SKRIPSI
Diajukan untuk Memenuhi Salah Satu Syarat
Memperoleh Gelar Sarjana Teknik
Jurusan Teknik Informatika
Oleh :
Florensius Phangestu
NIM : 065314063
PROGRAM STUDI TEKNIK INFORMATIKA
JURUSAN TEKNIK INFORMATIKA
FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA
YOGYAKARTA
2010
A THESIS
Presented as Partial Fulfillment of the Requirements
To Obtain the
Sarjana Teknik
Degree
In Department of Informatics Engineering
By :
Florensius Phangestu
Student ID : 065314063
INFORMATICS ENGINEERING STUDY PROGRAM
INFORMATICS ENGINEERING DEPARTMENT
FACULTY OF SCIENCE AND TECHNOLOGY
SANATA DHARMA UNIVERSITY
YOGYAKARTA
2010
Skripsi ini kupersembahkan untuk :
untuk Tuhan Yang Maha Pengasih, yang selalu menuntun, membimbing dan
menguatkanku dalam setiap langkah yang kutempuh.
untuk Bunda Maria yang selalu menyertai, melindungi dan mendoakanku sehingga
saya mampu menghadapi setiap percobaan.
untuk keluargaku yang bergitu pengertian dan pemberi semangat dan kehangatan
untuk romo Kuntoro yang menjadi pembimbingku, yang selalu bersedia meluangkan
waktu, tenaga, pikiran serta kesabaran dalam mendidikku
untuk Evi Michella Veronika, my spring of joy
untuk almamaterku,
untuk Indonesia,
dan, untuk setiap orang yang mempelajari Speaker Identification
PERI\TYATAAI\T
KEASTIAI{ KARYA
Saya menyatakan
dengan
sesungguhnya
bahwa skripsi yang saya tulis ini
tidak memuat
karya/bqgian
karya orang lain, kecuali yang telatr disebutkan
dalam
kutipan dan daftar pustaka sebagaimana
layaknya
karya ilmiah.
Yogyakarta 29 Maret 2010
Penulis
fr"w
Florensius
Phangestu
I
l ,
Yang bertanda tangan dibawah ini, saya mahasiswa Universitas Sanata Dharma :
Nama : Florensius Phaneesfu
NIM :065314063
Demi pengembangan ilmu pengetahuano saya memberikan kepada Perpustakaan
Universitas Sanata Dharma karya ilmiah saya yang berjudul :
IDENTIHKASI INDTWDU BTJRT]FIG SECARA OTOMATIS DENGAN
MENGGT}NAKAN PEIIDEKATAIY HIDDEN MARKOV MODELS
Beserta perangkat yang diperlukan (bila ada). Dengan demikian saya memberikan
kepada Perpustakaan Universitas Sanata Dharma untuk hak menyimpan,
mengalihkan dalam bentuk media lain, mengolahnya dalam bentuk pangkalan
data, mendistribusikannya secara terbatas, dan mempublikasikannya di internet
dan media lain untuk kepentian akademis tanpa perlu meminta izin dari saya
maupun memberikan royalti kepada saya selama tetap mencantumkan nama saya
sebagai penulis.
Demikian pemyataan ini saya buat dengan sebenamya.
Yogyakart4 29 Maret 2010
Penulis
I
{l*;,,f
--V
Florensius Phangestu
dapat dimanfaatkan untuk mengidentifikasi identitas burung. Pada tugas akhir ini
dibangun suatu metode untuk mengidentifikasi secara otomatis individu burung
berdasarkan suara kicauan (
acoustic features
) dengan menggunakan pendekatan
Hidden Markov Models
. Pendekatan ini secara umum digunakan pada
signal
prosessing
dan untuk
speaker identification
pada manusia.
Penelitian ini menggunakan burung ortolan bunting sebagai objek
penelitian dengan jumlah sebanyak 8 ekor (100 data
sample
untuk masing-masing
burung). Pembagian data untuk proses
testing
dan
training
menggunakan metode
5 fold cross-validation
.
Berdasarkan hasil pengujian yang dilakukan dengan berbagai kombinasi
feature
dan jumlah state diperoleh tingkat akurasi yang bervariasi mulai dari
terendah yaitu 78,857% sampai dengan tertinggi yaitu 81,875% .
used to identify the individual bird. This research built a method for identifying
automatically each individual bird based on their sound (acoustics features) using
Hidden Markov Models. Generally this approach is used for signal processing and
for human speaker identification.
This research employed eight Emberiza hortulana birds as the object for
the study (100 data sample for every birds). Data for testing and training were
separated using 5 fold cross-validation method.
The results using any combination of features and number of states show
variation of accuracy started from 78,857% to 81,875%.
karunia-Nya sehingga penulis dapat menyelesaikan skripsi dengan judul
“
Identifikasi Individu Burung Secara Otomatis dengan Menggunakan
Pendekatan
Hidden Markov Models” .
Dalam kesempatan ini, penulis ingin mengucapkan terima kasih yang
sebesar-besarnya kepada semua pihak yang turut memberikan dukungan,
semangat dan bantuan hingga selesainya skripsi ini :
1.
Romo Dr. Cyprianus Kuntoro Adi, S.J.,M.A.,M.Sc
atas semua bantuan,
bimbangan, kesabaran, waktu, dan semangat yang telah romo berikan,
membuat skripsi ini dapat terselesaikan. Apa jadinya semua ini tanpa bantuan
romo?
2.
Yosef Agung Cahyanta, S.T., M.T., selaku Dekan Fakultas Sains dan
Teknologi Universitas Sanata Dharma.
3.
Bapak Puspaningtyas Sanjoyo Adi, S.T., M.T., sebagai Ketua Jurusan Teknik
Informatika Universitas Sanata Dharma.
4.
Bapak Bambang Soelistijanto, S.T., M.Sc., sebagai dosen penguji, atas saran
dan kritik yang diberikan.
5.
Bapak
Eko Hari Parmadi, S.Si., M.Kom., sebagai dosen penguji, atas saran
dan kritik yang diberikan.
6.
Ridowati Gunawan, S.Kom., M.T., yang telah memberikan dukungan dan
semangat.
jalannya pendadaran.
9.
Seluruh Staff Universitas Sanata Dharma, yang atas kerja kerasnya, membuat
perkuliahan menjadi terasa nyaman.
10.
Kedua orang tua saya, Mikael Phang Min Khong dan Lim Djan Fa, serta
kakak saya Valeria Pangesti, S.E., atas doa, semangat, dukungan baik
moril maupun finansial serta cinta yang begitu besar, selalu ada dan tak
akan pernah berhenti.
11.
Evi Michella Veronika,Heribertus Henta Nooristyanto, Julianto, Charles,
Tulus Wardoyo, Maya yang sangat banyak membantu dalam proses
pembuatan skripsi ini, atas dukungan, semangat, dan bantuan.
12.
Serta semua pihak yang telah membantu kelancaran dalam penulisan tugas
akhir ini. Penulis mengucapkan banyak terima kasih.
Penulis menyadari bahwa masih banyak kekurangan yang terdapat
pada laporan tugas akhir ini. Saran dan kritik sangat penulis harapkan
untuk perbaikan-perbaikan dimasa yang akan datang. Akhir kata, penulis
berharap tulisan ini bermanfaat bagi kemajuan dan perkembangan ilmu
pengetahuan serta berbagai pengguna pada umumnya.
Yogyakarta ,29 Maret 2010
Penulis
HALAMAN JUDUL BAHASA INGGRIS ...
ii
HALAMAN PERSETUJUAN PEMBIMBING ...
iii
HALAMAN PENGESAHAN ...
iv
HALAMAN PERSEMBAHAN ...
v
PERNYATAAN KEASLIAN KARYA ...
vi
HALAMAN PERSETUJUAN PUBLIKASI ...
vii
ABSTRAK ... viii
ABSTRACT ...
ix
KATA PENGANTAR ...
x
DAFTAR ISI ...
xii
BAB I. PENDAHULUAN ...
1
1.1. Latar Belakang ...
1
1.2. Rumusan Masalah ...
2
1.3. Tujuan ...
3
1.4. Batasan Masalah ...
3
1.5. Metodologi Penelitian ...
4
1.6. Sistematika Penulisan ...
5
2.1.1. Pengenalan
Speaker Recognition
...
7
2.1.2. Prinsip
Speaker Recognition
...
8
2.2.
Feature
...
10
2.2.1.
Feature Extraction
...
10
2.2.2.
Greenwood Function Cepstral Coefficients
...
10
2.3. Teori Dasar Markov Model...
14
2.4.
Hidden Markov Models
...
17
2.5. Terminologi HMM ...
21
2.6.
Trellis Diagram
...
22
2.7.
Hidden Markov Models
untuk
Speaker Recognition
...
24
2.8. Pengoptimalisasi State
Sequence
...
24
2.9. Algoritma
Baum-Welch
...
34
BAB III. METODOLOGI PENELITIAN ...
38
3.1. Data Burung Ortolan Bunting ...
38
3.2. Proses
Training
...
40
3.3. Proses
Testing
...
41
3.4. Metode
5 Folds Cross-Validation
...
42
3.5. Perancangan Sistem ...
44
3.6.2.
Software
...
50
BAB IV. IMPLEMENTASI DAN ANALISA SISTEM ...
51
4.1. Implementasi Antar Muka yang Digunakan pada Sistem ...
51
4.1.1. Halaman Depan ...
51
4.1.2. Halaman Pengujian
Hidden Markov Models
...
52
4.1.3. Halaman Pengidentifikasian ...
53
4.1.4. Halaman Bantuan Program ...
55
4.1.5. Halaman Tentang Program ...
56
4.2. Analisis Akurasi Identifikasi Burung ...
57
BAB V. KESIMPULAN DAN SARAN ...
63
5.1. Kesimpulan ...
63
5.2. Saran...
65
DAFTAR PUSTAKA ...
66
LAMPIRAN I ...
69
LAMPIRAN II ...
71
2.1
besok berdasarkan cuaca hari ini
15
2.2
Probabilitas
membawa payung
berdasarkan cuaca
pada hari
i
|
19
3.1 Contoh
confusion matrix
43
4.1
Hasil akurasi identifikasi individu burung dengan
kombinasi
feature
dan jumlah
state
57
4.2
Identifikasi individu burung dengan variasi tipe
feature
60
4.3
Confusion matrix
untuk hasil akurasi paling tinggi
61
1996)
2.2
Struktur dasar sistem
speaker varification
(Reynolds, 2002)
9
2.3
Langkah-langkah untuk proses menghitung
koefisien dari GFCC
12
2.4
Greenword filterbanks
13
2.5
Markov model untuk cuaca dengan probabilitas
transisi state berdasarkan table 2.1
15
2.6 HMM
untuk suara burung pertama ab02_88_1
18
2.7
Trellis diagram
22
2.8
Trellis diagram
untuk contoh no.2 pada HMM
23
2.9 Algoritma
viterbi
untuk
part
untuk state
“sunny”
pada
n
= 2
28
2.10 Algoritma
viterbi
untuk
part
untuk state
“rainy”
pada
n
= 2
29
2.11 Algoritma
viterbi
untuk
part
untuk state
“foggy”
pada
n
= 2
30
2.12 Algoritma
viterbi
untuk
part
akhir pada
n
= 3
32
2.13 Algoritma
viterbi
33
2.14
Probability function
dengan state
S
pada saat t dan
beralih ke state
S
pada saat t+1
35
3.1
Syllable
burung ortolan bunting
(Osiejuk, 2003)
39
3.2
Time series
dan
spectrogram
dari tipe nyanyian ab
39
3.3
Menggunakan HMM untuk
training
model
40
3.4
Menggunakan HMM untuk identifikasi data suara
baru
41
3.5
Pembagian tiap kelompok data menjadi 5 bagian
42
3.6
Iterasi pengujian untuk salah satu kelompok data
43
3.7
Halaman Depan (
Home
) 45
3.8 Halaman
pengujian
Hidden Markov Models
46
3.9 Halaman
pengidentifikasian
47
3.10
Halaman bantuan program
48
3.11
Halaman tentang program
48
3.12
Halaman peringatan (jika tidak data suara input
untuk diproses)
49
3.13
Halaman peringatan (jika tidak data suara input
untuk didengarkan)
49
3.14
Halaman konfirmasi (jika ingin mengakhiri
penggunaan sistem)
50
4.1
Halaman depan (
home
) 51
xvii
menekan tombol “mainkan”)
4.6
Peringatan jika belum ada sua
ra inputan (jika
54
menekan tombol “proses”)
4.7
Halaman bantuan program
55
4.8
Halaman tentang program
56
4.9 Tingkat
akurasi
identifikasi individu burung
ze
dan
(
feature
GFCC) dengan kombinasi
window si
jumlah state yang berbeda
60
4.10
Spectrogram
suara kicauan
burung5
62
1.1
Latar Belakang
Burung mempunyai suara kicauan yang berbeda untuk mengenali sesama
anggota spesies atau mengenali rekan, orang tua, maupun dengan burung dari
spesies lain (Holschuch, 2004). Keunikan dari masing-masing suara kicauan
burung ini dapat dimanfaatkan untuk proses pengidenfikasian individu burung.
Pengidentifikasian individu burung yang ada pada saat ini dapat dilakukan
secara manual maupun secara otomatis. Secara manual, cara yang dilakukan
adalah capture dan handling burung secara langsung. Namun cara ini tentu sangat
tidak efektif jika burung-burung yang dilibatkan bersifat sensitif terhadap
gangguan (disturbance) dan burung yang sulit diobservasi secara langsung. Secara
otomatis adalah dengan menggunakan suara kicauan burung yang selanjutnya
akan di identifikasi dengan program bantu pada komputer.
Teknik-teknik yang digunakan untuk mengidentifikasi individu binatang
secara otomatis berdasarkan suara dibagi menjadi dua kategori yaitu kualitatif dan
kuantitatif (Mc.Gregor et al., 2000). Pendekatan kualitatif meliputi perbandingan
spectrogram yang dilakukan oleh para peniliti. Pendekatan ini mempunyai konsep
yang sederhana dan mudah dioperasikan. Namun, variable yang dilibatkan dalam
perhitungan dengan spectrogram tidak cukup untuk menggambarkan karakteristik
dari isi spectrum dan pola sinyal sehingga tingkat akurasinya tergolong rendah
(Wakita, 1976). Jadi diperlukan metode kuantitatif yang lebih teliti dalam
pengukuran secara detail frekuensi dan temporal parameters dari suara tersebut.
Salah satu metode pendekatan kuantitatif adalah metode Hidden Markov
Models. Metode ini tidak membutuhkan banyak usaha, tidak mengkonsumsi
waktu yang lama dalam pengolahan, dan hasil yang diperoleh lebih akurat.
Dalam penulisan tugas akhir ini, akan diterapkan metode Hidden Markov
Models sebagai metode untuk mengidentifikasi individu burung secara otomatis
(speaker recognition).
1.2
Rumusan Masalah
Dari latar belakang masalah diatas dapat dirumuskan menjadi beberapa
masalah sebagai berikut :
1.
Bagaimana mengimplementasi indentifikasi individu burung
berdasarkan suara kicauan dengan pendekatan metode Hidden Markov
Models dalam suatu perangkat lunak?
2.
Bagaimana tingkat akurasi identifikasi individu burung dengan
1.3
Tujuan
1.
Membangun suatu metode untuk mengidentifikasi secara otomatis
individu burung menggunakan pendekatan Hidden Markov Models.
2.
Menemukan parameter yang berpengaruh dalam pengenalan
(identifikasi).
3.
Menghitung akurasi identifikasi individu burung.
1.4
Batasan Masalah
Adapun masalah yang akan diselesaikan dibatasi oleh hal-hal berikut :
1.
Hanya satu spesies burung yang diteliti dengan satu tipe nyanyian (ab).
2.
Suara kicauan yang dapat diproses adalah suara wav (*.WAV).
3.
Feature extraction dilakukan dengan menggunakan metode GFCC
(Greenwood Functions Ceptral Coefficients).
4.
Pemodelan suara burung menggunakan algoritma Baum-Welch.
5.
Pengidentifikasian suara burung menggunakan algoritma Viterbi.
1.5
Metodologi Penelitian
Metode yang digunakan dalam penelitian meliputi :
1.
Studi Pustaka
Dengan mempelajari buku-buku referensi yang berkaitan dengan
speaker recognition, metode Hidden Markov Models,
feature
extraction, algoritma Baum-Welch, algoritma Viterbi dan pemrograman
matlab.
2.
Analisa Kebutuhan
Pada tahap ini mengumpulkan sampel suara (*.WAV) untuk setiap
burung ortolan bunting dalam satu jenis tipe nyanyian yaitu ‘ab’ .
3.
Perancangan
Tahap ini digunakan untuk mengubah model matematika menjadi
sebuah representasi perangkat lunak.
4.
Implementasi
Hasil dari tahap perancangan dengan diterjemahkan dalam suatu sistem.
5.
Pengujian dan Evaluasi
Tahap ini dilakukan pengujian terhadap sistem yang sudah dibuat untuk
mengetahui tingkat akurasi identifikasi individu burung ortolan bunting.
6.
Kesimpulan
1.6
Sistematika Penulisan
BAB I : PENDAHULUAN
Bab ini berisi latar belakang, rumusan masalah, tujuan, batasan
masalah, metodologi penelitian dan sistematika penulisan.
BAB II : LANDASAN TEORI
Bab ini berisi tentang penjelasan mengenai speaker recognition,
feature extraction, Greenwood function cepstral coefficients
(GFCC), dasar metode Hidden Markov Models, algoritma
Baum-Welch dan algoritma Viterbi.
BAB III : METODOLOGI
Bab ini berisi tentang data burung ortolan bunting, alur proses
training dan proses testing serta penjelasan rancangan sistem
yang akan di implementasi.
BAB IV : IMPLEMENTASI DAN ANALISA HASIL
Bab ini berisi implementasi antarmuka sistem dan analisa hasil
BAB V : PENUTUP
Bab ini berisi kesimpulan dan saran-saran yang dapat
dipertimbangkan agar sistem dapat digunakan dan dikembangkan
BAB II
LANDASAN TEORI
Pada landasan teori ini akan dijelaskan secara singkat hal-hal yang berkaitan
dengan identifikasi individu burung, teori dasar Markov model beserta contoh
dasar untuk memudahkan pemahaman, trellis diagram serta algoritma-algoritma
lain yang akan digunakan pada proses pengidentifikasian.
2.1
S
peaker Recognition
2.1.1 Pengenalan S
peaker Recognition
Speaker
recognition
dengan komputer merupakan tugas untuk
mengidentifikasi (recognizing)
secara otomatis identitas speaker berdasarkan isi
informasi yang diperoleh dari sinyal suara (O’Saughnessy,2000).
Speaker recognition
mencakup dua tugas utama yaitu speaker
identification dan speaker verification.
Speaker identification mengacu pada
penentuan 1 (satu) identitas speaker dari sekumpulan speaker terdefinisi secara
terbatas. Sedangkan speaker verification atau dikenal dengan speaker
authentication
mengacu pada tugas mengklasifikasikan untuk menerima atau
menolak secara otomatis terhadap identitas yang mengklaim sebagai speaker.
Selama proses pengidentifikasian, model referensi untuk masing-masing
speaker yang sudah dibentuk akan digunakan untuk menghitung nilai
perbandingan dengan input sinyal suara. Pada proses speaker verification,
nilai
yang mengklaim dan alternatif model lain atau disebut dengan imposter speakers.
Perbedaan antara speaker identification dan speaker verification terletak
pada jumlah alternatif pengambilan keputasan. Pada speaker identification jumlah
pengambilan keputusan adalah sama dengan ukuran jumlah populasi. Pada
speaker verification jumlah pengambilan keputusan hanya terdiri dari dua
kemungkinan yaitu menerima atau menolak tanpa memperhatikan ukuran
populasi.
2.1.2 Prinsip
Speaker Recognition
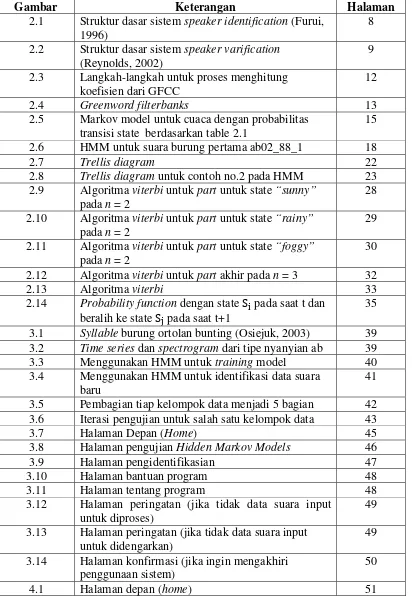
Gambar 2.1 dan 2.2 akan menunjukan struktur sistem speaker recognition.
Dalam
speaker identification,
speech signal yang sebelumnya tidak
diketahui identitas speaker
akan dianalisis. Sistem akan melakukan pencocokan
kesamaan dengan model-model yang ada untuk mengetahui identitas dari speaker.
Gambar 2.2.
Struktur dasar sistem speaker varification (Reynolds, 2002)
Sebuah sistem speaker verification akan mengimplementasikan test
perbandingan untuk menganalisis diantara dua hipotesis yaitu test speech berasal
dari speaker model atau impostor model.
Feature ektraksi dari input sinyal akan
dibandingkan dengan daftar speaker model dan dibandingkan dengan beberapa
model yang merepresentasikan imposter speaker. Nilai dari pebandingan ini
digunakan untuk mengambil keputusan untuk menerima atau menolak speaker
2.2
Feature
2.2.1
Feature Extraction
Pengidentifikasian
individu
burung yang menggunakan data yang
memiliki label disebut sebagai “supervised”. Data suara yang diambil merupakan
data audio (signal). Namun tidak semua data audio tersebut dipergunakan,
sehingga diperlukan proses feature extraction untuk menentukan hanya feature
penting yang diperlukan. Feature yang di ekstrak diharapkan mempunyai
kemampuan untuk membedakan kemiripan vokalisasi serta mempunyai
kemampuan untuk membuat model tanpa membutuhkan sebuah data training
yang berlebihan.
Tujuan dari proses feature extraction adalah untuk parameterisasi suara
(audio) kedalam rangkaian vector
feature yang ringkas dan relevan, sehingga
dapat mewakili informasi dari suara tersebut.
2.2.2
Greenwood Function Cepstral Coefficients
(GFCC)
Pada Subbab ini
akan menjelaskan secara singkat (review) mengenai
Greenwood function cepstral coefficients (GFCC) yang telah didiskusikan lebih
detail di dalam (Clemins et al., 2006).
Greenwood function cepstral coefficients (GFCC) merupakan salah satu
pendekatan yang digunakan untuk mengekstrak feature berdasarkan pada
perceptual model dari spesies. Dalam kasus ini adalah suara dari spesies burung
Greenwood (Greenword,1961,1990) menunjukan bahwa beberapa dari
spesies mamalia baik mamalia darat maupun perairan menerima frekuensi pada
sebuah skala algoritmik yang dimodelkan dengan persamaan :
f = A(
10
-b)
(2-1)
Keterangan :
f adalah frekuensi (Hz)
A, a dan b merupakan konstanta (spesifik untuk masing-masing spesies)
x menunjukan posisi dari selaput pendengaran
Untuk frekuensi f, maka frequency warping didefinisikan sebagai :
(2-2)
Dengan pendekatan range pendengaran (
) dari spesies tersebut, dan
menggunakan pendekatan b
=
0.88
(LePage, 2003), konstanta A dan a dapat
diturunkan sebagai berikut
:
A =
(2-3)
Gambar 2.3 berikut akan ditunjukan diagram blok dalam proses Greenwood
function cepstral coefficients.
Windowed FFT
Greenwood filterbank
Discrete cosine transform Suara
burung coefficientCepstral
Gambar 2.3.
Langkah-langkah untuk proses menghitung koefisien dari GFCC
Sinyal suara akan dilakukan segmentasi menjadi frame-frame dan
masing-masing dari frame di window.
Window dari data suara ditransformasi dengan
menggunakan fast fourier transform.
∑
exp
2
/
(2-5)
/
ln ∑
|
|
,
Dimana
x(n)
adalah signal dalam diskrit waktu dengan panjang N
,
k=0,1,..N-1, dan k
berkorespondensi dengan frekuensi f(k) =
,
adalah
sampling frekuensi (Hz) dan w(n)
adalah
time-window (sering menggunakan
Hamming window dengan w(n) = 0.54 – 0.46 cos (
n / N)).
Suara burung ortolan bunting mempunyai range frekuensi dengan ukuran
window 3ms-6ms. Koefisien magnitude |X(k)| dikorelasikan dengan
masing-masing
triangular filter dalam greenwood filterbank H(k,m). Ini berarti
masing-masing koefisien magnitude dari fast fourier transform dikalikan dengan
filter-gain dan hasilnya di akumulasikan sebagai berikut:
Untuk m = 1,2,…,M, dimana M adalah jumlah dari filter banks dan M<<N.
Greenwood filterbank merupakan sebuah kumpulan dari triangular
filters yang
didefinisikan oleh center frequencies.
Filterbank center frequencies dihitung dengan skala Greenwood
dari
persamaan (2-2). Tringular filters tersebar di seluruh frequency range dari 0
sampai
Nyquist frequency.
Band-limiting
menggunakan frekuensi bawah (lower)
dan atas (upper) untuk me-reject
frekuensi yang tidak diinginkan. Untuk suara
burung ortolan bunting, Greenwood filterbank (gambar 2.4) biasa mempunyai
range 400 sampai 7400 Hz yang merupakan
dan
dari spesies nyanyian
burung (Edward, 1945).
∑
cos
Gambar 2.4.
Greenword filterbanks
Discrete cosine transform digunakan untuk menghitung cepstral coefficients dari
log filterbank amplitudes X’(m) sebagai berikut :
0.5
(2-7)
2.3
Teori Dasar
Markov Model
Markov model
menggambarkan sistem dengan serangkaian state
dan
transisi state (setiap transisi dari state mempunyai sebuah probabilitas) dimana
rangkaian dari state-state tersebut disebut dengan Markov chain.
Dalam Markov model atau first-order-markov mengasumsikan bahwa
probabilitas observasi pada waktu n
hanya tergantung pada observasi
yang
dilakukan pada waktu n-1. Untuk serangkaian {
, ,..,} maka
|
,|
,
|
|
P(
,
,…,
) = P(
)
(asumsi Markov)
(2-8)
Untuk memperoleh penggabungan probabilitas (joint probability) dari baik
observasi-observasi sebelumnya maupun observasi sekarang dapat diturunkan
menjadi:
P(
,…,
) =
∏
(2-9)
Contoh soal :
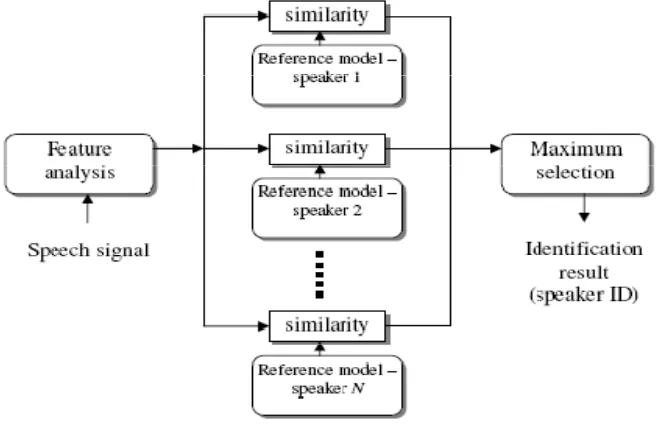
Misalkan terdapat 3 tipe cuaca : “sunny” , “rainy” dan “foggy”, berikut
dengan tabel probabilitas P(
) cuaca yang akan terjadi besok (
)
Tabel 2.1.
Probabilitas p(
) cuaca yang akan terjadi besok berdasarkan
cuaca hari ini
|
Cuaca
besok
Cuaca hari ini
sunny rainy foggy
sunny
0.8 0.05
0.15
rainy
0.2 0.6 0.2
foggy
0.2 0.3 0.5
State yang ada S = {sunny,
rainy,
foggy} dan setiap hari mempunyai
kemungkinan transisi p(
) state berdasarkan tabel probabilitas 2.1.
Berikut gambar untuk state-state tersebut :
|
Sunny
Foggy
Rainy
0.6
0.15
0.2
0.8
0.5
0.2
0.2
0.3
0.05
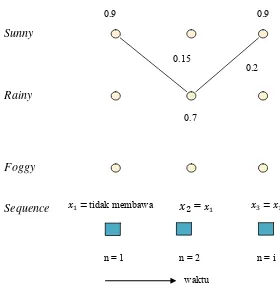
Gambar 2.5.
Markov model untuk cuaca dengan probabilitas transisi state
1.
Jika hari ini cuacanya adalah “sunny” berapakah probabilitas besok bercuaca
“sunny” dan hari berikutnya ( ) adalah “rainy” ?
Dengan menggunakan teori asumsi Markov pada pembahasan diatas dan dengan
tabel probabilitas 2.1 maka permasalahan ini dapat di terjemahkan menjadi:
P(
,
|
P(
,
.
P(
|
|
|
|
,
|
=
|
=
P(
) . (
(markov
asumsi)
= 0.05 . 0.8
= 0.04
2.
Jika cuaca kemarin
adalah
“rainy” dan cuaca hari ini adalah “foggy”,
berapakah probabilitas besok dengan cuaca “sunny” ?
P(
= P(
2.4
Hidden Markov Models
genalan pola pada speaker recognition yang
memili
asarkan
observ
|
=
|Salah satu metode pen
ki akurasi baik adalah metode Hidden Markov Models. Metode ini
merupakan perluasan dari Markov model yang populer dipakai untuk pengenalan
pola akustik. Hidden Markov Models adalah sebuah model statistik dengan
Markov model yang state-state (transisi state) tidak dapat diamati secara langsung
atau dengan kata lain parameter-parameter tersebut tersembunyi (hidden).
Untuk menentukan probabilitas setiap state hanya diperoleh berd
asi , sehingga kondisi probabilitas
|
dapat dirumuskan dengan:
(2-10)
engan memperhatikan probabilitas
yang tidak berubah untuk setiap state
ang
|
=
(2-11)
tau untuk jumlah n maka :
L(
,…..,|
,……,) =
∏
|
∏
|
(2-12)
D
maka masing-masing potensi state y
akan diuji atau diperiksa mempunyai
probabilitas
yang sama sehingga persamaan (2-10) dapat rumuskan dengan
persamaan (2-11) berikut ini :
|
Dalam kasus pengidentifikasi individu burung ortolan bunting, HMM akan
memod
bunting terlihat
pada g
Gambar 2.6.
HMM untuk suara burung pertama ab02_88_1
Contoh soal :
ntoh Markov model, keadaan cuaca dapat diobservasi secara
langsun
elkan karakteristik sinyal atau suara yang secara temporal dan spectrum
yang memiliki variasi yang beragam. Dalam state terdapat suatu runtun waktu
sinyal yang dihasilkan oleh suara burung ortolan bunting tersebut.
State yang dimiliki oleh salah satu suara burung ortolan
ambar di bawah ini:
start
end
Pada co
g. Namun pada HMM, cuaca-cuaca dalam keadaan ”hidden”. Hal ini dapat
kita umpamakan seandainya kita dikunci di sebuah kamar untuk beberapa hari
(tidak dapat melihat kondisi cuaca luar). Untuk melakukan prediksi cuaca yang
akan terjadi, maka hanya terdapat tanda yaitu pada orang yang setiap hari datang
ke kamar untuk membawakan makanan, apakah orang tersebut membawa payung
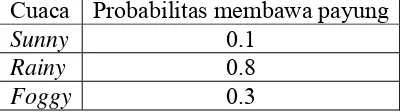
Tabel 2.2 berikut akan ditampilkan probabilitas membawa payung
berdasa
abel 2.2.
Probabilitas
|
membawa payung berdasarkan cuaca
pada
1.
Seandainya hari pada saat Anda terkunci bercuaca “sunny”. Hari berikutnya
Kemungkinan hari kedua adalah “sunny”:
=
| ) . P( | 0.1 . 0.8 = 0.08
Kemungkinan hari kedua adalah “rainy”:
| , =
| 0.8 . 0.05 .04
Cuaca
Probabilitas membawa payung
rkan keadaan cuaca. Jika orang tersebut membawa payung maka 0.1 cuaca
pada hari itu “sunny”, 0.5 bercuaca “rainy” dan 0.3 adalah “foggy”.
T
hari i
Sunny
0.1
Rainy
0.8
Foggy
0.3
orang yang mengantarkan makanan membawa payung. Berapakah probabilitas
masing-masing cuaca pada hari itu?
9
L( | ,
P(
9
L(
P( | ) . P(
9
Kemungkinan hari kedua adalah “foggy”:
( | , =
| 0.3 . = 0.045
2.
eandainya Anda tidak mengetahui cuaca pada hari Anda dikunci dalam
amar, tiga hari berturut-turut orang yang mengantarkan makanan tidak
, , ,
,
| ) .
| ) .
P( | ) .
. P( | ) . P( | )
.9 . 0.7 . 0.9 . 1/3 . 0.15 . 0.2 = 0.0057
L
P( | ) . P(
015
S
k
membawa payung. Berapakah likelihood cuaca tersebut adalah {
,,,
}?
L( |
= P( P( P(
= 0
2.5
Terminologi
HMM
-
Sebuah model HMM terdiri dengan:
¾
Sekumpulan dari state (set of states) S = { ,
,. . . ,
} dan
ameter (set of parameters)
Θ
= { , A, B}:
) merupakan probabilitas dari
¾
Transition probabilities adalah probabilitas dari state i ke state j :
= P(
= s |
). Transition probabilities dihimpun
dalam matrik
A
.
¾
Emission probabilities merupakan likelihood dari observasi x
jika
modelnya adalah . Berikut jenis observasi x :
Observasi diskrit,
{
,
. . . ,
} :
,= P(
=
|
)
rvasi jika state sekarang adalah
. Untuk
,, dihimpun dalam sebuah matrik
B
.
Observasi continue : kumpulan (set) fungsi
= p(
|
)
¾
Rangkaian state (hidden state sequence) Q = {
,
,. . . ,
},
servasi (observation sequence) X = {
,
,. . . ,
}.
sekumpulan par
¾
Prior probabilities
= P(
yang menjadi state pertama dalam rangkaian state ( untuk N state,
prior probabilities adalah = 1 /
).
,
probabilitas obse
mendeskripsikan probability density function (pdf) pada observation
space
untuk sebuah sistem dalam state , dihimpun dalam fungsi
vector
B
(x).
-
Sifat dari operasi HMM adalah:
S.
2.6
Trellis Diagram
untuk menvisualisasikan perhitungan
kemungkina
elihood) dalam HMM. Gambar 2.7 menunjukan sebuah trellis
diagram
Sta
State
2
tate
3
Se
waktu
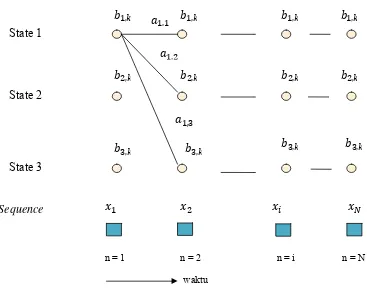
Gambar 2.7.
Trellis diagram
Masing-masing kolom dalam trellis menunjukkan kemungkinan state pada
saa
n. Masing-masing state dalam satu kolom dihubungkan dengan
masing-masing state dalam kolom yang
robabilitas transisi
yaitu pada elemen
,dalam matrik transisi
A
.
Trellis diagram dapat digunakan
n (lik
dari HMM dengan 3 state.
te
1
S
quence
t
berdampingan dengan sebuah p
,
,
,
, , ,
,
,
, , ,
, ,
, ,
Sunny
Rainy
Foggy
waktu
.8.
Tre
tuk co
o.2 pada HMM
Gambar 2.8 menunjukkan
diagram
k contoh
no.2 pada
pem ahasan mengenai teori HMM. Likelihood
rangkaian state dari rangkaian
(sequence) obs
ebut.
P =
= 0.005
Sequence
Gambar 2
llis diagram un
ntoh n
trellis
untu
soal
b
ervasi dapat diperoleh dangan path dalam trellis diagram ters
.
,.
,.
,
.
,.
,= 1/3 . 0.9 . 0.15 . 0.7 . 0.2 . 0.9
tidak membawa
=
n = 1
0.9 0.9
0.15
0.2
0.7
2.7
Hidden Markov Mode
Speaker Recognition
secara otomatis terdapat tugas utama yang
harus dilakukan yaitu mencari individu atau speaker berdasarkan rangkaian kata
(sequence word)
dalam input akustik.
ction,
akan dicari sebagai rangkaian
kat
yang merupakan maksimum
dar
em
dengan contoh sebelu
2.8
“optimal” state dengan rangkaian dari
observasi. Sebagai contoh dalam kasus speaker / speech recognition mengetahui
k masing-masing state sangat penting
supaya
t
ls
untuk
Dalam
speaker recognition
= arg max P(W|X)
W
(2-13)
Dimana, X = {
,
, . . . ,
} merupakan rangkaian dari “feature vector”
yang sudah dilakukan proses feature extra
a dari W (semua kemungkinan dari rangkaian W )
i
P(W | X). Untuk memperjelas p
bahasan diatas maka akan dibandingkan
mnya yaitu contoh tipe cuaca yang sudah dibahas
sebelumnya.
Feature vector merupakan object yang diobservasi, berkaitan dengan
observasi terhadap ada tidaknya membawa payung (contoh tipe cuaca), rangkaian
kata terkait dengan cuaca yang terjadi.
Pengoptimalisasi State
Sequence
Didalam
speaker atau speech recognition sangat penting untuk
mengasosiasikan sebuah rangkaian
feature frame mana yang termasuk untu
Algoritma
viterbi digunakan sebagai kriteria pengoptimalisasi yang
dilakukan dengan menemukan rangkaian state (part) yang mempunyai likelihood
maksimum sehingga pada saat n hanya terdapat part yang paling mungkin dipilih
untuk setiap state . Algoritma ini menggunakan dua variable yaitu:
1.
| Θ)
2.
Variable
(i) merupakan track untuk “best part” berakhir dalam state
pada saat n:
(i)
= arg max p( , , . . . , , = , , , . . . , | Θ)pakan algoritma dari viterbi :
Untuk HMM dengan
state
1.
Inisialisasi (Initialization)
= ,
(i) = 0
untuk state pada waktu n = 1.
merupakan
likelihood tertinggi (highest) dari single part diantara
semua path yang berakhir dalam state pada saat n:
= max p( , , . . . , , = , , , . . . ,
, ,
Berikut meru
. , i = 1,…,
Dimana merupakan prio probability
2.
Rekursif (R urs
x (
.) .
,2
≤
n
≤
N
(i)
=arg max (
.) 2
≤
n
≤
N
13.
Termination
(X |
Θ
) = max
arg
“best likelihood” ketika tercapai sequence dari
pengobservasian terakhir t = T.
4.
Backtracking
= {
, . . . ,
} maka
=
(
), n = N-1, N-2, . . . , 1
Membaca (decode) “best sequence” dari state yang dimulai dari vektor
ec
ion)
=
ma
1
1 ≤ i ≤
1 ≤ i ≤
1 ≤ i ≤
Menemukan
.
Contoh:
U
n
digunakan contoh sederhana yaitu pada contoh sebelumnya mengenai prediksi
cuaca pada HMM, Anda terkunci dalam kamar sehingga Anda tidak mengetahui
keadaan cuaca diluar. Pada tiga hari pertama observasi terhadap seseorang yang
datang dengan membawa payung atau tidak adalah {tidak membawa payung,
a payung, membawa payung}. Carilah probabilitas terbesar dari
rangka
=
.
,= 1/3 . 0.2 = 0.0667
,
3
ntuk mempermudah pemahaman mengenai algoritma viterbi maka aka
membaw
ian (sequence) cuaca dari ketiga hari tersebut?
1.
Initialization
n = 1
=
.
,= 1/3 . 0.9 = 0.3
(sunny) = 0
(rainy) = 0
=
.
= 1/3 . 0.7 = 0.23
2.
Recursion
n =
Menghitung
likelihood
terjadinya state “sunny”
dari 3 kemungkinan state
sebelumnya dan pilih satu yang tertinggi (terbesar).
max (
.
,,
.
,.
.
,) .
,= max (0.3 . 0.8 , 0.0667 . 0.2 , 0.233 . 0.2) . 0.1 = 0.024
(sunny) = sunny
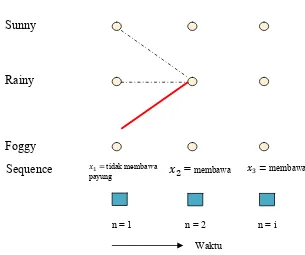
Berikut gam
Sunny
Rai
Foggy
Waktu
Gambar
“sunny” pada n = 2
2
=
bar trellis diagram:
ny
Sequence
2.9.
Algoritma viterbi untuk part untuk state
tidak membawa
pa ung y
=
membawa membawa
n = 1 n = 2 n = i
= max (0.3 . 0.8 .0667 . 0.2 , 0 3 . 0.2) . 0.1 = 0.024
unny) = sun
, 0 .23
Hal yang sama juga akan dilakukan untuk keadaan cuaca “rainy” dan “foggy”.
= max (
.
,,
.
,.
.
,) .
,= max (0.3 . 0.05 , 0.0667 . 0.6 , 0.233 . 0.3) . 0.8 = 0.056
.
,) .
,= max (0.3 . 0.15 , 0.0667 . 0.2 , 0.233 . 0.5) . 0.3 = 0.035
(foggy) = foggy
mbar
Sunny
Foggy
Gambar 2
rt
“rainy” pada n = 2
(rainy) = foggy
= max (
.
,
.
,.
Ga
trellis diagram untuk “rainy” :
Rainy
.10.
Algoritma viterbi untuk pa
untuk state
tidak membawa
payung
=
membawa membawaSequence
n = 1 n = 2 n = i
= max (0.3 . 0.05 , 0. 3) . 0.8 = 0.056
(rainy) = rainy
Waktu
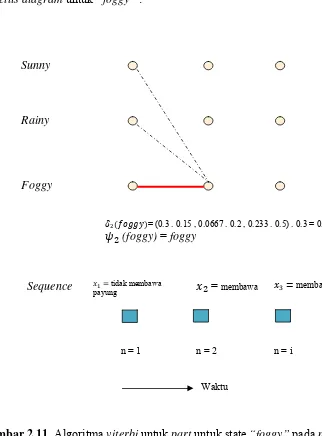
Gambar trellis diagram untuk “foggy”
y
Rainy
Waktu
Gambar 2.11.
Algoritma viterbi untuk part untuk state “foggy” pada n = 2
:
Sunn
Foggy
tidak membawa
payung
=
membawa membawan = 1 n = 2 n = i
= (0.3 . 0.15 , 0.0667 . 0.2 , 0.233 . 0.5) . 0.3 = 0.035
) = foggy
(foggy
n = 3
= max (
.
,,
.
,.
.
,) .
,= max (0.024 . 0.8 , 0.056 . 0.2 , 0.035 . 0.2) . 0.1 = 0.0019
(sunny) = sunny
= max (
.
,,
.
,.
.
,) .
,= max (0.024 . 0.05 , 0.056 . 0.6 , 0.035 . 0.3) . 0.8 = 0.0269
(rainy) = rainy
= max (
.
,,
.
,.
.
,) .
,= max (0.0024 . 0.15 , 0.056 . 0.2 , 0.035 . 0.5) . 0.3 = 0.0052
Trellis diagram
Sunny
= 0.0019Rainy
= 0.0269Foggy
= 0.0052
Sequence
Gambar 2.12.
akhir pada n = 3
3.
ermination
Seca
uhan
pa
in (
ly part) telah
ditentukan, maka untuk termination
akan dimulai dari state terakhir dari
sequence yang paling m
n.
(X |
Θ
) = max (
) = = 0.0269ar
untuk semua secara keseluruh
an (n = 3):
Algoritma vite
Waktu
rbi untuk part
T
ra keselur
part yang
ling mungk
most like
ungki
g
3 = rainytidak
membawa payung
=
membawa membawa4.
=
(
) =
(
n
=
(
) =
(
y
Jadi untuk rangkaian cuaca yang paling mungkin adalah
} ={foggy,rainy,rainy}
= 0.0019
Backtracking
Rangkaian state terbaik (best sequence state) dapat diperoleh dari vector .
n = N-1 = 2:
) = rainy
= N-1 = 1:
) = fogg
= {
,
,
State1
Gambar 2.13.
Algoritma viterbi
tidak membawa
payung
=
membawa membawan = 1 n = 2 n = 3
= 0.0269
State2
= 0.0052
State3
Sequence
2.9
Algorit
Dalam p
Φ
= {A, B,
emperoleh model terbaik yang
merepresentasikan
set dari observasi. Salah satu pendekatan yang digunakan
untuk m
berikan mode
ik adalah algoritma Baum-Welch.
Didefinisikan
merupakan probabilitas terjadinya state
pada saat t,
dengan (diketahui) seque
ka:
= P
=
| X,
Φ
)
(2-14)
P
Juga mendefinisikan probability function
,
, yang merupakan probabilitas
terjadinya state pada saat t dan beralih ke state pada saat t+1, dengan model
Φ
dan sequence observasi X sebagai berikut:
,
= P
=
,
=
| X,
Φ
)
(2-16)
ma
Baum-Welch
embentukan model, pengoptimalisasi parameter-parameter model
} sangat diperlukan untuk m
em
l terba
nce observasi X dan model
Φ
ma
ersamaan (2-13) dapat diekspresikan dengan istilah variable forward-backward
sebagai
=
=
(2-15)
Untuk memperjelas persamaan
:
.
.
.
.
Gambar 2.14.
Probability function dengan state pada saat t dan beralih
pada saat t+1
rd, persam
=
(2-17)
=
∑
,
(2-18)
(2-15) berikut gambar untuk probability function
.
.
ke state
Dengan variable forward-backwa
aan diatas dapat ditulis dalam bentuk:
,
=
Relasi antara
dan
,
dapat diperoleh dengan penjumlahan j :
1
+1
+2
| Φ
Pe
a waktu t=T
maka aka
mes” untuk state
yang telah dilalui (visited). Penjumlahan
,
selama
tate
. Re-estimasi untuk parameter model mengikuti proses beriku
(2-19)
=
=
(2-21)
njumlahan
selam
n diperoleh “expected number of
ti
waktu
t=T
akan memperoleh “expected number of transitions” dari state
ke
s
t:
= expected number of times pada state
pada saat (t=1) =
=
Expected nu
mber of transition
s dari state
ke
,
=
=
(2-20)
=
Expected number of transitions dari state
Expected number of times pada state
j
Expected number of times pada state j dan observasi
∑
,
∑
∑
∑
∑
∑
Setelah re-estimasi parameter model, akan diperoleh model baru
Φ
. Proses
re-estimasi berlanjut sampai model yang dibentuk stabil.
a Baum-Welch yang ideskr
as merupa
sebuah implementasi dari algoritma EM. Dimulai dengan beberapa inisialisasi
dari parameter HMM
Φ
= (A, B, ), langkah E (expectation) dan langkah M
) dikerjakan atau dijalankan. Dalam langkah E akan menghitung
expected state” dan “expected state transition” dari inisialisasi awal A,
B
aan (2-15), (2-17), sedangkan langkah M dan digunakan untuk
enghitung ulang parameter baru yaitu A, B, dengan menggunakan persamaan
Algoritm
d
ipsikan diat
kan merupakan
(maximization
“
dengan persam
m
BAB III
METODOLOGI PENELITIAN
Pada metodologi penelitian ini akan dibahas hal-hal mengenai data burung ortolan
bunting, termasuk mengenai alur proses training dan proses testing
beserta
penjelasan mengenai metode evaluasi yang digunakan untuk menghitung akurasi
hasil identifikasi. Bagian terakhir dari bab ini akan memaparkan perancangan
sistem yang akan di implementasikan.
3.1
Data Burung Ortolan Buntin
Burung ortolan bunting berim
p,
Perrins, 1994). Burung ini mempunyai nyanyian (songs) yang sederhana dengan
nit minimal nyanyian yang dihasilkan.
Sebuah nyanyian dideskripsikan menggunakan notasi huruf seperti aaaabb
atau
merupakan bagian dari syllable. Tipe
nyanyi
g
igrasi dari Eropa barat ke Mongolia (Cram
2-3 tipe nyanyian untuk setiap individu. Frekuensi nyanyian berkisar antara 1.9
kHz – 6.7 kHz. Nyanyian dari burung ini dideskripsikan dengan istilah syllable,
tipe nyanyian, dan varian nyanyian. Secara keseluruhan terdapat 63 tipe nyanyian,
234 varian nyanyian serta 20 syllable.
Syllable (suku kata)
adalah u
hhhhuff, dimana huruf-huruf tersebut
an merupakan kelompok atau group dari nyanyian dengan syllable
yang
sama dan mempunyai urutan yang sama. Contoh tipe ab (aaabb), tipe kb
(kkkkkbb). Varian nyanyian adalah perbedaan jumlah syllable dalam tipe nyanyian
ggbbbb,
gggbb. Pada penulisan tugas akhir ini, burung ortolan bunting yang
digunakan hanya satu jenis tipe nyanyian yaitu nyanyian tipe ab. Gambar berikut
ini aka
Gambar 3.1.Syllable burung ortolan bunting (Osiejuk, 2003)
Gambar 3.2.
Time series dan spectrogram dari tipe nyanyian ab
n menunjukkan syllable burung ortolan bunting (gambar 3.1) serta time
series dan spectogram (gambar 3.2) burung ortolan bunting dengan tipe nyanyian
Feature extraction Sample suara burung1 Estimate model M1 Feature extraction Feature extraction Sample suara burung2 Estimate model M2 Feature extraction Feature extraction Sample suara burung8 Estimate model M8 Feature extraction •••
3.2
n algoritma Baum-Welch
Sesuai dengan metode ka pada tugas akhir ini, proses ak 80% dari total 800 data suar nunjukkan proses pembuatan model.
Gambar 3.3.
Menggunakan HMM untuk training model
Proses
Training
Training
dalam membentuk model menggunaka
dengan perhitungan parameter
yang telah dibahas pada bab 2.
5 Fold Cross-Validation (dibahas pada subbab 3.4) ma
training dalam membentuk setiap model membutuhkan sebany
Pengujian atau
me
bilitas data baru
ini dengan m
antara mo
odel
sehi gga data ters
enunjukkan
proses proses tes
Gambar 3.4.
Menggunakan HMM untuk identifikasi data suara baru
Untuk mengeksporasi pengimplementasian HMM dalam identifikasi
individu burung, pembuatan sistem
tugas akhir ini
toolkit (HTK). HTK ini dirancang dengan tujuan utama
dalam
3.3
Proses
Testing
testing model, dilakukan dengan data baru. Untuk
ngenali suatu suara baru, sistem akan menghitung berapa proba
masing model yang telah ada. Probabilitas paling tinggi di
del yang ada akan menunjukkan kedekatan data terhadap m
ebu
diiden
Gambar 3.4 berikut m
ting.
asing-n
t dapat
tifikasi.
identifikasi pada
Suara burung yang tidak dikenal
mempergunakan HMM
teknologi “speech recognition”. HTK menyediakan seperangkat tools
termasuk algoritma Baum-Welch untuk menghitung pemodelan data dalam proses
training dan identifikasi data suara baru dengan algoritma Viterbi.
Feature extraction Observation O Probability computation
P(O|M1) P(O|M2) P(O|M3) P(O|M4)
Select maximum
3.4
Metode
5 Fold Cross-Validation
Dalam proses traning dan testing akan menggunakan metode 5 fold cross-
validation. Metode ini akan membagi setiap kelompok data (masing-masing
individu burung) menjadi 5 bagian data yang secara bergantian dijadikan data
untuk
testing maupun training dalam lim la
gujian. Data dibagi atau
dipisah untuk memastikan bahwa evaluasi dilakukan tanpa memproses data yang
sama.
Dalam tugas akhir ini, terdapat 8 kelompok data, masing-masing
kelompok data mewakili individu burung yang berbeda dan jumlah data untuk
tiap kelompok adalah 100 yang kemudian dibagi menjadi 5 bagian dengan setiap
bagian adalah 20 data. Gambar 3.5 akan menunjukkan pembagian data untuk
setiap k
Gambar 3.5.
Pembagian tiap kelompok data menjadi 5 bagian
1
a
ngkah pen
elompok data.
2 3 4 5 1 2 3 4 5 1 2 3 4 5 1 2 3 4 5 Kelompok data 1(burung 1)
Kelompok data 2 (burung 2)
Kelompok data 3
(burung 3) Kelompok data 8 (burung 8)
Langkah - langkah pengujian data dapat dilihat pada gambar 3.6. Dari
gambar tersebut terlihat bahwa setiap iterasi pengujian, data-data yang digunakan
untuk
Pengujian ke-3
-4
Pengujian ke-5
Gambar 3.6.
Iterasi pengujian untuk salah satu kelompok data
Pengukuran tingkat akurasi dilakukan dengan m
kan
onfusion
matrix seperti tabel 3.1 berikut ini :
Tabel 3.1.
Contoh confusion matrix
Burung 1 Burung 2 Burung 3 Burung 4 Burung 5 Burung 6 Burung 7 Burung 8
traning maupun testing adalah data yang berbeda.
Testing
Training
Pengujian ke-1
Pengujian
ke-2
Pengujian ke
engguna
c
Burung 1 Burung 2 Burung 3 Burung 4 Burung 5 Burung 6 Burung 7 Burung 8
1 2 3 4
5
1 2 3 5
4
1 3
4 5
2
1 2 4 5
3
Evaluasi
ketep an confusion matrix di atas dilakukan dengan cara
at
ji yang
at
tersebut. Perhitungan jum
persentase label yang
en
adalah sebagai berikut:
Akurasi = S/T x 100%
K
S = jumlah sample yang dikenal secara benar oleh sistem (jumlah diagonal
dari confusion matrix ).
T = jumlah total sample untuk pengujian.
3.5
Perancangan Sistem
S
ang dibang n dan erfungs sebagai alat bantu terdiri dari 3
halam n
yait :
a
n De an (Home).
b
Halaman Pengujian Hidden Markov Models.
c
Halaman Pengidentifikasian.
Sistem ini juga
a)
b)
c)
d)
Halam n Konfirmasi.
membandingkan output hasil identifikasi oleh sistem dengan label u
tersedia untuk d a
lah
dikenal secara b
ar
eterangan :
istem y
u
b
i
a utama,
u
)
Halama
p
)
)
terdiri dari beberapa halaman pendukung lainnya seperti :
Halaman Bantuan Program.
Halaman Tentang Program.
Halaman Peringatan.
1.
Halaman Depan
Ha
fungsi sebagai halaman pembuka, yang berisi judul sistem,
logo Universitas Sanata Dharma, identitas pembuat sistem, identitas dosen
pembim
Halaman de
rti pada Gambar 3.7.
(
Home
)
laman ini ber
bing dan terdiri dari 2 menu utama yaitu “Program” dan “Bantuan”.
pan (home) tampak sepe
2.
alaman Pengujian
Hidden Markov Models
Halaman ini berfungsi sebagai halaman untuk menguji akurasi hasil
identifikasi yang melibatkan 800 data suara dengan 5 fold cross-validation
sebagai metode evaluasi akurasi. Halaman pengujian Hidden Markov Models
dapat dilihat pada gambar 3.8 berikut ini :
H
Pengujian Akurasi Hidden Markov Models
Jumlah Data = 800 Suara Data Untuk Training = 640 Suara Data Untuk Testing = 160 Suara
Test Option = 5 folds Cross - Validation
Keterangan Data
Feature Option
Window Size 3
Tipe Parameter
GFCC GFCC_D GFCC_D_A
Jumlah State 10
Proses
Proses
Menampilkan Langkah-Langkah Proses
Kelluar
CONFUSI ON MATRI X
Hasil %
Estimasi Waktu Keseluruhan detik
3.
alaman Pengidentifikasian
Halaman ini berfungsi sebagai halaman contoh untuk mengidentifikasi
burung ortalan bunting. Inputan berupa suara kicauan (.wav) dan output berupa
label (individu) yang dikenali. Halaman pengidentifikasian dapat dilihat pada
gambar 3.9 berikut ini :
H
Identifikasi Individu Burung
Enter Text Browse
Visualisasi
Spectogram Visualisasi Spectrogram (berdasarkan inputan)
Signal Visualisasi Signal
(berdasarkan inputan)
Proses Keluar
Mainkan
Dikenal sebagai :
Estimasi Waktu Keseluruhan detik Proses
4.
alaman Bantuan Program
Rancangan halaman bantuan program berisi informasi yang dapat membantu
pengguna agar dapat menggunakan sistem ini. Pada halaman ini akan dijelaskan
bagian-bagian sistem termasuk fungsi-fungsi yang terdapat pada sistem beserta
kegunaanya. Halaman bantuan program dapat dilihat pada gambar 3.10 berikut
ini:
H
Gambar 3.10.
Halaman bantuan program
5.
Halaman Bantuan Program
Rancangan halaman tentang program berisi informasi mengenai sistem dan
pembuat sistem. Halaman ini dapat dilihat pada gambar 3.11 berikut ini :
6.
Halaman Peringatan
Rancangan halaman peringatan digunakan untuk memberikan peringatan
kepada pengguna bila pengguna melakukan kesalahan prosedural, seperti
misalnya pengguna tidak memasukkan data suara ketika mengeksekusi tombol
untuk melakukan proses identifikasi dan ketika mengeksekusi tombol untuk
mendengarkan suara kicauan burung. Gambar 3.12 akan ditampilkan ketika
pengguna mengeksekusi tombol proses identifikasi dan gambar 3.13 ditampilkan
ketika pengguna me
ngeksekusi tombol mainkan suara kicauan.
Gambar 3.12.
Halaman peringatan (jika tidak data suara input untuk diproses)
Gambar 3.13.
H
uara input untuk
kan)
alaman peringatan (jika tidak data s
7.
Halaman Konfirmasi
Rancangan halaman konfirmasi berguna untuk memastikan bahwa pengguna
benar-benar menginginkan sistem mengerjakan suatu proses, seperti misalnya
konfirmasi agar pengguna dapat keluar dari sistem. Halaman konfirmasi
ditunjukkan pada gambar 3.14 berikut ini.
Gambar 3.14.
Halaman konfirmasi (jika ingin mengakhiri penggunaan sistem)
3.6
Spesifikasi
Hardware
dan
Software
membangun sistem
dividu burung :
.6.1
Hardware
•
Processor : Intel(R) Core(TM)2 Duo T5870 @2.00GHz
•
Memory (RAM) : 4GB
e : 32-bit Operating System
•
Matlab 7.0
Berikut adalah spesifikasi hardware dan software yang digunakan untuk
identifikasi in
3
•
System typ
3.6.2
Software
BAB IV
IMPLEMENTASI DAN ANALISA HASIL
Pada bab ini akan dibahas hal-hal mengenai hasil tampilan antar muka sistem
beserta penjelasan penggunaan tombol dan keterangan untuk setiap bagian sistem
yang penting. Pembahasan terpenting dalam bab ini difokuskan pada analisis hasil
identifikasi individu burung ortolan bunting dari serangkaian pengujian yang telah
d
feature
dengan jumlah state yang berbeda-beda.
unakan pada Sistem
4.1.1.
pertama kali ditampilkan ketika
kan sistem. Halaman ini terdapat 2 menu utama yaitu
menu
t
pada gam
ilakukan. Setiap pengujian melibatkan kombinasi feature (window size dan tipe
)
4.1
Implementasi Antar Muka yang Dig
Halaman Depan
Halaman depan merupakan halaman yang
pengguna (user) menjalan
“Program” dan menu “Bantuan”. Implementasi halaman depan dapat diliha
bar 4.1 berikut ini :
4.1.2. Halaman Pengujian Hidden Markov Models
engenai test option
(5 folds cross-validation). Pada kotak feature extraction,
user dapat melakukan
emantau perkembangan langkah-langkah
pengujian. Hasil proses diperoleh berupa
Gambar 4.2.
Halaman pengujian Hidden Markov Models
Halaman pengujian Hidden Markov Models (gambar 4.2) adalah halaman
yang berfungsi untuk pengujian Hidden Markov Models dengan berbagai variasi
dalam proses feature extraction dan jumlah state. Pengujian ini dilakukan untuk
menghitung tingkat akurasi identifikasi melalui analisa confusion matrix.
Kotak keterangan data mendeskripsikan jumlah seluruh data suara dengan
rincian data suara untuk training dan testing serta keterangan m
variasi dengan mengubah window-size, tipe feature dan jumlah state. Sedangkan
kotak proses digunakan untuk m
confusion matrix yang ditampilkan pada
4.1.3.
browse.
Jendela
spectrogram
signal
pengidentifikasian suara mulai dari feature extraction sampai dengan proses
testing. Berikut gambar untuk halaman pengidentifikasian :
Halaman Pengidentifikasian
Halaman pengidentifikasian merupakan halaman contoh yang digunakan
untuk memproses identifikasi individu burung ortolan bunting. User harus
menginputkan suara burung yang akan dikenali (*.wav) melalui tombol
file selector (gambar 4.4) akan ditampilkan setelah tombol browse ditekan
sehingga user dapat memilih suara kicauan yang akan kenali atau di identifikasi.
User juga dapat mendengar suara kicauan burung yang dipilih secara langsung
dengan menekan tombol “mainkan”.
Kotak visualisasi data akan menampilkan
dan
dari
suara yang di indentifikasi dan kotak proses identifikasi adalah jendela untuk
memantau perkembangan identifikasi dengan menampilkan langkah-langkah
Gambar 4.4.
Jendela file selector
Gambar 4.5.
Peringatan jika belum ada suara inputan (jika menekan tombol
“mainkan”)
Gambar 4.6.
Peringatan jika belum ada suara inputan (jika menekan tombol
4.1.4. Halama Bantuan Program
Halaman bantuan digunakan untuk membantu user menggunakan sistem
agar sistem dapat berjalan dengan baik dan lancar. Halaman ini menjelaskan
langkah-langkah penggunaan program. Halaman bantuan ditampilkan setelah user
mengklik submenu bantuan program pada halaman depan.