Fakultas Ilmu Komputer
507
Identifikasi Penyakit
Diabetes Mellitus
Menggunakan Metode
Modified
K-Nearest Neighbor
(MKNN)
Silvia Ikmalia Fernanda1, Dian Eka Ratnawati2, Putra Pandu Adikara3
Program Studi Teknik Informatika, Fakultas Ilmu Komputer, Universitas Brawijaya Email: 1[email protected], 2[email protected], 3[email protected]
Abstrak
Diabetes mellitus merupakan salah satu jenis penyakit yang dapat menyebabkan kematian dan salah satu penyakit faktor keturunan. Kebanyakan masyarakat tidak peduli akan pola hidup yang sehat. Kesehatan merupakan hal yang sangat penting dalam kehidupan sehari-hari. Kurangnya kesadaran masyarakat dalam masalah penanganan kesehatan sehingga tingkat kematian di seluruh dunia mengalami peningkatan. Masyarakat juga kurang paham pada kemiripan gejala-gejala penyakit yang muncul mengakibatkan penyakit tidak cepat ditangani. Untuk mengatasi hal tersebut maka dibuat sistem untuk identifikasi penyakit diabetes mellitus menggunakan metode Modified K-Nearest Neighbor (MKNN). Modified K-Nearest Neighbor (MKNN) merupakan salah satu metode klasifikasi berdasarkan kemunculan kelas terbanyak pada data latih. Terdapat 15 gejala dan 2 tipe penyakit yang digunakan sebagai parameter dalam pengembangan sistem. Keluaran yang dihasilkan sistem berupa diagnosis tipe penyakit serta cara pengendaliannya. Berdasarkan pengujian yang telah dilakukan memperoleh hasil akurasi terbaik 93,33% dengan error rate 6,67%. Berdasarkan hasil tersebut, sistem yang menggunakan metode Modified K-Nearest Neighbor (MKNN) dapat diimplementasikan dalam kehidupan sehari-hari.
Kata Kunci: diabetes mellitus, klasifikasi, Modified K-Nearest Neighbor (MKNN)
Abstract
Diabetes mellitus is one of the diseases that can cause death and one of the diseases heredity. Most people do not care about a healthy lifestyle. Health is very important in everyday life. The public is less aware of the problem of health care so that the rate of deaths worldwide has increased. The public salso did not understand the similarity of the symptoms of disease appear not treated quickly lead to disease. To overcome these problems invented a system for the identification of diabetes mellitus using the Modified K-Nearest Neighbor (MKNN). Modified K-Nearest Neighbor (MKNN) is one method of classification is based on the number of class occurrence on data mining. There are 15 symptoms and 2 types of diseases are used as parameters in development of the system. An output as the result produced by the system is diagnosis of the type of disease and how to control. Based on method, this research obtain 93,33% of good accuracy and error rate of 6,67%. The system using of method Modified K-Nearest Neighbor (MKNN) can be applied in society based on result.
Keywords: diabetes mellitus, classification, Modified K-Nearest Neighbor (MKNN)
1. PENDAHULUAN
Diabetes mellitus merupakan penyakit kronis yang terjadi karena kelainan sekresi insulin pada kenaikan glukosa yang tidak teratur. Diabetes mellitus akan meningkatkan gula darah dalam tubuh sehingga terjadi penyakit komplikasi yang dapat menyebabkan beberapa risiko seperti stroke, penyakit jantung, kebutaan, gagal ginjal dan kematian(V & Ravikumar, 2014). Penyakit diabetes mellitus dibagi menjadi
2 jenis yaitu diabetes tipe 1 dan tipe 2. Diabetes mellitus tipe 1 terjadi karena kerusakan dari tubuh menghasilkan insulin dan tubuh tidak dapat menggunakan insulin sebagaimana mestinya. Diabetes mellitus tipe 2 menghasilkan kelas dari resistensi insulin dimana sel-sel tidak bisa menggunakan insulin dalam proporsi yang tepat (Karthikeyan & Vembandadsamy, 2015).
kebiasaan aktivitas fisik dengan diet tinggi kalori dan lemak yang tidak cukup serat pada makanan. Identifikasi penyakit diabetes diperlukan sebagai pencegahan penyakit diabetes. Dengan pemanfaatan pendekatan Data mining dapat mengekstraksi informasi yang tidak diketahui sebelumnya. Oleh karena itu, dibutuhkan sistem yang dapat membantu mengidentifikasi penyakit diabetes mellitus agar memudahkan masyarakat dalam penanganan yang tepat (Ahmed et al., 2012). Pada penelitian ini menggunakan metode Modified K-Nearest Neighbor (MKNN).
Penelitan lain yang berjudul “Diagnosis
Penyakit Tanaman Tomat Menggunakan
Algoritma Modified K-Nearest Neighbor
(MKNN)”. Penelitian ini menggunakan metode
Modified K-Nearest Neighbor (MKNN) yang merupakan metode modifikasi dari metode K-Nearest Neighbor (KNN). Pada penelitian ini terdapat 15 gejala dan 6 jenis penyakit sebagai parameter yang digunakan dalam sistem. Metode ini dapat mempermudah dalam mendiagnosis penyakit pada tanaman tomat. Hasil pengujian metode ini didapatkan nilai rata akurasi maksimum 98,92% dan nilai rata-rata minimum 89,04% (Basuki, 2015).
Berdasarkan penelitian sebelumnya maka penulis melakukan penelitian menggunakan metode Modified K-Nearest Neighbor. Metode Modified K-Nearest Neighbor sebelumnya menghasilkan akurasi yang baik dalam penelitian sebelumnya. Sehingga digunakan untuk mengidentifikasikan penyakit diabetes mellitus. Oleh karena itu, metode Modified K-Nearest Neighbor ini diharapkan dapat membantu masyarakat dalam mengidentifikasi penyakit diabetes mellitus.
2. LANDASAN KEPUSTAKAAN
2.1 Diabetes Mellitus
Diabetes mellitus merupakan penyakit yang berisiko kematian tinggi. Penyakit diabetes mellitus terjadi ketika produksi insulin dalam tubuh tidak memadai atau tubuh tidak dapat memproduksi insulin dengan tepat. Pada umumunya penderita diabetes mellitus terjadi ketika kadar gula darah berada di atas normal (Iyer et al., 2015). Penyakit diabetes mellitus sering mengancam kesehatan semua orang di seluruh dunia. Penyakit diabetes mellitus disebut juga penyakit komplikasi karena memiliki banyak gejala yang dapat mengakibatkan penyakit lainnya ataupun kematian (Juliyet & Amanullah, 2015).
2.1.1 Jenis Penyakit Diabetes Mellitus
Penyakit diabetes mellitus dibagi menjadi 2 jenis yaitu:
1. Diabetesmellitus Tipe 1
Penyakit diabetes mellitus tipe 1 biasanya disebut insulin dependent. Diabetes mellitus tipe 1 ini terjadi pada usia muda di bawah 30 tahun. Seseorang yang menderita diabetes mellitus tipe 1 perlu dilakukan suntik insulin. Suntik insulin dilakukan karena glukosa darah dalam tubuh tidak dapat memproduksi insulin sebagaimana mestinya (Sa’di et al., 2015).
2. Diabetes mellitus Tipe 2
Penyakit diabetes mellitus tipe 2 biasanya disebut non-insulin dependent yang ditandai dengan resistensi insulin dan gangguan sekresi insulin. Tipe ini sering diderita oleh seseorang yang berusia di atas 40 tahun. Hal ini terjadi ketika tubuh manusia tidak dapat secara aktif menggunakan insulin yang dihasilkan oleh tubuh. Biasanya disebabkan faktor keturunan, obesitas, kurang aktivitas, penyakit lain dan usia (V & Ravikumar, 2014).
2.1.2 Faktor Penyakit Diabetes Mellitus
Faktor risiko penyakit diabetes mellitus adalah suatu kondisi dimana kesehatan pada seseorang terkena penyakit diabetes mellitus. Apabila kondisi ini tidak ada penanganan khusus maka dapat memperburuk keadaan dan dapat mengakibatkan terjadinya penyakit komplikasi ataupun kematian. Terdapat beberapa faktor risiko pada penyakit diabetes mellitus seperti (Devi & Shyla, 2016):
1. Nafsu Makan Meningkat 2. Sering Buang Air Kecil 3. Peningkatan Kehausan 4. Turunnya Berat Badan 5. Usia (15-40) tahun 6. Faktor Keturunan 7. Mulut Kering
8. Mudah Kelelahan/Kurangnya Aktivitas Fisik
9. Sering Mengantuk 10. Mual/Muntah-Muntah
11. Timbulnya Luka yang Tak Kunjung Sembuh
12. Gatal-Gatal
13. Mengonsumsi Makanan Berkolesterol Tinggi
14. Obesitas
2.2 Data Mining
Data mining merupakan salah satu ilmu komputer yang melibatkan beberapa proses komputasi, teknik statistik, clustering, klasifikasi dan menemukan pola yang terdapat pada dataset. Tujuan utama Data mining digunakan untuk mengekstrak informasi dari dataset yang besar dengan mengubah menjadi format yang dapat dimengerti serta dipahami untuk penggunaan masa depan (V & Ravikumar, 2014).
Data mining merupakan proses pengambilan data dari data warehouse berdasarkan prediksi variabel. Data mining juga sebagai penemuan pada KDD database. Prediksi digunakan untuk menemukan data dari sekumpulan data yang ditentukan dengan berbagai domain seperti kecerdasan buatan, basis data, dan lain-lain. Penggunaan data mining memiliki dampak di berbagai bidang seperti bidang kesehatan. Data mining pada sistem medis dibutuhkan untuk mengekstrak informasi dari database sehingga dapat melakukan diagnosis penyaikit (Poonguzhali, Kabilan, Kannan, & Sivagami, 2014).
2.3 K-Nearest Neighbor
Konsep K-Nearest Neighbor digunakan untuk mengklasifikasikan objek berdasarkan nilai k pada ruang fitur. Metode ini memerlukan ukuran jarak untuk menentukan kedekatan suatu objek. Objek pada data uji akan diklasifikasikan dengan tetangga terdekat. Metode ini mencari tetangga terdekat dan memilih mayoritas kelas yang terdapat pada cluster. K-Nearest Neighbor
dapat memberikan keputusan untuk
mengklasifikasikan data dari data latih dan mendapatkan hasil yang baik jika menggunakan data dalam jumlah besar (Saxena et al., 2014).
2.3.1 Algoritma K-Nearest Neighbor
Langkah-langkah pada algoritma K-Nearest Neighbor untuk mengklasifikasikan data yaitu (Karegowda et al., 2012):
1. Mendefinisikan nilai K
2. Melakukan perhitungan nilai jarak antara data latih dengan data uji
3. Mengelompokkan data berdasarkan
perhitungan jarak
4. Mengelompokkan data berdasarkan nilai tetangga terdekat
5. Memilih nilai yang sering muncul dari tetangga terdekat sebagai prediksi data selanjutnya
2.3.2 Euclidean Distance
Euclidean Distance digunakan untuk mencari jarak antara titik data dengan tetangga terdekat degan menggunakan Persamaan (1):
𝑑 (𝑃, 𝑄) = √∑ (𝑃𝑛𝑖=1 𝑖− 𝑄𝑖)2 (1)
dimana n merupakan jumlah data latih, P merupakan masukkan data ke-i dari data uji, dan Q merupakan masukkan data ke-i dari data latih (Saxena et al., 2014).
2.4 Modified K-Nearest Neighbor
Metode Modified K-Nearest Neighbor menempatkan label kelas dari data sesuai dengan nilai k yang dihitung dengan perhitungan validitas pada semua data yang terdapat pada data latih. Selanjutnya perhitungan weight voting dilakukan untuk semua data uji yang menggunakan validitas data. Adanya validasi pada data latih dapat menghasilkan hasil akurasi yang baik (Parvin, Alizadeh, & Minaei-bidgoli, 2008). Berikut diagram alir ditunjukkan pada Gambar 1.
Gambar 1. Diagram Alir Algoritma Modified K-Nearest Neighbor
Langkah-langkah pada algoritma Modified K-Nearest Neighbor yaitu (Basuki, 2015):
1. Menentukan nilai k
data latih. Kemudian hasil perhitungan diurutkan secara ascending dengan memilih tetangga terdekat sesuai nilai k.
3. Validitas data training
Validitas merupakan proses perhitungan jumlah titik dengan label yang sama pada semua data latih. Setiap data memiliki validitas yang bergantung pada tetangga terdekatnya. Rumus yang digunakan untuk menghitung validitas pada data latih yaitu pada Persamaan (2) (Parvin et al., 2008):
𝑽𝒂𝒍𝒊𝒅𝒊𝒕𝒂𝒔(𝒊)=𝟏𝒌∑𝒌𝒊=𝟏𝑺(𝒍𝒃𝒍(𝒙) , 𝒍𝒃𝒍 𝑵𝒊(𝒙))
(2)
Keterangan:
- k = jumlah titik terdekat - lbl (x) = kelas x
- lbl Ni (x) = label kelas titik terdekat x dimana S digunakan menghitung kesamaan antara titik a dan data ke- b pada tetangga terdekat dengan menggunakan Persamaan (3):
𝑺 𝒂, 𝒃 = {𝟏 𝒂 = 𝒃𝟎 𝒂 ≠ 𝒃
(3)
dimana a merupakan kelas a pada data training dan b merupakan kelas selain a pada data training.
4. Jarak antara data uji dengan data latih menggunakan Persamaan (1).
Perhitungan dilakukan untuk selurah data latih.
5. Weight voting (pembobotan)
Perhitungan ini menggunakan k tetangga terdekat yang merupakan variasi metode K-Nearest Neighbor. Selanjutnya dilakukan validitas dari setiap data training yang akan dikalikan dengan weight voting berdasarkan jarak pada setiap tetangganya. Rumus weight voting seperti Persamaan (4) (Parvin et al., 2008):
𝑾(𝒊)=𝑽𝒂𝒍𝒊𝒅𝒊𝒕𝒂𝒔(𝒙) 𝒙 𝒅𝒆𝟏+ 𝜶
(4)
Keterangan:
- W(i) merupakan perhitungan weight voting
- Validitas (x) merupakan nilai validasi - 𝑑𝑒 merupakan jarak Euclidean
- alfa(𝛼) merupakan nilai regulator smoothing (pemulusan)
6. Menentukan kelas dari data uji dengan memilih bobot terbesar sesuai dengan nilai k Hasil perhitungan weight voting yang telah didapatkan, selanjutnya diurutkan secara descending untuk mendapatkan klasifikasi kelas.
3. PENGUMPULAN DATA
Lokasi penelitian ini terletak di RSUD Kota Mataram. Kasus ini dianalisis melalui pengumpulan data dengan cara wawancara secara langsung. Variabel penelitian ini adalah gejala-gejala pada pasien diabetes mellitus termasuk ke dalam diabetes mellitus Tipe 1 atau 2 berdasarkan perhitungan menggunakan metode Modified K-Nearest Neighbor. Pengumpulan data pada penelitian ini menggunakan metode data sekunder. Kriteria penyakit diabetes mellitus, yaitu:
1. Nafsu Makan Meningkat 2. Sering Buang Air Kecil 3. Peningkatan Kehausan 4. Turunnya Berat Badan 5. Usia (15-20) tahun 6. Faktor Keturunan 7. Mulut Kering
8. Mudah kelelahan / kurangnya aktivitas fisik 9. Sering Mengantuk
10. Mual/Muntah-Muntah
11. Timbulnya luka yang tak kunjung sembuh 12. Gatal-Gatal
13. Mengonsumsi makanan berkolesterol tinggi
14. Obesitas
15. Kadar Glukosa Darah Meningkat
Masukkan dalam sistem ini yaitu 15 pertanyaan gejala penyakit yang diderita pengguna dan jawaban dari masukan tersebut diklasifikasikan menggunakan metode Modified K-Nearest Neighbor. Data latih yang digunakan dalam penelitian yaitu sebanyak 100 data latih dengan 30 data uji.
4. PENGUJIAN
Pengujian ini dilakukan untuk mengetahui hasil akurasi yang didapatkan dari implementasi sistem yang telah dilakukan. Ada beberapa skenario pengujian yang dilakukan, yaitu pengujian pengaruh nilai k, pengujian pengaruh nilai alfa, pengaruh jumlah data latih, pengaruh jumlah data uji, dan pengujian confusion matrix.
4.1 Pengujian Pengaruh Nilai K
Gambar 2. Pengujian Pengaruh Nilai K
Dari Gambar 2 dapat dilihat bahwa grafik mengalami kenaikan pada rentang nilai k=1 sampai k=3 dan penurunan rata-rata akurasi pada rentang nilai k=4 sampai k=9. Kenaikan rata-rata akurasi pada rentang nilai k=1 sampai k=3 terjadi karena semakin kecil nilai k, maka
tetangga yang dibandingkan tidak
memperhitungkan pengaruh keanggotaan kelas yang lainnya. Namun penurunan rata-rata akurasi dikarenakan dengan semakin banyaknya nilai k maka semakin banyak kemungkinan tetangga dengan pola yang berbeda akan ikut dalam proses klasifikasi. Sedangkan ketidakstabilan tingkat akurasi yang dihasilkan disebabkan adanya pola dari data latih yang sangat berdekatan dengan tetangga terdekatnya, sehingga nilai validitas menjadi besar dan memperbesar nilai weight voting yang menjadi dasar prediksi. Namun, nilai akurasi tidak hanya dipengaruhi oleh besarnya nilai k tetapi juga dipengaruhi oleh sebaran data dari masing-masing kelas dan jumlah data latih yang digunakan.
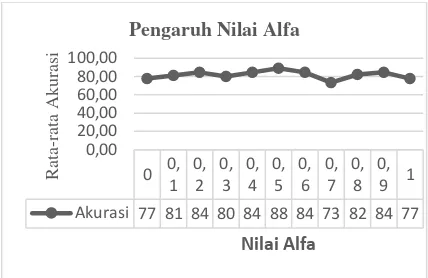
4.2 Pengujian Pengaruh Nilai Alfa
Pengujian menggunakan nilai alfa dari 0 sampai 1 dan nilai k terbaik yaitu k=3 kemudian masing-masing nilai alfa dicoba pada kombinasi data uji dan data latih dengan total 100% yaitu pada 30%:70%. Uji coba dilakukan sebanyak 3 kali pada masing-masing alfa, kemudian akan didapatkan nilai akurasi rata-rata. Jumlah data yang digunakan pada pengujian ini yaitu 100 data latih dan 30 data uji yang diambil 50 data secara acak. Hasil pengujian ditunjukkan pada Gambar 3.
Gambar 3. Pengujian Pengaruh Nilai Alfa
Dari Gambar 3 perubahan nilai alfa dapat memberikan pengaruh terhadap nilai rata-rata akurasi yang dihasilkan. Dapat dilihat pada grafik bahwa nilai alfa mengalami kenaikan pada rentang nilai alfa=0,4 sampai nilai alfa=0,6. Namun ketika penambahan nilai alfa maka rata-rata akurasi cenderung mengalami naik dan turun. Dapat dilihat hasil rata-rata akurasi pengaruh nilai alfa tidak membentuk pola. Hal ini terjadi karena alfa merupakan konstanta dalam perhitungan weight voting. Namun, nilai akurasi juga dipengaruhi oleh sebaran data dari masing-masing kelas dan jumlah data latih yang digunakan.
4.3 Pengujian Pengaruh Jumlah Data Latih
Pengujian dilakukan dengan cara mengubah jumlah data latih sebanyak lima kali dengan menggunakan nilai k dan nilai alfa terbaik yang dihasilkan dari pengujian sebelumnya yaitu k=3 dan alfa=0,5. Jumlah data latih yang digunakan dimulai dari 20 hingga 100 dengan rentang jumlah data latih yaitu 20. Jumlah data uji yang digunakan tetap yaitu 30 data uji. Hasil pengujian ditunjukkan pada Gambar 4.
Gambar 4. Pengujian Pengaruh Jumlah Data Latih
Dari Gambar 4 dapat dilihat bahwa, semakin banyak jumlah data latih yang digunakan maka akan didapatkan nilai rata-rata akurasi yang lebih baik, terlebih data latih yang digunakan yaitu data dengan kelas seimbang. Hal ini terjadi 1 2 3 4 5 6 7 8 9
71,11 82,22 85,55 93,33 95,56
karena jika semakin banyak jumlah data latih yang digunakan maka sistem dapat mengenali pola yang ada pada data latih saat pengujian. Selain itu, semakin banyaknya data memungkinkan mendukung keanggotaan kelas klasifikasi. Jika data latih yang digunakan yaitu 80 data, maka kemungkinan kelas klasifikasi yang sesuai dengan data uji hanya berdasarkan keanggotaan kelas terdekat dari 80 data tersebut. Namun dengan bertambahnya jumlah data latih sampai 100 data, maka kemungkinan kelas klasifikasi dari keanggotaan kelas terdekat mencapai 100 data latih tersebut.
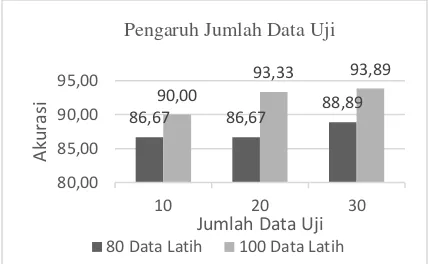
4.4 Pengujian Pengaruh Jumlah Data Uji
Pengujian dilakukan dengan cara mengubah jumlah data uji sebanyak tiga kali uji coba pada masing-masing jumlah data latih dengan menggunakan nilai k dan nilai alfa terbaik yang dihasilkan pada pengujian sebelumnya yaitu k=3 dan alfa=0,5. Jumlah data uji yang digunakan dimulai dari 10 hingga 30 dengan rentang jumlah data uji yaitu 10. Untuk data latih yang digunakan yaitu data latih yang memiliki akurasi terbaik pada pengujian sebelumnya yaitu 80 data dan 100 data latih dengan kelas yang seimbang. Berikut ini hasil pengujian ditunjukkan pada Gambar 5.
Gambar 5. Pengujian Pengaruh Jumlah Data Uji
Dari Gambar 5 dapat dilihat bahwa semakin banyak data uji maka peluang data uji yang benar dalam pengklasifikasian semakin besar, sehingga akurasi semakin tinggi. Hal ini terjadi karena jumlah data latih yang digunakan dalam pengujian lebih banyak dibandingkan dengan jumlah data ujinya dan kemungkinan pada pengujian data uji tersebut semua sebaran variasi data uji yang digunakan sudah banyak diwakili oleh data latihnya.
4.5 Pengujian Confusion Matrix
Pengujian ini dilakukan untuk melihat label kelas yang bernilai benar yang teridentifikasi dengan benar dan tabel confusion matrix digunakan untuk mengetahui hasil aktual dan prediksi yang dihasilkan oleh pengklasifikasian data. Pengujian dilakukan dengan menggunakan parameter terbaik dari pengujian sebelumnya yaitu pada nilai k=3 dan nilai alfa terbaik yaitu 0,5. Nilai k dan alfa diuji pada jumlah data latih dan data uji yang mendapatkan akurasi terbaik pada pengujian sebelumnya yaitu pada data latih 100 dan data uji 30. Berikut ini hasil pengujian ditunjukkan pada Tabel 1.
Tabel 1. Pengujian Confusion Matrix
DM Tipe 1 DM Tipe 2
DM Tipe 1 13 0
DM Tipe 2 2 15
Sensitivity (%) 93,33
Error rate (%) 6,67
Dari uji coba yang telah dilakukan dengan menggunakan parameter terbaik dan jumlah data latih dengan data uji yang mendapatkan akurasi terbaik, maka di dapatkan nilai sensitivity yang tinggi dengan nilai error rate yang rendah.
5. KESIMPULAN
Algoritma Modified K-Nearest Neighbor untuk mengidentifikasi penyakit diabetes mellitus diimplementasikan dengan menggunakan 15 parameter yaitu gejala-gejala penyakit yang dirasakan oleh penderita penyakit diabetes mellitus dengan 2 tipe penyakit yaitu tipe 1 dan tipe 2. Penelitian ini dapat mengklasifikasikan pasien apakah tergolong tipe 1 atau tipe 2 dengan cara menghitung jarak antar data latih, menghitung nilai validitas data training, menghitung jarak antara data uji dengan data latih, dan menghitung weight voting.
Dari hasil pengujian yang telah dilakukan didapatkan akurasi terbaik sebesar 93,33% dengan error rate sebesar 6,67%. Adapaun parameter terbaik yang diperoleh melalui serangkaian percobaan dengan berbagai macam kombinasi nilai. Nilai terbaik untuk nilai k yaitu 3, nilai alfa yaitu 0,5 dengan jumlah data latih sebanyak 100 dan 30 data uji.
86,67 86,67 88,89
90,00
93,33 93,89
80,00 85,00 90,00 95,00
10 20 30
Aku
ra
si
Jumlah Data Uji Pengaruh Jumlah Data Uji
80 Data Latih 100 Data Latih
Truth Test
DAFTAR PUSTAKA
Ahmed, K., Jesmin, T., & Fatima, U. (2012). Intelligent and Effective Diabetes Risk Prediction System Using Data Mining. Oriental Journal of Computer Science & Technology, 5(2), 215–221.
AL-Nabi, D. L. A., & Ahmed, S. S. (2013). Survey on Classification Algorithms for
Data Mining:(Comparison and
Evaluation). Computer Engineering and Intelligent Systems, 1719(8), 18–25. Basuki, M. P. (2015). Diagnosis Penyakit
Tanaman Tomat Menggunakan Metode Modified K-Nearest Neighbor. Universitas Brawijaya.
Devi, M. R., & Shyla, J. M. (2016). Analysis of Various Data Mining Techniques to Predict Diabetes Mellitus. International Journal of Applied Engineering Research, 11, 727–730.
Iyer, A., Jeyalatha, S., & Sumbaly, R. (2015). Diagnosis Of Diabetes Using Classfication Mining Techniques. International Journal of Data Mining & Knowledge Management Process (IJDKP), 5(1).
Juliyet, L. C., & Amanullah, K. M. (2015). The Surveillance on Diabetes Diagnosis Using Data Mining Techniques A case study in the Medical Diagnosis. IJSART, 1(4).
Karegowda, A. G., Jayaram, M. A., & Manjunath, A. S. (2012). Cascading K-means Clustering and K-Nearest Neighbor Classifier for Categorization of Diabetic Patients. International Journal of Engineering and Advanced Technology, 1(3), 147–151.
Karthikeyan, T., & Vembandadsamy, K. (2015). An Analytical Study on Early Diagnosis and Classification of Diabetes Mellitus. In International Journal of Computer Application (Vol. 5).
Khotimah, H. (2015). Penentuan Status Gizi Balita Menggunakan Metode Modified K-Nearest Neighbor (MK-NN). Universitas Brawijaya.
Oswal, A., Shetty, V., Badshah, M., Pitre, R., & Vashi, M. (2014). A SURVEY ON DISEASE DIAGONSIS ALGORITHMS. International Journal of Advanced Research in Computer Engineering &
Technology (IJARCET), 3(11), 3757–3761. Pandeeswari, L., Rajeswari, K., & Phill, M. (2015). K-Means Clustering and Naive Bayes Classifier For Categorization Of Diabetes Patients. IJISET - International Journal of Innovative Science, Engineering & Technology, 2(1), 179–185.
Parvin, H., Alizadeh, H., & Minaei-bidgoli, B.
(2008). MKNN : Modified K-Nearest Neighbor. Proceedings of the World Congress on Engineering and Computer Science, WCECS, 22–25.
Poonguzhali, E., Kabilan, S., Kannan, S., & Sivagami, P. (2014). Diagnosis of Diabetes Mellitus Type 2 using Neural Network. International Journal of Emerging Technology and Advanced Engineering, 4(2), 939–942.
Sa’di, S., Maleki, A., Hashemi, R., Panbechi, Z.,
& Chalabi, K. (2015). Comparison of Data Mining Algorithms in the Diagnosis of Type Ii Diabetes. In International Journal on Computational Science & Applications (Vol. 5, hal. 1–12).
Saxena, K., Khan, Z., & Singh, S. (2014). Diagnosis of Diabetes Mellitus using K Nearest Neighbor Algorithm. International Journal of Computer Science Trends and Technology (IJCST), 2(4), 36–43.
Senan, N., Ibrahim, R., Nawi, N. M., & Mokji, M. M. (2009). Feature Extraction for Traditional Malay Musical Instruments Classification System. International Conference of Soft Computing and Pattern Recognition.
Singh, S., & Kaur, K. (2013). A Review on Diagnosis of Diabetes in Data Mining. International Journal of Science and Research (IJSR), 2406–2408.
Thirumal, P. C., & Nagarajan, N. (2014). Applying Average K Nearest Neighbour Algorithm to Detect Type-2 Diabetes. Australian Journal of Basic and Applied Sciences, 8(7), 128–134.