PENDEKATAN MODEL RATA-RATA SEBAGAI METODE
ALTERNATIF DALAM PENANGANAN REGRESI
BERDIMENSI TINGGI
NIDA ASHMA ADILAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Pendekatan Model Rata-Rata sebagai Metode Alternatif dalam Penanganan Regresi Berdimensi Tinggi adalah benar karya saya denganarahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2015
Nida Ashma Adilah
ABSTRAK
NIDA ASHMA ADILAH. Pendekatan Model Rata-Rata sebagai Metode Alternatif dalam Penanganan Regresi Berdimensi Tinggi. Dibimbing oleh BAGUS SARTONO dan LA ODE ABDUL RAHMAN.
Pendekatan model rata-rata mengatasi kekurangan pada regresi berdimensi tinngi dengan jumlah peubah penjelas (𝑝) lebih banyak dari jumlah amatannya (𝑛). Kondisi 𝑛 < 𝑝 memberikan pengaruh matriks rancangan peubah penjelas tidak mempunyai matriks kebalikan yang bersifat unik sehingga tidak dapat menggunakan metode kuadrat terkecil untuk pendugaan parameter regresi. Tujuan penelitian ini adalah menduga respon dengan merata-ratakan nilai dugaan respon setiap kelompok model yang terboboti. Data yang digunakan adalah data spektrum FTIR (Fourier Transform Infrared) serbuk tanaman obat yang memiliki komposisi utama berupa temulawak dan komposisi campuran berupa bangle dan kunyit. Penelitian ini hanya berfokus pada pendugaan persentase temulawak sajayang diperoleh dari pengukuran spektroskopi FTIR pada bilangan gelombang 4000-650 cm-1. Hasil penelitian menunjukkan bahwa pengelompokan peubah penjelas yang lbaik adalah kelompok dengan model yang lebih sedikit dengan peubah penjelas yang lebih banyak pada setiap kelompoknya. Pembobot model yang terbesar adalah model yang memiliki nilai korelasi antara nilai dugaan respon kelompokdanpeubah responnya terkuat.
Kata kunci: data spektrum FTIR, pendekatan model rata-rata, regresi berdimensi tinggi
ABSTRACT
NIDA ASHMA ADILAH. Model Averaging Approach as Alternative Method for
High-Dimensional Regression. Supervised by BAGUS SARTONO and LA ODE
ABDUL RAHMAN.
Model averaging approach is used to overcome the problems of high-dimensional regression, that is the number of predictors (𝑝) more than the
number of observations (𝑛). The condition of 𝑛 < 𝑝 effects the design matrix has
no unique general inverse matrix. So that least-square method can not be used. The purpose of this research is to estimate response value by averaging the response value of each model with their weights. The data that used in this research is FTIR (Fourier Transform Infrared) spectrum data of herb powder which contain ginger as primary composition and mixture compositions (bangle and turmeric). This study focuses on estimating the proportion of ginger from FTIR spectroscopic measurementbetween 4000-650 cm-1. The result showed that better grouping of predictors is a group with fewer models with more predictors in each model. The largest model weight is a model that has largest coefficient correlation between fitted value and its response.
Keywords: FTIR spectrum data, high-dimensional regression, model averaging
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
PENDEKATANMODEL RATA-RATASEBAGAI METODE
ALTERNATIF DALAM PENANGANAN REGRESI
BERDIMENSI TINGGI
NIDA ASHMA ADILAH
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
PRAKATA
Puji dan syukur penulis panjatkan kepada Allah subhanahu wa ta’ala atas segala karunia-Nya sehingga karya ilmiah ini berhasil diselesaikan. Tema yang dipilih dalam penelitian yang dilaksanakan sejak bulan Desember 2014 ini ialah Analisis Regresi, dengan judul Pendekatan Model Rata-Rata sebagai Metode Alternatif dalam Penanganan Regresi Berdimensi Tinggi.
Terima kasih penulis ucapkan kepada Bapak Dr Bagus Sartono, MSi dan Bapak La Ode Abdul Rahman, MSi selaku pembimbing. Di samping itu, penghargaan penulis sampaikan kepada Bapak Rudi Heryanto, MSi selaku kepala laboratorium Pusat Studi Biofarmaka IPB, Bapak Dr Farit Mochamad Affendiselaku dosen Departemen Statistika yang telah membantu dalam mendesain penelitian. Ungkapan terima kasih juga disampaikan kepada ayah, ibu, serta seluruh keluarga, atas segala doa dan kasih sayangnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, Agustus 2015
DAFTAR ISI
DAFTAR TABEL vi DAFTAR GAMBAR vi DAFTAR LAMPIRAN vi PENDAHULUAN 1 Latar Belakang 1 Tujuan Penelitian 2 TINJAUAN PUSTAKA 2Spektroskopi FTIR (Fourier Transform Infrared) 2
Pendekatan Model Rata-rata 3
Korelasi Marjinal (Marginal Correlation) 3
Pembobot Model 3
METODE 4
Data 4
Prosedur Analisis Data 4
HASIL DAN PEMBAHASAN 6
Eksplorasi Data 6
Korelasi Marjinal antara Nilai Absorban dan Persentase Temulawak 8 Penentuan Kandidat Model dan Optimasi Pembobot Model 9
Perbandingan Nilai Jumlah Kuadrat Sisaan 12
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 14
DAFTAR PUSTAKA 14
LAMPIRAN 15
DAFTAR TABEL
1 Daerah identifikasi spektrum IR kurkuminoid 2
2 Pembobot model dan nilai korelasi marjinal pengelompokan tipe 1 9 3 Pembobot model dan nilai korelasi marjinal pengelompokan tipe 2 10 4 Pembobot model dan nilai korelasi marjinal pengelompokan tipe 3 11
DAFTAR GAMBAR
1 Spektrum inframerah serbuk simplisia dengan temulawak 100% 6 2 Perbandingan spektrum FTIR serbuk simplisia temulawak, bangle, dan
kunyit 7
3 Perbandingan spektrum inframerah temulawak 100% - 80% 7 4 Nilai korelasi antara nilai absorban dan persentase temulawak 8 5 Sebaran nilai korelasi antara nilai absorban dan persentase temulawak 8 6 Perbandingan nilai jumlah kuadrat sisaan untuk setiap tipe
pengelompokan 12
DAFTAR LAMPIRAN
1
PENDAHULUAN
Latar BelakangBeberapa data hasil penelitian kimia sering kali menggunakan analisis statistika untuk mendeskripsikan suatu gugus fungsi, mengklasifikasi senyawa tertentu, mengetahui hubungan antara satu peubah dan peubah lainnya atau memprediksi suatu peubah menggunakan model yang terbangun dari peubah-peubah yang ada. Salah satu data yang memerlukan analisis statistika cukup intensif adalah data spektrum FTIR (Fourier Transform Infra Red) suatu serbuk simplisia yang digunakan untuk mengidentifikasi kandungan komposisi tanaman temulawak, kunyit, dan bangle. Data ini merupakan hasil percobaan Pusat Studi Biofarmaka LPPM IPB tahun 2015. Data sampel sebanyak 280 serbuk simplisia dengan kombinasi komposisi tanaman obat tertentu dianalisis menggunakan ATR-FTIR (Attenuated Total Reflectance Fourier Transform Infra Red) sehingga diperoleh 1798 spektrum FTIR berupa nilai reflektan yang telah dikonversi menjadi nilai absorban untuk dicatat sebagai peubah penjelas dengan peubah respon persentase komposisi utama yaitu temulawak. Analisis statistika diperlukan untuk mengetahui persentase temulawak dalam serbuk simplisia berdasarkan spektrum FTIR.
Dengan demikian diperlukan pendugaan hubungan antara spektrum FTIR dengan kandungan temulawak. Salah satu analisis statistika yang digunakan untuk mengetahui hubungan suatu peubah dengan peubah lainnya adalah analisis regresi (Draper &Smith 1992). Metode Kuadrat Terkecil adalah salah satu metode pendugaan parameter dalam pemodelan analisis regresi. Pendugaan parameter regresi diperoleh dengan menyelesaikan persamaan 𝛽̂ = (𝑿′𝑿)−1𝑿′𝑦, dengan 𝛽̂ sebagai vektor penduga parameter regresi, matriks 𝑿 adalah matriks rancangan peubah bebas, dan 𝑦 adalah vektor peubah respon. Salah satu syarat cukup dalam menggunakan metode ini adalah banyaknya amatan (n) harus lebih besar dari banyaknya peubah penjelas (p) agar matriks (𝑿′𝑿) mempunyai matriks kebalikan. Sedangkan jika 𝑛 ≤ 𝑝 maka akan menyebabkan matriks (𝑿′𝑿) bersifat singular
dan tidak memiliki matriks kebalikan (Notodiputro 2003). Artinya, terdapat kendala pendugaan parameter regresi menggunakan MKT pada data spektrum FTIR, yaitu adanya masalah pada tingginya dimensi peubah penjelas yang dilibatkan sedangkan jumlah amatannya sangat terbatas atau yang biasa disebut regresi berdimensi tinggi (high-dimensional regression). Oleh karena itu, diperlukan metode lain untuk mengatasi permasalahan regresi berdimensi tinggi.
Regresi berdimensi tinggi merupakan kondisi dimana banyaknya peubah penjelas (p) lebih besar dari banyaknya amatan (n). Metode yang dapat dilakukan untuk analisis data berdimensi tinggi antara lain analisis komponen utama,
partial-least square, Metode Lasso, Bayesian Lasso, least-angle regression, the smoothly clipped absolute deviation, dan pendekatan model rata-rata (Ando dan
Li 2014).
Pada penelitian ini diharapkan tetap menggunakan MKT pada pendugaan parameter regresi tetapi tetap dapat mengatasi kendala regresi berdimensi tinggi. Sehingga metode yang dapat diterapkan sebagai solusi alternatif adalah pendekatan model rata-rata. Pendekatan model rata-rata yaitu analisis regresi
2
dengan mengelompokkan peubah penjelas berdasarkan kriteria tertentu kemudian nilai dugaan respon dari model yang dibangun pada setiap kelompok dirata-ratakan dengan bobot tertentu. Kriteria pengelompokan yang digunakan adalah korelasi marjinal. Salah satu alasan penerapan metode ini adalah hasil simulasi menunjukkan bahwa metode ini memberikan hasil prediksi yang lebih valid dari metode lainnya seperti lasso, grup lasso, dan smoothly clipped absolute deviation (Ando dan Li 2014).
Tujuan Penelitian
Tujuan dari penelitian ini adalah menerapkan pendekatan model rata-rata dalam menangani masalah pendugaan respon pada regresi berdimensi tinggi (high-dimensional regression).
TINJAUAN PUSTAKA
Spektroskopi FTIR (Fourier Transform Infrared)
Spektroskopi FTIR adalah teknik pengukuran untuk mengumpulkan spektrum inframerah (IR). Spektrum IR suatu senyawa dapat menggambarkan struktur molekul senyawa tersebut dengan mengukur absorbsi radiasi, refleksi atau emisi di daerah IR.
Spektroskopi IR dibagi menjadi tiga jenis radiasi yaitu inframerah dekat (bilangan gelombang 12800–4000 cm-1), inframerah tengah (bilangan gelombang 4000-200 cm-1), dan inframerah jauh (bilangan gelombang 200-10 cm-1). FTIR merupakan salah satu teknik spektroskopi inframerah pertengahan (Nur & Adijuwana 1989).
Spektrum inframerah senyawa tumbuhan dapat diukur dalam bentuk cairan, bentuk gerusan dalam minyak nujol, dan bentuk padat yang dicampur dengan kalium bromide. Setiap senyawa akan menyerap berbagai frekuensi radiasi elektromagnetik dalam daerah spektrum inframerah. Setiap ikatan yang berbeda mempunya sifat frekuensi vibrasi yang berbeda pula. Tipe ikatan yang sama dalam dua senyawa yang berbeda dan terletak di lingkungan yang berbeda, maka molekul tersebut tidak akan mempunyai struktur serapan yang tepat sama.
FTIR dapat digunakan untuk analisis kuantitatif yang menghubungkan konsentrasi dengan nilai absorban. Nilai absorban merupakan nilai yang diukur pada berbagai bilangan gelombang yang digunakan untuk menduga konsentrasi suatu senyawa.
Tabel 1 Daerah identifikasi spektrum IR kurkuminoid
No Jenis Vibrasi Bilangan Gelombang (cm-1) Intensitas
1 Ikatana Hidrogen OH 3600-3300 sedang-kuat
2 C-H alkana 3000-2850 Kuat
3 Karbonil 1820-1660 sangat kuat
4 Aromatik -C=C rentangan 1660-1450 Kuat
5 R - O-Ar 1300-1000 Sedang
3
Pendekatan Model Rata-Rata
Pendekatan model rata-rata (model averaging approach) adalah suatu pendekatan untuk meningkatkan keakuratan pendugaan regresi klasik dengan membuat beberapa kelompok berbeda. Pada data berdimensi tinggi, model-model berbeda tersebut diperoleh dengan memodelkan 𝑌 terhadap kelompok-kelompok peubah 𝑋 dengan banyak peubah 𝑋 di masing-masing kelompok lebih sedikit dari banyaknya amatan. Misalkan, peubah penjelas dikelompokkan menjadi M kelompok, yaitu 𝐴1, 𝐴2, … 𝐴𝑀 dan dari setiap kelompok disusun model regresi linear 𝑀𝑘, 𝑘 = 1,2, … , 𝑀 dengan 𝑝 adalah banyaknya peubah penjelas pada setiap
kelompok. Model hasil pengelompokan dapat dituliskan sebagai berikut: 𝑀𝑘∶ 𝑦 = ∑𝑗∈𝐴𝑘𝛽𝑗𝑥𝑗+ 𝜀,
dengan 𝐴𝑘 adalah kelompok peubah penjelas, 𝑥𝑗 dan 𝑦 merupakan peubah penjelas dan peubah respon yang telah dibakukan. Kemudian dituliskan dengan notasi matriks 𝑦 = 𝑿𝑘𝛽𝑘+ 𝜺, dengan 𝑿𝑘 adalah matriks peubah penjelas pada kelompok ke-k, 𝛽𝑘 adalah parameter regresi sebanyak𝑝pada model ke-k dan 𝜺 merupakan vektor sisaan berdimensi 𝑛 amatan. Koefisien regresi didapatkan menggunakan MKT:
𝛽̂𝑘 = 𝑎𝑟𝑔𝑚𝑖𝑛 ‖𝑦 − 𝑿𝑘𝛽𝑘‖2 sehingga didapatkan 𝛽̂𝑘= (𝑿𝑘′𝑿𝑘)−1𝑿
𝑘
′𝑦dan nilai dugaan respon kelompok
ke-𝑘adalah 𝜇̂𝑘 = 𝑿𝑘𝛽̂𝑘, untuk 𝑘 = 1, … , 𝑀. Nilai dugaan respon akhir 𝜇̂ diduga dengan merata-ratakan nilai dugaan respon setiap kelompokdengan bobot tertentu.
Korelasi Marjinal (Marginal Correlation)
Korelasi marjinal (marginal correlation) merupakan nilai yang menjelaskan kekuatan hubungan antara peubah respon dan peubah penjelasnya. Asumsi matriks rancangan X telah dibakukan sehingga pada setiap kolom 𝑗 adalah (𝑛 − 1)−1‖𝑿(𝑗)‖
2
= (𝑛 − 1)−1𝑿(𝑗)′ 𝑿(𝑗) = 1 dan vektor peubah respon yang
dibakukan pula (𝑛 − 1)−1‖𝑦‖2 = (𝑛 − 1)−1𝑦′𝑦 = 1, sehingga nilai korelasi
marjinal dapat diduga dengan 𝛾̂ = (𝑛 − 1)−1𝑿′𝑦.
Pembobot Model
Pembobot model merupakan bobot yang diberikan pada nilai dugaan respon setiap model. Pembobot model yang dipilih adalah pembobot yang dapat meminimumkan kriteria validasi silang. Validasi silang membagi data menjadi dua yaitu data latih dan data validasi. Data latih akan digunakan untuk membentuk suatu model, sedangkan data validasi akan digunakan untuk penentuan bobot dari respon pada model yang terbentuk sebelumnya dari data latih.
Validasi silang lipat K yaitu salah satu metode validasi silang dengan membagi seluruh data secara acak ke dalam 𝐾 subcontoh. Salah satu subcontoh digunakan sebagai data validasi, sedangkan 𝐾 − 1 subcontoh digunakan sebagai data latih. Proses validasi silang dilakukan pada setiap kelompok peubah yang
4
sebelumnya terbentuk dan berulang sampai 𝐾 kali, dengan masing-masing K subcontoh digunakan satu kali sebagai validasi model. Misalkan, matriks Hat 𝑿𝑘(𝑿𝑘′𝑿
𝑘)−1𝑿𝑘 dinotasikan sebagai 𝑯𝑘 maka nilai dugaan respon akhir adalah
sebagai berikut: 𝜇̂ = ∑ 𝑤𝑘𝜇̂𝑘 = 𝑀 𝑘=1 ∑ 𝑤𝑘 𝑀 𝑘=1 𝑿𝑘(𝑿𝑘′𝑿𝑘)−1𝑿𝑘′𝑦 = ∑ 𝑤𝑘𝑯𝑘 = 𝑀 𝑘=1 𝑯(𝑤)𝑦
𝑤𝑘 merupakan pembobot model yang diduga melalui proses validasi silang.
Pembobot model yang dipilih adalah bobot yang meminimumkan kriteria validasi silang:
𝑤̂ = 𝑎𝑟𝑔𝑚𝑖𝑛𝒘𝜖𝑄𝑛𝐶𝑉(𝑤) dengan𝑄𝑛 = {𝑤 ∈ [0,1]𝑀 ∶ 0 ≤ 𝑤
𝑘 ≤ 1} dan ∑𝑀𝑘=1𝑤𝑘= 1 (Ando dan Li 2014).
Jumlah kuadrat sisaan dari nilai dugaan respon data validasi pada validasi silang lipat 𝐾 digunakan untuk membentuk kriteria validasi silang:
𝐶𝑉(𝑤) = (𝑦 − 𝜇̂)′(𝑦 − 𝜇̂) = (𝑦 − 𝑯(𝑤)𝑦)′(𝒚 − 𝑯(𝑤)𝑦)
METODE
Data
Data yang digunakan dalam penelitian ini merupakan data hasil percobaan yang dilakukan oleh Pusat Studi Biofarmaka LPPM IPB yang bekerjasama dengan Depertemen Statistika IPB tahun 2015. Data sampel merupakan data spektrum FTIR persentase tanaman obat pada serbuk simplisia dengan berat empat gram yang mengandung dua komposisi yaitu komposisi utama dan kompisisi campuran. Komposisi utama berupa temulawak, sedangkan komposisi campuran terdiri dari kunyit dan bangle. Proses pengambilan data dimulai dengan penyiapan sampel dalam bentuk simplisia, kemudian pencampuran komposisi sampel. Penelitian ini hanya menduga kandungan temulawak pada serbuk simplisia tanaman obat yang dijadikan sebagai peubah respon. Jumlah sampel dalam penelitian ini sebanyak 280 dengan kombinasi persentase komposisi utama dan komposisi campuran ditunjukkan pada Lampiran 1. Kemudian dilanjutkan dengan analisis menggunakan ATR-FTIR sehingga diperoleh 1798 (p = 1798) spektrum FTIR berupa nilai absorban yang dicatat sebagai peubah penjelas pada bilangan gelombang 4000-650 cm-1.
Prosedur Analisis Data
Analisis dalam penelitian menggunakan Ms. Excel 2007 dan Minitab 16. Tahapan analisis yang dilakukan dalam penelitian ini adalah sebagai berikut: 1. Melakukan eksplorasi data
2. Menentukan kandidat model
5
b. Mengurutkan peubah penjelas yang memiliki nilai korelasi terkuat hingga yang terlemah, kemudian lakukan pengelompokan berdasarkan nilai korelasi marjinalnya
c. Pengelompokan dilakukan sebanyak tiga kali untuk melihat karakteristik setiap tipe pengelompokan:
Pengelompokan tipe 1 : Membentuk 9 model dengan masing-masing model mempunyai kurang lebih 200 peubah penjelas yaitu 7 model dengan 200 peubah penjelas dan 2 model dengan 199 peubah penjelas Pengelompokan tipe 2 : Membentuk 10 model dengan masing-masing
model mempunyai kurang lebih 180 peubah penjelas yaitu 8 model dengan 180 peubah penjelas dan 2 model dengan 179 peubah penjelas Pengelompokan tipe 3 : Membentuk 12 model dengan masing-masing
model mempunyai kurang lebih 150 peubah penjelas yaitu 10 model dengan 150 peubah penjelas dan 2 model dengan 149 peubah penjelas d. Berdasarkan hasil pengelompokan tersebut, didapatkan peubah penjelas
yang lebih kecil dari amatannya (𝑝 < 𝑛), sehingga memungkinkan untuk melakukan pendugaan parameter regresi menggunakan MKT pada setiap kelompok dan didapatkan nilai dugaan responnya sebagai berikut:
𝜇̂𝑘 = ∑ 𝛽̂𝑗.𝑘 𝑝 𝑗=1 𝑥𝑗.𝑘 keterangan: 𝑗 : 1, 2, 3, … , 𝑝 𝑘 : 1, 2, 3, … , 𝑀
𝜇̂𝑘 : vektor nilai dugaan respon kelompok ke-𝑘
𝛽̂𝑗.𝑘 : dugaan parameter regresi ke-𝑗 pada kelompok ke-𝑘 𝑥𝑗.𝑘 : vektor peubah penjelas ke-𝑗 pada kelompok ke-𝑘 Pengelompokan tipe 1 : 𝜇̂1 = 𝛽̂1.1𝑥1.1+ 𝛽̂2.1𝑥2.1+ ⋯ + 𝛽̂200.1𝑥200.1 𝜇̂2 = 𝛽̂1.2𝑥1.2+ 𝛽̂2.2𝑥2.2+ ⋯ + 𝛽̂200.2𝑥200.2 . . . 𝜇̂9 = 𝛽̂1.9𝑥1.9+ 𝛽̂2.9𝑥2.9+ ⋯ + 𝛽̂199.9𝑥199.9 Pengelompokan tipe 2 : 𝜇̂1 = 𝛽̂1.1𝑥1.1+ 𝛽̂2.1𝑥2.1+ ⋯ + 𝛽̂180.1𝑥180.1 𝜇̂2 = 𝛽̂1.2𝑥1.2+ 𝛽̂2.2𝑥2.2+ ⋯ + 𝛽̂180.2𝑥180.2 . . . 𝜇̂10 = 𝛽̂1.10𝑥1.10+ 𝛽̂2.10𝑥2.10+ ⋯ + 𝛽̂179.10𝑥179.10
6 Pengelompokan tipe 3 : 𝜇̂1 = 𝛽̂1.1𝑥1.1+ 𝛽̂2.1𝑥2.1+ ⋯ + 𝛽̂150.1𝑥150.1 𝜇̂2 = 𝛽̂1.2𝑥1.2+ 𝛽̂2.2𝑥2.2+ ⋯ + 𝛽̂150.2𝑥150.2 . . . 𝜇̂12= 𝛽̂1.12𝑥1.12+ 𝛽̂2.12𝑥2.12+ ⋯ + 𝛽̂149.12𝑥149.12
e. Menduga nilai dugaan respon akhir pada setiap kelompok Pengelompokan tipe 1: 𝜇̂ = 𝑤̂1𝜇̂1+ 𝑤̂2𝜇̂2+ ⋯ + 𝑤̂9𝜇̂9 Pengelompokan tipe 2: 𝜇̂ = 𝑤̂1𝜇̂1+ 𝑤̂2𝜇̂2+ ⋯ + 𝑤̂10𝜇̂10 Pengelompokan tipe 3: 𝜇̂ = 𝑤̂1𝜇̂1+ 𝑤̂2𝜇̂2+ ⋯ + 𝑤̂12𝜇̂12 3. Mengoptimasi pembobot model (𝑤̂)
a. Melakukan validasi silang lipat 10, sehingga diperoleh nilai dugaan respon yang merupakan data validasi {𝜇̂1, … , 𝜇̂𝑀} untuk menduga pembobot
model.
b. Memilih dugaan pembobot model 𝑤̂ yang meminimumkan nilai kriteria 𝐶𝑉(𝑤).
HASIL DAN PEMBAHASAN
Eksplorasi DataTeknik spektroskopi FTIR dapat menghasilkan spektrum FTIR dari suatu senyawa yang kompleks. Pola spektrum disusun oleh serapan vibrasi dari seluruh konsituen dalam senyawa. Spektrum FTIR dijadikan alat investigasi komposisi suatu sampel biologis. Gambar 1 merupakan plot antara nilai-nilai absorban dan bilangan gelombang 4000-650 cm-1 dari 10 sampel serbuk simplisia tanaman obat yang memiliki kandungan temulawak murni, sehingga dari plot tersebut dapat dilihat pola spektrumnya.
Gambar 1 Spektrum inframerah serbuk simplisia dengan temulawak 100%
-0,10 0,00 0,10 0,20 0,30 0,40 0,50 0,60 3 9 9 9 3 7 8 8 3 5 7 8 3 3 6 7 3 1 5 7 2 9 4 6 2 7 3 5 2 5 2 5 2 3 1 4 2 1 0 4 1 8 9 3 1 6 8 2 1 4 7 2 1 2 6 1 1 0 5 1 8 4 0 Nila i A bs o rba n Bilangan Gelombang Sampel 1 Sampel 2 Sampel 3 Sampel 4 Sampel 5 Sampel 6 Sampel 7 Sampel 8
7
Gambar 1 memperlihatkan pola yang sama untuk puncak atau lembah setiap spektrum pada selang bilangan gelombang tertentu. Puncak atau lembah yang cukup jelas adalah pada bilangan gelombang 3500-3200cm-1, 3000-2850cm-1, 1700-1550cm-1, dan 1130-930cm-1. Hal itu menunjukkan bahwa puncak atau lembah yang terbentuk merupakan daerah identifikasi yang terdapat ikatan-ikatan kimia yaitu ikatan hidrogen O-H, C-H alkana, aromatik –C=C, dan R-O-Ar.
Gambar 2 Perbandingan spektrum FTIR serbuk simplisia temulawak, bangle, dan kunyit
Gambar 2 merupakan gambar sampel spektrum temulawak, bangle, dan kunyit murni. Jika gambar sampel spektrum tersebut dibandingkan, secara kasat mata dapat dilihat perbedaannya. Perbedaan spektrum tersebut adalah adanya pergeseran puncak atau lembah yang mengindikasikan bahwa adanya perbedaan ikatan kimia antara temulawak, bangle, dan kunyit.
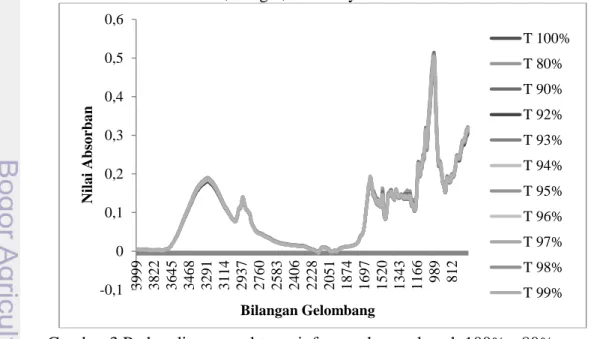
Gambar 3 Perbandingan spektrum inframerah temulawak 100% - 80% Persentase temulawak yang dominan pada serbuk simplisia akan memiliki pola spektrum yang sama dengan puncak atau lembah yang sama. Oleh karena adanya kemiripan setiap spektrum FTIR serbuk simplisia dengan persentase
-0,1 0 0,1 0,2 0,3 0,4 0,5 0,6 39 99 37 88 35 78 33 67 31 57 29 46 27 35 25 25 23 14 21 04 18 93 16 82 14 72 12 61 10 51 840 N ilai A b sor b an Bilangan Gelombang Temulawak Bangle Kunyit -0,1 0 0,1 0,2 0,3 0,4 0,5 0,6 3 9 9 9 3 8 2 2 3 6 4 5 3 4 6 8 3 2 9 1 3 1 1 4 2 9 3 7 2 7 6 0 2 5 8 3 2 4 0 6 2 2 2 8 2 0 5 1 1 8 7 4 1 6 9 7 1 5 2 0 1 3 4 3 1 1 6 6 9 8 9 8 1 2 Nila i A bs o rba n Bilangan Gelombang T 100% T 80% T 90% T 92% T 93% T 94% T 95% T 96% T 97% T 98% T 99%
8
temulawak yang dominan, maka dilakukan analisis regresi untuk mengetahui persentase temulawak melalui nilai absorban dari spektrum tersebut.
Korelasi Marjinal antara Nilai Absorban dan Persentase Temulawak Analisis korelasi antara persentase temulawak dan nilai absorban pada bilangan gelombang 4000-650 cm-1 sebagai peubah respon dan peubah penjelas dilakukan untuk mengelompokkan peubah penjelas.
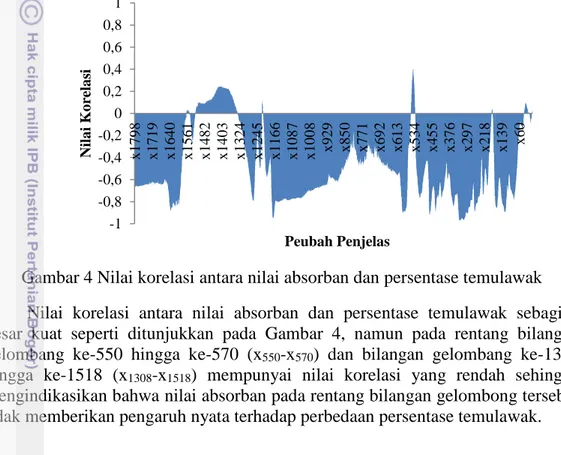
Gambar 4 Nilai korelasi antara nilai absorban dan persentase temulawak Nilai korelasi antara nilai absorban dan persentase temulawak sebagian besar kuat seperti ditunjukkan pada Gambar 4, namun pada rentang bilangan gelombang ke-550 hingga ke-570 (x550-x570) dan bilangan gelombang ke-1308
hingga ke-1518 (x1308-x1518) mempunyai nilai korelasi yang rendah sehingga
mengindikasikan bahwa nilai absorban pada rentang bilangan gelombong tersebut tidak memberikan pengaruh nyata terhadap perbedaan persentase temulawak.
Gambar 5 Sebaran nilai korelasi antara nilai absorban dan persentase temulawak Seperti ditunjukkan Gambar 5, sebaran nilai korelasi menunjukkan jumlah peubah penjelas dengan korelasi kuat lebih banyak dibandingkan dengan peubah penjelas yang memiliki korelasi lemah, sehingga dalam penelitian ini seluruh peubah penjelas akan digunakan untuk menduga persentase temulawak tanpa menyisihkan peubah-peubah penjelas yang memiliki korelasi lemah.
-1 -0,8 -0,6 -0,4 -0,2 0 0,2 0,4 0,6 0,8 1 x 1 7 9 8 x 1 7 1 9 x 1 6 4 0 x 1 5 6 1 x 1 4 8 2 x 1 4 0 3 x 1 3 2 4 x 1 2 4 5 x 1 1 6 6 x 1 0 8 7 x 1 0 0 8 x 9 2 9 x 8 5 0 x 7 7 1 x 6 9 2 x 6 1 3 x 5 3 4 x 4 5 5 x 3 7 6 x 2 9 7 x 2 1 8 x 1 3 9 x 6 0 Nila i K o re la si Peubah Penjelas
9
Penentuan Kandidat Model dan Optimasi Pembobot Model
Penentuan kandidat model dilakukan dengan melakukan pengelompokan peubah penjelas yang sebelumnya telah dibakukan dan diurutkan berdasarkan nilai korelasi marjinal yang terkuat hingga terlemah. Pengelompokan diulang sebanyak 3 kali untuk mengetahui tipe pengelompokan yang paling baik.
Pengelompokan Tipe 1
Pengelompokan tipe 1 yaitu pengelompokan peubah penjelas dengan membentuk 9 model yang terdiri dari 200 peubah penjelas pada 7 model dan 199 peubah penjelas pada 2 model. Model-model pengelompokan tipe 1 adalah:
𝜇̂1= 2.200𝑥1.1 + 0.600𝑥2.1 + … + 0.143𝑥200.1 𝜇̂2= 0.187𝑥1.2 + 0.078𝑥2.2 + … + 0.039𝑥200.2 𝜇̂3= −0.37𝑥1.3 − 0.171𝑥2.3 + … − 0.388𝑥200.3 𝜇̂4= 1.173𝑥1.4 + 0.230𝑥2.4 + … − 0.109𝑥200.4 𝜇̂5= −0.03𝑥1.5 + 0.474𝑥2.5 + … − 0.013𝑥200.5 𝜇̂6= 0.174𝑥1.6 + 0.044𝑥2.6 + … + 0.021𝑥200.6 𝜇̂7= 0.478𝑥1.7 + 0.062𝑥2.7 + … − 0.709𝑥200.7 𝜇̂8= 0.371𝑥1.8 − 0.314𝑥2.8 + … + 0.382𝑥199.8 𝜇̂9= 0.793𝑥1.9 − 0.402𝑥2.9 + … + 0.176𝑥199.9
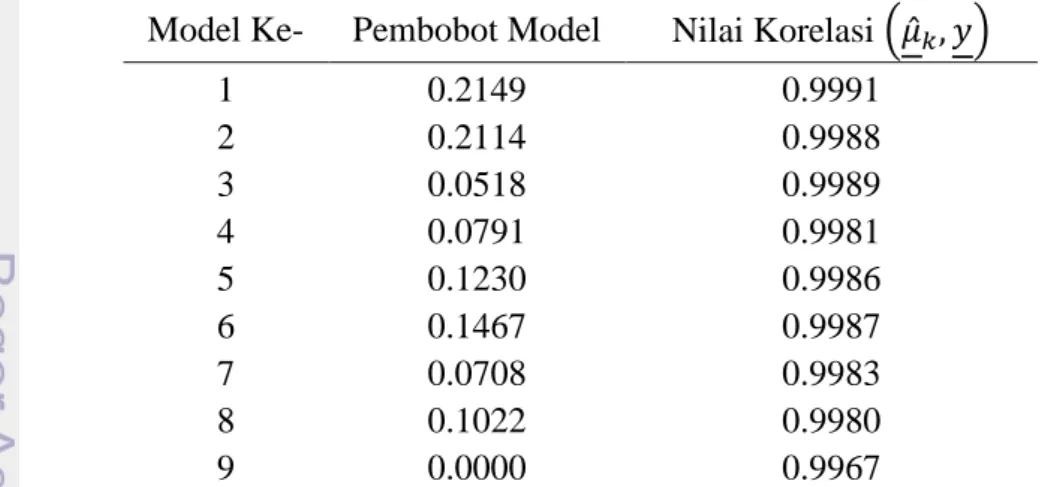
Pembobot model diduga dengan meminimumkan JKS (jumlah kuadrat sisaan) dan nilai JKS paling minimum yang didapatkan adalah 0.2114. Tabel 2 merupakan tabel pembobot model dan nilai korelasi marjinal antara nilai dugaan respon dan peubah respon pada setiap model.
Tabel 2 Pembobot model dan nilai korelasi marjinal pengelompokan tipe 1 Model Ke- Pembobot Model Nilai Korelasi (𝜇̂𝑘, 𝑦)
1 0.2149 0.9991 2 0.2114 0.9988 3 0.0518 0.9989 4 0.0791 0.9981 5 0.1230 0.9986 6 0.1467 0.9987 7 0.0708 0.9983 8 0.1022 0.9980 9 0.0000 0.9967
Tabel 2 menjelaskan bahwa nilai korelasi tertinggi terdapat pada model 1 sebesar 0.9991 dengan pembobot model sebesar 0.21492. Setelah dilakukan pembobotan model, maka nilai dugaan respon akhirnya didapatkan sebagai berikut:
10 𝜇̂ = 0.215 [ −0.290 −0.279 . . . 0.485 ] + 0.211 [ −0.235 −0.238 . . . 0.538 ] + ⋯ + 0 [ −0.240 −0.308 . . . 0.601 ] = [ −0.265 −0.256 . . . 0.517 ] Hasil perhitungan nilai korelasi antara nilai dugaan respon akhir dan peubah responnya sebesar 0.9996, artinya nilai korelasi setelah diboboti lebih besar dari nilai korelasi model pertama.
Pengelompokan Tipe 2
Pengelompokan tipe 2 yaitu pengelompokan peubah penjelas dengan 180 peubah penjelas pada 8 model dan 179 peubah penjelas pada 2 model terahir. Model-model yang terbangun pada pengelompokan tipe 2 sebagai berikut:
𝜇̂1 = 7.710𝑥1.1 − 6.690𝑥2.1 + … + 0.010𝑥180.1 𝜇̂2 = −2.12𝑥1.2 − 0.393𝑥2.2 + … − 0.288𝑥180.2 𝜇̂3 = 0.425𝑥1.3 − 0.370𝑥2.3 + … + 0.105𝑥180.3 𝜇̂4 = −0.60𝑥1.4 − 0.230𝑥2.4 + … − 0.230𝑥180.4 𝜇̂5 = −0.16𝑥1.5− 0.474𝑥2.5 + … + 0.014𝑥180.5 𝜇̂6 = 0.658𝑥1.6− 0.214𝑥2.6 + … + 0.129𝑥180.6 𝜇̂7 = −0.03𝑥1.7 − 1.139𝑥2.7 + … − 0.111𝑥180.7 𝜇̂8 = −2.97𝑥1.8 − 0.042𝑥2.8 + … + 0.279𝑥180.8 𝜇̂9 = −0.51𝑥1.9 − 0.205𝑥2.9 + … − 0.075𝑥179.9 𝜇̂10= 0.347𝑥1.10− 0.147𝑥2.10+ … − 0.826𝑥179.10
Penentuan pembobot model juga dilakukan dengan meminimumkan JKS. Namun pada pengelompokan tipe 2 ini nilai JKS paling minimum adalah 0.265.
Tabel 3 Pembobot model dan nilai korelasi marjinal pengelompokan tipe 2 Model ke- Pembobot Model Nilai Korelasi (𝜇̂𝑘, 𝑦)
1 0.226 0.999 2 0.152 0.998 3 0.133 0.999 4 0.120 0.998 5 0.000 0.997 6 0.175 0.998 7 0.055 0.998 8 0.119 0.998 9 0.014 0.997 10 0.006 0.995
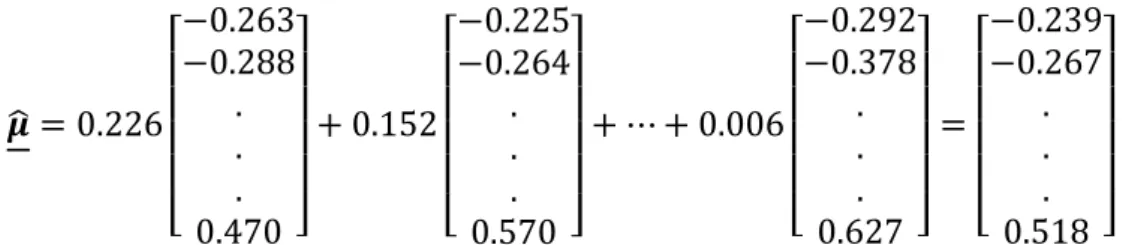
Tabel 3 menunjukkan tabel perbandingan pembobot model dan nilai korelasi peubah respon terhadap nilai dugaan respon setiap kelompoknya.Nilai korelasi tertinggi terdapat pada model 1 sebesar 0.9990 dengan pembobot model sebesar 0.2559.
11 𝝁̂ = 0.226 [ −0.263 −0.288 . . . 0.470 ] + 0.152 [ −0.225 −0.264 . . . 0.570 ] + ⋯ + 0.006 [ −0.292 −0.378 . . . 0.627 ] = [ −0.239 −0.267 . . . 0.518 ] Berdasarkan hasil perhitungan tersebut, nilai korelasi antara nilai dugaan respon akhir dan peubah respon adalah 0.9995. Nilai tersebut lebih besar dari nilai korelasi kelompok yang membangun model pertama.
Pengelompokan Tipe 3
Pengelompokan tipe 3 yaitu pengelompokan peubah penjelas yang terdiri dari 150 peubah penjelas pada 10 model dan 149 peubah penjelas pada 2 model:
𝜇̂1 = 14.30𝑥1.1 − 11.05𝑥2.1 + … − 0.403𝑥150.1 𝜇̂2 = −1.70𝑥1.2 − 3.281𝑥2.2 + … + 0.023𝑥150.2 𝜇̂3 = 0.205𝑥1.3+ 0.251𝑥2.3 + … + 1.954𝑥150.3 𝜇̂4 = 0.604𝑥1.4 − 1.472𝑥2.4 + … − 0.433𝑥150.4 𝜇̂5 = −0.40𝑥1.5 + 0.911𝑥2.5 + … + 0.027𝑥150.5 𝜇̂6 = −0.06𝑥1.6+ 0.249𝑥2.6 + … + 0.175𝑥150.6 𝜇̂7 = −0.22𝑥1.7 − 0.214𝑥2.7 + … + 0.007𝑥150.7 𝜇̂8 = 0.065𝑥1.8 − 0.046𝑥2.8 + … − 0.244𝑥150.8 𝜇̂9 = 0.027𝑥1.9 − 0.086𝑥2.9 + … − 0.012𝑥150.9 𝜇̂10 = 0.027𝑥1.10− 0.071𝑥2.10+ … − 0.244𝑥150.10 𝜇̂11 = −0.62𝑥1.11− 0.043𝑥2.11+ … − 0.058𝑥149.11 𝜇̂12 = 0.104𝑥1.12 − 0.345𝑥2,12+ … − 1.365𝑥149.12
Pembobot model pada pengelompokan tipe 3 yang dipilih adalah pembobot model yang paling meminimumkan nilai JKS. Nilai JKS paling minimum pada pengelompokan ini adalah 0.445.
Tabel 4 Pembobot model dan nilai korelasi marjinal pengelompokan tipe 3 Model ke- Pembobot Model Nilai Korelasi(𝜇̂𝑘, 𝑦)
1 0.338 0.999 2 0.153 0.998 3 0.022 0.998 4 0.093 0.998 5 0.038 0.997 6 0.000 0.996 7 0.181 0.998 8 0.092 0.997 9 0.018 0.996 10 0.064 0.996 11 0.000 0.996 12 0.000 0.994
12
Tabel 4 menunjukkan pembobot-pembobot model yang didapatkan untuk setiap kelompok model. Nilai korelasi tertinggi terdapat pada model 1 sebesar 0.9990 dengan pembobot model sebesar 0.338. Pembobot-pembobot tersebut digunakan untuk memboboti nilai dugaan respon setiap kelompoknya, sehingga didapatkan nilai dugaan respon akhirnya sebagai berikut:
𝜇̂ = 0.338 [ −0.246 −0.298 . . . 0.491 ] + 0.153 [ −0.317 −0.275 . . . 0.596 ] + ⋯ + 0 [ −0.290 −0.388 . . . 0.618 ] = [ −0.274 −0.251 . . . 0.525 ] Hasil perhitungan nilai korelasi marjinal antara nilai dugaan respon akhir dan peubah respon sebesar 0.9992 lebih besar dari nilai korelasi kelompok peubah penjelas yang membangun model pertama.
Perbandingan Nilai Jumlah Kuadrat Sisaan
Berdasarkan perbandingan nilai korelasi antara nilai dugaan respon akhir dan peubah respon 𝑦 pada setiap tipe pengelompokan menunjukkan bahwa pendekatan model rata-rata efisien untuk diterapkan karena nilai korelasinya lebih besar dari nilai korelasi antara nilai dugaan respon pada masing-masing model dan peubah respon.
Sedangkan untuk melihat tipe pengelompokan yang paling baik, dapat dilakukan dengan melihat perbandingan nilai jumlah kuadrat sisaan yang juga dijadikan sebagai kriteria validasi silang.
Gambar 6 Perbandingan nilai jumlah kuadrat sisaan untuk setiap tipe pengelompokan
Gambar 6 memperlihatkan bahwa pengelompokan tipe 1 menghasilkan nilai sisaan paling kecil yaitu 0.211. Artinya, pendekatan model rata-rata lebih baik diterapkan dengan mengelompokkan peubah penjelas dengan model yang lebih sedikit yang banyaknya peubah penjelas masing-masing kelompoknya lebih banyak. 0,2110 0,2658 0,4457 0,0000 0,0500 0,1000 0,1500 0,2000 0,2500 0,3000 0,3500 0,4000 0,4500 0,5000
Tipe 1 Tipe 2 Tipe 3
13
Ilustrasi Penerapan Pendekatan Model Rata-Rata
Berdasarkan model dan pembobot model yang didapatkan dari hasil perhitungan, maka pada penelitian ini dapat dilakukan pendugaan persentase komposisi temulawak suatu serbuk simplisia tanaman obat. Suatu serbuk simplisia tanaman obat dengan komposisi temulawak yang sudah diketahui sebelumnya yaitu 88% diukur dengan ATR-FTIR, pengukuran tersebut menghasilkan 1798 nilai absorban pada bilangan gelombang 4000-650 cm-1. Nilai-nilai tersebut dikelompokkan sesuai dengan salah satu tipe pengelompokan, misalnya pengelompokan tipe 1. Nilai dugaan respon setiap kelompoknya diduga dengan menerapkan model-model pada pengelompokan tipe 1.
Tabel 5 Ilustrasi perhitungan nilai dugaan respon akhir Model ke-k 𝜇̂𝑘 𝑤𝑘 𝜇̂𝑘× 𝑤𝑘 1 0.8702 0.2149 0.1870 2 0.8705 0.2114 0.1840 3 0.8708 0.0518 0.0451 4 0.8702 0.0791 0.0687 5 0.8696 0.1230 0.1069 6 0.8697 0.1467 0.1276 7 0.8706 0.0708 0.0616 8 0.8699 0.1022 0.0889 9 0.8699 0.0000 0.000 𝜇̂ 0.8701
Tabel 5 menujukkan hasil perhitungan nilai dugaan persentase komposisi temulawak yaitu sebesar 0.8701 atau 87.01% dan memiliki selisih 0.0099 atau 0.99% dengan persentase komposisi temulawak sesungguhnya. Sehingga dapat dinyatakan bahwa pendekatan model rata-rata ini tepat digunakan.
SIMPULAN DAN SARAN
SimpulanNilai absorban pada bilangan gelombang 3500-3200 cm-1, 3000-2850 cm-1, 1700-1550 cm-1, dan 1130-930 cm-1 merupakan daerah identifikasi yang berpengaruh terhadap pendugaan persentase temulawak karena mencirikan kandungan ikatan-ikatan kimia tertentu. Penelitian ini menunjukkan bahwa pengelompokan yang paling baik adalah pengelompokan dengan model lebih sedikit dengan peubah penjelas lebih banyak. Nilai korelasi terbesar yaitu model 1 pada masing-masing kelompok sehingga diberikan pembobot model paling besar pula. Artinya, hasil pembobotan model menunjukkan bahwa semakin besar nilai korelasi maka semakin besar pula pembobot modelnya. Selain itu, nilai korelasi antara nilai dugaan respon akhir dan peubah respon lebih besar dari nilai korelasi antara nilai dugaan respon setiap kelompok dan peubah respon. Berdasarkan hal ini, pendekatan model rata-rata tepat dalam menangani regresi berdimensi tinggi.
14
Saran
Penelitian ini hanya fokus dalam pendugaan persentase komposisi utama saja yaitu persentase temulawak. Penelitian selanjutnya dapat mengkaji kembali data ini untuk pendugaan persentase komposisi campuran yang terdiri dari persentase bangle dan kunyit. Selain itu, dalam mengelompokkan peubah penjelas sebaiknya tidak ditentukan secara subjektif. Namun sebaiknya menggunakan metode lain yang dapat meminimumkan resiko kesalahan.
DAFTAR PUSTAKA
Ando T, Li KC. 2014. A Model-Averaging Approach for High-Dimensional Regression. Journal of the American Statistical Assosiation. 109(505): 254-265.
Draper N, Smith H. 1992. Analisis Regresi Terapan. Ed ke-2. Sumantri B, penerjemah. Jakarta (ID): Gramedia Pustaka Utama. Terjemahan dari:
Applied Regression Analysis.
Notodiputro KA. 2003. Pendekatan Statistika dalam Kalibrasi. Proseding Konferensi Statistika dan Matematika Masyarakat Islam Asia Tenggara Bandung.
Nur MA, Adijuwana H. 1989. Teknik Spektroskopi dalam Analisis Biologi. Bogor: Institut Pertanian Bogor.
Tibshirani R. 1996. Regression Shrinkage and Selection via the LASSO. Journal
15
Lampiran 1 Kode dan komposisi sampel Kode komposisi (%)
kunyit bangle Temulawak TML 0.00 0.00 100.00 KYT 100.00 0.00 0.00 BGL 0.00 100.00 0.00 3.96.1 0.00 1.00 99.00 3.96.2 0.25 0.75 99.00 3.96.3 0.50 0.50 99.00 3.96.4 0.75 0.25 99.00 3.96.5 1.00 0.00 99.00 3.92.1 0.00 2.00 98.00 3.92.2 0.50 1.50 98.00 3.92.3 1.00 1.00 98.00 3.92.4 1.50 0.50 98.00 3.92.5 2.00 0.00 98.00 3.88.1 0.00 3.00 97.00 3.88.2 0.75 2.25 97.00 3.88.3 1.50 1.50 97.00 3.88.4 2.25 0.75 97.00 3.88.5 3.00 0.00 97.00 3.84.1 0.00 4.00 96.00 3.84.2 1.00 3.00 96.00 3.84.3 2.00 2.00 96.00 3.84.4 3.00 1.00 96.00 3.84.5 4.00 0.00 96.00 3.8.1 0.00 5.00 95.00 3.8.2 1.25 3.75 95.00 3.8.3 2.50 2.50 95.00 3.8.4 3.75 1.25 95.00 3.8.5 5.00 0.00 95.00 3.76.1 0.00 6.00 94.00 3.76.2 1.50 4.50 94.00 3.76.3 3.00 3.00 94.00 3.76.4 4.50 1.50 94.00 Kode komposisi (%) kunyit bangle Temulawak 3.76.5 6.00 0.00 94.00 3.72.1 0.00 7.00 93.00 3.72.2 1.75 5.25 93.00 3.72.3 3.50 3.50 93.00 3.72.4 5.25 1.75 93.00 3.72.5 7.00 0.00 93.00 3.68.1 0.00 8.00 92.00 3.68.2 2.00 6.00 92.00 3.68.3 4.00 4.00 92.00 3.68.4 6.00 2.00 92.00 3.68.5 8.00 0.00 92.00 3.64.1 0.00 9.00 91.00 3.64.2 2.25 6.75 91.00 3.64.3 4.50 4.50 91.00 3.64.4 6.75 2.25 91.00 3.64.5 9.00 0.00 91.00 3.6.1 0.00 10.00 90.00 3.6.2 2.50 7.50 90.00 3.6.3 5.00 5.00 90.00 3.6.4 7.50 2.50 90.00 3.6.5 10.00 0.00 90.00 3.4.1 0.00 15.00 85.00 3.4.2 3.75 11.25 85.00 3.4.3 7.50 7.50 85.00 3.4.4 11.25 3.75 85.00 3.4.5 15.00 0.00 85.00 3.2.1 0.00 20.00 80.00 3.2.2 5.00 15.00 80.00 3.2.3 10.00 10.00 80.00 3.2.4 15.00 5.00 80.00 3.2.5 20.00 0.00 80.00
16
RIWAYAT HIDUP
Penulis dilahirkan di Kendal pada tanggal 17 November1993 dari ayah Ruswito dan ibu Nur Alifah. Penulis adalah putri pertama dari tiga bersaudara. Tahun 2011 penulis lulus dari SMA Negeri 1 Kendal dan pada tahun yang sama penulis lulus seleksi masuk Institut Pertanian Bogor (IPB) melalui jalur undangan SNMPTN dan diterima di Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam.
Selama mengikuti perkuliahan, penulis menjadi asisten praktikum Metode Statistika pada tahun ajaran 2014/2015, dan pengajar mata pelajaran matematika di suatu bimbingan belajar untuk kelas XI SMA. Penulis juga pernah aktif sebagai anggota Beta Club Himpunan Keprofesian Gamma Sigma Beta pada tahun 2013 dan menjadi bendahara Beta Club Himpunan Keprofesian Gamma Sigma Beta pada tahun 2014. Pada bulan Juni - Agustus 2014 penulis melaksankan Praktik Lapangan di Balai Besar Penelitian dan Pengem-bangan Bioteknologi dan Sumberdaya Genetik Pertanian (BB Biogen) dengan judul Pengaruh Varietas terhadap Pertumbuhan Tanaman Jewawut (Setaria Italic) dengan Analisis Rancangan Acak Lengkap.
Penulis juga aktif mengikuti lomba non akademik seperti lomba kesenian. Beberapa prestasi yang diraih oleh penulis adalah Juara II akustik PORSTAT tahun 2013, Juara II Drama Musikal SPIRIT FMIPA tahun 2014, dan Juara I Akustik PORSTAT tahun 2014.