Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains Program Studi Matematika
Teks penuh
Gambar






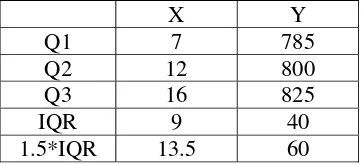
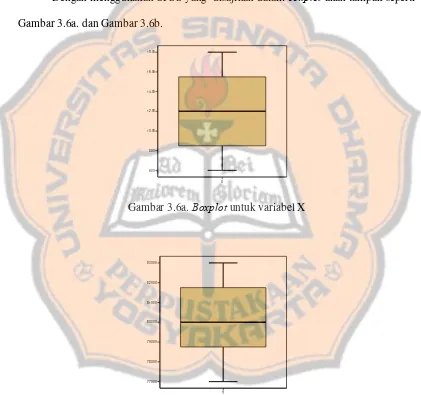


Dokumen terkait
Dari hasil tersebut dapat disimpulkan bahwa komitmen organisasi tidak mempengaruhi perilaku karyawan dalam meringankan problem-problem yang berkaitan dengan pekerjaan yang
Penyesuaian diri terhadap hilangnya pasangan hidup pada lansia pria lebih tinggi dibanding lansia wanita yang ditunjukkan dengan mean empirik pria > mean empirik wanita =
Geometri kabur yang dibahas dalam skripsi ini meliputi titik kabur, jarak kabur antara dua buah titik kabur, garis kabur, luas dan keliling himpunan bagian kabur, tinggi
Dalam himpunan kabur juga dikenal operasi-operasi antar himpunan, seperti dalam himpunan tegas. Karena himpunan kabur dinyatakan dengan fungsi keanggotaan, maka operasi pada
(1) Proses pembelajaran dengan model PBL berbasis etnomatematika pada materi segiempat dilaksanakan dengan membimbing siswa untuk membentuk pemahamannya mengenai segiempat
Berdasarkan makna dari istilah – istilah yang telah dijabarkan, maka yang dimaksud dengan efektivitas pembelajaran menggunakan model Think Pair Square pada
Metode pertumbuhan eksponensial merupakan model yang lebih baik daripada model pertumbuhan logistik untuk menduga model hubungan antara nilai harapan hidup dan biaya
Konsisten yang artinya tidak ada dua pernyataan ( dua aksioma, aksioma dengan teorema, atau dua teorema yang bertentangan satu sama lain ). Independen artinya jika
