CLUSTERING
PAKAN TERNAK RUMINANSIA
BERDASARKAN KANDUNGAN KIMIA MENGGUNAKAN
ENHANCED
K-MEANS
FITRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA
Dengan ini saya menyatakan bahwa skripsi berjudul Clustering Pakan Ternak Ruminansia Berdasarkan Kandungan Kimia Menggunakan Enhanced K-Means adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Agustus 2015
Fitri
ABSTRAK
FITRI. Clustering Pakan Ternak Ruminansia Berdasarkan Kandungan Kimia Menggunakan Enhanced K-Means. Dibimbing oleh AZIZ KUSTIYO dan ANURAGA JAYANEGARA.
Peternak sering mengalami kesulitan dalam penggantian suatu pakan dengan pakan lain agar kebutuhan ternak tetap terpenuhi. Oleh karena itu, perlu diketahui pakan-pakan yang mirip berdasarkan kandungan kimia pakan. Tujuan penelitian ini adalah melakukan clustering pakan ternak ruminansia berdasarkan kandungan kimia menggunakan enhanced k-means. Enhanced k-means meningkatkan akurasi dengan menentukan nilai centroid awal secara sistematis dan menemukan cara yang efisien untuk melalukan clustering. Kandungan kimia yang digunakan sebagai
input untuk clustering adalah kategori main constituents dan ruminant nutritive
values. Data penelitian berjumlah 96 jenis pakan ternak ruminansia bersumber dari National Institute for Agricultural Research (INRA). Data ini adalah input untuk algoritme enhanced k-means. Hasil clustering dievaluasi menggunakan indeks Davies-Bouldin (DBI). Nilai DBI terkecil pada penelitian ini sebesar 5.58, diperoleh pada ukuran cluster 10.
Kata kunci: clustering, enhanced k-means, pakan, ruminansia
ABSTRACT
FITRI. Clustering Ruminant Feed by Chemical Composition Using Enhanced K-Means. Supervised by AZIZ KUSTIYO dan ANURAGA JAYANEGARA.
Breeders often have difficulties in substituting a feed with other feed in order to make livestock needs are fulfilled. Therefore, breeders need to know the feed that are similar based on the chemical composition of the feed. The purpose of this study is to perform clustering ruminant feed based chemical composition using the enhanced k-means. Enhanced k-means improves the accuracy to determine the value of the initial centroid systematically and creates clustering efficiently. Chemical composition that are used as input are the main constituents and ruminants nutritive values. Research data consist of 96 types of fodder sourced from National Institute for Agricultural Research (INRA). The data are used as input for enhanced k-means algorithm. Clustering result is evaluated using Davies-Bouldin index (DBI). DBI minimal value in this study is 5.58 with cluster size 10.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Komputer
pada
Departemen Ilmu Komputer
CLUSTERING
PAKAN TERNAK RUMINANSIA
BERDASARKAN KANDUNGAN KIMIA MENGGUNAKAN
ENHANCED
K-MEANS
FITRI
DEPARTEMEN ILMU KOMPUTER
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Clustering Pakan Ternak Ruminansia Berdasarkan Kandungan Kimia Menggunakan Enhanced K-Means
Nama : Fitri
NIM : G64110006
Disetujui oleh
Aziz Kustiyo, SSi MKom Pembimbing I
Dr Anuraga Jayanegara, SPt MSc Pembimbing II
Diketahui oleh
Dr Ir Agus Buono, MSi MKom Ketua Departemen
PRAKATA
Puji dan syukur penulis panjatkan kepada Tuhan Yang Maha Esa atas segala karunia-Nya sehingga skripsi ini berhasil diselesaikan. Tema yang dipilih dalam penelitian ini ialah pakan ternak ruminansia, dengan judul Clustering Pakan Ternak Ruminansia Berdasarkan Kandungan Kimia Menggunakan Enhanced K-Means.
Penulis mengucapkan banyak terima kasih kepada berbagai pihak yang telah membantu dalam penyelesaian tugas akhir ini, antara lain kepada:
1 Orang tua (Bapak Tiong Heng Alias Herman dan Ibu Bie Kwan), dan keluarga penulis yang telah memberikan doa dan dukungan, terlebih kepada abang kedua saya yang banyak mengajarkan penulis dalam menyelesaikan tugas akhir. 2 Aziz Kustiyo, SSi MKom dan Dr Anuraga Jayanegara, SPt MSc sebagai
pembimbing skripsi yang telah membimbing dengan sabar serta memberi masukan dan motivasi kepada penulis.
3 Hari Agung Adrianto, SKom MSi sebagai dosen penguji yang memberikan kritik dan saran untuk perbaikan penelitian ini.
4 Seluruh dosen dan staf Departemen Ilmu Komputer yang membantu penulis selama menempuh perkuliahan.
5 Teman-teman satu bimbingan yang setopik: Selma dan Ulfa atas bantuan dan dukungan yang diberikan.
6 Fadil, Ira, Citra, dan teman-teman seperjuangan Ilmu Komputer angkatan 48 atas segala bantuan, dukungan dan kenangan bagi penulis selama menjalani masa studi.
Semoga skripsi ini bermanfaat bagi pihak yang membutuhkannya.
Bogor, Agustus 2015
DAFTAR ISI
DAFTAR TABEL viii
DAFTAR LAMPIRAN viii
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 2
Tujuan Penelitian 2
Manfaat Penelitian 2
Ruang Lingkup Penelitian 2
TINJAUAN PUSTAKA 3
METODE 5
Data Penelitian 5
Tahapan Penelitian 5
Praproses Data 5
Clustering Menggunakan Enhanced K-Means 5
Validasi Cluster Menggunakan Indeks Davies-Bouldin 6
Representasi Pengetahuan 6
Lingkungan Pengembangan 6
HASIL DAN PEMBAHASAN 7
Pengumpulan Data 7
Praproses Data 7
Clustering Menggunakan Enhanced K-Means 7
SIMPULAN DAN SARAN 13
Simpulan 13
Saran 13
DAFTAR PUSTAKA 14
LAMPIRAN 15
vi
DAFTAR TABEL
1 Indeks Davies-Bouldin terbaik untuk tiap ukuran cluster 8 2 Jumlah anggota masing-masing cluster pada setiap perlakuan yang
memiliki DBI minimal 8
3 Anggota hasil clustering perlakuan 1 dengan ukuran cluster 8 9 4 Anggota hasil clustering perlakuan 2 dengan ukuran cluster 8 10 5 Anggota hasil clustering perlakuan 3 dengan ukuran cluster 10 11 6 Karakteristik masing-masing cluster berdasarkan centroid cluster
pada perlakuan 1 dengan ukuran cluster 8 12
7 Karakteristik masing-masing cluster berdasarkan centroid cluster pada perlakuan 3 dengan ukuran cluster 10 12
DAFTAR LAMPIRAN
1 Data pakan ternak ruminansia perlakuan 1 15
2 Centroid akhir hasil clustering perlakuan 1 dengan ukuran cluster 8 18 3 Centroid akhir hasil clustering perlakuan 2 dengan ukuran cluster 8 19 4 Centroid akhir hasil clustering perlakuan 3 dengan ukuran cluster 10 20
PENDAHULUAN
Latar Belakang
Pakan adalah semua bahan pakan yang mengandung zat-zat yang diperlukan tubuh ternak seperti karbohidrat, lemak, protein, mineral, dan air (Parakkasi 1999). Pakan ternak harus terjaga kualitas dan kuantitasnya agar proses produksi yang dihasilkan menjadi baik (Anas et al. 2011). Kebutuhan ternak akan pakan terdiri atas kebutuhan hidup pokok dan kebutuhan produksi. Ternak yang memperoleh makanan yang hanya cukup untuk kebutuhan hidup pokok, bobot badannya akan tetap. Ternak yang memperoleh makanan lebih dari kebutuhan hidup pokok, maka sebagian kelebihan makanan akan digunakan untuk kebutuhan produksi (Tillman
et al. 1984). Salah satu ternak yang hasil produksinya banyak digunakan adalah ruminansia.
Ternak ruminansia merupakan ternak yang sistem pencernaan makanannya didahului proses fermentasi biologis dalam tubuh, misalnya domba, kambing, kerbau, dan sapi (Rukmana 2001). Hasil produksi ternak ruminansia banyak diperlukan untuk kebutuhan sehari-hari manusia seperti produksi susu, konsumsi daging, bulu wol, dan lain-lain. Produktivitas ternak ruminansia dipengaruhi oleh faktor kualitas pakan. Pakan berkualitas baik dapat meningkatkan produksi ternak (McIlroy 1977). Pakan berkualitas baik merupakan pakan yang disukai ternak (palatabel), mudah dicerna dan kandungan proteinnya tinggi. Kemampuan ternak dalam mencerna pakan menjadi daging (kebutuhan produksi) juga sangat tergantung dari kandungan kimianya yaitu protein, energi, dan serat kasar (Soewardi 1974).
Sayangnya, peternak mengalami kesulitan dalam penggantian suatu pakan dengan pakan lain agar kebutuhan ternak tetap terpenuhi. Pemberian jenis pakan sering berganti dengan jumlah nutrisi yang tidak memenuhi kebutuhan. Penggantian pakan biasanya terjadi saat musim panen padi. Sapi yang biasanya diberi pakan hijauan berupa rumput diganti dengan jerami sisa panen yang kandungan nutrisinya lebih rendah (Fikar dan Ruhyadi 2010). Pemberian pakan berkualitas rendah belum dapat mencukupi kebutuhan hidup pokok dan produksi. Oleh karena itu, perlu usaha untuk membantu peternak dalam pemberian pakan. Berbagai penelitian telah dikembangkan untuk mengetahui pakan yang kandungan kimianya dicerna secara tepat. Penelitian terkait dilakukan Febrisahrozi (2014) untuk mengestimasi nilai kecernaan pakan ternak ruminansia melalui kandungan utama pakan menggunakan metode artificial neural network (ANN). Struktur ANN yang dibangun dapat mengestimasi nutrien dengan baik, ditunjukkan oleh RMSE terkecil bernilai 3.33 yang diperoleh dari struktur ANN dengan empat neuron hidden layer. Dengan estimasi kecernaan yang baik, dapat diketahui pakan yang benar-benar dicerna tetapi penggantian pakan masih sulit dilakukan.
Tidak cukup sampai tahap estimasi, pakan perlu dikelompokkan berdasarkan kandungan kimia agar dapat diketahui pakan-pakan yang mirip. Dengan begitu, biaya pakan dapat diturunkan dengan memilih pakan yang paling murah dalam satu
cluster. Selain itu, ketika suplai suatu pakan kosong, pakan tersebut dapat digantikan pakan lain yang berada dalam satu cluster. Pada penelitian ini, dilakukan
2
merupakan proses pengelompokan sekumpulan objek ke dalam kelas yang objeknya mirip (Han et al. 2011). Kandungan kimia yang dijadikan inputclustering adalah main constituents (kandungan utama pakan) dan ruminant nutritive values (nilai kecernaan pakan). K-Means merupakan algoritme yang komputasinya tinggi dan hasil pengelompokannya sangat bergantung pada pemilihan centroid awal. Penelitian menggunakan algoritme enhanced k-means karena enhanced k-means lebih akurat dan efisien dibanding k-means. Enhanced k-means menemukan
centroid awal yang lebih baik dan menemukan cara yang efisien untuk melakukan
clustering (Abdul-Nazeer dan Sebastian 2009).
Perumusan Masalah
Melihat kesulitan peternak dalam penggantian suatu pakan dengan pakan lain, maka rumusan masalah penelitian ini adalah melakukan clustering pakan ternak ruminansia berdasarkan kandungan kimia menggunakan enhanced k-means.
Tujuan Penelitian
Tujuan dari penelitian ini adalah melakukan clustering pakan ternak ruminansia (kambing, domba, dan sapi) berdasarkan kandungan kimia yang terdapat dalam pakan menggunakan enhanced k-means.
Manfaat Penelitian
Manfaat dari penelitian ini adalah memberi pertimbangan bagi peternak dalam memberi pakan ternak ruminansia sehingga kebutuhan biaya pakan rendah dan produktivitas ternak tinggi. Selain itu, ketika suplai pakan kosong, peternak dapat memberikan pakan lain yang mirip dengan pakan tersebut.
Ruang Lingkup Penelitian
Ruang lingkup penelitian adalah:
1 Data penelitian merupakan bahan pakan ternak ruminansia yang biasa digunakan Negara Prancis yang bersumber dari National Institute for Agricultural Research (INRA) (Bontems et al. 2004).
2 Kandungan kimia yang dijadikan sebagai input clustering merupakan main
constituents (kandungan utama) dan ruminant nutritive values (nilai kecernaan pakan). Main constituents merupakan kandungan utama yang terdapat dalam pakan. Ruminant nutritive values menyatakan banyaknya komposisi nutrisi suatu bahan maupun energi yang dapat diserap dan digunakan. Output clustering merupakan cluster sejumlah k tertentu.
3
TINJAUAN PUSTAKA
Kandungan Kimia pada Tumbuhan Pakan Ternak
Menurut Givens et al. (2000), kandungan kimia pada tumbuhan pakan ternak terdiri atas empat kategori, yaitu main analysis (constituents), mineral, asam amino, dan metabolit sekunder. Beberapa istilah yang sering dijumpai dalam main
constituents, yaitu:
3 Lemak kasar (ether extract): semua senyawa pada pakan yang dapat larut dalam pelarut organik.
4 Abu (ash): sisa hasil pengabuan yang terkandung pada bagian pakan.
5 Neutral-detergent fiber: ukuran yang digunakan untuk mengestimasi jumlah makanan yang dapat diterima hewan.
6 Acid detergent fiber: ukuran yang digunakan untuk mengestimasi energi yang akan diperoleh dari pakan yang dapat digunakan hewan.
7 Lignin: bagian dinding sekunder tumbuhan yang berupa polimer kompleks, biasa terakumulasi pada batang tumbuhan berkayu dan semak.
8 Energi bruto (gross energy): jumlah kalor (panas) hasil pembakaran pakan dalam bom kalorimeter.
Beberapa penjelasan untuk main constituents lainnya menurut Bontems et al. (2004).
1 Insoluble ash: abu yang tidak larut.
2 Insoluble cell water: bagian dinding sel tanaman yang tidak larut dalam air. 3 Starch: pati (sumber energi)
4 Total sugars: total gula yang terkandung dalam pakan.
Ruminant nutritive values terdiri atas unité fourragère lait (UFL), unité
fourragère viande (UFV), protéine digestible dans l’intestin d’origine alimentaire (PDIA), metabolisable energy (ME), energy digestibility (Ed), organic matter
digestibility (OMd), nitrogen digestibility value (Nd), dan true intestinal
digestibility (TId). UFL merupakan indeks energi untuk produksi susu. UFV menunjukkan unit pakan yang diperlukan agar menghasilkan 1 kg daging. PDIA adalah jumlah protein yang dapat dicerna di usus halus. ME adalah energi yang dapat dicerna dan digunakan. Ed merupakan kecernaan energi dan OMd merupakan banyaknya komponen gizi yang dapat dicerna di saluran pencernaan. Nd adalah persentase nitrogen yang dicerna terhadap kandungan nitrogen dalam pakan. TId adalah nilai suatu kandungan kimia yang benar-benar dicerna oleh usus (Bontems
et al. 2004).
Algoritme Enhanced K-Means
4
pada EKM ditingkatkan dengan membandingkan jarak titik dalam cluster terhadap iterasi sebelum dan iterasi sesudah. Tahapan algoritme EKM terdiri atas (Abdul-Nazeer dan Sebastian 2009):
Tahap finding the initial centroids
Input:
D = {d1, d2,...,dn} // set of n data-points k //number of desired clusters
Output: A set of k initial centroids Steps:
1 1 Set m=1;
2 Compute the distance between each data point and all other data-points in the set D;
3 Find the closest pair of data points from the set D and form a data-point set Am (1<= m <=k) which contains these two data-points, Delete these two data points from the set D;
4 Find the data point in D that is closest to the datapoint set Am, Add it to Am and delete it from D;
5 Repeat step 4 until the number of data points in Am reaches 0.75*(n/k);
6 If m<k, then m = m+1, find another pair of datapoints from D between which the distance is the shortest, form another data-point set Am and delete them from D, Go to step 4;
7 For each data-point set Am (1<=m<=k) find the arithmetic mean of the vectors of data points in Am, these means will be the initial centroids.
Tahap assigning data-points to clusters
Input: centroids cj (1<=j<=k) as d(di, cj);
2 For each data-point di, find the closest centroid cj and assign di to cluster j.
3 Set ClusterId[i]=j; // j:Id of the closest cluster
4 Set Nearest_Dist[i]=d(di,cj);
5 For each cluster j (1<=j<=k), recalculate the centroids;
6 Repeat
7 For each data-point di,
7.1 Compute its distance from the centroid of the present nearest cluster;
7.2 If this distance is less than or equal to the present nearest distance, the data-point stays in the cluster;
Else
7.2.1 For every centroid cj (1<=j<=k) Compute the distance d(di, cj); Endfor;
7.2.2 Assign the data-point dito the cluster with the nearest centroid cj
7.2.3 Set ClusterId[i]=j;
7.2.4 Set Nearest_Dist[i]= d(di, cj); Endfor;
5
METODE
Data Penelitian
Data penelitian bersumber dari National Institute for Agricultural Research (INRA) (Bontems et al. 2004). Berbagai jenis pakan ternak dimuat dalam buku tersebut, di antaranya pakan ikan, kuda, kelinci, kambing, domba, sapi, babi, dan unggas. Data yang digunakan hanya pakan ternak ruminansia (kambing, domba, dan sapi). Data tersebut akan dikelompokkan menurut kandungan kimia dalam pakan.
Tahapan Penelitian
Tahapan penelitian yang dilakukan dalam penerapan enhanced k-means untuk melakukan clustering dapat dilihat pada Gambar 1.
Gambar 1 Diagram tahapan penelitian
Praproses Data
Tahapan praproses data pakan ternak ruminansia dimulai dengan normalisasi data dan penanganan terhadap data kosong. Jenis pakan dan variabel yang kosong akan dihapus. Selain itu, variabel kosong diisi dengan nilai rata-rata variabel dan diganti dengan nilai variabel yang mempunyai korelasi tertinggi dengan variabel yang kosong. Sebelum dilakukan penanganan terhadap data kosong, data dinormalisasi menggunakan metode minimum-maksimum dengan Persamaan 1 (Han et al. 2011):
x'
=
xx - xminmax-xmin (1)
dengan x adalah titik dalam suatu cluster, xmin dan xmax adalah titik minimum dan maksimum pada suatu variabel clustering.
Clustering Menggunakan Enhanced K-Means
Metode yang digunakan pada penelitian ini adalah clustering data menggunakan enhanced k-means untuk melihat karakteristik pakan ternak ruminansia berdasarkan kandungan kimia. Kandungan kimia yang dijadikan input
6
untuk clustering adalah main constituents dan ruminant nutritive values. Output yang dihasilkan pada penelitian ini yaitu cluster pakan ternak ruminansia sejumlah
cluster tertentu. Fungsi jarak yang digunakan ialah jarak Euclid.
Validasi Cluster Menggunakan Indeks Davies-Bouldin
Validasi cluster adalah prosedur evaluasi hasil analisis cluster secara kuantitatif dan objektif (Jain dan Dubes 1988). Evaluasi kuantitatif dapat dilakukan menggunakan indeks validitas. Indeks Davies-Bouldin (DBI) merupakan indeks validitas yang digunakan untuk mengukur kinerja enhanced k-means dalam proses
clustering. Pengukuran DBI memaksimalkan jarak antar cluster dan meminimalkan jarak setiap titik dalam sebuah cluster. DBI dihitung menggunakan Persamaan 2 (Zaki dan Meira 2014):
DB(nc)=nc1 ∑ max
l≠k {
∑i‖XiNk-Ck‖ + ∑i‖XiNl-Cl‖
‖Ck-Cl‖ } nc
k=1 (2)
dengan Nk dan Nl adalah banyak titik yang termasuk dalam clusterQk dan Ql, Ck dan Cl adalah centroid dari clusterQk dan Ql, dan nc adalah banyak cluster. Hasil
clustering yang optimal memiliki DBI minimal. Dari 2 sampai 10 cluster yang dihasilkan akan dilihat hasil clustering yang mempunyai DBI minimal. Hasil
clustering terbaik akan dianalisis sehingga diperoleh informasi mengenai cluster tersebut.
Representasi Pengetahuan
Setelah tahap validasi, representasi akan dilakukan terhadap cluster. Hasil representasi pengetahuan berupa karakteristik masing-masing cluster. Karakteristik tersebut dianalisis dari centroid setiap cluster. Dengan analisis tersebut, diharapkan informasi yang diperoleh dapat menjadi pertimbangan saat peternak memberi pakan ternak ruminansia.
Lingkungan Pengembangan
7
HASIL DAN PEMBAHASAN
Pengumpulan Data
Penelitian ini berfokus pada data pakan ternak ruminansia. Data pakan ternak yang dimasukkan ke database hanya yang telah selesai dianalisis kandungan kimianya. Kandungan kimia yang dijadikan input clustering merupakan main
constituents dan ruminant nutritive values. Pakan ternak ruminansia berjumlah 96 jenis pakan dan memiliki 20 variabel (12 variabel main constituents dan 8 variabel
ruminant nutritive value). Data penelitian untuk perlakuan 1 disajikan pada Lampiran 1.
Praproses Data
Tahapan praproses meliputi normalisasi data dan penanganan data kosong. Normalisasi data dilakukan untuk mendapatkan akurasi hasil cluster yang lebih baik. Pada penelitian ini, EKM menggunakan jarak Euclid untuk menghitung kedekatan antar jenis pakan. Variabel atau kandungan kimia setiap pakan mempunyai rentang nilai berbeda-beda dan cukup besar. Dengan rentang nilai yang cukup besar, hasil cluster akan cenderung berisi pakan yang nilai kandungan kimianya tinggi. Hal ini menyebabkan hasil cluster kurang akurat. Oleh karena itu, dilakukan normalisasi data agar data mempunyai rentang nilai yang sama.
Pada tahap berikutnya, data diberi 4 perlakuan penanganan data kosong. Pada perlakuan 1, pakan yang nilai input clustering-nya kosong dihilangkan sehingga data berjumlah 46 jenis pakan. Perlakuan 2 membuang input clustering yang nilainya tidak lengkap, inputclustering yang tersisa berjumlah 11 input. Pengisian data kosong dilakukan pada perlakuan 3 dan 4. Perlakuan 3 mengisi nilai input
clustering yang kosong dengan rata-rata input clustering tersebut sehingga data berjumlah tetap yaitu 97 jenis pakan dan 20 inputclustering. Perlakuan 4 menduga nilai input clustering yang kosong dengan persamaan regresi. Persamaan regresi yang dilakukan merupakan persamaan yang memiliki korelasi tertinggi. Setelah dicari korelasi tertinggi dan persamaan regresinya, didapati kurang tepat untuk menduga nilai kosong dengan persamaan regresi pada kasus ini. Kekurangtepatan ini disebabkan adanya variabel x dan y yang kosong secara bersamaan. Ketika ingin menduga variabel y menggunakan variabel x, variabel x kosong sehingga variabel
y tidak bisa diduga. Oleh karena itu, perlakuan 4 ditiadakan. Clustering Menggunakan Enhanced K-Means
8
Indeks Davies-Bouldin (DBI)
Setiap hasil clustering EKM divalidasi menggunakan nilai DBI. Nilai DBI minimal menunjukkan hasil clustering paling optimal. Hasil pengamatan DBI masing-masing perlakuan dengan ukuran cluster 2 sampai 10 disajikan pada Lampiran 5. DBI terbaik untuk tiap perlakuan dapat dilihat pada Tabel 1.
Tabel 1 Indeks Davies-Bouldin terbaik untuk tiap ukuran cluster Ukuran cluster Perlakuan DBI
8 1 1.08
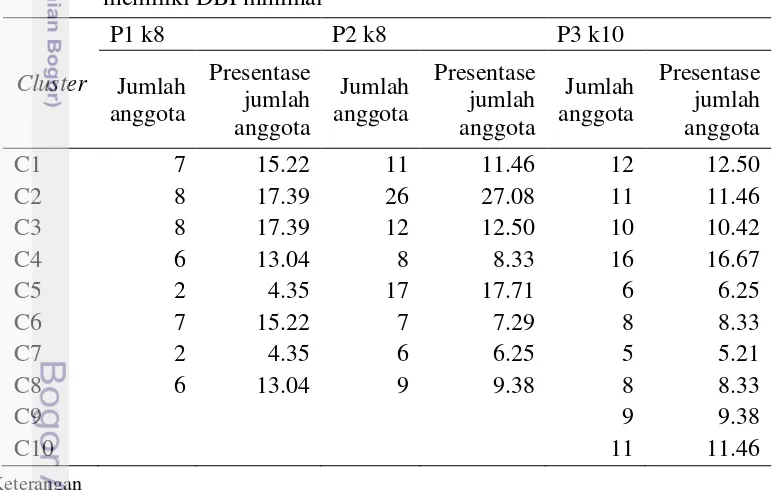
cluster pada setiap perlakuan yang memiliki DBI minimal dapat dilihat pada Tabel 2. Centroid hasil clustering masing-masing perlakuan dengan DBI minimal disajikan pada Lampiran 2, 3, dan 4. Anggota hasil clustering masing-masing perlakuan dengan DBI minimal ditunjukkan pada Tabel 3, 4, dan 5.
9
Tabel 3 Anggota hasil clustering perlakuan 1 dengan ukuran cluster 8
Cluster Anggota
C1 Corn gluten meal, lupin blue, lupin white, soybean full fat extruded, soybean meal 46, soybean meal 48, dan soybean meal 50
C2 Barley, maize, shorgum, triticale, wheat soft, rice broken, chickpea, dan pea
C3 Oat, wheat bran, wheat middlings, wheat bran durum, wheat gluten feed starch 28%, maize feed flour, beet pulp pressed, dan citrus pulp dried C4 Corn gluten feed, maize bran, rice bran extracted, rice bran full fat, beet
pulp dried, dan beet pulp dried molasses added C5 Cassava starch 67% dan cassava starch 72%
C6 Wheat distillers grains starch < 7% 110, copra meal expeller, cottonseed meal crude fibre 7-14%, cottonseed meal crude fibre 14-20%, rapeseed meal, sunflower meal partially decorticated, dan sunflower meal undecorticated
C7 Rapeseed full fat dan sunflower seed full fat
C8 Cottonseed full fat 146, palm kernel meal expeller, carob pod meal, soybean hulls, alfalfa dehydrated protein < 16% dry matter, dan alfalfa dehydrated protein 18-19% dry matter
Deskripsi Hasil Cluster
Hasil cluster akan dideskripsikan untuk memperoleh karakteristik kelompok pakan ternak ruminansia. Dari hasil pengamatan perlakuan 1 sampai perlakuan 3, diperoleh nilai DBI minimal berturut-turut sebesar 1.08, 5.82, dan 5.58. DBI minimal dimiliki masing-masing perlakuan dengan ukuran cluster 8, 8, dan 10.
Tabel 3, 4, dan 5 menunjukkan anggota masing-masing cluster untuk perlakuan 1, 2, dan 3 dengan ukuran cluster berturut-turut 8,8, dan 10. Perbandingan yang dilakukan terlebih dahulu adalah perlakuan 2 dan perlakuan 3 karena jumlah data yang dikelompokkan sama. Anggota hasil clustering perlakuan 2 dan perlakuan 3 memiliki kemiripan walaupun ukuran cluster dan letak anggota pada
cluster berbeda. Hal ini ditunjukkan dengan adanya isi cluster yang semuanya sama yaitu C3 pada perlakuan 2 sama dengan C1 pada perlakuan 3 dan C7 pada perlakuan 2 sama dengan C5 pada perlakuan 3. Selain itu, terdapat cluster yang semua isinya sama dengan sebagian isi cluster perlakuan lainnya yaitu semua C2 pada perlakuan 3 merupakan C2 pada perlakuan 2 dan semua C3 pada perlakuan 3 merupakan C5 pada perlakuan 2. Selebihnya, cluster memiliki sebagian anggota yang sama dan sebagian berbeda. Perbandingan selanjutnya yang dilakukan yaitu perlakuan 1 dan 3 karena hasil clustering perlakuan 2 dengan 3 memiliki kemiripan dan DBI perlakuan 3 lebih optimal dibanding perlakuan 2.
10
Tabel 4 Anggota hasil clustering perlakuan 2 dengan ukuran cluster 8
Cluster Anggota
1 Barley rootlets dried, cottonseed full fat 146, cocoa meal extracted, grapeseed oil meal solvent extracted, buckwheat hulls, carob pod meal, cocoa hulls, grape marc dried, grape seeds, soybean hulls, dan alfalfa dehydrated protein < 16% dry matter
2 Barley, maize, rice brown, rye, triticale, wheat durum, wheat soft, wheat feed flour, corn distillers, corn gluten meal, maize germ meal expeller, maize germ meal solvent extracted, hominy feed, rice broken, chickpea, faba bean coloured flowers, faba bean white flowers, lupin blue, lupin white, pea, soybean full fat extruded, copra meal expeller, cottonseed meal crude fibre 7-14%, groundnut meal detoxified crude fibre > 9%, sunflower meal partially decorticated, dan citrus pulp dried 3 Groundnut meal detoxified crude fibre < 9%, soybean meal 46, soybean meal 48, soybean meal 50, maize starch, alfalfa protein concentrate, brewers yeast dried, potato protein concentrate, milk powder skimmed, milk powder whole, whey powder acid , dan whey powder sweet 4 Wheat bran, wheat bran durum, maize bran, rice bran extracted, rice
bran full fat, soybean full fat toasted, alfalfa dehydrated protein 22-25% dry matter, dan grass dehydrated
5 Oat Groats, wheat middlings, wheat shorts, wheat middlings durum, wheat distillers grains starch < 7% 110, wheat distillers grains starch > 7%, wheat gluten feed starch 25%, wheat gluten feed starch 28%, corn gluten feed, maize feed flour, linseed full fat, cottonseed meal crude fibre 14-20%, linseed meal expeller, linseed meal solvent extracted, potato tuber dried, beet pulp dried, dan beet pulp dried molasses added 6 Brewers dried grains, sunflower meal undecorticated, cassava starch 67%, cassava starch 72%, sweet potato dried, beet pulp pressed, dan liquid potato feed
7 Sesame meal expeller, molasses beet, molasses sugarcane, vinasse different origins, vinasse from the production of glutamic acid, dan vinasse from yeast production
8 Oat, Shorgum, rapeseed full fat, sunflower seed full fat, palm kernel meal expeller, rapeseed meal, potato pulp dried, alfalfa dehydrated protein 17-18% dry matter, dan alfalfa dehydrated protein 18-19% dry matter
11
Tabel 5 Anggota hasil clustering perlakuan 3 dengan ukuran cluster 10
Cluster Anggota
C1 Groundnut meal detoxified crude fibre < 9%, soybean meal 46, soybean meal 48, soybean meal 50, maize starch, slfalfa protein concentrate, brewers yeast dried, potato protein concentrate, milk powder skimmed, milk powder whole, whey powder acid, dan whey powder sweet
C2 Barley, maize, triticale, wheat durum, wheat soft, wheat feed flour, rice broken, chickpea, faba bean coloured flowers, faba bean white flowers, dan pea
C3 Wheat middlings durum, wheat distillers grains starch < 7% 110, wheat distillers grains starch > 7%, wheat gluten feed starch 25%, wheat gluten feed starch 28%, corn gluten feed, linseed meal expeller, linseed meal solvent extracted, beet pulp dried, dan beet pulp dried molasses added
C4 Oat, shorgum, wheat bran, wheat bran durum, maize bran, rice bran extracted, rice bran full fat, rapeseed full fat, sunflower seed full fat, palm kernel meal expeller, rapeseed meal, potato pulp dried, alfalfa dehydrated protein 17-18% dry matter, alfalfa dehydrated protein 18-19% dry matter, alfalfa dehydrated protein 22-25% dry matter, dan grass dehydrated
C5 Sesame meal expeller, molasses beet, molasses sugarcane, vinasse different origins, vinasse from the production of glutamic acid, dan vinasse from yeast production
C6 Rye, wheat middlings, wheat shorts, maize germ meal expeller, maize germ meal solvent extracted, hominy feed, lupin white, dan soybean full fat extruded
C7 Brewers dried grains, cottonseed meal crude fibre 14-20%, sunflower meal undecorticated, beet pulp pressed, dan liquid potato feed
C8 Oat Groats, maize feed flour, linseed full fat, soybean full fat toasted, cassava starch 67%, cassava starch 72%, potato tuber dried, dan sweet potato dried
C9 Rice brown, corn distillers, corn gluten meal, lupin blue, copra meal expeller, cottonseed meal crude fibre 7-14%, groundnut meal detoxified crude fibre > 9%, sunflower meal partially decorticated, dan citrus pulp dried
C10 Barley rootlets dried, cottonseed full fat 146, cocoa meal extracted, grapeseed oil meal solvent extracted, buckwheat hulls, carob pod meal, cocoa hulls, grape marc dried, grape seeds, soybean hulls, dan alfalfa dehydrated protein < 16% dry matter
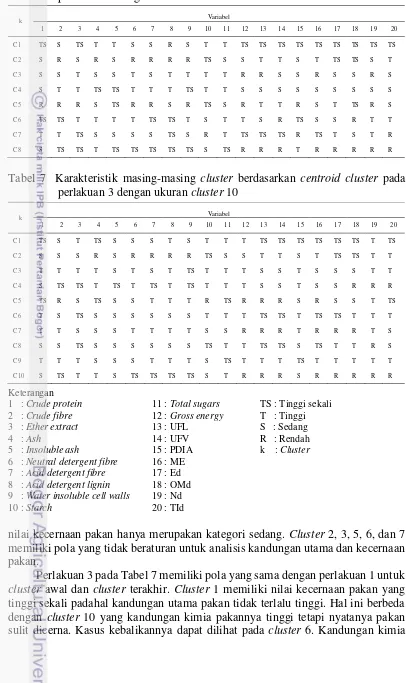
Berdasarkan data pada Tabel 6 dan Tabel 7, diketahui bahwa perlakuan 1 dan 3 memiliki beberapa pola yang dapat dikenali. Tabel 6 menunjukkan bahwa
12
Tabel 6 Karakteristik masing-masing cluster berdasarkan centroid cluster pada perlakuan 1 dengan ukuran cluster 8
k Variabel
Tabel 7 Karakteristik masing-masing cluster berdasarkan centroid cluster pada perlakuan 3 dengan ukuran cluster 10
k Variabel
nilai kecernaan pakan hanya merupakan kategori sedang. Cluster 2, 3, 5, 6, dan 7 memiliki pola yang tidak beraturan untuk analisis kandungan utama dan kecernaan pakan.
Perlakuan 3 pada Tabel 7 memiliki pola yang sama dengan perlakuan 1 untuk
13
pakan pada cluster 6 kebanyakan berkategori sedang namun nilai kecernaan pakan yang dihasilkan termasuk kategori tinggi. Melihat hasil analisis pada perlakuan 1 dan 3, diketahui bahwa pakan yang kandungan kimianya tinggi belum tentu memiliki nilai kecernaan pakan yang tinggi dan begitu sebaliknya.
Pakan yang terdapat dalam satu cluster memiliki karakteristik yang mirip. Dengan mengetahui kemiripan karakteristik pakan, hal ini berguna dalam formulasi ransum pakan. Peternak dapat memberikan substitusi pakan yang harganya lebih murah sehingga biaya untuk pakan rendah tetapi produksi ternak tetap tinggi. Selain itu, ketika suplai pakan yang diinginkan kosong, pakan tersebut bisa diganti dengan pakan lain dalam satu cluster. Misal ternak sedang membutuhkan kandungan protein yang tinggi. Bila dilihat karakteristik hasil clustering perlakuan 3 pada Tabel 7, cluster 1 memiliki kandungan protein kasar (variabel 1) dan nilai kecernaan protein (variabel 15) yang tinggi sekali. Berdasarkan data anggota hasil clustering perlakuan 3 pada Tabel 5, bila persedian tepung kacang tanah habis, ternak dapat diberikan tepung kedelai, tepung jagung atau pakan lainnya yang berada dalam
cluster 1.
SIMPULAN DAN SARAN
Simpulan
Dari perlakuan yang diberikan, diketahui bahwa clustering data perlakuan 1 memiliki indeks Davies-Bouldin (DBI) minimal pada ukuran cluster 8 sebesar 1.08. Perlakuan 2 mempunyai DBI minimal pada ukuran cluster 8 sebesar 5.82. Sementara itu, DBI minimal perlakuan 3 terdapat pada ukuran cluster 10 dengan nilai sebesar 5.58. Berdasarkan hasil ketiga perlakuan, perlakuan 3 memiliki DBI terkecil karena perlakuan 3 memiliki jumlah data dan variabel clustering yang lengkap. Selain itu, diketahui bahwa perlakuan 2 dan 3 yang jumlah datanya sebesar 96 pakan memiliki nilai DBI yang tidak berbeda jauh. Berdasarkan karakteristik hasil clustering, diketahui bahwa pakan yang kandungan kimianya tinggi belum tentu memiliki nilai kecernaan pakan yang tinggi dan begitu sebaliknya.
Saran
Penelitian selanjutnya dapat menggunakan aspek lain untuk mengelompokkan pakan ternak ruminansia seperti umur, bobot badan, jenis kelamin, kondisi dan kesehatan ternak. Dengan memberikan pakan sesuai aspek tersebut, ternak ruminansia diberi pakan yang lebih tepat sesuai dengan kebutuhan spesifiknya. Saran untuk sistem, sebaiknya anggota dalam satu cluster ditampilkan berdasarkan centroid tertinggi hingga terendah. Ketika suplai pakan dengan
14
DAFTAR PUSTAKA
Abdul-Nazeer KA, Sebastian MP. 2009. Improving the accuracy and efficiency of the k-means clustering algorithm. Di dalam: Ao SI, Gelman L, Hukins DWL, Hunter A, Korsunsky AM, editor. Proceedings of the World Congress on
Engineering. 2009 Jul 1-3; London, Inggris. London (GB): Newswood Limited. hlm 308-312.
Anas S, Zubair A, Rohmadi D. 2011. Kajian pemberian pakan kulit kakao fermentasi terhadap pertumbuhan sapi bali. Agrisistem. 7(2):79-86.
Bontems V, Noblet J, Chapoutot P, Perez JM, Doreau B, Peyraud JL, Jondreville C, Rulquin H, Kaushik SJ, Sauvant D et al. 2004. Tables of Composition and
Nutritional Value of Feed Materials. Ponter A, penerjemah; Sauvant D, Perez JM, Tran G, editor. Den Haag (NL): INRA. Terjemahan dari: Tables de
Composition et de Valeur Nutritive des Matières Premières Destinées aux Animaux d’Élevage. Ed ke-2.
Febrisahrozi D. 2014. Estimasi utilisasi nutrien melalui komposisi kimia pada pakan ternak ruminansia menggunakan metode artificial nerural network (ANN) [skripsi]. Bogor (ID): Institut Pertanian Bogor.
Fikar S, Ruhyadi D. 2010. Beternak & Bisnis Sapi Potong. Jakarta (ID): Agromedia Pustaka. hlm 8-9.
Givens DI, Owen E, Axford RFE, Omed HM. 2000. Forage Evaluation in
Ruminant Nutrition. New York (US): CABI.
Han J, Kamber M, Pei J. 2011. Data Mining Concepts and Techniques. Ed ke-3. San Fransisco (US): Morgan Kaufmann.
Jain AK, Dubes RC. 1988. Algorithms for Clustering Data. New Jersey (US): Prentice Hall.
McIlroy RJ. 1977. Pengantar Budidaya Padang Rumput Tropika. Jakarta (ID): Prandya Paramita.
Parakkasi A. 1999. Ilmu Nutrisi dan Makanan Ternak Ruminansia. Jakarta (ID): UI Pr.
Rukmana HR. 2001. Silase dan Permen Ternak Ruminansia. Yogyakarta (ID): Kanisius.
Soewardi B. 1974. Gizi Ruminansia. Bogor (ID): IPB Pr.
Tillman AD, H Hartadi, S Reksohadiprodjo, S Prawirokusumo, S Lebdosoekojo. 1984. Ilmu Makanan Ternak Dasar. Yogyakarta (ID): Gajah Mada University Pr.
Lampiran 1 Data pakan ternak ruminansia perlakuan 1
Feed materials
Main constituents Ruminant nutritive value
Crude
Wheat distillers’ grains, starch < 7%
Lampiran 1 Lanjutan
Feed materials
Main constituents Ruminant nutritive value
Lampiran 1 Lanjutan
Feed materials
Main constituents Ruminant nutritive value
Crude
Alfalfa, dehydrated, protein < 16% dry matter
13.8 29.2 2.2 9.9 1.0 45.9 33.1 8.3 45.3 0.0 3.2 0.4 0.60 0.51 43 7.4 56 60 65
Alfalfa, dehydrated, protein 18-19% dry matter
16.7 25.7 2.6 10.6 1.8 41.8 29.5 7.5 43.3 0.0 4.2 16.3 0.63 0.55 56 7.7 60 63 69
Lampiran 3 Centroid akhir hasil clustering perlakuan 2 dengan ukuran cluster 8
Cluster Crude
protein (%)
Ether extract (%)
Ash
(%)
UFL (per kg)
UFV (per kg)
PDIA (g/kg)
ME (kcal/kg)
Ed (%)
OMd (%)
Nd (%)
TId (%)
A1 13.93 4.64 5.65 0.54 0.45 29.55 6.71 48.91 50.64 55.73 50.45
A2 22.08 3.92 3.31 1.04 1.04 75.77 11.72 85.23 86.38 74.12 89.73
A3 36.63 4.47 6.75 1.15 1.15 136.9 12.73 91.83 92.00 71.92 94.92
A4 17.44 7.04 7.53 0.85 0.80 58.50 9.99 71.00 72.88 68.75 80.25
A5 19.05 5.22 4.86 0.97 0.94 57.71 11.08 79.12 80.53 72.18 85.29
A6 9.36 1.57 3.36 0.66 0.63 33.43 7.53 75.43 78.29 57.57 84.71
A7 33.03 2.38 8.07 0.74 0.71 21.83 8.50 79.83 80.83 71.50 99.50
A8 15.54 12.29 5.20 0.95 0.90 45.11 11.03 71.00 71.56 64.33 77.78
Lampiran 5 Pengamatan terhadap indeks Davies-Bouldin
Perlakuan Cluster
2 3 4 5 6 7 8 9 10
1 (46 data) 2.37 1.37 1.31 1.91 1.39 1.48 1.09 1.53 1.72 2 (96 data) 6.78 7.47 6.13 6.51 6.64 6.61 5.83 5.85 5.84 3 (96 data) 7.12 7.33 7.08 6.84 6.25 6.16 6.2 6.26 5.59
22
RIWAYAT HIDUP
Penulis lahir di Pekanbaru, Riau pada tanggal 7 Oktober 1993. Penulis merupakan anak bungsu dari lima bersaudara, anak dari pasangan Tiong Heng Alias Herman dan Bie Kwan (almarhum). Penulis adalah lulusan dari Sekolah Menengah Atas Negeri 8 Pekanbaru (2008-2011). Pada tahun 2011, penulis diterima sebagai Mahasiswa Departemen Ilmu Komputer, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor melalui jalur SNMPTN Undangan.