Informasi Dokumen
- Sekolah: Apress
- Mata Pelajaran: Big Data
- Topik: Big Data Application Architecture
- Tipe: Book
Ringkasan Dokumen
I. Big Data Introduction
This section provides an overview of big data, focusing on its significance in contemporary data management. It explains the shift from traditional relational databases to big data technologies, emphasizing the need for robust solutions to handle the increasing volume, variety, and velocity of data. The text outlines the challenges organizations face in harnessing big data, such as the complexity of integrating diverse data types and the necessity for real-time processing capabilities. This foundational knowledge is crucial for students and professionals aiming to understand the landscape of big data technologies.
II. Big Data Application Architecture
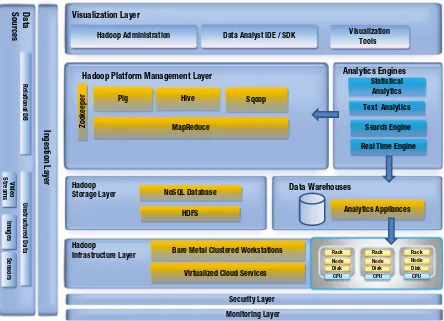
This section delves into the architecture required for effective big data solutions. It discusses the essential components of a big data architecture, including data ingestion, storage, processing, and visualization layers. The section highlights the importance of selecting the right architecture to optimize data management and analysis. It serves as a guide for students and professionals to understand how to structure big data applications effectively, ensuring alignment with organizational goals and technological capabilities.
III. Big Data Ingestion and Streaming Patterns
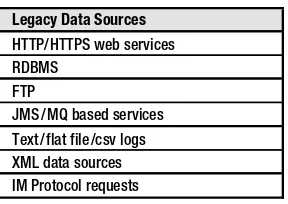
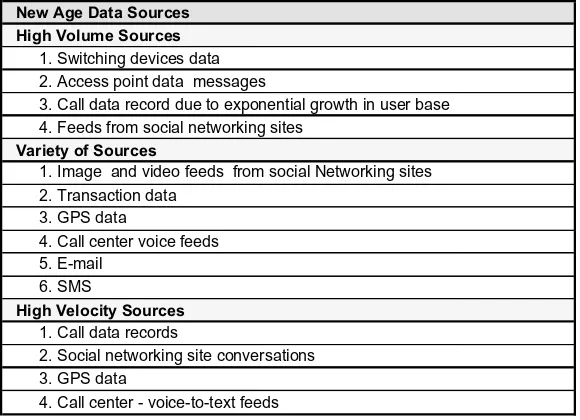
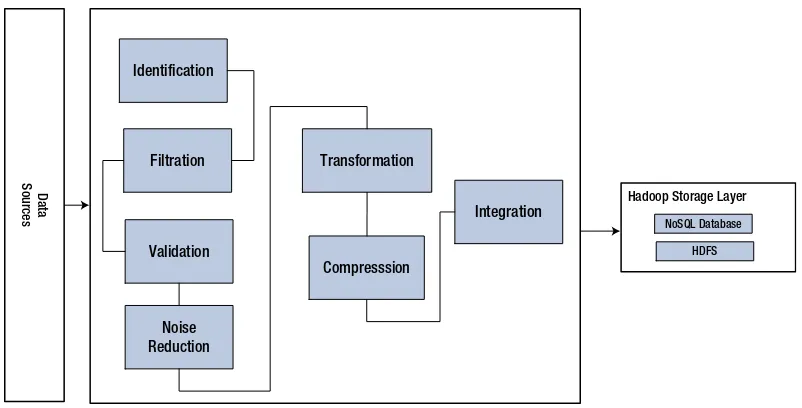
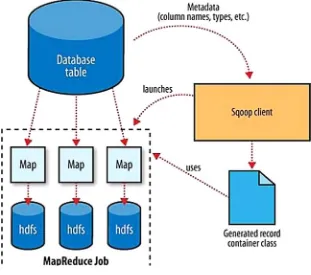
In this section, the focus is on the methods and patterns for ingesting data into big data systems. It emphasizes the importance of filtering and cleansing data to ensure quality before analysis. The section also explores various ingestion patterns, including batch and real-time processing, which are critical for maintaining data integrity and relevance. Understanding these patterns is vital for students and professionals who aim to implement effective data ingestion strategies in their projects.
IV. Big Data Storage Patterns
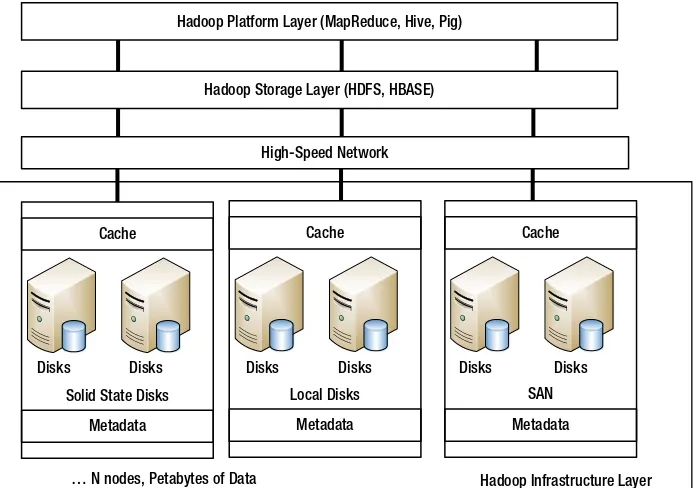
This section discusses the various storage solutions for big data, highlighting the role of distributed file systems like Hadoop Distributed File System (HDFS). It examines the characteristics of NoSQL databases and their suitability for managing unstructured data. The discussion on storage patterns provides insights into how to effectively store and retrieve large volumes of data, which is essential for data scientists and IT professionals working with big data technologies.
V. Big Data Access Patterns
This section covers the methods for accessing data stored in big data systems. It introduces query languages and tools such as Hive and Pig, which facilitate data manipulation and retrieval. The section emphasizes the importance of understanding data access patterns to optimize query performance and enhance user experience. This knowledge is crucial for students and professionals tasked with developing applications that require efficient data access.
VI. Data Discovery and Analysis Patterns
Focusing on the analytical capabilities of big data systems, this section explores various patterns for data discovery and analysis. It discusses techniques for deriving insights from both structured and unstructured data, emphasizing the role of analytics in driving business intelligence. This section is particularly relevant for students and professionals interested in data science and analytics, providing them with the tools to analyze complex datasets effectively.
VII. Big Data Visualization Patterns
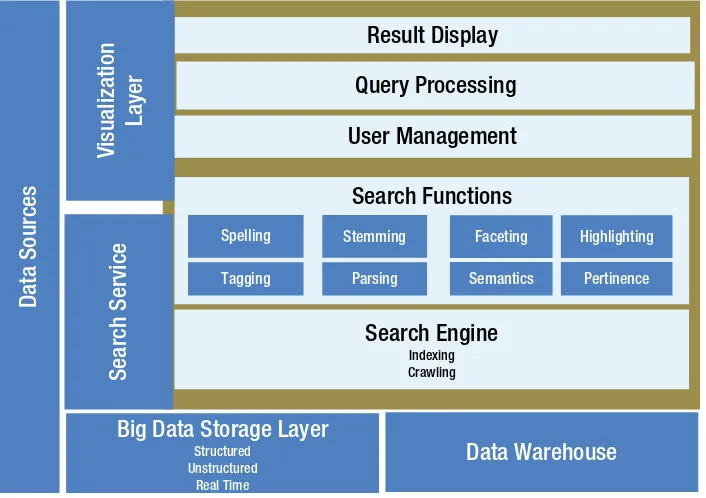
This section highlights the importance of data visualization in interpreting big data. It discusses various visualization techniques and tools that help in presenting complex data insights in an understandable manner. The ability to visualize data effectively is essential for data analysts and decision-makers, making this section valuable for students and professionals focused on data presentation and storytelling.
VIII. Big Data Deployment Patterns
In this section, the focus shifts to the deployment strategies for big data solutions. It discusses best practices for implementing big data architectures in various environments, including cloud and on-premises solutions. Understanding deployment patterns is crucial for IT professionals and architects who need to ensure that big data applications are scalable, reliable, and efficient.
IX. Big Data Non-Functional Requirements (NFRs)
This section addresses the non-functional requirements critical for big data applications, such as scalability, performance, security, and maintainability. It emphasizes the need for a comprehensive approach to meet these requirements, ensuring that big data solutions are robust and fit for purpose. This knowledge is essential for software architects and developers involved in designing and implementing big data systems.
X. Big Data Case Studies
This section presents real-world case studies that illustrate the application of big data architectures across various industries. These examples provide practical insights into how organizations leverage big data to drive innovation and improve decision-making. Case studies are invaluable for students and professionals as they bridge the gap between theory and practice, showcasing successful implementations of big data solutions.
XI. Resources, References, and Tools
The final section provides a curated list of resources, references, and tools that support further learning and exploration in the field of big data. This compilation is essential for students and professionals seeking to deepen their understanding and stay updated on the latest trends and technologies in big data analytics and architecture.
Referensi Dokumen
- Software Engineering ( Institute of System Science, National University of Singapore )
- Electronics Engineering ( Bombay University )
- Computers and Applications ( College of Engineering and Technology, Orissa University of Agriculture and Technology )