Spesifikasi dari masing-masing komputer yang digunakan adalah:
1. Intel Pentium® Core 2 Duo ( 2,20 GHz). 2. DDR2 RAM 1024 MB.
3. Hard disk 80 GB. 4. Mouse dan Keyboard. 5. LAN 100 Mbps.
6. Sistem operasi Linux (openSUSE 11.2). 7. Library MPI ( OpenMPI 1.4.7). 8. OpenMP runtime library (libgomp44). Analisis Hasil Percobaan
Pada tahap ini akan dianalisis dengan menghitung performance metric berdasarkan waktu eksekusi dari hasil percobaan yang diperoleh. Analisis dilakukan terhadap hasil percobaan implementasi sekuensial, MPI, dan hybrid.
HASIL DAN PEMBAHASAN Analisis dan Implementasi Algoritme CG Sekuensial
Analisis algoritme CG sekuensial hanya diukur berdasarkan persamaan kompleksitas, namun karena pembahasan meliputi keseluruhan waktu eksekusi, maka tiap-tiap tahap akan dihitung, termasuk dalam pembacaan file matriks berukuran n x n maupun file vektor berukuran n. Adapun keseluruhan tahap dalam algoritme sekuensial adalah:
1. Membaca file matriks (n x n blok) sebagai koefisien SPL.
2. Membaca file vektor (n blok) sebagai nilai target dari SPL.
3. Fungsi CG sekuensial untuk menghasilkan solusi SPL.
Kompleksitas fungsi CG sekuensial berdasarkan Gambar 1 untuk tiap tahap disajikan pada Gambar 4. Untuk N kali iterasi pada CG, maka total kompleksitas pada keseluruhan tahap yaitu:
tsekuensial=N n
2
5n. [9]
Dari Persamaan 10 dapat diketahui bahwa kompleksitas sangat tergantung dari ukuran matriks/vektor n dan banyaknya iterasi CG N . Waktu eksekusi dari implementasi sekuensial dapat direpresentasikan oleh Persamaan 9. Grafik hasil perhitungan Persamaan 9 disajikan pada Gambar 5.
Implementasi atau kode program yang dibuat terdiri atas fungsi-fungsi yang mewakili
proses-proses yang ada pada algoritme CG sekuensial, seperti fungsi untuk membaca file matriks, membaca file vektor, dan fungsi CG. Di dalam fungsi CG terdapat beberapa fungsi lagi, seperti fungsi perkalian matriks vektor, fungsi perkalian dua vektor, dan fungsi saxpy. Fungsi pencatat waktu diletakkan di bagian awal sebelum proses membaca file matriks dan sesudah fungsi CG. 1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i
7 While imax and ∥r i∥≥tol
8 q=A d i n2 9 dq=d iT q n 10 i=rr / dq 11 x i1=x i i d i n 12 r i 1=r i − i q i n 13 rr2=r i1 T r i1 n 14 i =rr2 / rr
15 d i1=r i1 i d i n
16 i=i1
Gambar 4 Kompleksitas tahapan pada fungsi CG sekuensial.
Gambar 5 Grafik perhitungan kompleksitas CG sekuensial.
Penerapan Metode Foster
Algoritme CG paralel didisain berdasarkan metode Foster, namun penggunaan metode Foster ini hanya digunakan untuk membuat algoritme CG MPI. Berikut ini adalah penjelasan dari tahapan-tahapannya.
1. Partitioning
Dalam menentukan strategi dekomposisi yang digunakan, pertama-tama harus diketahui
dulu komputasi yang ada. Komputasi yang ada dapat terlihat dari stuktur atau alur algoritme dan dari skema keterkaitan antar fungsi yang ada pada algoritme yang akan diparalelkan. Berdasarkan Gambar 1, skema keterkaitan antar fungsi di dalam iterasi CG disajikan pada Gambar 6.
Gambar 6 Skema keterkaitan fungsi pada iterasi CG.
Dari gambar tersebut dapat dilihat bahwa tiap tahap pada algoritme CG saling memiliki keterkaitan, sehingga sulit jika diterapkan teknik pipeline. Untuk penerapan functional decomposition sebenarnya dapat dilakukan pada bagian komputasi saxpy (no 4, dan 5), hanya saja kurang tepat untuk diterapkan pada paralel MPI, karena biaya komunikasi yang dibutuhkan lebih besar dari pada beban komputasi yang ada. Oleh karena itu dekomposisi yang paling mungkin dan mudah dilakukan adalah domain decomposition.
Domain decomposition yang dilakukan tidak pada semua tahapan algoritme CG, hanya pada perkalian matriks vektor saja. Pada perkalian dua vektor dan saxpy sebenarnya dapat diterapkan domain decomposition, hanya saja kurang tepat untuk paralel MPI, karena beban komputasinya terlalu kecil, sehingga jika dipaksakan untuk diparalelkan hanya akan menambah besar biaya komunikasi.
Dalam melakukan domain decomposition, file matriks dengan ukuran n2 akan dibaca oleh
node root, kemudian didistribusikan kepada seluruh node p. Tiap node akan mendapatkan matriks sebesar n2/ p. Matriks akan didekomposisi secara row-wised bukan secara column-wised, karena kompleksitas komunikasi secara row-wised lebih kecil.
Pada distribusi vektor, file vektor dengan ukuran n akan dibaca oleh node root, kemudian didistribusikan kepada seluruh node. Tiap node akan mendapatkan vektor yang sama dengan ukuran n pula.
Di dalam fungsi CG, komputasi perkalian matriks vektor dilakukan oleh tiap node. Komputasi ini dilakukan sesuai dengan matriks yang didapatkan masing-masing node. Hasil yang diperoleh masing-masing node n / p didistribusikan kepada keseluruhan node untuk digunakan pada tahapan komputasi berikutnya.
Jadi seluruh tahapan yang ada pada Gambar 6 akan dikerjakan oleh seluruh node yang terlibat saat eksekusi. Untuk perkalian matriks vektor (no 1), masing-masing node akan melakukan komputasi dengan data matriks yang berbeda, sedangkan untuk komputasi no 2-8 masing-masing node akan mengerjakannya dengan data vektor yang sama.
2. Communication
Berdasarkan tahap partitioning, proses komunikasi yang diterapkan yaitu secara global communication. Proses komunikasi ini dibutuhkan pada setiap tahap. Komunikasi pertama terjadi pada saat pendistribusian matriks oleh node root yang dilakukan dengan fungsi MPI_Scatterv. Proses komunikasi yang kedua pada saat pendistribusian vektor oleh node root dengan menggunakan fungsi MPI_Bcast. Komunikasi ketiga yaitu di dalam fungsi CG, pada saat tiap-tiap node mendistribusikan hasil perkalian matriks vektor ke seluruh node dan ini dilakukan pada setiap iterasi. Fungsi yang digunakan pada komunikasi ini adalah MPI_Allgatherv.
3. Agglomeration
Berdasarkan pengertian dari agglomeration, maka tidak terdapat proses agglomeration secara eksplisit pada disain algoritme CG paralel. Hal ini dikarenakan memang tidak ada pengombinasian task-task yang saling terkait, namun secara implisit terdapat pada fungsi-fungsi MPI yang digunakan, seperti MPI_Gatherv, MPI_Bcast, dan MPI_Allgatherv. 4. Mapping
Komputasi yang diparalelkan secara MPI hanyalah pada bagian perkalian matriks vektor, jadi mapping yang dilakukan yaitu menugaskan seluruh node yang tersedia untuk melakukan komputasi tersebut sesuai komputasi yang didapat masing-masing node.
Berdasarkan strategi paralel yang telah dirancang dengan metode Foster, maka struktur algoritme CG pada bagian iterasinya disajikan pada Gambar 7.
Komputasi Keterangan
qlocal= Alocaldi
Perkalian MatVec, tiap node memiliki matriks berbeda Alocal, dan
memiliki vektor di
yang sama, dihasilkan vektor qlocal berukuran n/ p yang berbeda pada tiap node.
q=Allgatherqlocal
Semua node melakukan allgather, sehingga tiap node memiliki vektor q
yang berukuran n
secara utuh.
dq=d i T q
Semua node akan
melakukan komputasi pada bagian ini dan akan
menghasilkan data
vektor yang sama.
i=rr / dq x i1= x i i d i r i 1=r i − i q i rr2=r i1 T r i1 i=rr2 / rr
d i1=r i1 i d i i=i1
Gambar 7 Struktur algoritme CG MPI pada bagian iterasi.
Analisis dan Implementasi Algoritme CG MPI
Algoritme paralel MPI yang dibuat terdiri dari tiga bagian, pertama bagian distribusi matriks, kedua distribusi vektor dan ketiga bagian iterasi fungsi CG. Dalam menganalisis kompleksitas algoritme MPI yang telah dibuat, ketiga bagian tersebut diikutsertakan seluruhnya dalam perhitungan. Berikut ini adalah kompleksitas dari masing-masing bagian tersebut:
1. Distribusi matriks
Dalam mendistribusikan file matriks berukuran n2 , masing-masing node mendapatkan bagian matriks sebesar n2
/ p. Dalam mendistribusikan file matriks tersebut, implementasi MPI yang dibuat yaitu menggunakan fungsi MPI_Scatterv.
Menurut Grama et al (2003), kompleksitas MPI_Scatter / MPI_Scatterv dan MPI_Gather dengan mengabaikan startup time ts yaitu:
twm p – 1. [10]
tw : waktu dibutuhkan untuk mentransfer message per word.
m : ukuran message yang akan dikirim.
p : banyaknya node yang menerima message. Ukuran message yang akan dikirim m adalah n2/ p, sehingga berdasarkan
kompleksitas MPI_Scatterv, maka kompleksitas dalam mendistribusikan file matriks tmatriks
yaitu: tmatriks= twn 2 p p – 1. [11] 2. Distribusi vektor
Dalam mendistribusikan vektor, ukuran vektor yang didapatkan oleh seluruh node adalah sama besar, yaitu n. Fungsi MPI_Bcast digunakan dalam pendistribusian vektor ke seluruh node. Menurut Grama et al (2003), kompleksitas MPI_Bcast dengan mengabaikan startup time ts yaitu:
twm log p. [12]
sehingga kompleksitas mendistribusikan file vektor tvektor adalah:
tvektor=twn log p. [13] 3. Iterasi fungsi CG
Berdasarkan partitioning yang telah ditentukan, maka pada bagian iterasi fungsi CG bagian yang diparalelkan secara MPI adalah pada perkalian matriks vektor. Hasil perkalian ini kemudian didistribusikan ke seluruh node.
Pada implementasinya, fungsi-fungsi sekuensial yang digunakan tidak mengalami perubahan, namun hanya dilakukan penambahan fungsi dalam pendistribusian hasil perkalian matriks vektor saja. Fungsi yang digunakan dalam hal ini adalah MPI_Allgatherv.
Pada dasarnya fungsi MPI_Allgatherv hampir sama dengan MPI_Gatherv, hanya saja pada MPI_Allgatherv seluruh node melakukan pengiriman data, sehingga kompleksitasnya pun sama. Dengan demikian kompleksitas pada bagian iterasi ini titerasi adalah:
titerasi= N n
nptwp p – 15
. [14]Struktur algoritme MPI dan
kompleksitasnya tiap tahap pada bagian iterasi CG disajikan pada Gambar 8. Berdasarkan Gambar 8, maka total kompleksitas algoritme CG MPI tmpi pada tiga bagian yang telah dijelaskan diatas adalah:
tmpi=tmatrikstvektortiterasi. [15] tmpi=n
tw p−1 p N ntwlog p N
n p5
. [16] 1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i 7 While imax and ∥r i∥≥tol
8 qlocal= Alocaldi n2/ p
9 q=Allgather qlocal twn/ p p – 1
10 dq=d i
T q n
11 i=rr / dq
12 x i1=x i i d i n
13 r i1=r i− i q i n
14 rr2=r i1 T r
i1 n
15 i=rr2 / rr
16 d i1=r i1 i d i n
17 i=i1
Gambar 8 Struktur algoritme dan kompleksitas fungsi CG MPI. Dalam perhitungan kompleksitas pada penelitian ini, kecepatan jaringan (LAN) yang digunakan adalah 100 Mbps dan tipe data yang digunakan adalah double. Karena tipe data double, maka ukuran message per word adalah 8 byte, sehingga nilai tw adalah 0.64 x 106.
Gambar 9 Grafik perhitungan kompleksitas CG MPI.
Grafik hasil perhitungan kompleksitas berdasarkan Persamaan 16 terhadap lima ukuran matriks yang digunakan disajikan pada Gambar 9.
Setelah diketahui kompleksitas total dari implementasi yang telah dibuat, selanjutnya dilakukan analisis performance-nya.
1. Speedup
Berdasarkan Persamaan 1, 9, dan 16 maka speedup dapat dihitung menggunakan Persamaan 17. S=t Nn5 w p−1 p N ntwlog pN
n p5
. [17] Pada Gambar 10 disajikan grafik hasil perhitungan speedup berdasarkan Persamaan 17 terhadap lima ukuran matriks yang digunakan.Gambar 10 Grafik perhitungan speedup CG MPI.
Dari Gambar 10, dapat diketahui bahwa: • Nilai speedup yang diperoleh hampir
mendekati dengan nilai ideal dari speedup untuk setiap jumlah node yang digunakan, yaitu mendekati linear.
• Untuk setiap ukuran matriks yang diinputkan, semakin tinggi jumlah node yang digunakan, semakin tinggi speedup yang diperoleh.
• Semakin tinggi jumlah node yang digunakan, untuk ukuran matriks yang semakin kecil, maka nilai speedup yang diperoleh semakin menurun dan menjauhi nilai ideal.
2. Efisiensi
Nilai efisiensi didapatkan dengan menggunakan Persamaan 18.
E=t Nn5
w p−1N ntwp log pN n5 p . [18]
Pada Gambar 11, disajikan grafik hasil perhitungan efisiensi berdasarkan Persamaan 18 terhadap lima ukuran matriks yang digunakan.
Gambar 11 Grafik perhitungan efisiensi CG MPI.
Dari Gambar 11, dapat diketahui bahwa: • Efisiensi yang diperoleh hampir mendekati
nilai ideal dari efisiensi, yaitu 1.
• Semakin tinggi jumlah node yang digunakan, nilai efisiensinya mengalami penurunan, namun tingkat penurunannya kecil.
• Semakin tinggi jumlah node yang digunakan, untuk ukuran matriks yang semakin kecil, maka nilai efisiensi yang diperoleh semakin menurun dan menjauhi nilai ideal.
3. Cost
Untuk nilai cost didapatkan dengan Persamaan 19.
C=ntw p−1 N ntwp log p N n5 p. [19] 4. Total Parallel Overhead
Untuk nilai overhead didapatkan dengan Persamaan 20.
To=ntw p−1N ntwplog p5 N p−1.
[20] 5. Isoefisiensi
Dari Persamaan overhead yang diperoleh, maka dapat diketahui isoefisiensi dari algoritme yang dibuat. Untuk setiap peningkatan jumlah node, seberapa besar problem size W yang harus menjadi input untuk mempertahankan nilai efisiensi yang ingin diperoleh.
W =E n tw p−1 N ntwp log p5 N p−1
E−1 .
[21] Jadi jika ingin diperoleh nilai efisiensi sebesar E untuk setiap peningkatan jumlah node, maka ukuran problem size yang harus
digunakan dapat diketahui dengan persamaan 21. Penerapan Model Hybrid
Dalam penerapan model paralel hybrid dari model paralel message-passing atau MPI, hal pertama yang dilakukan adalah identifikasi bagian-bagian yang dapat diparalelkan secara shared-memory atau OpenMP. Berdasarkan struktur algoritme CG MPI yang telah dibuat, terdapat tiga bagian utama, yaitu distribusi matriks, distribusi vektor, dan iterasi fungsi CG.
Dari kompleksitas tiga bagian tersebut, kompleksitas tertinggi ada pada bagian iterasi dikarenakan pada bagian ini terjadi komputasi, sehingga pada bagian inilah yang lebih tepat diparalelkan secara OpenMP. Sebenarnya pada bagian distribusi matriks dan distribusi vektor dapat diparalelkan secara OpenMP, namun pada kedua bagian ini komputasi yang terjadi hanyalah baca file dan distribusi data lewat jaringan. Oleh karena itu lamanya waktu komputasi pada bagian ini lebih ditentukan oleh kecepatan hardware, sehingga tidak tepat diparalelkan secara OpenMP.
Pada bagian Penerapan Metode Foster pada tahap partitioning, disebutkan bahwa ada beberapa komputasi yang tidak tepat bila dipararelkan secara MPI. Bagian-bagian inilah yang akan dipararelkan secara OpenMP. Berdasarkan Gambar 8, komputasi-komputasi yang ada adalah perkalian matriks vektor, perkalian dua vektor, dan saxpy. Pada ketiga komputasi ini terdapat konstruksi-konstruksi loop yang dapat diparalelkan, jadi pada komputasi-komputasi inilah dilakukan pararel OpenMP. Cara seperti ini sama saja dengan melakukan domain decomposition, karena pada hakikatnya yang dipararelkan adalah data.
Selain dengan melakukan pararel pada kontruksi loop, bila dilihat Gambar 6 pada no 4 dan 5, bagian ini dapat dilakukan partitioning secara functional decomposition. Bagian ini tidak tepat jika dipararelkan secara MPI, namun lebih tepat dipararelkan secara OpenMP. Dengan dilakukannya functional decomposition, maka pada bagian ini terjadi dua pararelisasi, yaitu pararelisasi fungsi secara struktural dan paralelisasi data didalamnya.
Berdasarkan strategi paralel hybrid yang telah dirancang, maka struktur algoritme CG hybrid pada bagian iterasinya disajikan pada Gambar 12.
Komputasi Keterangan
qlocal=Alocaldi
Perkalian MatVec akan dilakukan oleh semua node secara MPI, dan dilakukan oleh semua thread secara OpenMP pada tiap node.
q=Allgather qlocal
Semua node melakukan allgather, sehingga tiap node memiliki vektor q
yang berukuran n secara utuh.
dq=d iT q
Semua node akan
melakukan komputasi
secara paralel OpenMP.
i=rr / dq x i1= x i i d i
Semua node akan
melakukan komputasi
secara paralel OpenMP dan kedua operasi saxpy ini diparalel secara data dan fungsi
r i 1=r i − i q i
rr2=r i1 T r
i1
Semua node akan
melakukan komputasi
secara paralel OpenMP.
i=rr2 / rr
d i1=r i 1 i d i
Semua node akan
melakukan komputasi
secara paralel OpenMP.
i=i1
Gambar 12 Struktur algoritme CG hybrid pada bagian iterasi.
Analisis dan Implementasi Algoritme CG
Hybrid
Dalam eksekusi bagian loop yang diparalelkan secara OpenMP, sejumlah thread akan dibangkitkan untuk mengeksekusi bagian loop tersebut secara bersamaan. Jika suatu konstruksi loop memiliki kompleksitas n dieksekusi oleh t thread, maka kompleksitasnya menjadi n/t. Dengan demikian kompleksitas algoritme CG hybrid akan ditentukan oleh banyaknya node p , banyaknya thread t, ukuran matriks dan vektor n, serta banyaknya iterasi CG N .
Agar suatu loop dieksekusi secara paralel OpenMP, maka digunakanlah compiler directive atau pragma. Berikut ini adalah kode program pada bagian perkalian matriks vektor yang sudah ditambahkan pragma.
#pragma omp parallel for default(none) shared(rowSize, colSize, q, A, x) private(i, j)
for(i=0;i<rowSize;i++) //outer loop
{
q[i] = 0;
for(j=0;j<colSize;j++) //inner loop
q[i]+= A[i*colSize+j]*x[j]; }
Pada kode program tersebut, matriks A
akan dipartisi secara row-wised, karena yang diparalelkan adalah outer loop. Jika dieksekusi oleh t thread, maka masing-masing thread akan melakukan outer loop sebanyak rowSize/t dan melakukan inner loop sebanyak
colSize.
Berdasarkan strategi paralel hybrid yang telah ditentukan, maka struktur dan kompleksitas dari algoritme CG hybrid disajikan pada Gambar 13.
1 Diberikan SPL Ax=b 2 Pilih x0 awal, x0=0 3 r0=b – Ax0 4 d0=r0 5 i=0 6 rr=r i T r i
7 While imax and ∥r i∥≥tol
8 qlocal=Alocaldi n2/ pt
9 q= Allgather qlocal twn/ p p – 1
10 dq=d i
T q n/ t
11 i=rr / dq
12 x i1= x i i d i n/ t
13 r i1=r i− i q i
14 rr2=r i1 T r
i1 n/ t
15 i=rr2 / rr
16 d i1=r i1 i d i n/ t
17 i=i1
Gambar 13 Struktur algoritme dan kompleksitas fungsi CG hybrid.
Berdasarkan Gambar 13, maka kompleksitas pada bagian fungsi CG hybrid adalah:
titerasi= N n
n pt tw p p – 1 4 t
. [22]Dengan demikian kompleksitas total algoritme CG thybrid hybrid menjadi:
thybrid=n
tw p−1 p N ntwlogp N t
n p4
. [23] Pada Gambar 14 disajikan hasil perhitungan kompleksitas berdasarkan Persamaan 23 untuksetiap jumlah thread dengan ukuran matriks tetap. Sedangkan pada Gambar 15 ditampilkan hasil perhitungan terhadap lima ukuran matriks yang digunakan dengan jumlah thread tetap.
Gambar 14 Grafik perhitungan kompleksitas untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548.
Gambar 15 Grafik perhitungan kompleksitas untuk tiap ukuran matriks dengan 2 thread.
Setelah diketahui kompleksitas total dari implementasi hybrid yang telah dibuat, selanjutnya dilakukan analisis performance-nya. 1. Speedup
Berdasarkan Persamaan 23, maka speedup dari implementasi hybrid dihitung dengan Persamaan 24. S=t Nn5 w p−1 p N ntwlog p N t
n p4
. [24] Berdasarkan Persamaan 24, pada Gambar 16 disajikan grafik hasil perhitungan speedup hybrid dengan jumlah thread 1, 2, 3, dan 4 pada salah satu ukuran matriks yang digunakan. Kemudian pada Gambar 17 disajikan grafik speedup hybrid untuk setiap ukuran matriks yang digunakan dengan dua thread.Dari Gambar 16 dan Gambar 17 dapat diketahui bahwa:
• Speedup yang diperoleh hampir mendekati nilai ideal pada tiap-tiap kombinasi node dan thread.
• Untuk setiap ukuran matriks yang diinputkan, semakin tinggi jumlah node dan thread yang digunakan, semakin tinggi speedup yang diperoleh.
• Semakin tinggi jumlah node yang digunakan dengan jumlah thread tetap, untuk ukuran matriks yang semakin kecil, maka nilai speedup yang diperoleh semakin menurun dan menjauhi nilai ideal.
Gambar 16 Grafik perhitungan speedup untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548.
Gambar 17 Grafik perhitungan speedup untuk tiap ukuran matriks dengan 2 thread. 2. Efisiensi
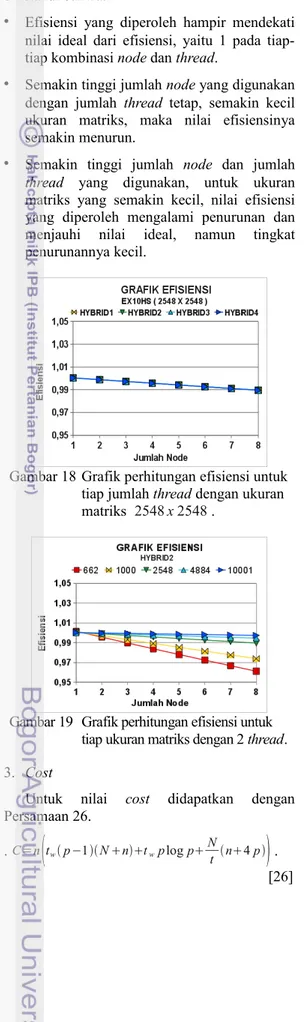
Untuk nilai efisiensi, maka dapat dihitung dengan persamaan 25. E= N n5 tw p−1 N ntwplog p N t n4 p . [25] Grafik hasil perhitungan dari Persamaan 25, disajikan pada Gambar 18 dan Gambar 19. Grafik untuk salah satu matriks yang digunakan disajikan pada Gambar 18, sedangkan pada Gambar 19 disajikan grafik untuk setiap ukuran
matriks yang digunakan dengan dua thread. Dari kedua Gambar 18 dan Gambar 19 dapat diketahui bahwa:
• Efisiensi yang diperoleh hampir mendekati nilai ideal dari efisiensi, yaitu 1 pada tiap-tiap kombinasi node dan thread.
• Semakin tinggi jumlah node yang digunakan dengan jumlah thread tetap, semakin kecil ukuran matriks, maka nilai efisiensinya semakin menurun.
• Semakin tinggi jumlah node dan jumlah thread yang digunakan, untuk ukuran matriks yang semakin kecil, nilai efisiensi yang diperoleh mengalami penurunan dan menjauhi nilai ideal, namun tingkat penurunannya kecil.
Gambar 18 Grafik perhitungan efisiensi untuk tiap jumlah thread dengan ukuran matriks 2548 x 2548.
Gambar 19 Grafik perhitungan efisiensi untuk tiap ukuran matriks dengan 2 thread. 3. Cost
Untuk nilai cost didapatkan dengan Persamaan 26.
.C=n
tw p−1Nntwplog pNt n4 p
. [26]4. Total Parallel Overhead
Untuk nilai overhead didapatkan dengan Persamaan 27. To=n
tw p−1 Nntwplogp N t n4 p−n t−5 t
. [27] 5. IsoefisiensiKemudian untuk memperoleh efisiensi yang tetap E, maka untuk setiap peningkatan jumlah node dan jumlah thread, problem size W yang harus digunakan dihitung dengan Persamaan 28.
W= E
E−1To. [28]
Analisis Hasil Waktu Eksekusi
Untuk menganalisis hasil waktu eksekusi, dilakukan perbandingan hasil perhitungan kompleksitas dengan hasil waktu percobaan yang diperoleh. Waktu eksekusi hasil percobaan implementasi CG sekuensial dibandingkan dengan hasil kompleksitas yang telah dihitung pada Persamaan 9. Grafik waktu eksekusi implementasi CG sekuensial disajikan pada Gambar 20.
Setelah dibandingkan dengan seksama antara Gambar 5 dan Gambar 20, terlihat bahwa keduanya memiliki kesamaan bentuk, berarti hal ini menunjukkan hasil perhitungan kompleksitas dan hasil percobaan memiliki kesesuaian. Semakin besar ukuran matriks semakin tinggi waktu eksekusinya, jadi waktu eksekusi sekuensial benar dipengaruhi oleh ukuran matriks/vektor.
Gambar 20 Grafik waktu eksekusi implementasi CG sekuensial. Pada implementasi MPI, grafik waktu eksekusi percobaan pada tiap ukuran matriks disajikan pada Gambar 21. Jika Gambar 9 dibandingkan dengan Gambar 21, maka akan
terlihat memiliki kesesuaian bentuk walaupun tidak terlalu sama persis. Hal ini menunjukkan bahwa hasil perhitungan kompleksitas CG MPI bersesuaian dengan hasil percobaan implementasi MPI.
Gambar 21 Grafik waktu eksekusi implementasi MPI.
Dari Gambar 21 juga dapat diketahui bahwa waktu eksekusi dipengaruhi oleh jumlah node yang digunakan, namun bukan berarti semakin banyak node yang digunakan waktu eksekusi akan menurun signifikan. Grafik tersebut menunjukkan untuk jumlah node mendekati 8, maka semakin landai bentuk garisnya. Hal ini berarti menunjukkan pengaruh jumlah node semakin berkurang terhadap menurunnya waktu eksekusi.
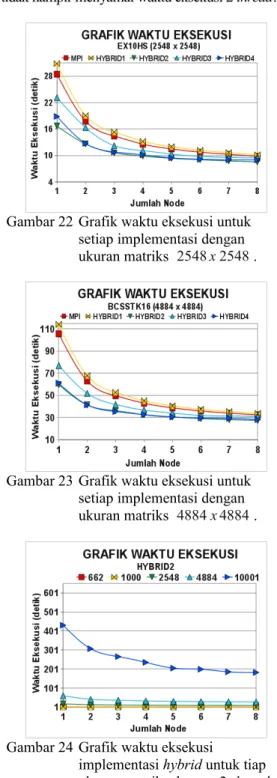
Selanjutnya disajikan grafik perbandingan waktu eksekusi untuk implementasi MPI dan hybrid untuk ukuran matriks 2548 x 2548 dan 4884 x 4884 pada Gambar 22 dan Gambar 23. Sedangkan pada Gambar 24, disajikan grafik waktu eksekusi pada tiap matriks dengan menggunakan 2 thread.
Jika dibandingkan Gambar 22 dan Gambar 23 dengan Gambar 14, maka ada kesesuaian bentuk yakni menurun pada setiap thread yang digunakan, namun tingkat penurunannya lebih rendah dibandingkan Gambar 14. Selain itu pada Gambar 22 dan Gambar 23, urutan waktu eksekusi hybrid pada penggunaan 1 thread sampai 4 thread tidak sesuai dengan hasil perhitungan kompleksitas seperti pada Gambar 8. Seharusnya semakin tinggi jumlah thread yang digunakan, semakin rendah waktu eksekusi, namun tidak demikian adanya. Waktu eksekusi dengan 3 thread lebih rendah dari pada waktu eksekusi 2 thread, dan waktu eksekusi 4 thread hampir menyamai waktu eksekusi 2 thread walaupun masih lebih rendah sedikit pada 2 thread. Anomali ini terjadi karena processor pada komputer yang digunakan hanya
memiliki 2 core. Sehingga penggunaan jumlah thread lebih dari jumlah core processor menjadi penyebab waktu eksekusi lebih lambat atau paling tidak hampir menyamai waktu eksekusi 2 thread.
Gambar 22 Grafik waktu eksekusi untuk setiap implementasi dengan ukuran matriks 2548 x 2548.
Gambar 23 Grafik waktu eksekusi untuk setiap implementasi dengan ukuran matriks 4884 x 4884.
Gambar 24 Grafik waktu eksekusi
implementasi hybrid untuk tiap ukuran matriks dengan 2 thread. Berdasarkan hasil perhitungan kompleksitas, untuk perbandingan waktu eksekusi hybrid 1 thread dengan MPI, seharusnya nilai kompleksitas implementasi MPI lebih tinggi sedikit dari hybrid 1, akan tetapi pada hasil waktu eksekusi memperlihatkan sebaliknya.
Kemudian dilakukan pengamatan processor usage pada saat eksekusi program berlangsung. Saat eksekusi hybrid 1 thread, pada masing-masing komputer hanya 1 core processor yang melakukan komputasi dengan nilai usage hampir 100%. Sedangkan pada saat eksekusi MPI, 2 core processor yang tersedia pada masing-masing komputer melakukan eksekusi dengan nilai usage sekitar 50%. Jadi pada eksekusi MPI, komputasi didistribusikan pada seluruh core processor yang tersedia. Hal inilah yang menyebabkan waktu eksekusi implementasi MPI lebih rendah dibandingkan dengan hybrid 1 thread.
Pada Gambar 24, grafik yang dihasilkan sedikit berbeda dengan hasil perhitungan kompleksitas pada Gambar 15. Garis-garis pada Gambar 24 terlihat lebih landai, namun secara keseluruhan masih menurun seiring semakin tinggi jumlah node yang digunakan. Grafik untuk setiap kombinasi matriks, jumlah node, dan jumlah thread yang digunakan lebih lengkapnya disajikan pada Lampiran 1.
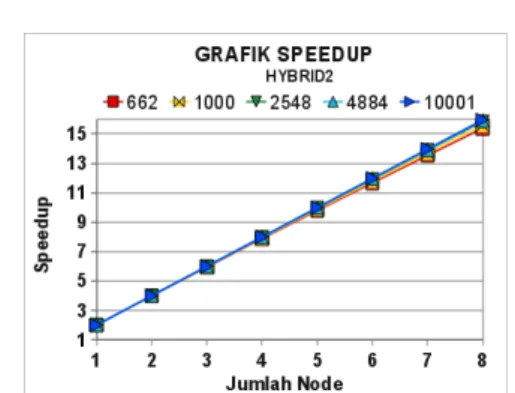
Dari Gambar 22, Gambar 23, dan Gambar 24, dapat diketahui bahwa waktu eksekusi implementasi hybrid memang sangat dipengaruhi oleh ukuran matriks/vektor, jumlah node, dan jumlah thread yang digunakan. Waktu eksekusi tercepat diperoleh oleh hybrid 2 thread dengan 8 node.
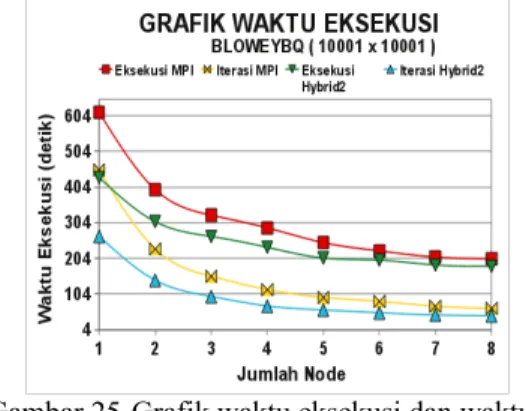
Secara umum pada grafik-grafik waktu eksekusi hasil percobaan MPI dan hybrid, seharusnya waktu eksekusi semakin menurun drastis untuk setiap peningkatan jumlah node pada ukuran matriks 10001. Akan tetapi tidak demikian adanya, penurunan waktu eksekusi tidak terlampau tinggi sebagaimana mestinya. Kemudian dilakukan analisis lebih lanjut, yaitu dengan dilakukan pemisahan waktu komputasi yang ada, seperti waktu distribusi matriks/vektor dan waktu iterasi CG. Grafik hasil pemisahan disajikan pada Gambar 25.
Dari pemisahan tersebut dapat diketahui bahwa waktu iterasi CG pada kedua implementasi jauh lebih kecil dari pada total waktu eksekusi. Berarti lamanya waktu eksekusi pada ukuran matriks 10001 disebabkan oleh lamanya waktu distribusi matriks/vektor. Lebih tepatnya waktu distribusi matriks yang menjadi penyebab lamanya waktu eksekusi. Lamanya waktu ini lebih disebabkan oleh proses I/O. Pada masing-masing komputer, hanya terdapat main memory (RAM) sebesar 1 GB, sehingga swap memory yang terdapat di
hard disk dilibatkan dalam proses pembacaan matriks yang berukuran besar. Jadi lamanya waktu distribusi matriks dikarenakan saat eksekusi berlangsung terdapat proses baca tulis ke hard disk.
Gambar 25 Grafik waktu eksekusi dan waktu iterasi implementasi MPI dan hybrid 2 thread untuk ukuran matriks 10001 x10001. Analisis Hasil Speedup
Berdasarkan hasil waktu eksekusi, kemudian dihitung nilai speedup dari tiap-tiap implementasi dan tiap-tiap kombinasi. Grafik speedup untuk implementasi MPI disajikan pada Gambar 26.
Gambar 26 Grafik speedup hasil percobaan implementasi MPI.
Jika dilakukan perbandingan antara Gambar 26 dengan Gambar 16, maka akan tampak sangat berbeda. Pada Gambar 16 nilai speedup hampir mendekati nilai idealnya pada tiap jumlah node, namun pada Gambar 26 nilai speedup tertinggi tidak sampai 4. Hal ini diakibatkan dari waktu eksekusi yang dihasilkan implementasi MPI tidak sesuai dengan hasil perhitungan kompleksitas. Pada Gambar 21 semakin tinggi jumlah node, maka semakin landai grafiknya, sehingga pada Gambar 26 semakin tinggi jumlah node, maka speedup yang diperoleh semakin menjauhi nilai ideal.
Kemudian untuk grafik speedup implementasi hybrid disajikan pada Gambar 27 dan Gambar 28. Grafik speedup untuk setiap kombinasi matriks, jumlah node, dan jumlah thread yang digunakan lebih lengkapnya disajikan pada Lampiran 2.
Gambar 27 Grafik speedup hasil percobaan hybrid untuk setiap ukuran matriks dengan 2 thread.
Gambar 28 Grafik speedup hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548. Jika Gambar 27 dan Gambar 28 dibandingkan dengan Gambar 16 dan Gambar 17, maka terlihat perbedaannya. Seharusnya speedup tertinggi diperoleh dengan penggunaan 4 thread, namun tidak demikian pada hasil percobaan. Pada hybrid 4 thread, speedup yang diperoleh hampir sama dengan hybrid 2 thread, sesuai dengan waktu komputasi yang diperoleh. Namun begitu secara keseluruhan speedup yang diperoleh semakin tinggi seiring dengan bertambahnya jumlah node. Speedup implementasi hybrid tertinggi diperoleh pada penggunaan 8 node dengan 2 thread.
Analisis Hasil Efisiensi
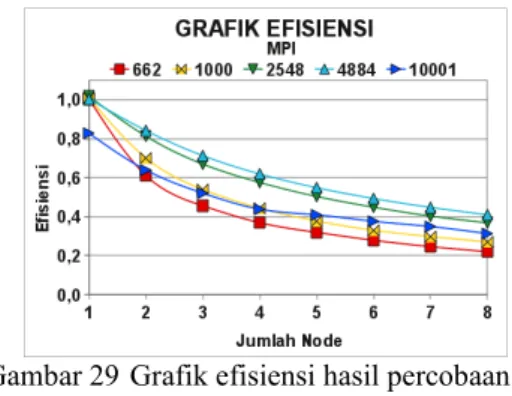
Selanjutnya setelah dilakukan analisis speedup, berikut ini pada Gambar 29 disajikan grafik efisiensi dari hasil percobaan implementasi MPI. Jika Gambar 29 dibandingkan dengan Gambar 17, maka jelas sangat terlihat berbeda. Pada Gambar 17
penurunan efisiensi tidak sampai 0.9, namun pada Gambar 29 penurunan efisiensi sampai pada 0.2. Dari grafik ini dapat diketahui bahwa nilai efisiensi semakin menurun seiring bertambahnya jumlah node yang digunakan.
Gambar 29 Grafik efisiensi hasil percobaan implementasi MPI.
Kemudian untuk efisiensi hasil percobaan hybrid disajikan pada Gambar 30 dan Gambar 31. Jika kedua gambar ini dibandingkan dengan Gambar 18 dan Gambar 19, maka efisiensi yang diperoleh juga terlihat menurun drastis sesuai dengan speedup yang diperoleh.
Gambar 30 Grafik efisiensi hasil percobaan hybrid untuk setiap ukuran matriks dengan 2 thread.
Gambar 31 Grafik efisiensi hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548. Seharusnya semakin tinggi ukuran matriks, semakin tinggi pula efisiensinya. Namun jika dilihat dari waktu komputasi, memang terdapat
anomali seperti dijelaskan pada Gambar 25, sehingga efisiensi tertinggi ada pada ukuran matriks 4884. Grafik efisiensi dari implementasi hybrid lebih lengkapnya disajikan pada Lampiran 3.
Secara keseluruhan efisiensi yang diperoleh implementasi MPI dan hybrid, nilai tertinggi diperoleh oleh implementasi MPI. Hal ini dikarenakan speedup yang diperoleh tidak sesuai seperti yang diharapkan. Efisiensi adalah nilai speedup dibagi dengan jumlah processor. Pada hakikatnya total seluruh processor yang digunakan untuk implementasi hybrid adalah jumlah node dikali jumlah thread p x t. Semakin besar kombinasi yang digunakan, semakin besar pembagi speedup untuk menghasilkan nilai efisiensi, sehingga nilai efisiensi semakin kecil. Seharusnya bila diimbangi dengan peningkatan nilai speedup, maka nilai efisiensi akan stabil, namun tidak demikian, sehingga nilai efisiensi semakin kecil. Analisis Cost
Pada hasil percobaan implementasi MPI, nilai cost terbesar ada pada ukuran matriks 10001. Grafiknya cost implementasi MPI disajikan pada Gambar 32.
Gambar 32 Grafik cost hasil percobaan implementasi MPI.
Gambar 33 Grafik cost hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548.
Pada hasil percobaan hybrid, nilai cost terbesar diperoleh pada implementasi hybrid 3 thread pada setiap ukuran matriks dan pada setiap jumlah node yang digunakan. Hal ini memang wajar adanya karena waktu eksekusi yang diperoleh pada hybrid 3 thread tidak lebih cepat dari pada hybrid 2 thread dan hybrid 4 thread. Berdasarkan Gambar 33, dengan mengabaikan nilai cost pada hybrid 3 thread, dapat diketahui bahwa semakin besar kombinasi node dan thread, semakin besar nilai cost yang dihasilkan. Grafik cost untuk implementasi hybrid dengan kombinasi node dan thread lainnya disajikan pada Lampiran 4.
Berdasarkan Persamaan 19 dan Persamaan 26, seharusnya nilai cost untuk setiap jumlah node yang digunakan dengan ukuran matriks tetap, idealnya nilainya hampir tetap atau meningkat namun kecil, tetapi tidak demikian dengan nilai cost hasil percobaan. Hal ini terjadi karena tingkat penurunan waktu eksekusi seiring dengan semakin besar jumlah node yang digunakan yang sangat dipengaruhi oleh waktu distribusi matriks.
Analisis Total Parallel Overhead
Gambar 34 Grafik overhead hasil percobaan implementasi MPI.
Gambar 35 Grafik overhead hasil percobaan untuk setiap implementasi dengan ukuran matriks 2548 x 2548.
Pada Gambar 34 dan Gambar 35 disajikan grafik overhead untuk implementasi MPI dan hybrid. Dari Gambar 34 dapat diketahui bahwa untuk implementasi MPI, nilai overhead pada semua matriks semakin besar seiring bertambahnya jumlah node dan nilai overhead tertinggi ada pada ukuran matriks 10001. Sedangkan pada Gambar 35 dapat diketahui bahwa nilai overhead semakin tinggi seiring dengan semakin tingginya kombinasi jumlah node dan thread yang digunakan dengan pengecualian pada hybrid 3 thread.
Berdasarkan hasil perhitungan Persamaan 20 dan Persamaan 27, seharusnya nilai overhead memang mengalami kenaikan, namun tidak sebesar seperti yang terlihat pada Gambar 34 dan Gambar 35. Hal ini sesuai dengan yang terjadi pada nilai cost, karena memang nilai cost dan overhead saling berkaitan. Grafik overhead implementasi hybrid lebih lengkapnya disajikan pada Lampiran 5.
KESIMPULAN DAN SARAN Kesimpulan
Dari hasil pembahasan dapat disimpulkan bahwa:
1. Waktu eksekusi metode CG untuk semua implementasi semakin meningkat seiring dengan semakin besarnya ukuran matriks yang digunakan. Sebagai contoh:
• Implementasi sekuensial secara berturut-turut untuk ukuran matriks 1000, 2548, dan 4884 dibutuhkan waktu sebesar 4.47, 28.94 dan 42.84 detik.
• Implementasi MPI dengan 4 node secara berturut-turut untuk ukuran matriks 1000, 2548, dan 4884 dibutuhkan waktu sebesar 2.52, 12.57, dan 42.84 detik. • Implementasi hybrid 2 thread dengan 4
node secara berturut-turut untuk ukuran matriks 1000, 2548, dan 4884 dibutuhkan waktu sebesar 2.12, 9.87 dan 32.44 detik.
2. Waktu eksekusi metode CG pada implementasi MPI menurun dibandingkan dengan waktu eksekusi implementasi sekuensial. Waktu implementasi MPI juga semakin menurun seiring dengan semakin besar jumlah node yang digunakan. Sebagai contoh untuk ukuran matriks 2548, secara berturut-turut pada implementasi sekuensial, MPI dengan 1, 2, 3, 4 node dibutuhkan
waktu 28.94,28.44,17.79,14.40,12.57 detik. 3. Waktu eksekusi metode CG pada
implementasi hybrid menurun dibandingkan dengan waktu eksekusi implementasi MPI. Waktu eksekusi implementasi hybrid juga semakin menurun seiring dengan semakin besarnya kombinasi node dan thread yang digunakan. Sebagai contoh:
• Untuk ukuran matriks 2548, secara berturut-turut pada implementasi MPI dengan 2 node, hybrid 1 thread, 2 thread dengan 2 node dibutuhkan waktu 17.79, 19.07, 12.61.
• Untuk ukuran matriks 4884, secara berturut-turut pada implementasi MPI dengan 4 node, MPI dengan 5 node, hybrid 2 thread 4 node, hybrid 2 thread 5 node dibutuhkan waktu 29.37, 24.32, 18.95, 16.01.
4. Pengaruh bertambahnya jumlah node dan jumlah thread yang digunakan terhadap penurunan waktu eksekusi pada implementasi CG MPI dan CG hybrid secara keseluruhan semakin berkurang.
5. Nilai speedup tertinggi didapatkan pada implementasi hybrid 2 thread, karena sesuai dengan jumlah core processor pada komputer yang digunakan. Nilai speedup semakin bertambah seiring dengan bertambahnya jumlah node dan thread yang digunakan, namun nilai speedup yang diperoleh baik pada implementasi MPI maupun hybrid dapat dikatakan jauh dari nilai ideal yaitu sebesar p.
6. Nilai efisiensi tertinggi didapatkan pada implementasi MPI. Nilai efisiensi semakin menurun seiring dengan bertambahnya jumlah node dan thread yang digunakan, namun masih jauh berbeda dari nilai efisiensi yang didapat dari hasil perhitungan yaitu antara 0.9 - 1.
7. Nilai cost tertinggi didapatkan pada implementasi hybrid 3 thread. Nilai cost yang didapat semakin besar seiring dengan bertambahnya jumlah node dan thread yang digunakan. Seharusnya nilai cost yang diperoleh berdasarkan hasil perhitungan nilainya cenderung tetap pada setiap jumlah node dan jumlah thread. Hal ini disebabkan oleh waktu eksekusi yang tidak sesuai sebagaimana mestinya berdasarkan hasil perhitungan kompleksitas.