ISSN: 2339-2541 JURNAL GAUSSIAN, Volume 4, Nomor 4, Tahun 2015, Halaman 1007-1016 Online di: http://ejournal-s1.undip.ac.id/index.php/gaussian
PERBANDINGAN ANALISIS KLASIFIKASI ANTARA DECISION TREE DAN SUPPORT VECTOR MACHINE MULTICLASS
UNTUK PENENTUAN JURUSAN PADA SISWA SMA Rizky Ade Putranto1, Triastuti Wuryandari2, Sudarno3 1
Mahasiswa Jurusan Statistika FSM Universitas Diponegoro 2,3
Staff Pengajar Jurusan Statstika FSM Universitas Diponegoro
ABSTRACT
Data mining is a process that employs one or more of Machine Learning techniques to analyze and extract knowledge automatically. Analysis of data mining is to determine the classification of a new data record into one of several categories that have been defined previously, also known as Supervised Learning. Classification Decision Tree is one of the well-known technique in data mining and is one of the popular methods in the decision making process of a case in which the method is obtained entropy criteria, information gain and gain ratio. Classification Support Vector Machine Multiclass (SVMM) is known as the most advanced machine learning techniques to handle multi-class case where the output of the data set has more than two classes or categories. This final project aims to compare the level of accuracy and error rate of Decision Tree classification and prediction majors SVMM for high school students at SMAN 1 Jepara. The total accuracy of 88,57% and 11,43% error rate for the classification decision tree and the total accuracy of 87,14% and the error rate for the classification SVMM 12,86%.
Keywords : Data Mining, Machine Learning, Supervised Learning, Decision Tree, Support Vector Machine Multiclass
1. PENDAHULUAN
Setiap lembaga mempunyai sistem operasional yang setiap transaksi kegiatan operasinya selalu dicatat dan didokumentasikan. Pendokumentasian setiap transaksi sangat berguna bagi lembaga tersebut untuk segala keperluan. Data-data tersebut tersimpan dalam sebuah basis data berkapasitas besar [6].
Munculnya data mining didasarkan pada kenyataan bahwa jumlah data yang tersimpan dalam basis data semakin besar. Data mining sendiri berisi pencarian trend atau pola tertentu yang diinginkan dalam basis data yang besar untuk membantu pengambilan keputusan di waktu yang akan dating [3]. Data mining berhubungan dengan sub-area statistik yang disebut Exploratory Data Analysis (Analisis Data Eksplorasi) yang mempunyai tujuan sama dan bersandar pada ukuran statistik. Data mining berpotensi tinggi jika data yang tepat dikumpulkan dan disimpan dalam sebuah gudang data (data warehouse) [3].
Analisis klasifikasi data mining adalah menentukan sebuah record data baru ke salah satu dari beberapa kategori yang telah didefinisikan sebelumnya, disebut juga dengan supervised learning [10]. Metode-metode yang telah dikembangkan oleh periset untuk menyelesaikan kasus klasifikasi, antara lain: Pohon keputusan (Decision Tree), Naïve Bayes, Jaringan Syaraf Tiruan, Analisis Statistik, Algoritma Genetik, Rough Sets, k-Nearest Neighbour, Metode Berbasis Aturan, Memory Based Reasoning, Support Vector Machine [10].
Berdasarkan beberapa metode klasifikasi tersebut, ingin dilakukan perbandingan analisis klasifikasi antara metode Decision Tree dan Support Vector Machine Multiclass untuk penentuan jurusan pada siswa SMA. Tingkat penguasaan ilmu pengetahuan dan teknologi erat kaitannya dengan kesejahteraan dan perekonomian suatu negara. Masyarakat yang berpendidikan, berwawasan, berbudi, dan terampil dapat membawa bangsanya
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1008 menjadi negara yang maju dan disegani bangsa lain. Oleh karena itu, pendidikan sebagai salah satu landasan utama meraih impian tersebut. Generasi berpendidikan turut mempengaruhi angkatan kerja di sebuah negara, tanpa terkecuali Indonesia.
Tujuan penjurusan ini adalah agar minat dan bakat seseorang dapat terarah dengan spesifik pada bidang ilmu tersebut yang selanjutnya dapat melanjutkan ke jenjang perguruan tinggi dan setelah itu memperoleh suatu pekerjaan yang sesuai minat dan bakat seseorang. Akhirnya tercapai suatu tujuan peningkatan penguasaan ilmu pengetahuan dan teknologi yang erat kaitannya dengan kesejahteraan dan perekonomian suatu negara. 2. TINJAUAN PUSTAKA
2.1 Konsep Data Mining
Data mining adalah proses yang melakukan satu atau lebih teknik pembelajaran komputer (machine learning) untuk menganalisis dan mengekstraksi pengetahuan (knowledge) secara otomatis. Pembelajaran data mining berbasis induksi (induction-based learning) merupakan proses pembentukan definisi-definisi konsep umum yang dilakukan dengan cara mengobservasi contoh-contoh spesifik dari konsep yang akan dipelajari [3]. 2.2 Operasi Data Mining
1. Prediksi (prediction driven)
Untuk menjawab pertanyaan apa dan sesuatu yang bersifat remang-remang atau transparan. Operasi prediksi digunakan untuk validasi hipotesis, querying dan pelaporan, analisis multidimensi, OLAP (Online Analytic Processing), serta analisis statistik.
2. Penemuan (discovery driven)
Bersifat transparan dan untuk menjawab pertanyaan “mengapa?”, operasi penemuan digunakan untuk analisis data eksplorasi, pemodelan prediktif, segmentasi database, analisis keterkaitan (link analysis) dan deteksi deviasi [3].
2.3 Konsep Decision Tree
Klasifikasi decision tree merupakan salah satu teknik terkenal dalam data mining dan merupakan salah satu metode yang popular dalam menentukan keputusan suatu kasus. Metode ini tidak memerlukan proses pengelolaan pengetahuan terlebih dahulu dan dapat menyelesaikan kasus-kasus yang memiliki dimensi yang besar[13].
2.4 Algoritma C4.5
Dalam analisis decision tree ini sebenarnya jenis algoritma yang bisa digunakan ada beberapa macam, seperti algoritma induksi CART (Classification and Regression Tree), algoritma induksi ID3 yang dibuat tahun 1970 sampai awal tahun 1980 oleh J. Ross Quinlan, seorang peneliti di bidang machine learning dan yang ketiga adalah algoritma induksi C4.5. Dari ketiga algoritma induksi tersebut peneliti memilih algoritma induksi C4.5. Algoritma C4.5 ini merupakan pengembangan dari algoritma ID3 yang dibuat oleh Quinlan, dan algoritma ini memiliki kelebihan yaitu mudah dimengerti, fleksibel, dan menarik karena dapat divisualkan dalam bentuk gambar decision tree [2].
2.5 Memilih Atribut Decision Tree
Atribut Decision Tree adalah atribut yang memungkinkan untuk mendapatkan decision tree yang paling kecil ukurannya atau atribut yang bisa memisahkan obyek menurut kelasnya. Atribut yang dipilih adalah atribut yang “purest” (paling murni). Dalam satu cabang anggotanya berasal dari satu kelas maka cabang ini disebut pure. Semakin pure suatu cabang maka semakin baik. Ukuran purity dinyatakan dengan tingkat impurity. Salah satu kriteria impurity adalah information gain [7].
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1009 S = Himpunan kasus
m = Banyak kelas data
= Proporsi kelas ke-i dalam semua data latih yang diproses di node S Information Gain
Information gain dari output data atau variabel dependent S yang dikelompokkan berdasarkan atribut J, dinotasikan dengan gain(S,J). Information gain, gain dari atribut J relatif terhadap output data S [7]. Dirumuskan sebagai berikut
dengan:
S = Himpunan kasus
J = Fitur
n = Banyak kelas dalam node (akar)
= Proporsi nilai v muncul pada kelas dalam node (akar)
= Entropi komposisi nilai v dari kelas ke-j dalam data ke-i node tersebut Split Information dan Gain Ratio
Untuk menghitung gain ratio perlu diketahui split information. Split information dihitung dengan formula sebagai berikut [7].
Selanjutnya gain ratio dihitung dengan cara [7].
2.7 Support Vector Machine
Support Vector Machine (SVM) dikenal sebagai teknik pembelajaran mesin (Machine Learning) paling mutakhir setelah pembelajaran mesin sebelumnya yang dikenal sebagai Neural Networks (NN). Baik SVM maupun NN tersebut telah berhasil digunakan dalam pengenalan pola. Pembelajaran dilakukan dengan menggunakan pasangan data input dan data output berupa sasaran yang diinginkan. Pembelajaran dengan cara ini disebut dengan pembelajaran terarah (supervised learning) [5].
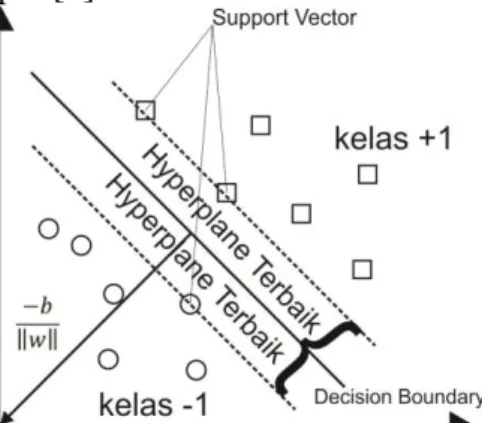
2.7.1 Hyperplane
Klasifikasi SVM dijelaskan secara sederhana untuk mendapatkan atau mencari garis terbaik sebagai hyperplane terbaik yang dapat memisahkan dua kelas berbeda antara kelas (+1) dan kelas (-1) pada ruang input [7].
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1010 dengan:
Hyperplane = Kelas -1 = Kelas +1 = 2.7.2 Klasifikasi Linear Separable
Hyperplane klasifikasi linier SVM dinotasikan sebagai berikut [9].
Untuk mencari hyperplane terbaik dapat digunakan metode Quadratic Programing (QP) yaitu dengan cara meminimalkan [9].
Solusi untuk optimalisasi ini dapat diselesaikan dengan Lagrange Multiplier sebagai berikut [6].
dengan syarat:
= Lagrange multiplier berkorespondensi dengan =
Setelah permasalahan QP ditemukan nilai maka kelas dari data yang akan diprediksi atau data testing dapat ditentukan berdasarkan persamaan berikut [7].
dengan:
= jumlah data yang menjadi support vector = support vector
= data uji yang akan diprediksi kelasnya (data testing) = inner-product antara dan
2.7.3 Klasifikasi Linear Non Separable
Pembatas yang sudah dimodifikasi untuk kasus non-separable [7]. fungsi lagrange sebagai berikut [11].
2.7.4 Klasifikasi Non Linear
Algoritma mengenai pemetaan dengan kernel [6].
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1011 dengan:
= fungsi kernel yang digunakan untuk pemetaan = set fitur dalam data yang lama
= set fitur yang baru sebagai hasil pemetaan untuk setiap data training
= data training, dimana merupakan fitur yang akan dipetakan ke fitur berdimensi tinggi
macam-macam fungsi kernel sebagai berikut [6]. 1. Kernel Linear 2. Kernel Polynomial 3. Kernel Gaussian RBF
2.8 Konsep SVMM (Support Vector Machine Multiclass)
Ada dua pendekatan utama untuk SVMM. Pertama, menemukan dan menggabung beberapa fungsi pemisah persoalan klasifikasi dua kelas untuk menyelesaikan persoalan klasifikasi multi kelas. Yang kedua, secara langsung menggunakan semua data dari semua kelas dalam satu formulasi persoalan optimisasi [4]. Satu lawan semua (One against all, OAA) dan Satu lawan satu (One against one, OAO) [12].
Dengan metode ini diperlukan untuk menemukan nilai fungsi pemisah dimana setiap fungsi dilatih dengan data dari dua kelas. Untuk melatih data dari kelas ke-i dan ke-j, dilakukan dengan menyelesaikan persoalan klasifikasi 2-kelas berikut:
dengan:
= Margin antara 2 grup data i dan j
= Parameter i dan j yang akan dicari nilainya = Variabel Slack i dan j
C = Nilai parameter
2.9 Pengukuran Uji Ketepatan Klasifikasi
Sebuah sistem yang melakukan klasifikasi diharapkan dapat melakukan klasifikasi semua himpunan data dengan benar, tetapi tidak dipungkiri bahwa kinerja suatu sistem tidak bisa 100% benar sehingga sebuah sistem klasifikasi harus diukur tingkat ketepatan klasifikasinya menggunakan matriks konfusi [6].
Tabel 1. Matriks Konfusi untuk Klasifikasi Tiga Kelas fij
Kelas hasil prediksi (j)
kelas = 1 kelas = 2 kelas = 3 Kelas asli (i)
kelas = 1 f11 f12 f13
kelas = 2 f21 f22 f23
kelas = 3 f31 f32 f33
Untuk menghitung akurasi klasifikasi digunakan formula Akurasi =
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1012
Untuk menghitung laju error (kesalahan prediksi) digunakan formula
Laju Error =
3. METODE PENELITIAN
Data yang digunakan dalam penelitian ini adalah data yang diambil dari rekapitulasi data jurusan dan rata-rata nilai mata pelajaran yang diambil dari database SMA Negeri 1 Jepara tahun pelajaran 2013/2014 yang banyaknya rekapitulasi data ada 348 buah. Selanjutnya data ini digunakan sebagai data simulasi klasifikasi perbandingan menggunakan Decision Tree dan Support Vector Machine Multiclass (SVMM).
Tahapan analisis yang dilakukan adalah sebagai berikut: 3.1 Melakukan Klasifikasi Menggunakan Decision Tree
Pada tahap ini dilakukan persiapan data training dengan algoritma C4.5 sebagai berikut :
1. Menyiapkan data training dan testing. Data training diambil dari data histori yang pernah terjadi sebelumnya dan sudah dikelompokkan ke dalam 3-kelas kategori mata pelajaran IPA, IPS dan BAHASA.
2. Menentukan akar dari pohon, dihitung terlebih dahulu entropy.
3. Selanjutnya akar akan diambil dari atribut yang terpilih, dengan cara menghitung nilai gain dari masing-masing atribut, nilai gain yang paling tinggi menjadi akar pertama.
4. Ulangi langkah ke-2 hingga semua record terpartisi. 5. Proses partisi decision tree akan berhenti saat :
a. Semua record dalam simpul N mendapat kelas yang sama. b. Tidak ada atribut di dalam record yang dipartisi lagi. c. Tidak ada record di dalam cabang yang kosong.
6. Studi Kasus Decision Tree menggunakan software Matlab selanjutnya diinterpretasikan dengan membuat aplikasi berbasis Decision Tree dengan GUI (Graphical User Interface).
3.2 Melakukan Klasifikasi Menggunakan SVMM
Pada tahap ini dilakukan persiapan data training dan testing dengan algoritma SVMM sebagai berikut :
1. Melakukan analisis data sesuai dengan SVMM
2. Melakukan pendekatan utama pada data training dan testing dengan cara menemukan dan menggabung beberapa fungsi pemisah persoalan klasifikasi SVM dua kelas untuk menyelesaikan klasifikasi SVMM dengan metode Satu Lawan Satu (SLU)
3. Studi Kasus SVMM menggunakan software Matlab yaitu dilakukan pembuatan persamaan antara kelas IPA dan IPS, persamaan antara kelas IPA dan Bahasa, serta persamaan antara kelas IPS dan Bahasa.
4. Membuat aplikasi klasifikasi SVMM berbasis text dan GUI (Graphical User Interface).
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1013 3.3. Analisis Hasil Perbandingan
Pada tahap ini dapat dilakukan evaluasi dari hasil training dan testing, dimana dilakukan perbandingan ketepatan klasifikasi dengan metode Decision Tree dan Support Vector Machine Multiclass (SVMM).
4. HASIL DAN PEMBAHASAN
4.1 Analisis Klasifikasi Metode Decision Tree
Dilakukan analisis Decision Tree mengenai penjurusan siswa Sekolah Menengah Atas (SMA) dalam jurusan IPA, IPS dan Bahasa. Penentuan penjurusan berdasarkan Data Mining akan berbeda dengan yang bukan Data Mining.
4.2 Menentukan Akar Dari Pohon Keputusan
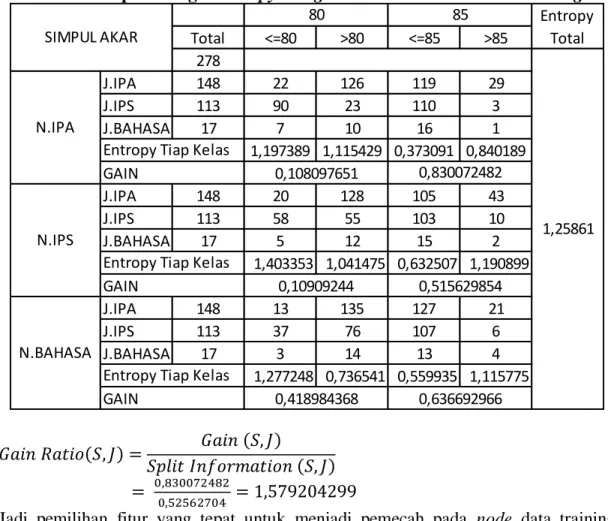
Dari data traning sebanyak 278 dan data testing sebanyak 70 buah, dihitung nilai entropy, information gain, dan gain ratio yang memiliki fitur berjumlah 3 menggunakan tipe numerik dengan rincian sebagai berikut :
IPA = kontinu IPS = kontinu BAHASA = kontinu
Tabel 2. Hasil perhitungan entropy dan gain untuk node akar data training
Jadi pemilihan fitur yang tepat untuk menjadi pemecah pada node data training sebesar Total <=80 >80 <=85 >85 278 J.IPA 148 22 126 119 29 J.IPS 113 90 23 110 3 J.BAHASA 17 7 10 16 1 1,197389 1,115429 0,373091 0,840189 J.IPA 148 20 128 105 43 J.IPS 113 58 55 103 10 J.BAHASA 17 5 12 15 2 1,403353 1,041475 0,632507 1,190899 J.IPA 148 13 135 127 21 J.IPS 113 37 76 107 6 J.BAHASA 17 3 14 13 4 1,277248 0,736541 0,559935 1,115775 1,25861 SIMPUL AKAR N.IPA N.IPS N.BAHASA 0,10909244 0,515629854 0,418984368 0,636692966 GAIN 0,108097651 0,830072482 GAIN
Entropy Tiap Kelas GAIN
Entropy Tiap Kelas
Entropy Tiap Kelas
Entropy Total
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1014 Tabel 3. Hasil perhitungan entropy dan gain untuk node akar data testing
Jadi pemilihan fitur yang tepat untuk menjadi pemecah pada node data training sebesar
4.3 Analisis Klasifikasi Metode SVMM
Persoalan klasifikasi menggunakan metode SVMM adalah melakukan klasifikasi lebih dari satu kelas. Dalam kasus ini digunakan persoalan 3 kelas yang terdiri dari jurusan IPA, IPS, dan Bahasa.
Jumlah fungsi pemisah dapat dirumuskan dengan dengan k= 3 kelas. Jadi nilai = 3
Fungsi pemisah per kelas yaitu :
Kelas 1 = pemisah antara jurusan IPA dan jurusan IPS ( Data training diberi label +1
Data training diberi label -1
Kelas 2 = pemisah antara jurusan IPA dan jurusan Bahasa ( Data training diberi label +1
Data training diberi label -1
Kelas 3 = pemisah antara jurusan IPS dan jurusan Bahasa ( Data training diberi label +1
Data training diberi label -1
Total <=80 >80 70 J.IPA 38 6 32 J.IPS 28 27 1 J.BAHASA 4 3 1 0,78234 0,880472 J.IPA 38 6 32 J.IPS 28 18 10 J.BAHASA 4 3 1 1,330245 1,050569 J.IPA 38 10 28 J.IPS 28 15 13 J.BAHASA 4 1 3 1,489234 1,239291 N.IPS
Entropy Tiap Kelas
GAIN 0,084736291
N.BAHASA
Entropy Tiap Kelas
GAIN -0,088946583
SIMPUL AKAR
80
N.IPA
Entropy Tiap Kelas
GAIN 0,413175803
Entropy Total
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1015 4.4 Analisis Hasil Perbandingan
Hasil dari prediksi tingkat error dari klasifikasi decision tree didapatkan hasil sebagai berikut:
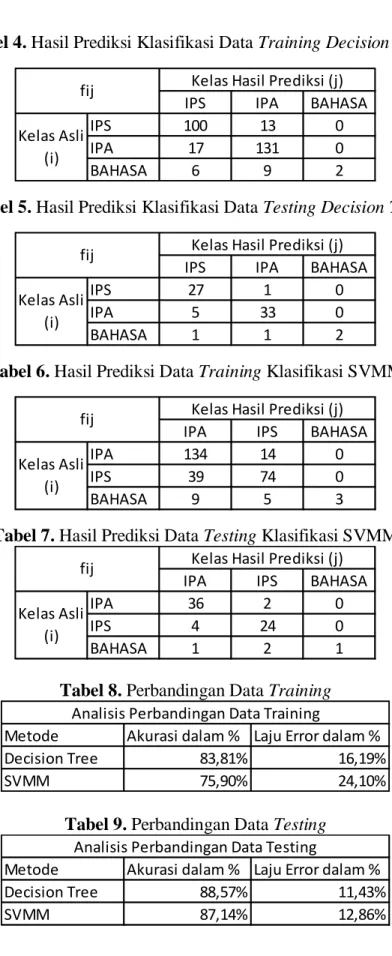
Tabel 4. Hasil Prediksi Klasifikasi Data Training Decision Tree
Tabel 5. Hasil Prediksi Klasifikasi Data Testing Decision Tree
Tabel 6. Hasil Prediksi Data Training Klasifikasi SVMM
Tabel 7. Hasil Prediksi Data Testing Klasifikasi SVMM
Tabel 8. Perbandingan Data Training
Tabel 9. Perbandingan Data Testing
IPS IPA BAHASA
IPS 100 13 0
IPA 17 131 0
BAHASA 6 9 2
Kelas Hasil Prediksi (j) fij
Kelas Asli (i)
IPS IPA BAHASA
IPS 27 1 0
IPA 5 33 0
BAHASA 1 1 2
Kelas Hasil Prediksi (j) fij
Kelas Asli (i)
IPA IPS BAHASA
IPA 134 14 0
IPS 39 74 0
BAHASA 9 5 3
Kelas Hasil Prediksi (j) fij
Kelas Asli (i)
IPA IPS BAHASA
IPA 36 2 0
IPS 4 24 0
BAHASA 1 2 1
Kelas Hasil Prediksi (j) fij
Kelas Asli (i)
Metode Akurasi dalam % Laju Error dalam %
Decision Tree 83,81% 16,19%
SVMM 75,90% 24,10%
Analisis Perbandingan Data Training
Metode Akurasi dalam % Laju Error dalam %
Decision Tree 88,57% 11,43%
SVMM 87,14% 12,86%
JURNAL GAUSSIAN Vol. 4, No. 4, Tahun 2015 Halaman 1016 5. KESIMPULAN
Hasil analisis menunjukkan metode klasifikasi decision tree data dibangun berdasarkan objek yang dimiliki dalam data latih. Decision tree secara penuh merefleksikan semua isi himpunan data latih daripada klasifikasi SVMM karena harus menyimpan sebagian kecil data latih untuk digunakan kembali pada saat proses prediksi. Tingkat akurasi dan laju error lebih baik pada decision tree dimana nilai total akurasi sebesar 88,57% dan error 11,43% untuk klasifikasi decision tree dan total akurasi sebesar 87,14% dan error 12,86% untuk klasifikasi SVMM.
6. DAFTAR PUSTAKA
[1] Gunn, S.R. 1998. Support Vector Machines for Classification and Regression. University of Southampton : Southampton.
[2] Han, J dan Kamber, M. 2006. Data Mining Concepts and Teqniques – 2nd Ed. San Fransisco: Elsevier Inc.
[3] Hermawati, A.F. 2013. Data Mining. Surabaya: Universitas 17 Agustus 1945 & ANDI.
[4] Hsu, C.W. dan Lin, C.J. 2002. A Comparison of Methods for Multiclass Support Vector Machines. IEE Transactions on Neural Network, 13(2), 415-425.
[5] Kerami, D. dan Murfi,H. 2004. Kajian Kemampuan Generalisasi Support Vector Machine dalam Pengenalan Jenis Splice Site pada Barisan DNA. Jurnal Makara Sains Vol 8 No 3. Hal 89-95.
[6] Prasetyo, E. 2012. Data Mining Mengolah Data Menjadi Informasi Menggunakan MATLAB. Yogyakarta: ANDI.
[7] Prasetyo, E. 2014. Data Mining Konsep dan Aplikasi Menggunakan MATLAB. Yogyakarta: ANDI.
[8] Santosa, B. dan Trafalis, T. 2004. Multiclass Procedure for Minimax Probability Machine. ASME Press, 14, 447-452.
[9] Santosa, B. 2007. Data Mining Teknik Pemanfaatan Data untuk Keperluan Bisnis. Yogyakarta: Graha Ilmu.
[10] Sumathi, S. 2006. Introduction to Data Mining and Its Applications. Germany: Springer Verlag berlin Heidelberg.
[11] Vapnik, V. dan Cortes, C. 1995. Support Vector Networks. Machine Learning, 20, 273-297
[12] Weston, J. dan Watkins, C. 1998. Support Vector Machine forMulticlass Pattern Recognition. Proceeding of the seventh European Symposium on Articial Neural Networks ICANN’97.
[13] Widodo, P. P., Handayanto, R. T. dan Herlawati. 2013. Penerapan Data Mining dengan Matlab. Bandung: Rekayasa Sains.