HUSMUL BEZE
SEKOLAH PASCASARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2008
Dengan ini saya menyatakan bahwa tesis Karakter Pelanggan PLN Menggunakan Algoritma Fuzzy C Mean adalah karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apapun kepada perguruan tinggi manapun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir tesis ini.
Bogor, Juli 2008
Husmul Beze NRP. G651050034
Berdasarkan sudut pandang teknologi, CRM adalah alat bantu sistem dalam melakukan analisis perilaku pelanggan berdasarkan data historis. Satu tugas penting dari CRM adalah mengidentifikasi karakter pelanggan PLN berdasarkan perilaku dalam menggunakan energi listrik. Dalam penelitian ini, identifikasi terhadap pelanggan dilakukan dengan cara melakukan segmentasi pelanggan. Golongan pelanggan yang akan disegmentasi antara lain pelanggan rumah tangga, bisnis dan industri. Variabel yang digunakan sebagai atribut dalam proses segmentasi adalah lama berlangganan, jumlah pembayaran listrik, kedisiplinan membayar dan jumlah pemakaian listrik. Dalam sistem yang dikembangkan dalam penelitian ini disediakan berbagai pilihan kombinasi variabel untuk disegmentasi. Tujuannya untuk memberi banyak pilihan bagi PLN dalam melakukan segmentasi terhadap pelanggan sesuai keperluan.
Metode yang digunakan untuk melakukan segmentasi pelanggan adalah algoritma fuzzy c-mean. Untuk mengukur keakuratan segmentasi, hasil klasterisasi divalidasi menggunakan metode indeks Xie dan Beni. Hasil penelitian memperlihatkan, pelanggan rumah tangga dan bisnis lebih akurat jika dikelompokkan ke dalam 3 klaster, sementara pelanggan industri pada beberapa kombinasi variabel lebih akurat dikelompokkan ke dalam 3 klaster dan beberapa kombinasi variabel lainnya lebih akurat dikelompokkan ke dalam 4 klaster. Dalam implementasi CRM, analisis karakter-karakter segmen merupakan salah satu bagian analisis terhadap pelanggan.
Based on the technology point of view, CRM is a system tool in analyzing customers’ behavior based on customer histories data. One of the important tasks of CRM is identifying PLN customers’ behavior based on their behavior in using electricity. Customer identification is done by segmenting customers. In this research, the customer that will be segmented are home, business and industrial customer. The variable that used as a attribute in segmentation process are the duration of subscribing, total payment, discipline in paying and total electric usage. The system that developed in this research provided many choice of variable combination to be segmented. The goal is to provide many choice for PLN in segmenting customer.
The method used for segmenting customer is fuzzy c-mean algorithm. To measure the segmentation accuration, the result of the clustering is validated by the Xie and Beni index method. The result of the research showed that business and home customer are more accurate if they are clustered into 3 clusters, while the industrial customer in some variable combination are more accurate if they are clustered into 3 clusters and the some variable combination are more accurate if they are clustered into 4 clusters. The result of customers’ character segmentation can be used as supporting data in making PLN’s business decision which is related to CRM.
Manajemen hubungan pelanggan (CRM) adalah sebuah strategi yang berfokus pada perilaku konsumen dan cara berkomunikasi dengan mereka. Berdasarkan sudut pandang teknologi, CRM adalah alat bantu sistem untuk melakukan analisis perilaku konsumen berdasarkan data historis pelanggan dalam rangka pelayanan terhadap pelanggan.
Perusahaan listrik negara (PLN) merupakan perusahaan negara yang menyediakan tenaga listrik untuk seluruh wilayah Indonesia. Visi dan misi pelayanannya antara lain menjadikan pelanggan sebagai mitra sejajar, menjamin kepuasan dan kesetiaan pelanggan, menjamin pertumbuhan perusahaan yang berkesinambungan dan menciptakan pelayanan berbasis sistem teknologi informasi. Sebagai perusahaan yang berorientasi pada pelanggan (customer oriented enterprise) manajemen PLN telah mengembangkan sistem pengelolaan pelanggan yang bernama customer information system (CIS). Namun pelayanan yang dilakukan dalam sistem ini masih bersifat teknik, belum melakukan pengelolaan pelanggan secara lebih mendalam umpamanya melakukan analisa terhadap perilaku pelanggan dalam menggunakan energi listrik.
Sehubungan dengan komitmen PLN sebagai perusahaan yang berorientasi pada pelanggan, di dalam penelitian ini akan dilakukan riset terhadap salah satu bagian CRM yaitu segmentasi pelanggan. Hal ini sesuai dengan pendapat Han dan Kamber (2001) bahwa segmentasi terhadap pelanggan dapat menolong pelaku pemasaran menemukan kelompok berbeda pada pelanggan dan karakteristik pelanggan berdasarkan perilaku pelanggan. Salah satu metode segmentasi yang bisa digunakan untuk melakukan segmentasi pelanggan adalah algoritma fuzzy c-mean (FCM). Algoritma FCM sudah cukup luas digunakan dalam melakukan segmentasi pelanggan diantaranya penelitian Ho (1999), Simha dan Iyengar (2005), Tsangarides dan Qureshi (2006), Daulay (2006) dan Zumstein (2007). Namun semua penelitian di atas belum ada yang menerapkan pada pelanggan PLN. Padahal karakteristik pelanggan PLN berbeda dengan objek penelitian yang telah dilakukan di atas. Padahal penting bagi PLN untuk tidak mengabaikan kepuasan pelanggan.
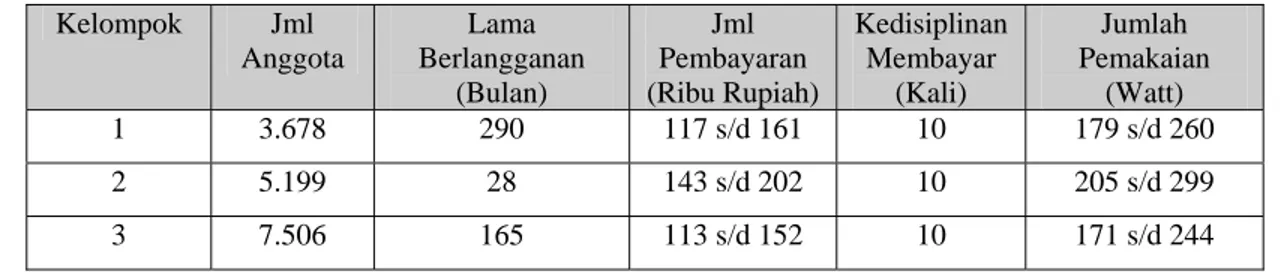
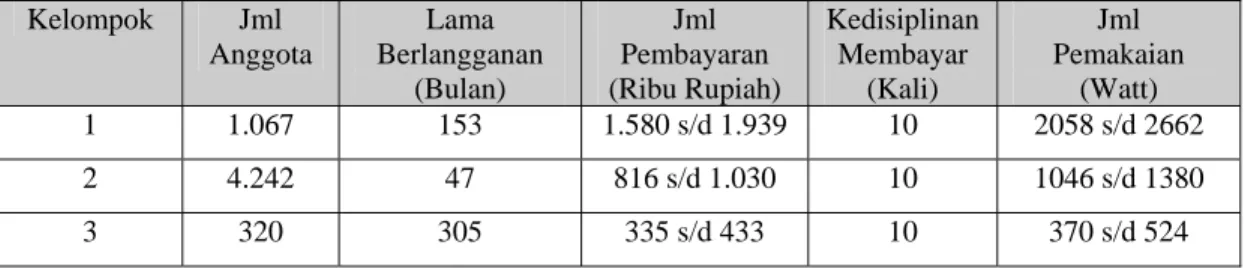
Data yang digunakan dalam penelitian ini adalah data transaksi pelanggan dari Bulan November 2006 hingga Oktober 2007. Sebagai data masukan sistem digunakan tiga data masukan yaitu data pelanggan rumah tangga, bisnis dan industri. Empat variabel yang digunakan sebagai atribut data masukan yaitu (1) lama berlangganan, (2) jumlah pembayaran, (3) kedisiplinan membayar dan (4) jumlah pemakaian listrik.
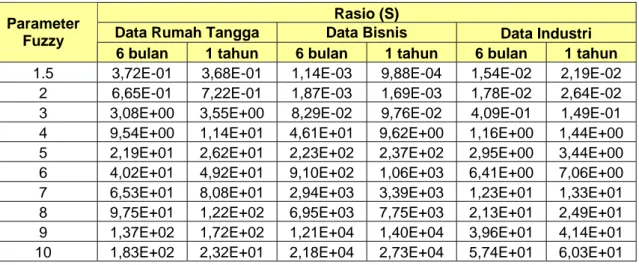
Ada empat parameter yang akan ditetapkan pada tahap awal dalam menggunakan algoritma fuzzy c-mean yaitu jumlah klaster, nilai error, iterasi maksimal dan nilai parameter fuzifikasi. Keempat parameter ini sangat penting dalam proses analisis pengelompokan terutama dalam menentukan karakter data yang tengah dikelompokkan. Jumlah klaster yang digunakan dalam penelitian ini adalah 3, 4 dan 5. Sementara nilai parameter fuzzifikasi yang digunakan adalah
ataupun 5 klaster. Sementara untuk pelanggan industri, pada kombinasi variabel A, B, C, AB, AC, BC, BD, ABC, ABD, BCD dan ABCD lebih akurat dikelompokkan ke dalam 3 klaster, sedangkan kombinasi D, AD, CD dan ACD lebih akurat jika dikelompokkan ke dalam 4 klaster di bandingkan 3 klaster ataupun 5 klaster. Nilai parameter fuzzifikasi yang direkomendasikan untuk melakukan klastering data pelanggan golongan rumah tangga, bisnis dan industri adalah 1,5. Sementara nilai error dan iterasi maksimal yang direkomendasikan digunakan saat melakukan klastering terhadap data pelanggan rumah tangga, bisnis dan industri adalah 0,00001 dan 100.
Variabel lama berlangganan, jumlah pembayaran, kedisplinan membayar dan jumlah pemakaian listrik yang digunakan dalam penelitian ini cukup untuk menggambarkan perilaku pelanggan dalam menggunakan energi listrik. Dalam implementasi CRM, hasil analisis karakter segmen pelanggan merupakan salah satu bagian analisis pelanggan. Analisis lainnya yang bisa dilakukan untuk melengkapi bagian CRM antara lain analisis profit pelanggan dan analisis kepuasan pelanggan. Beberapa pelayanan yang bisa dilakukan PLN sehubungan dengan hasil karakter segmen-segmen pelanggan antara lain dalam program prioritasisasi terhadap pelanggan, pemberian penghargaan, insentif khusus dan isyarat dini.
© Hak cipta milik IPB, Tahun 2008
Hak Cipta dilindungi Undang-Undang
1. Dilarang mengutip sebagian atau seluruh karya tulis ini tanpa mencantumkan atau menyebutkan sumbernya.
a. Pengutipan hanya untuk kepentingan pendidikan, penelitian, penulisan karya ilmiah, penyusunan laporan, penulisan kritik atau tinjauan suatu masalah; b. Pengutipan tersebut tidak merugikan kepentingan yang
wajar IPB.
2. Dilarang mengumumkan dan memperbanyak sebagian atau seluruh Karya tulis dalam bentuk apapun tanpa izin IPB.
HUSMUL BEZE
Tesis
Sebagai salah satu syarat untuk memperoleh gelar Magister Sains pada
Program Studi Ilmu Komputer
SEKOLAH PASCA SARJANA
INSTITUT PERTANIAN BOGOR
BOGOR
2008
Disetujui Komisi Pembimbing
Prof. Dr. Ir. Kudang Boro Seminar, M.Sc Ir Agus Buono, M.Si, M.Kom
Ketua Anggota
Diketahui
Ketua Program Studi Dekan Sekolah Pascasarjana Ilmu Komputer
Dr. Sugi Guritman Prof Dr Khairil Anwar A. Notodiputro, M.S
Halaman
DAFTAR TABEL... xii
DAFTAR GAMBAR ... xiii
DAFTAR LAMPIRAN... xiv
I. PENDAHULUAN 1.1. Latar Belakang ... 1
1.2. Tujuan Penelitian ... 2
1.3. Manfaat Penelitian ... 2
1.4. Ruang Lingkup Penelitian... 2
II. TINJAUAN PUSTAKA 2.1. Objek Penelitian ... 3
2.1.1. Perilaku Konsumen ... 3
2.1.2. Segmentasi Konsumen dan Pasar ... 4
2.1.3. Manajemen Hubungan Pelanggan ... 5
2.1.4. PT PLN Distribusi Jakarta Raya dan Tangerang ... 8
2.2. Alat dan Teknik Penelitian... 11
2.2.1. Himpunan Fuzzy... 11
2.2.2. Fuzzy Klastering ... 14
2.2.3. Fuzzy C Mean Klastering... 17
2.2.4. Validasi Klaster... 21
2.3. Penelitian yang Relevan... 21
III. METODOLOGI 3.1. Tahapan Penelitian ... 22
3.1.1. Analisis Masalah ... 22
3.1.2. Persiapan Data... 23
3.1.3. Desain Model Sistem ... 23
3.1.4. Implementasi Pengembangan Model Prototipe Sistem... 25
3.2. Alat Bantu Riset ... 26
4.3. Desain Antarmuka... 30
4.4. Validasi Hasil Pengelompokan Pelanggan... 32
4.4.1. Nilai Error dan Iterasi Maksimal... 32
4.4.2. Parameter Fuzzy... 33
4.4.3. Jumlah Klaster ... 33
4.5. Karakter Pelanggan ... 36
4.6. Implementasi CRM di PLN ... 47
V. SIMPULAN DAN SARAN 5.1. Simpulan ... 60
5.2 Saran... 60
DAFTAR PUSTAKA ... 61
1. Tabel masukan sistem pengelompokkan pelanggan ... 23
2. Tabel parameter dan nilainya ... 24
3. Tabel matriks keanggotaan (Un) terhadap k cluster ... 29
4. Hasil validasi pengelompokkan terhadap nilai error dan iterasi maksimal 31 5. Karakter pelanggan rumah tangga berdasarkan lama berlangganan ... 36
6. Karakter pelanggan rumah tangga berdasarkan jumlah pembayaran listrik 37 7. Karakter pelanggan rumah tangga berdasarkan kedisiplinan membayar .. 38
8. Karakter pelanggan rumah tangga berdasarkan jumlah pemakaian listrik 39 9. Karakter pelanggan rumah tangga berdasarkan lama berlangganan dan kedisiplinan membayar ... 40
10. Karakter pelanggan bisnis berdasarkan lama berlangganan ... 41
11. Karakter pelanggan bisnis berdasarkan kedisiplinan membayar ... 42
12. Karakter pelanggan bisnis berdasarkan lama berlangganan dan jumlah pembayaran ... 42
13. Karakter pelanggan bisnis berdasarkan jumlah pembayaran ... 43
14. Karakter pelanggan industri berdasarkan lama berlangganan ... 45
15. Karakter pelanggan industri berdasarkan jumlah pembayaran ... 45
16. Karakter pelanggan industri berdasarkan kedisiplinan membayar... 46
17. Karakter pelanggan industri berdasarkan jumlah pemakaian listrik ... 46
18. Karakter pelanggan industri berdasarkan lama berlangganan dan kedisiplinan membayar ... 47
2. Komponen himpunan fuzzy... 12
3. Himpunan fuzzy untuk variabel umur ... 13
4. Jarak poin data terhadap sebuah klaster ... 14
5. Jarak poin data terhadap dua klaster 15 6. Tahapan algoritma fuzzy c-mean... 20
7. Tahapan penelitian ... 22
8. Tatalaksana pengembangan prototipe karakterisasi pelanggan PLN ... 25
9. Fitur-fitur matriks data masukan sistem ... 28
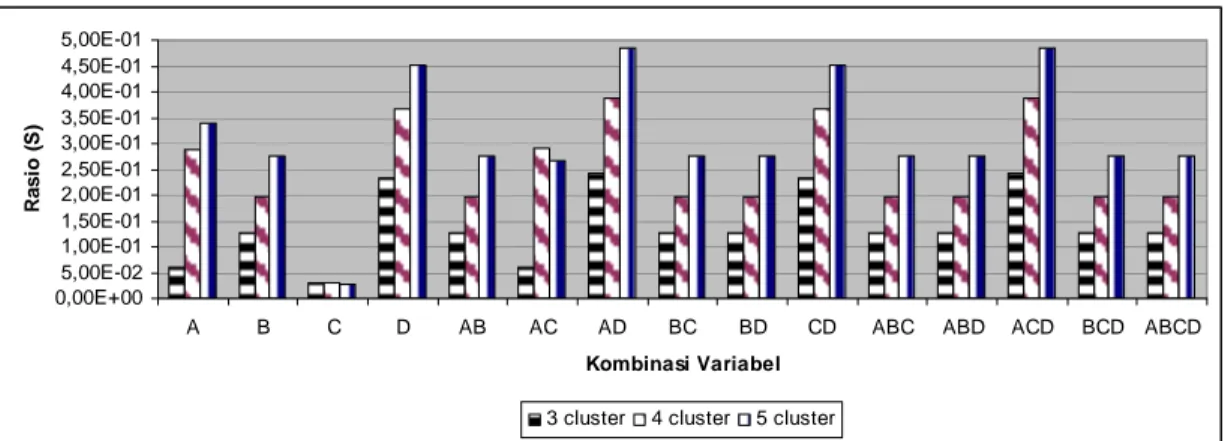
10.Hasil validasi pengelompokkan pada data pelanggan rumah tangga dengan 3 klaster, 4 klaster dan 5 klaster ... 33
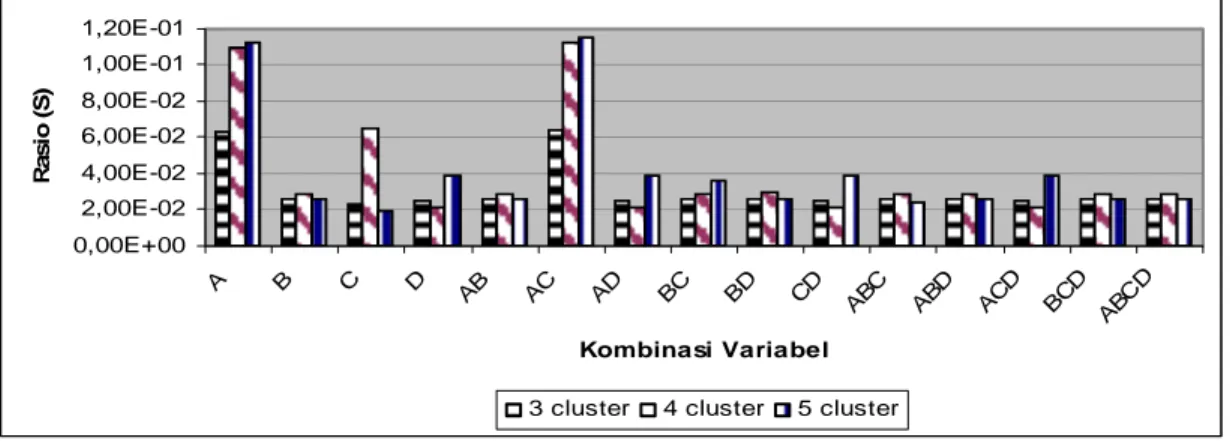
11.Hasil validasi pengelompokkan pada data pelanggan bisnis dengan 3 klaster, 4 klaster dan 5 klaster ... 34
12.Hasil validasi pengelompokkan pada data pelanggan industri dengan 3 klaster, 4 klaster dan 5 klaster ... 35
13.Pilar CRM ... 47
14.Momentum interaksi pelanggan dengan sistem CRM ... 48
15.Saluran pengumpulan informasi dan sarana layanan ... 49
16.Hubungan aktivitas sistem CRM PLN... 57
1. Hasil uji validasi hasil pengelompokkan pada data pelanggan rumah tangga, bisnis dan industri. ... 65 2. Panduan penggunaan sistem... 81 3. Karakter pelanggan rumah tangga dilihat dari berbagai kombinasi
variabel ... 85 4. Karakter-karakter pelanggan bisnis dilihat dari berbagai kombinasi
variabel ... 87 5. Karakter-karakter pelanggan industri dilihat dari berbagai kombinasi
1.1. Latar Belakang
Manajemen hubungan pelanggan (CRM) adalah sebuah strategi yang berfokus pada perilaku konsumen dan cara berkomunikasi dengan mereka. Berdasarkan sudut pandang teknologi, CRM adalah dasar untuk melakukan analisis perilaku konsumen berdasarkan data historis pelanggan. CRM bukan hanya bisa digunakan sebagai strategi dalam rangka memenangkan kompetisi di bidang pemasaran. Namun bisa juga digunakan untuk memberikan pelayanan prima kepada pelanggan dengan tujuan memberi kepuasan kepada pelanggan.
Perusahaan listrik negara (PLN) merupakan perusahaan negara yang menyediakan tenaga listrik untuk seluruh wilayah Indonesia. Visi dan misi pelayanannya antara lain menjadikan pelanggan sebagai mitra sejajar, menjamin kepuasan dan kesetiaan pelanggan, menjamin pertumbuhan perusahaan yang berkesinambungan dan menciptakan pelayanan berbasis sistem teknologi informasi. Sebagai perusahaan yang berorientasi pada pelanggan (customer oriented enterprise) manajemen PLN telah mengembangkan sistem pengelolaan pelanggan yang bernama customer information system (CIS). Namun pelayanan yang dilakukan dalam sistem ini masih bersifat teknik, belum melakukan pengelolaan pelanggan secara lebih mendalam yaitu melakukan analisa terhadap perilaku pelanggan dalam menggunakan energi listrik.
Sehubungan dengan komitmen PLN sebagai perusahaan yang berorientasi pada pelanggan, di dalam penelitian ini akan dilakukan riset terhadap salah satu bagian CRM yaitu segmentasi pelanggan. Hal ini sesuai dengan pendapat Kertajaya (2005) yaitu mengungkapkan identifikasi pelanggan sangat penting dilakukan dalam membangun manajemen hubungan pelanggan terutama dalam rangka memetakan interaksi hubungan apa yang harus dilakukan perusahan. Pengelompokkan pelanggan menurut Han dan Kamber (2001) bisa menolong pelaku pemasaran dalam menemukan karakteristik dan perilaku pelanggan yang berbeda dalam setiap kelompok. Adanya gambaran nyata tentang pelanggan memudahkan perusahaan menentukan strategi alokasi dan penggunaan sumber daya yang ada dan memberikan pelayanan terbaik bagi pelanggannya. Dengan
demikian, energi perusahaan dapat lebih dihemat dan manajemen dapat memfokuskan pelayanan pada konsumen, yang secara langsung telah memberikan profit signifikan kepada perusahaan.
Salah satu metode segmentasi yang bisa digunakan untuk melakukan segmentasi pelanggan adalah algoritma fuzzy c-mean (FCM). Algoritma FCM sudah cukup luas digunakan dalam melakukan segmentasi pelanggan diantaranya penelitian Ho (1999), Simha dan Iyengar (2005), Tsangarides dan Qureshi (2006), Daulay (2006) dan Zumstein (2007).
Semua penelitian di atas belum ada yang menerapkan pada pelanggan PLN. Padahal karakteristik pelanggan PLN berbeda dengan objek penelitian yang telah dilakukan di atas. Sebagai perusahaan yang memonopoli distribusi listrik di Indonesia, penting bagi PLN untuk tidak mengabaikan kepuasan pelanggan. Penerapan CRM merupakan alternatif tepat dalam rangka memberikan pelayanan yang prima pada pelanggan.
1.2. Tujuan Penelitian
Tujuan penelitian ini adalah melakukan karakterisasi pelanggan di PLN menggunakan algoritma fuzzy c-mean untuk mendukung program CRM.
1.3. Ruang Lingkup Penelitian
Ruang lingkup penelitian ini adalah :
1. Data yang digunakan pada penelitian ini adalah data transaksi pelanggan PT PLN Distribusi Jakarta Raya dan Tangerang Area Pelayanan Cengkareng dari bulan November 2006 sampai Oktober 2007.
2. Penelitian ini dibatasi pada karakterisasi pelanggan di PLN.
1.4. Manfaat Penelitian
Penelitian ini diharapkan mampu mengidentifikasi karakter pelanggan dan mendukung manajemen dalam upaya memberikan pelayanan prima yang pada akhirnya mampu memberi kepuasan pada pelanggan. Sekaligus menjadi kerangka kerja bagi perusahaan dalam membangun CRM.
2.1. Objek Penelitian
2.1.1. Perilaku Konsumen
Jika dilihat dari daya tarik transaksinya, pelanggan menurut Kertajaya (2005) terbagi dalam empat kategori yakni star customer, question mark customer, profit making customer dan profit taking customer. Tujuan mengidentifikasi
pelanggan adalah untuk mengetahui pelanggan yang bernilai dan pelanggan yang tidak bernilai. Menurutnya pelanggan yang potensial tidak boleh dibiarkan, tapi harus dikelola dan diperhatikan lewat berbagai pelayanan.
Potensi pelanggan adalah nilai-nilai positip yang dimiliki pelanggan. Potensi pelanggan sangat erat kaitannya dengan karakter pelanggan. Karakter pelanggan bisa diketahui lewat perilaku pelangggan. Sementara itu, Paul dan Oslo (1996) dalam Rangkuti (2006) menyatakan perilaku pelanggan adalah interaksi dinamis antara pengaruh dan kognisi, perilaku dan kejadian di sekitar kita dimana manusia melakukan aspek pertukaran dalam hidup mereka. Sedangkan menurut Engel (1996) dalam Rangkuti (2006) perilaku konsumen adalah tindakan yang langsung terlibat dalam mendapatkan, mengkonsumsi dan menghabiskan produk dan jasa, termasuk proses keputusan yang mendahului tindakan tersebut. Kotler dan Armstrong (2001) menambahkan perilaku konsumen secara kuat dipengaruhi oleh karateristik budaya, sosial, pribadi dan psikologis.
Sementara itu Assael (1992) mengemukakan ada empat tipe perilaku konsumen dalam proses pembelian yaitu pembeli membuat keputusan pada saat proses pembelian melakukan keterlibatan tinggi, interaksi ini menghasilkan tipe perilaku pembelian yang kompleks, konsumen melakukan pembelian terhadap merek tertentu secara berulang-ulang dan mempunyai keterlibatan tinggi dalam proses pembelian, konsumen ini tipe loyal terhadap merek, pembelinya membuat keputusan tapi dalam proses pembeliannya merasa kurang terlibat. Tipe ini merupakan perilaku konsumen limited decision making. Pembelian atas dasar
kebiasaan dan dalam proses pembelian konsumen merasa kurang terlibat, tipe ini merupakan perilaku konsumen inertia.
Hawkins dalam Maulana (1999) menegaskan bahwa keputusan pembelian konsumen dipengaruhi oleh banyak faktor, antara lain, budaya, nilai-nilai yang dianut konsumen, status sosial, persepsi, dan keadaan demografi.
2.1.2. Segmentasi Konsumen dan Pasar
Pasar terdiri dari banyak pembeli dan para pembeli berbeda untuk satu dan banyak hal. Mereka dapat berbeda dalam kebutuhan, sumberdaya, lokasi, sifat pembelian dan pola pembelian. Melalui segmentasi pasar, perusahaan membagi pasar yang besar dan heterogen menjadi segmen yang lebih kecil yang dapat diliput secara efisien dengan produk dan layanan yang memenuhi kebutuhan unik mereka. (Kotler dan Armstrong, 2001).
Menurut Amir (2005) segmentasi memegang peranan penting. Segmentasi yang tepat bisa menjadi awal yang menentukan bagi penerapan strategi dan taktik pemasaran. Dengan segmentasi dapat dilakukan perumusan kebutuhan dan keinginan pasar, merancang strategi dan program yang tepat, menganalisis persaingan, menyesuaikan sumber daya dan menemukan potensi permintaan baru. Dengan ada segmentasi yang baik maka ada batasan yang jelas antara kelompok satu dengan kelompok lain. Hal ini memudahkan perusahaan dalam menentukan target, memperkecil resiko salah sasaran dan menyesuaikan kemampuan. Secara umum segmentasi bisa dilakukan berdasarkan demografis, geografi, psikografis dan sosial.
Kotler dan Armstrong (2001) mengatakan bahwa segmentasi konsumen atau pasar tidak mudah. Perusahaan harus mencoba berbagai variabel segmentasi, baik sendirian maupun kombinasi, untuk menemukan cara terbaik dalam memandang struktur pasar. Segmentasi bisa dilakukan berdasarkan geografis, demografis, psikografis ataupun perilaku.
Dengan mengamati hubungan pelanggan pada berbagai segmen kita bisa memberikan perlakuan hubungan pelanggan yang berbeda untuk masing-masing pasar sasaran secara spesifik. (Rangkuti, 2006).
2.1.3. Manajemen Hubungan Pelanggan
Manajemen hubungan pelanggan (customer relationship management)
bagaimana kita berinteraksi dan proaktif mengatur hubungan pelanggan kita. CRM lanjutnya merupakan sistem ril bagaimana kita bekerja dengan para pelanggan, memecahkan problem pelanggan, mendorong pelanggan untuk membeli produk dan jasa serta melakukan kesepakatan dalam transaksi finansial. CRM katanya lagi merupakan sebuah sistem dalam proses bisnis, sebuah teknologi dan seperangkat aturan untuk melakukan kesepakatan dengan pelanggan pada berbagai tingkatan dalam aktifitas bisnis.
Danardatu (2003) menyebut CRM sebagai pengelolaan hubungan dua arah antara suatu perusahaan dengan orang yang menjadi pelanggan di perusahaan tersebut. CRM bisa juga didefinisikan sebagai sebuah istilah industri TI untuk metodologi, strategi, perangkat lunak (software) dan atau aplikasi berbasis web
lainnya yang mampu membantu sebuah perusahaan (enterprise, kalau besar ukurannya) untuk mengelola hubungannya dengan para pelanggan.
Sementara itu, CRM menurut Tourniare (2003) bisa diartikan menjadi tiga yakni pertama, semua fungsi yang mengacu pada konsumen seperti pemasaran, sales dan consumen support. Kedua, CRM diartikan sebagai perangkat otomatis dalam teknik pemasaran. Terakhir CRM didefinisikan sebagai suatu proses yang digunakan dalam melakukan manajemen terhadap pelanggan.
Untuk mengimplementasikan sebuah strategi CRM menurut Danardatu (2003) diperlukan paling tidak tiga faktor kunci yaitu orang-orang yang profesional (kualifikasi memadai), proses yang didesain dengan baik dan dan teknologi yang memadai (leading-edge technology).
Fungsi-fungsi yang ada dalam CRM yang tradisional menurut Tourniare (2003) antara lain untuk sales force automation, telemarketing and telesales tracking, product configuration, marketing automation, support tracking, field service, knowledge base, customer portal and analytics.
Sementara itu, Danardatu menyebutkan teknologi CRM paling tidak harus memiliki elemen-elemen sebagai berikut:
1. Aturan-aturan Bisnis. Namun hal ini tergantung dari kompleksitas transaksi, aturan-aturan bisnis harus dibuat untuk memastikan bahwa transaksi dengan pelanggan dilakukan dengan efisien. Misalnya pelanggan dengan pembelian besar
yang mendatangkan keuntungan besar harus dilayani oleh staf penjualan senior dan berpengalaman, dst.
2. Penggudangan Data (data warehousing). Konsolidasi dari informasi tentang
pelanggan harus dilakukan dalam satu sistem terpadu. Hasil analisa harus mampu menampilkan petunjuk-petunjuk tertentu tentang pelanggan sehingga staf penjualan dan marketing mampu melakukan kampanye terfokus terhadap grup pelanggan tertentu. Nantinya gudang data ini juga harus mampu menaikkan volume penjualan dengan cross-selling atau up-selling.
3. Situs (web). CRM harus memiliki kemampuan swalayan. Hanya aplikasi berbasis situs (web based) yang bisa mendukung ini. Pelanggan bisa melakukan transaksi sendiri, tahu berapa yang harus dibayar, dan sebagainya.
4. Pelaporan (reporting). Teknologi CRM harus mampu menghasilkan laporan
yang akurat dan komprehen, nantinya berguna untuk menganalisa kelakuan pelanggan, dan lain-lain.
5. Meja Bantu (helpdesk). Teknologi yang mampu mengintegrasikan informasi
pelanggan ke aplikasi meja bantu akan menunjukkan ke pelanggan seberapa serius sebuah enterprise menangani pelanggannya.
Penggunaan CRM menurut Tourniaire (2003) akan memberikan sejumlah keuntungan antara lain menghemat biaya, membangun kepuasaan dan loyalitas pelanggan, meningkatkan pendapatan, meningkatkan akuntabilitas secara internal, meningatkan kepuasaan pekerja dan membangun business intelligent menjadi
lebih baik.
Secara konsep menurut Rangkuti (2006), terdapat delapan pedoman untuk membuat CRM yaitu :
1. Perencanaan. Diperlukan perencanaan yang komprehensif pada saat menggabungkan keterampilan dan sumber daya dari dua perusahaan yang independen sehingga bisa mencapai tujuan strategis.
2. Kepercayaan dan penghargaan. Hubungan yang berhasil memerlukan kepercayaan dan penghargaan antara dua rekan dan keduanya berniat untuk saling memercayai dan saling menghargai kepentingan masing-masing.
3. Konflik. Konflik sering terjadi dan merupakan aspek penting dalam hubungan. Partner harus cepat melakukan respon bila terjadi konflik dan bertindak secara proaktif untuk mengatasi konflik ini.
4. Struktur kepemimpinan. Struktur kepemimpinan yang efektif dapat memperlancar koordinasi dan sistem pengambilan keputusan.
5. Fleksibilitas. Mengetahui interpedensi masing-masing rekan merupakan faktor penting dalam membangun relationship yang berhasil. Rekanan yang bersifat fleksibel dapat mengantisipasi perubahan.
6. Perbedaan budaya. Perbedaan budaya berkaitan dengan tahap pengembangan industri, sistem politik, kepercayaan ekonomi dan sebagainya.
7. Transfer teknologi. Kedua rekan harus dapat mengembangkan teknologi ke dalam bentuk aplikasi komersil.
8. Pembelajaran dari kekuatan yang dimiliki oleh rekan.
Secara umum sistem CRM terdiri dari fungsi-fungsi yang bersifat front-end, core-end dan back-end. Untuk lebih jelasnya bisa dilihat pada gambar 1 berikut. - marketing - sales - customer service Communication CRM (front-end) Analytics CRM (back-end) - Information search - Analysis algoritma - call center - e-commerce - web - wireless Operation CRM (core-end) Database
Gambar 1. Generalisasi Arsitektur Sistem CRM (Lin, 2003).
Menurut Kertajaya (2007), setidaknya ada empat tahap yang harus dilakukan CRM agar fungsinya benar-benar bisa berjalan yakni identifikasi pelanggan, diferensiasi pelanggan, interaksi dan customized. Identifikasi
nama, alamat, nomor telepon, jabatan lainnya. Langkah berikutnya adalah diferensiasi yakni mengkategorikan pelanggan menurut nilai dan kebutuhannya. Hal ini bertujuan untuk mengukur sejauh mana keuntungan total yang bisa diperoleh perusahaan apabila melanjutkan transaksi dengan pelanggan. Langkah selanjutnya adalah menentukan nilai-nilai yang dimiliki pelanggan. Apakah menguntungkan bagi perusahaan atau tidak. Setelah semua tersebut diketahui maka perusahaan bisa melakukan kustomisasi pelayanan yang tepat diberikan kepada pelanggan.
2.1.4. PT PLN Distribusi Jakarta Raya dan Tangerang
PT PLN Distribusi Jakarta Raya dan Tangerang berdiri tahun 1897, yaitu dengan mulai digarapnya bidang listrik oleh salah satu perusahaan Belanda (NV NIGM) yang ditandai dengan pendirian pusat pembangkitan tenaga listrik (PLTU) yang berlokasi di Gambir.
Pada tanggal 17 Agustus 1945 dibentuk Djawatan Listrik dan Gas Tjabang Djakarta yang selanjutnya dikembalikan lagi kepada pemilik asal (NV NIGM) pada tahun 1947 dan namanya berubah menjadi NV OGEM. Kemudian dengan berakhirnya masa konsesi NV OGEM Cabang Jakarta yang selanjutnya diikuti dengan nasionalisasi oleh Pemerintah Indonesia sesuai Keputusan Menteri PU dan Tenaga No. U 16/9/I tanggal 30 Desember 1953, maka pada tanggal 01 Januari 1954 dilakukan serah terima dan pengelolaannya diserahkan ke Perusahaan Listrik Jakarta dengan wilayah kerjanya adalah meliputi Jakarta Raya dan Ranting Kebayoran & Tangerang.
Seiring dengan berjalannya waktu, maka perubahan pun terus bergulir. Keputusan terakhir yakni berdasarkan white paper Mentamben Agustus 1998,
maka Pemerintah meluncurkan kebijakan Restrukturisasi Sektor Ketenagalistrikan sesuai Keputusan Menko WASPAN No. 39/KEP/MK.WASPAN/9/1998 serta kebijakan PT PLN (Persero) Kantor Pusat, maka PT PLN (Persero) Distribusi Jakarta Raya & Tangerang diarahkan kepada Stategic Business Unit/Investment Centre.
PT PLN Distribusi Jakarta dan Tangerang melayani masyarakat yang ada di Jakarta dan Tangerang. Khusus untuk area pelayanan Cengkareng, hingga akhir
April 2007 lalu sedikitnya ada 80 ribu pelanggan yang telah dilayani. Berdasarkan peruntukannya, manajemen PT PLN membedakan pelangganya menjadi lima golongan pelanggan yaitu pelanggan golongan rumah tangga, bisnis, industri, sosial dan pemerintah.
Sehubungan dengan komitmen PT PLN sebagai perusahaan yang berorientasi terhadap pelanggan, manajemen membangun sistem pengelolaan pelanggan yang bernama customer information system (CIS). Program-program
pelayanan merupakan salah satu bagian dari CIS. Program-program pelayanan yang dibangun manajemen PT PLN antara lain :
1. Pelayanan satu tempat (Pesat)
Layanan ini memberikan solusi dan kemudahan bagi pelanggan/calon pelanggan yang ingin pasang baru, penambahan daya, pengaduan rekening listrik atau permasalahan listrik lainnya dapat diselesaikan satu tempat, yaitu di kantor Area Pelayanan (AP). Tujuan layanan ini memudahkan pelanggan berurusan dengan PLN di satu tempat dan pelanggan tidak terjerumus oleh oknum-oknum yang tidak bertanggung jawab (calo). Dalam program ini manajemen mengharapkan kerjasama dengan pelanggan yaitu tidak berurusan dengan calo dan tidak segan-segan memberi masukkan kepada PLN bila mendapatkan pelayanan yang tidak memuaskan. Untuk mencapai tujuan di atas, petugas di area pelayanan telah diberikan pelatihan mengenai etika pelayanan, proses bisnis, penyederhanaan pengurusan dan membuat branding
serta membuka waktu pelayanan pada hari Sabtu dan Minggu. 2. Peduli pelanggan inti (Pelangi)
Pelangi merupakan pelayanan kepada pelanggan potensial yang bersifat individual agar mendapatkan pelayanan yang khusus. Dengan perubahan paradigma sebagai pelayan kepada pelanggan maka PT PLN Distribusi Jakarta Raya dan Tangerang harus menjemput bola yaitu mendekatkan diri kepada semua pelanggan khususnya pelanggan potensial (Pelanggan tegangan menengah dan pelanggan tegangan tinggi). Untuk mencapai tujuan di atas maka dilakukan identifikasi dan segmentasi pelanggan tegangan menengah dan pelanggan tegangan tinggi serta melakukan kunjungan ke pelanggan potensial untuk mengetahui kebutuhan/masalah pelanggan.
Program layanan ini dilaksanakan langsung oleh Manager Area Pelayanan dibantu oleh staf dan membuat branding dari PELANGI dengan motto layanan pribadi untuk anda.
3. Peningkatan dan Pengembangan Pusat Pelayanan Gangguan melalui nomor telepon 123
Call center 123 merupakan pusat pelayanan informasi dan keluhan pelanggan
baik masalah gangguan listrik, catat meter, tagihan rekening, tarif, dan keluhan lainnya. Saat ini call center 123 menggunakan 60 satuan sambungan
telepon (SST) dan dilayani oleh 58 teleponis yang bekerja tiga shift selama 24 jam, dalam bahasa Indonesia dan Inggris. Berbagai informasi dapat dilayani di antaranya gangguan listrik, tagihan, pemadaman, pemeliharaan, catat meter, info biaya pasang baru/rubah daya, dan keluhan non teknis.
4. Peningkatan Mutu Baca Meter
Untuk meningkatkan mutu baca meter, PT PLN (PERSERO) Distribusi Jakarta Raya dan Tangerang bekerja sama dengan perusahaan profesional pengelola tenaga kerja pencatatan meter untuk mengatasi masalah pencatatan meter. Program ini bertujuan untuk menunjukkan keseriusan PLN dalam menangani masalah kesalahan baca meter sehingga pembacaan standar meter dapat dilakukan setiap bulan sesuai jadwal dan dapat melayani koreksi rekening seketika dengan penggunaan PDE (Portable Data Entry).
Untuk mencapai sasaran di atas telah dilakukan pelatihan bagi petugas catat meter dan penataan ulang rute baca meter dan sekaligus pembacaan percontohan masing-masing area pelayanan sebanyak 3 RBM (rute baca meter) untuk ± 500 pelanggan.
5. Kemudahan Pembayaran rekening listrik melalui PRAQTIS (Pembayaran Rekening Listrik Fleksibel dan Otomatis)
Sampai saat ini bank-bank yang sudah bekerja sama bertindak sebagai penyelnggaran PRAQTIS adalah Bank BRI, Bank Lippo, Bank Ekonomi, Bank Buana, Bank Haga, Bank Hagakita, Bank Bumiputera, Bank BCA, Bank Victoria, Bank Panin, Bank Bukopin, Bank BTN, Bank Tokyo Mitsubishi. Tujuan program ini adalah memberikan fasilitas kemudahan untuk pembayaran rekening listrik dan memberikan alternatif kepada pelanggan
mengenai cara pembayaran rekening selain tempat pembayaran secara tradisional yaitu pembayaran melalui bank. Pembayaran melalui bank ini bisa dilakukan dengan cara off line maupun bank dengan cara on line atau
pembayaran melalui ATM (PRAQTIS).
2.2. Alat dan Teknik
2.2.1. Himpunan Fuzzy
Himpunan tradisional adalah himpunan yang memiliki batasan yang jelas (crisp). Berbeda dengan himpunan fuzzy, sesuai namanya, himpunan fuzzy kata
Jang et al (1997) tidak memiliki batasan yang jelas. Artinya transisi antara harus
masuk sebuah himpunan dan tidak harus masuk sebuah himpunan. Transisi yang halus ini merupakan karakteristik fungsi keanggotaan yang diberikan himpunan
fuzzy dalam model umumnya yang menggunakan ekpresi linguistik.
Dalam bahasa definisi, himpunan fuzzy menurut Kusumadewi (2003)
merupakan suatu grup yang mewakili suatu kondisi atau keadaan tertentu dalam suatu variabel fuzzy. Variabel fuzzy itu sendiri merupakan variabel yang hendak di
bahas dalam suatu sistem fuzzy, misalnya umur, temperatur, permintaan dan
sebagainya.
Sementara itu, Cox ((2005) menyatakan bahwa dalam sebuah himpunan
fuzzy, sebuah elemen dapat berada dalam tiga kondisi yakni bukan merupakan
anggota dari himpunan, merupakan anggota secara penuh dalam himpunan dan keanggotaannya tidak penuh terhadap himpunan. Keanggotaan himpunan dipresentasikan dengan sebuah nilai yang kontinu dengan interval 0 hingga 1. Angka 0 menunjukkan bukan termasuk dalam keanggotaan himpunan, angka 1 mengindikasikan keanggotaan secara penuh sedangkan nilai antara 0 dan 1 menunjukkan derajat keanggotaan yang tidak penuh dalam himpunan. Kondisi keanggotaan elemen di atas sering disebut derajat keanggotaan element di dalam sebuah himpunan fuzzy.
Jang (1997) lebih jauh menjelaskan bahwa jika X adalah koleksi dari objek-objek yang dinotasikan secara generik oleh x maka suatu himpunan fuzzy A
dalam X adalah suatu himpunan pasangan berurutan :
dengan µÃ (x) adalah derajat keanggotaan x di à yang memetakan X ke ruang
keanggotaan M yang terletak pada rentang [0,1].
Sebuah himpunan fuzzy kata Cox (2005) memiliki tiga komponen prinsip
yakni derajat keanggotaan yang dinyatakan dengan garis vertikal (Y), kemungkinan nilai domain untuk himpunan yang dinyatakan sebagai garis horisontal (X) dan fungsi keanggotaan (sebuah kurva kontinu yang menghubungkan nilai sebuah domain dengan derajat keanggotaan dalam himpunan). Domain dalam hal ini merupakan keseluruhan nilai yang diizinkan dalam semesta pembicaraan dan boleh dioperasikan dalam suatu himpunan fuzzy.
Jadi nilai domain bisa berupa bilangan negatif maupun bilangan positif. Sementara itu semesta pembicaraan diartikan sebagai keseluruhan nilai yang diperbolehkan untuk dioperasikan dalam suatu variabel fuzzy. Semesta
pembicaraan merupakan himpunan bilangan real yang senantiasa naik (bertambah) secara monoton dari kiri ke kanan. Nilai semesta pembicaraan bisa berupa bilangan positif maupun negatif. Namun adakalanya nilai semesta pembicaraan tidak dibatasi batas atasnya. Contoh semesta pembicaraan untuk varibel umur [0 +∞], variabel temperatur [0 40] dan sebagainya.
1 0 Grade of membership m(x) Support Universe of discourse (domain) Membershi p function
Gambar 2. Komponen himpunan fuzzy (Cox, 2005)
Untuk lebih jelasnya kita bisa melihat contoh himpunan fuzzy tentang
umur berikut ini. Jika muda didefinisikan sebagai umur < 35 tahun lalu parobaya berumur antara 35 ≤ umur ≤ 55 tahun dan umur tua > 55 tahun, maka dalam himpunan fuzzy kasus umur ini akan digambar sebagai berikut.
0 25 35 40 45 50 55 65
MUDA PAROBAYA TUA 1
µ(x) 0,5 0,25
Gambar 3 . Himpunan Fuzzy untuk Variabel Umur.
Berdasarkan gambar di atas ternyata seseorang yang berumur 40 tahun termasuk dalam himpunan muda dengan derajat keanggotaan (µMUDA) = 0,25.
Namun dia juga termasuk dalam himpunan parobaya dengan derajat keanggotaan (µPAROBAYA) = 0,5. Begitu juga dengan seseorang yang berumur 50 tahun, termasuk
dalam himpunan muda dengan derajat keanggotaan (µTUA) = 0,25. Namun ia juga
termasuk dalam himpunan parobaya dengan derajat keanggotaan (µPAROBAYA) = 0,5.
Namun perlu diingat, keanggotaan fuzzy dengan probabilitas berbeda.
Walau keduanya memiliki nilai pada interval [0 1] tapi intrepetasi nilainya sangat berbeda antara kedua kasus tersebut. Keanggotaan fuzzy memberikan suatu ukuran
terhadap pendapat atau keputusan, sedangkan probabilitas mengindikasikan proporsi terhadap keseringan suatu hasil bernilai benar dalam jangka panjang.
Teori himpunan fuzzy tegas Jang et al (1997) akan memberikan jawaban
terhadap suatu masalah ketidakpastian. Namun pada beberapa kasus khusus seperti nilai keanggotaan yang kemudian akan menjadi 0 atau 1, teori dasar tersebut akan identik dengan teori himpunan biasa, dan himpunan fuzzy akan
menjadi himpunan crisp tradisional.
2.2.2. Fuzzy Klasterisasi
Pengelompokkan (klasterisasi) bisa diselesaikan secara fuzzy dan non fuzzy.
Pada fuzzy klasterisasi hasil matriks transformasinya berupa nilai derajat
keanggotaan antara 0 dan 1, sedangkan pada non fuzzy nilainya 0 dan 1. Proses
klasterisasi pada dasarnya merupakan proses pembuatan gugus atau himpunan yang memiliki anggota elemen-elemen yang akan diklaster. Pengelompokkan
dikatakan fuzzy jika tiap-tiap objek dihubungkan dengan menggunakan derajat
keanggotaan (bukan dengan keanggotaan crisp). (Kusumadewi, 2002).
Bila dalam pengelompokkan konvensional, sebuah poin data keanggotaannya hanya pada satu kelompok saja, namun dalam fuzzy klasterisasi,
sebuah poin data bisa menjadi anggota dalam banyak kelompok tapi tentunya dengan derajat keanggotaan berbeda-beda. Derajat keanggotaan adalah ukuran seberapa kuat sebuah poin data menjadi bagian dalam klaster. Ukuran ini penting dalam proses pembuatan aturan. ( Cox, 2005).
Keanggotaan dalam sebuah klasterisasi jelas Cox (2005) merupakan ukuran jarak dari sebuah pusat klaster ke data point. Gambar 4 di bawah ini
menggambarkan jarak sebuah data point (pj) terhadap satu pusat klaster(c).
C 100 200 300 400 500 600 700 800 900 1000 1100 40 30 20 10 0 pi di Keterangan : pj: point data ke-i
c: pusat klaster di: jarak point data (pi)
ke pusat klaster (c)
Gambar 4 . Jarak poin data terhadap sebuah klaster (Cox, 2005)
Dalam fuzzy klasterisasi keanggotaan sebuah data poin tidak hanya
terhadap satu kelompok tapi juga ke beberapa kelompok. Hal ini merupakan keistimewaan pengelompokkan menggunakan fuzzy klasterisasi dibandingkan
dengan pengelompokkan tradisional. Gambar 5 berikut ini akan menggambarkan keanggotaan sebuah point data pj (dalam hal ini dinyatakan dalam jarak) pada dua
C2 C1 100 200 300 400 500 600 700 800 900 1000 1100 40 30 20 10 0 di1 pi di2 Keterangan :
di1 : jarak point data (pi) ke pusat klaster 1 di2 : jarak point data (pi) ke pusat klaster 2 pi : point data ke-i c1 : pusat klaster ke-1 c2 : pusat klaster ke-2
Gambar 5 . Jarak point data terhadap dua klaster (Cox,2005)
Menurut Han dan Kamber (2001) dan Pedrycz (2005) kesamaan dan ketidaksamaan antara dua objek bisa digambarkan sebagai jarak. Jarak menurut Santosa (2007) merupakan aspek penting dalam pengembangan metode pengklasifikasian maupun regresi. Ukuran jarak menurut Han dan Kamber (2001), Pedrycz (2005) dan Santosa (2007) harus memenuhi syarat-syarat sebagai berikut: 1. d (i, j) ≥ 0 ;
Jarak adalah sebuah angka non negatif. Tidak ada jarak yang mempunyai nilai negatif.
2. d (i, j) = 0 ;
Jarak dari objek terhadap dirinya sendiri yakni jarak antara suatu objek atau titik dengan objek atau titik itu sendiri adalah nol.
3. d (i, j) = d (j, i) ;
Jarak adalah sebuah fungsi simetrik. Jarak dari i ke j adalah sama dengan jarak dari j ke i.
4. d (i, j) ≤ d (i, h) + d (h, j) ;
Jika diatur dari objek i ke objek j dalam ruang yang sama tidak lebih dari pembuatan cara lain pada objek h yang lain (triangular inequality).
Salah satu pengukuran jarak yang cukup populer di dalam Han dan Kamber (2001), Pedrycz (2005) dan Santosa (2007) adalah pengukuran jarak
euclidean. Pengukuran jarak euclidean akan dihitung berdasarkan persamaan 2
berikut ini :
( )
i,j xi1 xj1 2 xi2 xj2 2 ... xik xjn 2,dimana titik pusat klaster ke-i = (xi1,xi2,...,xik) dan titik int data ke-j = (xj1,
xj2,...,xjn) dengan jumlah klaster k serta jumlah data n.
a adalah metode partitional.
Metode
kuantifikasi kelompok-kelompok. Kuanti
n mengkategorikan data tapi juga bisa digunakan untuk melaku
ntuk basis fungsi radial
al di atas, teknik klasterisasi juga bisa digunakan untuk
istic
(Jang e
an
lgoritma Fuzzy C-Mean Klasterisasi (FCM) juga dikenal sebagai fuzzy
tma yang mengelompokkan data dimana setiap titik data dalam sebuah klaster ditentukan oleh derajat keanggotaannya. Bezdek
po
Menurut Pedrycz (2005) dan Cox (2005) ada beberapa pendekatan yang digunakan dalam melakukan klasterisasi. Salah satuny
partitional membangun sebuah partisi dari sebuah basisdata D dengan n
objek ke dalam himpunan k klaster. Pada fuzzy c-mean, partisi dilakukan dengan
membagi data menjadi dua atau lebih klaster.
Tujuan dari analisis klaster menurut Kusumadewi (2002), Cox (2005) dan Pedrycz (2005) adalah untuk mengenali dan
fikasi ada dua proses yakni identifikasi keanggotaan sebuah point data
dalam beberapa grup dan meletakkan pusat klaster (centroid). Membangun pusat
klaster dilakukan lewat proses iterasi dimana setiap iterasi dilakukan perbaikan hingga konvergen.
Dalam pemanfaatannya algoritma klasterisasi tidak hanya digunakan untuk mengorganisasi da
kan kompresi dan mengkonstruksi model data. Caranya, algoritma klasterisasi membagi-bagi sebuah set data ke dalam beberapa grup berdasarkan kemiripannya ke dalam satu grup atau lebih (Jang et al, 1997).
Teknik klasterisasi juga digunakan untuk menghubungkan jaringan basis fungsi radial atau dasar model fuzzy dalam menandai lokasi u
atau aturan fuzzy if-then. Untuk hal ini teknik klasterisasi melakukan
validasi pada basis berdasarkan asumsi :
1. Kemiripan input untuk sistem target menjadi model dan menghasilkan output
yang mirip.
2. Pasangan input-output disatukan dalam klaster di dalam set data training.
Selain h
mengidentifikasi struktur di dalam model neural atau fuzzy yang lebih heur t al, 1997).
2.2.3. Fuzzy C-Me
A
mengu
iripan yang paling minimal.
lidean. Proses ini
dilakuk
ra 0 hingga 1.
an dari set data mengg
sulkan algoritma ini tahun 1973 sebagai pengembangan awal dari hard c-mean (HCM). (Jang et al, 1997).
FCM membagi sebuah koleksi ke-n dari vektor xi, dimana i = 1,2,3,...,n ke
dalam c grup fuzzy dan mencari pusat klaster pada masing-masing grup yakni
fungsi biaya dari ukuran ketidakm
Tidak berbeda jauh dengan Jang et al (1997) Cox (2005) mengatakan fuzzy c-mean memiliki dua proses yakni menghitung pusat klaster dan menandai poin
untuk pusat klaster menggunakan sebuah bentuk jarak euc
an berulang hingga pusat klaster stabil.
Perbedaan mendasar dari FCM dan HCM kata Jang et al (1997), FCM
adalah suatu teknik klasterisasi yang keberadaan setiap titik data dalam suatu klaster ditentukan oleh derajat keanggotaan anta
Untuk mengakomodasi fuzzy partisi jelas Jang et al (1997) dan Pedrycz
(2005), keanggotaan matrik U harus memiliki nilai antara 0 dan 1. Untuk melakukan normalisasi penetapan hasil derajat keanggota
unakan persamaan berikut :
n j u c i ij 1, 1,2,3,..., 1 = ∀ =
∑
=Dimana µij adalah derajat keanggotaan point data terhadap pusat-pusat klaster dan
jumlah klaster C serta jumlah da
Untuk menghitung fungsi objektif pada fuzzy c-mean ketika dilakukan
d
u 2 (4)
dalah derajat keanggotaan poin data terhadap klaster-klaster yang nilainya
klaster adalah c dan n adalah banyaknya poin data, lalu m adalah nilai parameter
(3)
ta n.
generalisaasi digunakan persamaan 4 berikut ini :
∑
∑
∑
= = c J c n c c U J( , ,..., ) = = j ij ij i i i c 1 1 1Dimana J adalah fungsi objektif , sementara u
m
ij a
antara 0 dan 1, kemudian jumlah
fuzzy dan dij adalah jarak euclidean antara pusat klaster ke-i hingga ke-j dari point data dan m Є (1,∞) sebagai ekponen pembobot. Jarak euclidean ini
Berdasarkan persamaan (2.2) untuk mencari nilai minimum dari pusat klaster digunakan persamaan 5 seperti di bawah ini :
∑
∑
= = n m n j j m ij i u x u c 1 = j 1 ij (5) Dimana ci adalah pusaterhadap klaster-klaster dengan nilainya antara 0 dan 1, lalu n adalah banyaknya t klaster ke-i dan uij adalah derajat keanggotaan poin data
poin data dan m adalah nilai parameter fuzzy serta xj adalah data poin ke-j.
Untuk menghitung perubahan matrik partisi (derajat keanggotaan poin data terhadap semua klaster yang baru) digunakan persamaan :
∑
= − ⎟ ⎞ ⎜ ⎛ = c m ij ij d u 1 2/( 1) (6). ⎟ ⎠ ⎜ ⎝ k kj d 1Dimana uij adalah derajat keanggotaan poin data terhadap klaster-klaster yang
nilainya antara 0 dan 1 dengan c sebagai jumlah pusat klaster dari grup fuzzy ke-i,
ap klaster berdasarkan derajat keangg
ter akan bergeser ke titik yang tepat. O
ah-langkah sebagai berikut :
1. Inis
sedangkan m adalah parameter fuzzy dan dij adalah jarak euclidean antara pusat klaster ke-i hingga ke-j dari poin data dan m Є (1,∞) sebagai ekponen pembobot
serta dkj adalah jarak euclidean antara pusat klaster ke-k hingga ke-j dari poin
data dan m Є (1,∞) sebagai ekponen pembobot.
Proses algoritma FCM di awali dengan menentukan derajat keanggotaan (secara acak) pada setiap titik data terhad
otaan, kemudian ditentukan oleh pusat klaster. Pada kondisi awal pusat klaster belum akurat. Derajat keanggotaan selanjutnya diperbaiki berdasarkan fungsi jarak antara titik data dengan pusat klaster.
Dengan memperbaiki pusat klaster dan derajat keanggotaan tiap titik data secara berulang dan terus menerus maka pusat klas
utput FCM adalah deretan pusat klaster dan derajat keanggotaan data
terhadap setiap klaster.
FCM menentukan pusat klaster ci dan keanggotaan matriks U dalam Jang et al (1997) dengan langk
ialisasi keanggotaan matrik U dengan nilai random antara 0 dan 1 dengan persamaan (3)
2. Hitung c pusat klaster fuzzy ci, i = 1,2,3,...c menggunakan persamaan (5)
Hitung fungsi o
3. bjektif berdasarkan persamaan (4). Berhenti jika hasil fungsi
telah
4.
dili
objektifnya mencapai nilai toleransi atau hasil fungsi objektifnya se iterasi maksimal yang ditetapkan.
Hitung matrik partisi baru menggunakan persamaan (6) dan kembali ke langkah ke-2.
Diagram alir proses klasterisasi data pada algoritma fuzzy c-mean bisa
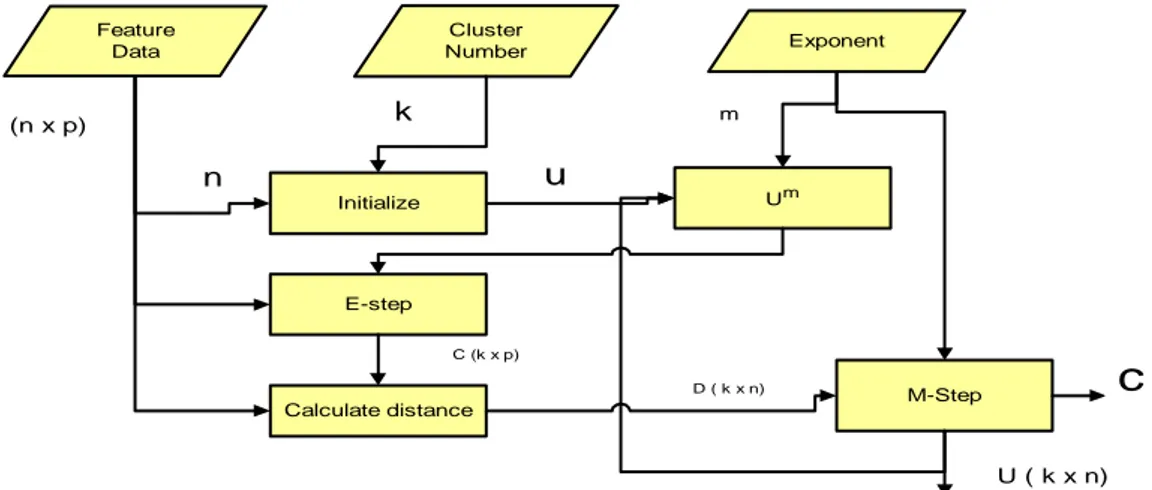
hat pada Gambar 6 di bawah ini. Feature Data Cluste Numb r er Exponent Initialize E-step Um M-Step Calculate distance k (n x p) u n C (k x p)
c
D ( k x n) U ( k x n) mGambar 6. Tahapan algoritma fuzzy c-mean klasterisasi (Jiang, 2003)
Dimana U merupakan matrik partisi, lalu C adalah pusat klaster, dan D
merup nilai
k =
akan distance matrix. Kemudian K ialah jumlah klaster, m merupakan parameter fuzzifikasi, k adalah jumlah klaster dan jumlah datanya adalah n dan p adalah p jumlah atribut data.
Kemudian nilai α n X U
∑
E-step : m α ik n i i ik i U∑
= = 1 1 (7) M-step : Uik =∑
= − ⎟ ⎟ ⎠ ⎞ ⎜ ⎜ ⎝ ⎛ − − 1 1 1 1 l i l k i m x m x α (8)Dimana mk merupakan pusat klaster ke-k dan Uik adalah derajat keanggotaan poin
Menurut Jang Et al (1997), Cox (2005), Pedrycz (2005) dan Kusumadewi (2002) dalam proses analisis pengelompokkan menggunakan algoritma fuzzy c-mean p
ujuan melakukan klasterisasi adalah mengumpulkan objek-objek yang g tinggi dalam satu klaster yang sama. Menurut Xie dan Beni d
usat klaster akan diinisialisasi kali pertama dan kemudian diperbaiki pada setiap iterasinya. Menurut Kusmadewi (2002) tidak ada jaminan FCM akan konvergen pada solusi optimum. Kinerja tergantung pada inisialisasi pusat klaster. Hasil dari algoritma fuzzy c mean adalah derajat keanggotaan poin data terhadap
pusat klaster dan pusat klaster. Dalam algoritma fuzzy c-mean ada beberapa hal
yang perlu diperhatikan saat membangun sistem diantaranya iterasi maksimal, error terkecil yang diinginkan (ξ), pemangkat (m > 1) dan inisialisasi terhadap pusat awal klaster (c ≥ 2).
2.2.4. Validasi Klaster T
memiliki kemiripan yan
alam Halkidi et al (2002) dan Pedrycz (2005) ukuran kevalidan klaster
merupakan proses evaluasi hasil klasterisasi untuk menentukan kualitas klaster. Kevalidan suatu klaster lanjutnya merupakan hasil rasio dari kepadatan
(compactness) dengan keterpisahan (separation). Kepadatan adalah ukuran
kedekatan antaranggota pada tiap klaster sedangkan keterpisahan adalah ukuran keterpisahan antarklaster satu dengan klaster lainnya. Rasio dari kepadatan dan keterpisahan tersebut didefinisikan sebagai berikut :
S = π / N.Dmin ; (9) n x c s Compactnes j i j ij i 1 1 ) ( = = = π (10) n c 2 2 −
∑
∑
μDmin (Separation) = minij || ci – cj ||2 (11)
Dimana || xi – cj || merupakan jarak euclid dari j j dan
|| ci – lah
pusat klaster c ke poin data x cj || adalah jarak euclid dari pusat klaster ci ke cj, sementara µij ada
derajat keanggotaan poin data ke-j pada klaster ke-i dan N adalah jumlah data. Semakin kecil nilai S maka semakin bagus hasil klaster yang telah dilakukan.
2.3. Penelitian yang Relevan
Teknik fuzzy c-mean klasterisasi kali pertama diperkenalkan tahun 1981
teknik klasterisasi data yang mana keberadaan tiap-tiap titi
knik fuzzy c-mean klasterisasi, k
mean d
secara baik terhadap segmentasi pasar kartu kredit di Taiwan
butkan bahwa fuzzy c-mean bisa digunakan untuk mengelompokkan
negara-ap pelanggan produk mie instan. Untuk menvalidasi klasterisasi,
Daulay
oleh Jim Bezdek. FCM adalah
k data dalam suatu klaster ditentukan oleh derajat keanggotaan. Konsep dasarnya adalah dengan menentukan pusat klaster, dimana pusat klaster ini akan menandai lokasi rata-rata untuk tiap-tiap klaster.
Simha dan Iyengar (2005) melakukan penelitian terhadap pelanggan telepon di telecom India menggunakan dengan te
an EM. Hasil penelitian mereka menyebutkan bahwa fuzzy c-mean secara
umum mampu mereflesikan perilaku pelanggan dengan cukup baik dibanding algoritma k-mean dan EM.
Kemudian, Ho (1999) dalam penelitiannya juga menyebutkan bahwa FCM mampu melakukan analisis
. Selanjutnya dalam penelitian yang dilakukan Ahmad Irfani (2007) juga disebutkan bahwa FCM mampu bekerja secara baik melakukan pengelompokkkan dokumen.
Sementara itu dalam penelitian yang dilakukan Tsangarides dan Qureshi (2006) dise
negara di Afrika Barat berdasarkan kondisi ekonomi dan moneternya. Dalam penelitian tersebut Tsangarides dan Qureshi menggunakan metode indeks Xie dan Beni sebagai salah satu metode validasi terhadap hasil klasterisasi. Metode indeks Xie dan Beni dalam penelitian Tsangarides dan Qureshi dalam validasi hasil klasterisasi tidak menunjukkan adanya perbedaan hasil dengan metode lain yang digunakan yaitu metode Dunn’s Partition Coefficient dan Silhouette Plot.
Daulay (2006) juga menggembangkan algoritma FCM dalam melakukan segmentasi terhad
menggunakan metode indeks Xie dan Beni. Hasilnya penelitian yang dilakukan Daulay cukup baik. Pada penelitian lainnya, yaitu Zumstein (2007) disebutkan bahwa metode fuzzy klasterisasi lebih fleksibel dalam melakukan
menurutnya sangat baik dalam membantu proses bisnis terutama manajemen pengelolaan pelanggan.
3.1. Tahapan Penelitian
Ada empat tahap utama yang dilakukan dalam penelitian ini. Tahap-tahap tersebut antara lain analisa masalah, persiapan data, pengumpulan data, pengembangan model dan pembuatan prototipe sistem.
Mulai Persiapan Data Desain Model Implementasi Pengembangan Model Prototipe Sistem Prototipe Sesuai Selesai Tidak Ya Analisis Masalah
Gambar 7. Tahapan Penelitian
Diagram alir di atas mengambarkan tahap-tahap penelitian yang akan dilaksanakan. Selain itu, diagram alir di atas juga mengambarkan keterkaitan antara tahap yang satu dengan tahap lainnya.
3.1.1. Analisis Masalah
Identifikasi terhadap karakter pelanggan merupakan salah satu langkah penting dalam manajemen hubungan pelanggan. Dengan melakukan identifikasi terhadap karakter pelanggan maka pemetaan terhadap pelanggan bisa dilakukan. Adanya pemetaan terhadap pelanggan mempermudah pihak manajemen PLN melakukan perencanaan pelayanan prima terhadap pelanggan. Langkah yang dilakukan untuk melakukan identifikasi pelanggan salah satunya adalah melakukan segmentasi terhadap pelanggan. Yakni mengelompokkan pelanggan berdasarkan kemiripan ciri yang dimiliki pelanggan. Metode algoritma fuzzy
c-mean merupakan salah satu cara yang bisa dilakukan untuk melakukan pengelompokkan.
3.1.2. Persiapan Data
Data yang digunakan dalam penelitian ini adalah data transaksi pelanggan PT PLN distribusi Jakarta Raya dan Tangerang area pelayanan Cengkareng satu periode pemakaian listrik yaitu mulai November 2006 hingga Oktober 2007. Pada tahap persiapan, data-data pelanggan yang tidak lengkap akan dihilangkan agar tidak menimbulkan error pada sistem yang akan dibangun. Berdasarkan data yang dimiliki ada empat variabel yang digunakan sebagai variabel masukan sistem. Empat variabel masukan tersebut antara lain (1) variabel lama berlangganan, (2) variabel jumlah pembayaran listrik per bulan, (3) jumlah kesetiaan membayar tepat waktu dan (4) jumlah pemakaian listrik per bulan. Untuk lebih jelasnya bisa dilihat pada Tabel 1 berikut ini.
Tabel 1. Tabel masukan sistem penggelompokkan pelanggan
No Jenis Input Satuan
1. Lama berlangganan (A) Bulan 2. Nilai pembayaran listrik (C) Rupiah
3. Kedisiplinan membayar listrik (D) Jumlah pembayaran tepat waktu 4 Jumlah pemakaian listrik (D) Watt
Variabel-variabel masukan di atas diharapkan mampu menggambarkan karakter pelanggan PLN. Dalam tahap lanjutan data-data masukan di atas akan dijadikan matriks agar mudah diproses dalam model pengelompokkan sistem. 3.1.3. Desain Model Sistem
Ada tiga hal yang dilakukan dalam desain model sistem yakni melakukan desain terhadap masukan, melakukan desain prosedur dan terakhir melakukan desain terhadap antarmuka.
1. Desain Masukan
Berdasarkan jumlah daya yang terpasang, pelanggan PLN dibedakan menjadi lima golongan yakni golongan pelanggan rumahtangga (1), pelanggan bisnis (2), pelanggan industri (3), pelanggan pemerintah (4) dan pelanggan sosial
(5). Dalam penelitian ini digunakan tiga golongan pelanggan saja yakni golongan pelanggan rumahtangga (1), pelanggan bisnis (2) dan pelanggan industri (3) sebagai data masukan bagi sistem. Variabel yang digunakan sebagai masukan sistem ini adalah variabel-variabel seperti yang telah disebutkan pada tabel 1. Sebelum dilakukan analisis pengelompokkan menggunakan algoritma fuzzy c-mean, data-data masukan diubah dalam bentuk matriks. Untuk mempermudah pengolahan data masukan, data disimpan dalam perangkat lunak microsoft office excel 20003.
Selain melihat karakter pelanggan pada semua variabel, dalam penelitian ini juga akan dilihat karakter pelanggan dari berbagai variasi variabel. Variasi- variabel yang dimaksud antara lain variasi A, B, C, D, AB, AC, AD, BC, BD, CD, ABC, ABD, ACD, BCD dan ABCD.
Selain mendesain masukan, hal yang sangat penting dilakukan sebelum melakukan analisis pengelompokkan menggunakan algoritma FCM adalah menetapkan parameter masukan. Parameter yang dimaksud adalah jumlah klaster, nilai error terkecil yang diinginkan (eps), iterasi maksimal dan parameter fuzzifikasi (m>1). Dalam penelitian ini ditetapkan parameter sebagai berikut :
Tabel 2. Tabel parameter dan nilainya
Parameter Nilai
Jumlah klaster 3; 4; 5 Nilai error terkecil 0,00001 Iterasi maksimal 100 Parameter fuzzifikasi 1,5 - 10
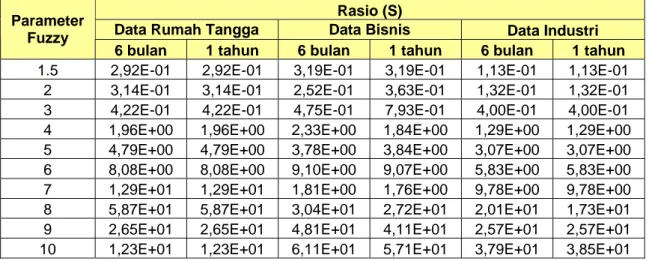
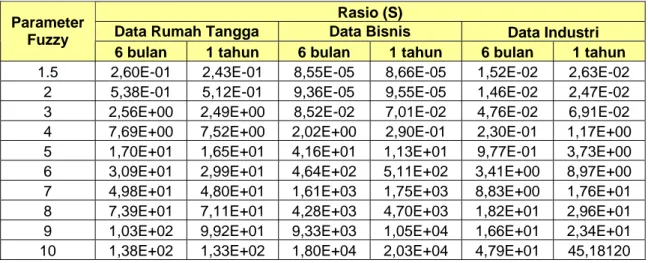
Jumlah klaster 3, 4 dan 5 yang digunakan dalam penelitian ini dimaksudkan untuk menyesuaikan pengaplikasian hasil penelitian dalam manajemen bisnis manajemen PLN terhadap pelanggannya. Untuk melakukan validasi terhadap hasil klasterisasi dalam penggunaan parameter masukan digunakan indeks Xie dan Beni. Metode ini membandingkan rasio kepadatan data dalam klaster dengan keterpisahan data antarklaster. Semakin kecil nilai rasio yang dihasilkan artinya hasil pengelompokkan semakin baik.
2. Desain Proses
Ada 5 modul yang akan dikembangkan pada tahap desain proses yakni modul masukan, modul analisa pengelompokkan algoritma fuzzy c-mean, modul validasi hasil pengelompokkan, modul pengkategorian dan modul representasi hasil.
3. Desain antarmuka
Untuk memudahkan penggunaan prototipe oleh pemakai maka dibuat antarmuka (user interface). Antarmuka dibuat sesederhana mungkin dengan tujuan agar mudah digunakan.
3.1.4. Pengembangan Model Prototipe Sistem
Pengembangan sistem perangkat lunak karakterisasi pelanggan PLN ini dilakukan dengan cara melakukan analisa kebutuhan sistem hingga mengecek prototipe sistem apakah telah sesuai dengan keperluan atau tidak. Untuk melihat lebih jelas tatalaksana pengembangan sistem bisa dilihat pada Gambar 8 yakni tatalaksana pengembangan prototipe sistem.
Analisa Kebutuhan
Pengembangan Modul Input
Pengembangan Modul Pengelompokkan, Validasi dan
Pengkategorian Pengembangan Modul Representasi Hasil Prototipe Sistem Sesuai Selesai Mulai
Perancangan dan Implementasi
tidak
ya
3.2. Alat Bantu Penelitian
Sistem akan dirancang dengan menggunakan alat bantu perangkat lunak sebagai berikut :
1. Matlab versi 7.0.1.
Perangkat lunak Matlab versi 7.0.1 akan digunakan untuk melakukan pengembangan prototipe perangkat lunak pengelompokkan pelanggan PLN menggunakan algoritma fuzzy c-mean..
2. Microsoft Office Excel
Perangkat lunak Microsoft Office Excell digunakan sebagai alat bantu dalam melakukan pra-proses data.
3.3. Waktu dan Tempat Penelitian
Penelitian dilakukan di dua tempat yakni di PT PLN Area Pelayanan Cengkareng dan Laboratorium Pascasarjana Departemen Ilmu Komputer FMIPA-IPB. Mulai Mei hingga Juli 2007 dilakukan pengumpulan data penelitian dan konsultasi dengan manajemen PLN penelitian di PT PLN Area Pelayanan Cengkareng. Sementara mulai Juni 2007 hingga Januari 2008 dilakukan pengembangan prototipe sistem dan penulisan dokumentasinya di Laboratorium Pascasarjana Departemen Ilmu Komputer FMIPA-IPB.
4.1. Desain Masukan
Data pelanggan yang akan disegmentasi dalam penelitian ini adalah (1) data pelanggan golongan rumah tangga, (2) golongan bisnis dan (3) golongan industri. Ketiga data tersebut merupakan data perilaku pelanggan dalam menggunakan energi listrik selama satu tahun dan akan dijadikan sebagai data masukan sistem. Data perilaku pelanggan dalam menggunakan energi listrik selama satu tahun dipilih dalam penelitian ini dengan alasan lebih menggambarkan perilaku pelanggan dalam menggunakan energi listrik selama satu periode pemakaian listrik.
Untuk menggambarkan karakteristrik pelanggan perlu digunakan variabel-variabel data yang relevan dengan perilaku pelanggan dalam menggunakan energi listrik sebagai variabel masukan dalam proses klasterisasi. Variabel-variabel masukan yang dianggap relevan untuk menggambarkan karakter pelanggan di PLN berdasarkan data transaksi pelanggan antara lain lama berlangganan (A), jumlah pembayaran (B), kedisiplinan membayar (C) dan jumlah pemakaian listrik (D). Dalam sistem yang dikembangkan dalam penelitian ini disediakan pilihan semua kemungkinan kombinasi variabel dari keempat variabel yang disebutkan di atas. Hal itu dimaksudkan untuk memberikan banyak pilihan bagi manajemen dalam menggambarkan segmen pelanggan sesuai keperluan bisnis manajemen saat melakukan segmentasi pelanggan. Ada 15 kombinasi variabel yang akan dijadikan sebagai kombinasi variabel masukan pada sistem yaitu :
1. Kombinasi variabel A 9. Kombinasi variabel BD
2. Kombinasi variabel B 10. Kombinasi variabel CD
3. Kombinasi variabel C 11. Kombinasi variabel ABC
4. Kombinasi variabel D 12. Kombinasi variabel ABD
5. Kombinasi variabel AB 13. Kombinasi variabel ACD
6. Kombinasi variabel AC 14. Kombinasi variabel BCD
7. Kombinasi variabel AD 15. Kombinasi variabel ABCD
Satu hal yang harus diperhatikan dalam mendesain data masukkan, sebelum diproses menggunakan algoritma FCM, data-data terlebih dulu dijadikan dalam bentuk matriks. Untuk mempermudah pengolahan data dalam sistem, dalam penelitian ini data disimpan dalam perangkat lunak microsoft office excel 20003.
4.2. Desain Proses.
Pada tahap ini dilakukan desain terhadap proses memasukkan data hingga keluaran dari sistem. Ada 5 modul yang dikembangkan dalam penelitian ini. Modul tersebut antara lain modul masukkan, modul analisa pengelompokkan algoritma fuzzy c-mean, modul validasi hasil pengelompokkan, modul pengkategorian dan modul representasi hasil.
1. Modul Masukkan
Modul ini berfungsi membaca data masukan yang telah dipersiapan sebelumnya dalam format excell. Hasil dari modul ini adalah berupa matriks masukan. Hal ini sesuai dengan keperluan sistem yang menggunakan algoritma FCM dalam melakukan proses pengelompokkan pelanggan, yakni memerlukan masukkan dalam bentuk matriks.
⎪ ⎪ ⎭ ⎪ ⎪ ⎬ ⎫ ⎪ ⎪ ⎩ ⎪ ⎪ ⎨ ⎧ = n n n n b c d a d c b a d c b a matriks Contoh ... ... ... ... 2 2 2 2 1 1 1 1
Gambar 9. Fitur-fitur matriks data masukan sistem Keterangan fitur : a = lama berlangganan b = jml pembayaran c = kesetiaan membayar d = jumlah pemakaian listrik
2. Modul Analisa dengan Algoritma FCM
Modul ini berfungsi mengelompokkan data yang telah tersedia dalam bentuk matriks menjadi kelompok-kelompok berdasarkan kemiripannya. Tingkat kemiripan tersebut ditentukan dengan mengukur jarak euclidean data ke pusat klaster. Hasil dari modul ini berupa matriks U yang merepresentasikan derajat keanggotaan point data
dan titik pusat klaster. Matriks keanggotaan (Uij) yang dihasilkan pada proses analisis
pengelompokkan menggunakan algoritma FCM berdimensi k x n, dimana k adalah jumlah klaster dan n adalah jumlah data yang digunakan sebagai masukkan. Untuk lebih jelasnya Tabel 4 berikut ini akan menggambarkan matriks keanggotaan (Uij)
hasil analisis pengelompokkan menggunakan algoritma FCM.
Tabel 3. Tabel matrik keanggotaan (Uij) terhadap k klaster
Jumlah Data
Klaster 1 Klaster 2 ... Klaster k
1 U11 U21 ... U1k
2 U21 U22 ... U2k
... ... ... ... ...
... ... ... ... ...
n Un1 Un2 ... Unk
Dalam proses analisis pengelompokkan titik pusat klaster yang dihasilkan algoritma FCM akan mengalami perbaikan selama proses iterasi. Jumlah titik pusat yang dihasilkan sistem sama dengan jumlah klaster yang dimasukkan pada saat memasukkann nilai parameter algoritma.
3. Modul Uji Validasi terhadap Hasil Analisa FCM
Metode yang dikembangkan dalam modul uji validasi hasil analisa FCM ini adalah metode Xie dan Beni (1991). Modul ini bekerja mengukur rasio kepadatan poin-poin data pada masing-masing klaster dan keterpisahan point-point data antarklaster. Fungsi dari modul ini adalah memberikan informasi tentang kualitas pengelompokkan yang dihasilkan modul analisa FCM. Semakin kecil nilai yang dihasilkan artinya semakin bagus hasil pengelompokkan yang telah dilakukan algoritma FCM. Hasil validasi pengelompokkan data pelanggan rumah tangga, pelanggan bisnis dan pelanggan industr bisa dilihat pada Lampiran 1.
4. Modul Kategorisasi Kelompok
Modul ini berfungsi memberikan kategori kelompok pada setiap point data sesuai dengan derajat keanggotaannya terhadap pusat kelompok. Derajat keanggotaan paling tinggi yang dimiliki point data akan dikategorikan pada point data tersebut.
5. Modul Representasi Hasil.
Modul ini berfungsi untuk merepresentasikan hasil dari tahap sebelumnya. Yang ditampilkan oleh modul ini antara lain titik pusat klaster, jumlah pelanggan per kelompok dan data rata-rata per variabel per kelompok. Hasil ditampilkan ke dalam bentuk visual berupa angka rata-rata.
4.3. Desain Antarmuka
Untuk memudahkan penggunaan prototipe oleh pemakai maka dibuat antarmuka (user interface). Antarmuka dibuat sesederhana mungkin dengan tujuan agar mudah digunakan oleh pengguna. Ada dua tampilan utama antarmuka dalam prototipe sistem yang dibangun yakni tampilan antarmuka bagian depan dan tampilan antarmuka analisis pengelompokkan. Tampilan antarmuka bagian depan hanya berfungsi untuk menampilkan informasi tentang prototipe sistem. Tampilan antarmuka analisis pengelompokkan berfungsi sebagai antarmuka melakukan analisis pengelompokkan data dan menampilkan data karakter pelanggan. Pada antarmuka ini dibagi menjadi dua bagian yakni bagian proses klasterisasi dan bagian karakter data. Antarmuka bagian klasterisasi berfungsi untuk melakukan proses pengelompokkan data hingga dicapai hasil klaster terbaik. Sementara antarmuka bagian karakter data berfungsi untuk menampilkan data-data karakter kelompok pelanggan yang terbentuk dari hasil klaster terbaik. Tampilan antarmuka dapat dilihat selengkapnya pada panduan penggunaan sistem yang tertera pada Lampiran 2.
4.4. Uji Validasi Hasil Pengelompokkan Pelanggan
Uji validasi terhadap nilai parameter yang digunakan pada algoritma FCM dalam penelitian ini dilakukan untuk mendapatkan hasil paling maksimal dengan
biaya komputasi terkecil saat proses klasterisasi. Nilai parameter algoritma FCM yang yang memberikan hasil klasterisasi paling akurat menjadi rekomendasi kepada pengguna saat melakukan klasterisasi terhadap data pelanggan rumah tangga, bisnis dan industri. Namun pengguna juga bisa menggunakan nilai parameter lain sesuai keperluannya saat melakukan klasterisasi terhadap data pelanggan rumah tangga, bisnis dan industri.
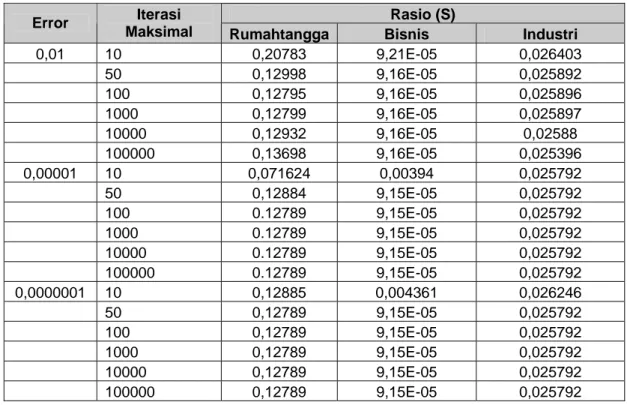
4.4.1. Nilai Error dan Iterasi Maksimal
Semakin kecil nilai error yang digunakan maka semakin baik hasil pengelompokkan yang dilakukan. Namun semakin kecil nilai error yang digunakan berimplikasi pada biaya komputasi yaitu biaya komputasi menjadi semakin besar. Sebab nilai error yang semakin kecil maka jumlah iterasi yang terjadi akan semakin banyak. Namun hal ini tergantung juga pada penggunaan iterasi maksimal yang digunakan. Sebab nilai error hanya merupakan salah satu parameter untuk menghentikan iterasi komputasi proses klasterisasi menggunakan algoritma fuzzy c-mean selain iterasi maksimal.
Tabel 4. Hasil validasi pengelompokkan terhadap nilai error dan iterasi maksimal
Rasio (S)
Error Iterasi
Maksimal Rumahtangga Bisnis Industri
0,01 10 0,20783 9,21E-05 0,026403 50 0,12998 9,16E-05 0,025892 100 0,12795 9,16E-05 0,025896 1000 0,12799 9,16E-05 0,025897 10000 0,12932 9,16E-05 0,02588 100000 0,13698 9,16E-05 0,025396 0,00001 10 0,071624 0,00394 0,025792 50 0,12884 9,15E-05 0,025792 100 0.12789 9,15E-05 0,025792 1000 0.12789 9,15E-05 0,025792 10000 0.12789 9,15E-05 0,025792 100000 0.12789 9,15E-05 0,025792 0,0000001 10 0,12885 0,004361 0,026246 50 0,12789 9,15E-05 0,025792 100 0,12789 9,15E-05 0,025792 1000 0,12789 9,15E-05 0,025792 10000 0,12789 9,15E-05 0,025792 100000 0,12789 9,15E-05 0,025792