ANALISIS SENTIMENT REVIEW HOTEL DENGAN ALGORITMA
SUPPORT VECTOR MACHINES DAN NAÏVE BAYES
AHMAD JAI
P31.2014.01622
Proposal Tesis Research Metodologi Penelitian
Program Megister Ilmu Komputer
PASCASARJANA TEKNOLOGI INFORMASI UNIVERSITAS DIAN NUSWANTORO
BAB I
PENDAHULUAN
1.1 Latar Belakang
Hotel adalah bangunan yang dikelola secara komersil dan memberikan fasilitas penginapan untuk masyarakat umum. Ada banyak sekali fasilitas yang disediakan untuk memanjakan tamu, salah satunya adalah penyediaan akomodasi antar jemput atau pelayanan makanan dan minuman, pelayanan barang bawaan, pakain cucian serta penggunaan fasilitas penggunaan perabot dan hiasan-hiasan yang ada didalamnya. Namun tidak semua hotel memiliki kualitas yang baik sesuai dengan apa yang diperoleh tamu. Sebelum konsumen memutuskan untuk memilih, sebaiknya konsumen mengetahui detail fasilitas apa saja yang ditawarkan atau kualitas yang diberikan.
Hal ini dapat dipelajari dari testimoni dan opini atau hasil review dari konsumen yang pernah mempunyai pengalaman pada hotel tersebut sebelumnya. Beberapa review tentang hotel dapat membantu konsumen dalam mengetahui kualitas hotel service layak atau tidak untuk dipilih. Saat ini konsumen yang menulis opini dan pengalaman secara online semakin meningkat. Membaca review tersebut secara keseluruhan dapat memakan waktu yang sangat lama, namun jika hanya sedikit review yang dibaca dievaluasi akan menjadi bias. Klarifikasi sentiment bertujuan untuk mengatasi masalah ini dengan secara otomatis mengelompokkan review pengguna menjadi opini positif atau negatif [14]. Untuk itu perlunya pengkajian ulang tentang review hotel dengan cara klasifikasi review kedalam class positif dan negatif agar pada akhirnya konsumen dapat mengetahui tanggapan konsumen lain tentang hotel tersebut secara cepat dan tepat.
Analisa sentiment atau opinion mining adalah studi komputasi mengenai pendapat, perilaku dan emosi seseorang terhadap entitas. Entitas tersebut dapat menggambarkan individu, kejadian atau topik, dan topic tersebut kemungkinan besar dapat berupa review [9]. Teknik klasifikasi yang biasa digunakan untuk analisis sentiment review diantaranya Naïve bayes, Support Vector Machine (SVM), dan K-Nearest Neighbor (KNN) [3].
sentimen pada review film dan beberapa produk dari Amazon.com menggunakan pengklasifikasi Support Vector Machine dan Artificial Neural Network [10]. Pengklasifikasian sentimen pada review restoran di internet yang ditulis dalam Bahasa Canton menggunakan pengklasifikasi Naïve Bayes dan Support Vector Machine [14]. Analisa sentimen pada sosial media Republik Ceko menggunakan Supervised Machine Learning [4]. Dari beberapa teknik tersebut yang paling sering digunakan untuk klasifikasi data adalah Support Vector Machine (SVM).
SVM merupakan metode supervised learning yang menganalisa data dan mengenali pola-pola yang digunakan untuk klasifikasi [1]. Support Vector Machine (SVM) adalah kasus khusus dari keluarga algoritma yang disebut sebagai regularized metode klasifikasi linier dan metode yang kuat untuk meminimalisasi resiko [11]. SVM memiliki kelebihan yaitu mampu mengidentifikasi hyperplane terpisah yang memaksimalkan margin antara dua kelas yang berbeda [2]. Namun Support Vector Machine memiliki kekurangan terhadap masalah pemilihan parameter atau fitur yang sesuai [1]. Pemilihan fitur sekaligus penyetingan parameter di SVM secara signifikan mempengaruhi hasil akurasi klasifikasi [15].
Dalam masalah aplikasi tertentu, tidak semua fitur ini sama pentingnya. Kinerja yang lebih baik dapat dicapai dengan membuang beberapa fitur. Dengan demikian, dapat dihilangkannya data yang noise, data yang tidak relevan dan berlebihan [15]. Particle Swarm Optimization (PSO) banyak digunakan untuk memecahkan masalah optimasi serta sebagai masalah seleksi fitur [8]. Dalam teknik Particle Swarm Optimization (PSO) terdapat beberapa cara untuk melakukan pengoptimasian diantaranya meningkatkan bobot atribut (attribute weight) terhadap semua atribut atau variabel yang dipakai, menyeleksi atribut (attribute selection) dan feature selection.
1.2 Rumusan Masalah
Ada beberapa pokok masalah yang akan dikaji dalam penelitian ini, antara lain : 1. Algoritma pemilihan fitur apa yang performanya terbaik untuk menyelesaikan
masalah banyaknya atribut yang digunakan pada sebuah dataset?
2. Algoritma meta learning apa yang performanya terbaik untuk menyelesaikan masalah data noise dalam klasifikasi teks?
3. Bagaimana pengaruh penggabungan algoritma pemilihan fitur dan metode meta learning terbaik pada peningkatan akurasi klasifikasi teks?
1.3 Tujuan Penelitian
Adapun tujuan penelitian dalam penelitian ini adalah untuk mengindentifikasi fitur apa yang memiliki performa terbaik apabila digunakan untuk menyelesaikan masalah banyaknya atribut yang digunakan pada sebuah dataset klasifikasi teks, selain itu mengindentifikasi algoritma meta learning apa yang memiliki performa terbaikapabila digunakan untuk menyelesaikan data noise dalam klasifikasi teks. Dan yang terakhir adalah untuk mengembangkan algoritma pemilihan fitur dan meta learning terbaik untuk meningkatkan akurasi klasifikasi teks.
1.4 Manfaat Penelitian
Manfaat dari penelitian ini antara lain adalah : 1. Bagi peneliti
Mengintegrasikan algoritma meta learning dengan algoritma selection feature sebagai metode untuk mendapatkan akurasi terbaik dalam klasifikasi teks.
2. Bagi pengguna
Konsumen dapat lebih mudah memilih kategori hotel yang pelayanannya memuaskan, dan manfaat bagi pengembang adalah agar lebih meningkatkan pelayanan atau kebutuhan yang paling sesuai dengan harapan konsumen.
1.5 Ruang Lingkup Penelitian
BAB II
LITERATUR REVIEW
2.1 Review Hotel
Salah satu wadah untuk berpendapat mengenai review hotel dan memiliki kredibilitas yang tinggi dimuat dalam bentuk website adalah tripadvisor.com. Dalam situs ini ada banyak sekali ulasan-ulasan hotel yang dapat diklasifikasikan menjadi tiga kategori, yaitu positif, negative dan netral. Sebagai contoh berikut adalah contoh review hotel di tripadvisor.com:
Gambar 1 Review hotel tripadvisor.com
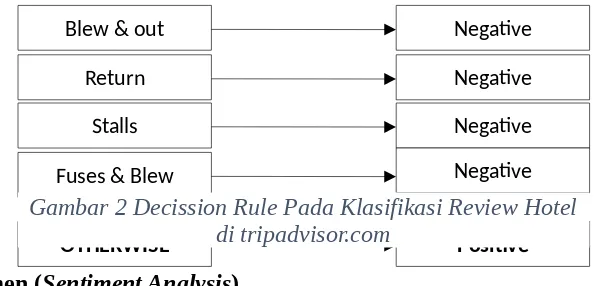
Setelah dianalisis melalui pengumpulan teks maka didapatkan secission rule pada klasifikasi review hotel sebagai berikut :
2.2 Analisa Sentimen (Sentiment Analysis)
Menurut Tang dalam [5], analisa sentimen pada review adalah proses menyelidiki review hotel di internet untuk menentukan opini atau perasaan terhadap suatu produk secara keseluruhan. Menurut Thelwall [5], analisa sentimen diperlakukan sebagai suatu tugas klasifikasi yang mengklasifikasikan orientasi suatu teks ke dalam positif atau negatif. Menurut Mejova dalam [1], tujuan dari analisa sentimen adalah untuk
Blew & out Negative
Return Negative
Stalls Negative
Fuses & Blew Negative
OTHERWISE Positive
menentukan perilaku atau opini dari seorang penulis dengan memperhatikan suatu topik tertentu. Perilaku bisa mengindikasikan alasan, opini atau penilaian, kondisi kecenderungan (bagaimana si penulis ingin mempengaruhi pembaca). Langkah-langkah yang umumnya ditemukan pada klasifikasi teks analisa sentimen diantaranya [10]:
1. Definisikan Domain Dataset
Pengumpulan dataset yang melingkupi suatu domain, misalnya dataset review film, dataset review hotel dan lain sebagainya.
2. Pre-processing
Tahap pemrosesan awal yang umumnya dilakukan dengan proses Tokenization, Generate N-Gram dan Stemming.
3. Transformation
Proses representasi angka yang dihitung dari data tekstual. Binary representation yang umumnya digunakan dan hanya menghitung kehadiran atau ketidakhadiran sebuah kata di dalam dokumen. Berapa kali sebuah kata muncul di dalam suatu dokumen juga digunakan sebagai skema pembobotan dari data tekstual. Proses yang umumnya digunakan yaitu TF-IDF, Binary transformation dan Frequency transformation.
4. Feature Selection
Pemilihan fitur (feature selection) bisa membuat pengklasifikasi lebih efisien/efektif dengan mengurangi jumlah data untuk dianalisa dengan mengidentifikasi fitur yang relevan yang selanjutnya akan diproses. Metode pemilihan fitur yang biasanya digunakan adalah Expert.
5. Classification Proses
Klasifikasi umumnya menggunakan pengklasifikasi seperti Naïve Bayes, Support Vector Machine, dan lain sebagainya.
6. Interpretation/Evaluation
2.3 Pemilihan Fitur (Feature Selection)
Pemilihan Fitur (Feature Selection) Seleksi fitur adalah salah satu faktor yang paling penting yang dapat mempengaruhi tingkat akurasi klasifikasi karena jika dataset berisi sejumlah fitur, dimensi ruang akan menjadi besar, merendahkan tingkat akurasi klasifikasi [8]. Seleksi fitur mempengaruhi beberapa aspek yaitu pola klasifikasi, akurasi klasifikasi, waktu yang diperlukan untuk pembelajaran fungsi klasifikasi, jumlah contoh yang dibutuhkan untuk pembelajaran dan biaya yang terkait dengan fitur menurut Yang dan Honavar dalam [15].
Seleksi fitur merupakan proses optimasi untuk mengurangi satu set besar fitur besar sumber asli agar subset fitur yang relatif kecil yang signifikan untuk meningkatkan akurasi klasifikasi cepat dan efektif. Particle Swarm Optimization (PSO) banyak digunakan untuk memecahkan masalah optimasi serta sebagai masalah seleksi fitur [8]. Optimasi adalah proses menyesuaikan kepada masukan atau karakteristik perangkat, proses matematis, atau percobaan untuk menemukan output minimum atau maksimum hasil. Input terdiri dari variabel, proses atau fungsi dikenal sebagai fungsi biaya, fungsi tujuan atau kemampuan fungsi dan output adalah biaya atau tujuan, jika proses adalah sebuah percobaan, kemudian variabel adalah masukan fisik untuk percobaan [6].
Dalam teknik Particle Swarm Optimization (PSO) terdapat beberapa cara untuk melakukan pengoptimasian diantaranya meningkatkan bobot atribut (attribute weight) terhadap semua atribut atau variabel yang dipakai, menseleksi atribut (attribute selection) dan feature selection. Particle Swarm Optimization (PSO) adalah suatu teknik optimasi yang sangat sederhana untuk menerapkan dan memodifikasi beberapa parameter.
2.4 Algoritma Support Vector Machine (SVM)
Support Vector Machines (SVM) adalah seperangkat metode yang terkait untuk suatu metode pembelajaran, untuk kedua masalah klasifikasi dan regresi. Dengan berorientasi pada tugas, kuat, sifat komputasi yang mudah dikerjakan, SVM telah mencapai sukses besar dan dianggap sebagai state of- the art classifier saat ini [7].
SVM merupakan metode supervised learning yang menganalisa data dan mengenali pola-pola yang digunakan untuk klasifikasi [1]. SVM memiliki kelebihan yaitu mampu mengidentifikasi hyperplane terpisah yang memaksimalkan margin antara dua kelas yang berbeda [2]. Namun Support Vector Machine memiliki kekurangan terhadap masalah pemilihan parameter atau fitur yang sesuai [1]. Pemilihan fitur sekaligus penyetingan parameter di SVM secara signifikan mempengaruh hasil akurasi klasifikasi [15].
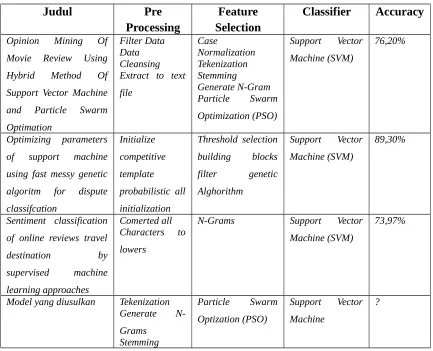
Berikut adalah beberapa penelitian yang menggunakan algoritma Support Vector Machine sebagai pengklasifikasian dalam klasifikasi teks sentimen pada review online yang digunakan peneliti sebagai perbandingan tinjauan studi terdahulu, sebagai berikut:
Table 1 Studi Penelitian
DAFTAR PUSTAKA
[1] Basari, A. S. H., Hussin, B., Ananta, I. G. P., & Zeniarja, J. (2013). Opinion Mining of Movie Review using Hybrid Method of Support Vector Machine and Particle Swarm Optimization. Procedia Engineering, 53, 453–462. doi:10.1016/j.proeng.2013.02.059.
[2] Chou, J.-S., Cheng, M.-Y., Wu, Y.-W., & Pham, A.-D. (2014). Optimizing parameters of support vector machine using fast messy genetic algorithm for dispute classification. Expert Systems with Applications, 41(8), 3955–3964. doi:10.1016/j.eswa.2013.12.035.
[3] Dehkharghani, R., Mercan, H., Javeed, A., & Saygin, Y. (2014). Sentimental causal rule discovery from Twitter. Expert Systems with Applications, 41(10), 4950–4958. doi:10.1016/j.eswa.2014.02.024.
[4] Habernal, I., Ptáček, T., & Steinberger, J. (2014). Supervised sentiment analysis in Czech social media. Information Processing & Management, 50(5), 693–707. doi:10.1016/j.ipm.2014.05.001
[5] Haddi, E., Liu, X., & Shi, Y. (2013). The Role of Text Pre- processing in Sentiment Analysis. Procedia Computer Science, 17, 26–32. doi:10.1016/j.procs.2013.05.005
[7] Haupt, R. L., & Haupt, S. E. (2004). Practical Genetic Algorithms. Untied States Of America: A John Wiley & Sons Inc Publication.
[8] [7] Huang, K., Yang, H., King, I., & Lyu, M. (2008). Machine Learning Modeling Data Locally And Globally. Berlin Heidelberg: Zhejiang University Press, Hangzhou And Springer-Verlag Gmbh.
[9] Liu, Y., Wang, G., Chen, H., Dong, H., Zhu, X., & Wang, S. (2011). An Improved Particle Swarm Optimization for Feature Selection. Journal of Bionic Engineering, 8(2), 191– 200. doi:10.1016/S1672-6529(11)60020-6.
[10] Medhat, W., Hassan, A., & Korashy, H. (2014). Sentiment analysis algorithms and applications: A survey. Ain Shams Engineering Journal. doi:10.1016/j.asej.2014.04.011.
[11] Weiss, S. M., Indurkhya, Nitin & Zhang, Tong. (2010). Fundamentals of Predictive Text Mining. London: Springer- Verlag.
[12] Ye, Q., Zhang, Z., & Law, R. (2009). Sentiment classification of online reviews to travel destinations by supervised machine learning approaches. Expert Systems with Applications, 36(3), 6527–6535. doi:10.1016/j.eswa.2008.07.035.