ANALISIS REGRESI LOGISTIK SPASIAL UNTUK
MENDUGA STATUS KEMISKINAN DESA DI KABUPATEN
MAJALENGKA
HENDRA JANUAR ANDRIANA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
PERNYATAAN MENGENAI SKRIPSI DAN
SUMBER INFORMASI SERTA PELIMPAHAN HAK CIPTA*
Dengan ini saya menyatakan bahwa skripsi berjudul Analisis Regresi Logistik Spasial untuk Menduga Status Kemiskinan Desa di Kabupaten Majalengka adalah benar karya saya dengan arahan dari komisi pembimbing dan belum diajukan dalam bentuk apa pun kepada perguruan tinggi mana pun. Sumber informasi yang berasal atau dikutip dari karya yang diterbitkan maupun tidak diterbitkan dari penulis lain telah disebutkan dalam teks dan dicantumkan dalam Daftar Pustaka di bagian akhir skripsi ini.
Dengan ini saya melimpahkan hak cipta dari karya tulis saya kepada Institut Pertanian Bogor.
Bogor, Mei 2013
Hendra Januar Andriana
ABSTRAK
HENDRA JANUAR ANDRIANA. Analisis Regresi Logistik Spasial untuk Menduga Status Kemiskinan Desa di Kabupaten Majalengka. Dibimbing oleh ANIK DJURAIDAH dan DIAN KUSUMANINGRUM.
Status kemiskinan desa dipengaruhi oleh beberapa faktor yang saling berhubungan antara satu desa dengan desa yang lain. Pemodelan dengan regresi logistik spasial diperlukan untuk menentukan faktor-faktor yang mempengaruhi hotspot kemiskinan desa yang bersifat spasial. Pengkategorian desa menjadi desa hotspot (1) dan desa bukan hotspot (0) dilakukan dengan metode pendeteksian hotspot Upper Level Set (ULS) Scan Statistic dan dihasilkan sebanyak 187 desa hotspot dan 149 desa bukan hotspot. Kelompok desa hotspot memiliki karakteristik yang hampir sama dengan kelompok desa bukan hotspot pada berbagai aspek. Model regresi logistik dengan peubah spasial memberikan hasil yang lebih baik dibandingkan dengan model regresi logistik tanpa peubah spasial dalam menduga status kemiskinan desa di Kabupaten Majalengka. Model regresi logistik dengan peubah Spasial memiliki nilai ketepatan klasifikasi (CCR) lebih tinggi dibandingkan dengan model regresi logistik tanpa peubah Spasial. Peubah penjelas yang berpengaruh signifikan terhadap status kemiskinan desa adalah peubah Persentase Keluarga Buruh Tani dan peubah Spasial.
Kata kunci: status kemiskinan desa, regresi logistik, regresi logistik spasial, metode hotspot, Upper Level Set (ULS) Scan Statistic
ABSTRACT
HENDRA JANUAR ANDRIANA. Spatial Logistic Regression Analysis to Estimate The Status of Rural Poverty in Majalengka Regency. Supervised by ANIK DJURAIDAH and DIAN KUSUMANINGRUM.
Rural poverty status is influenced by several factors that are correlated between one rural area and the other. Logistic regression modeling with spatial weights is needed to determine the factors that affect rural poverty hotspots that are spatially correlated. Categorization of rural areas into hotspot (1) and non hotspot (0) was based on a hotspot Upper Level Set (ULS) Scan Statistic method which obtained 187 hotspot rural areas and 149 rural non hotspot. Rural hotspot areas have characteristics similar to non rural hotspot areas in various aspects. Logistic regression models with Spatial variable enhances logistic regression model without Spatial variable in predicting the status of rural poverty areas in Majalengka. Logistic regression models with Spatial variable has a higher correct classification rate (CCR) compared to logistic regression without Spatial variable. The explanatory variables that have a significant influence towards the status of rural poverty are Percentage of Farm Worker Families variable and Spatial variable.
Skripsi
sebagai salah satu syarat untuk memperoleh gelar Sarjana Statistika
pada
Departemen Statistika
ANALISIS REGRESI LOGISTIK SPASIAL UNTUK
MENDUGA STATUS KEMISKINAN DESA DI KABUPATEN
MAJALENGKA
HENDRA JANUAR ANDRIANA
DEPARTEMEN STATISTIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM INSTITUT PERTANIAN BOGOR
Judul Skripsi : Analisis Regresi Logistik Spasial untuk Menduga Status Kemiskinan Desa di Kabupaten Majalengka
Nama : Hendra Januar Andriana NIM : G14080061
Disetujui oleh
Dr. Ir. Anik Djuraidah, MS Pembimbing I
Dian Kusumaningrum, S.Si, M.Si Pembimbing II
Diketahui oleh
Dr. Ir. Hari Wijayanto, M.Si Ketua Departemen
PRAKATA
Puji syukur penulis panjatkan kehadirat Allah SWT atas segala berkah dan rahmat-Nya sehingga penulis dapat menyelesaikan karya ilmiah
berjudul ”Analisis Regresi Logistik Spasial untuk Menduga Status Kemiskinan
Desa di Kabupaten Majalengka”. Karya ilmiah ini penulis susun sebagai salah
satu syarat untuk mendapatkan gelar Sarjana Statistika pada Departemen Statistika, Fakultas Matematika dan Ilmu Pengetahuan Alam, Institut Pertanian Bogor.
Penulisan karya ilmiah ini dapat diselesaikan oleh penulis tidak lepas dari dukungan, bimbingan dan bantuan dari banyak pihak yang sangat berarti bagi penulis. Oleh karena itu, dalam kesempatan ini penulis menyampaikan ucapan terima kasih kepada:
1. Ibu Dr. Ir. Anik Djuraidah, MS dan Ibu Dian Kusumaningrum S.Si, M.Si selaku dosen pembimbing yang telah memberikan bimbingan, masukan dan arahan selama penulisan karya ilmiah ini.
2. Badan Pusat Statistik (BPS) yang telah membantu penulis dalam menyediakan data penelitian.
3. Ibu Dr. Ir. Indahwati, M.Si selaku dosen penguji yang telah memberikan beberapa masukan dan arahan kepada penulis.
4. Kedua orang tua dan keluarga yang telah memberikan doa, kasih sayang serta dorongan baik moril maupun materil kepada penulis.
5. Yayasan Beasiswa Karya Salemba Empat yang telah memberikan beasiswa kepada penulis selama mengikuti perkuliahan.
6. Teman-teman seperjuangan statistika khususnya statistika angkatan 45 yang telah membantu penulis menyelesaikan karya ilmiah ini.
Semoga karya ilmiah ini dapat memberikan manfaat bagi semua pembaca.
Bogor, Mei 2013
DAFTAR ISI
DAFTAR TABEL vi
DAFTAR GAMBAR vi
DAFTAR LAMPIRAN vi
PENDAHULUAN 1
Latar Belakang 1
Perumusan Masalah 1
Tujuan Penelitian 2
TINJAUAN PUSTAKA 2
Pendeteksian Hotspot dengan Upper Level Set(ULS) Scan Statistic 2
Regresi Logistik 3
Uji Signifikansi Model 4
Interpretasi Koefisien 5
Regresi Logistik Spasial 5
METODE 6
Bahan 6
Prosedur Analisis Data 7
HASIL DAN PEMBAHASAN 8
Eksplorasi Data 8
Regresi Logistik 13
Model tanpa Peubah Spasial 13
Model dengan Peubah Spasial 14
SIMPULAN DAN SARAN 17
Simpulan 17
Saran 18
DAFTAR PUSTAKA 18
LAMPIRAN 19
DAFTAR TABEL
1 Perbandingan peubah penjelas berskala rasio 9
2 Ketepatan klasifikasi desa model regresi logistik tanpa peubah Spasial 14 3 Hasil regresi logistik model penuh dengan peubah Spasial pada taraf
nyata 10% 14
4 Nilai rasio odds model penuh regresi logistik dengan peubah Spasial 15 5 Ketepatan klasifikasi desa model penuh regresi logistik dengan peubah
Spasial 16
6 Hasil regresi logistik dengan peubah Spasial pada taraf nyata 10% 16 7 Ketapatan klasifikasi desa model regresi logistik dengan peubah Spasial 17
DAFTAR GAMBAR
1 Perbandingan dan penyebaran desa hotspot dan bukan hotspot 8 2 Perbandingan peubah Pemberantasan Buta Aksara dan SMP pada aspek
pendidikan, Pendidikan Paket A/B/C dan PAUD pada aspek program pemerintah, Pasar pada aspek pangan, dan Puskesmas pada aspek kesehatan di kelompok desa hotspot dan kelompok desa bukan hotspot 10 3 Perbandingan peubah Sumber Penghasilan pada aspek ketenagakerjaan
di kelompok desa hotspot dan kelompok desa bukan hotspot 11 4 Perbandingan peubah Bahan Bakar yang Digunakan pada aspek
perumahan di kelompok desa hotspot dan kelompok desa bukan hotspot 11 5 Perbandingan peubah Tempat Buang Air Besar pada aspek perumahan
di kelompok desa hotspot dan kelompok desa bukan hotspot 12 6 Perbandingan peubah Sumber Air Minum pada aspek perumahan di
kelompok desa hotspot dan kelompok desa bukan hotspot 12 7 Perbandingan peubah Tipe Jalan pada aspek infrastruktur desa di
kelompok desa hotspot dan kelompok desa bukan hotspot 13
DAFTAR LAMPIRAN
1 Peubah penjelas yang digunakan dalam penelitian 19 2 Penyebaran desa hotspot dan desa bukan hotspot di tiap kecamatan 20
3 Korelasi Pearson peubah penjelas 21
4 Analisis deskriptif peubah penjelas 21
PENDAHULUAN
Latar Belakang
Kemiskinan merupakan salah satu masalah mendasar yang menjadi pusat perhatian di negara manapun termasuk Indonesia. Badan Pusat Statistik (BPS) menyebutkan bahwa pada tahun 2011 jumlah penduduk miskin di Indonesia adalah sebanyak 29.89 juta jiwa atau 12.36% dari total penduduk Indonesia. Mayoritas 63.37% penduduk miskin tersebut diketahui adalah penduduk miskin yang tinggal di pedesaan (BPS 2011). Banyak faktor yang membuat tingkat kemiskinan di Indonesia berfluktuasi dari tahun ke tahun. Faktor-faktor tersebut diantaranya adalah faktor pangan, pendidikan, kesehatan, perumahan, ketenagakerjaan, ekonomi dan program pemerintah (BPS 2010). Faktor-faktor tersebut secara langsung atau tidak terjadi di pedesaan dan saling berhubungan antara satu desa dengan desa yang lain. Dengan kata lain, faktor-faktor tersebut bersifat spasial.
Penelitian terdahulu mengenai status kemiskinan desa telah dilakukan oleh Thaib (2008) tentang pemodelan regresi logistik spasial dengan pendekatan matriks contiguity dan Solimah (2010) tentang analisis regresi logistik spasial untuk status kemiskinan desa di Kabupaten/Kota Cirebon. Majalengka sebagai salah satu kabupaten di Jawa Barat merupakan kabupaten yang sedang berkembang dengan berbagai potensi daerah yang terus ditingkatkan. Akan tetapi, Majalengka masuk ke dalam lima besar kabupaten dengan persentase penduduk miskin terbanyak di Jawa Barat (BPS 2010). Oleh karena itu, perlu adanya perhatian khusus untuk mengetahui faktor-faktor yang mempengaruhi kemiskinan di Majalengka dengan melihat daerah-daerah mana saja yang berpotensi menyebabkan tingkat kemiskinan di Majalengka menjadi tinggi. Daerah-daerah yang memiliki tingkat kemiskinan tinggi dapat dikatakan sebagai suatu hotspot.
Pemodelan dengan regresi logistik spasial diperlukan untuk menentukan faktor-faktor yang mempengaruhi status kemiskinan desa yang bersifat spasial atau saling berhubungan. Model yang dihasilkan dari analisis ini dapat digunakan oleh Pemerintah Daerah Kabupaten Majalengka untuk mengetahui kesejahteraan masyarakatnya dengan melihat status kemiskinan desa beserta faktor-faktor yang mempengaruhinya dan menjadikannya acuan untuk dapat melakukan pembangunan masyarakat secara merata khususnya dalam upaya mengentaskan masalah kemiskinan.
Perumusan Masalah
2
karena itu, perlu dilakukan analisis regresi logistik spasial untuk mendapatkan model status kemiskinan desa dan faktor apa saja yang sebenarnya mempengaruhi status kemiskinan desa.
Tujuan Penelitian
Tujuan dari penelitian ini adalah untuk menentukan faktor-faktor yang mempengaruhi status kemiskinan desa di Kabupaten Majalengka dengan menggunakan analisis regresi logistik spasial.
TINJAUAN PUSTAKA
Pendeteksian Hotspot dengan Upper Level Set (ULS) Scan Statistic
Hotspot didefinisikan sebagai sesuatu yang tidak biasa, menyimpang atau area kritis (Patil dan Taillie 2004). Sedangkan menurut Haran et al. (2006) hotspot merupakan lokasi atau wilayah yang memiliki tingkat kekonsistenan tinggi dalam suatu kejadian (seperti jumlah kemiskinan, pengangguran, atau orang yang menderita kekurangan makanan/kelaparan) dan memiliki ciri yang berbeda dari daerah sekitar. Metode pendeteksian hotspot terdiri dari tiga komponen, yaitu identifikasi calon hotspot, evaluasi nilai hotspot yang signifikan, dan menduga peubah bebas yang berhubungan dengan hotspot.
ULS merupakan metode statistika yang dapat digunakan untuk mendeteksi hotspot. Secara umum metode ini mengelompokkan area-area sebagai suatu gerombol dan memeriksanya sebagai suatu hotspot atau tidak dengan menggunakan uji Rasio Kemungkinan (Kulldorff 1997). Di dalam ULS, Z dinotasikan sebagai zona yang merupakan bagian dari area G . Masing-masing area yang berada dalam zona memiliki peluang p sebagai anggota gerombol dan area yang berada di luar zona memiliki peluang q. Peluang area tersebut adalah saling bebas satu sama lain. Hipotesis yang diuji adalah H0: p=q
(area bukan hotspot) dan H1: p>q (area hotspot).
Misal nZ dinotasikan sebagai jumlah kasus yang diamati pada zona Z dan nG
adalahjumlah total kasus. NZ dinotasikan sebagai total populasi di zona Z dan NG
dinotasikan sebagai total keseluruhan populasi. Fungsi kemungkinan untuk model Bernoulli dituliskan sebagai:
3
= ketika
lainnya
Kemudian mencari solusi ̂ dan menarik kesimpulan secara statistik.
Misal dan statistik uji rasio kemungkinan (λ) dapat ditulis:
̂
Nilai λ yang dihasilkan dari uji rasio kemungkinan pada masing-masing gerombol (Z) tidak perlu semuanya dibandingkan dengan hasil simulasi Monte Carlo. Hanya gerombol (Z) yang disebut sebagai calon hotspot saja yang nilai λ nya dapat dibandingkan dengan simulasi Monte Carlo. Resiko Relatif (RR) merupakan suatu metode untuk mengevaluasi apakah suatu gerombol merupakan calon hotspot atau tidak. Resiko Relatif dapat dihitung sebagai
, dengan nz jumlah kasus yang diamati, E(c) adalah nilai harapan kasus yang ada di
area dan dihitung dengan dengan Nz adalah jumlah populasi di
gerombol yang diamati, nG dan NG berturut-turut adalah jumlah total kasus dan
jumlah total populasi (Kulldorff 2006). Suatu gerombol (W) disebut sebagai calon hotspot jika memiliki nilai resiko relatif lebih dari satu.
Regresi Logistik
Regresi logistik merupakan analisis statistika yang digunakan untuk menjelaskan hubungan antara peubah respon yang berskala kategorik dengan satu atau lebih peubah penjelas yang berskala kategorik atau numerik. Pada model regresi logistik tidak diperbolehkan adanya multikolinearitas (Hosmer dan Lemeshow 2000).
Misal data pengamatan memiliki p peubah penjelas yaitu x1, x2,…xp dan
4
Pada regresi logistik peubah respon (Y) akan mengikuti sebaran Binomial jika kejadian Y berjumlah n, peluang setiap kejadian sama dan setiap kejadian saling bebas satu sama lain. Model umum dari regresi logistik yaitu:
dengan π(x) = E(Y|x) adalah kondisi rataan bersyarat dari Y jika x diketahui menggunakan regresi logistik. Dengan menggunakan transformasi logit diperoleh:
( )
dimana g(x) = 0+ 1x1+…+ pxp merupakan penduga logit yang berperan
sebagai fungsi linear dari peubah penjelas. Karena fungsi penghubung yang digunakan adalah fungsi penghubung logit maka sebaran peluang yang digunakan disebut sebaran logistik (Hosmer dan Lemeshow 2000)
Uji Signifikansi Model
Pengujian signifikansi model regresi logistik dilakukan dengan dua tahap. Tahap pertama yaitu melakukan Uji Rasio Kemungkinan atau Uji G untuk mengetahui peran seluruh peubah penjelas di dalam model secara simultan. Hipotesis yang diuji adalah:
H0: = =…= =0
H1: paling sedikit ada satu ≠0, i=1,2,…,p
Statistik uji-G didefinisikan sebagai:
⌈ ⌉
dengan L0 adalah fungsi kemungkinan maksimum tanpa peubah penjelas, dan Lp
merupakan fungsi kemungkinan maksimum dengan p peubah penjelas. Hipotesis
nol ditolak jika G > χ2
p(α) (Hosmer dan Lemeshow 2000).
Tahap kedua yaitu melakukan Uji Wald untuk menguji pengaruh masing- masing peubah penjelas. Hipoteisi yang diuji adalah:
H0: = 0
H1: ≠ 0; i=1,2,…,p
Statistik uji Wald didefinisikan sebagai berikut:
̂
5 dengan ̂ adalah nilai dugaan parameter ke-i dan ̂ adalah nilai galat baku dari penduga parameter ke-i. Keputusan menolak H0 diambil jika
| |
> Zα/2(Hosmer dan Lemeshow 2000).
Interpretasi Koefisien
Interpretasi koefisien untuk model regresi logistik adalah rasio oddsnya. Ψ yang didefinisikan sebagai rasio peluang kejadian sukses dengan kejadian tidak sukses dari peubah penjelas terhadap peubah respon. Nilai odds dapat dituliskan sebagai berikut:
Untuk peubah penjelas yang memiliki dua kategori yaitu x1 dan x2 dan memiliki
nilai x1=1 dan x2=0, maka rasio odds:
⁄
dapat disederhanakan menjasi
Rasio odds untuk peubah kategorik menjelaskan bahwa kategori x=1 memiliki kecenderungan untuk terjadi y=1 sebesar Ψ kali dibandingkan kategori x=0. Sedangkan jika peubahnya berskala numerik, maka interpretasinya setiap kenaikan satu satuan pada peubah x maka kecenderungan untuk terjadinya y=1 akan naik sebesar Ψ kali (Hosmer dan Lemeshow 2000).
Regresi Logistik Spasial
Regresi logistik spasial merupakan regresi logistik dengan memasukkan pengaruh spasial ke dalam modelnya. Pengaruh spasial yang dimaksud adalah dengan membentuk suatu peubah baru yang disebut peubah Spasial. Peubah Spasial ini dibentuk dari matriks pembobot spasial yang dikalikan dengan vektor peubah respon (Y). Matriks pembobot spasial diperoleh dari matriks kebertetanggaan (Contiguity).
Matriks kebertetanggan merupakan matriks yang dapat menggambarkan hubungan kedekatan antar daerah. Kedekatan suatu daerah dihitung berdasarkan Kriterian ratu. Kriteria ratu adalah gerakan langkah ratu pada pion catur yaitu menunjukan daerah yang menghimpit pion catur ke arah kanan, kiri, atas dan bawah. Matriks ini menunjukan hubungan spasial suatu daerah dengan daerah lainnya yang bertetangga. Pemberian nilai 1 diberikan jika daerah-i bertetangga langsung dengan daerah-j, dan nilai 0 diberikan jika daerah-i tidak bertetangga langsung dengan daerah-j. Matriks ini juga disebut dengan matriks biner, dan juga disebut matriks penghubung, yang dinotasikan dengan C dan cij merupakan nilai
6
bertetangga dengan daerah-j dan cij bernilai 0 jika daerah-i tidak bertetangga
dengan daerah-j. nilai pada matriks ini akan digunakan untuk perhitungan matriks pembobot spasial W. Isi dari matriks pembobot spasial pada baris ke-i dan kolom ke-j adalah wij . Nilai wij pada penelitian ini yaitu ∑
.
Persamaan dari regresi logistik spasial dapat dituliskan sebagai berikut:
dengan ( ) , ( ) W merupakan matriks pembobot spasial berukuran nxn, adalah vektor peubah respon dan adalah koefisien spasial otoregressif. Persamaan tersebut diperoleh dari penggabunagn dua model linear. Model yang pertama adalah model non spasial dengan data spasial yang setara dengan asumsi dan dapat didefinisikan sebagai berikut:
i
Sedangkan model linear kedua merupakan model linear spasial dengan data spasial yang murni otoregressif. Model tersebut memiliki asumsi bahwa peubah non spasial X=0 atau tidak ada peubah penjelas yang berpengaruh terhadap respon. Respon hanya dipengaruhi oleh dirinya sendiri. Model tersebut dapat didefinisikan sebagai berikut:
i
METODE
Bahan
7 Prosedur Analisis Data
Prosedur yang dilakukan dalam peneltian ini adalah dimulai dengan mengelompokkan desa menjadi desa hotspot (1) dan desa bukan hotspot (0). Pengelompokan desa dilakukan dengan menggunakan metode Upper Level Set (ULS) Scan Statistic dengan langkah-langkah sebagai berikut:
a. Hitung rasio antara jumlah keluarga miskin dengan jumlah keluarga pada masing-masing desa (336 desa) dan urutkan dari yang terbesar sampai terkecil.
b. Tentukan desa yang memiliki rasio jumlah keluarga miskin terhadap jumlah keluarga terbesar. Hitung jumlah desa tetangga yang dimiliki desa tersebut.
c. Ulangi langkah (b) sesuai urutan rasio yang diperoleh pada langkah (a) d. Dalam area suatu desa beserta desa tetangganya atau yang disebut
gerombol (Z) hitung jumlah kasus (nZ) dan ukuran populasinya (NZ)
e. Ulangi langkah (d) untuk masing-masing area
f. Nilai (nZ,NZ) pada masing-masing area kemudian dimasukan ke uji Rasio
Kemungkinan menurut persamaan yang telah ditentukan dan
menghasilkan suatu nilai yang dilambangkan dengan λ. Nilai λ tersebut
kemudian dibandingkan dengan suatu nilai hasil dari simulasi Monte Carlo untuk menguji suatu gerombol (Z) merupakan suatu hotspot atau bukan. g. Gerombol hotspot yang terbentuk merupakan kumpulan dari berbagai area
(desa) yang dikategorikan sebagai desa hotspot.
Setelah diperoleh sejumlah desa yang berstatus hotspot dan bukan hotspot maka langkah selanjutnya adalah sebagai berikut:
1. Memilih peubah-peubah penjelas yang akan digunakan berdasarkan studi literatur mencakup aspek-aspek yang mempengaruhi kemiskinan desa. 2. Membuat matriks kebertetanggaan (contiguity) antar desa.
3. Membuat matriks pembobot spasial (W).
4. Membentuk peubah spasial yaitu dengan mengalikan matriks pembobot spasial (W) dengan vektor respon (Y).
5. Memeriksa asumsi multikolinearitas pada regresi logistik dengan melihat nilai korelasi antar peubah penjelas.
6. Membuat model regresi logistik tanpa peubah spasial dan dengan peubah spasial.
7. Melihat peubah-peubah penjelas mana saja yang berpengaruh terhadap respon dengan uji signifikansi, baik secara serentak (Uji G) maupun secara parsial (Uji Wald).
8. Interpretasi model logit yang terbentuk dengan melihat nilai rasio odds peubah penjelas yang berpengaruh.
9. Menghitung kesesuaian masing-masing model dengan melihat nilai
Correct Classification Rate (CCR) yang merupakan persentase ketepatan nilai dugaan dengan pengamatannya. Perhitungan CCR menggunakan persamaan:
8
Semakin besar persentase CCR yang dihasilkan maka tingkat akurasi yang dihasilkan semakin tinggi (Hosmer dan Lemeshow 2000). Software yang digunakan dalam penelitian ini adalah Microsoft Excel 2007, software statistika dan software pemetaan.
HASIL DAN PEMBAHASAN
Eksplorasi Data
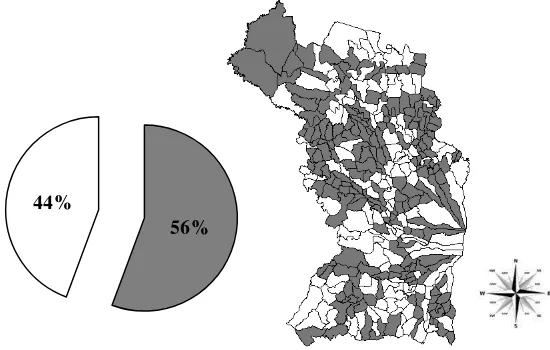
Metode pendeteksian hotspot dengan cara Upper Level Set (ULS) Scan Statistic mengkategorikan desa menjadi desa hotspot (1) dan desa bukan hotspot (0). Metode ini menghasilkan 187 desa hotspot dan 149 desa bukan hotspot. Desa hotspot tersebar di beberapa zona hotspot. Setiap zona memiliki jumlah desa hotspot yang beragam. Ada zona yang hanya memiliki satu desa, dua desa, dan bahkan ada yang memiliki lebih dari 50 desa hotspot. Hal ini disebabkan oleh setiap desa hotspot dapat masuk ke dalam lebih dari satu zona hotspot. Perbandingan dan penyebaran desa hotspot dan desa bukan hotspot di Kabupaten Majalengka dapat dilihat pada Gambar 1.
Gambar 1 Perbandingan dan penyebaran desa hotspot ( ) dan bukan hotspot ( ) Penyebaran desa hotspot dan berstatus bukan hotspot terjadi di seluruh kecamatan di Kabupaten Majalengka. Kecamatan yang memiliki desa hotspot lebih banyak daripada desa bukan hotspot adalah Kecamatan Bantarujeg, Cikijing, Cingambul, Banjaran, Majalengka, Cigasong, Sindang, Rajagaluh, Leuwimunding, Jatiwangi, Kasokandel, Panyingkiran, Kadipaten, Kertajati dan Sumberjaya. Sedangkan kecamatan yang memiliki desa bukan hotspot lebih banyak daripada desa hotspot adalah Kecamatan Malausma, Argapura, Maja, Sindangwangi, Palasah, Dawuan, Jatitujuh dan Ligung. Dari data yang diperoleh diketahui bahwa seluruh desa di Kecamatan Talaga dan Sukahaji tidak ada yang berstatus hotspot. Hal ini terjadi karena seluruh desa di Kecamatan Talaga dan Sukahaji memiliki nilai rasio jumlah keluarga miskin per jumlah keluarga yang sangat kecil.
9 Penyebaran desa hotspot dan bukan hotspot yang seimbang terjadi di Kecamatan Lemahsugih. Sebaran desa hotspot dan bukan hotspot untuk tiap kecamatan dapat dilihat pada Lampiran 2.
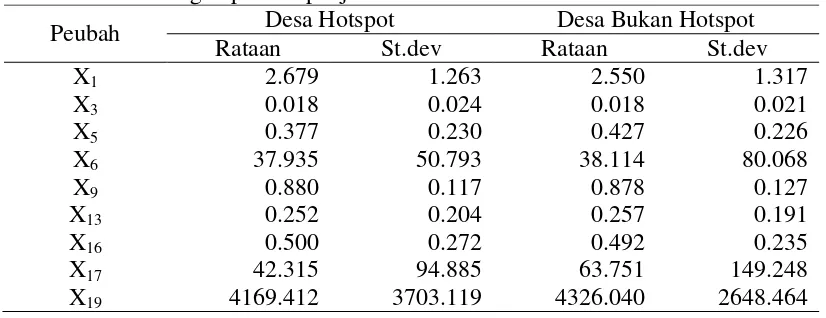
Perbandingan kelompok desa hotspot dan kelompok desa bukan hotspot dapat dilihat pada Tabel 1. Terlihat bahwa kelompok desa hotspot memiliki nilai ragam yang lebih tinggi pada peubah Jumlah Industri Kecil dan Mikro (X17) dan
memiliki nilai rataan yang lebih tinggi pada peubah Jumlah Sekolah Dasar (X1),
Keluarga Pengguna Listrik (X9) dan Persentase Keluarga Pertanian (X16).
Persentase Keluarga Buruh Tani yang lebih kecil dibandingkan desa bukan hotspot. Nilai tersebut berbeda dari keadaaan yang seharusnya yaitu desa hotspot cenderung memiliki rataan Persentase Keluarga Buruh Tani yang lebih tinggi. Selain itu, terlihat juga bahwa desa dengan Persentase Keluarga Pertanian yang lebih tinggi cenderung masuk ke dalam kelompok desa hotspot. Seperti pada kenyataannya ,desa yang sebagian besar masyrakatnya bermatapencaharian pada bidang pertanian akan cenderung dekat dengan masalah kemiskinan.
Tabel 1 Perbandingan peubah penjelas berskala rasio
Peubah Desa Hotspot Desa Bukan Hotspot
Rataan St.dev Rataan St.dev
X19 4169.412 3703.119 4326.040 2648.464
Kelompok desa hotspot memiliki karakteristik atau ciri yang hampir sama dengan kelompok desa bukan hotspot pada berbagai aspek. Hal ini disebabkan oleh penentuan kriteria keluarga miskin yang hanya menggunakan Surat Miskin. Banyaknya surat miskin di suatu desa belum dapat menggambarkan banyaknya keluarga miskin yang ada. Penentuan keluarga miskin itu sendiri sebaiknya dilakukan dengan menggunakan data Survey Sosial Ekonomi Nasional (SUSENAS) dan menggunakan kriteria garis kemiskinan yaitu jika suatu rumah tangga memiliki pendapatan perkapita di bawah garis kemiskinan maka rumah tangga tersebut dinyatakan sebagai kelurga miskin (BPS 2011).
10
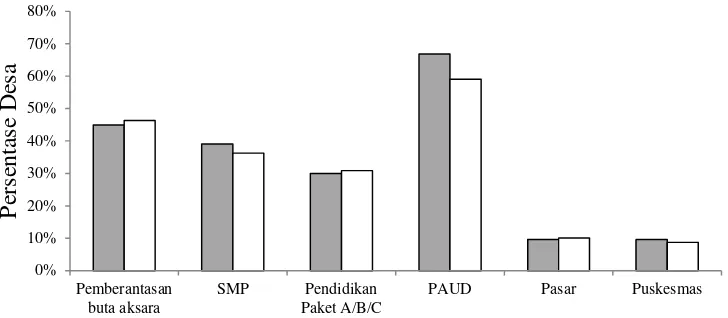
Dalam mewujudkan Kabupaten Majalengka yang lebih baik, pemerintah daerah Kabupaten Majalengka juga melaksanakan beberapa program seperti pendidikan paket A/B/C dan Pendidikan Anak Usia Dini (PAUD). Gambar 2 memperlihatkan program Pendidikan paket A/B/C belum banyak dilaksanakan di kedua kelompok desa. Akan tetapi, sebagian besar desa di kelompok desa hotspot dan di kelompok desa bukan hotspot sudah memiliki PAUD
Keberadaan pasar dan toko atau warung kelontong sangatlah penting untuk memenuhi kebutuhan pangan masyarakat di desa. Akan tetapi, keberadaan pasar baik di kelompok desa hotspot maupun kelompok desa bukan hotspot masih jarang, hanya sebagian kecil saja desa yang memiliki pasar (Gambar 2).
Pelayanan kesehatan di suatu desa secara tidak langsung akan mempengaruhi kemajuan suatu desa. Dengan adanya pelayanan dan fasilitas kesehatan yang baik, masyarakat suatu desa akan lebih produktif dalam memenuhi kebutuhan hidupnya dan pada akhirnya dapat membangun desa tempat tinggalnya. Pada Gambar 2 terlihat bahwa di Kabupaten Majalengka keberadaan Puskesmas masih jarang ditemukan baik di kelompok desa hotspot maupun di kelompok desa bukan hotspot.
Gambar 2 Perbandingan peubah Pemberantasan Buta Aksara dan SMP pada aspek pendidikan, Pendidikan Paket A/B/C dan PAUD pada aspek program pemerintah, Pasar pada aspek pangan, dan Puskesmas pada aspek kesehatan di kelompok desa hotspot ( ) dan kelompok desa bukan hotspot ( )
Di aspek ketenagakerjaan, sebagian besar sumber penghasilan masyarakat di desa baik di kelompok desa hotspot maupun di kelompok desa bukan hotspot adalah berasal dari pertanian. Gambar 3 menunjukan bahwa hanya sebagian kecil desa yang sumber penghasilan masyaraktnya di luar pertanian, seperti industri pengolahan, perdagangan besar/eceran dan rumah makan dan lainnya. Terlihat juga kelompok desa hotspot memiliki jenis sumber penghasilan yang lebih beragam dibandingkan dengan kelompok desa bukan hotspot.
11
Gambar 3 Perbandingan peubah Sumber Penghasilan pada aspek ketenagakerjaan di kelompok desa hotspot dan kelompok desa bukan hotspot
Di aspek perumahan, sebagian besar desa di kelompok desa hotspot maupun di kelompok desa bukan hotspot sudah menggunakan LPG sebagai bahan bakar (Gambar 4) dan sudah memiliki jamban sendiri sebagai tempat buang besar (Gambar 5). Untuk memenuhi kebutuhan air minum, sebagian besar desa di kelompok desa hotspot maupun di kelompok desa bukan hotspot terlihat masih banyak yang memanfaatkan mata air sebagai sumber air minum. Akan tetapi, sudah banyak juga desa yang menggunakan sumur dan pompa listrik/tangan sebagai sumber air minum (Gambar 6).
Gambar 4 Perbandingan peubah Bahan Bakar yang Digunakan pada aspek perumahan, LPG ( ) dan kayu bakar ( ) di kelompok desa hotspot dan kelompok desa bukan hotspot
12
Gambar 5 Perbandingan peubah Tempat Buang Air Besar pada aspek perumahan di kelompok desa hotspot dan kelompok desa bukan hotspot
Gambar 6 Perbandingan peubah Sumber Air Minum pada aspek perumahan di kelompok desa hotspot dan kelompok desa bukan hotspot
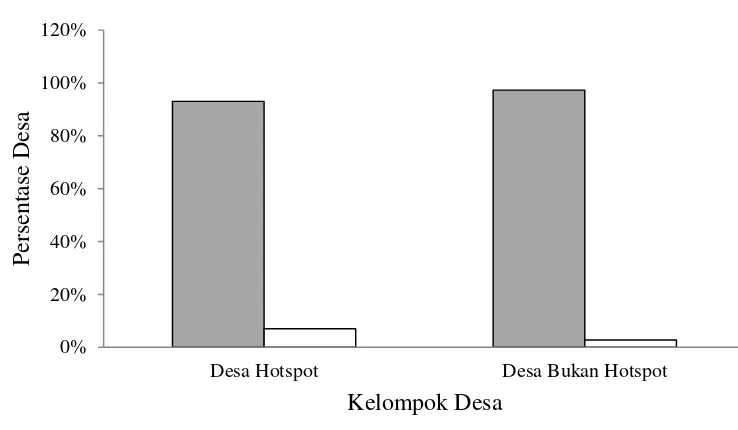
Kemiskinan suatu desa tidak lepas pengaruhnya dari faktor infrastruktur desa. Fasilitas jalan di desa tentu akan mempengaruhi akses atau kemudahan transportasi dalam menjalankan perekonomian desa. Gambar 7 menunjukan sebagian besar desa di kelompok desa hotspot dan di kelompok desa bukan hotspot sudah memiliki infrastruktur jalan yang terbuat dari aspal/beton.
13
Gambar 7 Perbandingan peubah Tipe Jalan pada aspek infrastruktur desa, Aspal/beton ( ) dan diperkeras/kerikil ( ) di kelompok desa hotspot dan kelompok desa bukan hotspot
Regresi Logistik
Model tanpa Peubah Spasial
Sebelum melakukan analisis regresi logistik, pemeriksaan korelasi (Lampiran 3) diantara peubah penjelas yang digunakan dilakukan untuk menghindari terjadinya multikolinearitas. Hasil pemeriksaan korelasi menunjukkan bahwa nilai korelasi di antara peubah penjelas relatif kecil (kurang dari 0.5) sehingga disimpulkan tidak terjadi multikolinearitas.
Model regresi logistik tanpa peubah spasial yang dihasilkan memiliki nilai rasio kemungkinan atau Uji G sebesar 25.770 dengan nilai p=0.420. Nilai tersebut menujukan bahwa keputusan yang diambil adalah tidak tolak H0, artinya tidak ada
peubah penjelas yang berpengaruh terhadap status kemiskinan desa pada taraf nyata 10%. Hal ini terjadi karena dalam penentuan peubah respon (Y) sendiri didasarkan pada ketergantungan spasial antar desa yang diamati. Oleh karena itu, model regresi logistik yang dihasilkan akan menjadi tidak nyata jika tidak memasukan peubah spasial.
Berdasarkan Tabel 2, dapat dilihat nilai ketepatan klasifikasi atau Correct Classification Rate (CCR) untuk model regresi logistik tanpa peubah spasial adalah sebesar 61.0%. Nilai tersebut menunjukan bahwa sebesar 61.0% desa di Kabupaten Majalengka diprediksi dengan tepat menjadi desa hotspot dan desa bukan hotspot.
0% 20% 40% 60% 80% 100% 120%
Desa Hotspot Desa Bukan Hotspot
P
erse
ntase
De
sa
14
Tabel 2 Ketepatan klasifikasi desa model regresi logistik tanpa peubah Spasial Aktual
Ketepatan klasifikasi keseluruhan (CCR) (%) 61.0
Model dengan Peubah Spasial
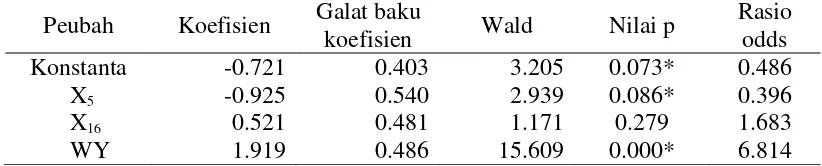
Model regresi logistik yang ditambahkan dengan peubah spasial memiliki nilai Uji G sebesar 39.053 dan nilai p = 0.048. Nilai ini menunjukkan bahwa keputusan yang diambil adalah menolak H0 , yaitu setidaknya ada satu peubah
penjelas yang berpengaruh terhadap status kemiskinan desa. Dari hasil Uji Wald pada Tabel 3 dapat dilihat bahwa peubah penjelas yang berpengaruh signifikan terhadap status kemiskinan desa adalah peubah X5 atau peubah Persentase
Keluarga Buruh Tani, peubah X16 atau Persentase Keluarga Pertanian, dan peubah
WY atau peubah Spasial.
Tabel 3 Hasil regresi logistik model penuh dengan peubah Spasial pada taraf nyata 10%
Peubah Koefisien Galat baku
15 Tabel 3 Hasil regresi logistik model penuh dengan peubah Spasial pada taraf
nyata 10% (lanjutan)
Peubah Koefisien Galat baku
koefisien Wald Nilai p
X17 0.000 0.001 0.826 0.363
X18(1) 0.080 0.265 0.090 0.764
X19 0.000 0.000 0.961 0.327
X20(1) -0.774 0.642 1.453 0.228
WY 1.885 0.530 12.663 0.000*
*nyata pada α=0.10
Uji kebaikan model untuk model penuh regresi logistik dengan peubah spasial memiliki nilai Khi Kuadrat sebesar 6.885 dan nilai p = 0.549. Nilai ini menunjukan bahwa model telah cukup baik untuk menjelaskan data. Interpretasi model dapat dilakukan dengan melihat nilai rasio odds masing-masing peubah penjelas. Peubah penjelas dan nilai rasio odds dapat dilihat di Tabel 4.
Peubah Spasial (WY) memiliki rasio odds tertinggi yaitu sebesar 6.587 yang disusul dengan peubah Persentase Keluarga Pertanian (X16) dan Persentase
Keluarga Buruh Tani (X5). Nilai rasio odds pada peubah spasial berarti bahwa jika
ada suatu desa yang dinyatakan sebagai desa hotspot, maka desa-desa lain yang menjadi tetangga desa hotspot tersebut akan memiliki kecenderungan menjadi desa hotspot 6.814 kali dibandingan dengan desa-desa lain yang bukan tetangganya. Peubah X16 atau Persentase Keluarga Pertanian memiliki nilai rasio
odds 2.768, artinya setiap peningkatan Persentase Keluarga Pertanian sebesar satu persen maka kecenderungan desa dikategorikan hotspot naik sebesar 2.768 kali. Peubah X5 atau Persentase Keluarga Buruh Tani memiliki nilai rasio odds 0.365,
artinya bahwa setiap Peningkatan Persentase Keluarga Buruh Tani sebesar satu persen maka kecenderungan desa untuk dikategorikan hotspot akan turun sebesar 1/0.365 kali atau 2.739 kali. Nilai tersebut menunjukkan desa lebih cenderung dikategorikan sebagai desa bukan hotspot.
Tabel 4 Nilai rasio odds model penuh regresi logistik dengan peubah Spasial
Peubah penjelas Rasio odds SK 90%
Batas bawah Batas atas
X5 0.365 0.136 0.979
X16 2.768 1.035 7.405
WY 6.587 2.756 15.745
16
Tabel 5 Ketepatan klasifikasi desa model penuh regresi logistik dengan peubah Spasial
Ketepatan klasifikasi keseluruhan (CCR) (%) 63.7
Peubah-peubah yang signifikan pada hasil regresi logistik model penuh kemudian diregresikan kembali untuk mendapatkan suatu model yang lebih sederhana. Model ini memiliki nilai Uji G sebesar 21.808 dan nilai p = 0.000. Nilai ini menunjukan bahwa keputusan yang diambil adalah menolak H0 , yaitu
setidaknya ada satu peubah penjelas yang berpengaruh terhadap status kemiskinan desa.Hasil regresi logistik yang sudah disederhanakan dapat dilihat pada Tabel 6. Dari Nilai p yang dihasilkan menunjukkan bahwa peubah yang berpengaruh signifikan adalah peubah X5 atau peubah Persentase Keluarga Buruh Tani dan
WY atau peubah Spasial.
Interpretasi model dapat dilakukan dengan melihat nilai rasio odds masing-masing peubah penjelas. Peubah penjelas dan nilai rasio odds dapat dilihat di Tabel 6. Peubah Spasial (WY) memiliki rasio odds tertinggi yaitu sebesar 6.814 yang berarti bahwa jika ada suatu desa yang dinyatakan sebagai desa hotspot, maka desa-desa lain yang menjadi tetangga desa hotspot tersebut akan memiliki kecenderungan menjadi desa hotspot 6.814 kali dibandingan dengan desa-desa lain yang bukan tetangganya. Peubah X5 atau Persentase Keluarga Buruh Tani
memiliki nilai rasio odds 0.396, artinya bahwa setiap peningkatan Persentase Keluarga Buruh Tani sebesar satu persen maka kecenderungan desa untuk dikategorikan hotspot turun sebesar 1/0.396 kali atau 2.525 kali. Nilai tersebut menunjukkan desa lebih cenderung dikategorikan sebagai desa bukan hotspot. Peubah X16 memiliki nilai rasio odds sebesar 1.683 yang berarti bahwa setiap
kenaikan Persentase Keluarga Pertanian sebesar satu persen maka kecenderungan desa dikategorikan hotspot naik sebesar 1.683 kali. Akan tetapi, secara statistik peubah Persentase Keluarga Pertanian ini tidak berpengaruh signifikan terhadap status kemiskinan desa. Hal ini terjadi karena peubah Persentase Keluarga Pertanian belum cukup menggambarkan kesejahteraan keluarga pertanian yang sebenarnya. Oleh karena itu, perlu dilihat juga faktor-faktor lain seperti kepemilikan luas lahan dan faktor lain dalam hal pertanian di desa.
Tabel 6 Hasil regresi logistik dengan peubah Spasial pada taraf nyata 10% Peubah Koefisien Galat baku
17 Uji kebaikan model untuk model regresi logistik dengan peubah Spasial memiliki nilai Khi Kuadrat sebesar 7.830 dan nilai p = 0.450. Nilai ini menunjukan bahwa model telah cukup baik untuk menjelaskan data. Model logit dari regresi logistik dengan peubah Spasial berdasarkan Tabel 6 adalah:
Model yang dihasilkan memperlihatkan bahwa faktor pertanian adalah faktor yang paling berpengaruh terhadap kemiskinan suatu desa setelah faktor spasial. Namun dalam penelitian ini diperoleh bahwa nilai rasio odds dari peubah Persentase Keluarga Buruh Tani pada model yang dihasilkan menunjukkan kecenderungan desa dikategorikan menjadi desa bukan hotspot. Hal ini dapat terjadi karena adanya kemungkinan bahwa masyarakat buruh tani di desa mempunyai sumber penghasilan lain di luar buruh tani seperti buruh pabrik, kuli bangunan, pedagang kecil, beternak dan lain-lain (Loesasi 2012).
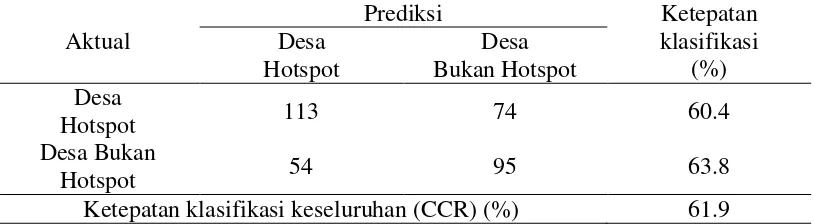
Model regresi logistik dengan peubah spasial memiliki nilai ketepatan klasifikasi (CCR) sebesar 61.9%. Nilai tersebut menunjukkan bahwa sebesar 61.9% desa di Kabupaten Majalengka diprediksi dengan tepat menjadi desa hotspot atau desa bbukan hotspot (Tabel 7).
Tabel 7 Ketepatan klasifikasi desa model regresi logistik dengan peubah spasial Aktual
Ketepatan klasifikasi keseluruhan (CCR) (%) 61.9
SIMPULAN DAN SARAN
Simpulan
18
Saran
Penentuan keluarga yang dinyatakan sebagai keluarga miskin sebaiknya tidak melihat dari Surat Miskin yang diperoleh karena banyaknya surat miskin di suatu desa tidak mencerminkan banyaknya keluarga miskin. Penentuan suatu keluarga dinyatakan miskin akan lebih baik jika menggunakan aturan Garis Kemiskinan yang telah ditetapkan BPS atau Bank Dunia. Penambahan peubah penjelas disarankan terutama peubah yang berhubungan dengan faktor pertanian seperti peubah luas kepemilikan sawah.
DAFTAR PUSTAKA
[BPS] Badan Pusat Statistik. 2010. Data dan Informasi Kemiskinan Kabupaten Kota 2010. Jakarta: Badan Pusat Statistik.
[BPS] Badan Pusat Statistik. 2011. Perhitungan dan Analisis Kemiskinan Makro Indonesia Tahun 2011. Jakarta: Badan Pusat Statistik.
Haran M, Molineros J, Patil GP. 2006. Large Scale Plant Disease Forecasting: Case Study of Fusarium Head Blight. DGO 2006 Converence.
Hosmer DW, Lemeshow S. 2000. Applied Logistic Regression. Edisi ke-2. New York : John Wiley and Sons.
Kulldorff M. 1997. A Spatial Scan Statistic. Communications in Statistics: Theory and Method. [Internet]. [diunduh 24 Feb 2013]. 26:1481-1496. Tersedia pada: http://www.satscan.org/papers/k-scanbook1999.pdf
Kulldorff M. 2006. SaTScanTM User Guide for version 6.1. [Internet]. [diunduh 24 Feb 2013]. Tersedia pada: http://www.satscan.org/ cgi-bin /satscan /register.pl/Current%20Version:%20SaTScan%20v9.1.1%20released%20Mar ch%209%202011.?todo=process_userguide_download.
Loesasi AR. 2012. Pengaruh Mekanisasi Pertanian Padi Terhadap Penyerapan Tenaga Kerja di Desa Sukowiyono Kecamatan Padas Kabupaten Ngawi. [Internet]. [diunduh 17 Mei 2013]. Tersedia pada: http:// ejournal. unesa.ac.id /article/1897/40/article.pdf
Solimah. 2010. Analisis Regresi Logistik Spasial untuk Menelaah Faktor-Faktor yang Mempengaruhi Status Kemiskinan Desa [Tesis]. Bogor: Program Pasca Sarjana. Institut Pertanian Bogor.
Taillie C, Patil GP. 2004. Upper Level Set Scan Statistc for Detecting Arbitrarily Shaped Hotspots. New York: Kluwer Academic Publishers.
Thaib Z. 2008. Pemodelan Regresi Logistik Spasial dengan Pendekatan Matriks
19 Lampiran 1 Peubah penjelas yang digunakan dalam penelitian
Kode Nama Peubah Aspek Skala
Ketenagakerjaan Rasio - X4 Sumber
Penghasilan
Ketenagakerjaan Nominal 1 = Pertanian 2 = Industri
Ketenagakerjaan Rasio -
X6 Jumlah Toko /
20
Lampiran 1 Peubah penjelas yang digunakan dalam penelitian (lanjutan)
Kode Nama Peubah Aspek Skala
X20 Tipe Jalan Infrastuktur
desa
Nominal 1 = Aspal/beton 2 = Diperkeras /kerikil
WY Peubah Spasial Spasial Rasio -
Lampiran 2. Penyebaran desa hotspot dan desa bukan hotspot di tiap kecamatan
Kecamatan Desa Hotspot Desa
21 Lampiran 2. Penyebaran desa hotspot dan desa bukan hotspot di tiap kecamatan
(lanjutan)
Kecamatan Desa Hotspot Desa
Bukan Hotspot Total
Sumberjaya 10 3 13
Total 187 149 336
Lampiran 3. Korelasi Pearson peubah penjelas
X1 X3 X5 X6 X9 X13 X16 X17 X19 WY
X5 = Persentase Keluarga Buruh Tani
X6 = Jumlah Toko / warung kelontong
X9 = Keluarga Pengguna Listrik
X13 = Penerima Jamkesda/nas
X16 = Persentase Keluarga Pertanian
X17 = Jumlah Industri kecil dan mikro
X19 = Jarak ke Kecamatan
WY = Peubah Spasial Lampiran 4. Analisis deskriptif peubah penjelas
Peubah penjelas dengan skala pengukuran nominal
Peubah Persentase Desa
Desa Hotspot Desa Bukan Hotspot Pemberantasan buta aksara
Perdagangan besar/eceran 7% 3%
Lainnya 2% 0%
Pasar
Ada 10% 10%
22
Lampiran 4. Analisis deskriptif peubah penjelas (lanjutan) Peubah penjelas dengan skala pengukuran nominal
Peubah Persentase Desa
Desa Hotspot Desa Bukan Hotspot Puskesmas
Ada 10% 9%
Tidak ada 90% 91%
Bahan bakar
LPG 89% 86%
Kayu bakar 11% 14%
Tempat buang air besar
Jamban sendiri 84% 82%
Bukan jamban 10% 11%
Jamban bersama 6% 7%
Sumber air minum
Pompa listrik/tangan 28% 27%
Sumur 30% 32%
Mata air 34% 37%
Lainnya 7% 5%
Pendidikan paket A/B/C
Ada 30% 31%
Tidak ada 70% 69%
PAUD
Ada 67% 59%
Tidak ada 33% 41%
SMP
Ada 39% 36%
Tidak ada 61% 64%
Tipe jalan
Aspal/beton 93% 97%
23 Lampiran 5. Proses perhitungan matriks pembobot spasial dengan langkah ratu
Matriks Kebertetanggaan (Contiguity)
24
RIWAYAT HIDUP
Penulis dilahirkan di Majalengka pada tanggal 10 Januari 1990 sebagai anak pertama kembar dari lima bersaudara dari pasangan Eja Susteja dan Ema Ratmala. Penulis semenjak kecil tinggal di Majalengka dan sebelum memasuki perguruan tinggi berhasil menyelesaikan pendidikan di SMAN 1 Majalengka, SLTPN 3 Majalengka, dan SDN Majalengka Kulon II. Penulis memasuki perguruan tinggi pada tahun 2008 di Institut Pertanian Bogor melalui jalur USMI dengan memilih mayor Statistika di Fakultas Matematika dan Ilmu Pengetahuan Alam.