dari berbagai system operasional. Oleh sebab itu terdapat kemungkinan bahwa terjadi beberapa perbedaan, yaitu dalam konvensi penamaan, representasi kode, atribut data dan pengukuran data. Keempat perbedaan tersebut harus disamakan terlebih dahulu sesuai dengan standar tertentu agar data yang nantinya tersimpan dalam data warehouse dapat terintegrasi.
3. Time variant.
Pada data warehouse, data yang tersimpan adalah data historis dalam kurun waktu tertentu, bukan data terkini. Oleh karena itu data yang tersimpan mengandung keterangan waktu, misalnya tanggal, minggu, bulan, catur wulan,dan sebagainya. Karakteristik time variant pada data warehouse memiliki karakteristik sebagai berikut:
a. Melakukan analisa terhadap hal di masa lalu.
b. Mencari hubungan antara informasi dengan keadaan saat ini. c. Melakukan prediksi hal yang akan datang.
4. Non-volatile.
Data dalam sistem operasional dapat di update sesuai transaksi bisnis. Setiap kali terjadi transaksi bisnis. Namun dalam data warehouse, data tidak dapat diubah karena bersifat read only.
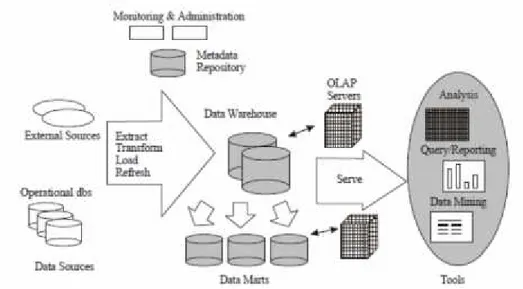
Arsitektur data warehouse (gambar 2.1) mencakup proses ETL (Extraction,Transformation, Loading) untuk memindahkan data dari operational data source dan sumber data eksternal lainnya ke dalam data warehouse . Data warehouse dapat dibagi menjadi beberapa data mart, berdasarkan fungsi bisnisnya (contoh: data mart untuk penjualan, pemasaran, dan keuangan). Data
dalam data warehouse dan data mart diatur oleh satu atau lebih server yang mewakili multidimensional view dari data terhadap berbagai front end tool, seperti querytools, analysis tools, report writers, dan data mining tools.
Gambar 2.1 Arsitektur Data Warehouse (Prabhu, 2007)
2.1.2. Proses Data Mining
Data mining merupakan rangkaian proses, data mining dapat dibagi menjadi beberapa tahap yang diilustrasikan di Gambar 2.2. Tahap-tahap tersebut bersifat interaktif, pemakai terlibat langsung atau dengan perantaraan knowledge base.
Gambar 2.2. Tahapan Data Mining
Karena data mining adalah suatu rangkaian proses, maka data mining dapat dibagi menjadi beberapa tahap seperti yang diilustrasikan pada gambar 2.2
1. Pembersihan data (membuang data yang tidak konsisten atau noise)
Pembersihan data merupakan proses menghilangkan noise dan data yang tidak konsisten atau data tidak relevan. Pada umumnya data yang diperoleh, baik dari database suatu perusahaan maupun hasil eksperimen, memiliki isian-isian yang tidak sempurna seperti data yang hilang, data yang tidak valid atau juga hanya sekedar salah ketik
2. Integrasi data (penggabungan data dari beberapa sumber)
Integrasi data merupakan penggabungan data dari berbagai database ke dalam satu database baru. Tidak jarang data yang diperlukan untuk data mining tidak hanya berasal dari satu database tetapi juga berasal dari beberapa database atau file teks. Integrasi data dilakukan pada atribut-aribut yang mengidentifikasikan entitas-entitas
3. Transformasi data (mengubah data menjadi bentuk lain)
Data diubah atau digabung ke dalam format yang sesuai untuk diproses dalam data mining. Beberapa metode data mining membutuhkan format data yang khusus sebelum bisa diaplikasikan. Sebagai contoh beberapa metode standar seperti analisis asosiasi dan clustering hanya bisa menerima input data kategorikal. Oleh sebab itu data berupa angka/ numerik perlu dibagi-bagi menjadi beberapa interval. Proses ini sering disebut transformasi data
4. Aplikasi teknik data mining
Merupakan suatu proses utama saat metode diterapkan untuk menemukan pengetahuan berharga dan tersembunyi dari data.
5. Evaluasi dan Presentasi pengetahuan (dengan teknik visualisasi)
Menyajikan pengetahuan mengenai metode yang digunakan untuk memperoleh pengetahuan yang diperoleh pengguna. Tahap terakhir dari proses data mining adalah bagaimana memformulasikan keputusan atau aksi dari hasil analisis yang didapat. Ada kalanya hal ini harus melibatkan orang-orang yang tidak memahami data mining. Karenanya presentasi hasil data mining dalam bentuk pengetahuan yang bisa dipahami semua orang adalah satu tahapan yang diperlukan dalam proses data mining
2.1.3. Teknik Data Mining
Data mining berkaitan dengan bidang ilmu – ilmu lain, seperti database system, data warehousing, statistik, machine learning, information retrieval, dan komputasi tingkat tinggi. Selain itu, data mining didukung oleh ilmu lain seperti neural network, pengenalan pola, spatial data analysis, image database, signal processing. Pada dasarnya penggalian data dibedakan menjadi dua fungsionalitas, yaitu
1. Deskripsi
memperoleh pola (correlation, trend,cluster, trajectory, anomaly) untuk menyimpulkan hubungan di dalam data
2. Prediksi
memprediksikan nilai dari atribut tertentu berdasarkan nilai dari atribut lainnya. Atribut yang diprediksi dikenal sebagai target atau dependent variable, sedangkan atribut yang digunakan untuk membuat prediksi disebut penjelas atau independent variable
Beberapa teknik yang sering terdapat dalam literatur data mining antara lain yaitu association rule mining, clustering, klasifikasi, neural network dan lain-lain.
a. Association rule mining adalah teknik mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Contoh dari aturan assosiatif dari analisa pembelian di suatu pasar swalayan adalah bisa diketahui berapa besar kemungkinan seorang pelanggan membeli roti bersamaan dengan susu. Dengan pengetahuan tersebut, pemilik pasar swalayan dapat mengatur penempatan barangnya atau merancang kampanye pemasaran dengan memakai kupon diskon untuk kombinasi barang tertentu. Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support yaitu persentase kombinasi item tersebut dalam database dan confidence yaitu kuatnya hubungan antar item dalam aturan assosiatif. b. Classification adalah proses untuk menemukan model atau fungsi yang
menjelaskan atau membedakan konsep atau kelas data, dengan tujuan untuk dapat memperkirakan kelas dari suatu objek yang labelnya tidak diketahui.
c. Decision tree adalah salah satu metode classification yang paling populer karena mudah untuk diinterpretasi oleh manusia. Setiap percabangan menyatakan kondisi yang harus dipenuhi dan tiap ujung pohon menyatakan kelas data. Algoritma decision tree yang paling terkenal adalah C4.5, tetapi akhir-akhir ini telah dikembangkan algoritma yang mampu menangani data skala besar yang tidak dapat ditampung di main memory seperti RainForest.
d. Clustering
Berbeda dengan association rule dan classification dimana kelas data telah ditentukan sebelumnya, clustering melakukan pengelompokan data tanpa berdasarkan kelas data tertentu. Bahkan clustering dapat dipakai untuk memberikan label pada kelas data yang belum diketahui itu. Karena itu clustering sering digolongkan sebagai metode unsupervised learning. Prinsip clustering adalah memaksimalkan kesamaan antar anggota satu kelas dan meminimumkan kesamaan antar kelas/cluster. Clustering dapat dilakukan pada data yang memiliki beberapa atribut yang dipetakan sebagai ruang multidimensi.
e. Neural Network
Merupakan pendekatan perhitungan yang melibatkan pengembangan struktur secara matematis dengan kemampuan untukbelajar dan mampu menurunkan pengertian dari data yang kompleks dan tidak jelas dan dapat digunakan pula untuk mengekstrak pola dan mendeteksi trend-trend yang sangat kompleks untuk dibicarakan baik oleh manusia maupun teknik komputer lainnya. Jaringan syaraf buatan yang terlatih dapat dianggap sebagai pakar dalam kategori informasi yang akan dianalisis. Pakar ini dapatbdigunakan untuk memproyeksi situasi baru dari ketertarikan informasi
2.2. Metode Rough Set 2.2.1. Pengantar Rough Set
Teori rough set adalah sebuah teknik matematik yang dikembangkan oleh Pawlack pada tahun 1980 (Chouchoulas, 1999). Rough Set salah satu teknik data mining yang digunakan untuk menangani masalah Uncertainty, Imprecision dan Vagueness dalam aplikasi Artificial Intelligence (AI). Rouh set merupakan teknik yang efisien untuk Knowledge Discovery in Database (KDD) dalam tahapan proses dan Data Mining.
Secara umum, teori rough set telah digunakan dalam banyak aplikasi seperti medicine, pharmacology, business, banking, engineering design, image processing dan decision analysis.
1. Representasi Data Dalam Rough Set
Rough set direpresentasikan dalam 2 elemen yakni Information Systems (IS) dan Decision Systems (DS).
U={e1, e2,…, em} dan A={a1, a2, …, an} merupakan sekumpulan example dan attribute kondisi secara berurutan.
Definisi di atas memperlihatkan bahwa sebuah Information Systems terdiri dari sekumpulan example, seperti {e1, e2, …, em} dan attribute kondisi, seperti {a1, a2,
…, an}. Sebuah Information Systems yang sederhana diberikan dalam tabel 2.1.
Tabel 2.1. Information Systems
Example Studies Education ….. Works
1 Poor SMU ….. Poor
2 Poor SMU ….. Good
3 Moderate Diploma ….. Poor
4 Moderate MSc ….. Poor
5 Poor Diploma ….. Good
6 Good SMU ….. Poor
7 Moderate Diploma ….. Poor
… … … ….. …
… … … ….. …
100 Good MSc ….. Good
Data di atas merupakan kumpulan data 100 orang dengan melihat tingkat pendapatan berdasarkan kriteria studies, education dan works . Dalam Information System, tiap-tiap baris merepresentasikan objek sedangkan column merepresentasikan attribute yang terdiri dari m objek,
U={e1, e2,…, em}: Example 1,2,3…
A={a1, a2, …, an}: Studies, Education…Works
Dalam banyak aplikasi, sebuah outcome / keputusan dari pengklasifikasian diketahui yang direpresentasikan dengan sebuah Decision Attribute, C={C1, C2,
…, Cp}. Maka Information Systems (IS) menjadi IS=(U,{A,C}). Decision Systems (DS) yang sederhana diperlihatkan pada table 2.2.
Table 2.2. Sistem Informasi dan Keputusan
Example Studies Education ….. Works Income
(D)
1 Poor SMU ….. Poor None
2 Poor SMU ….. Good Low
3 Moderate Diploma ….. Poor Low
4 Moderate MSc ….. Poor Medium
5 Poor Diploma ….. Good Medium
6 Good SMU ….. Poor Low
7 Moderate Diploma ….. Poor Medium
… … … ….. … …
… … … ….. … …
100 Good MSc ….. Good High
Tabel 2.2. memperlihatkan sebuah Decision Systems yang sederhana, terdiri dari m objek, seperti E1, E2, …, Em, dan n attribute, seperti Studies,
Education, …, Works dan Income (D). Dalam tabel ini, n-1 attribute, Studies, Education, …, Works, adalah attribute kondisi, sedangkan Income adalah decision
attribute.
2. Equivalence Class
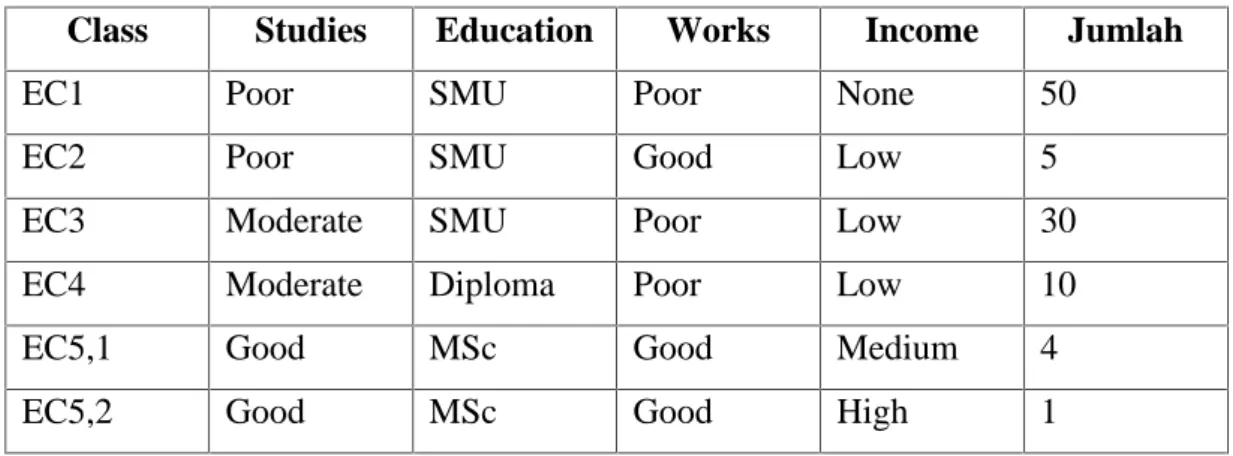
Equivalence class adalah mengelompokan objek-objek yang sama untuk attribute A (U, A). Diberikan Decision Systems pada table 2.2, dapat memperoleh equivalence class (EC1-EC5) seperti digambarkan pada tabel-2.3
Tabel 2.3. Equivalen Class
Class Studies Education Works Income Jumlah
EC1 Poor SMU Poor None 50
EC2 Poor SMU Good Low 5
EC3 Moderate SMU Poor Low 30
EC4 Moderate Diploma Poor Low 10
EC5,1 Good MSc Good Medium 4
Class EC5adalah sebuah indeterminacy yang memberikan 2 (dua) keputusan yang berbeda. Situasi ini dapat ditangani dengan teknik data cleaning karena kelas EC5,2hanya memiliki 1objek. Kolom yang paling kanan mengindikasikan jumlah objek yang ada dalam Decision System untuk class yang sama.Contoh dalam table 2.4 disederhanakan kedalam numerical representation untuk mempermudah pengolahan datanya, dengan transformasi atribut sebagai berikut.
Tabel 2.4 memperlihatkan numerical representation dari equivalence class dari table 2.3
Tabel 2.4. Equivalen Class(Transformasi)
Class Studies Education Works Income Jumlah
EC1 1 2 3 1 50 EC2 1 2 1 2 5 EC3 2 2 3 2 30 EC4 2 3 3 2 10 EC5,1 3 5 1 3 4 EC5,2 3 5 1 4 1 2.2.4. Discernibility Matrix S t u d i e s : P o o r : 1 M o d e r a t e : 2 G o o d : 3 E d u c a t i o n : S M U : 2 D i p l o m a : 3 M S c : 5
Diberikan sebuah IS A=(U,A) and B A, discernibility matrix dari A adalah MB, dimana tiap-tiap entry MB(I,j) tediri dari sekumpulan attribute yang berbeda antara objek Xidan Xj. Bandingkan setiap class, bila ada perbedaan pada atribut class kemudian tuliskan pada table discerdibility matrix, sedangkan jika semua atribut sama maka tuliskan dengan tanda kali (X). Atribut dimodelkan dengan:
Studies : A Education : B
Works : C
Contoh: EC1 dengan EC1, semua atribut sama sehingga hasilnya X(Baris 2 kolom 2), EC1 dengan EC2, terdapat perbedaan yaitu atribut works, sehingga pada table 2.5 baris 2 kolom 3 hasilnya C, begitu selanjutnya. Tabel 2.5 memperlihatkan discerniblity matrix dari table 2.4.
Table 2.5. Discernibility Matrix
EC1 EC2 EC3 EC4 EC5
EC1 X C A AB ABC
EC2 C X AC ABC AB
EC3 A AC X B ABC
EC4 AB ABC B X ABC
EC5 ABC AB ABC ABC X
2.2.5. Discernibility Matrix Modulo D
Diberikan sebuah DS A=(U,A{d{) dan subset dari attribute B A, discernibility matrix modulo D dari A, MBd, didefinisikan seperti berikut dimana MB(I,j)
adalah sekumpulan attribute yan berbeda antara objek Xidan Xj dan juga berbeda attribute keputusan. Berdasarkan table 2.5, bandingkan setiap class berdasarkan decision/keputusan, jika keputusan(income) sama maka tuliskan tanda kali(X), jika income berbeda tuliskan perbedaan atributnya berdasarkan table 2.5. Contoh EC3 dengan EC2 income sama sehingga hasilnya : X (baris 4 kolom 3)
Table 2.6. Discernibility Matrix Modulo D
EC1 EC2 EC3 EC4 EC5
EC1 X C A AB ABC
EC2 C X X X AB
EC3 A X X X ABC
EC4 AB X X X ABC
EC5 ABC AB ABC ABC X
2.2.6. Reduct
Reduct adalah penyeleksian attribut minimal (interesting attribute) dari sekumpulan attribut kondisi dengan menggunakan Prime Implicant fungsi Boolean. Kumpulan dari semua Prime Implicant mendeterminasikan sets of reduct. Discernibility matrix modulo D pada table 2.6 dapat ditulis sebagai formula CNF seperti diperlihatkan pada table 2.7. Gunakan aljabar Boolean untuk mencari prime implicant
A+1=1+A=1 AA=A
Class EC1 terdiri dari X,C,A,AB,ABC menjadi C^A^(AvB)^(AvBvC) =C^A^(AvB)^(AvBvC)
=C^(AA+AB) ^(AvBvC) =C^(A+AB)^(AvBvC)
=C^(A(1+B))^(AvBvC) =C^A^(AvBvC) =C^AA+AB+AC =C^A(1+B)+AC =C^A+AC =C^A(1+C) =C^A=A^C=AC
Class EC2 terdiri dari C,X,X,X,AB menjadi C^(AvB) =AC+BC
=AC,BC
Class EC3 terdiri dari A,X,X,X,ABC menjadi A^(AvBvC) =AA+AB+AC
=A(1+B)+AC =A+AC =A(1+C) =A
Class EC4 terdiri dari AB,X,X,X,ABC menjadi (AvB)^(AvBvC) =AA+AB+AC+AB+BB+BC
=A(1+B)+AC+AB+BB+BC =A+AC+AB+BB+BC =A(1+C)+AB+BB+BC
=A+AB+BB+BC =A(1+B)+BB+BC =A+B(1+C) =A+B =A,B
Calss EC5 terdiri dari ABC,AB,ABC,ABC,X menjadi (AvBvC)^(AvB)^(AvBvC)^(AvBvC) =(AvBvC)^(AvB)^(AvBvC)^(AvBvC) =AA+AB+AB+BB+AC+BC^(AvBvC)^(AvBvC) =A(1+B)+AB+BB+AC+BC^(AvBvC)^(AvBvC) =A+AB+BB+AC+BC^(AvBvC)^(AvBvC) =A(1+B)+BB+AC+BC^(AvBvC)^(AvBvC) =A+AC+BB+BC^(AvBvC)^(AvBvC) =A(1+C)+BB+BC^(AvBvC)^(AvBvC) =A+B(1+C)^(AvBvC)^(AvBvC) =A+B^(AvBvC)^(AvBvC) =B+A^(AvBvC)^(AvBvC) =B+AA+AB+AC^(AvBvC) =B+A(1+B)+AC^(AvBvC) =B+A+AC^(AvBvC) =B+A(1+C)^(AvBvC)
=B+A^(AvBvC) =B+AA+AB+AC =B+A(1+B)+AC =B+A+AC =B+A(1+C) =B+A=A,B Tabel 2.7. Reduce
Class CNF of Function Boolean Prime Implicant Reduce
EC1 C^A^(AvB)^(AvBvC) A^C {A,C}
EC2 C^(AvB) C(AvB) {A,C},{B,C}
EC3 A^(AvBvC) A {A}
EC4 (AvB)^(AvBvC) AvB {A},{B}
EC5 (AvBvC)^(AvB) AvB {A},{B}
2.2.7. Generating Rules
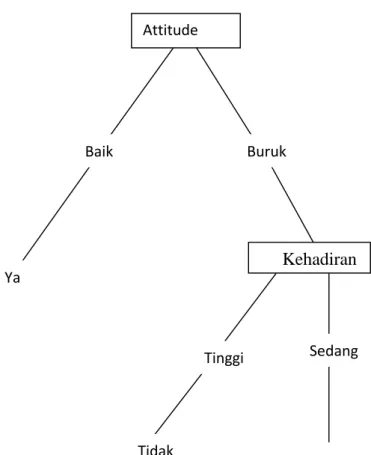
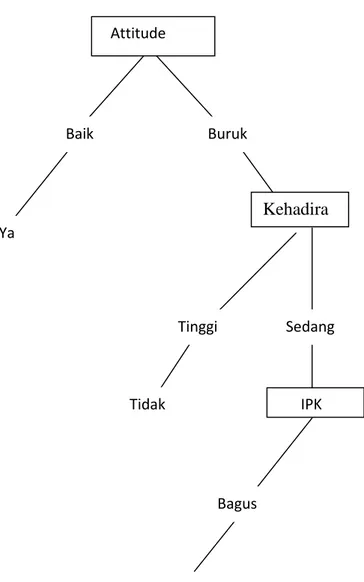
Setelah mendapatkan reduce, maka dapat ditarik kesimpulan atau ditentukan rule dengan menyesuaikan reduce setiap equivalen class terhadap table 2.3(Equivalen Class). Contoh untuk EC1 reduce={A,C}. Pada table discerdibility matrix Studies dimodelkan dengan A, Education : B dan Works : C, sehingga rulenya adalah Jika studies=poor dan work=poor maka income=none.
Berikut akan ditarik kesimpulan untuk semua kelas
a. Class EC1 menghasilkan prime implicant {A,C}, Rulenya adalah 1. Jika studies=poor dan work=poor maka income=none b. Class EC2 menghasilkan prime implicant {AC},{BC}, Rulenya adalah
2. Jika studies=poor dan work=good maka income=low 3. Jika education=SMU dan work=good maka income=low c. Class EC3 menghasilkan prime implicant {A}, Rulenya adalah
4. Jika studies=moderate maka income low
d. Class EC4 menghasilkan prime implicant {A},{B}, Rulenya adalah 5. Jika studies=moderate maka income=low
6. Jika education=Diploma maka income=low
e. Class EC5 menghasilkan prime implicant {A},{B}, Rulenya adalah 7. Jika studies=good maka income=moderate
8. Jika education=MSc maka income=moderate
Dari 8 rule diatas dapat disimpulkan dengan menggunakan logika OR, menjadi 1. Jika studies=poor dan work=poor maka income=none
2. Jika (studies=poor dan work=good) atau(education=SMU dan work=good) atau studies=moderate ataueducation=Diploma maka income=low
3. Jika studies=good atau education=MSc maka income=moderate
2.3. Metode Association Rules 2.3.1. Pengantar Association Rules
Analisis asosiasi atau association rule adalah teknik data mining untuk menemukan aturan assosiatif antara suatu kombinasi item. Aturan asosiasi merupakan pernyataan implikasi bentuk XY, dimana X dan Y adalah itemset yang lepas(disjoint)dan memenuhi persyaratan X∩ Y={}(Eko Prasetyo, 2012),
Contoh aturan assosiatif dari analisa pembelian di suatu pasar swalayan adalah dapat diketahuinya berapa besar kemungkinan seorang pelanggan membeli gula bersamaan dengan susu. Dengan pengetahuan tersebut pemilik pasar swalayan dapat mengatur tata letak atau penempatan barang dagangannya(Kantardzic,2003).
Algoritma A Priori termasuk jenis aturan asosiasi pada data mining. Selain a priori, yang termasuk pada golongan ini adalah metode generalized rule induction dan algoritma hash based. Aturan yang menyatakan asosiasi antara beberapa atribut sering disebut affinity analysis atau market basket analysis. Analisis asosiasi menjadi terkenal karena aplikasinya untuk menganalisa isi keranjang belanja di pasar swalayan. Analisis asosiasi juga sering disebut dengan istilah market basket analysis. Analisis asosiasi dikenal juga sebagai salah satu teknik data mining yang menjadi dasar dari berbagai teknikdata mining lainnya. Khususnya salah satu tahap dari analisis asosiasi yang disebut analisis pola frequensi tinggi (frequent pattern mining) menarik perhatian banyak peneliti untuk menghasilkan algoritma yang efisien (Kantardzic, 2003).
Penting tidaknya suatu aturan assosiatif dapat diketahui dengan dua parameter, support (nilai penunjang)yaitu persentase kombinasi item tersebut dalam database dan confidence (nilai kepastian) yaitu kuatnya hubungan antar item dalam aturan assosiatif.
Nilai support untuk 2 item diperoleh dengan rumus
Support(a ∩ b) = Jumlah transaksi mengandung a dan bTotal transaksi x 100%
Nilai confidence untuk 2 item diperoleh dengan rumus
Conidence = p(b|a) =Jumlah transaksi mengandung a dan bTotal transaksi a x 100%
Aturan assosiatif biasanya dinyatakan dalam bentuk : {gula, kopi}{susu} (support = 60%, confidence = 50%)
Yang artinya : "50% dari transaksi di database yang memuat item gula dan kopi juga memuat item susu. Sedangkan 60% dari seluruh transaksi yang ada di
database memuat ketiga item itu." Dapat juga diartikan : "Seorang konsumen yang membeli gula dan susu mempunyai kemungkinan 50% untuk juga membeli susu. Aturan ini cukup signifikan karena mewakili 60% dari catatan transaksi selama ini."
Analisis asosiasi didefinisikan suatu proses untuk menemukan semua aturan assosiatif yang memenuhi syarat minimum untuk support (minimum support) dan syarat minimum untuk confidence (minimumconfidence).
2.3.2. Terminologi Association Rule
1. I adalah himpunan yang tengah dibicarakan.
Contoh:{Gula,Kopi,Susu, …,Mentega}
2. D adalah Himpunan seluruh transaksi yang tengah dibicarakan
Contoh:{Transaksi 1, transaksi 2, …, transaksi n}
3. Proper Subset adalah Himpunan Bagian murni Contoh:
- Ada suatu himpunan A={a,b,c,} - Himpunan Kosong = {}
- Himpunan 1 Unsur = {a},{b},{c} - Himpunan 2 Unsur = {a,b},{a,c},{b,c} - Himpunan 3 Unsur = {a,b,c,}
Proper subset nya adalah Himpunan 1 Unsur dan Himpunan 2 Unsur 4. Item set adalah Himpunan item atau item-item pada I
Contoh:
Ada suatu himpunan A={a,b,c,}
Item set nya adalah{a};{b}:{c};{a,b};{a,c};{b,c}
5. K- item set adalah Item set yang terdiri dari K buah item yang ada pada I atau K adalah jumlah unsur yang terdapat pada suatu Himpunan
Contoh:3-item set adalah yang bersifat 3 unsur
6. Item set Frekuensi adalah Jumlah transaksi di I yang mengandung jumlah item set tertentu. Intinya jumlah transaksi yang membeli suatu item set.
- frekuensi Item set yang sekaligus membeli susu dan roti adalah 3
- frekuensi item set yang membeli sekaligus membeli roti,susu dan kopi adalah 2
7. Frekuen Item Set adalah item set yang muncul sekurang-kurangnya sekian kali
di D. Kata “sekian” biasanya di simbolkan dengan Ф. Ф merupakan batas
minimum dalam suatu transaksi
8. Fk adalah Himpunan semua frekuen Item Set yang terdiri dari K item. 2.3.3. Langkah-Langkah Algoritma PadaAssociation Rule
1. Tentukan Ф
2. Tentukan semua Frekuen Item set
3. Untuk setiap Frekuen Item set lakukan hal sbb: 1. Ambil sebuah unsur, namakanlah s 2. Untuk sisanya namakanlah ss-s
3. Masukkan unsur-unsur yang telah di umpamakan ke dalam rule If (ss-s) then s
Untuk langkah ke 3 lakukan untuk semua unsur. Contoh: Data Penjualan Transaksi Item 1 Gula,Susu,Kopi 2 Roti,Susu,Mentega 3 Gula,Roti,Susu,Mentega 4 Roti,Mentega
Langkah 1: Pisahkan semua item Gula,Kopi,Susu,Roti, Mentega Langkah 2: Lakukan Transformasi
Misalkan A:Gula, B:Roti, C:Susu, D:Kopi, E:Mentega, sehingga table data penjualan menjadi sbb
Transaksi Item
2 B,C,E
3 A,B,C,E
4 B,E
Langkah 3: Buat dalam matrix untuk menentukan jumlah item muncul dalam database Transaksi A B C D E 1 1 0 1 1 0 2 0 1 1 0 1 3 1 1 1 0 1 4 0 1 0 0 1 Jumlah 2 3 3 1 3
Langkah 4: Tentukan frekuen item set(Ф), misalkan Ф =2 atau 50%
Sesuai dengan frekuen item set yang telah ditentukan, maka item yang memenuhi adalah A,B,C,E, sedangkan D tidak termasuk karena hanya 1 kali muncul dalam database.
Langkah 5: Tentukan item set
a. 2 item set, merupakan kombinasi dari item yang memenuhi frekuen item set yaitu AB,AC,AE,BC,BE,CE
b. Lakukan pengujian untuk calon 2 item set untuk mengetahui 2 item set yang memenuhi syarat sesuai frekuen item set yang telah ditentukan sebelumnya Item set AB Transaksi A B Hasil 1 1 0 0 2 0 1 0 3 1 1 1 4 0 1 0 Total 1 Item set AC Transaksi A C Hasil
1 1 1 1 2 0 1 0 3 1 1 1 4 0 0 0 Total 2 Item set AE Transaksi A E Hasil 1 1 0 0 2 0 1 0 3 1 1 1 4 0 1 0 Total 1 Item set BC Transaksi B C Hasil 1 0 1 0 2 1 1 1 3 1 1 1 4 1 0 0 Total 2 Item set BE Transaksi B E Hasil 1 0 0 0 2 1 1 1 3 1 1 1 4 1 1 1 Total 3 Item set CE Transaksi C E Hasil 1 1 0 0 2 1 1 1
3 1 1 1
4 0 1 0
Total 2
Dari ke 6 calon 2 item set yang memenuhi syarat sesuai dengan frekuen item yaitu minimal 2 adalah AC,BC,BE,CE
c. Tentukan 3 item set(bila diperlukan)
Untuk menentukan calon 3 item set, merupakan kombinasi dari 2 item set yaitu dengan 2 item yang bersamaan, maka calon 3 item set adalah AC dengan BC: ABC
AC dengan EC: AEC BC dengan EC: BCE
d. Lakukan pengujian untuk calon 3 item set untuk mengetahui 3 item set yang memenuhi syarat sesuai frekuen item set yang telah ditentukan sebelumnya
Item set ABC
Transaksi A B C Hasil 1 1 0 1 0 2 0 1 1 0 3 1 1 1 1 4 0 1 0 0 Total 1
Item set AEC
Transaksi A E C Hasil 1 1 0 1 0 2 0 1 1 0 3 1 1 1 1 4 0 1 0 0 Total 1
Item set BCE
1 0 1 0 0
2 1 1 1 1
3 1 1 1 1
4 1 0 1 0
Total 2
Dari ke 3 calon 3 item set yang memenuhi syarat sesuai dengan frekuen item yaitu minimal 2 adalah BCE
Langkah 6: Membuat rule
Rule yang dipakai adalah if x then y, dimana x adalah antecendent dan y adalah consequent. Berdasarkanrule tersebut, maka dibutuhkan 2 buah item yang mana salah satunya sebagai antecedent dan sisanya sebagai consequent. Untuk antecedent boleh lebih dari 1 unsur, sedangkan untuk consequent terdiri dari 1unsur.
a. Rule 2 item set (AC,BC,BE,CE) 1. If buy A then buy C 2. If buy C then buy A 3. If buy B then buy C 4. If buy C then buy B 5. If buy B then buy E 6. If buy E then buy B 7. If buy C then buy E 8. If buy E then buy C b. Rule 2 item set (BCE)
1. If buy B and C then buy E 2. If buy B and E then buy C 3. If buy C and E then Buy B
Langkah 7: hitung support dan confidence c. Kandidat association rule 2 item set
1. If buy A then buy C 2/4x100%=50% 2/2x100%=100%
2. If buy C then buy A 2/4x100%=50% 2/3x100%=75%
3. If buy B then buy C 2/4x100%=50% 2/3x100%=75%
4. If buy C then buy B 2/4x100%=50% 2/3x100%=75%
5. If buy B then buy E 3/4x100%=75% 3/3x100%=100%
6. If buy E then buy B 3/4x100%=75% 3/3x100%=100%
7. If buy C then buy E 2/4x100%=50% 2/3x100%=75%
8. If buy E then buy C 2/4x100%=50% 2/3x100%=75%
d. Kandidat association rule 3 item set
Rule Support Confidence 1. If buy B and C then buy E 2/4x100%=50%
2/2x100%=100%
2. If buy B and E then buy C 2/4x100%=50% 2/3x100%=68%
3. If buy C and E then Buy B 2/4x100%=50% 2/2x100%=100%
Langkah 8: Lakukan perkalian support dan confidence, nilai paling tinggi itulah rule of the best sebagai rule association
e. Untuk 2 item set, nilai paling tinggi adalah
Rule Support Confidence 1. If buy B then buy E 3/4x100%=75%
2. If buy E then buy B 3/4x100%=75% 3/3x100%=100%
Jika membeli roti maka membeli mentega Jika membeli mentega maka memebeli roti f. Kandidat association rule 3 item set
Rule Support Confidence 4. If buy B and C then buy E 2/4x100%=50%
2/2x100%=100%
5. If buy C and E then Buy B 2/4x100%=50% 2/2x100%=100%
2.4.Metode Clustering 2.4.1. Pengantar Clustering
Kesamaan adalah dasar untuk mendefinisikan cluster , ukuran kesamaan antara dua pola yang diambil dari ruang fitur yang sama sangat penting di dalam algoritma clustering. Penentuan kesamaan sangat hati-hati karena kualitas proses pengelompokan tergantung pada keputusan ini(Kantardzic,2003).
Custering menganalisis objek data
yang digunakan untuk menghasilkan grup, grup tersebut didapatkan berdasarkan prinsip memaksimalkan kesamaan dalam kelas dan meminimalkan kesamaan antar kelas, artinya bahwa kelompok terbentuk sehingga objek dalam cluster memiliki kemiripan yang tinggi dibandingkan dengan yang lain, tetapi sangat berbeda dengan objek dalam cluster lain(Jiawei,2000).
Salah satu metode yang diterapkan dalam KDD adalah clustering. Clustering adalah membagi data ke dalam grup‐grup yang mempunyai obyek dengan karakteristiknya sama. Clustering memegang peranan penting dalam aplikasi data mining,misalnya eksplorasi data ilmu pengetahuan, pengaksesan informasi dan textmining, aplikasi basis data spasial, dan analisis web. Clustering diterapkan dalam mesin pencari di Internet. Web mesin pencari akan mencari
ratusan dokumen yang cocok dengan kata kunci yang dimasukkan. Dokumen dokumen tersebut dikelompokkan dalam cluster‐cluster sesuai dengan kata-kata yang digunakan(Sri Andayani, 2007). Pada dasarnya metode pengelompokan ada 2 yakni Hierarchical clustering method dan Non Hierarchical clustering method. Metode Hirarki digunakan jika jumlah kelompok tidak diketahui sebelumnya, sedangkan non hirarki digunakan jika jumlah kelompok sudah diketahui dari sejumlah objek. Salah satu algoritma yang termasuk dalam non hirarki adalah algoritma K-Means.
Metode Hirarki memulai pengelompokan dengan dua atau lebih obyek yang mempunyai kesamaan paling dekat. Kemudian diteruskan pada obyek yang lain dan seterusnya hingga cluster akan membentuk semacam pohon dimana terdapat tingkatan (hirarki) yang jelas antar obyek, dari yang paling mirip hingga yang paling tidak mirip. Non Hirarki dimulai dengan menentukan terlebih dahulu jumlah cluster yang diinginkan (dua,tiga, atau yang lain). Setelah jumlah cluster ditentukan, maka proses cluster dilakukan dengan tanpa mengikuti proses hirarki
2.4.3. Algoritma K-Means
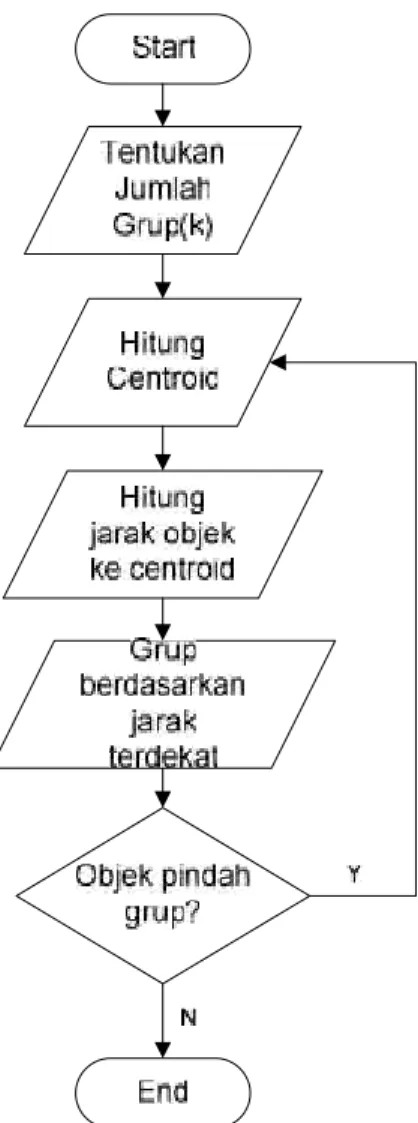
Algoritma K‐Means adalah algoritma clustering yang popular dan banyak digunakan dalam dunia industri. Algoritma ini disusun atas dasar ide yang sederhana. Pada awalnya ditentukan berapa cluster yang akan dibentuk. Sebarang obyek atau elemen pertama dalam cluster dapat dipilih untuk dijadikan sebagai titik tengah (centroid point) cluster. Algoritma K‐Means selanjutnya akan melakukan pengulangan langkah‐langkah berikut sampai terjadi kestabilan (tidak ada obyek yang dapat dipindahkan).
Konsep kesamaan adalah hal yang fundamental dalam analisis cluster. Kesamaan antar objek merupakan ukuran korespondensi antar objek. Ada tiga metode yang dapat diterapkan, yaitu ukuran korelasi, ukuran jarak, dan ukuran asosiasi. Dengan menggunakan ukuran jarak, ukuran kemiripan yang dapat digunakan adalah jarak dEeculidean dan dManhattan City. Jika objek pertama
yang diamati adalah X=[X1,X2..Xp] dan Y=[Y1,Y2…Yp] antara 2 objek dari p
dEculidean: , = ∑ ( − ) dManhattan: , = ∑ | − |
Adapun pun langkah-langkahnya dengan menggunakan algoritma K-Means sebagai berikut
1. Tentukan jumlah cluster
2. Menentukan centroid(koordinat titik tengah setiap cluster), untuk iterasi pertama diambil secara random
3. Menghitung jarak obyek ke centroid dengan menggunakan rumus jarakEuclidean atau Manhattan.
4. Menentukan jarak setiap obyek terhadap koordinat titik tengah,
5. mengelompokkan obyek‐obyek tersebut berdasarkan pada jarak terdekat
Gambar 2.4. Algoritma K-Means Contoh:
Mahasiswa IPK Alamat
Paijo 3,5 Siantar
Sarinem 2,9 Berastagi
Karsono 1,0 Tj. Morawa
Tukiman 1,8 Medan
Langkah 1: lakukan transformasi, karena data harus dalam bentuk numeric sesuai dengan rumus kedekatan yang digunakan Distance Euqlidean
IPK ALAMAT
Mahasiswa IPK Alamat
Paijo 5 4
Sarinem 4 3
Karsono 1 1
Tukiman 2 1
Langkah 2: tentukan grup(misalkan k=2)
Langkah 3: Tentukan centroid, misalkan (C1:5,4|C2:4,3) Langkah 4: hitung objek terhadap centroid
P(1,1)= (5 − 5) + (4 − 4) =0 P(1,1)= (5 − 4) + (4 − 3) =1,4 S(1,1)= (4 − 5) + (3 − 4) =1,4 S(1,1)= (4 − 4) + (3 − 3) =0 K(1,1)= (1 − 5) + (1 − 4) =5
K(1,1)= (1 − 4) + (1 − 3) =3,6 T(1,1)= (2 − 5) + (1 − 4) =4,2 T(1,1)= (2 − 4) + (1 − 3) =2,8
Langkah 5: grupkan berdasarkan jarak terdekat
Objek IPK Alamat Jarak C1 Jarak C2 Grup
Paijo 5 4 0 1,4 1
Sarinem 4 3 1,4 0 2
Karsono 1 1 5 3,6 2
Tukiman 2 1 4,2 2,8 2
Grup baru : 1 2 2 2, iterasi pertama dianggap berpindah grup sehingga dilanjutkan ke iterasi ke 2, iterasi pertama belum ada grup karena centroid diambil secara acak ITERASI II
Langkah 1 dan 2 sama dengan itetarsi ke 2 Langkah 3: Tentukan centroid
Centroid I: 5|4
Centroid II: diambil dari grup 2 yaitu Sarinem, Karsono dan Tukiman=( ))=2,3|=( ))=1,6
Langkah 4: hitung objek terhadap centroid P(1,1)= (5 − 5) + (4 − 4) =0
P(1,1)= (5 − 2,3) + (4 − 1,6) =3,6 S(1,1)= (4 − 5) + (3 − 4) =1,4
S(1,1)= (4 − 2,3) + (3 − 1,6) =2,2 K(1,1)= (1 − 5) + (1 − 4) =5 K(1,1)= (1 − 2,3) + (1 − 1,6) =1,4 T(1,1)= (2 − 5) + (1 − 4) =4,2 T(1,1)= (2 − 2,3) + (1 − 1,6) =0,6
Langkah 5: grupkan berdasarkan jarak terdekat
Objek IPK Alamat Jarak C1 Jarak C2 Grup
Paijo 5 4 0 3,6 1
Sarinem 4 3 1,4 2,2 1
Karsono 1 1 5 1,4 2
Tukiman 2 1 4,2 0,6 2
Grup lama : 1 2 2 2 dan Grup baru : 1 1 2 2, terjadi perpindahan grup maka dilanjutkan iterasi berikutnya yaitu iterasi ke 3
ITERASI III
Langkah 1 dan 2 sama dengan itetarsi ke 3 Langkah 3: Tentukan centroid
Centroid I: diambil dari grup 1 yaitu Paijo dan Sarinem=( ))=4,5|=( ))=3,5
Centroid II: diambil dari grup 2 yaitu Karsono dan Tukiman=( ))=1,5|=( ))=1 Langkah 4: hitung objek terhadap centroid
P(1,1)= (5 − 4,5) + (4 − 3,5) =0,7 P(1,1)= (5 − 1,5) + (4 − 1) =4,6
SP(1,1)= (4 − 4,5) + (3 − 3,5) =0,7 S(1,1)= (4 − 1,5) + (3 − 1) =3,2 KP(1,1)= (1 − 4,5) + (1 − 3,5) =4,3 K(1,1)= (1 − 1,5) + (1 − 1) =0,5 T(1,1)= (2 − 4,5) + (1 − 3,5) =3,5 T(1,1)= (2 − 1,5) + (1 − 1) =0,5
Langkah 5: grupkan berdasarkan jarak terdekat
Objek IPK Alamat Jarak C1 Jarak C2 Grup
Paijo 5 4 0,7 4,6 1
Sarinem 4 3 0,7 3,2 1
Karsono 1 1 4,3 0,5 2
Tukiman 2 1 3,5 0,5 2
Grup lama : 1 1 2 2 dan Grup baru : 1 1 2 2, tidak terjadi perpindahan grup maka stop dengan
Centroid I: diambil dari grup 1 yaitu Paijo dan Sarinem=( ))=4,5|=( ))=3,5
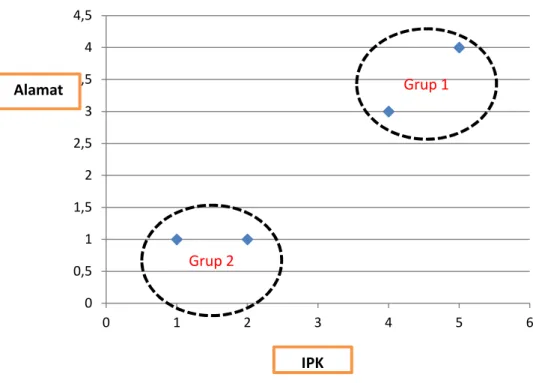
Centroid II: diambil dari grup 2 yaitu Karsono dan Tukiman=( ))=1,5|=( ))=1 Secara grafik dapat digambarkan sebagai berikut
Gambar 2.5. Hasil Clustering Dari gfarik di atas dapat ditarik kesimpulan
Goup 1: IPK tinggi dan alamat jauh dari kampus Group 2: IPK rendah dan alamat dekat dengan kampus
Sehingga disimpulkan mahasiswa yang rumahnya jauh dengan kampus akan memperoleh IPK tinggi
2.5. Artificial Neural Networ(ANN) 2.5.1. Pengantar Jaringan syaraf Tiruan
Jaringan saraf tiruan (Artificial Nueral Network) atau disingkat JST adalah sistem komputasi dimana arsitektur dan operasi diilhami dari pengetahuan tentang sel saraf biologis di dalam otak manusia, yang merupakan salah satu representasi
0 0,5 1 1,5 2 2,5 3 3,5 4 4,5 0 1 2 3 4 5 6 IPK Alamat Grup 2 Grup 1
buatan dari otak manusia yang selalu mencoba menstimulasi proses pembelajaran pada otak manusia tersebut. Model saraf ditunjukkan dengan kemampuannya dalam emulasi, analisis, prediksi dan asosiasi. Kemampuan yang dimiliki JST dapat digunakan untuk belajar dan menghasilkan aturan atau operasi dari beberapa contoh atau input yang dimasukkan dan membuat prediksi tentang kemungkinan output yang akan muncul atau menyimpan karaktristik dari input yang disimpan kepadanya.
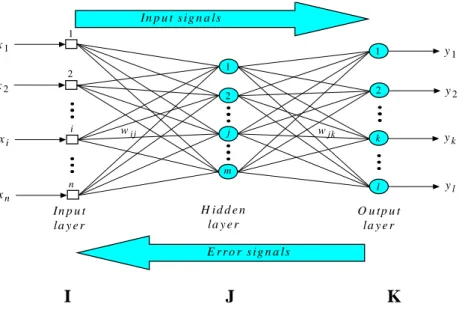
Valluru B.Rao dan Hayagriva V.Rao (1993) mendefenisi jaringan saraf sebagai sebuah kelompok pengolahan elemen dalam suatu kelompok yang khusus membuat perhitungan sendiri dan memberikan hasilnya kepada kelompok kedua atau berikutnya. Setiap sub kelompok menurut gilirannya harus membuat perhitungan sendiri dan memberikan hasilnya untuk subgrup atau kelompok yang belum melakukan perhitungan. Pada akhirnya sebuah kelompok dari satu atau beberapa pengolahan elemen tersebut menghasilkan keluaran (output) dari jaringan.
Setiap pengolahan elemen membuat perhitungan berdasarkan pada jumlah masukan (input). Sebuah kelompok pengolahan elemen disebut layer atau lapisan dalam jaringan. Lapisan pertama adalah input dan yang terakhir adalah output. Lapisan di antara lapisan input dan output disebut dengan lapisan tersembunyi (hidden layer). Jaringan saraf tiruan merupakan suatu bentuk arsitektur yang terdistribusi paralel dengan sejumlah besar node dan hubungan antar node tersebut. Tiap titik hubungan dari satu node ke node yang lain mempunyai harga yang diasosiasikan dengan bobot. Setiap node memiliki suatu nilai yang diasosiasikan sebagai nilai aktivasi node.
Salah satu organisasi yang dikenal dan sering digunakan dalam paradigma jaringan saraf buatan adalah perambatan Galat Mundur (back-propagation). Sebelum dikenal adanya jaringan saraf perambatan Galat Mundur pada tahun 1950-1960-an,dikenal dua paradigma penting yang nantinya akan menjadi dasar dari saraf Perambatan Galat Mundur, yakni perceptron dan Adaline/Madaline
(adaptive linier neuron/multilayer adaline). Dalam buku ini akan dibahas Perceptron dan Back Propagation( Arif Hermawan, 2006).
2.5.2. Perceptron
Arsitektur pembelajaran perceptron yakni dengan mengenali pola dengan metode belajar terbimbing. Pola yang diklasifikasikan biasanya berupa bilangan biner (kombinasi 1 dan 0) dan kategori pengklasifikasian juga di wujudkan dalam bilangan biner. Perceptron dibatasi untuk dua lapisan pengolah dengan satu lapisan bobot yang dapat beradabtasi.
Gambar 2.6. Arsitektur Perceptron
Elemen pada Gambar 2.6 adalah unit pengolah dasar dari perceptron. Unit pengolah ini mendapat masukan dari unit pengolah lain yang masing-masing dihubungkan melalui bobot interkoneksi Wi. Unit pengolah melakukan penjumlahan berbobot untuk masukannya, dengan rumus berikut ini.
n i i iw x X 1 Dengan:Wi=bobot sambungan dari unit input ke output Xi=masukan yang berasal dari unit input
Threshold Inputs x1 x2 Output Y
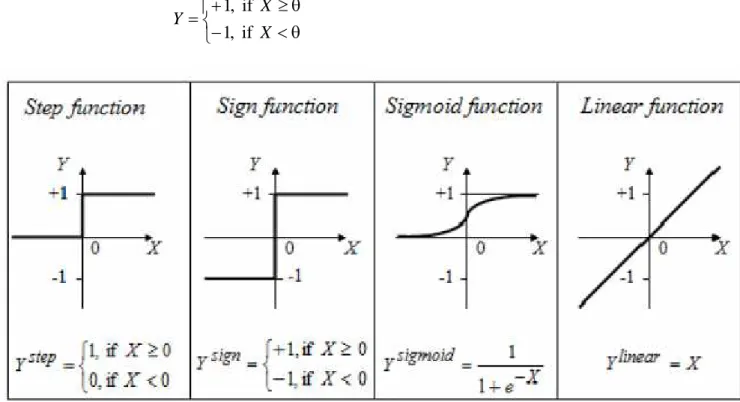
Hard Limiter w2 w1 Linear Combiner Sebuah nilai prasikap(fungsi aktivasi) diberikan sebagai tambahan masukan kepada unit pengolah. Nilai fungsi aktivasi ini pada umumnya menggunakan FA(Fungsi Aktivasi)Ystep yaitu 1 atau 0, dan dihubungkan dengan unit pegolah output melalui pembobot yang nilainya selalu beradaptasi selama jaringan mengalami pelatihan.
Fungsi Aktivasi YStep
X X Y if , 1 if , 1
Gambar 2.7. Jenis-Jenis Fungsi Aktivasi
Perceptron dilatih dengan menggunakan sekumpulan pola yang diberikan kepadanya secara berulang-ulang selama latihan. Setiap pola yang diberikan merupakan pasangan pola masukan dan pola yang diinginkan. Perceptron melakukan penjumlahan berbobot terhadap tiap-tiap masukannya dan menggunakan fungsi ambang untuk menghitung keluaraannya. Keluaran ini kemudian dibandingkan dengan hasil yang diinginkan dengan rumus
) ( ) ( ) (p Y p Y p e d Dimana
E=eror
Yd=output destination(diharapkan) Yp=output actual
Perbedaan yang dihasilkan dari perbandingan ini digunakan untuk merubah bobot-bobot yang ada dalam jaringan. Demikian dilakukan berulang-ulang sehingga dihasilkan keluaran yang sesuai dengan hasil yang diinginkan.
Langkah-langkah Penyelesaian Perceptron 1. Inisiali
Tentukan input, bobot awal, output yang diharapkan, threshold dan training rate
2. Hitung keluaran(output actual) dengan rumus
n i i i p w p x step p Y 1 ) ( ) ( ) (Gunakan fungsi aktivasi Y step untuk menentukan output actual
0 if , 0 0 if , 1 X X Y
3. Hitung eror dengan menggunakan rumus ) ( ) ( ) (p Y p Y p e d
4. Update bobot dengan menggunakan rumus ) ( ) ( ) 1 (p w p w p wi i i ) ( ) ( ) (p x p e p wi i 5. Lakukan iterasi Contoh Penerapan Input Output yg diharapkan
Bobot awal Output actual
Error Bobot akhir
0 0 0 0,3 -0,1
0 1 0
1 0 0
1 1 1
Threshold: = 0.2; learning rate: = 0.1
Dengan arsitektur 2-1(2 input dan 1 output)
Epoch I Iterasi 1
1. Hitung output actual