PERINGKASAN DOKUMEN BAHASA INDONESIA
MENGGUNAKAN METODE MAXIMUM MARGINAL
RELEVANCE
LUTFIA AFIFAH
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
PERNYATAAN MENGENAI SKRIPSI DAN SUMBER
INFORMASI SERTA
PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Peringkasan Dokumen Ba-hasa Indonesia Menggunakan Metode Maximum Marginal Relevance adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam ben-tuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, November 2015 Lutfia Afifah G64134014
LUTFIA AFIFAH. Peringkasan Dokumen Bahasa Indonesia Menggunakan Metode Maximum Marginal Relevance. Dibawah bimbingan JULIO ADISANTOSO. Ringkasan dokumen diperlukan untuk memudahkan memahami informasi berukuran be-sar dengan cepat. Peringkasan dokumen otomatis merupakan solusi untuk mendapatkan ringkasan dokumen dengan cepat. Penelitian ini mengusulkan untuk membuat peringkasan dokumen otomatis menggunakan metode Maximum Marginal Relevance (MMR) dan fi-tur kata untuk dokumen skripsi. Metode ini menggabungkan relevansi antara kalimat de-ngan query dan kalimat dede-ngan kalimat yang telah terpilih sebagai ringkasan. Hasil peneli-tian yang telah dilakukan menghasilkan rata-rata akurasi 60.67%, recall 24.50%, precision 48.46%, dan f-1 30.88%.
Kata kunci: fitur kata; Maximum Marginal Relevance; MMR; peringkasan dokumen
ABSTRACT
LUTFIA AFIFAH. Text Summarization For Indonesian Language Using Maximum Marginal Relevance Method. Supervised by JULIO ADISANTOSO.
Text summarization is required to facilitate understanding the large volume of infomation in documents. Automatic text summarization is a solution to get summary of documents quickly. This research proposes an automatic text summarization using Maximum Marginal Relevance (MMR) method and word features for minithesis documents. This method merges query-relevance and information-novelty or relevance of sentence with selected sentence. Result of this research produces average accuracy of 60.67%, recall of 24.50%, precision of 48.46%, and f-1 of 30.88%.
PERINGKASAN DOKUMEN BAHASA INDONESIA
MENGGUNAKAN METODE MAXIMUM MARGINAL
RELEVANCE
LUTFIA AFIFAH
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
BOGOR 2015
1. Dr Imas Sukaesih Sitanggang, SSi MKom 2. Muhammad Abrar Istiadi, SKomp MKom
Judul Skripsi : Peringkasan Dokumen Bahasa Indonesia Menggunakan Metode Maximum Marginal Relevance
Nama Mahasiswa : Lutfia Afifah
NIM : G64134014
Disetujui oleh
Ir Julio Adisantoso, MKom Pembimbing
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
Alhamdulillahirabbil ’aalamiin, puji syukur penulis panjatkan kehadirat Allah SWT yang telah memberikan rahmat dan hidayah-Nya sehingga penulis dapat menyele-saikan skripsi yang berjudul “Peringkasan Dokumen Bahasa Indonesia Menggu-nakan Metode Maximum Marginal Relevance”.
Skripsi ini disusun sebagai syarat mendapat gelar Sarjana Komputer (SKomp) pada Program Sarjana Ilmu Komputer di Fakultas Matematika dan Ilmu Pengetahuan Alam Institut Pertanian Bogor (IPB).
Penulis mengucapkan terima kasih kepada Bapak Ir. Julio Adisantoso, M.Kom se-laku dosen pembimbing skripsi yang telah memberikan saran, arahan, serta dukung-annya selama penelitian ini. Ungkapan terima kasih juga penulis sampaikan kepada orang tua tercinta, ibunda Yusroniyah, ayahanda Ihun Solihun, dan adik-adik yang saya sayangi, Zia dan Fahmy, atas segala doa, kasih sayang, dukungan semangat, serta motivasi kepada penulis untuk kelancaran penelitian ini. Tak lupa juga penulis ucapkan terima kasih kepada rekan-rekan satu bimbingan, Yozi dan Boge, atas ban-tuan dan kerjasamanya dalam melakukan penelitian ini, serta kepada rekan-rekan seperjuangan di Ekstensi Ilmu Komputer angkatan 8, atas dukungan, bantuan, dan kebersamaannya selama menjalani masa studi. Dan terakhir, terima kasih kepada seluruh staf Departemen Ilmu Komputer, khususnya Alih Jenis, yang telah banyak membantu, baik selama pengerjaan skripsi maupun kegiatan perkuliahan. Semoga skripsi ini dapat memberikan kontribusi yang bermakna bagi pengembangan wawa-san para pembaca, khususnya mahasiswa dan masyarakat pada umumnya.
Semoga karya ilmiah ini bermanfaat.
Bogor, November 2015 Lutfia Afifah
DAFTAR ISI
Halaman DAFTAR TABEL v DAFTAR GAMBAR v PENDAHULUAN 1 Latar Belakang . . . 1 Perumusan Masalah . . . 2 Tujuan Penelitian . . . 2 Manfaat Penelitian . . . 3Ruang Lingkup Penelitian . . . 3
METODE PENELITIAN 3 Pengumpulan Dokumen . . . 3
Pengindeksan . . . 5
Pemilihan Fitur Kata . . . 5
Proses Peringkasan . . . 5
ParsingKalimat . . . 5
Pembobotan TF.ISF . . . 6
Penghitungan Cosine Similarity . . . 6
Seleksi Kalimat Menggunakan MMR . . . 7
Evaluasi . . . 7
HASIL DAN PEMBAHASAN 9 Pengumpulan Dokumen . . . 9
Pengindeksan . . . 9
Pemilihan Fitur Kata . . . 10
Proses Peringkasan . . . 10
ParsingKalimat . . . 10
Pembobotan TF.ISF . . . 11
Seleksi Kalimat Menggunakan MMR . . . 11
Evaluasi Hasil Ringkasan . . . 13
SIMPULAN DAN SARAN 20 Simpulan . . . 20
Saran . . . 20
DAFTAR PUSTAKA 20 LAMPIRAN 22 1. Daftar dokumen skripsi yang digunakan . . . 22
2. Grafik Akurasi maksimum (a), rata-rata (b), dan minimum (c) tiap kompresi ringkasan . . . 26
3. Grafik Recall maksimum (a), rata-rata (b), dan minimum (c) tiap kom-presi ringkasan . . . 27 4. Grafik Recall maksimum (a), rata-rata (b), dan minimum (c) tiap nilai λ 28 5. Grafik Precision maksimum (a), rata-rata (b), dan minimum (c) tiap
kompresi ringkasan . . . 29 6. Grafik Precision maksimum (a), rata-rata (b), dan minimum (c) tiap
nilai λ . . . 30 7. Grafik F-1 maksimum (a), rata-rata (b), dan minimum (c) tiap kompresi
ringkasan . . . 31 8. Grafik F-1 maksimum (a), rata-rata (b), dan minimum (c) tiap nilai λ . 32
DAFTAR TABEL
1 Confusion Matrix . . . 8 2 Matriks TF.ISF . . . 11 3 Statistik Recall, Precision, F-1, Akurasi . . . 20
DAFTAR GAMBAR
1 Skema tahapan peringkasan dokumen . . . 4 2 Akurasi maksimum (a), rata-rata (b), dan minimum (c) untuk nilai
λ = 0.50 . . . 14 3 Akurasi maksimum (a), rata-rata (b), dan minimum (c) untuk nilai
λ = 0.25 . . . 15 4 Akurasi maksimum (a), rata-rata (b), dan minimum (c) untuk nilai
λ = 0.75 . . . 15 5 Akurasi rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50
(b), dan λ = 0.25 (c) . . . 16 6 Recallrata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50
(b), dan λ = 0.25 (c) . . . 17 7 Precision rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ =
0.50 (b), dan λ = 0.25 (c) . . . 18 8 F-1rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50 (b),
1
PENDAHULUAN
Latar Belakang
Membaca merupakan salah satu kegiatan yang tidak bisa lepas bagi manusia, baik membaca buku, majalah maupun teks iklan. Masalah muncul apabila teks atau dokumen yang akan dibaca panjang dan sangat banyak karena membutuhkan waktu yang lama untuk dapat memahami isi dokumen tersebut. Salah satu cara agar dapat memahami isi dokumen keseluruhan dengan cepat adalah dengan membaca ringkasannya.
Peringkasan dokumen merupakan proses meringkas atau mengurangi panjang teks asli dengan cara mengambil kata-kata atau kalimat-kalimat penting untuk men-dapatkan informasi atau gambaran umum dari suatu dokumen. Cara untuk menda-patkan ringkasan dokumen yaitu bisa dengan meringkasnya secara manual ataupun menggunakan aplikasi peringkasan otomatis. Aplikasi peringkasan dokumen otoma-tis bisa digunakan untuk mendapatkan ringkasan dokumen dengan cepat. Pering-kasan dokumen secara otomatis telah dikembangkan sejak tahun 1958 oleh Luhn (1958).
Terdapat dua jenis pendekatan untuk peringkasan dokumen yaitu ekstraksi dan abstraksi. Peringkasan dokumen dengan metode ekstraksi yaitu dengan cara meng-ambil kalimat-kalimat penting dari teks asli kemudian menyusunnya kembali men-jadi ringkasan, sedangkan metode abstraksi yaitu mengambil intisari dari teks asli yang kemudian dituangkan ke dalam kalimat-kalimat baru yang akan menjadi se-buah ringkasan (Jezek dan Steinberger 2008). Keuntungan dari metode ekstraksi yaitu mudah untuk diterapkan dan didasarkan pada fitur-fitur statistik dalam memilih kalimat penting atau kata kunci dari dokumen. Kekurangannya adalah ringkasan yang dihasilkan cenderung tidak konsisten dan kalimat yang mengandung informasi yang tidak berhubungan tidak dapat disajikan secara akurat. Sedangkan keuntungan dari metode abstraksi yaitu menghasilkan ringkasan yang lebih akurat. Kekurangan-nya yaitu lebih sulit diterapkan karena membutuhkan pemahaman teks asli (Munot dan Govilkar 2014).
Selain ekstraksi dan abstraksi, terdapat pendekatan lain berdasarkan ada atau tidaknya campur tangan manusia dalam memproses ringkasan otomatis yaitu su-pervised dan unsupervised. Perbedaan kedua metode tersebut yaitu metode super-vised menggunakan ringkasan manual buatan manusia untuk mengidentifikasi pa-rameter atau fitur ringkasan, sedangkan pada metode unsupervised tidak menggu-nakan ringkasan manual buatan manusia dalam menentukan parameter yang relevan (Elfayoumy dan Thoppil 2014).
Secara umum, proses peringkasan dokumen otomatis terdiri atas beberapa taha-pan yaitu pengumpulan dokumen, praproses, pemilihan fitur, pembobotan kalimat dan pengujian. Tahapan praproses sendiri terbagi lagi menjadi beberapa bagian, di antaranya pemecahan kalimat, case folding, tokenisasi dan filtering. Ada tahapan yang sangat penting dalam peringkasan dokumen yaitu pembobotan kalimat.
Taha-pan inilah yang menentukan diambil atau tidaknya suatu kalimat sebagai ringkasan. Pembobotan kalimat dalam peringkasan dokumen dapat dilakukan dengan berba-gai macam metode antara lain yang pernah dilakukan yaitu menggunakan Algo-ritme Genetika oleh Aristoteles (2011). Gerbawani (2013) membuat peringkasan dokumen bahasa Indonesia menggunakan logika Fuzzy. Marlina (2012) membuat ringkasan dokumen bahasa Indonesia dengan metode Regresi Logistik Biner un-tuk menganalisis beberapa faktor dengan sebuah variabel yang bersifat biner. Se-lain metode-metode tersebut, peringkasan dokumen juga dapat dilakukan dengan menggunakan metode Maximum Marginal Relevance (MMR). MMR adalah sebuah metode untuk menggabungkan query-relevance dengan information-novelty dalam peringkasan dokumen (Carbonell dan Goldstein 1998). Metode ini menggunakan teknik ekstraksi yang digunakan untuk mengurangi redundansi kalimat dengan cara menghitung kesamaan (similarity) antara kalimat dengan query dan kalimat dengan kalimat lain yang telah terpilih sebagai ringkasan. Penelitian yang pernah dilakukan dengan menggunakan metode ini salah satunya dilakukan oleh Mustaqhfiri (2011) pada dokumen berita bahasa Indonesia. Penelitian tersebut menghasilkan rata-rata recall60%, precision 76%, dan f-measure 65%.
Penelitian yang sudah sering dilakukan umumnya digunakan untuk dokumen pendek seperti dokumen berita, sedangkan untuk dokumen panjang seperti doku-men karya ilmiah bahasa Indonesia yang terdiri atas beberapa bab belum pernah dilakukan. Oleh karena itu, penelitian yang akan dilakukan adalah membuat pe-ringkasan dokumen otomatis untuk dokumen karya ilmiah bahasa Indonesia, yaitu skripsi, menggunakan pendekatan supervised dengan metode pembobotan MMR dan teknik ekstraksi.
Perumusan Masalah
Perumusan masalah dalam penelitian ini di antaranya:1. Bagaimana metode pembobotan kalimat berdasarkan fitur kata?
2. Apakah metode MMR tepat digunakan untuk pembobotan kalimat berdasar-kan fitur kata?
3. Bagaimana implementasi metode MMR untuk dokumen skripsi?
Tujuan Penelitian
Tujuan dari penelitian ini antara lain:1. Mengembangkan peringkasan dokumen otomatis menggunakan pembobotan kalimat berdasarkan fitur kata.
2. Menganalisis ketepatan penggunaan metode MMR dengan pembobotan kali-mat berdasarkan fitur kata untuk peringkasan dokumen otokali-matis.
3
Manfaat Penelitian
Manfaat dari penelitian ini diharapkan aplikasi yang dibangun dapat mengha-silkan ringkasan yang relevan dengan informasi penting pada dokumen dan dapat membantu mahasiswa memahami isi dokumen skripsi dengan cepat.
Ruang Lingkup Penelitian
Penelitian ini dibatasi hanya menggunakan dokumen skripsi bahasa Indonesia, fitur kata untuk pembobotan kalimat dan metode MMR dengan teknik ekstraksi.
METODE PENELITIAN
Tahapan dalam peringkasan dokumen otomatis diawali dengan pengumpulan dokumen, selanjutnya dilakukan pengindeksan, proses peringkasan, dan tahap ter-akhir yaitu evaluasi hasil ringkasan sistem dengan ringkasan manual. Skema taha-pan peringkasan dokumen dapat dilihat pada Gambar 1.
Pengumpulan Dokumen
Penelitian ini menggunakan dokumen skripsi mahasiswa Ilmu Komputer Institut Pertanian Bogor (IPB) sebanyak 100 dokumen dengan bentuk PDF yang berasal dari repository.ipb.ac.id. Setiap dokumen telah dibuat ringkasan manualnya yang digunakan untuk membandingkan dengan hasil ringkasan sistem, serta mengukur seberapa akurat sistem peringkasan otomatis yang dibuat. Caranya yaitu dengan menghitung secara manual ada berapa kalimat yang sama dan tidak sama pada ring-kasan manual dan hasil ringring-kasan sistem yang kemudian dihitung nilai recall, pre-cision, f-1, dan akurasinya. Dari hasil tersebut barulah nanti dapat terlihat apakah hasil ringkasan sistem sudah memuaskan. Dokumen dikumpulkan dan dikonversi ke dalam bentuk teks dengan format dokumen.txt dengan cara copy-paste manual setiap kalimat. Bagian tinjauan pustaka dihilangkan karena pada umumnya suatu ringkasan karya ilmiah tidak mengikutsertakan tinjauan pustaka. Di dalam pemisah judul dokumen juga ditambahkan kata kunci dokumen yang terdapat pada abstrak. Selain itu, ada beberapa aturan yang digunakan dalam pengumpulan dokumen, di antaranya:
1. Tidak termasuk tabel, gambar, lampiran, persamaan, algoritme beserta penje-lasannya.
2. Bukan berupa list pendek, kecuali pada bagian kesimpulan dan saran. 3. Judul bab dan sub bab dihilangkan.
Gambar 1 Skema tahapan peringkasan dokumen
4. Catatan kaki dihilangkan.
5. Kalimat yang mengandung titik dua ditulis berulang kali sebanyak list kalimat yang menyertainya.
Pada umumnya ringkasan hanya berupa kalimat, oleh karena itu dibuatlah at-uran pengumpulan dokumen poin 1. Masih pada poin 1, ”penjelasannya” disini maksudnya adalah kalimat yang menjelaskan tentang tabel, gambar, lampiran, per-samaan, atau algoritme tersebut, misalnya ”Gambar 1 menunjukkan bahwa ...”. List pendek pada poin 2 juga dihilangkan karena list pendek bukan merupakan kalimat utuh kecuali pada kesimpulan dan saran karena diasumsikan bagian tersebut meru-pakan poin penting dari sebuah dokumen skripsi. Poin 3, judul bab dan subbab, juga bukan merupakan kalimat utuh, jadi dihilangkan, sedangkan poin 4, catatan kaki, merupakan penjelasan dari suatu kata dalam dokumen yang diletakkan se-cara terpisah, bukan pada isi dokumen, jadi catatan kaki juga dihilangkan. Poin 5 maksudnya adalah list panjang atau list yang mengandung kalimat utuh, tidak dihilangkan melainkan kalimat penjelasan sebelumnya mengenai list tersebut, bi-asanya mengandung titik dua, ditulis berulang kali di depan tiap kalimat list panjang tersebut. Tujuannya adalah agar informasi pada kalimat list panjang tersebut dapat tersampaikan secara jelas.
5
Pengindeksan
Tahap awal pemrosesan dokumen adalah pengindeksan. Tahap ini merupakan tahap memilih fitur kata yang akan dijadikan acuan dalam pembobotan kalimat. Langkah pertama yang dilakukan yaitu case folding atau menyeragamkan jenis dan ukuran huruf. Dalam penelitian ini, jenis huruf semua dokumen akan diseragamkan menjadi huruf kecil.
Pemilihan Fitur Kata
Penelitian ini menggunakan fitur kata untuk memperoleh ringkasan otomatis. Langkah pertama yang harus dilakukan adalah memisahkan kata dari tiap doku-men, kemudian dilakukan pemilihan fitur kata. Terdapat 3 cara pemilihan fitur kata yaitu Mutual Information (MI), Chi-square (χ2), dan berbasis frekuensi dokumen (Manning et al. 2008). MI dan χ2 baik digunakan sebagai metode pemilihan fi-tur kata untuk klasifikasi teks, sedangkan metode berbasis frekuensi dokumen baik digunakan untuk peringkasan teks. Oleh karena itu, pada penelitian ini digunakan metode berbasis frekuensi dokumen, yaitu Inverse Document Frequency (IDF) un-tuk menenun-tukan fitur kata. Xia dan Chai (2011) mendefinisikan IDF sebagai salah satu metode pemilihan fitur kata yang berdasarkan pada perhitungan jumlah doku-men yang diindeks oleh term. Menurut Manning et al. (2008) persamaan yang digunakan untuk menghitung nilai IDF dari suatu kata adalah
IDFt= log(
N
DFt) (1)
dengan N merupakan jumlah seluruh dokumen dan DFt adalah jumlah dokumen
yang mengandung kata t. Apabila sebuah kata muncul di banyak dokumen, maka hasil dari IDF akan semakin kecil, begitu pula sebaliknya. Kata-kata yang sering muncul pada setiap dokumen biasanya adalah kata-kata yang tidak penting. Oleh karena itu, IDF sesuai untuk diterapkan pada pemilihan fitur kata dalam peringkasan dokumen karena kata-kata dengan nilai IDF tertinggi merupakan kata-kata yang jarang muncul atau hanya muncul pada dokumen dengan kategori tertentu.
Proses Peringkasan
Proses peringkasan dokumen terdiri atas parsing kalimat, pembobotan Term Fre-quency - Inverse Sentence FreFre-quency (TF.ISF), penghitungan nilai kemiripan (co-sine similarity), dan seleksi kalimat menggunakan metode MMR.
Parsing Kalimat
Tahap pertama proses peringkasan dokumen yaitu memecah isi dokumen men-jadi kumpulan kalimat. Parsing kalimat adalah proses memisahkan teks dalam
dokumen menjadi kalimat-kalimat berdasarkan tanda baca tertentu sebagai pemisah diantaranya tanda baca titik (.), tanda tanya (?), dan tanda seru (!). Tetapi sebelum menganalisis adanya 3 tanda pemisah tersebut, terlebih dahulu dicari adanya tanda kutip (“ ”) yang merupakan tanda dari kutipan langsung. Apabila terdapat kutipan langsung, kalimat dalam tanda kutip dianggap sebagai 1 kalimat. Selain memecah isi dokumen, dilakukan juga pemisahan query. Baris pertama dalam dokumen merupakan judul dokumen serta kata kunci yang akan digunakan sebagai query yang diperlukan untuk seleksi kalimat.
Pembobotan TF.ISF
Tahap berikutnya setelah ditentukan fitur kata yang akan digunakan, adalah me-lakukan pembobotan TF.ISF untuk tiap fitur kata tersebut pada masing-masing kali-mat dalam dokumen. TF.ISF merupakan suatu indikator penting atau tidaknya su-atu kata dalam merepresentasikan kalimat (Xia dan Chai 2011). Metode ini meng-gabungkan jumlah kemunculan kata pada tiap kalimat atau Term Frequency (TF) de-ngan banyaknya kalimat dimana suatu kata muncul atau Sentence Frequency (SF). Pembobotan diperoleh berdasarkan TF dan Inverse Sentence Frequency (ISF). Nilai ISF sebuah kata dapat dihitung menggunakan persamaan sebagai berikut:
ISFt= log(n+ 1 SFt
) (2)
dengan n merupakan jumlah kalimat dalam dokumen dan SFt merupakan jumlah
kalimat dalam dokumen yang mengandung kata t. Adapun persamaan yang digu-nakan untuk menentukan TF.ISF sebagai berikut:
T F.ISFt,s= T Ft,s× ISFt (3)
dengan T Ft,s adalah jumlah kata t pada kalimat s, sedangkan ISFt adalah nilai ISF
untuk kata t. Nilai T F.ISFt,stinggi jika kata t muncul beberapa kali dalam kalimat
dan jarang muncul pada kalimat lain, sedangkan rendah jika kata t muncul hampir di seluruh kalimat masing-masing sebanyak 1 kali (Manning et al. 2008).
Penghitungan Cosine Similarity
Salah satu ukuran kemiripan kalimat yang paling umum digunakan adalah Co-sine Similaritydimana tiap kalimat direpresentasikan sebagai vektor (Xie dan Liu 2008). Jarak antarvektor menentukan kemiripannya, dimana semakin dekat jaraknya maka 2 vektor tersebut semakin mirip (Turney dan Pantel 2010). Manning et al. (2008) mendefinisikan cosine similarity antara kalimat s1dan s2sebagai berikut:
sim(s1, s2) = ~s1· ~s2 |~s1||~s2|= ∑iw1,i· w2,i q ∑iw21,i q ∑iw22,i (4)
dengan |~s1| dan |~s2| adalah panjang vektor, w1,i adalah bobot kata i pada dokumen
7
Seleksi Kalimat Menggunakan MMR
Maximum Marginal Relevance (MMR) merupakan salah satu metode pering-kasan dokumen yang menggunakan teknik ekstraksi. Metode ini mengkombinasikan cosine similarityantara kalimat dengan query (query-relevance) dan kalimat dengan kalimat lain yang telah terpilih sebagai ringkasan dengan tujuan memaksimalkan kesamaan kalimat dengan query dan meminimalkan redundansi kalimat atau de-ngan kata lain meminimalkan adanya kalimat yang mempunyai kesamaan makna pada hasil ringkasan.
Salah satu cara untuk mendapatkan ringkasan yang relevan yaitu dengan mengu-kur relevansi antara informasi pada kalimat dengan query (Carbonell dan Goldstein 1998). Untuk setiap kalimat si, nilai MMR dapat dicari menggunakan persamaan
berikut:
MMRi= argmax[λ sim1(si, Q) − (1 − λ ) max sj∈S
(sim2(si, sj))] (5)
dengan λ merupakan parameter dengan interval [0-1] untuk mengatur tingkat ke-pentingan relatif antara relevansi dan redundansi. sim1 adalah ukuran kesamaan
kalimat dengan query, sedangkan sim2 adalah ukuran kesamaan kalimat dengan
kalimat lainnya yang telah terpilih sebagai ringkasan (Waliprana dan Khodra 2013). Nilai MMR tiap kalimat pada dokumen dihitung untuk tiap iterasi dan akan di-ambil kalimat dengan nilai MMR maksimum sebagai hasil ringkasan. Mustaqhfiri (2011) menyatakan bahwa sebuah kalimat memiliki nilai MMR tinggi jika kalimat tersebut relevan terhadap isi dokumen dan memiliki bobot kesamaan maksimum terhadap query.
Seleksi kalimat dilakukan dengan mengambil kalimat dengan nilai MMR ter-tinggi pada setiap iterasi. Iterasi yang akan dilakukan yaitu sebanyak persentase jumlah kalimat hasil ringkasan yang ditentukan. Penelitian ini menggunakan kom-presi ringkasan sebesar 10%, 20%, dan 30% yang berarti ringkasan yang terbentuk yaitu sebanyak 10%, 20%, dan 30% dari jumlah kalimat pada dokumen.
Evaluasi
Untuk mengetahui kualitas hasil ringkasan sistem diperlukan adanya evaluasi. Pada tahap evaluasi, hasil ringkasan sistem dibandingkan dengan hasil ringkasan manual. Metode evaluasi yang digunakan pada penelitian ini adalah menentukan nilai Recall, Precision, F-1, dan akurasi dari setiap dokumen.
Recalladalah peluang kasus dengan kategori positif yang dengan tepat diprediksi positif, sedangkan Precision adalah peluang kasus yang diprediksi positif yang pada kenyataannya termasuk kasus dengan kategori positif (Powers 2007). Dalam pe-ringkasan dokumen, Recall berarti peluang dokumen relevan yang terambil sebagai ringkasan dan Precision berarti peluang dokumen yang terambil sebagai ringkasan adalah relevan. F-Measure didapat dari hasil Recall dan Precision antara kate-gori hasil prediksi dengan katekate-gori sebenarnya (Wicaksana dan Widiartha 2012).
Akurasi dalam peringkasan dokumen didapatkan dari jumlah kalimat kategori posi-tif yang diprediksi posiposi-tif dan kalimat kategori negaposi-tif yang diprediksi negaposi-tif dibagi dengan seluruh kalimat dalam dokumen. Dalam penghitungan pada tahap evaluasi ini membutuhkan matriks yang disebut Confusion Matrix yang dapat dilihat pada Tabel 1. Confusion Matrix ini berisi informasi tentang kelas sebenarnya (hasil ring-kasan sistem) dan kelas prediksi (hasil ringring-kasan manual) (Manning et al. 2008). Kolom Relevant merupakan kalimat dalam dokumen yang termasuk ke dalam ring-kasan manual, sedangkan Non-Relevant merupakan kalimat dalam dokumen yang tidak termasuk ke dalam ringkasan manual. Baris Retrieved merupakan kalimat dalam dokumen yang terambil sebagai ringkasan sistem, sedangkan baris Not Re-trievedmerupakan kalimat dalam dokumen yang tidak terambil sebagai ringkasan sistem.
Tabel 1 Confusion Matrix
Relevant Non-Relevant
Retrieved tp fp
Not Retrieved fn tn
Berdasarkan Tabel 1 dapat dihitung nilai Recall, Precision, F-1, dan Akurasi sebagai berikut: Recall= t p t p+ f n (6) Precision= t p t p+ f p (7) F-1= 2 × Recall × Precision Recall+ Precision (8) Akurasi= t p+ tn t p+ f p + f n + tn (9)
dengan tp (true positive) adalah jumlah dokumen relevan yang terambil, fp (false positive) adalah jumlah dokumen yang tidak relevan yang terambil,fn (false nega-tive) adalah jumlah dokumen relevan yang tidak terambil, dan tn (true neganega-tive) adalah jumlah dokumen yang tidak relevan yang tidak terambil.
9
HASIL DAN PEMBAHASAN
Pengumpulan Dokumen
Penelitian ini menggunakan dokumen skripsi mahasiswa Ilmu Komputer Insti-tut Pertanian Bogor yang berasal dari repository.ipb.ac.id sebanyak 100 dokumen dalam bentuk PDF. Daftar dokumen yang digunakan pada penelitian ini dapat di-lihat pada Lampiran 1. Dokumen-dokumen tersebut kemudian dikonversi secara manual ke dalam bentuk TXT dengan hanya mengambil bab pendahuluan sampai bab kesimpulan dan saran. Proses ini menghasilkan rata-rata jumlah kalimat se-banyak 212 kalimat, sedangkan jumlah kalimat maksimum sese-banyak 420 kalimat pada dokumen 9 dan jumlah kalimat minimum sebanyak 100 kalimat pada doku-men 61.
Proses selanjutnya yang dilakukan adalah proses pembersihan dokumen TXT sesuai dengan aturan yang telah dijelaskan pada bagian metode penelitian dengan melakukan copy-paste per kalimat dalam dokumen. Proses ini memakan waktu cukup lama karena kalimat dalam tiap dokumen harus diperiksa satu per satu bil-amana terdapat kalimat yang harus dihilangkan sesuai aturan pengumpulan doku-men. Dari 100 dokumen TXT yang terkumpul rata-rata ukuran dokumennya sebe-sar 21 KB. Rata-rata jumlah kalimat yang dihasilkan dari proses ini sebanyak 134 kalimat per dokumen, sedangkan jumlah maksimum kalimat sebanyak 308 kalimat pada dokumen 9 dan jumlah kalimat minimum sebanyak 64 kalimat pada dokumen 31.
Jika dihitung berdasarkan persentase, rata-rata jumlah kalimat yang digunakan sebagai korpus yaitu 65.67% dari jumlah kalimat awal. Dokumen 99 menjadi doku-men yang paling sedikit doku-menghilangkan kalimat-kalimat sesuai dengan aturan pe-ngumpulan dokumen yaitu sebesar 93.22% dengan hanya menghilangkan 8 kalimat, sedangkan dokumen yang paling banyak menghilangkan kalimat-kalimat sesuai ngan aturan pengumpulan dokumen adalah dokumen 100 yaitu sebesar 35.97% de-ngan menghilangkan 162 kalimat.
Selain proses pembersihan dokumen, ringkasan manual untuk tiap dokumen juga dibuat sebagai pembanding hasil ringkasan sistem. Keseluruhan dokumen tersebut digunakan sebagai data latih untuk menentukan fitur kata dan juga sebagai data uji untuk pengujian sistem.
Pengindeksan
Tahap pengindeksan dilakukan dengan mengunggah 100 dokumen TXT satu per satu ke dalam sistem, kemudian sistem akan melakukan pemisahan kata. Kata-kata tersebut kemudian dihitung nilai IDF-nya untuk seleksi fitur kata.
Pemilihan Fitur Kata
Pemilihan fitur kata dalam penelitian ini dihitung menggunakan persamaan 1 un-tuk tiap kata unik dalam keseluruhan dokumen. Kemudian dilakukan filtering atau penghapusan kata unik yang terdiri atas kurang dari tiga huruf. Setelah dilakukan fil-tering, terdapat lebih dari 10000 kata unik dari seluruh dokumen dan sebanyak 894 fitur kata terpilih merupakan kata unik yang memiliki nilai 0.1 ≤ IDF < 2.0. Alasan penentuan rentang tersebut karena ingin mengabaikan kata yang hanya muncul pada 1 dokumen dari 100 dokumen dan juga kata yang muncul pada lebih dari 80 doku-men karena kata-kata tersebut kurang baik untuk merepresentasikan fitur kata. Kata unik terpilih tersebut kemudian disimpan ke dalam database untuk digunakan seba-gai fitur kata.
Fitur kata terpilih tersebut masih mengandung kata-kata yang merupakan stop-wordsseperti kata ”agar”, ”adapun”, ”jika”, dan lain sebagainya. Ada sekitar 111 stopwordsyang terambil sebagai fitur kata. Namun, tidak semua stopwords muncul sebagai fitur kata, misalnya kata ”dan”, ”dari”, ”ada”, dan lain sebagainya tidak ter-pilih sebagai fitur kata kerena kata-kata tersebut muncul di hampir seluruh dokumen. Fitur kata yang memiliki nilai IDF tertinggi sebanyak 68 kata yang masing-masing muncul pada 14 dokumen dengan nilai IDF 0.86. Kata-kata tersebut diantaranya ”xml”, ”pohon”, ”inisialisasi”, dan lain sebagainya. Sebaliknya, kata yang memiliki nilai IDF terendah adalah kata ”informasi” yang muncul pada 90 dokumen dengan nilai IDF 0.05 atau jika dibulatkan menjadi 0.1 yang merupakan batas bawah nilai IDF untuk fitur kata.
Proses Peringkasan
Proses peringkasan dilakukan untuk tiap dokumen dengan cara mengunggah dokumen tersebut ke dalam sistem. Sistem kemudian akan melakukan proses pe-ringkasan di antaranya: parsing kalimat, pembobotan TF.ISF, penghitungan nilai kemiripan cosine similarity, dan seleksi kalimat menggunakan metode MMR.
Parsing Kalimat
Tahap awal dari proses peringkasan dokumen adalah memecah dokumen men-jadi potongan kalimat proses pemisahan kalimat ini dilakukan berdasarkan aturan yang telah dijelaskan pada metode penelitian. Namun, dalam prosesnya terdapat kendala pada penggunaan tanda titik (.). Dalam dokumen skripsi tanda titik (.) bukan hanya digunakan sebagai tanda akhir kalimat, tetapi juga digunakan untuk penulisan bilangan desimal atau penulisan format file. Oleh karena itu, dibuat aturan tambahan untuk mengganti tanda titik (.) pada kasus-kasus tersebut, di antaranya:
1. Tanda titik (.) pada bilangan desimal diganti dengan tanda bintang (*). Mi-salnya 44.87 diganti menjadi 44*87. Begitu juga untuk alamat website. 2. Tanda titik (.) pada penulisan ”et al.” dihilangkan dan menjadi ”et al”.
11
3. Tanda titik (.) pada format file diganti menjadi tanda bintang (*). Misalnya .txt diganti menjadi *txt.
Aturan tersebut hanya digunakan dalam pemrosesan pada sistem, sedangkan untuk hasil akhir kalimat ringkasan yang akan ditampilkan akan diubah kembali menjadi tanda titik (.). Hasil dari proses parsing kalimat menghasilkan kalimat-kalimat yang merupakan kandidat kalimat ringkasan kecuali judul dokumen atau query.
Pembobotan TF.ISF
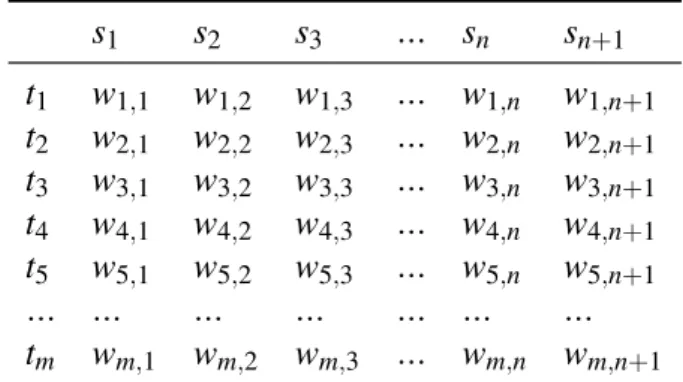
Proses selanjutnya dalam proses peringkasan dokumen adalah menghitung bobot kata dalam kalimat. Asumsikan dokumen yang akan diringkas adalah D yang memi-liki sebanyak n kalimat yaitu s1, s2, s3, s4, . . . , snserta query sn+1, maka bobot TF.ISF
wm,n dihitung menggunakan persamaan 3. Nilai ISF tiap kalimat didapat dari
per-samaan 2. Hasil dari pembobotan tersebut menghasilkan matriks seperti pada Tabel 2. Matriks tersebut berukuran besar dan banyak terdapat nilai 0 dikarenakan fitur kata yang muncul pada suatu kalimat tidak mencapai 10 kata dari 894 fitur kata yang digunakan. Bahkan ada beberapa kalimat yang sama sekali tidak mengandung salah satu fitur kata tersebut.
Tabel 2 Matriks TF.ISF
s1 s2 s3 ... sn sn+1 t1 w1,1 w1,2 w1,3 ... w1,n w1,n+1 t2 w2,1 w2,2 w2,3 ... w2,n w2,n+1 t3 w3,1 w3,2 w3,3 ... w3,n w3,n+1 t4 w4,1 w4,2 w4,3 ... w4,n w4,n+1 t5 w5,1 w5,2 w5,3 ... w5,n w5,n+1 ... ... ... ... ... ... ... tm wm,1 wm,2 wm,3 ... wm,n wm,n+1
Rata-rata matriks tersebut berukuran 894 × 135 dengan jumlah data TF.ISF mak-simum sebanyak 276246 data dan minimum 58110 data. Lebih dari 99% data terse-but bernilai 0 dan hanya kurang dari 1% yang ada nilainya. Dokumen yang memi-liki jumlah data TF.ISF terbanyak adalah dokumen 88 sebesar 0.93% dengan jumlah data TF.ISF yang tidak 0 sebanyak 608 data dari 65262 data, sedangkan yang paling sedikit adalah dokumen 55 sebesar 0.48% dengan jumlah data TF.ISF yang tidak 0 sebanyak 643 data dari 134994 data.
Seleksi Kalimat Menggunakan MMR
Penghitungan MMR dilakukan dengan iterasi yang mengkombinasikan nilai ke-miripan kalimat dengan query dan kalimat dengan kalimat yang telah terpilih se-bagai ringkasan. Pada iterasi pertama, nilai kemiripan sim2(si, sj) bernilai 0 karena
belum ada kalimat yang terambil sebagai ringkasan. Setelah itu, untuk semua kali-mat dalam dokumen dihitung nilai MMR-nya menggunakan persamaan 5. Kalikali-mat dengan nilai MMR tertinggi pada iterasi pertama akan dijadikan ringkasan, misal-nya sj1. Berikut potongan kode program untuk iterasi 1.
1. if($iterasi == 1){ 2. $mmr[$loopSeBanyakKalimat] = ($lambda * 3. $nilai_kemiripan[0][$loopSeBanyakKalimat]) - ((1-$lambda) * 0); 4. if($mmr[$loopSeBanyakKalimat] > $hitmax){ 5. $hitmax = $mmr[$loopSeBanyakKalimat]; 6. $inmax = $loopSeBanyakKalimat; 7. } 8. }
Pada iterasi kedua, dihitung kembali nilai MMR tiap kalimat selain kalimat sj1.
Untuk tiap kalimat, nilai kemiripan sim2(si, sj) yang digunakan adalah nilai
kemi-ripan antara kalimat dengan kalimat sj1 karena hanya terdapat satu kalimat
ring-kasan. Selanjutnya seperti pada iterasi pertama, dipilih kembali kalimat dengan nilai MMR tertinggi, misalnya kalimat sj2. Sampai disini kalimat yang telah
teram-bil sebagai ringkasan ada 2 kalimat. Berikut potongan kode program untuk iterasi 2.
1. else if($iterasi == 2){
2. if(!array_search($loopSeBanyakKalimat, $array)){
3. $mmr[$loopSeBanyakKalimat] = ($lambda * $nilai_kemiripan[0][$loopSeBanyakKalimat])
-4. ((1-$lambda) * $nilai_kemiripan[$maxim][$loopSeBanyakKalimat]); 5. if($mmr[$loopSeBanyakKalimat] > $hitmax){ 6. $hitmax = $mmr[$loopSeBanyakKalimat]; 7. $inmax = $loopSeBanyakKalimat; 8. } 9. } 10. }
Pada iterasi ketiga, karena ada lebih dari 1 kalimat ringkasan yaitu sj1 dan sj2,
maka nilai kemiripan yang digunakan adalah nilai kemiripan maksimum yang di-dapat setelah membandingkan nilai kemiripan seluruh kandidat kalimat yang ter-sisa dengan kalimat sj1 dan sj2. Misalnya nilai kemiripan maksimum yang didapat
adalah nilai kemiripan antara kalimat ke-i dengan kalimat sj1, maka yang
digu-nakan sebagai pembanding kemiripan adalah kalimat sj1. Berarti, pada iterasi ketiga
dibandingkan nilai kemiripan seluruh kandidat kalimat tersisa dengan kalimat sj1.
Selanjutnya setelah dihitung kembali nilai MMR-nya, kalimat dengan nilai MMR tertinggi diambil sebagai ringkasan. Berikut potongan kode program untuk iterasi 3.
1. else{
2. if(!array_search($loopSeBanyakKalimat, $array)){
3. $mmr[$loopSeBanyakKalimat] = ($lambda * $nilai_kemiripan[0][$loopSeBanyakKalimat])
-4. ((1-$lambda)*$nilai_kemiripan[$indexbesar][$loopSeBanyakKalimat]); 5. if($mmr[$loopSeBanyakKalimat] >= $hitmax ){ 6. $hitmax = $mmr[$loopSeBanyakKalimat]; 7. $inmax = $loopSeBanyakKalimat; 8. } 9. } 10. } 1. $array[$iterasi] = $inmax; 2. $maxim = $inmax; 3. if($iterasi >= 2){ 4. $bandingbesar = 0;
13 6. $kalmbil = $array[$i]; 7. if($kalmbil != 0){ 8. for($loopSeBanyakKalimat2=1; $loopSeBanyakKalimat2<$BanyakKalimat; 9. $loopSeBanyakKalimat2++){ 10. if(!array_search($loopSeBanyakKalimat2, $array)){ 11. if($nilai_kemiripan[$loopSeBanyakKalimat2][$kalmbil] > $bandingbesar){ 12. $bandingbesar = $nilai_kemiripan[$loopSeBanyakKalimat2][$kalmbil]; 13. $indexbesar = $kalmbil; 14. } 15. } 16. } 17. } 18. } 19. }
Untuk iterasi keempat dan seterusnya, lakukan hal yang sama seperti pada iterasi ketiga. Iterasi dilakukan hingga mencapai kompresi ringkasan yang telah diten-tukan. Untuk penelitian ini, kompresi ringkasan yang digunakan sebesar 10%, 20%, dan 30%. Selain itu ditentukan pula nilai parameter λ yang digunakan dalam peneli-tian ini yaitu 0.25, 0.50, dan 0.75. Parameter tersebut digunakan sebagai bobot nilai kemiripan.
Nilai MMR tertinggi diperoleh kalimat 14 pada iterasi 1 di dokumen 54 untuk nilai λ = 0.75 yaitu sebesar 0.75. Ini artinya nilai MMR yang didapat sempurna karena nilai kemiripan kalimat 14 dengan query sim1(s14, Q) = 1. Kata-kata yang
terdapat pada query dan termasuk fitur kata terdapat juga pada kalimat 14, sedang-kan kalimat selain kalimat yang sama antara kalimat 14 dengan query, baik yang pada kalimat 14 maupun query, tidak terdapat pada fitur kata.
Nilai MMR terendah yaitu 0. Misalnya seperti yang diperoleh kalimat 1 pada iterasi 2 di dokumen 56 untuk nilai λ = 0.5. Iterasi 2 berarti selain menghitung nilai kemiripan kalimat 1 dengan query, dihitung juga kemiripan kalimat 1 dengan kalimat hasil iterasi 1, yaitu kalimat 17. Untuk kemiripan kalimat 1 dengan query, hanya terdapat 1 kata yang sama tetapi kata tersebut bukan merupakan fitur kata, berarti nilai kemiripannya 0. Untuk kemiripan kalimat 1 dengan kalimat 17, terdapat 2 kata yang sama dan juga bukan merupakan fitur kata, berarti nilai kemiripannya 0. Oleh karena itu, kombinasi keduanya akan menghasilkan nilai MMR = 0.
Hasil ringkasan menggunakan MMR masih belum bisa mengambil kalimat di setiap bagian dokumen skripsi. Misalnya pada dokumen 12, hasil ringkasan kalimat pertama yaitu kalimat 40 yang merupakan bagian dari metode penelitian, sedangkan bagian pendahuluan tidak terseleksi. Ini dikarenakan kalimat-kalimat pada bagian pendahuluan tidak relevan dengan query, dan jikalau ada kata dalam kalimat yang relevan dengan query, kata tersebut bukan termasuk fitur kata. Pada dokumen 12, hanya terdapat 2 kata pada query yang juga terdapat pada fitur kata. Ini menjadi penyebab banyaknya kalimat yang menghasilkan nilai MMR = 0.
Evaluasi Hasil Ringkasan
Tahap evaluasi hasil ringkasan sistem dengan ringkasan manual untuk nilai λ = 0.50, yang berarti bobot kemiripan kalimat dengan judul dan kalimat dengan
kali-mat ringkasan yang telah terpilih seimbang, menghasilkan nilai akurasi ringkasan sebesar 58.67% pada kompresi ringkasan 30%, 61.05% pada kompresi ringkasan 20%, dan 62.14% pada kompresi ringkasan 10%. Akurasi tertinggi yang dida-patkan sebesar 85.67% pada kompresi ringkasan 10%, sedangkan akurasi terendah adalah sebesar 39.74% pada kompresi ringkasan 30%. Perbandingan akurasi untuk λ = 0.50 dapat dilihat pada Gambar 2.
Gambar 2 Akurasi maksimum (a), rata-rata (b), dan minimum (c) untuk nilai λ = 0.50
Untuk nilai λ = 0.25, dimana bobot nilai kemiripan kalimat dengan query lebih kecil dibandingkan dengan bobot nilai kemiripan kalimat dengan kalimat terpilih, akurasi yang didapatkan sebesar 57.68% pada kompresi ringkasan 30%, 60.26% pada kompresi ringkasan 20%, dan 61.61% pada kompresi ringkasan 10%. Nilai ini sedikit lebih rendah dibandingkan dengan penggunaan nilai λ = 0.50. Sama seperti percobaan dengan nilai λ = 0.50, akurasi tertinggi yang didapatkan yaitu sebesar 85.67% pada kompresi ringkasan 10% dan akurasi terendah juga pada kompresi ringkasan 30% sebesar 42.86%. Perbandingan akurasi untuk nilai λ = 0.25 dapat dilihat pada Gambar 3.
Nilai akurasi mengalami peningkatan setelah menaikkan nilai λ menjadi 0.75. Untuk nilai λ tersebut nilai akurasinya sebesar 59.87% pada kompresi ringkasan 30%, 62.11% pada kompresi ringkasan 20%, dan 62.61% pada kompresi ringkasan 10%. Akurasi tertinggi dan terendah yang dicapai masih sama dengan percobaan sebelumnya, yaitu untuk nilai akurasi tertinggi berada pada kompresi ringkasan 10% sebesar 82.95% dan nilai akurasi terendah berada pada kompresi ringkasan 30% sebesar 43.75%. Perbandingan akurasi untuk nilai λ = 0.75 dapat dilihat pada Gambar 4.
Berdasarkan percobaan yang telah dilakukan pada kompresi ringkasan 10%, 20%, dan 30% untuk masing-masing nilai λ sebesar 0.25, 0.50, dan 0.75
didapat-15
Gambar 3 Akurasi maksimum (a), rata-rata (b), dan minimum (c) untuk nilai λ = 0.25
Gambar 4 Akurasi maksimum (a), rata-rata (b), dan minimum (c) untuk nilai λ = 0.75
kan nilai akurasi rata-rata tertinggi yaitu pada kompresi ringkasan 10% dan λ = 0.75 sebesar 62.61%. Perbandingan nilai akurasinya dapat dilihat pada Gambar 5.
Penurunan yang terjadi pada saat λ = 0.25 dan peningkatan pada saat λ = 0.75 wajar terjadi karena ringkasan yang baik adalah ringkasan yang relevan terhadap query. Penggunaan nilai λ = 0.75 berarti bobot query-relevance lebih diperbesar, sehingga otomatis akurasinya menjadi lebih besar. Untuk tiap kompresi ringkasan, jumlah dokumen yang bisa dikatakan query-relevance atau semakin besar nilai λ
Gambar 5 Akurasi rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50 (b), dan λ = 0.25 (c)
maka semakin besar pula nilai akurasinya yaitu sebanyak 53 dokumen untuk kom-presi ringkasan 30%, 59 dokumen untuk komkom-presi ringkasan 20%, dan 52 dokumen untuk kompresi ringkasan 10%. Jadi, bisa dikatakan hasil ringkasan sudah cukup baik karena jumlah dokumen yang query-relevance sudah lebih dari 50%. Artinya, sebagian besar hasil ringkasan sudah sesuai untuk merepresentasikan isi dokumen.
Sementara itu, peningkatan nilai akurasi pada kompresi ringkasan 10% juga wa-jar terjadi karena nilai akurasi hasil ringkasan sistem akan lebih besar jika hasil ringkasan sistem lebih sedikit, yang berarti batas nilai MMR minimum semakin tinggi, dengan asumsi bahwa hasil ringkasan manual, yang digunakan sebagai pem-banding, sudah baik.
Peningkatan akurasi yang terjadi untuk setiap nilai λ tidak terlalu signifikan. Jadi dapat disimpulkan bahwa nilai λ tidak terlalu mempengaruhi hasil akurasi ring-kasan, sedangkan kompresi ringkasan hanya sedikit mempengaruhi akurasi hasil ringkasan.
Selain nilai akurasi, dalam evaluasi hasil ringkasan juga dihitung nilai recall, precision, dan f-1 yang menghasilkan rata-rata seperti pada Gambar 6, 7, dan 8. Re-call, precision, dan f-1 merupakan ukuran keakuratan ringkasan yang hanya mem-perhatikan kalimat yang relevan. Recall merupakan ukuran keakuratan ringkasan terhadap ringkasan manual, precision merupakan ukuran keakuratan ringkasan ter-hadap ringkasan sistem, sedangkan f-1 merupakan gabungan keduanya, yakni keaku-ratan ringkasan diukur berdasarkan ringkasan sistem dan ringkasan manual. Semen-tara itu, akurasi memperhatikan seluruh kalimat, baik yang relevan maupun yang
17
tidak relevan.
Gambar 6 Recall rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50 (b), dan λ = 0.25 (c)
Pada Gambar 6 terlihat nilai recall rata-rata untuk masing-masing nilai λ pada tiap kompresi ringkasan tidak jauh berbeda. Namun, untuk setiap kenaikan kom-presi ringkasan pada nilai λ yang sama memiliki perbedaan kurang lebih 10%. Un-tuk kompresi ringkasan yang menghasilkan persentase recall rata-rata terbesar yaitu pada kompresi ringkasan 30%.
Nilai recall dipengaruhi oleh jumlah kalimat yang sama dalam hasil ringkasan sistem dan ringkasan manual dengan hasil ringkasan manual. Nilai recall tertinggi yaitu 54.05% pada dokumen 3 dengan kompresi ringkasan 30% dan λ = 0.50 dan 0.75. Jumlah kalimat yang sama sebanyak 20 kalimat dan jumlah kalimat ringkasan manual sebanyak 37 kalimat. Sementara itu, nilai recall terendah sebesar 2.94% pada dokumen 44 dengan kompresi ringkasan 10% dan λ = 0.75 dengan jumlah kalimat yang sama hanya 1 kalimat, sedangkan jumlah ringkasan manual ada 34 kalimat. Jika dilihat, ada selisih yang cukup banyak antara kalimat yang sama de-ngan ringkasan manual. Jadi, dapat disimpulkan semakin sedikit selisih jumlah kalimat yang sama dengan hasil ringkasan manualnya, maka semakin besar nilai recall-nya, begitu pula sebaliknya.
Gambar 7 menunjukkan nilai precision rata-rata baik untuk masing-masing ni-lai λ maupun kompresi ringkasan tidak terdapat perbedaan yang signifikan. Kom-presi ringkasan 10% menghasilkan nilai precision rata-rata yang paling besar karena
Gambar 7 Precision rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50 (b), dan λ = 0.25 (c)
peluang kemunculan kalimat hasil ringkasan sistem pada ringkasan manual akan lebih besar jika hasil ringkasan sistem lebih sedikit, sedangkan jumlah ringkasan manual sama. Namun, perbedaan nilai precision antarkompresi ringkasan maupun antarnilai λ tidak terlalu jauh, jadi setiap kalimat hasil ringkasan sistem mempunyai peluang yang hampir sama terdapat dalam ringkasan manual.
Nilai precision dipengaruhi oleh jumlah kalimat yang sama dalam ringkasan sis-tem dan ringkasan manual dengan hasil ringkasan sissis-tem. Nilai precision tertinggi yaitu 92.86% pada dokumen 81 untuk kompresi ringkasan 10% dan λ = 0.50. Jum-lah kalimat yang sama sebanyak 13 kalimat dan jumJum-lah kalimat hasil peringkasan sistem sebanyak 14 kalimat. Sementara itu, nilai precision terendah sebesar 3.33% pada dokumen 9 untuk kompresi ringkasan 10% dan λ = 0.75 dengan jumlah kali-mat yang sama hanya 1 kalikali-mat, sedangkan jumlah hasil ringkasan sistem ada 30 kalimat. Jika dilihat, ada selisih yang cukup banyak antara kalimat yang sama de-ngan ringkasan sistem. Jadi, dapat disimpulkan semakin sedikit selisih jumlah kali-mat yang sama dengan hasil ringkasan sistemnya, maka semakin besar nilai preci-sion-nya.
Pada Gambar 8 terlihat nilai f-1 yang didapat untuk tiap nilai λ pada kompresi ringkasan yang sama tidak berbeda jauh, sedangkan untuk kompresi ringkasan yang berbeda terlihat cukup ada perbedaan. Kompresi ringkasan 30% menghasilkan nilai f-1tertinggi.
19
Gambar 8 F-1 rata-rata hasil ringkasan untuk nilai λ = 0.75 (a), λ = 0.50 (b), dan λ = 0.25 (c)
Nilai f-1 dipengaruhi oleh jumlah kalimat yang sama di dalam ringkasan manual dan hasil ringkasan sistem karena f-1 hanya memperhatikan jumlah kalimat yang relevan. Nilai f-1 tertinggi adalah 62.61% pada dokumen 81 dengan kompresi ring-kasan 30% dan λ = 0.25. Jumlah kalimat yang sama sebanyak 36 kalimat dari hasil ringkasan sistem sebanyak 44 kalimat dan ringkasan manual sebanyak 71 kalimat. Sementara itu, untuk nilai f-1 terendah adalah 3.45% berada pada dokumen 9 de-ngan kompresi ringkasan 10% dan λ = 0.75. Jumlah kalimat yang sama pada doku-men tersebut hanya 1 kalimat dari hasil ringkasan sistem sebanyak 30 kalimat dan ringkasan manual 28 kalimat. Dengan demikian, dapat disimpulkan bahwa semakin banyak kalimat yang sama, maka nilai f-1 semakin tinggi, begitu pula sebaliknya. Dalam hal ini, pada kompresi ringkasan 30% jumlah kalimat hasil ringkasan lebih banyak, jadi kemungkinan terdapat kata yang sama akan lebih besar. Statistik hasil recall, precision, f-1, dan akurasi dapat dilihat pada Tabel 3.
Minimum Maksimum Rata-rata Recall (%) 2.94 54.05 24.50 Precision (%) 3.33 92.86 48.46 F-1 (%) 3.45 62.61 30.88 Akurasi (%) 39.74 85.67 60.67
SIMPULAN DAN SARAN
Simpulan
Berdasarkan penelitian yang telah dilakukan, dapat disimpulkan beberapa hal sebagai berikut:
1. Sistem peringkasan dokumen otomatis berdasarkan fitur kata telah berhasil dikembangkan.
2. Penggunaan metode MMR dengan pembobotan berdasarkan fitur kata meng-hasilkan rata-rata akurasi 60.67%, recall 24.50%, precision 48.46%, dan f-1 30.88%.
3. Untuk dokumen panjang seperti skripsi, hasil akurasi yang didapatkan telah cukup baik karena meringkas dokumen skripsi yang terdiri atas beberapa bab tidaklah mudah. Dibutuhkan keterampilan untuk memilih kalimat ringkasan manual. Atas dasar itulah kemungkinan ada kalimat yang seharusnya tidak dijadikan kalimat ringkasan manual malah dipilih sebagai ringkasan manual atau sebaliknya. Dengan kata lain ada pertimbangan terjadinya human error.
Saran
Jumlah kalimat dalam ringkasan manual sebaiknya diatur proporsinya terhadap jumlah kalimat pada dokumen korpus karena itu mempengaruhi akurasi. Selain itu, pembuatan ringkasan manual untuk setiap dokumen sebaiknya dibuat oleh lebih dari satu orang dengan harapan akurasi yang didapatkan akan lebih baik.
DAFTAR PUSTAKA
Aristoteles. 2011. “Pembobotan Fitur Pada Peringkasan Teks Bahasa Indonesia Menggunakan Algoritme Genetika”. Tesis. Departemen Ilmu Komputer, Institut Pertanian Bogor.
Carbonell, J dan J Goldstein. 1998. “The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries”, pp. 335–336.
Elfayoumy, S dan J Thoppil. 2014. “A Survey of Unstructured Text Summarization Techniques” dalam: IJACSA 5 (4), pp. 149–154.
21
Gerbawani, RAS. 2013. “Peringkasan Dokumen Bahasa Indonesia Menggunakan Logika Fuzzy”. Skripsi. Departemen Ilmu Komputer, Institut Pertanian Bogor. Jezek, K dan J Steinberger. 2008. “Automatic Text Summarization (The State of
The Art 2007 and New Challenges)”, pp. 1–12.
Luhn, HP. 1958. “The Automatic Creation of Literature Abstracts” dalam: IBM Journal, pp. 159–165.
Manning, C.D, P Raghavan, dan H Schutze. 2008. Introduction to Information Re-trieval. Cambridge: Cambridge University Press.
Marlina, M. 2012. “Sistem Peringkasan Dokumen Berita Bahasa Indonesia Meng-gunakan Metode Regresi Logistik Biner”. Skripsi. Departemen Ilmu Komputer, Institut Pertanian Bogor.
Munot, N dan SS Govilkar. 2014. “Comparative Study of Text Summarization Methods” dalam: International Journal of Computer Applicants 102 (12), pp. 33–37.
Mustaqhfiri, M. 2011. “Peringkasan Teks Otomatis Berita Olahraga Berbahasa In-donesia Menggunakan Metode Maximum Marginal Relevance”. Skripsi. Univer-sitas Islam Negeri Maulana Malik Ibrahim.
Powers, DMW. 2007. “Evaluation: From Precision, Recall and F-Factor to ROC, Informedness, Markedness and Correlation” dalam: School of Informatics and Engineering, pp. 1–24.
Turney, PD dan P Pantel. 2010. “From Frequency to Meaning: Vector Space Models of Semantics” dalam: JAIR 37 (5), pp. 141–188.
Waliprana, WE dan ML Khodra. 2013. “Update Summarization Untuk Kumpulan Dokumen Berbahasa Indonesia” dalam: Jurnal Cybermatika 1 (2), pp. 6–10. Wicaksana, IMK dan IM Widiartha. 2012. “Penerapan Metode Ant Colony
Op-timization Pada Metode K-Harmonic Means Untuk Klasterisasi Data” dalam: Jurnal Ilmu Komputer5 (1), pp. 55–62.
Wijakso, B, L Muflikhah, dan A Ridok. 2012. “Klasifikasi Jurnal Ilmiah Berbahasa Inggris Berdasarkan Abstrak Menggunakan Algoritma ID3”, pp. 1–8.
Xia, T dan Y Chai. 2011. “An Improvement to TF-IDF: Term Distribution based Term Weight Algorithm” dalam: Journal of Software 6 (3), pp. 413–420.
Xie, S dan Y Liu. 2008. “Using Corpus and Knowledge Based Similarity Measure In Maximum Marginal Relevance for Meeting Summarization” dalam: ICASSP, pp. 4985–4988.
Lampiran 1. Daftar dokumen skripsi yang digunakan
No. Nama File Judul Dokumen
1 G06amu.pdf Pengembangan Aplikasi Data Mining Menggunakan Fuzzy Association Rules
2 G06ede.pdf Sistem Informasi Untuk Melihat Rute Terpendek dan Jalur Angkot Berbasis SMS
3 G06fso.pdf Pengembangan Sistem Informasi Geografis Hutan Kota Propinsi DKI Jakarta
4 G06hag.pdf Penentuan Pola Sekuensial Pada Data Transaksi Perpustakaan IPB Meng-gunakan Algoritma Graph Search Techniques
5 G06rhs.pdf Sistem Informasi Dinas Pendidikan Berorientasi Objek dan Berbasis Web (Studi Kasus Kota Tanjung Pinang Kepulauan Riau)
6 G09apa2.pdf Sistem Informasi Geografi Asrama Putri TPB IPB Berbasis Web Menggu-nakan Alov Map
7 G09eap.pdf Pengenalan Wajah Dengan Citra Pelatihan Tunggal Menggunakan Algo-ritme VF15 Berbasis Histogram
8 G09nls.pdf Ekspansi Kueri Pada Sistem Temu Kembali Informasi Berbahasa Indonesia Menggunakan Kamus Dwibahasa
9 G09sha.pdf Perancangan Prototipe Ebook Reader Menggunakan Usability Engineering 10 G09wsj.pdf Optimasi Query Citra Dengan Relevance Feedback dan Support Vector
Ma-chine
11 G09yar.pdf Penentuan Tingkat Keberhasilan Mahasiswa Tingkat I IPB Menggunakan Induksi Pohon Keputusan dan Bayesian Classifier
12 G11afr.pdf Identifikasi Campuran Nada Pada Suara Piano Menggunakan Codebook 13 G11ara.pdf Klasifikasi Dokumen Bahasa Indonesia Menggunakan Metode Semantic
Smoothing
14 G11hra.pdf ClusteringKonsep Dokumen Berbahasa Indonesia Menggunakan Bisecting K-Means
15 G11jaz.pdf Pengenalan Iris Mata Dengan Backpropagation Neural Network Menggu-nakan Praproses Transformasi Wavelet
16 G11kau.pdf Data Warehousedan Aplikasi OLAP Akademik Kurikulum Mayor-Minor Berbasis Linux
17 G11kpa.pdf Klasifikasi Dokumen Tumbuhan Obat Menggunakan Algoritma KNN Fuzzy
18 G11mrf.pdf Klasifikasi Genre Musik Menggunakan Learning Vector Quantization (LVQ)
19 G11mus.pdf Pengembangan Distribusi ILOS Multimedia (ILOSMEDIA)
20 G11pra.pdf Pengenalan Kata Berbasiskan Fenom Dengan Pemodelan Resilient Back-propagation
21 G12kab.pdf Rancang Bangun Komunikasi Data Wireless Mikrocontroler Menggunakan Modul Xbee Zigbee (IEEE 802.15.4)
22 G12nsa2.pdf Klasifikasi Dokumen Bahasa Indonesia Menggunakan Semantic Smoothing Dengan Ekstraksi Ciri Chi-Square
23 G12zmu.pdf Analisis Pengaruh Dinamika Peer Pada Hierarchical Peer-To-Peer Meng-gunakan Topologi Superpeer
24 G13ant.pdf Penerapan Teknik Penarikan Contoh Kuota Untuk Penentuan Aplikasi Pada Distro IPB Linux Operating System (ILOS)
25 G13cpy.pdf Implementasi Jaringan Peer-To-Peer Tak Terstrukstur Menggunakan Pro-tokol JXTA
26 G13cws.pdf Deteksi Malware Berbasis System Call Dengan Klasifikasi Support Vector MachinePada Android
23
No. Nama File Judul Dokumen
27 G13dan.pdf Perbandingan Algoritme C4.5 dan Cart Pada Data Tidak Seimbang Untuk Kasus Prediksi Risiko Kredit Debitur Kartu Kredit
28 G13dsu.pdf Pengindeksan Ontologi Dokumen Bahasa Indonesia Menggunakan Latent Semantic Analysis
29 G13eap.pdf Pencarian Teks Bahasa Indonesia Pada Mesin Pencari Berbasis Soundex 30 G13ens.pdf Identifikasi Varietas Ubi Jalar Menggunakan Metode Decision Tree J48 31 G13esa.pdf Aplikasi Bagan Warna Daun Untuk Optimasi Pemupukan Tanaman Padi
Menggunakan K-Nearest Neighbor
32 G13fam.pdf Cross Language Question Answering System Menggunakan Pembobotan Heuristicdan Multidokumen
33 G13fdh.pdf Sistem Pendeteksi Plagiat Harfiah Pada Dokumen Teks Berbahasa Indone-sia Dengan Memanfaatkan Mesin Pencari
34 G13fir.pdf Pembangunan Framework Untuk Deteksi Perubahan dan Irisan Wilayah Pada Data Spatiotemporal
35 G13gka.pdf Sistem Pencarian Turunan Kata Pada Al-Quran Menggunakan Light Stem-mingdan Clustering Untuk Pembicara Bahasa Indonesia
36 G13hap.pdf Analisis Pengaruh Kecepatan Mobilitas Terhadap Kinerja Video Streaming Pada Jaringan Wireless Ad Hooc
37 G13ita.pdf Peningkatan Pelayanan Penilangan Melalui Sistem E-Violation (Studi Ka-sus Satuan Lalu Lintas Polres Bogor)
38 G13mam.pdf Sistem Informasi Geografis Ruang Kuliah Kampus IPB Dramaga Berbasis MobileDengan Platform Android OS
39 G13mir.pdf Penerapan Algoritme Dijkstra Pada Rute Angkot Bogor Berbasis Android 40 G13mpa.pdf Optimasi Jaringan Saraf Tiruan Menggunakan Algoritme Genetika Untuk
Peramalan Panjang Musim Hujan
41 G13naz1.pdf Identifikasi Kolektibilitas Kredit Menggunakan Decision Tree 42 G13nca.pdf Koreksi DNA Sequencing Error Dengan Metode Spectral Alignment 43 G13nfp.pdf Sistem Deteksi Luka Pada Otot Kaki Abalon (Haliotis Asinina)
Menggu-nakan Metode Histogram dan Morfologi
44 G13rjs.pdf Identifikasi Varietas Kunyit Berdasarkan Ciri Fisik Menggunakan Algo-ritme C4.5
45 G13rrp.pdf Peringkas Dokumen Berbahasa Indonesia Berbasis Kata Benda Dengan BM25
46 G13rsu.pdf Penentuan Jalur Tercepat dan Terpendek Berdasarkan Kondisi Lalu Lin-tas Di Kota Bogor Menggunakan Algoritme Dijkstra dan Algoritme Floyd-Warshall
47 G13sba.pdf Pelayanan Publik Online: Sistem Online dan SMS Gateway Pada Pelayanan Izin Usaha Industri
48 G13sra1.pdf Pembangunan Data Warehouse dan Aplikasi OLAP Kepegawaian Institut Pertanian Bogor
49 G13swi.pdf Peringkasan Teks Bahasa Indonesia Dengan Pemilihan Fitur C4.5 dan Klasifikasi Naive Bayes
50 G14aam1.pdf Pengembangan Sistem Informasi Desain Lanskap Tanaman Obat Keluarga Pada Cloud Computing
51 G14aau.pdf Penerapan SOM Untuk Pengenalan Nada Pada Angklung Modern
52 G14ada.pdf Pengklasifikasian Genre Musik Berdasarkan Sinyal Audio Menggunakan Support Vector Machine
53 G14adn.pdf Post PruningPohon Keputusan Spasial Untuk Klasifikasi Kemunculan Titik Panas
No. Nama File Judul Dokumen
55 G14aha1.pdf Implementasi dan Analisis Kinerja Switch Openflow dan Switch Konven-sionalPada Jaringan Komputer
56 G14amu5.pdf Penerapan Jaringan Saraf Tiruan Untuk Pemodelan Prakiraan Curah Hujan Bulanan
57 G14apr1.pdf Penambahan Layer Google Maps Pada Spatial Data Warehouse Titik Panas Di Indonesia
58 G14ash.pdf Klasifikasi Fragmen Metagenom Menggunakan Oblique Decision Tree De-ngan Optimasi Algoritme Genetika
59 G14ask.pdf Steganografi Linguistik Metode Nicetext Menggunakan Kata dan Variasi Pola Kalimat Dasar Bahasa Indonesia
60 G14atr.pdf Aplikasi Mobile Identifikasi Penyakit Daun Kubis Dengan Fast Fourier Transformdan Probabilistic Neural Network
61 G14bsi.pdf Pengelompokan Sekuens DNA Menggunakan Metode K-Means dan Fitur N-Mers Frequency
62 G14cfr.pdf Pencarian Jarak Titik Akses Sinyal Wireless Fidelity (WiFi) Dengan Loca-tion Based Servise(LBS) Pada Android Di Area IPB Darmaga
63 G14dam.pdf Deteksi Data Titik Api Di Provinsi Riau Menggunakan Algoritme Cluster-ing K-Means
64 G14dfm.pdf Klasifikasi Formula Jamu Berdasarkan Khasiat Menggunakan Oblique De-cision TreeDengan Optimasi Menggunakan Algoritme Genetika
65 G14ead.pdf Analisis Sentimen Dengan Klasifikasi Naive Bayes Pada Pesan Twitter Menggunakan Data Seimbang
66 G14egp.pdf Web Log MiningMenggunakan K-Means Pada Server Proxy Untuk Peran-cangan Manajemen Bandwidth IPB
67 G14esy.pdf Pengembangan Aplikasi Pertukaran SMS Rahasia Berbasis Android Meng-gunakan Algoritme RSA
68 G14fam.pdf Pemodelan Biplot Pada Klasifikasi Fragmen Metagenom Dengan K-Mers Sebagai Ekstraksi Ciri dan Probabilistic Neural Network Sebagai Classifier 69 G14fap1.pdf Implementasi Bidirectional HTTP Pada Aplikasi Chat Berbasis Web
Meng-gunakan Protokol Bayeux
70 G14fel.pdf Klasifikasi Fragmen Metagenom Menggunakan Fitur Spaced N-Mers dan K-Nearest Neighbour
71 G14gpr.pdf Aplikasi Mobile GIS Pencarian Tempat Olahraga Di Bogor
72 G14htr.pdf Analisis dan Perancangan Sistem Tata Kelola Kelembagaan dan Sumber Daya FMIPA IPB Menggunakan Enterprise Architecture Planning 73 G14iad.pdf Hierarchical ClusteringPada Data Time Series Hotspot Provinsi Riau 74 G14ins.pdf Identifikasi Plat Nomor Dengan Principal Component Analysis
Menggu-nakan Metode Jaringan Syaraf Tiruan Propagasi Balik
75 G14kil.pdf Teknik Penyisipan Informasi Pada Fitur Poligon Peta Vektor Menggunakan Reversible Watermarking
76 G14kum.pdf Optimasi Penggunaan Lahan Menggunakan Algoritme Genetika Untuk Mendukung Peningkatan Produktivitas Pertanian
77 G14lns.pdf Penerapan Learning Vector Quantization (LVQ) dan Ekstraksi Ciri Meng-gunakan Mel-Frequency Ceptrum Coeficients (MFCC) Untuk Transkripsi Suara Ke Teks
78 G14man.pdf Migrasi Spatial Data Warehouse Hotspot Ke Sistem Operasi Linux Ubuntu 79 G14mch.pdf Identifikasi Citra Luka Abalon (Haliotis Asinina) Menggunakan Gray Level
Co-occurrence Matrixdan Klasifikasi Probabilistic Neural Network 80 G14mdh.pdf Klasifikasi Fragmen Metagenom Menggunakan KNN dan PNN Dengan
Ekstraksi Fitur Gray Level Co-occurrence Matrix (GLCM) Pada Variasi Panjang Fragmen
25
No. Nama File Judul Dokumen
81 G14mhu.pdf Integrasi Basis Data dan Pipeline Single Nucleotide Polymorphism Untuk Pemuliaan Tanaman Kedelai
82 G14mlr.pdf Pengembangan dan Implementasi Sistem Pemadaman Api Pada Fire-Fighting Robot
83 G14naf.pdf ClusteringData Indeks Pembangunan Manusia (IPM) Pulau Jawa Menggu-nakan Algortime ST-DBSCAN dan Bahasa Pemrograman R
84 G14nas1.pdf ClusteringDokumen Skripsi Berdasarkan Abstrak Dengan Menggunakan Bisecting K-Means
85 G14rad.pdf Penentuan Lokasi Ideal Berdasarkan Total Jarak Tempuh Terpendek Dari Berbagai Lokasi Menggunakan Algoritme Dijkstra
86 G14ref.pdf Pengembangan Sistem Informasi Tanaman Hias Lanskap Untuk Masyarakat Umum Pada Cloud Computing
87 G14rfh.pdf Pendeteksian Kemiripan Kode Program C Dengan Algoritme K-Medoids 88 G14rku.pdf Temu Kembali Informasi Dokumen XML Dengan Pembobotan Per Konteks 89 G14rku2.pdf Klasifikasi Protein Family Menggunakan Algoritme Probabilistic Neural
Network(PNN)
90 G14rma.pdf Clustering DatasetTitik Panas Dengan Algoritme DBSCAN Menggunakan Web Framework ShinyPada Bahasa Pemrograman R
91 G14rmf.pdf Aplikasi Perangkat Uji Pupuk Berbasis Android Menggunakan Fitur Warna 92 G14rse.pdf Pengembangan Sistem Keamanan Traksaksi Peta Digital Menggunakan
Teknik Kriptografi
93 G14rtr.pdf Pengelompokan Kode Program C Berdasarkan Kemiripan Struktur Meng-gunakan Metode Hierarchical Agglomerative Clustering
94 G14sda.pdf Pemanfaatan Citra Satelit Untuk Identifikasi Tingkat Perubahan Tutupan Lahan Dengan Menggunakan Metode Fuzzy C-Means
95 G14sro1.pdf Transkripsi Suara Ke Teks Bahasa Indonesia Berbasis Suku Kata Menggu-nakan Codebook dan 2-Level Dynamic Programming
96 G14tmp.pdf Pengembangan Silsilah (Tarombo) Adat Batak Berbasis Web Menggunakan R4 Framework
97 G14yse.pdf Simulasi Master Data Untuk Data Exchange Evaluasi Kinerja Dosen Berba-sis Replika BaBerba-sis Data
98 G15ekd.pdf Pemodelan Support Vector Machine Untuk Klasifikasi Bakteri Patogen dan Non Patogen Berdasarkan Data Sekuens Genom
99 G15fdw.pdf Online Analytical Processing (OLAP) Berbasis Web Untuk Tanaman Holtikultura Menggunakan Palo
100 G15hri.pdf Aplikasi Android Untuk Pengenalan Citra Karakter Jepang Dengan Library Tesseract
Lampiran 2. Grafik Akurasi maksimum (a), rata-rata (b), dan
minimum (c) tiap kompresi ringkasan
1. Grafik Akurasi untuk kompresi ringkasan 30 %
2. Grafik Akurasi untuk kompresi ringkasan 20 %
27
Lampiran 3. Grafik Recall maksimum (a), rata-rata (b), dan
min-imum (c) tiap kompresi ringkasan
1. Grafik Recall untuk kompresi ringkasan 30 %
2. Grafik Recall untuk kompresi ringkasan 20 %
Lampiran 4. Grafik Recall maksimum (a), rata-rata (b), dan
min-imum (c) tiap nilai λ
1. Grafik Recall untuk nilai λ = 0.25
2. Grafik Recall untuk nilai λ = 0.50
29
Lampiran 5. Grafik Precision maksimum (a), rata-rata (b), dan
minimum (c) tiap kompresi ringkasan
1. Grafik Precision untuk kompresi ringkasan 30 %
2. Grafik Precision untuk kompresi ringkasan 20 %
Lampiran 6. Grafik Precision maksimum (a), rata-rata (b), dan
minimum (c) tiap nilai λ
1. Grafik Precision untuk nilai λ = 0.25
2. Grafik Precision untuk nilai λ = 0.50
31
Lampiran 7. Grafik F-1 maksimum (a), rata-rata (b), dan
mini-mum (c) tiap kompresi ringkasan
1. Grafik F-1 untuk kompresi ringkasan 30%
2. Grafik F-1 untuk kompresi ringkasan 20%
Lampiran 8. Grafik F-1 maksimum (a), rata-rata (b), dan
mini-mum (c) tiap nilai λ
1. Grafik F-1 untuk nilai λ = 0.25
2. Grafik F-1 untuk nilai λ = 0.50
33
RIWAYAT HIDUP
Penulis dilahirkan di Cirebon pada tanggal 28 September 1990. Penulis meru-pakan putri pertama dari tiga bersaudara dari ayah H. Ihun Solihun dan ibu Hj. Yusroniyah. Tahun 2008 penulis lulus dari SMA Negeri 7 Cirebon dan pada tahun yang sama penulis melanjutkan pendidikan pada program D3, program studi Teknik Informatika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Universitas Padja-djaran, Bandung. Penulis lulus dari Universitas Padjadjaran pada tahun 2011. Pada tahun 2013, penulis lulus seleksi masuk program Sarjana Alih Jenis, Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Perta-nian Bogor.