commit to user
28
BAB III
METODE PENELITIAN
A. Populasi dan Sampel
1. Populasi mengacu pada keseluruhan kelompok orang, kejadian atau hal
minat yang ingin peneliti investigasi (Sekaran, 2011: 121). Populasi yang diteliti adalah masyarakat Surakarta.
2. Sampel
Sampel adalah sebagian dari populasi. Sampel terdiri atas sejumlah anggota yang dipilih dari populasi. Dengan kata lain, sejumlah tapi tidak semua, elemen populasi akan membentuk sampel (Sekaran, 2011: 123).
Teknik Maximum Likelihood Estimation (ML) efektif untuk sampel
berkisar 150-400 sampel (Mustafa dan Wijaya, 2012: 8). Dalam penelitian ini sampel yang diambil sebanyak 300 masyarakat Surakarta. Kota Surakarta terdiri atas 5 kecamatan, diantaranya kecamatan Banjarsari, Jebres, Laweyan, Pasar Kliwon dan Serengan, sehingga dalam pengambilan sampel dibagi ke lima wilayah kecamatan dan masing-masing diambil sampel sebanyak 60 responden (300 dibagi 5).
B. Data dan Sumber Data
Penelitian ini menggunakan data primer yang bersumber dari jawaban
responden atas pernyataan yang berhubungan dengan pengaruh attitude
commit to user
29
toward brand, perceived quality dan brand uniqueness terhadap brand
advocacy yang dimediasi oleh self-brand connection. Data Penelitian ini
dikumpulkan dengan cara memberikan kuesioner ke responden secara langsung.
C. Metode Pengumpulan Data
Adapun teknik yang digunakan untuk memperoleh data adalah menggunakan kuesioner yang menggunakan daftar pernyataan kepada pihak-pihak yang berkaitan dengan masalah yang diteliti. Pengambilan sampel
dalam penelitian ini dilakukan dengan menggunakan teknik purposive
sampling yaitu cara pengambilan sampel yang didasarkan pada
pertimbangan-pertimbangan tertentu (Sanusi, 2012: 95). Pertimbangan dalam penelitian ini yaitu warga Surakarta yang mengenal “Solo, The Spirit of Java”.
D. Variabel Penelitian
Dalam penelitian ini variabel yang diuji meliputi :
1. Variabel dependen
Variabel dependen yaitu variabel yang nilainya dipengaruhi oleh variabel independen (Umar, 2002). Variabel dependen dalam penelitian ini adalah
brand advocacy.
2. Variabel independen
Variabel independen yaitu variabel yang menjdi sebab terjadinya atau terpengaruhnya variabel dependen (Umar, 2002). Variabel independen
commit to user
30
pada penelitian ini adalah attitude toward brand, perceived quality, brand
uniqueness.
3. Variabel antara (mediasi)
Adalah variabel yang fungsinya bertindak sebagai perantara dalam hubungan antara variabel bebas dengan variabel terikat. Variabel antara merupakan faktor yang secara teori berpengaruh pada fenomena yang sedang diamati, tetapi tidak dilihat, diukur atau dimanipulasi (Sanusi,
2012: 51). Variabel mediasi pada penelitian ini adalah self-brand
connection.
E. Definisi Operasional
1. Attitude toward brand
Attitude toward brand merupakan perilaku konsumen yang erat kaitannya
dengan nilai merek bagi konsumen dan ekspekstasi konsumen (Rossiter dan Percy, 1998). Menurut Keller, 1998 (Rio et al., 2001) sikap merek
(brand attitude) adalah evaluasi keseluruhan konsumen terhadap sebuah
merek. Variabel ini diukur dengan 4 item pernyataan yang diadopsi dari Kemp et al. (2012). Indikator-indikator diukur dengan rnenggunakan 5 point skala Likert (1= sangat tidak setuju sampai dengan 5= sangat setuju).
commit to user
31
Indikator dari variabel attitude toward brand meliputi;
- Berharga/Tidak Berharga
- Bagus/Jelek,
- Suka/Tidak suka
- Menyenangkan/Tidak menyenangkan
2. Perceived quality
Perceived quality adalah persepsi pelanggan terhadap kualitas atau
keunggulan suatu produk atau layanan ditinjau dari fungsinya secara relatif dengan produk-produk lain (Simamora, 2001: 78). Variabel ini diukur dengan 4 item pernyataan yang diadopsi dari Dodds et al., 2012 (Kemp et al., 2012). Indikator-indikator diukur dengan rnenggunakan 5 point skala Likert (1= sangat tidak setuju sampai dengan 5= sangat
setuju). Indikator dari variabel perceived quality meliputi;
- Budaya Jawa di Solo berkualitas tinggi
- Kualitas acara atau event budaya di Solo sangat tinggi
- Acara budaya di Solo sangat baik
- Budaya Jawa di Solo dapat diandalkan
3. Brand uniqueness
Brand uniqueness (keunikan merek) sering terbentuk melalui iklan atau
dari pengalaman masa lalu dengan merek. Aspek unik dari merek sering diasosiasikan konsumen dengan nilai terbaik dan kualitas yang lebih
commit to user
32
tinggi (Netemeyer et al., 2004). Variabel ini diukur dengan 4 item pertanyaan yang diadopsi Netemeyer et al. (Kemp et al., 2012). Indikator-indikator diukur dengan rnenggunakan 5 point skala Likert (1= sangat tidak setuju sampai dengan 5= sangat setuju). Indikator dari
variabel brand uniqueness meliputi;
- Upaya branding tidak sama dengan kota lain
- Merek unik
- Merek menonjol
- Usaha branding yang berbeda dari kota lain
4. Self-brand connection
Variabel mediasi dalam penelitian ini adalah self-brand connection.
Makna pribadi yang terkait dengan merek bisa berasal dari: (a) gambar atau "kepribadian" dari merek yang berkembang dari waktu ke waktu dari program iklan dan dinamika budaya populer di masyarakat (Keller, 2008 dalam Moore dan Homer, 2008), dan (b) pengalaman pribadi individu dengan merek. Menurut Escalas, 2004 (Moore dan Homer,
2008), premis dasar dari konstruksi self-brand connection bahwa ketika
asosiasi merek (makna) yang digunakan untuk membangun diri sendiri atau untuk berkomunikasi diri sendiri kepada orang lain, hubungan yang
kuat terbentuk antara merek dan identitas diri konsumen. Penciptaan
self-brand connection yang kuat dan bermakna lebih mungkin terjadi ketika
commit to user
33
citra merek, dan ketika merek itu sendiri memenuhi identifikasi kebutuhan psikologis (Moore dan Homer, 2008). Variabel ini diukur dengan 6 item pernyataan yang diadopsi dari Escalas dan Bettman (Kemp et al., 2012). Indikator-indikator diukur dengan rnenggunakan 5 point skala Likert (1= sangat tidak setuju sampai dengan 5= sangat
setuju). Indikator dari variabel self-brand connection meliputi;
- Budaya Jawa Solo mencerminkan siapa saya
- Saya merasa punya hubungan pribadi untuk merek “Solo, The Spirit
of Java”
- Saya dapat menggunakan merek “Solo, The Spirit of Java” untuk
berkomunikasi siapa saya kepada orang lain
- Saya pikir merek “Solo, The Spirit of Java” membantu saya menjadi
orang yang seperti saya inginkan.
- Saya menganggap branding “Solo, The Spirit of Java” sebagai
“saya” (hal itu mencerminkan siapa saya, ingin seperti apa saya atau cara saya menampilkan diri kepada orang lain)
- Upaya branding “Solo, The Spirit of Java” sesuai dengan saya
5. Brand advocacy
Variabel dependen dalam penelitian ini adalah brand advocacy. Variabel
ini diukur dengan 4 item pernyataan yang diadopsi dari Kim et al., 2001 (Kemp et al., 2012). Indikator-indikator diukur dengan rnenggunakan 5
commit to user
34
point skala Likert (1= sangat tidak setuju sampai dengan 5= sangat
setuju). Indikator dari variabel brand advocacy meliputi;
- Merekomendasikan untuk mendukung acara budaya kota Solo
- Berbagi pengalaman
- Menganjurkan untuk menghadiri acara budaya kota Solo
- Mengajurkan kepada orang lain untuk ikut serta dalam acara budaya
kota Solo
F. Metode Analisis Data
1. Teknik skala pengukuran
Skala pengukuran yang digunakan dalam penelitian ini adalah skala likert dengan skala penilaian 1 – 5 yaitu :
- Sangat tidak setuju : 1
- Tidak setuju : 2
- Netral : 3
- Setuju : 4
- Sangat setuju : 5
2. First Order Confirmatory Factor Analysis (CFA)
Pengujian analisis konfirmatori faktor dilakukan untuk menguji validitas dan reliabilitas secara keseluruhan dari jumlah sampel yang
dipakai (digunakan) untuk penelitian dan menguji normalitas data, outlier,
serta pengukuran goodness of fit. Alat analisis ini digunakan untuk
commit to user
35
apakah indikator-indikator yang ada memang benar-benar dapat menjelaskan sebuah konstruk (Santoso, 2014: 13).
a. Validitas Konvergen
Uji validitas bertujuan mengetahui ketepatan dan kecermatan suatu alat ukur dalam melakukan fungsi ukurnya. Suatu instrumen dianggap memiliki validitas tinggi jika dapat memberikan hasil pengukuran yang sesuai dengan tujuannya. Pengujian validitas dalam
penelitian menggunakan convergent validity atau validitas konvergen.
Validitas konvergen dapat dinilai dari measurement model yang
dikembangkan dalam penelitian dengan menentukan apakah setiap indikator yang diestimasikan secara valid mengukur dimensi dari konsep yang diujinya. Sebuah indikator dimensi menunjukkan validitas konvergen yang signifikan apabila koefisien variabel indikator itu lebih besar dari dua kali standar errornya (Anderson & Gerbing dalam Ferdinand, 2005: 187). Bila setiap indikator memiliki
critikal ratio (C.R) yang lebih besar dari dua kali standar errornya
(S.E), hal ini menunjukkan bahwa indikator itu secara valid mengukur apa yang seharusnya diukur dalam model yang disajikan.
b. Reliabilitas Konstruk
Reliabilitas konstruk dinilai dengan menghitung indeks
reliabilitas instrumen yang digunakan (composite reliability) dari
model SEM yang dianalisis. Nilai batas yang digunakan untuk menilai sebuah tingkat reliabilitas yang dapat diterima adalah 0,70, walaupun
commit to user
36
angka itu bukanlah sebuah ukuran yang “mati”. Artinya, bila penelitian yang dilakukan bersifat eksploratori, maka nilai dibawah 0,70 pun masih dapat diterima sepanjang disertai dengan alasan-alasan empirik yang terlihat dalam proses eksplorasi. Nunally dan Bernstein (Ferdinand, 2005: 193) memberikan pedoman yang baik untuk menginterpretasikan indeks reliabilitas. Mereka menyatakan bahwa dalam penelitian eksploratori, reliabilitas yang sedang antara 0,5 – 0,6 sudah cukup untuk menjustifikasi sebuah hasil penelitian.
Adapun rumus reliabilitas konstruk sebagai berikut:
Construct Reliability j 2 2 Loading Std. Loading Std. Keterangan:
Std. Loading = diperoleh langsung dari standarrized loading untuk tiap-tiap indikator (perhitungan komputer AMOS).
εj = adalah measurement error dari tiap-tiap indikator.
c. Evaluasi Asumsi SEM
1) Ukuran Sampel
Sampel ditetapkan lebih dari 100 atau minimal 5 kali jumlah observasi. Namun apabila jumlah sampel yang terlalu banyak dan
tidak memungkinkan untuk dilakukan penarikan sampel
seluruhnya, maka penelitian akan menggunakan rekomendasi
commit to user
37
yaitu penarikan sampel antara 150-400 sampel (Mustafa dan Wijaya, 2012: 8). Pada penelitian ini sampel yang diambil sebanyak 300 responden.
2) Normalitas
Uji normalitas bertujuan untuk mengetahui apakah distribusi data
mengikuti atau mendekati distribusi normal. Normalitas univariate
dilihat dengan nilai critical ratio (cr) pada skewness dan kurtosis
dengan nilai batas di bawah + 2,58. Normalitas multivariate dilihat
pada assessment of normality baris bawah kanan, dan mempunyai
nilai batas + 2,58. Apabila data terdistribusi normal baik secara
univariate (individu) dan multivariate secara bersama-sama maka
pengujian data outlier tidak perlu dilakukan (Santoso, 2007: 81).
3) Outliers
Data outlier adalah data yang secara nyata berbeda dengan
data-data yang lain. Nilai kritis sebenarnya adalah nilai chi-square pada
degree of freedom sebesar jumlah sampel pada taraf signifikansi
sebesar 0,001. Asumsi terpenuhi jika tidak terdapat observasi yang mempunyai nilai Z-score di atas + 3 atau 4. Sebuah data termasuk outlier jika mempunyai nilai p1 dan p2 yang kurang dari 0,05 pada
pengujian outlier mahalanobis distance (Santoso, 2007: 75).
4) Multicollinearity dan Singularity
Multikolinearitas dilihat pada determinant matriks kovarians. Nilai yang terlalu kecil menandakan adanya multikolinearitas atau
commit to user
38
singularitas. Dalam program komputer SEM telah menyediakan
fasilitas “warning” setiap kali terdapat indikasi multikolinieritas
atau singularitas.
d. Evaluasi Atas Kriteria Goodness of Fit
1) Likelihood ratio chi-square statistic ( )
Merupakan ukuran fundamental dari overall fit. Nilai chi square
yang tinggi terhadap degree of freedom menunjukkan bahwa
korelasi yang diobservasi dengan yang diprediksi berbeda secara nyata dan ini menghasilkan probabilitas lebih kecil dari tingkat
signifikansi. Sebaliknya, nilai chi square yang rendah terhadap
degree of freedom menunjukkan bahwa korelasi yang diobservasi
dengan yang diprediksi tidak berbeda secara signifikan. Oleh sebab itu maka nilai yang diharapkan adalah kecil, atau lebih kecil dari
pada chi square tabel.
Dalam model maximum likelihood atau jumlah sampel dibawah
200 pengujian goodness of fit (kesesuaian) dapat dilakukan hanya
dengan melakukan pengujian chi-square statistic saja dengan
ketentuan apabila nilai chi-square kecil atau nilai probabilitas
>0,05 maka model sudah dapat dikatakan fit. Chi-square juga bersifat sangat sensitif terhadap besarnya sampel yang digunakan (Hair et al., 1995; Tabachnick & Fidell, 1996 dalam Ferdinand, 2005: 55). Model yang diuji akan dipandang baik atau memuaskan bila nilai
commit to user
39
(karena dalam uji beda chi square, 2=0, berarti benar-benar tidak ada
perbedaan, Ho diterima) dan diterima berdasarkan probabilitas dengan
cut-off value sebesar p>0.05 atau p>0.10 (Hulland et. al, 1996 dalam
Ferdinand, 2005).
2) RMSEA - The Root Mean Square Error of Approximation
RMSEA adalah sebuah indeks yang dapat digunakan untuk mengkompensasi chi-square statistic dalam sampel yang besar. Nilai
RMSEA menunjukkan goodness-of-fit yang dapat diharapkan bila
model diestimasi dalam populasi (Hair et. al. 1995). Nilai RMSEA yang lebih kecil atau sama dengan 0.08 merupakan indeks untuk dapat
diterimanya model yang menunjukkan sebuah close fit dari model itu
berdasarkan degrees of freedom (Browne & Cudeck, 1993). Lebih
lanjut, Browne & Cudeck menulis: “we are also of the opinion that
a value of about 0.08 or less for the RMSEA would indicate a
reasonable error of approximation and would not want to employ
a mode,' with a RMSEA greater than 0.1” (Browne & Cudeck,
1993).
3) GFI - Goodness of Fit Index
Indeks kesesuaian (fit index) ini akan digunakan untuk menghitung
proporsi tertimbang dari varian dalam matriks kovarian sampel
yang dijelaskan oleh matriks kovarian populasi yang
terestimasikan. Indeks ini mencerminkan tingkat kesesuaian model secara keseluruhan yang dihitung dari residual kuadrat model yang
commit to user
40
dipredikasi dibandingkan dengan data yang sebenarnya. Nilai
Goodness of Fit Index biasanya dari 0 (nol) sampai 1. Nilai yang
lebih baik mendekati 1 mengindikasikan model yang diuji memiliki
kesesuaian yang baik, nilai GFI dikatakan baik adalah 0,90
(Mustafa dan Wijaya, 2012).
4) AGFI – Adjusted Goodness-of-Fit Index
AGFI merupakan pengembangan dari GFI yang disesuaikan
dengan degree of freedom yang tersedia untuk menguji diterima
tidaknya model. Tingkat penerimaan yang direkomendasikan adalah bila AGFI mempunyai nilai sama dengan atau lebih besar dari 0.90 (Hair et al., 1995; Hulland et al., 1996 dalam Ferdinand, 2005). Perlu diketahui bahwa baik GFI maupun AGFI adalah kriteria yang memperhitungkan proporsi tertimbang dari varians dalam sebuah matriks kovarians sampel. Menurut Hulland et. al., 1996 (Ferdinand, 2005), Nilai sebesar 0.95 dapat diinterpretasikan sebagai tingkatan
yang baik-good overall model fit (baik) sedangkan besaran nilai
antara 0.90-0.95 menunjukkan tingkatan cukup-adequate fit.
5) CMIN/DF
CMIN/DF: The minimum sample discrepancy function (CMIN)
dibagi dengan degree of freedomnya akan menghasilkan indeks
CMIN/DF, yang umumnya dilaporkan oleh para peneliti sebagai salah satu indikator untuk mergukur tingkat fitnya sebuah model.
commit to user
41
dibagi DFnya sehingga disebut 2relatif. Nilai 2relatif kurang dari
2.0 atau bahkan kadang kurang dari 3.0 adalah indikasi dari
acceptable fit antara models dan data.
6) Tucker Lewis Index (TLI).
TLI adalah sebuah alternatif incremental fit index yang
membandingkan sebuah model yang diuji terhadap sebuah baseline
model. Nilai yang direkomendasikan sebagai acuan untuk diterimanya sebuah model adalah lebih besar atau sama dengan 0,9
dan nilai yang mendekati 1 menunjukkan a very good fit. TLI
merupakan index fit yang kurang dipengaruhi oleh ukuran sampel
(Mustafa dan Wijaya, 2012).
7) Comparative Fit Index (CFI).
CFI juga dikenal sebagai Bentler Comparative Index. CFI
merupakan indels kesesuaian incremental yang juga
membandingkan model yang diuji dengan null model. Indeks ini
dikatakan baik untuk mengukur kesesuaian sebuah model karena tidak dipengaruhi oleh ukuran sampel (Hair et al., 2006 dalam Mustafa dan Wijaya, 2012). Indeks yang mengidikasikan bahwa model yang diuji memiliki kesesuaian yang baik adalah apabila CFI 0,90 (Mustafa dan Wijaya, 2012).
commit to user
42
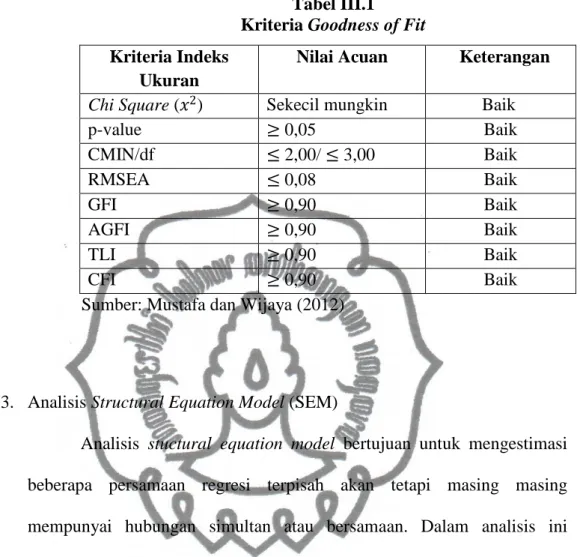
Tabel III.1
Kriteria Goodness of Fit
Kriteria Indeks Ukuran
Nilai Acuan Keterangan
Chi Square ( ) Sekecil mungkin Baik
p-value 0,05 Baik CMIN/df 2,00/ 3,00 Baik RMSEA 0,08 Baik GFI 0,90 Baik AGFI 0,90 Baik TLI 0,90 Baik CFI 0,90 Baik
Sumber: Mustafa dan Wijaya (2012)
3. Analisis Structural Equation Model (SEM)
Analisis stuctural equation model bertujuan untuk mengestimasi
beberapa persamaan regresi terpisah akan tetapi masing masing mempunyai hubungan simultan atau bersamaan. Dalam analisis ini dimungkinkan terdapat beberapa variabel dependen, dan variabel ini dimungkinkan menjadi variabel independen bagi variabel dependen yang lainnya.
Pada prinsipnya, model struktural bertujuan untuk menguji hubungan sebab akibat antar variabel sehingga jika salah satu variabel diubah, maka terjadi perubahan pada variabel yang lain. Dalam studi ini,
data diolah dengan menggunakan Analysis of Moment Structure atau
commit to user
43
Adapun rumus persamaan struktural dalam penelitian ini adalah sebagai berikut :
ε1 = γ1ξ1 + γ2ξ2 + γ3ξ3 + δ1 ... (1) ε2 = β1ε2 + δ2 ... (2) Keterangan:
ξ1 = Attitude toward brand sebagai variabel eksogen (bebas);
ε1 = Self-brand connection sebagai variabel laten endogen/terikat pertama
(mediasi);
ε2 = Brand advocacy sebagai variabel laten endogen (terikat) kedua; γ1,... = Hubungan langsung variabel eksogen dengan endogen
β1 = Hubungan langsung variabel endogen dengan endogen δ1, 2 = Measurement error (residual) endogen.
Analisis SEM memungkinkan perhitungan estimasi seperangkat persamaan regresi yang simultan, berganda dan saling berhubungan. Karakteristik penggunaan model ini: (1) untuk mengestimasi hubungan dependen ganda yang saling berkaitan, (2) kemampuannya untuk memunculkan konsep yang tidak teramati dalam hubungan serta dalam menentukan kesalahan pengukuran dalam proses estimasi, dan (3) kemampuannya untuk mengakomodasi seperangkat hubungan antara variabel independen dengan variabel dependen serta mengungkap variabel laten (Ghozali, 2005).