KUESIONER
ANALISIS FAKTOR YANG MEMPENGARUHI TINGKAT KEPUASAN PASIEN TERHADAP PELAYANAN RUMAH SAKIT UMUM
KOTA PADANG SIDIMPUAN
Survey ini adalah survey untuk penulisan skripsi di Fakultas Matematika dan Ilmu Pengetahuan Alam Universitas Sumatera Utara (USU), oleh karena itu sebagai peneliti akan sangan berterima kasih jika Bapak/Ibu/Saudara/Saudari bersedia mengisi dan menjawab setiap pertanyaan dengan sukarela.
Adapun cara pengisian dari jawaban saudar/i antara lain:
1. Mohon dengan hormat bantuan saudara/i untuk mengisi seluruh pernyataan yang ada.
2. Pada kuesioner ini terdapat 6 variabel.
3. Berilah tanda (√) atau tanda (×). Cukup 1 (satu) kali pengisian pada setiap pernyataan.
4. Ada 5 (lima) alternative jawaban,yaitu SS = SangatSetuju
S = Setuju
CS = Cukup Setuju TS = Tidak Setuju STS = SangatTidakSetuju
IDENTITAS RESPONDEN
Nama :
Usia : ……… Tahun
JenisKelamin :[ ]Laki-laki [ ]Perempuan
1 bertanggung jawab dan berani megambil keputusan yang tepat, saat melakukan tindakan keperawatan
2
Rumah sakit umum sidimpuan terlihat bersih. Kelengkapan, kesiapan dan kebersihan alat-alat yang dipakai juga modern
3
Pelayanan Rumah sakit umum Padang Sidimpuan yang profesional, ramah dan selalu tanggap dalam membantu pengobatan pasien.
4 Obat dijual dengan harga yang wajar dan cepat dalam memberikan pelayanan
5 Petugas memberikan pelayanan kepada konsumen tanpa memandang stratus sosial. 6 Terjadinya komunikasi antara petugas dan
TABULASI DATA PENELITIAN RESPONDEN
NO X1 X2 X3 X4 X5 X6
1 3 4 5 5 2 2
2 3 3 4 5 4 2
3 3 4 4 4 3 2
4 5 5 5 5 2 2
5 5 5 5 5 3 2
6 5 5 5 5 4 2
7 5 5 5 5 4 5
8 5 5 5 5 5 4
9 4 5 5 5 4 4
10 4 5 4 5 2 3
11 4 3 4 4 3 4
12 3 3 4 3 3 2
13 5 4 5 4 3 4
14 3 4 5 5 3 5
15 5 4 4 4 4 1
16 3 4 3 4 3 1
17 5 4 5 4 4 4
18 4 5 4 5 4 4
19 4 4 5 4 3 4
20 5 5 5 3 5 5
21 4 5 5 5 3 4
22 4 5 4 5 4 5
23 4 3 4 4 3 5
24 3 3 4 3 4 3
25 5 4 5 4 4 3
26 3 4 5 5 4 2
27 5 4 4 4 5 2
28 3 4 3 4 5 2
29 5 4 5 4 2 3
30 4 5 4 5 4 4
31 4 4 5 4 4 4
32 5 5 5 3 3 4
33 3 4 4 5 4 4
34 3 3 4 5 4 4
35 3 4 5 4 3 4
36 5 5 5 5 3 4
37 5 5 5 5 4 5
38 5 5 5 5 4 5
39 5 5 5 5 4 5
40 5 5 4 5 3 5
41 3 3 4 3 3 3
44 5 4 4 4 4 3
45 3 4 3 4 4 3
46 5 4 5 4 4 3
47 4 5 4 5 5 4
48 4 4 5 4 5 4
49 5 5 5 3 4 4
50 3 4 5 5 4 2
51 3 3 4 5 3 2
52 3 4 5 5 5 2
53 3 3 4 5 2 3
54 3 4 4 4 3 4
55 5 5 5 5 3 2
56 5 5 5 5 4 2
57 5 5 5 5 4 2
58 5 5 5 5 5 2
59 5 5 5 5 5 4
60 4 5 5 5 5 4
61 4 5 5 5 5 4
62 4 3 4 4 5 5
63 3 3 4 3 3 5
64 5 4 4 4 3 5
65 3 4 5 5 2 3
66 5 4 5 4 2 3
67 3 4 4 4 2 3
68 5 4 3 4 2 3
69 4 5 5 4 4 3
SUCCESIVE DETAIL PENSKALAAN SUCCESIVE DETAIL
Col Category Freq Prop Cum Density Z Scale 1 3.000 23.000 0.329 0.329 0.362 -0.444 1.000 4.000 17.000 0.243 0.571 0.393 0.180 1.973
5.000 30.000 0.429 1.000 0 3.016
2 3.000 11.000 0.157 0.157 0.240 -1.006 1.000 4.000 31.000 0.443 0.600 0.386 0.253 2.201
5.000 28.000 0.400 1.000 0.000 3.496
3 3.000 4.000 0.057 0.057 0.115 -1.579 1.000 4.000 26.000 0.371 0.429 0.393 -0.180 2.258
5.000 40.000 0.571 1.000 0.000 3.693
4 3.000 7.000 0.100 0.100 0.175 -1.282 1.000 4.000 27.000 0.386 0.486 0.399 -0.036 2.176
5.000 36.000 0.514 1.000 0.000 3.530
5 2.000 10.000 0.143 0.143 0.226 -1.068 1.000 3.000 20.000 0.286 0.429 0.393 -0.180 1.995 4.000 28.000 0.400 0.829 0.254 0.949 2.925
5.000 12.000 0.171 1.000 0.000 4.064
HASIL SKALA AKHIR SUCCESIVE INTERVAL TIAP VARIABEL
NO X1 X2 X3 X4 X5 X6
1 1.000 2.201 3.693 3.530 1.000 2.191
2 1.000 1.000 2.258 3.530 2.925 2.191
3 1.000 2.201 2.258 2.176 1.995 2.191
4 3.016 3.496 3.693 3.530 1.000 2.191
5 3.016 3.496 3.693 3.530 1.995 2.191
6 3.016 3.496 3.693 3.530 2.925 2.191
7 3.016 3.496 3.693 3.530 2.925 4.728
8 3.016 3.496 3.693 3.530 4.064 3.705
9 1.973 3.496 3.693 3.530 2.925 3.705
10 1.973 3.496 2.258 3.530 1.000 2.992
11 1.973 1.000 2.258 2.176 1.995 3.705
12 1.000 1.000 2.258 1.000 1.995 2.191
13 3.016 2.201 3.693 2.176 1.995 3.705
14 1.000 2.201 3.693 3.530 1.995 4.728
15 3.016 2.201 2.258 2.176 2.925 1.000
16 1.000 2.201 1.000 2.176 1.995 1.000
17 3.016 2.201 3.693 2.176 2.925 3.705
18 1.973 3.496 2.258 3.530 2.925 3.705
19 1.973 2.201 3.693 2.176 1.995 3.705
20 3.016 3.496 3.693 1.000 4.064 4.728
21 1.973 3.496 3.693 3.530 1.995 3.705
22 1.973 3.496 2.258 3.530 2.925 4.728
23 1.973 1.000 2.258 2.176 1.995 4.728
24 1.000 1.000 2.258 1.000 2.925 2.992
25 3.016 2.201 3.693 2.176 2.925 2.992
26 1.000 2.201 3.693 3.530 2.925 2.191
27 3.016 2.201 2.258 2.176 4.064 2.191
28 1.000 2.201 1.000 2.176 4.064 2.191
29 3.016 2.201 3.693 2.176 1.000 2.992
30 1.973 3.496 2.258 3.530 2.925 3.705
31 1.973 2.201 3.693 2.176 2.925 3.705
32 3.016 3.496 3.693 1.000 1.995 3.705
33 1.000 2.201 2.258 3.530 2.925 3.705
34 1.000 1.000 2.258 3.530 2.925 3.705
35 1.000 2.201 3.693 2.176 1.995 3.705
36 3.016 3.496 3.693 3.530 1.995 3.705
37 3.016 3.496 3.693 3.530 2.925 4.728
38 3.016 3.496 3.693 3.530 2.925 4.728
39 3.016 3.496 3.693 3.530 2.925 4.728
40 3.016 3.496 2.258 3.530 1.995 4.728
41 1.000 1.000 2.258 1.000 1.995 2.992
44 3.016 2.201 2.258 2.176 2.925 2.992
45 1.000 2.201 1.000 2.176 2.925 2.992
46 3.016 2.201 3.693 2.176 2.925 2.992
47 1.973 3.496 2.258 3.530 4.064 3.705
48 1.973 2.201 3.693 2.176 4.064 3.705
49 3.016 3.496 3.693 1.000 2.925 3.705
50 1.000 2.201 3.693 3.530 2.925 2.191
51 1.000 1.000 2.258 3.530 1.995 2.191
52 1.000 2.201 3.693 3.530 4.064 2.191
53 1.000 1.000 2.258 3.530 1.000 2.992
54 1.000 2.201 2.258 2.176 1.995 3.705
55 3.016 3.496 3.693 3.530 1.995 2.191
56 3.016 3.496 3.693 3.530 2.925 2.191
57 3.016 3.496 3.693 3.530 2.925 2.191
58 3.016 3.496 3.693 3.530 4.064 2.191
59 3.016 3.496 3.693 3.530 4.064 3.705
60 1.973 3.496 3.693 3.530 4.064 3.705
61 1.973 3.496 3.693 3.530 4.064 3.705
62 1.973 1.000 2.258 2.176 4.064 4.728
63 1.000 1.000 2.258 1.000 1.995 4.728
64 3.016 2.201 2.258 2.176 1.995 4.728
65 1.000 2.201 3.693 3.530 1.000 2.992
66 3.016 2.201 3.693 2.176 1.000 2.992
67 1.000 2.201 2.258 2.176 1.000 2.992
68 3.016 2.201 1.000 2.176 1.000 2.992
69 1.973 3.496 3.693 2.176 2.925 2.992
LAMPIRAN 5
HASIL OUTPUT SPSS
HASIL PERHITUNGAN UJI VALIDITAS
Correlations
X1 X2 X3 X4 X5 X6 SCORETOTAL
X1 Pearson Correlation 1 .569** .394** .027 .174 .166 .431**
Sig. (2-tailed) .000 .001 .822 .150 .170 .000
N 70 70 70 70 70 70 70
X2 Pearson Correlation .569** 1 .445** .425** .235 .134 .697**
Sig. (2-tailed) .000 .000 .000 .051 .269 .000
N 70 70 70 70 70 70 70
X3 Pearson Correlation .394** .445** 1 .252* .086 .108 .551**
Sig. (2-tailed) .001 .000 .035 .477 .375 .000
N 70 70 70 70 70 70 70
X4 Pearson Correlation .027 .425** .252* 1 .060 -.061 .473**
Sig. (2-tailed) .822 .000 .035 .622 .617 .000
N 70 70 70 70 70 70 70
Sig. (2-tailed) .150 .051 .477 .622 .270 .000
N 70 70 70 70 70 70 70
X6 Pearson Correlation .166 .134 .108 -.061 .134 1 .586**
Sig. (2-tailed) .170 .269 .375 .617 .270 .000
N 70 70 70 70 70 70 70
SCORETOTAL Pearson Correlation .431** .697** .551** .473** .574** .586** 1
Sig. (2-tailed) .000 .000 .000 .000 .000 .000
N 70 70 70 70 70 70 70
**. Correlation is significant at the 0.01 level (2-tailed).
Lanjutan Lampiran 5
HASIL PERHITUNGAN RELIABILITAS
Case Processing Summary
N %
Cases Valid 70 100.0
Excludeda 0 .0
Total 70 100.0
a. Listwise deletion based on all variables in the
procedure.
Reliability Statistics
Cronbach's Alpha
Cronbach's Alpha Based on
Standardized Items N of Items
Item-Total Statistics
Scale Mean if
Item Deleted
Scale Variance if
Item Deleted
Corrected
Item-Total Correlation
Cronbach's
Alpha if Item
Deleted
X1 20.16 5.526 .431 .461
X2 20.01 5.522 .697 .403
X3 19.74 6.426 .551 .496
X4 19.84 6.975 .473 .569
X5 20.66 6.113 .574 .562
Lanjutan Lampran 5
Correlation Matrixa
x1 x2 x3 x4 x5 x6
Correlation x1 1.000 .566 .398 .021 .166 .160
x2 .566 1.000 .452 .434 .235 .130
x3 .398 .452 1.000 .260 .086 .102
x4 .021 .434 .260 1.000 .059 -.049
x5 .166 .235 .086 .059 1.000 .122
x6 .160 .130 .102 -.049 .122 1.000
Sig. (1-tailed) x1 .000 .000 .431 .085 .093
x2 .000 .000 .000 .025 .142
x3 .000 .000 .015 .240 .200
x4 .431 .000 .015 .312 .343
x5 .085 .025 .240 .312 .157
x6 .093 .142 .200 .343 .157
Lanjutan Lampiran 5
Anti-image Matrices
x1 x2 x3 x4 x5 x6
Anti-image Covariance x1 .582 -.275 -.149 .204 -.020 -.044
x2 -.275 .466 -.113 -.271 -.108 -.042
x3 -.149 -.113 .747 -.109 .026 -.039
x4 .204 -.271 -.109 .714 .021 .077
x5 -.020 -.108 .026 .021 .934 -.084
x6 -.044 -.042 -.039 .077 -.084 .955
Anti-image Correlation x1 .552a -.527 -.226 .316 -.027 -.060
x2 -.527 .581a -.191 -.470 -.164 -.062
x3 -.226 -.191 .799a -.149 .031 -.046
x4 .316 -.470 -.149 .526a .025 .094
x5 -.027 -.164 .031 .025 .744a -.089
x6 -.060 -.062 -.046 .094 -.089 .728a
Lanjutan lampiran 5
KMO and Bartlett's Test
Kaiser-Meyer-Olkin Measure of Sampling Adequacy. .591
Bartlett's Test of Sphericity Approx. Chi-Square 71.964
df 15
Sig. .000
Communalities
Initial Extraction
x1 1.000 .603
x2 1.000 .770
x3 1.000 .518
x4 1.000 .670
x5 1.000 .566
x6 1.000 .529
Extraction Method: Principal
Lanjutan Lampiran 5
Total Variance Explained
Compon
ent
Initial Eigenvalues Extraction Sums of Squared Loadings Rotation Sums of Squared Loadings
Total % of Variance Cumulative % Total % of Variance Cumulative % Total % of Variance Cumulative %
1 2.221 37.011 37.011 2.221 37.011 37.011 2.000 33.338 33.338
2 1.136 18.939 55.950 1.136 18.939 55.950 1.357 22.612 55.950
3 .922 15.367 71.317
4 .835 13.910 85.228
5 .594 9.905 95.133
6 .292 4.867 100.000
Component Matrix
Component
1 2
x1 .727 .273
x2 .869 -.120
x3 .709 -.125
x4 .480 -.663
x5 .366 .363
x6 .264 .678
Extraction Method: Principal
Component Analysis.
a. 2 components extracted.
Rotated Component Matrixa
Component
1 2
x1 .526 .572
x2 .830 .285
x3 .689 .208
x4 .727 -.376
x5 .163 .489
x6 -.070 .724
Extraction Method: Principal
Component Analysis.
Rotation Method: Varimax with
Kaiser Normalization.
a. Rotation converged in 3
iterations.
Component Transformation
Matrix
Compo
nent 1 2
1 .893 .451
2 -.451 .893
Extraction Method: Principal
Component Analysis.
Rotation Method: Varimax with
LAMPIRAN 6
Secara manual mencari nilai Cronback Alpha pertama dengan mencari nilai variansi dari masing-masing variabel dengan rumus sebagai berikut:
=
2−( )2
1 =
82369−287 2
70
70 = 1159,89 4 =
95481−306 2
70
70 = 1344,528
2 =
88209−297 2
70
70 = 1242,127 5 =
63504−252 2
70
70 = 894,24
3 =
99856−316 2
70
70 = 1406,136 6 =
1990921−1411 2
70
70 = 790,9512
∑ = 1159,89 + 1242,127 + 1406,136 + 1344,528 + 894,24 + 790,9512 = 6837.872
Mencari Nilai Variansi total: Mencari Nilai Alpha:
∑ =28823−
1411 2 70
70 = 5,446 = −1 1−
�2 �2
= 6
6−1 1−
6837.872
5,446 = 1,2 1254,576
LAMPIRAN 7
Perhitungan Korelasi Produck Momen X2 Nomor
Responden X2 Y X2Y X2
2
Y2
1 4 17 68 16 289
2 3 18 54 9 324
3 4 16 64 16 256
4 5 19 95 25 361
5 5 20 100 25 400
6 5 21 105 25 441
7 5 24 120 25 576
8 5 24 120 25 576
9 5 22 110 25 484
10 5 18 90 25 324
11 3 19 57 9 361
12 3 15 45 9 225
13 4 21 84 16 441
14 4 21 84 16 441
15 4 18 72 16 324
16 4 14 56 16 196
17 4 22 88 16 484
18 5 21 105 25 441
. . . .
. . . .
. . . .
70 4 21 84 16 441
Jumlah 297 1401 6014 1295 28421
2 =
2 − ( 2. )
{ 22− ( 2)2}{ 2− ( )2}
2 =
70 6014 − (297 1401 )
70 1295 − 2972 {70 28421 − 14012}
1 =
420980−416097
90650−88209 (1989470−1962801)
2 = 4883 (2441)(26669) 2 = 4883 √65099029 2 = 4883 8068,397
Perhitungan Korelasi Produck Momen X3 Nomor
Responden X3 Y X3Y X3
2
Y2
1 5 16 80 25 256
2 4 17 68 16 289
3 4 16 64 16 256
4 5 19 95 25 361
5 5 20 100 25 400
6 5 21 105 25 441
7 5 24 120 25 576
8 5 24 120 25 576
9 5 22 110 25 484
10 4 19 76 16 361
11 4 18 72 16 324
12 4 14 56 16 196
13 5 20 100 25 400
14 5 20 100 25 400
15 4 18 72 16 324
16 3 15 45 9 225
17 5 21 105 25 441
18 4 22 88 16 484
. . . .
. . . .
. . . .
70 4 21 84 16 441
Jumlah 316 1382 6282 1452 27728
3 =
3 − ( 3. )
{ 32− ( 3)2}{ 2− ( )2}
3 =
70 6282 − ( 316 1382 )
70 1452 − 316 2 {7027728 − 1382 2}
3 =
439740−436712
101640−99856(1940960−1909924)
3 = 3028 (1784)(31036) 3 = 3028 √55368224 3 = 3028 7440,983
Perhitungan Korelasi Produck Momen X4 Nomor
Responden X4 Y X4Y X4
2
Y2
1 5 16 80 25 256
2 5 16 80 25 256
3 4 16 64 16 256
4 5 19 95 25 361
5 5 20 100 25 400
6 5 21 105 25 441
7 5 24 120 25 576
8 5 24 120 25 576
9 5 22 110 25 484
10 5 18 90 25 324
11 4 18 72 16 324
12 3 15 45 9 225
13 4 21 84 16 441
14 5 20 100 25 400
15 4 18 72 16 324
16 4 14 56 16 196
17 4 22 88 16 484
18 5 21 105 25 441
. . . .
. . . .
. . . .
70 4 21 84 16 441
Jumlah 309 1389 6153 1395 28043
4 =
4 − ( 4. )
{ 42− ( 4)2}{ 2− ( )2}
4 =
70 6153 − (309 1389)
70 1395 − 3092 {70 28043 − 13892}
4 =
430710−429201
97650−95481 (1963010−1929321)
4 = 1509 (2169)(33689) 4 = 1509 √73071441 4 = 1509 8548,183
Perhitungan Korelasi Produck Momen X5 Nomor
Responden X5 Y X5Y X5
2
Y2
1 2 19 38 4 361
2 4 17 68 16 289
3 3 17 51 9 289
4 2 22 44 4 484
5 3 22 66 9 484
6 4 22 88 16 484
7 4 25 100 16 625
8 5 24 120 25 576
9 4 23 92 16 529
10 2 21 42 4 441
11 3 19 57 9 361
12 3 15 45 9 225
13 3 22 66 9 484
14 3 22 66 9 484
15 4 18 72 16 324
16 3 15 45 9 225
17 4 22 88 16 484
18 4 22 88 16 484
. . . .
. . . .
. . . .
70 4 21 84 16 441
Jumlah 252 1446 5242 968 30292
5 =
5 − ( 5. )
{ 52− ( 5)2}{ 2− ( )2}
5 =
70 5242 − (252 1446 )
70 968 − 2522 {70 30292 − 1446 2}
5 =
366940−364392
67760−63504 (2120440−2090916)
5 = 2548 (4256)(29624) 5 = 2548 √125654144 5 = 2548 11209,556
Perhitungan Korelasi Produck Momen X6 Nomor
Responden X6 Y X6Y X6
2
Y2
1 2 19 38 4 361
2 2 19 38 4 361
3 2 18 36 4 324
4 2 22 44 4 484
5 2 23 46 4 529
6 2 24 48 4 576
7 5 24 120 25 576
8 4 25 100 16 625
9 4 23 92 16 529
10 3 20 60 9 400
11 4 18 72 16 324
12 2 16 32 4 256
13 4 21 84 16 441
14 5 20 100 25 400
15 1 21 21 1 441
16 1 17 17 1 289
17 4 22 88 16 484
18 4 22 88 16 484
. . . .
. . . .
. . . .
70 5 20 100 25 400
Jumlah 237 1461 4977 891 30899
6 =
6 − ( 6. )
{ 62− ( 6)2}{ 2− ( )2}
6 =
70 4977 − (237 1461 )
70 891 − 2372 {70 30899 − 1461 2}
6 =
348390−346257
62370−56169 (2162930−2134521 )
6 = 2133 (6201)(28409) 6 = 2133 √176164209 6 = 2133 13272 ,687
Adlin, 2002, Kecerdasan Spiritual dan Kecerdasan Abritasi Diantara Agama dan Semiotika, http://www.paramartha.com. 12 Juni 2005
Aida & Listianingsih, 2004. Pengaruh sistem pengukuran kinerja sistem reward
dan profit center terhadap hubungan antara total Quality management
dengan kinerja kerja manajerial. SNA VIII. Solo
Agoes, Sukrisno. 2004. Auditing (Pemeriksaan Akutansi) Oleh kantor Akuntan
Publik, Jakarta: Lembaga penerbit Fakultas Ekonomi Universitas
Indonesia
Anastasi, A, dan Urbina, S. 1997. Tes Psikologi (Psykological testing), PT. Prehanllindo, Jakarta
Arens, elder dan beasley. 2006. Auditing dan Jasa Assurance, Edisi Indonesi, Salemba Empati, Jakarta
Arikunto, Suharsimi. 2002. Prosedur. Metodelogi Penelitian: Suatu Pendekatan
Praktik. Jakarta: Pinerbit Rineka Cipta
Azwar, Saifuddin. 1996. Reliabilitas dan Validitas.Yogyakarta. Pustaka Pelajar Cochran, William G. 1991. Teknik Penarikan Sampling. Terjemahan Rudiansyah,
Erwin R. Osman: Jakarta UI-Press
Carruso, D, R, 1999, Applying The Ability Model Of Emotional Intelligence To The World Of Work, http://cjwolfe.com/article.doc, 15 Oktober 2005. Dillon, R. W. Dan Goldstein, M.1984. multivariate Analysis and Aplication
New York: John Wiley & Sains, Inc,
Goleman, D. (2003). Working with Emosional Intelligence Terjemahan). Jakarta: PT Gramedia Pustaka Utama
Greenbaum, 2006, “creating dynamioc brand awareness”. Franchsing World, Vol.38 Pg.46.
Johnson, R. A and D. W. Wichern. (1982). Applied Multivariate Statistical
Analysis, Prentice-Hall, Inc. New Jersey.
Pedgett, D. K. (1999), Qualitative Methods in Social Work Research Challanges
And Rewards. London: Sage Publication.
PEMBAHASAN DAN HASIL
3.1 Populasi, Sampel dan Teknik Pengambilan Sampel
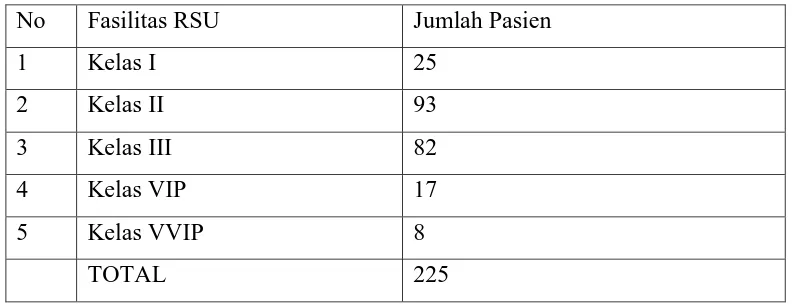
Populasi dalam penelitian ini adalah seluruh pasien pada RS Umum Padang Sidempuan. Jumlah pasien yang telah menggunakan RSU Padang Sidempuan pada tahun 2015 adalah 99524 (data diperoleh dari website resmi RSU Padang Sidempuan). Adapun jumlah pengunjung atau pasien RSU padang Sidempuan di bulan Desember 2015 adalah sebanyak 225
Tabel 3.1 Daftar Jumlah Pasien RSU Padang Sidempuan Tahun 2015
No Fasilitas RSU Jumlah Pasien
1 Kelas I 25
2 Kelas II 93
3 Kelas III 82
4 Kelas VIP 17
5 Kelas VVIP 8
TOTAL 225
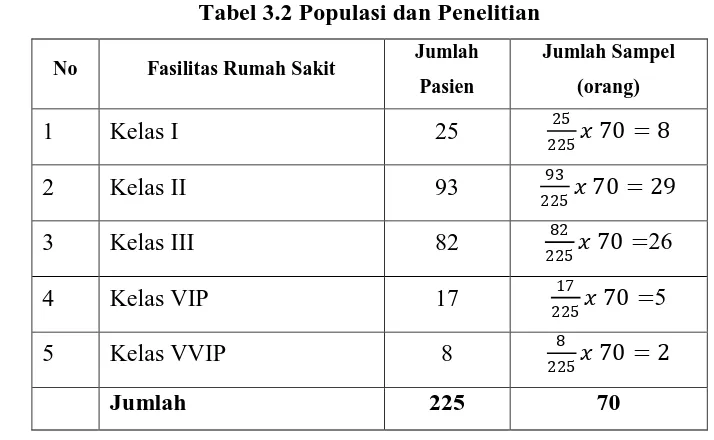
Jumlah sampel dalam penelitian ini adalah 70 responden. Langkah-langkah dalam penentuan sampel, tahap pertama adalah menentukan banyaknya jumlah sampel dari seluruh populasi yang telah diketahui dan kemudian tentukan tingkat presisi yang ditetapkan yaitu 10% dengan rumus slovin sebagai berikut:
=
1 + 2
= 225
1 + 225(0,1)2
= 225
3,25= 69,23
= 70
Proportionale Stratified random sampling yaitu pengambilan sampel dilakukan
secara acak dengan memperhatikan strata yang ada. Artinya setiap strata terwakili sesuai proporsinya. Kemudian secara manual menentukan sampel secara prporsional dengan rumus:
= .
Tabel 3.2 Populasi dan Penelitian
No Fasilitas Rumah Sakit Jumlah
Pasien
Jumlah Sampel
(orang)
1 Kelas I 25 25
225 70 = 8
2 Kelas II 93 93
225 70 = 29
3 Kelas III 82 82
225 70 =26
4 Kelas VIP 17 17
225 70 =5
5 Kelas VVIP 8 8
225 70 = 2
Jumlah 225 70
3.2 Variabel Penelitian
Variabel yang digunakan dalam penelitian ini adalah:
1= Skill para perawat 2= Fasilitas
3= Pelayanan
4= Kelengkapan Obat 5= Empati
6= Ketanggapan
3.3 Sumber Data
terstruktur yaitu kuisioner dalam bentuk pernyataaan yang telah disertai dengan pilihan jawaban dalam bentuk skala.
Skala yang digunakan dalam penelitian ini adalah skala likert. Skala likert yaitu skala yang memiliki jarak (interval), skala likert digunakan untuk mengukur sikap, pendapat dan persepsi seseorang ata kelompok tentang suatu kejadian atau gejala sosial (Riduwan, 2005).
Pada penelitan ini skala telah dimodifikasi dalam bentuk pilihan ganda dimana setiap pernyataan diberikan range skor 1 sampai dengan 5, masing-masing adalah :
5 = Sangat Setuju 4 = Setuju
3 = Ragu-rgu/tidak tahu 2 = Tidak Setuju
1 = Sangat tidak setuju
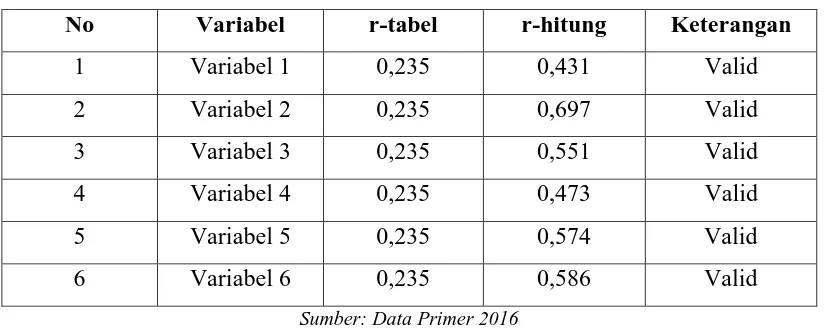
3.4 Pengolahan Data 3.4.1 Uji Validitas
Hasil uji validitas kuesioner dari 4 variabel yang diukur kemudian dihitung dengan menggunakan software SPSS yang ditunjukkan pada tabel.
Tabel 3.3 Uji Validitas
No Variabel r-tabel r-hitung Keterangan
1 Variabel 1 0,235 0,431 Valid
2 Variabel 2 0,235 0,697 Valid
3 Variabel 3 0,235 0,551 Valid
4 Variabel 4 0,235 0,473 Valid
5 Variabel 5 0,235 0,574 Valid
6 Variabel 6 0,235 0,586 Valid
Sumber: Data Primer 2016
bahwa 6 variabel pada tabel diatas dinyatakan valid.
Secara manual perhitungan korelasi Product Moment antara variabel X1 dengan skor total variabel lainnya (Y) dapat dilihat pada tabel berikut:
Tabel 3.4 Contoh Perhitungan Korelasi Product Moment Nomor
Responden X1 Y X1Y X1
2
Y2
1 3 18 54 9 324
2 3 18 54 9 324
3 3 17 51 9 289
4 5 19 95 25 361
5 5 20 100 25 400
6 5 21 105 25 441
7 5 24 120 25 576
8 5 24 120 25 576
9 4 23 92 16 529
10 4 19 76 16 361
11 4 18 72 16 324
12 3 15 45 9 225
13 5 20 100 25 400
14 3 22 66 9 484
15 5 17 85 25 289
16 3 15 45 9 225
17 5 21 105 25 441
18 4 22 88 16 484
. . . .
. . . .
. . . .
70 4 21 84 16 441
Jumlah 287 1411 5846 1229 28823
1 =
1 − ( 1. )
{ 12− ( 1)2}{ 2− ( )2}
1 =
70 5846 − ( 287 1411)
70 1229 − 2872 {70 28823 − 1411 2}
1 =
409920−404957
86030−82369 (2017610−1990921)
1 = 0,431
Diperoleh nilai validitas 1 dengan perhitungan manual adalah 0,431 sama dengan output SPSS yakni 0,431. Selanjutnya untuk perhitungan lainnya akan dilakukan dengan software SPSS.
3.4.2 Uji Reliabilitas
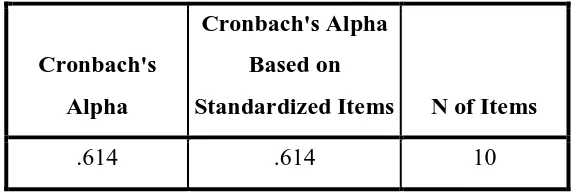
Setelah dilakukan uji validitas dan dinyatakan valid dilanjutkan dengan uji reliabilitas. Suatu variabel dikatakan reliabel apabila setelah dilakukan uji reliabel diperoleh nilai Cronbach Alpha > 0,60 atau nilai Cronbach Alpha >0,80.
[image:30.595.168.456.397.493.2]Berikut adalah hasil perolehan data dari uji reliabilitas dengan SPSS. Tabel 3.5 Hasil Cronback Alpha Reliability Test Reliability Statistics
Cronbach's Alpha
Cronbach's Alpha Based on
Standardized Items N of Items
.614 .614 10
Berdasarkan hasill perhitungan di atas, nilai Cronbach Coeficien Alpha adalah 0,614 untuk uji reliabilitas atas daftar pilihan responden. Nilai tersebut menyatakan bahwa 6 variabel yang valid tersebut memenuhi syarat uji reliabilitas, dimana nilai yang diperoleh sudah lebih dari minimum untuk sebuah penelitian yaitu 0,6.
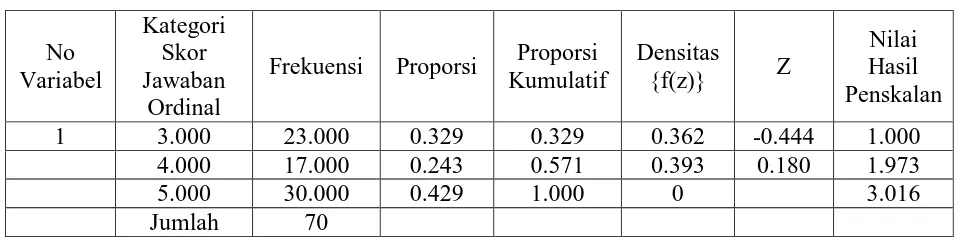
3.4.3 Penskala Data Ordinal Menjadi Data Interval
Interval.
Tabel 3.6 Penskalaan Variabel 1
No Variabel Kategori Skor Jawaban Ordinal
Frekuensi Proporsi Proporsi Kumulatif
Densitas
{f(z)} Z
Nilai Hasil Penskalan
1 3.000 23.000 0.329 0.329 0.362 -0.444 1.000
4.000 17.000 0.243 0.571 0.393 0.180 1.973
5.000 30.000 0.429 1.000 0 3.016
Jumlah 70
Langkah-langkah Methods Successive Internal
1. Menghitung frekuensi skor jawaban dalam skala ordinal.
2. Menghitung proporsi dan proporsi kumulatif untuk masing-masing skor jawaban.
3. Menentukan nilai Z untuk setiap kategori, dengan asumsi bahwa proporsi kumulatif dianggap mengikuti distribusi normal baku. Nilai Z diperoleh dari tabel Distribusi Normal baku.
4. Menghitung nilai densitas dari nilai Z yang diperoleh dengan cara memasukkan nilai Z tersebut kedalam fungsi densitas normal baku sebagai berikut:
= 1
√2�
−12 2
−1,902 = 1
√2�
−12 −1,902 2
= 0,361517
5. Menghitung Scale Value (SV) dengan rumus:
= −−
1 =
0,000−0,361517
0,328571−0,000 = −1,1002
2 =
0,361517−0,392531
0,571429−0,328571 = −0,1277
3 =
0,392531−0,000000
1 = −1,1002 (SV terkecil)
Nilai 1 diperoleh dari:
−1,1002 + X = 1
X = 1 + 1,1002 X = 2,1002
−1,1002 + 2,1002 = 1 sehingga Y1 =1
7. Menentukan nilai skala dengan mengunakan rumus:
= +
2 = −1,1002 + 2,1002 = 1
3 = −0,1277 + 2,1002 = 1,9725
[image:32.595.150.480.385.488.2]4 = 0,9159 + 2,1002 = 3,0161
Tabel 3.7 Hasil Penskalaan Variabel
1 2 3 4 5 6
1 1.000
2 1.000 2.191
3 1.000 1.000 1.000 1.000 1.995 2.992 4 1.973 2.201 2.258 2.176 2.925 3.705 5 3.016 3.496 3.693 3.530 4.064 4.728
3.5Analisis Data
Metode analisis data yang digunakan dalam teknik analisis faktor dengan pendekatan komponen utama. Langkah-langkah dalam analisis faktor adalah sebagai berikut:
3.5.1 Proses Analisis Faktor I
sebesar 0,591 dengan signifikan sebesar 0,000. Berdasarkan teori nilai KMO memang harus diatas 0,5 dan signifikan atau probabilitas dibawah 0,5 maka variabel layak dan dapat dianalisa lebih lanjut (Santoso, 2002).
Tabel 3.8 KMO and Bartlett's Testa Kaiser-Meyer-Olkin Measure of Sampling Adequacy.
.591 Bartlett's Test of
Sphericity
Approx. Chi-Square 71.964
Df 15
Sig. .000
a. Based on correlations
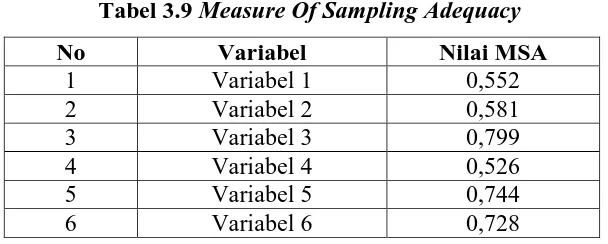
Perhitungan selanjutnya adalah dengan melihat nilai MSA. Hasil nilai MSA dapat dilihat pada tabel dibawah. Hasil pada tabel menunjukkan bahwa 6 variabel yang tersisa mempunyai nilai lebih dari 0,5 berdasarkan 6 variabel yang dinilai dalam kuesioner yang merupakan jawaban 70 responden, diperoleh bahwa nilai MSA yang diperoleh di atas 0,5. Ini menandakan bahwa semua variabel memiliki korelasi cukup tinggi dengan variabel lainnya, sehingga selanjutnya dapat dilakukan analisis pada seluruh variabel yang diteliti.
Tabel 3.9 Measure Of Sampling Adequacy
No Variabel Nilai MSA
1 Variabel 1 0,552
2 Variabel 2 0,581
3 Variabel 3 0,799
4 Variabel 4 0,526
5 Variabel 5 0,744
6 Variabel 6 0,728
3.6 Proses Anlasisi faktor II (Ekstraksi)
Dalam penelitian ini metode yang akan digunakan adalah Principal Componen
Analysis (Analisis Komponen Utama). Didalam Principal Componen Analysis
[image:33.595.175.479.478.600.2]berkorelasi. Communalities adalah jumlah varians yang disumbangkan oleh suatu variabel dengan seluruh variabel lainnya dengan analisis.
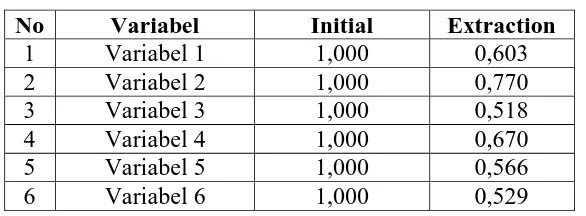
3.6.1 Communalities
Communalities pada dasarnya adalah jumlah varians dari suatu variabel awal yang
[image:34.595.167.460.287.395.2]bisa dijelaskan oleh faktor yang ada. Semakin besar communalities sebuah variabel, maka semakin erat hubungannya dengan faktor.
Tabel 3.10 Communalities
No Variabel Initial Extraction
1 Variabel 1 1,000 0,603
2 Variabel 2 1,000 0,770
3 Variabel 3 1,000 0,518
4 Variabel 4 1,000 0,670
5 Variabel 5 1,000 0,566
6 Variabel 6 1,000 0,529
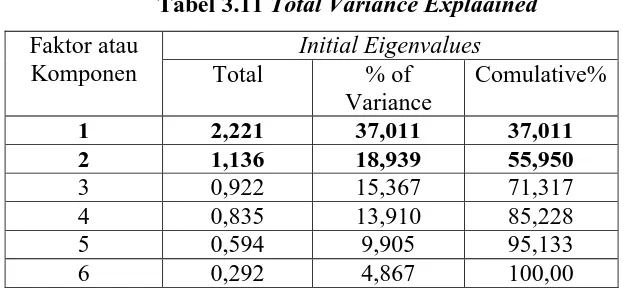
3.6.2 Total variance Explained
Total Variance Explaned menerangkan nilai persen dari varainsi yang mampu
diterangkan oleh banyaknya faktor yang terbentuk. Nilai ini berdasarkan nilai
eigenvalue.
Ada 6 variabel yang dimasukkan dalam analisis faktor, dengan masing masing varian memiliki varian 1, maka total varian adalah 6 x 1 = 6. Jika keempat variabel diringkas menjadi 1 faktor, maka varians yang bisa dijelaskan oleh satu faktor tersebut adalah (lihat kolom Component 1 pada Tabel ):
2,221
6 100%= 37,011%
faktor tersebut akan menjelaskan 55,950% dari variabilitas kedua yang asli tersebut.
Sedangkan eigenvalue manunjukkan kepentingan relatif masing-masing faktor dalam menghitung varians kesepuluh variabel yang dianalisis.
1. Jumlah angka egenvalue untuk kesepuluh variabel adalah sama dengan total varian kesepuluh variabel atau 2,221 + 1,136 + 0,922 + 0,835 + 0,594 + 0,292 = 6
[image:35.595.156.468.380.527.2]2. Susunan eigenvalue selalu diurutkan dari yang terbesar sampai dengan yang terkecil, dengan kriteria bahwa angka eigenvalue dibawah 1 tidak digunakan dalam menghitung faktor yang terbentuk.
Tabel 3.11 Total Variance Explaained Faktor atau
Komponen
Initial Eigenvalues
Total % of
Variance
Comulative%
1 2,221 37,011 37,011
2 1,136 18,939 55,950
3 0,922 15,367 71,317
4 0,835 13,910 85,228
5 0,594 9,905 95,133
6 0,292 4,867 100,00
Dari tabel 3.11 diatas menyatakan bahwa hanya 2 faktor yang terbentuk, terlihat dari eigenvalue dengan nilai diatas 1, namun pada faktor yang ketiga angka
eigenvalue sudah dibawah 1, yakni 0,922 sehingga proses Faktoring seharusnya
berhenti pada dua faktor saja, maka dalam penelitian ini hanya dua faktor yang terbentuk.
3.6.3 Scree Plot
meringkas ke 6 variabel tersebut.
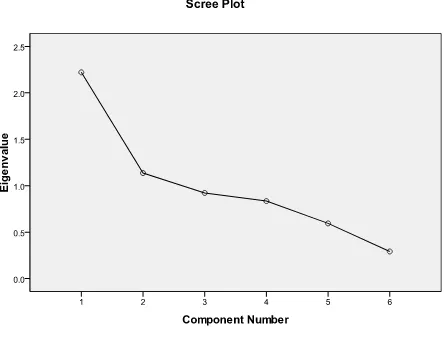
Gambar 3.1 Scree Plot
Suatu Scree plot adalah plot dari eigen value melawan banyaknya faktor yang bertujuan untuk melakukan ekstraksi agar diperoleh jumlah faktor. Scree plot berupa suatu kurva yang diperoleh dengan memplot eigen value sebagai sumbu vertikal dana banyaknya faktor sebagai sumbu horizontal. Bentuk kurva atau plotnya dipergunakan untuk menentukan banyaknya faktor.
Jika tabel total variansi menjelaskan dasar jumlah faktor yang didapat dengan perthitungan angka, maka scree plot memperlihatkan hal tersebut dengan grafik. Terlihat bahwa dari suatu ke dua faktor (baris dari sumbu Component 1 ke-2), arah garis cukup menurun tajam. Kemudian dari 2 ,3 dan 4 garis juga menurun. Pada faktor 3 sudah dibawah angka 1 dari sumbu eigen value. Hal ini menunjukkan bahwa ada 2 faktor yang mempengaruhi tingkat kepuasan pasien terhadap pelayanan rumah sakit umum kota padang sidimpuan, yang dapat diekstraksi berdasarkan scree plot.
3.7 Proses Analisis Faktor III (Rotasi)
Tabel 3.12 Faktor Loading Variabel
Penelitian
Faktor
1 2
1 0,727 0,273
2 0,869 -0,120
3 0,709 -0,125
4 0,480 -0,663
5 0,366 0,363
6 0,264 0,678
Dari Tabel diatas dapat dilihat bahwa variabel-variabel berkorelasi kuat dengan lebih dari satu faktor, sehingga sulit untuk menginterpretasikan faktor-faktor tersebut. Dalam hal ini, faktor loading perlu dirotasi agar masing-masing variabel berkorelasi kuat hanya pada satu faktor. Berikut ini adalah Faktor Loading setelah dirotasi (Rotated Faktor Loading).
Tabel 3.13 Rotated Factor Loading Variabel
Penelitian
Faktor
1 2
1 0,526 0,572
2 0,830 0,285
3 0,689 0,208
4 0,727 -0,376
5 0,163 0,489
6 -0,070 0,724
Faktor Loading hasil rotasi menunjukkan bahwa variabel-variabel berkorelasi
kuat hanya pada satu faktor tertentu, misalnya korelasi antara variabel X1 dan faktor 2 sebesar 0,572 (Korelai kuat), sedangkan korelasi dengan faktor 1 adalah 0,526 (korelasi lemah).
3.8 Proses Analisis Faktor IV (Interpretasi Faktor) Faktor Pertama
[image:37.595.200.426.372.500.2]Tabel 3.14 Bobot Variabel Pendukung Faktor Pertama Variabel
Pendukung Nama Variabel
Bobot Variabel X2
Rumah sakit umum sidimpuan terlihat bersih. Fasilitasnya yang lengkap, kesiapan dan kebersihan alat-alat yang dipakai juga modern.
0,830
X3
Pelayanan Rumah sakit umum Padang Sidimpuan yang profesional, ramah dan selalu tanggap dalam membantu pengobatan pasien
0,689 X4
Obat dijual dengan harga yang wajar dan cepat dalam
memberikan pelayanan 0,727
Dari tabel diatas variabel X2 mempunyai bobot terbesar yaitu 0,830. Berdasarkan uraian tersebut dapat disimpulkan bahwa untuk faktor pertama cukup layak diberi nama Faktor Fasilitas.
Faktor ini adalah faktor yang paling kuat yang mendasari tingkat kepuasan pasien terhadap pelayanan Rumah Sakit Umum Padang Sidimpuan dengan variansi sebesar 37,011% serta melibatkan 3 variabel.
Faktor Kedua
[image:38.595.111.518.529.680.2]Faktor kedua hasil rotasi faktor didukung oleh 3 variabel. Bobot masing-masing variabel pendukung faktor kedua tersebut sesuai tabel berikut:
Tabel 3.15 Bobot Variabel Pendukung Faktor Kedua Variabel
Pendukung Nama Variabel
Bobot Variabel X1
Memberikan asuhan keperawatan secara menyeluruh/holistik pada pasien dan bertanggung jawab dan berani megambil keputusan yang tepat, saat melakukan tindakan keperawatan
0,572
X5 Petugas memberikan pelayanan kepada konsumen tanpa
memandang stratus sosial 0,489
X6
Terjadinya komunikasi yang baik antara petugas dan
konsumen 0,724
KESIMPULAN DAN SARAN
4.1 Kesimpulan
Dari hasil pengolahan data dan analisa, maka hasil penelitian dengan 70 responden dan 6 variabel pernyataan penelitian mengambil kesimpulan:
1. Terdapat 2 faktor hasil ekstraksi yang berpengaruh terdapat kepuasan pasien terhadap pelayanan rumah sakit umum kota Padang Sidimpuan. Hal ini digambarkan dari varainsi kumulatif sebesar 55,950%.
2. Kedua faktor tersebut adalah Faktor Fasilitas 37,011%, dan faktor Ketanggapan 18,939%.
3. Faktor Fasilitas ternyata merupakan faktor dominan yang menjadi pengaruh terkuat dalam tingkat kepuasan terhadap pelayanan rumah sakit umum kota Padang Sidimpuan.
4.2 Saran
Menurut hasil penelitian diatas ada 2 hal yang dapat disampaikan sebaga saran yaitu:
1. RSU Padang Sidempuan agar lebih memperhatikan faktor yang mendapatkan nilai terendah dalam mempengaruhi keputusan pasien untuk berobat di RSU Padang Sidempuan yaitu Empati (0,489). Menurut penulis faktor tersebut diharapkn dapat dimaksimalkan dengan cara pemberian special pada momen-momen tertentu dan hari-hari besar (natal,imlek dan idul fitri). Penulis juga menyarankan agar sering dilakukan perbaikan pada kelas I,II,dan III.
LANDASAN TEORI
2.1 Gambaran Umum RS Umum Padang Sidempuan
Rumah Sakit Umum Padang Sidempuan beralamat di Jl. Dr.F.L TobingPd Sidempuan. RSU Padang Sidempuan adalah rumah sakit negeri kelas B. Rumah sakit ini juga menampung rujukan dari rumah sakit ini juga menampung pelayanan rujukan dari rumah sakit kabupaten. RSU ini termasuk RSU besar dimana tempat ini tersedia 225 tempat tidur inap, lebih banyak dibanding setiap rumah sakit di Sumatera Utara yang tersedia rata-rata 80 tempat tidur inap.
Jumlah dokter yang tersedia disini sedikit dengan 31 dokter, rumah sakit ini tersedia lebih sedikit dibanding rata-rata rumah sakit di Sumatera Utara. Pelayanan inap termasuk kelas tinggi dimana 25 dari 225 tempat tidur dirumah sakit ini berkelas VIP ke atas. Jumlah dokter sedikit RSU Padang Sidempuan tersedia 31 dokter, sama dengan rumah sakit tipikal di Sumatera Utara, tetapi 2 lebih banyak daripada rumah sakit tipikal di Sumatera.
Sebagian besar dokter umum dari 31 dokter di rumah sakit ini, 14 adalah dokter umum. Dibandingkan dengan rata-rata rumah sakit diwilayah ini:
5 lebih banyak daripada rumah sakit tipikal di Sumatera Utara
4 lebih banyak daripada rumah sakit tipikal di Sumatera
2.2. Populasi dan Sampel 2.2.1 Populasi
Sidempuan.
2.2.2. Sampel
Sampel adalah bagian dari jumlah dan karakteristik yang dimiliki oleh populasi( Sugiono, 2011: 11). Pada penelitian ini, peneliti mengambil sampel diwilayah RS Umum Padang Sidempuan. Teknik pengambilan sampel menggunakan rumus Slovin (Umar, 2003 : 120), yaitu:
n =
1+( . 2)
dimana :
n = jumlah elemen/anggota sampel N = jumlah elemen/anggota populasi
e = error level (tingkat kesalahan) (catatan : umumnya digunakan 1% atau 0,01, 5% atau 0,05, dan 10% atau 0,1) catatan dapat
dipilih oleh peneliti.
Pemilihan sampel dilakukan dengan metode simple random sampling. Menurut Sugiyono(2011 : 64) metode simple random sampling adalah pengambilan anggota sampel dari populasi yang dilakukan secara acak tanpa memperhatikan strata yang ada dalam populasi itu.
2.3 Variabel Penelitian
Data merupakan komponen utama dalam statistika. Data adalah bahan baku yang jika diolah melalui berbagai analisis dapat melahirkan informasi, dimana dengan informasi tersebut dapat diambil suatu keputusan. Jenis dan sumber data pada penelitian ini adalah sebagai berikut:
1. Data primer, yaitu data yang diperoleh secara langsung dari pengamatan di RS Umum Padang Sidempuan. Kuesioner diberikan pada responden yang merupakan pasien dari RS Umum Padang Sidempuan.
2. Data sekunder, yaitu data yang diperoleh melalui studi dokumnetasi, baik dari buku, jurnal majalah dan situs internet yang mendukung penelitian ini.
2.5 Skala Pengukuran
Skala pengukuran suatu prosedur pemberian angka atau simbol lain kepada sejumlah ciri suatu objek agar dapat menyatakan karakteristik angka pada ciri tersebut. Skala pengukuran oleh S.S Steven (1976) dibagi atas 4 bagian:
a. Skala Nominal
Skala nominal adalah skala pengukuran yang paling sederhana yang dilambangkan dengan kata-kata, huruf, simbol atau bilangan. Skala ini digunakan untuk mengklasifikasikan objek-objek atau kejadian-kejadian kedalam kelompok (kategori) yang terpisahuntuk menunjukan kesaman atau perbedaan ciri-ciri tertentu dari objek yang diamati. Pada skala nominal hasil pengukurannya bisa dibedakan tetapi tidak bisa diurutkan mana yang lebih tinggi, mana yang lebih rendah dan mana yang lebih di kesampingkan. Skala nominal merupakan skala yang paling rendah atau jenis pengukurannya terbatas.
Contoh: Jenis kelamin, 1= pria; 2 = wanita. b. Skala Ordinal
hubungan lebih dari atau kurang dari menurut aturan penataan tertentu. c. Skala Interval
Skala interval adalah skala pengukuran yang mengelompokkan objek-objek ke dalam kelas-kelas yang mempunyai urutan dan perbedaan dalam jarak yang sama. Misalnya, suhu tertinggi pada bulan Maret dikota A, Kota B dan Kota C, berturut-turut adalah 20,23,16 derajat celcius. Kita dapat membedakan dan mengurutkan besarnya suhu di kota tersebut, sebab 1 derajat celcius menyatakan satu unti pengukuran yang tetap.
d. Skala Rasio (Nisbah)
Skala rasio adalah skala yang mempunyai 4 ciri, yaitu membedakan, mengurutkan, jarak yang sama, dan mempunyai titik nol tulen ( titik nol yang berarti) sehingga dapat menghitung rasio atau perbandingan antar nilai. Semua ciri skala interval menjadi ciri skala rasio, perbedaan antar nilai-nilai diketahui dan bernilai tetap, kategori-kategori nilai juga bersifat lepas. Hanya saja skala rasio mempunyai titik nol yang berarti dan rasio(perbandingan) antar dua nilai juga berarti.
Misalnya, Pak Anto mempunyai uang nol rupiah, artinya Pak Anto tidak mempunyai uang.
2.6 Skala untuk Instrumen( Model Skala Sikap)
Bentuk-bentuk skala sikap yang sering digunakan dalam penelitian ada 5 macam, yaitu:
a. Skala Likert
dilengkapi dengankata-kata, misalnya:
Sangat setuju = 5
Setuju = 4
Ragu-ragu/ Tidak tahu = 3
Tidak Setuju = 2
Sangat Tidak Setuju = 1 b. Skala Gutman
Skala Gutman mengukur suatu dimensi saja dari suatu variabel multidimensi. Skala Gutman adalah skala yang digunakan untuk jawaban yang bersifat jelas (tegas) dan konsisten.
Contoh : yakin – tidak yakin, benar – salah, setuju – tidak setuju, dan sebagainya.
c. Skala Diferensial Semantik
Berisikan serangkaian bipolar (dua kutub). Responden diminta untuk menilai suatu objek atau konsep pada suatu skala yang mempunyai 2 ajektif yang bertentangan. Misalnya: panas-dingin, populer-tidak populer, bagus-buruk, dan sebagainya.
d. Rating Scale
Rating scale yaitu data mentah yang didapat berupa angka kemudian ditafsirkan dalam pengertian kualitatif.
Misalnya: ketat-longgar, lemah-kuat, positif-negatif e. Skala Thurstone
Meminta responden untuk memilih jawaban yang ia setujui dari beberapa pertanyaan yang menyajikan pandangan-pandangan berbeda-beda. Pada umumnya asosiasi antara 1 sampai 9 tetapi nilai tidka diketahui oleh responden.
2.7Metode Pengumpulan Data
cara tertentu. Adapun metode pengumpulan data yang diunakan secara umum adalah:
a. Metode dokumentasi
Adalah mencari data mengenai hal-hal atau variabel yang berupa catatan, transkip, buku, surat kabar, majalah, prasasti, notulen rapat, agenda dan sebagainya. Metode dokumnetasi dalam penelitian ini digunakan untuk mengumpulkan data tentang pasien RS Umum Padang Sidempuan.
b. Metode Angket (kuesioner)
Adalah pertayaan tertulis yang digunakan untuk memperoleh informasi dari responden dalam arti laporan tentang pribadinya atau hal-hal yang ia ketahui. Metode ini digunakan untuk mencari tahu atau mengenal faktor strategi campuran pemasaran yang mepengaruhi keputusan pasien dalam kepuasan di RS Umum Padang Sidempuan. Untuk mengetahui distribusi frekuensi masing-masing variabel yang pengumpulan datanya menggunakan angket (kuesioner), setiap indikator dari data yang dikumpulkan terlebih dahulu diklasifikasikan dan diberi skor atau nilai yaitu:
Skor 5 jika jawaban responden sangat setuju Skor 4 jika jawaban responden setuju
Skor 3 jika jawaban responden ragu-ragu/ tidak tahu Skor 2 jika jawaban responden tidak setuju
Skor 1 jika jawaban responden sangat tidak setuju 3. Wawancara
2.8.1 Uji Validitas
Validitas menunjukkan sejauh mana ketepatan dan kecermatan suatu alat ukur dalam melakukan fungsi ukurnya. Suatu test atau instrumen pengukur dapat dikatakan mempunyai validitas yang tinggi apabila alat ukur tersebut menjalankan fungsi ukurnya, atau memberikan hasil ukur yang sesuai dengan maksud dilakukannya pengukuran tersebut. Metode yang digunakan untuk menguji validitas adalah dengan korelasi Product
moment yang rumusnya sebagai berikut:
= ( )−( . )
2−( )²} { 2−( )²
Keterangan:
= koefisien korelasi X = skor variabel Y= skor total N = Jumlah sampel
Untuk menentukan valid tidaknya variabel adalah dengan cara mengkonsultasikan hasil perhitungan koefisien korelasi dengan tabel nilai koefisien (r) pada taraf kepercayaan 95%.
Apabila ≥ →
Apabila < → (Ade fatma, 2007)
2.8.2 Uji Realibilitas
menggunakan rumus sebagai berikut:
=
−1 1− �2
�2
Keterangan:
r = nilai (koefisien) Alpha Cronbach k = banyaknya variabel penelitian
�2 = jumlah varians variabel penelitian
�2 = varians total
2.9 Analisis Faktor
2.9.1 Pengertian Analisis Faktor
Analisis faktor adalah sebuah analisa yang mensyaratkan adanya keterkaitan antar variabel. Pada prinsipnya analisis faktor menyederhanakan hubungan yang beragam dan kompleks pada variabel yang diamati dengan menyatukan faktor atau dimensi yang saling berhubungan atau mempunyai korelasi pada suatu struktur data yang baru yang mempunyai set faktor lebih kecil. Data-data yang dimasukkan pada umumnya data metrik dan terdiri dari variabel-variabel dengan jumlah besar.
Analisis faktor dapat digunakan di dalam situasi sebagai berikut:
1. Mengenali atau mengidentifikasi dimenesi yang mendasari (underlying
dimensions) atau faktor, yang menjelaskan korelasi antara suatu set
variabel.
diskriminan.
3. Mengenali atau mengidentifikasi suatu set variabel yang penting dari suatu set variabel yang lebih banyak jumlahnya untuk dipergunakan di dalam analisi multivariate selanjutnya.
2.9.2 Model Analisis Faktor
Secara matematis, analisis faktor hampir sama dengan analisis regresi. Yaitu dalam bentuk fungsi linear. Jumlah varians yang dikotribusi dari sebuah variabel dengan seluruh variabel lainnya lbih dikelompokkan sebagai komunitas. Kovarians diantara variabel dijelaskan terbatas dalam sejumlah komponen kecil ditambah sebuha faktor unnik untuk setiap variabel. Faktor-faktor tersebut tidak secara eksplisit diamati. Jika variabel distandarisasi, maka model analisis faktor dapat ditulis sebagai berikut:
= 1�1+ 2�2+ 3�2+⋯+ � +⋯+ � +
Dimana :
= Variabel ke i yang dibakukan
= Koefisien regresi yang dibakukan untuk variabel i pada komponen faktor j
� = Komponen faktor ke j
= Koefisien regresi yang dibakukan untuk variabel ke-i pada faktor yang unik ke-i
µ = Faktor unik variabel ke-i M = Banyaknya komponen faktor
terobservasi hasil penelitian lapangan.
� = 1 1+ 2 2+ 3 3+⋯+
Dimana :
� = Perkiraan faktor ke i (didasarkan pada nilai variabel ) = Koefisien nilai faktor ke i
= Banyaknya variabel
2.9.3 Statistik yang Berkaitan Dengan Analisis Faktor Statistik yang berkaitan dengan faktor adalah :
a. Barlett’s test of sphericity
Barlett’s test of sphericity adalah uji statistik yang digunakan untuk menguji
hipotesis yang mengatakan bahwa variabel-variabel tersebut tidak berkorelasi dalam populasinya. Dengan kata lain, matriks korelasi populasi adalah sebuah matriks identitas, dimana setiap variabel berkorelasi dengan variabel itu sendiri. (r=1), tetapi tidak berkorelasi dengan variabel lainnya (r=0).
Statistik uji barlett adalah sebagai berikut : 2 = − −1 − 2 +5
6 1 | |
Dengan derajat kebebasan (degree of freedom) df = = ( −1)/2
Keterangan :
= jumlah observasi = jumlah variabel
Matriks korelasi adalah matriks yang menunjukan korelasi sederhana (r) antara seleruh kemungkinan pasangan variabel yang dilibatkan dalam analisis. Nilai atau seluruh kemungkinan pasangan variabel yang dilibatkan dalam analisis. Nilai atau angka pada diagonal utama semuanya sama yaitu 1. Jadi kalau ada 3 atau 4 variabel, bentuk matriks korelasi menjadi :
n = 3 → 121 121 1323
31 32 1
n = 4 →
1 12 13 14
21 1 23 24
31 32 1 34
41 42 43 1
c. Communality(Komunitas)
Komunalitas adalah jumlah varian yang dikontribusi dari sebuah variabel dengan seluruh variabel lainnya dalam analisis. Ini juga merupakan proporsi dari varians yang diterangkan oleh komponen faktor.
ℎ = �21+�22+⋯+�2
Dimana :
ℎ = communality variabel ke-i ; i = 1,2,3,...m.
� = nilai factor loading
d. Eigenvalue (Nilai Eigen)
Nilai eigen merupakan jumlah varians yang dijelaskan oleh setiap fator-faktor yang mempunyai nilai eigenvalue > 1, maka faktor tersebut akan dimasukkan ke dalam model.
vector eigen (eigenvector) dari jika adalah sebuah kelipatan skalar dari x, jelasnya,
- �
Untuk skalar sebarang λ, skalar λ disebut nilai eigen (eigenvalue) dari ,
dan disebut sebagai vector eigen dari yang terkait dengan λ. (Anton Howard,2000).
e. Factor loadings (Faktor Muatan)
Faktor muatan adalah korelasi sederhana antara variabel dengan faktor.
f. Factor Loading Plot (Plot Faktor Muatan)
Plot faktor muatan adalah suatu plot dari variabel asli dengan menggunakan factor loading sebagai koordinat.
g. Factor Matrix (Faktor Matriks)
Matriks faktr mengandung factor loading dari seluruh variabel dalam seluruh faktor yang dikembangkan.
h. Kaiser – Meyer – Olkin (KMO) measure of sampling adequency
Kaiser – Meyer – Olkin (KMO) merupakan suatu indeks yang digunakan untuk menguji ketepatan analisis faktor. Nilai yang tinggi (antara 0,5 – 1,0) mengidentifikasi analisis faktor tepat). Apabila dibawah 0,5 menunjukkan bahwa analisis faktor tidak tepat untuk diaplikasikan.
= Σi=1
p
Σk=1 p
rik2 Σi=1
p
Σk=1 p
= koefisien korelasi sederhana antara variabel ke- dan ke-k
� = koefisien korelasi parsial antara variabel ke- dan ke-
Measure of Sampling Adequency (MSA) yaitu suatu indeks perbandingan
antara koefisienkorelasi parsial untuk setiap untuk variabel. MSA digunakan untuk mengukur kecukupan sampel.
i. Percentage of variance (Persentasi Varians)
Persentasi varans adalah persentase total varians yang disumbangkan oleh setiap faktor.
j. Residuals
Residuals adalah selisih antara korelasi yang terobservasi berdasarka input
correlation matrix dan korelasi hasil reproduksi yang diestimasi dari matriks
faktor.
k. Scree plot
Scree plot adalah sebuah plot dari eigenvalue untuk menentukan banyaknya
faktor.
2.12 Langkah-langkah analaisis Faktor
Langkah-langkah dalam analisis faktr adalah sebagai berikut : 1.Merumuskan masalah
2. Membentuk matriks korelasi 3. Menentukan metode analisis faktor 4. Menentukan banyaknya faktor 5. Melakukan rotasi terhadap faktor
Merumuskan masalah meliputi beberapa kegiatan. pertama, tujuan analisis faktor harus diidentifikasi. Variabel yang akan digunakan daam analisis faktor harus dispesifikasi berdasarkan penelitian sebelumnya, teori dan pertimbangan subjektif dari peneliti. Pengukuran variabel berdasarkan skala interval dan rasio. Besarnya sampel harus tepat, sebagai petunjuk umum besarnya sampel paling sedikit empat atau lima kali banyaknya variabel.
2. Membentuk matriks Korelasi
Proses nalaisis didasarkan pada suatu matriks korelasi antar variabel. Agar analisis faktor menjadi tepat, variabel-variabel yang dikumpulkan harus berkorelasi. Dilakukan perhitungan matriks korelasi Σ Matriks korelasi digunakan sebagai input analisis faktor.
3. Menghitung nilai karakteristik (eigenvalue)
Perhitungan nilai karakteristik (eigenvalue), dimana perhitungan ini berdasarkan persamaan karakteristik :
det(�� − ) = 0
Dengan :
= matriks korelasi
� = eigenvalue
� = matriks identitas
Eigenvalue adalah jumlah varian yang dijelaskan oleh setiap faktor. (Anton Howard, 2000)
4. Menghitung vektor karakteristik (eigenvector)
Penentuan vektor karakteristik (eigenvector) yang bersesuaian dengan nilai karaktristik (eigenvalue), yaitu dengan persamaan :
=λ
Dengan:
=eigenvector,(Anton Howard, 2000) 5. Menentukan Banyaknya Faktor
varians, penentuan berdasarkan Split-Half Reliabilitiy, dan penentuan berdasarkan uji signifikan.
a. Penentuan Secara A Priori
Kadang-kadang karena adanya dasarr teori atau pengalaman sebelumnya, peneliti sudah dapat menentukan banyak faktor yang akan diekstraksi. Hampir sebagian besar program komputer memungkinkan peneliti untuk menentukan banayaknya faktor yang diinginkan dengan pendekatan ini.
b. Penentuan Berdasarkan Eigenvalue
Pada pendekatan ini, hanya faktor dengan eigenvalue lebih besarnya dari satu yang dipertahankan. Eigenvalue mempresentasikan besarnya sumbangan dari faktor terhadap varians seluruh variabel aslinya. Hanya faktor dengan varians lebih besar dari satu yang dimasukkan dalam model. Faktor dengan varians lebih kecil dari satu tidak lebih dari variabel aslinya, sebab variabel yang dibakukan
(distandarisasi) yang berarti rata-ratanya nol dan divariasinya satu.
c. Penentuan Berdasarkan Scree Plot
Scree Plot merupakan plot dari nilai eigenvalue terhadap banyaknya faktor dalam
ekstraksinya. Bentuk plot yang dihasikaan digunakan untuk menentukan banyaknya faktor. Biasanya plot akan berbeda antara slope tegak faktor, dengan
eigenvalue yang besar dan makin kecil pada sisa faktor yang tidak perlu
diekstraksi.
d. Penentuan berdasarkan Persentase Varians
Dalam pendekatan ini, banyaknya faktor yang diekstraksi ditentukan berdasarkan persentasi kumulatif varians mencapai tingkat yang memuaskan peneliti. Tingkat persentase kumulatif yang memuaskan peneliti tergantung kepada permasalahannya. Sebagai petunjuk umum bahwa ekstraksi faktor dihentikan kalau kumulatif persentase varians sudah mencapai paling sedikit 60% atau 75% dari seluruh varians variabel asli.
masing bagian. Hanya faktor yang memiliki faktor loading tinggi antar dua bagian itu yang akan dipertahankan.
f. Penentuan Berdasarkan Uji Signifikan
Dimungkinkan untuk menentukan signifikansi statisstik untuk eiganvalue yang terpisah dan mempertahankan fakto-faktor yang berdasarkan uji statistik
eigenvaluenya signifikan pada α = 5% atau α = 1% . Penentuan banyaknya faktor
dengan cara ini memiliki kelemahan, khususnya pada ukuran sampe yang besar misalnya diatas 200 responden, banyak faktor yang menunjukkan uji signifikan, walaupun dari pendangan praktis banyak faktor yang mempunyai sumbangan terhadap seluruh varians hanya kecil.
6. Menghitung matriks faktor loading
Matriks loading factor (Ʌ) diperoleh dengan mengalikan matriks eigenvector ( )
dengan akar dari matriks eigenvalue ( ). Atau dalam persamaan matematis ditulis
Ʌ=��√�
7. Melakukan Rotasi Faktor
Sebuah output penting dari analisis faktor dalah matriks faktor atau disebut juga sebagai matriks faktor pola. Matriks faktor mengandung koefisien yang digunakan untuk mengekspresikan variabel yang dibakukan (distandarisasi) dinyatakan dalam faktor. Koefisien-koefisien tersebut atau faktor loadings merupakan korelasi antara faktor dengan variabelnya, Sebuah koefisien dengan nilai absolut yang besar mengindikasikan bahwa faktor dan variabel berkorelasi kuat. Koefisien tersebut bisa digunakan untuk menginterprestasi faktor.
Walaupun faktor awal atau unroatated factor matrix mengindikasikan hubungan antara faktor dengan variabel individu tertentu, akan tetapi masih sulit. Diambil kesimpulannya tentang banyaknya faktor yang bisa diekstraksi, hal ini disebabkan karena faktor berkorelasi dengan banyaknya variabel atau sebaliknya variabel tertentu masih banyak berkorelasi dengan banyak faktor.
Namun demikian, rotasi berpengaruh terhadap persentase varians dari setiap faktor. Beberapa metode rotasi yang bisa digunakan adalah orthogonal rotation,
varimax rotation, dan oblique rotation.
Orthogonal rotation adalah kalau sumbu dipertahankan tegak lurus
sesamanya (bersudut 90 derajat). Yang paling banyak digunakan adalah varimax
rotation, yaitu rotasi ortogonal dengan meminimumkan banyaknya variabel yang
memiliki loadings tinggi pda sebuah faktor, sehingga lebih mudah menginterprestasikan faktor. Rotasi orotogonal menghasilkan faktor-faktor yang tidak berkorelasi. Oblique rotation adalah jika sumbu-sumbu tidak dipertahankan harus tegak lurus sesamanya (bersudut 90 derajat) dan faktor-faktor berkorelasi. Kadang-kadang, mentoleransi korelasi antar fakto-faktor bisa menyederhanakan matriks pola faktor. Oblique rotation harus dipergunakan kalau faktor dalam populasi berkorelasi sangat kuat.
8. Interprestasi Faktor
Interprestasi dipermudah dengan mengidentifikasi variabel yang loadingnya besar pada faktor yang sama. Faktor tersebut kemudian dapat diinterprestasikan menurut variabel-variabel yang memiliki loading tinggi dengan faktor tersebut. Cara lain yang bisa digunakan adalah memalui pivot variabel dengan faktor
loading sebagai koordinat. Variabel yang berada pada akhir sebuah sumbu adalah
variabel yang memiliki loading tinggi hanya pada faktor yang bersangkutan, sehingga bisa digunakan untuk menginterprestasi faktor. Variabel yang berada di dekat titik origin memiliki loading yang rendah terhadap kedua faktor. Variabel yang tidak berada di dekat sumbu mengindikasi bahwa variabel tersebut berkorelasi dengan kedua faktor. Jika sebuah faktor tidak bisa secara jelas didefinisikan dalam batas variabel awalnya, maka disebut faktor umum.
9. Menentukan Ketetapan Model (model fit)
PENDAHULUAN
1.1Latar Belakang
Rumah sakit adalah tempat penyedia pelayanan kesehatan bagi masyarakat. Menurut keputusan Menteri Republik Indonesia nomor 983.MENKES/SK/1992 mengenai pedoman rumah sakit umum dinyatakan bahwa: “Rumah Sakit Umum adalah rumah sakit yang memberikan pelayanan kesehatan”. Menurut WHO rumah sakit adalah keseluruh dari organisasi dan medis, berfungsi memberkan layanan kesehatan kepada masyarakat, dimana output layanannya menjangkau pelayanan keluarga dan lingkungan. Rumah Sakit juga merupakan pusat pelatihan tenaga kesehatan serta untuk penelitan biososial.
Di kota Padang sidimpuan ada 3 rumah sakit besar untuk pemenuhan kesehatan masyarakat kota Padangsidimpuan, yaitu: Rumah Sakit Umum Kota Padangsidimpuan, Rumah Sakit Umum Inanta dan Rumah Sakit Umum TNI Kota Padangsidimpuan. Namun, pada penelitian ini saya sebagai peneliti memilih salah satu rumah sakit saja, yaitu Rumah Sakit Umum Kota Padangsidimpuan, karena sudah termasuk yang terlengkap di Kota padangsidimpuan. Untuk menunjang visi dan misinya, Rumah Sakit Umum Kota Padangsidimpuan menawarkan sarana prasarana kepada para pasien, seperti: kamar VIP, kamar kelas 1, kamar kelas 2, kamar kelas 3, ruang UGD, ruang operasi, ruang poliklinik umum, ruang laboratorium, ruang farmasi, dokter spesialis, dokter umum, perawat, bidan mobil ambulans, peralatan kesehatan, ruang konsultasi dokter, dll.
KOTA PADANGSIDIMPUAN”
1.2Rumusan masalah
Permasalahan yang akan diteliti dalam masalah ini adalah factor yang sangat berpengaruh terhadap tingkat kepuasan pasien Rumah Sakit Umum Kota Padangsidimpuan.
1.3Batasan Masalah
Agar masalah yang diteliti tidak menyimpang dari sarana yang dituju, maka perlu dibuat batasan yang lingkup permasalahannya, yaitu:
1. Data di analisis menggunakan metode analisis faktor 2. Data diambil dari Rumah Sakit Kota Padangsidimpuan
3. Responden adalah pasien rawat inap dan pasien rawat jalan di Rumah Sakit Umum Kota Padangsidimpuan
1.4Tujuan Penelitian
1. Untuk mengetahui tingkat kepuasan pasien terhadap pelayanan RSU Padangsidimpuan
2. Untuk mengetahui factor yang sangat berpengaruh terhadap kepuasan pasien RSU Padangsidimpuan
1.5Manfaat Penelitian
Bagi Penulis
1. Untuk memenuhi persyaratan Tugas Akhir
1. Dapat disajikan sebagai bahan masukan untuk memperbaiki tingkat pelayanan di RSU Padangsidimpuan
2. Sebagai bahan referensi
Bagi Universitas/ Fakultas
1. Sebagai tumbuhan referensi tentang penelitian yang berkaitan dengan statistika (Metode analisis Faktor)
PASIEN TERHADAP PELAYANAN RUMAH SAKIT UMUM PADANG SIDIMPUAN
ABSTRACT
Analisis faktor adalah satu teknik analisis data yang ditujukan untuk mereduksi sejumlah variabel menjadi beberapa kelompok lebih kecil yang disebut sebagai faktor. Tujuan penelitian ini adalah mengidentifikasi faktor-faktor yang mempengaruhi kepuasan pasien terhadap pelayanan rumah sakit umum kota Padang Sidimpuan. Teknik pengambilan sampel yang digunakan adalah cluster
sampling. Variabel yang digunakan sebanyak 6. Dari data yang diperoleh
dilakukan uji validitas dan reliabilitas serta analisis faktor menggunakan software
SPSS 17.0 for windows. Berdasarkan hasil penelitian diperoleh 2 faktor dominan
yang mempengaruhi kepuasan pasien terhadap pelayanan rumah sakit umum kota Padang Sidimpuan yaitu faktor Fasilitas (37,011%), faktor Ketanggapan (18,939%). Kedua faktor tersebut memberikan proporsi keragaman kumulatif sebesar 55,950% artinya kedua faktor tersebut merupakan faktor dominan dan sisanya dapat dipengaruhi faktor-faktor lainnya yang tidak teridentifikasi oleh penelitian.
THE ANALYSIS FACTORS THAT AFFECT THE LEVEL OF PATIENT SATISFACTION ON HOSPITAL SERVICES
PADANGSIDIMPUAN
ABSTRACT
Factor analysis is a data analysis technique that is intended to reduce the number of variables into smaller groups called factors. The purpose of this study is identifying the factors that affect patient satisfaction of general hospital of the sidimpuan. The sampling technique that used cluster sampling. Variables used as many as 6. From the data obtained to test the validity and reliability and factor analysis using SPSS 17.0 software for windows. Based on the research results of research by two dominant fasctor that affects the level of patient satisfaction to the service of general hospital sidimpuan of the facilities (37,011%) and the response(18,939%). These two factors is giving the proportion of the diversity of gasoline 55,950% means the four factors is a dominant factor and the rest of it can be influenced by factors others were not identified by research.
KOTA PADANG SIDIMPUAN
SKRIPSI
AGLUR MUNANDAR SIREGAR 120823007
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
PASIEN TERHADAP PELAYANAN RUMAH SAKIT UMUM KOTA PADANG SIDIMPUAN
SKRIPSI
Diajukan untuk melengkapi tugas dan memenuhi syarat mencapai gelar Sarjana Sains
AGLUR MUNANDAR SIREGAR 120823007
DEPARTEMEN MATEMATIKA
FAKULTAS MATEMATIKA DAN ILMU PENGETAHUAN ALAM UNIVERSITAS SUMATERA UTARA
Judul : ANALISA FAKTOR YANG MEMPENGARUHI KEPUASAN PASIEN TERHADAP PELAYANAN RUMAH SAKIT UMUM KOTA PADANG