i S K R I P S I
Diajukan untuk Memenuhi Salah Satu Syarat Memperoleh Gelar Sarjana Sains
Program Studi Ilmu Komputer
Oleh :
Henry Prasista Kurniawan
NIM : 043124009
PROGRAM STUDI ILMU KOMPUTER FAKULTAS SAINS DAN TEKNOLOGI
UNIVERSITAS SANATA DHARMA YOGYAKARTA
ii
FINAL PROJECT
Presented as Partial Fullfilment of the Requirements To Obtain Sarjana Sains Degree
Computer Science Study Program
Oleh :
Henry Prasista Kurniawan
NIM : 043124009
COMPUTER SCIENCE STUDY PROGRAM FACULTY OF SAINS AND TECHNOLOGY
SANATA DHARMA UNIVERSITY YOGYAKARTA
v
dunia pendidikan dan semua orang yang peduli dengan kebudayaan
Negara kita Indonesia. Serta saya persembahkan bagi mereka para
pecinta hal-hal yang bergaya Jepang. Karya bergaya Jepang ini
sebagai timbal balik akan rasa cinta yang mendalam akan kebudayaan
Indonesia dan keprihatinan akan budaya Indonesia yang semakin
ditinggalkan oleh anak muda Negara kita sendiri. Karya ini sebagai
sumbangan pertama saya untuk dunia pendidikan khususnya pendidikan
di Indonesia. Hasil dan pesan moral yang terkandung di dalam karya
saya ini semoga bermanfaat.
MOTTO
Siapkan yang terburuk dari yang terbaik,
dan dapatkan yang terbaik dari yang terburuk.
vi
Huruf Katakana adalah salah satu huruf yang dipakai di Jepang. Huruf ini dipakai untuk menuliskan kata-kata asing atau kata-kata dari luar Jepang terutama kata-kata dalam bahasa Inggris. Pengenalan pola huruf Jepang Katakana menggunakan logika kabur adalah perluasan dari pengenalan pola menggunakan metode Tuple-N. Metode Tuple-N ini memiliki kelemahan diantaranya mensyaratkan kecocokan mutlak antara huruf masukan dengan pola template yang dinyatakan dalam DoM(Degree of Match). Selain itu Skor Kemiripan memiliki kelemahan yaitu posisi suatu pixel dari suatu gambar kurang menjadi penentu kecocokan suatu pola masukan dengan pola-pola template. Untuk mengatasi kelemahan-kelemahan tersebut digunakan perluasan dengan logika kabur.
Pada pengenalan pola huruf Jepang Katakana menggunakan logika kabur ini menggunakan sistem kabur yang meliputi proses fuzzifikasi, proses implikasi, proses mesin inferensi kabur, dan proses defuzzifikasi. Proses fuzzifikasi mengunakan metode Singleton Fuzzifier, implikasi menggunakan implikasi Mamdani, mesin inferensi kabur menggunakan Generalisasi Modus Ponen dan proses defuzzifikasi menggunakan metode Center Average. Masukan sistem berupa DoM dan IoT(Important of Tuple) sedangkan keluaran berupa Css.
vii
Katakana is one of characters used in Japan. This character used to writing foreign words or words from the outside of Japan specially English words. Japanese Katakana Character Recognition using Fuzzy Logic is a extensification of pattern recognition using Tuple-N method. This method has weakness, one of it is presuppose absolut match between input character and template character which call as DoM (Degree of Match). Beside that, Resemblance Score has weakness is the position of pixel from the picture is not enough to be matching determiner between input character and template patterns. To handle that weakness used extensification using Fuzzy Logic.
This Japanese Katakana Character Recognition using Fuzzy Logic using Fuzzy System are fuzzification process, implication process, fuzzy inference engine process and defuzzification process. Fuzzification process using Singleton Fuzzifier method, implication process using Mamdani method, fuzzy inference engine process using Generalization of Ponen Mode and defuzzification process using Center Average Defuzzifier. System input are DoM and IoT (Important of Tuple) and system output is Css.
viii
memuat karya atau bagian karya orang lain, kecuali yang telah disebutkan dalam kutipan dan daftar pustaka, sebagaimana layaknya karya ilmiah.
Yogyakarta, 12 Juni 2008 Penulis,
ix
judul PENGENALAN HURUF JEPANG KATAKANA MENGGUNAKAN LOGIKA KABUR yang sekiranya dapat bermanfaat bagi perkembangan ilmu pengetahuan.
Adapun skripsi ini ditulis untuk memenuhi salah satu syarat memperoleh gelar Sarjana Sains pada Program Studi Ilmu Komputer, Jurusan Matematika, Fakultas Sains dan Teknologi, Universitas Sanata Dharma Yogyakarta.
Dalam penulisan skripsi penulis menyadari banyak pihak yang telah memberikan sumbangan baik pikiran, waktu, tenaga, bimbingan dan dorongan yang sangat tulus dan sangat berarti bagi penulis sehingga skripsi ini dapat penulis selesaikan. Oleh karena itu dengan segala kerendahan hati yang paling dalam penulis menyampaikan ucapan terima kasih yang sebesar-besarnya kepada :
1. Bapak Eko Hari Parmadi, S.Si, M.Kom. selaku dosen pembimbing. Bimbingan Anda saat bermanfaat sehingga skripsi ini dapat selesai. Terima kasih juga atas kesabarannya. Maaf jika saya telah berbuat banyak kesalahan.
2. Bapak Yanuarius Joko Nugroho, S.Si. dan Ibu Anastasia Rita Widiarti, S.Si., M.Kom. yang telah bersedia menjadi dosen penguji.
3. Romo Ir. Gregorius Heliarko, S.J., S.S., B.S.T., M.A., M.Sc. selaku Dekan Fakulktas Sains dan Teknologi.
4. Ibu P.H. Prima Rosa, S.Si., selaku Kaprodi Ilmu Komputer.
5. Seluruh dosen yang telah mengajar penulis selama menjadi mahasiswa Ilmu Komputer dari tahun 2004 hingga 2008.
6. Mas Widodo (dulu) dan Mas Susilo selaku petugas laboratoriumyang telah memberikan kenyamanan dalam menggunakan laboratorium.
x
adalah orangtua paling luar biasa di seluruh alam semesta.
10.Kakakku Ivan dan Adikku Intan yang telah membantu memberikan semangat, kalian adalah saudaraku yang sangat luar biasa.
11.Simbah buyut(Alm), Mbah Akung(Alm), Mbah Uti dan Pakde yang telah memberikan nasehat, semangat dan motivasi kesuksesan bagi cucu-cucunya.
12.Seluruh saudaraku dimanapun kalian berada, terima kasih atas nasehatnya. 13.Spesial thanks buat Willy Ikom’04, Yo Mat’04 dan Mbak Niken, S.Si.
yang telah membantu penulis hingga titik darah penghabisan.
14.Sahabat-sahabat Ikom’04. Beni Cahyo, Beni Aji, Hali, Kornel, Bli Adi, Ipung, Steven, Adit, Bosgenk dan semuanya yang berjumlah 35 anak. Yus dkk. Juga teman-teman Matematika’04 dan Fisika’04 serta kakak-kakak Ikom’03, 02, 01, 00, terima kasih banyak Kritik dan saran kalian sangat berpengaruh kepada penulis.
15.Teman-teman KKN di Dusun Gersik, Sumbermulyo, Bantul angkatan XXXV terima kasih banyak atas kerjasamanya dan janjiku sudah terpenuhi alias Mission Complete.
16.Teman-teman Mudika Wilayah 3 terima kasih, tahun-tahun kebangkitan Mudika kita baru saja dimulai. Penulis harap Mudika kita terus dan semakin maju. Juga Mudika Paroki serta seluruh umat Paroki St. Joseph Medari.
17.Romo Sunu dan Romo Heru terima kasih atas nasehat-nasehat yang mengubah alam bawah sadar bagi penulis. Sehingga perubahan besar telah terjadi dan terbukti sangat “manjur”.
xi
20.Semua pihak yang tidak dapat disebutkan namanya satu-persatu yang telah membantu penulis selama ini.
Penulis menyadari bahwa skripsi ini masih jauh dari sempurna. Harapan penulis semoga skripsi ini bermanfaat bagi kemajuan kita semua.
xii
HALAMAN PENGESAHAN... iv
HALAMAN PERSEMBAHAN... v
ABSTRAK... vi
ABSTRACT... vii
HALAMAN KEASLIAN KARYA... viii
KATA PENGANTAR... ix
DAFTAR ISI... xii
DAFTAR TABEL... xvi
DAFTAR GAMBAR... xvii
BAB I PENDAHULUAN... 1
A. Latar Belakang... 1
B. Rumusan Masalah... 3
C. Batasan Masalah... 3
D. Tujuan Penelitian... 4
E. Manfaat Penelitian... 4
F. Metode Penelitian... 4
G. Sistematika Penulisan... 5
BAB II DASAR TEORI... 7
A. Pengenalan Pola Otomatis... 7
B. Pengenalan Pola Karakter... 8
C. Tahapan Pengenalan Karakter... 8
D. Penggunaan dan Penulisan Huruf Katakana... 10
a. Belajar Menulis KANA... 10
b. Peraturan-peraturan Menulis Katakana... 10
c. Penggunaan-penggunaan Katakana... 12
d. Menulis Katakana... 12
xiii
4. DoM (Degree of Match)... 22
G. Logika Kabur... 23
1. Himpunan Kabur... 23
a. Fungsi Keanggotaan / Membership Function... 24
b. Penyajian Himpunan Kabur... 25
2. Operasi Baku Himpunan Kabur... 26
3. Relasi Kabur... 29
4. Variabel Linguistik... 29
5. Proposisi Kabur... 31
6. Implikasi Kabur... 32
7. Pengambilan Keputusan (Mesin Inferensi)... 34
8. Sistem Kabur... 36
1. Fuzzifikasi... 38
2. Defuzzifikasi... 39
BAB III ANALISIS DAN PERANCANGAN... 42
A. Gambaran Sistem Secara Umum... 42
B. Proses Kerja Sistem... 43
C. Analisis Sistem... 46
1. Proses Fuzzifikasi... 46
a. Variabel Input IoT (Important of Tuple)... 47
b. Variabel Input DoM (Degree of Match)... 48
c. Css... 50
d. Aturan Kabur... 51
2. Proses Defuzzifikasi... 53
D. Perangkat Lunak... 54
E. Perangkat Keras... 54
xiv
5. Perancangan Tampilan Kesimpulan Akhir... 59
6. Perancangan Tampilan Kesimpulan Spesifik... 60
7. Perancangan Tampilan Detail... 61
8. Perancangan Tampilan Informasi... 63
9. Perancangan Tampilan Tentang Program... 63
10.Perancangan Tampilan MessageBox... 63
11.Perancangan Tampilan Waitbar... 64
BAB IV IMPLEMENTASI... 65
A. Gambaran Sistem Secara Umum... 65
B. Form yang Digunakan Dalam Sistem... 68
1. Form Awal / Home... 68
2. Form Pilih Masukan... 69
3. Form Input Menggunakan Mouse... 70
4. Form Input Menggunakan Gambar... 72
5. Form Kesimpulan... 74
6. Form Skor Kemiripan... 76
7. Form DoM dan IoT... 77
8. Form Fuzzy Logic... 78
9. Form Proses... 79
10. Form Input... 79
11. Form Preprocessing... 80
12. Form Aturan Kabur... 81
13. Form Output... 81
14. Form Template... 82
15. Form Informasi... 83
16. Form Waitbar... 83
xv
3. Membuat Figure... 89
4. Membuat Fungsi Kontrol dan Fungsi Pemanggil... 89
5. Membuat Fungsi Penampil Gambar... 90
6. Algoritma Tuple-N Menghitung Skor Mirip... 91
7. Algoritma Tuple-N Menghitung IoT... 92
8. Algoritma Tuple-N Menghitung DoM... 93
9. Sistem Kabur... 94
E. Batasan-batasan Program... 96
F. Hasil Analisa Program... 96
BAB V PENUTUP... 100
A. Kesimpulan... 100
B. Saran... 100 DAFTAR PUSTAKA
xvi
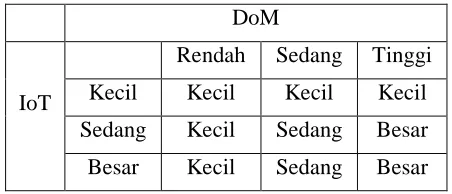
Tabel 2.2. Tabel DoM... 23
Tabel 2.3. Tabel Kebenaran Himpunan Tegas... 27
Tabel 2.4. Tabel Persamaan Dienes Rescher... 34
Tabel 2.5. Tabel Persamaan Mamdani... 34
xvii
Gb 2.2. Contoh Menulis Huruf Katakana... 13
Gb 2.3. Tuple & Pixel... 15
Gb 2.4. Template... 15
Gb 2.5. Input... 17
Gb 2.6. Huruf HE dan Imbuhannya... 19
Gb 2.7. Struktur Dasar Suatu Sistem Kabur... 37
Gb 3.1. Skema Proses Pengenalan Pola... 43
Gb 3.2. Cara Membuat Pola Input... 44
Gb 3.3. Cara Mengatur Font Pola Input... 44
Gb 3.4. Preprocessing... 45
Gb 3.5. Bentuk Kurva Segitiga IoT... 47
Gb 3.6. Bentuk Kurva Segitiga DoM... 48
Gb 3.7. Bentuk Kurva Segitiga Css... 49
Gb 3.8. Penarikan Kesimpulan dengan Generalisasi Modus Ponen... 52
Gb 3.9. Nilai Css... 53
Gb 3.10. Rancangan Tampilan Form Awal... 54
Gb 3.11. Rancangan Tampilan Pilih Input... 56
Gb 3.12. Rancangan Tampilan Input Mouse... 57
Gb 3.13. Rancangan Tampilan Input Gambar... 58
Gb 3.14. Rancangan Tampilan Kesimpulan Akhir... 59
Gb 3.15. Rancangan Tampilan Kesimpulan Spesifik... 60
Gb 3.16. Rancangan Tampilan Detail... 61
Gb 3.17. Tampilan Informasi... 63
Gb 3.18. Rancangan Tampilan Tentang Program... 63
Gb 3.19 Rancangan Tampilan MessageBox... 64
Gb 3.20. Rancangan Tampilan Waitbar... 64
Gb 4.1. Diagram Alur Proses Sistem... 65
xviii
Gb 4.7. Form Input Menggunakan Mouse... 70
Gb 4.8. Form Input Menggunakan Gambar... 72
Gb 4.9. Form Kesimpulan... 74
Gb 4.10. Form Skor Kemiripan... 76
Gb 4.11. Form DoM dan IoT... 77
Gb 4.12. Form Fuzzy Logic... 78
Gb 4.13. Form Proses Pengenalan Pola... 79
Gb 4.14. Form Input... 79
Gb 4.15. Form Preprocessing... 80
Gb 4.16. Form Aturan Kabur... 81
Gb 4.17. Form Output... 81
Gb 4.18. Form Template... 82
Gb 4.19. Form Informasi... 83
Gb 4.20. Form Waitbar... 83
Gb 4.21. Form Credit 1... 84
Gb 4.22. Form Credit 2... 84
Gb 4.23. Tampilan Fuzzy Toolbox... 85
Gb 4.24. Tampilan Aturan Kabur... 86
Gb 4.25. Tampilan Hasil Css Berdasarkan Aturan Kabur... 86
Gb 4.26. Tampilan Hasil Secara 3 Dimensi... 87
Gb 4.27. Diagram Alir Skor Kemiripan... 91
Gb 4.28. Diagram Alir IoT... 92
Gb 4.29. Diagram Alir DoM... 93
Gb 4.30. Mengenali Huruf ‘FU’... 97
Gb 4.31. Mengenali Huruf ‘NA’... 98
1 A. Latar Belakang
Seiring dengan semakin berkembangnya ilmu pendidikan dan teknologi dewasa ini telah banyak ditemukan teknologi-teknologi yang semakin hari semakin canggih. Sebagai contoh adalah komputer. Komputer telah berkembang sangat pesat dan telah bertahan selama hampir satu abad lamanya. Jika kita mau melihat lagi pada masa lalu dimana komputer pertama di dunia masih berukuran sangat besar (sebesar ruang kelas), kemudian berukuran satu lemari pakaian, dibandingkan saat ini komputer ada yang bahkan hanya berukuran saku. Program dan aplikasi yang dipakai dalam komputer masa kini juga sudah sangat beragam dan canggih. Bahkan komputer mulai dikembangkan supaya mampu meniru pola pikir manusia. Dengan kata lain, komputer diprogram untuk memiliki kecerdasan seperti manusia.
layaknya manusia. Salah satunya adalah komputer mampu membedakan suatu pola (identifikasi pola) seperti mengenali pola huruf, mengenali sidik jari seseorang, mengenali tanda tangan, mengenali wajah, mengenali retina mata seseorang dan masih banyak lagi hal-hal yang dapat dilakukan komputer. Sehingga komputer sangat berguna diberbagai bidang, antara lain kedokteran dan kepolisian.
Merasa tertarik dengan ilmu pengenalan pola, penulis memiliki keinginan untuk membuat suatu aplikasi yang mampu mengenali suatu pola. Salah satu metode yang ingin diangkat oleh penulis adalah metode Tuple-N dengan Logika Kabur. Dimana metode ini akan dipakai untuk mengenali pola huruf Jepang Katakana. Alasan penulis untuk memilih pengenalan huruf Jepang Katakana
adalah penulis menyukai bahasa dan tulisan Jepang, juga karena penulis memiliki banyak sekali koleksi buku-buku yang ditulis memakai huruf Jepang Katakana, tetapi penulis kesulitan untuk dapat membacanya dengan baik sehingga harus diperlukan kamus huruf Jepang Katakana. Oleh karena itu, penulis bermaksud untuk membuat suatu program yang mampu mengenali pola huruf Jepang Katakana tersebut menggunakan metode Tuple-N dan Logika Kabur.
Huruf Katakana adalah salah satu dari tiga macam huruf di Jepang. Selain Katakana juga terdapat Hiragana dan Kanji. Huruf Hiragana adalah huruf yang
menuliskan kata-kata serapan / kata-kata dari luar Jepang, bisa juga untuk menuliskan suatu kata dari bahasa Indonesia dan bahasa Inggris.
B. Rumusan Masalah
Bagaimana membangun suatu aplikasi yang dapat mengenali huruf-huruf Jepang Katakana dengan metode Tuple-N dan Logika Kabur?
C. Batasan Masalah
Penelitian ini ditulis dengan batasan masalah sebagai berikut :
1. Huruf yang digunakan pada penelitian ini hanya huruf Katakana saja, dengan program yang dapat mengenali satu-persatu huruf Katakana dan menterjemahkan ke dalam huruf abjad biasa.
2. Masukan dilakukan dengan memakai mouse atau gambar yang telah di-scan.
3. Aplikasi ini tidak menghiraukan cara penulisan huruf Jepang Katakana, seperti titik pertama yang digoreskan pada layar.
4. Implikasi kabur yang digunakan adalah Implikasi Mamdani, proses pengaburan menggunakan Singleton Fuzzifier, proses penegasan menggunakan CAD (Center Average Defuzzifer) dan unit penalaran menggunakan Generalisasi Modus Ponen.
5. Software yang akan digunakan dalam penelitian ini antara lain : a. MATLAB 6.5.1,
D. Tujuan Penelitian
Membangun suatu aplikasi yang dapat mengenali huruf-huruf Jepang Katakana dengan metode Tuple-N dan Logika Kabur.
E. Manfaat Penelitian
Manfaat dari penelitian ini adalah :
1. Sebagai alat bantu dalam menterjemahkan dan membaca huruf Jepang Katakana.
2. Sebagai tambahan pengetahuan tentang penggunan metode Tuple-N dan Logika Kabur sebagai suatu metode pengenalan pola.
F. Metode Penelitian
Metode yang digunakan dalam penelitian ini adalah metode Waterfall. Adapun metode-metode yang digunakan dalam melakukan penelitian ini, antara lain :
a. Pengumpulan Kebutuhan
Metode ini dilakukan yaitu dengan mengumpulkan kebutuhan-kebutuhan yang diperlukan dalam pembuatan suatu perangkat lunak. Misalnya pengumpulan template-template yang diperlukan sebagai pembanding dengan pola input.
b. Rancangan Sistem
c. Penulisan Program (Coding)
Dalam tahap ini yang akan dilakukan adalah merepresentasikan hasil rancangan ke dalam program. Mengimplementasikan algoritma-algoritma dan modul-modul yang ada untuk membuat suatu perangkat lunak yang telah dirancang.
d. Pengujian (Testing)
Dalam tahap ini yang dilakukan adalah menguji program yang telah dibuat sudah apakah sudah sesuai dengan yang diinginkan. Serta digunakan untuk mencari kesalahan yang terjadi dalam sistem yang telah diujikan.
G. Sistematika Penulisan BAB I Pendahuluan
Merupakan pendahuluan yang berisi latar belakang masalah, rumusan masalah, batasan masalah, tujuan penelitian, manfaat penelitian, metode penelitian dan sistematika penulisan.
BAB II Landasan Teori
Berisi landasan teori yang dipakai dalam penelitian tentang pengenalan pola huruf Jepang Katakana. Meliputi Pengenalan Pola, Pengenalan Pola Huruf Jepang KATAKANA, Algoritma Tuple-N dan Logika Kabur.
BAB III Analisa dan Perancangan
BAB IV Implementasi
Bab ini berisi program-program yang telah dibuat dan hasil pengujian serta hasil akhir dari aplikasi yang telah dibuat. Dalam Bab ini terdapat pula hasil capture antar muka dari program yang telah dibuat.
BAB V Penutup
7 A. Pengenalan Pola Otomatis
Secara umum pengenalan pola (pattern recognition) adalah suatu proses untuk mengenali pola-pola yang terdapat pada sekumpulan data dan menggolongkannya dalam kelompok-kelompok sehingga pola-pola yang berada dalam satu kelompok mempunyai derajat kemiripan yang tinggi dan pola-pola yang berada dalam kelompok yang berbeda mempunyai derajat kemiripan yang rendah. Salah satu cara untuk mengelompokkan pola-pola itu, yang disebut metode daftar keanggotaan, mengkarakteristik setiap kelompok (kelas) pola dengan suatu himpunan pola tertentu. Suatu pola yang akan diklasifikasikan dibandingkan dengan pola-pola acuan dalam himpunan itu, dan dikelompokkan ke dalam suatu kelompok pola jika pola itu cocok dengan salah satu pola acuan dari kelompok itu. (Susilo, 2006)
Secara umum teknik pengenalan pola bertujuan untuk mengklarifikasikan dan mendeskripsikan pola atau objek kompleks melalui pengukuran sifat-sifat atau ciri-ciri yang dimiliki oleh objek yang bersangkutan. Dengan kata lain, pengenalan pola dapat membedakan suatu objek dengan objek yang lain. (Munir, 2004).
jari) dan temporal (muka gelombang, ucapan), dimana seseorang membutuhkan bantuan alat penginderaan (sensor). Pengenalan akan hal yang abstrak seperti konsep dan gagasan disatu pihak dapat dilakukan tanpa bantuan sensor. Kenyataan diatas masing-masing diistilahkan sebagai pengenalan sensoris dan pengenalan konseptual. (Pal & Majumder, 1989).
B. Pengenalan Pola Karakter
Pengenalan pola huruf adalah salah satu ilmu dari berbagai macam pengenalan pola. Pengenalan pola huruf termasuk pengenalan pola yang paling tua daripada pengenalan pola yang lainnya, seperti : pengenalan pola sidik jari, pengenalan pola wajah dan pengenalan pola retina mata yang masih baru dan terus dikembangkan.
Pengenalan pola huruf yang telah ditemukan dapat dengan baik mengenali pola kode pos, angka, huruf cetak bahkan ada juga yang mampu mengenali pola tulisan tangan manusia. (Anzai, 1989)
Pengenalan pola huruf mulai terus dikembangkan dan dipergunakan untuk mengenali pola-pola baru, misalnya mengenali pola huruf China dan Jepang.
C. Tahapan Pengenalan Karakter
Gb. 2.1 : Skema Sistem Pengenalan Pola
Pertama masukan akan dirubah dari dokumen biasa menjadi bentuk digital (digitalisasi) sehingga dapat dikenali oleh komputer. Kemudian masukan tersebut akan dikenai proses preprocessing seperti mengganti ukuran (sizing) menghilangkan noise, dan sebagainya. Hasil preprocessing tersebut akan dikenai proses ekstraksi ciri dan kemudian akan dicocokkan dengan pola pembanding dan dengan pengambilan keputusan dapat diputuskan pola masukan tersebut dapat dikenali.
Optical Scanner adalah perangkat keras yang berfungsi memindai dokumen dari
luar komputer menjadi bentuk digital yang mampu dikenali oleh komputer. Preprocessing adalah suatu proses untuk mengatur suatu pola (baik masukan
tersebut. Prosesnya disebut ekstraksi ciri. Decision Maker atau pengambil keputusan adalah orang atau entitas yang membuat keputusan, sedangkan proses untuk membuat suatu keputusan dalam proses pengenalan pola disebut decision making. Proses ini akan menentukan hasil perhitungan dan kecocokan antara pola
masukan dengan pola-pola pembanding yang disediakan sistem. Sehingga didapat hasil pengenalan berupa nilai dari hasil pencocokan pola masukan dengan pola-pola pembanding.
D. Penggunaan dan Penulisan Huruf KATAKANA a. Belajar Menulis KANA
Cara terbaik untuk menguasai tulisan Jepang dimulai dengan belajar menulis KANA (Hiragana dan Katakana). Ada beberapa alasan mengapa disarankan memulai belajar dengan kana, yaitu :
1. Jumlah suku kata hanya 46 buah.
2. Bentuk-bentuknya sederhana sehingga mudah dipelajari dan hanya terdiri dari 1 sampai 4 tarikan (stroke). Terkadang untuk huruf yang terdapat imbuhan terdiri sampai 5 stroke (huruf BO dan PO).
3. Ada hubungan yang erat antara bunyi dan lambang tulisannya.
4. Setiap suku kata mencakup semua bunyi bahasa Jepang sehingga semua wacana dapat ditulis dengan Katakana dan Hiragana.
b. Peraturan-peraturan Menulis Katakana
2. Bunyi yang diucapkan dengan getaran pita suara (daku-on) seperti g,z,d dan b ditulis dengan sepasang tarikan pendek melintang (daku-ten) di sudut kanan atas bunyi yang berhubungan yang tidak diucapkan.
Bunyi p (handaku-on) ditulis dengan cara menambahkan sebuah lingkaran kecil di sudut kanan atas kana yang berhubungan dari deretan ha.
3. Bunyi-bunyi yang membaur (soku-on) yang pada huruf Latin ditulis dengan konsonan rangkap ditulis dengan huruf ‘tsu’ kecil di depan konsonan.
= huruf tsu kecil
4. Bilamana menjadi sebuah sukukata, huruf E,O dan WA ditulis huruf Katakana aslinya atau bukan berupa perpanjangan.
c. Penggunaan-penggunaan Katakana
Katakana digunakan untuk menulis hal-hal sebagai berikut :
1. Untuk menuliskan kata-kata yang diserap dari bahasa asing, misalnya bahasa Inggris
2. Kata-kata dan nama diri asing, kecuali nama-nama Korea dan Cina Raya.
3. Nama-nama tumbuhan dan hewan, terutama yang digunakan dalam ilmu pengetahuan.
4. Untuk telegram
(Mangunsuwito, 2001)
d. Menulis Katakana
stroke terkecil yaitu 1 stroke hingga jumlah stroke terbesar yaitu 5 stroke.
(Mangunsuwito, 2001)
Gb 2.2 : Contoh Menulis Huruf Katakana
E. Pengenalan Huruf Jepang KATAKANA
Huruf Jepang dibedakan menjadi 3 macam, yaitu huruf Kanji, huruf Katakana dan huruf Hiragana. Dari ketiga jenis huruf Jepang diatas,
masing-masing memiliki pola huruf yang berbeda-beda. Pola huruf Katakana sendiri lebih menekankan pada garis lurus dan sudut lancip, tidak seperti huruf Hiragana yang lebih menekankan pada kurva dan garis parabola. Proses pengenalan pola huruf Katakana sebenarnya sama seperti proses-proses pengenalan pola yang lainnya,
yaitu langkah pertama adalah memasukkan input kemudian input tersebut dirubah menjadi suatu matriks berukuran tertentu misal m x n. Setelah itu dikenai proses threshold dan binerisasi yaitu merubah nilai pixel input menjadi bernilai ‘0’ dan
(
)
∑
∏
(
( )
)
= =
= p
k n
l
ilk il
i
i x x f x
x Fi
1 1
2 1, ,...,
F. Algoritma Pengenal Huruf Tuple-N
Salah satu algoritma yang dapat digunakan untuk mengenali huruf adalah algoritma pengenal Tuple-N. Prinsip algoritma Tuple-N ini mirip dengan algoritma pengenalan pola yang lain yaitu dengan membandingkan input dengan template(pembanding), tetapi dalam Tuple-N ini akan dilakukan penghitungan
skor kemiripan dari input dengan template. Dalam algoritma ini input yang dimasukkan harus berukuran sama dengan template yang berukuran m x n dengan masing-masing elemennya harus bernilai ’0’ dan ’1’. Ada 4 hal pokok yang menjadi cara pengenalan pola dari algoritma Tuple-N ini, yaitu : skor kemiripan, skor pixel, IoT (Important of Tuple) dan DoM (Degree of Match). (Priyatma & Parmadi, 2004)
1. Skor Kemiripan
Skor kemiripan didapat dari penjumlahan masing-masing pixel dari masing-masing tuple (baris) dari template-template yang kemudian dibandingkan dengan masukan. Skor kemiripan dapat dihitung dengan menggunakan rumus :
Dimana
f( Xilk ) = X’il , jika pixel berwarna hitam ( Xilk = 0 )
’ = menyatakan operator NOT
P = jumlah citra pembanding
n = jumlah elemen dalam setiap tuple / baris
(Priyatma & Parmadi, 2004) Contoh :
Terdapat 3 buah template berukuran 5 x 5 untuk menghitung skor kemiripan, dalam huruf Jepang Katakana template-template ini berbunyi ‘SU’.
Dari template di atas menggunakan ukuran 5 x 5, jadi tuple di atas berjumlah 5 tuple / baris dengan ketentuan baris 1 adalah F1, baris 2 adalah F2 dan seterusnya, dan masing – masing tuple memiliki 5 elemen.
Tuple ke 1 Tuple ke 2 Tuple ke 3
Pixel
Gb 2.3 : Tuple & Pixel
Dengan menggunakan rumus diatas setiap tuple dapat dihitung, sebagai berikut :
F1 (x11 , x12 , x13 , x14 , x15) = (x’11 , x’12 , x’13 , x’14 , x’15) + (x’11 , x’12 , x’13 , x’14 , x15) + (x11 , x’12 , x’13 , x’14 , x’15) F2 (x21 , x22 , x23 , x24 , x25) = (x21 , x22 , x23 , x’24 , x25) + (x21 , x22 , x23 ,
x24 , x’25) + (x21 , x22 , x23 , x’24 , x25) Dapat disederhanakan menjadi
(x21 , x22 , x23 , x’24 , x25) + (x21 , x22 , x23 , x24 , x’25)
F3 (x31 , x32 , x33 , x34 , x35) = (x31 , x32 , x’33 , x34 , x35) + (x31 , x32 , x’33 , x’34 , x35) + (x31 , x32 , x’33 , x’34 , x35)
Dapat disederhanakan menjadi
(x31 , x32 , x’33 , x34 , x35) + (x31 , x32 , x’33 , x’34 , x35)
F4 (x41 , x42 , x43 , x44 , x45) = (x41 , x’42 , x43 , x’44 , x45) + (x41 , x’42 , x43 , x’44 , x45) + (x41 , x’42 , x43 , x44 , x’45) Dapat disederhanakan menjadi
(x41 , x’42 , x43 , x’44 , x45) + (x41 , x’42 , x43 , x44 , x’45)
F5 (x51 , x52 , x53 , x54 , x55) = (x’51 , x52 , x53 , x54 , x’55) + (x’51 , x52 , x53 , x54 , x’55) + (x’51 , x52 , x53 , x54 , x’55) Dapat disederhanakan menjadi
Setelah membuat kelima fungsi di atas, selanjutnya diberikan sebuah input berupa gambar dengan ukuran yang sama yaitu 5 x 5. Seperti
terlihat pada gambar dibawah ini.
Sama seperti template, baris 1 adalah F1, dan seterusnya. Dari rumus di atas telah ditentukan bahwa pixel hitam bernilai 0, dan pixel putih bernilai 1, maka dapat ditentukan nilai pixel tiap baris menjadi :
F1 (x11 , x12 , x13 , x14 , x15) = F1 (0, 0, 0, 0, 0) F2 (x21 , x22 , x23 , x24 , x25) = F2 (1, 1, 1, 1, 0) F3 (x31 , x32 , x33 , x34 , x35) = F3 (1, 1, 0, 1, 1) F4 (x41 , x42 , x43 , x44 , x45) = F4 (1, 0, 1, 1, 0) F5 (x51 , x52 , x53 , x54 , x55) = F5 (0, 1, 1, 1, 1) Skor kemiripan = F1 + F2 + F3 + F4 + F5
Langkah selanjutnya adalah memasukkan fungsi dari template di atas ke dalam nilai input. Fungsi OR adalah (+), dan fungsi AND adalah (*). Sehingga hasilnya akan sebagai berikut :
F1 (0, 0, 0, 0, 0) = (0’* 0’* 0’* 0’* 0’) + (0’* 0’* 0’* 0’* 0) + (0* 0’* 0’* 0’* 0’)
= (1* 1* 1*1* 1) + (1* 1* 1* 1* 0) + (0* 1* 1* 1* 1) = 1 + 0 + 0 = 1
F2 (1, 1, 1, 1, 0) = (1* 1* 1* 1’* 0) + (1* 1* 1* 1* 0’) = (1* 1* 1* 0* 0) + (1* 1* 1* 1* 1) = 0 + 1 = 1
F3 (1, 1, 0, 1, 1) = (1* 1* 0’* 1* 1) + (1* 1* 0’* 1’* 1) = (1* 1* 1* 1* 1) + (1* 1* 1* 0* 1) = 1 + 0 = 1
F4 (1, 0, 1, 1, 0) = (1* 0’* 1* 1’* 1) + (1* 0’* 1* 1* 0’) = (1* 1* 1* 0* 0) + (1* 1* 1* 1* 1) = 0 + 1 = 1
F5 (0, 1, 1, 1, 1) = (0’* 1* 1* 1* 1’) = (1* 1* 1* 1* 0) = 0
Skor Kemiripan diperoleh dengan menjumlahkan masing-masing fungsi pada gambar masukan, sehingga:
Skor Kemiripan = F1 + F2 + F3 + F4 + F5 = 1 + 1 + 1 + 1 + 0 = 4
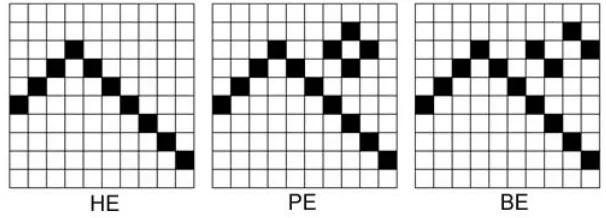
Dari metode Skor Kemiripan ini memiliki kelemahan yaitu posisi suatu pixel dari suatu gambar kurang menjadi penentu kecocokan suatu pola
masukan dengan pola-pola template. Ini akan menjadi suatu kesalahan jika gambar suatu input memiliki struktur pixel yang hampir sama dengan template dan akan dikenali sebagai pola template yang salah. Seperti pada contoh di bawah ini:
Gb 2.6 : Huruf HE dan Imbuhannya
2. Skor Pixel
Skor pixel merupakan skor kepentingan dari tiap tuple dalam tiap kelompok template suatu huruf. Skor pixel dapat dicari dengan menggunakan rumus :
Skor pixel = | NH – NP | / M Dimana :
NH = Nilai berapa kali pixel berwarna hitam dalam kelompok template. NP = Nilai berapa kali pixel berwarna putih dalam kelompok template. M = Banyaknya anggota (template) dari kelompok huruf = NH + NP | | = Operator Absolut
(Priyatma & Parmadi, 2004)
Jadi, dari gambar template (Gb. 2.4) dapat dihitung bahwa untuk pixel (1,1) NH = 2 dan NP = 1 sehingga skor pixel pixel (1,1) menjadi | 2 – 1 | / 3 = 1/3. Dan untuk pixel yang lain menjadi :
Pixel (1,2) = | 3 – 0 | / 3 = 1 Pixel (1,3) = | 3 – 0 | / 3 = 1 Pixel (1,4) = | 3 – 0 | / 3 = 1 Pixel (1,5) = | 2 – 1 | / 3 = 1/3
Pixel (2,4) = | 2 – 1 | / 3 = 1/3 Pixel (2,5) = | 1 – 2 | / 3 = 1/3 Pixel (3,1) = | 0 – 3 | / 3 = 1 Pixel (3,2) = | 0 – 3 | / 3 = 1 Pixel (2,1) = | 0 – 3 | / 3 = 1
Pixel (2,2) = | 0 – 3 | / 3 = 1 Pixel (2,3) = | 0 – 3 | / 3 = 1
Dan seterusnya dilakukan hal yang sama terhadap pixel-pixel yang lain, sehingga keseluruhan didapat skor pixel sebagai berikut:
Tabel 2.1 : Tabel Skor Pixel
1/3 1 1 1 1/3
1 1 1 1/3 1/3
1 1 1 1/3 1
1 1 1 1/3 1/3
1 1 1 1 1
3. IoT (Important of Tuple)
Skor pixel yang telah didapat di atas sebenarnya akan digunakan untuk mendapatkan derajat kepentingan suatu tuple, disebut IoT (Important of Tuple). IoT dapat didefinisikan sebagai berikut :
IoT = jumlah skor pixel pada suatu tuple.
(Priyatma & Parmadi, 2004)
Cara mendapatkan nilai IoT hanya dengan menjumlahkan nilai suatu tuple yang telah dihitung pada skor pixel diatas. Seperti berikut ini:
Tuple 4 = ( 1 + 1 + 1 + 1/3 + 1/3 ) = 3 2/3 Tuple 5 = ( 1 + 1 + 1 + 1 + 1 ) = 5
Dari percobaan di atas dapat disimpulkan bahwa nilai IoT maksimal adalah bernilai 5. Jadi dari tuple di atas, tuple ke-5 menjadi tuple yang paling konsisten dibanding dengan tuple yang lain yaitu nilai antara hitam dan putih selalu sama dalam tiap template pada suatu kelompok. Sehingga tuple ke-5 ini dapat dijadikan pedoman dalam pembandingan antara masukan dengan kelompok template ini (huruf ‘SU’). Jumlah IoT dari kelompok template ini adalah 20 1/3.
4. DoM (Degree of Match)
Dalam algoritma pengenalan pola Tuple-N, syarat untuk mampu mengidentifikasi pola masukan sebagai pola yang dapat dikenali adalah pada skor kecocokan. Kecocokan (matching) antara tuple masukan dengan tuple template merupakan syarat untuk dapat menentukan skor kecocokan total.
Untuk mendapatkan skor tersebut, dapat digunakan DoM (Degree of Match / Derajat Kecocokan) yang didefinisikan sebagai berikut :
DoM = NM / P
Dimana :
NM = Jumlah huruf pembanding yang tuple-nya cocok dengan tuple huruf yang diuji
Sehingga dari template (Gb.2.4) dengan input (Gb.2.5) dapat dihitung nilai DoM sebagai berikut :
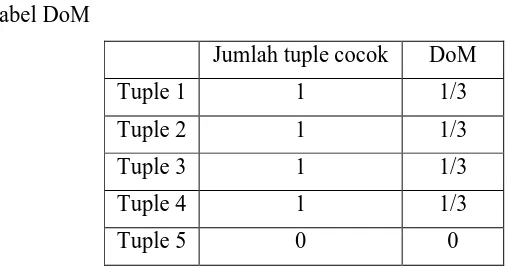
Tabel 2.2 : Tabel DoM
Jumlah tuple cocok DoM
Tuple 1 1 1/3
Tuple 2 1 1/3
Tuple 3 1 1/3
Tuple 4 1 1/3
Tuple 5 0 0
Sehingga dari percobaan di atas dapat disimpulkan bahwa nilai antara tuple input dengan tuple template kecil (tidak ada yang bernilai 1. Sehingga
disimpulkan bahwa input hanya memiliki 1 1/3 kecocokan dengan kelompok huruf ’SU’.
G. Logika Kabur
1. Himpunan Kabur
himpunan. Untuk mengabaikan ketegasan tersebut dibuatlah suatu fungsi, yaitu fungsi keanggotaan dan nilai fungsinya disebut derajat keanggotaan suatu unsur dalam himpunan itu, yang selanjutnya disebut himpunan kabur (fuzzy set). (Susilo,2006).
Misal :
S adalah himpunan hewan dengan anggota : sapi, kambing, ikan, ayam, ular, anjing. Diketahui himpunan A adalah himpunan hewan menyusui / mamalia, à S, maka himpunan à dapat didefinisikan dengan menggunakan fungsi keanggotaan sebagai berikut :
a. Fungsi Keanggotaan / Membership Function
Fungsi Keanggotaan dinotasikan dengan notasi µ, dimana µ berfungsi untuk memetakan suatu himpunan semesta S kesebuah nilai pada interval [0,1]. Misalnya terdapat suatu himpunan à dengan semesta S maka Fungsi Keanggotaan dari himpunan à (µÃ (x)), didefinisikan :
Maka untuk :
S = {sapi, kambing, ikan, ayam, ular, anjing} Ã = {x | x = hewan menyusui є Ã }
Fungsi Keanggotaan dari himpunan à (µÃ(x)) adalah : µÃ(x) =
1, jika x Ã
µÃ(x) =
1, jika x = sapi, kambing, anjing
0, jika x = ikan, ayam, ular
Himpunan kabur (fuzzy sets) dalam semesta pembicaraan S dikarakteristikkan dengan sebuah Fungsi Keanggotaan µÃ(x) yang berada dalam interval [0,1].
µÃ(x) = S [ 0,1 ] (Wang, 1997)
b. Penyajian Himpunan Kabur
Himpunan Kabur dapat disajikan ke dalam beberapa cara, yaitu : 1. Pasangan berurut
Himpunan Kabur à dalam semesta S dapat disajikan dengan cara pasangan berurut, sebagai berikut :
à = {(x, µÃ(x)) | x є S} 2. Kontinyu
Apabila semesta S adalah himpunan yang continue, maka himpunan kabur à dinyatakan dengan :
3. Diskrit
Apabila S merupakan nilai diskrit, himpunan kabur à dinyatakan dengan :
( )
x /x à Ãu
∫
= µ
( )
xS
15
87
.
0
14
75
.
0
13
62
.
0
12
5
.
0
11
37
.
0
10
25
.
0
9
12
.
0
8
0
Ã
=
+
+
+
+
+
+
+
Contoh :Misal µÃ(x) = ( x – 8 ) / 8 dan x є {8,9,10,11,12,13,14,15} a. Pasangan berurut
Maka :
à = {(8, 0), (9, 0.12), (10, 0.25), (11, 0.37), (12, 0.5), (13, 0.62), (14, 0.75), (15, 0.87)}
b. Kontinyu
à = {(0,7), (0,6), (0,5), (0,4), (0,3), (0,2), (0,1), (0,0)}
c. Diskrit
2. Operasi Baku Himpunan Kabur
Seperti halnya pada himpunan tegas, kita dapat mendefinisikan operasi biner ”komplemen” dan operasi-operasi biner ”gabungan” dan ”irisan” pada himpunan-himpunan kabur. Karena suatu himpunan tegas dapat dinyatakan secara lengkap dengan fungsi karakteristiknya, maka ketiga operasi pada himpunan tegas itu dapat didefinisikan dengan menggunakan fungsi karakteristik itu. (Susilo, 2006)
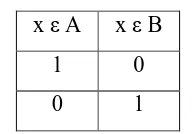
Misalnya A adalah suatu himpunan tegas dalam semesta X, maka komplemen dari A, yaitu A’, dapat didefinisikan dengan tabel nilai kebenaran sebagai berikut :
Tabel 2.3 :
Tabel Kebenaran Himpunan Tegas x ε A x ε B
1 0
0 1
Bila µ A adalah fungsi karakteristik dari himpunan kabur à tersebut, maka definisi komplemen dari himpunan kabur à itu juga dapat dinyatakan dengan menggunakan fungsi keanggotaan sebagai berikut :
µ A’ (x) = 1 - µ A (x), untuk setiap x ε X.
a. Gabungan (union)
Gabungan dari himpunan kabur à dan himpunan kabur B dinotasikan dengan ÃUB, yaitu himpunan kabur µAUB(x); dengan membership
function :
µ AUB(x)= maks { µ A(x), µ B(x) }, untuk setiap x ε X
µ Ã(x) merupakan fungsi keanggotaan dari himpunan kabur à µ B(x) merupakan fungsi keanggotaan dari himpunan kabur B
~ ~
~ ~ ~ ~
~
~ ~
~
~
~
b. Irisan (intersection)
Irisan dari himpunan kabur A dan himpunan kabur B dinotasikan dengan A∩B, yaitu himpunan kabur µ A∩B(x); dengan fungsi keanggotaan :
µ A∩B(x) = min { µ A(x), µ B(x)} , untuk setiap x ε X
µ A(x) merupakan fungsi keanggotaan dari himpunan kabur A µ B(x) merupakan fungsi keanggotaan dari himpunan kabur B
c. Komplemen (complement)
Komplemen himpunan kabur A dinotasikan dengan Ac adalah sebuah himpunan kabur dengan fungsi keanggotaan
µÃ c (x) = 1 - µÃ (x) , untuk setiap x ε X
µÃ (x) merupakan fungsi keanggotaan dari himpunan kabur Ã. Contoh :
Semesta X = {-4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6} Diketahui himpunan-himpunan kabur
à = {(0.3/-3) + (0.5/-2) + (0.7/-1) + (1/0) + (0.7/1) + (0.5/2) + (0.3/3)}
B = {(0.1/-1) + (0.3/0) + (0.8/1) + (1/2) + (0.7/3) + (0.4/-4) + (0.2/5)}
Jawab :
à U B = {(0.3/-3) + (0.3/0) + (0.8/-1) + (1/0) + (0.7/1) + (0.5/2) + (0.3/3)}
~
~
~ ~
~ ~ ~
~ ~
~ ~
~
~
à ∩ B = {(0.1/-1) + (0.5/-2) + (0.7/-1) + (1/2) + (0.7/3) + (0.4/-4) + (0.2/5)}
à c = {(-3.3/-3) + (-2.5/-2) + (-1.7/-1) + (-1/0) + (0.3/1) + (1.5/2) + (2.7/3)}
3. Relasi Kabur
Relasi kabur (biner) R antara elemen-elemen dalam himpunan X dengan elemen – elemen dalam himpunan Y didefinisikan sebagai himpunan bagian kabur dari darab Cartesius X x Y. Yaitu himpunan kabur
R = {(x,y), µ R (x,y))| (x,y) ε X x Y }
Relasi Kabur R itu juga disebut relasi kabur pada himpunan (semesta) X x Y. Jika X = Y, maka R disebut relasi kabur pada himpunan X.
Relasi tegas hanya menyatakan ada atau tidak adanya hubungan antara elemen-elemen dari suatu himpunan dengan elemen – elemen dari himpunan lainnya, sedangkan relasi Kabur lebih luas dari itu juga menyatakan derajat eratnya hubungan tersebut. Dengan demikian relasi kabur memperluas konsep relasi tegas untuk dapat menangkap dan menyajikan realita dunia nyata dengan lebih baik. (Susilo, 2006)
4. Variabel Linguistik
Variabel Linguistik adalah himpunan kata-kata atau istilah – istilah dari bahasa sehari-hari (misalnya : tinggi, cepat, muda, dst). Suatu variabel linguistik adalah suatu rangkap-5 (x, T, X, G, M), dimana :
~
~
~
~
~
x = lambang variabel
T = himpunan nilai-nilai linguistik yang dapat menggantikan x X = adalah semesta wacana (numeris) dari nilai-nilai linguistik
dalam T
G = himpunan aturan-aturan sintaksis yang mengatur pembentukan istilah-istilah anggota T
M = himpunan aturan-aturan semantik yang mengaitkan setiap istilah dalam T dengan suatu himpunan kabur dalam semesta X.
Contoh :
Variabel Linguistik = “umur”, maka :
T = {muda, sangat muda, tua, agak tua, sangat tua} X = [0, 100] nilai min = 0 dan nilai maks = 100 M = aturan semantik (misal : muda, agak tua, tua). (Susilo, 2006)
Perhatikan bahwa dalam himpunan T dalam contoh di atas terdapat dua macam istilah, yaitu :
a. Istilah primer, misalnya : ‘tua’,’muda’
Jika istilah A dan B dalam T oleh aturan semantik dalam M dikaitkan dengan berturut-turut himpunan kabur à dan B dalam semesta X, maka istilah-istilah ‘tidak A’,’A dan B’, ‘A atau B’ dikaitkan berturut-turut dengan himpunan-himpunan kabur Ã’, à ∩ B dan à U B.
5. Proposisi Kabur
Proposisi Kabur adalah kalimat yang memuat predikat kabur, yaitu predikat yang dapat direpresentasikan dengan suatu himpunan kabur. Proposisi kabur yang mempunyai nilai kebenaran tertentu disebut pernyataan kabur. Nilai kebenaran dari suatu pernyataan kabur disajikan dengan suatu bilangan real dalam selang [0,1]. Nilai kebenaran itu disebut juga derajat kebenaran dari pernyataan kabur itu. Bentuk umum dari suatu proposisi kabur adalah :
X adalah A
Dimana x adalah suatu variabel linguistik dan predikat A adalah suatu nilai linguistik dari x. Bila à adalah himpunan kabur yang dikaitkan dengan nilai linguistik A dan
x
0 adalah suatu elemen tertentu dalam semesta X dari himpunan kabur Ã, makax
0 mempunyai derajat keanggotaan µÃ (x0) dalam himpunan kabur Ã(x0). Derajat kebenaran dari pernyataan kaburx0 adalah A
~
~ ~
~
didefinisikan sama dengan derajat keanggotaan x0 dalam himpunan kabur Ã, yaitu µÃ (x0).
Misalkan :
Proposisi kabur “x adalah A” dilambangkan dengan p(x), pernyataan kabur “x0 adalah A” dengan p(x0), dan derajat kebenaran dari p(x0) dengan z(p(x0)), maka :
z(p(x0)) = µÃ (x0)
Contoh :
Dalam proposisi kabur : “Kecepatan mobil itu adalah sedang”
Predikat ‘sedang’ dapat dikaitkan dengan himpunan kabur S dengan fungsi keanggotaan µ S. Dengan ketentuan : lambat = 0, sedang = 0,7 dan tinggi = 1. Dan 55 km/jam = sedang. Maka :
Derajat kebenaran dari pernyataan kabur “Kecepatan mobil 55 km/jam adalah sedang” sama dengan keanggotaan 55 (km/jam) dalam himpunan kabur
‘sedang’, yaitu µ S (55) = 0.7. (Susilo, 2006)
6. Implikasi Kabur
Bentuk umum suatu implikasi kabur adalah : Bila x adalah A, maka y adalah B
~
~
~
~
Dimana A dan B adalah predikat-predikat kabur yang dikaitkan dengan himpunan-himpunan kabur A dan B dalam semesta X dan Y berturut-turut.(Susilo, 2006)
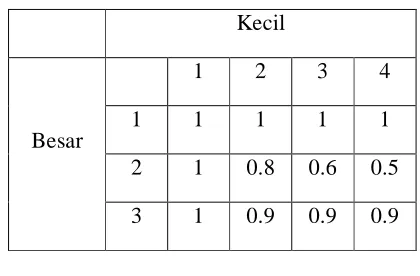
Secara umum, dalam logika kabur dikenal berbagai macam implikasi, seperti implikasi Dienes-Rescher, implikasi Mamdani, implikasi Zadeh, dan sebagainya. Penjabaran dari implikasi Dienes-Rescher dan implikasi Mamdani, yaitu :
a. Implikasi Dienes-Rescher
Implikasi Dienes-Rescher dapat dituliskan sebagai berikut : µQ(x,y) = max (1 - µA(x), µB(y))
b. Implikasi Mamdani
Implikasi Mamdani dapat dituliskan sebagai berikut : µQ(x,y) = min [(µA(x), µB(y)]
Contoh :
“ Jika x besar maka y kecil ”
x adalah variabel besar =
3 1 . 0 2 5 . 0 1 0 + +
y adalah variabel kecil =
4 4 . 0 3 6 . 0 2 8 . 0 1 1 + + +
maka dengan persamaan diatas dapat dicari nilainya : ~ ~
~
~ ~ ~
a. Tabel Persamaan Dienes-Rescher Tabel 2.4 :
Tabel Persamaan Dienes Riescher Kecil
1 2 3 4
1 1 1 1 1
2 1 0.8 0.6 0.5 Besar
3 1 0.9 0.9 0.9
b. Tabel Persamaan Mamdani Tabel 2.5 :
Tabel Persamaan Mamdani Kecil
1 2 3 4
1 0 0 0 0
2 0.5 0.5 0.5 0.4 Besar
3 0.1 0.1 0.1 0.1
7. Pengambilan Keputusan ( Mesin Inferensi)
Dalam logika klasik dikenal adanya modus ponen, sebagai berikut : a. Modus Ponen
Disimbolkan dengan
Premis 1 : x adalah A
Dalam logika kabur semua model dari inferensi logika klasik akan digeneralisasi menjadi :
b. Generalisasi Modus Ponen (GMP) Disimbolkan dengan
Premis 1 : x adalah A’
Premis 2 : Jika x adalah A maka y adalah B Kesimpulan : y adalah B’
A’ bisa berupa hedges agak, sangat dan sebagainya.
Misal himpunan kabur A’ dan relasi kabur A B U x V Himpunan kabur B’ V direferensikan sebagai berikut :
; dimana t adalah suatu norma-t Norma-T baku : t(x,y) = min(x,y)
(Susilo, 2006) Contoh :
Himpunan Semesta U = {x1,x2,x3}
V = {y1,y2} A’ = A
A = himpunan kabur U B = himpunan kabur V
Misalkan digunakan implikasi Dienes Riescher µA B(x,y) = max (1 - µA(x), µB(y))
⊆
⊆
( )
y t[
A( )
x A B( )
x y]
U x
B' sup ' , → ,
∈ = µ µ µ 3 6 , 0 2 1 1 5 , 0 x x x
A= + +
2 4 , 0 1 1 y y
B= +
µA B(x,y) =
Dengan menggunakan Generalisasi Modus Ponen
Nilai y1 dan y2 dibandingkan dengan semua nilai U = sup{min[0.5,1]} = 0.5 untuk x,y1 = sup{min[0.5,0.4]} = 0.4 untuk x,y2
8. Sistem Kabur
Sistem kabur berfungsi untuk mengendalikan proses tertentu dengan mempergunakan aturan inferensi berdasarkan logika kabur. Pada dasarnya sistem kabur semacam itu terdiri dari empat unit, yaitu :
1. Unit pengaburan (fuzzification unit), unit ini akan merubah/ mengkonversi nilai tegas menjadi nilai kabur.
2. Unit penalaran logika kabur (fuzzy logic reasoning unit) berisi proses - proses penalaran salah satunya adalah unit basis pengetahuan.
3. Unit basis pengetahuan (knowledge base unit), yang terdiri 2 bagian :
(
) (
) (
) (
) (
) (
3, 2)
4 . 0 1 , 3 1 2 , 2 4 . 0 1 , 2 1 2 , 1 5 . 0 1 , 1 1 y x y x y x y x y x y
x + + + + +
~ ~
( )
y t[
A( )
x A B( )
x y]
U x
B' sup ' , → ,
∈ = µ µ µ~ ~ ~ ~
( )
2 4 . 0 1 5 . 0 ' y y yB = +
µ~
(x1,y1) = max(1 - 0.5, 1) = 1 (x1,y2) = max(1 - 0.5, 0.4) = 0.5 (x2,y1) = max(1 - 1, 1) = 1
o Basis data (database), yang memuat fungsi-fungsi keanggotaan dari himpunan-himpunan kabur yang terkait dengan nilai dari variabel-variabel linguistik yang dipakai.
o Basis kaidah (rulebase), yang memuat kaidah-kaidah berupa implikasi kabur
4. Unit penegasan (defuzzification unit), unit ini akan mengkonversikan kembali nilai kabur menjadi nilai tegas.
Gb 2.7. Struktur Dasar Suatu Sistem Kabur
Suatu sistem kendali mula - mula mengukur nilai - nilai tegas dari semua variabel masukan yang terkait dalam proses yang akan dikendalikan. Nilai-nilai itu kemudian dikonversikan oleh unit pengaburan ke Nilai-nilai kabur yang sesuai. Hasil pengukuran yang telah dikaburkan itu kemudian diproses oleh unit penalaran yang dengan menggunakan unit basis pengetahuan, menghasilkan himpunan - himpunan kabur sebagai keluarannya. Langkah terakhir dikerjakan oleh unit penegasan, yaitu menerjemahkan himpunan kabur keluaran itu ke dalam nilai yang tegas. Nilai tegas inilah yang kemudian
Basis Data Basis Kaidah
Unit Penalaran
Unit Pengaburan
Unit Penegasan
Unit Basis Pengetahuan
(kabur) (kabur)
Keluaran (tegas) Masukan
µ Ã (x) =
1, if x = x’
0, if x ≠ x’
direalisasikan dalam bentuk suatu tindakan yang dilaksanakan dalam proses pengendalian itu. (Susilo, 2006)
1. Fuzzifikasi
Fuzzifikasi merupakan proses mengubah suatu nilai (masukan) x є R ke suatu himpunan kabur (menjadi himpunan kabur). (Susilo, 2006)
Karena sistem kendali logika kabur bekerja dengan kaidah dan masukan kabur, maka langkah pertamaalah mengubah masukan yang tegas yang diterima menjadi masukan kabur. Disebut juga proses pengaburan.
Kriteria yang harus dipenuhi dalam proses pengaburan adalah : i. Masukan harus real
ii. Jika masukannya tak hingga, maka sistem kabur harus mampu menahan masukan tersebut.
iii. Harus dapat disederhanakan dengan fuzzy inference engine
2. Defuzzifikasi
Merupakan proses mengubah dari himpunan kabur ke nilai real (keluaran). Pemilihan defuzzifikasi biasanya ditentukan oleh beberapa kriteria :
1. Masuk akal / dapat diterima himpunan kabur. 2. Kemudahan komputasi.
3. Kontinyu artinya perubahan kecil pada à tidak akan mengakibatkan perubahan besar pada t(Ã).
Dalam defuzzifikasi ini terdapat 3 tipe yang biasa digunakan, adalah : a. Center of Gravity (Pusat Gravitasi)
Bila himpunan kabur à terdefinisi pada semesta berhingga X={x1,x2,…,xn}, maka
Nilai t(Ã) ini dapat dipandang sebagai nilai harapan dari variabel x.
b. Mean of Maximum (Purata Maksimum)
Pada metode ini solusi diperoleh dengan cara mengambil nilai rata-rata domain yang memiliki nilai keanggotaan maksimum.
Apabila himpunan kabur à terdefinisi pada semesta berhingga X = {x1,x2,…,xn}, maka bilangan tegas t(Ã) didefinisikan sebagai rerata dari semua nilai xi dalam himpunan tegas
M = {xi ε X | µÃ (xi)=Tinggi(Ã)}, yaitu :
Xi
(
∫
(
)
x
t
)
(
)
∫
=
xxdx
X
à Ã
Ã
( )
M
Xi
t
XiM∑
=
εÃ
( )
∑
∑
= =
= m
i i m
i i i
b
x
b
t
1 1 Ã
Dimana |M| menyatakan banyaknya anggota dari himpunan tegas M.
c. Center Average Defuzzifier (CAD ) / Rerata pusat
Misalkan dimiliki sebuah data (y1,m1),(y2,m2),…,(yn,mn). Dengan menggunakan Center Average Defuzzifier, maka t(Ã) dapat dinyatakan sebagai berikut :
Dimana xi adalah pusat dari himpunan kabur t(Ã) dan bi = tinggi (Ãi). Fungsi penegasan CAD adalah fungsi penegasan yang paling banyak dipakai dalam sistem kendali kabur, karena memenuhi ketiga kriteria yang disebutkan diatas. Fungsi penegasan Center of Gravity memang masuk akal, tetapi proses komputasinya tidak mudah. Fungsi penegasan Mean of Maksimum juga masuk akal dan cukup mudah dalam komputasinya, tetapi
tidak kontinyu.(Susilo, 2006)
Contoh :
M = {x ε R | µÃ (x) = Tinggi (Ã)} = [60,90] Pusat (Ã1) = 52,5
Dengan fungsi penegasan Mean of Maksimum diperoleh bilangan tegas
Pusat(Ã2) = 75
Sehingga dengan fungsi penegasan CAD diperoleh bilangan tegas :
( )
( )( ) ( )( )
(
)
64.67 . 0 6 . 0
75 7 . 0 5 . 52 6 . 0
à =
+ + =
t
( )
752 90 60
Ã2 = + =
42 A. Gambaran Sistem Secara Umum
Secara umum program yang akan dibuat ini adalah program yang mampu mengenali huruf Jepang Katakana menggunakan Skor Kemiripan, DoM dan IoT serta Logika Kabur. Cara untuk menjalankannya adalah user memasukkan input memakai mouse atau memakai input gambar. Dari pola input tadi akan dikenai preprocessing yaitu pola masukan akan di binerisasi (thresholding) kemudian
akan dirubah ukuran pixelnya menjadi ukuran 8x8. Dari perbandingan pola input dengan template yang juga sudah dikenai preprocessing akan dicari nilai/ skor kemiripan diantara keduanya.
kelompok huruf menurut Logika Kabur. Besarnya skor kemiripan tersebut akan menentukan besarnya tingkat pengenalan suatu pola.
Skor kemiripan = ; y adalah jumlah tuple suatu huruf
B. Proses Kerja Sistem
Dalam menjalankan sistem ini, pertama-tama user membuat masukan. Masukan sendiri dibedakan menjadi 2 macam jenis masukan, pertama dengan mouse yaitu user melakukan click button yang berjumlah 64 button yang telah disediakan
dalam sistem ini, sehingga membentuk suatu pola huruf Katakana. Masukan kedua adalah masukan menggunakan gambar, yaitu gambar dimasukkan dengan cara menggambar menggunakan kertas atau media penulisan yang lain untuk kemudian di-scan. Hasil scan tersebut sebelumnya harus diolah dahulu menggunakan software image editing sehingga pola / citra masukan memenuhi
User Preprocessing Feature
Extraction
Fuzzy Logic Result
Hardware
Pattern capturing
Gb 3.1 : Skema Proses Pengenalan Pola
( )
∑
−
y
n
i
Css
syarat sebagai pola masukan terhadap sistem. Syarat-syarat yang harus dipenuhi adalah :
1. Pola masukan harus atau mendekati M = N, atau berbentuk persegi. Dimana M = panjang dan N = lebar.
2. Sedapat mungkin pola terletak di tengah dengan acuan N (lebar) dari kanvas (horizontal alignment = center) dan pola tersebut harus tepat (atau mendekati) berada pada batas maksimal / tepi suatu kanvas.
Gb 3.2 : Cara Membuat Pola Input
3. Ukuran font pola jangan terlalu tipis dan terlalu tebal. Ukuran font paling tidak 1/8 dari ukuran kanvas tersebut.
Proses selanjutnya adalah proses preprocessing. Preprocessing yang digunakan adalah binerisasi dan resize (merubah ukuran). Proses binerisasi yaitu pola masukan yang telah diproses di atas akan dirubah nilainya sehingga didapat nilai biner dengan interval [0 1]. Pola biner tersebut kemudian akan dikenai proses resize dengan ukuran 8 x 8. Sebagai contoh terlihat pada gambar dibawah ini :
Gb 3.4 : Preprocessing
Kemudian masukan yang telah dikenai proses preprocessing di atas akan dilakukan proses pengenalan pola yaitu dengan cara ekstraksi ciri. Dalam Tuple-N, ekstraksi dilakukan dengan menggunakan 3 metode, yaitu Skor
Kemiripan, IoT dan DoM. IoT akan mencari ekstraksi ciri dari template saja. Sehingga akan didapatkan nilai-nilai Skor kemiripan, IoT dan DoM. Yang kemudian nilai-nilai tersebut akan dibandingkan dan dicari nilai yang tertinggi yang dapat digunakan untuk mengenali suatu pola masukan.
Singleton Fuzzifier dan aturan kabur yang berjumlah 9 aturan dengan input
adalah nilai-nilai IoT dan nilai-nilai DoM dan output-nya adalah nilai-nilai Css. Fuzzifikasi akan merubah nilai real ke nilai kabur yaitu nilai-nilai IoT dan DoM yang akan dicari fungsi keanggotaan keduanya. Untuk menarik kesimpulan digunakan Mesin Inferensi yaitu Implikasi dan Modus Ponen. Implikasi yang digunakan adalah Implikasi Mamdani. Untuk merubah nilai kabur ke nilai real akan digunakan proses Defuzzifikasi. Defuzzifikasi menggunakan metode Center Average Defuzzifier (CAD). Sehingga akan menghasilkan nilai akhir Css yang akan digunakan untuk mengenali pola. Nilai-nilai tersebut akan saling dibandingkan, sehingga nilai yang terbesar adalah nilai yang tepat untuk mengenali suatu pola masukan.
C. Analisis Sistem 1. Proses Fuzifikasi
Fuzifikasi merupakan suatu proses dalam Logika Kabur dimana proses tersebut akan mengubah nilai real menjadi nilai kabur atau mencari fungsi keanggotaan untuk masing-masing variabelnya. Fuzifikasi yang digunakan adalah Singleton Fuzzifier
a. Variabel Input IoT (Important of Tuple)
IoT dapat disebut juga derajat kepentingan suatu tuple. Nilai-nilai tersebut didapat dari penghitungan nilai-nilai dari setiap pixel yang dijumlahkan untuk mendapatkan nilai dari setiap tuple dari suatu karakter. Fungsi keanggotaan IoT dinyatakan dalam persamaan dan grafis berikut ini :
Gb 3.5 : Bentuk Kurva Segitiga IoT Menggunakan persamaan linear
didapat
•Fungsi keanggotaan KECIL
•Fungsi keanggotaan SEDANG
•Fungsi keanggotaan BESAR
b. Variabel Input DoM (Degree of Match)
DoM disebut juga Derajat Kepentingan. Dalam algoritma pengenalan pola Tuple-N, syarat untuk mampu mengidentifikasi pola masukan sebagai pola yang dapat dikenali adalah pada skor kecocokan
Jika dinyatakan dalam persamaan dan grafis, fungsi keanggotaan DoM adalah :
Gb 3.6 : Bentuk Kurva Segitiga DoM
•Fungsi keanggotaan RENDAH
•Fungsi keanggotaan SEDANG
•Fungsi keanggotaan TINGGI
c. Css
Css adalah hasil keluaran dari sistem yang merupakan hasil perhitungan dari nilai-nilai IoT dan nilai-nilai DoM yang diteruskan dengan Logika Kabur. Dari nilai-nilai Css dari setiap aturan yang berjumlah 9 aturan tersebut akan dijumlahkan dan nilainya akan digunakan untuk mendapatkan skor kemiripan. Jika dinyatakan dalam persamaan dan grafis, fungsi keanggotaan Css adalah:
Gb 3.7 : Bentuk Kurva Segitiga Css
•Fungsi keanggotaan KECIL
•Fungsi keanggotaan SEDANG
•Fungsi keanggotaan BESAR
d. Aturan Kabur
Untuk menentukan nilai dari Css, maka akan digunakan suatu aturan yang disebut Aturan Kabur.
Aturan kabur yang digunakan dalam sistem adalah sebagai berikut : Tabel 3.1 :
Tabel Aturan Kabur
DoM
Rendah Sedang Tinggi Kecil Kecil Kecil Kecil Sedang Kecil Sedang Besar IoT
Besar Kecil Sedang Besar
Penjabaran dari tabel diatas adalah:
1. Jika IoT bernilai Kecil dan DoM bernilai Rendah maka Css bernilai Kecil
2. Jika IoT bernilai Kecil dan DoM bernilai Sedang maka Css bernilai Kecil
3. Jika IoT bernilai Kecil dan DoM bernilai Tinggi maka Css bernilai Kecil
4. Jika IoT bernilai Sedang dan DoM bernilai Rendah maka Css bernilai Kecil
5. Jika IoT bernilai Sedang dan DoM bernilai Sedang maka Css bernilai Sedang
6. Jika IoT bernilai Sedang dan DoM bernilai Tinggi maka Css bernilai Besar
7. Jika IoT bernilai Besar dan DoM bernilai Rendah maka Css bernilai Kecil
8. Jika IoT bernilai Besar dan DoM bernilai Sedang maka Css bernilai Sedang
9. Jika IoT bernilai Besar dan DoM bernilai Tinggi maka Css bernilai Besar
Contoh : Misalkan diberikan suatu nilai IoT = 2 dan DoM = 0.3
Dengan menggunakan 9 aturan kabur di atas dan disajikan secara grafis, maka : (keterangan : at = aturan)
Setelah ditemukan nilai µ B’ (y) atau hasil gabungan dari kesembilan aturan kabur, maka dapat dicari nilai real Css dengan cara memakai proses defuzzifikasi.
2. Proses Defuzifikasi
Setelah diperoleh nilai Css untuk masing-masing aturan kabur, nilai Css tersebut akan dicari nilai maksimumnya dan dari nilai maksimum tersebut akan mengalami proses defuzzifikasi berdasarkan nilai kesimpulan di atas dari kesembilan aturan yang dipergunakan. Proses Defuzzifikasi yang dipakai dalam program ini adalah Center Average Defuzzifier (CAD).
Contoh penggunaan CAD menurut contoh diatas adalah :
Gb 3.9 : Nilai Css
total = sum(tinggi) diurutkan berdasarkan aturan 1 sampai 9 = 0.25 + 0.33 + 0 + 0.2 + 0.2 + 0 + 0 + 0 + 0 = 0.98 defuzzifikasi = sum(tinggi x elemen - elemen real) / total
= ((0.25*0.3) + (0.33*0.2667) + 0 + (0.32*0.2) + (0.5*0.2) + 0 + 0 + 0 + 0) / 0.98
= 0.075 + 0.08801 + 0.64 + 0.05334 / 0.98 = 0.333
D. Perangkat Lunak
Perangkat lunak – perangkat lunak yang digunakan untuk mengerjakan dan menyelesaikan tugas akhir ini adalah :
a. Matlab 6.5.1 : digunakan untuk membuat program ini b. Adobe Photoshop 7.0 : digunakan untuk meng-edit gambar c. Macromedia Flash MX : digunakan untuk mendesain tampilan
program dan membuat sebagian rancangan program.
E. Perangkat Keras
Perangkat keras yang dipergunakan dalam penelitian ini adalah seperangkat komputer dengan spesifikasi sebagai berikut :
a. Prosesor : Intel Celeron 2.00 GHz b. Sistem Operasi : Windows XP Second Edition
c. VGA : Nvidia GeForce 2 MX/MX 400
d. Memory : 512 MB e. Harddisk : Seagate 40 GB
f. Input : Mouse dan Keyboard Standard
F. Tampilan Antar Muka (Interface)
1. Perancangan Tampilan Awal
Gb 3.10 : Rancangan Tampilan Form Awal
Tampilan ini adalah tampilan paling awal dari seluruh program yang dibuat. Dari figure ini terdapat satu tombol yaitu tombol masuk yang terdapat pada bagian tengah bawah dari figure. Tombol ini adalah tombol yang berfungsi untuk masuk ke program pengenalan pola. Pada bagian atas terdapat judul dari penelitian ini yaitu “Pengenalan Huruf Jepang Katakana Menggunakan Logika Kabur” dan di bawahnya terdapat tulisan Universitas Sanata Dharma. Kemudian bagian kiri atas terdapat logo Universitas Sanata Dharma. Pada figure ini juga terdapat menubar yang terdapat dalam bagian kiri atas dari figure.
Isinya adalah File dan Help. File :
Help :
a. Lihat Informasi
Submenu ini berisi tentang cara menggunakan software, dan juga metode-metode yang digunakan untuk menyelesaikan software ini. b. About Software
Berisi tentang software yang meliputi pembuat software, tahun pembuatan dan sebagainya.
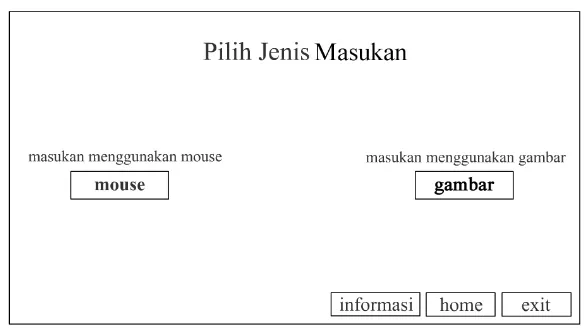
2. Perancangan Tampilan Pilihan Input
Gb 3.11 : Rancangan Tampilan Pilih Input
Figure ini berfungsi untuk memilih jenis masukan apakah berupa masukan
berfungsi untuk menampilkan informasi dari software, dan tombol exit untuk keluar dari aplikasi program ini. Desain dibuat cukup sederhana untuk memudahkan dalam pemilihan jenis input yaitu bagian kiri masukan menggunakan mouse dan bagian kanan adalah masukan menggunakan gambar.
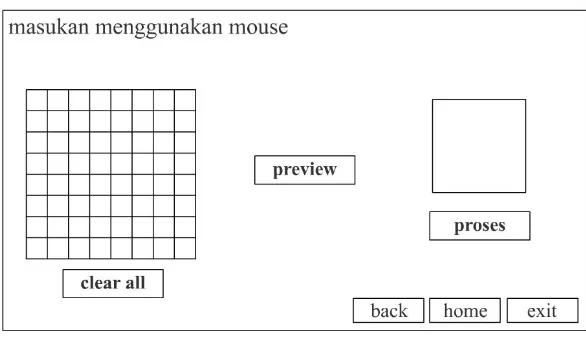
3. Perancangan Tampilan Masukan Menggunakan Mouse
Gb 3.12 : Rancangan Tampilan Input Mouse
adalah tombol proses. Yaitu tombol yang berguna untuk memproses masukan yang kita masukkan, dan akan menuju ke kesimpulan. Sedangkan Bagian keempat adalah tombol back untuk kembali ke form sebelumnya, serta tombol home dan exit.
4. Perancangan Tampilan Masukan Menggunakan Gambar
Gb 3.13 : Rancangan Tampilan Input Gambar
Seperti masukan menggunakan mouse, figure ini juga memiliki bagian-bagian yang terstruktur. Bagian pertama yaitu bagian buka gambar, buka gambar digunakan untuk membuka gambar masukan yang telah tersedia di folder program. Bagian kedua adalah bagian preview. Preview sendiri dibedakan menjadi 3, yaitu preview : berfungsi untuk menampilkan gambar masukan secara nyata / sesuai dengan gambar masukan aslinya. Preview in biner : berfungsi untuk menampilkan gambar masukan yang telah menjadi biner. Dan in biner 8x8 yaitu menampilkan input gambar secara biner dengan dimensi
memproses masukan yang kita masukkan, dan akan menuju ke kesimpulan. Sedangkan Bagian keempat adalah tombol clear all untuk reset figure, tombol back untuk kembali ke figure sebelumnya, serta tombol home dan exit.
5. Perancangan Tampilan Kesimpulan Akhir
Gb 3.14 : Rancangan Tampilan Kesimpulan Akhir
Figure kesimpulan ini adalah form yang akan menunjukkan hasil dari