7
LANDASAN TEORI
2.1 Teori Umum
2.1.1 Definisi Data dan Informasi
Menurut O’brien (2006, p29), data adalah hasil observasi atau fakta mentah, biasanya mengenai kejadian atau transaksi bisnis. Berdasarkan Whitten et al (2004, p27), data adalah fakta mentah tentang orang, tempat, kejadian dan barang yang penting dalam suatu organisasi di mana setiap fakta itu hampir tidak mempunyai arti. Sedangkan menurut Turban, Rainer dan Potter (2005, p38), data adalah deskripsi dasar dari suatu benda, kejadian, kegiatan, dan transaksi yang direkam, diklasifikasikan dan disimpan tetapi tidak diorganisasikan untuk menyampaikan arti yang spesifik.
Turban, Rainer dan Potter (2005, p38) juga mengungkapkan bahwa informasi adalah data yang telah diorganisasikan supaya data – data itu mempunyai arti dan nilai bagi penerima. Sedangkan menurut Whitten et al (2004, p27), informasi adalah data yang telah diproses atau diorganisasikan menjadi bentuk yang lebih berarti bagi seseorang. Informasi dibentuk dari kombinasi data yang mempunyai arti bagi penerima.
2.1.2 Definisi Database
Whitten et al (2004, p518) mengemukakan definisi database secara sederhana yaitu sebagai kumpulan file yang saling terkait. Sedangkan menurut Turban, Rainer dan Potter (2005, pp37-38), database adalah sekumpulan tabel
berisi data yang saling berhubungan yang disimpan dan diorganisasikan untuk diambil datanya. Connoly dan Begg (2005, p15) mengemukakan definisi yang lebih luas yaitu database adalah kumpulan data yang saling berhubungan satu sama lain secara logis yang digunakan secara bersama – sama dan kumpulan data ini dirancang untuk memenuhi kebutuhan informasi suatu organisasi.
Menganalisis kebutuhan informasi suatu organisasi berarti berusaha mengidentifikasikan entitas, atribut, dan relationship. Entitas merupakan objek- objek berbeda (orang, tempat, benda, konsep atau kejadian) dalam suatu organisasi yang direpresentasikan di dalam database. Contohnya, PELANGGAN, KARYAWAN, PRODUK, dan PESANAN. Atribut menggambarkan beberapa aspek dari objek yang ingin disimpan. Misalnya untuk entitas PELANGGAN, atribut – atributnya adalah nomor pelanggan, nama pelanggan, alamat pelanggan, batas kredit pelanggan dan lain - lain. Sedangkan relationship merupakan hubungan antar entitas tersebut. Sebagai contoh, PELANGGAN mempunyai PESANAN. Di sini, “mempunyai” merupakan relationship antara tabel PELANGGAN dan PESANAN.
Untuk itu, suatu database harus dapat menyajikan entitas, atribut dan relationship logis dari objek-objek yang ingin direpresentasikannya. Sehubungan dengan hal ini, ada istilah data model yang merupakan kumpulan konsep terintegrasi yang menjelaskan dan memanipulasi data, relationship antar data dan batasan – batasan pada data dalam organisasi.
2.1.3 Elemen-elemen Database
Menurut Whitten et al (2004, pp520-521), dalam sebuah database terdapat beberapa elemen sebagai berikut:
1. Field merupakan unit terkecil dari data yang berarti untuk disimpan pada sebuah database. Ada empat macam tipe field yang dapat disimpan yaitu:
a. Primary key merupakan field yang secara unik mengidentifikasi record pada tabel. Contohnya PELANGGAN_ID secara unik mengidentifikasi sebuah record tunggal pada tabel PELANGGAN di database.
b. Secondary key merupakan sebuah field yang mengidentifikasi record tunggal atau sebuah subset dari record-record yang terkait. Misalnya, semua PESANAN yang memiliki STATUS ‘lunas’. Untuk memfasilitasi pencarian dan pengurutan, maka dibuatlah index untuk kunci-kunci tersebut.
c. Foreign key merupakan field yang menunjuk kepada record pada tabel lain dalam database. Contohnya, pada tabel PESANAN, berisi foreign key PELANGGAN_ID untuk mengidentifikasikan record PELANGGAN yang diasosiasikan dengan PESANAN.
d. Descriptive field merupakan semua field lainnya (nonkey) yang menyimpan data-data. Misalnya, pada tabel KARYAWAN, ada field NAMA, ALAMAT, GAJI, dan lain-lain.
2. Record merupakan kumpulan field yang disusun dalam format yang telah ditetapkan. Contohnya record PELANGGAN dapat dideskripsikan dengan field-field berikut. Field yang digaris bawahi merupakan primary key. Contoh,
Pelanggan (Pelanggan_Id, Nama, Alamat, Kota, Kredit, Hutang, …)
3. Table merupakan kumpulan record-record yang sama. Record-record yang berisi data tentang pelanggan misalnya akan diorganisasikan membentuk tabel PELANGGAN.
2.1.4 Database Management System
Berdasarkan Whitten et al (2004, pp524 - pp525), Database Management System atau sering disebut DBMS adalah sistem perangkat lunak komputer khusus yang disediakan oleh vendor-vendor komputer yang digunakan untuk membuat, mengakses, mengontrol dan mengelola database. Inti dari DBMS sering disebut database engine. Mesin ini merespons perintah-perintah khusus untuk membuat struktur database kemudian membuat, membaca, memperbarui, dan menghapus record-record pada sebuah database. DBMS dapat dibeli dari sebuah vendor teknologi database seperti Oracle, IBM, Microsoft, atau Sybase.
Dalam DBMS, dikenal dua istilah yaitu Data Definition Language dan Data Manipulation Language. Data Definition Language (DDL) merupakan sebuah bahasa yang digunakan oleh DBMS untuk menentukan sebuah database atau melihat isi database. Dalam menentukan sebuah database, DDL digunakan untuk menetapkan secara fisik tipe, record, field, dan hubungan struktural.
Sedangkan Data Manipulation Language (DML) merupakan bahasa DBMS yang digunakan untuk membuat, membaca, memperbarui, dan menghapus record-record serta untuk menjelajahi record-record-record-record yang ada walaupun tipenya berbeda-beda.
Ada beberapa tipe Database Management System menurut cara menyusun record. Salah satunya adalah Relational Database Management System (RDBMS) yang mengimplementasikan data pada satu seri tabel dua dimensi yang dihubungkan satu dengan yang lain melalui foreign key. Ada pula Object Oriented Database Management System (OODBMS) yang menggunakan konsep pemrograman berbasis objek serta Object Relational Database Management System (ORDBMS) yang merupakan gabungan dari konsep Relational DBMS dan Object Oriented DBMS. Vendor RDBMS terkemuka saat ini seperti Oracle, Microsoft dan IBM mulai mengembangkan sistem mereka menjadi ORDBMS.
Tiga istilah kunci yang sering digunakan pada RDBMS adalah relation, attribute, dan domain. Relation merupakan tabel dengan kolom dan baris (disebut juga tuple). Sedangkan kolom disebut attribute dan domain merupakan nilai yang boleh dimiliki atribut. Konsep dasar dari RDBMS adalah database schema yang merupakan struktur logis dari sekumpulan tabel yang berhubungan satu sama lain dalam database. Schema selalu dikaitkan dengan user dan dapat didefinisikan juga sebagai koleksi objek yang dimiliki seorang user. Oleh sebab itu, istilah user dan schema digunakan hampir sama terutama pada DBMS milik Oracle.
Pada lingkungan object oriented, ada beberapa istilah sebagai berikut: 1. Object merupakan entitas yang mengandung atribut.
2. Property merupakan atribut-atribut suatu object
3. Method merupakan fungsi atau behavior dari suatu object. 4. Message merupakan cara berkomunikasi object
5. Class merupakan sekelompok object yang memiliki atribut-atribut yang sama.
6. Instance merupakan wujud nyata object dalam class
7. Superclass sebagai parent class dan subclass sebagai children class
Tiga konsep utama pada sistem object oriented adalah sebagai berikut:
1. Polymorphism merupakan kemampuan object untuk bereaksi secara berbeda-beda terhadap informasi atau parameter yang berbeda-beda. Di sini, method dapat memiliki nama yang sama tetapi dengan parameter yang berbeda sehingga object akan mengenalinya secara berbeda. Pada pemrograman yang tidak berorientasi objek, hal ini tidak bisa dilakukan. Untuk dua tugas yang berbeda, harus ada dua fungsi yang mempunyai nama yang berbeda.
2. Encapsulation merupakan kemampuan object untuk menyimpan informasi tentang property dan method yang dimiliki secara bersama - sama. Dengan demikian, data dan code dipaketkan bersama.
3. Inheritance merupakan kemampuan class untuk mewariskan karakteristik yang dimiliki kepada class lain. Sebagai contoh, class Mobil merupakan subclass dari class Kendaraan.
2.1.5 Structured Query Language
Menurut Whitten et al (2004, pp526-527), Structured Query Language atau SQL merupakan bahasa standar yang telah digunakan secara resmi dan luas sebagai Data Definition Language dan Data Manipulation Language pada Database Management System. SQL ini merupakan bahasa non-prosedural yang mengandung kata dalam bahasa Inggris sederhana seperti CREATE, SELECT, INSERT dan DELETE yang dapat digunakan oleh profesional maupun non-profesional. Selain mendefinisikan dan memanipulasi database, SQL juga mendukung trigger dan stored procedure. Trigger merupakan sebuah program yang dilekatkan pada sebuah tabel dan akan dijalankan secara otomatis dengan memperbarui tabel lain. Sebagai contoh, jika sebuah record dihapus dari tabel PELANGGAN, trigger dapat secara otomatis menghapus semua record yang terkait pada tabel PESANAN pelanggan tersebut. Sedangkan stored procedure adalah program – program yang dilekatkan di dalam sebuah tabel yang dapat dipanggil dari program aplikasi. Contohnya, sebuah algoritma validasi data dapat dilekatkan pada sebuah tabel untuk menjamin bahwa record-record baru dan yang telah diperbarui berisi data yang valid sebelum record itu disimpan. Stored procedure pada Microsoft disebut Transact SQL sedangkan pada Oracle disebut PL/SQL (Programming Language/SQL).
2.1.6 Definisi Aplikasi
Menurut Kamus Istilah Komputer dan Informatika, aplikasi adalah perangkat lunak yang dibuat untuk mengerjakan tugas tertentu. Sedangkan menurut kamus Komputer dan Teknologi Informasi, aplikasi adalah program komputer yang ditulis untuk melaksanakan tugas khusus dari pengguna.
2.1.7 Definisi Report
Menurut Longman Dictionary of Contemporary English, report berarti penjelasan tertulis sebuah keadaan atau kejadian yang memberikan informasi kepada orang-orang. Sedangkan berdasarkan Webster’s New WorldTM College Dictionary, report merupakan sebuah presentasi formal atau resmi tentang kenyataan atau record yang biasanya diterbitkan secara berkala.
2.1.8 Definisi Purchase Oder
Menurut Longman Dictionary of Contemporary English, purchase merupakan kegiatan membeli sesuatu. Sedangkan order merupakan permintaan yang dilakukan pelanggan kepada perusahaan yang menyediakan barang-barang. Berdasarkan pengertian tersebut, purchase order dapat diartikan sebagai permintaan yang dilakukan oleh pelanggan untuk membeli barang-barang kepada perusahaan yang menyediakannya.
2.1.8 Definisi Performance
Berdasarkan Webster’s New WorldTM College Dictionary, performance merupakan operasi atau fungsionalitas, yang biasanya berkaitan dengan efektitivitas, misalnya pada sebuah mesin. Menurut Longman Dictionary of Contemporary English, performance berarti ukuran seberapa baik atau buruknya seseorang, perusahaan atau sistem dalam melakukan suatu pekerjaan atau kegiatan tertentu.
2.2 Teori Khusus 2.2.1 Oracle
Oracle merupakan salah satu vendor DBMS yang terkenal di dunia. Walaupun terkenal sebagai vendor RDBMS, Oracle mulai menerapkan konsep object-oriented sehingga untuk saat ini, Oracle lebih tepat disebut sebagai vendor ORDBMS. Fitur-fitur object oriented pada Oracle adalah sebagai berikut:
1. User defined data type: Oracle mendukung tipe data yang didefinisikan oleh pengguna.
2. Method: Oracle mengimplementasikan method pada PL/SQL
3. Collection type: Ada tipe array yang dikenal sebagai varray dan tipe tabel yang disebut nested table.
4. Large object: Oracle juga mendukung penggunaan Binary Large Object (BLOB) dan Character Large Object (CLOB).
DBMS Oracle merupakan produk yang dirancang untuk menampung jumlah data dan informasi yang besar serta akses transaksi yang berjumlah besar. DBMS Oracle terdiri dari database (data dan informasi itu sendiri) dan instance (keseluruhan sistem). Database terdiri dari data fisik yang disimpan dalam sistem serta struktur logikanya yaitu database schema. Sedangkan instance merupakan metode yang digunakan untuk mengakses data atau informasi pada database dan terdiri dari proses-proses serta struktur memori.
Database pada DBMS Oracle terdiri dari beberapa komponen logis dan fisik penyimpanan data. Berikut merupakan komponen-komponen logis database Oracle:
1. Data block merupakan satuan terkecil penyimpanan data pada database Oracle. Data block merupakan alokasi disk space dalam byte pada sistem operasi.
2. Extent merupakan gabungan dua atau lebih data block yang berhubungan. 3. Segment merupakan sekumpulan extent yang dialokasikan untuk struktur
logis seperti tabel atau index.
4. Tablespace terdiri dari satu atau beberapa data file dan biasanya mengandung segment yang berhubungan. Data file menyimpan data semua struktur logis yang merupakan bagian dari tablespace seperti tabel dan index.
Selain komponen logis, database Oracle juga terdiri dari komponen-komponen fisik utama sebagai berikut:
1. Data file yang menyimpan data pada tabel dan index.
2. Control file yang menyimpan perubahan yang terjadi pada struktur database serta isi dan status database.
3. Redo log file yang menyimpan perubahan yang dibuat pada tabel dikarenakan transaksi atau aktivitas lain.
Instance pada Oracle dapat didefinisikan sebagai area shared memory dan proses-proses background. Area shared memory disebut System Global Area (SGA) dan terdiri dari beberapa komponen utama berikut:
1. Database buffer cache menyimpan salinan data file
2. Shared pool menyimpan SQL dan PL/SQL yang dapat digunakan secara bersama – sama.
3. Redo log buffer menyimpan informasi yang diperlukan untuk merekonstruksi perubahan pada database karena operasi DML.
4. Java pool menyimpan status eksekusi program Java.
5. Large Pool menyimpan alokasi memori yang besar untuk proses tertentu seperti operasi backup dan recovery.
Sedangkan proses-proses background utama yang terjadi tanpa diketahui pengguna adalah sebagai berikut:
1. Database Writer (DBWR) memodifikasi data dari database buffer cache ke data file.
2. Log Writer (LGWR) mencatat isi redo log buffer ke redo log file. Ketika transaksi terjadi, informasi tentang redo akan disimpan di redo log buffer. Ketika transaksi tersebut commit, informasi ini akan disimpan oleh LGWR ke redo log file.
3. Checkpoint (CKPT) memperbarui semua data file dan control file untuk mencatat detail checkpoint.
4. Process Monitor (PMON) memantau seluruh proses yang dilakukan pengguna dan bertugas membereskan sumber daya pada proses yang telah selesai dan proses yang gagal.
5. System Monitor (SMON) bertugas memonitor keseluruhan instance dan menjalankan recovery jika terjadi kegagalan instance.
6. Archiver (ARC) bertugas mencatat online redo log file ke archive log.
Ada beberapa produk DBMS Oracle, salah satunya adalah Database Oracle 10g yang diluncurkan pada tahun 2003. Huruf 'g' pada 10g merupakan singkatan dari kata grid dan merujuk pada grid computing yang merupakan cara paling fleksibel dan cost-effective karena membuat semua sumber daya yang ada dikelola sebagai satu kesatuan sistem di mana suatu komputer misalnya dapat memakai sumber daya dari komputer lain untuk suatu aplikasi. Tiga komponen utama grid
computing pada DBMS Oracle adalah Database Oracle 10g, Oracle Entreprise Manager 10g dan Oracle Application Server 10g.
Oracle juga menyediakan fitur Oracle Developer Suite untuk para pengembang aplikasi agar dapat membuat aplikasi yang baik dengan mudah. Salah satu tool pada Oracle Developer Suite adalah Oracle Report Developer yang menyediakan lingkungan pengembangan report berbasis web dengan HTML (Hypertext Markup Language) serta CSS (Cascade Style Sheet). Data dapat disajikan menjadi informasi dalam tabel, matriks, grafik dan kombinasinya.
2.2.2 Definisi Tuning
Berdasarkan Webster’s New WorldTM College Dictionary, tuning merupakan sesuatu yang dilakukan untuk menyesuaikan sistem agar mendapatkan performance yang diinginkan. Menurut Edward Whalen (2004, p4) pada White Paper yang berjudul Tuning Oracle on Windows for Maximum Performance on PowerEdge Servers, tuning merupakan sebuah seni dan pengetahuan ilmiah dalam memodifikasi dan melakukan rekonfigurasi pada sistem untuk mendapatkan performance yang lebih baik.
2.2.3 Jenis-jenis Tuning
Setiap sistem mempunyai karakteristik yang berbeda tergantung pada kebutuhan pengguna. Oleh sebab itu, sebelum melakukan tuning, sangat penting untuk mengetahui alasan dilakukannya tuning tersebut. Tujuan spesifik dilakukannya tuning akan membantu menemukan metode tuning yang tepat. Jenis-jenis tuning berdasarkan tujuannya menurut Whalen (1996, pp42-pp44) adalah sebagai berikut:
1. Tuning for response time
Response time merupakan waktu yang dibutuhkan dari saat menekan tombol terakhir pada input form untuk meminta data sampai semua data telah ditampilkan pada layar. Atau dengan kata lain, response time merupakan waktu yang dihabiskan pengguna untuk menunggu proses – proses di belakang layar pada suatu transaksi. Transaksi yang dimaksud di sini merupakan istilah untuk menyebutkan suatu unit pekerjaan logis yang terdiri dari satu atau lebih pernyataan SQL, yang berakhir dengan commit atau rollback. Jumlah transaksi per detik biasanya sering dijadikan sebagai ukuran performance.
Dengan demikian, tuning for response time berarti memodifikasi sistem untuk membuat transaksi berjalan lebih cepat. Tuning for response time biasanya dilakukan dengan melakukan tuning pada aplikasi atau pada Oracle instance dan schema dengan melakukan partitioning, indexing, dan tuning lainnya.
2. Tuning for throughput
Throughput merupakan jumlah transaksi yang dapat dikerjakan dalam suatu waktu. Oleh sebab itu, tuning for throughput berarti memodifikasi sistem untuk memungkinkan lebih banyak transaksi tanpa mempercepat setiap proses individual. Sebagai contoh, jika suatu transaksi membutuhkan waktu 10 detik untuk dijalankan maka setelah melakukan tuning, akan ada dua transaksi yang dijalankan bersama – sama dalam waktu 10 detik. Inilah yang dimaksud meningkatkan throughput sistem tanpa meningkatkan response time transaksi individual.
3. Tuning for connectivity
Connectivity merupakan kemampuan untuk mendukung koneksi pada suatu sistem. Tuning mungkin saja dilakukan dengan memungkinkan kapasitas terbatas untuk mendukung jumlah pengguna yang besar pada sistem. Sebagai contoh, sebuah sistem bisnis membutuhkan karyawan tambahan pada masa – masa sibuk. Untuk mendukung pengguna tambahan ini, tuning dapat dilakukan dengan memperhatikan memori yang ada. Tuning ini disebut juga memory tuning di mana kebutuhan memori harus direncanakan dengan baik dan jangan sampai melebihi sumber daya yang tersedia terutama pada masa – masa sibuk. Ini berarti sumber daya sistem operasi yang berkaitan dengan jaringan harus diperhatikan.
4. Tuning for fault tolerance
Fault tolerance atau toleransi terhadap kesalahan yang terjadi pada sistem sangat penting untuk diperhatikan. Tuning for fault tolerance biasanya memperhatikan hardware yang ada seperti Redundant Array of Inexpensive Disks (RAID) untuk melindungi data dari kerusakan disk.
5. Tuning for load time
Beberapa sistem membutuhkan data tertentu yang harus di-load setiap malam agar tersedia untuk proses hari selanjutnya. Namun, biasanya load time terbatas padahal sangat penting untuk sejumlah data tertentu di-load hanya dalam waktu tertentu. Dalam hal ini, penambahan hardware yang tentunya menambah biaya bisa saja menjadi solusi permasalahan. Namun, tuning I/O (input/output) untuk load time dan run time akan lebih mempengaruhi performance sistem secara keseluruhan.
Dari jenis-jenis tuning yang telah dituliskan di atas, dapat disimpulkan tuning untuk response time dan throughput merupakan tuning yang paling relevan dengan performance pada database.
Selain berdasarkan tujuan, tuning juga dapat dibedakan berdasarkan waktu pelaksanaan tuning. Mengacu pada waktu pelaksanaanya, tuning dapat dibedakan menjadi dua yakni proactive performance tuning di mana tuning dilakukan dari awal pembuatan aplikasi dan reactive performance tuning di mana tuning dilakukan setelah aplikasi telah selesai dirancang dan telah diimplementasikan.
2.2.4 Manfaat Tuning pada Database
Menurut Connoly dan Begg (2005, p533), manfaat melakukan tuning pada database adalah sebagai berikut:
1. Tuning dapat meminimalisasi penambahan hardware.
2. Memungkinkan penurunan spesifikasi hardware yang dibutuhkan sehingga menurunkan biaya pengadaan hardware dan biaya pemeliharaannya.
3. Menghasilkan waktu respon yang lebih cepat dan throughput yang lebih baik sehingga membuat pengguna dan perusahaan menjadi lebih produktif. 4. Meningkatnya response time dapat meningkatkan moral atau semangat
kerja para pegawai perusahaan.
5. Meningkatnya response time dapat meningkatkan kepuasan pelanggan.
2.2.5 Metodologi Tuning
Metodologi untuk melakukan tuning merupakan suatu proses dan langkah - langkah yang harus diikuti secara konsisten untuk mengoptimalkan sistem. Berikut merupakan metodologi tuning yang baik menurut Whalen (2004, p4):
1. Lakukan penilaian awal pada sistem. 2. Melakukan survei atau monitor sistem. 3. Analisis hasil survei yang dilakukan. 4. Membuat hipotesis penyebab masalah. 5. Mengajukan solusi.
6. Mengimplementasikan solusi.
Selain itu Whalen (2004, p5) juga mengungkapkan bahwa metodologi tuning ini bisa berbeda – beda walaupun akan cenderung mirip satu sama lain.
Pada e-book Oracle Performance Method, Milsap (2003, Chapter 1.2) mengungkapkan metodologi tuning yang baik seharusnya memenuhi kriteria-kriteria berikut:
1. Impact
Metodologi tuning yang baik harus menghasilkan peningkatan atau perubahan yang lebih baik pada performance.
2. Efficiency
Metodologi yang baik harus bisa meningkatkan performance dengan biaya, waktu dan usaha seminimimal mungkin. Metodologi itu tidak bisa disebut pengoptimalan jika ada metodologi lain yang bisa berhasil dengan biaya yang lebih kecil atau waktu yang lebih sedikit.
3. Measurability
Metodologi harus menghasilkan peningkatan performance yang dapat diukur dalam suatu satuan unit.
4. Predictive capacity
Metodologi harus bisa memprediksikan impact dari solusi yang diajukan. 5. Reliability
Metodologi harus dapat mengidentifikasikan akar permasalahan, tidak peduli apapun akar permasalahan tersebut.
6. Determinism
Metodologi harus dapat membimbing peneliti melalui langkah – langkah yang tidak ambigu, bukan melalui pengalaman atau intuisi.
7. Finiteness
Sebuah metodologi harus mempunyai batasan yang jelas mengenai kondisi akhir sistem, misalnya bukti pengoptimalan yang dilakukan.
8. Practicality
Metodologi harus dapat dipakai pada keadaan apapun, dalam berbagai lingkungan.
2.2.6 Normalisasi
Menurut Powell (2004, Chapter 2.1), tuning pada data model harus memperhatikan normalisasi yang dilakukan. Menurut Connoly dan Begg (2005, p388), normalisasi merupakan teknik untuk menghasilkan sekumpulan tabel dengan karakteristik yang tepat dan sesuai dengan kebutuhan data suatu perusahaan. Karakteristik sekumpulan relasi yang dimaksud adalah sebagai berikut:
1. Jumlah minimal atribut yang memenuhi kebutuhan data perusahaan
2. Atribut-atribut yang memiliki hubungan logis yang dekat (disebut juga functional dependency) terdapat pada tabel yang sama.
3. Tingkat redudansi yang minimal ditandai dengan setiap atribut hanya didefinisikan sekali selain atribut yang merupakan foreign key.
Manfaat menggunakan database yang sudah dinormalisasi adalah database tersebut akan lebih mudah diakses dan dipelihara datanya oleh pengguna serta tempat penyimpanan yang dibutuhkan jauh lebih sedikit.
Normalisasi dilakukan dengan cara menganalisis tabel dari primary key dan functional dependency melalui serangkaian aturan sehingga database dapat dinormalisasikan menjadi beberapa tingkat.
Ada beberapa tingkatan normalisasi, tetapi tidak semuanya dilakukan. Tiga tingkat dasar normalisasi yang disarankan adalah First Normal Form (1NF), Second Normal Form (2NF), dan Third Normal Form (3NF). Tingkat yang lebih tinggi seperti Boyce-Codd Normal Form (BCNF), Fourth Normal Form, dan Fifth Normal Form tidak harus dilakukan. Penjelasan lebih lanjut mengenai tiga tiga tingkat dasar normalisasi adalah sebagai berikut:
1. First Normal Form (1NF)
Unnormalized Form (UNF) merupakan tabel yang memiliki satu atau lebih kelompok data yang berulang. Sedangkan 1NF merupakan UNF yang sudah dinormalisasikan sehingga tidak ada kelompok data berulang. Pada tabel 1NF, perpotongan antara setiap baris dan kolom hanya mengandung satu nilai. Cara menghilangkan kelompok data berulang ini adalah sebagai berikut:
a. Memasukkan data yang tepat ke kolom kosong pada baris-baris yang mengandung data berulang.
b. Mengganti data berulang dengan atribut kunci dan diletakkan pada tabel terpisah.
2. Second Normal Form (2NF)
Second Normal Form merupakan tabel yang sudah dalam bentuk 1NF dan setiap atribut yang bukan primary key bergantung penuh pada primary key.
3. Third Normal Form (3NF)
Third Normal Form merupakan tabel yang sudah dalam bentuk 2NF dan 3NF dan setiap atribut yang bukan primary key tidak bergantung secara transitif pada primary key.
Hubungan normalisasi dengan tuning dijabarkan oleh Powell dalam poin – poin berikut:
1. Normalisasi yang terlalu sedikit akan menyebabkan terlalu banyak duplikasi data sehingga ukuran database menjadi besar. Data yang terlalu besar dapat menyebabkan waktu akses yang lambat.
2. Normalisasi yang tidak tepat jelas akan menyebabkan aplikasi menjadi lebih rumit dan sulit ketika mengakses database.
3. Normalisasi yang terlalu banyak akan mengakibatkan SQL code yang terlalu rumit.
4. Seringkali database dirancang tanpa pengetahuan mengenai aplikasi sehingga data model hanya dirancang berdasarkan teori dan sulit digabungkan dengan aplikasi. Normalisasi sering kali dilakukan tidak berdasarkan kebutuhan perusahaan melainkan hanya sebatas teori sehingga seringkali justru mempersulit aplikasi.
5. Tingkat normalisasi yang terlampau tinggi seperti 4NF dan 5NF biasanya akan mengurangi efisiensi.
Powell (2004, Chapter 2.4) juga mengungkapkan bahwa normalisasi cenderung menimbulkan masalah bagi performance dalam pengambilan data pada data model. Maka dari itu proses denormalisasi yang merupakan proses kebalikan dari normalisasi dapat dilakukan untuk meningkatkan performance.
2.2.7 Materialized View
Menurut Alapati (2005, pp209-pp212), materialized view merupakan view yang dibuat secara fisik. Jika view dibuat untuk mengurangi kompleksitas suatu query maka materialized view menyimpan hasil query tersebut secara fisik seperti tabel, sehingga akses dan proses join pada tabel dasar penyusunnya tidak lagi diperlukan. Pada view, jika tabel dasarnya diubah, maka hasil query dari view akan langsung menunjukkan perubahan tersebut karena view memang mengakses tabel dasar penyusun view tersebut, sedangkan materialized view tidak dapat langsung menampilkan perubahan tersebut. Materialized view harus di-refresh terlebih dahulu sehingga isi data dari materialized view tetap sesuai dengan isi pada tabel dasarnya. Dengan demikian, jika terjadi perubahan pada tabel dasar, materialized view harus di-refresh terlebih dahulu untuk menghasilkan data yang tetap terjaga integritasnya. Proses ini tentunya memakan waktu sehingga data yang sering mengalami perubahan tidak cocok untuk dijadikan materialized view.
Mode refresh yang dapat digunakan ada dua macam yakni:
1. ON COMMIT, pada mode ini materialized view akan di-refresh secara otomatis jika ada perubahan data pada salah satu dari tabel dasar materialized view bersangkutan yang di-commit.
2. ON DEMAND, pada mode ini materialized view hanya akan di-refresh jika prosedur seperti DBMS_MVIEW.REFRESH telah dieksekusi secara manual. ON DEMAND adalah mode yang terpilih secara default.
Tipe refresh yang dipakai pada materialized view ini, ada empat macam tipe yakni: 1. COMPLETE, jenis refresh ini akan melakukan update pada isi
materialized view dengan melakukan pembentukan ulang seluruh isi materialized view dari awal, sehingga lama waktu yang dibutuhkan untuk membuat materialized view dapat dikatakan relatif hampir sama dengan waktu yang dibutuhkan ketika menjalankan refresh ini.
2. FAST, jenis refresh ini akan melakukan update pada isi materialized view dengan melakukan update hanya pada record-record yang mengalami perubahan pada tabel dasar penyusun materialized view tersebut. Hal ini dimungkinkan karena adanya pembuatan materialized view log pada tabel dasar yang menyusun materialized view. Materialized view log ini akan mencatat segala perubahan yang terjadi pada record di tabel dasar dari materialized view dengan cara menyimpan primary key serta atribut lain dari record yang mengalami perubahan sehingga ketika refresh dijalankan, di materialized view, hanya record-record yang telah mengalami perubahan pada tabel dasar yang akan di-update.
3. FORCE, jenis refresh ini akan membuat Oracle untuk mencoba melakukan FAST refresh dan jika ternyata karena satu dan lain hal metode refresh FAST tidak bisa dijalankan, maka Oracle akan menggunakan metode refresh COMPLETE. Tipe FORCE refresh adalah tipe yang terpilih secara default.
4. NEVER, jenis refresh ini untuk memastikan agar materialized view tidak di-refresh. Tentu saja jenis refresh ini tidak disarankan untuk materialized view yang tabel dasar penyusunnya sering mengalami perubahan.
2.2.8 Index
Menurut Connolly dan Begg (2005, p1277), index merupakan struktur data yang memungkinkan DBMS untuk mengakses record-record pada tabel dengan cepat sehingga mampu meningkatkan response time dari pengguna. Index pada database dapat diilustrasikan seperti indeks yang terdapat pada buku. Ketika seseorang ingin melakukan pencarian terhadap suatu topik khusus tertentu pada sebuah buku yang tebal, penggunaan indeks, yang berisikan daftar halaman beserta topik-topiknya, akan mempercepat pencarian topik. Pada database, index ini akan menunjuk pada record – record tertentu.
Meskipun demikian, Powell (2004, chapter 7.1) mengemukakan bahwa penggunaan index pada setiap tabel tidak disarankan. Pada tabel yang hanya memiliki jumlah atribut sedikit, pengunaan index akan sia-sia jika sebagian besar record selalu diambil dari tabel. Selain itu, seharusnya hanya persentase kecil kolom pada tabel yang dibuatkan index karena rasio index dan ukuran tabel yang besar akan mengurangi efektivitas index yang bertujuan untuk mengurangi ukuran
tabel yang dibaca. Hal ini akan semakin parah jika kolom selain yang di-index ternyata banyak mengandung nilai NULL. Pada kasus seperti ini, pembacaan keseluruhan tabel tanpa penggunaan index akan jauh lebih cepat.
Alapati (2005, p197) juga mengungkapkan bahwa walaupun index sudah diketahui secara umum dapat meningkatkan performance pada database, penggunaan index yang tidak tepat dapat berakibat sebaliknya yakni menurunkan performance. Beberapa petunjuk pembuatan index yang tepat pada tabel Oracle adalah sebagai berikut:
1. Index hanya dibuat jika akses data tidak lebih dari 10 sampai 15 persen data dalam tabel. Full table scan yang membaca tabel dari awal hingga akhir akan lebih cepat jika persentase data yang dibutuhkan dari tabel sangat besar. Perlu diketahui bahwa dengan menggunakan index berarti pembacaan tabel dilakukan lebih dari satu kali yakni melalui index dan tabel.
2. Hindari penggunaan index pada tabel yang berukuran kecil. Full table scan sudah cukup untuk tabel berukuran kecil sehingga penyimpanan data pada tabel dan index tidak diperlukan.
3. Pembuatan primary key pada semua tabel karena kolom yang dijadikan primary key akan secara otomatis dijadikan sebagai index dari tabel tersebut.
4. Pemakaian index sangat disarankan pada kolom-kolom yang terlibat dalam operasi multi-join tabel.
5. Pemakaian index sangat disarankan pada kolom-kolom yang sering digunakan oleh klausa WHERE.
6. Pemakaian index sangat disarankan pada kolom-kolom yang sering digunakan pada operasi yang melibatkan proses pengurutan seperti ORDER BY dan GROUP BY, serta UNION dan DISTINCT. Hal ini dikarenakan kolom yang dipakai sebagai index secara otomatis sudah diurutkan sehingga dapat membantu pemrosesan jauh lebih cepat.
7. Kolom-kolom yang mengandung string berkarakter panjang secara umum tidak ideal untuk dijadikan sebagai index.
8. Kolom-kolom yang sering di-UPDATE secara umum juga tidak ideal untuk dijadikan sebagai index.
9. Pembuatan index sebaiknya pada tabel yang memiliki selectivity tinggi atau yang memiliki sedikit baris yang memiliki nilai serupa.
10. Jumlah pemakaian index diusahakan agar tetap sedikit.
11. Pembuatan index yang terdiri dari dua atau lebih kolom atau sering disebut sebagai composite index diperbolehkan jika nilai setiap kolom tidak unik.
Selain itu, prinsip utama dalam pembuatan index pada tabel yang harus diingat adalah pembuatan index harus didasarkan pada jenis query yang sering terjadi pada kolom tabel bersangkutan. Pada sebuah tabel sangat mungkin ditemukan terdapat lebih dari satu index, misalkan pada kolom X, atau pada kolom Y, atau pada kedua kolom tersebut, bahkan mungkin saja composite index dari kedua kolom. Index yang tepat dapat dihasilkan jika pembuatanya memperhatikan jenis query yang paling sering dipakai pada tabel bersangkutan.
Ada beberapa jenis index pada Oracle yakni sebagai berikut: 1. B*tree index
B*tree index merupakan index yang dibuat ketika pernyataan CREATE INDEX dijalankan di Oracle.
Contoh:
CREATE INDEX employee_id ON employee(employee_id); Istilah B*tree index jarang digunakan dan biasanya hanya disebutkan sebagai index karena jenis ini adalah default index pada Oracle.
B*tree index diimplementasikan dengan algoritma binary search tree seperti pada ilustrasi berikut:
Gambar 2.1 Contoh Struktur B*tree Index
(Sumber : Oracle Database Concepts, 10g Release 2 (10.2) )
Dengan menggunakan B*tree index, pencarian data akan jauh lebih cepat dengan menggunakan binary search dibandingkan dengan full table scan.
Pada index jenis ini, nilai pada atribut yang dibuat index akan diurutkan terlebih dahulu dan kemudian pencarian akan dimulai dari nilai tengah urutan tersebut. Jika data yang ingin dicari bernilai lebih kecil dari nilai tengah, maka pencarian akan dilakukan pada nilai tengah dari daerah yang lebih kecil tersebut. Demikianlah seterusnya hingga data yang dicari berhasil ditemukan.
Pada gambar di atas, branch blocks menyimpan data index yang menunjuk pada blok di bawahnya yang kemudian akan digunakan untuk pencarian. Branch blocks menyimpan awalan kunci minimum yang digunakan untuk memutuskan arah pencarian di antara dua kunci dan pointer ke blok di bawahnya. Blok yang paling bawah atau leaf blocks menyimpan nilai atribut yang dibuatkan index dan ROWID yang menghubungkan ke baris pada tabel sesungguhnya.
2. Reverse Index
Reverse Index secara mendasar hampir sama dengan B*tree Index akan tetapi urutan byte pada nilai yang disimpan pada index dibalik sehingga jika nilainya adalah “ABCD” maka nilai pada reverse index adalah “DBCA”. Keuntungan menggunakan index ini adalah mampu menghindari kecenderungan data yang banyak di satu bagian saja yang diakibatkan proses insert data yang berurutan. Contoh SQL statement untuk membuat reverse index adalah sebagai berikut:
CREATE INDEX reverse_idx ON employee(emp_id) REVERSE;
Index ini dapat dikembalikan menjadi B*tree index kembali dengan SQL statement berikut:
ALTER INDEX reverse_idx REBUILD NOREVERSE;
3. Function-Based Index
Function-based index merupakan index yang menyimpan hasil perhitungan suatu fungsi pada kolom dalam tabel.
Contoh:
CREATE INDEX idx
ON table_1 (a+b*(c-1), a, b);
Yang dapat digunakan untuk query berikut: SELECT a FROM table_1
WHERE a+b*(c-1) < 100;
Fungsi seperti UPPER dan LOWER juga dapat digunakan seperti contoh berikut:
CREATE INDEX uppercase_idx
ON employees (UPPER(first_name));
Yang dapat digunakan untuk query berikut. SELECT * FROM employees
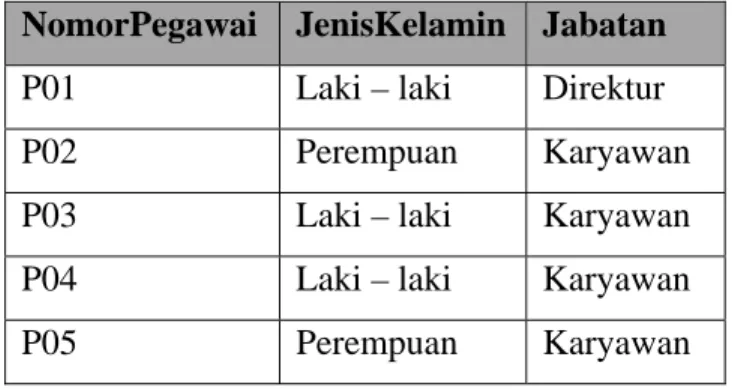
4. Bitmap Index
Bitmap Index menggunakan bit untuk menandai nilai kolom yang dibuat index. Bitmap index cocok untuk kolom yang memiliki cardinality rendah (jenis nilainya sedikit) dan tabel yang berukuran besar. Contoh penggunaan bitmap index misalnya pada tabel pegawai. Pada tabel tersebut terdapat atribut field NomorPegawai, JenisKelamin dan Jabatan. JenisKelamin dapat berisi laki – laki dan perempuan sedangkan Jabatan dapat berisi direktur dan karyawan. Proses pengaksesan data yang paling sering dilakukan adalah data dengan jenis kelamin perempuan dan memiliki jabatan karyawan. Maka, bitmap index dapat dibuat pada kedua kolom berikut:
SELECT * FROM pegawai
WHERE JenisKelamin = ‘perempuan’ AND Jabatan = ‘karyawan’;
NomorPegawai JenisKelamin Jabatan P01 Laki – laki Direktur
P02 Perempuan Karyawan
P03 Laki – laki Karyawan P04 Laki – laki Karyawan
P05 Perempuan Karyawan
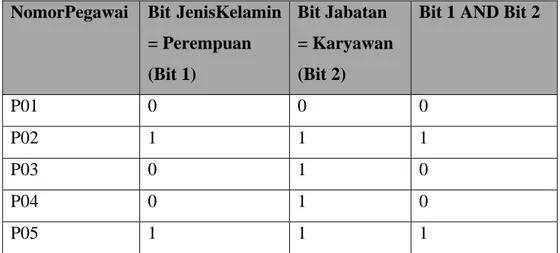
NomorPegawai Bit JenisKelamin = Perempuan (Bit 1) Bit Jabatan = Karyawan (Bit 2)
Bit 1 AND Bit 2
P01 0 0 0
P02 1 1 1
P03 0 1 0
P04 0 1 0
P05 1 1 1
Tabel 2.2 Tabel bit untuk Bitmap Index
Record yang memiliki nilai JenisKelamin = ‘Perempuan’ akan diberi nilai 1 sedangkan untuk JenisKelamin = ‘Laki – laki’ diberi nilai 0. Sedangkan untuk kolom Jabatan, Karyawan diberi nilai 1 sedangkan Direktur diberi nilai 0. Dengan adanya operator AND, maka hanya perlu mencari bit 1 AND bit 2 yang bernilai 1 untuk menemukan data yang diinginkan.
Berdasarkan Expert Oracle Database 10g Administration (2005, p199), perbandingan antara B*tree index dan bitmap index adalah
B*tree index bitmap index Tepat untuk data yang memiliki
cardinality tinggi
Tepat untuk data yang memiliki cardinality rendah
Tepat untuk database OLTP Tepat untuk aplikasi data warehouse
Menggunakan kapasitas penyimpanan yang besar
Menggunakan kapasitas penyimpanan yang kecil Mudah di-update Sulit di-update
2.2.9 Partitioning
Menurut Connolly dan Begg (2005, p529), partitioning merupakan pemecahan tabel menjadi pecahan-pecahan yang lebih kecil berdasarkan pembagian tertentu sehingga lebih mudah diatur. Pengaksesan tabel tetap menggunakan nama tabel yang sama tetapi pembacaan tabel dilakukan pada bagian tertentu saja. Gambar di bawah adalah contoh tabel yang dipartisi berdasarkan bulan sehingga jika terjadi pencarian data di bulan Maret, pembacaan data akan dilakukan pada bulan Maret saja. Dengan cara seperti ini performance dari pemrosesan suatu query akan berjalan lebih cepat dibandingkan melalui proses pembacaan seluruh tabel.
Gambar 2.2 Contoh Perbandingan Partitioned dan Non-partitioned Table
Suatu tabel dapat dipertimbangkan untuk dipartisi jika tabel tersebut berukuran lebih besar dari 2 GB dan mengandung data historis. Jenis-jenis partition adalah sebagai berikut:
1. Range Partition
Jenis partisi ini membagi row pada tabel berdasarkan cakupan nilai tertentu, misalnya memecah tabel suatu transaksi menjadi periode – periode tertentu berdasarkan tanggal transaksi.
Contoh:
CREATE TABLE sales_range (salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), sales_date DATE) PARTITION BY RANGE(sales_date) (
PARTITION sales_janfeb VALUES LESS
THAN(TO_DATE('03/01/2000','MM/DD/YYYY')), PARTITION sales_marapr VALUES LESS
THAN(TO_DATE('05/01/2000','MM/DD/YYYY')), PARTITION sales_mayjun VALUES LESS
THAN(TO_DATE('07/01/2000','MM/DD/YYYY')), PARTITION sales_julaug VALUES LESS
THAN(TO_DATE('09/01/2000','MM/DD/YYYY')) );
Gambar 2.3 Contoh Range Partition
2. List Partition
Jenis partisi ini membagi row berdasarkan daftar nilai yang dimiliki suatu kolom.
Contoh:
Gambar 2.4 Contoh List Partition
(Sumber : Oracle Database Concepts, 10g Release 2 (10.2) ) CREATE TABLE sales_list
(salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_state VARCHAR2(20), sales_amount NUMBER(10), sales_date DATE) PARTITION BY LIST(sales_state)( PARTITION sales_west
VALUES('California', 'Oregon', 'Hawaii'), PARTITION sales_east
VALUES ('New York', 'Virginia', 'Florida'), PARTITION sales_central
3. Hash Partition
Jenis partisi ini menggunakan algoritma hash yang memecah data berdasarkan jumlah partisi yang ada.
Contoh:
Gambar 2.5 Contoh Hash Partition
(Sumber : Oracle Database Concepts, 10g Release 2 (10.2) ) CREATE TABLE sales_hash
(salesman_id NUMBER(5), salesman_name VARCHAR2(30), sales_amount NUMBER(10), week_no NUMBER(2)) PARTITION BY HASH(salesman_id) PARTITIONS 4;
4. Composite Partition
Jenis partisi ini merupakan jenis partisi gabungan dari jenis – jenis partisi di atas seperti range-hash partition dan range-list partition.
Contoh:
CREATE TABLE bimonthly_regional_sales (deptno NUMBER,
item_no VARCHAR2(20), txn_date DATE,
txn_amount NUMBER, state VARCHAR2(2))
PARTITION BY RANGE (txn_date) SUBPARTITION BY LIST (state) SUBPARTITION TEMPLATE(
SUBPARTITION east
VALUES('New York', 'Virginia', 'Florida'), SUBPARTITION west
VALUES('California', 'Oregon', 'Hawaii'), SUBPARTITION central VALUES
('Illinois', 'Texas', 'Missouri') ) (
PARTITION janfeb_2000 VALUES
LESS THAN (TO_DATE('1-MAR-2000','DD-MON-YYYY')), PARTITION marapr_2000 VALUES
LESS THAN (TO_DATE('1-MAY-2000','DD-MON-YYYY')), PARTITION mayjun_2000 VALUES
LESS THAN (TO_DATE('1-JUL-2000','DD-MON-YYYY')) );
Gambar 2.6 Contoh Range - List Partition
(Sumber : Oracle Database Concepts, 10g Release 2 (10.2) )
2.2.10 SQL Tuning
SQL tuning merupakan tindakan pengoptimalan query yang menurut Connolly dan Begg (2005, 632), pengoptimalan query merupakan kegiatan memilih strategi eksekusi yang paling efisien dalam mengeksekusi sebuah query. Efisien yang dimaksud di sini secara umum dapat diukur dengan response time atau kadang dapat dipandang dari sisi jumlah pemakaian sumber daya yang digunakan pada proses pengeksekusian query.
Beberapa pedoman SQL statement yang efisien sehingga mempercepat pengaksesan data adalah sebagai berikut:
1. Penggunaan Equijoin
Jika memungkinkan, gunakanlah equijoin untuk penggabungan tabel pada nilai kolom yang belum diubah.
Contoh:
2. Hindari melakukan pengubahan nilai kolom pada klausa WHERE Contoh klausa WHERE yang buruk:
Klausa WHERE yang disarankan adalah seperti pada contoh berikut: WHERE TO_NUMBER
(SUBSTR(a.order_no,INSTR(b.order_no, '.')-1)) = TO_NUMBER
(SUBSTR(a.order_no, INSTR(b.order_no, '.') - 1)) SELECT m.no, m.nama, n.nilaiAkhir, n.status
FROM Mahasiswa m, Nilai n WHERE m.no = n.no;
3. Penggunaan EXISTS dan IN
a. Jika subquery mengandung selective WHERE, maka akan lebih baik dengan menggunakan IN.
Contoh:
b. Jika parent query mengandung selective WHERE, maka akan lebih baik dengan menggunakan EXIST.
Contoh:
SELECT e.employee_id, e.first_name, e.last_name, e.salary FROM employees e WHERE e.employee_id IN (SELECT o.sales_rep_id FROM orders o WHERE o.customer_id = 144);
SELECT e.employee_id, e.first_name, e.last_name, e.salary
FROM employees e
WHERE e.department_id = 80 AND e.job_id = 'SA_REP' AND EXISTS
(SELECT 1 FROM orders o
Selain itu, jika tidak ada penggunaan WHERE (selain penggunaan WHERE untuk penggabungan tabel dalam EXISTS), maka akan lebih baik menggunakan EXISTS daripada IN. Hal ini dikarenakan EXISTS hanya mengecek keberadaan record, sedangkan IN mengecek nilai aktual.
4. Penggunaan EXISTS dan DISTINCT
Kadangkala, kita dapat menggunakan EXISTS atau DISTINCT untuk melihat data yang sama. Misalnya, dalam melihat data produk yang telah dibeli seperti pada contoh berikut:
• Menggunakan EXISTS
• Menggunakan DISTINCT
SELECT DISTINCT pr.product_id, pr.name FROM products pr, purchases pu
WHERE pr.product_id = pu.product_id; SELECT product_id, name
FROM products outer WHERE EXISTS
(SELECT 1
FROM purchases inner
Dalam kasus seperti ini, penggunaan EXISTS akan lebih baik daripada DISTINCT. Hal ini disebabkan karena DISTINCT akan melakukan pengurutan data terlebih dahulu untuk menghilangkan duplikasi.
5. Gabungkan beberapa SQL statement yang dapat digabung dengan CASE Contoh statement-statement yang dapat digabung adalah sebagai berikut:
SELECT COUNT (*) FROM employees
WHERE salary < 2000;
SELECT COUNT (*) FROM employees
WHERE salary BETWEEN 2000 AND 4000;
SELECT COUNT (*) FROM employees
Statement-statement seperti contoh di atas dapat digabungkan dengan CASE seperti contoh berikut,
6. Penggunaan WHERE lebih baik dibandingkan HAVING
WHERE akan membatasi jumlah baris yang akan diakses sedangkan HAVING memiliki kecenderungan untuk mengakses jumlah baris lebih banyak daripada yang diperlukan. Hal ini dikarenakan WHERE akan melakukan penyeleksian pada setiap record sedangkan HAVING melakukan penyeleksian pada setiap kelompok record yang sudah dikelompokkan dengan GROUP BY.
Contoh:
• Penggunaan HAVING
SELECT COUNT (CASE WHEN salary < 2000
THEN 1 ELSE null END) count1, COUNT (CASE WHEN salary BETWEEN 2000 AND 4000
THEN 1 ELSE null END) count2, COUNT (CASE WHEN salary > 4000
THEN 1 ELSE null END) count3 FROM employees;
SELECT product_type_id, AVG(price) FROM products
GROUP BY product_type_id
• Penggunaan WHERE
7. Menggunakan UNION ALL daripada UNION
UNION ALL dapat digunakan untuk mengambil semua record yang diambil oleh dua query termasuk record yang sama sedangkan UNION hanya akan mendapatkan semua record non-duplikat yang diambil oleh query. UNION membutuhkan waktu yang lebih banyak untuk memproses query karena adanya proses penghilangan duplikasi yang tentunya membutuhkan waktu. Maka dari itu, penggunaan UNION ALL sangat disarankan jika memungkinkan.
Contoh:
• Penggunaan UNION
SELECT product_id, product_type_id, name FROM products
UNION
SELECT prd_id, prd_type_id, name FROM more_products;
SELECT product_type_id, AVG(price) FROM products
WHERE product_type_id IN (1, 2) GROUP BY product_type_id;
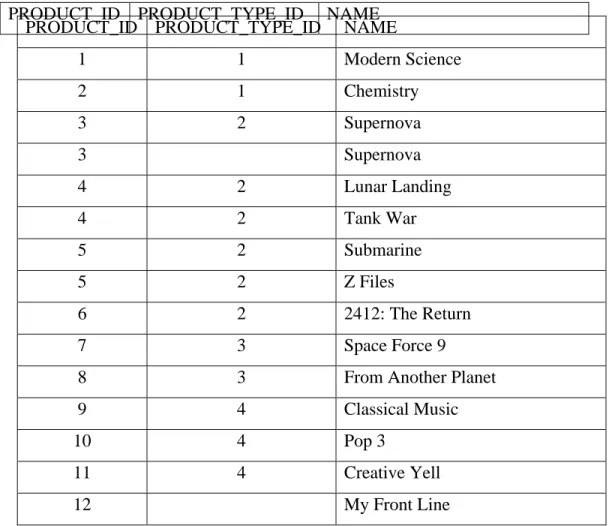
Tabel 2.4 Tabel Contoh Penggunaan UNION
• Penggunaan UNION ALL
PRODUCT_ID PRODUCT_TYPE_ID NAME
1 1 Modern Science 2 1 Chemistry 3 2 Supernova 3 Supernova 4 2 Lunar Landing 4 2 Tank War 5 2 Submarine 5 2 Z Files 6 2 2412: The Return 7 3 Space Force 9
8 3 From Another Planet
9 4 Classical Music
10 4 Pop 3
11 4 Creative Yell
12 My Front Line
PRODUCT_ID PRODUCT_TYPE_ID NAME
SELECT product_id, product_type_id, name FROM products
UNION ALL
SELECT prd_id, prd_type_id, name FROM more_products;
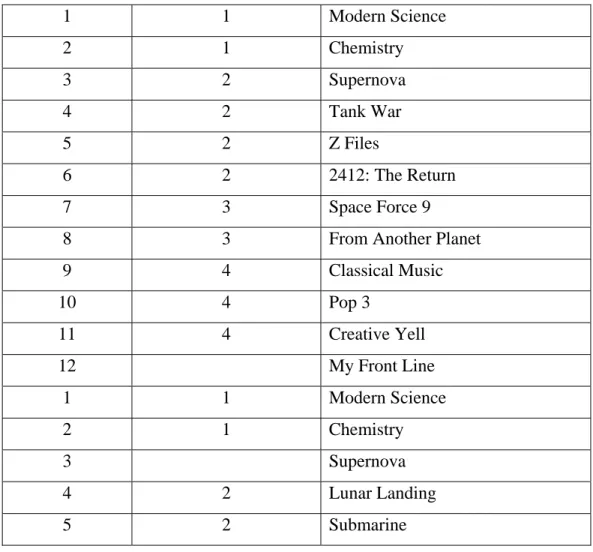
Tabel 2.5 Tabel Contoh Penggunaan UNION ALL
8. Hindari penggunaan SQL function seperti SUBSTR, INSTR, dan TO_DATE pada kolom yang memiliki index
Hal ini dikarenakan penggunaan SQL function semacam ini akan menyebabkan pemakaian index menjadi sia-sia.
1 1 Modern Science 2 1 Chemistry 3 2 Supernova 4 2 Tank War 5 2 Z Files 6 2 2412: The Return 7 3 Space Force 9
8 3 From Another Planet
9 4 Classical Music 10 4 Pop 3 11 4 Creative Yell 12 My Front Line 1 1 Modern Science 2 1 Chemistry 3 Supernova 4 2 Lunar Landing 5 2 Submarine
9. Menggunakan bind variable
Pada database Oracle terdapat cache, yang berfungsi untuk menampung stament-statement SQL yang sebelumnya digunakan, sehingga waktu eksekusi dari sebuah statement SQL akan berkurang jauh jika statement SQL tersebut sudah tersimpan terlebih dahulu di dalam cache. Akan tetapi hal ini hanya akan terjadi jika statement SQL tersebut sepenuhnya identik, yakni semua karakternya harus sama, semua huruf harus dalam jenis huruf yang sama (besar atau kecilnya), dan penggunaan spasi pun harus sama. Beberapa statement SQL yang terlihat sama tetapi tidak identik adalah sebagai berikut:
• Penggunaan spasi yang berbeda
• Penggunaan huruf besar dan kecil yang tidak sama
• Penggunaan nilai yang berbeda
SELECT * FROM products WHERE product_id = 1; SELECT * FROM products WHERE product_id = 1;
select * from products where product_id = 1; SELECT * FROM products WHERE product_id = 1;
SELECT * FROM products WHERE product_id = 1; SELECT * FROM products WHERE product_id = 2;
Pada contoh ke-3, statement SQL ini dapat dibuat menjadi identik dengan menggunakan bind variable. Bind variable ini dapat dibuat dengan menggunakan keyword VARIABLE. Contoh penggunaannya adalah sebagai berikut:
Penggunaan statement SQL yang identik dengan statement SQL yang sebelumnya telah tersimpan di cache akan meningkatkan performance.
VARIABLE product_id_bv NUMBER
BEGIN
:product_id_bv := 1; END;
/
SELECT * FROM products WHERE product_id = :product_id_bv;
BEGIN
:product_id_bv := 2; END;