Contoh Soal Analisis Diskriminan dengan Menggunakan Program
SPSS
1. Sebuah perusahaan bergerak dalam penjualan Air Mineral mengumpulkan data sekelompok konsumen air mineral dengan variabel berikut;
Tipe konsumen dari banyak tipe Air Mineral yang minum dengan kode:
Kode 0 = SEDIKIT (konsumne yang termasuk tipe sedikit minum air mineral) Kode 1 = BANYAK (konsumen yang termasuk tipe bnayak minum air Mineral) Usia konsumen (tahun)
Berat badan konsumen (kilogram) Tinggi badan konsumen (centimeter)
Pendapatan konsumen (ribuan rupiah/bulan) Jam kerja konsumen dalam sehari (jam)
Kegiatan olahraga konsumen dalam sehari (jam)
NB: Variabel NAMA tidak disetakan dalam proses Analisis diskriminan karena berupa data string (berisi karakter dan bukan angka)
70 Titik Sedikit 37 47 159 720 5.07 3.6
Pada baris pertama, konsumen dengan nama Rusdi ternyata termasuk orang yang sedikit minum Air Mineral. Ia berusia 40 tahun, berat badan 65 kilogram dengan tingga 154 centimeter, penghasilan perbulan Rp. 680.000,- dalam sehari pekerja rata-rata 5,33 jam, serta melakukan aktivitas berolah raga rata-rata 3 jam perhari. Demikian seterusnya untuk konsumen tau kasus selanjunya.
Dari file diskriminan yang berisi profil Pembelian Air Mineral dalam Kemasan (AMDK) dari segala macam merk tersebut, akan dilakukan analisis diskriminan untuk mengetahui:
Apakah ada perbedaan yang signifikan antara mereka yang banyak minum AMDK dengan
mereka yang sedikit meminumnya?
Jika ada perbedaan yang signifikan, variabel apa saja yang membuat perilaku konsumsi air
mineral mereka berbeda?
Membuat model diskriminan dua factor (karena hanya ada mereka yang SEDIKIT dengan yang
BANYAK) untuk kasus tersebut.
Menguji ketepatan model (fungsi) diskriminan.
Langkah-langkah Analisis Data dengan menggunakan SPSS:
• Buka file Diskriminan
2. Seorang peneliti menggunakan analisis diskriminan untuk mendapatkan fungsi guna menduga frekuensi liburan keluarga (Y), dimana variable Y terdiri dari 3 kategori, yakni Y=1 untuk frekuensi liburan rendah, Y=2 untuk frekuensi liburan sedang, Y=3 untuk frekuensi liburan tinggi. Variabel yang digunakan sebagai penduga Y adalah :
X1= pendapatan keluarga per bulan (juta rupiah)
X3= tingkat kepentingan liburan keluarga (skala 1-7, dari sangat tidak penting sampai sangat penting)
X4= jumlah anggota keluarga
X5=umur kepala keluarga
Adapun data sebagai berikut :
21 2 3,2 3 4 4 49
22 2 4,5 4 4 5 50
23 2 6,1 6 4 4 36
24 2 4,3 4 5 5 31
25 2 3,8 4 5 5 39
26 3 11 7 7 2 35
27 3 12 5 7 3 42
28 3 12,5 7 6 2 43
29 3 13,7 6 6 3 44
30 3 19 6 7 1 45
Berdasarkan hasil pengolahan tersebut:
A) Simpulkan apakah model analisis diskriminan yang didapat secara statistik signifikan pada taraf
nyata 5 %. Jelaskan !
B) simpulkan variabel apa saja yang pengaruhnya nyata dalam memisahkan ketiga kategori
frekuensi liburan keluarga? Jelaskan
C) beri penjelasan atas territorial map yang terbentuk
D) jika keluarga Hartono memiliki pendapatan 5 juta rupiah, sikap terhadap perjalanan=7, tingkat
Jawaban :
1 through 2 ,016 103,151 10 ,000
2 ,623 11,846 4 ,019
Tests of Equality of Group Means
X3 1,200 -,517
X4 -,260 ,446
X5 -,012 -,032
(Constant
) -7,681 -1,811
Unstandardized coefficients
Functions at Group Centroids
Y
Function
1 2
1 -6,979 ,552
2 -,275 -1,044
3 7,254 ,492
a. Hasil Uji Signifikasi Model Deskriminan
Tersaji di bagian wilks’ lambda, tampak bahwa fungsi diskriminan 1 hingga 2 diperoleh nilai sig 0.000 karena sig<5% maka disimpulkan fungsi diskriminan 1 hingga 2 signifikan pada taraf nyata 5%. Sedangkan untuk uji signifikasi diskriminan 2 diperoleh nilai sig sebesar 0,019. Karena sig<5% maka dapat disimpulkan fungsi diskriminan 2 juga signifikan untuk memisahkan ke tiga grup pada taraf nyata 5%. Proses di uraikan sebagai berikut :
HIPOTESIS :
Ho : Fungsi diskriminan tidak signifikan H1 : Fungsi diskriminan signifikan
STATISTIK UJI fungsi diskriminan 1 hingga 2 :
Wilks’ Lambda = = 0,016
Chi-Square = -[(n-1)-( )][ln ]=103,151
Statistik Chi-Square menyebar dengan derajat bebas fungsi diskriminan 1 hingga 2 (p-r+1)(G-r)=10 dari tabel diperoleh nilai (df=10)5%=18,307. Nilai Sig dihitung darii
Sig=peluang( df=10>103,151)=0,000. Karena Sig<5% atau Chi-Square> (df=10)5% maka disimpulkan tolak Ho pada taraf nyata 5%.
STATISTIK UJI fungsi diskriminan 2 : Wilks’ Lambda = = 0,623
Chi-Square = -[(n-1)-( )][ln ]= 11,846
Statistik Chi-Square menyebar dengan derajat bebas fungsi diskriminan 2 (p-r+1)(G-r)=4
dari tabel diperoleh nilai (df=4)5%=9,488. Nilai Sig dihitung darii Sig=peluang( df=4>103,151)=0,000. Karena Sig<5% atau Chi-Square> (df=4)5% maka disimpulkan tolak
Ho pada taraf nyata 5%.
b. Hasil Uji Signifikasi Variabel Independen
Tersaji di bagian Test Of Equality of Group Means, tampak bahwa nilai Sig untuk variabel X1, X2, X3 dan X4 kurang dari 5%, sehingga dapat disimpulkan variabel X1, X2, X3, dan X4 signifikan dalam mendeskriminasi frekuensi liburan keluarga pada taraf nyata 5%. Sementara variabel X5 tidak signifikan.
• Uji X1
HIPOTESIS :
Ho : Variabel 1 tidak berpengaruh signifikan terhadap frekuensi liburan keluarga H1 : Variabel 1 berpengaruh signifikan terhadap frekuensi liburan keluarga
STATISTIK UJI :
F = = 90,203
Statistik F menyebar mengikuti sebaran F dengan derajat bebas V1=2 V2=27. Pada tabel F diperoleh nilai F (V1=2 V2=27)5% = 3,35. Pada output diperoleh nilai Sig, dimana sig=peluang (F(v2,v2=27) > 90,203)=0,000. Karena Sig,5% atau F> Ftabel maka disimpulkan tolak Ho pada taraf nyata 5%.
• Uji X2
HIPOTESIS :
Ho : Variabel 1 tidak berpengaruh signifikan terhadap frekuensi liburan keluarga H1 : Variabel 1 berpengaruh signifikan terhadap frekuensi liburan keluarga
STATISTIK UJI :
Wilks’ Lambda = = 0,106
F = = 114,081
Statistik F menyebar mengikuti sebaran F dengan derajat bebas V1=2 V2=27. Pada tabel F diperoleh nilai F (V1=2 V2=27)5% = 3,35. Pada output diperoleh nilai Sig, dimana sig=peluang (F(v1=2,v2=27) >114,081
)=0,000. Karena Sig,5% atau F> Ttabel maka disimpulkan tolak Ho pada taraf nyata 5%.
• Uji X3
HIPOTESIS :
Ho : Variabel 1 tidak berpengaruh signifikan terhadap frekuensi liburan keluarga
H1 : Variabel 1 berpengaruh signifikan terhadap frekuensi liburan keluarga
STATISTIK UJI :
Wilks’ Lambda = =0,060
F = = 212,337
• Uji X4
HIPOTESIS :
Ho : Variabel 1 tidak berpengaruh signifikan terhadap frekuensi liburan keluarga
H1 : Variabel 1 berpengaruh signifikan terhadap frekuensi liburan keluarga
STATISTIK UJI :
Wilks’ Lambda = = 0,178
F = = 62,349 Statistik F menyebar mengikuti sebaran F dengan derajat bebas V1=2 V2=27.
Pada tabel F diperoleh nilai F (V1=2 V2=27)5% = 3,35. Pada output diperoleh nilai Sig, dimana sig=peluang (F(v1=2,v2=27) >62,349)=0,000. Karena Sig 5% atau F> Ttabel maka disimpulkan tolak Ho pada taraf nyata 5%.
c. Penjelasan Teritorrial Map
Berdasarkan Functions at Group Centroids dihasilkan teritorrial map berdimensi dua yang terbagi kedalam 3 wilayah
d. Dari fungsi diskriminan ke satu dapat diperoleh :
Berdasarkan hasil perhitungan skor =3,139 dan skor =-1.189 maka selanjutnya dapat
ASUMSI ANALISIS DISKRIMINAN
Analisis diskriminan mempunyai asumsi bahwa data berasal dari multivariate normal distribution dan matrik kovarian kedua kelompok perusahaan adalah sama. Asumsi multivariate normal distribution penting untuk menguji signifikansi dari variabel diskriminator dan fungsi diskriminan. Jika data tidak normal secara multivariate, maka secara teori uji signifikansi menjadi tidak valid. Hasil klasifikasi menurut teori juga dipengaruhi oleh multivariate normal distribution. Apabila diketahui bahwa asumsi multivariate normal distribution tidak dipenuhi maka sebaiknya menggunakan analisis logistic
regression. Logistic regression tidak memerlukan asumsi distribusi normal untuk variabel bebasnya.
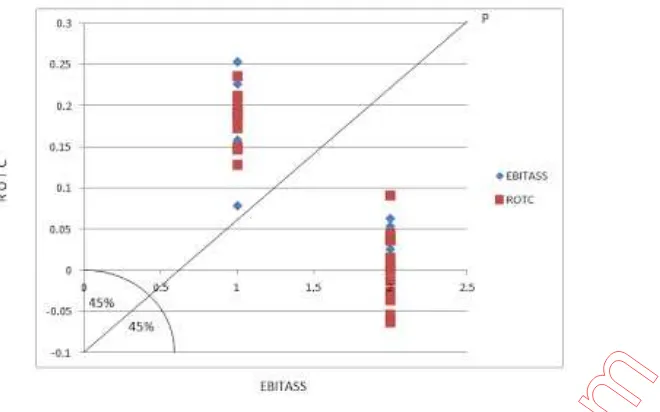
Data tentatif ini akan kita gunakan untuk menjelaskan teknik analisis diskriminan. Contoh berikut adalah dua rasio keuangan EBITASS (rasio earning before interest and tax terhadap total asset) dan ROTC (return on total capital) 24 sampel perusahaan yang dibagi ke dalam dua kelompok yaitu 12 perusahaan sehat dan 12 perusahaan bangkrut.
Gambar di atas menunjukkan bahwa kedua kelompok perusahaan sehat dan bangkrut dapat dipisahkan secara nyata dilihat dari rasio EBITASS DAN ROTC. Hal ini berarti bahwa setiap rasio keuangan dapat membedakan dua kelompok perusahaan sehat dan bangkrut. Melihat perbedaan dua kelompok perusahaan dengan hanya melihat satu variabel disebut dengan analisis univariate. Uji statistik untuk univariate dapat dilakukan dengan uji beda t-test. Sedangkan melihat perbedaan dua kelompok perusahaan berdasarkan pada kombinasi kedua rasio keuangan secara bersama-sama disebut dengan analisis multivariate. Variabel yang memberikan pembeda (diskriminan) terbaik disebut dengan variabel diskriminan (discriminator variable). Mengidentifikasi sekelompok variabel yang dapat menjadi
pembeda terbaik kedua kelompok perusahaan adalah tujuan utama dari analisis diskriminan.
Berikut ini langkah analisis diskriminan :
IDENTIFIKASI AXIS BARU
Apabila pada gambar di atas kita membuat axis baru Z yang merupakan garis diagonal dengan sudut 45o dari garis EBITASS, maka kita memproyeksikan katakanlah titik P pada garis diagonal Z dengan
persamaan :
Zp = w1 EBITASS + w2 ROTC
Besarnya w1 = cos 45 = 0,707 dan w2 = sin 45 = 0,707 dengan demikian persamaan Zp menjadi :
Zp = 0,707 EBITASS + 0,707 ROTC
variabel baru Z memberikan maksimum kemampuan untuk membedakan antara dua kelompok perusahaan. Axis baru ini disebut linear discriminant function atau sering disingkat discriminant function. Proyeksi suatu titik pada discriminant function (atau nilai dari variabel baru Z) disebut discriminant score. Tujuan ketiga yang ingin dicapai oleh analisis diskriminan adalah pengelompokkan atau klasifikasi observasi ke dalam satu dari dua kelompok perusahaan di masa datang.
MEMILIH VARIABEL DISKRIMINATOR
Perbedaan rata-rata masing-masing rasio keuangan untuk kedua kelompok perusahaan sehat dan bangkrut dapat diuji dengan uji beda t-test. Hasil uji t test dapat di bawah ini.
Nilai t hitung untuk EBITASS adalah 9,854 dan ROTC sebesar 11,528. Oleh karena nilai t hitung lebih besar dari nilai t tabel pada tingkat signifikan 5%, maka dapat disimpulkan bahwa kedua rasio keuangan ini mampu membedakan kedua kelommpok perusahaan dan akan digunakan untuk membentuk fungsi diskriminan. U t test hanya berdasarkan pada pendekatan univariate, yaitu uji t test untuk masing-masing rasio keuangan. Pendekatan yang lebih disukai adalah dengan uji multivariate, di mana kedua rasio keuangan diuji secara simultan atau bersama-sama.
FUNGSI DISKRIMINAN DAN KLASIFIKASI
Misalkan kombinasi linear atau fungsi diskrimina yang membentuk variabel baru (score discriminant) sebagai berikut :
Z = w1 EBITASS + w2 ROTC
Di mana Z adalah fungsi diskriminan, maka tujuan analisis diksriminan adalah menentukan nilai w1 dan w2 dari fungsi diskriminan di atas agar memaksimumkan nilai lambda.
lambda = between group sum of square / within group sum of square
Langkah analisis dengan SPSS.
a. buka file
b. dari menu utama SPSS, pilih menu Statistics/Analyze kemudian submenu Classify, lalu pilih Discriminant.
c. tampak di layar windows Discriminant Analysis.
d. pada Box Grouping Variable isikan CODE dan definisikan perusahaan sehat 1 dan bangkrut 2. e. pada Box Independent isikan variabel EBITASS dan ROTC.
Penilaian signifikan variabel diskriminan dapat dilihat dari nilai rata-rata dari rasio keuangan apakah berbeda secara signifikan untuk perusahaan sehat dan bangkrut. Untuk menguji apakah ada perbedaan secara signifikan antara kedua kelompok perusahaan dapat dilakukan dengan uji t test. Alternatif lain adalah dengan menggunakan Wilk's L test statistics. Semakin kecil nilai Wilk's L maka semakin besar probabilitas hipotesis nol (tidak ada perbedaan rata-rata populasi) ditolak. Untuk menguji signifikansi nilai Wilk's L maka dapat dikonversikan kedalam F ratio.
Dari tampilan group statistik jelas bahwa nilai rata-rata kedua rasio keuangan antara perusahaan sehat dan bangkrut berbeda yaitu 0,18533 untuk perusahaan sehat dan 0,035167 untuk perusahaan bangkrut dilihat dari rasio EBITASS. Sedangkan rasio ROTC dengan rata-rata 0,18350 untuk perusahaan sehat dan 0,00333 untuk perusahaan bangkrut.
Persamaan estimati fungsi diskriminan unstandardized dapat dilihat dari output Canonical Discriminant Function Coefficient dengan persamaan sebagai berikut :
Z = -3,195 + 13,430 EBITASS + 18,353 ROTC
Untuk menguji signifikansi statistik dari fungsi diskriminan digunakan multivariate test of signifikance. Oleh karena dalam kasus ini lebih dari satu variabel deskriminator yaitu EBITASS dan ROTC, maka untuk menguji perbedaan kedua kelompok perusahaan untuk semua variabel secara bersama-sama digunakan multivariate test. Uji Wilk's L dapat diaproksimasi dengan statistik Chi-square.
Besarnya nilai Wilk's L sebesar 0,115 atau sama dengan Chi-square 45,498 dan ternyata nilai ini
signifikan pada 0,000 maka dapat disimpulkan bahwa fungsi diskriminan signifikan secara statistik yang berarti nilai rata-rata score diskriminan untuk kedua kelompok perusahaan berbeda secara nyata.
Walaupun secara statistik perbedaan kedua kelompok perusahaan itu signifikan, tetapi untuk tujuan praktis perbedaan kedua kelompok perusahaan tadi tidak begitu besar. Hal ini dapat terjadi pada kasus dengan jumlah sampel yang besar. Untuk menguji seberapa besar dan berarti perbedaan antara kedua kelompok perusahaan dapat dilihat dan nilai Square Canonical Correlation (CR2). Square Canonical Correlation identik dengan R2 pada regresi yaituu mengukur variasi antara kedua kelompok perusahaan yang dapat dijelaskan oleh variabel diskriminannya. Jadi CR2 mengukur sebagai kuat fungsi diskriminan.
disimpulkan bahwa 88,5% variasi antara kelompok perusahaan sehat dan bangkrut yang dapat dijelaskan oleh variabel diskriminan rasio EBITASS dan ROTC.
Menilai pentingnya variabel diskriminan dan arti dari fungsi diskriminan dapat dilakukan dengan melihat fungsi diskriminan standardized.
Tampilan standardized canonical discriminat function menunjukkan bahwa besarnya koefisien EBITASS 0,501 dan koefisien ROTC sebesar 0,703. Koefisien yang sudah distandarisasi digunakan untuk menilai pentingnya variabel diskriminator secara relatif dalam membentuk fungsi diskriminan. Makin tinggi koefisien yang telah distandarisasi, maka makin penting variabel tersebut terhadap variabel lainnya dan sebaliknya. Variabel rasio EBITASS relatif lebih penting dibandingkan variabel rasio ROTC dalam
membentuik fungsi diskriminan.
Oleh karena score diskriminan adalah indeks gabungan atau kombinasi linear dari variabel awal, maka perlu untuk mengetahui apakah arti dari score diskriminan. Nilai loading dari structure coefficient dapat digunakan untuk menginterpretasikan kontribusi setiap variabel untuk membentuk fungsi diskriminan. Nilai loading variabel diskriminator merupakan korelasi antara score diskriminan dan variabel
diskriminator dan nilai loading akan berkisar +1 dan -1. Makin mendekati 1 (satu) nilai absolut dari loading, maka tinggi komunalitas antara variabel diskriminan dan fungsi diskriminan dan sebaliknya. Tampilan struktur matrik menunjukkan bahwa besarnya loading untuk EBITASS 0,756 dan besarnya loading untuk ROTC sebesar 0,884. Oleh karena loading kedua variabel rasio keuangan ini tinggi, maka score diskriminan dapat diinterpretasikan sebagai ukuran kesehatan keuangan perusahaan.
Klasifikasi dari observasi secara esensial akan mengurangi pembagian ruang diskriminan ke dalam dua region. Nilai score diskriminan yang membagi ruang kedalam dua region disebut nilai cutoff. Makin tinggi nilai EBITASS dan ROTC makin tinggi nilai score diskriminan dan sebaliknya. Oleh karena perusahaan yang mempunyai kesehatan keuangan akan memiliki nilai yang lebih tinggi untuk kedua rasio keuangan, perusahaan yang sehat akan memiliki score diskriminan lebih tinggi daripada
perusahaan bangkrut. Jadi perusahaan akan dikelompokkan sebagai perusahaan dapat sehat jika score diskriminannya lebih tinggi daripada nilai cutoff dan perusahaan akan dikelompokkan sebagai
perusahaan bangkrut jika score diskriminannya lebih kecil dari nilai cutoff.
Secara umum nilai cutoff yang dipilih nilai yang meminimumkan jumlah incorrect classification atau kesalahan misklasifikasi atau dapat dihitung dengan rumus:
Cutoff = (Z1 + Z2) / 2
Di mana Zj adalah rata-rata score diskriminan kelompok j. Rumus ini berasumsi jumlah sampel kedua kelompk sama. Dalam hal jumlah sampel kedua kelompok tidak sama maka rumus cutoff menjadi :
Di mana ng adalah jumlah observasi pada kelompok g. Tampilan output SPSS memberikan rata-rata score diskriminan untuk kelompok 1 sebesar 2,662 dan rata-rata score diskriminan untuk kelompok 2 sebesar -2,662 dan memberikan nilai cutoff nol.