MODUL : 5
ANALISIS REGRESI BERGANDA DENGAN VARIABEL DUMMY
Nama
Slamet Abtohi 13611198 10 Juni 2015
Nama Penilai Tanggal
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM
UNIVERSITAS ISLAM INDONESIA
YOGYAKARTA
1 1.1 Pengertian Regresi
Analisis regresi merupakan salah satu analisis yang bertujuan untuk mengetahui pengaruh suatu variabel terhadap variabel lain. Dalam analisis regresi, variabel yang mempengaruhi disebut independent variable (variabel bebas) dan variabel yang dipengaruhi disebut dependent variable (variabel terikat). Jika dalam persamaan regresi hanya terdapat satu variabel bebas dan satu variabel terikat, maka disebut sebagai persamaan regresi sederhana, sedangkan jika variabel bebasnya lebih dari satu, maka disebut sebagai persamaan regresi berganda.
Analisis regresi meliputi pengumpulan data berpasangan, pencarian pola garis (pendugaan parameter dan pengujian ketidakpastian model), pendugaan persamaan regresi (pendugaan dan pengujian parameter) serta interpretasi model dan parameter. Tahapan pembentukan model regresi yaitu :
1. Penentuan model 1.2 Defenisi Regresi Berganda dengan Variabel Independen Dummy
diduga mempunyai pengaruh terhadap variabel yang bersifat kontinu. Variabel dummy sering juga disebut variabel boneka, binary, kategorik atau dikotom. Variabel dummy hanya mempunyai 2 (dua) nilai yaitu 1 dan nilai 0, serta diberi simbol D. Dummy memiliki nilai 1 (D=1) untuk salah satu kategori dan nol (D=0) untuk kategori yang lain.
D = 1 untuk suatu kategori (laki- laki, kulit putih, sarjana dan sebagainya). D = 0 untuk kategori yang lain (perempuan, kulit berwarna, non-sarjana dan sebagainya).
Nilai 0 biasanya menunjukkan kelompok yang tidak mendapat sebuah perlakuan dan 1 menunjukkan kelompok yang mendapat perlakuan. Dalam regresi berganda, aplikasinya bisa berupa perbedaan jenis kelamin (1 = laki-laki, 0 = perempuan), ras (1 = kulit putih, 0 = kulit berwarna), pendidikan (1 = sarjana, 0 = non-sarjana).
1.3 Model Matematika Regresi Berganda dengan Variabel dummy
Variabel dummy digunakan sebagai upaya untuk melihat bagaimana klasifikasi-klasifikasi dalam sampel berpengaruh terhadap parameter pendugaan. Variabel dummy juga mencoba membuat kuantifikasi dari variabel kualitatif.
Kita pertimbangkan model berikut ini:
I. Y = a + bX + c D1 (Model Dummy Intersep) II. Y = a + bX + c (D1X) (Model Dummy Slope) III. Y = a + bX + c (D1X) + d D1 (Kombinasi)
1.4 Pemanfaatan Regresi Berganda dengan Variabel dummy
harus lebih dahulu di transformasikan ke dalam bentuk Kuantitatif. contoh data kualitatif misal jenis kelamin adalah laki-laki dan perempuan, harus di transform ke dalam bentuk Laki-laki = 1 ; Perempuan = 0. atau tingkat pendidikan misal SMA dan Sarjana, maka diubah menjadi SMA = 0 ; Sarjana = 1, skala yang terdiri dari dua yakni 0 dan 1 disebut kode binary, sedangkan persamaan model yang terdiri dari variabel dependennya kuantitatif dan variabel independennya skala campuran : kualitatif dan kuantitatif, maka persamaan tersebut disebut persamaan regresi berganda dummy. Dalam kegiatan penelitian, kadang variabel yang akan diukur bersifat kualitatif, sehingga muncul kendala dalam pengukuran, dengan adanya variabel dummy tersebut, maka besaran atau nilai variabel yang bersifat kualitatif tersebut dapat di ukur dan diubah menjadi kuantitatif. (
http://asfarsyafar.blogspot.com/2013/10/makalah-statistika-regresi-berganda.html) 1.5Uji Asumsi Klasik
Uji asumsi klasik adalah persyaratan statistik yang harus dipenuhi pada analisis regresi linear berganda yang berbasis ordinary least square (OLS). Uji asumsi klasik yang sering digunakan yaitu uji normalitas, uji multikolinearitas, heteroskedastisitas dan uji autokorelasi. Tidak ada ketentuan yang pasti tentang urutan uji mana dulu yang harus dipenuhi. Analisis dapat dilakukan tergantung pada data yang ada. Sebagai contoh, dilakukan analisis terhadap semua uji asumsi klasik, lalu dilihat mana yang tidak memenuhi persyaratan. Kemudian dilakukan perbaikan pada uji tersebut, dan setelah memenuhi persyaratan, dilakukan pengujian pada uji yang lain.
1.5.1 Uji Normalitas
bukan dilakukan pada masing-masing variabel tetapi pada nilai residualnya.
1.5.2 Uji Multikolinearitas
Uji multikolinearitas adalah untuk melihat ada atau tidaknya korelasi yang tinggi antara variabel-variabel bebas dalam suatu model regresi linear berganda. Jika ada korelasi yang tinggi di antara variabel-variabel bebasnya, maka hubungan antara variabel bebas terhadap variabel terikatnya menjadi terganggu.
1.5.3 Uji Heteroskedastisitas
Uji heteroskedastisitas adalah untuk melihat apakah terdapat ketidaksamaan varians dari residual satu ke pengamatan ke pengamatan yang lain. Model regresi yang memenuhi persyaratan adalah di mana terdapat kesamaan varians dari residual satu pengamatan ke pengamatan yang lain tetap atau disebut homoskedastisitas.
1.5.4 Uji Autokorelasi
Uji autokorelasi adalah untuk melihat apakah terjadi korelasi antara suatu periode t dengan periode sebelumnya (t -1). Secara sederhana analisis regresi digunakan untuk melihat pengaruh antara variabel bebas terhadap variabel terikat, jadi tidak boleh ada korelasi antara observasi dengan data observasi sebelumnya.
5
Pada bab ini praktikan akan mendeskripsikan langkah-langkah kerja dalam melakukan analisis regresi dengan menggunakan variabel dummy.
2.1 Studi Kasus
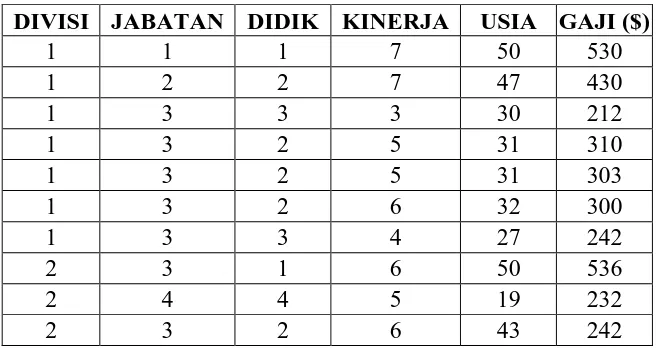
Sebuah perusahaan maskapai penerbangan sedang dalam kondisi pailit, untuk itu tim peneliti perusahaan berusaha untuk menemukan solusi yang tepat bagi keberlangsungan perusahaan. Salah satu opsi terakhir yang diajukan adalah melakukan Pemutusan Hubungan Kerja (PHK) bagi karyawan perusahaan dengan data karyawan calon PHK yang telah ada. Untuk itu perusahaan ingin mengetahui besar nilai yang harus dibayarkan perusahaan pada gaji terakhir sebelum di PHK. Hal tersebut didasarkan pada divisi yang dijalankan (penerbangan : 1, pemasaran: 2, akunting: 3, personalia: 4, sistem informasi: 5, public rela tion: 6, kredit : 7, armada: 8, ground handling: 9, penelitian: 10), jabatan dalam perusahaan (kepala divisi: 1, sekretaris divisi:2, staff divisi:3, office boy: 4) , tingkat pendidikan yang telah ditempuh (S2: 1, S1 : 2, D3: 3, SMA/Sederajat : 4) , penilaian hasil kinerja, dan usia. Berikut ini adalah data karyawan calon penerima keputusan PHK :
Tabel 2.1 Data Karyawan PHK
7 4 4 3 47 134
Dari data diatas, praktikan akan melakukan analisis diantaranya: 1. Mendapatkan pemodelan regresi linear
2. Melakukan uji hipotesis dengan mencantumkan variabel mana yang dijadikan sebagai variabel dummy
3. Melakukan uji asumsi
jabatan dalam perusahaan adalah sekretaris divisi, tingkat pendidikan S1, usia 35 tahun, nilai kerja 5.
2.2 Langkah Kerja
Adapun langkah-langkah kerja dalam melakukan analisis regresi dengan variabel dummy adalah sebagai berikut :
1. Buka software SPSS, klik variable view dan tentukan nama variabel yang meliputi divisi, jabatan, didik, kinerja, usia dan gaji seperti terlihat pada gambar 2.1 berikut :
Gambar 2.1 Mendefinisikan nama variabel
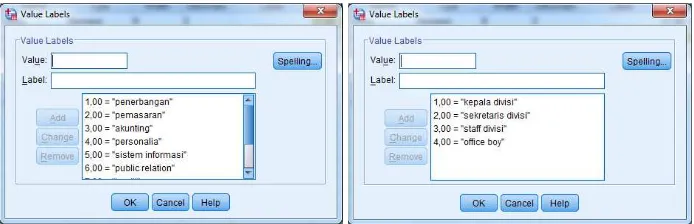
2. Definisikan kategori pada tiap-tiap variabel (divisi, jabatan dan pendidikan) kedalam bentuk angka sesuai dengan keterangan pada studi kasus dengan cara mengklik values pada masing-masing variabel seperti gambar berikut :
Gambar 2.2 Mendefinisikan keterangan variabel
Gambar 2.3 Menginput data pada tabel data view
4. Kemudian lakukan pengkategorian dalam bentuk variabel dummy 0 dan 1, pada variabel divisi dengan menjadikan divisi penerbangan = 1 sebagai reference category. Klik menu Transform Recode Into Different Variables, tentukan nama variabel dummy yang baru, kemudian klik old
and new values, lakukan seperti gambar dibawah ini.
Gambar 2.4 Kotak dialog recode into difference: Old and new values
6. Setelah selesai melakukan pengkategorian maka akan muncul variabel dummy yang baru sebanyak 15 variabel pada tabel, kemudian lakukan pengujian regresi dengan cara mengklik menu analyze regression linear sehingga muncul kotak linear regression, masukkan variabel gaji pada kolom dependent lalu masukkan semua variabel (kecuali divisi, jabatan dan didik) pada kolom independent, pilih method “stepwise” seperti terlihat pada gambar 2.5 berikut :
Gambar 2.5 Kotak dialog linear regresi
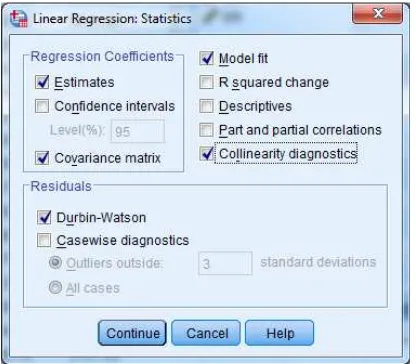
7. Klik button statistics, beri tanda check list pada bagian estimates, covariance matrix, model fit, collinearity diagnostics, durbin-watson seperti yang terlihat pada gambar berikut :
8. Klik Continue, kemudian klik button plots sehingga akan muncul kotak dialog linear regression: plots, lalu pindahkan *SRESID pada kolom Y dan *ZPRED pada kolom X, beri tanda ceklis pada normal probability plot, perhatikan gambar 2.7 berikut :
Gambar 2.7 Kotak dialog linear regression: plots
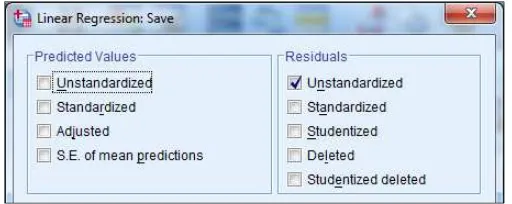
9. Klik Continue, kemudian klik button save, pada kotak dialog linear regression: save, beri tanda ceklis pada unstandardized di bagian residuals seperti terlihat pada gambar 2.8 berikut :
Gambar 2.8 Kotak dialog linear regression: save
10. Klik Continue, kemudian klik OK sehingga diperoleh output.
Gambar 2.9 Kotak dialog explore
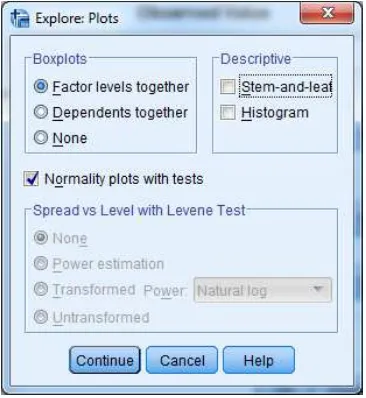
12. Klik button plots, kemudian beri tanda ceklis pada bagian normality plots with tests seperti terlihat pada gambar 2.10.
Gambar 2.10 Kotak dialog explore: plots
13
Pada bab ini praktikan akan menjelaskan hasil output dari analisis regresi berganda dengan variabel dummy menggunakan software SPSS untuk memprediksi besarnya nilai variabel tergantung/dependen atas dasar satu atau lebih variabel bebas/independen, di mana satu atau lebih variabel bebas yang digunakan bersifat dummy. Pada kasus ini, praktikan akan mencari pemodelan regresi dan melakukan pengujian asumsi serta menghitung perkiraan gaji yang harus dibayarkan oleh perusahaan kepada karyawan penerima keputusan PHK atas dasar variabel kinerja, usia dan variabel dummy yang meliputi beberapa kategori didalam variabel divisi, jabatan dan tingkat pendidikan.
Gambar 3.1 Output SPSS ANOVA (Uji Overall)
Dari hasil output pada gambar 3.1 diatas, dapat dilakukan analisis untuk mengetahui kesesuaian model dengan menggunakan pengujian hipotesis sebagai berikut :
a. Hipotesis
H0 : β1 = β2 = β3 = β4 = ... = β11 = 0 ( Model tidak sesuai )
H1 : Minimal ada satu βi ≠ 0, i =1,2,...,11 (Model sesuai ) b. Tingkat signifikansi
α = 0,05
c. Daerah kritis
Sig < α (Tolak H0)
d. Statistik Uji Sig = 0,000 e. Keputusan
0,000 < 0,05
Sig < α (Tolak H0)
f. Kesimpulan
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak H0
yakni nilai Sig < α yang berarti menunjukkan bahwa model sesuai
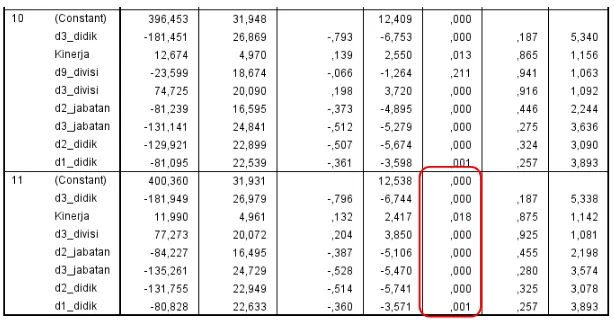
Gambar 3.2 Output SPSS tabel Coefficients
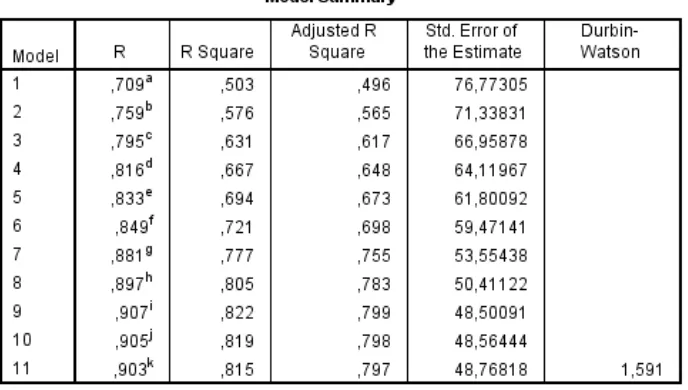
Dari output diatas, selanjutnya praktikan akan memilih model yang signifikan dengan cara melihat nilai p-value pada kolom sig. Variabel yang signifikan adalah variabel yang memiliki nilai p-value kurang dari alfa (α), dalam hal ini nilai alfa yang digunakan adalah 0,05. Dari tabel output, praktikan menggunakan model 11 karena jumlah variabel yang signifikan lebih banyak bila dibandingkan dengan variabel yang lain. Variabel signifikan menunjukkan variabel yang paling berpengaruh terhadap perhitungan gaji karyawan.
Dengan demikian dapat dituliskan pengujian hipotesisnya secara satu persatu sebagai berikut :
1) Pengujian hipotesis terhadap β0 (Konstanta/Intersep) a. Hipotesis
H0 : β0 = 0 ( Semua nilai Y dapat dijelaskan oleh X)
H1 : β0 ≠ 0 (Ada nilai Y yang tidak dapat dijelaskan oleh X) b. Tingkat signifikansi
α = 0,05
c. Daerah kritis
Sig < α (Tolak H0)
d. Statistik Uji Sig = 0,000 e. Keputusan
Sig < α (Tolak H0) f. Kesimpulan
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa ada nilai Y yang tidak dapat
dijelaskan oleh nilai X.
2) Pengujian hipotesis terhadap β1 (Kinerja)
a. Hipotesis
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya kinerja berpengaruh
secara signifikan terhadap perhitungan gaji karyawan
3) Pengujian hipotesis terhadap β2 (Variabel dummy divisi personalia)
d. Statistik Uji
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya variabel dummy pada
divisi personalia berpengaruh secara signifikan terhadap perhitungan gaji karyawan
4) Pengujian hipotesis terhadap β3 (Variabel dummy jabatan staff divisi)
a. Hipotesis
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya variabel dummy pada
5) Pengujian hipotesis terhadap β4 (Variabel dummy jabatan office boy)
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya variabel dummy pada
jabatan office boy berpengaruh secara signifikan terhadap perhitungan gaji karyawan
6) Pengujian hipotesis terhadap β5 (Variabel dummy pendidikan S1)
Sig < α (Tolak H0) f. Kesimpulan
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya variabel dummy pada
pendidikan S1 berpengaruh secara signifikan terhadap perhitungan gaji karyawan
7) Pengujian hipotesis terhadap β5 (Variabel dummy pendidikan D3) a. Hipotesis
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya variabel dummy pada
pendidikan D3 berpengaruh secara signifikan terhadap perhitungan gaji karyawan
8) Pengujian hipotesis terhadap β5 (Variabel dummy pendidikan D3) a. Hipotesis
H0 : β1 = 0 ( X1 tidak berpengaruh terhadap Y) H1 : β1 ≠ 0 ( X1 berpengaruh terhadap Y) b. Tingkat signifikansi
c. Daerah kritis
Dengan menggunakan tingkat kepercayaan 95% data yang ada menolak
H0 (nilai Sig < α) yang berarti bahwa besarnya variabel dummy pada
pendidikan SMA/Sederajat berpengaruh secara signifikan terhadap perhitungan gaji karyawan
Pada model 11 dapat diketahui bahwa variabel yang signifikan adalah kinerja dan beberapa variabel dummy diantaranya d3_divisi (divisi personalia), d2_jabatan (staff divisi), d3_jabatan(office boy), d1_didik (S1), d2_didik (D3) dan d3_didik (SMA/Sederajat). Adapun koefisien pada persamaan regresi dapat dilihat pada kolom B, dari output diatas diperoleh koefisien b0 = 400,360, b1 = 11,990, b2 = 77,273 b3 = -84,227, b4 = -135,261, b5 = -80,828, b6 = -131,755, b7 = -181,849 Sehingga diperoleh persamaan regresinya :
ŷ = 400,360 + 11,990X1 + 77,273d1 – 84,227d2 – 135,261d3 – 80,828d4 – 131,755d5 -181,849d6 atau dapat dituliskan :
Gaji = 400,360 + 11,990Kinerja + 77,273Personalia – 84,227Staff divisi – 135,261Office boy – 80,828 S1 – 131,755 D3 -181,849 SMA/Sederajat
Dari persamaan diatas, maka dapat diperkiraan besarnya gaji yang harus dibayarkan oleh perusahaan apabila terdapat seorang karyawan calon PHK, bekerja pada divisi pemasaran, dengan jabatan sekretaris divisi, tingkat pendidikan S1, usia 35 tahun, nilai kerja 5 dengan perhitungan sebagai berikut :
Gaji = 400,360 + 59,95 - 80,828 Gaji = $379,482
Selanjutnya setelah melakukan uji parsial, praktikan akan melihat besarnya koefisien determinasi (R2) dengan cara melihat output pada model summary seperti terlihat pada gambar berikut :
Gambar 3.3 Output SPSS model summary
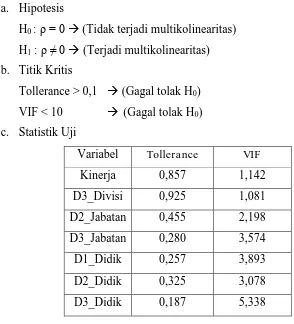
1. Uji Multikolinearitas
Output uji multikolinearitas dapat dilihat pada bagian collinearity statistics di tabel coefficients, yakni besaran nilai Tollerance dan VIF seperti terlihat pada gambar berikut :
Gambar 3.4 Output SPSS coefficients
Dari output pada gambar 3.6 dapat dilakukan pengujian hipotesis sebagai berikut :
a. Hipotesis
H0 : ρ = 0 (Tidak terjadi multikolinearitas)
H1 : ρ ≠ 0 (Terjadi multikolinearitas)
b. Titik Kritis
Tollerance > 0,1 (Gagal tolak H0) VIF < 10 (Gagal tolak H0) c. Statistik Uji
d. Keputusan tidak terjadi multikolinearitas atau dalam model regresi linear berganda tidak terdapat korelasi antar variabel independen (kinerja, divisi personalia, jabatan staff divisi, jabatan office boy, pendidikan S1, pendidikan D3 dan pendidikan SMA/Sederajat)
2. Uji Heteroskedastisitas
Gambar 3.5 Output SPSS Scatter plot
Pada gambar 3.5 terlihat bahwa persebaran residual terhadap data tersebar tanpa membentuk pola tertentu, sedangkan bila dilihat nilai batasan pada pita memiliki nilai batasan yang berbeda antara batasan yang atas dan batasan yang bawah, yakni 4 untuk batas atas dan -2 untuk batas bawah, hal ini menunjukkan data mengandung unsur heteroskedastisitas.
3. Uji Autokorelasi
Gambar 3.6 Output SPSS Model Summary
Dari hasil output diatas dapat dilakukan pengujian hipotesis seperti berikut :
1,1569 < 1,591 < 2,1704 e. Kesimpulan
Hasil pengujian autokorelasi menggunakan kriteria pengujian durbin watson dL < d < dU (1,1569 < 1,591 < 2,1704), sehingga pengujian autokorelasi tidak dapat diambil keputusan
Tolak H0
Tidak ada keputusan
4. Uji Normalitas
Untuk melihat hasil pengujian normalitas dapat dilihat nilai sig. pada output tabel tests of normality, apabila sampel yang digunakan lebih dari 50 maka digunakan tes kolmogorov-smirnov, sedangkan apabila sampel yang digunakan kurang dari 50 maka digunakan tes shapiro-wilk. Dalam kasus ini, sampel yang digunakan sebanyak 79, maka untuk menguji normalitas digunakan nilai sig. pada kolom Kolmogorov-smirnov.
Gambar 3.7 Output SPSS Tests of Normality
Dari output pada gambar 3.7, maka dapat dilakukan pengujian hipotesis sebagai berikut :
a. Hipotesis
28
karyawan yang harus dibayarkan perusahaan kepada calon penerima keputusan PHK sangat dipengaruhi oleh beberapa variabel, diantaranya kinerja, divisi personalia, staff divisi, office boy, pendidikan S1, pendidikan D3 dan pendidikan SMA/Sederajat. Adapun koefisien pada persamaan regresinya adalah b0 = 400,360, b1 = 11,990, b2 = 77,273 b3 = -84,227, b4 = -135,261, b5 = -80,828, b6 = -131,755, b7 = -181,849, sehingga persamaan regresinya dapat dituliskan :
Gaji = 400,360 + 11,990Kinerja + 77,273Personalia – 84,227Staff divisi – 135,261Office boy – 80,828 S1 – 131,755 D3 -181,849 SMA/Sederajat
Dengan demikian, perkiraan besarnya gaji yang harus dibayarkan oleh perusahaan apabila terdapat seorang karyawan calon PHK, bekerja pada divisi pemasaran, dengan jabatan sekretaris divisi, tingkat pendidikan S1, usia 35 tahun, dan nilai kerja 5 adalah sebesar $379,482.
Adapun besarnya nilai R-square adalah 79,7%, yang berarti kemampuan model memperkirakan besarnya perhitungan gaji karyawan adalah sebesar 79,7%, sedangkan sisanya sebesar 30,3% dijelaskan oleh model lain.
29 Universitas Islam Indonesia
Qudratullah, Farhan M.2013.Analisis Regresi Terapan Teori, Contoh Kasus, dan Aplikasi dengan SPSS.Yogyakarta: Andi Offset
Sufren dan Natanael, Yonathan.2013.Mahir Menggunakan SPSS Secara Otodidak. Jakarta: Kompas Gramedika
Syafar, Asfar.2013.Regresi Berganda dengan Variabel Independen Dummy. http://asfarsyafar.blogspot.com/2013/10/makalah-statistika-regresi-berganda.
html (diakses pada tanggal 10 juni 2015 pukul 1:56 WIB)
Ulwan, M. Nasihun.2014.Analisis Regresi Linear Berganda dan Variabel dummy dengan SPSS. http://www.portal-statistik.com/2014/11/analisis-regresi-linear-berganda-dan.html (diakses pada tanggal 9 juni 2015 pukul 23:35 WIB) Unknown.2009.Regresi Linear. http://www.konsultanstatistik.com/2009/03/
regresi-linear.html (diakses pada 30 April 2015 pukul 9:27 WIB)