Dalam dunia kesehatan mendiagnosis suatu penyakit adalah tindakan yang harus
dilakukan sedini mungkin agar penyakit yang ditemukan pada tubuh pasien dapat segera diobati,
sehingga tidak menimbulkan kematian. Penyakit Tuberkulosis (TB) merupakan penyakit yang
dapat menimbulkan kematian jika tidak diketahui dan tidak diobati secara rutin. Oleh karena itu,
untuk mengurangi angka kematian dari penderita Tuberkulosis, pakar kesehatan harus
mendiagnosis penyakit TB sedini mungkin.
Dari data gejala utama, hasil pemeriksaan laboratorium dan hasil rontgen dapat
dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan menggunakan
metode Naïve Bayesian. Metode Naïve Bayesian akan menghitung probabilitas untuk setiap nilai
kejadian dari atribut target pada setiap kasus (sampel data). Selanjutnya, Naïve Bayesian akan
mengelompokkan sampel data tersebut ke kelas yang mempunyai nilai probabilitas paling tinggi.
Keluaran dari sistem adalah sebuah identifikasi atau sebuah prediksi jenis TB yang
diderita oleh pasien berdasarkan lokasi anatomi yang terserang TB yaitu TB Paru, TB Ekstra
Paru dan tidak TB. Peneliti melakukan pengujian dengan data sebanyak 237 data dan
menggunakan fold bernilai 3, 5, 7 dan 9. Pengujian dilakukan sebanyak 24 kali dengan rata-rata
In the world of health diagnosing a disease is an act that should be done as early as possible in order for the disease were found can be treated immediately, so it won’t cause a death. Tuberculosis (TB) is a disease that can cause a death if unrecognized or treated regularly.
Therefore, to reduce the death rate of tuberculosis sufferers, the health experts have to diagnose
it as early as possible.
Based on the main indication data, laboratory test results and the results of rontgen can be
used to be proceed with the data mining techniques using Naïve Bayesian method. It will
calculate the probability for each case values of the target attribute in every case (sample data).
Next, this method will classify the sample data to the class which has the highest probability
value.
The output of the system is an identification or a prediction of a type of Tuberculosis that
suffered by the patients. Researcher conducted a testing with the data of 237 and using fold in 3,
i
IDENTIFIKASI PENYAKIT TUBERKULOSIS ( TB ) PADA MANUSIA MENGGUNAKAN METODE NAÏVE BAYESIAN
SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Komputer
Program Studi Teknik Informatika
Oleh :
Agustin Trihartati S.
NIM : 125314141
PROGRAM STUDI TEKNIK INFORMATIKA FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
THE IDENTIFICATION OF TUBERCULOSIS ( TB ) DISEASE IN HUMANS USING NAÏVE BAYESIAN METHOD
A THESIS
Presented as Partial FulFillment of the Requirements
To Obtain the Sarjana Komputer Degree
In Informatics Engineering Department
By :
Agustin Trihartati S
Student ID : 125314141
INFORMATICS ENGINEERING STUDY PROGRAM FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
HALAMAN PERSEMBAHAN
Segala perkara dapat ku tanggung di dalam Dia
yang memberi kekuatan kepadaku.
Filipi 4 : 13
Skripsi ini kupersembahkan untuk :
Tuhan Yesus Kristus
Keluargaku
viii
ABSTRAK
Dalam dunia kesehatan mendiagnosis suatu penyakit adalah tindakan yang
harus dilakukan sedini mungkin agar penyakit yang ditemukan pada tubuh pasien
dapat segera diobati, sehingga tidak menimbulkan kematian. Penyakit
Tuberkulosis (TB) merupakan penyakit yang dapat menimbulkan kematian jika
tidak diketahui dan tidak diobati secara rutin. Oleh karena itu, untuk mengurangi
angka kematian dari penderita Tuberkulosis, pakar kesehatan harus mendiagnosis
penyakit TB sedini mungkin.
Dari data gejala utama, hasil pemeriksaan laboratorium dan hasil rontgen
dapat dimanfaatkan untuk diolah menggunakan teknik penambangan data dengan
menggunakan metode Naïve Bayesian. Metode Naïve Bayesian akan menghitung
probabilitas untuk setiap nilai kejadian dari atribut target pada setiap kasus
(sampel data). Selanjutnya, Naïve Bayesian akan mengelompokkan sampel data
tersebut ke kelas yang mempunyai nilai probabilitas paling tinggi.
Keluaran dari sistem adalah sebuah identifikasi atau sebuah prediksi jenis
TB yang diderita oleh pasien berdasarkan lokasi anatomi yang terserang TB yaitu
TB Paru, TB Ekstra Paru dan tidak TB. Peneliti melakukan pengujian dengan data
sebanyak 237 data dan menggunakan fold bernilai 3, 5, 7 dan 9. Pengujian
ix
ABSTRACT
In the world of health diagnosing a disease is an act that should be done
as early as possible in order for the disease were found can be treated
immediately, so it won’t cause a death. Tuberculosis (TB) is a disease that can cause a death if unrecognized or treated regularly. Therefore, to reduce the death
rate of tuberculosis sufferers, the health experts have to diagnose it as early as
possible.
Based on the main indication data, laboratory test results and the results of
rontgen can be used to be proceed with the data mining techniques using Naïve
Bayesian method. It will calculate the probability for each case values of the
target attribute in every case (sample data). Next, this method will classify the
sample data to the class which has the highest probability value.
The output of the system is an identification or a prediction of a type of
Tuberculosis that suffered by the patients. Researcher conducted a testing with the
data of 237 and using fold in 3, 5, 7 and 9. The tests were done 24 times with the
x
KATA PENGANTAR
Puji syukur kepada Tuhan Yesus atas berkat-Nya yang melimpah sehingga
penulis dapat menyelesaikan skripsi dengan judul “Identifikasi Penyakit Tuberkulosis (TB) Pada Manusia Menggunakan Metode Naïve Bayesian”. Dalam kesempatan ini, penulis ingin mengucapkan terima kasih yang sebesar-besarnya
kepada semua pihak yang turut memberikan semangat, dukungan dan bantuan
hingga selesainya skripsi ini :
1. Tuhan Yesus Kristus atas segala berkatNya yang melimpah.
2. Romo Dr. Cyprianus Kuntoro Adi, S.J., M.A., M.Sc. selaku dosen
pembimbing, terima kasih atas bimbingan, saran, waktu dan kesabaran
dalam membimbing dan mengarahkan penulis dalam menyelesaikan tugas
akhir ini.
3. Bapak Eko Hari Parmadi, S.Si., M.Kom. selaku Dosen Penguji.
4. Ibu Dr. Anastasia Rita Widiarti selaku Kaprodi dan Dosen Penguji.
5. Bapak Sudi Mungkasi, S.Si., M.Math. Sc., Ph.D. selaku Dekan Fakultas
Sains dan Teknologi Universitas Sanata Dharma.
6. Bapak Drs. Johanes Eka Priyatma, M.Sc., Ph.D. selaku dosen pembimbing
akademik.
7. Seluruh staff pengajar Prodi Teknik Informatika Fakultas Sains dan
Teknologi Universitas Sanata Dharma.
8. Kedua orang tua saya, Yusup Sujana dan Lilis Tinae, terima kasih untuk
doa, semangat, perhatian dan dukungan yang diberikan selama
perkuliahan.
9. Kedua kakak saya, Susi Ariani S., S.Pd. dan Lusi Anggraeni S.,
A.md.Kep. terima kasih untuk semangat, doa dan bantuannya yang telah
diberikan.
10.Anak saya Johanes Lintang Sinartha, terima kasih untuk pengertian,
xi
11.Teman hati saya, Bayu Eko Sutrisno., S.Pd. yang sudah memberikan
semangat, dukungan dalam penyelesaianya skripsi ini.
12.Sahabat-sahabatku Ni Putu (peot), Riya (dalah), Monic (mondol) terima
kasih untuk pertemanan kita selama perkuliahan ini. Teman-teman kelas D
mas Eric, Bagus, Lukas, Vitto, Chandra, Bany, Tegar, Andre terima kasih
untuk tawa yang selalu kalian berikan. Teman-teman Teknik Informatika
angkatan 2012, terima kasih untuk kesan yang luar biasa selama
xii
HALAMAN PERSEMBAHAN………. iv
PERNYATAAN KEASLIAN KARYA……… Error! Bookmark not defined. LEMBAR PERNYATAAN PERSETUJUAN PUBLIKASI……… vi
ABSTRAK……… vii
1.2 Identifikasi Masalah……….. 5
1.3 Rumusan Masalah………. 5
1.4 Tujuan Penelitian……….. 5
1.5 Manfaat Penelitian……… 5
1.6 Batasan Masalah……… 6
1.7 Metodologi Penelitian………... 7
1.8 Sistematika Pembahasan………... 9
BAB II………... 10
LANDASAN TEORI………10
2.1 Tuberkulosis……… 10
2.2 Penambangan Data……….. 13
xiii
2.1.2 Pengelompokan Penambangan Data……… 15
2.1.3 Klasifikasi……… 17
2.3 Klasifikasi Naïve bayesian……….. 18
2.4 Cross Validation……….. 20
2.5 Akurasi dengan Matrixs Confusion……… 20
BAB II………... 22
METODOLOGI PENELITIAN………. 22
3.1 Data………. 22
3.2 Spesifikasi Software dan Hardware……… 25
3.3 Desain Alat Uji……… 25
3.3.1 Preprocessing………... 26
3.3.2 Pembagian Data………... 27
3.3.3 Pemisah Data………28
3.3.4 Modeling……….. 28
3.3.5 Akurasi………. 31
3.4 Desain Pengujian………. 32
BAB IV……….. 36
ANALISA HASIL DAN IMPLEMENTASI SISTEM... 36
4.1 Analisis Hasil……….. 36
4.2 User Interface……….. 39
BAB V... 43
PENUTUP……… 43
5.1 Kesimpulan………. 43
5.2 Saran……… 43
DAFTAR PUSTAKA………... 44
xiv
DAFTAR GAMBAR
GAMBAR2.1 LANGKAH-LANGKAHPENAMBANGANDATA ... 13
GAMBAR2.2 BLOKDIAGRAMMODELKLASIFIKASI ... 17
GAMBAR3.2 DIAGRAMALURPROSESALATUJI ... 25
GAMBAR3.3 DIAGRAMALURPENGUJIAN ... 33
GAMBAR4.1 GRAFIKRATA-RATAAKURASI ... 38
GAMBAR4.2 HALAMANUTAMA ... 39
GAMBAR4.3 HALAMANPRE-PREOCESSING ... 39
GAMBAR4.4 HALAMANPROSES ... 40
GAMBAR4.5 HALAMANCONFUSIONMATRIX ... 40
GAMBAR4.6 HALAMANAKURASI ... 41
GAMBAR4.7 HALAMANGRAFIKAKURASI ... 41
xv
DAFTAR TABEL
TABEL2.1 TABELMATRIXSCONFUSION ... 20
TABEL3.1 CONTOHDATAPASIENTUBERKULOSIS(TB) ... 24
TABEL3.2 CONTOHDATASETELAHTAHAPPRE-PROCESSING ... 27
TABEL3.3 CONTOHDATATRAINING ... 29
TABEL3.4 TABELCONTOHHASILCONFUSIONMATRIX ... 32
TABEL3.5 PEMBAGIAN3FOLD ... 33
TABEL3.6 PEMBAGIAN5FOLD ... 34
TABEL3.7 PEMBAGIAN7FOLD ... 34
TABEL3.8 PEMBAGIAN9FOLD ... 35
1
BAB I
PENDAHULUAN 1.1 Latar Belakang
Tuberkulosis adalah suatu penyakit menular langsung yang
disebabkan oleh kuman TB (Mycobacterium tuberculosis). Sebagian besar
kuman TB menyerang paru, tetapi dapat juga mengenai organ tubuh
lainnya (Petunjuk Teknis Manajemen TB Anak, 2013).
Berdasarkan buku Pedoman Nasional Pengendalian Tuberkulosis
(2014), TB sampai saat ini masih merupakan salah satu masalah kesehatan
masyarakat di dunia.
Dalam laporan WHO tahun 2013 :
1. Diperkirakan terdapat 8,6 juta kasus TB pada tahun 2012 dimana
1,1 juta orang meninggal (13%) diantaranya adalah pasien TB
dengan HIV positif. Sekitar 75% dari pasien tersebut berada di
wilayah Afrika.
2. Pada tahun 2012, diperkirakan 450.000 orang menderita TBMDR
dan 170.00 orang diantaranya meninggal dunia.
3. Meskipun kasus dan kematian karena TB sebagian besar pada pria
tetapi angka kesakitan dan kematian wanita akibat TB juga sangat
tinggi. Diperkirakan terdapat 2,9 juta kasus TB pada tahun 2012
dengan jumlah kematian karena TB mencapai 410.000 kasus
termasuk diantaranya adalah 160.000 orang wanita dengan HIV
positif. Separuh dari orang dengan HIV positif yang meninggal
karena TB pada tahun 2012 adalah wanita.
4. Pada tahun 2012 diperkirakan proporsi kasus TB diantara seluruh
kasus TB secara global mencapai 6% (530.000 pasien TB anak/
tahun). Sedangkan kematian anak (dengan status HIV negatif)
yang menderita TB mencapai 74.000 kematian/ tahun, atau sekitar
5. Meskipun jumlah kasus TB dan jumlah kematian TB tetap tinggi
untuk penyakit yang sebenarnya bisa dicegah dan disembuhkan
tetapi fakta juga menunjukkan keberhasilan dalam pengendalian
TB. Peningkatan angka indensi TB secara global telah berhasil
dihentikan dan telah menunjukkan tren penurunan (turun 2% per
tahun pada tahun 2012), angka kematian juga sudah berhasil
diturunkan 45% bila dibanding tahun 1990.
TB dapat diklasifikasikan berdasarkan lokasi anatomi atau lokasi
organ tubuh yang terserang TB yaitu:
1. Tuberkulosis Paru
Adalah TB yang terjadi pada parenkim (jaringan paru). Milier TB
dianggap sebagai TB paru karena adanya lesi pada jaringan paru.
Limfadenitis TB rongga dada (hilus dan atau mediastinum) atau
efusi pleura tanpa terdapat gambaran radiologis yang mendukung
TB pada paru, dinyatakan sebagai TB paru. Pasien yang menderita
TB paru dan sekaligus juga menderita TB Ekstra paru,
diklasifikasikan sebagai pasien TB paru.
2. Tuberkulosis Ekstra Paru
Adalah TB yang terjadi pada organ selain paru, misalnya : pleura,
kelenjar limfe, abdomen, saluran kencing, kulit, sendi, selaput otak
dan tulang. Diagnosis TB Ekstra paru dapat ditetapkan berdasarkan
hasil pemeriksaan bakteriologis atau klinis. Diagnosis TB Ekstra
paru harus diupayakan berdasarkan penemuan Mycobacterium
tuberculosis. Pasien TB Ekstra Paru yang menderita TB pada
beberapa organ, diklasifikasikan sebagai pasien TB Ekstra Paru.
TB umumnya terjadi pada paru (TB Paru). Namun, penyebaran melalui
aliran darah atau getah bening dapat menyebabkan terjadinya TB diluar
organ paru (TB Ekstra Paru). Oleh karena itu, penelitian ini hanya meneliti
tentang klasifikasi TB berdasarkan lokasi anatomi dari penyakit yaitu TB
Gejala utama pasien TB adalah batuk berdahak selama 2 minggu
atau lebih. Batuk dapat diikuti dengan gejala tambahan yaitu dahak
bercampur darah, batuk darah, sesak nafas, badan lemas, nafsu makan
turun, berat badan menurun, malaise, berkeringat malam hari tanpa
kegiatan fisik, demam meriang lebih dari satu bulan. Gejala-gejala tersebut
dapat dijumpai pula pada penyakit paru selain TB, seperti bronkiektasi,
bronchitis kronis, asma, kanker paru, dan lain-lain. Mengingat penderita
TB di Indonesia saat ini masih tinggi, maka setiap orang yang datang
dengan gejala tersebut diatas, dianggap sebagai seorang terduga pasien
TB, dan perlu dilakukan pemeriksaan dahak secara mikroskopis langsung.
Pemeriksaan dahak salah satunya berfungsi untuk menegakkan diagnosis.
Jika pemeriksaan mikroskopis bernilai negatif maka harus dilaksanakan
pemeriksaan foto rontgen yang mendukung adanya TB.
Indonesia telah mencapai kemajuan yang bermakna dalam upaya
pengandalian TB, namun perlu diwaspadai karena masih ada beberapa
tantangan utama yang harus dihadapi agar tidak menghambat laju
pencapaian target program selanjutnya. Salah satu tantangan terbesar yang
harus dihadapi adalah masih banyak kasus TB yang “hilang” atau tidak
terlaporkan ke program. Pada tahun 2012 diperkirakan ada sekitar 130.000
kasus TB yang diperkirakan ada tetapi belum terlaporkan. Pada tahun
2013 muncul usulan dari beberapa negara anggota WHO yang
mengusulkan adanya strategi baru untuk mengendalikan TB yang mampu
menahan laju infeksi baru, mencegah kematian akibat TB, mengurangi
dampak ekonomi akibat TB dan mampu meletakkan landasan kearah
eliminasi TB. Strategi tersebut dituangkan dalam 3 pilar strategi utama dan
komponen-komponennya. Salah satu komponen dari strategi tersebut
adalah diagnosis TB sedini mungkin. Penelitian ini akan mencoba
mengidentifikasi penyakit TB sedini mungkin dengan gejala utama yang
diderita pasien, hasil pemeriksaan laboratorium dan hasil rontgen.
Data yang digunakan adalah data rekam medis yang dimiliki oleh
penderita TB. Dari pengolahan data tersebut akan diperoleh suatu pola
gejala, hasil pemeriksaan dahak di laboratorium dan hasil rontgen yang
dimiliki oleh penderita TB. Untuk pengolahan data rekam medis, hasil
pemeriksaan dahak dan hasil rontgen digunakanlah suatu teknologi data
mining salah satunya Naïve Bayesian. Data mining yang dimaksud untuk
memberikan hasil dalam pengambilan keputusan di dunia kesehatan untuk
mengidentifikasi suatu penyakit.
Naïve Bayesian merupakan salah satu metode data mining yang
digunakan pada persoalan klasifikasi berdasarkan pada penerapan teorema
bayesian. Metode Naïve Bayesian akan menghitung probabilitas untuk
setiap nilai kejadian dari atribut target pada setiap sampel data.
Selanjutnya, Naïve Bayesian akan mengklasifikasikan sampel data tersebut
ke kelas yang mempunyai nilai probabilitas tertinggi. Penerapan metode
Naïve Bayesian ini diharapkan dapat membantu menghitung probabilitas
pada sampel data untuk mengidentifikasi adanya penyakit Tuberkulosis
(TB) pada manusia.
Pada penelitian sebelumnya sudah dilakukan penelitian kasus TB
dengan metode yang sama yaitu metode Naïve Bayesian. Pada penelitian
tersebut, peneliti sudah mengelompokkan TB ke dalam beberapa
kelompok yaitu Pulmonary TB yang merupakan TB Paru, TB
miningitis,TB Lymphadenopathy, TB Pleurisy, TB of the Spine,
Urogenital TByang merupakan TB Ekstra Paru. Data yang digunakan
pada penelitian sebelumnya adalah data set, dengan studi kasus daerah
Eropa. Pada penelitian ini, peneliti mencoba menggunakan algoritma yang
sama, dan data yang digunakan merupakan data gejala utama pasien, hasil
pemeriksaan dahak dan hasil rontgen penderita TB berdasarkan buku
Pedoman Nasional Pengendalian Tuberkulosis (2014). Hasil
pengelompokan dari penelitian ini adalah pengelompokkan berdasarkan
lokasi anatomi atau lokasi organ tubuh yang terserang TB yaitu TB Paru,
1.2 Identifikasi Masalah
Berdasarkan latar belakang yang telah diuraikan diatas, maka dapat
diidentifikasi permasalahan untuk penelitian ini adalah :
1. Perlunya mengetahui apakah metode Naïve Bayesian dapat
mengidentifikasi penyakit Tuberkolusis dengan baik.
1.3 Rumusan Masalah
1. Bagaimana merancang dan membangun metode Naïve Bayesian
untuk mengidentifikasi adanya penyakit Tuberkulosis (TB) pada
manusia berdasarkan gejala, hasil pemeriksaan dahak di
laboratorium dan hasil rontgen?
2. Bagaimana tingkat keakuratan prediksi yang dihasilkan dalam
mengidentifikasi adanya penyakit Tuberkulosis ( TB ) pada
manusia berdasarkan gejala, hasil pemeriksaan dahak di
laboratorium dan hasil rontgen?
1.4 Tujuan Penelitian
Tujuan dari penelitian tugas akhir ini adalah bagaimana merancang
dan membangun metode Naïve Bayesian sebagai salah satu metode dalam
data mining untuk membantu mengidentifikasi adanya penyakit
Tuberkulosis (TB) pada manusia berdasarkan gejala utama, hasil
laboratorium dan hasil rontgen.
1.5 Manfaat Penelitian
Mengetahui bagaimana metode Naïve Bayesian dapat diterapkan
untuk mengidentifikasi penyakit Tuberkolusis (TB) pada manusia
1.6 Batasan Masalah
Dalam identifikasi yang akan dilakukan dalam tugas akhir ini
memiliki batasan-batasan masalah, sebagai berikut :
1. Data yang diolah hanya data yang berhubungan dengan penyakit
pernapasan khususnya penyakit Tuberkolusis (TB).
2. Sumber data yang digunakan ialah data pasien penyakit TB Paru
dan TB Ekstra paru dan pasien tidak menderita TB hanya
berdasarkan data status rekam medis milik beberapa Puskesmas di
Kabupaten Kulon Progo yaitu dilihat dari gejala, hasil pemeriksaan
dahak di laboratorium serta hasil rontgen.
3. Pengelompokkan identifikasi penyakit Tuberkulosis ( TB ) hanya
berdasarkan klasifikasi secara anatomi atau lokasi organ tubuh
yang diserang yaitu TB Paru, TB Ekstra Paru dan Tidak TB
4. Data yang digunakan adalah data excel.
5. Metode yang akan digunakan untuk mengidentifikasi penyakit TB
adalah Metode Naïve Bayesian Classification.
6. Berdasarkan input data gejala, hasil pemeriksaan dahak di
laboratorium dan hasil rontgen, output program ini adalah
identifikasi untuk pasien yaitu menderita penyakit TB Paru atau TB
Ekstra Paru atau tidak menderita TB, serta tingkat keakuratan
1.7 Metodologi Penelitian
Dalam penyelesaian tugas akhir yang berjudul identifikasi penyakit
tuberkulosis ( TB ) pada manusia menggunakan metode Naïve Bayesian,
akan ditempuh langkah-langkah sebagai berikut :
1. Studi Pustaka
a. Penelitian pustaka, yaitu dengan memperlajari hal-hal yang
berkaitan dengan Data Mining metode Naïve Bayesian, dengan
mengumpulkan dan mempelajari informasi dari buku-buku,
artikel dan website internet.
b. Interview, yaitu dengan melakukan konsultasi atau tanya jawab
dengan orang-orang yang memiliki pengetahuan dan wawasan
yang berhubungan dengan topik tugas akhir ini.
2. Pengumpulan Data
Metodologi yang kedua adalah pengumpulan data. Data
yang digunakan dalam penelitian ini bersumber dari rekam medis
pasien TB Paru, TB Ekstra Paru dan tidak TB dibeberapa
puskesmas di Kabupaten Kulon Progo.
3. Pembuatan Alat Uji
Metodologi yang ketiga adalah pembuatan alat uji. Pembuatan alat
uji dilakukan dengan teknik penambangan data yang
langkah-langkahnya seperti dibawah ini :
a. Pembersihan data, menghilangkan noise, dan data yang tidak
konsisten.
b. Integrasi data, menggabungkan data dari berbagai sumber data
yang berbeda (data rekam medis, data hasil pemeriksaan dahak
di laboratorium dan data rontgen).
c. Seleksi data dan transformasi data, untuk menentukan kualitas
dari hasil data mining, sehingga data diubah menjadi bentuk
d. Penerapan teknik data mining, teknik yang digunakan adalah
teknik Naïve Bayesian.
e. Evaluasi pola yang ditentukan, menampilkan hasil dari teknik
data mining berupa pola yang khas maupun mengukur akurasi.
f. Presentasi pengetahuan, merupakan tahap terakhir dari proses
data mining yaitu memformulasikan keputusan atau aksi dari
hasil analisa yang didapat.
4. Pengujian dan Analisis Hasil
Metodologi yang keempat adalah pengujian dan analisis
hasil. Alat uji yang telah dibuat akan diuji menggunakan data TB
dan selanjutkan hasil dari pengujian akan dianalisis.
5. Pembuatan Dokumen
Metodologi yang terakhir adalah pembuatan dokumen
1.8 Sistematika Pembahasan
Bab I. Pendahuluan
Dalam bab ini berisi tentang latar belakang masalah, identifikasi masalah,
rumusan masalah, tujuan penelitian, batasan masalah, metodologi
penelitian, serta sistematika penulisan.
Bab II. Landasan Teori
Dalam bab ini berisi tentang teori yang dapat menunjang penelitian, yaitu
berupa pengertian penambangan data, proses penambangan data,
klasifikasi dan metode Naïve Bayesian.
Bab III. Analisa dan Perancangan Sistem
Dalam bab ini berisi tentang cara penerapan konsep dasar yang telah
diuraikan pada Bab II untuk menganalisis dan merancang tentang sistem
sesuai tahap-tahap penyelesaian masalah tersebut dengan menggunakan
metode Naïve Bayesian.
Bab IV. Implementasi dan Analisa Sistem
Dalam bab ini berisi tentang implementasi ke program komputer
berdasarkan hasil perancangan yang dibuat, analisis perangkat lunak yang
telah dibuat.
Bab V. Penutup
Dalam bab ini berisi tentang kesimpulan dan saran dari keseluruhan
10
BAB II
LANDASAN TEORI
Pada bab ini akan dibahas mengenai teori-teori yang digunakan untuk mendukung
penulisan tugas akhir identifikasi penyakit tuberkulosis ( TB ) pada manusia
menggunakan metode Naïve Bayesian.
2.1 Tuberkulosis
Tuberkulosis adalah suatu penyakit menular langsung yang
disebabkan oleh kuman TB (Mycobacterium tuberculosis). Sebagian besar
kuman TB menyerang paru, tetapi dapat juga mengenai organ tubuh
lainnya (Petunjuk Teknis Manajemen TB Anak, 2013).
Berdasarkan buku Pedoman Nasional Penanggulangan
Tuberkulosis (2014), TB dapat diklasifikasikan berdasarkan lokasi anatomi
dari penyakit atau lokasi organ tubuh yang diserang yaitu:
1. Tuberkulosis Paru
Adalah TB yang terjadi pada parenkim ( jaringan paru ). Milier TB
dianggap sebagai TB paru karena adanya lesi pada jaringan paru.
Limfadenitis TB rongga dada ( hilus dan atau mediastinum ) atau
efusi pleura tanpa terdapat gambaran radiologis yang mendukung
TB pada paru, dinyatakan sebagai TB paru. Pasien yang menderita
TB paru dan sekaligus juga menderita TB Ekstra paru,
diklasifikasikan sebagai pasien TB paru.
2. Tuberkulosis Ekstra Paru
Adalah TB yang terjadi pada organ selain paru, misalnya : pleura,
kelenjar limfe, abdomen, saluran kencing, kulit, sendi, selaput otak
dan tulang. Diagnosis TB paru dapat ditetapkan berdasarkan hasil
pemeriksaan bakteriologis atau klinis.Diagnosis TB Ekstra paru
harus diupayakan berdasarkan penemuan Mycobacterium
TB umumnya terjadi pada paru ( TB Paru ). Namun, penyebaran melalui
aliran darah atau getah bening dapat menyebabkan terjadinya TB diluar
organ paru ( TB Ekstra Paru ).
Gejala utama pasien TB adalah batuk berdahak selama 2 minggu
atau lebih. Batuk dapat diikuti dengan gejala tambahan yaitu dahak
bercampur darah, batuk darah, sesak nafas, badan lemas, nafsu makan
turun, berat badan menurun, malaise, berkeringat malam hari tanpa
kegiatan fisik, demam meriang lebih dari satu bulan. Gejala-gejala tersebut
dapat dijumpai pula pada penyakit paru selain TB, seperti bronkiektasi,
bronchitis kronis, asma, kanker paru, dan lain-lain. Mengingat penderita
TB di Indonesia saat ini masih tinggi, maka setiap orang yang datang
dengan gejala tersebut diatas, dianggap sebagai seorang terduga pasien
TB, dan perlu dilakukan pemeriksaan dahak secara mikroskopis langsung.
Pemeriksaan dahak berfungsi untuk menegakkan diagnosis, menilai
keberhasilan pengobatan dan menentukan potensi penularan. Pemeriksaan
dahak untuk penegakan diagnosis dilakukan dengan mengumpulkan 3
contoh uji dahak yang dikumpulkan dalam dua hari kunjungan yang
berurutan berupa dahak Sewaktu-Pagi-Sewaktu ( SPS ) :
1. S ( sewaktu ) : dahak ditampung pada saat terduga pasien TB
datang berkunjung pertama kali ke fasyankes. Pada saat pulang,
terduga pasien membawa sebuah pot dahak untuk menampung
dahak pagi pada hari kedua.
2. P ( pagi ) : dahak ditampung dirumah pada pagi hari kedua, segera
setelah bangun tidur. Pot dibawa dan diserahkan sendiri kepada
petugas di fasyankes.
3. S ( sewaktu ) : dahak ditampung di fasyankes pada kedua, saat
menyerahkan dahak pagi.
Pasien ditetapkan sebagai pasien TB apabila minimal 1 ( satu ) dari
pemeriksaan contoh uji dahak SPS hasilnya BTA ( Bakteri Tahan Asam )
Berikut ini adalah diagnosis tuberculosis pada orang dewasa :
1. Diagnosis TB Paru
a. Dalam upaya pengendalian TB secara Nasional, maka
diagnosis TB Paru pada orang dewasa harus ditegakkan
terlebih dahulu dengan pemeriksaan bateriologis.
Pemeriksaan bateriologis yang dimaksud adalah
pemeriksaan mikroskopis langsung, biakan dan tes cepat.
b. Apabila pemeriksaan secara bateriologi hasilnya
negatif,maka penegakan diagnosis TB dapat dilakukan
secara klinis(pemeriksaan tubuh pasien) menggunakan hasil
pemeriksaan klinis dan penunjang (setidak-tidaknya
pemeriksaan foto rontgen) yang sesuai dan ditetapkan oleh
dokter yang telah terlatih TB.
c. Untuk kepentingan diagnosis dengan cara pemeriksaan
dahak secara mikroskopis langsung, terduga pasien TB
diperiksa contoh uji dahak SPS (Sewaktu-Pagi-Sewaktu).
d. Ditetapkan sebagian pasien TB apabila minimal 1 (satu)
dari pemeriksaan contoh uji dahak SPS hasilnya BTA
positif.
2. Diagnosis TB Ekstra paru
a. Diagnosis pada pasien TB Ekstra paru ditegakkan dengan
pemeriksaan klinis (pemeriksaan tubuh pasien),
bakteriologis (pemeriksaan berdasarkan bakteri) dan atas
hiptopatologis (pengamatan terhadap jaringan yang
terserang) dari contoh uji yang diambil dari organ tubuh
yang terkena.
b. Dilakukan pemeriksaan bakteriologis juga apabila juga
ditemukan keluhan dan gejala yang sesuai, untuk
2.2 Penambangan Data
2.1.1 Pengertian Penambangan Data
Data mining, sering juga disebut knowledge discovery in database
(KDD), adalah kegiatan yang meliputi kegiatan pengumpulan, pemakaian
data histori untuk menemukan keteraturan, pola atau hubungan dalam set
data berukuran besar (Santosa, 2007).
Data mining mengacu pada mining knowledge dari data dalam
jumlah besar (Han & Kamber, 2006). Secara umum data mining di kenal
dengan proses Knowledge Discovery from Data (KDD). Proses KDD
tersebut ditunjukkan pada gambar 2.1 sebagai berikut :
GAMBAR 2.1 LANGKAH-LANGKAH PENAMBANGAN DATA
1. Pembersihan data (data cleaning)
Pada langkah ini noise dan data yang tidak konsisten akan dihapus.
Di dalam langkah pembersihan data terdapat proses deteksi
ketidakcocokan data.
2. Integrasi data (data integration)
Pada langkah ini dilakukan penggabungan dari beberapa data yang
berbeda. Data dari bermacam-macam sumber tempat penyimpanan
data akan digabungkan ke dalam satu tempat penyimpanan data
yang sesuai. Hal yang perlu diperhatikan saat melakukan integrasi
data adalah masalah struktur data.
3. Seleksi data (data selection)
Data yang relevan akan diambil dari basis data untuk dianalisis.
Pada langkah ini akan dilakukan analisis korelasi untuk analisis
gejala. Atribut - atribut data akan dicek apakah relevan untuk
dilakukan penambangan data. Atribut yang tidak relevan tersebut
tidak akan digunakan. Atribut yang diharapkan adalah atribut yang
bersifat independen. Artinya, antara atribut satu dengan atribut
yang lain tidak saling mempengaruhi.
4. Transformasi data (data transformation)
Data ditransformasikan ke dalam bentuk yang tepat untuk
ditambang. Data ditransformasikan ke dalam bentuk yang tepat
untuk ditambang. Yang termasuk dalam langkah transformasi data
adalah penghalusan (smoothing) yaitu menghilangkan noise yang
ada pada data, pengumpulan (aggregation) yaitu mengaplikasikan
kesimpulan pada data, generalisasi (generalization) yaitu
mengganti data level rendah menjadi data level tinggi,
(normalization) yaitu mengemas data atribut ke dalam skala kecil.
Dan konstruksi atribut (attribute construction/feature construction
) yaitu mengkonstruksi dan menambahkan atribut baru untuk
membantu proses penambangan. Selanjutnya dilakukan binerisasi
nilai 0 -1. Hasil binerisasi adalah berupa vektor baris yang bernilai
0 -1 untuk tiap elemennya.
5. Penambangan data (data mining)
Langkah ini adalah langkah yang paling penting yaitu melakukan
pengaplikasian metode yang tepat untuk mengk pola data.
6. Evaluasi pola (pattern evaluation)
Pada langkah ini akan dilakukan identifikasi pola yang benar dan
menarik. Pola tersebut akan dipresentasikan dalam bentuk
pengetahuan berdasarkan beberapa pengukuran yang penting.
7. Presentasi pengetahuan (knowledge presentation)
Pada langkah ini informasi yang sudah ditambang akan
divisualisasikan dan dipresentasikan kepada pengguna.
2.1.2 Pengelompokan Penambangan Data
Berdasarkan buku Algoritma Data Mining (2009), Data
mining dibagi menjadi beberapa kelompok berdasarkan tugas yang
dilakukan, yaitu (Lasore,2005) :
1. Deskripsi
Terkadang penelitian dan analis secara sederhana ingin
mencoba mencari cara untuk menggambarkan pola dan
kecenderungan yang terdapat dalam data. Sebagai contoh,
petugas pengumpulan suara mungkin tidak dapat
menemukan keterangan atau fakta bahwa siapa yang tidak
cukup profesional akan sedikit didukung dalam pemilihan
presiden. Deskripsi dari pola dan kecenderungan sering
memberikan kemungkinan penjelasan untuk suatu pola atau
kecenderungan.
2. Estimasi
Estimasi hampir sama dengan klasifikasi, kecuali variabel
target estimasi lebih ke arah numerik daripada ke arah
yang menyediakan nilai dari variabel target sebagai nilai
prediksi. Selanjutnya, pada peninjauan berikutnya estimasi
nilai dari variabel target dibuat berdasarkan nilai variabel
prediksi.
3. Prediksi
Prediksi hampir sama dengan klasifikasi dan estimasi,
kecuali bahwa dalam prediksi nilai dari hasil akan ada di
masa mendatang.
4. Klasifikasi
Dalam klasifikasi, terdapat target variabel kategori.Sebagai
contoh, penggolongan pendataan dapat dipisahkan dalam
tiga kategori, yaitu pendapatan tinggi, pendapatan sedang,
dan pendapatan rendah.
5. Pengklusteran
Pengklusteran merupakan pengelompokan record,
pengamatan, atau memperhatikan dan membentuk kelas
objek-objek yang memiliki kemiripan. Kluster adalah
kumpulan record yang memiliki kemiripan satu dengan
yang lainnya dan memiliki ketidakmiripan dengan
record-record dalam kluster lain. Pengklusteran berbeda dengan
klasifikasi yaitu tidak adanya variabel target dalam
pengklusteran. Pengklusteran tidak mencoba untuk
melakukan klasifikasi, mengetimasi, atau memprediksi nilai
dari variabel target. Akan tetapi, metode pengklusteran
mencoba untuk melakukan pembagian terhadap
keseluruhan data menjadi kelompok-kelompok yang
memiliki kemiripan (homogen), yang mana kemiripan
record dalam satu kelompok akan bernilai maksimal,
sedangkan kemiripan dengan record dalam kelompok lain
6. Asosiasi
Tugas asosiasi dalam data mining adalah menemukan
atribut yang muncul dalam satu waktu.Dalam dunia bisnis
lebih umum disebut analisis keranjang belanja.
2.1.3 Klasifikasi
Klasifikasi merupakan proses pembelajaran suatu fungsi
tujuan (target) f yang memetakan tiap himpunan atribut x ke satu
dari label kelas y yang didefinisikan sebelumya. Fungsi target
disebut juga model klasifikasi.
GAMBAR 2.2 BLOK DIAGRAM MODEL KLASIFIKASI
Ada dua jenis model Klasifikasi, yaitu :
a. Pemodelan Deskriptif (descriptive modelling) : Model
klasifikasi yang dapat berfungsi sebagai suatu alat penjelasan
untuk membedakan objek-objek dalam kelas-kelas yang
berbeda.
b. Pemodelan Prediktif (predictive modelling) : Model
klasifikasi yang dapat digunakan untuk memprediksi label
kelas record yang tidak diketahui.
Teknik Klasifikasi cocok untuk memprediksi atau menggambarkan
2.3 Klasifikasi Naïve bayesian
Klasifikasi Naïve Bayesian merupakan salah satu algoritma yang
terdapat pada teknik klasifikasi. Klasifikasi Naïve Bayesian adalah suatu
metode yang didasarkan pada teorema bayes yang ditemukan oleh Thomas
Bayes, yaitu memprediksi peluang dimasa depan terhadap pengalaman
dimasa sebelumnya dengan menggunakan metode probabilitas dan
statistik.Persamaan dari teorema Bayes adalah :
(Tan et al, 2006)
| | (2.1)
dalam hal ini :
X = Data dengan class yang belum diketahui (himpunan data
training)
Y = Hipotesis
(Y|X) = Probabilitas posterior, yaitu probabilitas bersyarat dari
hipotesis Y berdasarkan kondisi X.
(Y) = Probabilitas prior dari hipotesis Y, yaitu probabilitas bahwa
hipotesis Y bernilai benar sebelum data X muncul.
(X) = Probabilitas dari data X
(X|Y) = Probabilitas bersyarat dari X berdasarkan kondisi pada
Klasifikasi Naïve Bayesian beranggapan bahwa pengaruh dari nilai
atribut pada kelas tertentu tidak bergantung pada nilai-nilai dari atribut
lainnya, kondisi seperti ini dinyatakan dengan rumus seperti berikut :
(Han & Kamber, 2006)
| (2.2)
Keterangan :
X = Himpunan data training
Y = Hipotesis
(Y|X) = Probabilitas prior dari hipotesis Y, yaitu probabilitas
bersyarat dari hipotesis Y berdasarkan kondisi X
(Y) = Probabilitas prior dari hipotesis Y, yaitu probabilitas bahwa
hipotesis Y bernilai benar sebelum data X muncul.
(X) = probabilitas dari data X.
P(X1│Y)P(X2│Y)..P(Xn│Y)P(Y) = Probabilitas dari X1, X2, Xn untuk hipotesis Y, biasa disebut dengan likehood.
Karena P(X) irrelevant, maka untuk mencari peluang hanya menggunakan
rumus berikut ini : (Han & Kamber, 2006)
| | | | (2.3)
Jika nilai P(Xn|Y) adalah 0, maka nilai P(Y|X) = 0. Maka klasifikasi Naïve
Bayesian tidak bisa dilakukan, karena klasifikasi Naïve Bayesian tidak bisa
memprediksi record yang salah satu atributnya memiliki probabilitas
bersyarat (likehood) = 0. Untuk mengatasi hal tersebut, dilakukan
penambahan nilai 1 ke setiap evidence / P(X) dalam perhitungan sehingga
2.4 Cross Validation
Pada pendekatan cross validation, setiap data digunakan dalam jumlah yang sama untuk pelatihan dan tepat satu kali untuk pengujian.
Bentuk umum pendekatan ini disebut dengan k-fold cross validation, yang
memecah set data menjadi k bagian set data dengan ukuran yang sama.
Setiap kali berjalan, satu pecahan berperan sebagai set data uji sedangkan
pecahan lainnya menjadi set data latih. Prosedur tersebut dilakukan
sebanyak k kali sehingga setiap data berkesempatan menjadi data uji tepat
satu kali dan menjadi data latih sebanyak k-1 kali. Total error didapatkan
dengan menjumlahkan semua error yang didapatkan dari k kali proses
(Prasetyo,2014).
2.5 Akurasi dengan Matrixs Confusion
Matrixs confusion merupakan tabel yang mencatat hasil kerja klasifikasi. Contoh matrixs confusion ditunjukkan pada tabel berikut :
TABEL 2.1 TABEL MATRIXS CONFUSION
fij kelas hasil prediksi (j)
kelas = 1 kelas = 0
kelas asli(i) kelas = 1 f11 f10
kelas = 0 f01 f00
Tabel 2.1 merupakan contoh matrixs confusion yang melakukan klasifikasi
masalah biner (dua kelas) untuk dua kelas, misalnya kelas 0 dan 1. Setiap
sel fij dalam matrix menyatakan jumlah record/data dari kelas i yang hasil
prediksinya masuk ke kelas j. Misalnya sel f11 adalah jumlah data dalam
kelas 1 yang secara benar dipetakan ke kelas 1, dan f10 adalah data dalam
kelas 1 yang dipetakan secara salah ke kelas 0. Berdasarkan isi matrixs
confusion, maka dapat diketahui jumlah data dari masing-masing kelas
yang diprediksi secara benar yaitu ( f11 + f00 ) dan data yang diklasifikasi
diringkas menjadi dua nilai, yaitu akurasi dan laju error. Dengan
mengetahui jumlah data yang diklasifikasikan secara benar, maka dapat
diketahui akurasi hasil prediksi, dan dengan mengetahui jumlah data yang
diklasifikasikan secara salah maka dapat diketahui laju error dari prediksi
yang dilakukan. Dua kuantitas ini digunakan sebagai matrix kinerja
klasifikasi. Untuk menghitung akurasi digunakan formula sebagai berikut :
22
BAB III
METODOLOGI PENELITIAN
Pada bab ini akan dijelaskan analisa data dan analisa sistem yang akan dibuat
untuk identifikasi penyakit tuberkulosis ( TB ) pada manusia menggunakan
metode Naïve Bayesian.
3.1 Data
Penelitian ini dimulai dengan studi pustaka yang berhubungan
dengan metode dan penyakit TB. Selanjutnya adalah proses pengumpulan
data. Data yang akan digunakan diambil dari beberapa puskemas di
Kabupaten Kulon Progo yang berasal dari rekam medis pasien yang
menderita TB Paru, TB Ekstra Paru dan tidak menderita TB tetapi
memiliki gejala yang hampir sama dengan TB. Data dari rekam medis
akan diolah terlebih dahulu oleh petugas kesehatan untuk menemukan data
yang mendukung adanya penyakit TB pada pasien seperti batuk, sesak
napas, berat badan turun, demam, batuk darah dan hasil pemeriksaan
dahak atau hasil foto rontgen. Jika petugas sudah mengumpulkan data
tersebut maka petugas akan membacakan data tersebut kepada peneliti,
sehingga data yang didapat oleh peneliti sudah siap untuk diolah.
Untuk mengidentifikasi dini penyakit TB dapat dikaji dari
gejala-gejala yang dialami, seperti batuk lebih dari 2 minggu, demam, berat
badan turun, sesak napas dan batuk berdarah. Selain itu, pada data rekam
medis juga disimpan data hasil pemeriksaan laboratorium pasien dan hasil
pemeriksaan foto rontgen. Hasil pemeriksaan laboratorium berbentuk data
dengan keterangan negatif (-), positif (+1, +2, +3) dengan keterangan tidak
terdapat bakteri pada dahak (negatif) dan terdapat bakteri pada dahak
(positif), tingkat banyaknya bakteri pada dahak dapat digambarkan dengan
pemeriksaan dahak pasien dengan label A, B dan C dengan keterangan A
adalah dahak sewaktu datang periksa, B adalah dahak pagi keesokan hari,
C adalah dahak terakhir sewaktu periksa kembali. Selain itu terdapat juga
data hasil pemeriksaan foto rontgen dengan keterangan positif dan negatif .
Data status pasien yang terdiri dari gejala batuk lebih dari 2
minggu, demam, berat badan turun, sesak napas, batuk berdarah, hasil
pemeriksaan laboratorium dan hasil pemeriksaan foto rontgen tersebut
akan diteliti apakah mempengaruhi hasil diagnosis pasien yang
bersangkutan. Untuk meneliti apakah ada keterkaitan antara data pasien
dengan hasil diagnosis, akan dilakukan proses penambangan data.
Penambangan data akan menemukan informasi/pengetahuan dengan
mendeskrisikan apakah pasien menderita TB atau tidak dengan melihat
gejala dan hasil pemeriksaan laboratorium. Data status pasien ini adalah
pasien yang terdiagnosis TB Paru, TB Ekstra Paru dan bukan TB dari
beberapa puskesmas di Kulon Progo. Contoh data dapat dilihat pada Tabel
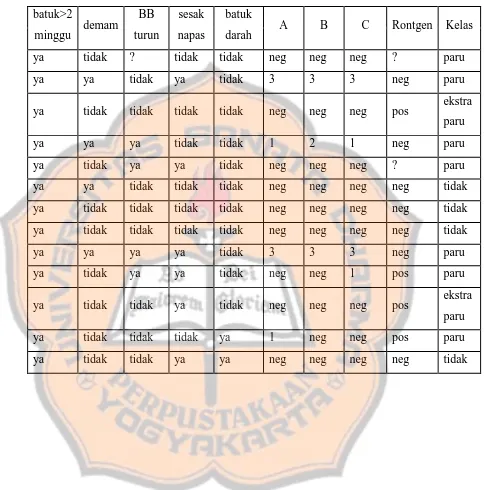
TABEL 3.1 CONTOH DATA PASIEN TUBERKULOSIS (TB)
batuk>2
minggu demam
BB
turun
sesak
napas
batuk
darah A B C Rontgen Kelas
ya tidak ? tidak tidak neg neg neg ? paru
ya ya tidak ya tidak 3 3 3 neg paru
ya tidak tidak tidak tidak neg neg neg pos ekstra paru
ya ya ya tidak tidak 1 2 1 neg paru
ya tidak ya ya tidak neg neg neg ? paru
ya ya tidak tidak tidak neg neg neg neg tidak
ya tidak tidak tidak tidak neg neg neg neg tidak
ya tidak tidak tidak tidak neg neg neg neg tidak
ya ya ya ya tidak 3 3 3 neg paru
ya tidak ya ya tidak neg neg 1 pos paru
ya tidak tidak ya tidak neg neg neg pos ekstra paru
ya tidak tidak tidak ya 1 neg neg pos paru
3.2 Spesifikasi Software dan Hardware
Spesifikasi software dan hardware yang digunakan dalam
implementasi sistem ini adalah :
Bahasa pemrograman : MATLAB R2012b
Processor : AMD E-300 APU with Radeon(tm) HD
Graphics 1.30 GHz
Memory : 2,00 GB
Operating System (OS) : Windows 7 Ultimate SP1 32 bit
3.3 Desain Alat Uji
Berikut ini adalah alur atau tahapan proses yang dilakukan pada
alat uji :
pasien 1. preprocessing
Data gejala, hasil lab dan rontgen
Data gejala, hasil lab dan rontgen
Data Testing Data Training
Label Hasil Prediksi Data Testing
Data gejala, hasil lab dan rontgen
Label data Testing
3.3.1 Preprocessing
Pada tahap pre-processing akan dilakukan tahap
pembersihan data, integrasi data,seleksi data dan transformasi data.
Data mentah akan diubah menjadi data dalam bentuk angka atau
dalam bentuk label dengan keterangan seperti berikut :
1. Untuk kolom satu sampai lima
a. Tidak = 1
b. Ya = 2
2. Untuk kolom enam sampai delapan
a. Negatif = 0
b. Jika nilai tidak negatif maka akan tetap diisi dengan angka
sesuai dengan data.
3. Untuk kolom sembilan
a. Positif = 1
b. Negatif = 0
4. Untuk kolom 10
a. Tidak = 1
b. Paru = 2
c. Ekstra Paru = 3
Pada tahap pre-processing ini juga dilakukan tahap mengisi data
yang tidak diketahui nilainya. Untuk setiap data yang tidak
diketahui nilainya akan diberi label 0. Dan untuk setiap data yang
tidak memiliki kelas akan dihapus. Tabel 3.2 adalah contoh data
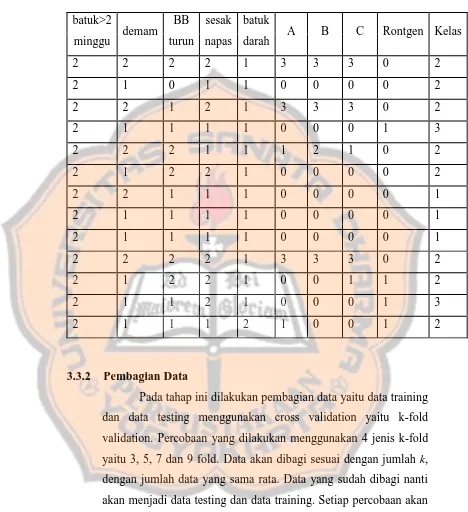
TABEL 3.2 CONTOH DATA SETELAH TAHAP PRE-PROCESSING
3.3.2 Pembagian Data
Pada tahap ini dilakukan pembagian data yaitu data training
dan data testing menggunakan cross validation yaitu k-fold
validation. Percobaan yang dilakukan menggunakan 4 jenis k-fold
yaitu 3, 5, 7 dan 9 fold. Data akan dibagi sesuai dengan jumlah k,
dengan jumlah data yang sama rata. Data yang sudah dibagi nanti
akan menjadi data testing dan data training. Setiap percobaan akan
mengambil 1 data testing dan data yang lainnya akan digunakan
sebagai data training, pada percobaan selanjutnya data testing akan
3.3.3 Pemisah Data
Pada tahap ini data testing akan dipisah menjadi 2 bagian.
Bagian pertama adalah bagian data yang memiliki isi semua data
gejala, data laboratorium dan hasil rontgen. Bagian kedua adalah
label data atau kelas akhir yang berisi TB Paru, TB Ekstra Paru dan
tidak TB. Data bagian pertama akan di uji pada proses modeling
dan akan menghasilkan label baru hasil prediksi. Setelah itu, label
testing asli dengan label testing hasil prediksi akan di bandingkan
dengan confusion matrix pada proses 5.
3.3.4 Modeling
Pada tahap ini dilakukan proses penambangan data
menggunakan algoritma Naïve Bayesian. Data yang sudah diolah
pada tahap sebelumnya akan diolah menggunakan perhitungan
algoritma. Data yang akan diolah adalah data testing berdasarkan
data training. Berikut adalah tahap yang akan dilakukan untuk
mengolah data TB menggunakan metode Naïve Bayesian. Data
yang akan digunakan adalah data yang sudah melewati proses
preprocessing dan proses pembagian data.
1. Data yang digunakan adalah data training dan data testing.
Data testing adalah data yang dicari hasil akhirnya
sedangkan data training adalah data yang akan digunakan
untuk menentukan hasil akhir atau label dari data testing.
2. Data testing yang sudah siap akan dipisahkan dari labelnya,
sehingga terdapat 2 kelompok untuk data testing yaitu
kumpulan data gejala, hasil laboratorium dan hasil rontgen
sedangkan kelompok yang kedua yaitu kelompok label dari
data training yang asli dengan isian TB paru, TB Ekstra
Paru atau tidak TB.
3. Data Testing yang tidak memiliki label akan melakukan
dengan berdasarkan data training. Di bawah ini merupakan
contoh perhitungan untuk mencari nilai probabilitas dari
setiap data, data testing yang akan dihitung dilambangkan
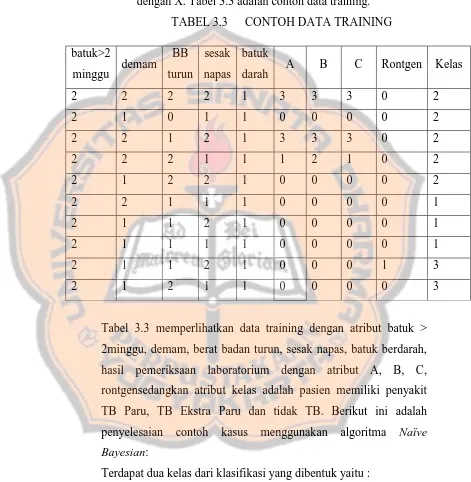
dengan X. Tabel 3.3 adalah contoh data training.
TABEL 3.3 CONTOH DATA TRAINING
batuk>2
2minggu, demam, berat badan turun, sesak napas, batuk berdarah,
hasil pemeriksaan laboratorium dengan atribut A, B, C,
rontgensedangkan atribut kelas adalah pasien memiliki penyakit
TB Paru, TB Ekstra Paru dan tidak TB. Berikut ini adalah
penyelesaian contoh kasus menggunakan algoritma Naïve
Bayesian:
Terdapat dua kelas dari klasifikasi yang dibentuk yaitu :
Y1 =TB Paru
Y2 =TB Ekstra Paru
Data yang akan diklasifikasikan adalah X = (batuk > 2 minggu =
ya, demam = tidak, berat badan turun = tidak, sesak napas = ya,
batuk berdarah = tidak, A = negatif, B = negatif, C = negatif,
rontgen = negatif). Langkah-langkah perhitungan sebagai berikut :
a. Mencari P(Y), sebagai berikut :
P(Y) merupakan prior probability untuk setiap kelas
berdasarkan data yaitu :
b. Menghitung probabilitas
Probabilitas untuk TB Paru
P(TB Paru) P(batuk>2 minggu = ya|TB Paru)
P(demam = tidak|TB Paru) p(berat badan turun =
tidak|TB paru) P(sesak napas = ya|TB paru) P(batuk
berdarah = tidak|TB Paru) P(A=negatif|TB Paru)
P(B=negatif|TB Paru) P(C=negatif|TB Paru)
P(rontgen=negatif|TB Paru)=
0.001536
Probabilitas untuk TB Ekstra Paru
P(TB Ekstra Paru) P(batuk>2 minggu = ya| TB
Ekstra Paru) P(demam = tidak| TB Ekstra Paru)
P(berat badan turun = tidak|TB Ekstra Paru) P(sesak
napas = ya| TB Ekstra Paru) P(batuk berdarah =
tidak| TB Ekstra Paru) P(A=negatif| TB EkstraParu)
EkstraParu)P(rontgen=negatif| TB Ekstra Paru)=
0.025
Probabilitas untuk tidak TB
P(tidak TB) P(batuk>2 minggu = ya| tidak TB)
P(demam = tidak| tidak TB) P(berat badan turun =
tidak| tidak TB) P(sesak napas = ya| tidak TB)
P(batuk berdarah = tidak| tidak TB) P(A=negatif|
tidak TB) P(B=negatif| tidak TB) P(C=negatif| tidak
TB)=
0.6
c. Setelah melakukan perhitungan probabilitas, akan
dibandingkan hasil yang lebih besar antara TB Paru, TB
Ekstra Paru dan tidak TB. Berdasarkan perhitungan data X
termasuk data pasien tidak TB dengan nilai probabilitas
sebesar 0,6.
Berdasarkan hasil perhitungan probabilitas diatas, maka hasil dari
data X adalah tidak TB sehingga label yang akan muncul yaitu
angka 1 untuk data X.
4. Hasil yang didapat dari langkah 3 akan dimasukkan pada label
baru. Setelah semua data testing dihitung dan diprediksi maka akan
terbentuk label baru yang berisi hasil prediksi dari data testing.
5. Label hasil prediksi akan dibandingkan dengan label asli dari data
X.Hasil perbandingan akan masuk ke tahap akurasi dengan
menggunakan confusion matrix.
3.3.5 Akurasi
Setelah dilakukan proses modeling, maka akan dilakukan
proses menghitung akurasimenggunakan confusion matrix, yaitu
dengan menjumlahkan data yang benar dan membaginya dengan
semua data baik yang benar maupun yang salah dan dikalikan
TABEL 3.4 TABEL CONTOH HASIL CONFUSION MATRIX
KELAS TB PARU TB EKSTRA
PARU TIDAK TB
TB PARU A B C
TB EKSTRA
PARU D E F
TIDAK TB G H I
Berdasarkan Tabel 3.4 diatas, jumlah akurasi dari setiap percobaan
dapat dihitung menggunakan rumus akurasi sebagai berikut.
Jumlah data yang diprediksi secara benar adalah data yang
terletak pada garis diagonal yaitu data A+E+I. Jumlah prediksi
yang dilakukan adalah jumlah semua hasil perhitungan confusion
matrix yaitu A+B+C+D+E+F+G+H+I. Setelah itu nilai akurasi
dapat dikalikan dengan 100%.
3.4 Desain Pengujian
Setiap data yang sudah melalui proses pembagian data akan diuji
pada proses modeling dengan metode Naïve Bayesian. Berikut ini adalah
Label data training hasil prediksi
akurasi confusion matrix
akurasi modeling naive
bayesian
Pemisah data Data Testing
Label Data Testing Data Training
Data Testing Data gejala, lab dan rontgen
label
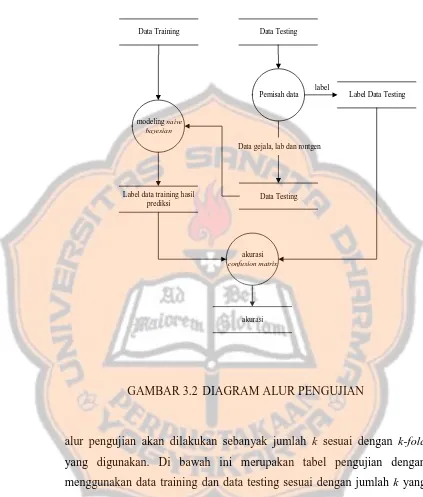
GAMBAR 3.2 DIAGRAM ALUR PENGUJIAN
alur pengujian akan dilakukan sebanyak jumlah k sesuai dengan k-fold
yang digunakan. Di bawah ini merupakan tabel pengujian dengan
menggunakan data training dan data testing sesuai dengan jumlah k yang
digunakan.
TABEL 3.5 PEMBAGIAN 3 FOLD
Pengujian Training Testing
1 1, 2 3
2 1, 3 2
Tabel 3.5 merupakan tabel pembagian data berdasarkan 3 fold. Semua data
akan dibagi 3 sama rata dan akan digunakan secara bergantian sebagai data
training dan data testing sesuai dengan Tabel 3.5.
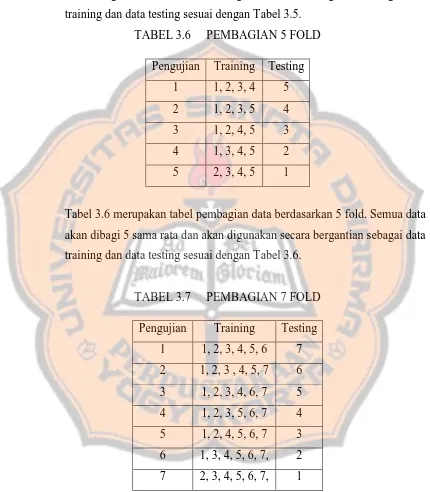
TABEL 3.6 PEMBAGIAN 5 FOLD
Pengujian Training Testing
1 1, 2, 3, 4 5
2 1, 2, 3, 5 4
3 1, 2, 4, 5 3
4 1, 3, 4, 5 2
5 2, 3, 4, 5 1
Tabel 3.6 merupakan tabel pembagian data berdasarkan 5 fold. Semua data
akan dibagi 5 sama rata dan akan digunakan secara bergantian sebagai data
training dan data testing sesuai dengan Tabel 3.6.
TABEL 3.7 PEMBAGIAN 7 FOLD
Pengujian Training Testing
1 1, 2, 3, 4, 5, 6 7
2 1, 2, 3 , 4, 5, 7 6
3 1, 2, 3, 4, 6, 7 5
4 1, 2, 3, 5, 6, 7 4
5 1, 2, 4, 5, 6, 7 3
6 1, 3, 4, 5, 6, 7, 2
7 2, 3, 4, 5, 6, 7, 1
Tabel 3.7 merupakan tabel pembagian data berdasarkan 7 fold. Semua data
akan dibagi 7 sama rata dan akan digunakan secara bergantian sebagai data
TABEL 3.8 PEMBAGIAN 9 FOLD
Pengujian Training Testing
1 1, 2, 3, 4, 5, 6, 7, 8 9
2 1, 2, 3, 4, 5, 6, 7, 9 8
3 1, 2, 3, 4, 5, 6, 8, 9 7
4 1, 2, 3, 4, 5, 7, 8, 9 6
5 1, 2, 3, 4, 6, 7, 8, 9 5
6 1, 2, 3, 5, 6, 7, 8, 9 4
7 1, 2, 4, 5, 6, 7, 8, 9 3
8 1, 3, 4, 5, 6, 7, 8, 9 2
9 2, 3, 4, 5, 6, 7, 8, 9 1
Tabel 3.8 merupakan tabel pembagian data berdasarkan 9 fold. Semua data
akan dibagi 9 sama rata dan akan digunakan secara bergantian sebagai data
36
BAB IV
ANALISA HASIL DAN IMPLEMENTASI SISTEM
Pada bab ini akan dibahas hal-hal yang berkaitan dengan implementasi sistem,
hasil yang didapatkan dari pengujian-pengujian yang akan dilakukan, serta
analisis dari hasil pengujian.
4.1 Analisis Hasil
Berdasarkan hasil pengujian yang dilakukan dengan menggunakan
klasifikasi Naïve Bayesian dan dengan menggunakan k-fold validation,
TABEL 4.1 TABEL HASIL PERCOBAAN
Gelaja, Lab dan Rontsen
3 Fold 85,53
dilakukan sebanyak dua puluh empat kali. Dari dua puluh empat pengujian
dengan penggunaan data yang berbeda dan dengan jumlah fold yang
berbeda didapat hasil klasifikasi dan hasil akurasi yang berbeda-beda.
feature lab dan rontgen, untuk 3 fold, 5 fold, 7 fold dan 9 fold
menghasilkan akurasi yang sama. Sedangkan hasil akurasi paling rendah
sebesar 57.44 dengan hanya menggunakan feature gejala dan dengan
menggunakan 5 fold. Grafik hasil rata-rata akurasi pengujian ditunjukkan
melalui gambar 4.1 dibawah ini:
GAMBAR 4.1 GRAFIK RATA-RATA AKURASI
Gambar 4.1 merupakan grafik akurasi rata-rata. Percobaan dilakukan
dengan feature/atribut yang berbeda. Setiap feature/atribut akan dilakukan
percobaan dengan empat fold yang berbeda yaitu 3 fold, 5 fold, 7 fold dan
9 fold. Hasil akurasi dari setiap fold dirata-rata untuk mencari nilai
maksimal dari percobaan berdasarkan feature/atribut. Berdasarkan hasil
rata-rata akurasi terbesar adalah percobaan menggunakan feature/atribut
lab dan rontgen. Sedangkan hasil rata-rata akurasi terkecil adalah
percobaan menggunakan feature/atribut gejala. Gejala memiliki hasil
rata-rata akurasi terendah. Hal ini dikarena gejala utama pasien TB seperti
batuk lebih dari 2 minggu, sesak napas, berat badan turun, demam, batuk
darah dapat dijumpai pula pada penyakit paru selain TB, seperti
bronkiektasi, bronchitis kronis, asma, kanker paru, dan lain-lain. Oleh
karena itu dibutuhkan data pendukung lainnya seperti hasil pemeriksaan
laboratorium dan hasil rontgen sangat berpengaruh terhadap proses
klasifikasi, hal ini dapat dilihat dari hasil akurasi rata-rata dengan
feature/atribut lab dan rontgen yang menghasilkan nilai sebesar 85.95 %
yang merupakan akurasi tertinggi dalam penelitian ini.
4.2 User Interface
Untuk mempermudah dalam melakukan tahap klasifikasi pada
penelitian ini dibuat user interface. User interface ini dibuat untuk
membantu dalam proses preprocessing, proses klasifikasi dan proses hasil
akurasi. Berikut merupakan halaman utama dalam penelitian ini :
GAMBAR 4.2 HALAMAN UTAMA
Halaman pre-processing digunakan untuk menampilkan data yang sudah
melalui proses pre-processing. Implementasi menu preprocessing dapat
dilihat pada gambar dibawah ini :
Halaman proses akan digunakan untuk melakukan proses pemilihan data
yang akan digunakan, pemilihan jumlah fold dan melalukan proses
klasifikasi. Implementasi menu proses dapat dilihat pada gambar dibawah
ini :
GAMBAR 4.4 HALAMAN PROSES
Halaman Confusion Matrix digunakan untuk menampilkan hasil
perhitungan Confusion Matrix akhir yang didapat dari semua percobaan.
Implementasi halaman Confusion Matrix dapat dilihat pada gambar
dibawah ini :
Halaman akurasi digunakan untuk menampilkan hasil akurasi akhir yang
didapat dari semua percobaan. Implementasi halaman akurasi dapat dilihat
pada gambar dibawah ini :
GAMBAR 4.6 HALAMAN AKURASI
Halaman akurasi untuk setiap fold yang dipilih digunakan untuk
menampilkan diagram akurasi untuk setiap percobaan yang dilakukan
berdasarkan jumlah fold. Implementasi halaman tersebut dapat dilihat pada
gambar berikut ini :
Halaman uji data tunggal digunakan untuk menguji satu data. Pada
halaman ini masukkan diambil dari menu pop up yang dipilih. Keluaran
dari proses uji data tunggal adalah kelas hasil prediksi yaitu Paru, Ekstra
Paru atau Tidak TB. Implementasi halaman uji data tunggal dapat dilihat
pada gambar berikut ini :
43
BAB V
PENUTUP 5.1 Kesimpulan
Dari hasil penelitian ini, dengan menggunakan metode Naïve
Bayesian untuk melakukan identifikasi adanya penyakit Tuberkulosis pada
manusia berdasarkan gejala utama, hasil pemeriksaan laboratorium dan
hasil rontgen, dapat diambil kesimpulan, sebagai berikut :
1. Metode Naïve Bayesian dapat melakukan identifikasi dari data
penyakit Tuberkulosis.
2. Algoritma Naïve Bayesian hanya memberikan hasil prediksi yang
diambil dari nilai tertinggi hasil perhitungan probabilitas
berdasarkan data gejala, hasil laboratorium dan hasil rontgen.
3. Penggunaan metode pemilihan data atau memilih feature/atribut
yang digunakan untuk proses klasifikasi sangat berpengaruh
terhadap hasil klasifikasi.
4. Dari pengujian sebanyak 24 kali dihasilnya rata-rata akurasi terbaik
sebesar 85,95% dengan hanya menggunakan data hasil
laboratorium dan hasil rontgen. Rata-rata akurasi terendah sebesar
58,08 dengan hanya menggunakan data gejala.
5.2 Saran
Saran untuk penelitian akhir ini adalah :
1. Data ditambah lebih banyak untuk setiap kategori.
2. Data rontgen bisa ditambah dengan menggunakan data gambar.
3. Menambah jenis klasifikasi/jenis kelas, tidak hanya menggunakan
pengelompokkan berdasarkan anatomi dari penyakit tetapi bisa
ditambah dengan pengelompokkan berdasarkan riwayat
pengobatan sebelumnya, hasil pemeriksaan uji kepekaan obat atau
44
DAFTAR PUSTAKA
Dinas Kesehatan Daerah Istimewa Yogyakarta (2015) Petunjuk Teknis
Manajemen TB Anak. Jakarta : Kementrian Kesehatan RI
Han,Jiawie and Micheline Kamber. (2006) Data Mining : Concepts and
Technique Second Edition. New York : Morgan Kaufman.
Han, Jiawie and Micheline Kamber. (2012) Data Mining : Concepts and
Technique Third Edition. New York : Morgan Kaufmann
Hermawati, F.A. (2013) Data Mining.Yogyakarta : Andi
Kementrian RI Direktorat Jenderal Pengendalian Penyakit dan Penyehatan
Lingkungan (2014) Pedoman Nasional Pengendalian
Tuberkulosis. Jakarta : Kementrian Kesehatan RI.
Kusrini dan Emha Taufiq Luthfi. (2009) Algoritma Data Mining.
Yogyakarta : Andi.
Prasetyo, E. (2014) Data Mining : Mengolah data Menjadi Informasi
Menggunakan Matlab. Yogyakarta : Andi
Setiawan, C. B. D. (2015) Prediksi Penjualan Helm Menggunakan
Algoritma Naïve Bayesian (Studi Kasus : Distribusi Perusahaan
XYZ di Wilayah Jawa Tengah dan Derah Istimewa Yogyakarta).
Yogyakarta.
Santosa, B. (2007) Data Mining : Teknik Pemanfaatan Data untuk
Tan,P.N.,Steinbach. M., Kumar, V.(2006) Data Mining : Introduction To
46
LAMPIRAN
1. prepData.m
function [newData] = prepData(filename)
[num,txt,raw]=xlsread(filename);
%membuat matrix baru dengan nilai 0
newData=zeros(size(raw));
%memisahkan data pada setiap kolom
col1to5=txt(:,1:5); col6to8=txt(:,6:8); col9=txt(:,9); class=txt(:,10);
%hitung kolom dan baris untuk looping
[r,c]=size(newData);
if(strcmp(col1to5(i,1),'ya')) kelas=2;
elseif(strcmp(col1to5(i,1),'tidak')) kelas=1;
else
kelas=0;
end
%masukin data ke matriks yang baru.
newData(i,j)=kelas;
case 2
if(strcmp(col1to5(i,2),'ya')) kelas=2;
elseif(strcmp(col1to5(i,2),'tidak')) kelas=1;
if(strcmp(col1to5(i,3),'ya')) kelas=2;
elseif(strcmp(col1to5(i,3),'tidak')) kelas=1;
else
kelas=0;
end
else
kelas=0;
end
newData(i,j)=kelas;
case 5
if(strcmp(col1to5(i,5),'ya')) kelas=2;
elseif(strcmp(col1to5(i,5),'tidak')) kelas=1;
if(strcmp(col6to8(i,1),'neg')) kelas=0;
elseif(strcmp(col6to8(i,1),'?')) kelas=0;
if(strcmp(col6to8(i,2),'neg')) kelas=0;
elseif(strcmp(col6to8(i,2),'?')) kelas=0;
if(strcmp(col6to8(i,3),'neg')) kelas=0;
elseif(strcmp(col6to8(i,3),'?')) kelas=0;
if(strcmp(col9(i,1),'neg')) kelas=0;
elseif(strcmp(col9(i,1),'pos')) kelas=1;
if(strcmp(class(i,1),'paru')) kelas=2;
elseif(strcmp(class(i,1),' paru')) kelas=3;
2. k-fold.m
function [ dTraining,dTesting ] = k_fold( k,data )
%Fungsi ini digunakan untuk membagi 'data' ke dalam beberapa bagian('k' bagian)
%sesuai dengan permintaan user.
%memisahkan data dengan label
[n,m]=size(data) label=data(:,m);
%mencari banyak jenis kelas dalam label
isi_label=numel(unique(label));
%membuat cell baru yang belum isi
kelas=cell(1,isi_label);
%perulangan sebanyak 'isi_label'/3 kali untuk mengelompokkan data %berdasarkan label i(1 2 3) kedalam kelas i (1 2 3)
for i=1:isi_label
kelas{i}=data(find(label==i),:);
end
%membuat cell kosong berdasarkan jumlah k dan isi_label
kelas_bagi=cell(k,isi_label);
%melakukan perulangan
for i=1:isi_label
%melihat jumlah data untuk setiap kelas yang sudah tersimpan dalam cell
%kelas
ndata=size(kelas{i},1);
%menghitung hasil bagi jika data dibagi sebanyak k bagian
x=floor(ndata/k);
%menghitung sisa dari jumlah data jika dibagi sebanyak k bagian
y=mod(ndata,k);
%n = nilai n yang paling akhir ditambah 1 sampai nilai n ditambah %nilai x
n=n(end)+1:n(end)+x;
end end