FEATURE SELECT
LECTION
SUPPORT VECTOR REGRESSION
iii
.
ERNA PIANTARI. Feature Selection of Hyperspectral Data for Predicting Productivity of Paddy Using Genetic Algorithm and Support Vector Regression. Supervised by HARI AGUNG ADRIANTO, MUHAMMAD EVRI and SIDIK MULYONO.
Hyperspectral remote sensing technology gives rich spectral information and more detail that of multispectral. However, the high,dimensional feature of hyperspectral data often cause the risk of “over fitting” when analyzed. Therefore, it is necessary to reduce the dimension of hyperspectral data, which can be done by feature selection. In this study, Genetic Algorithm (GA) and Support Vector Regression (SVR) are used to select the best band as the best feature of hyperspectral data for predicting productivity of paddy. GA selects the best band, parameter C and parameter γ for using in SVR. Parameter C is used as error penalty in SVR and parameter γ is used for kernel function in SVR. SVR uses the best band and the best parameter, which both of them are selected by GA to predict yield of paddy, then give fitness value for GA. Hyperspectral data that used in this research has been taken on June 2008 in Indramayu and Subang, while the heights of the spectral acquisition is 2000 m which is called hymap data.
GA,SVR method was implemented using IDL and LIBSVM in C languange. The result shows that the GA,SVR method could select the best band and decrease the error of the prediction. The best result was shown by Hymap data using RBF kernel. The number of band usage for prediction was reduced from 109 to 48, the RMSE was reduced from 0.301 to 0.017 and the R2 = 0.99.
ii
FEATURE SELECTION
SUPPORT VECTOR REGRESSION
!"#"
"$"% "&' (" "& ')&' * * +$ %
# $"
" ,")"
+* '&
"-"
iv Judul : Feature Selection Data Hiperspektral untuk Prediksi Produktivitas Padi dengan
Algoritme Genetika dan Support Vector Regression Nama : Erna Piantari
NRP : G64070014
Menyetujui: Pembimbing I,
Hari Agung Adrianto, S.Kom, M.Si NIP. 19760917 200501 1 001
Pembimbing II,
Dr. Muhammad Evri, M.Sc NIP. 19670701 199603 1 003
Pembimbing III,
Ir. Sidik Mulyono, M.Eng NIP. 19670124 198602 1 001
Mengetahui:
Ketua Departemen Ilmu Komputer,
Dr. Ir. Sri Nurdiati, M.Sc. NIP. 19601126 198601 2 001
v
/ 0
Erna Piantari dilahirkan pada tanggal 24 Februari 1989 di Sumedang, Jawa Barat, dari pasangan Ibu Aan Maskanah dan Bapak Sape’i. Penulis lulus dari Sekolah Menengah Atas (SMA) Negeri 1 Tanjungsari pada tahun 2007 dan diterima di Departemen Ilmu Komputer Institut Pertanian Bogor melalui jalur USMI.
vi Alhamdulillahirobbil’alamin, segala puji dan syukur penulis panjatkan ke hadirat Allah SWT atas limpahan rahmat dan karunia,Nya sehingga penulis dapat menyelesaikan skripsi yang berjudul Feature Selection Data Hiperspektral untuk Prediksi Produktivitas Padi dengan Algoritme Genetika dan Support Vector Regression. Tulisan ini merupakan hasil penelitian yang bekerja sama dengan Pusat Teknologi Inventarisasi Sumber Daya Alam , Badan Pengkajian dan Penerapan Teknologi (PTISDA BPPT), yang beralamat di Gedung 2 Lantai 19 jalan M.H. Thamrin no 8 Jakarta Pusat. Kegiatan penelitian dilaksanakan mulai Januari 2011 sampai dengan Agustus 2011.
Pembuatan tulisan ini tentu tidak lepas dari bantuan dan dukungan berbagai pihak, oleh karena itu penulis ingin menyampaikan ucapan terima kasih kepada:
1. Ibunda Aan Maskanah dan Ayahanda Sape’i tercinta serta Adik,adik tersayang, Agung Barkah dan Ajeng yang selalu memberikan doa, kasih sayang serta dukungan moril maupun materil yang tidak henti,hentinya.
2. Bapak Sukanto Tanoto dan keluarga yang telah menjadi orang tua asuh sekaligus inspirator dan selalu memberikan dukungan materiil sehingga penulis dapat menyelesaikan pendidikan S1 hingga selesai.
3. Bapak Hari Agung Adrianto, S.Kom, M.Si selaku pembimbing akademis di Institut Pertanian Bogor yang telah memberikan dukungan dan bimbingan dalam penyelesaian tugas akhir ini. 4. Bapak Dr. Muhammad Evri, M.Sc dan Bapak Ir. Sidik Mulyono, M.Eng selaku pembimbing
di PTISDA BPPT yang telah banyak membantu serta memberikan arahan pada pelaksanaan penelitian
5. Bapak Dr. M. Sadly selaku Direktur PTISDA BPPT yang telah mengizinkan penggunaan data hiperspektral milik PTISDA dalam penelitian ini.
6. Ibu Dr. Ir. Sri Nurdiati, M.Sc sebagai Ketua Departemen Ilmu Komputer sekaligus sebagai dosen penguji beserta seluruh staf Departemen Ilmu Komputer FMIPA IPB.
7. Ibu Ratih, Bapak Darmadi Chandra, Mba Vika Puspita serta semua keluarga Tanoto Foundation dan teman,teman Tanoto Scholars yang selalu menginspirasi dan memberi semangat.
8. Hendra Gunawan (G64070073), Ana Maulida dan seluruh teman satu bimbingan. Terima kasih atas semangat dan kerja sama juga kebersamaannya selama proses penyelesaian tugas akhir ini.
9. Keluarga Arsida 4, Switenia Wana Putri, Mery Purnamasarie, Hesti Paramitha dan Rithoh Yahya.
10. Eneng Maryani, Nova Maulizar, teman,teman Rimba Kom dan seluruh keluarga besar Ilkomerz 44. Terima kasih atas motivasi dan kebersamaan yang telah dilalui selama 3 tahun ini.
11. Ka Andri, Ka Rafki, Ka Suharboy, Tantia dan teman,teman di UKM Century.
12. Seluruh pihak yang tidak dapat disebutkan satu,persatu yang turut membantu baik secara langsung maupun tidak langsung dalam pelaksanaan tugas akhir.
Penulis menyadari dalam penulisan tugas akhir ini masih terdapat banyak kekurangan. Penulis berharap adanya saran atau kritik yang bersifat membangun dari pembaca. Semoga tugas akhir ini bermanfaat.
Bogor, 9 Nopember 2011
vii
%"$"*")
DAFTAR GAMBAR ... viii
PENDAHULUAN Latar Belakang ... 1
Tujuan Penelitian ... 1
Ruang Lingkup Penelitian ... 1
Manfaat Penelitian ... 1
TINJAUAN PUSTAKA Teknologi Hiperspektral ... 1
Feature Selection ... 2
ENVI dan IDL ... 2
Support Vector Machine (SVM) ... 2
Non%Linear SVM dengan kernel ... 4
Sequential Minimal Optimization (SMO) ... 4
Algoritme Genetika ... 5
Root Mean Square Error (RMSE) ... 5
Norm,p ... 5
METODE PENELITIAN Praproses ... 6
Data Latih dan Data Uji ... 6
Pendefinisian kromosom ... 6
Penentuan fungsi fitness ... 6
Menentukan populasi awal ... 7
Endcoding... 7
Penentuan nilai fitness dan Support Vector Regression (SVR) ... 7
Evaluasi fitness ... 7
Crossover dan Mutasi ... 7
Evaluasi Hasil ... 8
Lingkungan Implementasi ... 8
HASIL DAN PEMBAHASAN Hasil Praproses ... 8
Hasil pengolahan data dengan GA,SVR ... 8
Parameter C dan γ (gamma) ... 8
Penentuan kernel ... 9
Kernel linear ... 9
Kernel Radial Basis Function (RBF) ... 10
Kernel Sigmoid ... 11
Kernel Polinomial derajat 3 ... 11
Kernel Polinomial derajat 5 ... 12
Simpang data (galat) dengan kaidah norm%p ... 13
KESIMPULAN DAN SARAN Kesimpulan... 14
Saran ... 14
DAFTAR PUSTAKA ... 14
viii
%"$"*")
1.a Nilai Reflectance Hiperspectral ... 2
1.b Nilai Reflectance Multispektral ... 2
2 Beberapa Alternatif Hyperplane ... 3
3 Hyperplane Terbaik ... 3
4 Pemetaan data ke ruang vektor dimensi tinggi ... 4
5 Siklus GA ... 5
6 Metode penelitian ... 6
7 Desain kromosom biner ... 6
8 Data hymap sebelum praproses ... 8
9 Data hymap setelah praproses ... 8
10 Hasil prediksi 4 data testing dengan kernel linear menggunakan 109 kanal ... 9
11 Hasil prediksi 4 data testing dengan kernel linear menggunakan 43 kanal terbaik ... 9
12 Hasil prediksi semua data (34 data) dengan kernel linear menggunakan 43 kanal terbaik ... 10
13 Hasil prediksi 4 data testing dengan kernel RBF menggunakan 109 kanal ... 10
14 Hasil prediksi 4 data testing dengan kernel RBF menggunakan 54 kanal terbaik ... 10
15 Hasil prediksi semua data (34 data) dengan kernel RBF menggunakan 54 kanal terbaik ... 10
16 Hasil prediksi 4 data testing dengan kernel Sigmoid menggunakan 109 kanal ... 11
17 Hasil prediksi 4 data testing dengan kernel Sigmoid menggunakan 61 kanal terbaik ... 11
18 Hasil prediksi semua data (34 data) dengan kernel Sigmoid menggunakan 61 kanal terbaik ... 11
19 Hasil prediksi 4 data testing dengan kernel Polinomial derajat 3 menggunakan 109 kanal .. 12
20 Hasil prediksi 4 data testing dengan kernel Polinomial derajat 3 menggunakan 53 kanal terbaik ... 12
21 Hasil prediksi semua data (34 data) dengan Polinomial derajat 3 menggunakan 53 kanal terbaik ... 12
22 Hasil prediksi 4 data testing dengan kernel Polinomial derajat 5 menggunakan 109 kanal .. 12
23 Hasil prediksi 4 data testing dengan kernel Polinomial derajat 5 menggunakan 43 kanal terbaik ... 13
24 Hasil prediksi semua data (34 data) dengan Polinomial derajat 5 menggunakan 43 kanal terbaik ... 13
25 Diagram perubahan RMSE dengan menggunakan berbagai kernel ... 13
26 Perubahan nilai RMSE dengan menggunakan berbagai kernel ... 13
1
"&" $" ")#
Teknologi hiperspektral remote sensing merupakan teknologi baru dengan berlatar belakang teknologi konvensional yaitu multispektral remote sensing. Teknologi hiperspektral mampu memberikan informasi spektral yang lebih detail dan lebih kaya untuk digunakan dalam mengidentifikasi dan mengukur permukaan dari suatu objek lebih luas yang tidak dapat dilakukan oleh teknologi multispektral. Di Indonesia, proses pengambilan data hiperspektral remote sensing masih sulit dilakukan dan membutuhkan biaya yang mahal sehingga data yang terkumpul sangat terbatas. Selain itu, vektor fitur dimensi yang besar dari data hiperspektral dan hubungan antar kanal yang saling berdekatan dapat menimbulkan risiko terjadinya overfitting (Chen et al 2006). Pada tahun 2008 Li Zhuo et al dalam penelitiannya, telah mengurangi dimensi data hiperspektral dengan melakukan seleksi fitur data hiperspektral hyperion kota Guangzhou Cina dengan menggunakan metode GA,SVM. Dalam penelitiannya Li Zhou berhasil meningkatkan akurasi dari 88.81% menjadi 92.5% dan mengurangi jumlah kanal dari 198 kanal menjadi 13 kanal. Penelitian tersebut menunjukkan bahwa hasil analisis data hiperspektral dengan seleksi fitur lebih baik dibandingkan hasil analisis tanpa fitur seleksi.
Di Indonesia, teknologi hiperspektral masih merupakan teknologi rintisan. Dari tahun 2008 sampai saat ini, salah satu divisi dari Badan Pengkajian dan Penerapan Teknologi (BPPT) yaitu Pusat Teknologi Inventarisasi Sumber Daya Alam (PTISDA) mengkaji dan menerapkan teknologi hiperspektral pada bidang pertanian yaitu untuk memprediksi jumlah produksi padi per tahun di Indonesia. Dengan teknologi hiperspektral, analisis prediksi produksi tanaman padi dapat dilakukan secara lebih akurat dibandingkan dengan menggunakan foto udara dan sistem multispektral yang selama ini digunakan (Sadly, 2010).
Algoritme Genetika merupakan algoritme yang dapat menyelesaikan masalah optimasi. Algoritme ini dapat menangani beberapa fungsi objektif, bekerja pada sekumpulan calon solusi, dan menggunakan aturan transisi peluang. Dalam penelitian ini akan dilakukan feature selection dengan menggunakan Algoritme Genetika untuk
menentukan kanal data hiperspektral yang terbaik untuk proses prediksi produktivitas padi dengan SVR.
','") ) $ & ")
1. Melakukan feature selection untuk mencari kanal terbaik data hiperspektral yang digunakan dalam proses prediksi produktivitas padi dengan Algoritme GA, SVR.
2.
Membandingkan hasil prediksi data hiperspektral tanpa feature selection dengan hasil prediksi padi menggunakan data hiperspektral dengan feature selection.3.
Mendapatkan kernel terbaik untuk melakukan proses feature selection dengan metode GA,SVR.'")# )# ' ) $ & ")
Ruang lingkup penelitian yang dilakukan adalah mencari kanal terbaik data hiperspektral untuk proses prediksi produktivitas tanaman padi dengan metode GA,SVR. Hasil prediksi dievaluasi dengan menggunakan nilai Root Mean Square Error (RMSE).
Data yang digunakan adalah data produktivitas panen padi dan data hiperspektral padi milik PTISDA BPPT yang diambil di Indramayu dan Subang. Data hiperspektral diambil pada saat fase tumbuh padi generatif dan vegetative, yaitu pada bulan Juni 2008. Data produktivitas panen padi diambil pada saat panen yaitu bulan Agustus 2008. Data spektral diambil dari ketinggian 2000 m dengan menggunakan sensor Hyperspectral Mapper (Hymap) yang dipasang pada pesawat CESSNA 404. Pesawat tersebut melintas di wilayah pengambilan data sebanyak 15 lintasan.
")1""& ) $ & ")
Penelitian ini diharapkan dapat membantu penelitian mengenai pemanfaatan data hiperspektral dibidang pertanian yang difokuskan untuk meningkatkan nilai akurasi prediksi produktivitas padi dan mempermudah analisis data hiperspektral padi.
2
)+$+# & "$
2 panjang gelombang atau kanal yang banyak
sehingga dalam pemanfaatannya dapat memberikan informasi yang lebih akurat dibandingkan dengan teknologi sebelumnya yaitu multispektral. Secara definisi teknologi hiperspektral merupakan cara memperoleh gambaran kondisi di permukaan bumi secara simultan dengan jumlah kanal yang banyak (lebih dari 200) serta menggunakan panjang gelombang yang sempit (narrow band) dan saling berdekatan (Evri, M. et. al., 2004).
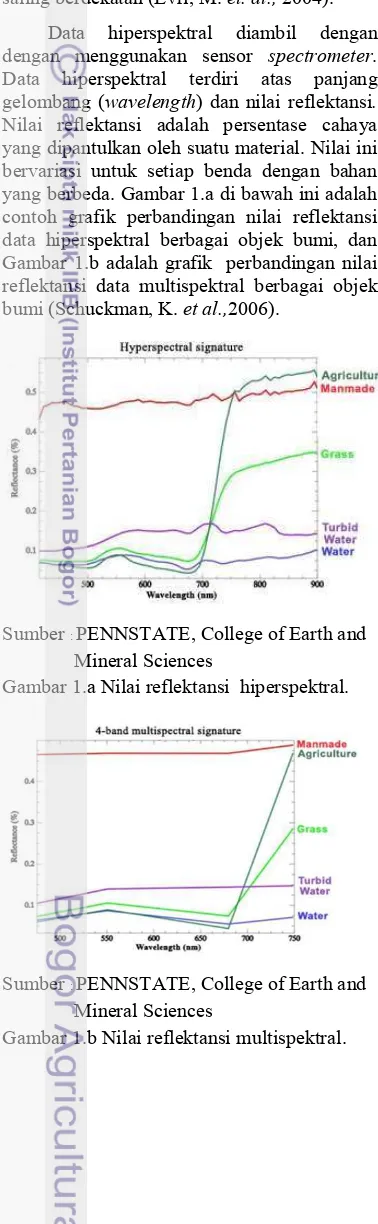
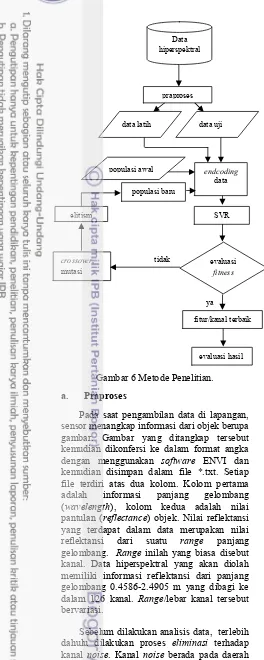
Data hiperspektral diambil dengan dengan menggunakan sensor spectrometer. Data hiperspektral terdiri atas panjang gelombang (wavelength) dan nilai reflektansi. Nilai reflektansi adalah persentase cahaya yang dipantulkan oleh suatu material. Nilai ini bervariasi untuk setiap benda dengan bahan yang berbeda. Gambar 1.a di bawah ini adalah contoh grafik perbandingan nilai reflektansi data hiperspektral berbagai objek bumi, dan Gambar 1.b adalah grafik perbandingan nilai reflektansi data multispektral berbagai objek bumi (Schuckman, K. et al.,2006).
Sumber : PENNSTATE, College of Earth and Mineral Sciences
Gambar 1.a Nilai reflektansi hiperspektral.
Sumber : PENNSTATE, College of Earth and Mineral Sciences
Gambar 1.b Nilai reflektansi multispektral.
Feature Selection
Data hiperspektral merupakan data yang berdimensi tinggi yang memiliki lebih dari ratusan kanal spektral yang sempit. Pada umumnya data yang berdimensi tinggi tidak memiliki data latih yang cukup. Secara umum untuk dapat melakukan analisis prediksi dari suatu data uji secara akurat, setidaknya data latih yang dibutuhkan adalah sepuluh kali jumlah fitur (dalam kasus ini fitur adalah jumlah kanal spektral) (Nakariyakul Songyot & David, 2008). Jumlah kanal yang ada pada data hiperspektral hasil praproses dalam penelitian ini adalah 109 kanal. Dalam proses analisis, kanal tersebut akan menjadi fitur data. Idealnya data latih yang diperlukan adalah 1090 data. Karena sample data uji sulit dalam jumlah banyak sulit didapatkan, maka upaya yang dapat dilakukan adalah mengurangi jumlah fitur (kanal spektra). Selain itu, jumlah dimensi data yang besar akan memerlukan proses komputasi yang tinggi untuk mengolahnya.
Ada dua cara yang dapat dilakukan untuk mengurangi jumlah fitur, yaitu dengan feature extraction dan feature selection. Feature extraction adalah upaya untuk memetakan semua fitur ke dalam fitur baru yang lebih sedikit. Feature selection adalah upaya untuk memilih fitur subset dari fitur asli yang paling berguna dalam proses klasifikasi. Kelebihan feature selection adalah akusisi data lebih cepat dan sistem lebih murah, sehingga untuk mengurangi fitur pada data hiperspektral akan lebih baik jika menggunakan feature selection dibandingkan feature extraction. (Songyot, David 2008)
-")
ENVI dengan IDL (Interactive Data Language) merupakan software ideal yang digunakan untuk pengolahan dan analisis data, visualisasi, dan pengembangan aplikasi lintas platform. Dibandingkan dengan software pengolahan data lain, ENVI/IDL language mampu mengolah data dengan banyak array dengan analisis matematika yang kompleks dan penyajian grafik yang lebih baik (TISDA, 2010).
Support Vector Machine3 4
3 Gambar 2 pattern yang tergabung pada class
–1 disimbolkan dengan kotak, sedangkan pattern pada kelas +1 disimbolkan dengan lingkaran. Pada gambar tersebut terdapat beberapa alternatif hyperplane yang dapat menjadi pemisah antara kelas ,1 dan kelas +1 (discrimination boundaries).
Sumber : http://asnugroho.net/papers/ ikcsvm .pdf
Gambar 2 Beberapa Alternatif Hyperplane.
Hyperplane pemisah terbaik antara kedua kelas dapat ditemukan dengan mengukur margin hyperplane dan mencari titik maksimalnya. Margin adalah jarak antara hyperplane tersebut dengan pattern terdekat dari masing,masing kelas. Pattern yang paling dekat ini disebut sebagai support vector. Garis solid merah pada Gambar 3 menunjukkan hyperplane yang terbaik, yaitu yang terletak tepat pada tengah,tengah kedua kelas.
Sumber : http://asnugroho.net/papers/ ikcsvm .pdf
Gambar 3 Hyperplane Terbaik.
Data yang tersedia dinotasikan sebagai di ̅ ∈ ℜ sedangkan label masing,masing dinotasikan {−1, +1} untuk i = 1,2,…l , dengan l adalah banyaknya data. Diasumsikan kedua class –1 dan +1 dapat terpisah secara sempurna oleh hyperplane berdimensi d, yang didefinisikan
. ̅ + = 0 (1)
Pattern ̅ yang masuk ke dalam class ,1 dapat dirumuskan sebagai pattern yang memenuhi Pertidaksamaan 2 berikut,
. ̅ + ≤ −1 , (2)
sedangkan pattern ̅ yang termasuk kelas+1 memenuhi Pertidaksamaan 3 berikut,
. ̅ + ≥ +1 (3)
Margin terbesar dapat ditemukan dengan memaksimalkan nilai jarak antara hyperplane dan titik terdekatnya, yaitu 2/‖ ‖. Hal ini dapat dirumuskan sebagai masalah Quadratic Programming (QP), yaitu mencari titik minimal Persamaan 4, dengan memperhatikan constrain Persamaan 5 di bawah ini,
= !"‖ ‖" (4)
̅ . + − 1 ≥ 0, ∀ (5)
Masalah ini dapat dipecahkan dengan berbagai teknik komputasi, di antaranya dengan Lagrange Multiplier.
$ , , % =!"‖ ‖"− ∑ % ̅ . + − 1 '!
(i = 1,2,….,l) (6) % adalah Lagrange multipliers yang bernilai nol atau positif. Nilai optimal dari Persamaan 6 dapat dihitung dengan meminimalkan L terhadap dan b , dan memaksimalkan L terhadap % . Dengan memperhatikan sifat bahwa pada titik optimal gradient L= 0, Persamaan 6 dapat dimodifikasi sebagai maksimalisasi problem yang hanya mengandung %, sebagaimana Persamaan 7 di kebanyakan bernilai positif. Data yang berkorelasi dengan % yang positif inilah yang disebut support vector.
4 softmargin, Persamaan (5) dimodifikasi
dengan memasukan slack variable . sebagai berikut.
̅ . + ≥ 1 − . , ∀ (9) Persamaan (4) diubah menjadi,
= !"‖ ‖"+ / ∑ .)
'! (10)
Parameter C digunakan untuk mengkontrol tradeoff antara margin dan galat .. Semakin besar nilai berarti semakin besar pinalti terhadap galat tersebut (Anto et al 2003).
+)5 ) " - )#")Kernel
Untuk menyelesaikan masalah pada domain non,linear, SVM dimodifikasi dengan memasukkan fungsi kernel. Dengan fungsi kernel, pertama,tama data ̅ akan dipetakan oleh fungsi Φ ̅ ke ruang vektor yang berdimensi tinggi. Pada dimensi inilah hyperplane paling baik akan dicari. Gambar 4 adalah ilustrasi konsep tersebut.
Input Space X
Gambar 4 Pemetaan data ke ruang vektor dimensi tinggi.
Proses pembelajaran SVM dalam menentukan support vektor, hanya bergantung pada dot product dari data yang sudah ditransformasikan, yaitu Φ ̅ . Φ ̅( . Umumnya transformasi Φ ̅ tidak diketahui dan sulit dipahami, maka perhitungan dot product tersebut dapat digantikan dengan fungsi kernel dengan fungsi 1 ̅ , ̅( (teori Mercer) yang dirumuskan pada Persamaan (11) di bawah ini:
12 ̅ , ̅(3 = Φ ̅ . Φ ̅( (11) sehingga Persamaan (6) menjadi,
$ , , % = ∑ %)
'! −!"∑ ∑ % %)'! ('! ( ( 1 , 4
(i = 1,2,….,l) (12)
Dan persamaan (1) menjadi, 52Φ ̅ 3 = . Φ ̅ +
= ∑4=1% 1 ̅, ̅( (13)
Beberapa fungsi kernel yang dikenal, dirangkum dalam Tabel 1. Pemilihan fungsi kernel tergantung pada karakteristik data.
Tabel 1 Daftar fungsi kernel
Kernel Definisi
Sequential Minimal Optimization3 4
Sequential Minimal Optimization (SMO) digunakan untuk mempercepat proses Support Vector Machine (SVM) yang bersifat Quadratic Programming (QP). Penggunaan SVM hanya dapat menyelesaikan masalah yang berukuran kecil karena pelatihan SVM cenderung lambat, kompleks, dan sulit untuk diimplementasikan. Sequential Minimal Optimization (SMO) mampu membagi SVM yang bersifat QP ke dalam bagian yang lebih sederhana (Platt , 1998).
Sequential Minimal Optimization (SMO) memilih menyelesaikan masalah optimasi pada Persamaan (7) dengan memilih Lagrange Multipliers % untuk dioptimasi bersama, sama, mencari nilai yang paling optimal untuk Langrange Multipliers tersebut dan memperbaharui SVM dengan nilai optimal yang baru. Metode alternatif sequential yang dikembangkan Vijayakumar tahun 1999 adalah sebagai berikut :
1. Inisialisasi % = 0 Hitung matriks :
A = ( 12 ̅ , ̅(3 + B"
2. Lakukan langkah di bawah ini, a. C = ∑ %)('! (A(
b. D% = { > E8 1 − C , %F, / − % } , 8 adalah parameter untuk mengkontrol kecepatan learning. c. % = % + D%
3. Kembali ke langkah 2 sampai nilai α mencapai konvergen.
(14)
Support Vector Regression 3 4
Support vector regression (SVR) merupakan penerapan SVM yang digunakan untuk proses regresi. Output SVR berupa bilangan real yang kontinu, sehingga proses prediksi yang tepat lebih sulit dilakukan Dimensi tinggi feature
5 karena banyaknya kemungkinan prediksi yang
tidak terbatas. Dalam kasus regresi biasanya memiliki nilai toleransi untuk deviasi paling besar adalah G (epsilon) terhadap margin. Jika G sama dengan 0 maka model yang didapatkan adalah model regresi yang sempurna.
$#+ &* ) & " 3 4
Basuki (2003) mengungkapkan bahwa genetic algorithm (GA) adalah algoritme yang memanfaatkan proses seleksi ilmiah yang dikenal dengan proses evolusi. Dalam proses evolusi, individu secara terus,menerus mengalami perubahan gen untuk menyesuaikan dengan lingkungan hidupnya. Algoritme ini ditemukan oleh John Holland dan dikembangkan oleh David Goldberg. Siklus Algoritme Genetika dapat dilihat pada Gambar 5.
Sumber : Basuki. 2003. Algoritma Genetika Gambar 5 Siklus Algoritme Genetika.
Dalam proses iterasi, individu yang akan dipertahankan untuk membangkitkan generasi selanjutnya adalah individu yang memiliki nilai fitness paling fit atau biasa disebut elitsm. Istilah,istilah yang digunakan pada Algoritme Genetika yaitu genotype (gen), allele, kromosom, individu, populasi, generasi, dan nilai fitness. Beberapa hal penting yang dilakukan untuk memulai Algoritme Genetika yaitu:
1. Mendefinisikan individu yang menyatakan salah satu solusi (penyelesaian) yang mungkin dari permasalahan yang diangkat. 2. Mendefinisikan nilai fitness yang
merupakan ukuran baik,tidaknya solusi yang didapatkan.
3. Menentukan proses pembangkitan populasi awal, biasanya menggunakan pembangkitan acak seperti random%walk.
4. Menentukan proses seleksi yang akan digunakan.
5. Menentukan proses perkawinan silang (crossover) dan mutasi gen yang akan digunakan
Root Mean Square Error3 4
Untuk menilai performa dari suatu model prediksi ada beberapa ukuran galat yang bisa digunakan. Salah satu pengukuran galat yang bisa digunakan adalah Root Mean Square
Dalam percobaan ini dilakukan analisis simpangan data (galat) hasil prediksi terhadap nilai aktual. Kaidah yang digunakan adalah berdasarkan kaidah norm%p dengan Persamaan (18) dibawah ini.
‖:‖9= ∑ | − L |M'! 9 ! 9N (18)
Dimana p merupakan anggota dari [1,2,∞], n adalah jumlah sample. Norm,1 merupakan jumlah galat absolut, norm,2 setara dengan root means square error (RMSE), dan norm,∞ adalah nilai galat maksimum dari seluruh data sample ( Francis Scheid, 1990 ).
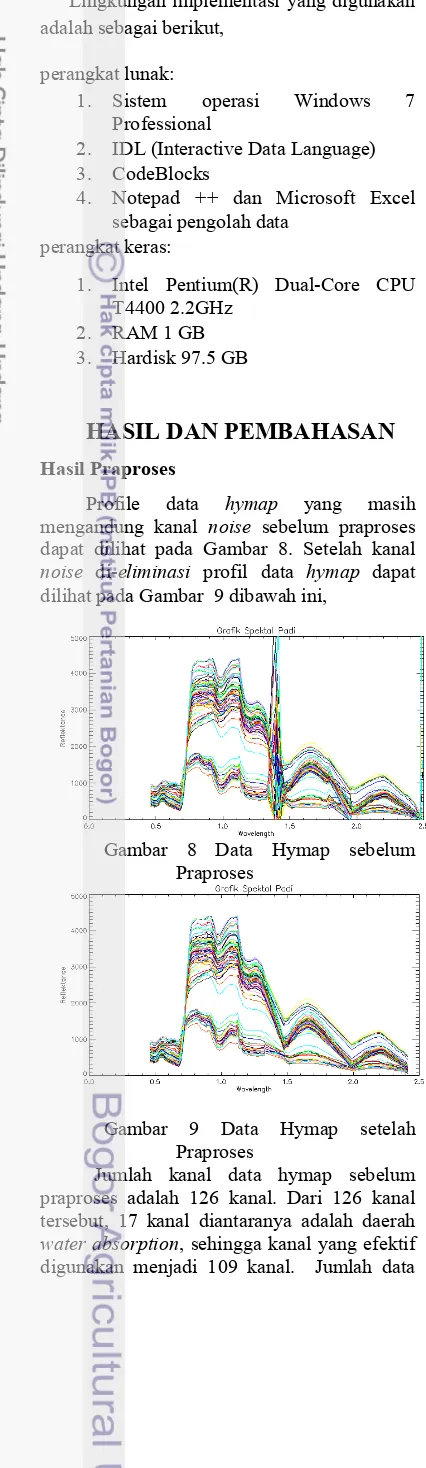
Secara garis besar, tahapan metode penelitian yang dilakukan terdiri atas praproses data, pemisahan data hiperspektral menjadi data latih dan data uji, tahapan implementasi feature selection dengan metode GA,SVM, dan evaluasi. Secara lebih terperinci tahapan alur metode penelitian yang akan dilakukan dapat dilihat pada Gambar 6. Populasi awal Seleksi
individu
Populasi baru
Reproduksi: Cross,over,
6 Gambar 6 Metode Penelitian.
"6 " +
Pada saat pengambilan data di lapangan, sensor menangkap informasi dari objek berupa gambar. Gambar yang ditangkap tersebut kemudian dikonfersi ke dalam format angka dengan menggunakan software ENVI dan kemudian disimpan dalam file *.txt. Setiap file terdiri atas dua kolom. Kolom pertama adalah informasi panjang gelombang (wavelength), kolom kedua adalah nilai pantulan (reflectance) objek. Nilai reflektansi yang terdapat dalam data merupakan nilai reflektansi dari suatu range panjang gelombang. Range inilah yang biasa disebut kanal. Data hiperspektral yang akan diolah memiliki informasi reflektansi dari panjang gelombang 0.4586,2.4905 m yang dibagi ke dalam 126 kanal. Range/lebar kanal tersebut bervariasi.
Sebelum dilakukan analisis data, terlebih dahulu dilakukan proses eliminasi terhadap kanal noise. Kanal noise berada pada daerah dengan panjang gelombang antara 1.359, 1.460, 1.774,1.970 dan 2.420,2500. Kanal
noise ini terjadi karena pada daerah tersebut terjadi peristiwa water absorption, yaitu peristiwa penyerapan cahaya pada panjang gelombang tertentu oleh zat cair di udara. Selanjutnya data hiperspektral yang sudah ter, eliminasi digabungkan ke dalam bentuk matriks. Jumlah kolom menunjukkan jumlah kanal, jumlah baris menunjukkan jumlah data.
!6 "&" "& % -") "&" ,
Setelah proposes data selesai dilakukan, semua data hiperspektral akan dibagi menjadi dua kelompok, yaitu data latih dan data uji. Metode yang akan digunakan dalam pemilihan pembagian data latih dan data uji ini adalah dengan bootstrapping (8,fold). Semua data akan dibagi menjadi 8 subset, dan setiap satu subset menjadi data uji, maka subset lainnya menjadi data latih. Data latih akan digunakan sebagai masukan dari pelatihan dengan metode GA,SVR, sedangkan data uji akan digunakan untuk menguji model hasil latih Algoritme SVR. Model yang memiliki nilai galat paling kecil yang akan dipilih (Sidik 2011).
76 )- 1 ) ") +*+ +*
Untuk mengotimalkan kanal atau feature subset dan parameter SVM (C dan gamma) secara simultan, kromosom setiap individu didefinisikan menjadi tiga bagian, yaitu kanal/fitur, C dan γ. Parameter C digunakan pada saat pembuatan model SVM dengan Persamaan (10). Parameter γ (gamma) digunakan untuk membentuk kernel Gaussian, polinomial, dan sigmoid. Pengkodean biner digunakan untuk merepresentasikan kromosom. Gambar 7 adalah desain kromosom biner yang akan digunakan.
F C Γ
f1 f… fn C1 C.. Cn γ1 γ.. γ n Gambar 7 Desain Kromosom Biner
-6 ) )&'") ')# Fitness
Kriteria penilaian yang digunakan dalam penelitian ini adalah tingkat akurasi model Support Vector Regression yang ditentukan dengan nilai RMSE. Dengan demikian, fungsi fitness yang digunakan adalah :
7
6 ) )&' ") + '$" 8"$
Populasi awal dibentuk sebagai inisialisasi yang terdiri atas individu dengan kromosom yang berbeda. Salah satu individu dalam populasi awal ini adalah individu dengan kanal/fitur yang masih utuh yaitu 109 kanal. Dan menggunakan parameter C dan γ yang maksimal yaitu 1000 dan 12. Sedangkan individu lainnya dalam populasi tersebut dibangkitkan secara random generator menggunakan fungsi random dalam IDL.
-6 Endcoding
Informasi genotif dari setiap kromosom individu dalam populasi di,endcoding menjadi informasi fenotif untuk digunakan sebagai input pada proses SVR. Kode biner sebanyak 109 pada awal adalah genotif yang merepresentasikan kanal yang dipilih. Kode biner ‘1’ menunjukkan bahwa kanal pada indeks tersebut dipilih, sedangkan biner ‘0’ menunjukkan bahwa kanal pada indeks tersebut tidak dipilih.
Kode biner selanjutnya adalah informasi genotif parameter C terdiri atas 10 gen. Untuk mengonversi kode genotif parameter C ke kode fenotifnya menggunakan Persamaan (17) di bawah ini.
/ = P>QR M+ S ∗ UVWXYZ["\VWX^ Y]^_ (17)
Parmin dan Parmax adalah nilai minimal dan nilai maksimal untuk parameter C yang di tentukan sebelumnya, d adalah representasi nilai desimal dari kromosom yang dibentuk untuk parameter C, n adalah jumlah bit pada kromosom C tersebut. Dalam percobaan ini nilai Parmindan Parmax yang digunakan untuk parameter C adalah 500 dan 1000. Persamaan (17) juga digunakan untuk menghitung parameter γ. Nilai Parmin dan Parmax yang digunakan untuk parameter γ adalah 10 dan 12.
6 ) )&'") $" &) -") Support Vector Regression3 4
Tahap selanjutnya yang dilakukan adalah mencari nilai fitness dari setiap individu dalam populasi. Berdasarkan Persamaan 16, nilai
fitness yang digunakan adalah nilai RMSE hasil uji model SVR. Input proses latih SVR adalah informasi fenotif kromosom individu yaitu indeks fitur/kanal dan parameter SVR yang dibutuhkan, yaitu C dan γ. Dalam penelitian ini pelatihan model SVR dilakukan dengan menggunakan LIBSVM dengan bahasa C oleh Chih,Chung Chang, et al 2003, yang di,import oleh program IDL. LIBSVM tersebut dapat digunakan tanpa menggunakan lisensi hak cipta.
16 9"$'" Fitness
Evaluasi fitness digunakan untuk menentukan apakah individu yang diharapkan sudah terbentuk atau belum. Jika individu yang diharapkan sudah terbentuk maka proses eksekusi program GA,SVR selesai. Jika individu yang diharapkan masih belum terbentuk sampai generasi maksimal yang ditentukan, maka individu hasil dari metode GA,SVR adalah individu dengan nilai fitness terbaik dan jumlah kanal paling minimal dari elitist setiap generasi.
Evaluasi nilai fitness yang digunakan untuk membangkitkan generasi selanjutnya adalah dengan cara mengurutkan nilai fitness% nya. Dalam percobaan ini, generasi selanjutnya akan dibangkitkan dari lima individu yang paling fit (nilai fitness paling kecil).
#6 Crossover-") '&"
Jika hasil evaluasi fitness populasi suatu generasi masih belum menemukan individu yang diharapkan, pembentukan generasi selanjutnya dilakukan dengan cara melakukan crossover (kawin silang) antara dua individu dalam populasi yang memiliki nilai fitness terbaik. Hasil dari crossover akan mengalami mutasi pada gen tertentu.
%6 9"$'" " $
8
)# ')#") * $ * )&"
Lingkungan implementasi yang digunakan adalah sebagai berikut,
perangkat lunak:
1. Sistem operasi Windows 7 Professional
2. IDL (Interactive Data Language) 3. CodeBlocks mengandung kanal noise sebelum praproses dapat dilihat pada Gambar 8. Setelah kanal noise di,eliminasi profil data hymap dapat dilihat pada Gambar 9 dibawah ini,
Gambar 8 Data Hymap sebelum tersebut, 17 kanal diantaranya adalah daerah water absorption, sehingga kanal yang efektif digunakan menjadi 109 kanal. Jumlah data
hymap yang sesuai dengan data produktivitas padi (yield padi) yang tersedia adalah sebanyak 34 data. Sehingga data yang akan dianalisis selanjutnya adalah 34 data.
" $ )#+$"%") "&" - )#") 5
Dalam penelitian ini, prosedur yang digunakan untuk mengetahui performa dari model yang dihasilkan adalah dengan melakukan pengujian terhadap model dengan data supplied data uji. Pemilihan data uji yang dilakukan adalah dengan cara bootstrapping (8,fold).
Analisis feature selection yang dilakukan metode GA,SVR melibatkan beberapa parameter GA, diantaranya adalah jumlah generasi maksimum, peluang crossover, peluang mutasi, jumlah individu dalam populasi dan jumlah individu yang dipilih untuk membentuk generasi selanjutnya. Dalam percobaan ini, jumlah generasi maksimal adalah 50 generasi. Pembatasan jumlah generasi ini karena mempertimbangkan waktu eksekusi program. Peluang crossover = 0.6, peluang mutasi = 0.01, jumlah individu dalam populasi = 25 dan jumlah individu yang dipilih = 5. Selain itu, inisialisasi awal juga diperlukan terhadap parameter C dan γ, yaitu nilai CmaksdanCmin, ditentukan pada saat inisialisasi awal untuk proses pelatihan SVR. Parameter tersebut adalah parameter C dan γ. Parameter C merupakan nilai pinalti terhadap galat model SVR, sedangkan parameter γ adalah parameter yang digunakan untuk sebagai masukan untuk fungsi,fungsi kernel yang akan digunakan. Salah satu kernel yang proses percobaan pelatihan dan pengujian sebanyak 48 kali dengan variasi nilai parameter C dan γ .
9 mampu mengenali data latihnya sendiri
dengan baik, maka model tersebut sudah dapat dilakukan pengujian dengan data uji baru. Namun jika model masih belum dapat mengenali data latihnya dengan baik, maka sangat kecil kemungkinan model dapat mengenali data uji baru.
Hasil percobaan menunjukkan bahwa pada saat percobaan menggunakan nilai parameter C=100 dan γ=0.8, nilai RMSE yang dihasilkan masih sangat besar yaitu 0.560, dan nilai R2 masih sangat kecil yaitu 0.554. Padahal data yang digunakan untuk pengujian adalah data yang digunakan untuk pelatihan model. Hal ini mengindikasi bahwa model masih belum bisa mengenali data latihnya sendiri dan sangat kecil kemungkinan model dapat menghasilkan prediksi yang baik untuk data uji baru.
Pada percobaan selanjutnya nilai parameter C dan γ dinaikkan. Seiring dengan naiknya parameter C, nilai RMSE dan R2 yang dihasilkan lebih baik . Untuk γ=15, nilai RMSE meningkat, dan nilai R2 menurun. Artinya γ maksimum kemungkinan besar tidak ada pada rentang γ>15. Dari hasil tersebut, maka inisialisasi awal nilai parameter C dan γ adalah Cmin=500 dan Cmaks=1000, γmin=10 dan γmaks=15. Nilai parameter C yang cukup besar berarti memberikan nilai pinalti yang besar terhadap variable slack (Persamaan 10), sehingga pada proses pelatihan dipastikan nilai slack sangat kecil. Dengan nilai slack yang sangat kecil diharapkan model yang didapat adalah model yang paling terbaik hasil pealtihan data latih yang ketat. Untuk menghindari overfiiting karena proses pelatihan yang cukup ketat maka proses pengujian dilakukan dengan menggunakan data uji saja, tanpa melibatkan data latih.
6 ) )&'")Kernel
Penentuan kernel yang digunakan pada SVR sangat berpengaruh terhadap performa model SVR yang akan diperoleh. Oleh karena itu, untuk mengetahui kernel yang paling baik untuk data hymap, dilakukan percobaan GA, SVR dengan kernel yang berbeda,beda.
"6 Kernel ) "
Proses pembentukan kernel linear tidak membutuhkan nilai konstanta. Sehingga pelatihan GA, SVR dengan kernel ini hanya melibatkan parameter C pada SVR. Penggunaan kernel linear pada pelatihan SVR tanpa kanal terbaik atau dengan semua kanal (109 kanal) dan parameter C =1000 menghasilkan nilai RMSE = 0.255 dengan nilai R2= 0.9714 (Gambar 10).
Metode GA,SVR dengan kernel linear telah menghasilkan kanal terbaik sebanyak 43 kanal dengan parameter terbaik C adalah 906.738. Dengan hasil tersebut, pengujian model SVR dengan supplied data uji menghasilkan nilai RMSE= 0.071 dan R2 = 0.791. Hasil optimisasi GA,SVR tersebut menurunkan nilai RMSE sebesar 0.184 (Gambar 11).
10 Gambar 11 Hasil Prediksi 4 Data Uji
dengan Kernel Linear menggunakan 43 Kanal Terbaik
Pengujian semua data (34 data) dilakukan terhadap model terbaik yang dihasilkan dari pelatihan SVR dengan kanal dan parameter C optimum menggunakan kernel linear. Hasil prediksi dari semua data tersebut menghasilkan nilai RMSE= 0.67 dan nilai R² = 0.275 (Gambar 12). Nilai RMSE tersebut menunjukkan bahwa galat simpang model prediksi produktivitas padi adalah 0.67 ton/hektar. Angka tersebut mengindikasikan bahwa model masih terlalu berisiko digunakan untuk memprediksi produktivitas padi.
Gambar 12 Hasil Prediksi Semua Data (34 data) dengan Kernel Linear Menggunakan 43 Kanal Terbaik
!6 Kernel Radial Basis Function
3 4
Pembentukan fungsi RBF membutuhkan parameter konstanta yaitu γ. Konstanta γ ini menetukan lebar atau sempitnya fungsi Gaussian yang dibentuk.
Pelatihan model SVR dengan kernel RBF tanpa menggunakan kanal dan parameter terbaik atau dengan semua kanal (109 kanal) dan mengunakan parameter C=1000 dan γ=12, menghasilkan nilai RMSE=0.376 dan R2 = 0.995 (Gambar 13). Pemilihan fitur dan parameter terbaik dengan mengeksekusi program GA,SVM kernel RBF menghasilkan kanal terbaik sebanyak 54 kanal dan parameter C dan γ terbaik yaitu 560.547 dan 11.064. Pelatihan model dengan kanal dan parameter terbaik tersebut telah berhasil menurunkan nilai RMSE menjadi 0.0171 dan meningkatkan nilai R2 menjadi 0.999. Nilai R2 positif dan mendekati angka 1 menunjukkan bahwa hubungan deterministik antara nilai aktual dengan nilai hasil prediksi berbanding lurus dan hampir sama (Gambar 14). Hasil prediksi untuk semua data (34 data) dengan menggunakan kernel RBF dan parameter terbaik dapat dilihat pada Gambar 15, dengan nilai R2= 0.954 dan RMSE= 0.158 .
11 Gambar 14 Hasil Prediksi 4 Data Uji
dengan Kernel RBF Menggunakan 54 Kanal Terbaik
Gambar 15 Hasil Prediksi Semua Data (34 data) dengan Kernel RBF Menggunakan 54 Kanal Terbaik
76 Kernel #*+
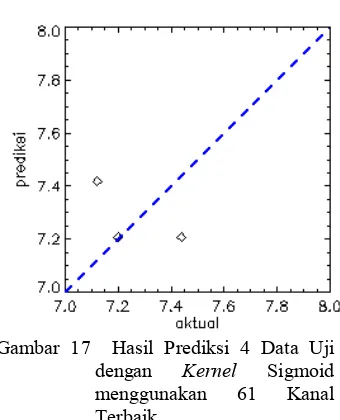
-Pengujian data uji pada model SVR yang diperoleh dari pelatihan dengan menggunakan semua kanal (109 kanal) dan kernel sigmoid, menghasilkan nilai RMSE = 0.229 dengan nilai R2= ,0.546 (Gambar 16). Nilai R2 negatif menunjukkan bahwa model SVR yang dihasilkan buruk. Hal ini dapat terjadi karena model SVR tidak bisa mengenali data uji dengan benar karena data yang dilatih untuk membentuk model SVR tidak sebanding jumlah dengan jumlah fitur data yang dimiliki. Untuk itu dilakukan feature selection dengan metode GA,SVM. Proses eksekusi metode tersebut menghasilkan 61 kanal terbaik, parameter terbaik C = 938.476, dan parameter terbaik γ = 12.5 . Dengan
menggunakan kanal dan parameter terbaik tersebut, pengujian supplied data uji pada model SVR yang diperoleh menghasilkan menurunkan nilai RMSE menjadi 0.189 dan memperbaiki R2 menjadi 0.333 (Gambar 17). Nilai RMSE yang masih cukup besar dan R2 yang masih bernilai terlalu kecil, menunjukkan bahwa model SVR yang dihasilkan walaupun sudah ada perbaikan, tetapi masih belum sesuai harapan. Hasil prediksi pada semua data dengan kernel Sigmoid dapat dilihat pada Gambar 18 dengan nilai R2= 0.028 dan RMSE= 1.027 .
Gambar 16 Hasil Prediksi 4 Data Uji dengan Kernel Sigmoid menggunakan 109 Kanal
12 Gambar 18 Hasil Prediksi Semua Data
(34 data) dengan Kernel Sigmoid Menggunakan 61 Kanal Terbaik
-6 Kernel +$ )+* "$ ","& :
Pengujian supplied data uji pada model SVR yang dihasilkan dari pelatihan dengan semua kanal yang menggunakan kernel polinomial derajat 3, menghasilkan nilai RMSE = 4.296 dan nilai R2 = 0.411 (Gambar 19).
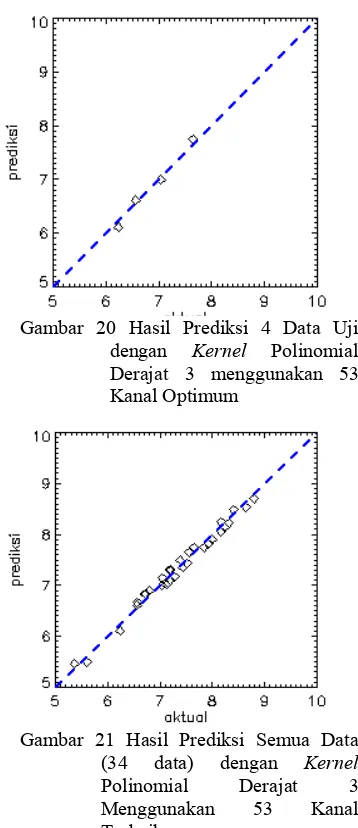
Metode feature selection GA, SVR menghasilkan 53 kanal terbaik, parameter terbaik C = 691.89 dan parameter terbaik γ = 12.72. Dengan menggunakan parameter tersebut, pengujian model SVR menghasilkan nilai RMSE = 0.087dan R2= 0.988 (Gambar 20). Grafik hasil prediksi dengan semua data dapat dilihat pada Gambar 21, dengan nilai RMSE= 0.098 R² = 0.984.
Gambar 19 Hasil Prediksi 4 Data Uji dengan Kernel Polinomial Derajat 3 Menggunakan 109 Kanal
Gambar 20 Hasil Prediksi 4 Data Uji dengan Kernel Polinomial Derajat 3 menggunakan 53 Kanal Optimum
Gambar 21 Hasil Prediksi Semua Data (34 data) dengan Kernel Polinomial Derajat 3 Menggunakan 53 Kanal Terbaik
6 Kernel +$ )+* "$ ","& ;
Perubahan hasil RMSE dan R2 pada pelatihan model dengan kernel polinomial derajat 3 menunjukkan hasil yang cukup signifikan. Oleh karena itu, dicobakan pula metode GA,SVR dengan menggunakan kernel polinomial derajat yang lebih tinggi, yaitu 5.
13 nilai C terbaik = 782.22 dan γ
terbaik = 14.97. Dengan menggunakan nilai,nilai terbaik tersebut RMSE menurun menjadi 0.162 dan R2= 0.98 (Gambar 23). Grafik hasil prediksi semua data dengan parameter dan kanal terbaik dapat dilihat pada Gambar 24 dengan nilai R² = 0.982 dan RMSE= 0.111.
Gambar 22 Hasil Prediksi 4 Data Uji dengan Kernel Polinomial Derajat 5 Menggunakan 109 Kanal
Gambar 23 Hasil Prediksi 4 Data Uji dengan Kernel Polinomial Derajat 5 Menggunakan 50 Kanal Terbaik
Gambar 24 Hasil Prediksi Semua Data (34 data) dengan Kernel Polinomial Derajat 5 Menggunakan 43 Kanal Terbaik
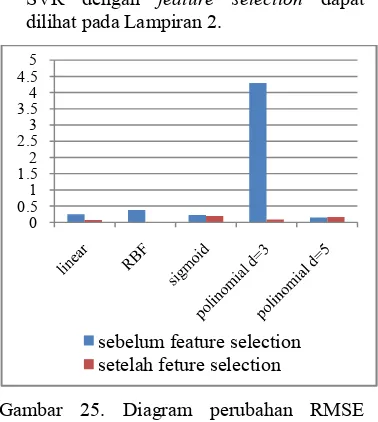
Dari hasil tersebut, untuk setiap SVM dengan berbagai kernel menunjukkan bahwa metode GA,SVM telah menghasilkan kanal terbaik yang dapat menurunkan nilai RMSE dan meningkatkan nilai R2. Penurunan nilai RMSE untuk setiap kernel berbeda. Perubahan nilai RMSE setiap kernel dapat dilihat pada Gambar 25. Secara terperinci perbedaan performa proses training SVR tanpa feature selection dan SVR dengan feature selection dapat dilihat pada Lampiran 2.
Gambar 25. Diagram perubahan RMSE dengan menggunakan berbagai kernel
Gambar 26 memperlihatkan performa setiap kernel yang diukur dengan nilai RMSE. Gambar tersebut menunjukkan bahwa pada mulai dari generasi 20 dan, nilai RMSE yang dihasilkan oleh setiap percobaan dengan kernel berbeda relatif konstan. Penurunan nilai RMSE pada generasi selanjutnya, tidak begitu signifikan. Pada generasi ke,50, nilai RMSE yang paling kecil ditunjukan oleh percobaan dengan menggunakan kernel RBF.
0 0.5 1 1.5 2 2.5 3 3.5 4 4.5 5
Keterangan :
Gambar 26 Perubahan Nila Menggunakan Ber
:6 * ")# "&" 3 "$"&4
-Norm$p
Dari percobaan diperoleh informasi bahwa menunjukkan performa yan dibandingkan kernel lainnya. O dalam percobaan kali ini kaida dicobakan pada kernel RBF. galat dengan kaidah norm recara terperinci pada Tabel tersebut, menunjukkan bahw percobaan norm%1 adalah dibandingkan norm%2 dan nor jumlah kanal yang dihasilka lebih sedikit dibandingkan kanal yang dihasilkan dengan norm,∞ . Dari hasil pelat dengan kernel RBF dan nor parameter C terbaik = 6 parameter γ terbaik = 11.811.
Tabel 2. Perbandingan Hasil dengan Menggunakan Kaidah dapat membandingkan perform
ial derajat 3 ial derajat 5
n Nilai RMSE dengan an Berbagai Kernel i kaidah norm,p hanya RBF. Hasil analisis
Tabel 3 merepresentasikan terbaik dengan bilangan b menunjukkan bahwa kanal kanal terbaik, angka “0” me kanal tersebut bukan kanal
Tabel 3. Konfigurasi kanal
Range
Gambar 27 adalah konfigu yang didapatkan. Ga menunjukkan bahwa kan digunakan untuk mempred padi cenderung berada pada dan daerah puncak nilai tanaman padi.
Gambar 27 Konfigurasi Kan Diperoleh
* '$")
Dari hasil peneliti disimpulkan beberapa hal, ya
1. Proses feature selectio GA,SVR dapat dilakuk kanal dan parameter S proses prediksi produk 2. Hasil prediksi produkt feature selection GA dibandingkan hasil pr
14 sikan konfigurasi kanal gan biner. Angka “1” kanal tersebut adalah menunjukkan bahwa
onfigurasi kanal terbaik Gambar tersebut kanal terbaik yang mprediksi produktivitas a pada daerah cekungan nilai reflektansi profil
si Kanal Terbaik yang
enelitian ini, dapat hal, yaitu:
ection dengan metode ilakukan untuk memilih eter SVR terbaik untuk roduktivitas padi. oduktivitas padi dengan
15 feature selection. Perbaikan ini
ditunjukkan oleh nilai RMSE yang lebih kecil dibandingkan tanpa adanya proses feature selection. Tingkat perbaikan nilai RMSE ini juga tergantung pada jenis kernel dan karakteristik data yang digunakan.
3. Untuk melakukan proses feature selection dengan data hiperspektral yang tersedia, kernel yang paling cocok digunakan adalah RBF.
4. Norm yang paling cocok digunakan adalah norm%1, yang menunjukkan jumlah galat mutlak. Kanal terbaik yang dihasilkan oleh pelatihan SVR yang menggunakan kernel RBF berjumlah 48, dengan nilai R2= 0.99, jumlah galat mutlak = 0.25, dan nilai RMSE= 0.017.
" ")
1. Prediksi produktivitas padi sebaiknya dilakukan untuk setiap fase tumbuh dan varietas padi. Hal ini karena nilai reflektansi tanaman padi pada setiap fase tumbuh berbeda, dan tingkat produksi setiap varietas padi juga berbeda.
2. Untuk meningkatkan akurasi sebaiknya jumlah data diperbanyak.
3. Pengawasan terhadap proses pengambilan data lebih diperketat untuk meminimalisasi kesalahan atau ketidaklengkapan data sehingga tidak ada data yang terbuang percuma.
4. Perlu adanya kajian lebih lanjut mengenai hubungan antara informasi fisis dengan kanal terbaik yang diperoleh untuk melakukan prediksi produktivitas padi.
Basuki A. 2003. Algoritme Genetika. Surabaya: Politeknik Elektro Negeri Surabaya.
Chen et al. 2006. Study of band selection methods of hyperspectral image based on grouping property. Bulletin of Surveying and Mapping. Hal 10,13. Cina.
Evri M. 2004. Rice Yield Prediction by Using Field Spectral Measurement and ASTER Data. [Master Thesis]. Japan: Gifu University.
Gunawan. 2010. Klasifikasi Data Diabetes dengan Menggunakan Support Vector Machine (SVM) dan Algoritme Genetika [skripsi]. Bogor: Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Mulyono Sidik et al. 2011. Pemilihan Fitur Citra Hiperspektral Hymap dan Model Prediksi Padi Menggunakan Algoritma Genetika dan Regresi Komponen Utama. Pertemuan Ilmiah Tahunan Masyarakat Pengindraan Jauh XVIII. Semarang, Jawa Tengah.
Nakariyakul Songyot, David Casasent. 2008. Hiperspektral Ratio Feature Selection : Agricultural Product Inspection Example. Department of Electrical and Computer Engineering. Carnegie Mellon University. Pittsburgh.
Platt JC. 1998. Sequential Minimal Optimization: A Fast Algorithm for Training Support Vector Machines. http://research.microsoft.com/users/jplatt. pdf [10 Desember 2010]
Satriyo Anto N et al. 2003. Support Vector Machine : Teori dan Aplikasinya dalam Bioinformatika.http://asnugroho.net/paper s/ikcsvm.pdf [11 November 2011]
Scheid F. 1990. 2000 Solved Problems In Numerical Analysis. Boston: Boston University.
Schuckman Karen et al. 2006. 4.3 Hyperspectral Remote Sensing Systems. PENNSTATE, College of Earth and Mineral Science. https://www.e, education.psu.edu/geog883/node/463. [11 November 2011]
Vijayakumar Sethu, Si Wu. 1999. Sequential Support Vector Classifiers and Regression. International Conference on Soft Computing(SOCO’99). Genoa, Italy.
17
Lampiran 1.
Tabel Hasil Percobaan Training SVR dengan Berbagai Variasi Nilai C dan γ.
ϒ C 100 500 1000 1500 2000 2300 2500 2600
0.8
RMSE 0.560 0.482 0.431 0.391 0.357 0.339 0.327 0.321
R2 0.554 0.768 0.826 0.856 0.886 0.902 0.913 0.917
3
RMSE 0.486 0.297 0.190 0.124 0.099 0.098 0.098 0.098
R2 0.749 0.934 0.980 0.988 0.988 0.988 0.988 0.988
5
RMSE 0.427 0.187 0.098 0.098 0.098 0.098 0.098 0.098
R2 0.828 0.978 0.986 0.987 0.987 0.987 0.987 0.987
10
RMSE 0.291 0.096 0.096 0.096 0.096 0.096 0.096 0.096
R2 0.926 0.989 0.989 0.989 0.989 0.989 0.988 0.989
12
RMSE 0.291 0.096 0.096 0.096 0.096 0.096 0.096 0.096
R2 0.926 0.988 0.989 0.989 0.989 0.989 0.989 0.989
15
RMSE 0.187 0.098 0.097 0.098 0.097 0.097 0.098 0.098
18 Lampiran 2
Hasil Perbandingan hasil uji tanpa feature selection dan dengan feature selection
Kernel
Tanpa feature selection Dengan feature selection 4 data uji Penu,
runan
RMSE
(%)
kanal C γ RMSE R2 kanal C γ RMSE R2
Linear 109 1000 , 0.255 0.971 43 906.74 , 0.071 0.79 72.17
RBF 109 1000 15 0.376 0.995 54 560.55 11.06 0.017 0.99 95.44
Sigmoid 109 1000 15 0.229 ,0.546 61 938.48 12.5 0.189
0.33 3
17.90
Polinomial
d=3 109 1000 15 4.296 0.411 53 691.89 12.72 0.087 0.98 97.97
Polinomial
19 Lampiran 3.
Gambar Contoh Format Penulisan Data Hiperspektral dalam File *.txt
20 Lampiran 4
21 Lampiran 5
Proses feature selection
, Button / yang pertama untuk memasukan data hiperspektral
, Button / yang kedua untuk memasukan data produktivitas padi (yield) , Label untuk memasukan generasi maksimum yang diizinkan.
, Button untuk memulai proses eksekusi program
22 Lampiran 6